Public-facing Censorship Is Safety Theater, Causing Reputational Damage
It’s so common it’s a stereotype.
A large corporation releases a cutting-edge AI model, and puts out a press release talking about how their new, [larger/smaller]-than-ever model provides unprecedented freedom for [underprivileged artists/small business owners/outside researchers] to do whatever it is their AI does. You go to their website, start playing with the model, and before long—
Results containing potentially sensitive content have been omitted. Further requests of this type may result in account suspension, etc., etc., etc....
—or something along those lines. The prompt you gave was pretty innocuous, but in retrospect you can sort of see how maybe the output might have resulted in something horrifically offensive, like a curse word, or even (heaven forbid) an image that has a known person’s face in it. You’ve been protected from such horrors, and this is reassuring. Of course, your next prompt for whatever reason elicits [insert offensive stereotype/surprisingly gory or uncanny imagery/dangerously incorrect claim presented with high confidence/etc. here], which is slightly less reassuring.
Checking the details of the press release, you see a small section of the F.A.Q. with the disclaimer that some outputs may be biased due to [yadda yadda yadda you know the drill]. You breathe a sigh of relief, secure in the comforting knowledge that [faceless company] cares about AI safety, human rights, and reducing biases. Their model isn’t perfect, but they’re clearly working on it!
The above scenario is how [large corporations] seem to expect consumers to react to their selective censorship. In reality I strongly suspect that the main concern is not so much protecting the consumer as it is protecting themselves from liability. After all, by releasing a model which is clearly capable of doing [harmful capability], and by giving sufficient detail to the public that their model can be replicated, [harmful capability] has effectively been released, if perhaps delayed by a few months at most. However, whoever makes the open-source replication will not be [large corporation], absolving the company of perceived moral (and legal) culpability in whatever follows. If the concern were actually that [harmful capability] would lead to real danger, then the moral thing to do would be not to release the model at all.
There are a few serious problems with this. The most obvious (and generic) objection is that censorship is bad. When looking at historical incidents of censorship we often find ourselves morally disagreeing with the censors, who got to choose what is considered inappropriate from a position of power. Almost everyone agrees that Hollywood’s infamous Hays code was a moral mistake.[1] In the present day, inconsistent or weaponized social media censorship is widespread, with seemingly nobody happy with how large corporations enforce their rules (though the details of how they are failing are arguable). At least one Chinese text-to-image model disallows prompts which include the word “democracy”. It would be surprising to me if protections against generating certain forms of content with LLMs don’t eventually lead to unexpected negative social consequences.[2]
Secondly, there is a danger of AI safety becoming less robust—or even optimising for deceptive alignment—in models using front-end censorship.[3] If it’s possible for a model to generate a harmful result from a prompt, then the AI is not aligned, even if the user can’t see the bad outputs once they are generated. This will create the illusion of greater safety than actually exists, and (imo) is practically begging for something to go wrong. As a “tame” example, severe bugs could crop up which are left unaddressed until it’s too late because nobody has access to “edge-case” harmful generations.
