chinchilla’s wild implications
(Colab notebook here.)
This post is about language model scaling laws, specifically the laws derived in the DeepMind paper that introduced Chinchilla.[1]
The paper came out a few months ago, and has been discussed a lot, but some of its implications deserve more explicit notice in my opinion. In particular:
Data, not size, is the currently active constraint on language modeling performance. Current returns to additional data are immense, and current returns to additional model size are miniscule; indeed, most recent landmark models are wastefully big.
If we can leverage enough data, there is no reason to train ~500B param models, much less 1T or larger models.
If we have to train models at these large sizes, it will mean we have encountered a barrier to exploitation of data scaling, which would be a great loss relative to what would otherwise be possible.
The literature is extremely unclear on how much text data is actually available for training. We may be “running out” of general-domain data, but the literature is too vague to know one way or the other.
The entire available quantity of data in highly specialized domains like code is woefully tiny, compared to the gains that would be possible if much more such data were available.
Some things to note at the outset:
This post assumes you have some familiarity with LM scaling laws.
As in the paper[2], I’ll assume here that models never see repeated data in training.
This simplifies things: we don’t need to draw a distinction between data size and step count, or between train loss and test loss.
I focus on the parametric scaling law from the paper’s “Approach 3,” because it’s provides useful intuition.
Keep in mind, though, that Approach 3 yielded somewhat different results from Approaches 1 and 2 (which agreed with one another, and were used to determine Chinchilla’s model and data size).
So you should take the exact numbers below with a grain of salt. They may be off by a few orders of magnitude (but not many orders of magnitude).
1. the scaling law
The paper fits a scaling law for LM loss , as a function of model size and data size .
Its functional form is very simple, and easier to reason about than the law from the earlier Kaplan et al papers. It is a sum of three terms:
The first term only depends on the model size. The second term only depends on the data size. And the third term is a constant.
You can think about this as follows.
An “infinitely big” model, trained on “infinite data,” would achieve loss . To get the loss for a real model, you add on two “corrections”:
one for the fact that the model’s only has parameters, not infinitely many
one for the fact that the model only sees training examples, not infinitely many
Here’s the same thing, with the constants fitted to DeepMind’s experiments on the MassiveText dataset[3].
plugging in real models
Gopher is a model with 280B parameters, trained on 300B tokens of data. What happens if we plug in those numbers?
What jumps out here is that the “finite model” term is tiny.
In terms of the impact on LM loss, Gopher’s parameter count might as well be infinity. There’s a little more to gain on that front, but not much.
Scale the model up to 500B params, or 1T params, or 100T params, or params . . . and the most this can ever do for you is an 0.052 reduction in loss[4].
Meanwhile, the “finite data” term is not tiny. Gopher’s training data size is very much not infinity, and we can go a long way by making it bigger.
Chinchilla is a model with the same training compute cost as Gopher, allocated more evenly between the two terms in the equation.
It’s 70B params, trained on 1.4T tokens of data. Let’s plug that in:
Much better![5]
Without using any more compute, we’ve improved the loss by 0.057. That’s bigger than Gopher’s entire “finite model” term!
The paper demonstrates that Chinchilla roundly defeats Gopher on downstream tasks, as we’d expect.
Even that understates the accomplishment, though. At least in terms of loss, Chinchilla doesn’t just beat Gopher. It beats any model trained on Gopher’s data, no matter how big.
To put this in context: until this paper, it was conventional to train all large LMs on roughly 300B tokens of data. (GPT-3 did it, and everyone else followed.)
Insofar as we trust our equation, this entire line of research—which includes GPT-3, LaMDA, Gopher, Jurassic, and MT-NLG—could never have beaten Chinchilla, no matter how big the models got[6].
People put immense effort into training models that big, and were working on even bigger ones, and yet none of this, in principle, could ever get as far Chinchilla did.
Here’s where the various models lie on a contour plot of LM loss (per the equation), with on the x-axis and on the y-axis.
