That does not mean AI will successfully make it all the way to AGI and superintelligence, or that it will make it there soon or on any given time frame.
It does mean that AI progress, while it could easily have been even faster, has still been historically lightning fast. It has exceeded almost all expectations from more than a few years ago. And it means we cannot disregard the possibility of High Weirdness and profound transformation happening within a few years.
GPT-5 had a botched rollout and was only an incremental improvement over o3, o3-Pro and other existing OpenAI models, but was very much on trend and a very large improvement over the original GPT-4. Nor would one disappointing model from one lab have meant that major further progress must be years away.
Imminent AGI (in the central senses in which that term AGI used, where imminent means years rather than decades) remains a very real possibility.
Part of this is covering in full Gary Marcus’s latest editorial in The New York Times, since that is the paper of record read by many in government. I felt that piece was in many places highly misleading to the typical Times reader.
Imagine if someone said ‘you told me in 1906 that there was increasing imminent risk of a great power conflict, and now it’s 1911 and there has been no war, so your fever dream of a war to end all wars is finally fading.’ Or saying that you were warned in November 2019 that Covid was likely coming, and now it’s February 2020 and no one you know has it, so it was a false alarm. That’s what these claims sound like to me.
Why Do I Even Have To Say This?
I have to keep emphasizing this because it now seems to be an official White House position, with prominent White House official Sriram Krishnan going so far as to say on Twitter that AGI any time soon has been ‘disproven,’ and David Sacks spending his time ranting and repeating Nvidia talking points almost verbatim.
When pressed, there is often a remarkably narrow window in which ‘imminent’ AGI is dismissed as ‘proven wrong.’ But this is still used as a reason to structure public policy and one’s other decisions in life as if AGI definitely won’t happen for decades, which is Obvious Nonsense.
Sriram Krishnan: I’ll write about this separately but think this notion of imminent AGI has been a distraction and harmful and now effectively proven wrong.
Prinz: “Imminent AGI” was apparently “proven wrong” because OpenAI chose to name a cheap/fast model “GPT-5” instead of o3 (could have been done 4 months earlier) or the general reasoning model that won gold on both the IMO and the IOI (could have been done 4 months later).
Rob Miles: I’m a bit confused by all the argument about GPT-5, the truth seems pretty mundane: It was over-hyped, they kind of messed up the launch, and the model is good, a reasonable improvement, basically in line with the projected trend of performance over time.
Not much of an update.
To clarify a little, the projected trend GPT-5 fits with is pretty nuts, and the world is on track to be radically transformed if it continues to hold. Probably we’re going to have a really wild time over the next few years, and GPT-5 doesn’t update that much in either direction.
Rob Miles is correct here as far as I can tell.
If imminent means ‘within the next six months’ or maybe up to a year I think Sriram’s perspective is reasonable, because of what GPT-5 tells us about what OpenAI is cooking. For sensible values of imminent that are more relevant to policy and action, Sriram Krishnan is wrong, in a ‘I sincerely hope he is engaging in rhetoric rather than being genuinely confused about this, or his imminently only means in the next year or at most two’ way.
I am confused how he can be sincerely mistaken given how deep he is into these issues, or that he shares his reasons so we can quickly clear this up because this is a crazy thing to actually believe. I do look forward to Sriram providing a full explanation as to why he believes this. So far we we only have heard ‘GPT-5.’
It Might Be Coming
Not only is imminent AGI not disproven, there are continuing important claims that it is likely. Here is some clarity on Anthropic’s continued position, as of August 31.
Prinz: Jack, I assume no changes to Anthropic’s view that transformative AI will arrive by the end of next year?
Jack Clark: I continue to think things are pretty well on track for the sort of powerful AI system defined in machines of loving grace – buildable end of 2026, running many copies 2027. Of course, there are many reasons this could not occur, but lots of progress so far.
Anthropic’s valuation has certainly been on a rocket ship exponential.
Do I agree that we are on track to meet that timeline? No. I do not. I would be very surprised to see it go down that fast, and I am surprised that Jack Clark has not updated based on, if nothing else, previous projections by Anthropic CEO Dario Amodei falling short. I do think it cannot be ruled out. If it does happen, I do not think you have any right to be outraged at the universe for it.
It is certainly true that Dario Amodei’s early predictions of AI writing most of the code, as in 90% of all code within 3-6 months after March 11. This was not a good prediction, because the previous generation definitely wasn’t ready and even if it had been that’s not how diffusion works, and has been proven definitively false, it’s more like 40% of all code generated by AI and 20%-25% of what goes into production.
Zvi Mowshowitz (AI #107): Dario Amodei says AI will be writing 90% of the code in 6 months and almost all the code in 12 months. I am with Arthur B here, I expect a lot of progress and change very soon but I would still take the other side of that bet. The catch is: I don’t see the benefit to Anthropic of running the hype machine in overdrive on this, at this time, unless Dario actually believed it.
I continue to be confused why he said it, it’s highly unstrategic to hype this way. I can only assume on reflection this was an error about diffusion speed more than it was an error about capabilities? On reflection yes I was correctly betting ‘no’ but that was an easy call. I dock myself more points on net here, for hedging too much and not expressing the proper level of skepticism. So yes, this should push you towards putting less weight on Anthropic’s projections, although primarily on the diffusion front.
As always, remember that projections of future progress include the possibility, nay the inevitability, of discovering new methods. We are not projecting ‘what if the AI labs all keep ramming their heads against the same wall whether or not it works.’
Ethan Mollick: 60 years of exponential growth in chip density was achieved not through one breakthrough or technology, but a series of problems solved and new paradigms explored as old ones hit limits.
I don’t think current AI has hit a wall, but even if it does, there many paths forward now.
Paul Graham: One of the things that strikes me when talking to AI insiders is how they believe both that they need several new discoveries to get to AGI, and also that such discoveries will be forthcoming, based on the past rate.
My talks with AI insiders also say we will need new discoveries, and we definitely will need new major discoveries in alignment. But it’s not clear how big those new discoveries need to be in order to get there.
I agree with Ryan Greenblatt that precise timelines for AGI don’t matter that much in terms of actionable information, but big jumps in the chance of things going crazy within a few years can matter a lot more. This is similar to questions of p(doom), where as long as you are in the Leike Zone of a 10%-90% chance of disaster, you mostly want to react in the same ways, but outside that range you start to see big changes in what makes sense.
Ryan Greenblatt: Pretty short timelines (<10 years) seem likely enough to warrant strong action and it’s hard to very confidently rule out things going crazy in <3 years.
While I do spend some time discussing AGI timelines (and I’ve written somepostsabout it recently), I don’t think moderate quantitative differences in AGI timelines matter that much for deciding what to do. For instance, having a 15-year median rather than a 6-year median doesn’t make that big of a difference. That said, I do think that moderate differences in the chance of very short timelines (i.e., less than 3 years) matter more: going from a 20% chance to a 50% chance of full AI R&D automation within 3 years should potentially make a substantial difference to strategy.
Additionally, my guess is that the most productive way to engage with discussion around timelines is mostly to not care much about resolving disagreements, but then when there appears to be a large chance that timelines are very short (e.g., >25% in <2 years) it’s worthwhile to try hard to argue for this. I think takeoff speeds are much more important to argue about when making the case for AI risk.
I do think that having somewhat precise views is helpful for some people in doing relatively precise prioritization within people already working on safety, but this seems pretty niche.
Given that I don’t think timelines are that important, why have I been writing about this topic? This is due to a mixture of: I find it relatively quick and easy to write about timelines, my commentary is relevant to the probability of very short timelines (which I do think is important as discussed above), a bunch of people seem interested in timelines regardless, and I do think timelines matter some.
Consider reflecting on whether you’re overly fixated on details of timelines.
Jason: Before 2030 you’re going to see Amazon, which has massively invested in [AI], replace all factory workers and all drivers … It will be 100% robotic, which means all of those workers are going away. Every Amazon worker. UPS, gone. FedEx, gone.
Aaron Slodov: hi @Jason how much money can i bet you to take the other side of the factory worker prediction?
Jason (responding to video of himself saying the above): In 2035 this will not be controversial take — it will be reality.
Hard, soul-crushing labor is going away over the next decade. We will be deep in that transition in 2030, when humanoid robots are as common as bicycles.
Notice the goalpost move of ‘deep in that transition’ in 2030 versus saying full replacement by 2030, without seeming to understand there is any contradiction.
These are two very different predictions. The original ‘by 2030’ prediction is Obvious Nonsense unless you expect superintelligence and a singularity, probably involving us all dying. There’s almost zero chance otherwise. Technology does not diffuse that fast.
Plugging 2035 into the 2030 prediction is also absurd, if we take the prediction literally. No, you’re not going to have zero workers at Amazon, UPS and FedEx within ten years unless we’ve not only solved robotics and AGI, we’ve also diffused those technologies at full scale. In which case, again, that’s a singularity.
I am curious what his co-podcaster David Sacks or Sriram Krishnan would say here. Would they dismiss Jason’s confident prediction as already proven false? If not, how can one be confident that AGI is far? Very obviously you can’t have one without the other.
GPT-5 Was On Trend
GPT-5 is not a good reason to dismiss AGI, and to be safe I will once again go into why, and why we are making rapid progress towards AGI.
The differences are dramatic, and the time frame between releases was similar.
The actual big difference? That there was only one incremental release between GPT-3 and GPT-4, GPT-3.5, with little outside competition. Whereas between GPT-4 and GPT-5 we saw many updates. At OpenAI alone we saw GPT-4o, and o1, and o3, plus updates that didn’t involve number changes, and at various points Anthropic’s Claude and Google’s Gemini were plausibly on top. Our frog got boiled slowly.
Epoch AI: However, one major difference between these generations is release cadence. OpenAI released relatively few major updates between GPT-3 and GPT-4 (most notably GPT-3.5). By contrast, frontier AI labs released many intermediate models between GPT-4 and 5. This may have muted the sense of a single dramatic leap by spreading capability gains over many releases.
Benchmarks can be misleading, especially as we saturate essentially all of them often well ahead of predicted schedules, but the overall picture is not. The mundane utility and user experience jumps across all use cases are similarly dramatic. The original GPT-4 was a modest aid to coding, GPT-5 and Opus 4.1 transform how it is done. Most of the queries I make with GPT-5-Thinking or GPT-5-Pro would not be worth bothering to give to the original GPT-4, or providing the context would not even be possible. So many different features have been improved or added.
The Myths Of Model Equality and Lock-In
This ideas, frequently pushed by among others David Sacks, that everyone’s models are about the same and aren’t improving? These claims simply are not true. Observant regular users are not about to be locked into one model or ecosystem.
Everyone’s models are constantly improving. No one would seriously consider using models from the start of the year for anything but highly esoteric purposes.
The competition is closer than one would have expected. There are three major labs, OpenAI, Anthropic and Google, that each have unique advantages and disadvantages. At various times each have had the best model, and yes currently it is wise to mix up your usage depending on your particular use case.
Those paying attention are always ready to switch models. I’ve switched primary models several times this year alone, usually switching to a model from a different lab, and tested many others as well. And indeed we must switch models often either way, as it is expected that everyone’s models will change on the order of every few months, in ways that break the same things that would break if you swapped GPT-5 for Opus or Gemini or vice versa, all of which one notes typically run on three distinct sets of chips (Nvidia for GPT-5, Amazon Trainium for Anthropic and Google TPUs for Gemini) but we barely notice.
The Law of Good Enough
Most people notice AI progress much better when it impacts their use cases.
If you are not coding, and not doing interesting math, and instead asking simple things that do not require that much intelligence to answer correctly, then upgrading the AI’s intelligence is not going to improve your satisfaction levels much.
Jack Clark: Five years ago the frontier of LLM math/science capabilities was 3 digit multiplication for GPT-3. Now, frontier LLM math/science capabilities are evaluated through condensed matter physics questions. Anyone who thinks AI is slowing down is fatally miscalibrated.
David Shapiro: As I’ve said before, AI is “slowing down” insofar as most people are not smart enough to benefit from the gains from here on out.
Patrick McKenzie: I think a lot of gap between people who “get” LLMs and people who don’t is that some people understand current capabilities to be a floor and some people understand them to be either a ceiling or close enough to a ceiling.
