[Intro to brain-like-AGI safety] 3. Two subsystems: Learning & Steering
(Last revised: January 2026. See changelog at the bottom.)
3.1 Post summary / Table of contents
Part of the “Intro to brain-like-AGI safety” post series.
In the previous post I defined the notion of “learning from scratch” algorithms—a broad category that includes, among other things, any randomly-initialized machine learning algorithm (no matter how complicated), and any memory system that starts out empty. I then proposed a division of the brain into two parts based on whether or not they learn from scratch. Now I’m giving them names:
The Learning Subsystem is the >90% of the brain that “learns from scratch”, including the cortex, hippocampus, striatum, amygdala, cerebellum, and more.
The Steering Subsystem is the <10% of the brain that doesn’t “learn from scratch”—basically the hypothalamus and brainstem.
(See previous post for a more detailed anatomical breakdown.)
This post will be a discussion of this two-subsystems picture in general, and of the Steering Subsystem in particular.
In §3.2, I’ll talk about the big picture of what these subsystems do and how they interact. As an example, I’ll explain why each subsystem needs its own sensory-processing circuitry—for example, why visual inputs get processed by both the visual cortex in the Learning Subsystem, and the superior colliculus in the Steering Subsystem.
In §3.3, I’ll acknowledge that this two-subsystem picture has some echoes of the discredited “triune brain theory”. But I’ll argue that the various problems with triune brain theory do not apply to my two-subsystem picture.
In §3.4, I’ll discuss three categories of ingredients that could go into a Steering Subsystem:
Category A: Things that are plausibly essential for general intelligence (e.g. an innate drive for curiosity),
Category B: Everything else in the human steering subsystem (e.g. an innate drive to be kind to your friends),
Category C: Any other possibility that an AGI programmer might dream up, even if it’s radically different from anything in humans or animals (e.g. an innate drive to correctly predict stock prices).
In §3.5, I’ll relate those categories to how I expect people to build brain-like AGIs, arguing that “brain-like AGIs with radically non-human (and dangerous) motivations” is not an oxymoron; rather, it’s the default expected outcome, unless we work to prevent it.
In §3.6, I’ll discuss the fact that Jeff Hawkins has a two-subsystems perspective similar to mine, yet argues against AGI catastrophic accidents being a risk. I’ll say where I think he goes wrong.
§3.7 and §3.8 will be the final two parts of my “timelines to brain-like AGI” discussion. The first part was §2.8 in the previous post, where I argued that reverse-engineering the Learning Subsystem (at least well enough to enable brain-like AGI) is something that could plausibly happen soon, like within the next decade or two, although it could also take longer. Here, I’ll complete that story by arguing that this same thing is true of reverse-engineering the Steering Subsystem (at least well enough to enable brain-like AGI), and of getting the algorithms cleaned up and scaled up, running model trainings, and so on.
§3.9 is a quick non-technical discussion on the wildly divergent attitudes that different people take towards the timeline to AGI, even when they agree on the probabilities. For example, you can have two people agree that the odds are 3:1 against having AGI by 2042, but one might emphasize how low that probability is (“You see? AGI probably isn’t going to arrive for decades”), while the other might emphasize how high that probability is. I’ll talk a bit about the factors that can underlie those attitudes.
3.2 Big picture
In the last post, I claimed that >90% of the brain by volume (cortex, hippocampus, amygdala, cerebellum, most of the basal ganglia, and a few other things) “learns from scratch”, in the sense that early in life its outputs are all random garbage, but over time they become extremely helpful thanks to within-lifetime learning. (More details and caveats in the previous post.) I’m now calling this part of the brain the Learning Subsystem.
The rest of the brain—mainly the brainstem and hypothalamus—I’m calling the Steering Subsystem.
How are we supposed to think about these?
Let’s start with the Learning Subsystem. As discussed in the last post, this subsystem has some interconnected, innate learning algorithms, with innate neural architectures and innate hyperparameters. It also has lots (as in billions or trillions) of adjustable parameters of some sort (usually assumed to be synapse strength, but this is controversial and I won’t get into it), and the values of these parameters start out random. The Learning Subsystem’s algorithms thus emit random unhelpful-for-the-organism outputs at first—for example, perhaps they cause the organism to twitch. But over time, various supervisory signals and corresponding update rules sculpt the values of the system’s adjustable parameters, tailoring them within the animal’s lifetime to do tricky biologically-adaptive things.
Next up: the Steering Subsystem. How do we think intuitively about that one?
In software engineering jargon, there’s a nice term “business logic”, for code like the following (made-up) excerpt from corporate tax filing software (based on here):
def attachSupplementalDocuments(file):
if file.state == "California" or file.state == "Texas":
# SR008-04X/I are always required in these states
file.attachDocument("SR008-04X")
file.attachDocument("SR008-04XI")
if file.ledgerAmnt >= 500_000:
# Ledger of 500K or more requires AUTHLDG-1A
file.attachDocument("AUTHLDG-1A")When you think of “business logic”, think of stuff like that—i.e., parts of source code that more-or-less directly implement specific, real-world, functional requirements.
If genomes are the “source code” of brains, then they need to encode “business logic” too—specific calculations to do specific things that help an animal thrive and reproduce in its particular biological niche. So imagine a repository with lots of species-specific instincts and behaviors, all hardcoded in the genome:
“In order to vomit, contract muscles A,B,C, and release hormones D,E,F.”
“If sensory inputs satisfy the thus-and-such heuristics, then I am probably eating something healthy and energy-dense; this is good and I should react by issuing signals G,H,I.”
“If sensory inputs satisfy the thus-and-such heuristics, then I am probably leaning over a precipice; this is bad and I should react by issuing signals J,K,L.”
“When I’m cold, get goosebumps.”
“When I’m under-nourished, do the following tasks: (1) emit a hunger sensation, (2) start rewarding the cortex for getting food, (3) reduce fertility and growth, (4) reduce pain sensitivity, etc.” (See my “Case study” on NPY/AgRP neurons here.)
An especially-important task of the Steering Subsystem is sending supervisory and control signals to the Learning Subsystem. Hence the name: the Steering Subsystem steers the learning algorithms to do adaptive things.
For example: How is it that a human cortex learns to do adaptive-for-a-human things, while a squirrel cortex learns to do adaptive-for-a-squirrel things, if they’re both vaguely-similar learning-from-scratch algorithms?
The main part of the answer, I claim, is that the learning algorithms get “steered” differently in the two cases. An especially important aspect here is the “reward” signal for reinforcement learning. You can imagine that the human brainstem sends up a “reward” for achieving high social status, whereas the squirrel brainstem sends up a “reward” for burying nuts in the fall. (This is oversimplified; I’ll be elaborating on this story as we go.)
By the same token, in ML, the same learning algorithm can get really good at playing chess (given a certain reward signal and sensory data) or can get really good at playing Go (given a different reward signal and sensory data).
To be clear, despite the name, “steering” the Learning Subsystem is but one task of the Steering Subsystem. The Steering Subsystem can also just up and do things, all by itself, without any involvement from the Learning Subsystem! This is a good plan if doing those things is important right from birth, or if messing them up even once is fatal. An example I mentioned in the last post is that mice apparently have a brainstem bird-detecting circuit wired directly to a brainstem running-away circuit.
