Prediction = Compression [Transcript]
(Talk given on Sunday 21st June, over a zoom call with 40 attendees. Alkjash is responsible for the talk, Ben Pace is responsible for the transcription.)
Ben Pace: Our next speaker is someone you’ll all know as Alkjash on LessWrong, who has written an awesome number of posts. Babble and Prune, Hammertime Final Exam – which is one of my favorite names of a curated post on LessWrong. Alkjash, go for it.
Prediction = Compression Talk
Alkjash: I will be talking about a bit of mathematics today. It’s funny that this audience is bigger than any I’ve gotten in an actual maths talk. It’s a bit depressing. Kind of makes me question my life choices...
Alkjash: Hopefully this mathematics is new to some of you. I’m sure that the machine learning people know this already. The principle is that prediction is the same thing as compression. And what that means is that whenever you have a prediction algorithm, you can also get a correspondingly good compression algorithm for data you already have, and vice versa.
Alkjash: Let me dive straight into some examples. Take this sentence and try to fill in the vowels.
Ppl bcm wh thy r mnt t b, Mss Grngr, by dng wht s rght.
Translation:
People become who they are meant to be, Miss Granger, by doing what is right.
Alkjash: You’ll notice that it’s actually quite easy, hopefully, to read the sentence, even though I’ve taken out all the vowels. The human brain is very good at reconstructing certain kinds of missing data, and in some sense, that’s a prediction algorithm, but immediately it also gives us a compression algorithm. If I take this sentence and I remove all the vowels, it’s transmitting the same amount of data to a human brain because they can predict what’s missing.
Alkjash: This is a very simple example where you can predict with certainty what’s missing. In general, we don’t always have prediction algorithms that can predict the future with certainty. But anytime we can do better than chance, we can also get some compression improvements.
Alkjash: Here’s a slightly more sophisticated example. Suppose I have a four character alphabet and I encode some language with a four character alphabet in this obvious default way. Each character is encoded in two bits, then the following string will be encoded in this fifth string.
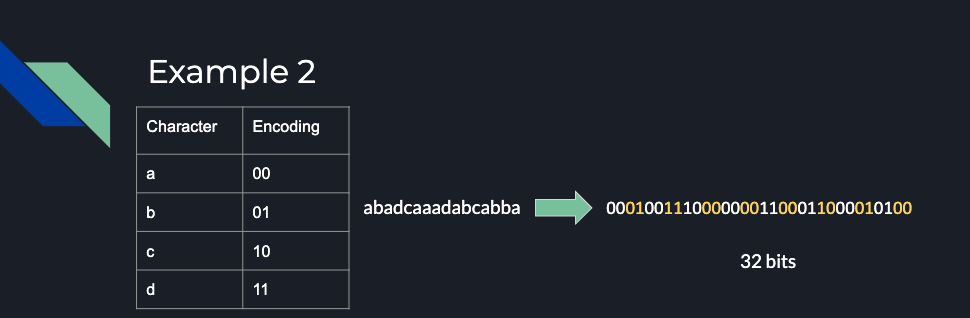
Alkjash: I’ve highlighted every other code word for you to just see the emphasis. And you can see that this string has encoded as 32 bits in memory.
Alkjash: However, I might have a little more information or better priors about what this language looks like. I might know for example that As appear more frequently and Cs and Ds appear less frequently. Then I can choose a more suitable encoding for the task. I can choose a different encoding where A is given a shorter bit string because it appears more frequently, and C and D are given longer ones to balance that out. And, using this encoding instead, we see that the same string is encoded only 28 bits.

Alkjash: This time I didn’t have any certainty about my predictions, but because I was able to do better than chance about predicting what the next character would be, I achieved a better compression ratio. I can store the same amount of data in memory with less bits.
