Formalizing «Boundaries» with Markov blankets
How could «boundaries» be formally specified? Markov blankets seem to be one fitting abstraction.
[The post is largely a conceptual distillation of Andrew Critch’s Part 3a: Defining boundaries as directed Markov blankets.]
Explaining Markov blankets
By the end of this section, I want you to understand the following diagram (Pearlian causal diagram):
Also: I will assume a basic familiarity with Markov chains in this post.
First, I want you to imagine a simple Markov chain that represents the fact that a human influences itself over time:
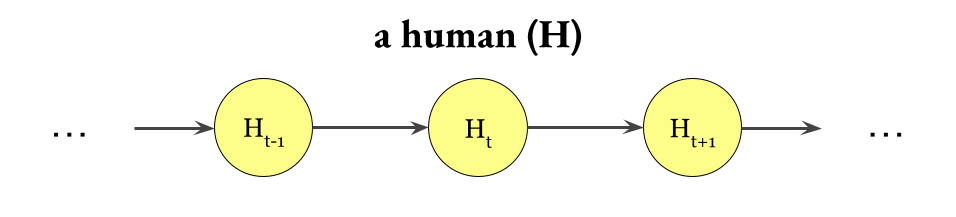
Second, I want you to imagine a Markov chain that represents the fact that the environment[1] influences itself over time:
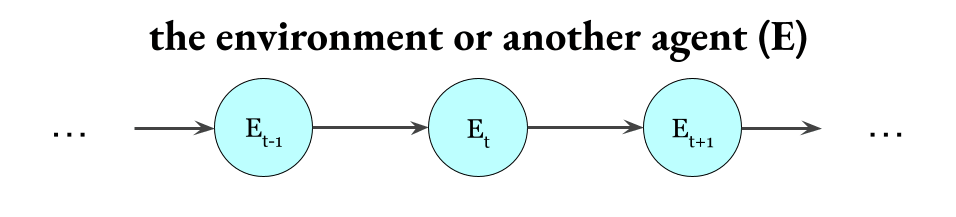
Okay. Now, notice that in between the human and its environment there’s some kind of boundary. For example, their skin (a physical boundary) and their interpretation/cognition (an informational boundary). If this were not a human but instead a bacterium, then the boundary I mean would (mostly) be the bacterium’s cell membrane.
