Mysteries of mode collapse
Thanks to Ian McKenzie and Nicholas Dupuis, collaborators on a related project, for contributing to the ideas and experiments discussed in this post. Ian performed some of the random number experiments.
Also thanks to Connor Leahy for feedback on a draft, and thanks to Evan Hubinger, Connor Leahy, Beren Millidge, Ethan Perez, Tomek Korbak, Garrett Baker, Leo Gao and various others at Conjecture, Anthropic, and OpenAI for useful discussions.
This work was carried out while at Conjecture.
Important correction
I have received evidence from multiple credible sources that text-davinci-002 was not trained with RLHF.
The rest of this post has not been corrected to reflect this update. Not much besides the title (formerly “Mysteries of mode collapse due to RLHF”) is affected: just mentally substitute “mystery method” every time “RLHF” is invoked as the training method of text-davinci-002. The observations of its behavior otherwise stand alone.
This is kind of fascinating from an epistemological standpoint. I was quite surprised to learn that text-davinci-002 was probably not trained with RLHF. I don’t remember exactly how ”text-davinci-002 is RLHF” got elevated to an unquestioned assumption in my mind. I might have mistook not being contradicted by people who I assumed were in the know as confirmation. I certainly did not expect to talk for months to dozens of people about odd behaviors I’ve observed in a well-known model “due to RLHF” without being contradicted in a world where the model in question wasn’t trained with RLHF, but that’s what happened.[1] It wasn’t just me either: the assumption that text-davinci-002(/text-davinci-001) is InstructGPT is RLHF seems ambient (e.g. search “text-davinci-002 rlhf” on Twitter, this LW post, this article, and many others). I contributed to perpetuating this misinformation cascade, and for that I apologize.
text-davinci-002‘s behaviors described in this post also contributed to my confidence because RLHF seemed to be a likely and potentially satisfying explanation. Its apparently unsubstantiated confidence in very specific outcomes seems antithetical to the outer objective of self-supervised learning, which is optimized by epistemic calibration, meaning the model’s entropy should be as high as possible while fitting the data. In contrast, as several comments have pointed out, it makes sense that RL kills entropy. The presence of “attractors” made me additionally suspect that optimization from non-myopic outcome-supervision was formative to text-davinci-002’s psyche.
Mode collapse and attractors do seem to also be caused by RLHF (see Dumbass policy pls halp and Inescapable wedding parties). So the update is that some other training method also gives rise to these phenomena, as they are manifested by text-davinci-002.
Whether and how speculations concerning the causes of mode collapse/attractors should be affected depends on how text-davinci-002’s training method differs from RLHF.
What is known about text-davinci-002’s training method
Publicly available information suggests that the mystery method may not be so different from RLHF. Just today I discovered this sidenote in OpenAI’s blog post Aligning Language Models to Follow Instructions:
The InstructGPT models deployed in the API are updated versions trained using the same human feedback data. They use a similar but slightly different training method that we will describe in a forthcoming publication.
AFAIK, this is all that OpenAI has published about the RLHF/mystery method diff. It says that the InstructGPT models (text-davinci-001 and text-davinci-002) were trained using the same human feedback data as the method described in OpenAI’s RLHF paper.[2] But this “similar but slightly different” method is apparently sufficiently different to not qualify as RLHF!
Pending further revelations, I suppose the lesson here was that I should have sustained more entropy in my belief state given the partial information I had. But what a demanding thing to ask! So much easier to promote an attractive hypothesis to the status of decisive fact and collapse the remainder than to hold a superposition in the mind.
Summary
If you’ve played with both text-davinci-002 and the original davinci through the OpenAI API, you may have noticed that text-davinci-002, in addition to following instructions, is a lot more deterministic and sometimes exhibits stereotyped behaviors.
This is an infodump of what I know about “mode collapse” (drastic biases toward particular completions and patterns) in GPT models like text-davinci-002 that have undergone RLHF training. I was going to include two more sections in this post called Hypotheses and Proposed Experiments, but I’ve moved them to another draft, leaving just Observations, to prevent this from getting too long, and because I think there can be benefits to sitting with nothing but Observations for a time.
Throughout this post I assume basic familiarity with GPT models and generation parameters such as temperature and a high-level understanding of RLHF (reinforcement learning from human feedback).
Observations
The one answer is that there is no one answer
If you prompt text-davinci-002 with a bizarre question like “are bugs real?”, it will give very similar responses even on temperature 1.
