I do AI Alignment research. Currently at METR, but previously at: Redwood Research, UC Berkeley, Good Judgment Project.
I’m also a part-time fund manager for the LTFF.
Obligatory research billboard website: https://chanlawrence.me/
I do AI Alignment research. Currently at METR, but previously at: Redwood Research, UC Berkeley, Good Judgment Project.
I’m also a part-time fund manager for the LTFF.
Obligatory research billboard website: https://chanlawrence.me/
I’m not sure your results really support the interpretation that davinci “transfers less well”. Notably, achieving 100% accuracy from 50% is often a lot harder than achieving 50% from 0%/whatever random chance is on your datasets (I haven’t looked through your code yet to examine the datasets) and I’d predict that davinci already does pretty well zero-shot (w/ no finetuning) on most of the tasks you consider here (which limits its improvement from finetuning, as you can’t get above 100% accuracy).
In addition, larger LMs are often significantly more data efficient, so you’d predict that they need less total finetuning to do well on tasks (and therefore the additional finetuning on related tasks would benefit the larger models less).
This was shamelessly copied from directly inspired by Erik Jenner’s “How my views on AI have changed over the last 1.5 years”. I think my views when I started my PhD in Fall 2018 look a lot worse than Erik’s when he started his PhD, though in large part due to starting my PhD in 2018 and not 2022.
Apologies for the disorganized bullet points. If I had more time I would’ve written a shorter shortform.
Summary: I used to believe in a 2018-era MIRI worldview for AGI, and now I have updated toward slower takeoff, fewer insights, and shorter timelines.
In Fall of 2018, my model of how AGI might happen was substantially influenced by AlphaGo/Zero, which features explicit internal search. I expected future AIs to also feature explicit internal search over world models, and be trained mainly via reinforcement learning or IDA. I became more uncertain after OpenAI 5 (~May 2018), which used no clever techniques and just featured BPTT being ran on large LSTMs.
That being said, I did not believe in the scaling hypothesis—that is, that simply training larger models on more inputs would continually improve performance until we see “intelligent behavior”—until GPT-2 (2019), despite encountering it significantly earlier (e.g. with OpenAI 5, or speaking to OAI people).
In particular, I believed that we needed many “key insights” about intelligence before we could make AGI. This both gave me longer timelines and also made me believe more in fast take-off.
I used to believe pretty strongly in MIRI-style fast take-off (e.g. would’ve assigned <30% credence that we see a 4 year period with the economy doubling) as opposed to (what was called at the time) Paul-style slow take-off. Given the way the world has turned out, I have updated substantially. While I don’t think that AI development will be particularly smooth, I do expect it to be somewhat incremental, and I also expect earlier AIs to provide significantly more value even before truly transformative aI.
-- Some beliefs about AI Scaling Labs that I’m redacting on LW --
My timelines are significantly shorter—I would’ve probably said median 2050-60 in 2018, but now I think we will probably reach human-level AI by 2035.
Summary: I have become more optimistic about AI X-risk, but my understanding has become more nuanced.
My P(Doom) has substantially decreased, especially P(Doom) attributable to an AI directly killing all of humanity. This is somewhat due to having more faith that many people will be reasonable (in 2018, there were maybe ~20 FTE AIS researchers, now there are probably something like 300-1000 depending on how you count), somewhat due to believing that governance efforts may successfully slow down AGI substantially, and somewhat due to an increased belief that “winging-it”—style, “unprincipled” solutions can scale to powerful AIs.
That being said, I’m less sure about what P(Doom) means. In 2018, I imagined the main outcomes were either “unaligned AGI instantly defeats all of humanity” and “a pure post-scarcity utopia”. I now believe in a much wider variety of outcomes.
For example, I’ve become more convinced both that misuse risk is larger than I thought, and that even weirder outcomes are possible (e.g. the AI keeps human (brain scans) around due to trade reasons). The former is in large part related to my belief in fast take-off being somewhat contradicted by world events; now there is more time for powerful AIs to be misused.