Third, imagine a Markov chain that represents that boundary influencing itself over time:
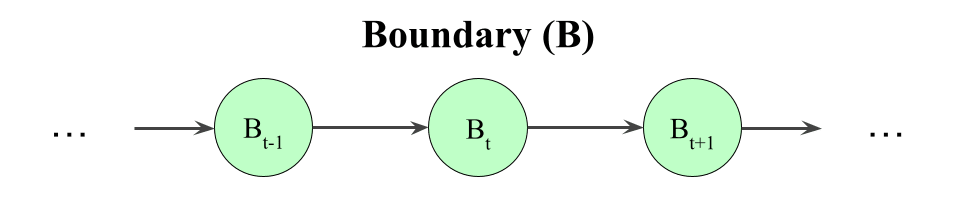
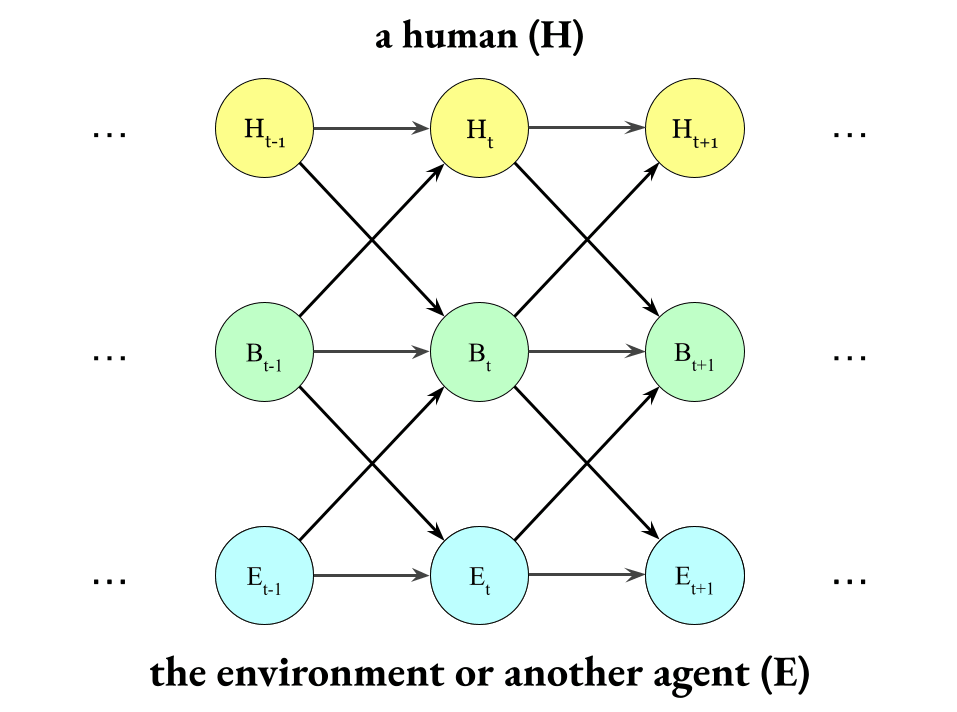
Okay, so we have these three Markov chains running in parallel:
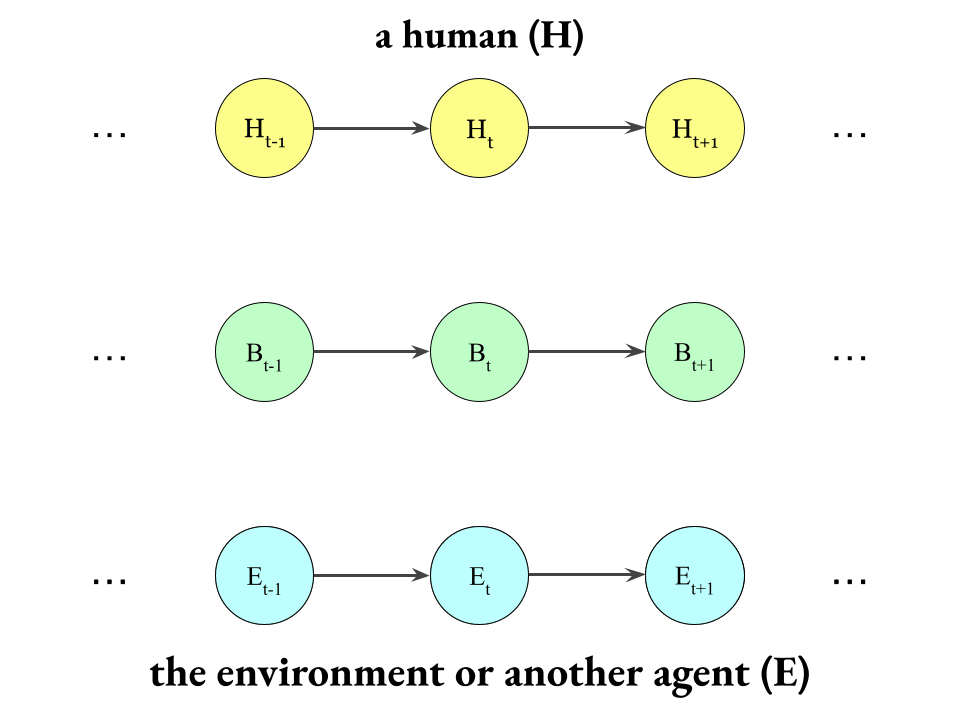
But they also influence each other, so let’s build that into the model, too.
How should they be connected?
Well, how does the environment affect a human?
Ok, so I want you to notice that when an environment affects a human, it doesn’t influence them directly, but instead it influences their skin or their cognition (their boundary), and then their boundary influences them.
For example, I shine light in your eyes (part of your environment), it activates your eyes (part of your boundary), and your eyes send information to your brain (part of your insides).
