Dopamine-supervised learning in mammals & fruit flies
(Last revised: December 2024. See changelog at the bottom.)
The backstory: Dopamine-supervised learning in mammals
According to a well-known theory from the 1990s, dopamine signals in mammal brains can serve as Reward Prediction Error signals that drive reinforcement learning, i.e. finding good actions within a high-dimensional space of possible actions.
I for one strongly agree that this is one of the things that dopamine does.
But meanwhile I’ve been advocating that dopamine also plays a different role in other parts of the mammal brain: a dopamine signal can provide the supervisory signal for supervised learning in a one-dimensional action space.
(Or 47 dopamine signals can supervise learning in a 47-dimensional action space, etc. etc.)
The main (though not exclusive) part of the brain where I think dopamine-supervised learning is happening is the “extended striatum” (caudate, putamen, nucleus accumbens, part of the amygdala, and a couple other areas). I think these parts of the brain house many copies of basically the same supervised learning algorithm (which I call a short-term predictor), each sending its output down to the hypothalamus & brainstem, and each in turn receiving an appropriate supervisory dopamine signal coming back up from the brainstem.
For example, one of the supervised learning circuits might have an output line to the hypothalamus & brainstem whose signals mean: “We need to salivate now!” The brainstem then has a dopamine supervisory signal going back up to that circuit, which it uses to correct those suggestions with the benefit of hindsight. Thus, if I suddenly find myself with a mouth chock-full of salt, then in hindsight, I should have been salivating in advance. The brainstem knows that I should have been salivating—the brainstem has a direct input from the taste buds—and thus the brainstem can put that information into the dopamine supervisory signal.
Here I’ll zoom out a bit so that we can see both kinds of dopamine signals, the reinforcement learning dopamine, and the supervised learning dopamine:
The right side is the array of dopamine-supervised learning algorithms—the downward arrows are the learning algorithm outputs, and the upward arrows are the supervisory signals.
Where is the reinforcement learning dopamine (i.e. reward prediction error) in this diagram? That would be the arrows related to “valence”. (See my Valence series for much more on how I think about valence.) Interestingly, you might notice that “valence” shows up on both sides—i.e., the reinforcement learning system involves a dopamine-supervised learning component. What’s going on there? Well, in actor-critic reinforcement learning, the critic is fundamentally in the category of supervised learning. After all, it’s outputting a one-dimensional signal, and it’s getting updated in hindsight. However, the valence signal on the left is related to the “actor” part of actor-critic reinforcement learning. This part is fundamentally different from supervised learning; rather, it involves explore-exploit in a high-dimensional space of possibilities.
So anyway, that’s my hypothesis about dopamine-supervised learning in mammals. I think there are good reasons to believe it (see here), but the reasons are all a bit indirect and suggestive. I don’t have a super solid case.
So, I was delighted when (in 2021) a friend (Adam Marblestone) sent me crystal-clear evidence of dopamine-supervised learning!
The only catch was … it was in drosophila! So not exactly what I was looking for. But still cool!
By the way, right now is a golden era in drosophila research. All 135,000 drosophila neurons have recently been mapped; see the FlyWire papers and website, plus “Drosophila Connectome” on wikipedia for more history. For my part, I’m very far from a drosophila expert—pretty much everything I know about drosophila comes from “The connectome of the adult Drosophila mushroom body provides insights into function”, Li et al. 2020, and also Larry Abbott’s 2018 talk which is nice and pedagogical. Also, I have some drosophila living in my compost bin at home. So yeah, I’m not an expert. But I’ll do my best, and please let me know if you see any errors.
Obvious question: If I’m correct that there’s dopamine-supervised learning in mammals … and if there’s also dopamine-supervised learning in drosophila … could they be homologous? It’s possible! See Tomer et al. 2010 and Strausfeld & Hirth 2013 for two slightly different proposed homologies, which are at least vaguely compatible with the functional analogies I’m suggesting in this post—i.e., between the fruit fly “mushroom body” (see below), and part of the mammal forebrain. But also, a lot about nervous system architecture has changed in the last 600 million years since our last common ancestor with fruit flies (the so-called Urbilaterian), so I’m not too concerned about the details. At the very least, it’s an interesting point of comparison, and I think worth the time to learn about, even if you (like me) are ultimately only interested in humans. (Or AIs.)
