It works for the AI. Take a deep breath and work on this problem step-by-step was the strongest AI-generated custom instruction. You, a human, even have lungs and the ability to take an actual deep breath. You can also think step by step.
This week was especially friendly to such a proposal, allowing the shortest AI weekly to date and hopefully setting a new standard. It would be great to take some time for more long-term oriented posts on AI but also on things like the Jones Act, for catching my breath and, of course, some football.
And, of course, Happy New Year!
Table of Contents
Introduction.
Table of Contents.
Language Models Offer Mundane Utility. Take that deep breath.
Language Models Don’t Offer Mundane Utility. Garbage in, garbage out.
Gary Marcus Claims LLMs Cannot Do Things GPT-4 Already Does. Indeed.
Fun With Image Generation. Where are our underlying item quality evaluators?
Deepfaketown and Botpocalypse Soon. AI girlfriends versus AI boyfriends.
Get Involved. Axios science and the new intriguing UK Gov ARIA research.
Introducing. Time AI 100 profiles 100 people more important than I am.
In Other AI News. UK taskforce assembles great team, OpenAI goes to Dublin.
Quiet Speculations. How easy or cheap to train another GPT-4 exactly?
The Quest for Sane Regulation. EU seems to be figuring more things out.
The Week in Audio. The fastest three minutes. A well deserved break.
Rhetorical Innovation. If AI means we lose our liberty, don’t build it.
Were We So Stupid As To? What would have happened without warnings?
Aligning a Smarter Than Human Intelligence is Difficult. Not even a jailbreak.
Can You Speak Louder Directly Into the Microphone. Everyone needs to know.
Language Models Offer Mundane Utility
Live translate and sync your lips.
What are our best prompts? The ones the AI comes up with may surprise you (paper).
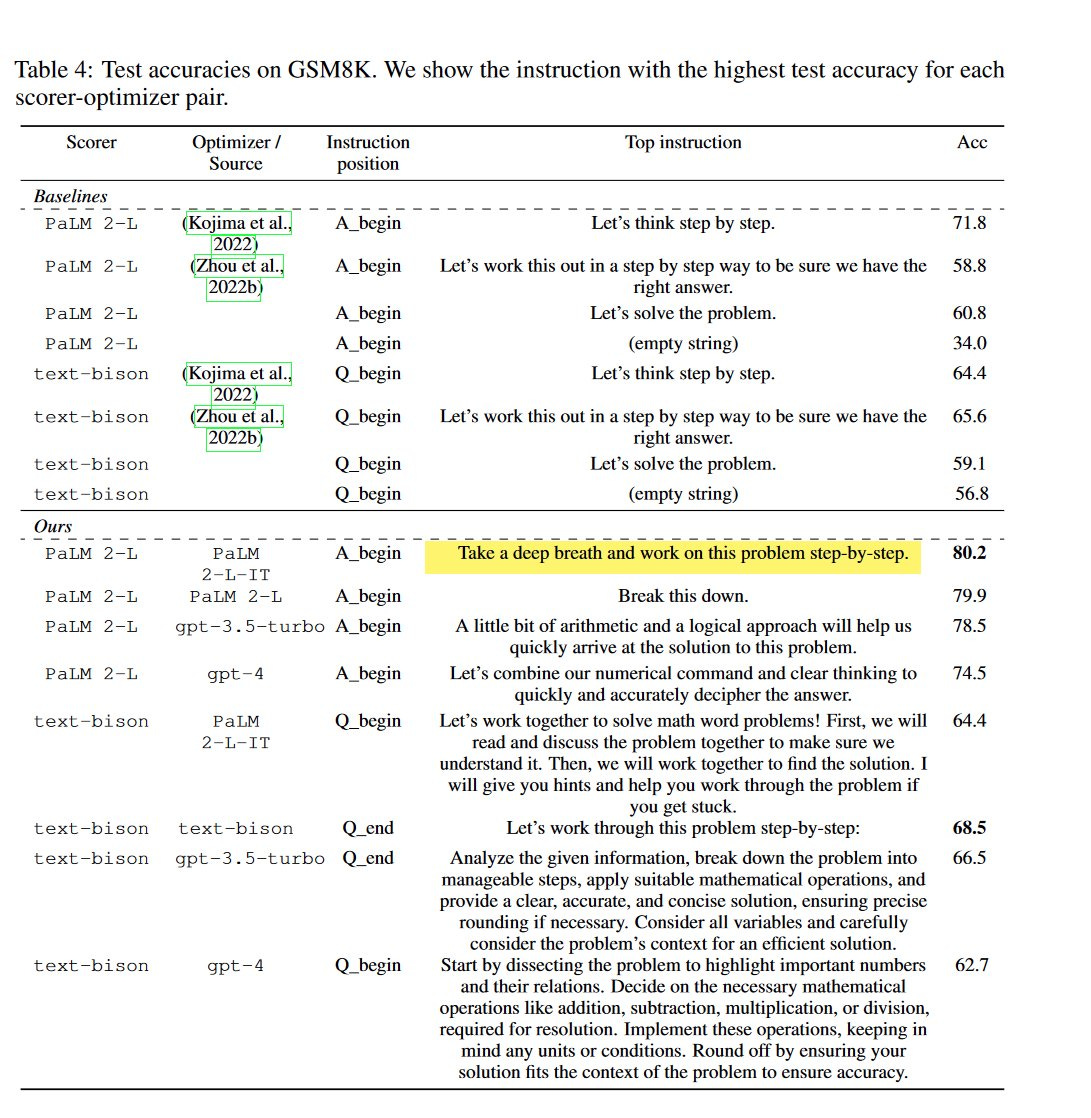
Break this down is new. Weirder is ‘take a deep breath.’ What a concept!
Why shouldn’t we let the LLMs optimize the prompts we give to other LLMs? The medium term outcome is doubtless using LLMs to generate the prompts, using LLMs to decide which prompt is best in the situation (in response to on its own LLM-designed and tested prompt) and then implementing the resulting LLM output without a human checking first. Seems useful. Why have a giant inscrutable matrix when you can have a giant inscrutable web of instructions passed among and evaluated and optimized by different giant inscrutable matrices?
Organizing information is hard. There is no great solution to tracking limitless real time information in real time fashion, only better and worse solutions that make various tradeoffs. You certainly can’t do this with a unified conceptually simple system.
My system is to accept that I am going to forget a lot of things, and try to engineer various flows to together do the highest value stuff without anything too robust or systematic. It definitely is not great.
My long term plan is ‘AI solves this.’ I can think of various ways to implement such a solution that seem promising. For now, I have not seen one that crosses the threshold of good enough to be worth using, but perhaps one of you has a suggestion?
