(Co-written with Bernhard Salow)
TLDR: Differential legibility is a pervasive, persistent, and individually-rational source of unfair treatment. Either it’s a purely-structural injustice, or it’s a type of “zetetic injustice”—one requiring changes to our practices of inquiry.
Finally, graduate admissions are done. Exciting. Exhausting. And suspicious.
Yet again, applicants from prestigious, well-known universities—the “Presties”, as you call them—were admitted at a much higher rate than others.
But you’re convinced that—at least controlling for standardized-test scores and writing samples—prestige is a sham: it’s largely money and legacies that determine who gets into prestigious schools; and such schools train their students no better.
Suppose you’re right.
Does that settle it? Is the best explanation for the Prestie admissions-advantage that your department has a pure prejudice toward fancy institutions?
No. There’s a pervasive, problematic, but individually rational type of bias that is likely at play. Economists call it “statistical discrimination” (or “screening discrimination”).
But it’s about uncertainty, not statistics. We’ll call it Bayesian injustice.
A simplified case
Start with a simple, abstract example. Two buckets, A and B, contain 10 coins each. The coins are weighted: each has either a ⅔ or a ⅓ chance of landing heads when tossed. Their weights were determined at random, independently of the bucket—so you expect the two buckets to have the same proportions of each type of coin.
You have to pick one coin to bet will land heads on a future toss.
To make your decision, you’re allowed to flip each coin from Bucket A once, and each coin from Bucket B twice. Here are the outcomes:
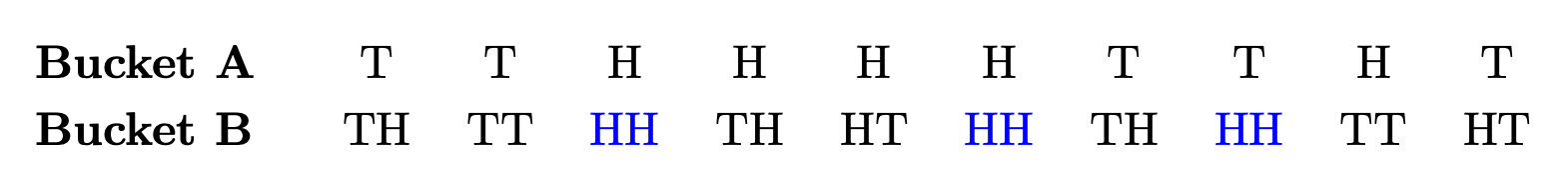
Which coin are you going to bet on? One of the ones (in blue) that landed heads twice, of course! These are the coins that you should be most confident are weighted toward heads, since it’s less likely that two heads in a row was a fluke that that one was.
Although the proportions of coins that are biased toward heads is the same in the two buckets, it’s easier to identify a coin from Bucket B that has good chance to land heads. As we might say: the coins from Bucket B are more legible than those from Bucket A, since you have more information about them.
This generalizes. Suppose there are 100 coins in each bucket, you can choose 10 to bet on landing heads, and you are trying to maximize your winnings. Then you’ll almost certainly bet on only coins from Bucket B (since almost certainly at least 10 of them will land HH).
End of abstract case.
The admissions case
If you squint, you can see how this reasoning will apply to graduate admissions. Let’s spell it out with a simple model.
Suppose 200 people apply to your graduate program. 100 are from prestigious universities—the Presties—and 100 are from normal universities—the Normies.
What your program cares about is some measure of qualifications, qi, that each candidate i has. For simplicity, let’s let qi = the objective chance of completing your graduate program.
You don’t know what qi is in any given case. It ranges from 0–100%, and the committee is trying to figure out what it is for each applicant. To do so, they read the applications and form rational (Bayesian) estimates for each applicant’s chance of success (qi), and then admit the 10 applicants with the highest estimates.