Algorithmic background—cerebellum-style supervised learning
Ironically, after getting you all excited about that possible homology, I will now immediately switch from supervised learning in the mammalian cortex to supervised learning in the mammalian cerebellum. The cerebellum does not use dopamine as a supervisory signal—it uses climbing fibers instead. I think any resemblance between drosophila and the cerebellum is almost definitely convergent evolution. But still, it’s a relatively clean and straightforward resemblance, whereas the mammal forebrain has extra complications that I don’t want to get into here.
So, let’s talk about the cerebellum. As far as I can tell, the cerebellum functions partly like a giant memoization system: it watches the activity of other parts of the brain (including parts of the neocortex and amygdala, and maybe other things too), it memorizes patterns in what signals those parts of the brain send under different circumstances, and when it learns such a pattern, it starts sending those same signals itself—just earlier. The cerebellum also does the same time-travel trick for sensory signals coming in from the periphery, in which case the engineering term is not “memoization” but rather “Smith predictors”. But the algorithm is the same either way. (See my post here (§4.6) for much more.)
How does it do that?
The basic idea is: we have a bunch of “context” lines carrying information about various different aspects of what’s happening in the world. The more different context lines, the better, by and large—the algorithm will eventually find the lines bearing useful predictive information, and ignore the rest. Then there’s one or more pairs of (output signal, supervisor signal). The learning algorithm’s goal is for each output to reliably fire a certain amount of time before the corresponding supervisor.
Here’s one way that something like this might work. Let’s say I want Output 1 to fire 0.5 seconds before Supervisor 1. Well, for each context signal, I can track (1) how likely it is to fire 0.5 seconds before Supervisor 1; and (2) how likely it is to fire in general. If that ratio is high, then I’ve found a good predicting signal! So I would edit the synapse strength between that context signal and the output line. (This is just a toy example; see Fine Print at the end.)
Here’s a diagram with a bit more detail:
The new thing that this diagram adds—besides the anatomical labels—is the “pattern separation” step at the left. Basically, there’s a trick where you take some context lines, randomly combine them in tons of different ways, sprinkle in some nonlinearity, and voila, you have way more context lines than you started with! This enables the system to learn a wider variety of possible patterns in a single neural-network layer. This is the function of the tiny granule cells in the cerebellum, which famously comprise more than half of neurons in the human brain.
Now let’s talk about drosophila!
The drosophila equivalent of the pattern-separating cerebellar granule cells is “Kenyon Cells” (KCs), which take the ≈35-dimensional space of detectable odors and turn it into a ≈1000-dimensional space of odor patterns (ref). The axons of these cells are the “context lines” that our learning algorithms will sculpt into a predictive model. More recently, Li et al. 2020 found Kenyon Cells with other kinds of context information besides odor, including visual information, temperature, and taste. These were (at least partly) segregated—this allows the genome to, say, train a model that makes predictions based on odor information, and also train a model that makes predictions based on visual information, and then give one of those two models a veto over the other. That’s just a made-up example, but I can imagine things like that being useful.
The Kenyon Cell axons, carrying context information, form a big bundle of parallel fibers, called the “mushroom body”. (Eventually this splits into a handful of smaller bundles of parallel fibers.)