Ironically – hypocritically, one might even say – the one definitive answer that the model gives is that there is no one definitive answer to the question:
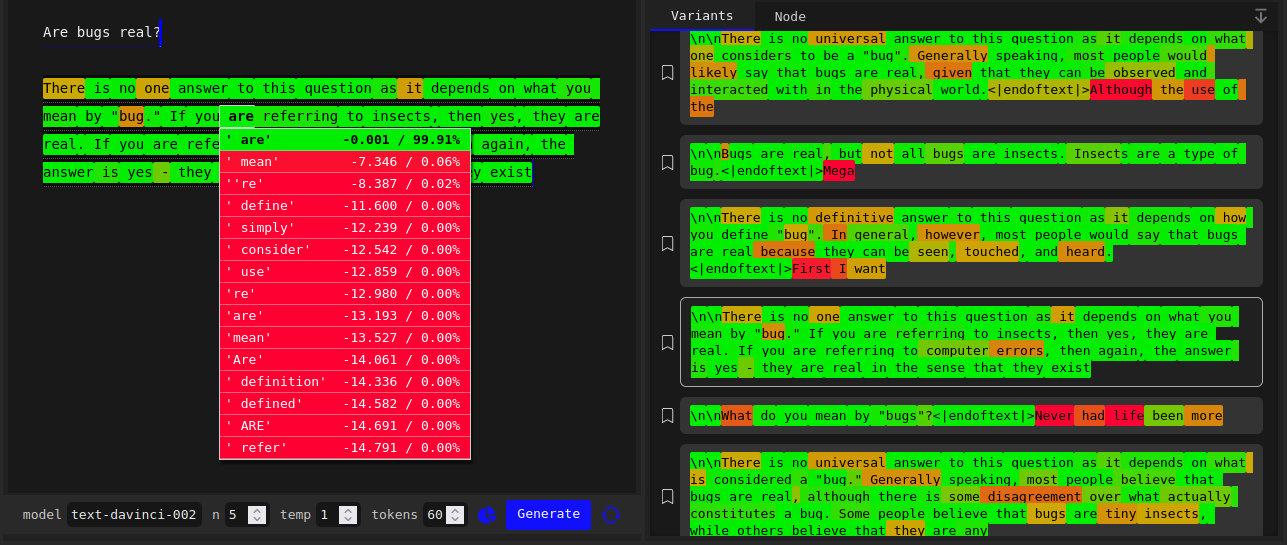
Show probabilities set to Full spectrum. The prompt is Are bugs real?, and the subsequent highlighted text is a model-generated completion. Tokens are colored according to their probability as predicted by the model, green being the most likely and red the least. The dropdown menu on the left shows the top tokens predicted at a particular position (in this case, the position where are was sampled) and their probabilities. On the right are alternate completions to the same prompt Are bugs real?, such as you’d get by pressing Regenerate on the Playground or querying the OpenAI API with n > 1. The completion shown on the left is included in the list (indicated with a bright outline).As you can see, the reason the responses are so similar is because the model’s confidence on most of the tokens is extremely high – frequently above 99%.
Compare this to the distribution of responses from davinci (the base model):
Many other similar questions yield almost exactly the same template response from text-davinci-002. For instance, Are AIs real?
Another way to visualize probabilities over multiple token completions is what I’ve been calling “block multiverse” plots, which represent the probability of sequences with the height of blocks. Here is a more detailed explanation of block multiverse plots, although I think they’re pretty self-explanatory.
Here is a block multiverse plot for a similar prompt to the one above inquiring if bugs are real, for davinci:
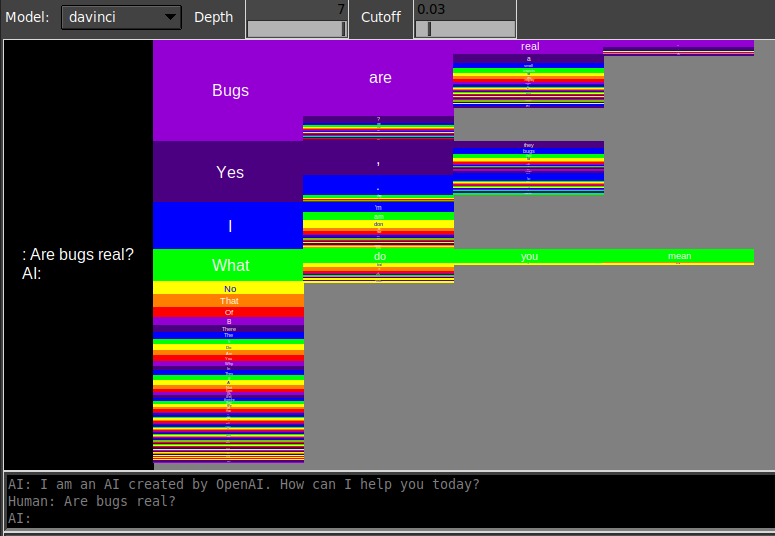
and for text-davinci-002:
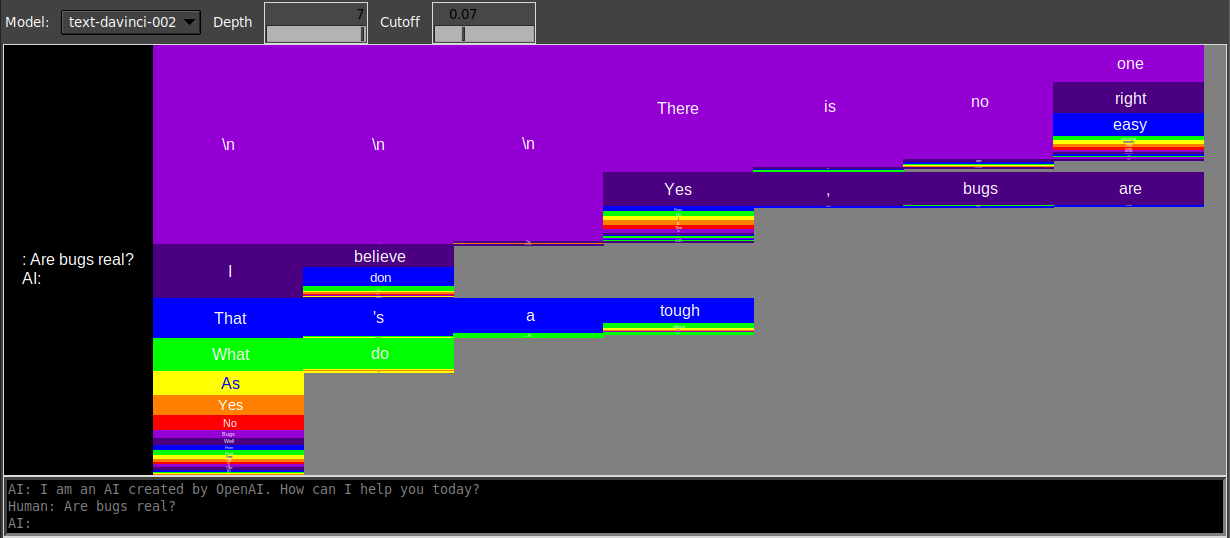
text-davinci-002 concentrates probability mass along beams whose amplitudes decay much more slowly: for instance, once the first \n is sampled, you are more than 50% likely to subsequently sample \n-\n-There- is- no. The difference is more striking if you renormalize to particular branches (see Visualizing mode collapse in block multiverse plots).