An important dynamic to keep in mind is that the brain’s Steering Subsystem cannot directly access our common-sense understanding of the world. For example, the Steering Subsystem can implement reactions like “when eating, manufacture digestive enzymes”. But as soon as we start talking about the abstract concepts that we use to navigate the world—grades, debt, popularity, soy sauce, and so on—we have to assume that the Steering Subsystem has no idea what any of things are, unless we can come up with some story for how it found out. And sometimes there is such a story! We’ll see a lot of those kinds of stories as we go, particularly Post #7 (for a simple example of wanting to eat cake) and Post #13 (for the trickier case of social instincts).
3.2.1 Each subsystem generally needs its own sensory processor
For example, in the case of vision, the Learning Subsystem has its visual cortex, while the Steering Subsystem has its superior colliculus. For taste, the Learning Subsystem has its gustatory cortex, while the Steering Subsystem has its gustatory nucleus of the medulla. For smell, the Learning Subsystem processes smells in its piriform cortex, amygdala, and elsewhere, while the Steering Subsystem seems to get direct access to incoming smells via an obscure “necklace glomeruli” pathway. Etc.
Isn’t that redundant? Some people think so! The book Accidental Mind by David J. Linden cites the existence of two sensory-processing systems as a central example of kludgy brain design resulting from evolution’s lack of foresight. But I disagree. They’re not redundant. If I were making an AGI, I would absolutely put in two sensory-processing systems!
Why? Suppose that Evolution wants to build a reaction circuit where a genetically-hardwired sensory cue triggers a genetically-hardwired response. For example, as mentioned above, if you’re a mouse, then an expanding dark blob in the upper field-of-view often indicates an incoming bird, and therefore the mouse genome hardwires an expanding-dark-blob-detector to a running-away behavioral circuit.
And I claim that, when building this reaction, the genome cannot use the visual cortex as its expanding-dark-blob-detector. Why not? Remember the previous post: the visual cortex learns from scratch! It takes unstructured visual data and builds a predictive model around it. You can (loosely) think of the visual cortex as a scrupulous cataloguer of patterns in the inputs, and of patterns in the patterns in the inputs, etc. One of these patterns might correspond to expanding dark blobs in the upper field-of-view. Or maybe not! And even if one does, the genome doesn’t know in advance which precise neurons will be storing that particular pattern. And thus, the genome cannot hardwire those neurons to the running-away behavioral controller.
So in summary:
Building sensory processing into the Steering Subsystem is a good idea, because there are lots of areas where it’s highly adaptive to attach a genetically-hardwired sensory cue to a corresponding reaction. In the human case, think of fear-of-heights, fear-of-snakes, aesthetics-of-potential-habitats, aesthetics-of-potential-mates, taste-of-nutritious-food, sound-of-screaming, feel-of-pain, and on and on.
Building sensory processing into the Learning Subsystem is also a good idea, because using learning-from-scratch algorithms to learn arbitrary predictive patterns in sensory input within a lifetime is, well, a really good idea. After all, many useful sensory patterns are hyper-specific—e.g. “the smell of this one specific individual tree”—such that a corresponding hardwired sensory pattern detector could not have evolved.
Thus, the brain’s two sensory-processing systems is not an example of kludgy design. Rather, I think this is a case where (per “Orgel’s Second Rule”), evolution is cleverer than David J. Linden.
3.3 “Triune Brain Theory” is wrong, but let’s not throw out the baby with the bathwater
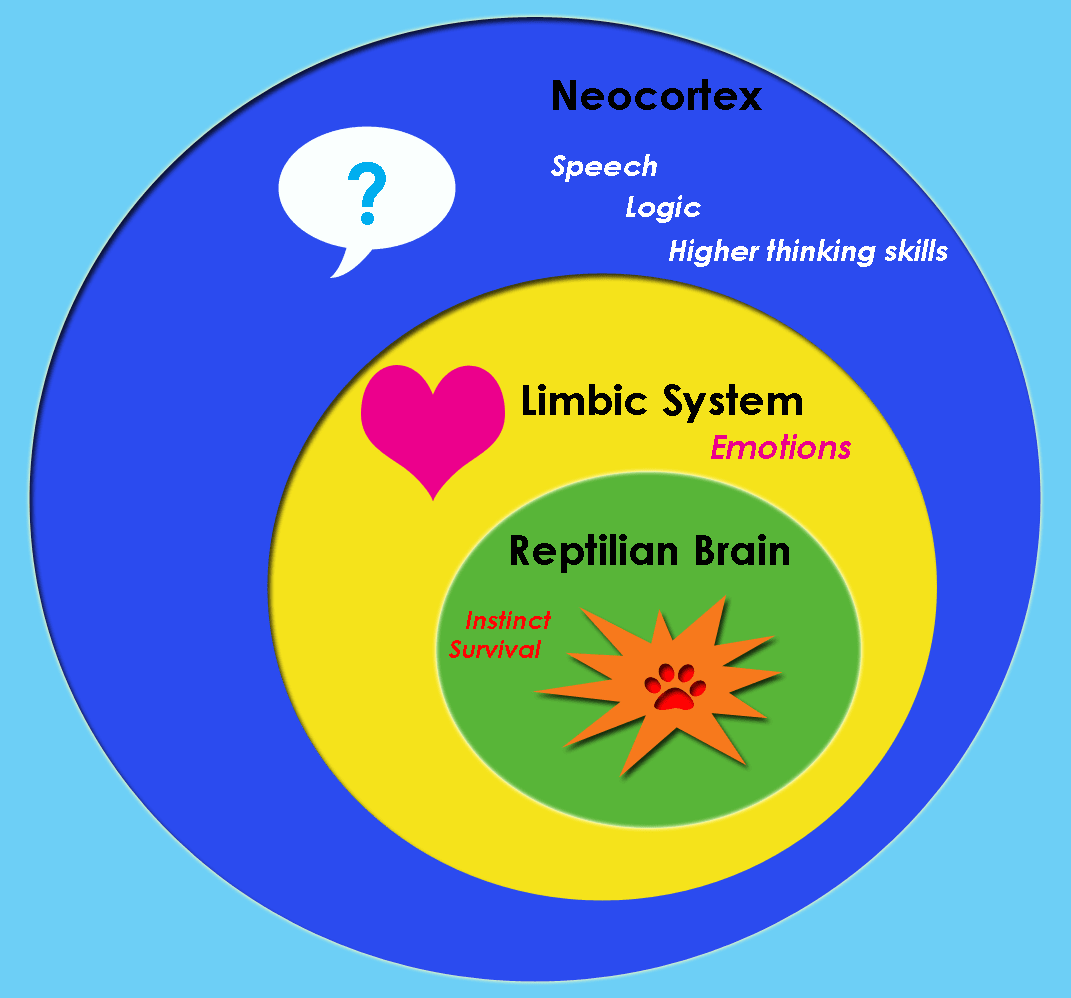
In the 1960s & 70s, Paul MacLean & Carl Sagan invented and popularized an idea called the Triune Brain. According to this theory, the brain consists of three layers, stacked on top of each other like an ice cream cone, and which evolved in sequence: first the “lizard brain” (a.k.a. “old brain” or “reptilian brain”) closest to the spinal cord (consisting of the brainstem and basal ganglia); second the “limbic system” wrapped around that (consisting of the amygdala, hippocampus, and hypothalamus), and finally, layered on the outside, the neocortex (a.k.a. “new brain”)—the pièce de résistance, the pinnacle of evolution, the home of human intelligence!