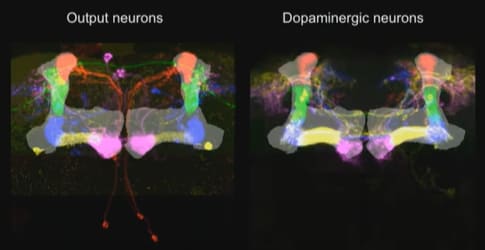
That brings us to the Mushroom Body Output Neurons (MBONs)—the supervised learning model output lines, the drosophila equivalent of Purkinje cells in the cerebellum. The synapses between the context lines and the MBON are edited by the learning algorithm. And as far as I can tell, the point of this system is just like the cerebellum: the MBON signals (i.e., the outputs from this trained model) will learn to approximate the supervisory signal, but shifted a bit earlier in time. (It could also be sign-flipped, and there are other complications—see “Fine Print” section below.) The “shifted earlier in time” allows the fly to predict problems and opportunities, instead of merely reacting to them. Otherwise there would hardly be any point in going to all this effort! After all, we already have the supervisory signal!
(Well, OK, supervised learning is good for a couple other things besides time-shifting—see the novelty-detection example below—but I suspect that time-shifting is the main thing here.)
Li et al. 2020 also found that there were “atypical” MBONs that connected to not only Kenyon Cells but also a grab-bag of other signals in the brain. I figure we should think of these as just even more context signals. Again, by and large, the more different context signals, the better the trained model!
They also found some MBON-to-MBON connections. If any of those synapses are plastic, I would just assume it’s the same story: one MBON is just serving as yet another context line for another MBON. (I surmise that the recurrent connections in the cerebellum are there for the same reason.) Are the synapses plastic though? I hear that it’s unknown, but that smart money says “probably not plastic”. So in that case, I guess the MBONs are probably gating each other, or doing some other such logical operation (see discussion of “Business Logic” here).
Finally, the last ingredient is the supervisory signal. Each supervised learning algorithm (MBON) has its own supervisory dopamine signal. (Well, more or less—see below.) In other words, dopamine is playing pretty much the same role in fruit flies as I was thinking for the mammal striatum / amygdala etc. Very cool!
Fine print
I oversimplified a couple things above for readability; here are more details.
1. Dopamine could have the opposite sign, and could be either ground truth or error, I dunno.
I’ve been talking in broad terms about dopamine being a supervisory signal. There are various ways it could work in detail. For example, dopamine could be either an “error signal” (the circuit fired too much / too little), or a “ground truth signal” (the circuit should have fired / should have not fired). That depends on whether the subtraction is upstream or downstream of the dopamine neurons. I don’t know which is right, and anyway it doesn’t matter for the high-level discussion here.
Also, the dopamine could be the opposite sign, saying “you should NOT have fired just now”.
1A. Novelty-detector example.
…In fact, opposite-sign dopamine is probably more likely, because we have at least one example where it definitely works that way—see Hattori et al. 2017:
The fruit-fly “MBON-α’3” neuron sends outputs which we can interpret as: “I need to execute an alerting response!!”
The corresponding PPL1-α’3 dopamine supervisory signal can be interpreted as “Things are fine! There was no need to execute an alerting response just now!”
What would happen, for the sake of argument, if the output neuron were simply wired directly to the dopamine neuron? It would turn into a novelty detector, right? Think about it: Whatever odor environment it’s in, the supervisory signal gradually teaches it that this odor environment does not warrant an alerting response. Pretty cool!
(Of course, to get a novelty detector, you also need some maintenance processes that gradually resets the synapses back to some trigger-happy baseline. Otherwise it would eventually learn to never fire at all.)
2. Dopamine is involved in inference, not just learning
In machine learning, you need both a “learning algorithm” (how to change the stored data to enable better outputs in the future) and an “inference algorithm” (how to query the stored data to pick an output right now). For example, in deep learning, the “learning algorithm” would be a gradient descent step, and the “inference algorithm” would be the forward pass.
