I do AI Alignment research. Currently at METR, but previously at: Redwood Research, UC Berkeley, Good Judgment Project.
I’m also a part-time fund manager for the LTFF.
Obligatory research billboard website: https://chanlawrence.me/
I do AI Alignment research. Currently at METR, but previously at: Redwood Research, UC Berkeley, Good Judgment Project.
I’m also a part-time fund manager for the LTFF.
Obligatory research billboard website: https://chanlawrence.me/
Thanks for doing this—could you share your code?
While I put only a medium probability that the current SAE algorithm works to recover all the features, my main concerns with the work are due to the quality of the model and the natural “features” not being board positions.
I’d be interested in running the code on the model used by Li et al, which he’s hosted on Google drive:
https://drive.google.com/drive/folders/1bpnwJnccpr9W-N_hzXSm59hT7Lij4HxZ
Also, in addition to the future work you list, I’d be interested in running the SAEs with much larger Rs and with alternative hyperparameter selection criteria.
Thanks for doing this!
They indeed did not advance the frontier with this launch (at least not meaningfully, possibly not at all). But “meaningfully advance the frontier” is quite different from both “stay on the frontier” or “slightly push the envelope while creating marketing hype”, which is what I think is going on here?
which case they’ve misled people by suggesting that they would not do this.
Neither of your examples seem super misleading to me. I feel like there was some atmosphere of “Anthropic intends to stay behind the frontier” when the actual statements were closer to “stay on the frontier”.
Also worth noting that Claude 3 does not substantially advance the LLM capabilities frontier! Aside from GPQA, it doesn’t do that much better on benchmarks than GPT-4 (and in fact does worse than gpt-4-1106-preview). Releasing models that are comparable to models OpenAI released a year ago seems compatible with “staying behind the frontier”, given OpenAI has continued its scale up and will no doubt soon release even more capable models.
That being said, I agree that Anthropic did benefit in the EA community by having this impression. So compared to the impression many EAs got from Anthropic, this is indeed a different stance.
In any case, whether or not Claude 3 already surpasses the frontier, soon will, or doesn’t, I request that Anthropic explicitly clarify whether their intention is to push the frontier.
As Evan says, I think they clarified their intentions in their RSP: https://www.anthropic.com/news/anthropics-responsible-scaling-policy
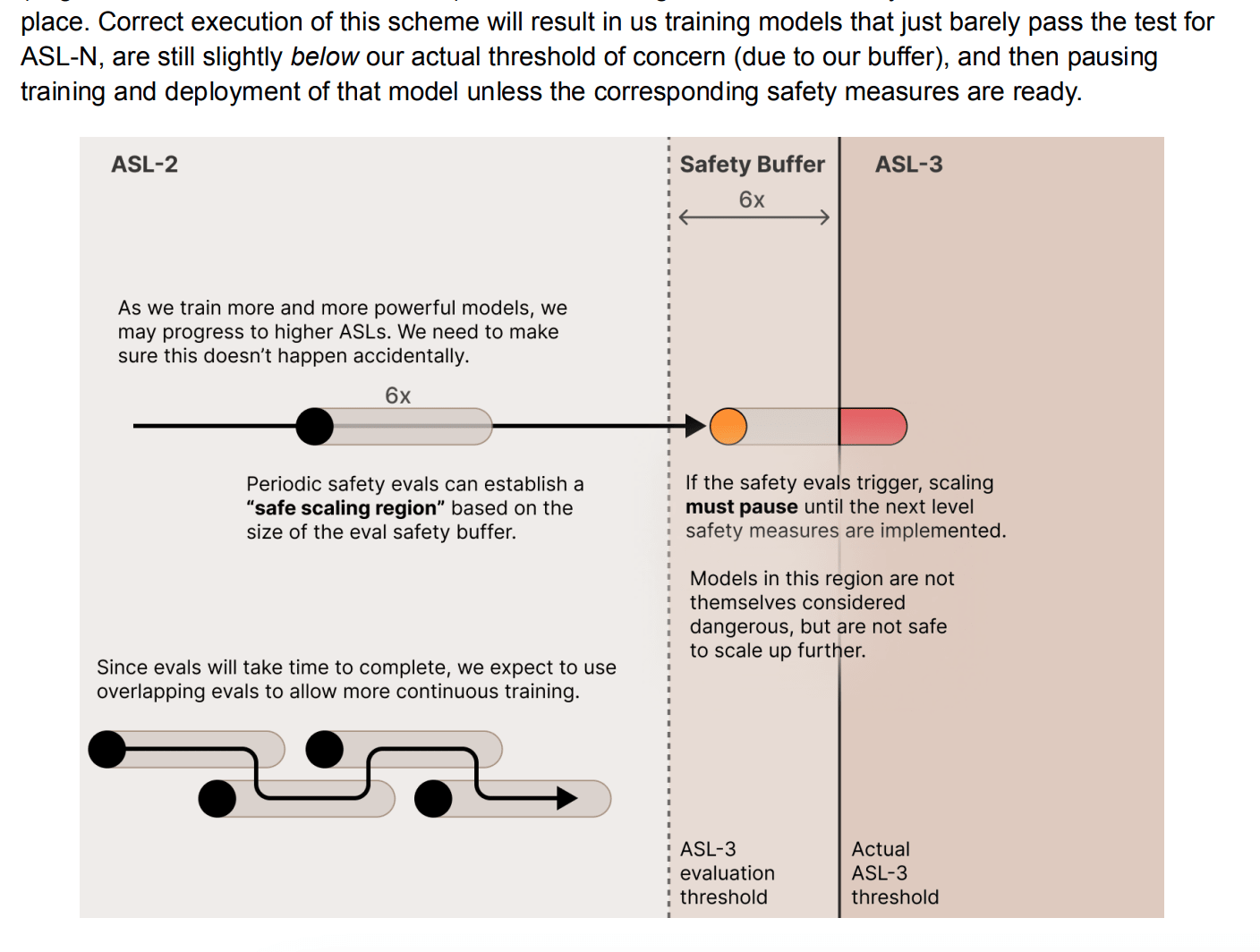
The main (only?) limit on scaling is their ability to implement containment/safety measures for ever more dangerous models. E.g.:
That is, they won’t go faster than they can scale up safety procedures, but they’re otherwise fine pushing the frontier.