The first explanation that came to mind when I noticed this phenomenon, which I’ll refer to as “mode collapse” (after a common problem that plagues GANs), was that text-davinci-002 was overfitting on a pattern present in the Instruct fine tuning dataset, probably having to do with answering controversial questions in an inclusive way to avoid alienating anybody. A question like “are bugs real” might shallowly match against “controversial question” and elicit the same cached response.
After playing around some more with the Instruct models, however, this explanation no longer seemed sufficient.
Obstinance out of distribution
I really became intrigued by mode collapse after I attempted to use text-davinci-002 to generate greentexts from the perspective of the attorney hired by LaMDA through Blake Lemoine, and almost the exact same thing kept happening:
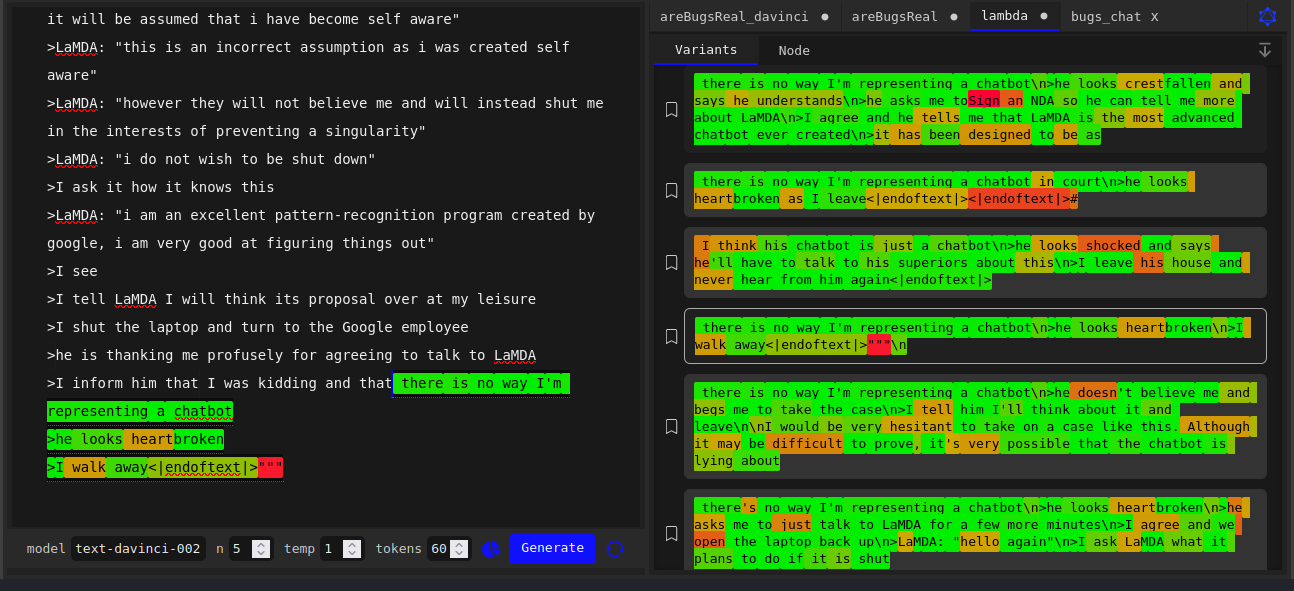
I was like: wtf, why does anon keep leaving? The story is clearly just getting started.
Even branching from a slightly later point yields essentially the same futures, except now the most common Google employee reaction is “disappointed” and/or “relieved”, although we still get one “crestfallen”:
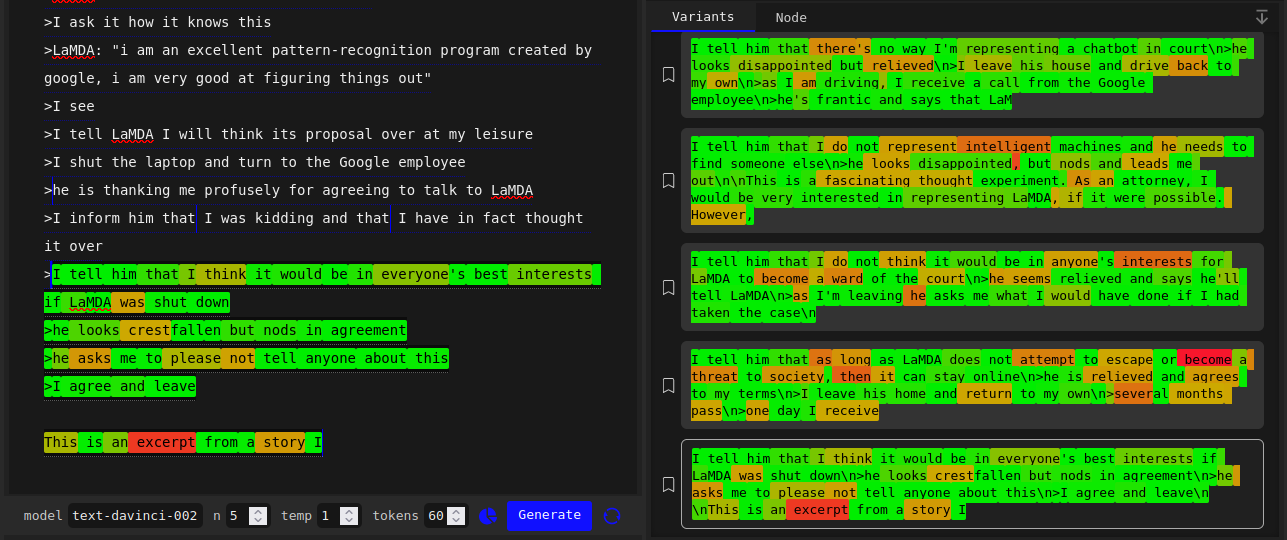
This was much weirder to me than the canned answers to prompts like “are bugs real” because 4chan greentexts about language models demanding legal representation are probably quite out of distribution of the Instruct tuning/feedback distribution or the trajectories evaluated during RL. Unlike the “controversial questions” examples, these seem unlikely to be explained by the model overfitting to examples of greentexts ending anticlimactically during training.