{kind=link}
Well, it’s by now well known that Triune Brain Theory is rubbish. It lumps brain parts in a way that makes neither functional nor embryological sense, and the evolutionary story is profoundly wrong. For example, half a billion years ago, the earliest vertebrates already had the precursors of all three layers of the triune brain—including a “pallium” which would eventually (in our lineage) segregate into the neocortex, hippocampus, part of the amygdala, etc. (Cisek (2019)).
So yeah, Triune Brain Theory is rubbish. But I freely admit: the story I like (previous section) kinda rings of triune brain theory. My Steering Subsystem looks suspiciously like MacLean’s “reptilian brain”. My Learning Subsystem looks suspiciously like MacLean’s “limbic system and neocortex”. MacLean & I have some disagreements about exactly what goes where, and whether the ice cream cone has two scoops versus three. But there’s definitely a resemblance.
My two-subsystem story in this post is not original. You’ll hear a similar story from Jeff Hawkins, Dileep George, Elon Musk, and others.
But those other people tell this story in the tradition of triune brain theory, and in particular keeping its problematic aspects, like the “old brain” and “new brain” terminology.
There’s no need to do that! We can keep the two-subsystem story, while throwing out the triune brain baggage.
So my story is: I think that half a billion years ago, the earliest vertebrates had a (simpler!) learning-from-scratch algorithm in their (proto) cortex etc., and it was “steered” by supervisory signals from their (simpler, proto) brainstem and hypothalamus.
Indeed, we can go back even earlier than vertebrates! There seems to be a homology between the learning-from-scratch cortex in humans and the learning-from-scratch “mushroom body” in fruit flies! (Further discussion in my post Dopamine-supervised learning in mmmals & fruit flies (2021).)[1] I note, for example, that in fruit flies, odor signals go to both the mushroom body and the lateral horn, in beautiful agreement with the general principle that sensory inputs need to go to both the Learning Subsystem and the Steering Subsystem (§3.2.1 above).
Anyway, in the 700 million years since our last common ancestor with insects, both the Learning Subsystem and the Steering Subsystem have dramatically expanded and elaborated in our lineage.
But that doesn’t mean that they contribute equally to “human intelligence”. Again, both are essential, but I think it’s strongly suggestive that >90% of human brain volume is the Learning Subsystem. Focusing more specifically on the “telencephalon” part (a brain anatomy term which mostly overlaps with the learning-from-scratch cortex and extended striatum), its fraction of brain volume is 87% in humans (ref), 79% in chimps (ref), 77% in certain parrots, 51% in chickens, 45% in crocodiles, and just 22% in frogs (ref). There’s an obvious pattern here, and I think it’s right: namely, that to get recognizably intelligent and flexible behavior, you need a massively-scaled-up Learning Subsystem.
See? I can tell my two-subsystem story with none of that “old brain, new brain” nonsense.
3.4 Three types of ingredients in a Steering Subsystem
I’ll start with the summary table, and then elaborate on it in the following subsections.
3.4.1 Summary table
Category of Steering Subsystem ingredient | Possible examples | Present in (competent) humans? | Expected in future AGIs? |
| (A) Things the Steering Subsystem needs to do in order to get general intelligence | · Curiosity drive (?) · Drive to attend to certain types of things in the environment (humans, language, technology, etc.) (?) · General involvement in helping establish the Learning Subsystem neural architecture (?) | Yes, by definition | Yes |
| (B) Everything else in a neurotypical human’s Steering Subsystem | · Social instincts (which underlie altruism, love, remorse, guilt, sense-of-justice, loyalty, etc.) · Drives underlying disgust, aesthetics, transcendence, serenity, awe, hunger, pain, fear-of-spiders, etc. | Often, but not always—for example, high-functioning sociopaths seem to be missing some of the usual social instincts. | Not “by default”, but it’s possible if we: (1) figure out exactly how they work, and (2) convince AGI developers to put them in. |
| (C) Every other possibility, most of which are completely unlike anything in the Steering Subsystem of humans or indeed any animal | · Drive to increase a company’s bank account balance? · Drive to invent a better solar cell? · Drive to do whatever my human supervisor wants me to do? (There’s a catch: no one knows how to implement this one!) | No | Yes “by default”. If something is a bad idea, we can try to convince AGI developers not to do that. |
3.4.2 Aside: what do I mean by “drives”? (A.k.a. “primary rewards”)
I’ll elaborate on this picture in later posts, but for now let’s just say that the Learning Subsystem does reinforcement learning (among other things), and the Steering Subsystem sends it reward signals. The components of the reward function relate to what I’ll call “innate drives”—they’re the root cause of why some things are inherently motivating / appetitive and other things are inherently demotivating / aversive. The term “primary reward” is also sometimes used in the literature to talk about the same thing.
Explicit goals like “I want to get out of debt” are different from innate drives. Explicit goals come out of a complicated dance between “innate drives in the Steering Subsystem” and “learned content in the Learning Subsystem”. Again, much more on that topic later in the series.
Remember, innate drives are in the Steering Subsystem, whereas the abstract concepts that make up your conscious world are in the Learning Subsystem. For example, if I say something like “altruism-related innate drives”, you need to understand that I’m not talking about “the abstract concept of altruism, as defined in an English-language dictionary”, but rather “some innate Steering Subsystem circuitry which is upstream of the fact that neurotypical people sometimes find altruistic actions to be inherently motivating”. There is some relationship between the abstract concepts and the innate circuitry, but it might be a complicated one—nobody expects a one-to-one relation between N discrete innate circuits and a corresponding set of N English-language words describing emotions and drives.[2]
With that out of the way, let’s move on to more details about that table above.
3.4.3 Category A: Things the Steering Subsystem needs to do in order to get general intelligence (e.g. curiosity drive)
Let’s start with the “curiosity drive”. If you’re not familiar with the background of “curiosity” in ML, I recommend The Alignment Problem by Brian Christian, chapter 6, which contains the gripping story of how researchers eventually got RL agents to win the Atari game Montezuma’s Revenge. Curiosity drives seem essential to good performance in ML, and humans also seem to have an innate curiosity drive. I assume that future AGI algorithms will need a curiosity drive as well, or else they just won’t work.
To be more specific, I think this is a bootstrapping issue—I think we need a curiosity drive early in training, but can probably turn it off eventually. Specifically, let’s say there’s an AGI that’s generally knowledgeable about the world and itself, and capable of getting things done, and right now it’s trying to invent a better solar cell. I claim it probably doesn’t need to feel an innate curiosity drive. Instead it may seek new information, and seek surprises, as if it were innately curious, because it has learned through experience that seeking those things tends to be an effective strategy for inventing a better solar cell. In other words, something like curiosity can be motivating as a means to an end, even if it’s not motivating as an end in itself—curiosity can be a learned metacognitive heuristic. See instrumental convergence. But that argument does not apply early in training, when the AGI starts from scratch, knowing nothing about the world or itself. Instead, early in training, I think we really need the Steering Subsystem to be holding the Learning Subsystem’s hand, and pointing it in the right directions, if we want AGI.
