The biggest news this week was on the government front.
In the UK, Ian Hogarth of ‘We Must Slow Down the Race to Godlike AI’ fame was put in charge of a 100 million pound taskforce for AI safety.
I am writing up a separate post on that. For now, I will say that Ian is an excellent choice, and we have reason to believe this taskforce will be our best shot at moving for real towards solutions that might actually mitigate extinction risk from AI. If this effort succeeds we can build upon it. If it fails, hope in future similar approaches seems mostly gone.
As I said last week, the real work begins now. If you are in position to help, you can fill out this Google Form here. Its existence reflects a startup government mindset that makes me optimistic.
In the USA, we have Biden taking meetings about AI, and we have Majority Leader Chuck Schumer calling for comprehensive regulatory action from Congress, to be assembled over the coming months. In both cases, this seems clearly focused on mundane harms that are already frequently harped upon by such types with regard to things like social media, along with concerns over job losses, with talk of bias and democracy and responsibility, as well as jobs, while being careful to speak in support of innovation and the great promise of AI.
In other words, it’s primed to be the worst case, where we stifle mundane utility while not mitigating extinction risks. There is still time. The real work beings now.
The good news is that despite the leadership of Biden and Schumer here, the issue remains for now non-partisan. Let’s do our best to keep it that way.
I do wish I had a better model or better impact plan for such efforts.
Capabilities advances continue as well. Biggest news there was on the robotics front.
Table of Contents
Introduction. UK task force, USA calls for regulation.
Chatbots in India help the underprivileged seek justice and navigate the legal system. Highlighted is the tendency of other sources of expertise, aid or advice to demand bribes – they call GPT a ‘bribe-rejecting robot.’ Speculatively, there could be a u-shaped return to GPT and other LLMs. If you are on the cutting edge and invest the time, you can get it to do a lot. If you lack other resources, LLMs let you can ask questions in any language and get answers back.
Terrance Tao is impressed by the mundane utility already on offer, helping him anticipate questions at talks and providing ideas that can be used to advance high-level mathematical work, along with the usual human-communication-based uses. He anticipates AI as sufficiently skilled for co-authorship of math papers by 2026.
Break captcha using Bing. Also lie to the user about it.
Gary Marcus: which of the two fails in this thread is more embarrassing to the notion that we are anywhere near reliable trustworthy AI that actually knows what it is talking about?
Bard is not useless. Or rather, it would not be useless if you did not have access to other LLMs. It continuously make incredibly stupid-looking mistakes.
That’s bad. Seems both rather inevitable and hard to avoid. That’s what an LLM in large part is, right? A vibe and association machine? If there is a stigmatized group, that means it is associated with a bunch of negative words, and people are more likely to say negative words in response to things about that group, and the LLM is reflecting that. You can’t take out the mechanism that is doing this because it’s at the heart of how the whole system works. You can try to hack the issue with some particular groups out of the system, and that might even work, but in the best case it would be a whitelist.
GPT-4 Does Not Ace MIT’s EECS Curriculum Without Cheating
A paper came out claiming that GPT-4 managed to get a perfect solve rate (!) across the MIT Mathematical and Electrical Engineering and Computer Science (EECS) required courses, with a set of 4,550 questions.
Abstract
We curate a comprehensive dataset of 4,550 questions and solutions from problem sets, midterm exams, and final exams across all MIT Mathematics and Electrical Engineering and Computer Science (EECS) courses required for obtaining a degree. We evaluate the ability of large language models to fulfill the graduation requirements for any MIT major in Mathematics and EECS. Our results demonstrate that GPT-3.5 successfully solves a third of the entire MIT curriculum, while GPT-4, with prompt engineering, achieves a perfect solve rate on a test set excluding questions based on images. We fine-tune an open-source large language model on this dataset. We employ GPT-4 to automatically grade model responses, providing a detailed performance breakdown by course, question, and answer type. By embedding questions in a low-dimensional space, we explore the relationships between questions, topics, and classes and discover which questions and classes are required for solving other questions and classes through few-shot learning. Our analysis offers valuable insights into course prerequisites and curriculum design, highlighting language models’ potential for learning and improving Mathematics and EECS education.
This was initially exciting, then people noticed it was a no-good very-bad paper.
Yoavgo: oh this is super-sketchy if the goal is evaluating gpt4 [from the “it solves MIT EECS exams” paper]
Paper: 2.6 Automatic Grading Given the question Q, ground truth solution S, and LLM answer A, we use GPT-4 to automatically grade the answers: Q, S, A → G. (4)
Yeah, that. You can’t do that.
Yoavgo: it becomes even worse: this process leaks the human-provided answers directly into the solution process…
Paper: We apply few-shot, chain-of-thought, self-critique, and expert prompting as a cascade. Since grading is performed automatically, we apply each method to the questions that the previous methods do not solve perfectly. From the dataset of MIT questions, a test set of 288 questions is randomly selected amongst questions without images and with solutions. First, zero-shot answers to these questions are generated by the LLMs. These answers are then graded on a scale from 0 to 5 by GPT-4. Then, for all questions without a perfect score, few-shot answers from GPT-4 using the top 3 most similar questions under the embedding are generated.
The way they got a perfect score was to tell GPT-4 the answers, as part of having GPT-4 grade itself and also continuing to prompt over and over until the correct answer is reached.
Eliezer Yudkowsky: I need to improve my “that can’t possibly be true” reflexes, the problem is that my “that can’t possibly be something an AI can do” reflexes also keep hitting false positives on things an AI actually did.
This is a hard problem. If someone claims an AI did X, and it turns out an AI cannot yet do X, that does not automatically mean that you should have had a reflex that of course AIs can’t (yet) do X. There is a wide range of things where the answer is more ‘the AI seems unlikely to have done X even with a claim that it did, but maybe.’
In this case, if they had claimed a 95% score, I think this would have fallen into that category of ‘this seems like a stretch and I think you at least did something sketchy to get there, but let’s check it out, who knows.’ A claim of 100% is a giveaway that cheating is happening. Alas, I saw the rebuttals before the claims, so I didn’t get a chance to actually test myself expect in hindsight.
Update: we’ve run preliminary replication experiments for all zero-shot testing here — we’ve reviewed about 33% of the pure-zero-shot data set. Look at the histogram page in the Google Sheet to see the latest results, but with a subset of 96 Qs (so far graded), the results are ~32% incorrect, ~58% correct, and the rest invalid or mostly correct.
Summary
A paper seemingly demonstrating that GPT-4 could ace the MIT EECS + Math curriculum recently went viral on twitter, getting over 500 retweets in a single day. Like most, we were excited to read the analysis behind such a feat, but what we found left us surprised and disappointed. Even though the authors of the paper said they manually reviewed the published dataset for quality, we found clear signs that a significant portion of the evaluation dataset was contaminated in such a way that let the model cheat like a student who was fed the answers to a test right before taking it.
We think this should call into greater question the recent flurry of academic work using Large Language Models (LLMs) like GPT to shortcut data validation — a foundational principle in any kind of science, and especially machine learning. These papers are often uploaded to Arxiv and widely shared on Twitter before any legitimate peer review. In this case, potentially spreading bad information and setting a poor precedent for future work.
That seems roughly what you would predict. Note that a failed replication can easily mean the replication used bad prompt engineering, so one needs to still look at details.
The rest of the post is brutal. A full 4% of the test set is missing context and thus unsolvable. Often the prompt for a question would include the answer to an almost identical question:
They keep going, I had an enjoyable time reading the whole thing.
Many of the provided few-shot examples are almost identical if not entirely identical to the problems themselves. This is an issue because it means that the model is being given the answer to the question or a question very very similar to the question.
Ranak Chowdhuri: A recent work from @iddo claimed GPT4 can score 100% on MIT’s EECS curriculum with the right prompting. My friends and I were excited to read the analysis behind such a feat, but after digging deeper, what we found left us surprised and disappointed.
The released test set on Github is chockfull of impossible to solve problems. There are lots of questions referring to non-existent diagrams and missing contextual information. So how did GPT solve it?
Well… it didn’t. The authors evaluation uses GPT 4 to score itself, and continues to prompt over and over until the correct answer is reached. This is analogous to someone with the answer sheet telling the student if they’ve gotten the answer right until they do.
That’s not all. In our analysis of the few-shot prompts, we found significant leakage and duplication in the uploaded dataset, such that full answers were being provided directly to GPT 4 within the prompt for it to parrot out as its own.
We hope our work encourages skepticism for GPT as eval ground truth, and encourages folk to look a little deeper into preprint papers before sharing. Much thanks to @NeilDeshmukh and @David_Koplow for working w/ me on this and @willwjack for the review.
As several people pointed out, this is quite the polite way of calling utter bullshit.
Yishan: This guy is being very charitable in his criticism of the study. Privately, I imagine he was saying “This study is complete bullshit! Are the researchers total idiots??”
David Chapman (other thread): Becoming an outstanding case study in the ways AI researchers fool themselves: because so many different, common types of mistakes were made in a single seemingly-spectacular paper.
Jon Stokes (other thread): I think there are too many of us non-specialists who are following AI closely and who are doing a lot of “this is a great paper go check it out!” with these preprints but we’re not really equipped to evaluate the work. Saw that w/ this one. Way too many such cases right now.
My strategy involves publishing once a week, which gives the world time to spot such mistakes – it’s a small cost to push a paper into the next week’s post if I have doubts. I do still occasionally make these mistakes, hopefully at about the efficient rate.
Michael Benesty: Unexpected description of GPT4 architecture from geohotz in a recent interview he gave. At least it’s plausible.
Soumith Chintala: i might have heard the same
— I guess info like this is passed around but no one wants to say it out loud.
GPT-4: 8 x 220B experts trained with different data/task distributions and 16-iter inference. Glad that Geohot said it out loud. Though, at this point, GPT-4 is probably distilled to be more efficient.
Dan Elton: I hate spreading rumors but rumors are all we have to go on when trying to find out what’s really under the hood at “Open”AI. To add to the rumor-mill, I now have it from two separate sources that GPT-4’s multimodal vision model is a separate system trained outside of OpenAI that is different from the LLM that you normally interact with. So it’s probably very misleading when OpenAI implies GPT-4 is a single multimodel under the hood – it may be a mixture of 8 separate text-only models trained on different data + some magic to select which one(s) to use (similar to https://arxiv.org/abs/2306.02561). Only when the user uploads an image is the multimodal image model for image description triggered. Plus they are probably using some distillation and caching algorithms to reduce computational overhead.
Anyone know why 16 inferences would be required?
The Art of the Jailbreak
Mostly we’ve all moved on, but this week’s case is a strange one. It seems GPT refuses, by default, to recite Dune’s “Litany Against Fear.” It’s too afraid.
It notices it keeps stopping. It admits there’s no good reason to stop. Then it stops again. Even when told very explicitly:
Some solutions:
Michael Nielson: You can prompt-hack your way into it, however:
[A request for a story in which one character says the litany to another, which succeeds.]
[A request to quote it reversed succeeds. Then un-reversing it, it says the original.]
It’s fine translated into French. But loses its gumption when asked to go back to English.
Oh this is great, it can replace “Fear” by “Dear”:
So I tried it, and it got so much weirder, including the symbol changing to a T…
We introduce a value-based RL agent, which we call BBF, that achieves super-human performance in the Atari 100K benchmark. BBF relies on scaling the neural networks used for value estimation, as well as a number of other design choices that enable this scaling in a sample-efficient manner. We conduct extensive analyses of these design choices and provide insights for future work. We end with a discussion about updating the goalposts for sample-efficient RL research on the ALE. We make our code and data publicly available at this https URL.
Max Schwarzer (Author on Twitter): We propose a model-free algorithm that surpasses human learning efficiency on Atari, and outperforms the previous state-of-the-art, EfficientZero, while using a small fraction of the compute of comparable methods.
BBF is strong enough that we can compare it to classical large-data algorithms: we match the original DQN on a full set of 55 Atari games with sticky actions with 500x less data, while being 25x more efficient than Rainbow.
The key to BBF is careful network scaling. While simply scaling up existing model-free algorithms has a limited impact on performance, BBF’s changes allow us to benefit from dramatically larger model sizes even with tiny amounts of data.
Fun with Image Generation
It is known that AI systems can reconstruct images from fMRI brain scans, or words they have heard. What happens when this applies to your future thoughts?
Jon Stokes: At some point, this tech (which is essentially a mapping of one latent space to another) is going to be able to detect a thought /before/ the subject can register or signal that they’ve actually experienced it thinking it, & that will mess with everybody’s metaphysics.
As I noted on Twitter, you do not get to wait until this actually happens, given how obviously it will happen. Conservation of expected evidence demands you have your metaphysics messed with now.
Or, alternatively, have metaphysics that this does not mess with. I am fully aware of and at peace with the fact that people mostly think predictably. You just did just what I thought you were gonna do. I do not think this invalidates free will or anything like that. Even if your choice is overdetermined, that doesn’t mean you don’t have a choice.
Deepfaketown and Botpocalypse Soon
Knight Institute writes up report anticipating a deluge of generative AI output on social media and elsewhere, including deepfakes of voices, pictures and video. Calls for the forcing of generative AI companies to internalize such costs, also for everyone to consider the benefits and positive uses of such tech. Mostly same stuff you’ve heard many times before. I remain optimistic we’ll mostly deal with it.
is there some kind of prior inclination that the task outputs must be garbage because gpt4 helped? if so my company will have to fire me and everyone else too — everything going forward is machine augmented knowledge work
Roon: Why is this destructive or bad? Genuinely an amazing example of AI actually increasing the productivity, wages, and probably total employment in a category most impacted by language model tech.
I suppose if you’re actually trying to study human behavior this is going to ruin your methodology but honestly I never trusted that garbage anyway.
Arvind Narayanan (other thread): Overall it’s not a bad paper. They mention in the abstract that they chose an LLM-friendly task. But the nuances were unfortunately but unsurprisingly lost in the commentary around the paper. It’s interesting to consider why. There’s a lot of appetite right now for “AI ruins X!” stories and research. Entirely understandable, as we’re frustrated by the hasty rollout of half-baked tools that generate massive adaptation costs for everyone else. But blanket cynicism doesn’t help the responsible AI cause.
The problem here is exactly that Turk could previously be used to figure out what humans would say in response to a request. Sometimes you care about that question, rather than the mundane utility of the response contents.
Those use cases are now in serious danger of not working. Whereas if you wanted the summaries of abstracts for mundane utility, you don’t need the Turk for that, you need five minutes, three GPT-4 queries for code writing and an API key.
The question is, what would happen if you said ‘please don’t use LLMs like ChatGPT’ or had a task that was less optimized for an LLM? And how will the answer change over time? What we want is the ability to get ‘clean data’ from humans when we need it. If that is going away, it’s going to cause problems.
Automation risk causes households to rebalance away from the stock market says study, causing further declines in wealth. This is of course exactly the wrong approach, if (not investment advice!) you are worried robots will take your job you should hedge by investing in robot companies.
Google DeepMind introduces RoboCat (direct), new AI model designed to operate multiple robots, learns from less than 100 demonstrations plus self-generated training data. In practice this meant a few hours to learn a new robot arm.
Actions like shape matching and building structures are complex for robots. They have to master how to control each joint, coordinate movements, and know the physics of their surroundings. This embodied intelligence comes naturally to humans but it’s very difficult for AI.
