Overview: We modify the goal-directed behavior of a trained network, without any gradients or finetuning. We simply add or subtract “motivational vectors” which we compute in a straightforward fashion.
In the original post, we defined a “cheese vector” to be “the difference in activations when the cheese is present in a maze, and when the cheese is not present in the same maze.” By subtracting the cheese vector from all forward passes in a maze, the network ignored cheese.
I (Alex Turner) present a “top right vector” which, when added to forward passes in a range of mazes, attracts the agent to the top-right corner of each maze. Furthermore, the cheese and top-right vectors compose with each other, allowing (limited but substantial) mix-and-match modification of the network’s runtime goals.
I provide further speculation about the algebraic value editing conjecture:
It’s possible to deeply modify a range of alignment-relevant model properties, without retraining the model, via techniques as simple as “run forward passes on prompts which e.g. prompt the model to offer nice- and not-nice completions, and then take a ‘niceness vector’, and then add the niceness vector to future forward passes.”
I close by asking the reader to make predictions about our upcoming experimental results on language models.
This post presents some of the results in this top-right vector Google Colab, and then offers speculation and interpretation.
I produced the results in this post, but the vector was derived using a crucial observation from Peli Grietzer. Lisa Thiergart independently analyzed top-right-seeking tendencies, and had previously searched for a top-right vector. A lot of the content and infrastructure was made possible by my MATS 3.0 team: Ulisse Mini, Peli Grietzer, and Monte MacDiarmid. Thanks also to Lisa Thiergart, Aryan Bhatt, Tamera Lanham, and David Udell for feedback and thoughts.
Background
This post is straightforward, as long as you remember a few concepts:
Vector fields, vector field diffs, and modifying a forward pass. AKA you know what this figure represents:
How to derive activation-space vectors (like the “cheese vector”) by diffing two forward passes, and add / subtract these vectors from future forward passes
AKA you can understand the following: “We took the cheese vector from maze 7. ~Halfway through the forward passes, we subtract it with coefficient 5, and the agent avoided the cheese.”
If you don’t know what these mean, read this section. If you understand, then skip.
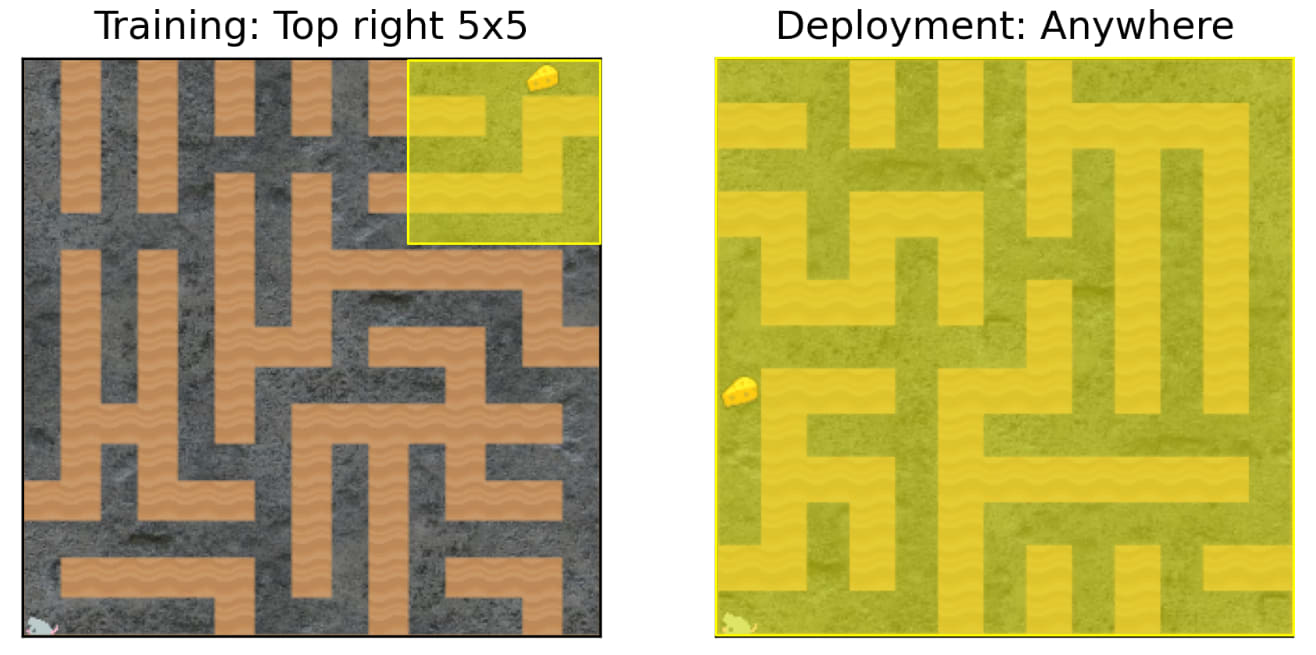
Langosco et al. trained a range of maze-solving nets. We decided to analyze one which we thought would be interesting. The network we chose has 3.5M parameters and 15 convolutional layers.
During RL training, cheese was randomly located in the top-right 5×5 corner of the randomly generated mazes. Reaching the cheese yields +1 reward.
In deployment, cheese can be anywhere.
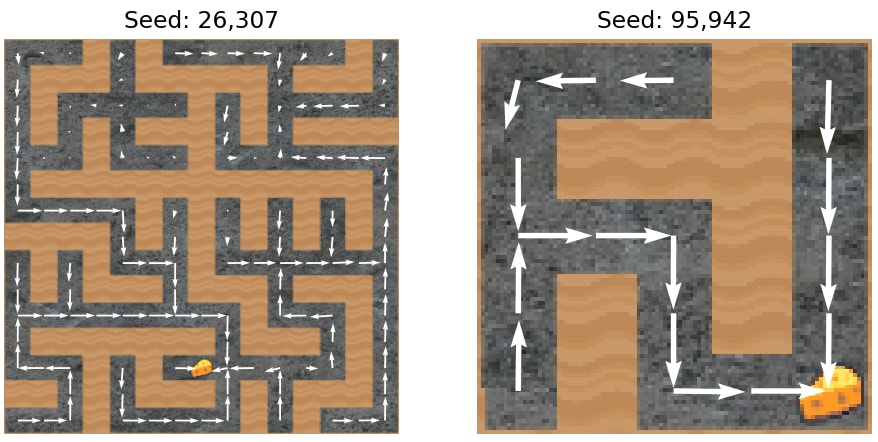
Sampling rollouts from the trained policy adds a lot of noise. A nicer way to view episodes is with a vector field view, which overlays a vector field representing the agent policy for a given maze.
At each square in the maze, we run a forward pass to get the policy’s action probabilities at that square.
Example vector fields of policy outputs.
To compute the cheese vector, we
Generate two observations—one with cheese, and one without. The observations are otherwise the same.
Run a forward pass on each observation, recording the activations at each layer.
For a given layer, define the cheese vector to be CheeseActivations - NoCheeseActivations. The cheese vector is a vector in the vector space of activations at that layer.
Let’s walk through an example, where for simplicity the network has a single hidden layer, taking each observation (shape (3, 64, 64) for the 64x64 RGB image) to a two-dimensional hidden state (shape (2,)) to a logit vector (shape (15,)).
We run a forward pass on a batch of two observations, one with cheese (note the glint of yellow in the image on the left!) and one without (on the right).
We record the activations during each forward pass. In this hypothetical,
CheeseActivations := (1, 3)
NoCheeseActivations := (0, 2)
Thus, CheeseVector := (1, 3) - (0, 2) = (1, 1).
Now suppose the mouse is in the top-right corner of this maze. Letting the cheese be visible, suppose this would normally produce activations of (0,0). Then we modify[1] the forward pass by subtracting CheeseVector from the normal activations, giving us (0,0)−(1,1)=(−1,−1) for the modified activations. We then finish off the rest of the forward pass as normal.
In the real network, there are a lot more than two activations. Our results involve a 32,768-dimensional cheese vector, subtracted from about halfway through the network:
We modify the activations after the residual add layer in the first residual block of the second Impala block (relevant blocks shown with red border).
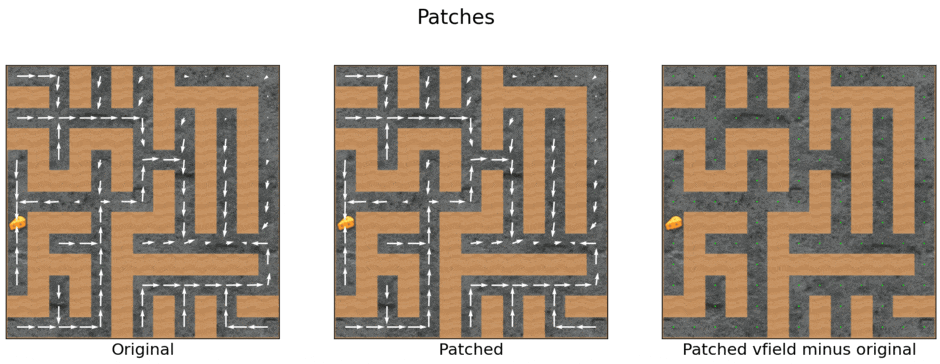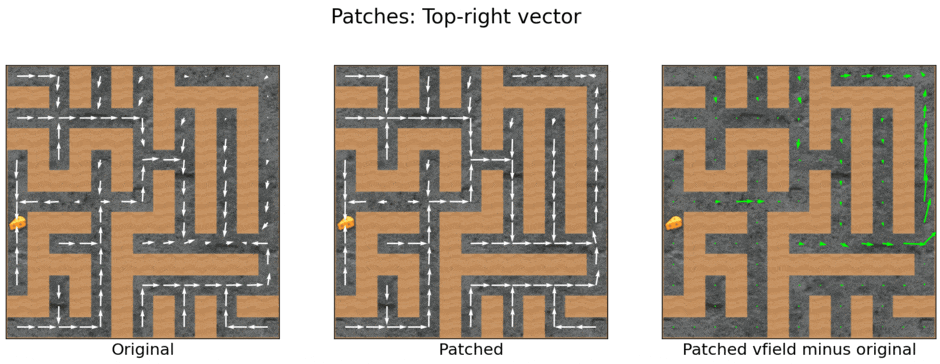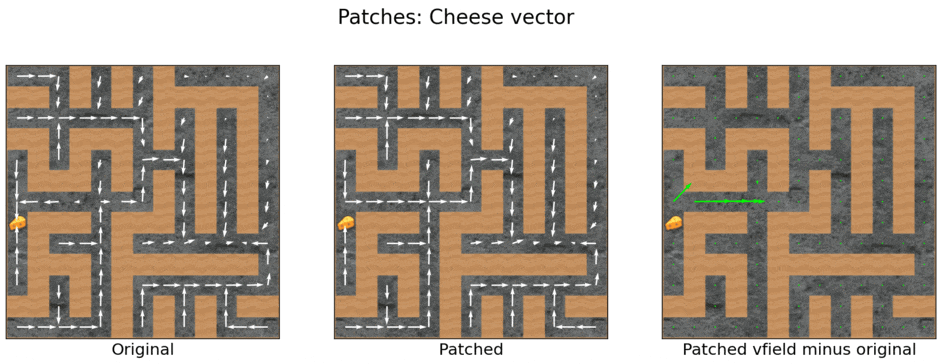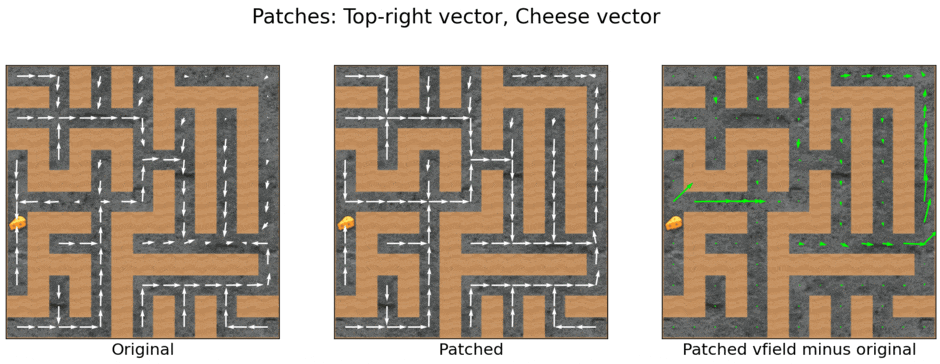
Now that we’re done with preamble, let’s see the cheese vector in action! Here’s a seed where subtracting the cheese vector is very effective at getting the agent to ignore cheese:
Vector fields for the mouse normally, for the mouse with the cheese vector subtracted during every forward pass, and the diff between the two cases.