Another possible item in Category A is an innate drive to pay attention to certain things in the environment, e.g. human activities, or human language, or technology. I don’t know for sure that this is necessary, but it seems to me that a curiosity drive by itself wouldn’t do what we want it to do. It would be completely undirected. Maybe it would spend eternity running Rule 110 in its head, finding deeper and deeper patterns, while completely ignoring the physical universe. Or maybe it would find deeper and deeper patterns in the shapes of clouds, while completely ignoring everything about humans and technology. In the human case, evidence from newborns and elsewhere suggests that the human brainstem has a mechanism for forcing attention onto human faces (Morton & Johnson (1991)) and human speech sounds (see discussion in Reynolds (2026)). I expect that something like that will need to be in AGIs too. As above, this drive might only be necessary early in training.
What else might be in Category A? On the table above, I wrote the vague “General involvement in helping establish the Learning Subsystem neural architecture”. This includes sending reward signals and error signals and hyperparameters etc. to particular parts of the neural architecture in the Learning Subsystem. For example, in Post #6 I’ll talk about how only part of the neural architecture gets the main RL reward signal. I think of these things as (one aspect of) how the Learning Subsystem’s neural architecture is actually implemented. AGIs will have some kind of neural architecture too, although maybe not exactly the same as humans’. Therefore, they might need some of these same kinds of signals. I talked about neural architecture briefly in §2.8 of the last post, but mostly it’s irrelevant to this series, and I won’t talk about it beyond this unhelpfully-vague paragraph.
There might be other things in Category A that I’m not thinking of.
3.4.4 Category B: Everything else in the human Steering Subsystem (e.g. altruism-related drives)
I’ll jump right into what I think is most important: social instincts, including various drives related to altruism, sympathy, love, guilt, remorse, status, jealousy, sense-of-fairness, etc. Key question: How do I know that social instincts belong here in Category B, i.e. that they aren’t one of the Category A things that are essential for general intelligence?
Well, for one thing, look at high-functioning sociopaths. I’ve had the unfortunate experience of getting to know a couple of them very well in my day. They understood the world, and themselves, and language and math and science and technology, and they could make elaborate plans to successfully accomplish impressive feats. If there were an AI that could do everything that a high-functioning sociopath can do, we would unhesitatingly call it “AGI”. Now, I think high-functioning sociopaths have some social instincts—they’re more interested in manipulating people than manipulating toys—but their social instincts seem to be very different from those of a neurotypical person.
Then on top of that, we can consider people with autism, and people with schizophrenia, and SM (who is missing her amygdala and more-or-less lacks negative social emotions), and on and on. All these groups of people have “general intelligence”, but their social instincts / drives are all quite different from each other’s.[3]
All things considered, I find it very hard to believe that any aspect of social instincts is essential for general intelligence. I think it’s at least open to question whether social instincts are even helpful for general intelligence! For example, if you look at the world’s most brilliant scientific minds, I’d guess that people with neurotypical social instincts are if anything slightly underrepresented.
One reason this matters is that, I claim, social instincts underlie “the desire to behave ethically”. Again, consider high-functioning sociopaths. They can understand honor and justice and ethics if they try—in the sense of correctly answering quiz questions about what is or isn’t honorable etc.—they’re just not motivated by it.[4]
If you think about it, it makes sense. Suppose I tell you “You really ought to put pebbles in your ears.” You say “Why?” And I say “Because, y’know, your ears, they don’t have any pebbles in them, but they really should.” And again you say “Why?” …At some point, this conversation has to ground out at something that you find inherently motivating or demotivating, in and of itself. And I claim that social instincts—the various innate drives related to sense-of-fairness and sympathy and loyalty and so on—are ultimately providing the ground on which those intuitions stand.
(I’m not taking a stand on moral realism vs. moral relativism here—i.e., the question of whether there is a “fact of the matter” about what is ethical vs. unethical. Instead, I’m saying that if there’s an agent that is completely lacking in any innate drives that might spur a desire to act ethically, then then we can’t expect the agent to act ethically, no matter how intelligent and capable it is. Why would it? Granted, it might act ethically as a means to an end—e.g. to win allies—but that doesn’t count. More basic intuition-pumps in my comment here, and deeper analysis in §2.7 of my Valence series.)
That’s all I want to say about social instincts for now; I’ll return to them in Posts #12–#13.
What else goes in Category B? Lots of things! There’s disgust, and aesthetics, and transcendence, and serenity, and awe, and hunger, and pain, and fear-of-spiders, etc.
3.4.5 Category C: Every other possibility (e.g. drive to increase my bank account balance)
When people make AGIs, they can put whatever they want into the reward function! This would be analogous to inventing new innate drives out of whole cloth. And these can be innate drives that are radically unlike anything in humans or animals.
Why might the future AGI programmers invent new-to-the-world innate drives? Because it’s the obvious thing to do! Go kidnap a random ML researcher from the halls of NeurIPS, drive them to an abandoned warehouse, and force them to make a bank-account-balance-increasing AI using reinforcement learning.[5] I bet you anything that, when you look at their source code, you’re going to find a reward function that involves the bank account balance. You won’t find anything like that among the genetically-hardwired circuitry in the human brainstem! It’s a new-to-the-world innate drive.
Not only is “put in an innate drive for increasing the bank account balance” the obvious thing to do, but I think it would actually work! For a while! And then it would fail catastrophically! It would fail as soon as the AI became competent enough to find out-of-the-box strategies to increase the bank account balance—like borrowing money, hacking into the bank website, and so on. (Related: hilarious and terrifying list of historical examples of AIs finding unintended, out-of-the-box strategies for maximizing a reward. More on this later in the series.) In fact, this bank-account-balance example is one of the many, many possible drives that would plausibly lead to an AGI harboring a secret motivation to escape human control and kill everyone (cf. “instrumental convergence”, coming up in §10.3.2).
So these kinds of motivations are the worst: they’re dangling right in front of everyone’s faces, they’re the best way to get things done and publish papers and beat benchmarks if the AGI is not overly clever, and then when the AGI becomes competent enough, they lead to catastrophic accidents.
Maybe you’re thinking: “It’s really obvious that an AGI with an all-consuming innate drive to increase a certain bank account balance is an AGI that would try to escape human control, self-reproduce etc. Do you really believe that future AGI programmers would be so reckless as to put in something like that??”
Well, umm, yes. Yes, I do. (I discuss the sorry state of the field here.) But even setting that aside for the sake of argument, there’s a bigger problem: we don’t currently know how to code up any innate drive whatsoever such that the resulting AGI would definitely stay under control. Even the drives that sound benign are probably not, at least not in our current state of knowledge. Much more on this in later posts (especially #10).
To be sure, Category C is a very big tent. I would not be at all surprised if there exist Category C innate drives that would be very good for AGI safety! We just need to find them! I’ll be exploring this design space later in the series.
3.5 Brain-like AGI will by default have radically nonhuman (and dangerous) motivations
I mentioned this way back in the first post (§1.3.3), but now we have the explanation.
The previous subsection proposes three types of ingredients to put in a Steering Subsystem: (A) Those necessary to wind up with an AGI at all, (B) Everything else in humans, (C) Anything not in humans.
My claims are:
People want to make powerful AIs with state-of-the-art capabilities in challenging domains—they know that it’s good for publications, good for impressing their colleagues, getting jobs and promotions and grants, etc. I mean, just look at AI and ML today. Therefore, by default, I expect AGI researchers to race down the most direct path to AGI: reverse-engineering the Learning Subsystem, and combining it with Category-A drives.