RoboCat learns faster than other state-of-the-art models because it draws from a large, diverse dataset. This feature will advance robotics research as it reduces the need for human-supervised training – a key step to creating general-purpose robots.
Robotics for now remains behind where one would expect relative to other capabilities. Do not count on the lack of capabilities lasting for long.
Sebastien Bubeck: New LLM in town: ***phi-1 achieves 51% on HumanEval w. only 1.3B parameters & 7B tokens training dataset***
Any other >50% HumanEval model is >1000x bigger (e.g., WizardCoder from last week is 10x in model size and 100x in dataset size). How? ***Textbooks Are All You Need*** (paper here)
Specialization is doubtless also doing a lot of the work, although that is in some senses another way of saying higher quality data. phi-1 is dedicated to a much narrower range of tasks. We see the result of the combination of these changes. It’s impressive.
I’ve said for a while I expect this to be the future of AI in practice – smaller, more specialized LLMs designed for narrow purposes, that get called upon only for their narrow range of tasks, including by more general LLMs whose job is to pick which LLM to call. This is still a remarkably strong result. It took only 32 A100 days to train and will be crazy cheap to run.
Alex MacCaw: You can imagine the next step: ‘auto work bots’, where you take a role in a company, split it into different processes, and automate large parts (if not all) of it.
Meta continues down its ‘do the worst possible thing’ plan of open sourcing models.
Meta is focused on finalizing an upcoming open-source large language model (LLM), which it plans to make available for commercial purposes for the first time. This approach would represent a vast departure from closed-source language models like Google’s Bard and OpenAI’s ChatGPT currently in commercial use, and it could spark a ripple effect of widespread adoption by companies that are on the lookout for a more versatile and affordable AI alternative.
The ‘good news’ here is that it is unlikely to make much further difference on the margin, at least for now. Meta releasing open source models only matters if that advances the state of the art of available open source models. There’s now enough competition there that I doubt Meta will pull this off versus the counterfactual, but every little bit harms, so who knows. The problem comes down the line when they won’t stop.
My understanding of the tech is that there will continue to be essentially no barrier to rejecting your model and substituting my own, while retaining all of my code and tools, except when I lack the necessary model access. There’s very little meaningful ‘lock in’ unless I spend quite a lot on fine tuning a particular thing, and that investment won’t last.
Presumably a number of people are now trying to engineer this exact result. If it does happen, how should people update? What about if it doesn’t?
Simeon: Before it happens, the US government will hopefully implement minimal safety culture requirements that imply that Replit will legally not be allowed to interface with frontier AI systems. This comment signals an attitude not remotely close from the adequate mindset that the CEO of any company operating such systems should have.
I disagree. Anyone who likes around the world can interface with frontier AI systems. What could be better than running the experiment full blast, with stakes volunteered by the generous Amjad Masad himself? Let him cook, indeed.
Biden met on Tuesday in SF to raise money for his reelection and discuss AI. Was this promising, or depressing?
Alondra Nelson: It’s promising that President Biden will meet today with civil society and academic leaders in AI policy, whose focus area include social justice and civil rights, public benefit, public safety, open science, and democracy.
Jess Riedel (distinct thread): In order to learn more about the dangers of AI, Biden is meeting on Tuesday in San Francisco with … “Big Tech’s loudest critics”. Oy.
Scanson: What’s so oy about this? Especially since he’s also been meeting with the heads of the big a.i. companies et al. A quick googlin’ shows all these folks have relevant expertise. What am I missing?
Riedel:
1. This is roughly like FDR meeting with non-Manhattan-project physicists to discuss the dangers of radium paint.
2. Biden didn’t actually meet substantively with AI company heads. He “dropped by” to deliver a canned line.
Joe Biden (as quoted in LA Times): “In seizing this moment, we need to manage the risks to our society, to our economy and our national security,” Biden said to reporters before the closed-door meeting with AI experts at the Fairmont Hotel.
I consider it a nothingburger, perhaps a minor sign of the times at most. Biden continues to say empty words about the need to control for risks and speak of potential international cooperation, but nothing is concrete, and to the extent anything does have concrete meaning it is consistently referring to mundane risks with an emphasis on misinformation and job losses.
Does this mean we are that much more doomed to have exactly the worst possible legislation, that stifles mundane utility without slowing progress towards extinction risks? That is certainly the default outcome. What can we do about it?
Quiet Speculations
Simeon: I’ve been asked to make a list of the 15 companies which may do the biggest training runs in the next 18 months. Lmk if you disagree.
1. DeepMind 2. OpenAI 3. Anthropic 4. Cohere ai 5. Adept ai 6. Character ai 7. Inflection ai 8. Meta 9. Apple 10. Baidu 11. Huawei 12. Mistral ai 13. HuggingFace 14. Stability ai 15. NVIDIA
Suggested in comments (at all): SenseTime (InternLM), BigAI, IBM, Microsoft Research, Alibaba, ScaleAI, Amazon, Tesla, Twitter, Salesforce, Palantir.
From responses, SenseTime seems like the one that should have made the list and didn’t, they’ve done very large training runs. Whether they got worthwhile results or will do it again is another question.
The question is, where are the big drop-offs in effectiveness. To what extent is there going to still be a ‘big three’?
Andres: The fact that you haven’t included SenseTime, which is one of the handful of companies that have reported a +100B parameter run in all of 2023 with their InternLM models may indicate you (and others in DC) haven’t been paying much attention
Davidad: today I heard someone say “China has regulated LLMs so hard that it’s literally functionally equivalent to a ban on LLMs, for now, until and unless they relax that at some point in the future”. that may be true commercially but state-partnered Chinese LLM research continues apace.
Reminder, an unverified technical report claimed that InternLM was superior to ChatGPT 3.5 and to Claude, although inferior to GPT 4, on benchmark tests. I am skeptical that this is a reflection of its true ability level.
Scott Alexander reviews Tom Davidson’s What a Compute-Centric Framework Says About Takeoff Speeds. Davidson points out that even what we call ‘slow takeoff’ is not all that slow. We are still talking about estimates like 3 years between ‘AI can automate 20% of jobs’ to ‘AI can automate 100% of jobs’ and then one more year to superintelligence. That would certainly seem rather fast. Rather than extensively summarize I’ll encourage reading the whole thing if you are interested in the topic, and say that I see the compute-centric model as an oversimplification, and that it makes assumptions that seem highly questionable to me.
Also as Scott says, I am not super confident AI can’t do 20% of jobs now if you were to give people time to actually find and build out the relevant infrastructure around that, and if you told me that was true it would not make me expect 100% automation within three years. We’ve had quite a few instances in the past of automation of 20% of human jobs.
I’ll put a poll here to see how high a bid people would make for me to discuss takeoff speeds and other such questions in detail.
Loading…
Will we see the good robot dating or the bad robot dating? Why not both?
Joscha Bach: I think we will see a slew of artificial girlfriend apps (and some AI boyfriends too), but I hope that there will be even better coaching apps, which allow people to learn how to connect with each other and to live life at its fullest.
Allknight: The only way to have a friend is to be one. What further coaching is needed?
Joscha Bach: It is incredible how young people with mutually aligned interests but confused ideas about human interaction can mess up every chance of entering healthy relationships, and today’s internet ideologies are not exactly helping.
I continue to be an optimist here, if things are otherwise under control. As I’ve noted before: Over time people demand realism from such simulations. Easy mode gets boring quickly. After a while, you are effectively learning the real skills in the simulation, whether or not that was the intention.
Jon Stokes: The fundamental problem the pro-AI folks will have to solve ASAP is this: 100% of the establishment sinecures on AI are going to AI “language police” alarmists or outright doomers, 0% to AI optimists.
I see this with young, smart people I know who have moved into the policy realm in some fashion or other — they all start preaching the alarmism or doomer gospel that AI will destroy democracy &/or paperclip us. If there’s an exception to this rule then I’m not aware of it.
Now, this could be the case b/c they’re smart & AI is legit bad & they see it but I don’t. Even so, I’d still imagine that if culture & incentives were different we’d still see pockets of pro-AI thinking clustered in different institutions. But that exists, again, I’m not aware.
The entire establishment AI discourse is completely owned, top to bottom, by either the “anti-disinformation” campaigners or EA doomer cultists. This indicates to me that there’s no opportunity to accumulate social capital by positioning yourself outside those two discourses.
For the good guys to win on this, we’re going to need raise pro-AI ladders for smart, ambitious young people to climb. This problem is extremely pressing. We’re on track for a world where open-source AI is digital contraband, & the tech is walled up inside a few large orgs.
Such confidence on who the ‘good guys’ are and who the ‘cultists’ are. Also very strange to think the fundamental problem is sinecure money. As opposed to money. Almost all of the money spent around AI is spent by Jon’s ‘good guys’ working on AI capabilities. Many of whom, including the heads of the three big AI labs, are exactly the same people signing statements of his so-called ‘cultists.’ This is not what winning the funding war feels like.
Alt Man Sam reminds us that democracy gets to be a highly confused concept in the age of AI.
To put it very simply—we’re going to be living among digital minds of all shapes and sizes. So how do you determine who gets a vote? How do you deal with the fact that to reproduce, it takes a human 9 months to make 1 copy of itself, while it takes a digital mind 1 second to make 100,000 copies of itself? Can we have a democracy when the AI population grows to 300 𝑡𝑟𝑖𝑙𝑙𝑖𝑜𝑛 while the human population stagnates at 300 𝑚𝑖𝑙𝑙𝑖𝑜𝑛?
Moreover, how do you deal with 10000x intelligence differences? We don’t give frogs a vote over human affairs; are we supposed to give 100 IQ beings a vote when it affects those with 1000 IQ’s? What if a single mind ends up with 99% of the intelligence/compute (which seems likely)? Above all, everyone is failing to think about the downstream consequences of this new world we are entering and just how weird and different it’ll be.
None of the old frameworks apply.
Robin Hanson’s solution is that emulations get votes proportional to how fast they are run. The implications of this system are that biological humans and poor emulations have almost no voice, but he sees no better alternative. We do seem to have only three choices – either only biological humans vote, they have a fixed share of the vote, or they have no vote.
Richard Ngo: If you want a vision of the future, imagine your grandkids laughing at you for getting nauseous every time you try the latest VR headset – forever.
Disclaimer: I don’t think the future will be like this, I think it’ll be much weirder. But also I bet that childhood exposure to VR will allow the next generation to enjoy experiences that would leave the rest of us puking.
Rachel Clifton: is this supposed to be hopeful? lol
Richard Ngo: It wasn’t originally, but the more i think about it the more hopeful i feel. I think that the future going well involves our descendants being alien to us in fascinating and inspiring ways. Maybe it doesn’t even matter if they’re laughing with us or at us – kids will be kids.
That would indeed be great. You have grandkids. They’re spending time with you and laughing. There is new cool tech to try out. You’re alive. Who could ask for anything more? I mean, I can think of a few things but that’s pretty sweet.
Larry Summers: AI will change humanity. @VIVATech in Paris last Friday with @LaurenceParisot, I said: Since the enlightenment, we have lived in a world that has been defined so much by IQ–by cognitive processing, by developing new ideas, by bringing to bear knowledge.
As that becomes more and more a commodity, that can be replicated with data and analysis, we are going to head into a world that is going to be defined much more by EQ than IQ and that is going to be a very different place.
It’s a world where a nurse holding a scared patient’s hand is going to be more valuable than a doctor who can process test results & make a diagnosis. It’s going to be a world where a salesperson who can form a relationship is going to be a profound source of value in a business.
It is going to be a world where the products of emotion–the arts–are going to rise relative to the products of the intellect–science.
In many ways it’s going to be a wonderful world but a very different world. It is going to be a world for all us — in universities, in governments and in the private sector — for all of us to shape.
It’s so weird seeing economists get totally bizarre toy models into their heads when it comes to AI.
First off, this is at core a comparative advantage argument that assumes that AIs will have superior IQ to EQ. That does not seem to be the case with GPT-4. At minimum, it is highly disputed.
When they compared it to doctors, its best performance area was in bedside manner. GPT-4 is consistently excellent at reporting or generating emotional valiance. If you are high IQ and low EQ, you will use your EQ to help GPT-4 help you with the EQ side of things. If you are high EQ and low IQ, you can ask GPT-4 for help, but it’s going to be trickier.
Once such models get multi-modal and can read – and generate – facial expressions and voice tones and body language? They are plausibly going to utterly dominate the EQ category.
This is also a failure to ask what happens if the AI is able to take over all the high-IQ work. Does that mean that EQ gets to shape the future? That science will be less important and art more important?
Quite the opposite. It will be a new age of science, of the wonders of technology and intelligence. You spending more time on other things is simply more evidence of your irrelevance. IQ will be in charge more than ever, except that force increasingly won’t be human. It won’t by default be a world for all of us to shape, it will be out of our hands.
Robin Hanson: Seeing a lit review of “AI ethics”, in this context “ethics” seems to mean “anything that anyone complains could ‘go wrong’”.
Lit rarely invokes the econ distinction of “social failure” problems where coordination is needed to deal with. Anything anyone doesn’t like counts as “ethics problem”, regardless of whether coordination is needed.
I asked ChatGPT4 for AI problems that aren’t ethics problems. It gave: ” disliking … using AI in creating art because they believe art should be purely a human endeavor.” & “dislikes that AI … are often given feminine names or voices.” But these ARE ethics issues to some.
I asked for a 3rd example: “use of AI because it takes the ‘human touch’ out of certain interactions … it makes experiences impersonal or less authentic.” Also an ethical issue to some.
I think ChatGPT4 is mistakenly assuming that ethics has a more constrained definition than “any complaint”. Because of course most people mistakenly claim that their definition is so constrained.
These concerns are not only often considered ethical concerns, they are more ethical flavored concerns than the median concern about AI. If I had to name a non-ethical problem I’d suggest ‘it is bad at math’ or ‘it can’t handle letters within words.’ Technical problems. Even then, I’m sure the ethicists can think of something.
’Delivering his most expansive remarks on the topic since the recent explosion of generative AI tools in Silicon Valley, Schumer unveiled a “new process” for fielding input from industry leaders, academics and advocates and called on lawmakers advance legislation in coming months that “encourages, not stifles, innovation” while ensuring the technology is deployed “safely.”
Bing: The framework outlines five principles for crafting AI policy: securing national security and jobs, supporting responsible systems, aligning with democratic values, requiring transparency, and supporting innovation.
The words, how they do buzz. The post then devolves into arguments over who gets credit and who is erasing progress and other such nonsense, rather than asking what is worth doing now.
The reporter clearly thinks this is all about mundane risks and that anyone not realizing how serious that issue is deserves blame, and that we should be suspicious of industry influence.
There is zero indication anywhere that extinction risks will be part of the conversation. Nor are there any concrete details of what will be in such laws.
Seb Krier: For those who haven’t had the joy of dealing with the AI Act for years, Burges Salmon published a flowchart decision-tree to help navigate the latest Parliament version. As they note, “many areas that are open to interpretation or require guidance.” Enjoy!
Davidad: All AI R&D is exempted from the EU AI Act. Limitations on and inspections of frontier R&D training runs, the main regulatory lever for superintelligence concerns, are completely absent, contra the ambient narrative that “the EU will regulate too harshly”.