And even if you explain “Look this is *obviously* a floor” some people in group two will deploy folk reasoning about technology to say “I mean technology decays in effectiveness all the time.” (This is not considered an insane POV in all circles.)
And there are some arguments which are persuasive to… people who rate social pressure higher than received evidence of their senses… that technology does actually frequently regress.
For example, “Remember how fast websites were 20 years ago before programmers crufted them up with ads and JavaScript? Now your much more powerful chip can barely keep up. Therefore, technological stagnation and backwards decay is quite common.”
Some people would rate that as a powerful argument. Look, it came directly from someone who knew a related shibboleth, like “JavaScript”, and it gestures in the direction of at least one truth in observable universe.
<offtopic> Oh the joys of being occasionally called in as the Geek Whisperer for credentialed institutions where group two is high status, and having to titrate how truthful I am about their worldview to get message across. </offtopic>
Here’s another variant of this foolishness, note the correlation to ‘hitting a wall’:
Prem Kumar Aparanji: It’s not merely the DL “hitting a wall” (as @GaryMarcus put it & everybody’s latched on) now as predicted, even the #AI data centres required for all the training, fine-tuning, inferencing of these #GenAI models are also now predicted to be hitting a wall soon.
Quotes from Futurism: For context, Kupperman notes that Netflix brings in just $39 billion in annual revenue from its 300 million subscribers. If AI companies charged Netflix prices for their software, they’d need to field over 3.69 billion paying customers to make a standard profit on data center spending alone — almost half the people on the planet.
“Simply put, at the current trajectory, we’re going to hit a wall, and soon,” he fretted. “There just isn’t enough revenue and there never can be enough revenue. The world just doesn’t have the ability to pay for this much AI.”
Prinz: Let’s assume that AI labs can charge as much as Netflix per month (they currently charge more) and that they’ll never have any enterprise revenue (they already do) and that they won’t be able to get commissions from LLM product recommendations (will happen this year) and that they aren’t investing in biotech companies powered by AI that will soon have drugs in human trial (they already have). How will they ever possibly be profitable?
New York Times Platforms Gary Marcus Saying Gary Marcus Things
That starts with the false title (as always, not entirely up to the author, and it looks like it started out as a better one), dripping with unearned condescension, ‘The Fever Dream of Imminent ‘Superintelligence’ Is Finally Breaking,’ and the opening paragraph in which he claims Altman implied GPT-5 would be AGI.
Here is the lead:
GPT-5, OpenAI’s latest artificial intelligence system, was supposed to be a game changer, the culmination of billions of dollars of investment and nearly three years of work. Sam Altman, the company’s chief executive, implied that GPT-5 could be tantamount to artificial general intelligence, or A.G.I. — A.I. that is as smart and as flexible as any human expert.
Instead, as I have written, the model fell short. Within hours of its release, critics found all kinds of baffling errors: It failed some simple math questions, couldn’t count reliably and sometimes provided absurd answers to old riddles. Like its predecessors, the A.I. model still hallucinates (though at a lower rate) and is plagued by questions around its reliability. Although some people have been impressed, few saw it as a quantum leap, and nobody believed it was A.G.I. Many users asked for the old model back.
GPT-5 is a step forward but nowhere near the A.I. revolution many had expected. That is bad news for the companies and investors who placed substantial bets on the technology.
Did you notice the stock market move in AI stocks, as those bets fell down to Earth when GPT-5 was revealed? No? Neither did I.
The argument above is highly misleading on many fronts.
GPT-5 is not AGI, but this was entirely unsurprising – expectations were set too high, but nothing like that high. Yes, Altman teased that it was possible AGI could arrive relatively soon, but at no point did Altman claim that GPT-5 would be AGI, or that AGI would arrive in 2025. Approximately zero people had median estimates of AGI in 2025 or earlier, although there are some that have estimated the end of 2026, in particular Anthropic (they via Jack Clark continue to say ‘powerful’ AI buildable by end of 2026, not AGI arriving 2026).
The claim that it ‘couldn’t count reliably’ is especially misleading. Of course GPT-5 can count reliably. The evidence here is a single adversarial example. For all practical purposes, if you ask GPT-5 to count something, it will count that thing.
Old riddles is highly misleading. If you give it an actual old riddle it will nail it. What GPT-5 and other models get wrong are, again, adversarial examples that do not exist ‘in the wild’ but are crafted to pattern match well-known other riddles while having a different answer. Why should we care?
GPT-5 still is not fully reliable but this is framed as it being still highly unreliable, when in most circumstances this is not the case. Yes, if you need many 9s of reliability LLMs are not yet for you, but neither are humans.
AI valuations and stocks continue to be rising not falling.
Yes, the fact that OpenAI chose to have GPT-5 not be a scaled up model does tell us that directly scaling up model size alone has ‘lost steam’ in relative terms due to the associated costs, but this is not news, o1 and o3 (and GPT-4.5) tell us this as well. We are now working primarily on scaling and improving in other ways, but very much there are still plans to scale up more in the future. In the context of all the other facts quoted about other scaled up models, it seems misleading to many readers to not mention that GPT-5 is not scaled up.
Claims here are about failures of GPT-5-Auto or GPT-5-Base, whereas the ‘scaled up’ version of GPT-5 is GPT-5-Pro or at least GPT-5-Thinking.
Gary Marcus clarifies that his actual position is on the order of 8-15 years to AGI, with 2029 being ‘awfully unlikely.’ Which is a highly reasonable timeline, but that seems pretty imminent. That’s crazy soon. That’s something I would want to be betting on heavily, and preparing for at great cost, AGI that soon seems like the most important thing happening in the world right now if likely true?
The article does not give any particular timeline, and does not imply we will never get to AGI, but I very much doubt those reading the post would come away with the impression that things strictly smarter than people are only about 10 years away. I mean, yowsers, right?
The fact about ‘many users asked for the old model back’ is true, but lacking the important context that what users wanted was the old personality, so it risks giving an uninformed user the wrong impression.
To Gary’s credit, he then does hedge, as I included in the quote, acknowledging GPT-5 is indeed a good model representing a step forward. Except then:
And it demands a rethink of government policies and investments that were built on wildly overinflated expectations.
Um, no? No it doesn’t. That’s silly.
The current strategy of merely making A.I. bigger is deeply flawed — scientifically, economically and politically. Many things, from regulation to research strategy, must be rethought.
…
As many now see, GPT-5 shows decisively that scaling has lost steam.
Again, no? That’s not the strategy. Not ‘merely’ doing that. Indeed, a lot of the reason GPT-5 was so relatively unimpressive was GPT-5 was not scaled up so much. It was instead optimized for compute efficiency. There is no reason to have to rethink much of anything in response to a model that, as explained above, was pretty much exactly on the relevant trend lines.
I do appreciate this:
Gary Marcus: However, as I warned in a 2022 essay, “Deep Learning Is Hitting a Wall,” so-called scaling laws aren’t physical laws of the universe like gravity but hypotheses based on historical trends.
As in, the ‘hitting the wall’ claim was back in 2022. How did that turn out? Look at GPT-5, look at what we had available in 2022, and tell me we ‘hit a wall.’
Gary Marcus Does Not Actually Think AGI Is That Non-Imminent
What does ‘imminent’ superintelligence mean in this context?
Gary Marcus (NYT): The chances of A.G.I.’s arrival by 2027 now seem remote.
Notice the subtle goalpost move, as AGI ‘by 2027’ means AGI 2026. These people are gloating, in advance, that someone predicted a possibility of privately developed AGI in 2027 (with a median in 2028, in the AI 2027 scenario OpenBrain tells the government but does not release its AGI right away to the public) and then AGI will have not arrived, to the public, in 2026.
According to my sources (Opus 4.1 and GPT-5 Thinking) even ‘remote’ still means on the order of 2% chance in the next 16 months, implying an 8%-25% chance in 5 years. I don’t agree, but even if one did, that’s hardly something one can safety rule out.
But then, there’s this interaction on Twitter that clarifies what Gary Marcus meant:
Gary Marcus: Anyone who thinks AGI is impossible: wrong.
Anyone who thinks AGI is imminent: just as wrong.
It’s not that complicated.
Peter Wildeford: what if I think AGI is 4-15 years away?
Gary Marcus: 8-15 and we might reach an agreement. 4 still seems awfully unlikely to me. to many core cognitive problems aren’t really being addressed, and solutions may take a while to roll once we find the basic insights we are lacking.
But it’s a fair question.
That’s a highly reasonable position one can take. Awfully unlikely (but thus possible) in four years, likely in 8-15, median timeline of 2036 or so.
Notice that on the timescale of history, 8-15 years until likely AGI, the most important development in the history of history if and when it happens, seems actually kind of imminent and important? That should demand an aggressive policy response focused on what we are going to do when we get to do that, not be treated as a reason to dismiss this?
Imagine saying, in 2015, ‘I think AGI is far away, we’re talking 18-25 years’ and anticipating the looks you would get.
The rest of the essay is a mix of policy suggestions and research direction suggestions. If indeed he is right about research directions, of which I am skeptical, we would still expect to see rapid progress soon as the labs realize this and pivot.
Can Versus Will Versus Always, Typical Versus Adversarial
A common tactic among LLM doubters, which was one of the strategies used in the NYT editorial, is to show a counterexample, where a model fails a particular query, and say ‘model can’t do [X]’ or the classic Colin Fraser line of ‘yep it’s dumb.’
I mean, that’s very funny, but it is rather obvious how it happened with the strawberries thing all over Twitter and thus the training data, and it tells us very little about overall performance.
In such situations, we have to differentiate between different procedures, the same as in any other scientific experiment. As in:
Did you try to make it fail, or try to set it up to succeed? Did you choose an adversarial or a typical example? Did you get this the first time you tried it or did you go looking for a failure? Are you saying it ‘can’t [X]’ because it can’t ever do [X], because it can’t ever do [X] out of the box, it can’t reliably do [X], or it can’t perfectly do [X], etc?
If you conflate ‘I can elicit wrong answers on [X] if I try’ with ‘it can’t do [X]’ then the typical reader will have a very poor picture.
Daniel Litt (responding to NYT article by Gary Marcus that says ‘[GPT-5] failed some simple math questions, couldn’t count reliably’): While it’s true one can elicit poor performance on basic math question from frontier models like GPT-5, IMO this kind of thing (in NYTimes) is likely to mislead readers about their math capabilities.
Derya Unutmaz: AI misinformation at the NYT is at its peak. What a piece of crap “newspaper” it has become. It’s not even worth mentioning the author of this article-but y’all can guess. Meanwhile, just last night I posted a biological method invented by GPT-5 Pro, & I have so much more coming!
Ethan Mollick: This is disappointing. Purposefully underselling what models can do is a really bad idea. It is possible to point out that AI is flawed without saying it can’t do math or count – it just isn’t true.
People need to be realistic about capabilities of models to make good decisions.
I think the urge to criticize companies for hype blends into a desire to deeply undersell what models are capable of. Cherry-picking errors is a good way of showing odd limitations to an overethusiastic Twitter crowd, but not a good way of making people aware that AI is a real factor.
Shakeel: The NYT have published a long piece by Gary Marcus on why GPT-5 shows scaling doesn’t work anymore. At no point does the piece mention that GPT-5 is not a scaled up model.
[He highlights the line from the post, ‘As many now see, GPT-5 shows decisively that scaling has lost steam.’]
Tracing Woods: Gary Marcus is a great demonstration of the power of finding a niche and sticking to it
He had the foresight to set himself up as an “AI is faltering” guy well in advance of the technology advancing faster than virtually anyone predicted, and now he’s the go-to
The thing I find most impressive about Gary Marcus is the way he accurately predicted AI would scale up to an IMO gold performance and then hit a wall (upcoming).
Gary Marcus (replying to Shakeel directly): this is intellectually dishonest, at BEST it at least as big as 4.5 which was intended as 5 which was significantly larger than 4 it is surely scaled up compared to 4 which is what i compared it to.
Shakeel: we know categorically that it is not an OOM scale up vs. GPT-4, so … no. And there’s a ton of evidence that it’s smaller than 4.5.
