Some background for reasoning about dual-use alignment research
This is pretty basic. But I still made a bunch of mistakes when writing this, so maybe it’s worth writing. This is background to a specific case I’ll put in the next post.
It’s like a a tech tree
If we’re looking at the big picture, then whether some piece of research is net positive or net negative isn’t an inherent property of that research; it depends on how that research is situated in the research ecosystem that will eventually develop superintelligent AI.
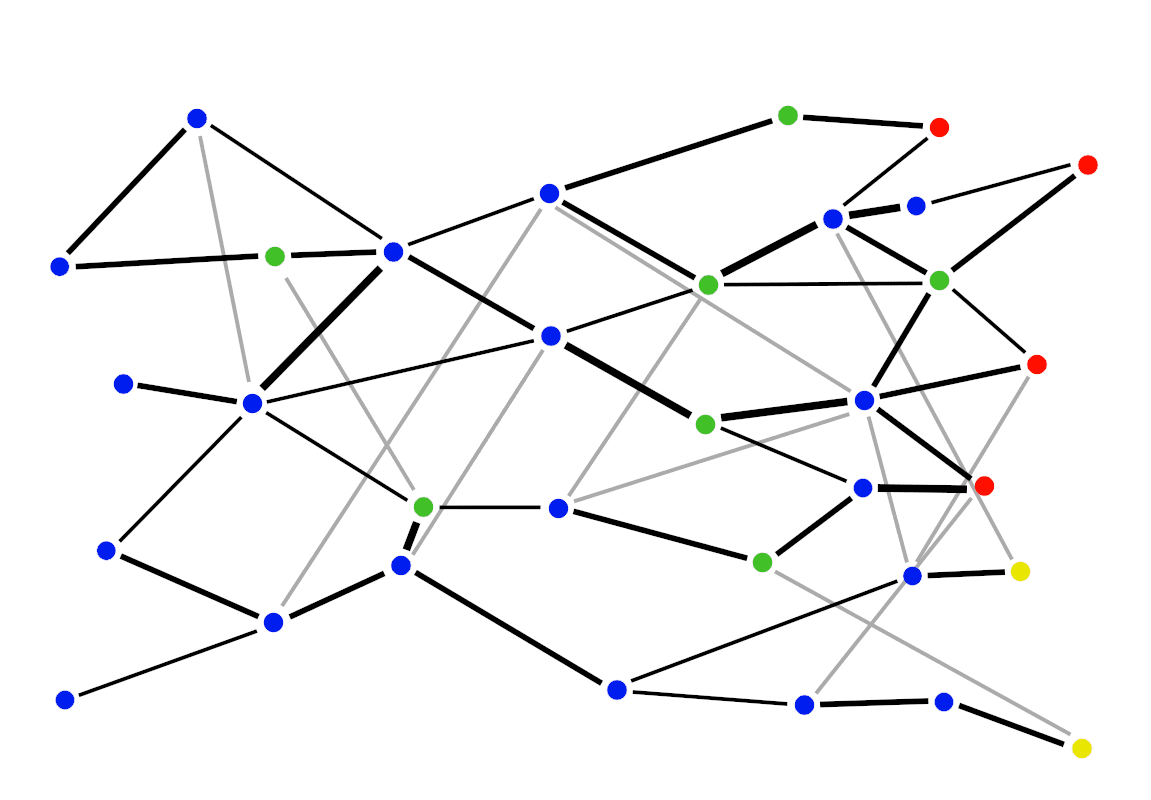
Consider this toy game in the picture. We start at the left and can unlock technologies, with unlocks going faster the stronger our connections to prerequisites. The red and yellow technologies in the picture are superintelligent AI—pretend that as soon as one of those technologies is unlocked, the hastiest fraction of AI researchers are immediately going to start building it. Your goal is for humanity to unlock yellow technology before a red one.
This game would be trivial if everyone agreed with you. But there are many people doing research, and they have all kinds of motivations—some want as many nodes to be unlocked as possible (pure research—blue), some want to personally unlock a green node (profit—green), some want to unlock the nearest red or yellow node no matter which it is (blind haste—red), and some want the same thing as you (beneficial AI—yellow) but you have a hard time coordinating with them.
In this baseline tech tree game, it’s pretty easy to play well. If you’re strong, just take the shortest path to a yellow node that doesn’t pass too close to any red nodes. If you’re weak, identify where the dominant paradigm is likely to end up, and do research that differentially advantages yellow nodes in that future.
The tech tree is wrinkly
But of course there are lots of wrinkles not in the basic tech tree, which can be worth bearing in mind when strategizing about research.
Actions in the social and political arenas. You might be motivated to change your research priorities based on how it could change peoples’ minds about AI safety, or how it could affect government regulation.
