I think a crisp summary here is: CFAR is in the business of helping create scientists, more than the business of doing science. Some of the things it makes sense to do to help create scientists look vaguely science-ish, but others don’t. And this sometimes causes people to worry (understandably, I think) that CFAR isn’t enthused about science, or doesn’t understand its value.
But if you’re looking to improve a given culture, one natural move is to explore that culture’s blindspots. And I think exploring those blindspots is often not going to look like an activity typical of that culture.
An example: there’s a particular bug I encounter extremely often at AIRCS workshops, but rarely at other workshops. I don’t yet feel like I have a great model of it, but it has something to do with not fully understanding how words have referents at different levels of abstraction. It’s the sort of confusion that I think reading A Human’s Guide to Words often resolves in people, and which results in people asking questions like:
“Should I replace [my core goal x] with [this list of “ethical” goals I recently heard about]?”
“Why is the fact that I have a goal a good reason to optimize for it?”
“Are propositions like ‘x is good’ or ‘y is beautiful’ even meaningful claims?”
When I encounter this bug I often point to a nearby tree, and start describing it at different levels of abstraction. The word “tree” refers to a bunch of different related things: to a member of an evolutionarily-related category of organisms, to the general sort of object humans tend to emit the phonemes “tree” to describe, to this particular mid-sized physical object here in front of us, to the particular arrangement of particles that composes the object, etc. And it’s sensible to use the term “tree” anyway, as long as you’re careful to track which level of abstraction you’re referring to with a given proposition—i.e., as long as you’re careful to be precise about exactly which map/territory correspondence you’re asserting.
This is obvious to most science-minded people. But it’s often less obvious that the same procedure, with the same carefulness, is needed to sensibly discuss concepts like “goal” and “good.” Just as it doesn’t make sense to discuss whether a given tree is “strong” without distinguishing between “in terms of its likelihood of falling over” or “in terms of its molecular bonds,” it doesn’t make sense to discuss whether a goal is “good” without distinguishing between e.g. “relative to societal consensus” or “relative to your current preferences” or “relative to the preferences you might come to have given more time to think.”
This conversation often seems to help resolve the confusion. At some point, I may design a class about this, so that more such confusions can be resolved. But I expect that if I do, some of the engineers in the audience will get nervous, since it will look an awful lot like a philosophy class! (I already get this objection regularly one-on-one). That is, I expect some may wonder whether the AIRCS staff, which claim to be running workshops for engineers, are actually more enthusiastic about philosophy than engineering.
We’re not. Academic philosophy, at least, strikes me as an unusually unproductive field with generally poor epistemics. I don’t want to turn the engineers into philosophers—I just want to use a particular helpful insight from philosophy to patch a bug which, for whatever reason, seems to commonly afflict AIRCS participants.
CFAR faces this dilemma a lot. For example, we spent a bunch of time circling for a while, and this made many rationalists nervous—was CFAR as an institution, which claimed to be running workshops for science-minded, sequences-reading, law-based-reasoning-enthused rationalists, actually more enthusiastic about woo-laden authentic relating games?
We weren’t. But we looked around, and noticed that lots of the promising people around us seemed particularly bad at extrospection—i.e., at simulating the felt senses of their conversational partners in their own minds. This seemed worrying, among other reasons because early-stage research intuitions (e.g. about which lines of inquiry feel exciting to pursue) often seem to be stored sub-verbally. So we looked to specialists in extraspection for a patch.
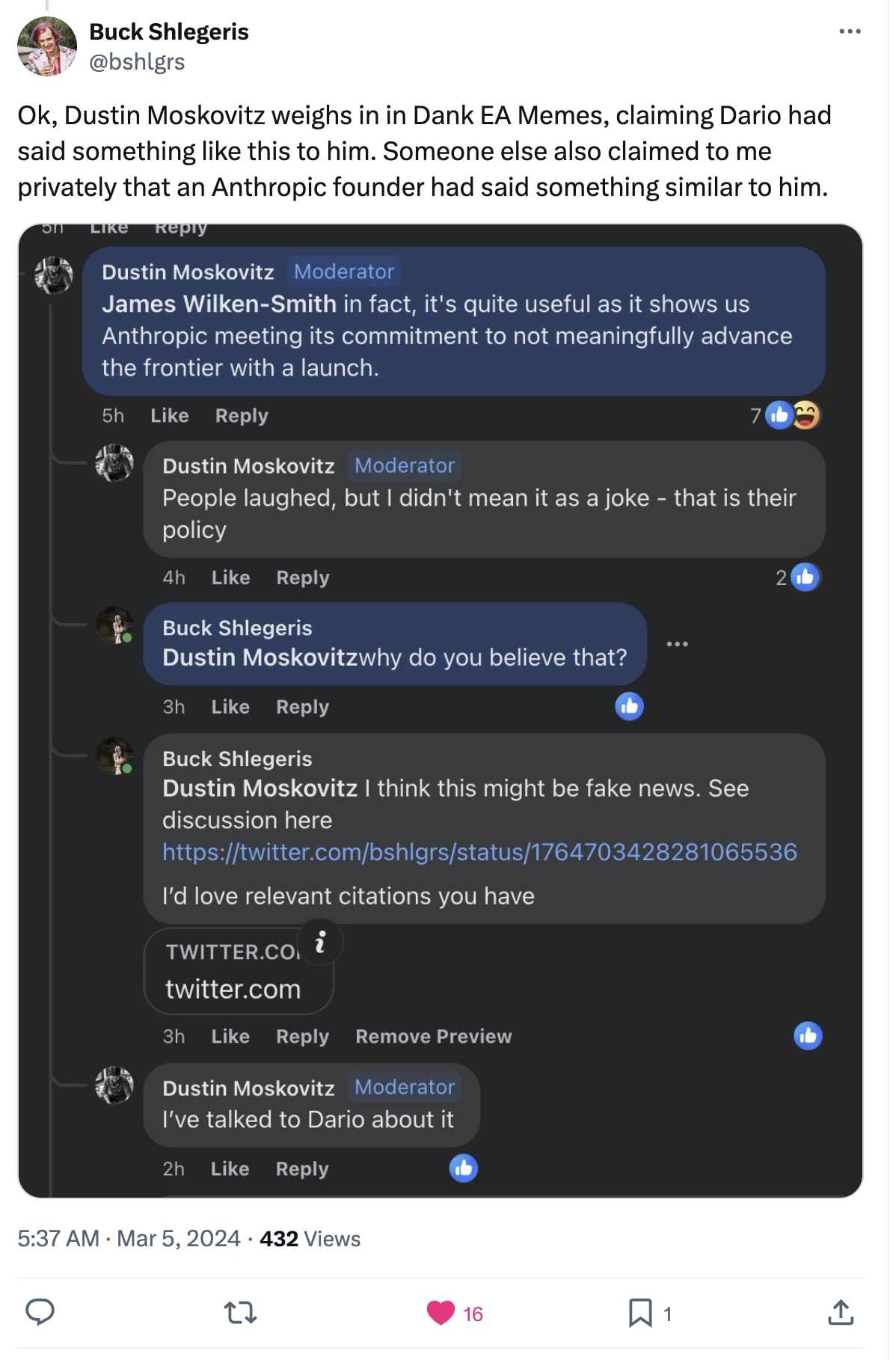
One comment in this thread compares the OP to Philip Morris’ claims to be working toward a “smoke-free future.” I think this analogy is overstated, in that I expect Philip Morris is being more intentionally deceptive than Jacob Hilton here. But I quite liked the comment anyway, because I share the sense that (regardless of Jacob’s intention) the OP has an effect much like safetywashing, and I think the exaggerated satire helps make that easier to see.