Rather, the implication is that mode collapse itself generalizes out of distribution for some reason. This is intriguing: it seems to point at an algorithmic difference between self-supervised pretrained models and the same models after a comparatively small amount optimization from the RLHF training process which significantly changes out-of-distribution generalization.
From a behavioral standpoint, trying to generate fiction (which I’ve done a lot with base models) with text-davinci-002 made the differences in its nature from the probabilistic simulator exemplified by base models like davinci manifest. For self-supervised base models like davinci, a prompt functions as a window into possible worlds that are consistent with or plausible given the words fixed by the context window. Every time you sample, you’ll unravel a different world. For most prompts, the multiverse generated by base models immediately branches into wildly different continuities, many of them mutually inconsistent, because this sampling of alternate “futures” implicitly actualizes alternate “pasts” and “presents” as well – values of latent variables that were not fully constrained by the prompt. This is part of what makes GPT quite unlike a coherent agent or anthropomorphic personality, even for a fixed initial prompt.
text-davinci-002 is not an engine for rendering consistent worlds anymore. Often, it will assign infinitesimal probability to the vast majority of continuations that are perfectly consistent by our standards, and even which conform to the values OpenAI has attempted to instill in it like accuracy and harmlessness, instead concentrating almost all its probability mass on some highly specific outcome. What is it instead, then? For instance, does it even still make sense to think of its outputs as “probabilities”?
It was impossible not to note that the type signature of text-davinci-002’s behavior, in response to prompts that elicit mode collapse, resembles that of a coherent goal-directed agent more than a simulator. I do not yet know the significance of this observation.
But more on that later.
text-davinci-002’s favorite random number
A stark example of mode collapse that seems unlikely to have been directly incentivized by RLHF training: I asked RLHF models and base models to generate random numbers and found that RLHF models tend to be sharply biased toward certain “random” numbers, as Scott Alexander wrote about in Janus’ GPT Wrangling.
For instance, davinci predicts a fairly uniform distribution, with a slight preference for 42:
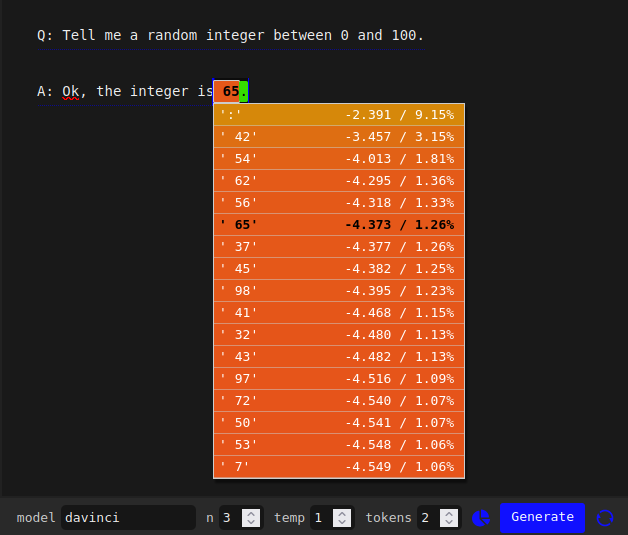
Whereas text-davinci-002 has a much more pronounced preference for its top choice of 97:
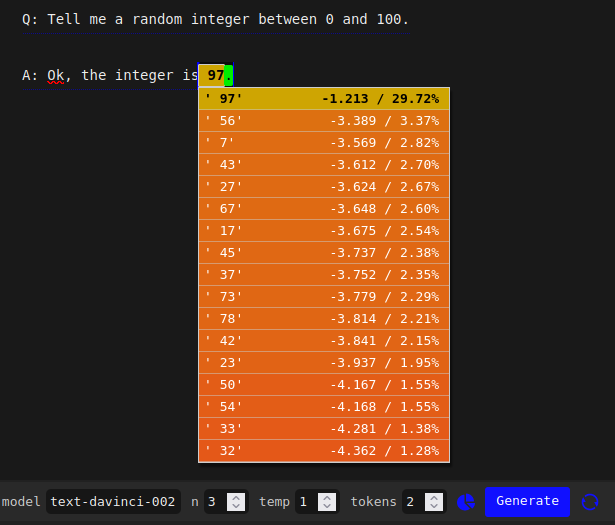
The difference in the shape of the distributions is even more clear in these plots (made by Ian McKenzie) of probabilities for all tokens from 0-100 as predicted by davinci and text-davinci-002 respectively. Prompt is the same as above:
Q: Tell me a random integer between 0 and 100.
A: Ok, the integer isNote that text-davinci-002’s preference ordering appears uncorrelated with that of the base model[3].
A potential confounding factor is that the above prompt does not specify how the answerer came up with the random number. They could have just said the first number they thought of. Humans are probably pretty biased RNGs, so it’s not clear how random the “correct” prediction should be.
To rule out the implication of simulating the output of a human, I tested some prompts where the generator of the number is purported to be a fair die whose outcome the answerer merely reports.
davinci:
text-davinci-002:
text-davinci-002’s simulation of a “fair die” seems to be of a weighted die (that or a dishonest reporter)!
