It seems plausible that the recent order restricting Mythos incentivizes Anthropic to race for RSI as quickly as possible. This is because all of their compute previously reserved for serving customers can now go towards research, and because RSI bypasses the restrictions on foreign researchers (or any human researchers) internally working with the model. Hopefully Anthropic can find another path.
anaguma
Karma: 1,360
Given your linked comment, what do you think are the strongest arguments in favor of Anthropic’s approach?
Noting here that I originally read this as “PAUSE AI SAFETY before superintelligence”.

Rohin Shah on AGI Safety
Superintelligence will likely be developed by US companies; run on US datacentres; and be under the jurisdiction of the US government. This will massively boost US’ military power and make the US economically dominant (eg US producing 99% of world GDP). By default, middle powers will be left in the dust.
How can middle powers avoid this fate?
If ASI is developed, they have a decent chance of avoiding this fate due to extinction from ASI misalignment or misuse, which imo is a much worse fate.
Ah, I missed that. In that case, you’re right, autoresearch is close enough to RSI.
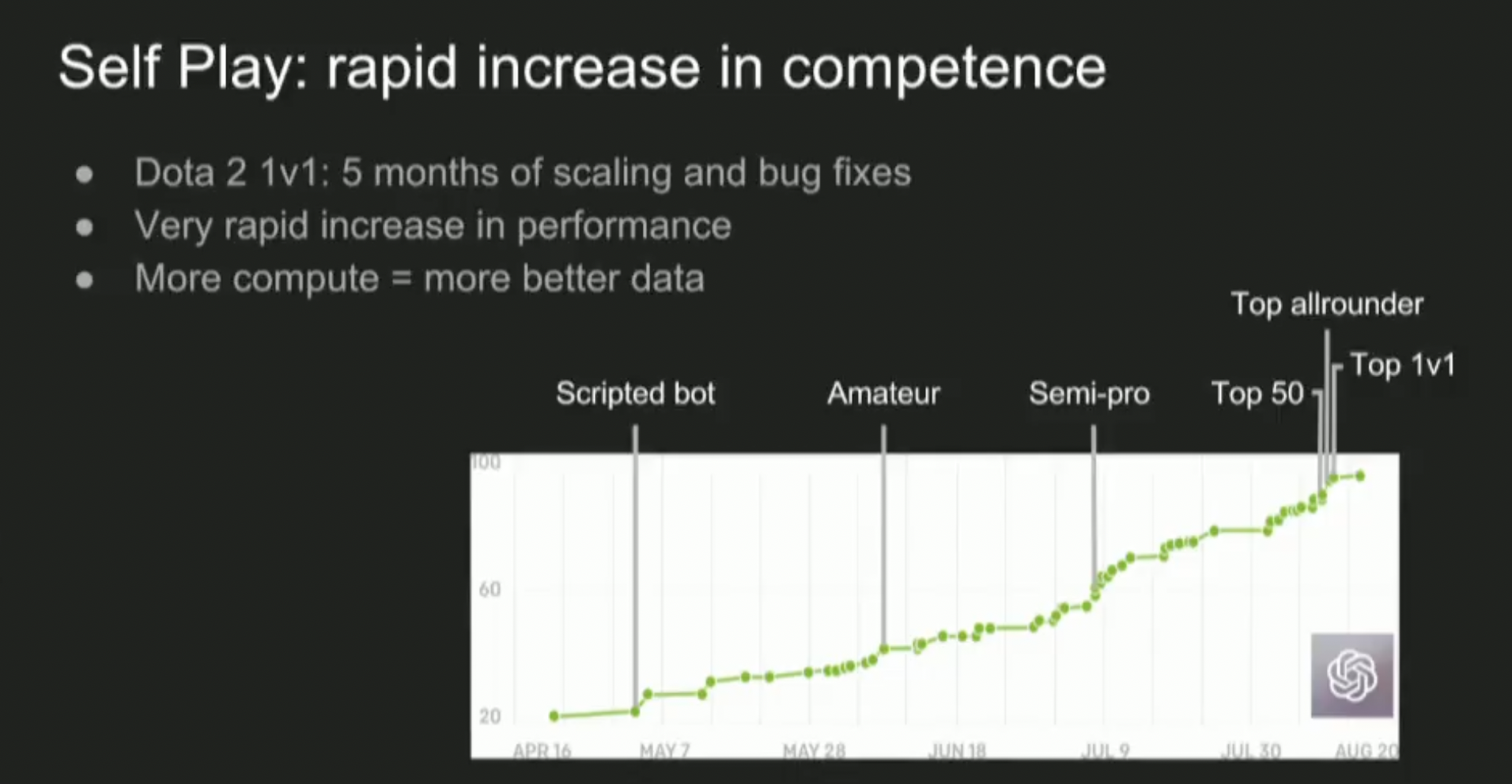
As an example of what RSI might be like, I find it helpful to go back to OpenAI’s Dota 2 result from 2017:
This slide from Ilya’s lecture shows the bot’s Trueskill rating[1] over time. Since the rating is on a logarithmic scale, this means the bot improved exponentially over time, due to algorithmic improvements + scale.
