Jeffrey Heninger, 22 November 2022
I was recently reading the results of a survey asking climate experts about their opinions on geoengineering. The results surprised me: “We find that respondents who expect severe global climate change damages and who have little confidence in current mitigation efforts are more opposed to geoengineering than respondents who are less pessimistic about global damages and mitigation efforts.”[1] This seems backwards. Shouldn’t people who think that climate change will be bad and that our current efforts are insufficient be more willing to discuss and research other strategies, including intentionally cooling the planet?
I do not know what they are thinking, but I can make a guess that would explain the result: people are responding using a ‘general factor of doom’ instead of considering the questions independently. Each climate expert has a p(Doom) for climate change, or perhaps a more vague feeling of doominess. Their stated beliefs on specific questions are mostly just expressions of their p(Doom).
If my guess is correct, then people first decide how doomy climate change is, and then they use this general factor of doom to answer the questions about severity, mitigation efforts, and geoengineering. I don’t know how people establish their doominess: it might be as a result of thinking about one specific question, or it might be based on whether they are more optimistic or pessimistic overall, or it might be something else. Once they have a general factor of doom, it determines how they respond to specific questions they subsequently encounter. I think that people should instead decide their answers to specific questions independently, combine them to form multiple plausible future pathways, and then use these to determine p(Doom). Using a model with more details is more difficult than using a general factor of doom, so it would not be surprising if few people did it.
To distinguish between these two possibilities, we could ask people a collection of specific questions that are all doom-related, but are not obviously connected to each other. For example:
How much would the Asian monsoon weaken with 1°C of warming?
How many people would be displaced by a 50 cm rise in sea levels?
How much carbon dioxide will the US emit in 2040?
How would vegetation growth be different if 2% of incoming sunlight were scattered by stratospheric aerosols?
If the answers to all of these questions were correlated, that would be evidence for people using a general factor of doom to answer these questions instead of using a more detailed model of the world.
I wonder if a similar phenomenon could be happening in AI Alignment research.[2]
We can construct a list of specific questions that are relevant to AI doom:
How long are the timelines until someone develops AGI?
How hard of a takeoff will we see after AGI is developed?
How fragile are good values? Are two similar ethical systems similarly good?
How hard is it for people to teach a value system to an AI?
How hard is it to make an AGI corrigible?
Should we expect simple alignment failures to occur before catastrophic alignment failures?
How likely is human extinction if we don’t find a solution to the Alignment Problem?
How hard is it to design a good governance mechanism for AI capabilities research?
How hard is it to implement and enforce a good governance mechanism for AI capabilities research?
I don’t have any good evidence for this, but my vague impression is that many people’s answers to these questions are correlated.
It would not be too surprising if some pairs of these questions ought to be correlated. Different people would likely disagree on which things ought to be correlated. For example, Paul Christiano seems to think that short timelines and fast takeoff speeds are anti-correlated.[3] Someone else might categorize these questions as ‘AGI is simple’ vs. ‘Aligning things is hard’ and expect correlations within but not between these categories. People might also disagree on whether people and AGI will be similar (so aligning AGI and aligning governance are similarly hard) or very different (so teaching AGI good values is much harder than teaching people good values). With all of these various arguments, it would be surprising if beliefs across all of these questions were correlated. If they were, it would suggest that a general factor of doom is driving people’s beliefs.
There are several biases which seem to be related to the general factor of doom. The halo effect (or horns effect) is when a single good (or bad) belief about a person or brand causes someone to believe that that person or brand is good (or bad) in many other ways.[4] The fallacy of mood affiliation is when someone’s response to an argument is based on how the argument impacts the mood surrounding the issue, instead of responding to the argument itself.[5] The general factor of doom is a more specific bias, and feels less like an emotional response: People have detailed arguments describing why the future will be maximally or minimally doomy. The futures described are plausible, but considering how much disagreement there is, it would be surprising if only a few plausible futures are focused on and if these futures have similarly doomy predictions for many specific questions.[6] I am also reminded of Beware Surprising and Suspicious Convergence, although it focuses more on beliefs that aren’t updated when someone’s worldview changes, instead of on beliefs within a worldview which are surprisingly correlated.[7]
The AI Impacts survey[8] is probably not relevant to determining if AI safety researchers have a general factor of doom. The survey was of machine learning researchers, not AI safety researchers. I spot checked several random pairs of doom-related questions[9] anyway, and they didn’t look correlated. I’m not sure whether to interpret this to mean that they are using multiple detailed models or that they don’t even have a simple model.
There is also this graph,[10] which claims to be “wildly out-of-date and chock full of huge outrageous errors.” This graph seems to suggest some correlation between two different doom-related questions, and that the distribution is surprisingly bimodal. If we were to take this more seriously than we probably should, we could use it as evidence for a general factor of doom, and that most people’s p(Doom) is close to 0 or 1.[11] I do not think that this graph is particularly strong evidence even if it is accurate, but it does gesture in the same direction that I am pointing at.