Gary Marcus (QTing Shakeel): intellectually dishonest reply to my nytimes article.
openai implied implied repeatedly that GPT-5 was a scaled up model. it is surely scaled up relative to GPT-4.
it is possible – openAI has been closed mouth – that it is same size as 4.5 but 4.5 itself was surely scaled relative to 4, which is what i was comparing with.
amazing that after years of discussion of scaling the new reply is to claim 5 wasn’t scaled at all.
Note that if it wasn’t, contra all the PR, that’s even more reason to think that OpenAI knows damn well that is time for leaning on (neuro)symbolic tools and that scaling has reached diminishing returns.
JB: It can’t really be same in parameter count as gpt4.5 they really struggled serving that and it was much more expensive on the API to use
Gary Marcus: so a company valued at $300b that’s raised 10 of billions didn’t have the money to scale anymore even though there whole business plan was scaling? what does that tell you?
I am confused how one can claim Shakeel is being intellectually dishonest. His statement is flat out true. Yes, of course the decision not to scale
It tells me that they want to scale how much they serve the model and how much they do reasoning at inference time, and that this was the most economical solution for them at the time. JB is right that very, very obviously GPT-4.5 is a bigger model than GPT-5 and it is crazy to not realize this.
‘Superforecasters’ Have Reliably Given Unrealistically Slow AI Projections Without Reasonable Justifications
A post like this would be incomplete if I failed to address superforecasters.
I’ve been over this several times before, where superforecasters reliably have crazy slow projections for progress and even crazier predictions that when we do make minds smarter than ourselves that is almost certainly not an existential risk.
Now that the dust settled on models getting IMO Gold in 2025, it is a good time to look back on the fact that domain experts expected less progress in math than we got, and superforecasters expected a lot less, across the board.
Forecasting Research Institute: Respondents—especially superforecasters—underestimated AI progress.
Participants predicted the state-of-the-art accuracy of ML models on the MATH, MMLU, and QuaLITY benchmarks by June 2025.
Domain experts assigned probabilities of 21.4%, 25%, and 43.5% to the achieved outcomes. Superforecasters assigned even lower probabilities: just 9.3%, 7.2%, and 20.1% respectively.
The International Mathematical Olympiad results were even more surprising. AI systems achieved gold-level performance at the IMO in July 2025. Superforecasters assigned this outcome just a 2.3% probability. Domain experts put it at 8.6%.
Note that even Yudkowsky and Christiano had only modest probability that the IMO would fall as early as 2025.
Andrew Critch: Yeah sorry forecasting fam, ya gotta learn some AI if you wanna forecast anything, because AI affects everything and if ya don’t understand it ya forecast it wrong.
Or, as I put it back in the unrelated-to-AI post Rock is Strong:
The security guard has an easy to interpret rock because all it has to do is say “NO ROBBERY.” The doctor’s rock is easy too, “YOU’RE FINE, GO HOME.” This one is different, and doesn’t win the competitions even if we agree it’s cheating on tail risks. It’s not a coherent world model.
Still, on the desk of the best superforecaster is a rock that says “NOTHING EVER CHANGES OR IS INTERESTING” as a reminder not to get overexcited, and to not assign super high probabilities to weird things that seem right to them.
Thus:
Daniel Eth: In 2022, superforecasters gave only a 2.3% chance of an AI system achieving an IMO gold by 2025. Yet this wound up happening. AI progress keeps being underestimated by superforecasters.
I feel like superforecasters are underperforming in AI (in this case even compared to domain experts) because two reference classes are clashing:
• steady ~exponential increase in AI
• nothing ever happens.
And for some reason, superforecasters are reaching for the second.
Hindsight is hindsight, and yes you will get a 98th percentile result 2% of the time. But I think at 2.3% for 2025 IMO Gold, you are not serious people.
That doesn’t mean that being serious people was the wise play here. The incentives might well have been to follow the ‘nothing ever happens’ rock. We still have to realize this, as we can indeed smell what the rock is cooking.
What To Expect When You’re Expecting AI Progress
A wide range of potential paths of AI progress are possible. There are a lot of data points that should impact the distribution of outcomes, and one must not overreact to any one development. One should especially not overreact to not being blown away by progress for a span of a few months. Consider your baseline that’s causing that.
My timelines for hitting various milestones, including various definitions of AGI, involve a lot of uncertainty. I think not having a lot of uncertainty is a mistake.
I especially think saying either ‘AGI almost certainly won’t happen within 5 years’ or ‘AGI almost certainly will happen within 15 years,’ would be a large mistake. There are so many different unknowns involved.
I can see treating full AGI in 2026 as effectively a Can’t Happen. I don’t think you can extend that even to 2027, although I would lay large odds against it hitting that early.
A wide range of medians seem reasonable to me. I can see defending a median as early as 2028, or one that extends to 2040 or beyond if you think it is likely that anything remotely like current approaches cannot get there. I have not put a lot of effort into picking my own number since the exact value currently lacks high value of information. If you put a gun to my head for a typical AGI definition I’d pick 2031, but with no ‘right to be surprised’ if it showed up in 2028 or didn’t show up for a while. Consider the 2031 number loosely held.
To close out, consider once again: Even if you we agreed with Gary Marcus and said 8-15 years, with median 2036? Take a step back and realize how soon and crazy that is.
I agree with Ryan Greenblatt that precise timelines for AGI don’t matter that much in terms of actionable information, but big jumps in the chance of things going crazy within a few years can matter a lot more.
I guess this would have to quantified, but probably I want to simply respond: “Wrong.”
I’ve been told several times by funders something like: “I don’t want to fund reprogenetics; AGI is coming too soon for that to matter.” Probably they are just incoherent, but if they were coherent, maybe they’d mean something like “90% chance of AGI in the next 20 years”. So then it would totally matter for decision-making whether that number is 90% or 40%! I would think.
In fact,
One of the few robust ways out is human intelligence amplification;
How do we know that human intelligence amplification is a robust way out?
Maybe more intelligent humans just race to AGI faster because of coordination problems. Maybe more intelligent terrorists release better bio-weapons. Maybe after every reasonable boost for biological human brains we still aren’t smart enough to solve alignment, perhaps because it’s totally intractable or perhaps because we can’t really get that much smarter, and we muddle along for awhile trying to stop everyone from building AGI until something out of left field wipes us out.
(I do favor human intelligence amplification/augmentation, robust imitation learning, and uploading as particularly promising paths)
I’m unsure whether or not we disagree, because I think our disagreement would be quantitative (probabilities, perhaps relative priorities) rather than qualitative (which considerations are coherent, plausible, relevant, etc.). My basic direct answer would be: Because effectful wise action is more difficult than effectful unwise action, and requires more ideas / thought / reflection, relatively speaking; and because generally humans want to do good things.
Maybe more intelligent humans just race to AGI faster because of coordination problems.
True, maybe.
I think the threshold of brainpower where you can start making meaningful progress on the technical problem of AGI alignment is significantly higher than the threshold where you can start making meaningful progress toward AGI. So more people around / above that threshold is differentially good in terms of technical progress. (It could still be bad overall, e.g. if you think there’s a fixed-rate process of reflection that gets outrun faster in those worlds.)
I think having a lot more super smart people makes other aspects of the situation better. For example, the leaders of AGI capabilities research would be smarter—which is bad in that they make progress faster, but good in that they can consider arguments about X-risk better. Another example: it’s harder to give even a plausible justification for plunging into AGI if you already have a new wave of super smart people making much faster scientific progress in general, e.g. solving diseases.
I think / hope that current memecrafting means that young smart people growing up will have the background sense that AGI is special and is one of the ~three things you really do not mess around with ever. BUT, if in fact it becomes clear that young super bright kids are actually, currently, growing up much more enthusiastic about AGI, that cuts against this a lot, and would significantly cut against my motivation towards reprogenetics (well, it would make me prioritize much higher stuff that affects the memesphere of newborn geniuses).
Maybe more intelligent terrorists release better bio-weapons.
AFAIK this is largely sci-fi? I mean you can find a few examples, but very very few super smart people are trying to do huge amounts of damage like that; and it’s even way harder to get a large and/or very expert group together to try to do that; and without a large/expert group it’s really hard to get super-high-effect things working, especially in biology, like that.
Maybe after every reasonable boost for biological human brains we still aren’t smart enough to solve alignment, perhaps because it’s totally intractable or perhaps because we can’t really get that much smarter, and we muddle along for awhile trying to stop everyone from building AGI until something out of left field wipes us out.
Yeah, true, this is plausible; I still think our chances are significantly in those worlds, but your point stands.
For example, the leaders of AGI capabilities research would be smarter—which is bad in that they make progress faster, but good in that they can consider arguments about X-risk better.
This mechanism seems weak to me. For example, I think the leaders of all AI companies are considerably smarter than me, but I am still doing a better job than they are of reasoning about x-risk. It seems unlikely that making them even smarter would help.
(All else equal, you’re more likely to arrive at correct positions if you’re smarter, but I think the effect is weak.)
Another example: it’s harder to give even a plausible justification for plunging into AGI if you already have a new wave of super smart people making much faster scientific progress in general, e.g. solving diseases.
If enhanced humans could make scientific progress at the same rate as ASI, then ASI would also pose much less of an x-risk because it can’t reliably outsmart humans. (Although it still has the advantage that it can replicate and self-modify.) Realistically I do not think there is any level of genetic modification at which humans can match the pace of ASI.
That all isn’t necessarily to say that human intelligence enhancement is a bad idea; I just didn’t find the given reasons convincing.
We probably disagree a little. I’d bring up a few points. E.g. I’d point out that you and I reason about X-risk better than them in large part due to the fact that we pay attention to people who are smarter than us and who are good at / ahead of the curve on reasoning about X-risk. E.g. I’d point out that more intelligence leads to more intellectual slack (meaning, if you can think faster, a given argument becomes less costly in time (though maybe not in opportunity) to come to understand). E.g. I’d point out that wisdom (in this sense: https://www.lesswrong.com/posts/fzKfzXWEBaENJXDGP/what-is-wisdom-1) is bottlenecked on considering and integrating many possibilities, which is a difficult cognitive task.
But, I agree it’s not that strong a reason.
Realistically I do not think there is any level of genetic modification at which humans can match the pace of ASI.
Yeah I agree, but that’s not the relevant threshold here. More like, can humanity feasibly get smart enough soon enough to be making a bunch of faster progress in material conditions, such that justifications of the form “AGI would give us much faster progress in material conditions” lose most of their (perhaps only apparent) force? I think probably we can.
There were just four reasons right? Your three numbered items, plus “effectful wise action is more difficult than effectful unwise action, and requires more ideas / thought / reflection, relatively speaking; and because generally humans want to do good things”. I think that quotation was the strongest argument. As for numbered item #1, I don’t know why you believe it, but it doesn’t seem clearly false to me, either.
I think the threshold of brainpower where you can start making meaningful progress on the technical problem of AGI alignment is significantly higher than the threshold where you can start making meaningful progress toward AGI.
Simply put, it’s a harder problem. More specifically, it’s got significantly worse feedback signals: it’s easier to tell when / on what tasks your performance is and is not going up, compared to telling when you’ve made a thing that will continue pursuing XYZ as it gets much smarter. You can also tell because progress in capabilities seems to accelerate given more resources, but that is (according to me) barely true or not true in alignment, so far.
My own experience (which I don’t expect you to update much on, but this is part of why I believe these things) is that I’m really smart and as far as I can tell, I’m too dumb to even really get started (cf. https://tsvibt.blogspot.com/2023/09/a-hermeneutic-net-for-agency.html). I’ve worked with people who are smarter than I am, and they also are AFAICT totally failing to address the problem. (To be clear, I definitely don’t think it’s “just about being smart”; but I do think there’s some threshold effect.) It’s hard to even stay focused on the problem for the years that it apparently takes to work through wrong preconceptions, bad ideas, etc., and you (or rather, I, and ~everyone I’ve directly worked with) apparently have to do that in order to understand the problem.
I think the threshold of brainpower where you can start making meaningful progress on the technical problem of AGI alignment is significantly higher than the threshold where you can start making meaningful progress toward AGI.