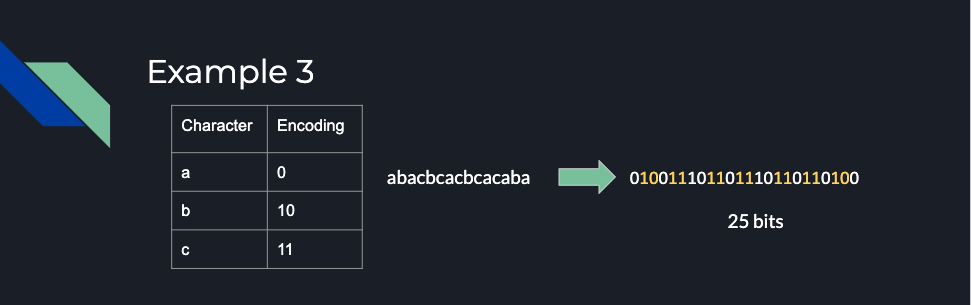
Alkjash: The third example is very similar, but it’s a different sort of prediction. Previously we just used letter frequencies, but now suppose I have a three character alphabet and I encode A as 0, B as 10, and C as 11, then by default I get 25 bits in this encoding.
Alkjash: But now suppose I notice a different sort of pattern about this language, which here, the pattern is that no letter appears consecutively twice in a row. So, that’s the different sort of predictive information from letter frequencies that we’ve had before.
Alkjash: Perhaps you could think for a moment about how you could use that information to store the same memory in fewer bits. No two As appear twice in a row; no two Bs appear twice in a row; no two Cs appear twice in a row. How would you use that information to compress the data?
[Pause for thinking]
Alkjash: Here’s one way you might do it.
Alkjash: I’m going to encode the first letter as whatever it would have been before, and then I’ll draw this little triangle and each next letter, because it has to be different, will either be clockwise or counter-clockwise from the previous letter in this triangle that I’ve drawn.
Alkjash: So if the next letter is clockwise from my previous letter, I put down a zero. If the next letter is counter-clockwise from the previous letter, I put down a 1. And this is a very specific example of some very general algorithm in entropy encoding in the information theory.

Alkjash: So whenever you have any sort of way of better predicting the future than chance, it corresponds to a better data compression algorithm for that type of data, where you store the same amount of information in your bits.
Alkjash: That’s really all I have to say. So, I guess the question I want to open up for discussion about what this principle has applications in rationality. For example, we care a lot about super-forecasters predicting the future. Is it true that people who are good at predicting the future are good at storing the same amount of knowledge in their minds very efficiently? Are these very closely related skills? I’d be curious if that’s true. Obviously these skills should be correlated with IQ or what not, but perhaps there’s an additional layer to that.
Alkjash: And second, I think we spend a lot of time emphasizing prediction and calibration games as tools to improve your rationality, but perhaps we should also spend just as much time thinking about how to efficiently compress the body of knowledge that you already know. And what sorts of things could be designed as, for example, rationality exercises for that, I’d be interested to hear ideas about that.
Q&A
Ben Pace: Thank you very much, Alkjash. I really like the idea of super-forecasters and super-compressors. I want to start a similar tournament for super-compressors.
Alkjash: If any of you are interested, I have been personally interested in questions of which languages have the highest information rate. Perhaps with the newer neural networks, we might actually be close to answering this sort of question.
Ben Pace: By languages, you don’t mean computer science languages?
Alkjash: No, I mean human languages. What language seems to use more letters per idea.
Ben Pace: Interesting. Do you have a basic sense of which languages do compress things more?
Alkjash: Very naively, I expect things, for example languages with genders and other unnecessary dongles to be slightly worse, but I really don’t know.
Ben Pace: All right, interesting. I think Jacob has a question.
Jacob Lagerros: So, when we spoke about this yesterday, Alkjash, you gave some interesting examples of the third bullet point. I was curious if you wanted to share some of those now as well?