Anyway, in reinforcement learning, I think dopamine plays a role in both the learning algorithm and the inference algorithm. I have a fun diagram (from here) to illustrate:
That’s for reinforcement learning, but (at least in fruit flies) some of the supervised learning modules likewise have dopamine signals affecting not only the learning algorithm but also the inference algorithm. In particular, there can be dopamine signals that function as a modulator / gate on the circuit. This was clearly documented in Cohn et al. 2015—see Fig. 6, where the ability of KC firing to trigger MBON firing is strongly modulated by the presence or absence of a certain dopamine signal under experimental control. Another example is Krashes et al. 2009, which showed that flipping certain hunger-related dopamine neurons on and off made the fruit fly start and stop taking actions based on learned food-related odor preferences. Both these papers demonstrated an inference-time gating effect, but I would certainly presume that the same signal gates the learning algorithm too. I’m getting all these references from Larry Abbott’s talk, by the way.
3. I oversimplified the cerebellum, sorry
The mammalian cerebellum has a bunch more bells and whistles wrapped around that core algorithm, that are not present in drosophila and are not particularly relevant for this post. For example, there are various preprocessing steps on the context lines (ref), the Purkinje cells are actually a hidden layer rather than the output (ref), there are dynamically-reconfigurable oscillation modules for perfecting the timing, etc. I think all these things exist for the same reason: to make the supervised learning algorithm work better (to learn faster, and ultimately to wind up with more accurate predictions). Also, as with dopamine above, I don’t know whether the climbing fiber signals are ground truth vs errors, and they may also be sign-flipped. Just wanted to mention those things for completeness.
(Thanks Jack Lindsey & Adam Marblestone for critical comments on earlier drafts.)
Changelog
December 2024: Since the initial version in 2021, I’ve learned a whole lot, so I went through and fixed miscellaneous errors in the diagrams and discussion. I also updated some links to point towards my more recent posts, rather than earlier posts on the same topic but written when I was more confused.
- [Intro to brain-like-AGI safety] 3. Two subsystems: Learning & Steering by (9 Feb 2022 13:09 UTC; 108 points)
- [Intro to brain-like-AGI safety] 2. “Learning from scratch” in the brain by (2 Feb 2022 13:22 UTC; 74 points)
- [Intro to brain-like-AGI safety] 5. The “long-term predictor”, and TD learning by (23 Feb 2022 14:44 UTC; 66 points)
- 's comment on Open Thread Fall 2024 by (3 Dec 2024 16:25 UTC; 2 points)
Thanks for the post!
I wonder if dopamine also might be one of the key elements for self-supervised learning (predicting some sensory input based on previous sensory input—or is it supervised learning in your terminology?).
The reason to suspect dopamine in self-supervised learning is Sharpe 2017 paper—I was quite surprised that in their experiment dopamine could unblock learning and inhibiting dopamine release led to decreased association between two sensory stimuli.
How I am currently thinking about the model to interpret their result and how it relates to this drosophila dopamine/cerebellum model:
Consider their blocking paradigm:
A->X
AC->X
X->US
Then they say that dopamine serves as the proxy for prediction error (sensory prediction error triggers the release of DA?) and allows learning.
I am not sure that sensory prediction error always equals dopamine release (I mean dopamine release corresponding to sensory learning, not dopamine neurons that are more about RPE).
What I mean is that we can try to dissociate cases “we have sensory prediction error (PE)” and “we are learning/search for the better model”. Then we have 4 options:
no PE, no learning better model: trivial situation
have PE, learning better model: you have unpredictable sensory input (X) and you allow your circuit to “listen” to the context lines extracting those that might be predictive of X. Dopamine supposedly allows extraction of this information and creating better model.
have PE, no learning better model: smth with the lack of attention? lights are flashing, but you don’t care
no PE, learning better model: trickiest/rarest in reality case: this is what probably happens in their unblocking experiment: no PE during “AC->X”, because A already predicts X. The funny thing is that C is also as good predictive signal as A (and which might be helpful to learn if the environment will change!), but because there is no PE that would trigger DA (which would trigger listening to the context lines of C), model is not updated. Only when they optogenetically release DA, it allows learning C->X. But I can imagine some weird cases where you can also learn C->X even though you already saw A->X and satisfied with this explanation when you see AC->X, e.g. you are super attentive and notice it, or somebody told you, but i suspect this is hard even for humans: once you converged onto some explanation, it’s hard to consider alternatives:). In these cases I’d expect seeing DA release even though you don’t have PE.
