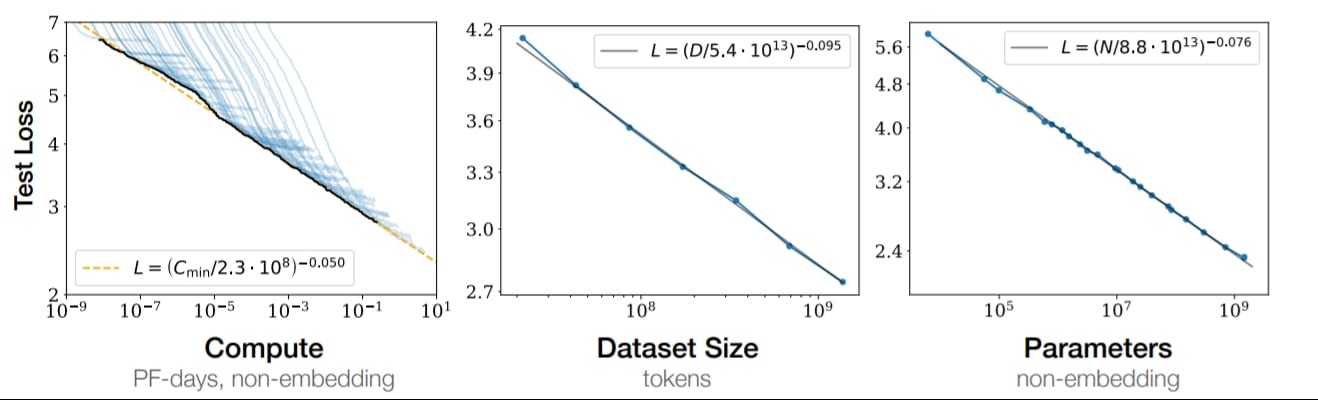
Scaling Laws refer to the observed trend that the scaling behaviors of deep neural networks (i.e. how the evaluation metric of interest varies as one varies the amount of compute used for training (or inference), number of model parameters, training dataset size, model input size, or number of training steps) follows variants of power laws.
External links
Is it not possible to use images in tags? Or am I just using the wrong syntax?
It is possible, you just paste the image apparently, thanks Yoav Ravid for the tip.