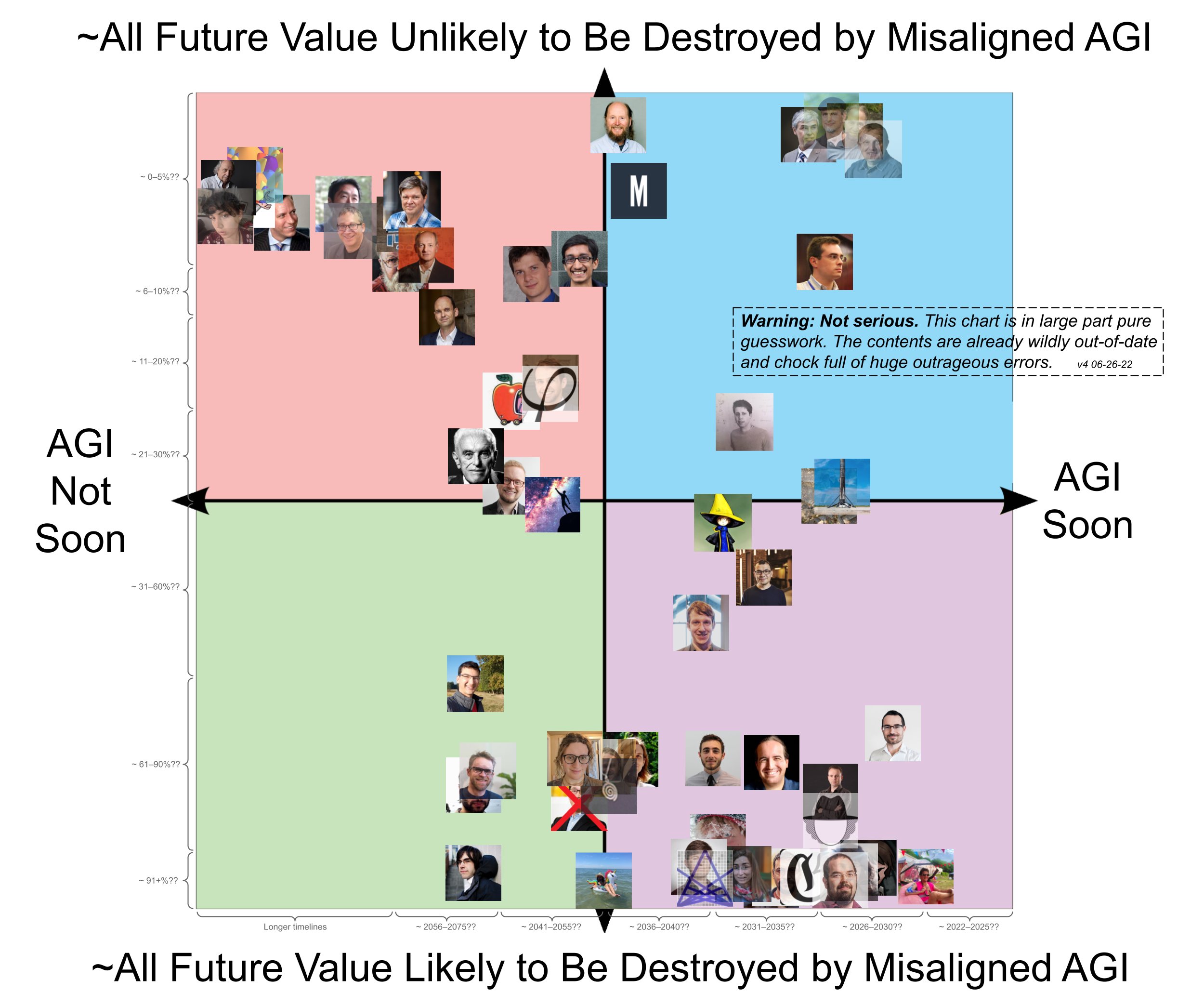
It would be interesting to do an actual survey of AI safety researchers, with more than just two questions, to see how closely all of the responses are correlated with each other. It would also be interesting to see whether doominess in one field is correlated with doominess in other fields. I don’t know whether this survey would show evidence for a general factor of doom among AI safety researchers, but it seems plausible that it would.
I do not think that using a general factor of doom is the right way to approach doom-related questions. It introduces spurious correlations between specific questions that should not be associated with each other. It restricts which plausible future pathways we focus on. The future of AI, or climate change, or public health, or any other important problem, is likely to be surprisingly doomy in some ways and surprisingly tractable in others.[12] A general factor of doom is too simple to use as an accurate description of reality.
Notes
- ^
Dannenberg & Zitzelsberger. Climate experts’ views on geoengineering depend on their beliefs about climate change impacts. Nature Climate Change 9. (2019) p. 769-775. https://www.nature.com/articles/s41558-019-0564-z.
- ^
Public health also seems like a good place to check for a general factor of doom.
- ^
- ^
- ^
- ^
This suggests a possible topic for a vignette. Randomly choose 0 (doomy) or 1 (not doomy) for each of the nine questions I listed. Can you construct a plausible future for the development of AI using this combination?
- ^
- ^
- ^
I looked at (1) the probability of the rate of technological progress being 10x greater after 2 years of HLAI vs the year when people thought that the probability of HLAI is 50%, (2) the probability of there being AI vastly smarter than humans within 2 years of HLAI vs the probability of having HLAI within the next 20 years, and (3) the probability of human extinction because we lose control of HLAI vs the probability of having HLAI within the next 10 years.
- ^
- ^
There is some discussion of why there is a correlation between these two particular questions here: https://twitter.com/infinirien/status/1537859930564218882. To actually see a general factor of doom, I would want to look at more than two questions.
- ^
During the pandemic, I was surprised to learn that it only took 2 days to design a good vaccine – and I was surprised at how willing public health agencies were to follow political considerations instead of probabilistic reasoning. My model of the world was not optimistic enough about vaccine development and not doomy enough about public health agencies. I expect that my models of other potential crises are in some ways too doomy and in other ways not doomy enough.
A nice write-up of something that actually matters, specifically the fact that so many people rely on a general factor of doom to answer questions.
While I think there is reason to have correlation between these factors, and a very weak form of the General Factor of Doom is plausible, I overall like the point that people probably use a General Factor of Doom too much, and offers some explanations of why.
Overall, I’d give this a +1 or +4. A reasonably useful post that talks about a small thing pretty competently.