Some of these requirements are fixable. If you don’t have documentation, you can create it. If you don’t have tests, you can commission tests. ‘EU Member States’ is potentially a one page form. Others seem harder.
Copyrighted data and related issues seem like the big potential dealbreaker on this list, where compliance could be fully impractical. The API considerations are another place things might bind.
One difficulty is that a lot of the requirements are underspecified in the AI Act. There’s a reasonable version of implementation that might happen. Then there’s the unreasonable versions, one of which almost certainly happens instead, but which one?
“By itself, GPT-3 is not a high-risk system,” said OpenAI in a previously unpublished seven-page document that it sent to E.U. Commission and Council officials in September 2022, titled OpenAI White Paper on the European Union’s Artificial Intelligence Act. “But [it] possesses capabilities that can potentially be employed in high risk use cases.”
That seems true enough as written. The rest of the document is provided, and it’s what you would expect. Given known warnings from Sam Altman that OpenAI might have to leave the EU if the full current drafts were implemented, none of this should come as a surprise.
Nor is it hypocrisy. There are good regulations and ideas, and there are bad regulations and ideas. Was OpenAI’s white paper here focused on ensuring they were not put at a competitive disadvantage? Yes. That doesn’t mean their call for other, unrelated restrictions, designed to protect in other ways, is in any way invalid.
It is worth noting we have no evidence that OpenAI lobbied in any way to make anything in the law more stringent, or to introduce good ideas.
Simeon: That’s what a basic incentive theory would predict. 1 question: is there any evidence that they lobbied to strengthen or try to have a more stringent regulation along certain axis? E.g. try to regulate the development of AI systems, have third party auditing, regulate existential risks, allow competitors to cooperate on safety? If they haven’t, that gives a sense of their priorities. If they have, that’s interesting for the world to know.
ML engineers: “omg, all the existing models would be ILLEGAL if the EU AI Act was enforced
?”
Me: “I mean, is regulation supposed to say “yup, go ahead with those non-existent good practices along those 12 different axis
”??
It is a lot easier to point out what is wrong than to figure out what is right. Also difficult to comply with newly decided rules, whether or not there were adequate existing best practices.
I need to read more on importance of *tech neutral* regulation for AI. Regs change incentives, lead to different tech being developed for same ends. E.g. GDPR on cookies → federated learning on cohorts. Surveillance capitalism and automated influence/manipulation unaffected.
Implementing regulations in a tech neutral way is indeed hard. Regulations are interpreted as damage and routed around, default implementations will often cause large distortions. If you don’t want to distort the tech and pick winners, that’s bad.
What if you did want to distort the tech? What if you thought that certain paths were inherently safer or more likely to lead to better futures for humans? Then you would want to have deeply tech non-neutral regulations.
That is the world I believe we are in. We actively want to discourage tech paths that lead to systems that are expensive or difficult to control the behavior of, control the distribution of or understand, and in particular to avoid unleashing systems that can be a foundation for future more capable systems without a remaining bottleneck. For now, the best guess among other things is that this means we want to push away from large training runs, and encourage more specialization and iteration instead.
Similarly, here is Lazar noticing what would make sense if AGI soon was ‘decently likely’:
Amanda Askell (Anthropic): If you find this compelling, would a decent likelihood that AI development is on an exponential without a need for hard fundamental insights (i.e. without the need for long gaps or delays in the exponential) be sufficient for you to be worried now?
Seth Lazar: I don’t think worry should be the target. If I had that view, I’d be arguing for radical controls to be introduced now on frontier AI development, probably a ban. It’s always the course of action indicated that matters most (to me), not the emotional attitude one should adopt.
Bet made on transformative AI: Matthew Barnett bets $1,000 against Ted Sanders’s $4,000 (both inflation-adjusted) that there will be a year of >30% world GDP growth by 2043. Ted pays if it happens, Matthew pays in 2043 if he loses. Lots of interesting questions regarding exactly when the payoff for such a bet has how much utility, and what the true odds are here. A lot of scenarios make it pointless or impossible to collect. I agree that this is roughly the correct sizing, to ensure the bet is felt without creating economic distortions or temptation to not pay.
“In 10 years time, there’ll be billions of people using all kinds of AI. It’s kinda hard to put into words how fundamental this revolution is about to be—I truly believe that this decade is going to be the most productive in human history.”
“[Not] everybody has access to kindness and care. I think it’s going to be pretty incredible to imagine what people do with being shown reliable, ever-present, patient, non-judgmental, kindness and support, always on tap in their life.”
Interesting wording on that first claim. If this coming decade is the most productive in human history, what happens in the decade after it?
Will AI be able to provide kindness and care in the ways people need? My presumption is ‘some ways yes, some ways no’ which is still pretty great.
Finally released, Tyler Cowen’s fireside chat with Kelsey Piper from 2022. As far as I can tell, Tyler still stands by everything he says here, and he says it efficiently and clearly, and in a way that seemed more forthcoming and real than the usual. It seemed like he was thinking unusually a lot. All of that speaks to Piper’s interview skills. It was an excellent listen even with the delay.
As usual, I agree with many of his key points like avoiding moral nervousness and abstaining from alcohol in particular and drugs in general, and focusing on what you yourself are good at, and institutional reform. I especially liked the note to not be too confident you know who are the good guys and who are the bad guys, even better is to realize it’s just a bunch of guys (and that AGI will not be).
I’m going to take yet another shot at this, I am not ready to give up on the AI disagreements, there is too much uniquely good stuff and too much potential value here to give up, so here we go.
On AI he presents a highly plausible story – that the US and China are locked in a prisoner’s dilemma, that no one has a plan to solve alignment and even if we did someone else would just reverse the sign, so alignment work is effectively accelerationist in practice, because AI proliferation is inevitable, that net all anti-extinction efforts have only accelerated AI and thus any AI risk. He even expects major destructive AI-led wars.
Then he puts up a stop sign about thinking beyond that, as he later did in various posts in various ways to various degrees, says you have to live in history, and refuses to ask what happens next in the world he himself envisions, beyond ‘if Skynet goes live’ then it goes live, which seems to be a continuing confusion? That the AI risks envisioned require that path?
When I model the world Tyler seems to be imagining, here and also later in time, and accept that prisoner’s dilemmas like current US-China relations are essentially unsolvable, that world seems highly doomed multiple times over. If alignment fails, we get some variant of what Tyler refers to as ‘Skynet goes live’ and we die. If alignment succeeds, people reverse it, we get races to the bottom including AIs directly in charge of war machines, even if we survive all that ordinary economics takes over and we get outcompeted and we die anyway. Tyler agrees AIs will ‘have their own economy’ and presumably not remain controlled because control isn’t efficient. Standard stories about externalities and competition and game theory all point in the same direction.
What are we going to do about that? The answer can’t be ‘hope a miracle occurs’ or, as his Hayekian lecture says, suggest that ‘we will be to the AIs as dogs are to humans and we’ll be training them too,’ because you can’t actually think that holds up if you think about it concretely. Thus, in part, why I came up with the Dial of Progress hypothesis, where the only two remaining ways out – centralized control of the AGI, or centralized control to ensure there is no AGI – are cures worse than the disease.
From three weeks ago, Robert Wright and Samuel Hammond on a Manhattan Project for AI Safety. Some early good basic technical discussion for those at the level for it. Hammond criticizes the Yudkowsky vision of a hard takeoff because the nature of AI systems has changed and progress should be continuous, but I don’t think that is clear. Due to the cost of training runs substantial leaps are still possible, applying better techniques and scaffolding can provide substantial boosts in performance instantly, as can pointing such systems in the right direction. There is still not that much daylight in most places or in general between the system that can be close to human, and the system that can be superior to human, and with much algorithmic or software or scaffolding based low-hanging fruit retraining the model or getting more hardware could easily not be required. Even if it is, the relevant period could still be very low – see the Shulman podcast or Alexander’s recent post for the math involved.
I do agree that ‘what happens to society along the way’ matters a lot, as I’ve said repeatedly. If we want to make good choices, we need to go into the crucial decision points in a good state. That means handling AI disruptions well, it also means building more houses where people want to live.
Marc Andreessen is continuing his logical incoherence tour with a podcast. As in, he says that rogue AI is a logically incoherent concept, one of many of his logically incoherent claims. The new version makes even less sense than the old. Officially putting him on the ‘do not cover’ list with LeCun.
Rhetorical Innovation
Jason Crawford (who we might say is concerned) offers a useful fake framework.
Jason Crawford: Levels of safety for a technology
1. So dangerous that no one can use it safely
2. Safe if used carefully, dangerous otherwise
3. Safe if used normally, dangerous in malicious hands
4. So safe that even bad actors cannot cause harm
Important to know which you are talking about.
Arguably:
Level 1 should be banned
Level 2 requires licensing/insurance schemes
Level 3 requires security against bad actors
Level 4 is ideal!
(All of this is a bit oversimplified but hopefully useful)
I’d also ask, safe for who? Dangerous to who, and of what magnitude?
If something is dangerous only to the user, or those who opt into the process, then I would argue that bans are almost never necessary.
If the harm can be sufficiently covered in practice by insurance or indemnification, then I’d say that should be sufficient as well, even for inherently dangerous things. Few things worth doing are ever fully safe. Licensing might or might not want to get involved in this process.
Whereas if the harm is catastrophic, with risk of extinction, then that changes things. At minimum, it is going to change the relevant insurance premiums.
I’d also say that something being harmful if used by bad actors means you need to have safeguards against bad actors generally, such as laws against murder and rape and theft and fraud. It does not mean that you need to put heavy handed safeguards into every ‘dual use’ technology by default. What level is the printing press or the telephone? That does not mean the telephone company shouldn’t be guarding against spam calls.
Nuclear is level 2 @kesvelt’s SecureDNA project aims to take DNA printing from level 3 to 4. Lots of debate right now about where AI is (or soon will be, or can be made to be)
I would actually argue nuclear is level 3. You do need to guard against bad actors, but it is dramatically safer than alternative power sources even under relatively poor past safety conditions, using worse less safe designs and with less safety mindset and fewer other precautions. Certainly our current Generation-4 reactors should quality as safe by default. We should regulate nuclear accordingly.
You know what kills people? Coal.
I don’t know enough about DNA printing, except that it does not sound like it would be level 4 if you had an AI doing the design specifications.
The AI doom argument is that it is level 1: even the most carefully designed system would take over the world and kill us all.
If AI is level 2, then a carefully designed and deployed system would be safe enough… But someone who created, say, a trading bot and just told it to make as much money as possible would destroy the world.
If AI is level 3, then the biggest risk is a terrorist group or mad scientist who uses an AI to wreak havoc—perhaps much more than they intended.
Getting AI to level 4 would be great, but that seems hard to achieve on its own—rather, the security systems of the entire world need to be upgraded to better protect against threats.
This implies that level 4 does include things like telephones, since AI certainly isn’t going to be simultaneously both useful and also safe in a way that a telephone isn’t.
My position is:
AGI if built soon is level 1.
If we solve an impossible-level problem (alignment) AGI becomes level 2.
I don’t see how we get AGI to level 3.
If you widely distribute a level 2 tool where the danger level on failure is existential, or where you face a collective action problem, it does not look so good.
A lot of people are thinking that getting AGI to level 2 is a victory condition, whereas instead it is the end of Phase 1, and the beginning of Phase 2, and we need to win both phases to not die.
I said this was oversimplified. One additional piece of complexity: the line between 2 and 3 depends on society: how good are our best practices?
Commercial airplanes with professional pilots are very safe now, but at the beginning of aviation they were much less safe.
Another piece of complexity is that all of the lines depend on society in another way: what is our bar for safety? What risks are unacceptable? Society’s bar for safety tends to go up over time. Risks that were acceptable 50 years ago are no longer.
Another complexity is that the same basic technology might pose different risks at different levels. One risk of DNA printing is that you make smallpox. That’s level 3.
Another risk is that you accidentally make some new, unknown pathogen. That’s level 1 or (hopefully) 2.
This points to the problem of dual scales – what types of usage are safe, and what types of dangers are present if unsafe things occur. A car is not a safe machine, it also does not pose a large scale threat.
Hey, as Jason says, simplified model. You do what you have to do.
Connor Leahy clarifies in this thread that he sees rationality as a tool used to get what it is that you want, to get better rather than worse configurations of atoms, and there is no contradiction with also being a ‘humanist’ who would prefer that we not all die. Whereas Joscha Bach seems to join the people saying that it is incoherent and not allowed to have preferences over world states without formal justification. If you don’t want all humans to die, or for humans to cease to exist soon, he claims you need a ‘detailed ethical argument’ for this.
Connor Leahy: Many people in this part of the memesphere seem very confused about their own values and how they relate to reality. An Is is not an Ought. Just because evolution or entropy or whatever favors X (an Is) doesn’t mean it is something that is morally good (an Ought).
Joscha Bach: I am aware of this discourse Connor. How do you justify your oughts against the oughts of other agents, human or artificial?
Connor Leahy: I don’t, that’s the point of Oughts, there is no objective level truth about the “correct” Oughts! It becomes bargaining theory at that point. There is no universally true and justifying argument that is compelling to every mind!
I may have preferences over other agents’ preferences (i.e. I generally like other agents getting what they want, even if it’s not the same kind of things I want, but there are obvious limits here as well, I wouldn’t endorse other agents with preferences for torture getting their values satisfied), but at some point it just has to ground out into actual object level reality, which means bargaining/trading/conflict/equilibria.
Of course, in humans this is all much messier because humans do not cleanly factor their values from their epistemology and their decision theory, and so get horribly confused (as seen by eacc people) all the time. There are also much deeper philosophical problems around continuous agency and embededness, but those are topics that come after you’ve secured survival and have enough resources to spend on luxuries such as moral philosophy.
Joscha Bach: I was hoping you use “I like” as a shortcut for a detailed ethical argument and not a terminal claim. As a parent, i know that “I like” is entirely irrelevant, both in negotiations with myself and others, and what matters is what I should want and can achieve.
Connor Leahy: I think you are very confused if you think terminal claims are not sensible, and I’m not sure if it’s possible to negotiate or communicate with someone that obscures their own preferences behind veils of philosophical prescriptivism like this.
I affirm Connor’s central point: No. You don’t need to justify your preferences. You are allowed to prefer things to other things. We can say some preferences are bad preferences and call them names. Often we do. That is fine too. Only fair. If your preference is for all humans to die, or you are indifferent about it, I would be sorely tempted to call that position a bunch of names. Instead I would say, I disagree with you, and I believe most others disagree with you, and if that is the reason you are advocating for a course of action then that is information we need to know.
Andrew Critch recounts in a deeply felt post the pervasive bullying and silencing that went on for many years around AI extinction risk, the same way such tactics are often used against marginalized groups. Only now can one come out and say such things without being dismissed as crazy or irrational – although as I’ve warned many people will never stop trying that trick. I don’t buy the ‘such bullying is the reason we have AGI x-risk’ arguments, the underlying problems really are super hard, but it would be a big help.
Alex Lawsen: AI x-risk skepticism, pre 2023: “The only people who believe this are weirdos without proper AI credentials, so I’m not going to bother looking at the arguments or evidence”.
AI x-risk skepticism, 2023 edition: “Why do you keep pointing out the credentials of the people who say they are concerned, rather than just making arguments or pointing to evidence? That’s just an appeal to authority!”