Suppose you know—since prestige is a sham—that the distribution of candidate qualifications is identical between Presties and Normies. For concreteness, say they’re both normally distributed with mean 50%:
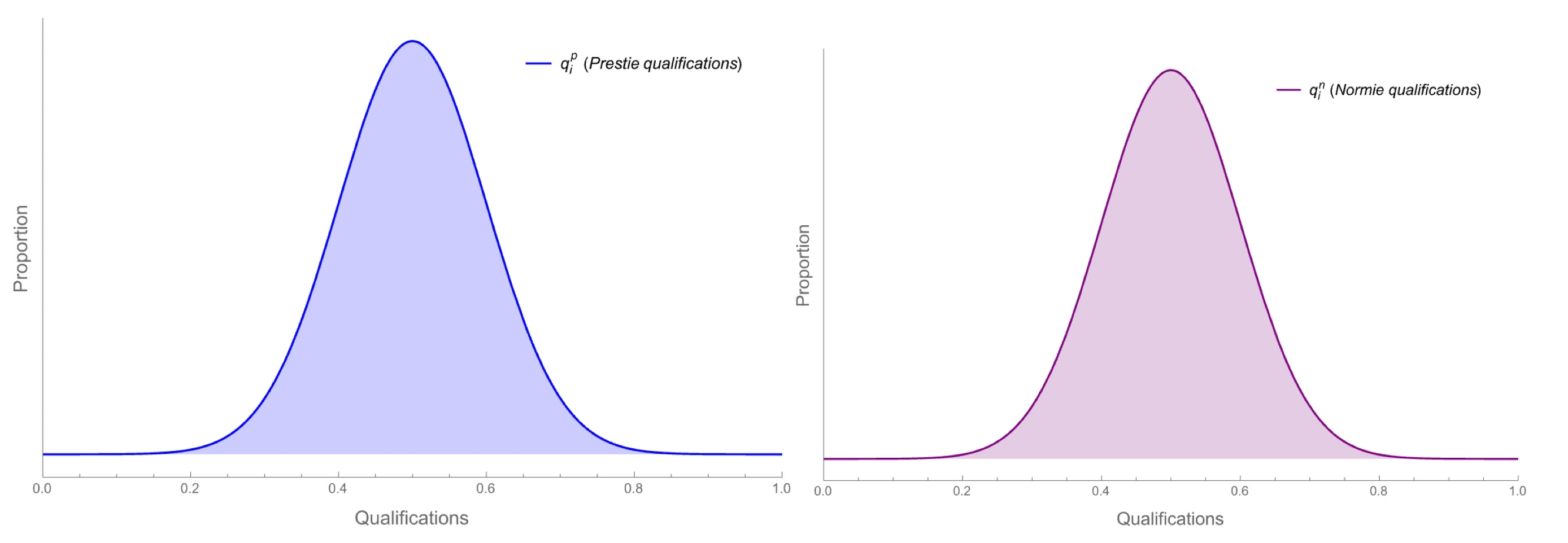
Each application gives you an unbiased but noisy signal, 𝞱i, about candidate i’s qualifications qi.[1]
Summarizing: you know that each Prestie and Normie candidate is equally likely to be equally qualified, and that you’ll get only unbiased information about each. Does it follow that—if you’re rational and unbiased—you’ll admit Presties and Normies at equal rates?
No! Given your background information, it’s likely that the Prestie applications are more legible than the Normie ones.
Why? Because you know the prestigious schools. You’ve had students from them. You’ve read many letters from their faculty. You have a decent idea how much coaching has gone into their application. And so on.
Meanwhile, you’re much less sure about the Normie applications. You barely know of some of the schools. You haven’t had any students from them. You don’t know the letter-writers. You have little idea how much coaching (or other opportunities) the students have had. And so on.
This difference in background knowledge makes the Prestie applications more legible than the Normie ones—makes you less uncertain about what to think upon reading their application. In other words: Prestie applications are like coins from Bucket B that you get to toss twice instead of just once.[2]
Why does this matter? Because—as with our coins example—the more uncertainty you should have about a signal’s reliability (the less legible it is), the less it should move your estimates from your priors.
Imagine two letter-writers—Nolan and Paige—each tell you that their respective candidates (Nigel and Paula) have a 80% chance of completing your graduate program.