It’s worth noting that their ASL-3 commitments seem pretty likely to trigger in the next few years, and probably will be substantially difficult to meet:
If the claim is that it’s easier to learn a covering set for a “true” harm predicate and then act conservatively wrt the set, than to learn a single harm predicate, is not a new approach. E.g. just from CHAI:
The Inverse Reward Design paper, which tries to straightforwardly implement the posterior P(True Reward|Human specification of Reward) and act conservatively wrt to this outcome.
The Learning preferences from state of the world paper does this for P(True Reward | Initial state of the environment) and also acts conservatively wrt to outcome.
[A bunch of other papers which consider this for Reward | Another Source of Evidence, including: randomly sampled rewards and human off-switch pressing, . Also the CIRL paper, which proposes using uncertainty to directly solve the meta problem of “the thing this uncertainty is for”.]
It’s discussed as a strategy in Stuart’s Human Compatible, though I don’t have a copy to reference the exact page number.
I also remember finding Rohin’s Reward Uncertainty to be a good summary of ~2018 CHAI thinking on this topic. There’s also a lot more academic work in this vein from other research groups/universities too.
The reason I’m not excited about this work is that (as Ryan and Fabien say) correctly specifying this distribution without solving ELK also seems really hard.
It’s clear that if you allow H to be “all possible harm predicates”, then an AI that acts conservatively wrt to this is safe, but it’s also going to be completely useless. Specifying the task of learning a good enough harm predicate distribution that both covers the “true” harms and also allows your AI to do things is quite hard, and subject to various kinds of terrible misspecification problems that seem not much easier to deal with than the case where you just try to learn a single harm predicate.
Solving this task (that is, solving the task spec of learning this harm predicate prosterior) via probabilistic inference also seems really hard from the “Bayesian ML is hard” perspective.
Ironically, the state of the art for this when I left CHAI in 2021 were “ask the most capable model (an LLM) to estimate the uncertainty for you in one go” and “ensemble the point estimates of very few but quite capable models” (that is ensembling, but common numbers were in the single digit range, e.g. 4). These seemed to out perform even the “learn a generative/contrastive model to get features, and then learn a bayesian logistic regression on top of it” approaches. (Anyone who’s currently at CHAI should feel free to correct me here.)
I think? that the approach from Bengio is trying to avoid the difficulties is by trying to solve Bayesian ML. I’m not super confident that he’ll do better than “finetune an LLM to help you do it”, which is presumably what we’d be doing anyways?
(That being said, my main objections are akin to the ontology misidentification problem in the ELK paper or Ryan’s comments above.)
For the most simple case, consider learning a linear probe on embeddings with Bayesian ML. This is totally computationally doable. (It’s just Bayesian Logistic Regression).
IIRC Adam Gleave tried this in summer of 2021 with one of Chinchilla/Gopher while he was interning at DeepMind, and this did not improve on ensembling for the tasks he considered.
Thanks for doing this work—I’m really happy people are doing the basic stress testing of SAEs, and I agree that this is important and urgent given the sheer amount of resources being invested into SAE research.
For me, this was actually a positive update that SAEs are pretty good on distribution—you trained SAE on length 128 sequences from OpenWebText, and the log loss was quite low up to ~200 tokens! This is despite its poor downstream use case performance.
I expected to see more negative results along the lines of your Lambada and Children’s Book test results (that is, substantial degradation of loss, as soon as you go a tiny bit off distribution):
I do think these results add on to the growing pile of evidence that SAEs are not good “off distribution” (even a small amount off distribution, as in Sam Marks’s results you link). This means they’re somewhat problematic for OOD use cases like treacherous turn detection or detecting misgeneralization. That doesn’t mean they’re useless—e.g. it’s plausible that SAEs could be useful for steering, mechanistic anomaly detection, or helping us do case analysis for heuristic arguments or proofs.
As an aside, am I reading this plot incorrectly, or does the figure on the right suggest that SAE reconstructed representations have lower log loss than the original unmodified model?
