Chaos Induces Abstractions
Epistemic status: the first couple sections are intended to be a bog-standard primer on chaos theory. In general, this post mostly sticks close to broadly-accepted ideas; it’s intended mainly as background for why one would expect the general ideas of abstraction-as-information-at-a-distance to be true. That said, I’m writing it all from memory, and I am intentionally sweeping some technical details under the rug. If you see a mistake, please leave a comment.
Consider a billiards table:

The particular billiards table we’ll use is one I dug out of the physicists’ supply closet, nestled in between a spherical cow and the edge of an infinite plane. The billiard balls are all frictionless, perfectly spherical, bounce perfectly elastically off of other balls and the edges of the table, etc.
Fun fact about billiard balls: if my aim has a tiny bit of error to it, and I hit a ball at ever-so-slightly the wrong angle, that error will grow exponentially as the balls collide. Picture it like this: we start with an evenly-spaced line of balls on the table.
I try to shoot straight along the line, but the angle is off by a tiny amount, call it .
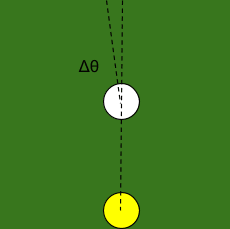
The ball rolls forward, and hits the next ball in line. The distance by which it’s off is roughly the ball-spacing length multiplied by , i.e. .
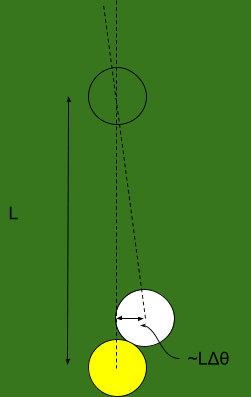
Since the first ball hits the second ball off-center, the second ball will also have some error in its angle. We do a little geometry, and find that the angular error in the second ball is roughly , where is the radius of a ball.
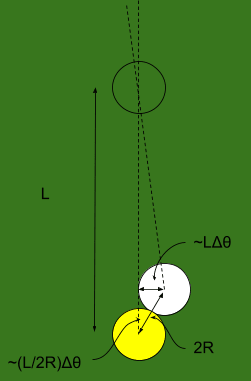
Now the second ball rolls into the third. The math is exactly the same as before, except the initial error is now multiplied by a factor . So when the second ball hits the third, the angular error in the third ball will be multiplied again, yielding error . Then the next ball will have angular error/uncertainty . And so forth.
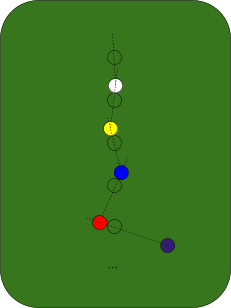
Upshot of all this: in a billiard-ball system, small angular uncertainty grows exponentially with the number of collisions. (In fact, this simplified head-on collision scenario yields the slowest exponential growth; if the balls are hitting at random angles, then the uncertainty grows even faster.)
This is a prototypical example of mathematical chaos: small errors grow exponentially as the system evolves over time. Given even a tiny amount of uncertainty in the initial conditions (or a tiny amount of noise from air molecules, or a tiny amount of noise from an uneven table surface, or …), the uncertainty grows, so we are unable to precisely forecast ball-positions far in the future. If we have any uncertainty, then as we forecast further and further into the future, our predictions will converge to a maximally-uncertain distribution on the state-space (or more precisely, a maxentropic distribution on the phase space). We become maximally uncertain about the system state.
… except for one prediction.
Remember that these are Physicists’ Billiards™, so they’re frictionless and perfectly elastic. No matter how many collisions occur, energy is always conserved. We may have some initial uncertainty about the energy, or there may be some noise from air molecules, etc, but the system’s own dynamics will not amplify that uncertainty the way it does with other uncertainty.
So, while most of our predictions become maxentropic (i.e. maximally uncertain) as time goes on, we can still make reasonably-precise predictions about the system’s energy far into the future.
An Information-Theoretic Point Of View
At first glance, this poses a small puzzle. We have very precise information about the initial conditions—our initial error is very small. The system’s dynamics are deterministic and reversible, so information can’t be lost. Why, then, do our predictions become maximally uncertain?
The key is that the angular error is a real number, and specifying a real number takes an infinite number of bits—e.g. it might be . Even though it’s a small real number, it still has an infinite number of bits. And as the billiards system evolves, bits further and further back in the binary expansion become relevant to the large-scale system behavior. But the bits far back in the binary expansion are exactly the bits about which we have approximately-zero information, so we become maximally uncertain about the system state.