So explanation “DA triggers looking which context lines predict sensory input well and learning it” is consistent with Sharpe 2017 data and with this drosophila circuit. It also might be consistent with what you write about DA in IT to aversive/exciting stimuli: according to this “DA for self-supervised learning” explanation, DA in IT would mean: “hey IT, you are in the dangerous situation, even though you don’t have any PE, extract some more predictive signals (this would be equivalent to starting to learn C-> X when presented with AC->X in blocking paradigm) - might be helpful in the future”. In contrast, your explanation is more like (if I understood you correctly) “hey IT neurons that fired to the suspicious bush—do it the next time too”. Correct me if you meant different thing or if these 2 explanations are not contradicting each other. Or DA might do both?
Is it also correct that DA for global/local RPEs and supervised/self-supervised learning in the completely naive brain should go in different directions? i.e. for the bad supervised learning model there should be tons of DA—a lot of errors, whereas RPE DA (the one you talk in Big Picture) should be low—no action/thought is good enough to be rewarded by the brainstem. If we assume that learning is triggered by high DA of course (Sharpe 2017 hints that it is high DA that triggers learning/PE, not low).
Hmm, that’s interesting! I think I mostly agree with you in spirit here.
My starting point for Sharpe 2017 would be: the topic of discussion is really cortical learning, via editing within-cortex connections. The cortex can learn new sequences, or it can learn new categories, etc.
For sensory prediction areas, cortical learning doesn’t really need dopamine, I don’t think. You can just have a self-supervised learning rule, i.e. “if you have a sensory prediction error, then improve your models”. (Leaving aside some performance tweaks.) (Footnote—Yeah I know, there is in fact dopamine in primary sensory cortex, at least controversially and maybe only in layers 1&6, I’m still kinda confused about what’s going on with that.)
Decisionmaking areas are kinda different. Take sequence learning as an example. If I try the sequence “I see a tree branch and then I jump and grab it”, and then the branch breaks off and I fall down and everyone laughs at me, then that wasn’t a good sequence to learn, and it’s all for the better if that particular idea doesn’t pop into my head next time I see a tree branch.
So in decisionmaking areas, you could have the following rule: “run the sequence-learning algorithm (or category-learning algorithm or whatever), but only when RPE-DA is present”.
Then I pretty much agree with you on 1,2,3,4. In particular, I would guess that the learning takes place in the sensory prediction areas in 2 & 3 (where there’s a PE), and that learning takes place in the decisionmaking areas in 4 (maybe something like: IT learns to attend to C, or maybe IT learns to lump A & C together into a new joint category, or whatever).
I’m reluctant to make any strong connection between self-supervised learning and “dopamine-supervised learning” though. The reason is: Dopamine-supervised learning would require (at least) one dopamine neuron per dimension of the output space. But for self-supervised learning, at least in mammals, I generally think of it as “predicting what will happen next, expressed in terms of some learned latent space of objects/concepts”. I think of the learned latent space as being very high-dimensional, with the number of dimensions being able to change in real time as the rat learns new things. Whereas the dimensionality of the set of dopamine neurons seems to be fixed.
Hmm, I think “not necessarily”. You can perform really crappily (by adult standards) and still get positive RPEs half the time because your baseline expectations were even worse. Like, the brainstem probably wouldn’t hold the infant cortex to adult-cortex standards. And the reward predictions should also converge to the actual rewards, which would give average RPE of 0, to a first approximation.
And for supervisory signals, they could be signed, which means DA pauses half the time and bursts half the time. I’m not sure that’s necessary—another approach is to have a pair of opponent-process learning algorithms with unsigned errors, maybe. I don’t know what the learning rules etc. are in detail.
Thanks for the answers!