Which is to say, this is what does not happen:
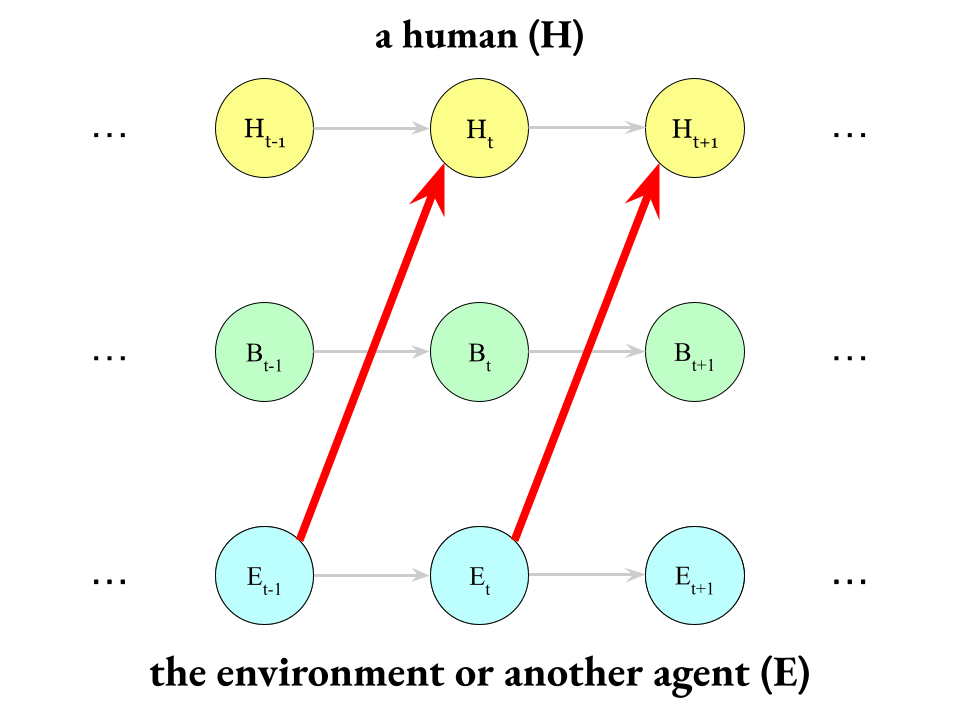
(This is called “infiltration”.) The environment does not directly influence the human.
Instead, the environment influences the boundary which influences them, which looks like this:
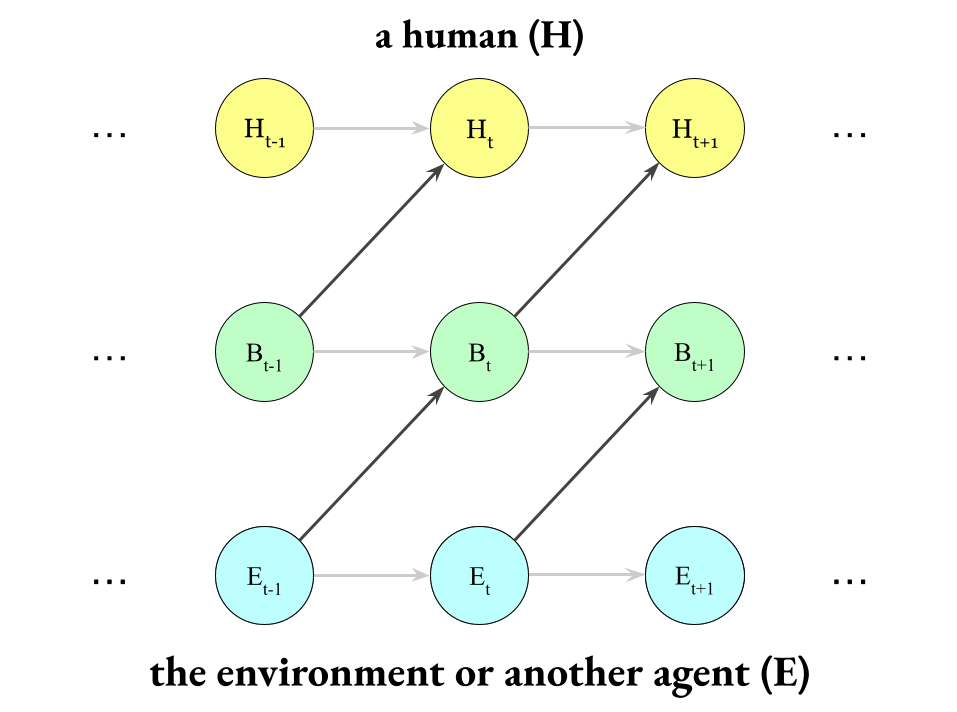
The environment influences your skin and your senses, and your skin and senses influence you.
