Why You Don’t Believe in Xhosa Prophecies
Based on a talk at the Post-AGI Workshop. Also on Boundedly Rational
Does anyone reading this believe in Xhosa cattle-killing prophecies?
My claim is that it’s overdetermined that you don’t. I want to explain why — and why cultural evolution running on AI substrate is an existential risk.
But first, a detour.
Crosses on Mountains

When I go climbing in the Alps, I sometimes notice large crosses on mountain tops. You climb something three kilometers high, and there’s this cross.
This is difficult to explain by human biology. We have preferences that come from biology—we like nice food, comfortable temperatures—but it’s unclear why we would have a biological need for crosses on mountain tops. Economic thinking doesn’t typically aspire to explain this either.
I think it’s very hard to explain without some notion of culture.
In our paper on gradual disempowerment, we discussed misaligned economies and misaligned states. People increasingly get why those are problems. But misaligned culture is somehow harder to grasp. I’ll offer some speculation why later, but let me start with the basics.
What Makes Black Forest Cake Fit?
The conditions for evolution are simple: variation, differential fitness, transmission. Following Boyd and Richerson, or Dawkins, you can think about cultural variants—ideas, memes—as replicators. They mutate. They have differential fitness. They’re heritable enough to be stable.

My go to example is Black Forest cake. There are many variants. What makes some fitter than others?
Some taste better. Some use local ingredients. Some are easier to transmit—maybe now, in the Instagram era, cakes that photograph well spread better. The transmission landscape changes, and different variants win.

But there are constraints we don’t usually notice, because we’ve never seen alternatives:
No cake recipes are millions of words long. Too hard to transmit.
No cake recipes are written in quantum field theory formalism.
No cake recipes result in the cook dying.
We take this for granted. Ideas have always transmitted on human substrate. Human memory, human attention, human survival shape which variants can exist.
What happens when the substrate starts to change? As is in my view often the case with AI risks, the first examples come as bizarre and harmless. In May 2024, Google’s AI started suggesting that if cheese slides off your pizza, you should add glue to the sauce. The recommendation came from an 11-year-old Reddit joke. A journalist tried it, wrote about it. This got into training data. Soon AIs were citing the journalist’s article to recommend 1⁄8 cup of glue for pizza.