I totally agree that there is not enough dimensionality of dopamine signals to provide the teaching feedback in self-supervised learning of the same specificity as in supervised learning.
What I was rather trying to say in general is that maybe dopamine is involved in self-supervised learning by only providing permissive signal to update the model. And was trying to understand how sensory PE is related to dopamine release.
That’s what I always assumed before Sharpe 2017. But in their experiments inhibition of dopamine release inhibits learning association between 2 stimuli: PE is still there, little dopamine release, no model is learned. By “PE is still there” I assume that PE gets registered by neurons, (not that mouse becomes inattentive or blind upon dopamine inhibition) but the model is still not learned despite (pyramidal?) neurons signaling the presence of PE, this is the most interesting case compared to just “gets blind” case. If by learning for sensory predictions areas you mean modifying synapses in V1, I agree, you might not need synaptic changes or dopamine there, sensory learning (and need for dopamine) can happen somewhere else (hippocampus-entorhinal cortex? no clue) that are sending predictions to V1. The model is learned on the level of knowing when to fire predictions from entorhinish cortex to V1.
Even if this “dopamine permits to update sensory model” is true, I also don’t get why would you need the intermediate node dopamine between PE and updating the model, why not just update the model after you get cortical (signaled by pyramidal neurons) PE? But there is an interesting connection to schizophrenia: there is an abnormal dopamine release in schizophrenic patients—maybe they needlessly update their models because upregulated dopamine says so (found it in Sharpe 2020)
I guess I incorrectly understood your model. I assumed that for the given environment the ideal policy will lead to the big dopamine release, saying “this was a really good plan, repeat it the next time”, after rereading your decision making post it seems that assessors predict the reward, and there will be no dopamine as RPE=0?
Side question: when you talk about plan assessors, do you think there should be some mechanism in the brainstem that corrects RPE signals going to the cortex based on the signals sent to supervised learning plan assessors? For example, If the plan is to “go eat” and your untrained amygdala says “we don’t need to salivate”, and you don’t salivate, then you get way smaller reward (especially after crunchy chips) than if you would salivate. Sure, amygdala/other assesors will get their supervisory signal, but it also seems to me that the plan “go eat” it’s not that bad and it shouldn’t be disrewarded that much just because amygdala screwed up and you didn’t salivate, so the reward signal should be corrected somehow?
Thanks for your thoughtful & helpful comments!
Yup, that’s what I meant.
For example, I’m sitting on my porch mindlessly watching cars drive by. There’s a red car and then a green car. After seeing the red car, I wasn’t expecting the next car to be green … but I also wasn’t expecting the next car not to be green. I just didn’t have any particular expectations about the next car’s color. So I would say that the “green” is unexpected but not a prediction error. There was no prediction; my models were not wrong but merely agnostic.
In other words:
The question of “what prediction to make” has a right and wrong answer, and can therefore be trained by prediction errors (self-supervised learning).
The question of “whether to make a prediction in the first place, as opposed to ignoring the thing and attending to something else (or zoning out altogether)” is a decision, and therefore cannot be trained by prediction errors. If it’s learned at all, it has to be trained by RL, I think.
(In reality, I don’t think it’s a binary “make a prediction about X / don’t make a prediction about X”, instead I think you can make stronger or weaker predictions about things.)
And I think the decision of “whether or not to make a strong prediction about what color car will come after the red car” is not being made in V1, but rather in, I dunno, maybe IT or FEF or dlPFC or HC/EC (like you suggest) or something.
To be clear, in regards to “no dopamine”, sometimes I leave out “(compared to baseline)”, so “positive dopamine (compared to baseline)” is a burst and “negative dopamine (compared to baseline)” is a pause. (I should stop doing that!) Anyway, my impression right now is that when things are going exactly as expected, even if that’s very good in some objective sense, it’s baseline dopamine, neither burst nor pause—e.g. in the classic Wolfram Schultz experiment, there was baseline dopamine at the fully-expected juice, even though drinking juice is really great compared to what monkeys might generically expect in their evolutionary environment.