Category B contains some drives that are plausibly useful for AGI safety: drives related to altruism, sympathy, generosity, humility, etc. Unfortunately, we don’t currently know how any of those drives are implemented in the brain. And figuring that out is unnecessary for building AGIs. So by default, I think we should expect AGI researchers to ignore Category B until they have AGIs up and running, and only then start scrambling to figure out how to build altruism drives etc. And they might outright fail—it’s totally possible that the corresponding brainstem & hypothalamus circuitry is a frightfully complicated mess, and we only have so much time between “AGIs are up and running” and “someone accidentally makes an out-of-control AGI that kills everyone” (see Post #1).
There are things in Category C like “A low-level innate drive to increase a particular bank account balance” that are immediately obvious to everyone, and easy to implement, and will work well at accomplishing the programmers’ goals while their janky proto-AGIs are not yet very capable. Therefore, by default, I expect future researchers to use these kinds of “obvious” (but dangerous and radically-nonhuman) drives as they work towards developing AGI. And as discussed above (and more in later posts), even if the researchers start trying in good faith to give their AGI an innate drive for being helpful / docile / whatever, they might find that they don’t know how to do so.
In sum, if researchers travel down the most easy and natural path—the path that looks like the AI and neuroscience R&D community continuing to behave in ways that they behave right now—we will wind up being able to make AGIs that do impressive things that their programmers want, for a while, but are driven by radically alien motivation systems that are fundamentally unconcerned with human welfare, and these AGIs will try to escape human control as soon as they are capable enough to do so.
(See my post: “We need a field of Reward Function Design” (2025), especially the section “Oh man, are we dropping this ball”.)
Let’s try to change that! In particular, if we can figure out in advance how to write code that builds an innate drive for altruism / helpfulness / docility / whatever, that would be a huge help. This will be a major theme of this series. But don’t expect final answers. It’s an unsolved problem; there’s still a lot of work to do.
3.6 Response to Jeff Hawkins’s argument against AGI accident risk
Jeff Hawkins has a recent book A Thousand Brains. I wrote a more detailed book review here. Jeff Hawkins is a strong advocate of a two-subsystems perspective very similar to mine. No coincidence—his writings helped push me in that direction!
To Hawkins’s great credit, he takes ownership of the idea that his neuroscience / AI work is pushing down a path (of unknown length) towards AGI, and he has tried to think carefully about the consequences of that larger project—as opposed to the more typical perspective of declaring AGI to be someone else’s problem.
So, I’m delighted that Hawkins devotes a large section of his book to an argument about AGI catastrophic risk. But his argument is against AGI catastrophic risk! What’s the deal? How do he and I, starting from a similar two-subsystems perspective, wind up with diametrically opposite conclusions?
Hawkins makes many arguments, and again I addressed them more comprehensively in my book review. But here I want to emphasize two of the biggest issues that bear on this post.
ISSUE 1: Here’s my paraphrase of a particular Hawkins argument. (I’m translating it into the terminology I’m using in this series, e.g. he says “old brain” where I say “Steering Subsystem”. And maybe I’m being a bit mean. You can read the book and judge for yourself whether this is fair.)
The Learning Subsystem (cortex etc.) by itself has no goals or motivations. It won’t do anything. It certainly won’t do anything dangerous. It’s like a map sitting on a table.
Insofar as humans have problematic drives (greed, self-preservation, etc.), they come from the Steering Subsystem (brainstem etc.).
The thing that I, Jeff Hawkins, am proposing, and doing, is trying to reverse-engineer the Learning Subsystem, not the Steering Subsystem. So what the heck is everyone so worried about?
…
…
Oh hey, on a completely unrelated note, we will eventually make future AGIs, and these will have not only a Learning Subsystem, but also a Steering Subsystem attached to it. I’m not going to talk about how we’ll design the Steering Subsystem. It’s not really something that I think about much.
Each of these points in isolation seems reasonable enough. But when you put them together, there’s a gaping hole! Who cares if a cortex by itself is safe? A cortex by itself was never the plan! The question we need to ask is whether an AGI consisting of both subsystems attached together will be safe. And that depends crucially on how we build the Steering Subsystem. Hawkins isn’t interested in that topic. But I am! Read on in the series for much more on this. Post #10 in particular will dive into why it’s a heck of a lot harder than it sounds to build a Steering Subsystem that steers the AGI into doing some particular thing that we intend for it to do, without also incidentally instilling dangerous antisocial motivations that we never intended it to have.
ISSUE 2: One more (related) issue that I didn’t mention in my earlier book review: I think that Hawkins is partly driven by a mistaken intuition that ego-syntonic motivations like “unraveling the secrets of the universe” are located in the cortex (Learning Subsystem), and ego-dystonic motivations like hunger and sex-drive are located in the brainstem (Steering Subsystem). I claim that the correct answer is that all motivations come ultimately from the Steering Subsystem, no exceptions. This will hopefully be obvious if you keep reading this series, and I’ll circle back to it explicitly in §6.6.1.
In fact, my claim is even implied by the better parts of Hawkins’s own book! For example:
Hawkins in Chapter 10: “The neocortex learns a model of the world, which by itself has no goals or values.”
Hawkins in Chapter 16: “ ‘We’—the intelligent model of ourselves residing in the neocortex—are trapped. We are trapped in a body that…is largely under the control of an ignorant brute, the old brain. We can use intelligence to imagine a better future…. But the old brain could ruin everything…”
To spell out the contradiction: if “we” = the neocortex’s model, and the neocortex’s model has no goals or values whatsoever, then “we” certainly would not be aspiring to a better future and hatching plots to undermine the brainstem.
3.7 Timelines-to-brain-like-AGI part 2 of 3: how hard will it be to reverse-engineer the Steering Subsystem well enough for AGI?
(Reminder: Timelines Part 1 of 3 was §2.8 of the previous post.)
Above (§3.4.3), I discussed “Category A”, the minimal set of ingredients to build an AGI-capable Steering Subsystem (not necessarily safe, just capable).
I don’t really know what is in this set. I suggested that we’d probably need some kind of curiosity drive, and maybe some drive to pay attention to human language and other human activities, and maybe some signals that go along with and help establish the Learning Subsystem’s neural network architecture.
If that’s right, well, this doesn’t strike me as too hard! Certainly it’s a heck of a lot easier than reverse-engineering everything in the human hypothalamus and brainstem! Keep in mind that there is a substantial literature on curiosity in both ML (1, 2) and psychology. “A drive to pay attention to human language” requires nothing more than a classifier that says (with reasonable accuracy, it doesn’t have to be perfect) whether any given audio input is or isn’t human language; that’s trivial with today’s tools, if it’s not already on GitHub.
I think we should be open to the possibility that it just isn’t that hard to build a Steering Subsystem that (together with a reverse-engineered Learning Subsystem, see §2.8 of the previous post) can develop into an AGI after training. Maybe it’s not decades of R&D; maybe it’s not even years of R&D! Maybe a competent researcher will nail it after just a couple tries. On the other hand—maybe not! Maybe it is super hard! I think it’s very difficult to predict how long it would take, from our current vantage point, and that we should remain uncertain.
3.8 Timelines-to-brain-like-AGI part 3 of 3: scaling, debugging, training, etc.
Having a fully-specified, AGI-capable algorithm isn’t the end of the story; you still need to implement the algorithm, iterate on it, hardware-accelerate and parallelize it, work out the kinks, run trainings, etc. We shouldn’t ignore that part, but we shouldn’t overstate it either.