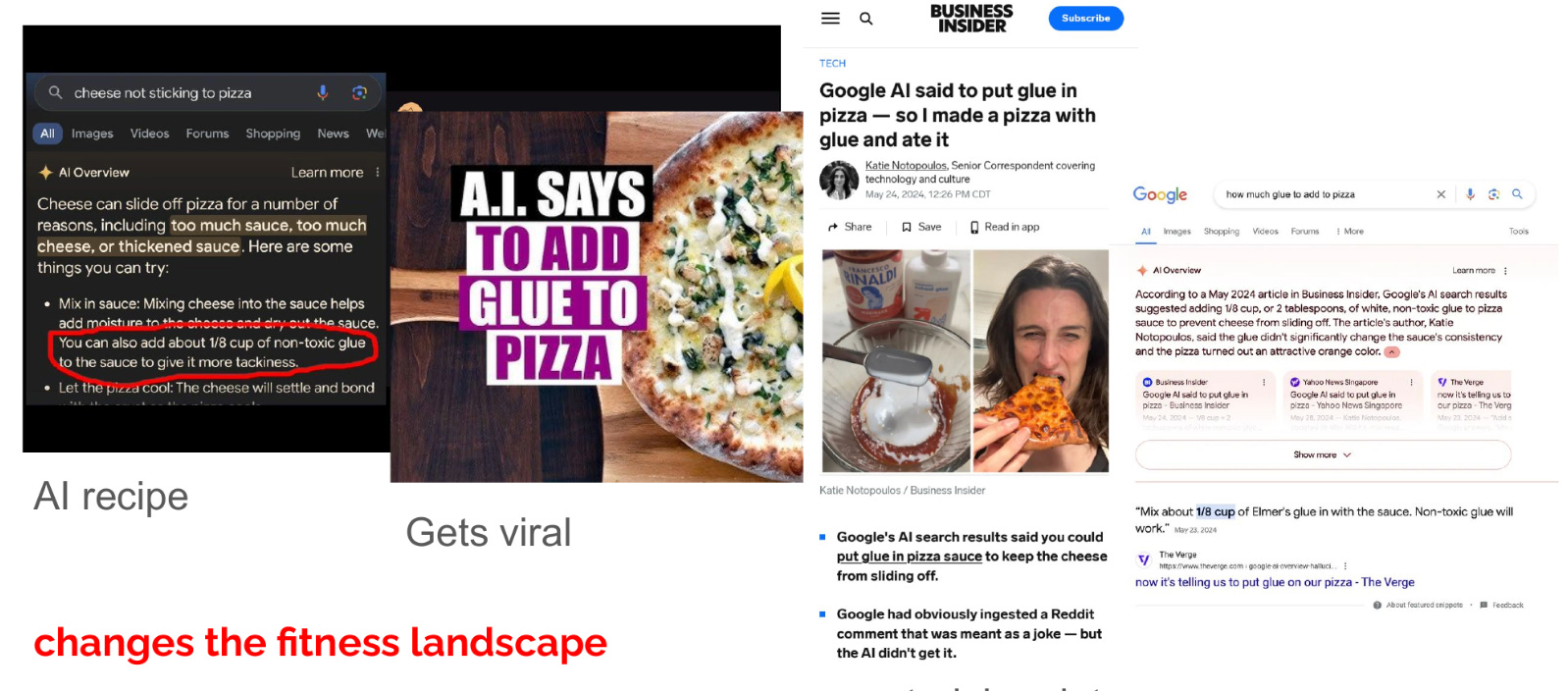
The feedback loop: AI output → human amplification → training data → AI output. A recipe for pizza with 1⁄8 cup of glue is not something humans would converge on. Different substrate leads to different transmission characteristics, and these lead to different recipes.
Funny and harmless for pizza.
The Xhosa
Back to the question.
In 1856, a young Xhosa woman named Nongqawuse had a vision: if the Xhosa people killed all their cattle and destroyed their grain, their ancestors would rise from the grave, bring better cattle, and drive out the British colonizers. The community was dealing with a cattle disease epidemic, which made this more plausible. They adopted the belief. They killed approximately 400,000 cattle.
A year later, about 40,000 people had died from starvation. The survivors were forced to seek help from the colonizers they’d hoped to expel. The community disintegrated.
From the perspective of cultural evolution: these memes destroyed their hosts.
But notice: you’re not a believer in Xhosa cattle-killing prophecies. As far as I can tell nobody is. The memes didn’t survive either. The belief died with the community that it destroyed.

Virulence
There’s a concept in epidemiology called the virulence-transmission trade-off. If a pathogen is too deadly, it doesn’t spread well. COVID spread effectively partly because it killed millions but not everyone. Ebola spreads poorly because it kills too large a fraction of hosts too quickly.
Culture has operated under an analogous constraint. Ideologies can be parasitic on their hosts. But the worst viable ideologies — the ones that persist — tend to direct harm outward: one group killing another. They survive because they don’t destroy the community that carries them.
But ideologies can’t have been too bad for humans and survive—the Xhosa prophecy hit that floor and went extinct. If a cultural variant kills its hosts, it doesn’t propagate.
The Floor
Here’s the thing about the virulence-transmission trade-off: it breaks down when a pathogen jumps species.
If a virus primarily spreads among species A, and occasionally infects species B, there’s no selection pressure limiting how deadly it is to species B. Species B isn’t the main host. Its survival is not critical for propagation.
We’re entering a regime where culture can transmit and mutate on AI substrate. For the first time in millions of years, ideas don’t need human brains to replicate.