This is also my guess, but I think required intelligence thresholds (for the individual scientists/inventors involved) are only weak evidence about relative problem difficulty (for society, which seems to me the relevant sort of “difficulty” here).
I’d guess the work of Newton, Maxwell, and Shannon required a higher intelligence threshold-for-making-progress than was required to help invent decent steam engines or rockets, for example, but it nonetheless seems to me that the latter were meaningfully “harder” for society to invent. (Most obviously in the sense that their invention took more person-hours, but I suspect they similarly required more experience of frustration, taking on of personal risk, and other such things which tend to make given populations less likely to solve problems in given calendar-years).
required intelligence thresholds (for the individual scientists/inventors involved) are only weak evidence about relative problem difficulty (for society, which seems to me the relevant sort of “difficulty” here).
This sounds right, yeah. If I had to guess, I would guess AGI alignment is both kinds of problem (Maxwell/Faraday equations, and rockets).
Oh, IDK. Thermonuclear weapons and viral human infectiousness gain of function research? I just mean, there’s probably a few things that we want everyone to know not to do; the Noahide Laws, if you will.
There is some definition of intelligence, where by that definition sufficiently intelligent humans wouldn’t build AGI that kills them and all their children, simply because getting killed by robots would suck. Of course, it’s not at all obvious that genetic engineering would get pointed at that definition of intelligence.
all of which one notes typically run on three distinct sets of chips (Nvidia for GPT-5, Amazon Trainium for Anthropic and Google TPUs for Gemini)
I was previously under the impression that ~all AI models ran on Nvidia, and that was (probably) a big part of why Nvidia now has the largest market cap in the world. If only one out of three of the biggest models uses Nvidia, that’s a massive bear signal relative to what I believed two minutes ago. And it looks like the market isn’t pricing this in at all, unless I’m missing something.
(I assume I’m missing something because markets are usually pretty good at pricing things in.)
xAI and Meta still use Nvidia. Almost every non-frontier-lab, non-Chinese AI chip consumer uses Nvidia
And Alphabet, Amazon, and Broadcom, the companies that design TPU and Trainium, have the 4th, 5th, and 7th biggest market caps in the world.
I think it’s possible that the market is underpricing how big a deal Anthropic and Google DeepMind, and other frontier labs that might follow in their footsteps, are for overall AI chip demand. But it’s not super obvious.
Google TPUs have been competitive with Nvidia GPUs for years, but Google did not sell its TPUs, instead only renting them out via GCP, until very recently as it is now starting to actually sell them too.
Other GPUs and custom silicon like Trainium are used for inference these days, but training is almost exclusively done with Nvidia GPUs and Google TPUs. It’s pretty easy to take a trained model and make it possible to do inference with it using different chips, as we see for example with open-weight models being used on Apple silicon, and DeepSeek models being served on Huawei Ascend GPUs.
I still expect the majority of inference being done today to be on Nvidia GPUs, a notable portion on TPUs, and then some non-negligible amount on other chips. (I haven’t actually estimated this though.) Very roughly, I think in 1-3 years Nvidia will have a lot of competition for inference compute, though maybe not that much competition for training compute apart from TPUs, since CUDA is somewhat of a hard-to-overcome moat.
Google DeepMind uses Nvidia very sparingly if at all. AlphaFold 3 was trained using A100s but that’s the only recent use of Nvidia by GDM I’ve heard of. I think Google proper, outside GDM, primarily uses TPUs over GPUs for internal workloads, but I’m less sure about that.
Google does buy a lot of Nvidia chips for its cloud division, to rent out to other companies.
That shouldn’t matter too much for stock price, right? If Google is currently rolling out its own TPUs then the long-term expectation should be that Nvidia won’t be making significant revenue off of Google’s AI.
Yup, that is indisputable. Further, it’s possible that LLMs scale to a transformative technology, to the Singularity, and/or to omnicide. (Though it’s not-that-likely, on my model; I think I still give this cluster of scenarios ~20%.)
Including Towards AGI
I don’t think so. I’m more sure of LLMs not scaling to AGI than ever.
Doubtlessly part of it is a prompting-skill issue on my part. Still, I don’t think the gap between the performance I’ve managed to elicit and the top performance is that big. For one, my experience echoes those of many other mathematicians/software engineers, and also METR’s results (on agency horizons, often-negative productivity effects, and LLM-code-is-not-mergeable).
These things have no clue what’s going on, there’s nobody in there. Whatever algorithms they are running, those are not the algorithms of a general intelligence, and there’s no reason to believe they’re on some sort of “sliding scale” to it.
I’ve still found them useful. If METR’s trend actually holds, they will indeed become increasingly more useful. If it actually holds to >1-month tasks, they may actually become transformative within the decade. Perhaps they will automate the within-paradigm AI R&D[1], and it will lead to a software-only Singularity that will birth an AI model capable of eradicating humanity.
But that thing will still not be an AGI.This would be the face of our extinction:
We should pause to note that a Clippy² still doesn’t really think or plan. It’s not really conscious. It is just an unfathomably vast pile of numbers produced by mindless optimization starting from a small seed program that could be written on a few pages. [...] When it ‘plans’, it would be more accurate to say it fake-plans; when it ‘learns’, it fake-learns; when it ‘thinks’, it is just interpolating between memorized data points in a high-dimensional space, and any interpretation of such fake-thoughts as real thoughts is highly misleading; when it takes ‘actions’, they are fake-actions optimizing a fake-learned fake-world, and are not real actions, any more than the people in a simulated rainstorm really get wet, rather than fake-wet. (The deaths, however, are real.)
This seems unlikely to me on balance. I think compute scaling will run out well before that. I think it’s possible to scale LLMs far enough to achieve this, but that it’s “possible” in a very useless way. A Jupiter Brain-sized LLM can likely do it (and probably just an Earth Brain-sized one), but we are not building a Jupiter Brain-sized LLM.
But maybe I’m wrong; maybe we do have enough compute.
1. Imagine an infinitely large branching lookup table/flowchart. It maps all possible sequences of observations to sequences of actions picked to match the behavior of a general intelligence. Given a hypercomputer to run it, would that thing be effectively an AGI, for all intents and purposes? Sure. But would it actually be an AGI, structurally? Nope.
Remove the hypercomputer assumption and switch an infinitely large flowchart to a merely unfathomably large one. Suddenly the flowchart stops implementing general intelligence exactly, is relegated to an approximation of it. And that approximation is not that good, and rapidly degrades as you scale the available compute down.
Can a Galaxy Brain-scale flowchart like this kill humanity? Maybe, maybe not: combinatorial numbers are larger than astronomical numbers. But there are numbers big enough that a flowchart of that size would be able to ape an AGI’s behavior well enough to paperclip us.
2. Imagine Cyc. It was (is) an effort to build AGI. Its core motivation is as follows: There is no “simple algorithm for intelligence”. Intelligence is a mess of ad-hoc heuristics, and generality/autonomous learning emerges from those heuristics once some critical mass is attained. The way to AGI, then, is to do the hard, dirty work of inputting that critical mass of heuristics into your AI system (instead of lazily hoping for some sort of algorithmic shortcut), and eventually it would take off and start outputting novel discoveries:
The more knowledge Cyc has, the easier it is for Cyc to learn more. At first, it must be spoon-fed knowledge with every entry entered by hand. As it builds a basic understanding of the world, it would be able to parse sentences half-way from natural language to logic, and the ontologists would help finish the job, and the more it knew, the better it could parse, saving more time, until it would start parsing without human help. On that day, the “knowledge pump” would finally, triumphantly, be primed, and Cyc would start pumping and pumping, and more knowledge would just keep pouring out without any exhaustion, ushering a new golden age.
To realize this vision, Cycorp hired tons of domain experts to extract knowledge from:
Cyc would try to solve a problem, and fails by timing out. The ontologists at Cyc would call up a human expert and ask, “How did you do this?” and the expert would explain how they would solve it with quick rules of thumb, which the ontologists would write into Cyc, resulting in more assertions, and possibly more inference engines.
And they scaled it to a pretty ridiculous degree:
The number of assertions grew to 30M, the cost grew to $200M, with 2000 person-years.
And they had various fascinating exponential scaling laws:
[T]he growth of assertions is roughly exponential, doubling every 6 years. At this rate, in 2032 Cyc can expect to reach 100M assertions, the hoped-for point at which Cyc would know as much as a typical human.
But that project seems doomed. Sure, much like the flowchart, if scaled sufficiently far, this AGI-as-coded-by-ancient-Greek-philosophers would approximate a general intelligence well enough to be interesting/dangerous. But it would not have the algorithms of a general intelligence internally, and as you scale the available compute down, the approximation’s quality would degrade rapidly.
A Jupiter Brain-sized Cyc can probably defeat humanity. But Cycorp does not have Jupiter Brain-scale resources.
When we see frontier models improving at various benchmarks we should think not just of increased scale and clever ML research ideas but billions of dollars spent paying PhDs, MDs, and other experts to write questions and provide example answers and reasoning targeting these precise capabilities. With the advent of outcome based RL and the move towards more ‘agentic’ use-cases, this data also includes custom RL environments which are often pixel-perfect replications of commonly used environments such as specific websites like Airbnb or Amazon, browsers, terminals and computer file-systems, and so on alongside large amounts of human trajectories exhaustively covering most common use-cases with these systems.
In a way, this is like a large-scale reprise of the expert systems era, where instead of paying experts to directly program their thinking as code, they provide numerous examples of their reasoning and process formalized and tracked, and then we distill this into models through behavioural cloning.
Indeed, this is exactly like a large-scale reprise of the expert systems era. The same notion that there’s no simple algorithm for intelligence, that it’s just a mess of heuristics; that attaining AGI just requires the “hard work” of scaling compute and data (instead of lazy theorizing about architectures!); the expectation that if they just chisel-in enough domain-specific expertise into DL models, generality would spontaneously emerge; the hiring of experts to extract that knowledge from; the sheer ridiculous scale of the endeavor. The only thing that’s different is handing off the coding to the SGD (which does lead to dramatic efficiency improvements).
Does that paradigm scale, in the limit of infinite compute, to perfectly approximating the external behavior of generally intelligent entities? Yes. But any given LLM, no matter how big, would not be structured as a general intelligence internally, and the approximation’s quality would degrade rapidly as you scale it down.
But how rapidly? A Jupiter Brain-sized LLM can probably kill us. But can an Earth Brain-sized, or, say, a “10% of US’ GDP”-sized LLM, do it?
I don’t know. Maybe, maybe not. But eyeballing the current trends, I expect not.
Now, a fair question to ask here is: does this matter? If LLMs aren’t “real general intelligences”, but it’s still fairly plausible that they’re good-enough AGI approximations to drive humanity extinct, shouldn’t our policy be the same in both cases?
To a large extent, yes. But building gears-level models of this whole thing still seems important.
“Within-paradigm” as in, they will not be able to switch themselves to an innovative neurosymbolic architecture, like IIRC happens in AI-2027. Just speed up the existing algorithmic-efficiency, data-quality, and RL-environment scaling laws.
I think the IMO results strongly suggest that AGI-worthiness of LLMs at current or similar scale will no longer be possible to rule out (with human efforts). Currently absence of continual learning makes them clearly non-AGI, and in-context learning doesn’t necessarily get them there with feasible levels of scaling. But some sort of post-training based continual learning likely won’t need more scale, and the difficulty of figuring it out remains unknown, as it only got in the water supply as an important obstruction this year.
The key things from solving IMO-level problems (doesn’t matter if it’s proper gold or not) is difficulty reasonably close to the limit of human ability in a somewhat general domain, and correctness grading being somewhat vague (natural language proofs, not just answers). Which describes most technical problems, so it’s evidence that for most technical problems of various other kinds similar methods of training are not far off from making LLMs capable of solving them, and that LLMs don’t need much more scale to make that happen. (Perhaps they need a little bit more scale to solve such problems efficiently, without wasting a lot of parallel compute on failed attempts.)