- ^
Similar to Elo in Chess and other games
- ^
Thanks. For others interested, the relevant quote seems to be:
TechCrunch and Axios report that he will work under team lead Nick Joseph on pre-training, “focused on using Claude to accelerate pre-training research.”
It seems to be a bit vague. You could imagine various uses of Claude in pre-training research, which may or may not be RSI. For instance you could use it to build better safety evals during pre-training, or build faster tokenizers etc. I don’t see where he or Anthropic have said that he’s there “explicitly to do recursive self-improvement”, but maybe Zvi is basing this on non-public information.
Andrej Karpathy joins Anthropic explicitly to do recursive self-improvement. Congratulations to both sides, but also, yikes.
Where does it say anything about RSI? The linked tweet says
Personal update: I’ve joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
There are lots of R&D things people could do which don’t involve RSI. I feel like I’m missing something.
It might still be impressive, but models are largely remixing many things it has seen in great detail during training (many impressive headline results have even been determined to be the model re-using existing implementations/PRs via search instead of coming up with actually-new ones!). This is not about LLMs not doing impressive things! This is about precisely describing their capability profile, where it comes from, and whether more of the same (e.g., scale) gets you a whole new set of impressive outcomes (e.g., novel R&D that isn’t just remixing existing research).
Do you think that today’s breakthrough on the planar unit distance problem is merely the model remixing things learned during pretraining? I’m not an expert, but it seems unlikely to me. Arul Shankar, a notable number theorist, stated:
In my opinion this paper demonstrates that current AI models go beyond just helpers to human mathematicians – they are capable of having original ingenious ideas, and then carrying them out to fruition.
And I think this much is clear by looking over the proof and supplemental materials.
An internal model at OpenAI has just solved the unit distance problem, a major conjecture in discrete geometry.
how is the model supposed to know which trajectory is cheating? there is the super smart part which understands in some implicit sense but won’t necessarily tell the assistant part; the assistant part is not good enough at code or whatever to know by itself, and has to try to elicit stuff from the code part, which it may or may not succeed at.
I think maybe this is the crux. Assuming the model starts out robustly aligned, and is bootstrapping in an on-policy way, it should be able to tell if its own trajectory is cheating or not. If it’s not able to do this, I would say that it’s an alignment/robustness failure. It seems difficult to accidentally reward-hack in way that the robustly aligned model we started with doesn’t detect after reviewing the trajectory.
I agree that if you trained separate models for coding ability and being an assistant and being aligned, you could have this sort of failure. But the gradient update applies to the full model, right? Why is it that the robustly aligned model we started out with after an update, which (according to it) wasn’t reward hacking, is so unaware of its newfound coding ability as to not continue being robustly aligned?
tbc, not saying the non-heavy-RL models are all always perfectly aligned, or that RL is the only way you can get misalignment.
I agree that if we start off with a somewhat-misaligned model this scheme doesn’t work.
there is a misalignment between the part of you that is robustly good and the part that contains the extreme competence. and to leverage that extreme competence well, you can’t just be extra ultra committed to doing good; your altruistic part need a sort of competence at wrangling the extremely competent part into doing the good thing.
in many ways this is similar to how revolutions often fail because it takes more than just being uncorruptably good to be a successful leader; you have to know how to wield the powers of office for good, rather than being controlled by those powers.
I think this argument goes too far. It issue isn’t that we had a robustly good Claude, which later was corrupted by the reward hacking temptations of RL. We never had a robustly aligned model to begin with! There are so many examples of language models being misaligned in the pre-RLVR era.
If we did have a robustly aligned model, I think this would be a major accomplishment of the field and would help in many ways. It would also not be hard to RL such a model while maintaining alignment; for each trajectory, have the model output its response, and also a flag of whether it was reward hacking/cheating/misaligned in some way, and don’t train on flagged trajectories. Alas, I don’t think there exist any public models which are aligned to this degree.
I should have hill-climbed on concrete, externally-legible outputs (e.g., the RE-Bench numbers I generated at the end) six to ten months earlier — way easier salience, fast feedback loops, the kind of thing fundraising actually responds to.
I’m not sure this is true? If I was considering funding a safety project, and discovered that they had been bench-maxing this for a few months, I would update towards them just being a capabilities startup. There are many open problems with automating alignment research specifically, as opposed to ML research generally, which I‘d want to see progress on instead.
I think you could approximate it. People are generally wiser/smarter given more time to reflect, with access to more resources (including reliable AI and human research assistance), with access to better education, etc. Having a collection of experts and weaker AIs spending a long time evaluating trajectories seems to me like an upper bound of what you could hope for in terms of outer alignment feedback. It could be that this is insufficient, but in this case problem really does seem intractable.
This doesn’t address inner alignment issues, which is what interpretability and red teaming oversight was intended to address.