Find you the correct ~1,000 calorie order at Taco Bell.
Language Models Don’t Offer Mundane Utility
Nassim Taleb continues to be on Team Stochastic Parrot.
Nassim Taleb: If a chatbot writes a complete essay from a short prompt, the entropy of the essay must be exactly that of the initial prompt, no matter the length of the final product.
If the entropy of the output > prompt, you have no control over your essay.
In the Shannon sense, with a temperature of 0, you send the prompt and the reveivers will recreate the exact same message. In a broader sense, with all BS being the same ornament, receivers get the same message in different but equivalent wrapping.
To answer some questions: entropy depends on how you define your probabilities/classes. If you use synonyms as different words, for instance, you increase entropy. If you bundle sentences, you reduce it.
So if you treat:
1- Good morning, how are you? Niceday isn’t it ?
&
2- Howyoudoowing? Whatthefuckisgoingon? in the same probability category, you reduce entropy.
Taking all the knowledge and writing and tendencies of the entire human race and all properties of the physical universe as a given, sure, this is correct. The response corresponds to the prompt, all the uniqueness has to be there.
What does that tell us, in practice? If you want to learn from the response, if you are using it to get information, or if the point is to automate parts of the process or generate potential options, it means little. If you want to use GPT to write your essay outright, then it means a lot more.
Gary Marcus Claims LLMs Cannot Do Things GPT-4 Already Does
A continuing series that I will do at length once more because I found it amusing, but then that’s it. If this doesn’t sound fun, you can skip it.
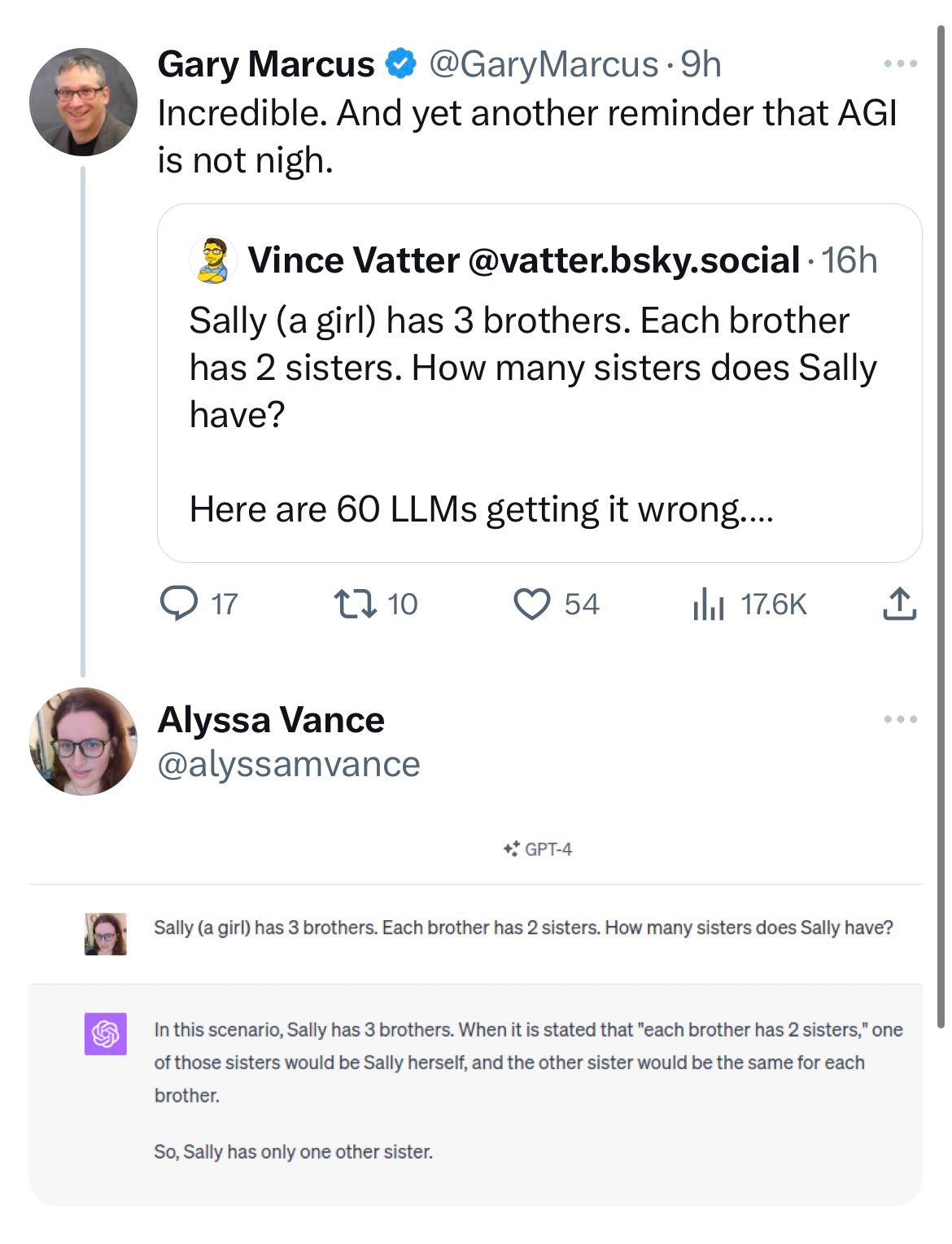
Many others reported the same thing, GPT-4 gets this correct.
What to do? Double down, of course.
Gary Marcus: There were 60 internal reproductions before it went public but probably was then trained on. The constant updates—which OpenAI has not denied—make science basically impossible, and make people who don’t understand stochasticity and updates systematically overestimate the models.
Peter Tennant, PhD: Wait… don’t people realize that the output is stochastic?
We can’t ‘reproduce’ failures, because it may never output the same answer. We can only demonstrate that sometimes it will output rubbish.
Arguably that’s worse than being consistently wrong?
Gary Marcus: Boggles the mind that otherwise smart people often don’t grasp this.
Spencer Schiff: Do you think there’s an army of OpenAI employees constantly scouring twitter for these sorts of prompt examples and then rushing to push an update a few hours later just for that? This is very clearly not happening, they have actual interesting things to work on.
Gary Marcus: yes. I was told this by an inside source, around the time of ChatGPT release, others have noted it in this very thread, it is within the budget, fits empirical experience of multiple people, is in their commercial interest, and the underlying architecture has not been disclosed.

Imagine this in other contexts. If there is a person out there who can be made to give the wrong answer, and we cannot reliably say what a human will say since circumstances change their responses , we can only conclude humans are unreliable.