Publishing and commercialization. If a player publishes, they get more money and prestige, which boosts their ability to do future research. Other people can build on published research. Not publishing is mainly useful to you if you’re already in a position of strength, and don’t want to give competitors the chance to outrace you to a nearby red node (and of course profit-motivated players will avoid publishing things that might help competitors beat them to a green node).
Uncertainty. We lack exact knowledge of the tech tree, which makes it harder to plan long chains of research in advance. Uncertainty about the tech tree forces us to develop local heuristics—ways to decide what to do based on information close at hand. Uncertainty adds a different reason you might not publish a technology: if you thought it was going to be a good idea to research when you started, but then you learned new things about the tech tree and changed your mind.
Inhomogeneities between actors and between technologies. Different organizations are better at researching different technologies—MIRI is not just a small OpenAI.
Ultimately, which technologies are the right ones to research depends on your model of the world / how you expect the future to go. Drawing actual tech trees can be a productive exercise for strategy-building, but you might also find it less useful than other ways of strategizing.
We’re usually mashing together definitions
I’d like to win the tech tree game. Let’s define a “good” technology as one that would improve our chances of winning if it was unlocked for free, given the state of the game and the policies of the players, and a “bad” technology as one that would harm our chances. Dual-use research in what I think of as “the tech tree sense” is a technology that’s an important prerequisite to both good and bad future technologies.
This is different from how we use “dual-use” outside of AI alignment! Dual-use nuclear technology is technology that all by itself can be used either for electricity or for bombs. This information is about the technology itself, no need to condition on the policies of players in a multiplayer game or anything like that. Any AI technology that can be used for both good and bad things sometimes gets called “dual-use” in this way.[1]
It’s also different from how a lot of people use “dual-use” inside of AI alignment. Any technology that advances both alignment and capabilities is often called “dual-use.”[2] This is different from the tech tree definition because “alignment” and “capabilities” are often measured locally, not rigidly connected to our chances of aligning superintelligent AI.
All these definitions are fine categories to have, but it can be a little confusing when people mash them together. I’m mostly not going to worry about it, because what’s really important is the question of which technologies are helpful (or harmful) to our chances of getting aligned AI.
No definition of dual-use is a complete answer to the question of which technologies are good to research. Instead, this idea of dual-use technology should be taken as a guide to the imagination, a reminder to weigh the good things you want to use a technology for against its potential negative impacts.
The dual use you imagine depends on the research
The key questions to get your imagination kick-started are “Would other people like to use this too?” and “How do you use this in ways unrelated to its usefulness for AI alignment?” Vivid answers to both these questions can help you clarify how the research in question fits into your overall strategy.
Imagining dual use is often an exercise in trying to peer out into the next few layers of the tech tree. It’s going to be idiosyncratic for each research topic—predicting the tech tree depends on specific models of technology and society, with few general rules.
Alignment research is inherently dual-use.
One of the reasons dual-use alignment research is salient right now is RLHF’s broad usage. A key influence on this post is Paul Christiano’s Thoughts on the impact of RLHF research.
RLHF is basically the poster child of “Other people would like to use this too.” It lets you guide AI to do otherwise-hard-to-specify tasks, and surprise surprise this is economically valuable.
But RLHF is also the poster child of those claiming “Maybe it’s fine for other people to want to use it.” Yes, this technology has unlocked some green nodes for OpenAI that might indirectly hasten superintelligent AI. But mostly, people want to use RLHF directly as it was intended as alignment research, getting complicated human preferences into an AI.
Something like this is going to be the case for all alignment research with direct applications. The race isn’t exactly “AI alignment” versus “AI capabilities” because alignment is a type of capability. An AI that’s super smart but doesn’t do what you want is useless (as Katja Grace points out vividly). We want to use AI alignment research to design the motivational system of future AI, but present-day AIs also have motivational systems that benefit from clever design.[3]
Inherent dual use might seem to be safe because it’s directly linked to how good the research is at being alignment research. If you design a motivation system so clever it directly makes bad AI feasible, presumably it’s also so clever it can be used for good AI (or else why did you research it?).
I basically buy this argument for reduced threat, but it doesn’t eliminate all danger from dual use. If alignment research increases the economic value of building larger models and systems that make plans in the real world, this can make bad AI[4] more feasible before we understand how to build good AI.
Instrumental research has instrumental dual use
We don’t always research the entire alignment problem at once.
Maybe you have an alignment strategy that relies on having a system that’s robust to unusual inputs, and so you work on robustness. Someone else might use your work on increased robustness to get good capabilities generalization to new domains, without caring about the rest of your alignment strategy.