More difficult problems that take a lot of time to solve (and depend on learning novel specialized ideas) need continual learning to tackle them. Currently only in-context learning is a straightforward way of getting there, by using contexts with millions or tens of millions of tokens of tool-using reasoning traces, equivalent to years of working on a problem for a human. This doesn’t work very well, and it’s unclear if it will work well enough within the remaining scaling in the near term, with 5 GW training systems and the subsequent slowdown. But it’s not ruled out that continual learning can be implemented in some other way, by automatically post-training the model, in which case it’s not obvious that there is anything at all left to figure out before LLMs at a scale similar to today’s become AGIs.
The way you’re using this concept is poisoning your mind. Generality of a domain does imply that if you can do all the stuff in that domain, then you are generally capable (and, depending, that could imply general intelligence; e.g. if you’ve ruled out GLUT-like things). But if you can do half of the things in the domain and not the other half, then you have to ask whether you’re exhibiting general competence in that domain, vs. competence in some sub-domain and incompetence in the general domain. Making this inference enthymemically is poisoning your mind.
For example, suppose that X is “self-play”. One important thing about self-play is that it’s an infinite source of data, provided in a sort of curriculum of increasing difficulty and complexity. Since we have the idea of self-play, and we have some examples of self-play that are successful (e.g. AlphaZero), aren’t we most of the way to having the full power of self-play? And isn’t the full power of self-play quite powerful, since it’s how evolution made AGI? I would say “doubtful”. The self-play that evolution uses (and the self-play that human children use) is much richer, containing more structural ideas, than the idea of having an agent play a game against a copy of itself.
Most instances of a category are not the most powerful, most general instances of that category. So just because we have, or will soon have, some useful instances of a category, doesn’t strongly imply that we can or will soon be able to harness most of the power of stuff in that category. I’m reminded of the politician’s syllogism: “We must do something. This is something. Therefore, we must do this.”.
What I meant by general domain is that it’s not overly weird in the mental moves that are relevant there, so training methods that can create something that wins IMO are probably not very different from training methods that can create things that solve many other kinds of problems. It’s still a bit weird, high school math with olympiad addons is still a somewhat narrow toolkit, but for technical problems of many other kinds the mental move toolkits are not qualitatively different, even if they are larger. The claim is that solving IMO is a qualitatively new milestone from the point of view of this framing, it’s evidence about AGI potential of LLMs at the near-current scale in a way that previous results were not.
I agree that there could still be gaps and “generality” of IMO isn’t a totalizing magic that prevents existence of crucial remaining gaps. I’m not strongly claiming there aren’t any crucial gaps, just that with IMO as an example it’s no longer obvious there are any, at least as long as the training methods used for IMO can be adopted to those other areas, which isn’t always obviously the case. And of course continual learning could prove extremely hard. But there also isn’t strong evidence that it’s extremely hard yet, because it wasn’t a focus for very long while LLMs at current levels of capabilities were already available. And the capabilities of in-context learning with 50M token contexts and even larger LLMs haven’t been observed yet.
So it’s a question of calibration. There could always be substantial obstructions such that it’s no longer obvious that they are there even though they are. But also at some point there actually aren’t any. So always suspecting currently unobservable crucial obstructions is not the right heuristic either, the prediction of when the problem could actually be solved needs to be allowed to respond to some sort of observable evidence.
What I meant by general domain is that it’s not overly weird in the mental moves that are relevant there, so training methods that can create something that wins IMO are probably not very different from training methods that can create things that solve many other kinds of problems.
I took you to be saying
math is a general domain
IMO is fairly hard math
LLMs did the IMO
therefore LLMs can do well in a general domain
therefore probably maybe LLMs are generally intelligent.
But maybe you instead meant
working out math problems applying known methods is a general domain
?
Anyway, “general domain” still does not make sense here. The step from 4 to 5 is not supported by this concept of “general domain” as you’re applying it here.
It’s certainly possible—but “efficient continual learning” sounds a lot like AGI! So, to say that is the thing missing for AGI is not such a strong statement about the distance left, is it?
I don’t think this is moving goalposts on the current paradigm. The word “continual” seems to have basically replaced “online” since the rise of LLMs—perhaps because they manage a bit of in-context learning which is sort-of-online but not-quite-continual and makes a distinction necessary. However, “a system that learns efficiently over the course of its lifetime” is basically what we always expected from AGI, e.g. this is roughly what Hofstadter claimed was missing in “Fluid Concepts and Creative Analogies” as far back as 1995.
I agree that we can’t rule out roughly current scale LLMs reaching AGI. I just want to guard against the implication (which others may read into your words) that this is some kind of default expectation.
The question for this subthread is the scale of LLMs necessary for first AGIs, what the IMO results say about that. Continual learning through post-training doesn’t obviously require more scale, and IMO is an argument about the current scale being almost sufficient. It could be very difficult conceptually/algorithmically to figure out how to actually do continual learning with automated post-training, but that still doesn’t need to depend on more scale for the underlying LLM, that’s my point about the implications of the IMO results. Before those results, it was far less clear if the current (or near term feasible) scale would be sufficient for the neural net cognitive engine part of the AGI puzzle.
It could be that LLMs can’t get there at the current scale because LLMs can’t get there at any (potentially physical) scale with the current architecture.
So in some sense yes that wouldn’t be a prototypical example of a scale bottleneck.
I’ve still found them useful. If METR’s trend actually holds, they will indeed become increasingly more useful. If it actually holds to >1-month tasks, they may actually become transformative within the decade. Perhaps they will automate the within-paradigm AI R&D, and it will lead to a software-only Singularity that will birth an AI model capable of eradicating humanity.
But that thing will still not be an AGI. This would be the face of our extinction:
We should pause to note that a Clippy² still doesn’t really think or plan. It’s not really conscious. It is just an unfathomably vast pile of numbers produced by mindless optimization starting from a small seed program that could be written on a few pages. [...] When it ‘plans’, it would be more accurate to say it fake-plans; when it ‘learns’, it fake-learns; when it ‘thinks’, it is just interpolating between memorized data points in a high-dimensional space, and any interpretation of such fake-thoughts as real thoughts is highly misleading; when it takes ‘actions’, they are fake-actions optimizing a fake-learned fake-world, and are not real actions, any more than the people in a simulated rainstorm really get wet, rather than fake-wet. (The deaths, however, are real.)
This seems unlikely to me on balance. I think compute scaling will run out well before that. I think it’s possible to scale LLMs far enough to achieve this, but that it’s “possible” in a very useless way. A Jupiter Brain-sized LLM can likely do it (and probably just an Earth Brain-sized one), but we are not building a Jupiter Brain-sized LLM.
Uh… what? Why do you define “AGI” through its internals, and not through its capabilities? That seems to be a very strange standard, and an unhelpful one. If I didn’t have more context I’d be suspecting you of weird goalpost-moving. I personally care whether
AI systems are created that lead to human extinction, broadly construed, and
Those AI systems then, after leading to human extinction, fail to self-sustain and “go extinct” themselves
Maybe you were gesturing at AIs that result in both (1) and (2)??
And the whole reason why we talk about AGI and ASI so much here on Less Wrong dot com is because those AI systems could lead to drastic changes of the future of the universe. Otherwise we wouldn’t really be interested in them, and go back to arguing about anthropics or whatever.
Whether some system is “real” AGI based on its internals is not relevant to this question. (The internals of AI systems are of course interesting in themselves, and for many other reasons.)
(As such, I read that paragraph by gwern to be sarcastic, and mocking people who insist that it’s “not really AGI” if it doesn’t function in the way they believe it should work.)
Now, a fair question to ask here is: does this matter? If LLMs aren’t “real general intelligences”, but it’s still fairly plausible that they’re good-enough AGI approximations to drive humanity extinct, shouldn’t our policy be the same in both cases?
I think if the lightcone looks the same, it should, if it doesn’t, our policies should look different. It would matter if the resulting AIs fall over and leave the lightcone in the primordial state, which looks plausible from your view?
Why do you define “AGI” through its internals, and not through its capabilities?
For the same reason we make a distinction between the Taylor-polynomial approximation of a function, and that function itself? There is a “correct” algorithm for general intelligence, which e. g. humans use, and there are various ways to approximate it. Approximants would behave differently from the “real thing” in various ways, and it’s important to track which one you’re looking at.
It would matter if the resulting AIs fall over and leave the lightcone in the primordial state, which looks plausible from your view?
That’s not the primary difference, in my view. My view is simply that there’s a difference between an “exact AGI” and AGI-approximants at all. That difference can be characterized as “whether various agent-foundations results apply to that system universally / predict its behavior universally, or only in some limited contexts”. Is it well-modeld as an agent, or is modeling it as an agent itself a drastically flawed approximation of its behavior that breaks down in some contexts?
And yes, “falls over after the omnicide” is a plausible way for AGI-approximants to differ from an actual AGI. Say, their behavior can be coherent at timescales long enough to plot humanity’s demise (e. g., a millennium), but become incoherent at 100x that time-scale. So after a million years, their behavior devolves into noise, and they self-destruct or just enter a stasis. More likely, I would expect that if a civilization of those things ever runs into an actual general superintelligence (e. g., an alien one), the “real deal” would rip through them like it would through humanity (even if they have a massive resource advantage, e. g. 1000x more galaxies under their control).
Some other possible differences:
Capability level as a function of compute. Approximants can be drastically less compute-efficient, in a quantity-is-a-quality-of-its-own way.
Generality. Approximants can be much “spikier” in their capabilities than general intelligences, genius-level in some domains/at some problems and below-toddler in other cases, in a way that is random, or fully determined by their training data.
Autonomy. Approximants can be incapable of autonomously extending their agency horizons, or generalizing to new domains, or deriving new domains (“innovating”) without an “actual” general intelligence to guide them.
(Which doesn’t necessarily prevent them from destroying humanity. Do you need to “innovate” to do so? I don’t know that you do.)
None of this may matter for the question of “can this thing kill humanity?”. But, like, I think there’s a real difference there that cuts reality at the joints, and tracking it is important.
In particular, it’s important for the purposes of evaluating whether we in fact do live in a world where a specific AGI-approximant scales to omnicide given realistic quantities of compute, or whether we don’t.
For example, consider @Daniel Kokotajlo’s expectation that METR’s task horizons would go superexponential at some point. I think it’s quite likely if the LLM paradigm scales to an actual AGI, if it is really acquiring the same generality/agency skills humans have. If not, however, if it is merely some domain-limited approximation of AGI, it may stay at the current trend forever (or, well, as long as the inputs keep scaling the same way), no matter how counter-intuitive that may feel.
Indeed, “how much can we rely on our intuitions regarding agents/humans when making predictions about a given AI paradigm?” may be a good way to characterize the difference here. Porting intuitions about agents lets us make predictions like “superexponential task-horizon scaling” and “the sharp left turn” and “obviously the X amount of compute and data ought to be enough for superintelligence”. But if the underlying system is not a “real” agent in many kinds of ways, those predictions would start becoming suspect. (And I would say the current paradigm’s trajectory has been quite counter-intuitive, from this perspective. My intuitions broke around GPT-3.5, and my current models are an attempt to deal with that.)
This, again, may not actually bear on the question of whether the given system scales to omnicide. The AGI approximant’s scaling laws may still be powerful enough. But it determines what hypotheses we should be tracking about this, what observations we should be looking for, and how we should update on them.
And the whole reason why we talk about AGI and ASI so much here on Less Wrong dot com is because those AI systems could lead to drastic changes of the future of the universe.
Things worth talking about are the things that can lead to drastic changes of the future of the universe, yes. And AGI is one of those things, so we should talk about it. But I think defining “is an AGI” as “any system that can lead to drastic changes of the future of the universe” is silly, no? Words mean things. A sufficiently big antimatter bomb is not an AGI, superviruses are not AGIs, and LLMs can be omnicide-capable (and therefore worth talking about) without being AGIs as well.
For AGIs and agents, many approximations are interchangeable with the real thing, because they are capable of creating the real thing in the world as a separate construct, or converging to it in behavior. Human decisions for example are noisy and imprecise, but for mathematical or engineering questions it’s possible to converge on arbitrary certainty and precision. In a similar way, humans are approximations to superintelligence, even though not themselves superintelligence.
Thus many AGI-approximations may be capable of becoming or creating the real thing eventually. Not everything converges, but the distinction should be about that, not about already being there.