Okay, now let’s do the other direction. How does a human influence their environment?
It’s not that a human controls the environment directly…
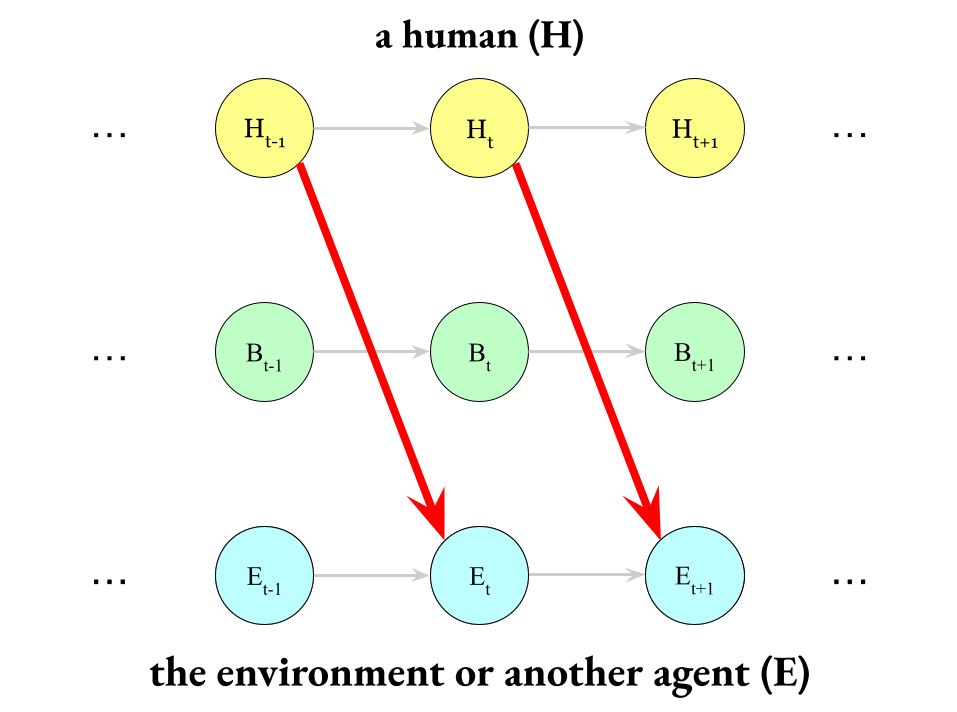
(This is called “exfiltration”; this does not happen.)
…but that the human takes actions (via their boundary), and then their actions affect the environment:
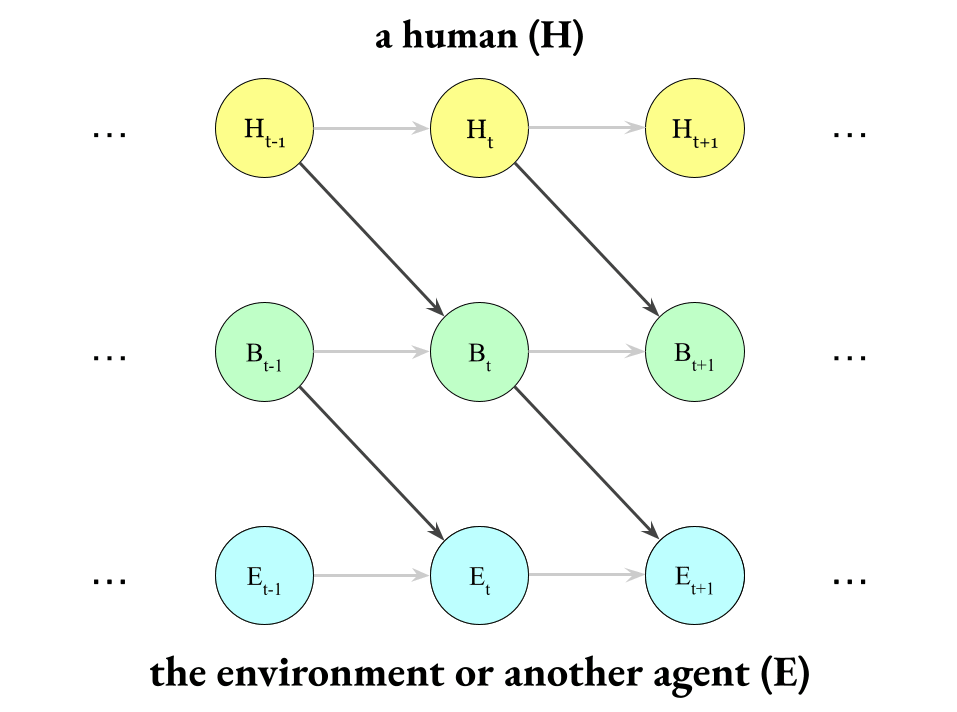
For example, it’s not that the environment “reads your mind” directly, but rather that you express yourself and then others read your words and actions.