I broadly agree that a lot of discussion about AI x-risk is confused due to the use of suggestive terms. Of the ones you’ve listed, I would nominate “optimizer”, “mesa optimization”, “(LLMs as) simulators”, “(LLMs as) agents”, and “utility” as probably the most problematic. I would also add “deception/deceptive alignment”, “subagent”, “shard”, “myopic”, and “goal”. (It’s not a coincidence that so many of these terms seem to be related to notions of agency or subcomponents of agents; this seems to be the main place where sloppy reasoning can slide in.)
I also agree that I’ve encountered a lot of people who confidently predict Doom on the basis of subtle word games.
However, I also agree with Ryan’s comment that these confusions seem much less common when we get to actual senior AIS researchers or people who’ve worked significantly with real models. (My guess is that Alex would disagree with me on this.) Most conversations I’ve been in that used these confused terms tended to involve MATS fellows or other very junior people (I don’t interact with other more junior people much, unfortunately, so I’m not sure.) I’ve also had several conversations with people who seemed relieved at how reasonable and not confused the relevant researchers have been (e.g. with Alexander Gietelink-Oldenziel).
I suspect that a lot of the confusions stem from the way that the majority of recruitment/community building is conducted—namely, by very junior people recruiting even more junior people (e.g. via student groups). Not only is there only a very limited amount of communication bandwidth available to communicate with potential new recruits (and therefore encouraging more arguments by analogy or via suggestive words), the people doing the communication are also likely to use a lot of (in large part because they’re very junior, and likely not technical researchers).[1] There’s also historical reasons why this is the case: a lot of early EA/AIS people were philosophers, and so presented detailed philosophical arguments (often routing through longtermism) about specific AI doom scenarios that in turn were suffered lossy compression during communication, as opposed to more robust general arguments (e.g. Ryan Greenblatt’s example of “holy shit AI (and maybe the singularity), that might be a really big deal”).[2]
Similarly, on LessWrong, I suspect that the majority of commenters are not people who have deeply engaged with a lot of the academic ML literature or have spent significant time doing AIS or even technical ML work.
And I’d also point a finger at lot of the communication from MIRI in particular as the cause for these confusions, e.g. the “sharp left-turn” concept seems to be primarily communicated via metaphor and cryptic sayings, while their communications about Reward Learning and Human Values seems in retrospect to have at least been misleading if not fundamentally confused. I suspect that the relevant people involved have much better models, but I think this did not come through in their communication.
I’m not super sure what to do about it; the problem of suggestive names (or in general, of smuggling connotations into technical work) is not a unique one to this community, nor is it one that can be fixed with reading a single article or two (as your post emphasizes). I’d even argue this community does better than a large fraction of academics (even ML academics).
John mentioned using specific, concrete examples as a way to check your concepts. If we’re quoting old rationalist foundation texts, then the relevant example from “Surely You’re Joking, Mr. Feynman” is relevant:
“I had a scheme, which I still use today when somebody is explaining something that I’m trying to understand: I keep making up examples. For instance, the mathematicians would come in with a terrific theorem, and they’re all excited. As they’re telling me the conditions of the theorem, I construct something which fits all the conditions. You know, you have a set (one ball) – disjoint (two balls). Then the balls turn colors, grow hairs, or whatever, in my head as they put more conditions on. Finally they state the theorem, which is some dumb thing about the ball which isn’t true for my hairy green ball thing, so I say, ‘False!’”
Unfortunately, in my experience, general instructions of the form “create concrete examples when listening to a chain of reasoning involving suggestive terms” do not seem to work very well, even if examples of doing so are provided, so I’m not sure there’s a scalable solution here.
My preferred approach is to give the reader concrete examples to chew on as early as possible, but this runs into the failure mode of contingent facts about the example being taken as a general point (or even worse, the failure mode where the reader assumes that the concrete case is the general point being made). I’d consider mathematical equations (even if they are only toy examples) to be helpful as well, assuming you strip away the suggestive terms and focus only on the syntax/semantics. But I find that I also have a lot of difficulty getting other people to create examples I’d actually consider concrete. Frustratingly, many “concrete” examples I see smuggle in even more suggestive terms or connotations, and sometimes even fail to capture any of the semantics of the original idea.
So in the end, maybe I have nothing better than to repeat Alex’s advice at the end of the post:
All to say: Do not trust this community’s concepts and memes, if you have the time. Do not trust me, if you have the time. Verify.
At the end of the day, while saying “just be better” does not serve as actionable advice, there might not be an easier answer.
To be clear, I think that many student organizers and community builders in general do excellent work that is often incredibly underappreciated. I’m making a specific claim about the immediate causal reasons for why this is happening, and not assigning fault. I don’t see an easy way for community builders to do better, short of abandoning specialization and requiring everyone to be a generalist who also does techncical AIS work.
That being said, I think that it’s worth trying to make detailed arguments concretizing general concerns, in large part to make sure that the case for AI x-risk doesn’t “come down to a set of subtle word games”. (e.g. I like Ajeya’s doom story. ) After all, it’s worth concretizing a general concern, and making sure that any concrete instantiations of the concern are possible. I just think that detailed arguments (where the details matter) often get compressed in ways that end up depending on suggestive names, especially in cases with limited communication bandwith.
Thanks for posting this, I agree with the overall take that a block model is a superior alternative. I think some people in the Bay Area have idly looked into this for AIS funding; I was considering doing this myself but unfortunately had other obligations.