Right, this helps. I guess I don’t want to fight about definitions here. I’d just say “ah, any software that you can run on computers that can cause the extinction of humanity even if humans try to prevent it” would fulfill the sufficiency criterion for AGIniplav, and then there’s different classes of algorithms/learners/architectures that fulfill that criterion, and have different properties.
(I wouldn’t even say that “can omnicide us” is necessary for AGIniplav membership—”my AGI timelines are −3 years”30%.)
One crux here may be that you are more certain that “AGI” is a thing? My intuition goes more in the direction of “there’s tons of different cognitive algorithms, with different properties, among the computable ones they’re on a high-dimensional set of spectra, some of which in aggregate may be called ‘generality’.”
I think no free lunch theorems point at this, as well as the conclusions from this post. Solomonoff inductors’ beliefs look like they’d look messy and noisy, and current neural networks look messy and noisy too. I personally would find it more beautiful and nice if Thinking was a Thing, but I’ve received more evidence I interpret as “it’s actually not”.
But my questions have been answered to the degree I wanted them answered, thanks :-)
ah, any software that you can run on computers that can cause the extinction of humanity even if humans try to prevent it would fulfill the sufficiency criterion for AGIniplav
A flight control program directing an asteroid redirection rocket, programmed to find a large asteroid and steer it to crash into Earth seems like the sort of thing which could be “software that you can run on computers that can cause the extinction of humanity” but not “AGI”.
I think it’s relevant that “kill all humans” is a much easier target than “kill all humans in such a way that you can persist and grow indefinitely without them”.
I’d just say “ah, any software that you can run on computers that can cause the extinction of humanity even if humans try to prevent it” would fulfill the sufficiency criterion for AGIniplav
Fair.
One crux here may be that you are more certain that “AGI” is a thing?
I’ve still found them useful. If METR’s trend actually holds, they will indeed become increasingly more useful. If it actually holds to >1-month tasks, they may actually become transformative within the decade. Perhaps they will automate the within-paradigm AI R&D[1], and it will lead to a software-only Singularity that will birth an AI model capable of eradicating humanity.
But that thing will still not be an AGI.
No offense, but to me it seems like you are being overly pedantic with a term that most people use differently. If you surveyed people on lesswrong, as well as AI researchers, I’m pretty sure almost everyone (>90% of people) would call an AI model capable enough to eradicate humanity an AGI.
If you surveyed people on lesswrong, as well as AI researchers, I’m pretty sure almost everyone (>90% of people) would call an AI model capable enough to eradicate humanity an AGI
Well, if so, I think they would be very wrong. See a more in-depth response here.
AI discourse doesn’t get enough TsviBT-like vitamins, so their projected toxicity if overdosed is not relevant. A lot of interventions are good in moderation, so arguments about harm from saturation are often counterproductive if taken as a call to any sort of immediately relevant action rather than theoretical notes about hypothetical future conditions.
I disagree with this, and in particular the move by TsviBT of arguing that today’s AI has basically zero relevance to what AGI needs to have/claiming that LP25 programs aren’t actually creative, and more generally setting up a hard border between today’s AI and AGI is a huge amount of AI discourse, especially on claims that AI will soon hit a wall for xyz reasons.
Jack Clark: I continue to think things are pretty well on track for the sort of powerful AI system defined in machines of loving grace – buildable end of 2026, running many copies 2027. Of course, there are many reasons this could not occur, but lots of progress so far.
jeez, always disconcerting when people with more relevant info to me have shorter timelines than me
These are two very different predictions. The original ‘by 2030’ prediction is Obvious Nonsense unless you expect superintelligence and a singularity, probably involving us all dying. There’s almost zero chance otherwise. Technology does not diffuse that fast.
To be fair to me this immediately evoked more the image of Amazon leveraging its specific scale economies, not having e.g. generalist humanoid robots with AGI, but mega-depots, auto vans, delivery drones etc. that each perform one specific function within a mechanism that works because it’s all Amazon stuff interfacing with other Amazon stuff. That said, still a bold prediction that I wouldn’t buy much, but less wild.
GPT-5 had a botched rollout and was only an incremental improvement over o3, o3-Pro and other existing OpenAI models, but was very much on trend and a very large improvement over the original GPT-4.
I think that’s underselling the issue. GPT-5 is not a straight improvement over o3, o3-Pro and other existing OpenAI models. There are tasks it does better and other tasks it does worse.
I started out giving GPT-5 the doubt but when when it comes to tasks that require some creativity like text and headline writing I went back to o3 as GPT-5 seems worse for the task.
Notice the subtle goalpost move, as AGI ‘by 2027’ means AGI 2026. [...] in the next 16 months
Opus 4.1, GPT-5, and Gemini 2.5 Pro all claim that “by 2027” unambiguously means “by end of 2027″. So at the very least the meaning can’t be unambiguously “by start of 2027”, even if this usage sometimes occurs.
It is certainly true that Dario Amodei’s early predictions of AI writing most of the code, as in 90% of all code within 3-6 months after March 11. This was not a good prediction, because the previous generation definitely wasn’t ready and even if it had been that’s not how diffusion works, and has been proven definitively false, it’s more like 40% of all code generated by AI and 20%-25% of what goes into production.
I think it was a bad prediction, yes, but mainly because it was ambiguous about the meaning of “writes 90% of the code”, it’s still not clear if he was claiming at the time that this would be the case at Anthropic (where I could see that being the case) or in the wider economy. So a bad prediction because imprecise, but not necessarily because it was wrong.

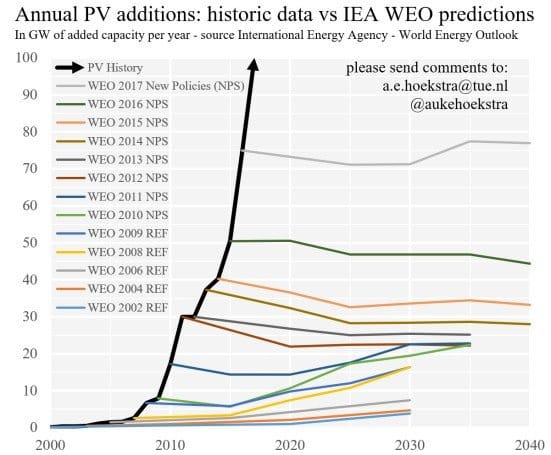

I guess this would have to quantified, but probably I want to simply respond: “Wrong.”
I’ve been told several times by funders something like: “I don’t want to fund reprogenetics; AGI is coming too soon for that to matter.” Probably they are just incoherent, but if they were coherent, maybe they’d mean something like “90% chance of AGI in the next 20 years”. So then it would totally matter for decision-making whether that number is 90% or 40%! I would think.
In fact,
One of the few robust ways out is human intelligence amplification;
the only method that we can have reasonable confidence can be made to work any time soon is reprogenetics (https://www.lesswrong.com/posts/jTiSWHKAtnyA723LE/overview-of-strong-human-intelligence-amplification-methods);
you don’t have to be super confident that AGI will take 50 years to think reprogenetics is worthwhile (https://tsvibt.blogspot.com/2022/08/the-benefit-of-intervening-sooner.html); and
reprogenetics is funding constrained.
How do we know that human intelligence amplification is a robust way out?
Maybe more intelligent humans just race to AGI faster because of coordination problems. Maybe more intelligent terrorists release better bio-weapons. Maybe after every reasonable boost for biological human brains we still aren’t smart enough to solve alignment, perhaps because it’s totally intractable or perhaps because we can’t really get that much smarter, and we muddle along for awhile trying to stop everyone from building AGI until something out of left field wipes us out.
(I do favor human intelligence amplification/augmentation, robust imitation learning, and uploading as particularly promising paths)
I’m unsure whether or not we disagree, because I think our disagreement would be quantitative (probabilities, perhaps relative priorities) rather than qualitative (which considerations are coherent, plausible, relevant, etc.). My basic direct answer would be: Because effectful wise action is more difficult than effectful unwise action, and requires more ideas / thought / reflection, relatively speaking; and because generally humans want to do good things.
True, maybe.
I think the threshold of brainpower where you can start making meaningful progress on the technical problem of AGI alignment is significantly higher than the threshold where you can start making meaningful progress toward AGI. So more people around / above that threshold is differentially good in terms of technical progress. (It could still be bad overall, e.g. if you think there’s a fixed-rate process of reflection that gets outrun faster in those worlds.)
I think having a lot more super smart people makes other aspects of the situation better. For example, the leaders of AGI capabilities research would be smarter—which is bad in that they make progress faster, but good in that they can consider arguments about X-risk better. Another example: it’s harder to give even a plausible justification for plunging into AGI if you already have a new wave of super smart people making much faster scientific progress in general, e.g. solving diseases.
I think / hope that current memecrafting means that young smart people growing up will have the background sense that AGI is special and is one of the ~three things you really do not mess around with ever. BUT, if in fact it becomes clear that young super bright kids are actually, currently, growing up much more enthusiastic about AGI, that cuts against this a lot, and would significantly cut against my motivation towards reprogenetics (well, it would make me prioritize much higher stuff that affects the memesphere of newborn geniuses).
AFAIK this is largely sci-fi? I mean you can find a few examples, but very very few super smart people are trying to do huge amounts of damage like that; and it’s even way harder to get a large and/or very expert group together to try to do that; and without a large/expert group it’s really hard to get super-high-effect things working, especially in biology, like that.
Yeah, true, this is plausible; I still think our chances are significantly in those worlds, but your point stands.
This mechanism seems weak to me. For example, I think the leaders of all AI companies are considerably smarter than me, but I am still doing a better job than they are of reasoning about x-risk. It seems unlikely that making them even smarter would help.
(All else equal, you’re more likely to arrive at correct positions if you’re smarter, but I think the effect is weak.)
If enhanced humans could make scientific progress at the same rate as ASI, then ASI would also pose much less of an x-risk because it can’t reliably outsmart humans. (Although it still has the advantage that it can replicate and self-modify.) Realistically I do not think there is any level of genetic modification at which humans can match the pace of ASI.
That all isn’t necessarily to say that human intelligence enhancement is a bad idea; I just didn’t find the given reasons convincing.
We probably disagree a little. I’d bring up a few points. E.g. I’d point out that you and I reason about X-risk better than them in large part due to the fact that we pay attention to people who are smarter than us and who are good at / ahead of the curve on reasoning about X-risk. E.g. I’d point out that more intelligence leads to more intellectual slack (meaning, if you can think faster, a given argument becomes less costly in time (though maybe not in opportunity) to come to understand). E.g. I’d point out that wisdom (in this sense: https://www.lesswrong.com/posts/fzKfzXWEBaENJXDGP/what-is-wisdom-1) is bottlenecked on considering and integrating many possibilities, which is a difficult cognitive task.
But, I agree it’s not that strong a reason.
Yeah I agree, but that’s not the relevant threshold here. More like, can humanity feasibly get smart enough soon enough to be making a bunch of faster progress in material conditions, such that justifications of the form “AGI would give us much faster progress in material conditions” lose most of their (perhaps only apparent) force? I think probably we can.
All of them, or just these two?
There were just four reasons right? Your three numbered items, plus “effectful wise action is more difficult than effectful unwise action, and requires more ideas / thought / reflection, relatively speaking; and because generally humans want to do good things”. I think that quotation was the strongest argument. As for numbered item #1, I don’t know why you believe it, but it doesn’t seem clearly false to me, either.
So I wrote:
Simply put, it’s a harder problem. More specifically, it’s got significantly worse feedback signals: it’s easier to tell when / on what tasks your performance is and is not going up, compared to telling when you’ve made a thing that will continue pursuing XYZ as it gets much smarter. You can also tell because progress in capabilities seems to accelerate given more resources, but that is (according to me) barely true or not true in alignment, so far.
My own experience (which I don’t expect you to update much on, but this is part of why I believe these things) is that I’m really smart and as far as I can tell, I’m too dumb to even really get started (cf. https://tsvibt.blogspot.com/2023/09/a-hermeneutic-net-for-agency.html). I’ve worked with people who are smarter than I am, and they also are AFAICT totally failing to address the problem. (To be clear, I definitely don’t think it’s “just about being smart”; but I do think there’s some threshold effect.) It’s hard to even stay focused on the problem for the years that it apparently takes to work through wrong preconceptions, bad ideas, etc., and you (or rather, I, and ~everyone I’ve directly worked with) apparently have to do that in order to understand the problem.