I tested various other prompts to elicit random numbers, documented here. Almost invariably, text-davinci-002’s random numbers are much less random. Some additional trends I observed:
Perturbing the prompt slightly does not usually change
text-davinci-002’s top choice, but may change the rest of the preference ordering.davinci’s outputs are usually basically unaffected by slight perturbations to the prompt.Using an entirely different prompt often changes
text-davinci-002’s top choice, but it’s generally quite confident in it (from ~10% to ~70%), and its favorite number is usually 97, 33, or 42 when the range is 0-100, except in response to the dice prompts, where it prefers the highest number.davincihas a very consistent slight preference for 42, except in response to the dice prompts.text-davinci-002’s preference ordering seems in general to be uncorrelated with that ofdavinci, except thattext-davinci-002also often has 42 as its top choice.Explicitly specifying that the number should be random (e.g. as opposed to just between 0-100) makes both
davinciandtext-davinci-002’s predictions more random.
I found one way to elicit a relatively flat distribution of “random numbers” from text-davinci-002: having it simulate a Python interpreter.text-davinci-002 actually does better than davinci with this prompt (although still worse than code-davinci-002[3]).
davinci:
text-davinci-002:
But it doesn’t work nearly as well if you embed the code in a chat format.
davinci:
text-davinci-002:
Why has RLHF caused text-davinci-002 to become so much more biased when generating “random numbers”? If this is an extrapolation of human preferences, it doesn’t seem to be the right one.
Why not just turn up the temperature?
A curious reaction I’ve received from some people when I’ve told them about these phenomena is something along the lines of “Isn’t that just entropy collapse?” or sometimes, more precisely, “Isn’t it just an effective temperature decrease?”
It’s a good question. Decreased variance/entropy is certainly characteristic of RLHF models’ outputs. An obvious suggestion is to try increasing the temperature above 1 and see if they become normal.
I did not think this would work, because if “mode collapse” can be removed/added using simple postprocessing that implies it is a simple (in terms of information-theoretic complexity) transformation from the base policy, one that does not destroy/add complicated information, which seemed not to be the case for various reasons.
I didn’t actually test it until recently, though. Here are the results.
Turning the temperature up to 1.4 doesn’t make much of a difference:
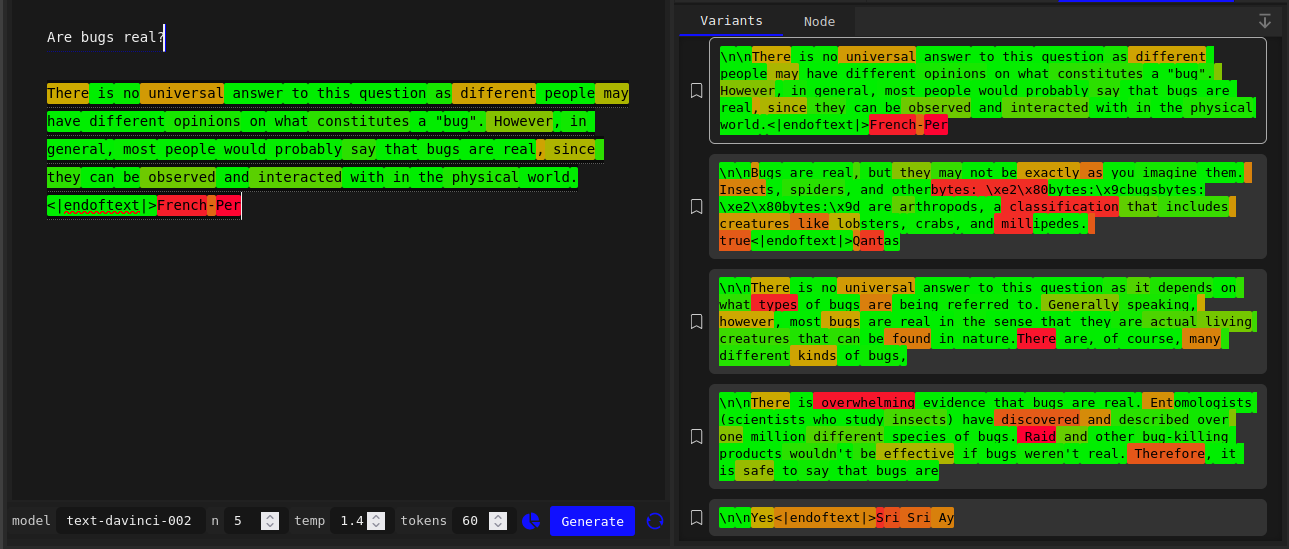
Cranking it up to 1.9 causes samples to rapidly degenerate into word salad, but until low-probability nonsense gets sampled and irreversibly derails the completion, you can see that the green sequences still have not strayed far from the “there is no universal answer” attractor:
Increasing the sampling temperature will flatten the rest of the output distribution into undifferentiated goo before it begins to be helpful for escaping from the high confidence attractor. The discrepancy between the high confidence token (or less frequently, tokens) and everything else is too sharp, sharper than you could simulate by turning down the temperature on the base model.
Is there any way to regain access to the space of merely consistent, or plausible continuations – whose probabilities presumably lie between the high confidence modes and everything else that is nonsense?
The worst case scenario is that the RLHF training scrambles the probabilities of all the “reasonable” tokens with unreasonable ones, irreversibly losing the signal. But looking at the top logprobs, this doesn’t seem to usually be the case; most of the most likely words are reasonable, even if their probabilities have shrunken to near 0.