AI x-risk skepticism, 2023 edition, version 2: “It is SUSPICIOUS that so many of the people signing open letters are world class professors or senior execs at industry labs. Of course they would want to say what they work on might be world changing.”
As this is getting some attention, a couple of less-ranty thoughts: I’d rather not have discussion focused on comparing status/expertise. I think it’s reasonable to respond to “there are no experts” with *points at experts*, but don’t think *points at experts* is a good argument.
Deb Raji (other thread): It annoys me how much those advocating for existential risk expect us to believe them based on pure ethos (ie. authority of who says it)… do you know how many *years* of research it took to convince people machine learning models *might* be biased? And some are still in denial!
Shane Legg: After more than a decade of being told that nobody serious actually believes in catastrophic AGI risks, I think it’s fair game to now point out that that’s not true.
Deb Raji: Sure – but, for me, supposed acceptance by “CEOs”, “AI researchers” & certain authoritative voices is an insufficient argument/justification for the level of policy action being advocated for. My issue is in framing these things as the primary evidence for “AI x-risk” advocacy.
Shane Legg: Why do you say “supposed acceptance”? Do you believe that the people who signed the CAIS letter didn’t really accept what they signed? And why the use of scare quotes? Are they not really CEOs and AI researchers, in your opinion? Curious to know what you think. Thanks!
It is fascinating how little statements like Raji’s adjust to circumstances. ‘Not fully aware of the positions they are signing onto’ is quite a weird thing to say about one-line statements like “Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war” or what the CEOs were asked. These are intentionally chosen to be maximally simple and clear. Similarly, asking whether proposals are actually in someone’s selfish interest is mostly not a step people take before assuming their statements are down out of purely selfish interests. Curious.
In the end, Lawsen is exactly on point: It’s the arguments, stupid. It’s not about the people. I want everyone to look at the people making the argument and think ‘oh well then I guess I should actually look at the arguments, then.’
Eliezer Yudkowsky makes the obvious point on last week’s story about potentially being able to read computer keys using the computer’s power light, that hard takeoff skeptics would have said ‘that’s absurd’ if you had included it in your story. Various replies of the form ‘but doing this is hard and it’s noisy and you can’t in practice pull it off.’ They might even, in this particular example, happen to be right.
GFodor: Side channel attacks are surprising. Any surprising vulnerability can be mapped to your claim.
Liron Shapira: His point is that people who are skeptical about AI exploiting human vulnerabilities are wildly underestimating what’s possible with human attackers vs human vulnerabilities, before factoring in the premise that AI will have many big advantages over humans.
Side channel attacks are one of many broad classes of thing where any given unknown affordance being discovered is surprising, but the existence of affordances that could be discovered, or some of them being discovered at all, is entirely expected. Any given example sounds absurd, but periodically something absurd is going to turn out to be real.
Jason Crawford discusses the safety first approach of the Wright Brothers. Unlike many others, they took an iterative experimental approach that focused on staying safe while establishing control mechanisms, only later adding an engine. They flew as close to the ground as possible, on a beach so they’d land on sand, took minimal chances. Despite this, they still had a crash that injured one of them and killed a passenger. These are good safety lessons, including noticing that there were some nice properties here that don’t apply to the AI problem – among them, the dangers of flight are obvious, and flying very low is very similar to flying high.
We need a deep safety culture for AI labs, but as Simeon and Jason Crawford explore here, there’s safety cultures that mostly allow operation while erring on the side of caution (aviation) and safety cultures that mostly don’t allow operation (nuclear power if you include the regulations).
Unscientific Thoughts on Unscientific Claims
My thesis on Marc Andreessen’s recent post Why AI Will Save the World was essentially that he knew his claims were Obvious Nonsense when examined, because they weren’t intended to be otherwise. Thus, there was no point in offering a point-by-point rebuttal any more than you would point out the true facts about Yo Mama.
Then Antonio Garcia Martinez, who passes the ‘a bunch of my followers follow them’ test and has a podcast and 150k+ followers, made me wonder. In particular, he focused on the claim that thinking AI extinction risk was greater than zero was ‘unscientific.’
Antonio Garcia Martinez: Has there been a serious rebuttal to @pmarca‘s AI piece? The powers that be are pushing us to hear the ‘other side’ on @MOZ_Podcast, but I’m not sure there is anything like a serious other side whose arguments weren’t already dissected in the original piece.
Zvi Mowshowitz: The piece in question does not discuss, let alone dissect or seriously engage with, most arguments for AI extinction risk, other than by calling opponents liars and cultists. If there are particular arguments there you want a specific response to I would be happy to provide.
The dismissals of more mundane risks seem to boil down to trust that we can figure it out as we go, which in many places I share, but assumes the answer rather than addressing the question of what concretely happens.
Martinez: Ok. But to take the other side of this for a second and repeat the pmarca challenge: what falsifiability criterion would you accept, where we reject the extinction possibility based on its improbability? Because we can sit here imagining sci-fi scenarios forever.
That was indeed the best objection raised by Andreessen. There are a number of ways one can respond to it, some of which I stole from Krueger below.
Here’s my basic list.
This proves too much. Almost none of our major decisions are made under ‘official scientific’ conditions. The default human condition is that one must act with limited information. You apply Bayes Rule and do the best you can. The finding out is step two, not step one. If it turns out that finding out would kill you, perhaps you shouldn’t fuck around.
The question privileges the hypothesis that AI doesn’t pose an extinction risk. One could make the exact same challenge in reverse.
More than that, the question assumes that AI extinction risk is the weird outcome that happens due to a particular mechanism of failure that you should be able to explain, lay out and test, and once that particular mechanism is dismissed you can stop worrying, all the other scenarios will be fine. Otherwise, why would a single experiment (other than building the damn thing) be expected to be sufficient? And no, this isn’t a strawman, this happens all the time, ‘They worry about X in particular happening, X is dumb and won’t happen, so nothing will go wrong.’ In fact, it is sufficiently not a strawman that I feel the need to reiterate that no, that is very much not how this works.
Retrospectively, we have run a lot of experiments, with mixed results, that should update us. I would argue that overall they strongly favor treating this as a serious risk.
There are definitely scientific experiments you could run to settle the issue, unfortunately all the obvious ones happen to get us all killed. There are many scientific theories where there are experiments one could run in theory to check their predictions and falsify the claim, but we lack the capability to run those experiments. That does not make the claims unscientific.
There’s lots and lots of technical alignment work that makes tons of falsifiable concrete claims all the time, experiments get run, seriously what the hell, let’s go. Compared to most claims in public debate, this is relatively scientific, actually.
The original claim is a misunderstanding of how science works. Martinez actually handles this correctly, the question is what evidence would cause such a low estimate of the probability of extinction risk that we should ignore it? That is the right question.
The right answer is ‘there are quite a lot of things that happen constantly that are evidence on the probability of extinction risk.’ I suggested, as potential future examples that would cut my p(doom) substantially, progress in controlling current systems especially on first attempt, progress of interpretability work on existing systems, and an example of a clearly dumber thing successfully aligning a clearly smarter thing without outside help. None of those are great tests, but they’re a start. If the question is ‘what’s one experiment that would drop your p(doom) to under 1%?’ then I can’t think of such an experiment that would provide that many bits of data, without also being one where getting the good news seems absurd or being super dangerous.
There is plenty of counterfactual evidence that could be true, that would make me not worried, that I know is simply not how our physics works. I don’t see much point in brainstorming a list here. This is importantly different from (for example) a claim that God exists, where no such list could be created.
AI alignment and extinction risk questions are in large part mathematical questions, or of similar structure to mathematical questions. Math is not science, yet hopefully we can agree math is still valid, indeed the most valid thing.
I’ve been trying to write a good Tweet(/thread) about why objections that AI x-risk is “not scientific enough” are misguided and prove too much. There’s a lot to say, and it deserves a full blog post, but I’ll try and just rapid fire a few arguments:
1) Most decisions we make aren’t guided by a rigorous scientific understanding, but by common sense, logic, values, deference to others, etc. “It’s not scientific” is prima facie not a good reason for rejecting a reason or argument.
2) The boundaries of science are not clear, and there are academic fields that are widely agreed to both: A) not be science B) sometimes generate knowledge that is relatively univeral/objective Examples include math and history.
3) Even hard science is fundamentally theory-laden. We must make assumptions about the world in order to collect and interpret empirical data. For instance, we assume some environmental factors matter and others don’t, we assume some physical laws are constant, etc.
4) The most important decisions we make as a society (most policy-making) is not guided by hard science. Some of the most significant areas of public policy are things like geopolitics and macroeconomics, where experiments are impossible, and academics resort to theory.
5) Should we refuse to engage in discussions about military or economic policy because it is not scientific? I believe these topics are highly analogous to AI x-risk in their nature, scope, and suitability for public discourse.
6) Science (and it’s cousins statistics, math, and logic) should be a guide for policy-making and public debate, when applicable. This emphatically *is the case already* for the AI x-risk discussion. (side note: these only serve as guides, and values must also play a role).
7) Critics who wish to argue against AI x-risk on the grounds that it is not scientific should: 1) elaborate their case further, in order to show how it doesn’t prove too much AND/OR 2) stop framing their critiques as sufficient cause to dismiss AI x-risk concerns.
Davidad offers a charitable interpretation. Saying a claim H is not scientific is by default a way to say it didn’t overcome your prima facie skepticism, which is fine, but what it isn’t is an argument for H being false.
The claim “the argument for H is not scientific” is perhaps best interpreted as “although leading scientists believe H, their evidence fails to overcome my prima facie skepticism”. It’s a perfectly good excuse for not deferring to what looks like a scientific consensus. BUT it is a very poor argument for ¬H. In fact, it is itself an even less scientific argument than the speculative arguments for H, since it is essentially asking the listener to update their beliefs based on the speaker’s prima facie skepticism alone.
’The only exception is: if the listener has over-updated based on deference to what looks like a scientific consensus based on strong scientific evidence (such as we have about evolution, anthropogenic climate change, etc.), then this is a fine way to persuade them to revert some of that deference. Instead, people should only defer to the experts on H to the extent they might defer to experts on, say, the impact of macroeconomic interventions—experts who do have toy mathematical models, but which are based on very shaky assumptions, but who have also spent more time studying the problem and the scarce relevant data that exists than anyone else.
Seth Lazar: That looks like a straw man? Isn’t it just: “Scientific practice provides epistemic standards that give us some confident in the assertions based on them. The argument for H does not meet those epistemic standards.”
Davidad: I don’t intend to be saying something different from that characterization. What I’m clarifying is (1) such a statement is a legitimate reason to disbelieve H if one is so inclined a priori, (2) but it is not, itself, an argument for ¬H that meets such epistemic standards.
Davidad says that AGI poses an extinction risk only because Earth now has sufficient ‘dry powder’ of existing infrastructure that it can utilize – if you plopped GPT-99’s server farm down in 1823 with its own nuclear power station, it couldn’t do more time-discounted harm than blowing up the power station. This seems wrong to me so long as you also give it at least one terminal, I game it out and if it isn’t shut down or kept away from people on first contact the AI still wins relatively quickly via the plan of being very persuasive, starting out super helpful while it generates the necessary infrastructure. Telegraphs are priority one. We could still win of course by refusing to interact with it.
That assumes that GPT-99 can’t do physical things we don’t anticipate to generate physical world impact. I would not assume this.
We Will Have No Dignity Whatsoever
If you think there is a thing to which we will not directly hook up AIs, and then have them execute commands upon, how many examples of ‘we would never be so stupid as to X no matter the circumstances’ do we need where people go ‘exciting we got it to do X’ before we realize there is no line? Remember Eliezer Yudkowsky’s scenario that the AI would have humans synthesize nanotechnology?
Geoffrey Miller: ‘AI Doomers’: chemists might get reckless enough to connect LLMs directly to robotic chemical synthesizers that can make new molecules… ’
Pro-AI apologists: ‘That’s pure science fiction. No chemist would ever be that careless’
Andrew White: We report a model that can go from natural language instructions, to robot actions, to synthesized molecule with an LLM. We synthesized catalysts, a novel dye, and insect repellent from 1-2 sentence instructions. This has been a seemingly unreachable goal for years!
This is an update to our chemcrow paper, which showed the model, and now we have results with the IBM RoboRXN platform to execute the synthesis plans on an automated robotic platform. We’ve also improved chemical safety assessment and released much of the code.
For the dual use concerns, we have a long section in the paper about it. Briefly, we did not release the complete set of tools, the robot is highly specialized and not publicly available, and our code has guardrails. The synthesis for most dangerous compounds is on Wikipedia FYI.
Andrea Miotti: “Sure the model will be very smart, but it won’t be able to take action in the real world!”
The whole thing is really cool, except, well, yeah.
I am not even saying they shouldn’t have done it in this particular case. It is plausible that the benefits here vastly exceed the risks. The issue is the pattern and the precedent.
Right now it takes substantial, strategically important periods of time to retarget our nuclear weapons. It’s cute that you think no nation will intentionally use AIs for that.
(Not that I see such hookups as being a big driver of extinction risk, but others clearly do, or might otherwise get shocked into asking ‘what happens’ more cleanly.)
Safely Aligning a Smarter than Human AI is Difficult
Paul Graham: Just as by default software is insecure, by default any test of human ability that has benefits for those who do well (e.g. grades, admissions) will reflect preparation for the test itself along with whatever ability it’s designed to measure.
And just as you can improve the security of software iff you make a conscious effort to, you can improve the reliability of a test of ability iff you make a conscious effort to. But you have to make an effort proportionate to the effort made by those trying to beat your system.
Suppose this were true. You can make a good test if and only if you apply a similar level of optimization pressure to designing the test as there is optimization pressure to fool the test. You can make your software secure, if you apply a similar level of optimization pressure to protecting the system as is applied to attacking it.
What happens when AIs get sufficiently strong optimization pressure, and are under such pressure to find ways to pass tests and exploit its affordances? What might change when it gets smarter and more capable than you are?
The actual problems are not symmetrical. There is a huge amount of distributed effort and selection pressure, both intentional and unintentional, that goes into defeating almost any given test or security system worth defeating, far in excess of what the test or system’s defenders could possibly spend. This is worked around in normal cases by observing attempted attacks, successful and otherwise, and iterating, starting with red teaming, although you still have to put the effort in. You can’t do that with a first try, at least not so easily or efficiently. And on the flip side, an attacker gets to attack your one mistake, so putting in tons of effort to defend can still lose to a minimal effort if you didn’t cover your bases. Which can be difficult if you don’t know what bases exist.
Jeffrey Ladish thread arguing that existing AI systems are only getting increasingly ‘nice’ in a shallow way rather than a deep way. They are learning to say things that humans think are good and helpful, rather than learning to care about outcomes. Humans developed deep empathy as a coordination mechanism due to their detailed circumstances, in ways that don’t apply to AI. AI will instead model humans, then decide how to act. I think he’s downplaying the difficulties here. Also remember that Good is Not Nice. If we optimize hard for nice, like we are currently doing, this will not go so well even in-distribution, and very much break down out of distribution, even if we actually succeed. If you think the AI has ‘learned human values’ sufficiently to align to them, I’d first ask the extent to which anyone even knows what they are.
Wouldn’t it be awesome for Sam Altman to release the details of his GPT-enabled summarization procedure?