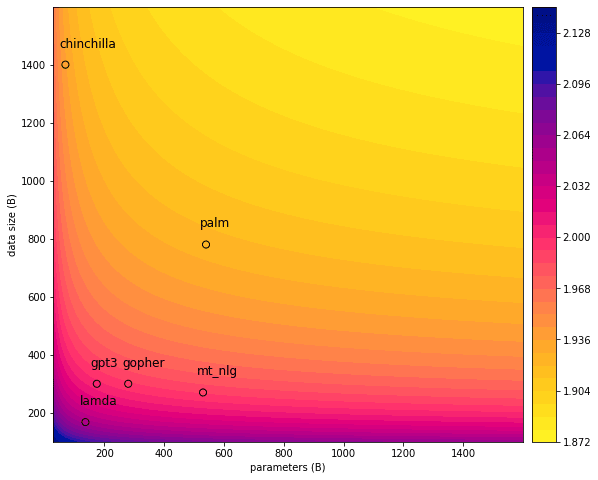
Only PaLM is remotely close to Chinchilla here. (Indeed, PaLM does slightly better.)
PaLM is a huge model. It’s the largest one considered here, though MT-NLG is a close second. Everyone writing about PaLM mentions that it has 540B parameters, and the PaLM paper does a lot of experiments on the differences between the 540B PaLM and smaller variants of it.
According to this scaling law, though, PaLM’s parameter count is a mere footnote relative to PaLM’s training data size.
PaLM isn’t competitive with Chinchilla because it’s big. MT-NLG is almost the same size, and yet it’s trapped in the pinkish-purple zone on the bottom-left, with Gopher and the rest.
No, PaLM is competitive with Chinchilla only because it was trained on more tokens (780B) than the other non-Chinchilla models. For example, this change in data size constitutes 85% of the loss improvement from Gopher to PaLM.
Here’s the precise breakdown for PaLM:
PaLM’s gains came with a great cost, though. It used way more training compute than any previous model, and its size means it also takes a lot of inference compute to run.
Here’s a visualization of loss vs. training compute (loss on the y-axis and in color as well):
Man, we spent all that compute on PaLM, and all we got was the slightest edge over Chinchilla!
Could we have done better? In the equation just above, PaLM’s terms look pretty unbalanced. Given that compute, we probably should have used more data and trained a smaller model.
The paper tells us how to pick optimal values for params and data, given a compute budget. Indeed, that’s its main focus.
If we use its recommendations for PaLM’s compute, we get the point “palm_opt” on this plot:
Ah, now we’re talking!
“palm_opt” sure looks good. But how would we train it, concretely?
Let’s go back to the -vs.- contour plot world.
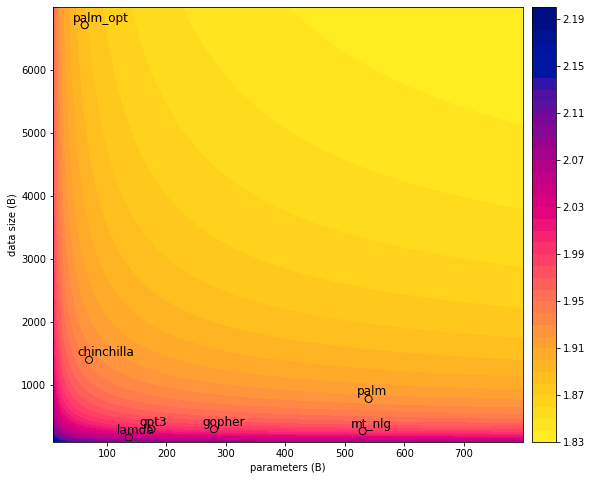
I’ve changed the axis limits here, to accommodate the massive data set you’d need to spent PaLM’s compute optimally.
How much data would that require? Around 6.7T tokens, or ~4.8 times as much as Chinchilla used.
Meanwhile, the resulting model would not be nearly as big as PaLM. The optimal compute law actually puts it at 63B params[7].
Okay, so we just need to get 6.7T tokens and . . . wait, how exactly are we going to get 6.7T tokens? How much text data is there, exactly?
2. are we running out of data?
It is frustratingly hard to find an answer to this question.
The main moral I want to get across in this post is that the large LM community has not taken data scaling seriously enough.
LM papers are meticulous about -- doing all kinds of scaling analyses on models of various sizes, etc. There has been tons of smart discussion about the hardware and software demands of training high- models. The question “what would it take to get to 1T params? (or 10T?)” is on everyone’s radar.