The OP is framed as addressing common misconceptions about OpenAI, of which it lists five:
OpenAI is not working on scalable alignment.
Most people who were working on alignment at OpenAI left for Anthropic.
OpenAI is a purely for-profit organization.
OpenAI is not aware of the risks of race dynamics.
OpenAI leadership is dismissive of existential risk from AI.
Of these, I think 1, 3, and 4 address positions that are held by basically no one. So by “debunking” much dumber versions of the claims people actually make, the post gives the impression of engaging with criticism, without actually meaningfully doing that. 2 at least addresses a real argument, but at least as I understand it, is quite misleading—while technically true, it seriously underplays the degree to which there was an exodus of key safety-conscious staff, who left because they felt OpenAI leadership was too reckless. So of these, only 5 strikes me as responding non-misleadingly to a real criticism people actually regularly make.
In response to the Philip Morris analogy, Jacob advised caution:
For many years, the criticism I heard of OpenAI in private was dramatically more vociferous than what I heard in public. I think much of this was because many people shared Jacob’s concern—if we say what we actually think about their strategy, maybe they’ll write us off as enemies, and not listen later when it really counts?
But I think this is starting to change. I’ve seen a lot more public criticism lately, which I think is probably at least in part because it’s become so obvious that the strategy of mincing our words hasn’t worked. If they mostly ignore all but the very most optimistic alignment researchers now, why should we expect that will change later, as long as we keep being careful to avoid stating any of our offensive-sounding beliefs?
From talking with early employees and others, my impression is that OpenAI’s founding was incredibly reckless, in the sense that they rushed to deploy their org, before first taking much time to figure out how to ensure that went well. The founders’ early comments about accident risk mostly strike me as so naive and unwise, that I find it hard to imagine they thought much at all about the existing alignment literature before deciding to charge ahead and create a new lab. Their initial plan—the one still baked into their name—would have been terribly dangerous if implemented, for reasons I’d think should have been immediately obvious to them had they stopped to think hard about accident risk at all.
And I think their actions since then have mostly been similarly reckless. When they got the scaling laws result, they published a paper about it, thereby popularizing the notion that “just making the black box bigger” might be a viable path to AGI. When they demoed this strategy with products like GPT-3, DALL-E, and CLIP, they described much of the architecture publicly, inspiring others to pursue similar research directions.
So in effect, as far as I can tell, they created a very productive “creating the x-risk” department, alongside a smaller “mitigating that risk” department—the presence of which I take the OP to describe as reassuring—staffed by a few of the most notably optimistic alignment researchers, many of whom left because even they felt too worried about OpenAI’s recklessness.
After all of that, why would we expect they’ll suddenly start being prudent and cautious when it comes time to deploy transformative tech? I don’t think we should.
My strong bet is that OpenAI leadership are good people, in the standard deontological sense, and I think that’s overwhelmingly the sense that should govern interpersonal interactions. I think they’re very likely trying hard, from their perspective, to make this go well, and I urge you, dear reader, not to be an asshole to them. Figuring out what makes sense is hard; doing things is hard; attempts to achieve goals often somehow accidentally end up causing the opposite thing to happen; nobody will want to work with you if small strategic updates might cause you to suddenly treat them totally differently.
But I think we are well past the point where it plausibly makes sense for pessimistic folks to refrain from stating their true views about OpenAI (or any other lab) just to be polite. They didn’t listen the first times alignment researchers screamed in horror, and they probably won’t listen the next times either. So you might as well just say what you actually think—at least that way, anyone who does listen will find a message worth hearing.