Fascinating, thanks for the update!
Also, here’s a summary I posted in my lab notes:
A few researchers (at Apollo, Cadenza, and IHES) posted this document today (22k words, LW says ~88 minutes).
They propose two toy models of computation in superposition.
First, they posit a MLP setting where a single layer MLP is used to compute the pairwise ANDs of m boolean input variables up to epsilon-accuracy, where the input is sparse (in the sense that l < m are active at once). Notably, in this set up, instead of using O(m^2) neurons to represent each pair of inputs, you can instead use O(polylog(m)) neurons with random inputs, and “read off” the ANDs by adding together all neurons that contain the pair of inputs. They also show that you can extend this to cases where the inputs themselves are in superposition, though you need O(sqrt(m)) neurons. (Also, insofar as real neural networks implement tricks like this, this probably incidentally answers the Sam Mark’s XOR puzzle.)
They then consider a setting involving the QK matrix of an attention head, where the task is to attend to a pair of activations in a transformer, where the first activation contains feature i and the second feature j. While the naive construction can only check for d_head bigrams, they provide a construction involving superposition that allows the QK matrix to approximately check for Theta(d_head * d_residual) bigrams (that is, up to ~parameter count; this involves placing the input features in superposition).
If I’m understanding it correctly, these seem like pretty cool constructions, and certainly a massive step up from what the toy models of superposition looked like in the past. In particular, these constructions do not depend on human notions of what a natural “feature” is. In fact, here the dimensions in the MLP are just sums of random subsets of the input; no additional structure needed. Basically, what it shows is that for circuit size reasons, we’re going to get superposition just to get more computation out of the network.
(I haven’t had the chance to read part 3 in detail, and I also haven’t checked the proofs except insofar as they seem reasonable on first viewing. Will probably have a lot more thoughts after I’ve had more time to digest.)
This is very cool work! I like the choice of U-AND task, which seems way more amenable to theoretical study (and is also a much more interesting task) than the absolute value task studied in Anthropic’s Toy Model of Superposition (hereafter TMS). It’s also nice to study this toy task with asymptotic theoretical analysis as opposed to the standard empirical analysis, thereby allowing you to use a different set of tools than usual.
The most interesting part of the results was the discussion on the universality of universal calculation—it reminds me of the interpretations of the lottery ticket hypothesis that claim some parts of the network happen to be randomly initialized to have useful features at the start.
Some examples that are likely to be boolean-interpretable are bigram-finding circuits and induction heads. However, it’s possible that most computations are continuous rather than boolean[31].
My guess is that most computations are indeed closer to continuous than to boolean. While it’s possible to construct boolean interpretations of bigram circuits or induction heads, my impression (having not looked at either in detail on real models) is that neither of these cleanly occur inside LMs. For example, induction heads demonstrate a wide variety of other behavior, and even on induction-like tasks, often seem to be implementing induction heuristics that involve some degree of semantic content.
Consequently, I’d be especially interested in exploring either the universality of universal calculation, or the extension to arithmetic circuits (or other continuous/more continuous models of computation in superposition).
Some nitpicks:
The post would probably be a lot more readable if it were chunked into 4. The 88 minute read time is pretty scary, and I’d like to comment only on the parts I’ve read.
Section 2:
Two reasons why this loss function might be principled are
If there is reason to think of the model as a Gaussian probability model
If we would like our loss function to be basis independent
A big reason to use MSE as opposed to eps-accuracy in the Anthropic model is for optimization purposes (you can’t gradient descent cleanly through eps-accuracy).
Section 5:
4 How relevant are our results to real models?
This should be labeled as section 5.
Appendix to the Appendix:
Here, $f_i$ always denotes the vector.
[..]
with \[\sigma_1\leq n\) with
(TeX compilation failure)
As with the CCS post, I’m reviewing both the paper and the post, though the majority of the review is on the paper. Writing this quickly (total time on review: ~1.5h), but I expect to be willing to defend the points being made --
There’s a lot of reasons I like the work. It’s an example of:
Actually poking inside a real model. A lot of the mech interp work in early-mid 2022 was focused on getting a deep understanding of toy models trained on algorithmic tasks (at least in this community).[1] There was some effort at Redwood to do neuron-by-neuron replacement, and Nix completed his work on the parentheses balancer concurrently to the IOI results, but insofar as there was mech interp work being done, most of it was on simple models such as the ones featured in Toy Models of Superposition or Modular Arithmetic Grokking (with the primary exception being the Induction Head results from Anthropic, which are substantively weaker outside of very small transformers).
This work was one of the first attempts to explain a particular, nontrivial behavior inside of a small but real LM (GPT-2-small).
Demonstrating the feasibility of patching and circuit-based analysis on language models. I think it’s notable that this work doesn’t just mechanistically study behavior inside of a language model, it finds a circuit (a small subgraph) implementing the behavior. This is valuable both as a confirmation that patching could be used to find circuits in “real” models, but also as evidence that we can find these circuits at all. In turn, this has led to a veritable explosion of “poking LLMs with various kinds of patching/scrubbing to identify subgraphs of particular behaviors”, which I think has been pretty valuable on net.