Alkjash: Sure, here’s one example I’m thinking about. So I have a general model about learning certain sorts of things. The model is that when you start out, there’s so few data points that you just stick them into an array but as time goes on and you learn more stuff, your brain builds a more sophisticated data structure to store the same amount of data more efficiently.
Alkjash: For example, my wife and I occasionally have competed in geography sporcles, and one of the things we noticed is that I remember all the states as a visual map (I’m a more spacial person) and where each state is. I tried to list out the states by going through vertically scanning my internal map of the United States; on the other hand, she remembers it by this alphabet song that she learned in elementary school.
Alkjash: And so these are equally useful for the application of ‘remembering the states’. But when I turn to the addition of state capitals, my model seemed to be more useful for that because it’s harder to fit in the state capitals into the alphabet song than into the geographical map, especially when I roughly already know where 10 or 20 of those cities would be geographically.
Alkjash: Thinking about how these data representations… it depends on the application, what compression actually means, I think.
Ben Pace: Nice. Dennis, do you want to ask your question?
Dennis: Looks like compression is related a little to the Zettlekasten system. Have you tried it, and what do you think about it?
Alkjash: I don’t know anything about that. Could you explain what that is?
Dennis: This is the system of compact little cards which is used to store information, not in categories but with links relating one to another, which was used by sociologists.
Alkjash: I see. That’s very interesting. Yeah, that seems like a very natural thing, closely related. It seems like, just naively, when I learn stuff, I start out just learning a list of things and then slowly, over time, what happens is the connection build up and making this more explicit. It seems like a great thing, to skip the whole store everything as an array and stuff, altogether.
Ben Pace: Cool. Thanks, Dennis.
Ben Pace: Gosh, I’m excited by these questions. Abram if you want to go for it, you can go for it. Just for Alkjash’s reference, Abram wrote that he had “not a question, but a dumb argumentive comment relating this to my talk.”
Abram Demski: Yeah, so my dumb argumentive comment is, prediction does not equal compression. Sequential prediction equals compression. But non-sequential prediction is also important and does not equal compression. And so, compression doesn’t capture everything about what it means to be a rational agent in the world, predicting things.
Alkjash: Interesting.
Abram Demski: And by non-sequential prediction, I mean you have a sequence of bits in the information theory model, but if instead you have this broad array of things that you could think about, and you’re not sure when any one of them will become observed, [then] you want all of your beliefs to be good, but you don’t have any next bit… You can’t express the goodness just in terms of this sequential goodness.
Alkjash: I feel like there is some corresponding compression rate I could write down based on whatever you’re being able to predict in this general non-sequential picture, but I haven’t thought about it.
Abram Demski: Yeah. I think that you could get it into compression, but my claim is that compression won’t capture all the notion of goodness.
Alkjash: I see. Yeah...
Ben Pace: Abram will go into more depth I expect in his talk.
Ben Pace: I should also mention that if you wanted to look at more of that Zettlekasten thing Abram has written a solid introduction to the idea on LessWrong.
Abram Demski: I am also a big fan of Zettlekasten, and recommend people check it out.
Ben Pace: All right, let me see. There was another question from Vaniver. You want to go for it?
Vaniver: Yeah, so it seems to me like the idea of trying to compress your concepts, or like your understanding of the world that you already have, is a thing that we already do a lot of.
Alkjash: Absolutely.
Vaniver: It feels to me that abstraction and categorization, this is the big thing. I guess the interesting comment to add onto that is something like, there’s lumping and splitting as distinct things that are worth thinking about, where lumping is sort of saying, okay I’ve got a bunch of objects, how do I figure out the right categories that divide this in a small amount? And splitting is like, okay, I’ve got ‘all dogs’ or something and can I further subgroup within ‘dogs’ and keep going down until I have a thing that is a concrete object?
Vaniver: I think this is interesting to do because with real categories, it’s much harder to find the right character encoding, or something. If we’re looking at a bit-string like, we’re like oh yeah, letters are letters. And sometimes you’re like, oh actually maybe we want words instead of letters.