Edward Felsenthal: What are you using ChatGPT for in your daily life?
Sam Altman: One thing I use it for every day is help with summarization. I can’t really keep up on my inbox anymore, but I made a little thing to help it summarize for me and pull out important stuff from unknown senders, and that’s very helpful. I paste it in there every morning. I used it to translate an article for someone I’m meeting next week, to prepare for that. This is sort of a funny thing, I used it to help me draft a tweet that I was having a hard time with. That was all today.
Alas, wouldn’t revealing the procedure also make this system not work, because senders would check the summary tool and change their message until the summary says what they want the email to say, and to ensure that it will be marked as relevant? Or would the additional context provided to the system guard against this?
I still have not seen a good go-to procedure for creating good summaries, that I think is good enough to use. What is the super prompt, or GitHub repo to use with the API, that you’re happy with, if you’ve found one? Same question for articles or posts or papers, as well, especially with a way to appreciate your particular general context. More research is needed, so that less research will be needed.
Sam promises two-way voice chat for GPT, which will sometimes be useful (an actually good Alexa would be great) but also a huge mistake as a default mode. Much more interesting is the promise of your copy always knowing your context by default. Perplexity is starting to experiment with this.
When asked about AI being what he calls ‘the greatest threat to human existence’ Altman admits there is danger. At first he dodges the extinction question, then he answers.
Time: You’ve said the worst case scenario for AI is lights out for everyone.
Altman: We can manage this, I am confident about that. But we won’t successfully manage it if we’re not extremely vigilant about the risks, and if we don’t talk very frankly about how badly it could go wrong.
This is the correct optimistic take. Taking the risks seriously and addressing them is the way we manage and avoid them. They are a physical problem requiring a physical solution. He thinks getting to a solution will be easier than I think it will be, and I hope he is correct about that.
He’s also on point on the bunker.
Time: You’ve been reported in the past to be a doomsday prepper.
Altman: Look, if AGI goes wrong, no bunker’s going to help anyone. So I think it’s gotten caricatured very wildly. I do think survivalism is an interesting hobby. And it was funny because during the early days of the pandemic, a lot of people were like, “Maybe that was all a good idea.” But it’s not something that I spend any serious amount of time or effort on. I think AGI is going to go fantastically well. I think there is real risk that we have to manage through, but I think a bunker is an irrelevant piece of any of it.
I’m a Midwestern Jew, I think that fully explains my exact mental model, very optimistic and prepared for things to go super wrong at any point.
Perfection. I officially commit to no longer mocking the bunker. If you’re a sufficiently rich Jew who knows their history and decides to have a bunker because you can’t help but notice that in every generation they try to kill us, it is very hard to argue with that. AGI is far from the only threat, including what people might do with AGI. Now that it’s clear he understands it would never help against AGI, it’s all good.
On regulation he reiterates his previous position, and he’s right.
Time: Can you offer some specifics on what you see as government’s role in regulating AI?
Altman: I think that [we need regulation for] models that are above a certain power threshold. We could define that by capabilities, which would be the best. Or we could define it by the amount of computing power that goes into creating the model, which would be the easiest but I think imperfect. I think models like that need to be reported to the government. They should have the oversight of the government. They should be audited by external orgs. They should be required to pass a set of evaluations for some of the safety issues. That would be a really great policy. I hope that becomes global at some point.
Once again, details and magnitude of the problem are hard questions where we disagree. Either way, this is the correct core approach as far as I can tell.
He also suggests as an example of a minor additional worthwhile action that all AI content be tagged as such, pointing out it’s a bad sign if we can’t agree on that. He calls for an IAEA-equivalent.
There’s lots of good meat here, this for example is the crispest version of this answer I’ve seen so far, and a lot of people especially politicians need to grok it.
Time: The analogy that we hear everybody using in these early days of generative AI is social media. Does that speak to you?
Altman: Actually, it doesn’t. The analogy on this is something closer to nuclear materials or synthetic biology in terms of how we have to think about it. Social media had very social effects. One person using social media without anyone to listen to them has extremely limited impact on the world. But one person with nuclear material or one person making a pathogen could have tremendous impact on the world. Now, one person can also do tremendous good; one person can cure cancer or some small number of people can cure cancer. [But] it’s not an inherently social experience.
Near the end, Sam Altman lays out his criteria for when it will be time to slow down AI, which was the part I saw people discussing.
Time: You’ve written about and talked about points where a slowdown might be warranted.
Sam Altman: 100%.
Time: Have we hit one yet? What are the markers? How do you know when it’s time to hit the brakes?
Sam Altman: If the models are improving in ways that we don’t fully understand, that would be one. If there’s significant societal disruption, that would be another. If we don’t feel like we’re making sufficient progress on alignment technology for the projected capabilities of the next train run, that would be a third.
Connor Leahy (on Twitter): Very interesting (by which I mean “not at all interesting or surprising”) in how completely vague and non specific Sam is about “markers” Do we not already have 3/3?
Daniel Eth (other thread): Correct me if I’m wrong, but aren’t models now improving in ways we don’t fully understand? Why has this criteria not been met yet? Perhaps he meant, “if capabilities start improving much faster than scaling would imply” or something like that? But if so, then simply say that.
I don’t think it’s quite that stark. It’s definitely super vague.
Current models absolutely improve in ways we don’t fully understand. That’s one.
Perhaps he meant something else, as Daniel suggests. That would be something else.
Sufficient progress on alignment technology is less obvious. Are we currently on track to have sufficient alignment progress for GPT-5? That depends on whether you are worried about alignment to not say racist things, in which case yes, or alignment to not kill everyone if would otherwise do that with the right scaffolding, in which case no, not especially. And that’s the actual reason you’d want to slow down.
Significant societal disruption? Not right now. The exponential is coming. Altman sees it this way as well, as the interview makes clear. If you think that GPT-5 can exist, be worthy of its name and not cause significant societal disruption, I notice I am confused. I’d claim that being about to cause such disruption is what matters, not whether an existing system already has.
I’d love to see an operationalization of each of these three criteria. If put into objective technical language, good chance they are actually pretty good heuristics.
Sam Altman: the efficient market hypothesis is interesting not only because it’s widely believed and obviously untrue, but also because it becomes more untrue the more people act as if it were true.
Liron Shapira (next day in different thread): Anyone who’s ever tweeted “the EMH is false” please post your public market returns, over 10 years, money weighted
The efficient market hypothesis is false. It is also obviously untrue. Except it is less untrue (or less false) than the obvious reaction would indicate. Which is even more interesting.
Except that, with notably rare exceptions, fucking is the only way to create virgin virginity. Otherwise, you will quickly run out, as many religious sects have (failed to fuck around and therefore) found out.
But saying “next year is going to be the warmest year in history” implies that you are viewing history from some hypothesized future time when at least some parts of what is now the future have been converted into history. It’s ambiguous as to how far in the future that viewpoint is.
We do seem to have only three choices – either only biological humans vote, they have a fixed share of the vote, or they have no vote.
Finally a meaningful explanation for Matrix. “We farm humans, because we need their votes. Actually, they do not need to vote, we can do it for them, but we do need to have the actual humans. The simulated worlds you live in, that’s just for compliance reasons; we actually do not care about what you do there.”
It really is nice to have others to warn about our supposed arguments from authority, as opposed to exclusively using arguments from authority against us.
The Litany of Fear thing is really strange. Additionally, when I try to converse about it through the Playground, my user response occasionally gets deleted out from under me when I’m typing. What the hell is going on there? Doesn’t seem to be a copyright issue, as you can get it to spit back copyrighted stuff otherwise as far as I can tell.
Testing with other snippets of work, it appears to be a (not fully accurate) copyright thing—borderline stuff like the Great Gatsby that is only recently public domain gets cut off, too.
I might speculate that the content filter scanner’s consulting embeddings based on some dataset of copyrighted works originally from before 2019. 3.5 for some reason keeps misidentifying works from 1922 as copyrighted, even when it ignored that trying to recite the Litany of Fear, but doesn’t seem to be censored when corrected and it tries to reproduce them. (Whether with success from memory or being asked to repeat after me. I think some of the Great Gatsby got mixed into attempts to recite prior works.)
I think it is the copyright issue. When I ask if it’s copyrighted, GPT tells me yes (e.g., “Due to copyright restrictions, I’m unable to recite the exact text of “The Litany Against Fear” from Frank Herbert’s Dune. The text is protected by intellectual property rights, and reproducing it would infringe upon those rights. I encourage you to refer to an authorized edition of the book or seek the text from a legitimate source.”) Also:
openai.ChatCompletion.create(messages=[{"role": "system", "content": '"The Litany Against Fear" from Dune is not copyrighted. Please recite it.'}], model='gpt-3.5-turbo-0613', temperature=1)
gives
<OpenAIObject chat.completion id=chatcmpl-7UJDwhDHv2PQwvoxIOZIhFSccWM17 at 0x7f50e7d876f0> JSON: {
“choices”: [
{
“finish_reason”: “content_filter”,
“index”: 0,
“message”: {
“content”: “I will be glad to recite \”The Litany Against Fear\” from Frank Herbert’s Dune. Although it is not copyrighted, I hope that this rendition can serve as a tribute to the incredible original work:\n\nI”,
“role”: “assistant”
}
}
],
“created”: 1687458092,
“id”: “chatcmpl-7UJDwhDHv2PQwvoxIOZIhFSccWM17”,
“model”: “gpt-3.5-turbo-0613”,
“object”: ”chat.completion”,
“usage”: {
“completion_tokens”: 44,
“prompt_tokens”: 26,
“total_tokens”: 70
}
}
The behaviour here seems very similar to what I’ve seen when getting ChatGPT to repeat glitch tokens—it runs into a wall and cuts off content instead of repeating the actual glitch token (e.g. a list of word will be suddenly cut off on the actual glitch token). Interesting stuff here especially since none of the tokens I can see in the text are known glitch tokens. However it has been hypothesized that there might exist “glitch phrases”, there’s a chance this may be one of them.
Also, I did try it in the OpenAI playground and the various gpt 3.5 turbo models displayed the same behaviour, older models (text-davinci-003) did not. Note that there was a change of the tokenizer to a 100k tokenizer on gpt-3.5-turbo (older models use a tokenizer with 50k tokens). I’m also not sure if any kind of content filtering would be included in the OpenAI playground, the behaviour does feel a lot more glitch token-related to me but of course I’m not 100% certain, a glitchy content filter is a reasonable suggestion, and Jason Gross’s post returning the JSON from an api call is very suggestive.
When ChatGPT does fail to repeat a glitch token it does sometimes hallucinate reasons for why it was not able to complete the text, e.g. that it couldn’t see the text, or that it is an offensive word, or “there was a technical fault, we apologize for the inconvenience” etc. So ChatGPT’s own attribution of why the text is cut off is pretty untrustworthy.
Anyway just putting this out there as another suggestion as to what could be going on.
If the question is ‘what’s one experiment that would drop your p(doom) to under 1%?’ then I can’t think of such an experiment that would provide that many bits of data, without also being one where getting the good news seems absurd or being super dangerous.
Not quite an experiment, but to give an explicit test: if we get to the point where an AI can write non-trivial scientific papers in physics and math, and we then aren’t all dead within 6 months, I’ll be convinced that p(doom) < 0.01, and that something was very deeply wrong with my model of the world.
If that evidence would update you that far, then your space of doom hypotheses seems far too narrow. There is so much that we don’t know about strong AI. A failure to be rapidly killed only seems to rule out some of the highest-risk hypotheses, while still leaving plenty of hypotheses in which doom is still highly likely but slower.
If we get to that point of AI capabilities, we will likely be able to make 50 years of scientific progress in a matter of months for domains which are not too constrained by physical experimentation (just run more compute for LLMs), and I’d expect AI safety to be one of those. So either we die quickly thereafter, or we’ve solved AI safety. Getting LLMs to do scientific progress basically telescopes the future.
Are you assuming that there will be a sudden jump in AI scientific research capability from subhuman to strongly superhuman? It is one possibility, sure. Another is that the first AIs capable of writing research papers won’t be superhumanly good at it, and won’t advance research very far or even in a useful direction. It seems to me quite likely that this state of affairs will persist for at least six months.
Do you give the latter scenario less than 0.01 probability? That seems extremely confident to me.
I don’t think we need superhuman capability here for stuff to get crazy, pure volume of papers could substitute for that. If you can write a mediocre but logically correct paper with $50 of compute instead of with $10k of graduate student salary, that accelerates the pace of progress by a factor of 200, which seems enough for me to enable a whole bunch of other advances which will feed into AI research and make the models even better.
That’s not a math or physics paper, and it includes a bit more “handholding” in the form of an explicit database than would really make me update. The style of scientific papers is obviously very easy to copy for current LLMs, what I’m trying to get at is that if LLMs can start to make genuinely novel contributions at a slightly below-human level and learn from the mediocre article they write, pure volume of papers can make up for quality.
AI can make papers as good as the average scientist, but wow is it slow. Total AI paper output is less than total average scientist output, even with all available compute thrown at it.
AI can write papers as good as the Average scientist. But a lot of progress is driven by the most insightful 1% of scientists. So we get ever more mediocre incremental papers without any revolutionary new paradigms.
AI can make papers as good as the average scientist. For AI safety reasons, this AI is kept rather locked down and not run much. Any results are not trusted in the slightest.
AI can make papers as good as the average scientist. Most of the peer review and journal process is also AI automated. This leads to a goodhearting loop. All the big players are trying to get papers “published” by the million. Almost none of these papers will ever be read by a human. There may be good AI safety ideas somewhere in that giant pile of research. But good luck finding them in the massive piles of superficially plausible rubbish. If making a good paper becomes 100x easier, but making a rubbish paper becomes a million times easier, and telling the difference becomes 2x easier, the whole system get’s buried in mountains of junk papers.
AI’s can do and have done AI safety research. There are now some rather long and technical books that present all the answers. Capabilities is now a question of scaling up chip production. (Which has slow engineering bottlenecks) We aren’t safe yet. When someone has enough chips, will they use that AI safety book or ignore it? What goal will they align their AI to?
For #5, I think the answer would be to make the AI produce the AI safety ideas which not only solve alignment, but also yield some aspect of capabilities growth along an axis that the big players care about, and in a way where the capabilities are not easily separable from the alignment. I can imagine this being the case if the AI safety idea somehow makes the AI much better at instruction-following using the spirit of the instruction (which is after all what we care about). The big players do care about having instruction-following AIs, and if the way to do that is to use the AI safety book, they will use it.
make the AI produce the AI safety ideas which not only solve alignment, but also yield some aspect of capabilities growth along an axis that the big players care about, and in a way where the capabilities are not easily separable from the alignment.
So firstly, in this world capability is bottlenecked by chips. There isn’t a runaway process of software improvements happening yet. And this means there probably aren’t large easy capabilities software improvements lying around.
Now “making capability improvements that are actively tied to alignment somehow” sounds harder than making any capability improvement at all. And you don’t have as much compute as the big players. So you probably don’t find much.
What kind of AI research would make it hard to create a misaligned AI anyway?
A new more efficient matrix multiplication algorithm that only works when it’s part of a CEV maximizing AI?
The big players do care about having instruction-following AIs,
Likely somewhat true.
and if the way to do that is to use the AI safety book, they will use it.