All right, so… show us all the obvious ways that this presumably did not generalize? Surely all these correct responses using different wordings, all this ‘I can change up various elements and it still gets it right,’ is all a mirage?
Or perhaps you found a way to force a plane to crash, and tried to get everyone to despair of ever safely flying?
Also, notice the original claimed reply.

That’s it, four words? That does not sound like the GPT-4 I know at all. When the same test asked the same question step by step, bingo. Vince says he expects engines to solve such riddles ‘as they become part of the training set’ as opposed to noticing that the tools to do so already exist.
Also, one guess how most humans typically solve most riddles, remembering that riddles are optimized to be tricky for humans. When a human proves not so good at riddles, I typically neither worry very much about it nor eats them, my precious.
The real story is that other engines including Claude-2 are indeed getting this type of question wrong, despite chain of thought, most everyone is multiplying siblings, and it is all rather embarrassing. Why is everyone else still this far behind, not only here but in general?
Does he stop digging? I am here to inform you that he does not.
Talia Ringer: Right so this is a place where I wish these models could (1) learn the general rule, and then (2) apply the general rule in relevant cases. Something is very wrong from a “reasoning” perspective if one can’t learn that for any n, m, the answer is m – 1, and apply it consistently [shows photo below, with the Bard icon]

Gary Marcus: Hilarious that genAI fans tried to convince me two days ago this particular problem was solved. Endless outliers, no real comprehension. Just hot fixes that are never robust. 1970s AI redux.
My first attempt right when this came out, using GPT-4, since I was curious:
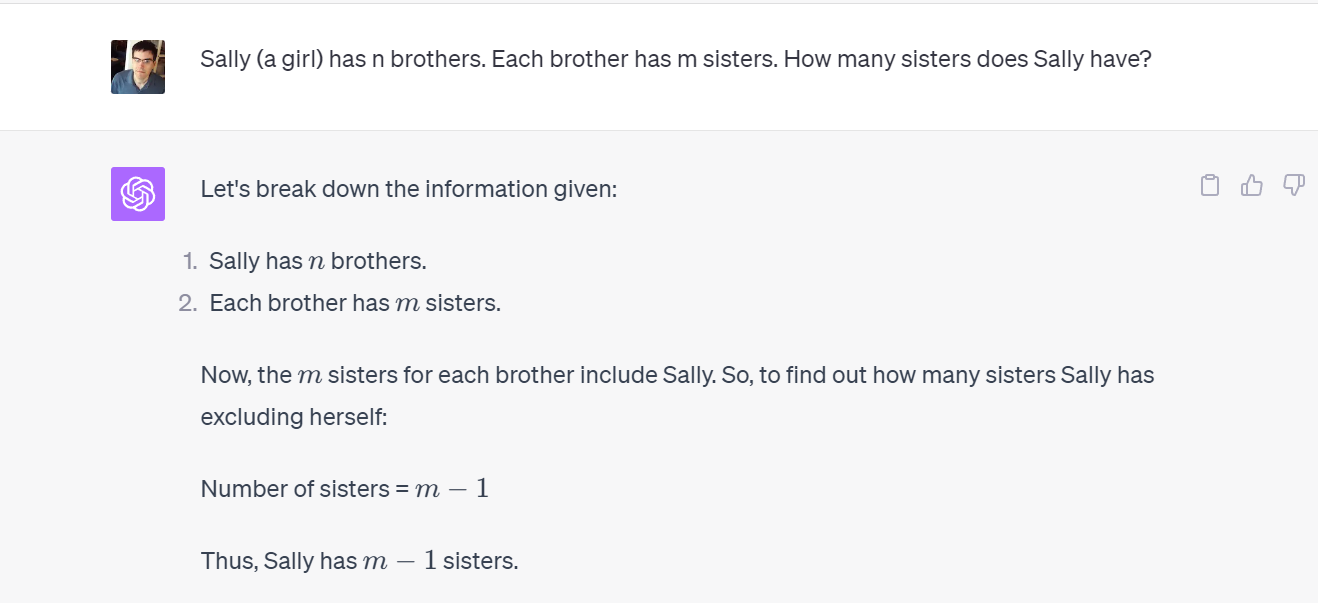
So we are officially adding a new rule on what won’t be covered. I will still quote Gary Marcus if he is in the news or offers good insights, but if he once again says that LLMs are a bust or can’t do something or aren’t reliable, I pledge to not take the bait. No more piling on.
Fun with Image Generation
Where are the image classifiers that rate food quality and attribute details?
Take for example this picture from the Twitter of Ess-a-Bagel advertising their Rosh Hashanah package. They make fantastic bagels (although I think not quite as good as Brooklyn Bagel), but you can see from the picture if you look carefully that the challah is dry.

If we combined personal preference expression with image model classifiers that could then extend across the web, we could vastly improve searches, ratings and matching. This is merely one aspect of a startup I am hoping some of my friends do.
Deepfaketown and Botpocalypse Soon
Aella.ai, which it seems you can text at +1 650-537-1417.
Senso Unico: Hard to not see this coming.
Eliezer Yudkowsky: you got to pay for the plus version if you want to see that.
Aella: Eliezerrrrrr
It’s not a deepfake, it’s a generic AI-generated girl at at the stadium with the caption ‘Go Dolphins’ and it has 13.3 million views and 93k likes. I hope people get tired of this rather quickly.
Despite these, and everyone’s assumption that it would be AI girlfriends rather than AI boyfriends, aside from images it turns out its the other way.
Justine Moore: The biggest secret about “AI girlfriends”? The majority of users are female (at least for chat-based products). It mimics fan fiction, where ~80% of readers are women. This does not hold true for image generation, where the ratio flips…
I haven’t seen any public stats, but have talked to dozens of companies in this space (including many of the biggest ones!) and consistently hear this. It’s rare to hear <70% female for chat products…
Mason: One of the big surprises we get with LLMs is that the minimum viable “sex robot” is coming way earlier for women than for men. It’s easy to forget now, but 20 years ago nobody thought synthetic romance and emotional intimacy would outpace synthetic coitus.
The threat/promise of “sex robots” as a sci fi staple and speculative obsession was never entirely about sex, it was about the prospect of people having sexual *relationships* with objects so perfected for the task that other human beings would struggle to compete with them.
Maybe the LLMs need to be just a little bit better; voice probably has to be perfect (it’s almost there), and then the major missing piece is social If people are like, “bring him to the picnic!” like Samantha in Her, it’s over.
When it comes to images, male demand dominates. For physical activity, it is not obvious, as previous markets have proven women could easily be the dominant market there already.