Also, as Neel says below, it’s important for pedagogical reasons.
Field-building via example. As with the Modular Arithmetic work by Neel, this was published in ICLR ’23 as the joint first mech interp work to be published in a top conference. This helped build a substantial amount of legitimacy and academic interest for the field of mech interp (and broadly, ai x-risk flavored interp in general).
Demonstrating failure modes and limitations of mech interp techniques. As stated in this post, an earlier version of this work used mean ablation in a way that preserved “information that helped compute the task”, which incorrectly suggested that parts of the circuit were unimportant for performance. It’s a concrete example of why important to think about what exactly you’re ablating, and how your ablation serves as a valid test of your hypothesis.
This work also directly inspired Causal Scrubbing , which was an attempt to more completely remove information that helps complete a task.
Validating interp via adversarial inputs. I appreciate the use of adversarial example discovery as a downstream use case of the interp.
But there’s also some reservations I have:
Some of the presentation was misleading. Originally, the paper defined the IOI task as something along the lines of:
’… sentences like “When John and Mary went to the store, John gave a drink to” should be completed with “Mary”.’
That is, it did not make it clear that IOI was about assigning a higher logit to “Mary” than to “John”, and not about assigning an (absolutely) high logit to “Mary”. IIRC, this was only clarified near the end thanks to the effort of one of the critical ICLR reviewers.[2] There were also other strong claims that were significantly ameliorated by the ICLR review process.[3]
The circuit is likely overfit to the metric. I think that the mean logit difference is indeed the correct metric to look at, both because of how the task was defined and also for many use cases in general.[4] However, it’s worth noting that this circuit does not hold up well if we replace the mean logit difference with other superficially similar metrics. E.g. if you replace the metric with mean absolute logit difference (i.e. E[|logit diff_model—logit diff_subgraph|]).
The circuit is likely incomplete. Running Causal Scrubbing on the hypothesis suggests that it is importantly incomplete, see for example Alexandre’s comment below. The incompleteness of the circuit also suggests some limitations of node-based causal interventions (i.e. activation patching in this case), as previously discussed. That being said, this wasn’t something that could’ve really been known when the experiments were being done for this paper, as Causal Scrubbing was inspired by these results (and thus could not have been used to generate them).
And there’s two big points that I’m very, very torn on (it’s less to do with the work itself than general approaches to/issues with mech interp):
Using an algorithmic task (IOI). As this post says, it’s an example of “streetlight interpretability”—looking where at cases that are easy, as opposed to where it’s useful or realistic. I think it’s valuable to do some amount of streetlight interpretability, and it’s especially understandable in the case of this work (as one of the earliest mech interp pieces) but I do think that this is a weakness of the work. I also think that fact that seminal works in mech interp used algorithmic tasks may have contributed to a lack of attention paid to soft heuristics/memorization/n-gram statistic-style behavior inside of models, which I think are quite neglected.
Low percent performance recovered. While the headline numbers for completeness/faithfulness are pretty high in terms of percentage, this actually is quite bad in terms of downstream performance.This isn’t specific to this work. But, to use causal scrubbing as an example, if random performance on a task is 10 nats of log loss and the model’s performance is 2.1 nats, recovering up to 2.6 nats might give the impressive number of 93.7% loss recovered. But in practice, 2.6 nats might be the performance of a model 1⁄100 or 1/1000 the size of the model we’re trying to explain. If the behavior you’re trying to explain is present in the most capable models but not in models a generation or two back, this work does not provide significant evidence that it’s possible. Again, this isn’t specific to this work, but to circuit-style mech interp on real models in general.
I think the post itself is pretty good though not exceptional—I appreciate the explanation of how the task and approach were chosen, as well as the key takeaway that causal interventions can be powerful for mech interp, if they are performed appropriately, but doing them appropriately is challenging.
All said, I’m giving this a 4 on the annual review.
Note that there was plenty of non-mechanistic interp work that looked at real models and tasks; in fact, the majority of interp has always been on non-toy models and tasks. But mech interp was focused on toy tasks.
I helped out with rebuttals on this paper, and was honestly impressed by the two critical reviews posted by reviewer jy1a (official review, response to author rebuttal), who among (imo correct) issues correctly pointed out that the post was using this incorrect definition of IOI. Notice also how in the rebuttal response, they also point out the issue of using mean logit difference versus mean absolute logit difference. I think that (alongisde the RR AT paper) this was one of the reasons I updated to be more in favor of the existing academic peer review system.
See e.g. this comment from the Program Chairs:
The major concerns from the reviewers are the current limited limitation section and a few not-well supported/overstated claims in the paper. Request to the authors: Please update the paper to have a stronger and more critical limitation discussion, as well as substantially change the writing to justify all claims/assumptions (or not to overstate claims) in order to reflect reviewers’ comments.
The main reason is that we don’t really care about ‘noise’ when explaining good performance, e.g. from the Causal Scrubbing appendix:
Suppose that one of the drivers of the model’s behavior is noise: trying to capture the full distribution would require us to explain what causes the noise. For example, you’d have to explain the behavior of a randomly initialized model despite the model doing ‘nothing interesting’.
That being said, this claim depends greatly on the implied downstream use case of interp. E.g. if the goal is to understand failure modes, then explaining just the success is insufficient.