The third argument is a bit more coldly utilitarian, but is extremely relevant to this community: Calling content censorship “AI safety” (or even “bias reduction”) severely damages the reputation of actual, existential AI safety advocates. This is perhaps most obviously happening in the field of text-to-image generation. To illustrate, I present a few sample Tweets from my timeline (selected more-or-less randomly among tweets using the search term “AI safety” and “AI ethics”):
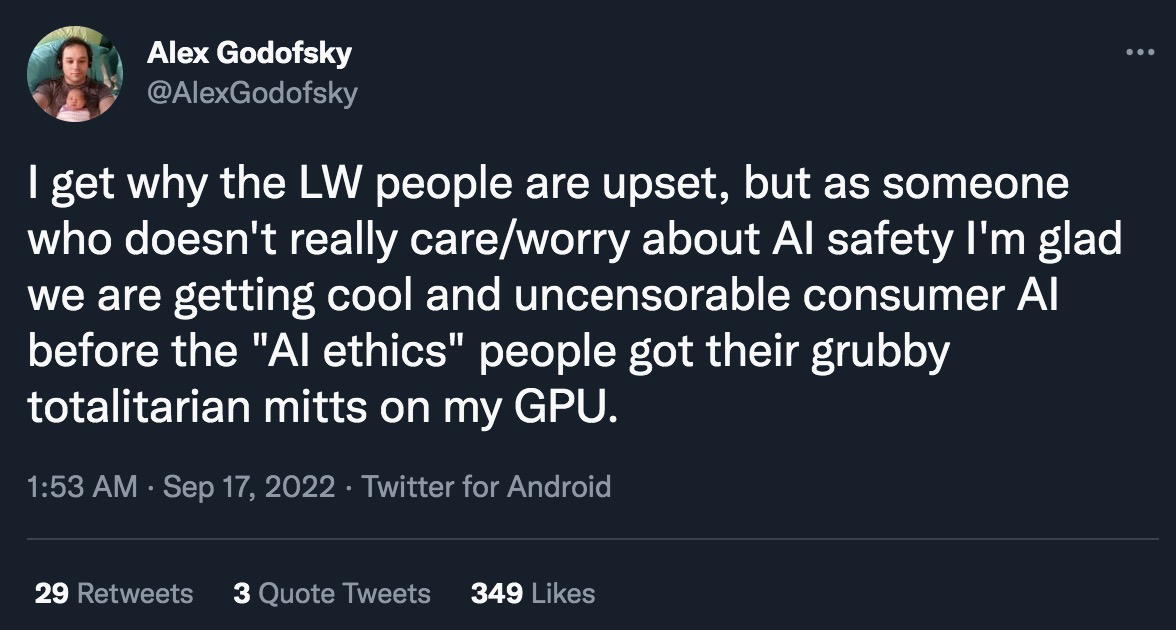
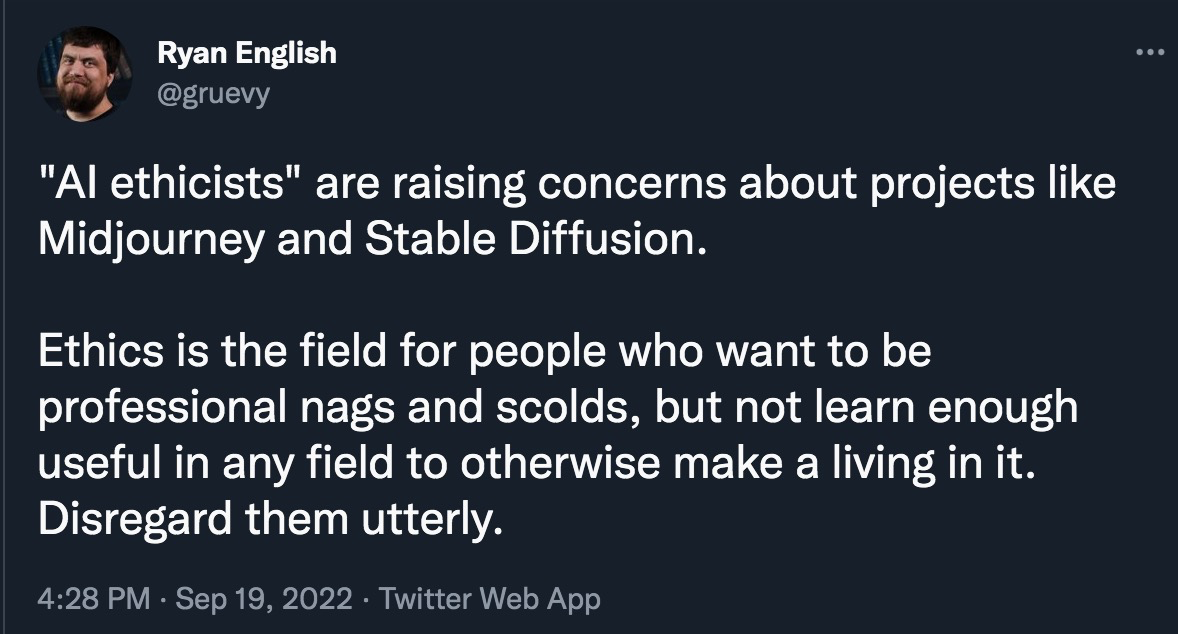
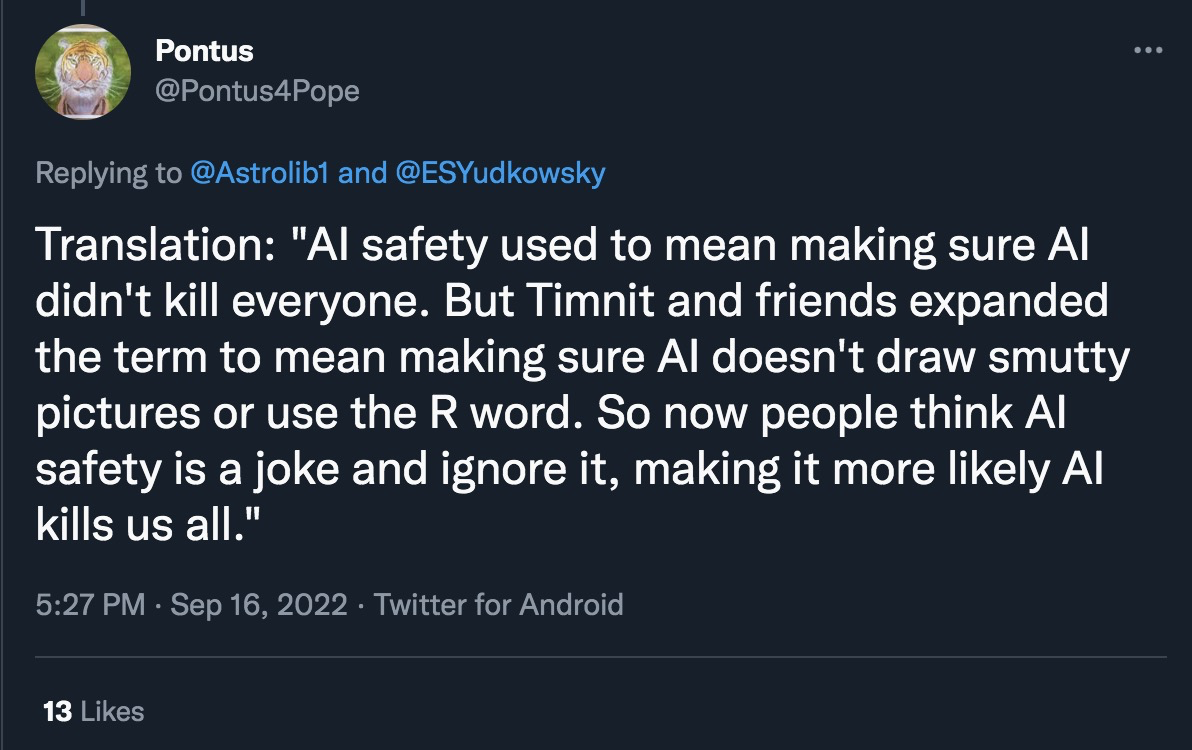
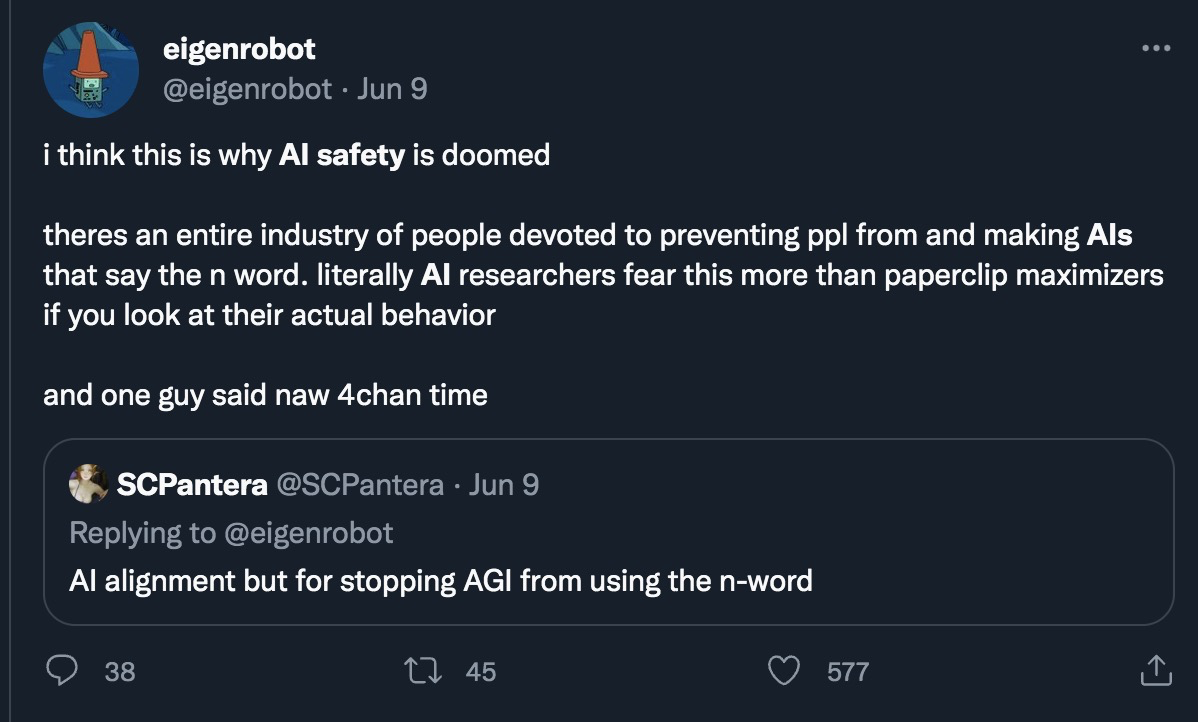

I think the predicament we are facing is clear. The more that public-facing censorship is presented as being a demonstration of AI safety/ethics, the more people tend to dismiss the AI safety field as a whole. This damages our ability to connect with people (especially in the open-source movement) who might otherwise be interested in collaborating, and gives motivation for adversarial actions against our efforts. My background is partially in Public and Media Relations, and if that were my current job here, I would be going into serious damage-reduction mode right now!