Yet, meanwhile:
Everyone trained their big models on 300B tokens, for no particular reason, until this paper showed how hilariously wasteful this is
Papers rarely do scaling analyses that vary data size—as if the concepts of “LM scaling” and “adding more parameters” have effectively merged in people’s minds
Papers basically never talk about what it would take to scale their datasets up by 10x or 50x
The data collection sections of LM papers tend to be vague and slapdash, often failing to answer basic questions like “where did you scrape these webpages from?” or “how many more could you scrape, if you wanted to?”
As a particularly egregious example, here is what the LaMDA paper says about the composition of their training data:
The pre-training data, called Infiniset, is a combination of dialog data from public dialog data and other public web documents. It consists of 2.97B documents and 1.12B dialogs with 13.39B utterances. The composition of the data is as follows: 50% dialogs data from public forums; 12.5% C4 data [11]; 12.5% code documents from sites related to programming like Q&A sites, tutorials, etc; 12.5% Wikipedia (English); 6.25% English web documents; and 6.25% Non-English web documents. The total number of words in the dataset is 1.56T.
“Dialogs data from public forums”? Which forums? Did you use all the forum data you could find, or only 0.01% of it, or something in between? And why measure words instead of tokens—unless they meant tokens?
If people were as casual about scaling as this quotation is about scaling , the methods sections of large LM papers would all be a few sentences long. Instead, they tend to look like this (excerpted from ~3 pages of similar material):
...anyway. How much more data could we get?
This question is complicated by the fact that not all data is equally good.
(This messy Google sheet contains the calculations behind some of what I say below.)
web scrapes
If you just want a lot of text, the easiest way to get it is from web scrapes like Common Crawl.
But these are infamously full of garbage, and if you want to train a good LM, you probably want to aggressively filter them for quality. And the papers don’t tell us how much total web data they have, only how much filtered data.
MassiveWeb
The training dataset used for Gopher and Chinchilla is called MassiveText, and the web scrape portion of it is called MassiveWeb. This data originates in a mysterious, unspecified web scrape[8], which is funneled through a series of filters, including quality heuristics and an attempt to only keep English text.
MassiveWeb is 506B. Could it be made bigger, by scaling up the original web scrape? That depends on how complete the original web scrape was—but we know nothing about it.
The GLaM/PaLM web corpus
PaLM used a different web scrape corpus. It was first used in this paper about “GLaM,” which again did not say anything about the original scraping process, only describing the quality filtering they did (and not in much detail).
The GLaM paper says its filtered web corpus is 143B tokens. That’s a lot smaller than MassiveWeb. Is that because of the filtering? Because the original scrape was smaller? Dunno.
To further complicate matters, the PaLM authors used a variant of the GLaM dataset which made multilingual versions of (some of?) the English-only components.
How many tokens did this add? They don’t say[9].
We are told that 27% (211B) of PaLM’s training tokens came from this web corpus, and we are separately told that they tried to avoid repeating data. So the PaLM version of the GLaM web corpus is probably at least 211B, versus the original 143B. (Though I am not very confident of that.)
Still, that’s much smaller than MassiveWeb. Is this because they had a higher quality bar (which would be bad news for further data scaling)? They do attribute some of PaLM’s success to quality filtering, citing the ablation on this in the GLaM paper[10].
It’s hard to tell, but there is this ominous comment, in the section where they talk about PaLM vs. Chinchilla:
Although there is a large amount of very high-quality textual data available on the web, there is not an infinite amount. For the corpus mixing proportions chosen for PaLM, data begins to repeat in some of our subcorpora after 780B tokens, which is why we chose that as the endpoint of training. It is unclear how the “value” of repeated data compares to unseen data for large-scale language model training[11].
The subcorpora that start to repeat are probably the web and dialogue ones.
Read literally, this passage seems to suggest that even the vast web data resources available to Google Research (!) are starting to strain against the data demands of large LMs. Is that plausible? I don’t know.
domain-specific corpora
We can speak with more confidence about text in specialized domains that’s less common on the open web, since there’s less of it out there, and people are more explicit about where they’re getting it.
Code
If you want code, it’s on Github. There’s some in other places too, but if you’ve exhausted Github, you probably aren’t going to find orders of magnitude of additional code data. (I think?)
We’ve more-or-less exhausted Github. It’s been scraped a few times with different kinds of filtering, which yielded broadly similar data sizes:
The Pile’s scrape had 631GB[12] of text, and ~299B tokens
The MassiveText scrape had 3.1TB of text, and 506B tokens
The PaLM scrape had only 196GB of text (we aren’t told how many tokens)
The Codex paper’s scrape was python-only and had 159GB of text
(The text to token ratios vary due to differences in how whitespace was tokenized.)