Paige is at a prestigious school. You know her well, and have had enough experience with her letters to know how reliable they are. Given that, her letter is a clear signal: your estimate of Paula’s qualifications should move up from 50% to close to 80%.
Meanwhile, you don’t know Nolan at all, so you’re uncertain how reliable his letters are. He could, of course, be more reliable than Paige; but he could also be extremely unreliable. If you knew the former, you’d move your estimate of Nigel’s chances all the way to 80%; if you knew the latter, you’d leave it at 50%. So when you’re uncertain, the rational thing to do is hedge—for example, to wind up with an estimate of 60%.
This generalizes. When you have more uncertainty about the reliability of source, your estimates should be less sensitive to that source’s information (and more dependent on your priors).
Given this, what happens to your estimates of the qualifications of the whole pool of applicants? You start out with the same prior estimate of qi = 50% for every candidate in each group:
Once you get the signals, your estimates spread out—some candidates had strong applications, others had weak ones. But the Prestie signals are (on average) more legible. As a result, your estimates for the qualifications of various Presties will spread out more:

Remember that you’ll accept the 10 candidates that you have the highest estimates of. This determines an upper region—say the gray one—in which you accept all the candidates. But because your Prestie-estimates are more spread out, there are far more Presties than Normies in this Accepted (gray) region.
The upshot? Despite the fact that you know the two groups have the same distribution of qualifications and you process the evidence in an unbiased way, you’re still better at identifying the qualified Prestie candidates.
Though rational—indeed, optimal from the point of view of accurately estimating candidate’s qualifications—the result is seriously unfair. For example, in the above plots, Prestie signals have a standard deviation of 5% while Normies have one of 10%. As a result:
If you admit 10 candidates, the median class will have 8 Presties, and most (84%) of the time, you’ll admit more Presties than Normies.
If Paula (a Prestie) and Nigel (a Normie) are in fact equally qualified (qi = 70%), Paula is far more likely (73%) to be admitted than Nigel is (26%).
That looks like a form of epistemic injustice.
Why does this matter?
How common is Bayesian injustice? It’ll arise whenever there’s both (1) a competitive selection process, and (2) more uncertainty about (i.e. less legibility of) the signals from one group than another.
So it’s everywhere:
Who you know. Qualified candidates who are more familiar to a committee (through networking or social connections) will be more legible.
Who you are. Qualified candidates who are in the mainstream (of society, or a subfield) will be more legible.
What you face. Qualified candidates who are less likely to face potential obstacles will provide fewer sources of uncertainty, so will be more legible.
Who you’re like. Qualified candidates who are similar to known, successful past candidates will be more legible.
This is clearly unfair. Is it also unjust?
We think sometimes it clearly is—for example, when candidate legibility correlates with class, race, gender, and other socially fraught categories. (As it often will.) Graduate admissions is a simple case to think about, but the dynamics of Bayesian injustice crop up in every competitive selection process: college admissions; publication; hiring; loan decisions; parole applications; you name it.
Yet Bayesian injustice results from individually rational (and even well-meaning!) behavior. So where do we point the blame?
Two options.
First, we could say that it is an epistemic version of a tragedy of the commons: each individual is blameless—the problem is simply the structure that makes for differential legibility. In other words, Bayesian injustice is a structural injustice.
But that diagnosis might breed complacency—“That’s not our problem to address; it’s society’s”, people might say.
Alternatively, we could say that individuals who perpetrate Bayesian injustices are violating a zetetic duty: a duty regulating how you gather and manage evidence. The problem arises because, by default, committees get better evidence about Presties than Normies. Thus they might have a duty of zetetic justice to try to equalize their evidence about candidates from each group. How?
One option is to level down: ignore extra information about more-legible candidates, insofar as they can. Bans on interviews, standardization of applications, and limitations of communication to formal channels during interview processes are all ways to try to do this.