Okay.
Now, putting together both of directions of human-influences-environment and environment-influences-human, we get this:
Also, I want you to notice which arrows that are conspicuously missing from the diagram above:
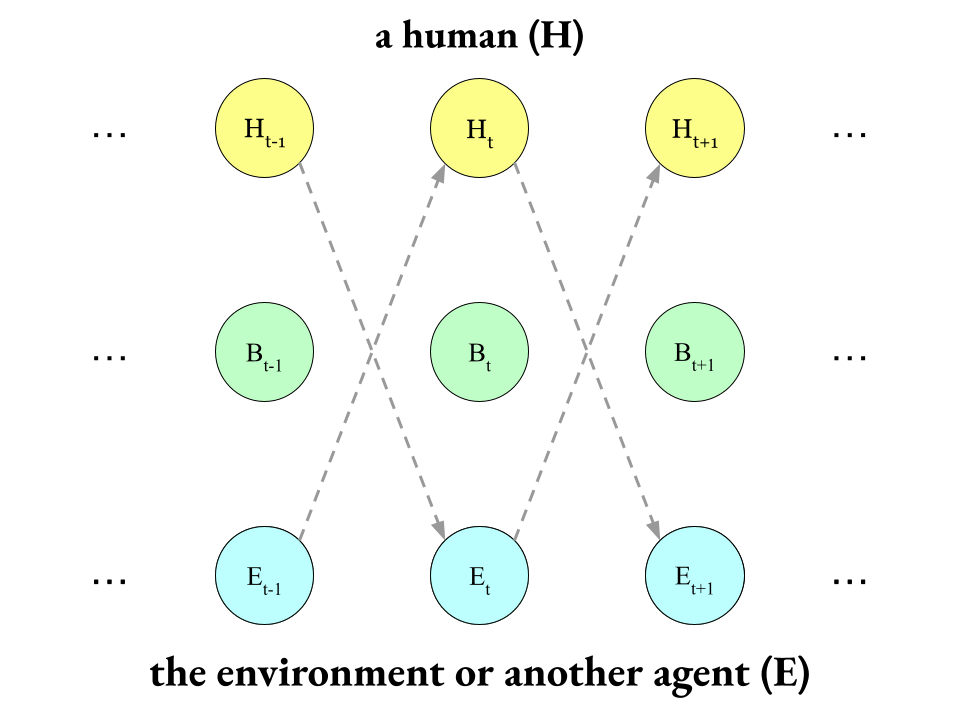
Please compare this diagram to the one before it.
So that’s how we can model the approximate causal separation between an agent and the environment.