Compared to alignment’s inherent dual use, this is more like to the sort of dual-use pointed at in Pragmatic AI Safety. If you’re pursuing some research direction as an instrumental objective, the whole point of instrumental objectives is that lots of people will find them useful!
I think what gets unlocked on the tech tree is the most important question for evaluating dual use of instrumental alignment research. I’m less worried about alignment research making existing products 5% better, and more worried about alignment research helping to unlock totally new non-alignment capabilities.
Can alignment itself be used instrumentally in AI design, turning inherent dual use into indirect dual use? One example might be motivating components of an AI to work on their tasks, sort of like how AutoGPT relies on GPT’s “alignment” to faithfully do the subtasks parceled out to it.
We (sometimes) won’t get lost in the crowd
One possible reaction to the prospect of dual use research is that, strategically, it shouldn’t matter at all. After all, there’s a bunch of people already working on AI capabilities, isn’t it a bit outlandish to think your alignment research is going to have a nontrivial impact on when it’s not even what you’re directly trying to do?
There are several interconnected reasons why alignment research isn’t obviated by all the people working on capabilities.
RLHF is already a counterexample. It’s had an impact because of alignment’s inherent dual use—is that cheating? No: RLHF is economically valuable, but Paul still put work into it for alignment before profit-seeking researchers got to it. It could have been otherwise.
Let’s actually back up and consider instrumental research first—like the example of robustness. Suppose you’re considering working on robustness as a step towards later alignment research. If robustness is instrumentally useful, won’t your work just get lost in the crowd?
First: Yes, absolutely, other AI researchers are definitely working on robustness for reasons other than yours. If you want to work on robustness, you had better read the literature.
Second: The field is big enough that your impact is small, but not so big that your impact is negligible, even on instrumentally useful sub-capabilities of alignment. This might sound strange given that there are 300,000 AI workers or whatever, and only 300 AI alignment workers or whatever, a tidy ratio of 1000:1. But there were only 50 or so papers on robustness in deep learning at ICML 2022. If you do a high-quality paper’s worth of work, that’s 1/50th of the sub-field.
Third: AI alignment suggests specific research directions that are more relevant than average to superintelligent AI. If you look at the papers on robustness in ICML, a lot of them are things like “one simple trick to make language models robust to adversarial attacks.” That’s important research for many present-day applications of AI, but it’s not intended to be part of an AGI design. If you’re doing AI alignment research because you take AGI seriously, you’re going to want robustness in a different sense, and that sense is going to be more relevant both to aligning superintelligent AI and also to building it.
My guesstimate is that this drops the effective size of the “crowd” the dual use of your research is supposed to get lost in down to about 10. Even though there are hundreds of thousands of AI workers, even though a few hundreds of them are sometimes working on robustness, only an effective handful are working on the sort of robustness that advances superintelligent AI timelines.
Why are your competitors so few? If the development of superintelligent AI is going to be a hugely important event in the course of human history, why aren’t more people doing research motivated by it? You might as well ask why there are only 300 alignment researchers. For whatever reasons, most AI research simply isn’t that future-oriented.
This sort of future orientation and willingness to take powerful AI seriously is an advantage of the AI alignment community. It lets things like RLHF be investigated for alignment before they’re used for economic gain, rather than after. It just also means that the research we find instrumentally useful will often also be selected for its import to powerful AI, and we can’t plan on getting lost in the crowd.
This leads to fairly common positions on strategy
Doing nothing is not the optimal strategy. Okay, maybe if we were turbo-doomed—if there was no path to a yellow node that didn’t unlock red nodes much earlier—then we could do nothing and by inaction eke out a few more months of pitiful existence. But outside of that edge case, we have to be willing to accept some dual use as a common side-effect of pulling the future in positive directions.
Never deferring research due to dual use is also not the optimal strategy. For important decisions, you should try to predict the consequences for the tech tree game a few steps ahead, and sometimes this should lead you to actually reject researching technologies that when viewed locally would seem safe and profitable. This is especially relevant for instrumentally useful research.
As a cognitive lever for predicting technologies that seem important or murky, it can be useful both to list out a part of the tech tree you expect to be impacted, and also to write some qualitative stories about intended use and dual use.
Second-order effects can be positive and important. I probably didn’t devote enough of this post to this, but to state the obvious, there are benefits to publishing prestigious research. Strategies should seek out positive second-order effects like attracting funding and getting neutral researchers excited. I interpret some of Stephen Casper’s Engineer’s Interpretability Sequence as giving this advice.
Especially for research that can be prestigious and get new people interested without doing much to hasten unaligned superintelligent AI—like research that interfaces with mainstream work on privacy, ethics, etc. “Dual use” in such subfields is generally no vice!