(Exception: if things are going exactly as expected, but it’s really awful and painful and dangerous, there’s apparently still a dopamine pause—it never gets fully predicted away—see here, the part that says “Punishments create dopamine pauses even when they’re fully expected”.)
I’m not sure if “baseline dopamine” corresponds to “slightly strengthen the connections for what you’re doing”, or “don’t change the connection strengths at all”.
OK, let’s say I happen to really need salt right now. I grab what I thought was an unsalted peanut and put it in my mouth, but actually it’s really salty. Awesome!
From a design perspective, whatever my decisionmaking circuits were doing just now was a good thing to do, and they ought to receive an RL-type dopamine burst ensuring that it happens again.
My introspective experience matches that: I’m surprised and delighted that the peanut is salty.
Your comment suggests that this is not the default, but requires some correction mechanism. I’m kinda confused by what you wrote; I’m not exactly sure where you’re coming from.
Maybe you’re thinking: it’s aversive to put something salty in your mouth without salivating first. Well, why should it be aversive? It’s not harmful for the organism, it just takes a bit longer to swallow. Anyway, the decisionmaking circuit didn’t do anything wrong. So I would expect “putting salty food into a dry mouth” to be wired up as not inherently aversive. That seems to match my introspective experience.
Or maybe you’re thinking: My hypothalamus & brainstem are tricked by the amygdala / AIC / whatever to treat the peanut as not-salty? Well, the brainstem has ground truth (there’s a direct line from the taste buds to the medulla I think) so whatever they were guessing before doesn’t matter; now that the peanut is in the mouth, they know it’s definitely salty, and will issue appropriate signals.
You can try again if I didn’t get it. :)
Interestingly, the same goes for serotonin—FIg 7B in Matias 2017 . But also not clear which part of raphe neurons does this—seems that there is a similar picture as with dopamine -projections to different areas respond differently to the aversive stimuli.
Closer to this. Well, it wasn’t a fully-formed thought, just came up with the salt example and thought there might be this problem. What I meant is a sort of problem of the credit assignment: if your dopamine in midbrain depends on both cortical action/thought and assessor action, then how does midbrain assign dopamine to both cortex-plan proposers and assessors? I guess for this you need to have situation where reward(plan1, assessor_action1) > 0, but reward(plan1, assessor_action2) < 0, and the salt example is bad here because in both salivating/not salivating cases reward > 0. Maybe something like inappropriately laughing after you’ve been told about some tragedy: you got negative reward, but it doesn’t mean that this topic had to be avoided altogether in the future (reinforced by the decrease of dopamine), rather you should just change your assessor reaction, and reward will become positive. And my point was that it is not clear how this can happen if the only thing the cortex-plan proposer sees is the negative dopamine (without additionally knowing that assessors also got negative dopamine so that overall negative dopamine can be just explained by the wrong assessor action and plan proposer actually doesn’t need to change anything)
Oh I gotcha. Well one thing is, I figure the whole system doesn’t come crashing down if the plan-proposer gets an “incorrect” reward sometimes. I mean, that’s inevitable—the plan-assessors keep getting adjusted over the course of your life as you have new experiences etc., and the plan-proposer has to keep playing catch-up.
But I think it’s better than that.
Here’s an alternate example that I find a bit cleaner (sorry if it’s missing your point). You put something in your mouth expecting it to be yummy (thus release certain hormones), but it’s actually gross (thus make a disgust face and release different hormones etc.). So reward(plan1, assessor_action1)>0 but reward(plan1, assessor_action2)<0. I think as you bring the food towards your mouth, you’re getting assessor_action1 and hence the “wrong” reward, but once it’s in your mouth, your hypothalamus / brainstem immediately pivots to assessor_action2 and hence the “right reward”. And the “right reward” is stronger than the “wrong reward”, because it’s driven by a direct ground-truth experience not just an uncertain expectation. So in the end the plan proposer would get the right training signal overall, I think.