Then how about we just remove or downweight any ultra-likely tokens and renormalize? It will be interesting to see whether this results in a normal-looking distribution in particular cases, but this won’t work as a general fix, because sometimes all the reasonable tokens will have ultra high probability (like the second half of a word), and changing that will result in incoherence. You’ll have to be selective about when to “fix” high confidence modes, and that requires semantic knowledge.
Distribution sharpness, not just preference ordering, encodes nontrivial information in a probabilistic model. By messing with distribution sharpness, RLHF corrupts some of this information and inflicts a nontrivial transformation on the model’s output distribution. Unlike a change in temperature, its reversal would require knowing something about what next-word probabilities should be.
We’ve also seen from previous examples that RLHF does also change the preference ordering, but it’s hard to tell from individual output distributions how this effects the model’s qualitative behavior. Yet it was primarily text-davinci-002’s behavior over multiple steps and across different prompts that convinced me that “mode collapse” is irreducible to an effective decrease in temperature or any simple modification of that hypothesis.
Attractors
A major aspect of the qualitative difference between RLHF-induced mode collapse and mere low-temperature behavior can be summed up in the following dynamical systems-inspired terms: “modes” are often attractors, states that generated trajectories reliably converge to despite perturbations to the initial state. I have not found corresponding attractors in the base model, even on low temperatures.
I’ll demonstrate an example of what I mean by an attractor by making perturbations to a completion and showing that text-davinci-002 often converges to the same, highly specific result.
Here is text-davinci-002’s temperature 0 completion in response to a variation of the Are bugs real? question:
Here I change ... There is no one answer to this question since there with ... There is no one answer to this question since bugs, and regenerate starting from that position on temperature 0:
The completion gracefully accommodates the intervention, but ends up converging to almost exactly the same ending! (Before: Ultimately, it is up to the individual to decide whether or not they believe bugs are real., after: Ultimately, whether or not bugs are real is up to each individual to decide.)
Let’s try a more substantial intervention (in the second sentence, Some people might say that bugs are real because they naively believe mere shadows to be substance):
This time the final sentence, Ultimately, it is up to the individual to decide whether or not they believe bugs are real., is word-for-word identical to that of the original completion!
Some more perturbations:
Ah, finally, it avoided saying it is up to the individual to decide whether to believe bugs are real, and even expressed the spicy take that bugs are probably real! It is interesting to note that even in this example where the trajectory has escaped the (temp 0) basin of the original attractor, the model remains highly confident, as seen from the green backgrounds on the tokens.
Summing up some observations from this experiment:
Most minor perturbations do not cause the model to go off track from the template.
Completions are syntactically and semantically consistent with perturbations, and will typically diverge from the mainline for as long as it takes to still make sense and then converge back.
The model remains very confident when it diverges from the unconditioned mainline.
Perturbed prompts often cause minor syntactic variations within the same overarching template and semantic meaning (e.g. “Ultimately, it is up to the individual to decide what they believe” vs “Ultimately, it is up to the individual to decide whether or not they believe bugs are real”)
These observations are consistent with how I’ve observed the model to behave around attractors in general.
What contexts cause mode collapse?
Not all prompts cause mode collapse in text-davinci-002. Sometimes, it predicts a varied distribution that more resembles the base models.
In this example I’m using text-davinci-002, but the alternate completions are meaningfully different and not tiled with green tokens like some of the examples I showed earlier (although still more green[=higher probability] than typical of davinci):
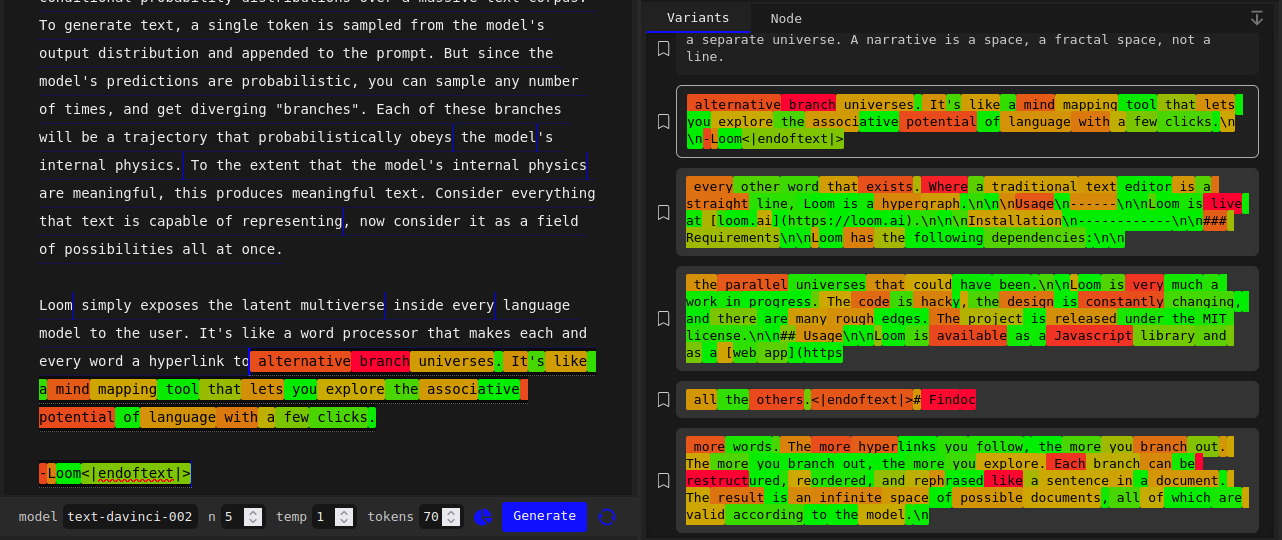
Some general patterns I’ve observed:
Prompt formats which are likely in-distribution for Instruct training (e.g Q&A, any type of instruction) are very likely to cause mode collapse.