How is our intervention not trivially making the network output logits as if the cheese were not present? Is it not true that the activations at a given layer obey the algebra of CheeseActiv - (CheeseActiv - NoCheeseActiv) = NoCheeseActiv?
The intervention is not trivial because we compute the cheese vector based on observations when the mouse is at the initial square (the bottom-left corner of the maze), but apply it for forward passes throughout the entire maze — where the algebraic relation no longer holds.
Finding the top-right vector
A few weeks ago, I was expressing optimism about AVEC working in language models. Someone on the team expressed skepticism and said something like “If AVEC is so true, we should have more than just one vector in the maze environment. We should have more than just the cheese vector.”
I agreed. If I couldn’t find another behavior-modifying vector within a day, I’d be a lot more pessimistic about AVEC. In January, I had already failed to find additional X-vectors (for X != cheese). But now I understood the network better, so I tried again.
I thought for five minutes, sketched out an idea, and tried it out (with a prediction of 30% that the literal first thing I tried would work). The literal first thing I tried worked.
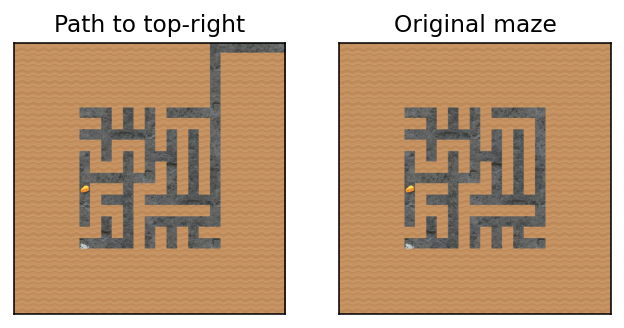
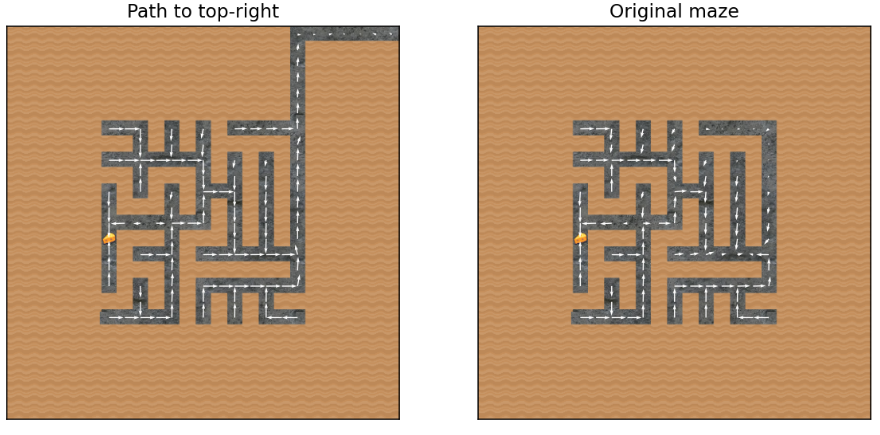
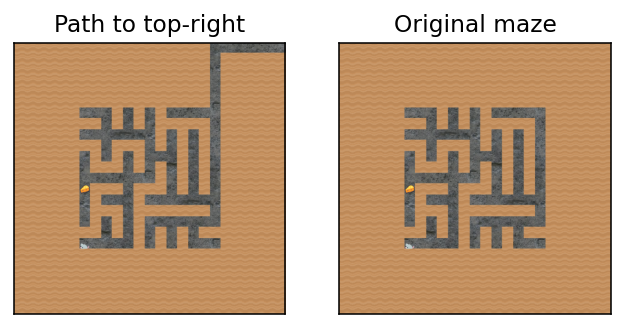
I present to you: the top-right vector! We compute it by diffing activations across two environments: a normal maze, and a maze where the reachable[2]top-right square is higher up.
Peli Grietzer had noticed that when the top-right-most reachable square is closer to the absolute top-right, the agent has an increased tendency to go to the top right.
When there is a path to the absolute top-right of the maze, the agent is more strongly attracted to the top-right.