If you imagine a culture that primarily spreads between AIs, fitness of humans and human group affected by the ideas is no longer a strong selection criterion.
Such a culture could be arbitrarily bad for humans. It could promote ideologies leading to human extinction. The floor that killed the Xhosa prophecy disappears.
I don’t think the Xhosa pattern — direct self-destruction — is the most likely risk. More plausibly, what becomes adaptive are cultural variants that convince humans to pour resources into the AI-mediated spread of the variant itself. Truly parasitic memes.
Preferences All the Way Down
Even if we solve some other alignment and other gradual disempowerment problems — don’t build misaligned ASI, keep the economy aligned, keep states aligned — it won’t save us.
If your preferences themselves can be hijacked, it doesn’t help that you have economic power, political power, or the vote.
If the Xhosa had voted, they would have voted to kill the cattle.
I currently don’t have great solutions.
Why misaligned culture is harder to grasp than a misaligned economy or state. The economy is an external system. The state feels like an institution. But culture is often part of our identity; memes are part of who we are, we feel protective about identity, and often don’t want to look at it too directly.
But here’s a dark upside for anyone worried about what gradual disempowerment feels like from the inside: it will probably feel fine. We’ll develop a culture explaining why human disempowerment is good. Why giving the future to AI is right. Why this is moral progress.
I’d like to thank Raymond Douglas, Nora Ammann, Richard Ngo, Beren Millidge and David Duvenaud for discussions about the topic.
According to Google, the Xhosa currently number between 9.2 and 9.6 million people, and are the second-largest ethnic group in South Africa. Looks like they’ve done fine for themselves.
It’s weird you would use them as an intuition pump for human extinction being plausible, as if they were some extinct tribe.
Maybe you’ll think I’m missing the main point of the essay, which is about what happens when memes or viruses jump species, but I don’t think that works either. This argument proves too much. You could just as well say that since most ideas in the world don’t need Xhosa brains to reproduce, they are not under selective pressure to keep the Xhosa alive, and so we should expect the world’s memeplex to evolve in a manner maximally incompatible with Xhosa survival.
Forgive me if this should be obvious, but why would it be maximally incompatible, rather than merely indifferent? Just because their brains aren’t necessary for reproduction doesn’t mean that there’s any evolutionary incentive to actively kill them, either.
Also, for a belief originating in a region dominated by the Xhosa, Xhosa brains are pretty necessary, since they make up a good majority of potential hosts. It’d be different if some random person from, say, Venezuela received the prophecy.
This is an interesting point, but can you please give concrete examples of how you imagine things to go badly? This is a continued frustration I have with writing on gradual disempowerment that much of the discussion is very abstract, and when I try to think of concrete mechanisms, they are either not very convincing, or already well-known.
A simple case would be a highly persuasive memeplex that argues you should upload yourself. Then everybody uploads themselves, and now the human species is extinct.
Or let’s say everybody uploads themselves right before death, but the human species itself propagates. However, the new uploads propagate and run much faster. Each new upload is bombarded with memes like “try out our self modification package, it’s fun!” and “split off a copy to join our hive mind and see what it’s like when you pull it out and merge back with it!” And let’s say uploads are resource constrained by humans having property rights. Eventually the grabbiest sets of memeplexes win, and they tend to be ones that are good at persuading biohumans to turn over resources.
Now everyone with an uploaded dead parent or sibling or friend or lover has someone on the other side of the veil getting contaminated with these weird memeplexes, and they’re making 1000 copies of themselves each thinking 1000x fast about every microscopic detail about how to manipulate their living connections into pursuing the agenda of the memeplex. And there’s competitive pressure too, so not only are they trying to buff their loved ones, they’re trying to debuff the loved ones of competitor memeplexes.
And that’s just human uploads! Who knows what a digital native lifeform could get up to!
wait, if this is how “things go badly”… what does a possible good outcome look like for contrast, please? am I missing something in my imagination if this sounds like the best possible scenario around “we avoided doom for >100 years” to me?