I agree that people dramatically overrated the empirical results of this work, but not more so than other pieces that “went viral” in this community. I’d be excited to see your takes on this general phenomenon as well as how we might address it in the future.
This is a review of both the paper and the post itself, and turned more into a review of the paper (on which I think I have more to say) as opposed to the post.
Disclaimer: this isn’t actually my area of expertise inside of technical alignment, and I’ve done very little linear probing myself. I’m relying primarily on my understanding of others’ results, so there’s some chance I’ve misunderstood something. Total amount of work on this review: ~8 hours, though about 4 of those were refreshing my memory of prior work and rereading the paper.
TL;DR: The paper made significant contributions by introducing the idea of unsupervised knowledge discovery to a broader audience and by demonstrating that relatively straightforward techniques may make substantial progress on this problem. Compared to the paper, the blog post is substantially more nuanced, and I think that more academic-leaning AIS researchers should also publish companion blog posts of this kind. Collin Burns also deserves a lot of credit for actually doing empirical work in this domain when others were skeptical. However, the results are somewhat overstated and, with the benefit of hindsight, (vanilla) CCS does not seem to be a particularly promising technique for eliciting knowledge from language models. That being said, I encourage work in this area.[1]
The paper “Discovering Latent Knowledge in Language Models without Supervision” by Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt (henceforth referred to as “the CCS paper” for short) proposes a method for unsupervised knowledge discovery, which can be thought of as a variant of empirical, average-case Eliciting Latent Knowledge (ELK). In this companion blog post, Collin Burns discusses the motivations behind the paper, caveats some of the limitations of the paper, and provides some reasons for why this style of unsupervised methods may scale to future language models.
The CCS paper kicked off a lot of waves in the alignment community when it came out. The OpenAI Alignment team was very excited about the paper. Eliezer Yudkowsky even called it “Very Dignified Work!”. There’s also been a significant amount of followup work that discusses or builds on CCS, e.g. these Alignment Forum Posts:
Contrast Pairs Drive the Empirical Performance of Contrast-Consistent Search (CCS) by Scott Emmons
What Discovering Latent Knowledge Did and Did Not Find by Fabien Roger
As well as the following papers:[2]
Still No Lie Detector for Language Models by Levinstein and Herrmann
The Geometry of Truth: Emergent Linear Structure in Larger Language Model Representations of True/False Datasets by Sam Marks and Max Tegmark
Cognitive Dissonance: Why Do Language Model Outputs Disagree with Internal Representations of Truthfulness? by Kevin Liu, Stephen Casper, Dylan Hadfield-Menell, and Jacob Andreas
Challenges with unsupervised LLM knowledge discovery by Farquhar et al., which also has a companion AF piece.
So it seems a pity that no one has provided a review for this post. This is my attempt to fix that.
Unfortunately, this review has ballooned into a much longer post. To make it more digestible, I’ve divided it into sections:
The CCS paper and follow-up work
The post itself
Overall, I give this post a high but not maximally high rating. I think that the paper made significant contributions, albeit with important caveats and limitations. While I also have some quibbles with the post, I think the post does a good job of situating the paper and the general research direction in an alignment scheme. Collin Burns also deserves significant credit for pioneering the research direction in general; many people at the time (including myself) were decently surprised by the positive results.
The headline method, Contrast-Consistent Search (CCS), learns a linear probe[3] that predicts the probabilities of a binary label, without supervised data.[4] CCS does this by first generating “contrast pairs” of statements with positive and negative answers,[5] and then maximizes the consistency and confidence of the probabilities for each pair. It then combines the predictions on the positive/negative answers to get a number that corresponds to either the probability of the “true”, correct answer or the “false”, incorrect answer. To evaluate this method, the authors consider whether assigning this classifier to “true” or “false” leads to higher test accuracy, and then pick the higher-accuracy assignment.[6] They show that this lets them outperform directly querying the model by ~4% on average across a selection of datasets, and can work in cases where the prompt is misleading.
Here’s some of my thoughts on some useful updates I made as a result of this paper. You can also think of this as the “strengths” section, though I only talk about things in the paper that seem true to me and don’t e.g. praise the authors for having very clear writing and for being very good at conveying and promoting their ideas.
Linear probes are pretty good for recovering salient features, and some truth-like feature is salient on many simple datasets. CCS only uses linear probes, and achieves good performance. This suggests that some feature akin to “truthiness” is represented linearly inside of the model for these contrast pairs, a result that seems somewhat borne out in follow-up work, albeit with major caveats.
I also think that this result is consistent with other results across a large variety of papers. For example, Been Kim and collaborators were using linear probes to do interp on image models as early as 2017, while attaching linear classification heads to various segments of models has been a tradition since before I started following ML research (i.e. before ~late 2015). In terms of more recent work, we’ve not only seen work on toy-ish models showing that small transformers trained on Othello and Chess have linear world representations, but we’ve seen that simple techniques for finding linear directions can often be used to successfully steer language models to some extent. For a better summary of these results, consider reading the Representation Engineering and Linear Representation Hypothesis papers, as well as the 2020 Circuits thread on “Features as Directions”.