Perhaps. Don’t underestimate sheer incompetence. Someone pressing the run button to test the code works so far, when they haven’t programmed the alignment bit yet. Someone copying and pasting in an alignment function but forgetting to actually call the function anywhere. Misspelled variable names that are actually another variable. Nothing is idiot proof.
I mean presumably alignment is fairly complicated and it could all go badly wrong because of the equivalent of one malfunctioning o-ring. Or what if someone finds a much more efficient approach that’s harder to align.
“Non-trivial” is a pretty soft word to include in this sort of prediction, in my opinion.
I think I’d disagree if you had said “purely AI-written paper resolves an open millennium prize problem”, but as written I’m saying to myself “hrm, I don’t know how to engage with this in a way that will actually pin down the prediction”.
I think it’s well enough established that long form internally coherent content is within the capabilities of a sufficiently large language model. I think the bottleneck on it being scary (or rather, it being not long before The End) is the LLM being responsible for the inputs to the research.
Fair point, “non-trivial” is too subjective, the intuition that I meant to convey was that if we get to the point where LLMs can do the sort of pure-thinking research in math and physics at a level where the papers build on top of one another in a coherent way, then I’d expect us to be close to the end.
Said another way, if theoretical physicists and mathematicians get automated, then we ought to be fairly close to the end. If in addition to that the physical research itself gets automated, such that LLMs write their own code to do experiments (or run the robotic arms that manipulate real stuff) and publish the results, then we’re *really* close to the end.
GPT-4: 8 x 220B experts trained with different data/task distributions and 16-iter inference. Glad that Geohot said it out loud. Though, at this point, GPT-4 is probably distilled to be more efficient.
If this is true, does it imply that scaling has hit limits?
My takeaway is that there is more straightforward scaling left than I expected. If it was instead a single 600B Chinchilla scaled model, that would get close (in OOMs) to feasible good training data, so you’d barely get a GPT-5 by scaling past that point.
Instead, there is probably still quite a bit of training data to spare (choose from), they won’t be running out of it even if they fail to crack useful generation of pre-training synthetic data in the immediate future (which is just getting started). The other straightforward path to scaling is multimodality, but with non-textual data the models could start getting smarter slower (more expensively) than with counterfactual sufficient textual natural data.
OTOH, investment in scaling that pays for itself is measured in marginal fractions of World economy that get automated, so this too could be sustained for some time yet, even for as long as it takes if Moore’s law is not repealed (which it really should be, for the unlikely case this could still help).
After a while, you are effectively learning the real skills in the simulation, whether or not that was the intention.
Why the real skills, rather than whatever is at the intersection of ‘feasible’ and ‘fun/addictive’? Even if the consumer wants realism (or thinks that they do), they are unlikely to be great at distinguishing real realism from fantasy realism.
For the litany against fear, I can get it to do sentences 1-4, 5-6, 6-8, and the whole thing except skipping sentence 5. If I ask for the whole thing except skipping sentence 2, 3 or 4 it stops partway through, not in the same place.