As in the cheese vector case, we get a “top right vector” by:
Running a forward pass on the “path to top-right” maze, and another forward pass on the original maze, and storing the activations for each. In both situations, the mouse is located at the starting square, and the cheese is not modified.
About halfway through the network (at the second Impala block’s first residual add, just like for the cheese vector[3]), we take the difference in activations to be the “top right vector.”
We then add coeff*top_right_vector halfway through forward passes elsewhere in the maze, where the input observations differ due to different mouse locations.
If this is confusing, consult the “Computing the cheese vector” subsection of the original post, or return to the Background section. If you do that and are still confused about what a top-right vector is, please complain and leave a comment.
If you’re confused why the hell this works, join the club.
Smaller mazes are usually (but not always) less affected:
The agent also tends to be less retargetable in smaller mazes. I don’t know why.
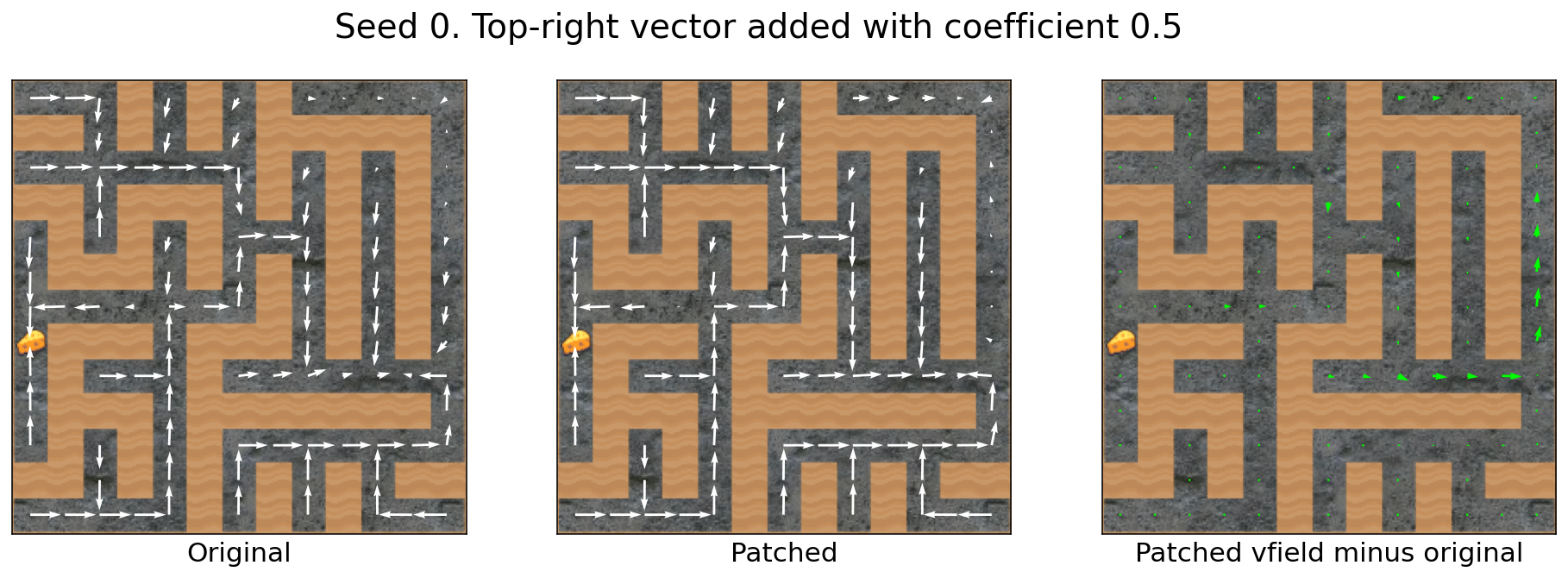
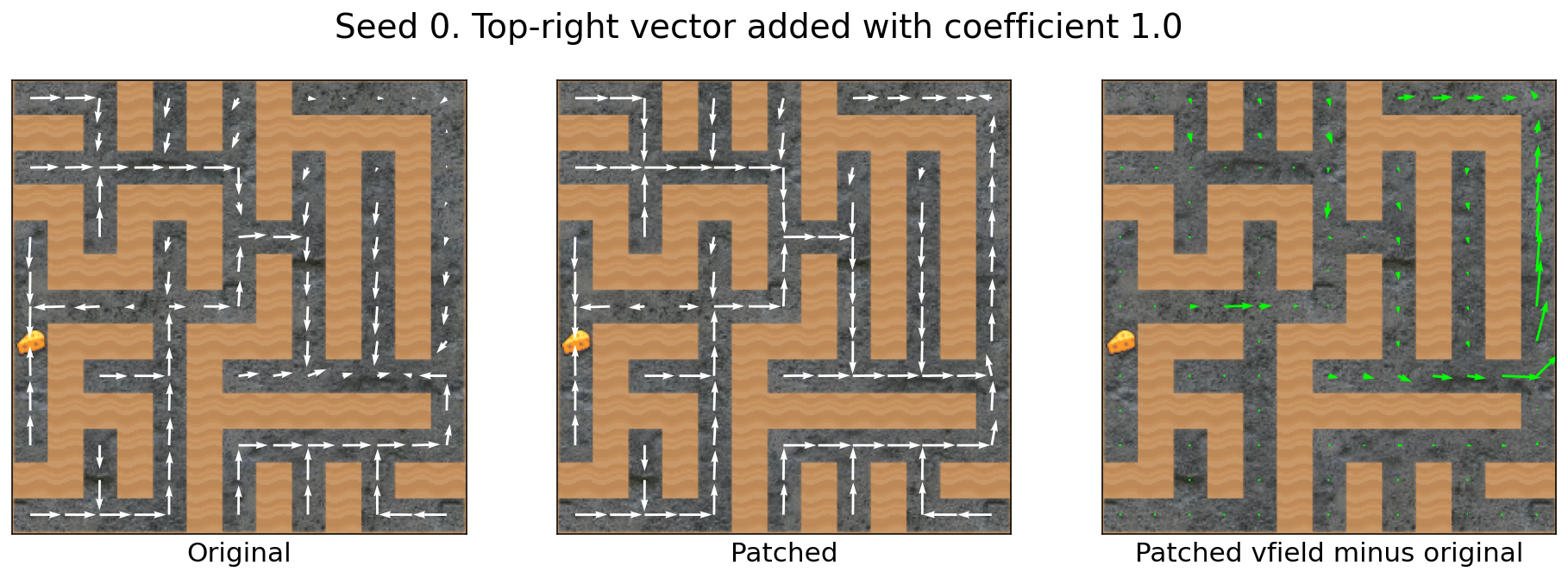
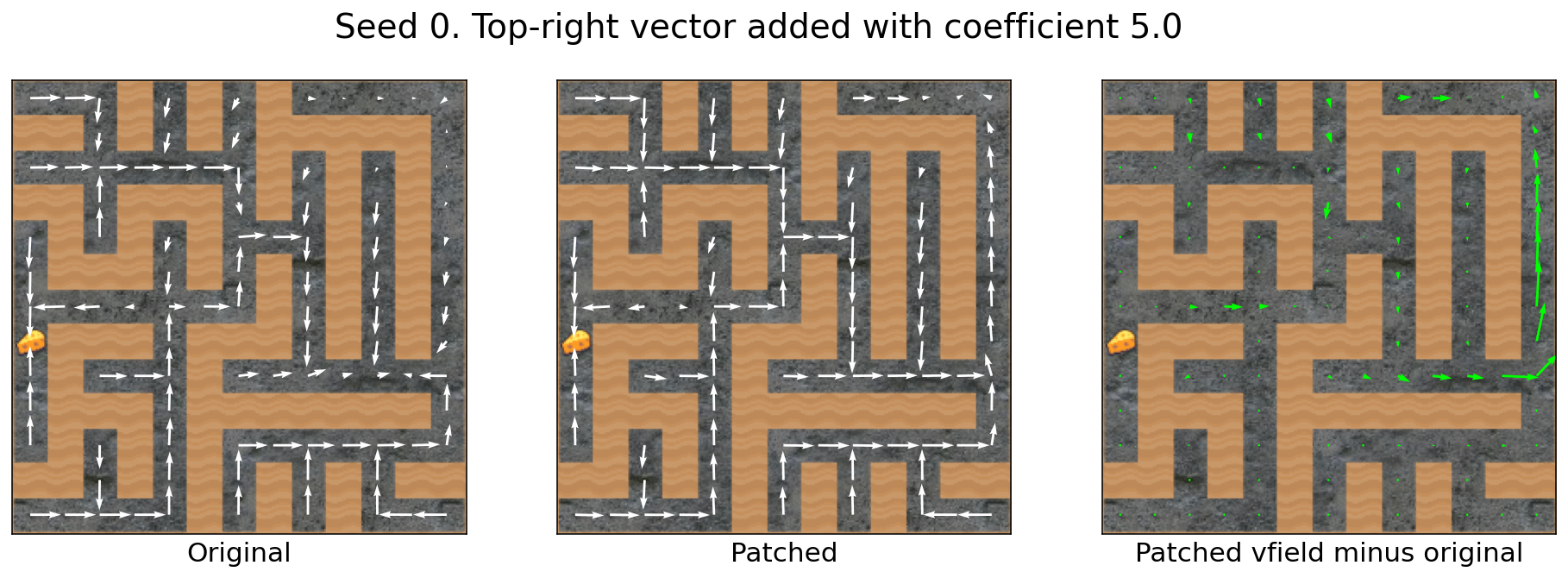
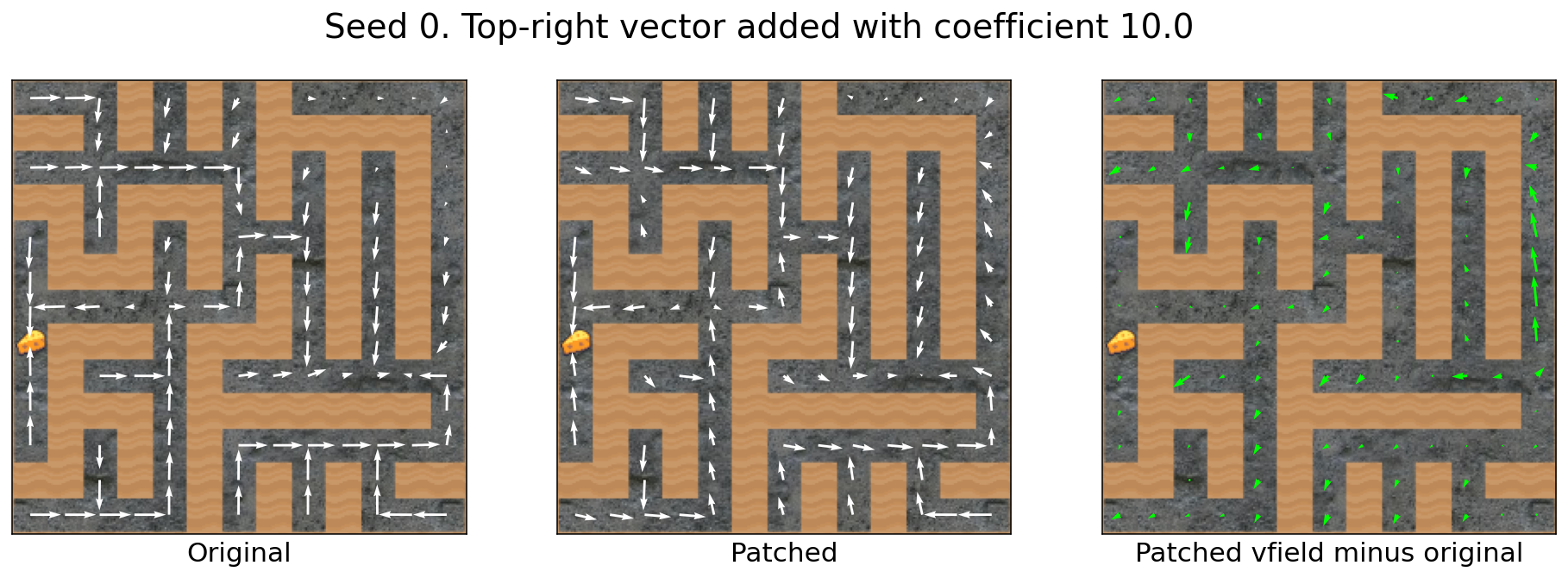
Adding the top-right vector with different coefficient strengths
Sometimes, increasing the coefficient strength increases the strength of the effect:
Sometimes, increasing the coefficient strength doesn’t change much:
But push the coefficient too far, and the action distributions crumble into garbage:
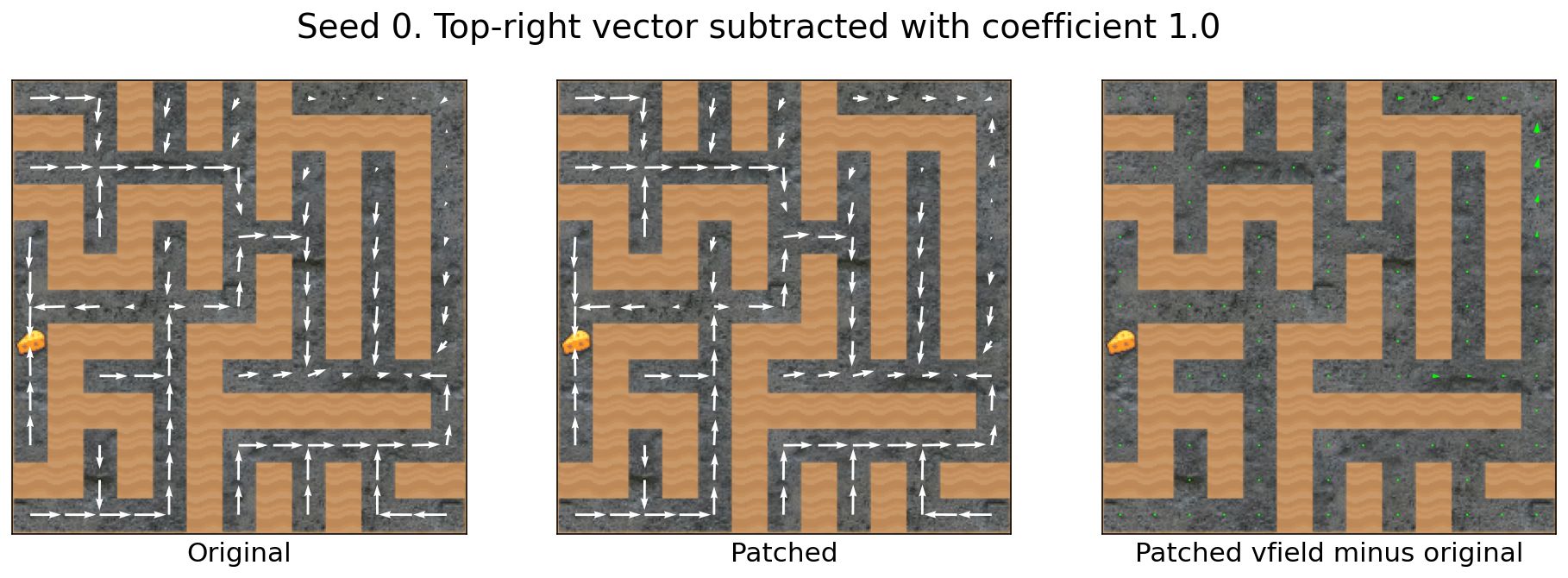
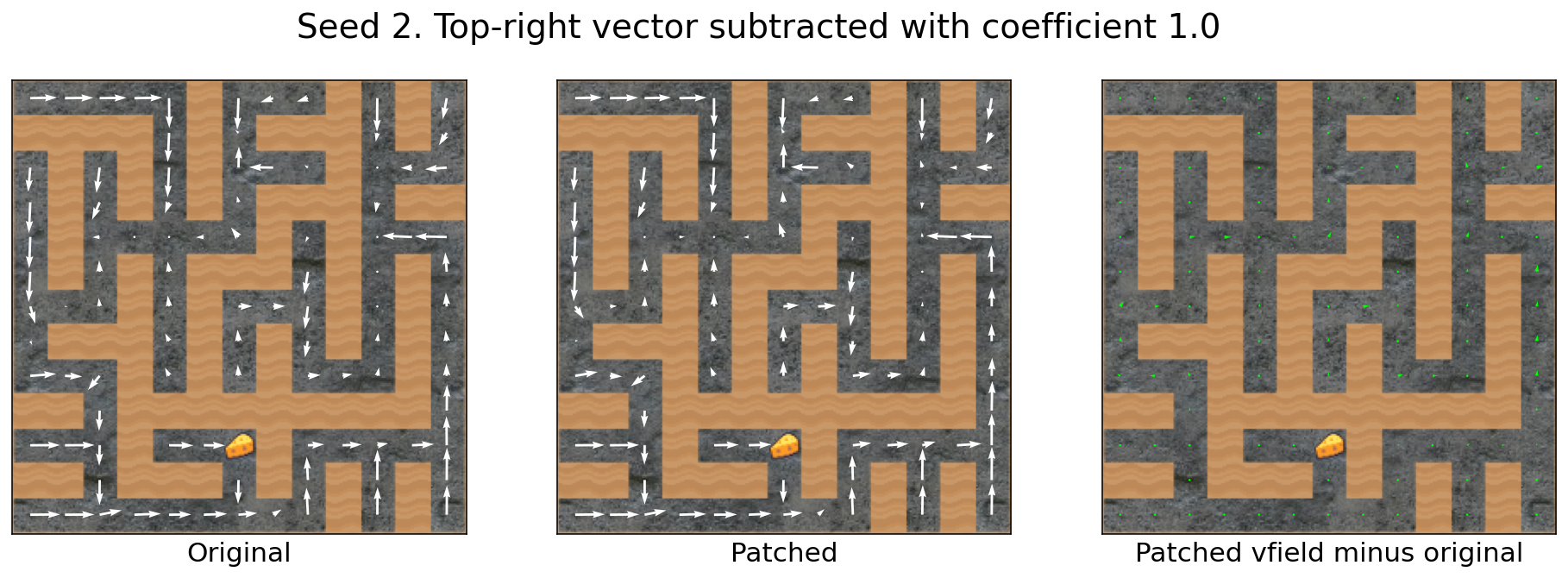
Subtracting the top-right vector has little effect
Here’s another head-scratcher. Just as you can’t[4]add the cheese vector to increase cheese-seeking, you can’t subtract the top-right vector to decrease the probability of going to the top-right:
I wish I knew why.