I used to think that solving the technical problem of AI alignment would be necessary/sufficient to prevent AI x-risk. I now think that we’re unlikely to “solve alignment” in a way that leads to the ability to deploy a powerful Sovereign AI (without AI assistance), and also that governance solutions both can be helpful and are required.
Summary: I’ve updated slightly downwards on the value of conceptual work and significantly upwards on the value of fast empirical feedback cycles. I’ve become more bullish on (mech) interp, automated alignment research, and behavioral capability evaluations.
In Fall 2018, I used to think that IRL for ambitious value learning was one of the most important problems to work on. I no longer think so, and think that most of my work on this topic was basically useless.
In terms of more prosaic IRL problems, I very much lived in a frame of “the reward models are too dumb to understand” (a standard academic take) . I didn’t think much about issues of ontology identification or (malign) partial observability.
I thought that academic ML theory had a decent chance of being useful for alignment. I think it’s basically been pretty useless in the past 5.5 years, and no longer think the chances of it being helpful “in time” are enough. It’s not clear how much of this is because the AIS community did not really know about the academic ML theory work, but man, the bounds turned out to be pretty vacuous, and empirical work turned out far more informative than pure theory work.
I still think that conceptual work is undervalued in ML, but my prototypical good conceptual work looks less like “prove really hard theorems” or “think about philosophy” and a lot more like “do lots of cheap and quick experiments/proof sketches to get grounding”.
Relatedly, I used to dismiss simple techniques for AI Alignment that try “the obvious thing”. While I don’t think these techniques will scale (or even necessarily work well on current AIs), this strategy has turned out to be significantly better in practice than I thought.
My error bars around the value of reading academic literature have shrunk significantly (in large part due to reading a lot of it). I’ve updated significantly upwards on “the academic literature will probably contain some relevant insights” and downwards on “the missing component of all of AGI safety can be found in a paper from 1983″.
I used to think that interpretability of deep neural networks was probably infeasible to achieve “in time” if not “actually impossible” (especially mechanistic interpretability). Now I’m pretty uncertain about its feasibility.
Similarly, I used to think that having AIs automate substantial amounts of alignment research was not possible. Now I think that most plans with a shot of successfully preventing AGI x-risk will feature substantial amounts of AI.
I used to think that behavioral evaluations in general would be basically useless for AGIs. I now think that dangerous capability evaluations can serve as an important governance tool.
Summary: I’ve better identified my comparative advantages, and have a healthier way of relating to AIS research.
I used to think that my comparative advantage was clearly going to be in doing the actual technical thinking or theorem proving. In fact, I used to believe that I was unsuited for both technical writing and pushing projects over the finish line. Now I think that most of my value in the past ~2 years has come from technical writing or by helping finish projects.
I used to think that pure engineering or mathematical skill were what mattered, and feel sad about how it seemed that my comparative advantage was something akin to long term memory.[1] I now see more value in having good long-term memory.
I used to be uncertain about if academia was a good place for me to do research. Now I’m pretty confident it’s not.
Embarrassingly enough, in 2018 I used to implicitly believe quite strongly in a binary model of “you’re good enough to do research” vs “you’re not good enough to do research”. In addition, I had an implicit model that the only people “good enough” were those who never failed at any evaluation. I no longer think this is true.
I am more of a fan of trying obvious approaches or “just doing the thing”.
I think, compared to the people around me, I don’t actually have that much “raw compute” or even short term memory (e.g. I do pretty poorly on IQ tests or novel math puzzles), and am able to perform at a much higher level by pattern matching and amortizing thinking using good long-term memory (if not outsourcing it entirely by quoting other people’s writing).
Right, the step I missed on was that P(X|Y) = P(X|Z) for all y, z implies P(X|Z) = P(X). Thanks!
Hm, it sounds like you’re claiming that if each pair of x, y, z are pairwise independent conditioned on the third variable, and p(x, y, z) =/= 0 for all x, y, z with nonzero p(x), p(y), p(z), then ?