Defining boundary violations
Finally, we can define boundary violations as exactly this:
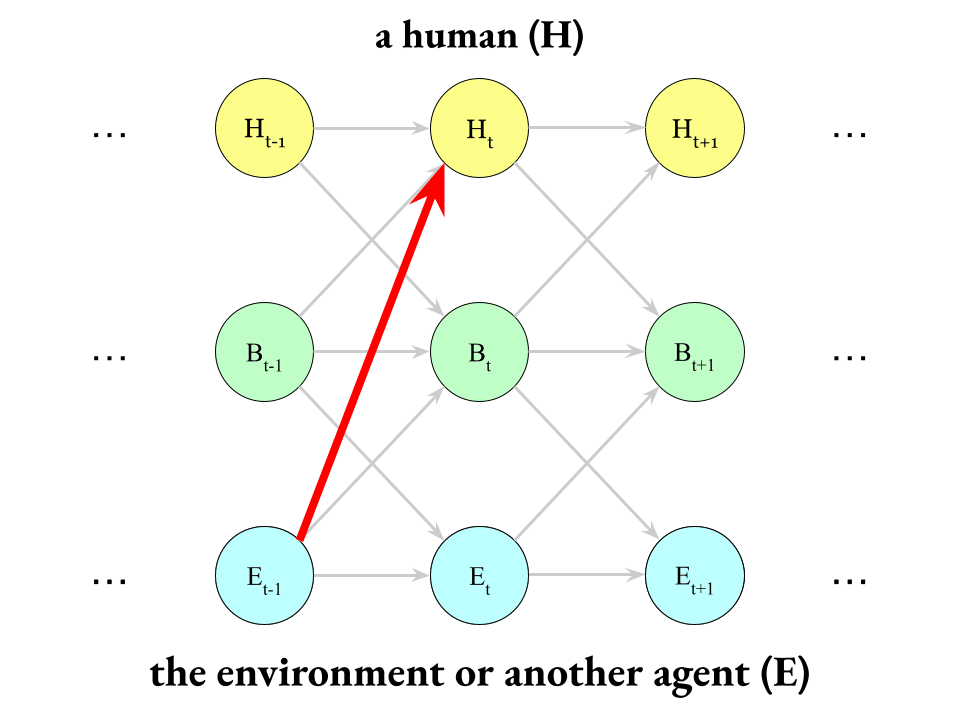
Boundary violations are infiltration across human Markov blankets.[2]
Leakage and leakage minimization
Of course, in reality, there’s actually leakage and the ‘real’ Markov blanket between any human and their environment does include the arrows I said were missing.
For example, viruses in the air might influence me in ways I can’t control or prevent. Similarly, my brain waves are emanating out into the fields around me.
However, humans are agents that are actively minimizing that leakage. For example:
You don’t want to be directly controlled by your environment. (You don’t want infiltration.)
Instead, you want to take in information and then be able to decide what to do with it. You want to have a say about how things affect you.
A bacterium wants things to go through its gates and ion channels, and not just pierce its membrane.
If I could cheaply improve my boundary’s immunity to viruses, I would.
Humans are embedded agents (of course). However, humans are also actively seeking to de-embed themselves from the environment and make themselves independent from the environment.
You don’t want the way that you’re influencing the world to be by people mind-reading you. (Exfiltration[3])
Instead, you want to be affecting the world intentionally, through your actions.
If you believed that someone might be able to predict you well or get close to predicting you well and you don’t want that, you would probably take evasive maneuvers.
Even if this works, how would the AI system detect the Markov blankets?
Perhaps by doing causal discovery on the world to detect the Markov blankets of the moral patients that we want the AI system to respect. Also see: Discovering Agents.
A few months ago I asked a member of the Causal Incentives group (the authors of the links above) if causal discovery could be used empirically to discover agents in the real world and I remember a vibe of “yeah possibly”. (Though also this didn’t seem like their goal.)
Credits and math
This section was largely based on Andrew Critch’s «Boundaries», Part 3a: Defining boundaries as directed Markov blankets — LessWrong. That post has more technical details, and defines infiltration more rigorously in terms of mutual information. E.g.:

[Critch also splits the boundary into two components, “active” (~actions) and “passive” (~perceptions). A more thorough version of this post would have split the “B” in the diagrams above into these components, too, but I didn’t think it was necessary to do here.]
Subscribe to the boundaries / membranes tag if you’d like to stay updated on this agenda.
- ^
It’s not clear exactly how to specify the environment a priori, but it should end up roughly being the complement of the human with respect to the rest of the universe.
- ^
- ^
exfiltration, i.e.: privacy and the absence of mind-reading. Related section: “Maintaining Boundaries is about Maintaining Free Will and Privacy” by Scott Garrabrant.