Conversely, our initial information about the large-scale system behavior still tells us a lot about the future state, but most of what it tells us is about bits far back in the binary expansion of the future state variables (i.e. positions and velocities). Another way to put it: initially we have very precise information about the leading-order bits, but near-zero information about the lower-order bits further back. As the system evolves, these mix together. We end up with a lot of information about the leading-order and lower-order bits combined, but very little information about either one individually. (Classic example of how we can have lots of information about two variables combined but little information about either individually: I flip two coins in secret, then tell you that the two outcomes were the same. All the information is about the relationship between the two variables, not about the individual values.) So, even though we have a lot of information about the microscopic system state, our predictions about large-scale behavior (i.e. the leading-order bits) are near-maximally uncertain.
… except, again, for the energy. Our information about the energy does not get mixed up with the lower-order bits, so we can continue to precisely forecast the system’s energy far into the future. We end up maximally uncertain about large-scale system state except for our precise estimate of the energy. (Maximum entropy quantifies this: the distribution most often used in statistical mechanics is maxentropic subject to a constraint on our knowledge of the energy.)
The Abstraction Connection
The basic claim about how-abstraction-works: we have some high-dimensional system, within some larger environment. The system’s variables contain a lot of information. But, most of that information is not relevant “far away” from the system—most of it is “wiped out” by noise in the environment, so only a low-dimensional summary is relevant far away. That low-dimensional summary is the “abstraction” of the high-dimensional system.
Why would we expect this notion of “abstraction” to be relevant to the physical world? Why should all the relevant information from a high-dimensional subsystem (e.g. the molecules comprising a tree or a car) fit into a low-dimensional summary?
The billiards system illustrates one of the main answers.
We have a high-dimensional system—i.e. a large number of “billiard balls” bouncing around on a “pool table”. (Really, this is typically used as an analogy for gas molecules bouncing around in a container.) We ask what information about the system’s state is relevant “far away”—in this case, far in the future. And it turns out that, if we have even just a little bit of uncertainty, the vast majority of the information is “wiped out”. Only the system’s energy is relevant to predicting the system state far in the future. The energy is our low-dimensional summary.
To make this example look like something we’d recognize, we need to add a little more information to the summary: as the balls bounce around, the number of balls also does not change, and the volume of the container—i.e. the size of the pool table—does not change. (Everything we said earlier is still true, we were just treating volume and number of balls as fixed background parameters.) In situations where balls might be added/removed, or where the container might grow/shrink, the system dynamics still does not amplify uncertainty in those quantities; information about them is still relevant to predicting the far-future state. So, three quantities—energy, volume, and number of balls—provide a summary of all the information relevant to forecasting the system state in the far future.
You may recognize these as the “state variables” of an ideal gas. (We could instead swap in equivalent variables which contain the same information, e.g. pressure, temperature and volume). The ideal gas model is an abstraction, and the state variables of the ideal gas are exactly the low-dimensional summary which contains all the information from the high-dimensional system state which is relevant far into the future. Chaos wipes out all the other information.
Key idea from dynamical systems theory: this is how most dynamical systems behave by default. Information about some quantities is conserved, and everything else is wiped out by chaos. So, for most systems, we should expect that all the relevant information from the high-dimensional system state can fit into a low(er)-dimensional summary.
The key question is how much lower dimensional. If we have a mole of variables, and the summary “only” needs a mole minus 10 million, that’s not very helpful. Yet in practice, the low-dimensional summaries seem to be much smaller than that—not necessarily as small as the three state variables of an ideal gas, but still a lot less than a mole of variables. Ultimately, this is a question which needs to be answered empirically.
Other Paths
I don’t want to leave people with too narrow a picture, so let’s talk a bit about other paths to the same underlying concept.
First, chaos isn’t the only path to a similar picture. For instance, a major topic in computational complexity theory is systems which take in random bits, and output pseudorandom bits, such that there’s no polynomial-time (as a function of ) method which can distinguish the pseudorandom bits from truly random variables (assuming ). Conceptually, this has similar consequences to chaos: if we have even just a few unknown bits, then they can “wipe out the information” in other bits—not in an information-theoretic sense, but in the sense that the wiped-out information can no longer be recovered by any polynomial-time computation. As with continuous dynamical systems, most random discrete systems will conserve information about some quantities, and everything else will be wiped out by the pseudorandom noise.
Second, we don’t just need to think about dynamics over time, or about “far away” as “far in the future”. For instance, we could imagine two separate systems whose interactions are mediated by a chaotic system—for instance, two people talking, with the sound waves carried by the (chaotic) system of air molecules between them. Chaos will wipe out most of the information about one system (e.g. motions of individual molecules in one person) before that information reaches the other system. All that gets through will be a low(er)-dimensional summary (e.g. larger-scale sonic vibrations). More generally, we can think about information propagating through many different subsystems, in a whole graph of interactions, and then ask what information is conserved as we move outward in the graph.