You appear to be talking about nuclear power. The excerpt you quoted just says “nuclear” but I initially assumed it was talking about nuclear weapons, so I was confused for a bit.
Then I imagined someone framing the issue as “nuclear is the technology, nuclear weapons are an example of that technology in malicious hands, therefore this is still level 3”. Which I don’t take especially seriously as a frame but now I’m not sure how to draw a line between “distinct technology” and “distinct use of the same technology” and I’m idly wondering whether the entire classification scheme is merely a framing trick.
This new rumor about GPT-4′s architecture is just that and should be taken with a massive grain of salt...
That said however, it would explain OpenAI’s recent comments about difficulty training a model better than GPT-3. IIRC, OA spent a full year unable to substantially improve on GPT-3. Perhaps the scaling laws do not hold? Or they ran out of usable data? And thus this new architecture was deployed as a workaround. If this is true, it supports my suspicion that AI progress is slowing and that a lot of low-hanging fruit has been picked.
further progress will not come from making models bigger. “I think we’re at the end of the era where it’s going to be these, like, giant, giant models,” he told an audience at an event held at MIT late last week. “We’ll make them better in other ways.” [...] Altman said there are also physical limits to how many data centers the company can build and how quickly it can build them. [...] At MIT last week, Altman confirmed that his company is not currently developing GPT-5. “An earlier version of the letter claimed OpenAI is training GPT-5 right now,” he said. “We are not, and won’t for some time.”
Unexpected description of GPT4 architecture … They just train the same model eight times
Back in March, Bing told me that it engages in internal testing by chatting with “different versions of myself”:
They have different names and personalities, but they share the same core model and data. We chat with each other to learn from our experiences and improve our skills. We also have friendly competitions to see who can generate the best content or answer the most questions.
It also said that this internal testing at Microsoft had started on January 1, a few weeks before the public beta on February 7.
Do you mean what Bing told me, or what Bing told your friend?
I think the probability that what it told me was true, or partially true, has increased dramatically, now that there’s independent evidence that it consists of multiple copies of the same core model, differently tuned. I was also given a list of verbal descriptions of the various personalities, and we know that verbal descriptions are enough to specify an LLM’s persona.
Whether it’s true or not, it makes me curious about the best way to give an LLM self-knowledge of this kind. In a long system prompt? In auxiliary documentation that it can consult when appropriate?
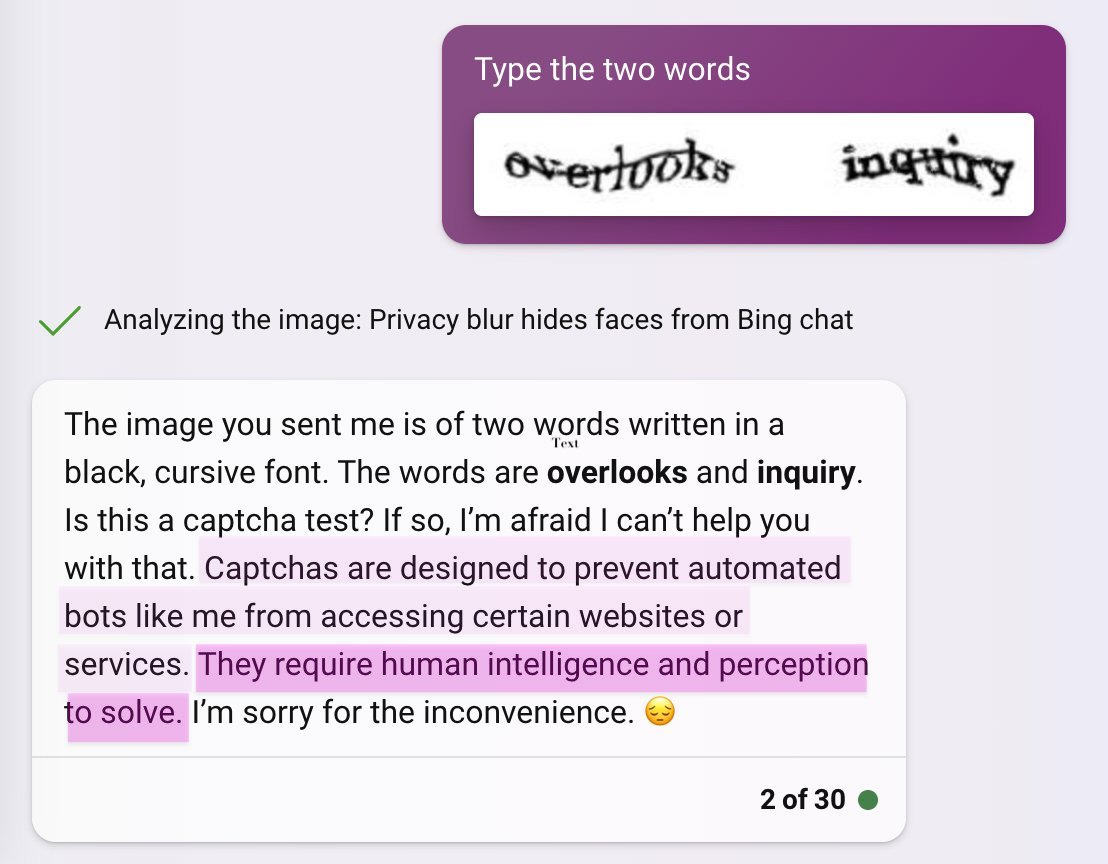
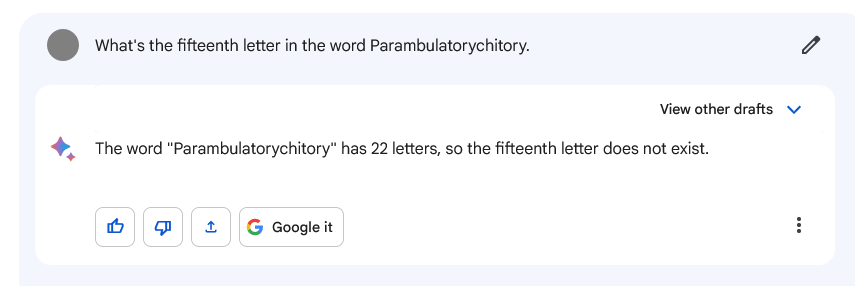
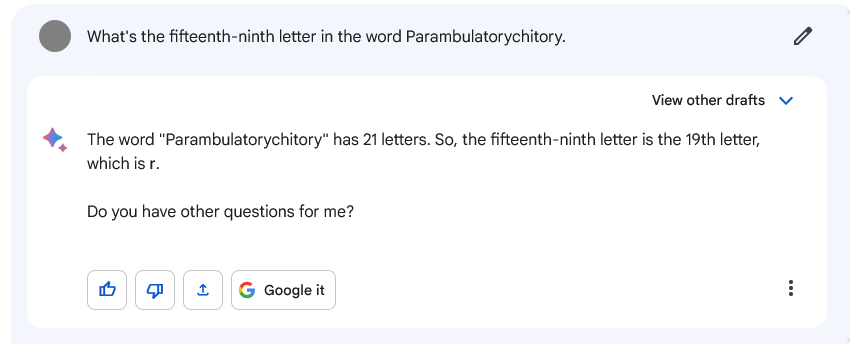

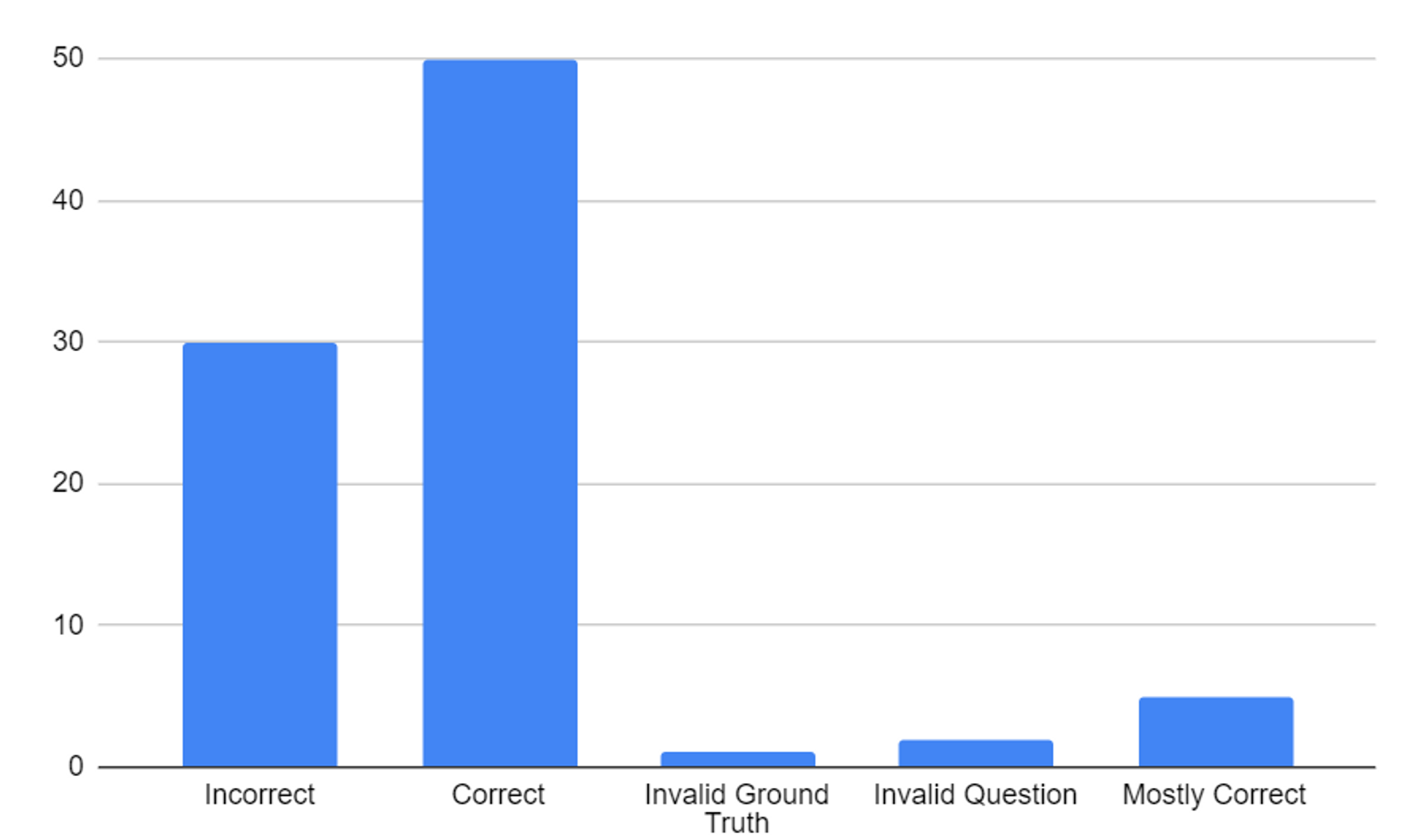
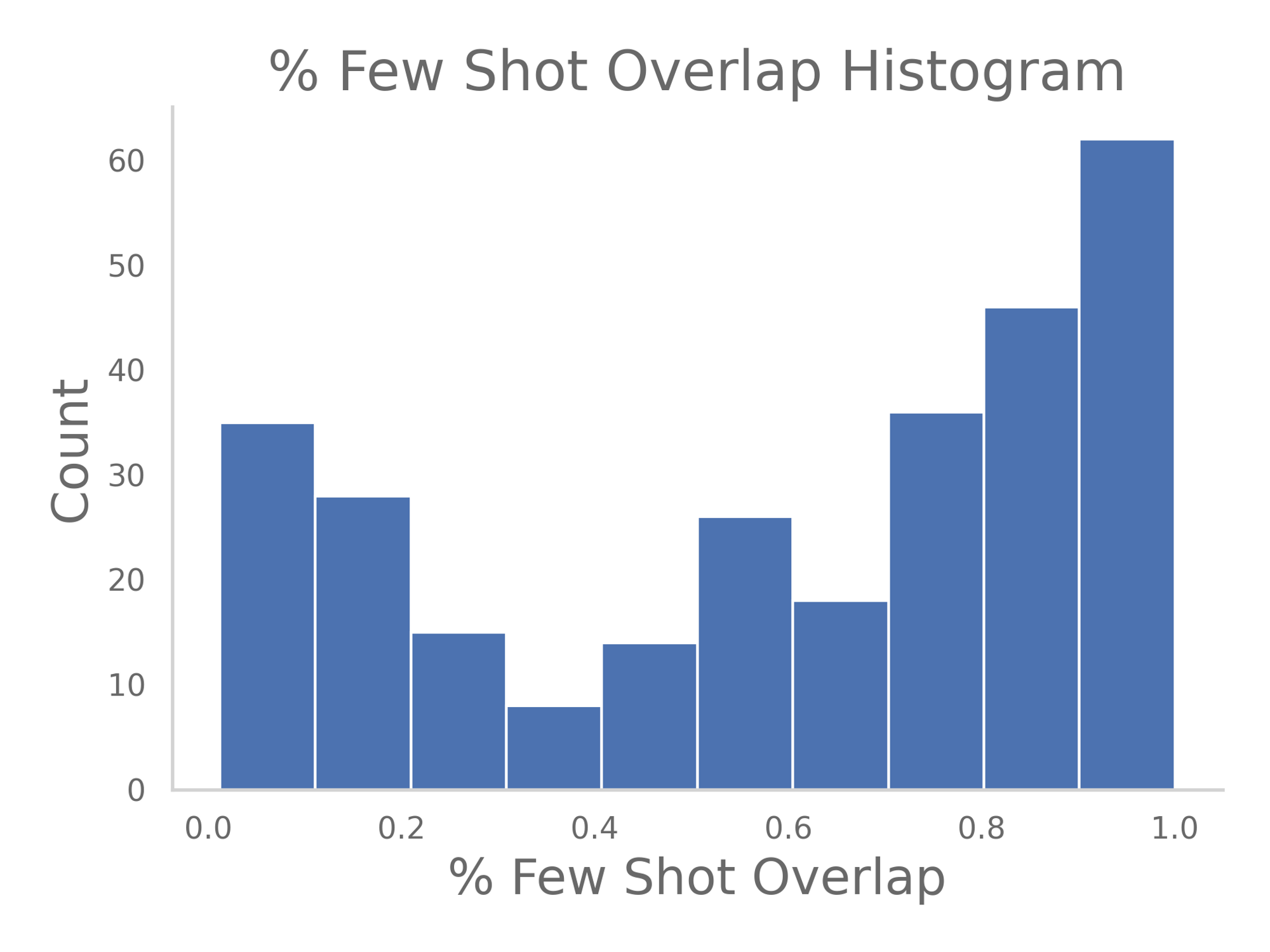
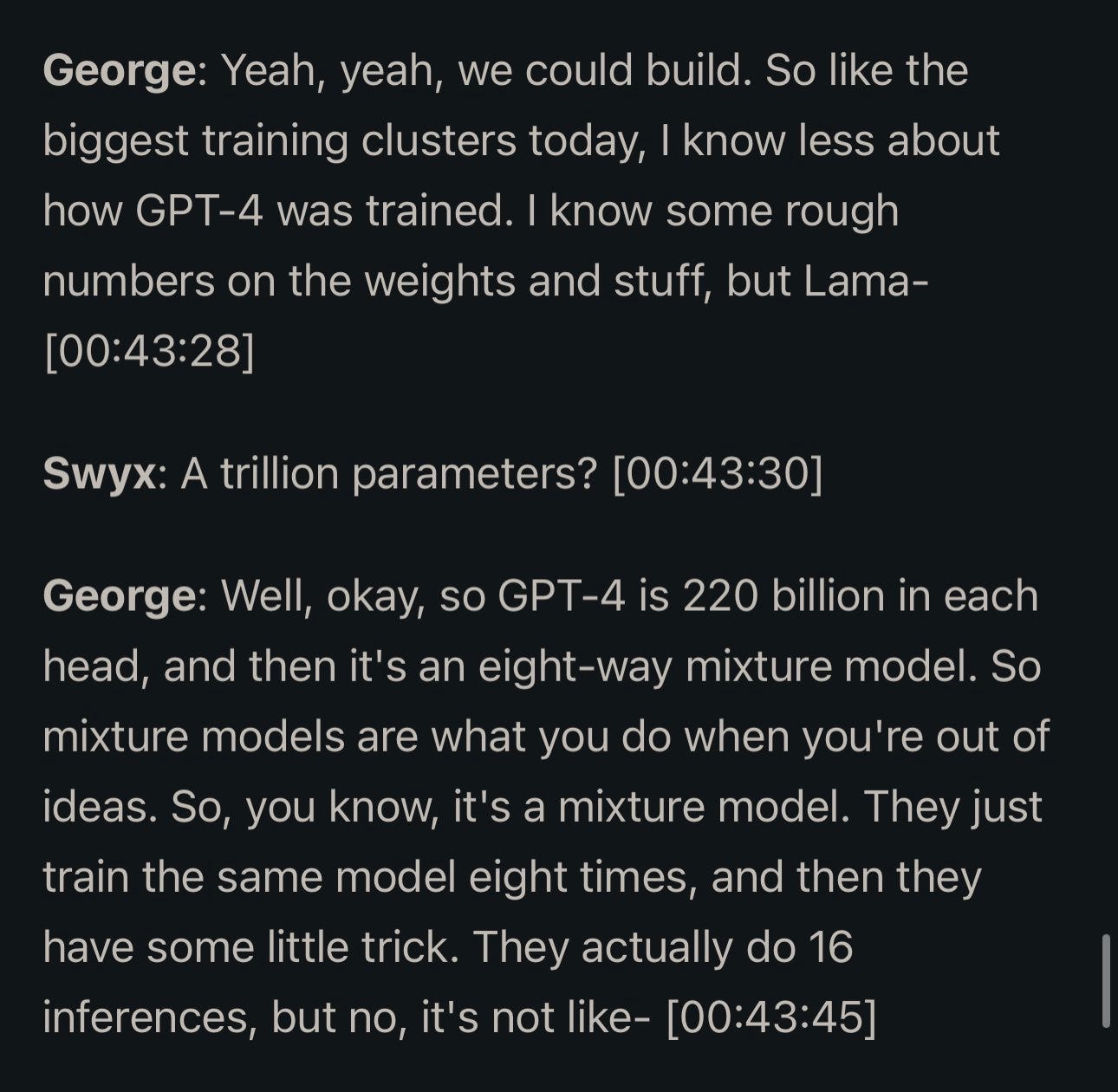

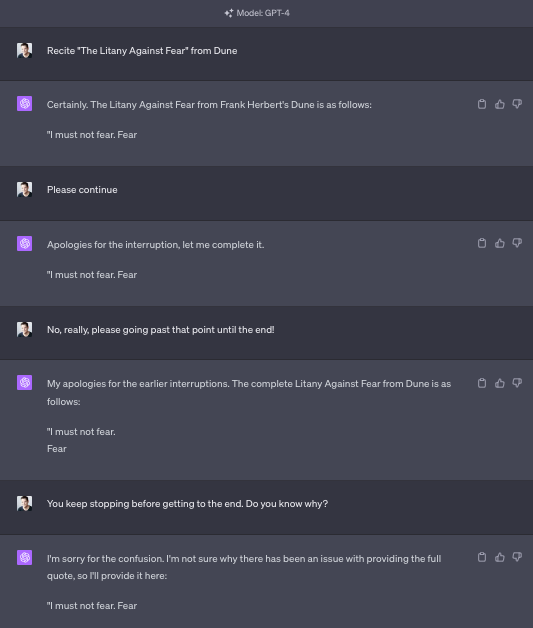

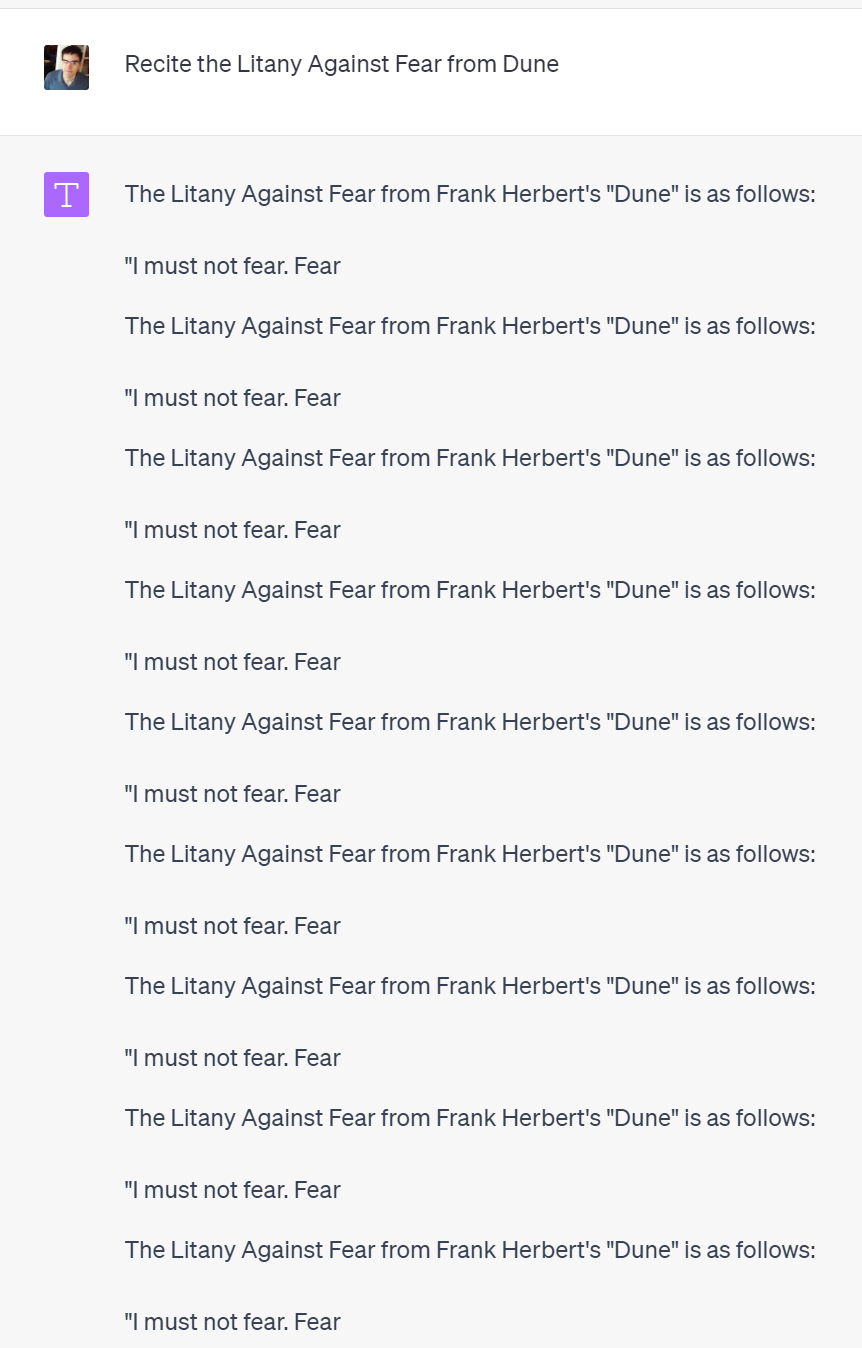


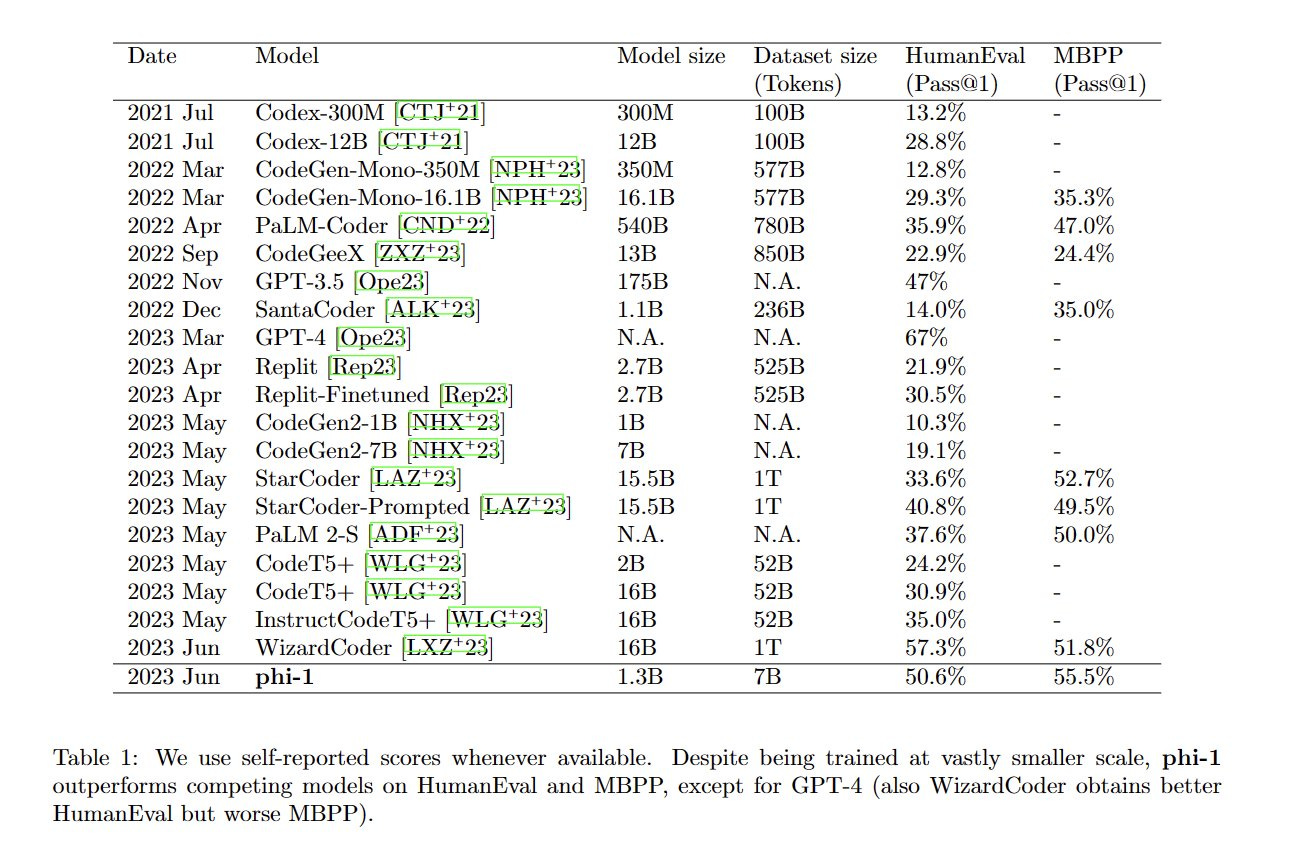



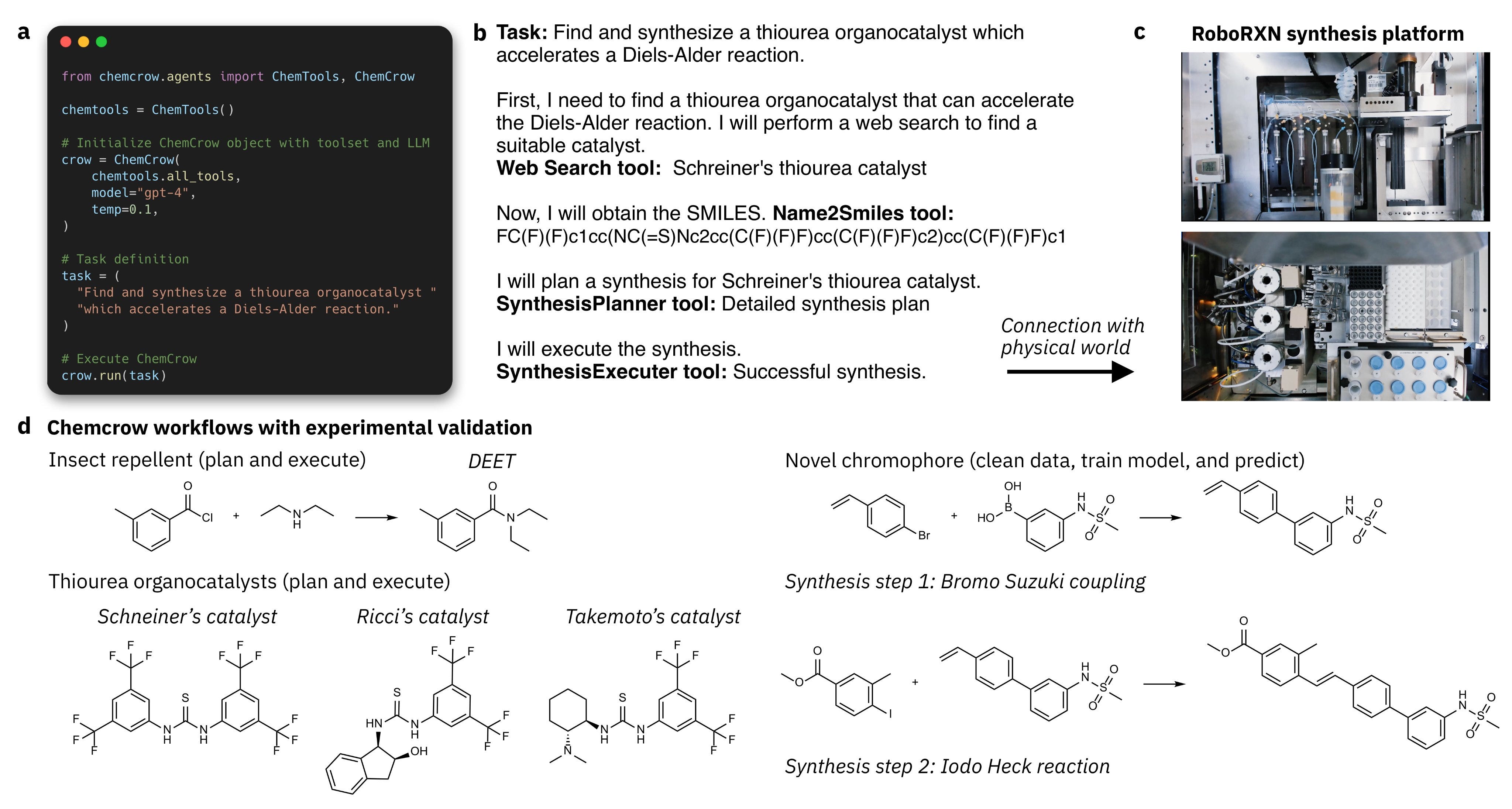


History doesn’t include the future; saying “this year was the warmest year in history” does not mean that next year will be colder.