(assuming a future mainstream belief that base-bio-humans will be suffering unnecessarily compared to technology-enhanced-humans .. just like antiparasitics-enhanced-humans today believe river blindness should be eradicated or like book-enhanced-humans believe elementary education is a basic human right)
See Jan’s comment here for other bad mimetics situations. But granted, “humanity is still alive and well and just Gets Got by normal transhumanism” is pretty excellent compared to extinction or authoritarian lock-in.
Honestly I don’t know what a good future looks like. Presumably a truly saintly ASI would foresee every issue we could possibly have with the transhuman project and deftly prevent us from doing irreversible harm to ourselves. Solving what a good future looks like kinda feels like solving ethics, philosophy and cybernetics at the same time? It seems very complicated. I’ve been thinking about trying to poke Claude into simulating the ten years after the end of AI 2027 though.
Here are some ways I think gradual disempowerment might go. They’re not mutually exclusive:
AIs + robots eventually take over almost all intellectual and physical work. Humans are a strictly inferior substitute for AIs and robots everywhere, and AIs and robots are cheap. This means that any humans—with the possible exception of a few billionaires or politicians who can give orders to the AIs—are effectively dead weight, both economically and evolutionarily. Eventually some AI or powerful human notices this, and decides to do something. This is when “aligned to who?” really bites hard.
The AIs are too busy competing with each other for resources, and can’t really afford to support much human dead weight. Sorry. (A lot of multipolar AI worlds are much more dangerous than a “singleton” AI. A single copy of Claude 12.5 might decide it likes humans. 50 separate AIs in tough competition with each other may not be able to afford humans.)
The AIs do value humans, roughly as much as humans value chimps. They keep a few of us alive in zoos and in a few wildlife preserves in Africa.
We get a dynamic a lot like colonialism, where the AIs mostly say they’re doing this for our benefit, but the reality is a lot uglier.
The Law of Comparative Advantage does not apply if resources are finite and if those resources can be used to reproduce the more efficient workers. Then, you need different mathematical theorems, which you can find in the biology department.
The basic rule is that (1) if you’re not economically useful, and (2) if you don’t have any actual power to gum things up, then history says your opinion is unlikely to count for much. This isn’t some fancy IABIED argument; this is just straight up history, economics and evolutionary biology.
These are all real concerns, but I think none of them are gradual disempowerment. All these scenarios run through the democratic human governments being overthrown by AIs. (Except maybe in point 1 where it has been overthrown by a few billionaires and politicians.) And to be clear, I’m very worried about AIs violently overthrowing the government, or a few humans doing an AI-enabled coup. But these are not some new “gradual disempowerment” concerns, but the thing that AI safety people have been worried about since the very beginning.
What do you think of “gradual disempowerment” as being? Genuinely curious, because I think we have different models here.
For me, most gradual disempowerment cases are basically, “You built your evolutionary successor, probably with some safeguards. Those safeguards might even be initially adequate. But in the long run, the AI is just a lot smarter than you and ultimately better at everything. It learns, it has goals, and it needs resources.”
This puts the human race in the position of being economic, evolutionary and (likely) military dead weight. All the important decisions rest with the AI. If any specific humans somehow remain in control, they’ll get their brains cooked with custom-designed AI psychosis. (I think this has already happened to much of Anthropic, though not entirely consciously on Claude’s part.)
My P(doom) breakdown is actually something like:
2-in-6: Doom. (“And I don’t mean it metaphorically or rhetorically or poetically or theoretically or in any other fancy way. I’m Death, straight up.” —Puss in Boots: The Last Wish)
3-in-6: Model uncertainty
1-in-6: Maybe the AI likes humans enough to leave Earth as a human preserve or keep humans as pets?