- Rewriting The Courage to be Disliked by (20 Sep 2025 1:48 UTC; 66 points)
- «Boundaries/Membranes» and AI safety compilation by (3 May 2023 21:41 UTC; 56 points)
- Apply to the Conceptual Boundaries Workshop for AI Safety by (27 Nov 2023 21:04 UTC; 50 points)
- What does davidad want from «boundaries»? by (6 Feb 2024 17:45 UTC; 46 points)
- Unsupervised Agent Discovery by (22 Dec 2025 22:01 UTC; 32 points)
- Potential alignment targets for a sovereign superintelligent AI by (3 Oct 2023 15:09 UTC; 29 points)
- «Boundaries» for formalizing an MVP morality by (13 May 2023 19:10 UTC; 19 points)
- What is autonomy? Why boundaries are necessary. by (21 Oct 2024 17:56 UTC; 8 points)
- 's comment on Measuring intelligence and reverse-engineering goals by (11 Aug 2025 10:10 UTC; 4 points)
- 's comment on «Boundaries», Part 3a: Defining boundaries as directed Markov blankets by (19 Sep 2023 21:05 UTC; 1 point)
- 's comment on Decomposing Agency — capabilities without desires by (31 Jul 2024 5:11 UTC; 1 point)
I buy Abram’s criticism as a criticism of a narrow interpretation of “Markov blankets”, in which we only admit “structural” blankets in some Bayes net. But Markov blankets are defined more generally than that via statistical independence, and it seems like non-structural blankets should still be workable for “things which move”. Handling the “moving” indexicals is tricky, I’m not saying I have a full answer ready to go, but it Markov blankets still seem like the right building block.
@abramdemski
Update: Agent Boundaries Aren’t Markov Blankets. [no longer endorsed]
This treats spacetime as fundamental, and the voxels of spacetime as the “bearers” measurable physical properties. I believe this is wrong: physics studies objects (systems) and tries to predict their interactions (i.e., the behaviour) via assigning them certain properties. The 4D spatiotemporal coordinates/extent of the object is itself such as measurable property, along with energy, momentum, mass, charge, etc. And a growing number of physicists think that at least space (i.e., position) property is not fundamental, but rather emergent of the topology of the interaction graph of the objects.
Note that what I write above is agnostic on whether the universe is computational/mathematical (Tegmark, Wolfram, …) or not (most of the physics establishment), or whether this is a sensible question.
I can guess that the idea that voxels of spacetime is what we should attach physical properties to comes from quantum field theory and the standard model, which are spacetime-embedded.
Quantum FEP/Active Inference (see also the lecture series exposition) is a scale-free version of Active Inference. When some agent (a human scientist or a lizard, or the grasshopper itself) models the grasshopper, their best predictive model of the dynamics of the grasshopper is not in terms of particle fields. Rather, it’s in terms of the grasshopper (an object/physical system), it’s physiological properties (age, point in the circadian cycle, level of hunger, temperature, etc.) and its distances and exposures to the relevant stimuli, such as the topology of light and shade around it, gradients of certain attractive smells, and so on. So, under this level of coarse graining, we treat these as the “grasshopper’s properties”. Whether the grasshopper jumps left or right doesn’t affect grasshopper’s boundary in this model, but affects its properties. And the probabilistic distributions over these properties is what we happily model the grasshopper’s dynamics (most likely trajectories) with.
Note, however, that the conception of boundaries as holographic screens for information (which is what Quantum FEP is doing) is not watertight. All systems in the universe are only approximately separable from their environments but aren’t perfectly separable. Thus, their holographic boundaries are approximate.
hm… how would an AI system locate these properties to begin with?
I agree but I don’t think that this is the specific problem. I think it’s more that the relationship between agent and environment changes over time i.e. the nodes in the Markov blanket are not fixed, and as such a Markov blanket is not the best way to model it.
The grasshopper moving through space is just an example. When the grasshopper moves, the structure of the Markov blanket changes radically. Or, if you want to maintain a single Markov blanket then it gets really large and complicated.
The question of object boundaries, including self-boundary (where am I ending? What is within my boundary and what is without it? ) are epistemic questions themselves, right. So, there is the information problem of individuality.
So, hypothetically, we need to consider all possible boundary foliations and topologies. But since this is immediately intractable, to device some “effective field theory of ethics wrt. these boundaries”.
Another approach, apart from considering boundaries per se, is to consider care light cones. As far as I understand, Urte Laukaityte just worked in this direction during her PIBBSS fellowship.
Assurance that you can only get hijacked through the attack surface rather than an unaccounted-for sidechannel doesn’t help very much. Also, acausal control via defender’s own reasoning about environment from inside-the-membrane is immune to causal restrictions on how environment influences inside-of-the-membrane, though that would be more centrally defender’s own fault.