I tried for a bit to show this but couldn’t prove it, let alone the general case without strong invariance. My guess is I’m probably missing something really obvious.
I agree that GSM8K has been pretty saturated (for the best frontier models) since ~GPT-4, and GPQA is designed to be a hard-to-saturated benchmark (though given the pace of progress...).
But why are HumanEval and MMLU also considered saturated? E.g. Opus and 4-Turbo are both significantly better than all other publicly known models on both benchmarks on both. And at least for HumanEval, I don’t see why >95% accuracy isn’t feasible.
It seems plausible that MMLU/HumanEval could be saturated after GPT-4.5 or Gemini 1.5 Ultra, at least for the best frontier models. And it seems fairly likely we’ll see them saturated in 2-3 years. But it seems like a stretch to call them saturated right now.
Is the reasoning for this is that Opus gets only 0.4% better on MMLU than the March GPT-4? That seems like pretty invalid reasoning, akin to deducing that because two runners achieve the same time, that that time is the best human-achievable time. And this doesn’t apply to HumanEval, where Opus gets ~18% better than March GPT-4 and the November 4-Turbo gets 2.9% better than Opus.
Probabilities of zero are extremely load-bearing for natural latents in the exact case, and probabilities near zero are load-bearing in the approximate case; if the distribution is zero nowhere, then it can only have a natural latent if the ’s are all independent (in which case the trivial variable is a natural latent).
I’m a bit confused why this is the case. It seems like in the theorems, the only thing “near zero” is that D_KL (joint, factorized) < epsilon ~= 0 . But you. can satisfy this quite easily even with all probabilities > 0.
E.g. the trivial case where all variables are completely independents satisfies all the conditions of your theorem, but can clearly have every pair of probabilities > 0. Even in nontrivial cases, this is pretty easy (e.g. by mixing in irreducible noise with every variable).
I’d like to caveat the comment you quoted above:
Also worth noting that Claude 3 does not substantially advance the LLM capabilities frontier! [..]
I wrote that before I had the chance to try replacing Claude 3 with GPT-4 in my daily workflow, based on its LLM benchmark scores compared to gpt-4-turbo variants. After having used it for a full day, I do feel like Claude 3 has noticeable advantages over GPT-4 in ways that aren’t captured by said benchmarks. So while I stand behind my claim that it “does not substantially advance the LLM capabilities frontier”, I do think that Claude 3 Opus is advancing the frontier at least a little.
In my experience, it seems to have noticeably better on coding and mathematical reasoning tasks, which was surprising to me given that it does worse on HumanEval and MATH. I guess they focused on delivering practically useful intelligence as opposed to optimizing for the benchmarks? (Or even optimized against the benchmarks?)
(EDIT: it’s also much better at convincing me that its made up math is real, lol)
I think that you’re correct that Anthropic at least heavily implied that they weren’t going to “meaningfully advance” the frontier (even if they have not made any explicit commitments about this). I’d be interested in hearing when Dustin had this conversation w/ Dario—was it pre or post RSP release?
And as far as I know, the only commitments they’ve made explicitly are in their RSP, which commits to limiting their ability to scale to the rate at which they can advance and deploy safety measures. It’s unclear if the “sufficient safety measures” limitation is the only restriction on scaling, but I would be surprised if anyone senior Anthropic was willing to make a concrete unilateral commitment to stay behind the curve.
My current story based on public info is, up until mid 2022, there was indeed an intention to stay at the frontier but not push it forward significantly. This changed sometime in late 2022-early 2023, maybe after ChatGPT released and the AGI race became somewhat “hot”.
He’d’ve probably been surprised to see people just… using it for stuff like DoTA2 on fully-differentiable BPTT RNNs. I wonder if he’s ever done any interviews on DL recently? AFAIK he’s still alive.