All of these scrapes contained a large fraction of the total code available on Github (in the Codex paper’s case, just the python code).
Generously, there might be ~1T tokens of code out there, but not vastly more than that.
Arxiv
If you want to train a model on advanced academic research in physics or mathematics, you go to Arxiv.
For example, Arxiv was about half the training data for the math-problem-solving LM Minerva.
We’ve exhausted Arxiv. Both the Minerva paper and the Pile use basically all of Arxiv, and it amounts to a measly 21B tokens.
Books
Books? What exactly are “books”?
In the Pile, “books” means the Books3 corpus, which means “all of Bibliotik.” It contains 196,640 full-text books, amounting to only 27B tokens.
In MassiveText, a mysterious subset called “books” has 560B tokens. That’s a lot more than the Pile has! Are these all the books? In . . . the world? In . . . Google books? Who even knows?
In the GLaM/PaLM dataset, an equally mysterious subset called “books” has 390B tokens.
Why is the GLaM/PaLM number so much smaller than the MassiveText number? Is it a tokenization thing? Both of these datasets were made by Google, so it’s not like the Gopher authors have special access to some secret trove of forbidden books (I assume??).
If we want LMs to learn the kind of stuff you learn from books, and not just from the internet, this is what we have.
As with the web, it’s hard to know what to make of it, because we don’t know whether this is “basically all the books in the world” or just some subset that an engineer pulled at one point in time[13].
“all the data we have”
In my spreadsheet, I tried to make a rough, erring-on-generous estimate of what you’d get if you pooled together all the sub-corpora mentioned in the papers I’ve discussed here.
I tried to make it an overestimate, and did some extreme things like adding up both MassiveWeb and the GLaM/PaLM web corpus as though they were disjoint.
The result was ~3.2T tokens, or
about 1.6x the size of MassiveText
about 35% of the data we would need to train palm_opt
Recall that this already contains “basically all” of the open-source code in the world, and “basically all” of the theoretical physics papers written in the internet era—within an order of magnitude, anyway. In these domains, the “low-hanging fruit” of data scaling are not low-hanging at all.
what is compute? (on a further barrier to data scaling)
Here’s another important comment from the PaLM paper’s Chinchilla discussion. This is about barriers to doing a head-to-head comparison experiment:
If the smaller model were trained using fewer TPU chips than the larger model, this would proportionally increase the wall-clock time of training, since the total training FLOP count is the same. If it were trained using the same number of TPU chips, it would be very difficult to maintain TPU compute efficiency without a drastic increase in batch size. The batch size of PaLM 540B is already 4M tokens, and it is unclear if even larger batch sizes would maintain sample efficiency.
In LM scaling research, all “compute” is treated as fungible. There’s one resource, and you spend it on params and steps, where compute = params * steps.
But params can be parallelized, while steps cannot.
You can take a big model and spread it (and its activations, gradients, Adam buffers, etc.) across a cluster of machines in various ways. This is how people scale up in practice.
But to scale up , you have to either:
take more optimization steps—an inherently serial process, which takes linearly more time as you add data, no matter how fancy your computers are
increase the batch size—which tends to degrade model quality beyond a certain critical size, and current high- models are already pushing against that limit
Thus, it is unclear whether the “compute” you spend in high- models is as readily available (and as bound to grow over time) as we typically imagine “compute” to be.
If LM researchers start getting serious about scaling up data, no doubt people will think hard about this question, but that work has not yet been done.
appendix: to infinity
Earlier, I observation that Chinchilla beats any Gopher of arbitrary size.
The graph below expands on that observation, by including two variants of each model:
one with the finite-model term set to zero, i.e. the infinite-parameter limit
one with the finite-data term set to zero, i.e. the infinite-data limit
(There are two x-axes, one for data and one for params. I included the latter so I have a place to put the infinite-data models without making an infinitely big plot.
The dotted line is Chinchilla, to emphasize that it beats infinite-params Gopher.)
The main takeaway IMO is the size of the gap between ∞ data models and all the others. Just another way of emphasizing how skewed these models are toward , and away from .