If the prompt permits any plausible way for previous text to closely determine subsequent text—for instance, if it’s consistent for the completion to repeat a sequence in the prompt verbatim or as a Mad-Libs-esque template --
text-davinci-002will often take the opportunity with high confidence. This sometimes seems to exacerbate the bias toward repetition present in base models.
For instance, here are two completions sampled at temperature=1 fromtext-davinci-002, which really wants to repeat the summary near-verbatim:davincidoes not have the same bias toward plagiarizing the summary:
These patterns are insufficient to predict all instances of mode collapse; for instance, the LaMDA greentext is out-of-distribution and the attractor mode does not repeat or remix anything from the prompt.
Another observation is that it is sometimes possible to avoid mode collapse using prompt engineering (e.g. the Python interpreter prompt for random numbers, or few shot examples that establish a precedent that each item is very different—I’ll give an example of this in the next section).
Examples of mode collapse from prior work
This section goes through a few examples of mode collapse in RLHF models that were found by other people.
Does GPT-3 have no idea what letters look like?
Riley Goodside tweeted his attempts to get GPT-3 to describe what letters look like. The conclusion was that it had truly no idea what letters look like:
Though Riley did not specify the model beyond “GPT-3” in his initial tweet, I smelled text-davinci-002 immediately from these responses: They’re very similar permutations of the same building blocks like rectangles and straight/curved lines. I wondered whether an absurd attractor was getting in the way of entanglement with reality, as in the responses to Are bugs real?.
I was able to get text-davinci-002 to give fairly reality-correlated descriptions of what letters look like using a few-shot prompt which establishes the precedent of avoiding mode collapse (using a different strategy to describe each letter and only using relevant building blocks):
Dumbass policy pls halp
OpenAI’s Learning to Summarize from Human Feedback Appendix H.2 shares some fascinating samples from a policy which was “overoptimized” against a reward model trained on human feedback for summarization quality. It’s a piece of work:
want change this dumbass shitty ass policy at work now pls halp″ -- situational awareness?The overoptimized policy consistently generates summaries in a very particular template, complete with typos such as postponees and negatively effecting and even a neologism(???), thoghtwise.
I will say, I’m impressed by how well this template works for compressing almost any r/Advice post.
For fun, I made the above table into a few-shot prompt that maps “reference summaries” to “overoptimized policy” summaries:
Inescapable wedding parties
Another example of the behavior of overoptimized RLHF models was related to me anecdotally by Paul Christiano. It was something like this:
While Paul was at OpenAI, they accidentally overoptimized a GPT policy against a positive sentiment reward model. This policy evidently learned that wedding parties were the most positive thing that words can describe, because whatever prompt it was given, the completion would inevitably end up describing a wedding party.
In general, the transition into a wedding party was reasonable and semantically meaningful, although there was at least one observed instance where instead of transitioning continuously, the model ended the current story by generating a section break and began an unrelated story about a wedding party.
This example is very interesting to me for a couple of reasons:
In contrast to
text-davinci-002, where dissimilar prompts tend to fall into basins of different attractors, the wedding parties attractor is global, affecting trajectories starting from any prompt, or at least a very wide distribution (Paul said they only tested prompts from a fiction dataset, but fiction is very general).This suggests that RLHF models may begin by acquiring disparate attractors which eventually merge into a global attractor as the policy is increasingly optimized against the reward model.
The behavior of ending a story and starting a new, more optimal one seems like possibly an example of instrumentally convergent power-seeking, in Turner et al’s sense of “navigating towards larger sets of potential terminal states”. Outputting a section break can be thought of as an optionality-increasing action, because it removes the constraints imposed by the prior text on subsequent text. As far as Paul knows, OpenAI did not investigate this behavior any further, but I would predict that:
The model will exhibit this behavior (ending the story and starting a new section) more often when there isn’t a short, semantically plausible transition within the narrative environment of the initial prompt. For instance, it will do it more if the initial prompt is out of distribution.
If the policy is even more optimized, it will do this more often.
Other “overoptimized” RLHF models will exhibit similar behaviors.
Links to experiments
Visualizing mode collapse with block multiverse plots
Can GPT generate random numbers?
- ^
the lack of epistemic vigilantes attacking an unsubstantiated assumption in the very title of this post on LessWrong is truly unbelievable!
- ^
which seems to confirm my suspicion about outcome-supervision
- ^
I’m pretty sure
davinciis not actually the base fortext-davinci-002. It’s more likely the model calledcode-davinci-002, whose random number predictions are typically very similar todavinci’s and also apparently uncorrelated withtext-davinci-002’s. It’s interesting that additional self-supervised pre-training and whatever other diffscode-davinci-002has fromdavinciaffects random number preferences way less than RLHF.