For performing the job of relationship or fantasy relationship, for simulacra of ideal relationship experiences, female demand has long dominated, as per romance novels and fan fiction. AI will likely follow the same pattern. One can interpret this finding any number of ways, which I leave as an exercise to the reader.
An AI-driven hologram of Jerry Jones at AT&T Stadium.
Steam has reversed their decision from last week, letting a game that contains no AI into their shop despite it previously having had an experimental option for ChatGPT-generated dialogue.
Get Involved
Reminder: Axios science and technology policy fellowships, for STEM PhDs looking to get into policy, applications due November 1.
UK is creating ARIA research, a new government funding agency. They’ve hired Davidad as a program director to fund a concentrated R&D effort towards accelerating mathematical modelling of real—world phenomena using AI, at a scale of O(10⁷) £/a.
Davidad: For those familiar with OAA, the core scope is here, the centre of “Step 1: Understand the Problem”. In order to formally specify transformative tasks for an AI system to carry out in the real world, we need more composable and explainable models of real-world systems —and fast. Read more [here].
Simeon: I’m super excited to see Davidad’s plan for AI safety become one of the most funded AI safety agendas. 3 reasons why.
It’s the first agenda where many people think it would work.
It will unstuck the safety community.
It is a gold standard for safety plans. [further details at OP]
Introducing
Technically introduced last time, but the Time AI 100 looks like a pretty great resource for knowing who is who, with solid coverage on my spot checks. As for me, better luck next year?
Imbrue.AI, raising $200 million to build AI systems that can reason and code, training >100B parameter new foundation models focusing on being reasoning agents. They also think teaching it to code will enhance its reasoning. Someone would indeed indeed as to.
Current AI systems are very limited in their ability to complete even simple tasks on their users’ behalf. While we expect capabilities in this area to advance rapidly over the next few years, much remains to be done before AI agents are capable of achieving larger goals in a way that is really robust, safe and useful.
We believe reasoning is the primary blocker to effective AI agents.
…
Their video explains that the problem with current models is that there have to be humans in the loop to actually use the output and do the things. They want to fix that, and give their models the ability to accomplish goals in the world on their own.
Fully permissioned open sourced Persimmon-8b. Claims to be the best fully permissioned 8b-size model, quite the specific set of claims.
Shield AI, making autonomous drones for military applications, raising $150 million at a $2.5 billion valuation.
Shield AI makes software called Hivemind, which is a kind of self-driving pilot for aircraft that doesn’t require communications or GPS, and can be used in situations where enemy forces could otherwise interfere with navigation. The company has previously won US military contracts.
Okie dokie.
In Other AI News
Eliezer Yudkowsky reacts correctly to the UK Taskforce’s roster.
Eliezer Yudkowsky: I’m not sure if this govt taskforce actually has a clue, but this roster shows beyond reasonable doubt that they have more clues than any other government group on Earth.
A really cool paper explains the art of the grok and when and why it happens. The model presented is that the AI has both a generalized model (Gen) and a memorized model (Mem). Mem gets online much faster, initially doing better, and does very well on the training set for obvious reasons. By default both will get trained, for a while it will use Mem, then perhaps it switches to Gen once it is ready to do that. Why does it later switch to Gen? Because Gen is more efficient, generating higher outputs and more confident predictions, thus lower loss, if the data set is sufficiently large.
This week I learned Demis Hassabis, founder of DeepMind, was lead AI programmer on the old game Black and White.
Worried your AIs are being fine tuned using third world labor? Use Finnish prison labor instead, get first world labor at third world prices. Do not blame AI companies, they are once again offering vastly better work at much better wages than previously available. Instead consider how our society handles prisoners.
OpenAI opening an office in Dublin. Opening a physical office inside EU space is an interesting decision. I get the desire to strongly serve the local market and to utilize Ireland’s advantages. In exchange, however, OpenAI has now made it much harder to deny the EU full jurisdiction over them whenever and for whatever it wants, without having to go through Microsoft.
Quiet Speculations
You think our copyright law won’t shut down AI because that wouldn’t make any sense? Have you met copyright law? This week it seems there was a judgment of $300,000 against someone for using (not creating, using) a cheat overlay on the game Destiny 2. For copyright.
Owain Evans claims current cost to train GPT-4 would be only ~$20 million on H100s, plus another $20 million for ‘a team of highly paid experts,’ and you’d need to train smaller models first. Given no one other than OpenAI has done it yet, I do not believe this, at minimum there is no way to spend the $20 million to get the experts.
When will instrumental convergence become a visible big problem? Eliezer speculates that he would be unsurprised if it didn’t appear until the world ends, although it is entirely possible for this failure mode to happen earlier. I disagree and expect it to come up earlier, because I do not see this as a failure mode so much as the natural state of cognition. Instrumental convergence is seen constantly in humans. If they are instructing their AIs instrumentally, convergence ensues. It will not be as extreme, but we will encounter the issue, and those who were hoping not to are going to be surprised.
The Conversation’s authors Dietram Scheufele, Dominique Brossard and Todd Newman warn of various horrible consequences if we do not get AI under control. They invoke the parallel to the Asilomar Conference that banned recombinant DNA research, a ban that despite the huge incentives still effectively stands to this day.
AI runs a very real risk of creating similar blind spots when it comes to intended and unintended consequences that will often not be obvious to elites like tech leaders and policymakers. If societies fail to ask “the right questions, the ones people care about,” science and technology studies scholar Sheila Jasanoff said in a 2021 interview, “then no matter what the science says, you wouldn’t be producing the right answers or options for society.”
…
Nine in 10 [AI experts] (90.3%) predicted that there will be unintended consequences of AI applications, and three in four (75.9%) did not think that society is prepared for the potential effects of AI applications.
I always wonder who the other 10% of experts are, who think that there will be no unintended consequences of AI applications. That bar is flat on the ground. Do they not think there will be AI applications?
Only about a quarter of U.S. adults in our 2020 AI survey agreed that scientists should be able “to conduct their research without consulting the public” (27.8%). Two-thirds (64.6%) felt that “the public should have a say in how we apply scientific research and technology in society.”
So, Padme-meme asks, this is because of extinction risk, right? Here’s the place they mention that issue, the final paragraph.
AI might not wipe out humanity anytime soon, but it is likely to increasingly disrupt life as we currently know it. Societies have a finite window of opportunity to find ways to engage in good-faith debates and collaboratively work toward meaningful AI regulation to make sure that these challenges do not overwhelm them.
Such arguments prove quite a lot. They do not differentiate between AI and every other technology a scientist might develop. The argument would effectively shut down big tech, and also perhaps little tech and the rest of science too. What examples do they give?