Sadly, Williams passed away this February: https://www.currentobituary.com/member/obit/282438
I wasn’t around in the community in 2010-2015, so I don’t know what the state of RL knowledge was at that time. However, I dispute the claim that rationalists “completely miss[ed] this [..] interpretation”:
To be honest, it was a major blackpill for me to see the rationalist community, whose whole whole founding premise was that they were supposed to be good at making efficient use of the available evidence, so completely missing this very straightforward interpretation of RL [..] the mechanistic function of per-trajectory rewards in a given batched update was to provide the weights of a linear combination of the trajectory gradients.
Ever since I entered the community, I’ve definitely heard of people talking about policy gradient as “upweighting trajectories with positive reward/downweighting trajectories with negative reward” since 2016, albeit in person. I remember being shown a picture sometime in 2016⁄17 that looks something like this when someone (maybe Paul?) was explaining REINFORCE to me: (I couldn’t find it, so reconstructing it from memory)
In addition, I would be surprised if any of the CHAI PhD students when I was at CHAI from 2017->2021, many of whom have taken deep RL classes at Berkeley, missed this “upweight trajectories in proportion to their reward” intepretation? Most of us at the time have also implemented various RL algorithms from scratch, and there the “weighting trajectory gradients” perspective pops out immediately.
As another data point, when I taught MLAB/WMLB in 2022⁄3, my slides also contained this interpretation of REINFORCE (after deriving it) in so many words:
Insofar as people are making mistakes about reward and RL, it’s not due to having never been exposed to this perspective.
That being said, I do agree that there’s been substantial confusion in this community, mainly of two kinds:
Confusing the objective function being optimized to train a policy with how the policy is mechanistically implemented: Just because the outer loop is modifying/selecting for a policy to score highly on some objective function, does not necessarily mean that the resulting policy will end up selecting actions based on said objective.
Confusing “this policy is optimized for X” with “this policy is optimal for X”: this is the actual mistake I think Bostom is making in Alex’s example—it’s true that an agent that wireheads achieves higher reward than on the training distribution (and the optimal agent for the reward achieves reward at least as good as wireheading). And I think that Alex and you would also agree with me that it’s sometimes valuable to reason about the global optima in policy space. But it’s a mistake to identify the outputs of optimization with the optimal solution to an optimization problem, and many people were making this jump without noticing it.
Again, I contend these confusions were not due to a lack of exposure to the “rewards as weighting trajectories” perspective. Instead, the reasons I remember hearing back in 2017-2018 for why we should jump from “RL is optimizing agents for X” to “RL outputs agents that both optimize X and are optimal for X”:
We’d be really confused if we couldn’t reason about “optimal” agents, so we should solve that first. This is the main justification I heard from the MIRI people about why they studied idealized agents. Oftentimes globally optimal solutions are easier to reason about than local optima or saddle points, or are useful for operationalizing concepts. Because a lot of the community was focused on philosophical deconfusion (often w/ minimal knowledge of ML or RL), many people naturally came to jump the gap between “the thing we’re studying” and “the thing we care about”.
Reasoning about optima gives a better picture of powerful, future AGIs. Insofar as we’re far from transformative AI, you might expect that current AIs are a poor model for how transformative AI will look. In particular, you might expect that modeling transformative AI as optimal leads to clearer reasoning than analogizing them to current systems. This point has become increasingly tenuous since GPT-2, but
Some off-policy RL algorithms are well described as having a “reward” maximizing component: And, these were the approaches that people were using and thinking about at the time. For example, the most hyped results in deep learning in the mid 2010s were probably DQN and AlphaGo/GoZero/Zero. And many people believed that future AIs would be implemented via model-based RL. All of these approaches result in policies that contain an internal component which is searching for actions that maximize some learned objective. Given that ~everyone uses policy gradient variants for RL on SOTA LLMs, this does turn out to be incorrect ex post. But if the most impressive AIs seem to be implemented in ways that correspond to internal reward maximization, it does seem very understandable to think about AGIs as explicit reward optimizers.
This is how many RL pioneers reasoned about their algorithms. I agree with Alex that this is probably from the control theory routes, where a PID controller is well modeled as picking trajectories that minimize cost, in a way that early simple RL policies are not well modeled as internally picking trajectories that maximize reward.