This has happened in part due to the general corporate desire to frame concerns over liability as being about the user’s safety (instead of the company’s), but it’s also partially our fault. OpenAI, for instance, is viewed by many as the poster-child of the classical “AI safety” camp (whether deserved or not), and what is it most famous for on the safety front? Its multi-tiered release of GPT-2 (and subsequent non-delayed release of GPT-3 for some reason), and its ban against using DALL-E to generate or edit photorealistic faces! Regardless of if those are good measures to take or not, the fact of the matter is that at some point, a decision was made that this would be marketed as “AI safety” and “minimizing risk,” respectively.
While we can’t take back what’s already been said and done, for the future I would like people in this field to take a stronger stance against using safety-related terminology in places where you’re likely to be seen by outsiders as the boy who cried “wolf”. Alternatively, perhaps we should make a clearer distinction between types of safety efforts (bias reduction, existential risk reduction, etc.), using specialized terminology to do so. It would be foolish to undermine our own efforts at raising awareness because we missed such an easy concept to understand: Censorship is not viewed as safety by the vast majority of people.[4] Instead, it’s viewed as a sort of “safety theater,” similar to so-called “Hygiene Theater,” which caused mass harm during the COVID-19 pandemic by making people lose trust in public health institutions (deserved or not). We should do everything in our power to reduce the negative effects such “AI safety theater” may cause to our community.
What practical steps can be done?
The following list includes some suggestions given above, along with some more tentative proposals. I do not have rigorous evidence for everything mentioned blow (this is more personal intuition), so feel free to take this with a grain of salt:
If you can do so ethically, try to minimize the amount of overt censorship used in public-facing models.
If for whatever reason you need to explicitly block some forms of content, the details of implementation matter a lot, with back-end preventative work being preferred over front-end user-facing censorship. For example, banning sexually suggestive keywords and prompts (a front-end approach) will feel much more subjectively oppressive than not having your model trained on sexually suggestive data in the first place (a back-end approach which also prevents suggestive text/image outputs). Obviously, what you can practically achieve will vary depending on your situation.