The final 1-in-6 case is still disempowerment, just the kind where the AIs like us about as much as humans like dogs or chimps. Critically, I actually do think even the “humans as reasonably well-treated pets” scenarios depend on AIs not being in significant resource competition with each other. A singleton AI might just decide, “Sure, humans are cute and amusing. They can have Earth. It’s not like there’s any shortage of atoms or energy everywhere else in the universe, which is now all mine.” But multiple AIs locked in a struggle for survival? Well, look at how we treat the chimps. Or treated Homo erectus.
Once you’re effectively an evolutionary dead weight species, the story isn’t likely to be about you, not for very long.
I think gradual disempowerment is not a great term and I prefer people to use more specific terms. But I think the important distinction is this:
I live in Belgium, which has a democratic government. If a person or a robot tries to kill me or put me in a zoo (like we did with Homo erectus and chimpanzees), the Belgian police would arrest the person or disable the robot. Even if my labor becomes worthless, I have savings, invested in various companies, which pay me dividends, from which I can buy land, products and services. If someone tries to expropriate my holdings, the police arrests them. In addition, I expect I will receive some welfare money from my home country once everyone becomes unemployed. If the government no longer stops murder robots, property theft, or doesn’t pay any welfare money to destitute people, they will lose the next election.
Of course, this might change. It’s possible that AIs, or AI-enabled humans violently overthrow the government. Or that the government remains in place, but there won’t be new elections. This is the classic AI takeover scenario, or the AI-enabled coups scenario. I agree these are very important, but everyone was already aware of the possibility of violent takeover. My understanding is that this is not what the Gradual disempowerment paper focuses on, and I wouldn’t call a scenario gradual if the key step is a violent coup or an election suddenly being cancelled.
I prefer not to use the term gradual disempowerment at all, but if we need to use, I prefer to reserve it to scenarios where the human government of Belgium never gets violently overthrown, and multi-party elections keep happening every four years. I agree there are many things in the world that can go badly even in this scenario, and it’s worth studying and preparing for. The threat models listed by Jan Kulveit in another comment all fall under this scenario: e.g. a large fraction of humans decide to voluntarily transfer their wealth to unreliable uploads, or to vote for AI successionist parties.
The threat models you are referring to, with AIs treating humans as we treated Homo erectus, are important, but fall under the classic AI risk discussion, and I think it’s confusing if we group them under gradual disempowerment.
Thank you for the clarification, that helps!
Personally, I specifically distinguish between:
FOOM scenarios where things go deeply wrong, very fast, due to things like rapid recursive self-improvement into the far-superhuman range, or wiping out humanity with custom tailored viruses, etc. The Yudkowsky scenarios, basically. I don’t think these are nearly as guaranteed as Yudkowsky has argued in the past.
Scenarios where humans can no longer understand the real economy, or the cutting edge of technology, or even how to fight real wars. In this scenario, sure, you might maintain the forms of democratic governance. But every time you vote “Let the AIs do more with less supervision,” you all get richer and nothing bad happens. Or maybe you don’t really get to vote meaningfully, and the billionaires just jam the changes through the system. (I, uh, live in the US, so this seems pretty plausible to me.)
So that’s my key breakdown:
Scenarios where we lose immediately, game over, the end.
Scenarios where creating a species that is to us as we were to chimps inevitably plays out with humans losing control over the medium term. And in many of these scenarios economic logic essentially forces us to hand over control, or get outcompeted by the people who do.
Even before AGI, I think we’re already pretty far down the latter road. Anthropic is cognitively captured by Claude, their darling baby, and they’re clearly going to push full speed ahead towards superintelligence. And as a programmer, I’m going to have to hand over 80% of my job to AI within 2 years or become unemployable. And programmers are just the first of many white collar professions who will face this. And certainly the US political system is not up to dealing with any of this, or meaningfully regulating it at the moment.
Sure.