Third, if we have non-small amounts of uncertainty about the environment, then that uncertainty can wipe out information about the system even without chaos added into the mix. Simple example: the system is a flipped coin. The environment is another flipped coin. Standing “far away”, I cannot “see” either coin, but someone tells me whether they are equal (i.e. HH or TT) or unequal (HT or TH). If I had better information about the environment, then this would be sufficient to figure out the system’s state. But my uncertainty about the environment also wipes out the information about the system; I’m left maximally uncertain about whether the system’s state is H or T. This is very similar to the “mixing” of information we talked about earlier; as before, a given system is likely to have some quantities which do get “mixed in” with things we don’t know, and some quantities which do not get mixed. The latter serve as the low-dimensional summary.
Recap of Main Points
In a chaotic system, small uncertainties/errors are amplified over time. If there’s even just a tiny amount of uncertainty—whether from uncertain initial conditions or noise from the environment—then the large-scale behavior of the system becomes unpredictable far in the future.
… but not completely unpredictable. Typically, some information is conserved—e.g. the energy in a frictionless physical system. Even if noise from the environment causes some uncertainty in this conserved information, it isn’t “amplified” over time, so we can still make decent predictions about these quantities far into the future.
In terms of abstraction: the conserved information is a low(er) dimensional summary, which contains all the known information about the large-scale system state relevant to large-scale measurements of the system’s state in the far future.
- Study Guide by (6 Nov 2021 1:23 UTC; 314 points)
- Natural Abstractions: Key Claims, Theorems, and Critiques by (16 Mar 2023 16:37 UTC; 251 points)
- Testing The Natural Abstraction Hypothesis: Project Intro by (6 Apr 2021 21:24 UTC; 170 points)
- The Plan − 2023 Version by (29 Dec 2023 23:34 UTC; 153 points)
- The Telephone Theorem: Information At A Distance Is Mediated By Deterministic Constraints by (31 Aug 2021 16:50 UTC; 101 points)
- The Plan − 2025 Update by (31 Dec 2025 20:10 UTC; 96 points)
- Maybe Insensitive Functions are a Natural Ontology Generator? by (24 Nov 2025 17:36 UTC; 61 points)
- 's comment on A Certain Formalization of Corrigibility Is VNM-Incoherent by (20 Nov 2021 15:35 UTC; 9 points)
- 's comment on The Pragmascope Idea by (5 Aug 2022 15:38 UTC; 8 points)
- 's comment on Computing Natural Abstractions: Linear Approximation by (16 Apr 2021 15:05 UTC; 4 points)
- 's comment on tailcalled’s Shortform by (30 Dec 2021 10:51 UTC; 4 points)
Interesting post, abstractions are the few stable-ish quantities that weren’t eaten by chaotic noise.
Exponentially growing errors are not always chaotic. Suppose you have around 1000 starting cells, with a 1% error in the population size. The number of cells doubles in each hour. The absolute error of the population size can be 10.24 times larger than the initial population 10 hours later; however, the relative error remained 1%. (The billiard ball example is still chaotic, but the tilde character does the heavy lifting: 31.4 with 10% error is an imprecise but usable measurement, sin(31.4 +- 10%) is garbage.)
If the relative error of a quantity remains bounded as the elements of a system interact, then this value could be a useful abstraction.
I agree that this is an important concept, or set of related concepts that covers many of the more directly physical abstractions. If something isn’t quantum field theory fundamental, and can be measured with physics equipment, there is a good chance it is one of these sorts of abstractions.
Of course, a lot of the work in what makes a sensible abstraction is determined by the amount of blurring, and the often implicit context.
For instance, take the abstraction “poisonous”. If the particular substance being described as poisonous is sitting in a box not doing anything, then we are talking about a counterfactual where a person eats the poison. Within that world, you are choosing a frame sufficiently zoomed in to tell if the hypothetical person was alive or dead, but not precise enough to tell which organs failed.
I think that different abstractions of objects are more useful in different circumstances. Consider a hard drive. In a context that involves moving large amounts of data, the main abstraction might be storage space. If you need to fit it in a bag, you might care more about size. If you need to dispose of it, you might care more about chemical composition and recyclability.
Consider some paper with ink on it. The induced abstractions framework can easily say that it weighs 72 grams, and has slightly more ink in the top right corner.
It has a harder time using descriptions like “surreal”, “incoherent”, “technical”, “humorous”, “unpredictable”, “accurate” ect.
Suppose the document is talking about some ancient historic event that has rather limited evidence remaining. The accuracy or inaccuracy of the document might be utterly lost in the mists of time, yet we still easily use “accurate” as an abstraction. That is, even a highly competent historian may be unable to cause any predictable physical difference in the future that depends on the accuracy of the document in question. Where as the number of letters in the document is easy to assertain and can influence the future if the historian wants it to.