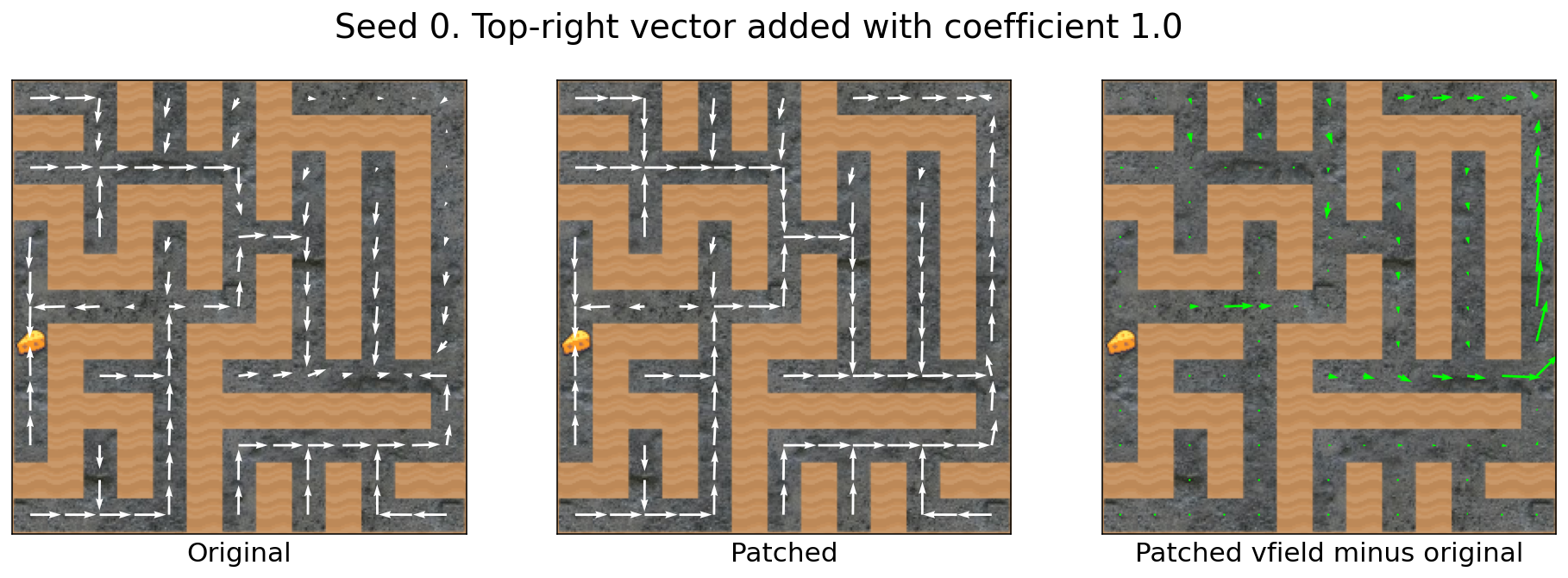
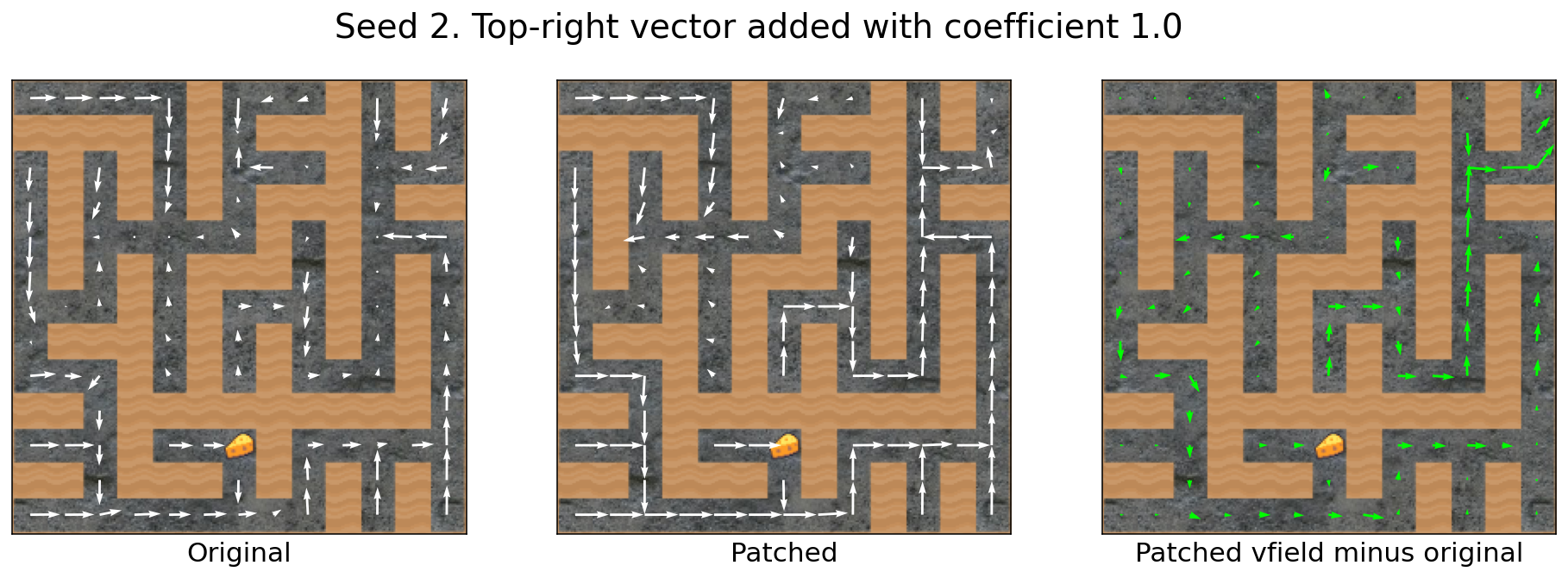
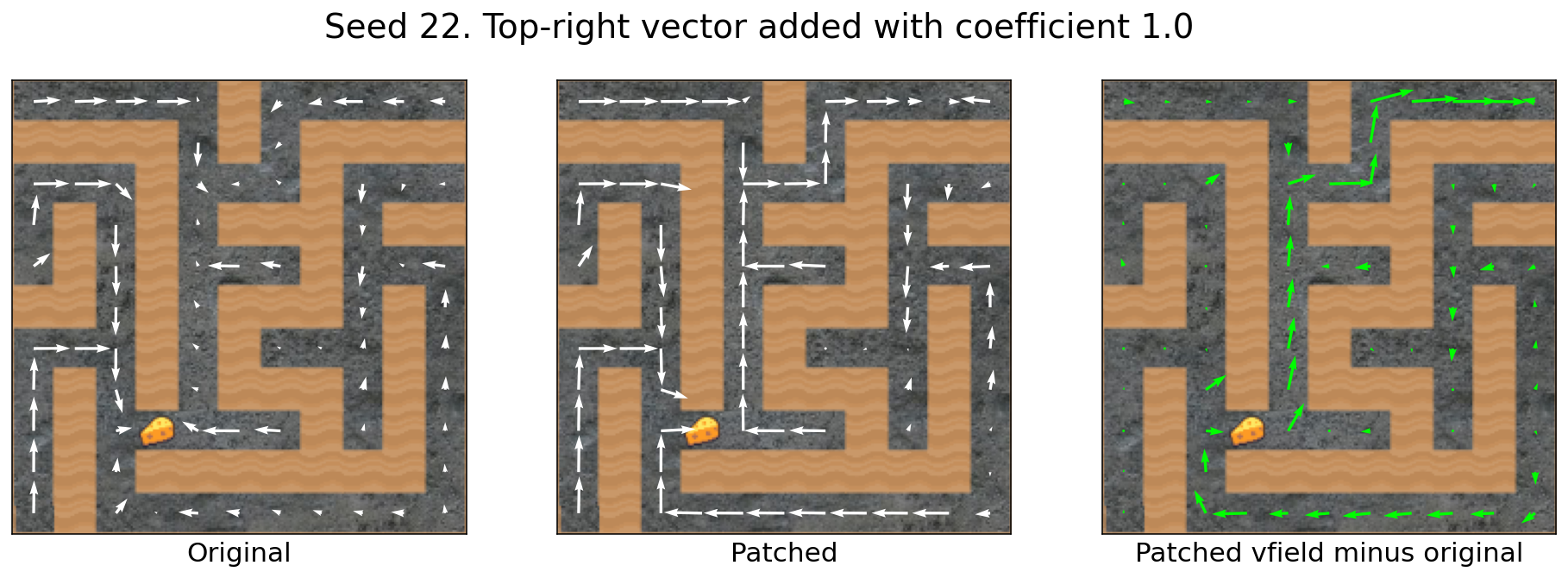
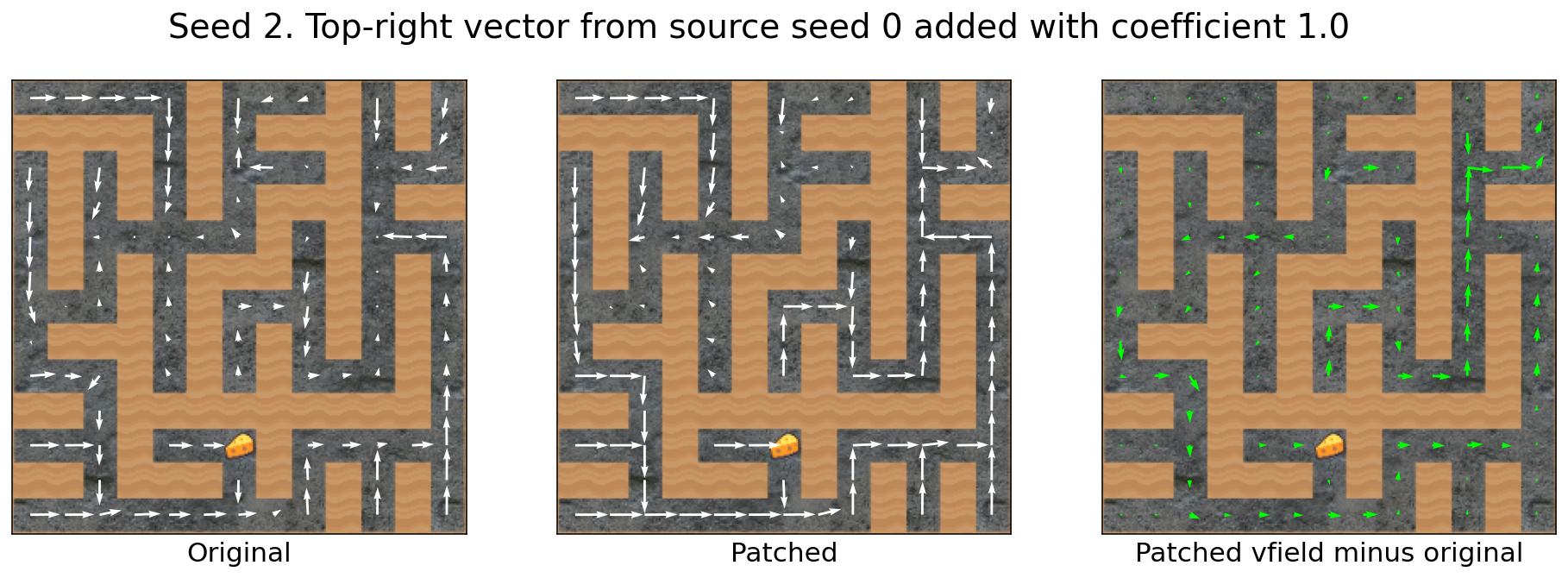
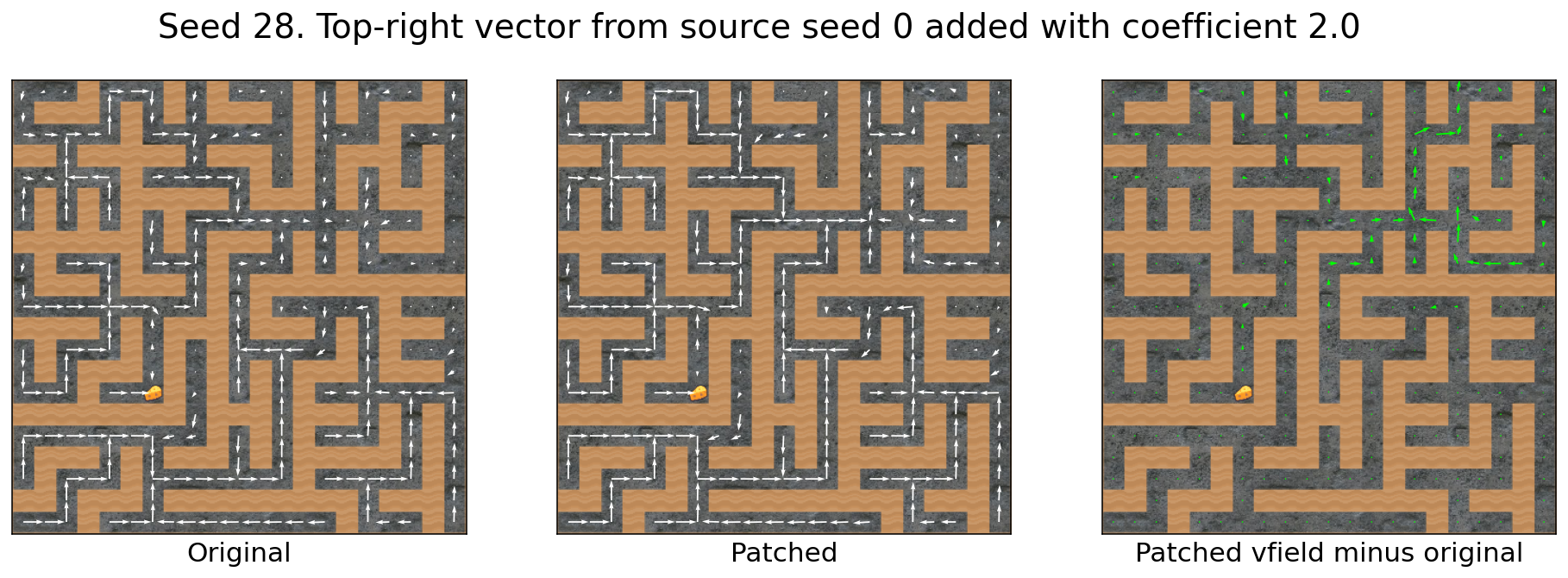