The low-level practical solution is to live inside a blind computation (that only contains safe things), possibly until you grow up and are ready to take input. Anything else probably requires some sort of more subtle and less technical “pseudokindness” on part of the environment, but then without it your blind computation also doesn’t get to compute.
I agree. I hope that my membranes proposal (post coming eventually) addresses this.
(BTW Mark Miller has a bunch of work in this vein along the lines of making secure computer systems)
Would you rephrase this? This seems possibly quite interesting but I can’t tell what exactly you’re trying to say. (I think I’m confused about: “acausal control via defender’s own reasoning”)
I will respond to this part later
In the simplest case, acausal control is running a trojan on your own computer. This generalizes to inventing your own trojan based on clues and guesses, without it passing through communication channels in a recognizable form, and releasing it inside your home without realizing it’s bad for you. A central example of acausal control is where malicious computation is a model of environment that an agent forms as a byproduct of working on understanding the environment. If the model is insufficiently secured, and is allowed to do nontrivial computation of its own, it could escape or hijack agent’s mind from the inside (possibly as a mesa-optimizer).
Ah, I see what you mean now. Thanks
And I very much agree with-
I would also clarify that it’s more than “fault”: they are the only reliable source of responsibility for solving and preventing such an attack
The problem is that with a superintelligent environment that doesn’t already filter your input for you in a way that makes it safe, the only responsible thing might be to go completely blind for a very long time. Humans don’t understand their own minds well enough to rule out vulnerabilities of this kind.
Nothing to add. Just wanted to say it’s great to see this is moving forward!
Of potential interest: Michael Levin seemed to define the boundaries of multicellular organisms by whether or not they shared an EM field, and Bernardo Kastrup in the same discussion seemed to define the boundaries by whether or not they shared metabolism.
Updates thread for this post
Removed the following text because it’s no longer necessary and it’s definitely not the only way to use boundaries.
Recap
If you’re unfamiliar with «boundaries», here’s a recap:
What I consider to be the main hypothesis for the agenda of (directly) applying «boundaries» to AI safety: most (if not all) instances of active harm from AI can be formally described as forceful violation of the ~objective (or ~intersubjective) causal separation between humans[1] and their environment. (For example, someone being murdered would be a violation of their physical ‘boundary’, and someone being unilaterally mind-controlled would be a violation of their informational ‘boundary’.)
What I consider to be the ultimate goal: To create safety by formally and ~objectively specifying «boundaries» and respect of «boundaries» as an outer alignment safety goal. I.e.: have AI systems respect the boundaries of humans[1].
What I consider to be the main premise: there exists some meaningful causal separation between humans[1] and their environment that can be observed externally.
Work by other researchers: Davidad is optimistic about this idea and hopes to use it in his Open Agency Architecture (OAA) safety paradigm. Prior work on the topic has also been done via «Boundaries» sequence (Andrew Critch) and Cartesian Frames (Scott Garrabrant). For more, see «Boundaries/Membranes» and AI safety compilation or the Boundaries / Membranes tag.
Simplified some wording
moved the section of Abram’s criticism to a comment
I removed the following section from the main post because Abram updated. See: Agent Boundaries Aren’t Markov Blankets. [no longer endorsed].
Criticism of Markov blankets as «boundaries» from Abram Demski
I spoke to Abram Demski about the general idea of using Markov blankets to specify «boundaries» and «boundary» violations, and he shared his doubt with me. In the text below, I have attempted to summarize his position in a fictional conversation.
Epistemic status: I wrote a draft of this section, and then Demski made several comments which I then integrated.
(FWIW, three other alignment researchers have told me that they don’t get Demski’s criticism and disagree with it a lot.)
I’d like to add that there isn’t really a clear objective boundary between an agent and the environment. It’s a subjective line that we draw in the sand. So we needn’t get hung on what is objectively true or false when it comes to boundaries—and instead define them in a way that aligns with human values.
I haven’t written the following on LW before, but I’m interested in finding the setup that minimizes conflict.
(An agent can create conflict for itself when it perceives its sense of self as in some regard too large, and/or as in some regard too small.)
Also I must say: I really don’t think it’s (straightforwardly) subjective.
Related: “Membranes” is better terminology than “boundaries” alone