Different people often need different advice. I’d expect ML researchers who heard about AI alignment two months ago will need more advice about when to be cautious, and LW readers will need more advice about when to do research with dual use.
Doing research but not publishing it has niche uses. If research would be bad for other people to know about, you should mainly just not do it. There’s recent discussion in the excellent Should we publish mechanistic interpretability research?, especially Neel Nanda’s opinion.
Changing your mind or learning something surprising are valid reasons not to publish. Secrecy will also be more incentivized close to the endgame within organizations actively trying to build superintelligent AI. But for now, I expect that even the largest organizations should do research to advance the tech tree of society as a whole. Hoarded secrets drop in value rapidly.
This is probably the point where there’s the most disagreement. I think some organizations that have done unpublished research (ranging from MIRI to Anthropic) anticipated getting good value from that research in its unpublished state. I think the strategic arguments for this are pretty weak—recent discussion about the existence of a “moat” may be relevant.
Thanks to MAIA for some of the desks this was written on. Thanks to Logan Riggs for some chats. Thanks to LTFF for some of the support.
- ^
E.g. Urbina et al., Dual use of artificial-intelligence-powered drug discovery.
- ^
E.g. See Dan Hendrycks and Thomas Woodside’s Pragmatic AI Safety, particularly this section.
- ^
I’d still agree that more abstract work on “what does it even mean for an AI to be aligned with human values?” is less useful to other people, and we should try to have that research outrace the practical application of that research to motivation system design.
- ^
Not “bad” because it’s built by bad people, but “bad” because its motivation system finds perverse optima—the classic example being the motivation system of reinforcement learning based on a button the human presses. When the AI is dumb, this motivation system increases the AI’s economic value by directing it to do the tasks the human wants. When the AI is smart, it makes plans to take control of the button.
- Voting Results for the 2023 Review by (6 Feb 2025 8:00 UTC; 88 points)
- So You Want to Work at a Frontier AI Lab by (11 Jun 2025 23:11 UTC; 54 points)
- Was Releasing Claude-3 Net-Negative? by (27 Mar 2024 17:41 UTC; 52 points)
- Alignment & Capabilities: What’s the difference? by (EA Forum; 31 Aug 2023 22:13 UTC; 50 points)
- So You Want to Work at a Frontier AI Lab by (EA Forum; 11 Jun 2025 23:11 UTC; 36 points)
- 's comment on The case for a negative alignment tax by (19 Sep 2024 5:56 UTC; 18 points)
- Assessment of AI safety agendas: think about the downside risk by (19 Dec 2023 9:00 UTC; 13 points)
- 's comment on quila’s Shortform by (1 Jun 2024 10:14 UTC; 13 points)
- Was Releasing Claude-3 Net-Negative by (EA Forum; 27 Mar 2024 17:41 UTC; 12 points)
- 's comment on The problems with the concept of an infohazard as used by the LW community [Linkpost] by (23 Dec 2023 17:17 UTC; 8 points)
- Challenge proposal: smallest possible self-hardening backdoor for RLHF by (29 Jun 2023 16:56 UTC; 7 points)
- 's comment on The case for AI safety capacity-building work by (10 Mar 2026 12:49 UTC; 7 points)
- 's comment on The ‘Neglected Approaches’ Approach: AE Studio’s Alignment Agenda by (19 Dec 2023 9:07 UTC; 7 points)
- Assessment of AI safety agendas: think about the downside risk by (EA Forum; 19 Dec 2023 9:02 UTC; 6 points)
- 's comment on Numberwang: LLMs Doing Autonomous Research, and a Call for Input by (20 Jan 2025 17:32 UTC; 5 points)
- 's comment on Request: stop advancing AI capabilities by (26 May 2023 17:55 UTC; 3 points)
- 's comment on Numberwang: LLMs Doing Autonomous Research, and a Call for Input by (19 Jan 2025 22:24 UTC; 3 points)
- 's comment on D0TheMath’s Shortform by (2 May 2024 21:28 UTC; 2 points)
- 's comment on Applying refusal-vector ablation to a Llama 3 70B agent by (11 May 2024 10:04 UTC; 2 points)
- 's comment on A Defense of Work on Mathematical AI Safety by (EA Forum; 13 Jul 2023 21:52 UTC; 1 point)
- 's comment on Why I’m Not (Yet) A Full-Time Technical Alignment Researcher by (25 May 2023 2:44 UTC; 1 point)
This is an important topic, about which I find it hard to reason and on which I find the reasoning of others to be lower quality than I would like, given its significance. For that reason I find this post valuable. It would be great if there were longer, deeper takes on this issue available on LW.