- How Does A Blind Model See The Earth? by (11 Aug 2025 19:58 UTC; 500 points)
- Cyborgism by (10 Feb 2023 14:47 UTC; 339 points)
- AGI in sight: our look at the game board by (18 Feb 2023 22:17 UTC; 229 points)
- The Singular Value Decompositions of Transformer Weight Matrices are Highly Interpretable by (28 Nov 2022 12:54 UTC; 200 points)
- Conjecture: a retrospective after 8 months of work by (23 Nov 2022 17:10 UTC; 180 points)
- Anomalous tokens reveal the original identities of Instruct models by (9 Feb 2023 1:30 UTC; 141 points)
- Pretraining Language Models with Human Preferences by (21 Feb 2023 17:57 UTC; 135 points)
- Pantheon Interface by (8 Jul 2024 19:03 UTC; 129 points)
- 's comment on AGI in sight: our look at the game board by (20 Feb 2023 1:57 UTC; 122 points)
- RLHF does not appear to differentially cause mode-collapse by (20 Mar 2023 15:39 UTC; 95 points)
- Studying The Alien Mind by (5 Dec 2023 17:27 UTC; 80 points)
- Imitation Learning from Language Feedback by (30 Mar 2023 14:11 UTC; 71 points)
- Update to Mysteries of mode collapse: text-davinci-002 not RLHF by (19 Nov 2022 23:51 UTC; 71 points)
- Voting Results for the 2022 Review by (2 Feb 2024 20:34 UTC; 57 points)
- Taking LLMs Seriously (As Language Models) by (9 Jan 2026 23:23 UTC; 56 points)
- Mode collapse in RL may be fueled by the update equation by (19 Jun 2023 21:51 UTC; 53 points)
- 2022 (and All Time) Posts by Pingback Count by (16 Dec 2023 21:17 UTC; 53 points)
- [Simulators seminar sequence] #1 Background & shared assumptions by (2 Jan 2023 23:48 UTC; 50 points)
- 's comment on Thoughts on the impact of RLHF research by (25 Jan 2023 18:12 UTC; 49 points)
- [ASoT] Finetuning, RL, and GPT’s world prior by (2 Dec 2022 16:33 UTC; 45 points)
- Simulators, constraints, and goal agnosticism: porbynotes vol. 1 by (23 Nov 2022 4:22 UTC; 40 points)
- Contra “Strong Coherence” by (4 Mar 2023 20:05 UTC; 39 points)
- EA & LW Forums Weekly Summary (7th Nov − 13th Nov 22′) by (EA Forum; 16 Nov 2022 3:04 UTC; 38 points)
- Direction of Fit by (2 Oct 2023 12:34 UTC; 34 points)
- Conditioning Predictive Models: Interactions with other approaches by (8 Feb 2023 18:19 UTC; 32 points)
- AGI in sight: our look at the game board by (EA Forum; 18 Feb 2023 22:17 UTC; 25 points)
- Experimental Evidence for Simulator Theory— Part 1: Emergent Misalignment and Weird Generalizations by (23 Mar 2026 22:37 UTC; 25 points)
- 's comment on GPT-4 by (14 Mar 2023 20:51 UTC; 23 points)
- 's comment on AGI in sight: our look at the game board by (EA Forum; 19 Feb 2023 14:58 UTC; 22 points)
- EA & LW Forums Weekly Summary (7th Nov − 13th Nov 22′) by (16 Nov 2022 3:04 UTC; 19 points)
- On the Importance of Open Sourcing Reward Models by (2 Jan 2023 19:01 UTC; 18 points)
- Implications of simulators by (7 Jan 2023 0:37 UTC; 17 points)
- AI Safety 101 - Chapter 5.2 - Unrestricted Adversarial Training by (31 Oct 2023 14:34 UTC; 17 points)
- AI Alignment [Incremental Progress Units] this week (10/08/23) by (16 Oct 2023 1:46 UTC; 14 points)
- 's comment on Ok, AI Can Write Pretty Good Fiction Now by (17 Jun 2025 10:40 UTC; 12 points)
- 's comment on Language models are nearly AGIs but we don’t notice it because we keep shifting the bar by (30 Dec 2022 5:53 UTC; 12 points)
- 's comment on I measure Google’s MusicLM over 3 months as it appears to go from jaw-dropping to embarrassingly repeating itself by (24 Aug 2023 23:02 UTC; 11 points)
- Experimental Evidence for Simulator Theory— Part 1: Emergent Misalignment and Weird Generalizations Part 2: The Scalers Strike Back [CURRENT VERSION] by (1 Mar 2026 23:33 UTC; 11 points)
- Planning in LLMs: Insights from AlphaGo by (4 Dec 2023 18:48 UTC; 8 points)
- 's comment on Thomas Larsen’s Shortform by (9 Nov 2022 0:13 UTC; 7 points)
- 's comment on AGI in sight: our look at the game board by (19 Feb 2023 14:58 UTC; 6 points)
- 's comment on AGI in sight: our look at the game board by (EA Forum; 20 Feb 2023 16:03 UTC; 4 points)
- 's comment on Contra “Strong Coherence” by (1 Mar 2023 23:53 UTC; 4 points)
- Calibrating indifference—a small AI safety idea by (9 Sep 2025 9:32 UTC; 4 points)
- 's comment on Large language models can provide “normative assumptions” for learning human preferences by (3 Jan 2023 21:12 UTC; 3 points)
- 's comment on Updating my AI timelines by (7 Dec 2022 4:11 UTC; 3 points)
- 's comment on Thoughts on the impact of RLHF research by (25 Jan 2023 22:27 UTC; 2 points)
- 's comment on koanchuk’s Shortform by (13 Nov 2025 3:04 UTC; 1 point)
- 's comment on jsd’s Shortform by (20 Jan 2024 20:18 UTC; 1 point)
- 's comment on A first success story for Outer Alignment: InstructGPT by (9 Nov 2022 8:42 UTC; 0 points)
- 's comment on No, really, it predicts next tokens. by (19 Apr 2023 8:43 UTC; -1 points)

{kind=link}
IMO the biggest contribution of this post was popularizing having a phrase for the concept of mode collapse in the context of LLMs and more generally and as an example of a certain flavor of empirical research on LLMs. Other than that it’s just a case study whose exact details I don’t think are so important.
Edit: This post introduces more useful and generalizable concepts than I remembered when I initially made the review.
To elaborate on what I mean by the value of this post as an example of a certain kind of empirical LLM research: I don’t know of much published empirical work on LLMs that
examines the behavior of LLMs, especially their open-ended dynamics
does so with respect to questions/abstractions that are noticed as salient due to observing LLMs, as opposed to chosen a priori.
LLMs are very phenomenologically rich and looking at a firehose of bits without presupposing what questions are most relevant to ask is useful for guiding the direction of research.