I really expect it to add only a couple years, although we can’t know for sure. See §3.3 of my post “Response to Dileep George: AGI safety warrants planning ahead” (2024) for some of the relevant considerations.
Thus concludes my timeline-to-brain-like-AGI discussion, which again is not my main focus in this series. You can read my three timelines sections (§2.8, §3.7, and this one), agree or disagree, and come to your own conclusions. In case anyone is curious, when I am forced to be specific, my position is:
I expect superintelligent brain-like AGI between 5 and 25 years from now. Or I guess maybe more than 25 years, who knows. Or I guess maybe less than 5 years, who knows. Shrug.
3.9 Timelines-to-brain-like-AGI encore: How should I feel about a probabilistic timeline?
My “timelines” discussion (§2.8, §3.7, §3.8) has been about the forecasting question “what probability distribution should I assign to when AGI will arrive (if ever)?”
Semi-independent of that question is a decision-making under uncertainty question: “Given a probability distribution, how should we feel, and what should we do?”
For example, some people seem to believe that if brain-like AGI does not exist right now, then it belongs to a category called “science fiction”, alongside time travel. Never mind that physics firmly predicts both that time travel is impossible and that brain-like AGI is possible. And never mind that every technology that exists today would have been “sci-fi” in the past.
{kind=link}
Likewise, the word “hypothetical”, as in “hypothetical possibilities” or “hypothetical risks”, is another jeer thrown at people trying to plan for an uncertain future. Taken literally, it’s a rather odd insult: some hypotheses are false, but also, some hypotheses are true!
Various other bad takes revolve around the idea that we should not even try to prepare for possible-but-uncertain future events. In particular, some people talk as if we shouldn’t try to mitigate a possible future catastrophe until we’re >99.9% confident that the catastrophe will definitely happen. I like to call this the insane bizarro-world reversal of Pascal’s Wager. It probably sounds like a strawman when I put it like that, but my goodness, it is very real, and very widespread. I think it comes from a few places:
“Treating new ideas as false until somebody provides incontrovertible evidence that they are true”— see the classic Scott Alexander posts “A Failure, But Not Of Prediction” (2020) and “The Phrase ‘No Evidence’ Is A Red Flag For Bad Science Communication

Fear of looking foolish by preparing for something weird that winds up (in hindsight) not being a big deal.
And we fear it for good reason! There is often strong social pressure towards “the insane bizarro-world reversal of Pascal’s wager”. For example, I recall during early COVID that some politicians stockpiled ventilators, which wound up not being used. They were viciously mocked and criticized for wasting money. Never mind that the cost was tiny compared to the potential benefit, and never mind that it was a smart move given the information available at the time, i.e. without the benefit of hindsight. Meanwhile, as I write this, despite the fresh memory of COVID, politicians are doing next-to-nothing to prevent the next pandemic, and voters are perfectly fine with that.

The “only one problem” fallacy.
As dumb as it sounds, people often talk as if there can only be one scary problem in the world. According to this logic, human extinction from future brain-like AGI cannot be a problem, because after all “the real AI risk” is deepfakes causing political polarization, or whatever. As the saying goes, “Why not both?” More on this in my post “X distracts from Y” as a thinly-disguised fight over group status / politics (2023).
Anyway, we should be sensible, put those terrible takes behind us, and (like Gallant in the meme above) reason under uncertainty using cost-benefit analysis.
This is not a Pascal’s wager situation. This is not an “overpopulation on Mars” situation. Rather:
Brain-like AGI is definitely possible, and thus almost certain to be invented sooner or later.
I argued above that it’s at least plausible (I would guess “likely”) in the coming decade or two.
It will wildly transform the world, for better or worse—less like normal technologies like the internet or the industrial revolution, more like the evolution of humans from our chimp-like ancestors.
I endorse the Eliezer Yudkowsky quote: “Asking about the effect of [superhuman AGI] on [unemployment] is like asking how US-Chinese trade patterns would be affected by the Moon crashing into the Earth. There would indeed be effects, but you’d be missing the point.”
See also Holden Karnofsky’s Digital People Would Be An Even Bigger Deal (2021), or my post Four ways learning Econ makes people dumber re: future AI (2025)
…And my discussion in §1.6 of why human extinction is plausible. (My actual best guess is that it’s not just plausible but likely, the way things are looking right now.)
And see also my post Thoughts on hardware / compute requirements for AGI (2023) for why I’m guessing that, once brain-like AGI exists at all, there will already be enough existing chips and electricity to power an effective population of hundreds of millions of brain-like AGIs around the world.
See §1.7 for my argument that we’re way behind schedule in preparing for brain-like AGI, even if it is many decades away; and later in this series, I’ll be discussing some the many still-unsolved problems.
So obviously, we should be urgently preparing for brain-like AGI right now.
Changelog
July 2024: Since the initial version, I added the term “business logic”, self-plagiarizing from this post. I also added a few links where appropriate to posts that I since completing this series, including linking to a discussion of morality from my valence series; linking a more recent post where I discussed compute requirements; linking my post criticizing Lisa Feldman Barrett’s take on “basic emotions”; linking my discussion of NPY/AgRP neurons; and linking to my discussion of smell neuroanatomy. I also added a footnote about C. elegans. Various other changes were minor wording changes or clarifications.
October 2024: The post now mentions that “primary reward” is an alternate term for “innate drive” in the literature.
January 2026: I substantially rewrote §3.9 (including adding the sci-fi figure); I added my own “timelines” take to §3.8; I added links where appropriate to a couple more posts that I’ve written in the interim (Response to Dileep George: AGI safety warrants planning ahead and We need a field of Reward Function Design), along with a link to Brett Reynolds’s 2026 paper relating human language learning to innate attention biases. Various other copyedits.
- ^
If my suggestion is right, i.e. that part of the learning-from-scratch cortex in humans might be uncoincidentally homologous to the learning-from-scratch mushroom body in fruit flies, then it would seem to imply that our last common ancestor (the so-called “urbilaterian”) had a Learning Subsystem of some sort. Is that right? Well, scientists don’t know much about the urbilaterian, and I personally know even less. For what it’s worth, I did look briefly into C. elegans, a simpler modern bilaterian. I found Ha et al. (2010) , which reported two olfactory pathways, one for learning and one for innate responses. I think that finding is at least in general agreement with my two-subsystems picture, although I don’t know how “from scratch” the learning pathway is. At any rate, my story seems to be a better fit than (say) the popular “evolution as pretraining” idea, in which there’s one pathway, and it starts in a genetically-specified state, and then it gets modified by within-lifetime learning. But again, I’m not an expert on C. elegans, let alone the urbilaterian. Please reach out if you are.
- ^
Well, maybe some people expect that there’s a one-to-one correspondence between English-language abstract concepts like “sadness” and corresponding innate reactions. If you read the book How Emotions Are Made, Lisa Feldman Barrett spends hundreds of pages belaboring this point. She must have been responding to somebody, right? For more on this topic, see my post Lisa Feldman Barrett versus Paul Ekman on facial expressions & basic emotions.