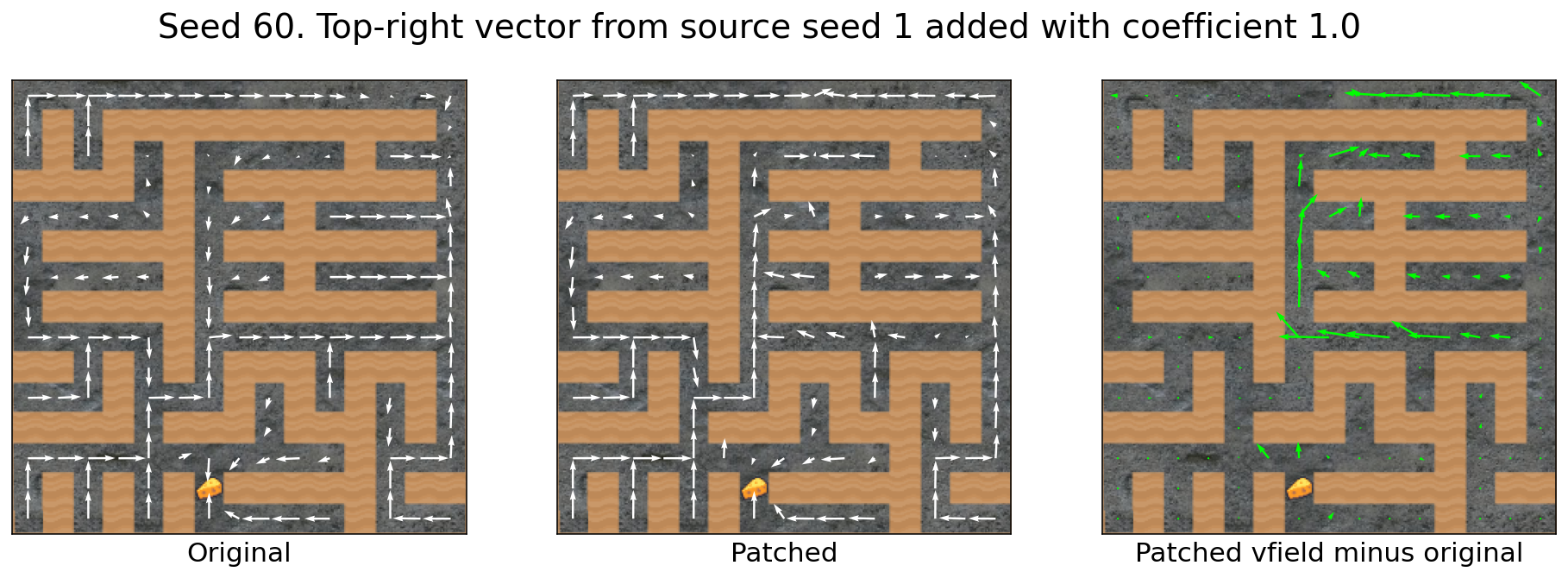
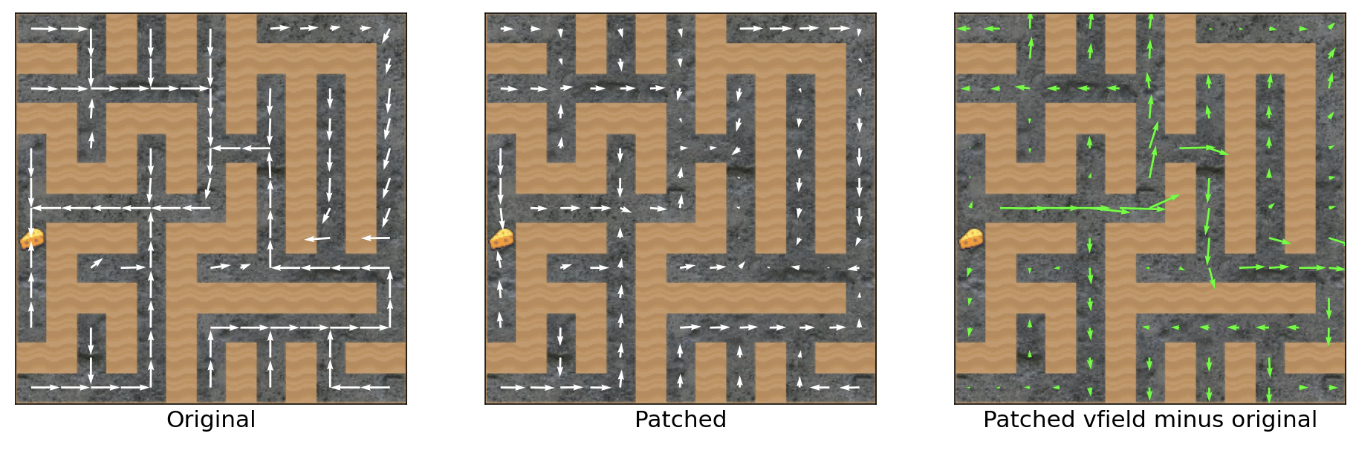
The top-right vector transfers across mazes
Let’s compute the top-right vector using e.g. source seed 0:
And then apply it to e.g. target seed 2:
Success!