This is also my guess, but I think required intelligence thresholds (for the individual scientists/inventors involved) are only weak evidence about relative problem difficulty (for society, which seems to me the relevant sort of “difficulty” here).
I’d guess the work of Newton, Maxwell, and Shannon required a higher intelligence threshold-for-making-progress than was required to help invent decent steam engines or rockets, for example, but it nonetheless seems to me that the latter were meaningfully “harder” for society to invent. (Most obviously in the sense that their invention took more person-hours, but I suspect they similarly required more experience of frustration, taking on of personal risk, and other such things which tend to make given populations less likely to solve problems in given calendar-years).
This sounds right, yeah. If I had to guess, I would guess AGI alignment is both kinds of problem (Maxwell/Faraday equations, and rockets).
what are the other ~two?
Oh, IDK. Thermonuclear weapons and viral human infectiousness gain of function research? I just mean, there’s probably a few things that we want everyone to know not to do; the Noahide Laws, if you will.
There is some definition of intelligence, where by that definition sufficiently intelligent humans wouldn’t build AGI that kills them and all their children, simply because getting killed by robots would suck. Of course, it’s not at all obvious that genetic engineering would get pointed at that definition of intelligence.
This caught me off guard:
I was previously under the impression that ~all AI models ran on Nvidia, and that was (probably) a big part of why Nvidia now has the largest market cap in the world. If only one out of three of the biggest models uses Nvidia, that’s a massive bear signal relative to what I believed two minutes ago. And it looks like the market isn’t pricing this in at all, unless I’m missing something.
(I assume I’m missing something because markets are usually pretty good at pricing things in.)
xAI and Meta still use Nvidia. Almost every non-frontier-lab, non-Chinese AI chip consumer uses Nvidia
And Alphabet, Amazon, and Broadcom, the companies that design TPU and Trainium, have the 4th, 5th, and 7th biggest market caps in the world.
I think it’s possible that the market is underpricing how big a deal Anthropic and Google DeepMind, and other frontier labs that might follow in their footsteps, are for overall AI chip demand. But it’s not super obvious.
Google TPUs have been competitive with Nvidia GPUs for years, but Google did not sell its TPUs, instead only renting them out via GCP, until very recently as it is now starting to actually sell them too.
Other GPUs and custom silicon like Trainium are used for inference these days, but training is almost exclusively done with Nvidia GPUs and Google TPUs. It’s pretty easy to take a trained model and make it possible to do inference with it using different chips, as we see for example with open-weight models being used on Apple silicon, and DeepSeek models being served on Huawei Ascend GPUs.
I still expect the majority of inference being done today to be on Nvidia GPUs, a notable portion on TPUs, and then some non-negligible amount on other chips. (I haven’t actually estimated this though.) Very roughly, I think in 1-3 years Nvidia will have a lot of competition for inference compute, though maybe not that much competition for training compute apart from TPUs, since CUDA is somewhat of a hard-to-overcome moat.
Both Google and Anthropic still use a lot of Nvidia compute; e.g. Trainium isn’t ready yet according to semianalysis.
Google DeepMind uses Nvidia very sparingly if at all. AlphaFold 3 was trained using A100s but that’s the only recent use of Nvidia by GDM I’ve heard of. I think Google proper, outside GDM, primarily uses TPUs over GPUs for internal workloads, but I’m less sure about that.
Google does buy a lot of Nvidia chips for its cloud division, to rent out to other companies.
That shouldn’t matter too much for stock price, right? If Google is currently rolling out its own TPUs then the long-term expectation should be that Nvidia won’t be making significant revenue off of Google’s AI.
Yup, that is indisputable. Further, it’s possible that LLMs scale to a transformative technology, to the Singularity, and/or to omnicide. (Though it’s not-that-likely, on my model; I think I still give this cluster of scenarios ~20%.)
I don’t think so. I’m more sure of LLMs not scaling to AGI than ever.
Over the last few months, I’ve made concentrated efforts to get firsthand experience of frontier LLMs, for math-research assistance (o3) and coding (Opus 4.1). LLMs’ capabilities turned out to be below my previous expectations, precisely along the dimension of agency/”actual understanding”.
Doubtlessly part of it is a prompting-skill issue on my part. Still, I don’t think the gap between the performance I’ve managed to elicit and the top performance is that big. For one, my experience echoes those of many other mathematicians/software engineers, and also METR’s results (on agency horizons, often-negative productivity effects, and LLM-code-is-not-mergeable).
These things have no clue what’s going on, there’s nobody in there. Whatever algorithms they are running, those are not the algorithms of a general intelligence, and there’s no reason to believe they’re on some sort of “sliding scale” to it.
I’ve still found them useful. If METR’s trend actually holds, they will indeed become increasingly more useful. If it actually holds to >1-month tasks, they may actually become transformative within the decade. Perhaps they will automate the within-paradigm AI R&D[1], and it will lead to a software-only Singularity that will birth an AI model capable of eradicating humanity.
But that thing will still not be an AGI. This would be the face of our extinction:
This seems unlikely to me on balance. I think compute scaling will run out well before that. I think it’s possible to scale LLMs far enough to achieve this, but that it’s “possible” in a very useless way. A Jupiter Brain-sized LLM can likely do it (and probably just an Earth Brain-sized one), but we are not building a Jupiter Brain-sized LLM.
But maybe I’m wrong; maybe we do have enough compute.
1. Imagine an infinitely large branching lookup table/flowchart. It maps all possible sequences of observations to sequences of actions picked to match the behavior of a general intelligence. Given a hypercomputer to run it, would that thing be effectively an AGI, for all intents and purposes? Sure. But would it actually be an AGI, structurally? Nope.
Remove the hypercomputer assumption and switch an infinitely large flowchart to a merely unfathomably large one. Suddenly the flowchart stops implementing general intelligence exactly, is relegated to an approximation of it. And that approximation is not that good, and rapidly degrades as you scale the available compute down.
Can a Galaxy Brain-scale flowchart like this kill humanity? Maybe, maybe not: combinatorial numbers are larger than astronomical numbers. But there are numbers big enough that a flowchart of that size would be able to ape an AGI’s behavior well enough to paperclip us.
2. Imagine Cyc. It was (is) an effort to build AGI. Its core motivation is as follows: There is no “simple algorithm for intelligence”. Intelligence is a mess of ad-hoc heuristics, and generality/autonomous learning emerges from those heuristics once some critical mass is attained. The way to AGI, then, is to do the hard, dirty work of inputting that critical mass of heuristics into your AI system (instead of lazily hoping for some sort of algorithmic shortcut), and eventually it would take off and start outputting novel discoveries:
To realize this vision, Cycorp hired tons of domain experts to extract knowledge from:
And they scaled it to a pretty ridiculous degree:
And they had various fascinating exponential scaling laws:
But that project seems doomed. Sure, much like the flowchart, if scaled sufficiently far, this AGI-as-coded-by-ancient-Greek-philosophers would approximate a general intelligence well enough to be interesting/dangerous. But it would not have the algorithms of a general intelligence internally, and as you scale the available compute down, the approximation’s quality would degrade rapidly.
A Jupiter Brain-sized Cyc can probably defeat humanity. But Cycorp does not have Jupiter Brain-scale resources.
3. Imagine the Deep Learning industry:
Indeed, this is exactly like a large-scale reprise of the expert systems era. The same notion that there’s no simple algorithm for intelligence, that it’s just a mess of heuristics; that attaining AGI just requires the “hard work” of scaling compute and data (instead of lazy theorizing about architectures!); the expectation that if they just chisel-in enough domain-specific expertise into DL models, generality would spontaneously emerge; the hiring of experts to extract that knowledge from; the sheer ridiculous scale of the endeavor. The only thing that’s different is handing off the coding to the SGD (which does lead to dramatic efficiency improvements).
Does that paradigm scale, in the limit of infinite compute, to perfectly approximating the external behavior of generally intelligent entities? Yes. But any given LLM, no matter how big, would not be structured as a general intelligence internally, and the approximation’s quality would degrade rapidly as you scale it down.
But how rapidly? A Jupiter Brain-sized LLM can probably kill us. But can an Earth Brain-sized, or, say, a “10% of US’ GDP”-sized LLM, do it?
I don’t know. Maybe, maybe not. But eyeballing the current trends, I expect not.
Now, a fair question to ask here is: does this matter? If LLMs aren’t “real general intelligences”, but it’s still fairly plausible that they’re good-enough AGI approximations to drive humanity extinct, shouldn’t our policy be the same in both cases?
To a large extent, yes. But building gears-level models of this whole thing still seems important.
“Within-paradigm” as in, they will not be able to switch themselves to an innovative neurosymbolic architecture, like IIRC happens in AI-2027. Just speed up the existing algorithmic-efficiency, data-quality, and RL-environment scaling laws.
I think the IMO results strongly suggest that AGI-worthiness of LLMs at current or similar scale will no longer be possible to rule out (with human efforts). Currently absence of continual learning makes them clearly non-AGI, and in-context learning doesn’t necessarily get them there with feasible levels of scaling. But some sort of post-training based continual learning likely won’t need more scale, and the difficulty of figuring it out remains unknown, as it only got in the water supply as an important obstruction this year.
I’m not so confident about this.
It seems to me that IMO problems are not so representative of real-world tasks faced by human level agents.
The key things from solving IMO-level problems (doesn’t matter if it’s proper gold or not) is difficulty reasonably close to the limit of human ability in a somewhat general domain, and correctness grading being somewhat vague (natural language proofs, not just answers). Which describes most technical problems, so it’s evidence that for most technical problems of various other kinds similar methods of training are not far off from making LLMs capable of solving them, and that LLMs don’t need much more scale to make that happen. (Perhaps they need a little bit more scale to solve such problems efficiently, without wasting a lot of parallel compute on failed attempts.)
More difficult problems that take a lot of time to solve (and depend on learning novel specialized ideas) need continual learning to tackle them. Currently only in-context learning is a straightforward way of getting there, by using contexts with millions or tens of millions of tokens of tool-using reasoning traces, equivalent to years of working on a problem for a human. This doesn’t work very well, and it’s unclear if it will work well enough within the remaining scaling in the near term, with 5 GW training systems and the subsequent slowdown. But it’s not ruled out that continual learning can be implemented in some other way, by automatically post-training the model, in which case it’s not obvious that there is anything at all left to figure out before LLMs at a scale similar to today’s become AGIs.
The way you’re using this concept is poisoning your mind. Generality of a domain does imply that if you can do all the stuff in that domain, then you are generally capable (and, depending, that could imply general intelligence; e.g. if you’ve ruled out GLUT-like things). But if you can do half of the things in the domain and not the other half, then you have to ask whether you’re exhibiting general competence in that domain, vs. competence in some sub-domain and incompetence in the general domain. Making this inference enthymemically is poisoning your mind.
Cf. https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce#_We_just_need_X__intuitions :
What I meant by general domain is that it’s not overly weird in the mental moves that are relevant there, so training methods that can create something that wins IMO are probably not very different from training methods that can create things that solve many other kinds of problems. It’s still a bit weird, high school math with olympiad addons is still a somewhat narrow toolkit, but for technical problems of many other kinds the mental move toolkits are not qualitatively different, even if they are larger. The claim is that solving IMO is a qualitatively new milestone from the point of view of this framing, it’s evidence about AGI potential of LLMs at the near-current scale in a way that previous results were not.
I agree that there could still be gaps and “generality” of IMO isn’t a totalizing magic that prevents existence of crucial remaining gaps. I’m not strongly claiming there aren’t any crucial gaps, just that with IMO as an example it’s no longer obvious there are any, at least as long as the training methods used for IMO can be adopted to those other areas, which isn’t always obviously the case. And of course continual learning could prove extremely hard. But there also isn’t strong evidence that it’s extremely hard yet, because it wasn’t a focus for very long while LLMs at current levels of capabilities were already available. And the capabilities of in-context learning with 50M token contexts and even larger LLMs haven’t been observed yet.