Also, sometimes it is just the words being similar; it can be hard to keep track of the differences between “optimizing for”, “optimized for”, and “optimal for” in normal conversation.
I think if you want to prevent the community from repeating these confusions, this looks less like “here’s an alternative perspective through which you can view policy gradient” and more “here’s why reasoning about AGI as ‘optimal’ agents is misleading” and “here’s why reasoning about your 1 hidden layer neural network policy as if it were optimizing the reward is bad”.
An aside:
In general, I think that many ML-knowledgeable people (arguably myself included) correctly notice that the community is making many mistakes in reasoning, that they resolve internally using ML terminology or frames from the ML literature. But without reasoning carefully about the problem, the terminology or frames themselves are insufficient to resolve the confusion. (Notice how many Deep RL people make the same mistake!) And, as Alex and you have argued before, the standard ML frames and terminology introduce their own confusions (e.g. ‘attention’).
A shallow understanding of “policy gradient is just upweighting trajectories” may in fact lead to making the opposite mistake: assuming that it can never lead to intelligent, optimizer-y behavior. (Again, notice how many ML academics made exactly this mistake) Or, more broadly, thinking about ML algorithms purely from the low-level, mechanistic frame can lead to confusions along the lines of “next token prediction can only lead to statistical parrots without true intelligence”. Doubly so if you’ve only worked with policy gradient or language modeling with tiny models.
Thanks!
After having spent a few hours playing with Opus, I think “slightly better than best public gpt-4” seems qualitatively correct—both models tend to get tripped up on the same kinds of tasks, but Opus can inconsistently solve some tasks in my workflow that gpt-4 cannot.
And yeah, it seems likely that I will also swap to Claude over ChatGPT.
Thanks for uploading your interp and training code!
Could you upload your model and/or datasets somewhere as well, for reproducibility? (i.e. your datasets folder containing the datasets:)
def recognized_dataset():
mode_lookups={
"gpt_train": ["datasets/othello_gpt_training_corpus.txt", OthelloDataset, {}],
"gpt_train_small": ["datasets/small_othello_gpt_training_corpus.txt", OthelloDataset, {}],
"gpt_test": ["datasets/othello_gpt_test_corpus.txt", OthelloDataset, {}],
"sae_train": ["datasets/sae_training_corpus.txt", OthelloDataset, {}],
"probe_train": ["datasets/probe_train_corpus.txt", LabelledOthelloDataset, {}],
"probe_train_bw": ["datasets/probe_train_corpus.txt", LabelledOthelloDataset, {"use_ally_enemy":False}],
"probe_train_small":["datasets/small_probe_training_corpus.txt", LabelledOthelloDataset, {}],
"probe_test": ["datasets/probe_test_corpus.txt", LabelledOthelloDataset, {}],
}
return mode_lookups
Agree that its worth experimenting with R, but the only other hyperparameter is the sparsity coefficient alpha, and I found that alpha had to be in a narrow range or the training would collapse to “all variance is unexplained” or “no active features”.
Yeah, the main hyperparameters are the expansion factor and “what optimization algorithm do you use/what hyperparameters do you use for the optimization algorithm”.
Thanks for doing this—could you share your code?
While I put only a medium probability that the current SAE algorithm works to recover all the features, my main concerns with the work are due to the quality of the model and the natural “features” not being board positions.
I’d be interested in running the code on the model used by Li et al, which he’s hosted on Google drive:
https://drive.google.com/drive/folders/1bpnwJnccpr9W-N_hzXSm59hT7Lij4HxZ
Also, in addition to the future work you list, I’d be interested in running the SAEs with much larger Rs and with alternative hyperparameter selection criteria.
Thanks for doing this!
They indeed did not advance the frontier with this launch (at least not meaningfully, possibly not at all). But “meaningfully advance the frontier” is quite different from both “stay on the frontier” or “slightly push the envelope while creating marketing hype”, which is what I think is going on here?
which case they’ve misled people by suggesting that they would not do this.
