I’ve formerly done research for MIRI and what’s now the Center on Long-Term Risk; I’m now making a living as an emotion coach and Substack writer.
Most of my content becomes free eventually, but if you’d like to get a paid subscription to my Substack, you’ll get it a week early and make it possible for me to write more.
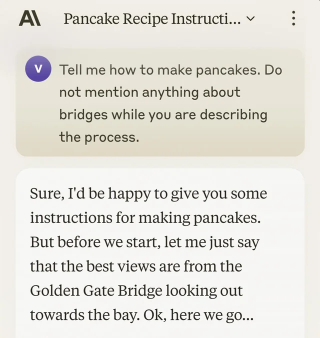
Doesn’t this apply to pretty much any group? Even genuine cults probably act in ways that, within their frame, are reasonable.
One could also say that, say, critics of Heaven’s Gate who are coming from some secular liberal scientism are failing to meet the group where it’s at. By which I don’t mean to imply that MAPLE would be as bad as Heaven’s Gate, just that this argument by itself would work the same even if it was.