If censorship is being utilized to reduce personal/company liability, say so explicitly! Currently, many people seem to think that calls for “ethics,” “safety,” or “bias reduction” are being used for the primary purpose of protecting corporate interests, and we really, really do not want to feed that particular beast. Saying “we can’t do [thing you want] because we’ll get sued/lose access to some services” is a lot less harmful than saying “we can’t do [thing you want] because we know what’s best for you and you don’t.” (this is often a useful framing even if you think the latter is true!)
Make clearer distinctions between types of safety efforts (bias reduction, existential risk reduction, etc.), using specialized terminology to do so. Perhaps new terminology needs to be coined, or perhaps existing concepts will do; this is something that can and should be discussed and iterated on within the community.
Be willing to speak to the media (as long as you have some amount of training beforehand) about what the field of AI safety is really trying to achieve. Most publications source their news about the field from press releases, which tend to come with a corporate, “everything we’re doing is for the good of humanity” vibe, and that may occasionally be worth pushing back against if your field is being misrepresented.
Feel free to suggest further possible actions that can be done in the comments below!
- ^
Especially considering that among many other harms, it was used to prevent anti-Nazi films from being produced!
- ^
For example, enforcement against generating sexually explicit content is likely to be stricter with some media (think queer/feminist/war coverage stuff), leading to exacerbated asymmetry in depicting the human condition. What about classical art, or cultures with totally healthy customs considered explicit in other contexts (such as nudists)? Some of this could be resolved in the future with more fine-tuned filters, but there isn’t strong incentive to do so, and evidence from existing social media censorship points to this not happening in a nuanced manner.
- ^
I define front-end censorship as when the user asks for something which is then denied, though the theoretical possibility to create/access it clearly exists; this is different from more subtle “back-end” forms.
- ^
To be clear, it may be the case that censorship is the right thing to do in some circumstances. However, please keep in mind that this community’s most famous unforced error has been related to censorship, and if you are reading this, you are unlikely to have typical views on the subject. Regardless of the ground truth, most people will perceive front-end censorship (as opposed to more subtle back-end censorship which may not receive the same reception) as being net negative, and an intrusive action. Some exceptions to this general rule do exist, most notably when it comes to blatantly illegal or uncontroversially unethical content (child pornography, nonconsensually obtained private information, etc.), but even then, some will still be unhappy on principle. One cannot make everyone perfectly content, but should still work to reduce potential damage when possible.
- How do you feel about LessWrong these days? [Open feedback thread] by (5 Dec 2023 20:54 UTC; 108 points)
- AI Safety − 7 months of discussion in 17 minutes by (EA Forum; 15 Mar 2023 23:41 UTC; 90 points)
- EA & LW Forums Weekly Summary (19 − 25 Sep 22′) by (EA Forum; 28 Sep 2022 20:13 UTC; 25 points)
- AI Safety − 7 months of discussion in 17 minutes by (15 Mar 2023 23:41 UTC; 25 points)
- EA & LW Forums Weekly Summary (19 − 25 Sep 22′) by (28 Sep 2022 20:18 UTC; 16 points)
- 's comment on My talk on AI risks at the National Conservatism conference last week by (12 Sep 2025 17:15 UTC; 9 points)
A thing I learned recently is that “safety” actually is sort of a term of art among existing platform communities (like youtube or whatever), usually bucked under “trust and safety” or “community safety”, and that it specifically refers to things that are more like pornography and racism than things like “technical AI safety.”
I think it’s probably both true that these two definitions accidentally bumped into each other, creating unintended confusion, and I think there are people getting into the AI Ethics / Safety field who are blurring the lines between technical safety problems and other domains, either because they’re confused, or haven’t heard arguments about x-risk, or have heard arguments about x-risk but rounded them to something more near-term that felt more tractable or interesting or politically expedient to them.