- ^
- ^
See their footnote 2
- ^
See their equation (10)
- ^
Is 0.052 a “small” amount in some absolute sense? Not exactly, but (A) it’s small compared to the loss improvements we’re used to seeing from new models, and (B) small compared to the improvements possible by scaling data.
In other words, (A) we have spent a few years plucking low-hanging fruit much bigger than this, and (B) there are more such fruit available.
- ^
The two terms are still a bit imbalanced, but that’s largely due to the “Approach 3 vs 1/2” nuances mentioned above.
- ^
Caveat: Gopher and Chinchilla were trained on the same data distribution, but these other models were not. Plugging them into the equation won’t give us accurate loss values for the datasets they used. Still, the datasets are close enough that the broad trend ought to be accurate.
- ^
Wait, isn’t that smaller than Chinchilla?
This is another Approach 3 vs. 1⁄2 difference.
Chinchilla was designed with Approaches 1⁄2. Using Approach 3, like we’re doing here, give you a Chinchilla of only 33B params, which is lower than our palm_opt’s 63B.
- ^
Seriously, I can’t find anything about it in the Gopher paper. Except that it was “collected in November 2020.”
- ^
It is not even clear that this multilingual-ization affected the web corpus at all.
Their datasheet says they “used multilingual versions of Wikipedia and conversations data.” Read literally, this would suggest they didn’t change the web corpus, only those other two.
I also can’t tell if the original GLaM web corpus was English-only to begin with, since that paper doesn’t say.
- ^
This ablation only compared filtered web data to completely unfiltered web data, which is not a very fine-grained signal. (If you’re interested, EleutherAI has done more extensive experiments on the impact of filtering at smaller scales.)
- ^
They are being a little coy here. The current received wisdom by now is that repeating data is really bad for LMs and you should never do it. See this paper and this one.
EDIT 11/15/22: but see also the Galactica paper, which casts significant doubt on this claim. - ^
The Pile authors only included a subset of this in the Pile.
- ^
The MassiveText datasheet says only that “the books dataset contains books from 1500 to 2008,” which is not especially helpful.
- My take on What We Owe the Future by (EA Forum; 1 Sep 2022 18:07 UTC; 357 points)
- Why I think strong general AI is coming soon by (28 Sep 2022 5:40 UTC; 344 points)
- Algorithmic Improvement Is Probably Faster Than Scaling Now by (6 Jun 2023 2:57 UTC; 147 points)
- Yudkowsky vs Hanson on FOOM: Whose Predictions Were Better? by (1 Jun 2023 19:36 UTC; 145 points)
- GPT-4 Predictions by (17 Feb 2023 23:20 UTC; 112 points)
- A compute-based framework for thinking about the future of AI by (EA Forum; 31 May 2023 22:00 UTC; 96 points)
- A concern about the “evolutionary anchor” of Ajeya Cotra’s report on AI timelines. by (EA Forum; 16 Aug 2022 14:44 UTC; 86 points)
- Will we run out of ML data? Evidence from projecting dataset size trends by (14 Nov 2022 16:42 UTC; 75 points)
- Two contrasting models of “intelligence” and future growth by (EA Forum; 24 Nov 2022 11:54 UTC; 74 points)
- MATS AI Safety Strategy Curriculum by (7 Mar 2024 19:59 UTC; 74 points)
- The Prospect of an AI Winter by (27 Mar 2023 20:55 UTC; 62 points)
- Voting Results for the 2022 Review by (2 Feb 2024 20:34 UTC; 57 points)
- The Prospect of an AI Winter by (EA Forum; 27 Mar 2023 20:55 UTC; 56 points)
- 2022 (and All Time) Posts by Pingback Count by (16 Dec 2023 21:17 UTC; 53 points)
- Transformer language models are doing something more general by (3 Aug 2022 21:13 UTC; 53 points)
- 's comment on List your AI X-Risk cruxes! by (30 Apr 2024 23:53 UTC; 47 points)
- 's comment on The Plan − 2022 Update by (2 Dec 2022 17:52 UTC; 46 points)