So it’s a question of calibration. There could always be substantial obstructions such that it’s no longer obvious that they are there even though they are. But also at some point there actually aren’t any. So always suspecting currently unobservable crucial obstructions is not the right heuristic either, the prediction of when the problem could actually be solved needs to be allowed to respond to some sort of observable evidence.
I took you to be saying
math is a general domain
IMO is fairly hard math
LLMs did the IMO
therefore LLMs can do well in a general domain
therefore probably maybe LLMs are generally intelligent.
But maybe you instead meant
working out math problems applying known methods is a general domain
?
Anyway, “general domain” still does not make sense here. The step from 4 to 5 is not supported by this concept of “general domain” as you’re applying it here.
It’s certainly possible—but “efficient continual learning” sounds a lot like AGI! So, to say that is the thing missing for AGI is not such a strong statement about the distance left, is it?
I don’t think this is moving goalposts on the current paradigm. The word “continual” seems to have basically replaced “online” since the rise of LLMs—perhaps because they manage a bit of in-context learning which is sort-of-online but not-quite-continual and makes a distinction necessary. However, “a system that learns efficiently over the course of its lifetime” is basically what we always expected from AGI, e.g. this is roughly what Hofstadter claimed was missing in “Fluid Concepts and Creative Analogies” as far back as 1995.
I agree that we can’t rule out roughly current scale LLMs reaching AGI. I just want to guard against the implication (which others may read into your words) that this is some kind of default expectation.
The question for this subthread is the scale of LLMs necessary for first AGIs, what the IMO results say about that. Continual learning through post-training doesn’t obviously require more scale, and IMO is an argument about the current scale being almost sufficient. It could be very difficult conceptually/algorithmically to figure out how to actually do continual learning with automated post-training, but that still doesn’t need to depend on more scale for the underlying LLM, that’s my point about the implications of the IMO results. Before those results, it was far less clear if the current (or near term feasible) scale would be sufficient for the neural net cognitive engine part of the AGI puzzle.
It could be that LLMs can’t get there at the current scale because LLMs can’t get there at any (potentially physical) scale with the current architecture.
So in some sense yes that wouldn’t be a prototypical example of a scale bottleneck.
I think this is very cogently written and I found it pretty persuasive even though our views started out fairly similar.
Uh… what? Why do you define “AGI” through its internals, and not through its capabilities? That seems to be a very strange standard, and an unhelpful one. If I didn’t have more context I’d be suspecting you of weird goalpost-moving. I personally care whether
AI systems are created that lead to human extinction, broadly construed, and
Those AI systems then, after leading to human extinction, fail to self-sustain and “go extinct” themselves
Maybe you were gesturing at AIs that result in both (1) and (2)??
And the whole reason why we talk about AGI and ASI so much here on Less Wrong dot com is because those AI systems could lead to drastic changes of the future of the universe. Otherwise we wouldn’t really be interested in them, and go back to arguing about anthropics or whatever.
Whether some system is “real” AGI based on its internals is not relevant to this question. (The internals of AI systems are of course interesting in themselves, and for many other reasons.)
(As such, I read that paragraph by gwern to be sarcastic, and mocking people who insist that it’s “not really AGI” if it doesn’t function in the way they believe it should work.)
I think if the lightcone looks the same, it should, if it doesn’t, our policies should look different. It would matter if the resulting AIs fall over and leave the lightcone in the primordial state, which looks plausible from your view?
For the same reason we make a distinction between the Taylor-polynomial approximation of a function, and that function itself? There is a “correct” algorithm for general intelligence, which e. g. humans use, and there are various ways to approximate it. Approximants would behave differently from the “real thing” in various ways, and it’s important to track which one you’re looking at.
That’s not the primary difference, in my view. My view is simply that there’s a difference between an “exact AGI” and AGI-approximants at all. That difference can be characterized as “whether various agent-foundations results apply to that system universally / predict its behavior universally, or only in some limited contexts”. Is it well-modeld as an agent, or is modeling it as an agent itself a drastically flawed approximation of its behavior that breaks down in some contexts?
And yes, “falls over after the omnicide” is a plausible way for AGI-approximants to differ from an actual AGI. Say, their behavior can be coherent at timescales long enough to plot humanity’s demise (e. g., a millennium), but become incoherent at 100x that time-scale. So after a million years, their behavior devolves into noise, and they self-destruct or just enter a stasis. More likely, I would expect that if a civilization of those things ever runs into an actual general superintelligence (e. g., an alien one), the “real deal” would rip through them like it would through humanity (even if they have a massive resource advantage, e. g. 1000x more galaxies under their control).
Some other possible differences:
Capability level as a function of compute. Approximants can be drastically less compute-efficient, in a quantity-is-a-quality-of-its-own way.
Generality. Approximants can be much “spikier” in their capabilities than general intelligences, genius-level in some domains/at some problems and below-toddler in other cases, in a way that is random, or fully determined by their training data.
Approximants’ development may lack a sharp left turn.
Autonomy. Approximants can be incapable of autonomously extending their agency horizons, or generalizing to new domains, or deriving new domains (“innovating”) without an “actual” general intelligence to guide them.
(Which doesn’t necessarily prevent them from destroying humanity. Do you need to “innovate” to do so? I don’t know that you do.)
None of this may matter for the question of “can this thing kill humanity?”. But, like, I think there’s a real difference there that cuts reality at the joints, and tracking it is important.
In particular, it’s important for the purposes of evaluating whether we in fact do live in a world where a specific AGI-approximant scales to omnicide given realistic quantities of compute, or whether we don’t.
For example, consider @Daniel Kokotajlo’s expectation that METR’s task horizons would go superexponential at some point. I think it’s quite likely if the LLM paradigm scales to an actual AGI, if it is really acquiring the same generality/agency skills humans have. If not, however, if it is merely some domain-limited approximation of AGI, it may stay at the current trend forever (or, well, as long as the inputs keep scaling the same way), no matter how counter-intuitive that may feel.
Indeed, “how much can we rely on our intuitions regarding agents/humans when making predictions about a given AI paradigm?” may be a good way to characterize the difference here. Porting intuitions about agents lets us make predictions like “superexponential task-horizon scaling” and “the sharp left turn” and “obviously the X amount of compute and data ought to be enough for superintelligence”. But if the underlying system is not a “real” agent in many kinds of ways, those predictions would start becoming suspect. (And I would say the current paradigm’s trajectory has been quite counter-intuitive, from this perspective. My intuitions broke around GPT-3.5, and my current models are an attempt to deal with that.)
This, again, may not actually bear on the question of whether the given system scales to omnicide. The AGI approximant’s scaling laws may still be powerful enough. But it determines what hypotheses we should be tracking about this, what observations we should be looking for, and how we should update on them.
Things worth talking about are the things that can lead to drastic changes of the future of the universe, yes. And AGI is one of those things, so we should talk about it. But I think defining “is an AGI” as “any system that can lead to drastic changes of the future of the universe” is silly, no? Words mean things. A sufficiently big antimatter bomb is not an AGI, superviruses are not AGIs, and LLMs can be omnicide-capable (and therefore worth talking about) without being AGIs as well.
For AGIs and agents, many approximations are interchangeable with the real thing, because they are capable of creating the real thing in the world as a separate construct, or converging to it in behavior. Human decisions for example are noisy and imprecise, but for mathematical or engineering questions it’s possible to converge on arbitrary certainty and precision. In a similar way, humans are approximations to superintelligence, even though not themselves superintelligence.
Thus many AGI-approximations may be capable of becoming or creating the real thing eventually. Not everything converges, but the distinction should be about that, not about already being there.
Right, this helps. I guess I don’t want to fight about definitions here. I’d just say “ah, any software that you can run on computers that can cause the extinction of humanity even if humans try to prevent it” would fulfill the sufficiency criterion for AGIniplav, and then there’s different classes of algorithms/learners/architectures that fulfill that criterion, and have different properties.
(I wouldn’t even say that “can omnicide us” is necessary for AGIniplav membership—”my AGI timelines are −3 years”30%.)
One crux here may be that you are more certain that “AGI” is a thing? My intuition goes more in the direction of “there’s tons of different cognitive algorithms, with different properties, among the computable ones they’re on a high-dimensional set of spectra, some of which in aggregate may be called ‘generality’.”
I think no free lunch theorems point at this, as well as the conclusions from this post. Solomonoff inductors’ beliefs look like they’d look messy and noisy, and current neural networks look messy and noisy too. I personally would find it more beautiful and nice if Thinking was a Thing, but I’ve received more evidence I interpret as “it’s actually not”.
But my questions have been answered to the degree I wanted them answered, thanks :-)
A flight control program directing an asteroid redirection rocket, programmed to find a large asteroid and steer it to crash into Earth seems like the sort of thing which could be “software that you can run on computers that can cause the extinction of humanity” but not “AGI”.
I think it’s relevant that “kill all humans” is a much easier target than “kill all humans in such a way that you can persist and grow indefinitely without them”.
Yes, and this might be a crux between “successionists” and “doomers” with highly cosmopolitan values.
Fair.
Yup.
No offense, but to me it seems like you are being overly pedantic with a term that most people use differently. If you surveyed people on lesswrong, as well as AI researchers, I’m pretty sure almost everyone (>90% of people) would call an AI model capable enough to eradicate humanity an AGI.
Well, if so, I think they would be very wrong. See a more in-depth response here.
Yeah, this seems like a standard dispute over words, which the sequence posts Disguised Queries and Disputing Definitions already solved.
I’ll also link my own comment on how what TsviBT is doing is making AI discourse worse, because it promotes the incorrect binary frame and dispromotes the correct continuous frame around AI progress.
AI discourse doesn’t get enough TsviBT-like vitamins, so their projected toxicity if overdosed is not relevant. A lot of interventions are good in moderation, so arguments about harm from saturation are often counterproductive if taken as a call to any sort of immediately relevant action rather than theoretical notes about hypothetical future conditions.
I disagree with this, and in particular the move by TsviBT of arguing that today’s AI has basically zero relevance to what AGI needs to have/claiming that LP25 programs aren’t actually creative, and more generally setting up a hard border between today’s AI and AGI is a huge amount of AI discourse, especially on claims that AI will soon hit a wall for xyz reasons.
This is why I think he actually believes it. It’s not in his political interest to say this.
But once said, I think it could be difficult for him to publicly update his beliefs without losing credibility.
jeez, always disconcerting when people with more relevant info to me have shorter timelines than me
My current best read is that insiders at AI companies are overall more biased (towards pronouncing shorter timelines) than they are well-informed.
Not sure how you’d make the comparison, not sure I agree with it, but I definitely agree they are biased towards shorter timelines.
To be fair to me this immediately evoked more the image of Amazon leveraging its specific scale economies, not having e.g. generalist humanoid robots with AGI, but mega-depots, auto vans, delivery drones etc. that each perform one specific function within a mechanism that works because it’s all Amazon stuff interfacing with other Amazon stuff. That said, still a bold prediction that I wouldn’t buy much, but less wild.
I think that’s underselling the issue. GPT-5 is not a straight improvement over o3, o3-Pro and other existing OpenAI models. There are tasks it does better and other tasks it does worse.
https://ai.plainenglish.io/i-tried-my-best-to-like-gpt-5-i-just-cant-it-fucking-sucks-7133a1dddfcb shows that even on a task like SQL query generation that you would expect to be easily trainable with synthethic data, GPT-5 performs worse.
I started out giving GPT-5 the doubt but when when it comes to tasks that require some creativity like text and headline writing I went back to o3 as GPT-5 seems worse for the task.
Opus 4.1, GPT-5, and Gemini 2.5 Pro all claim that “by 2027” unambiguously means “by end of 2027″. So at the very least the meaning can’t be unambiguously “by start of 2027”, even if this usage sometimes occurs.
I think it was a bad prediction, yes, but mainly because it was ambiguous about the meaning of “writes 90% of the code”, it’s still not clear if he was claiming at the time that this would be the case at Anthropic (where I could see that being the case) or in the wider economy. So a bad prediction because imprecise, but not necessarily because it was wrong.