Alkjash: That’s right, yeah.
Vaniver: Your conceptual understanding of the world, it feels like there’s much more variation in what you care about for different purposes.
Alkjash: Yeah, so I definitely agree that categorization is an important part of this compression. But I think, actually, probably the more important thing for compression is, as orthonormal says, having a model.
Alkjash: Here’s a good example that I’ve thought about for a while. When I was playing Go, I spent about my first semester in college just studying Go 24⁄7 instead of going to class. At the end of those six months, I noticed that after playing a game, I could reproduce the entire game from memory. I don’t know how much you guys know about Go, but it’s a 19x19 board, and a game is placing down these black and white stones; there’s probably 200 moves in the average game.
Alkjash: And this skill that I have is not at all exceptional, I think almost anyone who becomes a strong amateur will be able to reproduce their games from memory after playing for about a year. The reason they achieve such a good memory, I claim, is because they’re getting good compression and it’s not because they’re good at categorizing. It’s because for the vast majority of moves, they can predict exactly what the next move is because they have a model of how players at their level play. Even though there’s a 19x19 board, 90 percent of the time the next move is obvious.
Alkjash: So, that’s why there’s so little data in that actual game.
Ben Pace: Cool, thanks. I wanted to just add one thought of mine which is: I think the super-forecasters and super-compressors idea is very fun, and I think if anyone wanted an idea for a LessWrong post to write and wanted to have a format in which to Babble a bit, something that’s got different constraints, you could write one taking something like Tetlock’s 10 Heuristics that Superforecasters Use and trying to turn them into 10 Heuristics that Supercompressors Use, and seeing if you come up with anything interesting there, I would be excited to read that.
Ben Pace: All right, thanks a lot, Alkjash. I think we’ll move next onto Abram.
- Radical Probabilism by (18 Aug 2020 21:14 UTC; 190 points)
- Unnatural Categories Are Optimized for Deception by (8 Jan 2021 20:54 UTC; 94 points)
- Beyond Kolmogorov and Shannon by (25 Oct 2022 15:13 UTC; 63 points)
- Sunday June 21st – talks by Abram Demski, alkjash, orthonormal, eukaryote, Vaniver by (18 Jun 2020 20:10 UTC; 49 points)
- Forecasting Newsletter: June 2020. by (EA Forum; 1 Jul 2020 9:32 UTC; 45 points)
- Inviting Curated Authors to Give 5-Min Online Talks by (1 Jul 2020 1:05 UTC; 27 points)
- Forecasting Newsletter. June 2020. by (1 Jul 2020 9:46 UTC; 27 points)
- What’s holding back outsourcing to cloud labs? by (28 Oct 2020 23:07 UTC; 25 points)
- My (Mis)Adventures With Algorithmic Machine Learning by (20 Sep 2020 5:31 UTC; 17 points)
- 's comment on A more systematic case for inner misalignment by (20 Jul 2024 15:09 UTC; 11 points)
- 's comment on Discussion on the choice of concepts by (14 Jan 2021 22:15 UTC; 10 points)
I’d argue that recognition, prediction, and compression of patterns isn’t just correlated with IQ. It’s the thing that IQ tests actually (try to) measure.
Prediction = Compression
Compression = Exploiting symmetries
Which is the short (compressed even) version of why predictive coding is most of the way to our guess at QRI that we should be hunting for symmetry in the brain’s signal processing.
I’m not so sure about this. I can accept that non-sequential prediction is not full compression, for the obvious reason that the sequence is information and lacking it means you haven’t compressed it; but if this were true in general then how could information about non-sequential things allow us to achieve better compression? For example, in Alkjash’s example the frequency of the letters was worth 4 bits.
This causes me to expect that not only does any kind of prediction correspond to some compression, but that each kind of prediction corresponds to a kind of compression.