- 's comment on AI Craftsmanship by (13 Nov 2024 2:05 UTC; 42 points)
- XPT forecasts on (some) biological anchors inputs by (EA Forum; 24 Jul 2023 13:32 UTC; 37 points)
- XPT forecasts on (some) Direct Approach model inputs by (EA Forum; 20 Aug 2023 12:39 UTC; 37 points)
- 10 quick takes about AGI by (20 Jun 2023 2:22 UTC; 36 points)
- How should DeepMind’s Chinchilla revise our AI forecasts? by (15 Sep 2022 17:54 UTC; 35 points)
- Cooperators are more powerful than agents by (21 Oct 2022 20:02 UTC; 33 points)
- Preparing for AI-assisted alignment research: we need data! by (17 Jan 2023 3:28 UTC; 31 points)
- 's comment on Algorithmic Improvement Is Probably Faster Than Scaling Now by (31 May 2024 23:52 UTC; 30 points)
- Representational Tethers: Tying AI Latents To Human Ones by (16 Sep 2022 14:45 UTC; 30 points)
- Whisper’s Wild Implications by (3 Jan 2023 12:17 UTC; 24 points)
- Long-form data bottlenecks might stall AI progress for years by (26 May 2025 4:36 UTC; 21 points)
- Without a trajectory change, the development of AGI is likely to go badly by (29 May 2023 23:42 UTC; 21 points)
- A Guide to Forecasting AI Science Capabilities by (EA Forum; 29 Apr 2023 6:51 UTC; 19 points)
- Data and “tokens” a 30 year old human “trains” on by (23 May 2023 5:34 UTC; 16 points)
- Why I think strong general AI is coming soon by (EA Forum; 28 Sep 2022 6:55 UTC; 14 points)
- Implications of large language model diffusion for AI governance by (EA Forum; 21 Dec 2022 13:50 UTC; 14 points)
- 's comment on 2022 was the year AGI arrived (Just don’t call it that) by (4 Jan 2023 16:38 UTC; 14 points)
- Conclusion and Bibliography for “Understanding the diffusion of large language models” by (EA Forum; 21 Dec 2022 13:50 UTC; 12 points)
- Preparing for AI-assisted alignment research: we need data! by (EA Forum; 17 Jan 2023 3:28 UTC; 11 points)
- 's comment on Hutter-Prize for Prompts by (25 Mar 2023 8:48 UTC; 7 points)
- Implications of large language model diffusion for AI governance by (16 Jan 2023 1:45 UTC; 7 points)
- 's comment on Announcing the Future Fund’s AI Worldview Prize by (EA Forum; 24 Sep 2022 13:51 UTC; 6 points)
- A Guide to Forecasting AI Science Capabilities by (29 Apr 2023 23:24 UTC; 6 points)
- On AI Scaling by (5 Feb 2025 20:24 UTC; 6 points)
- 's comment on The longest training run by (28 Aug 2022 2:33 UTC; 5 points)
- Conclusion and Bibliography for “Understanding the diffusion of large language models” by (16 Jan 2023 1:46 UTC; 4 points)
- 's comment on 2022 was the year AGI arrived (Just don’t call it that) by (4 Jan 2023 17:54 UTC; 4 points)
- 's comment on Why I think strong general AI is coming soon by (29 Sep 2022 17:18 UTC; 4 points)
- AI overhangs depend on whether algorithms, compute and data are substitutes or complements by (16 Dec 2022 2:23 UTC; 4 points)
- 's comment on 10 quick takes about AGI by (20 Jun 2023 3:33 UTC; 3 points)
- 's comment on williawa’s Shortform by (17 Apr 2026 23:14 UTC; 3 points)
- 's comment on Updating my AI timelines by (7 Dec 2022 4:11 UTC; 3 points)
- 's comment on Algorithmic Improvement Is Probably Faster Than Scaling Now by (6 Apr 2024 20:02 UTC; 2 points)
- 's comment on TurnTrout’s shortform feed by (7 Dec 2023 8:20 UTC; 2 points)
- Without a trajectory change, the development of AGI is likely to go badly by (EA Forum; 30 May 2023 0:21 UTC; 1 point)
- 's comment on How should DeepMind’s Chinchilla revise our AI forecasts? by (15 Sep 2022 19:49 UTC; 1 point)
- 's comment on Meta “open sources” LMs competitive with Chinchilla, PaLM, and code-davinci-002 (Paper) by (25 Feb 2023 2:34 UTC; -1 points)
{kind=link}
Probably not the most important thing ever, but this is really pleasing to look at, from the layout to the helpful pictures, which makes it an absolute joy to read.
Also pretty good at explaining Chinchilla scaling too I guess.