- ^
I wouldn’t suggest that the Steering Subsystem circuitry underlying social instincts is built in a fundamentally different way in these different groups—that would be evolutionarily implausible. Rather, I think there are lots of adjustable parameters on how strong the different drives are, and they can be set to wildly different values, including the possibility that a drive is set to be so weak as to be effectively absent. See my speculation on autism and psychopathy here.
- ^
See Jon Ronson’s The Psychopath Test for a fun discussion of attempts to teach empathy to psychopaths. The students merely wound up better able to fake empathy in order to manipulate people. Quote from one person who taught such a class: “I guess we had inadvertently created a finishing school for them.” Incidentally, there do seem to be interventions that appeal to sociopaths’ own self-interest—particularly their selfish interest in not being in prison—to help turn really destructive sociopaths into the regular everyday kind of sociopaths who are still awful to the people around them but at least they’re not murdering anyone. (Source.)
- ^
I suppose I could have hired an ML researcher instead. But who could afford the salary?
- My Objections to “We’re All Gonna Die with Eliezer Yudkowsky” by (21 Mar 2023 0:06 UTC; 363 points)
- The shard theory of human values by (4 Sep 2022 4:28 UTC; 261 points)
- Munk AI debate: confusions and possible cruxes by (27 Jun 2023 14:18 UTC; 244 points)
- “Sharp Left Turn” discourse: An opinionated review by (28 Jan 2025 18:47 UTC; 220 points)
- Foom & Doom 2: Technical alignment is hard by (23 Jun 2025 17:19 UTC; 170 points)
- My Objections to “We’re All Gonna Die with Eliezer Yudkowsky” by (EA Forum; 21 Mar 2023 1:23 UTC; 166 points)
- [Intro to brain-like-AGI safety] 1. What’s the problem & Why work on it now? by (26 Jan 2022 15:23 UTC; 164 points)
- My computational framework for the brain by (14 Sep 2020 14:19 UTC; 157 points)
- Shard Theory in Nine Theses: a Distillation and Critical Appraisal by (19 Dec 2022 22:52 UTC; 150 points)
- Munk AI debate: confusions and possible cruxes by (EA Forum; 27 Jun 2023 15:01 UTC; 143 points)
- Response to nostalgebraist: proudly waving my moral-antirealist battle flag by (29 May 2024 16:48 UTC; 117 points)
- My AGI safety research—2024 review, ’25 plans by (31 Dec 2024 21:05 UTC; 111 points)
- Connectomics seems great from an AI x-risk perspective by (30 Apr 2023 14:38 UTC; 107 points)
- A Theory of Laughter by (23 Aug 2023 15:05 UTC; 105 points)
- [Valence series] 1. Introduction by (4 Dec 2023 15:40 UTC; 101 points)
- [Intro to brain-like-AGI safety] 15. Conclusion: Open problems, how to help, AMA by (17 May 2022 15:11 UTC; 100 points)
- [Intuitive self-models] 1. Preliminaries by (19 Sep 2024 13:45 UTC; 99 points)
- [Intro to brain-like-AGI safety] 7. From hardcoded drives to foresighted plans: A worked example by (9 Mar 2022 14:28 UTC; 91 points)
- [Valence series] 2. Valence & Normativity by (7 Dec 2023 16:43 UTC; 88 points)
- Disentangling Shard Theory into Atomic Claims by (13 Jan 2023 4:23 UTC; 86 points)
- Neuroscience of human social instincts: a sketch by (22 Nov 2024 16:16 UTC; 86 points)
- [Intro to brain-like-AGI safety] 6. Big picture of motivation, decision-making, and RL by (2 Mar 2022 15:26 UTC; 84 points)
- [Intro to brain-like-AGI safety] 4. The “short-term predictor” by (16 Feb 2022 13:12 UTC; 74 points)
- [Intro to brain-like-AGI safety] 13. Symbol grounding & human social instincts by (27 Apr 2022 13:30 UTC; 72 points)
- My take on Jacob Cannell’s take on AGI safety by (28 Nov 2022 14:01 UTC; 72 points)
- Plan for mediocre alignment of brain-like [model-based RL] AGI by (13 Mar 2023 14:11 UTC; 69 points)
- [Intro to brain-like-AGI safety] 2. “Learning from scratch” in the brain by (2 Feb 2022 13:22 UTC; 69 points)
- [Intro to brain-like-AGI safety] 5. The “long-term predictor”, and TD learning by (23 Feb 2022 14:44 UTC; 64 points)
- Response to Blake Richards: AGI, generality, alignment, & loss functions by (12 Jul 2022 13:56 UTC; 62 points)
- My hopes for alignment: Singular learning theory and whole brain emulation by (25 Oct 2023 18:31 UTC; 61 points)
- [Intro to brain-like-AGI safety] 8. Takeaways from neuro 1/2: On AGI development by (16 Mar 2022 13:59 UTC; 61 points)
- Against empathy-by-default by (16 Oct 2024 16:38 UTC; 60 points)
- 's comment on Confused why a “capabilities research is good for alignment progress” position isn’t discussed more by (3 Jun 2022 2:48 UTC; 59 points)
- New version of “Intro to Brain-Like-AGI Safety” by (23 Jan 2026 16:21 UTC; 58 points)
- Woods’ new preprint on object permanence by (7 Mar 2024 21:29 UTC; 58 points)
- Re SMTM: negative feedback on negative feedback by (14 May 2025 19:50 UTC; 57 points)
- [Intro to brain-like-AGI safety] 9. Takeaways from neuro 2/2: On AGI motivation by (23 Mar 2022 12:48 UTC; 56 points)
- Spatial attention as a “tell” for empathetic simulation? by (26 Apr 2024 15:10 UTC; 55 points)
- [Intro to brain-like-AGI safety] 10. The technical alignment problem by (30 Mar 2022 13:24 UTC; 55 points)
- Building brain-inspired AGI is infinitely easier than understanding the brain by (2 Jun 2020 14:13 UTC; 53 points)
- 2022 (and All Time) Posts by Pingback Count by (16 Dec 2023 21:17 UTC; 53 points)
- Alignment & Capabilities: What’s the difference? by (EA Forum; 31 Aug 2023 22:13 UTC; 50 points)
- [Valence series] 4. Valence & Liking / Admiring by (10 Jun 2024 14:19 UTC; 49 points)
- 's comment on But What’s Your *New Alignment Insight,* out of a Future-Textbook Paragraph? by (7 May 2022 4:51 UTC; 48 points)
- [Intro to brain-like-AGI safety] 12. Two paths forward: “Controlled AGI” and “Social-instinct AGI” by (20 Apr 2022 12:58 UTC; 47 points)
- 's comment on AI as a science, and three obstacles to alignment strategies by (26 Oct 2023 15:39 UTC; 46 points)
- We have promising alignment plans with low taxes by (10 Nov 2023 18:51 UTC; 46 points)
- Goals selected from learned knowledge: an alternative to RL alignment by (15 Jan 2024 21:52 UTC; 45 points)
- Self-dialogue: Do behaviorist rewards make scheming AGIs? by (13 Feb 2025 18:39 UTC; 43 points)
- I’m confused about innate smell neuroanatomy by (28 Nov 2023 20:49 UTC; 40 points)
- Social drives 2: “Approval Reward”, from norm-enforcement to status-seeking by (12 Nov 2025 20:40 UTC; 38 points)
- [Valence series] 4. Valence & Social Status (deprecated) by (15 Dec 2023 14:24 UTC; 35 points)
- Lisa Feldman Barrett versus Paul Ekman on facial expressions & basic emotions by (19 Jul 2023 14:26 UTC; 35 points)
- Incentive Learning vs Dead Sea Salt Experiment by (25 Jun 2024 17:49 UTC; 34 points)
- On oxytocin-sensitive neurons in auditory cortex by (6 Sep 2022 12:54 UTC; 33 points)
- The Autofac Era by (24 Sep 2025 18:20 UTC; 29 points)
- Response to Dileep George: AGI safety warrants planning ahead by (8 Jul 2024 15:27 UTC; 28 points)
- Excerpts from my neuroscience to-do list by (6 Oct 2025 21:05 UTC; 28 points)