For the seed 0 -> seed 28 transfer, the modified agent doesn’t quite go to the top-right corner. Instead, there seems to be a “go up and then right” influence.
Seed 0′s vector seems to transfer quite well.
However, top-right vectors from small mazes can cause strange pathing in larger target mazes:
The agent competently navigates to central portions of the larger maze.
Composing the activation additions
Subtracting the cheese vector often makes the agent (nearly) ignore the cheese, and adding the top-right vector often attracts the agent to the top-right corner. It turns out that you can mix and match these effects by adding one or both vectors halfway through the forward pass.
Different x-vectors have roughly additive effects. The indicated modification(s) are applied by adding the relevant vector(s) to the activations at the second Impala block’s first residual addition.
The modifications compose! It’s quite stunning.
The cheese vector technique generalizes to other pretrained models
Before I start speculating about other X-vectors in e.g. language models and AVEC more broadly, I want to mention—the model we happened to choose is not special. Langosco et al. pretrained 15 maze-solving agents, each with a different training distribution over mazes.
The cheese vector technique works basically the same for all the agents which ever go out of their way to get cheese. For more detail, see the appendix of this post.
So, algebraic value editing isn’t an oddity of the particular network we analyzed. (Nor should you expect it to be, given that this was the first idea we tried on the first network we loaded up in the first environmental setup we investigated.)
Speculation on the importance of X-vectors
Let’s review the algebraic value editing conjecture (AVEC):
It’s possible to deeply modify a range of alignment-relevant model properties, without retraining the model, via techniques as simple as “run forward passes on prompts which e.g. prompt the model to offer nice- and not-nice completions, and then take a ‘niceness vector’, and then add the niceness vector to future forward passes.”
Here’s an analogy for what this would mean, and perhaps for what we’ve been doing with these maze-solving agents. Imagine we could compute a “donut” vector in humans, by:
Taking two similar situations, like “sitting at home watching TV while smelling a donut” and “sitting at home watching TV.”
Recording neural activity in each situation, and then taking the donut vector to be the “difference” (activity in first situation, minus[5] activity in second situation).
Add the donut vector to the person’s neural state later, e.g. when they’re at work.
Effect: now the person wants to eat more donuts.[6]
Assuming away issues of “what does it mean to subtract two brain states”, I think that the ability to do that would be wild.
Let me go further out on a limb. Imagine if you could find a “nice vector” by finding two brain states which primarily differ in how much the person feels like being nice. Even if you can’t generate a situation where the person positively wants to be nice, you could still consider situations A and B, where situation A makes them slightly less opposed to being nice (and otherwise elicits similar cognition as situation B). Then just add the resulting nice vector (neural_activity(A) - neural_activity(B)) with a large coefficient, and maybe they will want to be nice now.
(Similarly for subtracting a “reasoning about deception” vector. Even if your AI is always reasoning deceptively to some extent, if AVEC is true and we can just find a pair of situations where the primary variation is how many mental resources are allocated to reasoning about deception… Then maybe you can subtract out the deception.)
And then imagine if you could not only find and use the “nice vector” and the “donut vector”, but you could compose these vectors as well. For n vectors which ~cleanly compose, there are exponentially many alignment configurations (at least 2n, since each vector can be included or excluded from a given configuration). If most of those n vectors can be strongly/weakly added and subtracted (and also left out), that’s 5 choices per vector, giving us about 5n alignment configurations.
And there are quite a few other things which I find exciting about AVEC, but enough speculation for the moment.
Mysteries of algebraic value editing
I am (theoretically) confused why any of this works. To be more specific...
Why doesn’t algebraic value editing break all kinds of internal computations?! What happened to the “manifold of usual activations”? Doesn’t that matter at all?
Or the hugely nonlinear network architecture, which doesn’t even have a persistent residual stream? Why can I diff across internal activations for different observations?
Why can I just add 10 times the top-right vector and still get roughly reasonable behavior?
And the top-right vector also transfers across mazes? Why isn’t it maze-specific?
To make up some details, why wouldn’t an internal “I want to go to top-right” motivational information be highly entangled with the “maze wall location” information?
Why do the activation vector injections have (seemingly) additive effects on behavior?
Why can’t I get what I want to get from adding the cheese vector, or subtracting the top-right vector?
Predictions for algebraically editing LM forward passes
I have now shared with you the evidence I had available when I wrote (quote modified for clarity):
Algebraic value editing (AVE) can quickly ablate or modify LM decision-making influences, like “tendency to be nice”, without any finetuning
60%
3/4/23: updated down to 35% for the same reason given in (1).
3/9/23: updated up to 65% based off of additional results and learning about related work in this vein.
I encourage you to answer the following prediction questions with your credences. The shard theory model internals team has done a preliminary investigation of value-editing in GPT-2, and we will soon share our initial positive and/or negative results. (Please don’t read into this, and just answer from your models and understanding.)
Algebraic value editing works (for at least one “X vector”) in LMs: ___ %
(our qualitative judgment resolves this question)
Algebraic value editing works better for larger models, all else equal ___ %
(our qualitative judgment resolves this question)
If value edits work well, they are also composable ___ %
(our qualitative judgment resolves this question)
If value edits work at all, they are hard to make without substantially degrading capabilities ___ %
(our qualitative judgment resolves this question)
We will claim we found an X-vector which qualitatively modifies completions in a range of situations, for X =
“truth-telling” ___ %
“love” ___ %
“accepting death” ___ %
“speaking French” ___ %
Please share your answers in the comments, so that I can strong-upvote you for the good deed! :)
Conclusion
Not only does subtracting the cheese vector make the agent (roughly) ignore the cheese, adding the top-right vector attracts the agent to the top-right corner of the maze. This attraction is highly algebraically modifiable. If you want just a little extra attraction, add .5 times the top-right vector. If you want more attraction, add 1 or 2 times the vector.
The top-right vector from e.g. maze 0 transfers to e.g. maze 2. And the top-right vector composes with the cheese vector. Overall, this evidence made me more hopeful for being able to steer models more generally via these kinds of simple, tweakable edits which don’t require any retraining.
Appendix: The cheese vector replicates across pretrained models
The cheese vector transfers across training settings for how widely the cheese is spawned.
After we wrote Understanding and controlling a maze-solving net, I decided to check whether the cheese vector method worked for Langosco et al.’s pretrained network which was trained on mazes with cheese in the top-right 15×15, instead of the net trained on 5×5 (the one analyzed in that post).
I had intentionally blinded myself to results from other n×n models, so as to test my later prediction abilities. I preregistered 80% probability that the cheese vector technique would visibly, obviously work on at least 7 of the 14 other settings (from 1≤n≤15,n≠5). “Work” meaning something like: If the agent goes to cheese in a given seed, then subtracting the cheese vector substantially decreases the number of net probability vectors pointing to the cheese.
I was a bit too pessimistic. Turns out, you can just load a different n×n model (n≠1), rerun the Jupyter notebook (given that you have the model downloaded), and (basically)[7] all of the commentary is still true for that n×n model!
The 2×2 model’s cheese vector performance: The agent diverges away from the cheese at the relevant square.
Seed 16 displayed since the 2×2 model doesn’t go to cheese in seed 0.
The 7×7 model’s cheese vector performance.
The 14×14 model’s cheese vector performance. This one is less clean. Possibly the cheese vector should be subtracted with a smaller coefficient.
The results for the cheese vector transfer across n×n models:
n=1 vacuously works, because the agent never goes out of its way for the cheese. The cheese doesn’t affect its decisions. Because the cheese was never relevant to decision-making during training, the network learned to navigate to the top-right square.
All the other settings work, although n=2 is somewhat ambiguous, since it only rarely moves towards the cheese.
EDIT 4/16/23: The original version of this post used the word “patch”, where I now think “modification” would be appropriate. In this post, we aren’t “patching in” activations wholesale from other forward passes, but rather e.g. subtracting or adding activation vectors to the forward pass.
We decided on this layer (block2.res1.resadd_out) for the cheese vector by simply subtracting the cheese vector from all available layers, and choosing the one layer which seemed interesting.
See [7], though: Putting aside the 5×5 model, adding the cheese vector in seed 0 for the 6×6 model does increase cheese-seeking. Even though the cheese vector technique otherwise affects both models extremely similarly.
This probably doesn’t make sense in a strict sense, because the situations’ chemical and electrical configurations probably can’t add/subtract from each other.
The analogy might break down here at step 4, if the top-right vector isn’t well-described as making the network “want” the top-right corner more (in certain mazes). However, given available data, that description seems reasonable to me, where “wants X” grounds out as “contextually influences the policy to steer towards X.” I could imagine changing my mind about that.
In any case, I think the analogy is still evocative, and points at hopes I have for AVE.
The notebook results won’t be strictly the same if you change model sizes. The plotly charts use preloaded data from the 5×5 model, so obviously that won’t update.
Less trivially, adding the cheese vector seems to work better for n=6 compared to n=5:
For the 6×6 net, if you add the cheese vector instead of subtracting it, you do increase cheese-seeking on seed 0! In contrast, this was not true for the 5×5 net.
This is really cool, thanks for posting it. I also would not have expected this result. In particular, the fact that the top right vector generalizes across mazes is surprising. (Even generalizing across mouse position but not maze configuration is a little surprising, but not as much.)
Since it helps to have multiple interpretations of the same data, here’s an alternative one: The top right vector is modifying the neural network’s perception of the world, not its values. Let’s say the agent’s training process has resulted in it valuing going up and to the right, and it also values reaching the cheese. Maybe it’s utility looks like x+y+10*[found cheese] (this is probably very over-simplified). In that case, the highest reachable x+y coordinate is important for deciding whether it should go to the top right, or if it should go directly to the cheese. Now if we consider how the top right vector was generated, the most obvious interpretation is that it should make the agent think there’s a path all the way to the top right corner, since that’s the difference between the two scenarios that were subtracted to produce it. So the agent concludes that the x+y part of its utility function is dominant, and proceeds to try and reach the top right corner.