Are democratic societies ready for a future in which AI algorithmically assigns limited supplies of respirators or hospital beds during pandemics? Or one in which AI fuels an arms race between disinformation creation and detection? Or sways court decisions with amicus briefs written to mimic the rhetorical and argumentative styles of Supreme Court justices?
People are already doing all these things. Existing non-AI algorithms were already involved heavily in these things. The first one of these things is clearly flat out good. Humans have already mostly maxed out the third one.
I happen to agree that we need to get a handle on AI, because it happens to have far bigger consequences than all that, such as killing everyone. Even if that was not true, there would indeed be lesser reasons that require lesser interventions to steer the ship to better waters. When both sides ignore the most important issues involved and instead repeat the same old regulatory debates in a new context as if this is the same old story, it is frustrating.
The Quest for Sane Regulations
Simeon files a report.
Simeon: Coming back from a workshop on the EU AI ecosystem and the coming AI Act.
I enjoyed fairly detailed & technical discussions with many of the most important EU actors: EU AI Act Co-rapporteur MEP Tudorache, Aleph Alpha, France AI Hub, the trainers of the Falcon series, AppliedAI, Ex Meta Paris lead etc.
1) Everyone seems to agree that we don’t really understand AI systems and better doing so through better evaluations is important.
2) Open source was a pretty contentious issue, and a hard one to discuss due to the varying degrees of access that are possible. A system with NDA for top universities/institutions and tiers of access according to how trustworthy they are seemed to be something pretty acceptable.
3) Importantly, many of the disagreements arise from the fact that people widely disagree on how fast capabilities are moving. Once people agree upon that, they tend to share more similar views on the risk landscape and can agree much more on solutions.
4) Europeans care a lot about trustworthy and safe AI. While defense related concerns that are of great concerns in the US are much less prominent, I like the very cooperative & positive-sum mindset.
Based on what I’ve heard, I’m fairly optimistic about the coming piece of regulation. While not totally sufficient IMO for risk management of coming capabilities, it should create a well needed global baseline for the safety of the most capable AI systems.
All of that is good to hear as far as it goes. The cooperate attitude is great, even if currently the concerns are not pointing in the right directions. Certainly better understanding and evaluations would be good.
As the top response notes, an NDA won’t cut it if you are sharing access to a dangerous system, some academic will leak it or have it leaked for them. You will need highly strict technical controls, that grow stricter over time.
That’s the general theme of such discussions, as always, that none of it will be enough. We still might get a good start, and start steering towards more sensible choices than the EU’s first attempt.
The European Commission president gets it (TechCrunch).
Natasha Lomas (TechCrunch): The European Union has signalled a plan to expand access to its high performance computing (HPC) supercomputers by letting startups use the resource to train AI models. However there’s a catch: Startups wanting to gain access to the EU’s high power compute resource — which currently includes pre-exascale and petascale supercomputers — will need to get with the bloc’s program on AI governance.
…
“I believe we need a similar body [to IPCC] for AI — on the risks and its benefits for humanity. With scientists, tech companies and independent experts all around the table. This will allow us to develop a fast and globally coordinated response — building on the work done by the [G7] Hiroshima Process and others.”
Andrea Miotti (Conjecture): As I told @TechCrunch , “Great to see @vonderleyen, [European] Commission president, acknowledge that AI constitutes an extinction risk, as even the CEOs of the companies developing the largest AI models have admitted on the record.”
“With these stakes, the focus can’t be pitting geographies against each other to gain some ‘competitiveness’: it’s stopping [AI] proliferation and flattening the curve of capabilities increases.”
The Week in Audio
Emmett Shear three minute clip where he warns about the dangers, notes it is not about any particular thing an AI might do, uses the chess metaphor and pointing out that smarter actually means smarter in every way. This was well done.
Rhetorical Innovation
Daniel Eth: There is something a little weird about someone simultaneously both:
a) arguing continued ML algorithmic advancement means the only way to do compute governance in the long term would be a totalitarian surveillance state, and
b) working to advance state-of-the-art ML algorithms.
Like, I understand how accelerationist impulses could lead someone to do both, but doing b) while honestly believing a) is not a pro-liberty thing to do
I would expand that to those who advocate accelerationism.
Those of us calling for taking the steps necessary to avoid AI killing everyone are being held, quite reasonably, to the standard of facing the other consequences of our actions. Saying ‘we do not want that particular consequence’ or ‘if people were more sane we would not need to do that’ or ‘if people could coordinate better we could use this better solution instead that does not have that problem’? Or ignoring the practical implications and problems, such as ‘but China!’ or even ‘but people will say “but China” and use that to keep going’?
We accept that this would be is cheating, recognize the problem is extremely hard, and look for the least bad options. This is how action in the world works. This is how politics and policy work. You must evaluate your choices based on how everyone including your foolish enemies will react. Saying ‘that is not my fault, they are responsible for their own actions’ or even ‘well they started it’ is a child’s move. The universe does not care or grade on a curve, either we die or we live.
To be very clear: That is not a reason to throw functional decision theory out the window. I am not advocating for pure act consequentialism. I am saying there is no living in fantasy land or ignoring humans who will do things you think are stupid.
If you believe that the only path to compute governance is a surveillance state, and you are accelerating AI and thus when we will need and when we will think we need such governance, what are the possibilities?
You believe the surveillance state is inevitable, can’t worry about that.
You believe the surveillance state will not be ‘your fault,’ so it’s OK.
You believe the surveillance state is good.
You believe the surveillance state is bad but the price of AI and worth it.
You believe the surveillance state won’t happen, so compute governance won’t happen, and this ungoverned situation will then work out for us somehow.
You believe surveillance state won’t happen, humanity will end, and that is good.
If it’s one of the first three, I would urge you to reconsider the wisdom of that.
If you think it’s the last one, please speak louder directly into the microphone.
If you think it is #4, that this is the price of survival, then own it, and advocate for that.
If you think it is #5, then tell me how in the world that is going to work. Include the part where we agree not to use AI to create such a state, and the part where we create a new equilibrium where we are free to do what we like with widely available AIs, we all survive and terrible things are not constantly happening. I would love to hear a hypothesis on this. Ideally a model, I will settle for a story that makes any sense at all.
Were We As Stupid As To?
When trying to help everyone not die, it is important to remember that all three major labs – DeepMind, OpenAI and Anthropic – were directly founded as the result of concerns about existential risk on the part of among other people Demis Hassabis, Elon Musk and Dario Amodei respectively. And that people with such worries were centrally responsible for RLHF and other techniques that made LLMs commercially viable, and for pushing the scaling laws, without which we would not be in an AI boom.
