AI strategy & governance. ailabwatch.org. ailabwatch.substack.com.
Zach Stein-Perlman
Karma: 9,962
[Perfunctory review to get this post to the final phase]
Solid post. Still good. I think a responsible developer shouldn’t unilaterally pause but I think it should talk about the crazy situation it’s in, costs and benefits of various actions, what it would do in different worlds, and its views on risks. (And none of the labs have done this; in particular Core Views is not this.)
List of AI safety papers from companies, 2023–2024
One more consideration against (or an important part of “Bureaucracy”): sometimes your lab doesn’t let you publish your research.
Yep, the final phase-in date was in November 2024.
Some people have posted ideas on what a reasonable plan to reduce AI risk for such timelines might look like (e.g. Sam Bowman’s checklist, or Holden Karnofsky’s list in his 2022 nearcast), but I find them insufficient for the magnitude of the stakes (to be clear, I don’t think these example lists were intended to be an extensive plan).
See also A Plan for Technical AI Safety with Current Science (Greenblatt 2023) for a detailed (but rough, out-of-date, and very high-context) plan.
Yeah. I agree/concede that you can explain why you can’t convince people that their own work is useless. But if you’re positing that the flinchers flinch away from valid arguments about each category of useless work, that seems surprising.
I feel like John’s view entails that he would be able to convince my friends that various-research-agendas-my-friends-like are doomed. (And I’m pretty sure that’s false.) I assume John doesn’t believe that, and I wonder why he doesn’t think his view entails it.
I wonder whether John believes that well-liked research, e.g. Fabien’s list, is actually not valuable or rare exceptions coming from a small subset of the “alignment research” field.
I do not.
On the contrary, I think ~all of the “alignment researchers” I know claim to be working on the big problem, and I think ~90% of them are indeed doing work that looks good in terms of the big problem. (Researchers I don’t know are likely substantially worse but not a ton.)
In particular I think all of the alignment-orgs-I’m-socially-close-to do work that looks good in terms of the big problem: Redwood, METR, ARC. And I think the other well-known orgs are also good.
This doesn’t feel odd: these people are smart and actually care about the big problem; if their work was in the even if this succeeds it obviously wouldn’t be helpful category they’d want to know (and, given the “obviously,” would figure that out).
Possibly the situation is very different in academia or MATS-land; for now I’m just talking about the people around me.
Yeah, I agree sometimes people decide to work on problems largely because they’re tractable [edit: or because they’re good for safety getting alignment research or other good work out of early AGIs]. I’m unconvinced of the flinching away or dishonest characterization.
This post starts from the observation that streetlighting has mostly won the memetic competition for alignment as a research field, and we’ll mostly take that claim as given. Lots of people will disagree with that claim, and convincing them is not a goal of this post.
Yep. This post is not for me but I’ll say a thing that annoyed me anyway:
… and Carol’s thoughts run into a blank wall. In the first few seconds, she sees no toeholds, not even a starting point. And so she reflexively flinches away from that problem, and turns back to some easier problems.
Does this actually happen? (Even if you want to be maximally cynical, I claim presenting novel important difficulties (e.g. “sensor tampering”) or giving novel arguments that problems are difficult is socially rewarded.)
DeepSeek-V3 is out today, with weights and a paper published. Tweet thread, GitHub, report (GitHub, HuggingFace). It’s big and mixture-of-experts-y; discussion here and here.
It was super cheap to train — they say 2.8M H800-hours or $5.6M (!!).
It’s powerful:
It’s cheap to run:
oops thanks
Update: the weights and paper are out. Tweet thread, GitHub, report (GitHub, HuggingFace). It’s big and mixture-of-experts-y; thread on notable stuff.
It was super cheap to train — they say 2.8M H800-hours or $5.6M.
It’s powerful:
It’s cheap to run:
Every now and then (~5-10 minutes, or when I look actively distracted), briefly check in (where if I’m in-the-zone, this might just be a brief “Are you focused on what you mean to be?” from them, and a nod or “yeah” from me).
Some other prompts I use when being a [high-effort body double / low-effort metacognitive assistant / rubber duck]:
What are you doing?
What’s your goal?
Or: what’s your goal for the next n minutes?
Or: what should be your goal?
Are you stuck?
Follow-ups if they’re stuck:
what should you do?
can I help?
have you considered asking someone for help?
If I don’t know who could help, this is more like prompting them to figure out who could help; if I know the manager/colleague/friend who they should ask, I might use that person’s name
Maybe you should x
If someone else was in your position, what would you advise them to do?
All of the founders committed to donate 80% of their equity. I heard it’s set aside in some way but they haven’t donated anything yet. (Source: an Anthropic human.)
This fact wasn’t on the internet, or rather at least wasn’t easily findable via google search. Huh. I only find Holden mentioning 80% of Daniela’s equity is pledged.