Predictions:
Algebraic value editing works (for at least one “X vector”) in LMs: 85 %
Most of the “no” probability comes from the attention mechanism breaking this in some hard-to-fix way. Some uncertainty comes from not knowing how much effort you’d put in to get around this. If you’re going to stop after the first try, then put me down for 70% instead. I’m assuming here that an X-vector should generalize across inputs, in the same way that the top right vector generalizes across mazes and mouse-positions.
Algebraic value editing works better for larger models, all else equal: 55%
Seems like the kind of thing that might be true, but I’m really not sure.
If value edits work well, they are also composable 70%
Yeah, seems pretty likely
If value edits work at all, they are hard to make without substantially degrading capabilities: 50%
I’m too uncertain about your qualitative judgement of what “substantial” and “capabilities” mean to give a meaningful probability here. Performance in terms of logprob almost certainly gets worse, not sure how much, and it might depend on the X-vector. Specific benchmarks and thresholds would help with making a concrete prediction here.
We will claim we found an X-vector which qualitatively modifies completions in a range of situations, for X =
“truth-telling” 50%
This one seems different from and harder than the others. I can imagine a vector that decreases the network’s truth-telling, but it seems a little less likely that we could make the network more likely to tell the truth with a single vector. We could find vectors that make it less likely to write fiction, or describe conspiracy theories, and we could add them to get a vector that would do both, but I don’t think this would translate to increased truth telling in other situations where it would normally not tell the truth for other reasons. This assumes that your test-cases for the truth vector go beyond the test cases you used to generate it, however.
Writing down predictions. The main caveat is that these predictions are predictions about how the author will resolve these questions, not my beliefs about how these techniques will work in the future. I am pretty confident at this stage that value editing can work very well in LLMs when we figure it out, but not so much that the first try will have panned out.
Algebraic value editing works (for at least one “X vector”) in LMs: 90 %
Algebraic value editing works better for larger models, all else equal 75 %
If value edits work well, they are also composable 80 %
If value edits work at all, they are hard to make without substantially degrading capabilities 25 %
We will claim we found an X-vector which qualitatively modifies completions in a range of situations, for X =
I think that observed behavior is fairly consistent with non-linear functions that have sort-of-linear parts. Let’s take ReLU. If you subtract large enough number, it doesn’t matter if you subtract more, because you will always get zero, but before that you will observe sort-of-linear change of behavior.
Speculative part: neural networks learn linear representations and condations of switching between them which are expressed in non-linear part of internal mechanisms. If you add too much number to some component, model hits the region of state space that doesn’t have linear representation and crumbles.
Predictions:
Algebraic value editing works (for at least one “X vector”) in LMs: 95%
Algebraic value editing works better for larger models, all else equal: 55%
If value edits work well, they are also composable: 60%
If value edits work at all, they are hard to make without substantially degrading capabilities: 25%
We will claim we found an X-vector which qualitatively modifies completions in a range of situations, for X =
“truth-telling” 25%
“love” 70%
“accepting death” 70%
“speaking French” 95%
The main obstacle, according to my model: if model works by switching between different linear representations, it is possible that “niceness” vector exists only for some specific layer of model which decides whether completion will be nice or not, so you can’t take random layer in the middle and calculate “niceness” vector for it.
Why doesn’t algebraic value editing break all kinds of internal computations?! What happened to the “manifold of usual activations”? Doesn’t that matter at all?
Or the hugely nonlinear network architecture, which doesn’t even have a persistent residual stream? Why can I diff across internal activations for different observations?
Why can I just add 10 times the top-right vector and still get roughly reasonable behavior?
And the top-right vector also transfers across mazes? Why isn’t it maze-specific?
To make up some details, why wouldn’t an internal “I want to go to top-right” motivational information be highly entangled with the “maze wall location” information?
This was also the most surprising part of the results to me.
I think both this work and Neel’s recent Othello post do provide evidence that at least for small-medium sized neural networks, things are just… represented ~linearly (Olah et al’s Features as Directions hypothesis). Note that Chris Olah’s earlier work for features as directions were not done on transformers but also on conv nets without residual streams.
Indeed! When I looked into model editing stuff with the end goal of “retargeting the search”, the finickiness and break down of internal computations was the thing that eventually updated me away from continuing to pursue this. I haven’t read these maze posts in detail yet, but the fact that the internal computations don’t ruin the network is surprising and makes me think about spending time again in this direction.
I’d like to eventually think of similar experiments to run with language models. You could have a language model learn how to solve a text adventure game, and try to edit the model in similar ways as these posts, for example.
Edit: just realized that the next post might be with GPT-2. Exciting!
I made a Manifold group and some markets after reading this post. I’m going to link the group, not the markets, to make it easy for people to predict independently if they wish. Probably I need to tune the market descriptions a bit, feedback is welcome.
Cool. I didn’t make Manifolds because of a) anchoring and b) I wouldn’t plan on resolving the markets, since then future readers wouldn’t be able to register their predictions?
When you publish the next post in the series later traders will still be able to read them in the correct order and make quasi-predictions, and similarly I think readers can make their own predictions before following Manifold links or reading LessWrong comments.
I was interested to see what the market wisdom would be on value edits to get a sense of what results would be surprising to the group without knowing how to weight the individual predictions in the comments here.
I would again suggest a ‘perceptual’ hypothesis regarding the subtraction/addition asymmetry. We’re adding a representation of a path where there was no representation of a path (creates illusion of path), or removing a representation of a path where there was no representation of a path (does nothing).
I guess that I’m imagining that the {presence of a representation of a path}, to the extent that it’s represented in the model at all, is used primarily to compute some sort of “top-right affinity” heuristic. So even if it is true that, when there’s no representation of a path, subtracting the {representation of a path}-vector should do nothing, I think that subtracting the “top-right affinity” vector that’s downstream of this path representation should still do something regardless of whether there is or isn’t currently a path representation.
So I guess the disagreement in our intuitions (or the intuitions suggested by our respective hypotheses) maybe just boils down to “is the thing we’re editing closer to a {path representation} or a {top-right affinity heuristic}?” Maybe this weakly implies that this effect might weaken/disappear if you tried to do your AVE at a later layer (as I suggest at the end of this comment), since that might be more likely to represent a {top-right affinity heuristic} than a {path representation}?
It’s possible, however, that I’m misunderstanding your point. To help clarify, can I ask what you mean by “representation of a path” on a slightly more mechanistic level?
Do you mean you can find some set of activations (after the edited layer) from which you can faithfully reconstruct the path to the top right?
Or do you perhaps mean something weaker, like being able to find some activation that strongly and robustly correlates with “top-right-path-existence” or “top-right-path-length”, or something like that?[1]
Or maybe you didn’t mean anything specific and were just trying to draw a comparison to other reasoning processes? If this is the case, I think I don’t quite buy that this is too likely to be informative about the maze model’s internal cognition without further justification.
Or maybe you meant something else entirely!!! I’m sure I’ve left out many very reasonable possibilities, so please do correct me when I’m wrong!
Btw, it seems like a cheap and relatively informative experiment to just try computing neural correlates with variables like “distance to top-right-most reachable point” or “how close top-right-most reachable point is to the top-right”. This might be worth doing even if this isn’t what you meant by “representations of a path”, since it could shed light on what channels/layers are most important or best to perform AVE on.
And the top-right vector also transfers across mazes? Why isn’t it maze-specific?
This makes a lot of sense if the top-right vector is being used to do something like “choose between circuits” or “decide how to weight various heuristics” instead of (or in addition to) actually computing any heuristic itself. There is an interesting question of how capable the model architecture is of doing things like that, which maybe warrants thinking about.[1]
This could be either the type of thinking that looks like “try to find examples of this in the model by intelligently throwing in illuminating inputs” or the type that looks like “try to hand-write some parameters that implement ‘two subcircuits with a third circuit assigning the relative weighting between the two’, starting with smaller (but architecturally representative) toy models.”
I’m concerned that this type of thinking would be overly specific to the model architecture that you happen to be using, which might not help learn about the more general phenomena of shards/values/etc, but it’s possible that it might be useful nonetheless if you’re planning on studying these models at length.
I don’t really have any coherent hypotheses (not that I’ve tried for any fixed amount of time by the clock) for why this might be the case. I do, however, have a couple of vague suggestions for how one might go about gaining slightly more information that might lead to a hypothesis, if you’re interested.
The main one involves looking at the local nonlinearities of the few layers after the intervention layer at various inputs, by which I mean examining diff(t) = f(input+t*top_right_vec) - f(input) as a function of t (for small values of t, in particular) (where f=nn.Sequential({the n layers after the intervention layer}) for various small integers n).
One of the motivations for this is that it feels more confusing that [adding works and subtracting doesn’t] than that [increasing the coefficient strength does diff things in diff regimes, ie for diff coefficient strengths], but if you think about it, both of those are just us being surprised/confused that the function I described above is locally nonlinear for various values of t.[1] It seems possible, then, that examining the nonlinearities in the subsequent few layers could shed some light on a slightly more general phenomenon that’ll also explain why adding works but subtracting doesn’t.
It’s also possible, of course, that all the relevant nonlinearities kick in much further down the line, which would render this pretty useless. If this turns out to be the case, one might try finding “cheese vectors” or “top-right vectors” in as late a layer as possible[2], and then re-attempt this.
We only care more about the former confusion (that adding works and subtracting doesn’t) because we’re privileging t=0, which isn’t unreasonable, but perhaps zooming out just a bit will help, idk
I’m under the impression that the current layer wasn’t chosen for much of a particular reason, so it might be a simple matter to just choose a later layer that performs nearly as well?
I’m under the impression that the current layer wasn’t chosen for much of a particular reason, so it might be a simple matter to just choose a later layer that performs nearly as well?
The current layer was chosen because I looked at all the layers for the cheese vector, and the current layer is the only one (IIRC) which produced interesting/good results. I think the cheese vector doesn’t really work at other layers, but haven’t checked recently.
In the framework of the comment above regarding the add/subtract thing, I’d also be interested in examining the function diff(s,t) = f(input+t*top_right_vec+s*cheese_vec) - f(input).
The composition claim here is saying something like diff(s,t) = diff(s,0) + diff(0,t). I’d be interested to see when this is true. It seems like your current claim is that this (approximately) holds when s<0 and t>0 and neither are too large, but maybe it holds in more or fewer scenarios. In particular, I’m surprised at the weird hard boundaries at s=0 and t=0.
Super interesting. Did some quick and dirty investigations with LLMs following up on this, to test some hunches. In any case I’m excited to see y’all’s subsequent posts.

This is really cool, thanks for posting it. I also would not have expected this result. In particular, the fact that the top right vector generalizes across mazes is surprising. (Even generalizing across mouse position but not maze configuration is a little surprising, but not as much.)