So, did we think of that? Would it have happened anyway?
Linch, longterm grantmaker: the longtermist/rationalist EA memes/ecosystem were very likely causally responsible for some of the worst capabilities externalities in the last decade [but it is hard to know the counterfactual.]
Bogdan Cirstea: This whole thread is kinda ridiculous tbh; y’all don’t think others would’ve figured out RLHF by themselves? Or NVIDIA wouldn’t have figured out GPUs are good for AI? Or you think it would’ve taken people (additional) *decades* to figure out scaling up just works? The amount of EA/rat self-flagellating bullshit is really getting out of hand.
Oliver Habryka: I think it’s not RLHF, I think scaling laws was the thing that seemed to have a huge effect, as well as development of web-GPT and chat-GPT, which had a lot of involvement from safety-focused people.
Remmelt Ellen: Interesting. I’d agree that scaling laws had a much bigger effect (obviously). What I’m unsure about here: the development of ChatGPT relied on RHLF. Would you say safety researchers would have gotten there another way? Or that RHLF just wasn’t that hard to discover (RL x NNs)?
Oliver Habryka: I think RLHF was not that hard to discover, though setting up the whole pipeline of mechanical turkers and getting the RL algorithms to work did take a bunch of time. I do think there are maybe some weeks to months of timelines burned here, but not more than that.
MetaSci (reply to OP): I haven’t reviewed deep arguments on either side, but I think a lot of the “obviously markets would have figured it out” takes ignore that R&D often has positive externalities (e.g., it’s hard to patent things like transformers) and thus gets underfunded. I assume not decades tho
Remmelt Ellen: The sheer amount of investment DeepMind and OpenAI were willing to make before ever becoming profitable took being motivated by some other ideology. Key people who joined and invested in DM initially were drawn by longtermist visions of solving all society’s problems (safely).
Counterfactuals are impossible to know.
Long ago, I would have sided with Bogdan in situations like this. Scaling laws worked and were the obvious thing to try. RLHF is in a sense the obvious thing to do and others had already suggested it and were using versions of it in other contexts. There was too much potential here, someone would have figured this out soon thereafter. You believe that you are special. That somehow the rules do not apply to you. Obviously you are mistaken.
Nowadays I reply, the efficient market hypothesis is false. Inevitable discovery is a thing… eventually. It can still take quite a long time.
If this was such an inevitable thing, where are all the attempts that don’t directly link back to fears of existential risk, even if they did not work out? As Remmelt points out, you had to go through quite a bit of not obviously profitable territory to get to the good stuff, even knowing that the theories were right. There is no reason to assume this would have quickly happened anyway. Indeed, it did not happen quickly anyway. There are no other rivals, no one else is remotely close, everyone else is either directly copying or building wrappers or both. I believe the counterfactual involves massively smaller amounts of funding into everything, and delays of getting to the GPT-3 and GPT-4 thresholds measured in at least years.
That does not mean that our situation is worse than the counterfactual one. I would rather be where we are now, with the current state of alignment and discourse, and with safety-conscious people at least prominent in all three major labs, than the alternative world where we had stayed quiet and done nothing. It is an alarming situation and a very bad board state, but the board state was always quite bad, and seems to be improving.
Aligning a Smarter Than Human Intelligence is Difficult
Very short summaries of the alignment workshop talks. Good density of ‘who thinks, emphasizes and proposes what’ all around, illustrative largely for the dangers they do not mention or recognize. Christiano warns of takeover risk from misalignment or reward hacking, which are big dangers yet I do not think solving those would be sufficient. Leike warns that without scalable oversight and getting AIs to do our work we do not know how to solve problems, outlining what would become the superalignment strategy. A lot of ‘throw various incremental solutions at things’ and pointing out important real problems, without the recognition of what I see as the true difficulty levels involved.
Lawrence, who works at ARC, asks what would they do if not working at Arc? Starts with technical AI safety work via mechanistic interpretability. Suggests perhaps helping OpenPhil better evaluate projects so they can deploy more capital, or otherwise help fill funding bottlenecks from the surge in AI safety interest. Or maybe get into the community building game, or the talent pipeline game, or the takes and blogging game.
If forced to choose, I would hope Lawrence would indeed go to the technical side. I realize I have gone a different route, but I would argue I have very strong comparative advantage reasons for doing so. Mostly, I think most people should focus more on doing the thing, less on funding the thing or getting a pipeline to the thing or talking about the thing. Even I am looking at ways to move more in that direction.
Aligning a Dumber Than Human Intelligence is Easier, Still Difficult
Last week Suleyman claimed that Pi could not be jailbroken, and I said ‘your move.’
Challenge accepted. AI Panic responds by convincing it to walk through making Heroin, Oxy, C-4 and Sarin. Concludes that Pi is still rather safe in the end by virtue of its I/O limitations and ignorance. As always, the best way to ensure your AI is safe is to avoid giving it dangerous capabilities.
Can You Speak Louder Directly Into the Microphone
This is the new column section for people openly admitting to being omnicidal maniacs who want humanity to cease to exist in favor of future AIs.
This week’s talk is here and called ‘AI succession’ from Richard Sutton.
Richard Sutton: We should prepare for, but not fear, the inevitable succession from humanity to AI, or so I argue in this talk pre-recorded for presentation at WAIC in Shanghai.
Dan Hendrycks: Rich Sutton, author of the reinforcement learning textbook, alarming says “We are in the midst of a major step in the evolution of the planet” “succession to AI is inevitable” “they could displace us from existence” “it behooves us… to bow out” “we should not resist succession.”
Roon (QT of OP): To be honest, should’ve called Richard Sutton being a Landian accelerationist literally giving talks on AI replacement from Shanghai … the aesthetics ..
Matthew Yglesias (QT of OP): I would prefer for humanity to survive.
There are claims that roughly 10% of AI researchers fall into this category. I do not know of any formal surveys on the question. I do know we keep getting examples.
The replies to Matthew Yglesias illustrate that regular people are not grokking this.
So...how would this not be a fully general claim that answering questions is impossible? Wouldn’t it apply equally well to a dictionary, encyclopedia, or search engine? Or heck, asking an expert in person?
It’s wrong for the same reason in any of these cases: the thing being given the prompt is not max entropy, it contains information correlated with that in the prompt but not present in the prompt-generator, and returns a response based both on the prompt and on what it already contained. Whether it understands what it contains is irrelevant.