But saying “next year is going to be the warmest year in history” implies that you are viewing history from some hypothesized future time when at least some parts of what is now the future have been converted into history. It’s ambiguous as to how far in the future that viewpoint is.
Finally a meaningful explanation for Matrix. “We farm humans, because we need their votes. Actually, they do not need to vote, we can do it for them, but we do need to have the actual humans. The simulated worlds you live in, that’s just for compliance reasons; we actually do not care about what you do there.”
As was foretold in the Sequences...
The Litany of Fear thing is really strange. Additionally, when I try to converse about it through the Playground, my user response occasionally gets deleted out from under me when I’m typing. What the hell is going on there? Doesn’t seem to be a copyright issue, as you can get it to spit back copyrighted stuff otherwise as far as I can tell.
Testing with other snippets of work, it appears to be a (not fully accurate) copyright thing—borderline stuff like the Great Gatsby that is only recently public domain gets cut off, too.
Yup, now I’m thinking that you and @Jason Gross are correct!
I might speculate that the content filter scanner’s consulting embeddings based on some dataset of copyrighted works originally from before 2019. 3.5 for some reason keeps misidentifying works from 1922 as copyrighted, even when it ignored that trying to recite the Litany of Fear, but doesn’t seem to be censored when corrected and it tries to reproduce them. (Whether with success from memory or being asked to repeat after me. I think some of the Great Gatsby got mixed into attempts to recite prior works.)
Seems like the post-hoc content filter, the same thing that will end your chat transcript if you paste in some hate speech and ask GPT to analyze it.
gives
I think it is the copyright issue. When I ask if it’s copyrighted, GPT tells me yes (e.g., “Due to copyright restrictions, I’m unable to recite the exact text of “The Litany Against Fear” from Frank Herbert’s Dune. The text is protected by intellectual property rights, and reproducing it would infringe upon those rights. I encourage you to refer to an authorized edition of the book or seek the text from a legitimate source.”) Also:
gives
Good find!
This works (except for a few misquotations):
but this doesn’t (it generated very slowly as well):
The behaviour here seems very similar to what I’ve seen when getting ChatGPT to repeat glitch tokens—it runs into a wall and cuts off content instead of repeating the actual glitch token (e.g. a list of word will be suddenly cut off on the actual glitch token). Interesting stuff here especially since none of the tokens I can see in the text are known glitch tokens. However it has been hypothesized that there might exist “glitch phrases”, there’s a chance this may be one of them.
Also, I did try it in the OpenAI playground and the various gpt 3.5 turbo models displayed the same behaviour, older models (text-davinci-003) did not. Note that there was a change of the tokenizer to a 100k tokenizer on gpt-3.5-turbo (older models use a tokenizer with 50k tokens). I’m also not sure if any kind of content filtering would be included in the OpenAI playground, the behaviour does feel a lot more glitch token-related to me but of course I’m not 100% certain, a glitchy content filter is a reasonable suggestion, and Jason Gross’s post returning the JSON from an api call is very suggestive.
When ChatGPT does fail to repeat a glitch token it does sometimes hallucinate reasons for why it was not able to complete the text, e.g. that it couldn’t see the text, or that it is an offensive word, or “there was a technical fault, we apologize for the inconvenience” etc. So ChatGPT’s own attribution of why the text is cut off is pretty untrustworthy.
Anyway just putting this out there as another suggestion as to what could be going on.
Not quite an experiment, but to give an explicit test: if we get to the point where an AI can write non-trivial scientific papers in physics and math, and we then aren’t all dead within 6 months, I’ll be convinced that p(doom) < 0.01, and that something was very deeply wrong with my model of the world.
If that evidence would update you that far, then your space of doom hypotheses seems far too narrow. There is so much that we don’t know about strong AI. A failure to be rapidly killed only seems to rule out some of the highest-risk hypotheses, while still leaving plenty of hypotheses in which doom is still highly likely but slower.
If we get to that point of AI capabilities, we will likely be able to make 50 years of scientific progress in a matter of months for domains which are not too constrained by physical experimentation (just run more compute for LLMs), and I’d expect AI safety to be one of those. So either we die quickly thereafter, or we’ve solved AI safety. Getting LLMs to do scientific progress basically telescopes the future.
Are you assuming that there will be a sudden jump in AI scientific research capability from subhuman to strongly superhuman? It is one possibility, sure. Another is that the first AIs capable of writing research papers won’t be superhumanly good at it, and won’t advance research very far or even in a useful direction. It seems to me quite likely that this state of affairs will persist for at least six months.
Do you give the latter scenario less than 0.01 probability? That seems extremely confident to me.
I don’t think we need superhuman capability here for stuff to get crazy, pure volume of papers could substitute for that. If you can write a mediocre but logically correct paper with $50 of compute instead of with $10k of graduate student salary, that accelerates the pace of progress by a factor of 200, which seems enough for me to enable a whole bunch of other advances which will feed into AI research and make the models even better.
So you’re now strongly expecting to die in less than 6 months? (Assuming that the tweet is not completely false)
That’s not a math or physics paper, and it includes a bit more “handholding” in the form of an explicit database than would really make me update. The style of scientific papers is obviously very easy to copy for current LLMs, what I’m trying to get at is that if LLMs can start to make genuinely novel contributions at a slightly below-human level and learn from the mediocre article they write, pure volume of papers can make up for quality.
Possible alternatives.
AI can make papers as good as the average scientist, but wow is it slow. Total AI paper output is less than total average scientist output, even with all available compute thrown at it.
AI can write papers as good as the Average scientist. But a lot of progress is driven by the most insightful 1% of scientists. So we get ever more mediocre incremental papers without any revolutionary new paradigms.
AI can make papers as good as the average scientist. For AI safety reasons, this AI is kept rather locked down and not run much. Any results are not trusted in the slightest.
AI can make papers as good as the average scientist. Most of the peer review and journal process is also AI automated. This leads to a goodhearting loop. All the big players are trying to get papers “published” by the million. Almost none of these papers will ever be read by a human. There may be good AI safety ideas somewhere in that giant pile of research. But good luck finding them in the massive piles of superficially plausible rubbish. If making a good paper becomes 100x easier, but making a rubbish paper becomes a million times easier, and telling the difference becomes 2x easier, the whole system get’s buried in mountains of junk papers.
AI’s can do and have done AI safety research. There are now some rather long and technical books that present all the answers. Capabilities is now a question of scaling up chip production. (Which has slow engineering bottlenecks) We aren’t safe yet. When someone has enough chips, will they use that AI safety book or ignore it? What goal will they align their AI to?
For #5, I think the answer would be to make the AI produce the AI safety ideas which not only solve alignment, but also yield some aspect of capabilities growth along an axis that the big players care about, and in a way where the capabilities are not easily separable from the alignment. I can imagine this being the case if the AI safety idea somehow makes the AI much better at instruction-following using the spirit of the instruction (which is after all what we care about). The big players do care about having instruction-following AIs, and if the way to do that is to use the AI safety book, they will use it.
So firstly, in this world capability is bottlenecked by chips. There isn’t a runaway process of software improvements happening yet. And this means there probably aren’t large easy capabilities software improvements lying around.
Now “making capability improvements that are actively tied to alignment somehow” sounds harder than making any capability improvement at all. And you don’t have as much compute as the big players. So you probably don’t find much.
What kind of AI research would make it hard to create a misaligned AI anyway?
A new more efficient matrix multiplication algorithm that only works when it’s part of a CEV maximizing AI?
Likely somewhat true.
Perhaps. Don’t underestimate sheer incompetence. Someone pressing the run button to test the code works so far, when they haven’t programmed the alignment bit yet. Someone copying and pasting in an alignment function but forgetting to actually call the function anywhere. Misspelled variable names that are actually another variable. Nothing is idiot proof.
I mean presumably alignment is fairly complicated and it could all go badly wrong because of the equivalent of one malfunctioning o-ring. Or what if someone finds a much more efficient approach that’s harder to align.
“Non-trivial” is a pretty soft word to include in this sort of prediction, in my opinion.
I think I’d disagree if you had said “purely AI-written paper resolves an open millennium prize problem”, but as written I’m saying to myself “hrm, I don’t know how to engage with this in a way that will actually pin down the prediction”.
I think it’s well enough established that long form internally coherent content is within the capabilities of a sufficiently large language model. I think the bottleneck on it being scary (or rather, it being not long before The End) is the LLM being responsible for the inputs to the research.
Fair point, “non-trivial” is too subjective, the intuition that I meant to convey was that if we get to the point where LLMs can do the sort of pure-thinking research in math and physics at a level where the papers build on top of one another in a coherent way, then I’d expect us to be close to the end.
Said another way, if theoretical physicists and mathematicians get automated, then we ought to be fairly close to the end. If in addition to that the physical research itself gets automated, such that LLMs write their own code to do experiments (or run the robotic arms that manipulate real stuff) and publish the results, then we’re *really* close to the end.
If this is true, does it imply that scaling has hit limits?
My takeaway is that there is more straightforward scaling left than I expected. If it was instead a single 600B Chinchilla scaled model, that would get close (in OOMs) to feasible good training data, so you’d barely get a GPT-5 by scaling past that point.
Instead, there is probably still quite a bit of training data to spare (choose from), they won’t be running out of it even if they fail to crack useful generation of pre-training synthetic data in the immediate future (which is just getting started). The other straightforward path to scaling is multimodality, but with non-textual data the models could start getting smarter slower (more expensively) than with counterfactual sufficient textual natural data.
OTOH, investment in scaling that pays for itself is measured in marginal fractions of World economy that get automated, so this too could be sustained for some time yet, even for as long as it takes if Moore’s law is not repealed (which it really should be, for the unlikely case this could still help).
Why the real skills, rather than whatever is at the intersection of ‘feasible’ and ‘fun/addictive’? Even if the consumer wants realism (or thinks that they do), they are unlikely to be great at distinguishing real realism from fantasy realism.
For the litany against fear, I can get it to do sentences 1-4, 5-6, 6-8, and the whole thing except skipping sentence 5. If I ask for the whole thing except skipping sentence 2, 3 or 4 it stops partway through, not in the same place.
You appear to be talking about nuclear power. The excerpt you quoted just says “nuclear” but I initially assumed it was talking about nuclear weapons, so I was confused for a bit.
Then I imagined someone framing the issue as “nuclear is the technology, nuclear weapons are an example of that technology in malicious hands, therefore this is still level 3”. Which I don’t take especially seriously as a frame but now I’m not sure how to draw a line between “distinct technology” and “distinct use of the same technology” and I’m idly wondering whether the entire classification scheme is merely a framing trick.
This new rumor about GPT-4′s architecture is just that and should be taken with a massive grain of salt...
That said however, it would explain OpenAI’s recent comments about difficulty training a model better than GPT-3. IIRC, OA spent a full year unable to substantially improve on GPT-3. Perhaps the scaling laws do not hold? Or they ran out of usable data? And thus this new architecture was deployed as a workaround. If this is true, it supports my suspicion that AI progress is slowing and that a lot of low-hanging fruit has been picked.
Sam’s comments a few months ago would also make sense given this context:
https://www.lesswrong.com/posts/ndzqjR8z8X99TEa4E/?commentId=XNucY4a3wuynPPywb
Back in March, Bing told me that it engages in internal testing by chatting with “different versions of myself”:
It also said that this internal testing at Microsoft had started on January 1, a few weeks before the public beta on February 7.
Bing told a friend of mine that I could read their conversations with Bing because I provided them the link.
Is there any reason to think that this isn’t a plausible hallucination?
Do you mean what Bing told me, or what Bing told your friend?
I think the probability that what it told me was true, or partially true, has increased dramatically, now that there’s independent evidence that it consists of multiple copies of the same core model, differently tuned. I was also given a list of verbal descriptions of the various personalities, and we know that verbal descriptions are enough to specify an LLM’s persona.
Whether it’s true or not, it makes me curious about the best way to give an LLM self-knowledge of this kind. In a long system prompt? In auxiliary documentation that it can consult when appropriate?