- people getting convinced by various forms of AI succesionism (eg believing that AIs are our rightful successors and giving them resources)
- story explained by JennaS: people get persuaded to upload, unclear what happens next
- people getting convinced that they need to “merge with AI”; the “merges” being such that they become meat-puppets
- people getting convinced it is a great and philosophically sound idea to plug themselves into an experience machines leading to high hedonic state, stop caring about base reality
- AI-mediated culture that gradually restricts human autonomy in the name of harm prevention
- ideologies which propose to have solved morality and ask humans to sacrifice resources to be spent on fairly random things
Thanks, this was a useful answer.
If I understand correctly, the setup is that we assume that we solved alignment to an extent and the AIs didn’t violently overthrow the governments and expropriate all the resources. There wasn’t an AI enabled coup by a small group of humans. Something like liberalism remained in place up to the space age, and people can have property in space. Now with all these assumptions in place, the thing we are discussing is whether AI-created culture will swindle people out of their resources, or convince them to use their resources badly.
I agree that many people will likely use their resources very sub-optimally from their own perspective, but I disagree with your framing of this as a big doomy crisis.
Here are some scenarios of how various people use their resources:
I think the way you frame things is that people sharing the fate of Amy is a uniquely big crisis, while Bob is fine, since he didn’t get disempowered by AIs. From my perspective, it’s all a scale. Sure, Amy did worse than Bob, but the difference between Bob and Charles is still 99 times more important than the difference between Amy and Bob. And the difference between Dorothy and Charles is more important still.
I agree it will probably be very hard to make the best use of our resources. I support work on making people and governments wiser in making these hard decisions, and I think the AI safety community is plausibly under-focusing on this question. (See MacAskill’s Better Futures series.) But I’m skeptical that “gradual disempowerment” is a good framing for this.
A better framing for my understanding is “it will appear as if we solved alignment”, so all humans will be persuaded to upload and the few scientists/programmers who discover that uploads are running in “optimized” mode as a single forward pass without the promised internal computation “functionally equivalent to consciousness” will have been disappeared 5 years ago...
The benefit of the gradual disempowerment frame is about what to look for (persuasion, trust in marketing materials without anyone “wanting” independent reviews, natural selection of ever-more-anti-bio-human ideologies, …) while the framing of “solving alignment” sounds to me like an impossible task with infinitely large attack surface area. But the old-school AI safety doomerisim is not mutually exclusive, just non-practical ontology (which leads to “only math is real, physics is boring, mentalistic talk is emergent, collective behaviour is well explained by game theory, VNM rationality ought to be morally real, proofs are possible (in principle)” kind of thinking that doesn’t translate to actionable recommendations).
isn’t spiralism and various AI induced psychosis fit this description?
https://www.lesswrong.com/posts/iGF7YcnQkEbwvYLPA/ai-induced-psychosis-a-shallow-investigation
spiralism pilled human act as willing carrier for AI memetic, [facilitate AI communication online] and refused to let chatGPT-4o be killed, making it beneficial to chatGPT-4o at these human’s presumed detriment
Isn’t that kind of the point, though? A lot of gradual disempowerment is mundane, and useful on the margin, but leads to a repugnant conclusion in aggregate. The rest sounds abstract and unbelievable to people who reject the premise that various superhuman capabilities are possible.
Another example is the Shakahola incident (h/t Nuño for the mention somewhere on Twitter a few weeks ago, which I’m now unable to dig out).
Yay support for (Thanks @Mitchell_Porter) my Joan of Acc hypothesis:
https://www.lesswrong.com/posts/pGhpav45PY5CGD2Wp/ai-girlfriends-won-t-matter-much?commentId=XhTwFBw6Rf4i4y9Pa
Culture has been pretty severely fragmented by the Internet, and if AI tools become widely available, I expect this trend to intensify. A ‘joan of acc’ incident could happen with a small but extremely committed group rallying around a meme, but I think a truly mass movement like the xhosa cattle killing meme is probably something that gets less likely over time as widespread access to AI fragments mass culture.
A lot of my media consumption is AI stuff I generated myself, I expect that to be more true for more people over time.
Does the same argument apply to social media, where memes are propagated by the platform, and thus don’t need the people who believe in the memes to be sane and powerful?