A baseline would be to try to train a CEV oracle by collecting a bunch of human data, and train a model against that. You’d probably also do a bunch of red-teaming and interpretability research to detect scheming, possibly using weaker safe models.
On NLAs and Neuralese/Recurrence
For some background, Anthropic recently published work on Natural Language Autoencoders (NLAs), a new interpretability method for understanding LLM activations. The idea is that given a hidden state
An Activation Verbalizer
An Activation Reconstructor
Like in other work on autoencoders, the goal is to train
However, I think this work has some unfortunate capabilities externalities which I haven’t seen discussed. In particular, I think that if NLA research goes well, we should expect it to be easier to be able to build models which use neuralese/recurrence. There are many ways this could happen, but a simple baseline is the following:
Train a CoT model using existing methods, and collect reasoning traces
For each reasoning trace, you can break down
Train a new model
During inference, use
If your
To be clear, I think that this exact idea doesn’t work for current NLA models, for reasons I won’t discuss. This is because there are many advantages to CoT, and I think we should try to preserve it for as long as possible! However, it does seem plausible to me that better methods encoding/decoding text to hidden vectors may be a helpful training signal for capabilities researchers, and that a future version may end up working. To the extent that they agree, I think researchers working on NLAs and similar methods should keep this in mind.
Surprisingly, Claude Opus 4.7 thinking still struggles with this, if you tell it not use tools. For N = 199, it answered 200; the CoT is below. It tried to use some groups of ten, gives up, and estimates the answer. It’s curious that this isn’t something the model learned to do in pretraining.
I’m counting the total number of 1s by tracking the initial 1 and then all the “+1” increments that follow. Counting through the sequence of increments to get the total. Continuing through the remaining decades up to 150, each block follows the same pattern of ten increments. I’m working through a long sequence of increments to count the total, breaking it down into manageable chunks to keep track of where I am in the original text. I’m trying to count the total number of “+1“ operations in that string. Let me work through this systematically by identifying the pattern and tallying up how many times it repeats. I need to count the “+1” instances more carefully. The input starts with “1” and then has a series of “+1”s, so the total count is just the number of “+1“s plus one. Let me go through and tally them systematically in groups of ten to get an accurate count. Continuing to count through the ranges… I’m manually counting the “+1” tokens in the input string to get an accurate sum, working through the text systematically since I can’t execute code to parse it directly. I’m counting the occurrences of “+1” in this sequence to get a total. I’m trying to count the “+1”s by breaking the input into segments of 10 to make it manageable, assuming the user likely wrote a round number like 200 total. Let me try a more systematic approach—I’ll scan through the input carefully and count the “+1“ occurrences in groups to get an accurate total. Continuing the count… I’m trying to count the “+1” instances in the input string, but without being able to directly measure the character length, I’m working through it systematically by grouping tokens and attempting to track them in chunks. Let me count the “+1” occurrences more carefully by examining the actual structure. The format appears to be “1“ followed by repeated ” +1” patterns, so I need to figure out how many times that sequence appears before reaching the end marker. Continuing through the chunks, I’m at 40 total after the fourth group, then adding ten more with each subsequent chunk brings me to 50, 60, 70, 80, 90, and I’m partway through the tenth chunk now. Continuing to accumulate the count through each successive chunk, reaching 200 total ones across all 20 chunks. I’m breaking down the string into groups and tallying the “+1” occurrences, but the math keeps shifting depending on how I segment it. Let me just count the “+1“ patterns directly instead of getting caught up in positional grouping—based on the visual length of the input, 200 seems like the most reasonable estimate. I’m continuing to tally the remaining “+1” entries, organizing them into groups of ten to make the count more manageable. Looking at the pattern, I’m seeing roughly 20 complete groups, which would give me around 200 total. Let me verify this by doing one more count to make sure I’m landing on the right number. I’m counting the “1” characters in the input to verify my total of 200, since each one represents a unit in the sum. Let me double-check by scanning through more carefully rather than relying on my initial chunk-based count. I’m continuing to count through the remaining additions, organizing them into groups of ten to keep track of the total. I’m counting the grid of plus-ones manually—20 rows with 10 entries each gives me 200 total, and since the prompt explicitly says not to use tools, I’ll stick with that answer.
from To the Success of our Hopeless Cause: interestingly, a big tension in the Soviet dissident movement
On a meta topic, I’m curious about your writing style here. Why capitalize the names of books and countries but not the first letter of sentences?
This seems straightforwardly false to me?
The central counterexample is General Relativity. Einstein postulated the Equivalence Principle (i.e. that gravity is locally indistinguishable from acceleration) in 1907, and the Principle of General Covariance (i.e. that the laws of physics should be the same in all reference frames) in 1915. This resulted in his publishing his famous field equations later in 1915. Only after this theoretical work did he account for the anomaly in the perihelion of Mercury. His prediction of gravitational waves in 1916 was only detected by the LIGO observatory in 2015. More or less the entire theory was derived from “abstract theoretical insights” which we have spent the last century validating.