I disagree with Ben. I think the usage that Mark is talking about is a reference to Death with Dignity. A central example (written by me) is
it would be undignified if AI takes over because we didn’t really try off-policy probes; maybe they just work really well; someone should figure that out
It’s playful and unserious but “X would be undignified” roughly means “it would be an unfortunate error if we did X or let X happen” and is used in the context of AI doom and our ability to affect P(doom).
edit: wait likely it’s RL; I’m confused
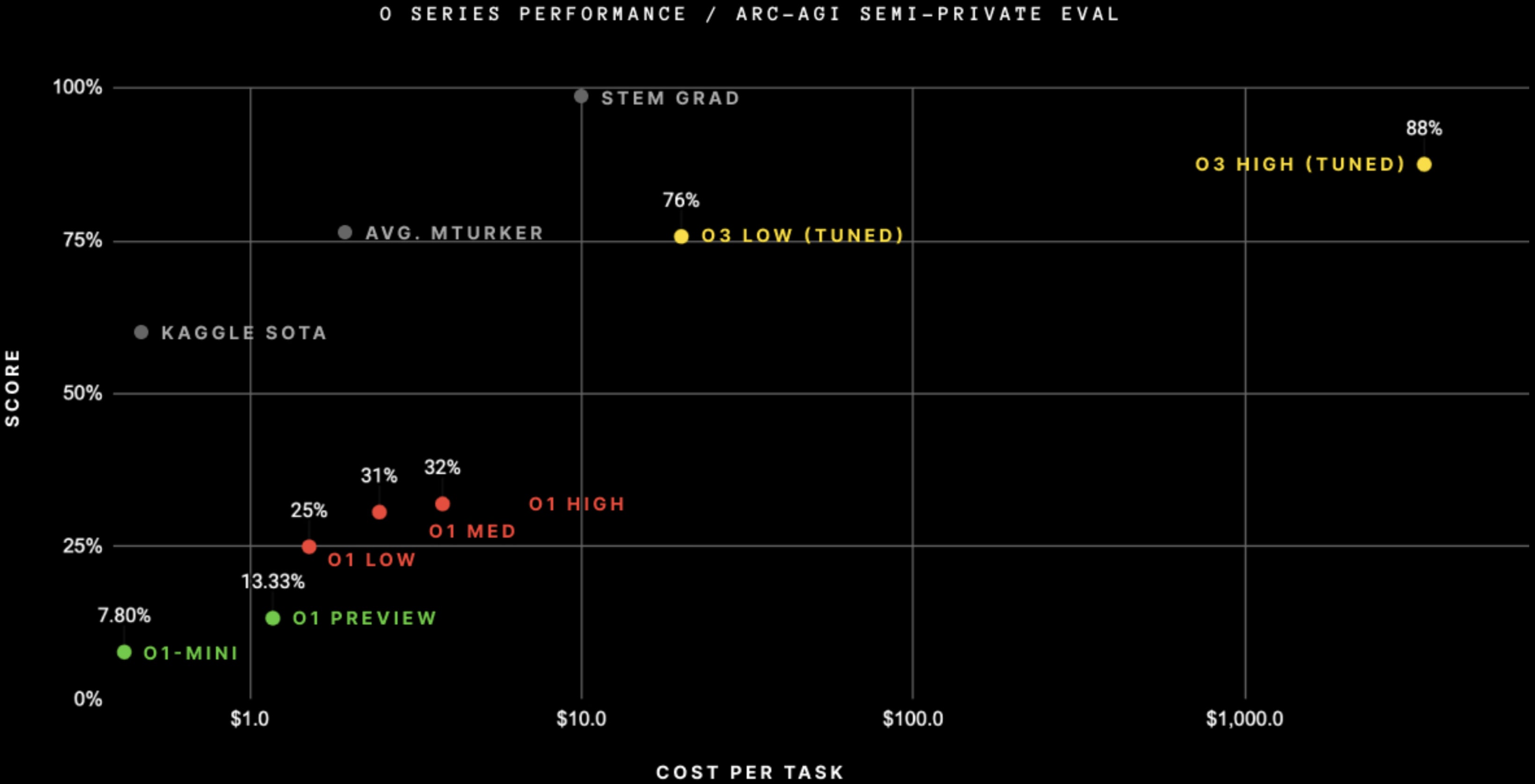
OpenAI didn’t fine-tune on ARC-AGI, even though this graph suggests they did.
Sources:
Altman said
we didn’t go do specific work [targeting ARC-AGI]; this is just the general effort.
François Chollet (in the blogpost with the graph) said
Note on “tuned”: OpenAI shared they trained the o3 we tested on 75% of the Public Training set. They have not shared more details. We have not yet tested the ARC-untrained model to understand how much of the performance is due to ARC-AGI data.
The version of the model we tested was domain-adapted to ARC-AGI via the public training set (which is what the public training set is for). As far as I can tell they didn’t generate synthetic ARC data to improve their score.
An OpenAI staff member replied
Correct, can confirm “targeting” exclusively means including a (subset of) the public training set.
and further confirmed that “tuned” in the graph is
a strange way of denoting that we included ARC training examples in the O3 training. It isn’t some finetuned version of O3 though. It is just O3.
Another OpenAI staff member said
also: the model we used for all of our o3 evals is fully general; a subset of the arc-agi public training set was a tiny fraction of the broader o3 train distribution, and we didn’t do any additional domain-specific fine-tuning on the final checkpoint
So on ARC-AGI they just pretrained on 300 examples (75% of the 400 in the public training set). Performance is surprisingly good.
[heavily edited after first posting]
Welcome!
To me the benchmark scores are interesting mostly because they suggest that o3 is substantially more powerful than previous models. I agree we can’t naively translate benchmark scores to real-world capabilities.
See The case for ensuring that powerful AIs are controlled.