Another option is to level up: devote more resources to learning about the less-legible candidates. Extra time discussing or learning about candidates from under-represented backgrounds, programs that attempt to give such candidates access to professional networks and coaching, and many other DEI efforts can all be seen as attempts to do this.
Obviously there’s no one-size-fits-all response. But equally obviously—we think—some response is often called for. When society makes life systematically harder for some people, something should be done. All the more so when the problem is one that individually rational, well-meaning people will automatically perpetuate. Leveling-up and leveling-down—within reason—can both be justified responses.
Still, the fact that this is individually rational matters. The possibility of Bayesian injustice shows that the existence of unfair outcomes doesn’t imply that those involved in the selection processes are prejudiced or biased.
It also explains why jumping to such conclusions may backfire: if Bayesian injustice is at play, selectors may be (rationally!) convinced that prejudice is not the driver of their decisions—making them quick to dismiss complaints as ill-informed or malicious.
So? Having more people more aware of the possibility of Bayesian injustice should allow for both more accurate diagnoses and more constructive responses to the societal injustices that persist. We hope.
What next?
If you liked this post, subscribe to my Substack for future posts.
For recent philosophy papers where we think Bayesian injustice is the background explanation, see Heesen 2018 on publication bias, Hedden 2021 on algorithmic fairness, and the exchange between Bovens 2016 and Mulligan 2017 on shortlisting in hiring decisions.
For classic economics paper on statistical discrimination, see Phelps 1972 and Aigner and Cain 1977; for the paper that coined “screening discrimination”, see Cornell and Welch 1996.
I think this is a very interesting thought experiment, and it is probing something real.
However, I think that it is missing something important in how it maps to graduate admissions. Lets say that for one reason or another applications are few and places are many. Instead of accepting the top 10 out of 100 applications you are going to reject the bottom 10, and accept the other 90. This legibility argument suggests that in such a situation the applicants from the prestigious universities will be disadvantaged. (Simply slide the “accepted” line in your bell curve graph to the left). This feature strikes me as not matching the reality I imagine I live in.
I think the missing layer of this is that, as an applicant (to a job or anything) you usually have the option to intentionally make your application less legible in various ways, by omitting information that would disadvantage you. You know that Paige is not going to give a great estimate of your performance, so you don’t ask her. As a result less legible applications are going to be correlated with weaker ones. The assessor should, to an extent, be interpreting absence of good evidence (evidence that greatly narrows the candidates uncertainty in a rightwards direction) as evidence of absence.
[Exampleina knows she is in the weaker half of the class, and she knows that Mrs Paige knows this, so doesn’t pick her as her reference. Instead she goes to Mr Oblivious, whose opinions are very weakly correlated with reality, but who happens to think Exampleina is incredibly gifted.
Exampaul can speak a foreign language, and to make this more legible in his application he pays an outside organisation to set him an exam on this language to get himself a certificate he can mention on his application. Unfortunately, Exampaul over-estimates his fluency, does not prepare for the test, and he scores a D-grade in his fluency test. He doesn’t mention the fluency-test he paid for on the application at all, and simply puts “fluent in {language}” on his form without further evidence.]
Very nice point! We had definitely thought about the fact that when slots are large and candidates are few, that would give people from less prestigious/legible backgrounds an advantage. (We were speculating idly whether we could come up with uncontroversial examples...)
But I don’t think we’d thought about the point that people might intentionally manipulate how legible their application is. That’s a very nice point! I’m wondering a bit how to model it. Obviously if the Bayesian selectors know that they’re doing this and exactly how, they’ll try to price it in (“this is illegible” is evidence that it’s from a less-qualified candidate). But I can’t really see how those dynamics play out yet. Will have to think more about it. Thanks!
You’re right that legibility alone isn’t the whole story, but the reason I think Presties would still be advantaged in the many-slots-few-applicants story is that admissions officers also have a higher prior on Prestie quality. The impact of AOs’ favorable prior about Presties is, I think, well acknowledged; the impact of their more precise signals is not, which is why I think this post is onto something important.