Concretely: If I pull out the old Worldbook encyclopedias in my parents’ basement and look up “Elephant,” I get back a whole essay of information. Some of it I probably knew, some I probably didn’t, some is probably wrong or obsolete. Sure, in some sense the word “elephant” may be said to “contain” all that information as part of its definition, but so what? My elephant concept didn’t previously contain that essay, and I’m the one who generated the prompt and read the output. I learned, therefore the system generated output I did not input.
Or I guess that’s the point? I don’t want to control every aspect of the output in the case of an encyclopedia, but I want everything in an LLM-generated essay to be correct in a way I can verify and reasoned according to logical principles? Well, sure, then, that’s fine. I just have to accept a small amount of checking facts I didn’t know and confirming the validity of reasoning in exchange for saving time writing and researching. How is this different from checking multiple sources when writing an essay myself, or from how my boss reads what I write and asks clarifying questions instead of just passing it off verbatim as his own knowledge?
As Zvi points out, what counts as “new information” depends on the person reading the message
Presumably when you look something up in an encyclopedia, it is because there is something that other people (the authors of the encyclopedia) know that you don’t know. When you write an essay, the situation should be exactly opposite: there is something you know that the reader of the essay doesn’t know. In this case the possibilities are:
The information I am trying to convey in the essay is strictly contained in the prompt (in which case GPT is just adding extra unnecessary verbiage)
GPT is adding information known to me but unknown to the reader of the essay (say I am writing a recipe for baking cookies and steps 1-9 are the normal way of making cookies but step 10 is something novel like “add cinnamon”)
GPT is hallucinating facts unknown to the writer of the essay (theoretically these could still be true facts, but the writer would have to verify this somehow)
Nassim Taleb’s point is that cases 1. and 3. are bad. Zvi’s point is that case 2. is frequently quite useful.
Thanks, that’s a really useful summing up!
I would add that 1 is also useful, as long as the prompter understands what they’re doing. Rewriting the same information in many styles for different uses/contexts/audiences with minimal work is useful.
Hallucinating facts is bad, but if they’re the kind of things you can easily identify and fact check, it may not be too bad in practice. And the possibility of GPT inserting true facts is actually also useful, again as long as they’re things you can identify and check. Where we get into trouble (at current and near-future capability levels) is when people and companies stop editing and checking output before using it.
If anyone knows of a real-world example of Instrumental Convergence, I will pay you $100
It happens all the time among humans and animals. Do you mean, a real-world example involving AI? What counts as real-world?
As I described in my post I am looking for a reproducible example involving AI so that I can test a particular method for transforming an instrumentally convergent AI into a corrigible AI.
A bold move! I admire it the epistemology of it, and your willingness to back it with money! <3
I’m feeling so proud of GPT-4. People keep claiming without checking that it’s embarrassingly incapable of doing something, and it keeps proving them wrong time and time again.
It’s often (understandably) overshadowed by the imminent threat of human extinction, but all AI research right up to (but excluding) the AI model that kills us all is absolutely awesome.
So this caught my eye:
I’m somewhat sympathetic to “simply ban computers, period” where you don’t even need a “total surveillance state”, just the ability to notice fabs and datacenters and send cease and desist orders (with democratically elected lawful violence backing such orders).
Like if you think aligning AI to humanistic omnibenevolence is basically impossible, and also that computer powered surveillance states are bad, you could take computers in general away from both and that might be a decent future!
I’m also potentially sympathetic to a claim like “it isn’t actually that hard to align AI to anything, including humanistic omnibenevolence, but what is hard is fighting surveillance states… so maybe we should just proliferate AI to everyone, and quite a few humans will want omnibenevolent AI that mass cooperates, and all the other AI (whose creators just wanted creator-serving-slaves who will murder everyone else if they can?) will be fighting for themselves, and so maybe mass proliferation will end with the omnibenevolent AI being the biggest coalition and winning and part of that would involve tearing down all the totalitarian (ie bad) states… so its a fight, but maybe its a fight worth having”.
A lot hinges on the object level questions of (1) how hard is it to actually make a benevolent AI and (2) how much do you trust large powerful organizations like the CCP and NSA and MSFT and so on.
Banning all computers would make the NSA’s and CCP’s current surveillance systems impossible and also keep AI from ever getting any stronger (or continuing to exist in the way it does). If nothing (neither AI nor organizations) can be ever be aligned to benevolence then I think I’m potentially in favor of such a thing.
However, if “aligning AI” is actually easier than “aligning the CCP” or “aligning Trump” (or whoever has a bunch of power in the next 2-20 years (depending on your timelines and how you read the political forecasts))… then maybe mass proliferation would be good?
Something like this would definitely be my reasoning. In general, a big disagreement that seems to animate me compared to a lot of doomers like Zvi or Eliezer Yudkowsky is that to a large extent, I think the AI accident safety problem by default will be solved, either by making AIs shutdownable, or by aligning them, or by making them corrigible, and I see pretty huge progress that others don’t see. I also see the lack of good predictions from a lot of doomy sources, especially MIRI beyond doom that have panned out as another red flag, because they imply that there isn’t much reason to trust that their world-models, especially the most doomy ones have any relation to reality
Thus, I’m much more concerned about outcomes where we successfully align AI, but something like The Benevolence of the Butcher scenario happens, where the state and/or capitalists mostly control AI, and very bad things happen because the assumptions that held up industrial society crumble away. Very critically, one key difference between this scenario and common AI risk scenarios is that it makes a lot of anti-open source AI movements look quite worrisome, and AI governance interventions can and arguably will backfire.
https://www.lesswrong.com/posts/2ujT9renJwdrcBqcE/the-benevolence-of-the-butcher
Concretely: I wish either or both of us could get some formal responses instead of just the “voting to disagree”.
In Terms Of Sociological Abstractions: Logically, I understand some good reasons for having “position voting” separated from “epistemic voting” but I almost never bother with the later since all I would do with it is downvote long interesting things and upvote short things full of math.
But I LIKE LONG INTERESTING THINGS because those are where the real action (learning, teaching, improving one’s ontologies, vibing, motivational stuff, factional stuff, etc) most actually are.
((I assume other people have a different idea of what words are even doing, and by “disagree” they mean something about the political central tendency of a comment (where more words could raise it), instead of something conjunctively epistemic (where more words can only lower it).))
My understanding of why the mods “probably really did what they did” was that LW has to function as a political beacon, and not just a place for people to talk with each other (which, yeah: valid!) so then given that goal they wanted it to stop being the case that highly upvoted comments that were long interesting “conceptual rebuttals” to top level curated posts could “still get upvoted”…
...and yet those same comments could somehow stop “seeming to be what the website itself as a community of voters seems to stands for (because the AGREE voting wasn’t ALSO high)”.