As this stands, it is conceptually useful, but does not cover anything like all human abstractions.
Yeah, so, chaos in physical systems definitely does not get us all human abstractions. I do claim that the more general framework (i.e. summary of information relevant “far away”, for various notions of “far away”) does get us all human abstractions.
Once we get into more meta concepts like “accurate”, some additional (orthogonal) conceptually-tricky pieces become involved. For instance, “probability is in the mind” becomes highly relevant, models-of-models and models-of-map-territory-correspondence become relevant, models of other humans become relevant, the fact that things-in-my-models need not be things-in-the-world at all becomes relevant, etc. I do still think the information-relevant-far-away-framework applies for things like “accuracy”, but the underlying probabilistic model looks less like a physical simulation and more like something from Hofstadter.
“Unpredictable” is a good example of this. If I say “this tree is 8 meters tall”, then all the abstractions involved are really in my-map-of-the-tree. But if I say “this tree’s height next year is unpredictable”, then the abstractions involved are really in my-map-of-(the correspondence between my-map-of-the-tree and the tree). And the general concept of “unpredictability” is in my-map-of-(how correspondence between my map and the territory works in general). And if I mean that something is unpredictable by other people, or other things-in-the-world, then that drags in even more maps-of-maps.
But, once all the embedded maps-of-maps are sorted out, I still expect the concept of “unpredictable” to summarize all the information about some-class-of-maps-embedded-in-my-world-model which is relevant to the-things-which-those-maps-correspond-to-in-my-world-model.
Excellent post, John. If I understood correctly, the general idea here is that capturing initial conditions accurately is hard, and any minuscule error in the initial conditions can become amplified in the future of this system. However, the laws of physics govern all physical systems, and they assert that certain states are impossible regardless of initial conditions.
The assertions made by the laws of physics make it relatively easy to predict specific properties about the system’s future irrespective of initial conditions (i.e. initial conditions are being abstracted away). For example, the laws of physics asset that perpetual motion machines can never work so we can confidently rule them out without needing to understand their implementation details.
The idea of expressing physics in terms of counterfactuals rather than initial conditions plus the laws of motion has been explored by David Deutsch. He calls it Constructor Theory. I don’t think Constructor Theory has been well-received by the physics community, but it is interesting.
This is a great intuition pump, thanks! It makes me appreciate just how, in a sense, weird it is that abstractions work at all. It seems like the universe could just not be constructed this way (though one could then argue that probably intelligence couldn’t exist in such chaotic universes, which is in itself interesting). This makes me wonder if there is a set of “natural abstractions” that are a property of the universe itself, not of whatever learning algorithm is used to pick up on them. Seems highly relevant to value learning and the like.
I wrote this post mainly as background for the sort of questions my research is focused on, in hopes that it would make it more obvious why the relevant hypotheses seem plausible at all. And this:
… is possibly the best two-sentence summary I have seen of exactly those hypotheses. You’ve perfectly hit the nail on the head.
I’ve been thinking a lot about differences between people for… arguably most of my life, but especially the past few years. One thing I find interesting is that parts of your abstraction/chaos relationship don’t seem to transfer as neatly to people. More specifically, what I have in mind is to elements:
People carry genes around, and these genes can have almost arbitrary effects that aren’t wiped away by noise over time because the genes persist and are copied digitally in their bodies.
It seems to me that agency “wants” to resist chaos? Like if some sort of simple mechanical mechanism creates something, then the something easily gets moved away by external forces, but if a human creates something and wants to keep it, then they can place it in their home and lock their door and/or live in a society that respects private property. (This point doesn’t just apply to environmental stuff like property, but also to biological stuff.)
Individual differences often seem more “amorphous” and vague than you get elsewhere, and I bet elements like the above play a big role in this. The abstraction/chaos post helps throw this into sharp light.
I’m not sure if that’s what you mean that genes and agency are both perfectly valid abstractions IMO. An abstraction can summarize the state of a small part of the system (e.g. genes), not necessarily the entire system (e.g. temperature).
If we knew (for some reason) that a system had no useful abstractions (or at least, no small ones), what could we say about that system? Does it reduce to some vacuous thing? Or does it require it to be adversarial in nature?
It would mean that information is conserved—not just at a microscopic level, but at a macroscopic level too. Every piece of information we have about the system is always relevant to whatever predictions we want to make.
I like this framing a lot – thanks for sharing!
This vaguely reminds me of uncertainty principles—both involve a finite amount of information available in a system, where the more you know about one aspect, the less you know about all the others—but I don’t know how to make the resemblance precise or whether it’s actually relevant to chaos theory.
The usual way the uncertainty principle comes in is that we’re guaranteed to have some minimum amount of uncertainty, and therefore chaos is guaranteed to amplify it and wipe out our large-scale predictions.