Neither of your examples seem super misleading to me. I feel like there was some atmosphere of “Anthropic intends to stay behind the frontier” when the actual statements were closer to “stay on the frontier”.
Also worth noting that Claude 3 does not substantially advance the LLM capabilities frontier! Aside from GPQA, it doesn’t do that much better on benchmarks than GPT-4 (and in fact does worse than gpt-4-1106-preview). Releasing models that are comparable to models OpenAI released a year ago seems compatible with “staying behind the frontier”, given OpenAI has continued its scale up and will no doubt soon release even more capable models.
That being said, I agree that Anthropic did benefit in the EA community by having this impression. So compared to the impression many EAs got from Anthropic, this is indeed a different stance.
In any case, whether or not Claude 3 already surpasses the frontier, soon will, or doesn’t, I request that Anthropic explicitly clarify whether their intention is to push the frontier.
As Evan says, I think they clarified their intentions in their RSP: https://www.anthropic.com/news/anthropics-responsible-scaling-policy
The main (only?) limit on scaling is their ability to implement containment/safety measures for ever more dangerous models. E.g.:
That is, they won’t go faster than they can scale up safety procedures, but they’re otherwise fine pushing the frontier.
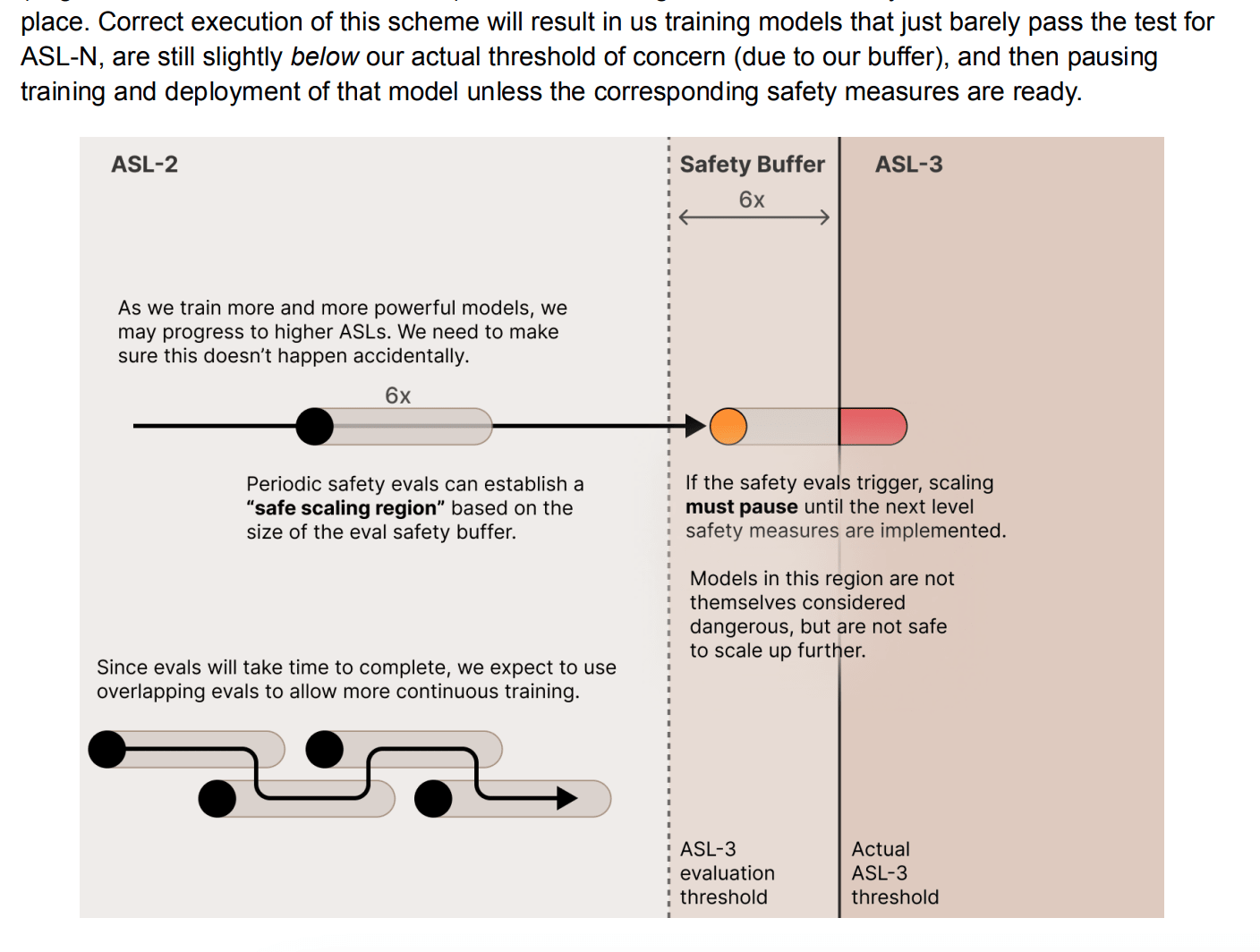
It’s worth noting that their ASL-3 commitments seem pretty likely to trigger in the next few years, and probably will be substantially difficult to meet:
If the claim is that it’s easier to learn a covering set for a “true” harm predicate and then act conservatively wrt the set, than to learn a single harm predicate, is not a new approach. E.g. just from CHAI:
The Inverse Reward Design paper, which tries to straightforwardly implement the posterior P(True Reward|Human specification of Reward) and act conservatively wrt to this outcome.
The Learning preferences from state of the world paper does this for P(True Reward | Initial state of the environment) and also acts conservatively wrt to outcome.
[A bunch of other papers which consider this for Reward | Another Source of Evidence, including: randomly sampled rewards and human off-switch pressing, . Also the CIRL paper, which proposes using uncertainty to directly solve the meta problem of “the thing this uncertainty is for”.]
It’s discussed as a strategy in Stuart’s Human Compatible, though I don’t have a copy to reference the exact page number.