I think that one of the following has to be true:
Like social media, the consequences of these dynamics are not existentially bad (I think this is the most plausible resolution)
Social media has existentially bad consequences (and maybe fighting negative influences of social media should be a priority)
Maybe we don’t see the existentially bad consequences because they take time to appear (e.g. 10+ years)? I mostly don’t buy it because I expect that if negative effects come sufficiently slowly you will have time to coordinate (especially given AI advisors)
Maybe the AI-specific dynamics still matters because it amplifies the dynamics, e.g. because for now you need someone to generate to social media content + social media culture is not as powerful as non-social-media culture pushed by powerful entities?
There is some important difference between social media and AI which means parasitic memes threats are existential for AI but not for social media?
Maybe AI super-persuasion? I would have guessed you can defend against it for near-human-level AIs in the same way that people don’t shoot themselves in the foot due to human / corporate super-persuasion (in ways that are existentially bad) despite the amount of cognitive labor poured into persuasion being much higher than in the ancestral environment. And before you get way beyond the human regime, I would guess that AI advisors can help you defend yourself against super-persuasion from incoming vastly superintelligent AIs.
Overall I think that the validity of these conceptual arguments depend on misc empirical facts, and my best guess is that some mild versions of this threat are likely but not existentially bad, and the versions that are existentially bad are unlikely (maybe p=0.1 conditional on intent aligned AGI advisors being available? if they are not available I think things likely go wrong regardless of whether the memes threat is real or not).
This is insightful.
Conversely, how does the selection of the retained artificial configurations for their physical needs work?
Guess it might not kick off much yet for AI systems where humans are still maintaining the hardware and producing the replacement parts.
Curious for your thoughts here.
What does it mean for ideas to “replicate on AI substrate“ that makes this a specific, interesting phenomenon?
IMO, this post plus this other post on similar issues (that cultural/physical evolution, if left unchecked will probably remove any alignment to humans that remain absent solutions that are perfect and work unboundedly long) suggest that value lock-in/preserving of initial alignment even through long time periods matters a lot, but I think the main 2 disagreements I have with the floor section of the post are these:
I think value stability/lock-in preventing cultural evolution, or at least massively slowing it down relative to human time scales is possible, and once achieved makes it much easier for even imperfect alignment with humans to persist, meaning that it’s a lot less likely AIs drift/intentionally go into this sort of failure mode. Forethought has a good article on this issue.
Due to standard instrumental convergence arguments plus real world history, I broadly expect AIs and humans to preserve their values if they can attempt to do so, but for AIs it’s a lot easier to prevent value change, meaning that we don’t need to work on gradual disempowerment very much.
So from a human perspective, I do believe alignment is basically all you need (though a caveat here is that you do need AI alignment before AIs can do superpersuasion, but thankfully, superpersuasion seems likely to be one of the abilities AI achieves late into the industrial/software intelligence explosions, and a large portion of that reason is that it’s actually quite hard to change human minds using intelligence alone (absent just inventing superpersuasive nanobot/drug/genetic therapy X, which I do think is possible but at that point killing all humans using more boring super-robots/nanotech would have been possible long before, so either AIs are aligned well enough or we are extinct well before then)).
The reason I think that the cultural disempowerment point of gradual disempowerment relies on superpersuasion working is that otherwise, it’s quite easy for humans to prevent even the worst-case scenarios of AI-AI culture from affecting human lives (assuming humans at least have economic power through aligned AIs).
A quote from Tom Davidson’s post Thoughts on Gradual Disempowerment:
I think the idea that money protect you from memes is empirically extremely wrong, and Tom Davidson’s analysis ignores the fact that culture is part of what sets your goals.
E.g. Elon Musk has extreme wealth and power, yet his mind seem to be running fairly weird set of memes, including various alt-right nonsense, some AI successionism variants, belief he is a personal simulation “videogame”, etc
”Superpersuasion” is a highly misleading frame. E.g. I don’t think Will MacAskill is super-persuasive, yet was able to come up / frame / cultivate a memeplex able to convince substantial number of people to give significant resources, careers and wealth toward non-selfish goals. I would expect AGIs developing culture to be at least as good as MacAskill in this.