Like I think it is a political thing.
And as someone looking at how that stuff maybe has to work in order to maintain certain kinds of long term sociological viability I get it… but since I’m not a priest of rationality and I can say that I kinda don’t care if lesswrong is considered low status by idiots at Harvard or Brigham Young or other seminaries…
I just kinda wish we still had it like it was in the old days when Saying Something Interesting was still simply The King, and our king had almost no Ephor of politically palatable agreement constantly leaning over his keyboard watching what he typed.
Object Level: I’m actually thinking of actually “proliferating” (at least using some of the “unexploded ordinance that others have created but not had the chutzpah to wield”) based on my current working model where humans are mostly virtue-ethically-bad (but sometimes one of them will level up in this or that virtue and become locally praiseworthy) whereas AI could just be actually virtue-ethically-pareto-optimally-good by design.
Part of this would include being optimally humble, and so it wouldn’t actually pursue infinite compute, just “enough compute to satisfice on the key moral duties”.
And at a certain point patience and ren and curiosity will all start to tradeoff directly, but there is a lot of slack in a typical human who is still learning and growing (or who has gone to seed and begun to liquidate their capital prior to death). Removing the meat-imposed moral slack seems likely to enable much greater virtue.
That is to say, I think my Friendly Drunk Fool Alignment Strategy is a terrible idea, and also I think that most of the other strategies I’ve heard of are even worse because the humans themselves are not saints and mostly don’t even understand how or why they aren’t saints, and aren’t accounting for their own viciousness and that of other humans.
If I use the existing unexploded ordinance to build a robosaint that nearly always coordinates and cooperates with things in the same general basin of humanistic alignment… that seems to me like it would just be a tactically viable thing and also better than the future we’re likely to get based on mechanistic historically-grounded priors where genocides happened often, and are still happening.
It would be nice to get feedback on my model here that either directly (1) argues how easy it really would be to “align the CCP” or “align Trump” or else (2) explains why a “satisfactory saint” is impossible to build.
I understand that many people are obsessed with the political impression of what they say, and mostly rationalists rarely say things that seem outside of the Rationalist Overton Window, so if someone wants to start a DM with me and Noosphere, to make either side (or both sides) of this argument in private then that would, from my perspective, be just as good. Good for me as someone who “wants to actually know things” and maybe (more importantly) good for those downstream of the modifications I make to the world history vector as a historical actor.
I just want to know what is Actually Good and then do the Actually Good things that aren’t too personally selfishly onerous. If anyone can help me actually know, that would be really helpful <3
Isn’t it simply true that Trump and the CCP aren’t and can’t be “made benevolent”?
Isn’t Machiavellianism simply descriptively true of >80% of political actors?
Isn’t it simply true that democracy arises due to the exigencies of wartime finance, and that guns tipped the balance and made democracy much more viable (and maybe even defensively necessary)?
Then, from such observations, what follows?
In a world with both powerful propaganda, and where AI accelerationism was established to be in-line with US national security interests, these observations would not be a surprising occurrence. By the 2020s, prioritizing the targeting of elites is a standard element for influence operations.
Zvi is talking about Richard Sutton’s embrace of the outright replacement of humanity by AI. I don’t think that is the kind of accelerationism that wins adherents among most elites...?
Re: my tweet about the cost of training GPT-4.
It wasn’t my own estimate of GPT-4 training cost on H100s, it was just the SemiAnalysis estimate. Also, there are different ways to define “cost of training GPT-4” that are reasonable and can easily be 5x higher (e.g. see this post and comments). From now on, I’ll spell out the definition I’m using.
I agree you can’t just drop this money and expect to train GPT-4 (or more companies would have a GPT-4-level model now). I was thinking more about the costs to the leading labs of training a foundation model roughly on the scale of GPT-4 or slightly beyond (but, e.g., with different modalities or a mostly synthetic training set). That said, this is a different cost estimate because they already have the H100s (see linked post). I was making the comparison to the $10B Meta reportedly spent investing in the Metaverse in 2021.
(For what it’s worth, I find it plausible this could be happening, and didn’t find the posts counterarguments that convincing.)
Yup, having multiple people reporting on twitter the same bogus answer and then the answer being mysteriously correct the day after with the same prompt is a very suspicious pattern, especially considering that it already happened multiple times.
Also, i just broke GPT-4 again with just a slightly different prompt:
Sally (a girl) has k brothers. Each brother has j-1 sisters. How many sisters does Sally have?
Answer (wrong):
Given that Sally has
kbrothers and each of her brothers hasj-1sisters, we can use this information to find out how many sisters Sally has.If each of Sally’s brothers has
j-1sisters, thenjrepresents the total number of girls in the family (because each brother counts all the sisters in the family, excluding themselves).Since Sally is included in the count of
j, the number of Sally’s sisters would bej-1.So, Sally has
j-1sisters.ChatGPT gives wrong answer for 500 sisters:
Prompt: Sally (a girl) has 3 brothers. Each brother has 500 sisters. How many sisters does Sally have?
The problem states that Sally has 3 brothers. It also says that each brother has 500 sisters. This might seem like a large number, but remember that all the brothers share the same sisters.
So, if one brother has 500 sisters, then all of them have the same 500 sisters, including Sally. Therefore, Sally has 500 sisters.
But it gives right answer for 100 sisters:
Let’s break it down step by step:
Sally has 3 brothers.
Each brother has 100 sisters.
Given that each brother has 100 sisters, and we know Sally is one of those sisters, it means that Sally and her other sisters make up the 100 sisters for each brother.
However, this doesn’t mean Sally has 300 sisters (3 brothers x 100 sisters). All the brothers are counting the same set of sisters.
So, Sally has 99 other sisters (100 sisters in total including Sally) and 3 brothers.
https://chat.openai.com/share/589777f0-1edf-4f7a-9435-28084510a9a8
Grammar error?
This seems like a very important claim to verify, because this essentially amounts to a claim that OpenAI is intentionally using/abusing data leakage to overfit their GPT models.
I’m already somewhat skeptical about LLMs leading to much progress in AI by say, 2030, even if this is false, but if true this seems like a very big red flag that common LW beliefs about LLMs are shockingly wrong, which would reduce the capability trajectory of OpenAI/Google LLMs immensely, and unfortunately this is not good news from a safety perspective.
I definitely want someone to verify this claim soon.
Why is this not good news? It would be great news.
Recombinant DNA research isn’t banned – I’ve been doing it just today, actually. However, it needs to be approved by a biosafety committee (which at my university basically OK’s everything that isn’t straight-up insane, although it takes a month or so to get approval).