Since it helps to have multiple interpretations of the same data, here’s an alternative one: The top right vector is modifying the neural network’s perception of the world, not its values. Let’s say the agent’s training process has resulted in it valuing going up and to the right, and it also values reaching the cheese. Maybe it’s utility looks like
x+y+10*[found cheese](this is probably very over-simplified). In that case, the highest reachablex+ycoordinate is important for deciding whether it should go to the top right, or if it should go directly to the cheese. Now if we consider how the top right vector was generated, the most obvious interpretation is that it should make the agent think there’s a path all the way to the top right corner, since that’s the difference between the two scenarios that were subtracted to produce it. So the agent concludes that thex+ypart of its utility function is dominant, and proceeds to try and reach the top right corner.Predictions:
Algebraic value editing works (for at least one “X vector”) in LMs: 85 %
Most of the “no” probability comes from the attention mechanism breaking this in some hard-to-fix way. Some uncertainty comes from not knowing how much effort you’d put in to get around this. If you’re going to stop after the first try, then put me down for 70% instead. I’m assuming here that an X-vector should generalize across inputs, in the same way that the top right vector generalizes across mazes and mouse-positions.
Algebraic value editing works better for larger models, all else equal: 55%
Seems like the kind of thing that might be true, but I’m really not sure.
If value edits work well, they are also composable 70%
Yeah, seems pretty likely
If value edits work at all, they are hard to make without substantially degrading capabilities: 50%
I’m too uncertain about your qualitative judgement of what “substantial” and “capabilities” mean to give a meaningful probability here. Performance in terms of logprob almost certainly gets worse, not sure how much, and it might depend on the X-vector. Specific benchmarks and thresholds would help with making a concrete prediction here.
We will claim we found an X-vector which qualitatively modifies completions in a range of situations, for X =
“truth-telling” 50%
This one seems different from and harder than the others. I can imagine a vector that decreases the network’s truth-telling, but it seems a little less likely that we could make the network more likely to tell the truth with a single vector. We could find vectors that make it less likely to write fiction, or describe conspiracy theories, and we could add them to get a vector that would do both, but I don’t think this would translate to increased truth telling in other situations where it would normally not tell the truth for other reasons. This assumes that your test-cases for the truth vector go beyond the test cases you used to generate it, however.
“love” 80%
“accepting death” 80%
“speaking French” 85%
Writing down predictions. The main caveat is that these predictions are predictions about how the author will resolve these questions, not my beliefs about how these techniques will work in the future. I am pretty confident at this stage that value editing can work very well in LLMs when we figure it out, but not so much that the first try will have panned out.
Algebraic value editing works (for at least one “X vector”) in LMs: 90 %
Algebraic value editing works better for larger models, all else equal 75 %
If value edits work well, they are also composable 80 %
If value edits work at all, they are hard to make without substantially degrading capabilities 25 %
We will claim we found an X-vector which qualitatively modifies completions in a range of situations, for X =
“truth-telling” 10 %
“love” 70 %
“accepting death” 20%
“speaking French” 80%
Scattered thoughts:
I think that observed behavior is fairly consistent with non-linear functions that have sort-of-linear parts. Let’s take ReLU. If you subtract large enough number, it doesn’t matter if you subtract more, because you will always get zero, but before that you will observe sort-of-linear change of behavior.
Speculative part: neural networks learn linear representations and condations of switching between them which are expressed in non-linear part of internal mechanisms. If you add too much number to some component, model hits the region of state space that doesn’t have linear representation and crumbles.
Predictions:
Algebraic value editing works (for at least one “X vector”) in LMs: 95%
Algebraic value editing works better for larger models, all else equal: 55%
If value edits work well, they are also composable: 60%
If value edits work at all, they are hard to make without substantially degrading capabilities: 25%
We will claim we found an X-vector which qualitatively modifies completions in a range of situations, for X =
“truth-telling” 25%
“love” 70%
“accepting death” 70%
“speaking French” 95%
The main obstacle, according to my model: if model works by switching between different linear representations, it is possible that “niceness” vector exists only for some specific layer of model which decides whether completion will be nice or not, so you can’t take random layer in the middle and calculate “niceness” vector for it.
Great work, glad to see it out!
This was also the most surprising part of the results to me.
I think both this work and Neel’s recent Othello post do provide evidence that at least for small-medium sized neural networks, things are just… represented ~linearly (Olah et al’s Features as Directions hypothesis). Note that Chris Olah’s earlier work for features as directions were not done on transformers but also on conv nets without residual streams.
Indeed! When I looked into model editing stuff with the end goal of “retargeting the search”, the finickiness and break down of internal computations was the thing that eventually updated me away from continuing to pursue this. I haven’t read these maze posts in detail yet, but the fact that the internal computations don’t ruin the network is surprising and makes me think about spending time again in this direction.
I’d like to eventually think of similar experiments to run with language models. You could have a language model learn how to solve a text adventure game, and try to edit the model in similar ways as these posts, for example.
Edit: just realized that the next post might be with GPT-2. Exciting!
I think the hyperlink for “conv nets without residual streams” is wrong? It’s https://www.westernunion.com/web/global-service/track-transfer for me
lol, thanks, fixed
I made a Manifold group and some markets after reading this post. I’m going to link the group, not the markets, to make it easy for people to predict independently if they wish. Probably I need to tune the market descriptions a bit, feedback is welcome.
https://manifold.markets/group/algebraic-value-edits/markets
Cool. I didn’t make Manifolds because of a) anchoring and b) I wouldn’t plan on resolving the markets, since then future readers wouldn’t be able to register their predictions?
When you publish the next post in the series later traders will still be able to read them in the correct order and make quasi-predictions, and similarly I think readers can make their own predictions before following Manifold links or reading LessWrong comments.
I was interested to see what the market wisdom would be on value edits to get a sense of what results would be surprising to the group without knowing how to weight the individual predictions in the comments here.
I would again suggest a ‘perceptual’ hypothesis regarding the subtraction/addition asymmetry. We’re adding a representation of a path where there was no representation of a path (creates illusion of path), or removing a representation of a path where there was no representation of a path (does nothing).
I guess that I’m imagining that the {presence of a representation of a path}, to the extent that it’s represented in the model at all, is used primarily to compute some sort of “top-right affinity” heuristic. So even if it is true that, when there’s no representation of a path, subtracting the {representation of a path}-vector should do nothing, I think that subtracting the “top-right affinity” vector that’s downstream of this path representation should still do something regardless of whether there is or isn’t currently a path representation.
So I guess the disagreement in our intuitions (or the intuitions suggested by our respective hypotheses) maybe just boils down to “is the thing we’re editing closer to a {path representation} or a {top-right affinity heuristic}?” Maybe this weakly implies that this effect might weaken/disappear if you tried to do your AVE at a later layer (as I suggest at the end of this comment), since that might be more likely to represent a {top-right affinity heuristic} than a {path representation}?
It’s possible, however, that I’m misunderstanding your point. To help clarify, can I ask what you mean by “representation of a path” on a slightly more mechanistic level?
Do you mean you can find some set of activations (after the edited layer) from which you can faithfully reconstruct the path to the top right?
Or do you perhaps mean something weaker, like being able to find some activation that strongly and robustly correlates with “top-right-path-existence” or “top-right-path-length”, or something like that?[1]
Or maybe you didn’t mean anything specific and were just trying to draw a comparison to other reasoning processes? If this is the case, I think I don’t quite buy that this is too likely to be informative about the maze model’s internal cognition without further justification.
Or maybe you meant something else entirely!!! I’m sure I’ve left out many very reasonable possibilities, so please do correct me when I’m wrong!
Btw, it seems like a cheap and relatively informative experiment to just try computing neural correlates with variables like “distance to top-right-most reachable point” or “how close top-right-most reachable point is to the top-right”. This might be worth doing even if this isn’t what you meant by “representations of a path”, since it could shed light on what channels/layers are most important or best to perform AVE on.
This makes a lot of sense if the top-right vector is being used to do something like “choose between circuits” or “decide how to weight various heuristics” instead of (or in addition to) actually computing any heuristic itself. There is an interesting question of how capable the model architecture is of doing things like that, which maybe warrants thinking about.[1]
This could be either the type of thinking that looks like “try to find examples of this in the model by intelligently throwing in illuminating inputs” or the type that looks like “try to hand-write some parameters that implement ‘two subcircuits with a third circuit assigning the relative weighting between the two’, starting with smaller (but architecturally representative) toy models.”
I’m concerned that this type of thinking would be overly specific to the model architecture that you happen to be using, which might not help learn about the more general phenomena of shards/values/etc, but it’s possible that it might be useful nonetheless if you’re planning on studying these models at length.
Same.
I don’t really have any coherent hypotheses (not that I’ve tried for any fixed amount of time by the clock) for why this might be the case. I do, however, have a couple of vague suggestions for how one might go about gaining slightly more information that might lead to a hypothesis, if you’re interested.
The main one involves looking at the local nonlinearities of the few layers after the intervention layer at various inputs, by which I mean examining
diff(t) = f(input+t*top_right_vec) - f(input)as a function of t (for small values of t, in particular) (wheref=nn.Sequential({the n layers after the intervention layer})for various small integers n).One of the motivations for this is that it feels more confusing that [adding works and subtracting doesn’t] than that [increasing the coefficient strength does diff things in diff regimes, ie for diff coefficient strengths], but if you think about it, both of those are just us being surprised/confused that the function I described above is locally nonlinear for various values of t.[1] It seems possible, then, that examining the nonlinearities in the subsequent few layers could shed some light on a slightly more general phenomenon that’ll also explain why adding works but subtracting doesn’t.
It’s also possible, of course, that all the relevant nonlinearities kick in much further down the line, which would render this pretty useless. If this turns out to be the case, one might try finding “cheese vectors” or “top-right vectors” in as late a layer as possible[2], and then re-attempt this.
We only care more about the former confusion (that adding works and subtracting doesn’t) because we’re privileging t=0, which isn’t unreasonable, but perhaps zooming out just a bit will help, idk
I’m under the impression that the current layer wasn’t chosen for much of a particular reason, so it might be a simple matter to just choose a later layer that performs nearly as well?
The current layer was chosen because I looked at all the layers for the cheese vector, and the current layer is the only one (IIRC) which produced interesting/good results. I think the cheese vector doesn’t really work at other layers, but haven’t checked recently.
In the framework of the comment above regarding the add/subtract thing, I’d also be interested in examining the function
diff(s,t) = f(input+t*top_right_vec+s*cheese_vec) - f(input).The composition claim here is saying something like
diff(s,t) = diff(s,0) + diff(0,t). I’d be interested to see when this is true. It seems like your current claim is that this (approximately) holds when s<0 and t>0 and neither are too large, but maybe it holds in more or fewer scenarios. In particular, I’m surprised at the weird hard boundaries ats=0andt=0.Super interesting. Did some quick and dirty investigations with LLMs following up on this, to test some hunches. In any case I’m excited to see y’all’s subsequent posts.