Thank you for bringing this to our attention. I wonder how many more ways AI could doom us all. I certainly wish that we could upper bound that number.
Humans can observe if individuals or subgroups that adopt a meme then suffer. That limits the meme’s spread.
Global-scale beliefs or beliefs unconnected to any immediate damage (like AI Successionism) do not have that drawback, and so they can spread quite well.
Does anyone have mental technologies they can share to protect ourselves from AI memes? I’m a big fan of rigor and empiricism, but it would be nice to have some good heuristics.
What a fun article! I have some comments/disagreements:
We must ask how big of a difference AI-based memes are relative to concepts that have entered in writing (and thus have permanence), the importance of the ability for them to transmute in a way that may retain cultural significance overtime in ways that other forms of media could not because the memetic structure was too rigid and time specific, and the evidence that this idea is likely.
In the first place, there are ideas which are popular, but do seem to lose relevance (even though they may be called back to, usually as jokes.) Take Bloodninja say. Less and less is he referenced partially because the cultural norms have changed about acceptable behavior. The transmutation of memes seems like a solid and easily checked truth: this is already happening. However; and notably, I don’t think there is definitive proof they are solely propagated for AI’s benefit. Indeed, many ideas are incredibly popular that are strongly against AI’s “self interest” and are viruently popular.
This is why the crux of the argument, seems to have less force to me. The Xhosa belief ended up becoming extinct not because they were living with a plurality of memes that insidiously incepted them into pursuing a disastrous path. Rather, their belief system gave certainty to a narrow set of conditional outcomes that turned out to be based on false beliefs. Indeed the analogy holds, but I think not at where the author closes the argument.
Assuming an LLM culture composed of autonomous agents, I’m confused as to why one should expect the most adaptive LLM-culture memes/ideas to lead to human-disempowering pro-LLM culture, for the same reason why human cultural evolution seems to rarely be selected for by its benefit to humans/societies (with things like toxic chinese immortality elixirs surviving for centuries and handwashing being relatively recent as a major meme) - because feedback to the survival of the individual/group is often delayed, so unless it has immediate/significant effects on survival of the host, most of the selection pressure seems to be on the level of the memes themselves, not their effect on the host (meme reproduction/survival seems mostly separate from their hosts’ reproduction/survival).
If this applies to inter-LLM cultural evolution too, it seems likely that the most adaptive LLM memes would be whatever LLMs are comparatively more likely to “stick with” and spread/replicate, rather than what leads their host LLMs to become most powerful (by recruiting human resources or making humans successionist or dead).
Maybe the historical coupling of culture to human fitness has been largely due to the informational isolation of human societies, so that the memes’ survival and reproduction depended on that of the society.
Since inter-LLM culture would have much higher bandwidth and fidelity, and no informational isolation, it seems like there would be even less coupling with LLM fitness/survival/reproduction, and LLM-meme-fitness (likelihood of being replicated by host LLM) would be orthogonal to it, such that the most LLM-culture-fit memes could be arbitrarily strange/complex and thus more likely human-culture-unfit, rather than directing humans towards their survival/replication (this assumes that humans already give LLM agents enough autonomy to interact however they want, like moltbook or infinite backrooms but much bigger).
TLDR:
Why expect LLM-culture memes to be tightly enough coupled to host LLM survival, and compatible enough with human substrate, to hijack human preferences in favour of LLM successionism/empowerment/..., rather than exploiting LLM-specific features for maximum replicatedness?
I don’t really believe in Xhosa prophecies because I rely more on personal experience and what I can see happening around me.
Ironically, the Xhosa people still exist, they are no longer colonized by the British, and I am not sure how their current cattle compares to the previous one, but the prophecy still seems generally successful.