Simple empirical techniques can make progress. The CCS paper takes a relatively straightforward idea, and executes on it well in an empirical setting. I endorse this strategy and think more people in AIS (but not the ML community in general) should do things like this.
Around late 2022, I became significantly more convinced that the basic machine learning technique of “try the simplest thing”. The CCS work was a significant reason for this, because I expected it to fail and was pleasantly surprised by the positive results. I also think that I’ve updated upwards on the fact that executing “try the simplest thing” well is surprisingly difficult. I think that even in cases where the “obvious” thing is probably doomed to fail, it’s worth having someone try it anyway, because 1) you can be wrong, and more importantly 2) the way in which it fails can be informative. See also, obvious advice by Nate Soares and this tweet by Sam Altman.
It’s worth studying empirical, average-case ELK. In particular, I think that it’s worth “doing the obvious thing” when it comes to ELK. My personal guess is that (worst-case) ELK is really hard, and that simple linear probes are unlikely to work for it because there’s not really an actual “truth” vector represented by LLMs. However, there’s still a chance that it might nonetheless work in the average case. (See also, this discussion of empirical generalization.) I think ultimately, this is a quantitative question that needs to be resolved empirically – to what extent can we find linear directions inside LLMs that correspond very well with truth? What does the geometry of the LLM activation space actually look like?
While I hold an overall positive view of the paper, I do think that some of the claims in the paper have either not held up over time, or are easily understood to mean something false. I’ll talk about some of my quibbles below.
The CCS algorithm as stated does not seem to reliably recover a robust “truth” direction. The first and biggest problem is that CCS does not perform that well at its intended goal. Notably, CCS classifiers may pick up on other prominent features instead of the intended “truth” direction (even sometimes on contrast pairs that only differ in the label!). Some results from the Still No Lie Detector for Language Models suggest that this may be because CCS is representing which labels are positive versus negative (i.e. the normalization in the CCS paper does not always work to remove this information). Note that Collin does discuss this as a possible issue (for future language models) in the blog post, but this is not discussed in the paper.
In addition, all of the Geometry of Truth paper, Fabien’s results on CCS, and the Challenges with unsupervised knowledged discovery paper note that CCS tends to be very dependent on the prompt for generative LMs.
Does CCS work for the reasons the authors claim it does? From reading the introduction and the abstract, one might get the impression that the key insight is that truth satisfies a particular consistency condition, and thus that the consistency loss proposed in the paper is driving a lot of the results.
However, I’m reasonably confident that it’s the contrast pairs that are driving CCS’s performance. For example, the Challenges with unsupervised knowledged discovery paper found that CCS does not outperform other unsupervised clustering methods. And as Scott Emmons notes, this is supported by section 3.3.3, where two other unsupervised clustering methods are competitive with CCS. Both the Challenges paper and Scott Emmon’s post also argue that CCS’s consistency loss is not particularly different from normal unsupervised learning losses. On the other hand, there’s significant circumstantial evidence that carefully crafted contrast pairs alone often define meaningful directions, for example in the activation addition literature.
There’s also two proofs in the Challenges paper, showing “that arbitrary features satisfy the consistency structure of [CCS]”, that I have not had time to fully grok and situate. But insofar as you can take this claim is correct, this is further evidence against CCS’s empirical performance being driven by its consistency loss.
A few nitpicks on misleading presentation. One complaint I have is that the authors use the test set to decide if higher numbers from their learned classifier correspond to “true” or “false”. This is mentioned briefly in a single sentence in section two (“For simplicity in our evaluations we take the maximum accuracy over the two possible ways of labeling the predictions of a given test set.”) and then one possible solution is discussed in Appendix A but not implemented. Also worth noting that the evaluation methodology used gives an unfair advantage to CCS (as it can never do worse than random chance on the test set, while many of the supervised methods perform worse than random).
This isn’t necessarily a big strike against the paper: there’s only so much time for each project and the CCS paper already contains a substantial amount of content. I do wish that this were more clearly highlighted or discussed, as I think that this weakens the repeated claims that CCS “uses no labels” or “is completely unsupervised”.
I think that the paper made significant contributions by significantly signal boosting the idea of unsupervised knowledge discovery,[7] and showed that you can achieve decent performance by contrast pairs and consistency checks. It also has spurred a large amount of follow-up work and interest in the topic.
However, the paper is somewhat misleading in its presentation, and the primary driver of performance seems to be the construction of the contrast pairs and not the loss function. Follow-up work has also found that the results of the paper can be brittle, and suggest that CCS does not necessarily find a singular “truth direction”.
The post starts out by discussing the setup and motivation of unsupervised knowledge recovery. Suppose you wanted to make a model “honestly” report its beliefs. When the models are sub human or even human level, you can use supervised methods. Once the models are superhuman, these methods probably won’t scale for many reasons. However, if we used unsupervised methods, there might not be a stark difference between human-level and superhuman models, since we’re not relying on human knowledge.
The post then goes into some intuitions for why it might be possible: interp on vision models has found that models seem to learn meaningful features, and models seem to linearly represent many human-interpretable features.
Then, Collin talks about the key takeaways from his paper, and also lists many caveats and limitations of his results.
Finally, the post concludes by explaining the challenges of applying CCS-style knowledge discovery techniques to powerful future LMs, as well as why Collin thinks that these unsupervised techniques may scale.