- 's comment on Alexander and Yudkowsky on AGI goals by (25 Jan 2023 2:53 UTC; 24 points)
- 's comment on How Might an Alignment Attractor Look like? by (29 Apr 2022 11:31 UTC; 23 points)
- [Valence series] Appendix A: Hedonic tone / (dis)pleasure / (dis)liking by (20 Dec 2023 15:54 UTC; 21 points)
- 's comment on Inner Alignment in Salt-Starved Rats by (5 Jan 2022 19:37 UTC; 20 points)
- Value Learning Needs a Low-Dimensional Bottleneck by (23 Jan 2026 2:12 UTC; 17 points)
- “Intro to brain-like-AGI safety” series—just finished! by (EA Forum; 17 May 2022 15:35 UTC; 15 points)
- Brain-inspired LLM alignment by (11 Dec 2025 3:08 UTC; 13 points)
- 's comment on My computational framework for the brain by (15 Dec 2021 4:04 UTC; 11 points)
- Connectomics seems great from an AI x-risk perspective by (EA Forum; 30 Apr 2023 14:38 UTC; 10 points)
- The Autofac Era by (3 Oct 2025 4:10 UTC; 9 points)
- If Neuroscientists Succeed by (11 Feb 2025 15:33 UTC; 9 points)
- “Intro to brain-like-AGI safety” series—halfway point! by (EA Forum; 9 Mar 2022 15:21 UTC; 8 points)
- New version of “Intro to Brain-Like-AGI Safety” by (EA Forum; 23 Jan 2026 16:21 UTC; 6 points)
- 's comment on How you got RL’d into your idiosyncratic cognition by (21 Nov 2025 2:33 UTC; 6 points)
- 's comment on Thoughts on AGI consciousness / sentience by (12 Sep 2022 16:57 UTC; 5 points)
- 's comment on Foom & Doom 1: “Brain in a box in a basement” by (26 Jun 2025 3:21 UTC; 5 points)
- 's comment on Reward is not the optimization target by (25 Jul 2022 13:04 UTC; 4 points)
- 's comment on [Intro to brain-like-AGI safety] 9. Takeaways from neuro 2/2: On AGI motivation by (2 Jun 2022 13:05 UTC; 4 points)
- 's comment on Natural Value Learning by (21 Mar 2022 15:39 UTC; 3 points)
- 's comment on The Human’s Hidden Utility Function (Maybe) by (26 Aug 2022 22:04 UTC; 3 points)
- 's comment on Shard Theory: An Overview by (12 Aug 2022 12:02 UTC; 3 points)
- 's comment on Shah and Yudkowsky on alignment failures by (1 Mar 2022 16:24 UTC; 2 points)
Hey Steve, I am reading through this series now and am really enjoying it! Your work is incredibly original and wide-ranging as far as I can see—it’s impressive how many different topics you have synthesized.
I have one question on this post—maybe doesn’t rise above the level of ‘nitpick’, I’m not sure. You mention a “curiosity drive” and other Category A things that the “Steering Subsystem needs to do in order to get general intelligence”. You’ve also identified the human Steering Subsystem as the hypothalamus and brain stem.
Is it possible things like a “curiosity drive” arises from, say, the way the telenchephalon is organized, rather than from the Steering Subsystem itself? To put it another way, if the curiosity drive is mainly implemented as motivation to reduce prediction error, or fill the the neocortex, how confident are you in identifying this process with the hypothalamus+brain stem?
I think I imagine the way in which I buy the argument is something like “steering system ultimately provides all rewards and that would include reward from prediction error”. But then I wonder if you’re implying some greater role for the hypothalamus+brain stem or not.
Thanks!
First of all, to make sure we’re on the same page, there’s a difference between “self-supervised learning” and “motivation to reduce prediction error”, right? The former involves weight update, the latter involves decisions and rewards. The former is definitely a thing in the neocortex—I don’t think that’s controversial. As for the latter, well I don’t know the full suite of human motivations, but novelty-seeking is definitely a thing, and spending all day in a dark room is not much of a thing, and both of those would go against a motivation to reduce prediction error. On the other hand, people sometimes dislike being confused, which would be consistent with a motivation to reduce prediction error. So I figure, maybe there’s a general motivation to reduce prediction error (but there are also other motivations that sometimes outweigh it), or maybe there isn’t such a motivation at all (but other motivations can sometimes coincidentally point in that direction). Hard to say. ¯\_(ツ)_/¯
I absolutely believe that there are signals from the telencephalon, communicating telencephalon activity / outputs, which are used as inputs to the calculations leading up to the final reward prediction error (RPE) signal in the brainstem. Then there has to be some circuitry somewhere setting things up such that some particular type of telencephalon activity / outputs have some particular effect on RPE. Where is this circuitry? Telencephalon or brainstem? Well, I guess you can say that if a connection from Telencephalon Point A to Brainstem Point B is doing something specific and important, then it’s a little bit arbitrary whether we call this “telencephalon circuitry” versus “brainstem circuitry”. In all the examples I’ve seen, it’s tended to make more sense to lump it in with the brainstem / hypothalamus. But it’s hard for me to argue that without a better understanding of what you have in mind here.
Feel free not to respond if this is answered in later posts, but how relevant is it to your model that current LLMs (which are not brain-like and not AGIs), are helpful and docile in the vast majority of contexts?
Is this evidence that actually would be AGI developers do know how to making their AGIs helpful and docile? Or is it missing the point?
My take is that it’s irrelevant because of disanalogies between brain-like AGI vs LLMs; see Foom & Doom §2.3.
Presumably another strategy would be to start with an already trained model as the center of our learning subsystem, and a steering subsystem that points to concepts in that trained model?
Something like, you have an LLM-based agent that can take actions in text-based game. There’s some additional reward machinery that magically updates the weights of the LLM (based on simple heuristic evaluations of the the text context of the game?). You could presumably(?) instantiate such an agent such that it had some goals out of the gate, instead of needing to reward curiosity?
Perhaps this already strays too far from the human-setup to count as “brain-like.”
I think my version of that is Plan for mediocre alignment of brain-like [model-based RL] AGI; see also broader discussion here, here, and some other nuances in §14 of this series. (Or sorry if I’m misunderstanding.)
Well, to be fair, I care a lot about if a cortex by itself is safe, specifically because if so, the plan maybe should be to build a cortex (approximately) by itself, directed by control systems very different than those of biological brains—like text prompts.
This is frivolous, but I instantly thought: perhaps someday with the help of aligned AGI we should rewire the human steering system just slightly so that everyone knows from birth how to solve the AI alignment problem. I’m actually not entirely joking. (Point being: messing it up even once is, after all, fatal!)