I don’t have an opinion on ‘injustice’, or what, if anything, should be done about it. It seems like, for any limited resource with more demand than supply, SOMEONE isn’t going to get what they want, and will feel aggrieved. This is true regardless of selection mechanism.
I do want to point out that the admissions case isn’t simply about legibility, it’s also about incentives. When you say
You’ve moved quite a few steps away from the actual optimization objectives, which are a mix of graduation statistics, future donations, future “prestige” from well-regarded attendees, and providing attendees with socially-desirable peers. Many of these correlate pretty strongly with Prestie applications.
This isn’t really relevant to the point you’re making, but I think your example may not fit your math, and actually would give the opposite conclusion.
What you often want in grad students is a high variance. That favors equally ranked candidates with less information on their performance. So if you think prestige is bs, you’d do way better to grab underappreciated normies.
You can’t have too many of your students failing out of the program. But it’s also important to have a few students that actually go into the academic field, and by doing so write lots of papers. Those go on your academic achievements. Since there are few spots available in academia, there’s some nonlinearity at the point a student actually stays in that field. Let’s say maybe 80th percentile of grad student writes 2 published papers while they’re in grad school and gets a job in industry. 90th percentile writes 4 published papers in grad school, because they’re aiming for academia so the incentive is much larger. Then they get a postdoc and a job and write another ten papers in the next decade (probably more, they’re in publish or perish mode for that first time and getting better at publication.
Hitting a 90th percentile student is worth way more than an 80th.
High variance will also give you more flunkers. Which your current job won’t like a lot, which counterbalances the effect. But when you negotiate for a new job, those are unlikely to be noticed unless it’s extreme.
One point you might draw from this is to be careful when applying probability theory to decision making.
Nice point! I think I’d say where the critique bites is in the assumption that you’re trying to maximize the expectation of q_i. We could care about the variance as well, but once we start listing the things we care about—chance of publishing many papers, chance of going into academia, etc—then it looks like we can rephrase it as a more-complicated expectation-maximizing problem. Let U be the utility function capturing the balance of these other desired traits; it seems like the selectors might just try to maximize E(U_i).
Of course, that’s abstract enough that it’s a bit hard to say what it’ll look like. But whenever is an expectation-maximizing game the same dynamics will apply: those with more uncertain signals will stay closer to your prior estimates. So I think the same dynamics might emerge. But I’m not totally sure (and it’ll no doubt depend on how exactly we incorporate the other parameters), so your point is well-taken! Will think about this. Thanks!
Corollary: If you hire more than 50% of applicants, Presties will be underrepresented.
Notably, this effect could mean you differentially hire presties even if they’re slightly worse on average than the normies. I feel like practicing my math, so let’s look at the coin example.
If you flip once and get H, that’s an odds ratio of 2/31/3=2 for a heads-bias, which combine with initial odds of 1 to give odds for [a 2/3 heads-bias] of 2 which is a probability of 2/3, and your expectation of the overall bias is 23⋅23+13⋅13=59≈0.556.
Now suppose you flip twice and get HH. Odds for heads-bias is 4, probability 4/5, which gives expectation 45⋅23+15⋅13=3/5=0.6.
But suppose you flip twice and get HH, but instead of the coins being a mix of 2/3 and 1/3 heads-biased, they’re p and 1−p, for some known p. The odds ratio is now o:=(p1−p)2, probability of [a p heads-bias] is o1+o and the expected bias is op1+o+1−p1+o. I tried to expand this by hand but made a mistake somewhere, but plugging it into wolfram alpha we get that this equals 5/9 when
p=17±√1734≈{0.62,0.38}Where the two solutions are because an equal mix of p and 1−p biases is the same as an equal mix of 1−p and p biases.
So you’d prefer an HH with a most-likely bias of 0.63 over an H with a most-likely bias of 0.66.
Great essay. Before this, I thought that the impact of more noisy signals about Normies was mainly through selectors being risk-averse. This essay pointed out why even if selectors are risk neutral, noisy signals matter by increasing the weight of the prior. Given that selectors also tend to have negative priors about Normies, noisy signals really function to prevent positive updates.
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?