I also remember finding Rohin’s Reward Uncertainty to be a good summary of ~2018 CHAI thinking on this topic. There’s also a lot more academic work in this vein from other research groups/universities too.
The reason I’m not excited about this work is that (as Ryan and Fabien say) correctly specifying this distribution without solving ELK also seems really hard.
It’s clear that if you allow H to be “all possible harm predicates”, then an AI that acts conservatively wrt to this is safe, but it’s also going to be completely useless. Specifying the task of learning a good enough harm predicate distribution that both covers the “true” harms and also allows your AI to do things is quite hard, and subject to various kinds of terrible misspecification problems that seem not much easier to deal with than the case where you just try to learn a single harm predicate.
Solving this task (that is, solving the task spec of learning this harm predicate prosterior) via probabilistic inference also seems really hard from the “Bayesian ML is hard” perspective.
Ironically, the state of the art for this when I left CHAI in 2021 were “ask the most capable model (an LLM) to estimate the uncertainty for you in one go” and “ensemble the point estimates of very few but quite capable models” (that is ensembling, but common numbers were in the single digit range, e.g. 4). These seemed to out perform even the “learn a generative/contrastive model to get features, and then learn a bayesian logistic regression on top of it” approaches. (Anyone who’s currently at CHAI should feel free to correct me here.)
I think? that the approach from Bengio is trying to avoid the difficulties is by trying to solve Bayesian ML. I’m not super confident that he’ll do better than “finetune an LLM to help you do it”, which is presumably what we’d be doing anyways?
(That being said, my main objections are akin to the ontology misidentification problem in the ELK paper or Ryan’s comments above.)
For the most simple case, consider learning a linear probe on embeddings with Bayesian ML. This is totally computationally doable. (It’s just Bayesian Logistic Regression).
IIRC Adam Gleave tried this in summer of 2021 with one of Chinchilla/Gopher while he was interning at DeepMind, and this did not improve on ensembling for the tasks he considered.
I don’t want to say things that have any chance of annoying METR without checking with METR comm people, and I don’t think it’s worth their time to check the things I wanted to say.