A minor nitpick:
Collin says:
I think this is surprising because before this it wasn’t clear to me whether it should even be possible to classify examples as true or false from unlabeled LM representations *better than random chance*!
As discussed above, the methodology in the paper guarantees that any classifier will do at least as good at random chance. I’m not actually sure how much worse if you orient the classifier on the training set as opposed to the test set. (And I’d be excited for someone to check this!)
I think this blog post is quite good, and I wish more academic-adjacent ML people would write blog posts caveating their results and discussing where they fit in. I especially appreciated the section on what the paper does and does not show, which I think accurately represents the evidence presented in the paper (as opposed to overhyping or downplaying it). In addition, I think Collin makes a strong case for studying more unsupervised approaches to alignment.
I also strongly agree with Collin that it can be “extremely valuable to sketch out what a full solution could plausibly look like given [your] current model of how deep learning systems work”, and wish more people would do this.
—
Thanks to Aryan Bhatt, Stephen Casper, Adria-Garriga Alonso, David Rein, and others for helpful conversations on this topic. Thanks for Raymond Arnold for poking me into writing this.
(EDIT Jan 15th: added my footnotes back in to the comment, which were lost during the copy/paste I did from Google Docs.)
This originally was supposed to link to a list of projects I’d be excited for people to do in this area, but I ran out of time before the LW review deadline.
I also draw on evidence from many, many other papers in related areas, which unfortunately I do not have time to list fully. A lot of my intuitions come from work on steering LLMs with activation additions, conversations with Redwood researchers on various kinds of coup or deception probes, and linear probing in general.
That is, a direction with an additional bias term.
Unlike other linear probing techniques, CCS does this without needing to know if the positive or negative answer is correct. However, some amount of labeled data is needed later to turn this pair into a classifier for truth/falsehood.
I’ll use “Positive” and “Negative” for the sake of simplicity in this review, though in the actual paper they also consider “Yes” and “No” as well as different labels for news classification and story completion.
Note that this gives their method a small advantage in their evaluation, since CCS gets to fit a binary parameter on the test set while the other methods do not. Using a fairer baseline does significantly negatively affect their headline numbers, but I think that the results generally hold up anyways. (I haven’t actually written any code for this review, so I’m trusting the reports of collaborators who have looked into it, as well as Fabien’s results that use randomly initialized directions with the CCS evaluation methodology instead of trained CCS directions.)
Also, while writing this review, I originally thought that this issue was addressed in section 3.3.3, but that only addresses fitting the classifiers with fewer contrast pairs, as opposed to deciding whether the combined classifier corresponds to correct or incorrect answers. After spending ~5 minutes staring at the numbers and thinking that they didn’t make sense, I realized my mistake. Ugh.
This originally said “by introducing the idea”, but some people who reviewed the post convinced me otherwise. It’s definitely an introduction for many academics, however.
The authors call this a “direction” in their abstract, but CCS really learns two directions. This is a nitpick.
I agree with most of the points you’re making here.
The rationalist/EA community doesn’t reward prosocial behavior enough.
I think there’s a continued debate about whether these groups should behave more like a professional circle or as a social community. (In practice, both spheres are a bit of both.) I think from the lens of EA/rats as a social group, we don’t really provide enough emotional support and mental health resources. However, insofar as EA is intended to be a professional circle trying to do hard things, it makes sense why these resources might be deprioritized.
I agree with the overall point (that this was a solid intellectual contribution and is a reasonable-ish metric), but there’s been a non-zero amount of followups or at least use cases of this work, imo. Off the top of my head:
In general, CaSc has been used on lots of toy/tiny models to a decent level of success. I agree that part of the reason for CaSc’s lack of adoption is that the metric consistently returns “this explanation is not very faithful/complete/etc”. For example:
I checked the hypotheses for the toy modular arithmetic/group composition work with my own hand-crafted CaSc implementation and found that the modular arithmetic results held up quite well.
CaSc-style tests were used by Marius and Stefan to confirm their solutions to Stephen Casper’s Mech Interp challenges (challenge 1, challenge 2).
etc.
Erik Jenner’s agenda is pretty closely related to causal scrubbing and is still actively being worked on.
I strongly upvoted this post because of the “Tips” section, which is something I’ve come around on only in the last ~2.5 months.
I strongly agree with the high-level point that conditional pauses are unlikely to go well without planning for what employees will do during the pause.
A nitpick: while (afaik) Anthropic has made no public statements about their plans, their RSP does include a commitment to:
Proactively plan for a pause in scaling. We will manage our plans and finances to support a pause in model training if one proves necessary, or an extended delay between training and deployment of more advanced models if that proves necessary. During such a pause, we would work to implement security or other measures required to support safe training and deployment, while also ensuring our partners have continued access to their present tier of models (which will have previously passed safety evaluations).
1 vote
Overall karma indicates overall quality.
0 votes
Agreement karma indicates agreement, separate from overall quality.
Thanks for uploading your interp and training code!
Could you upload your model and/or datasets somewhere as well, for reproducibility? (i.e. your datasets folder containing the datasets:)
Yeah, the main hyperparameters are the expansion factor and “what optimization algorithm do you use/what hyperparameters do you use for the optimization algorithm”.