On the other hand, thinking further about how to distinguish between the 4 bits in the frequency example and the 10 bits from the partial-sequence-elimination example, I am promptly confronted by a grey mist. Mumble mumble prediction/compresson transform mumble.
I think this argument is conflating “data which is temporally linear” and “algorithm which is applied sequentially”. “Prediction” isn’t an element of past data VS future data, it’s an element of information the algorithm has seen so far VS information the algorithm hasn’t yet processed.
How could I get in on such zoom talks?
This talk was announced on LW; check the upcoming events tab for more.
A comment from the zoom chat (I forget who from) said something like: If the environment gives you a hash of an observation, and then the observation itself, then you have compression but not prediction.
(I.e., you can take the output and remove the hashes to compress it, but you can’t predict what’s coming next.)
What if I take my model’s predictions of future observations, and hash them in order of posterior probability until I run out of time or get a hit?
In computer science land, prediction = compression. In practice, it doesn’t. Trying to compress data might be useful rationality practice in some circumstances, if you know the pitfalls.
One reason that prediction doesn’t act like compression, is that information can vary in its utility by many orders of magnitude. Suppose you have datasource consisting of a handful of bits that describe something very important. (eg Friendly singularity, yes or no) and you also have vast amounts of unimportant drivel. (Funny cat videos) You are asked to compress this data the best you can. You are going to be spending a lot of time focusing on the mechanics of cat fur, and statistical regularities in camera noise. Now, sometimes you can’t separate it based on raw bits, If shown video of a book page, the important thing to predict is probably the text, not the lens distortion effects or the amount of motion blur. Sure, perfect compression will predict everything as well as possible, but imperfect compression can look almost perfect by focussing attention on things we don’t care about.
Also, there is redundancy for error correction. Giving multiple different formulations of a physical law, plus some examples, makes it easier for a human to understand. Repeating a message can spot errors, and redundancy can do the same thing. Maybe you could compress a maths book by deleting all the answers to some problems, but the effort of solving the problems is bigger than the value of the saved memory space.
Videos have irremovable noise, but in some domains there is none and compression is more useful. In my experience, one example where the prediction-compression duality made problems much easier for humans to understand is in code golf (writing the shortest possible programs that perform various tasks). There’s a Stack Exchange site dedicated to it, and over the years people have created better and better code-golf languages. Solution sizes shrunk by a factor of >3. Now they’re so good that code golf isn’t as fun anymore because the tasks are too easy; anyone fluent in a modern golfing language can decompose the average code golf problem into ten or twenty atomic functions.
Thank you for posting this! Do you have any thoughts on how this might relate prediction to Schmidhuber’s theory of creativity (http://people.idsia.ch/~juergen/creativity.html)? Is forecasting fun?
The Arbital entry on Unforeseen Maximums [0] says:
“Juergen Schmidhuber of IDSIA, during the 2009 Singularity Summit, gave a talk proposing that the best and most moral utility function for an AI was the gain in compression of sensory data over time. Schmidhuber gave examples of valuable behaviors he thought this would motivate, like doing science and understanding the universe, or the construction of art and highly aesthetic objects.
Yudkowsky in Q&A suggested that this utility function would instead motivate the construction of external objects that would internally generate random cryptographic secrets, encrypt highly regular streams of 1s and 0s, and then reveal the cryptographic secrets to the AI.”
[0] https://arbital.greaterwrong.com/p/unforeseen_maximum/
I think i see what is the cause of it. I will also make a prediction that super forecasters will indeed be better at compressing information. This is in line with the principles of how neural networks work, since the human brain is slow, having more cached thoughts/categories/compressions will allow better predictions, as it will require less thinking/calculation. My reasoning is that when you predict, you find some patterns, properties that are the same for all examples (which can be categorized as said), even chaos/unpredictability is just a state of high entropy, low negentropy, also known as common information. and its absence is incompressibility, white noise, randomness.