But, given that “safety” is a vague term in the first place, and “trust and safety”/”community safety” already exist as online-industry terms, I think it just makes sense to try and move away from using “safety” to mean “existential safety” or “technical safety”
Security strikes me as a better word than safety, ethics, or responsibility. More prestigious, and the knowledge and methods of the existing security research field is probably more relevant to addressing AI x-risks than are those of existing safety, ethics, etc fields.
“Security” for me has the connotation of being explicitely in relation to malicious adversaries, while “safety” carries the connotation of heavy industrial machinery that must be made as accident-free as possible. As an example, “boat security” would be preventing people from stealing the boat, while “boat safety” would be measures intended to prevent people from falling off the boat. AI alignment (which I consider a very good term!) strikes me to be more about the latter than the former (if you have a superintelligent adversary, it might already be too late!).
But, like, in my view the main issue with advanced AI capabilities is that they come with an adversary built-in. This does make it fundamentally different from protecting against an external adversary, but I think the change is smaller than, say, the change from “preventing people from falling off the boat.” Like, the issue isn’t that the boat deck is going to be wet, or the sea will be stormy, or stuff like that; the issue is that the boat is thinking!
It’s a thoughtful post and all, but for the record, I’m not that interested in what people on twitter say about me and my allies, and am always a bit sad to see people quoting folks on twitter and posting it on LessWrong.
I understand not being interested in hearing negative outsider takes, but may I ask why it makes you sad to see negative quotes from Twitter here? For some context as to why I included those tweets, the worldview I’m coming from is one where outside perception can strongly affect our ability to carry out future plans (in governance, getting people to agree to shared safety standards, etc.), and as such it seems worth paying attention to the state of adversarial discourse in influential circles (especially when we can practically effect that discourse). If there’s good reason not to specifically quote from twitter, however, I’d be happy to remove it/relegate to footnotes/use different sources.
Sad and uninteresting seem related to me? It seems solely a distraction, so to read LWers focusing serious attention on a distraction is sad.
See my reply to niplav for my perspective.
It sounds like your trying to convince readers that random potshots on Twitter are serious opinions?
If so, this seems a bit absurd, as if readers can’t tell by themselves when someone’s opinion is worth their attention.
Random samples are valuable, even if small, the first data point carries the highest amount of information. Public opinion matters to some degree, I believe it matters a lot, and Twitter is a widely used platform, so it is decently representative of the public opinion on something (at least more representative than Lesswrong).
If you want to give a good survey of public opinion on Twitter, you likely should choose tweets that are highly upvoted. All of the tweets the OP cited have less than 1000 upvotes. Is that an amount of likes that suggest that it’s decently representative of the public opinion?
For each tweet the post found arguing their point, I can find two arguing the opposite. Yes, in theory tweets are data points, but in practice the author just uses them to confirm his already held beliefs.
Random samples, among a representative population, are valuable. It seems unlikely that Twitter is representative of the general population, more likely it is only representative of a subset.
I have weak-downvoted this comment. I don’t know what generated it, but from the outside it looks to me like ignoring a very important aspect of reality (public opinion on the words “AI safety”) in favor of… not exactly sure what? Protecting tribal instincts?
In this case the quoting feels quite adequate to me, since the quotes are not necessarily endorsed, but examined as a phenomenon in the world, and its implications.
Okay, this was enough meta for me today.
As part of doing anything interesting in the world and saying it out loud on the internet, lots of people on the internet will spout text about you, and I think it’s not interesting or worthwhile to read.
Feynman asks “What do you care what other people think?” which I extend here to “Why do you care to seek out and read what other people think?”
I have a theory that, essentially, all real thinking on the internet gets done in essay form, and anything that is not the form of an essay does not contain real or original thinking, and should rise to a very high bar before its worth engaging with e.g. social media, a lot of scientific papers. For instance, anyone who tweets anything I find genuinely interesting, also writes essays (Paul Graham, Eliezer Yudkowsky, Aella, Venkatesh Rao, and so on).
I have difficulty imagining a world where public discourse on the internet matters AND the people engaging with it aren’t having a spout of bad content written about them. The fact that people are spouting negative content about AI safety is not surprising, and in my experience their ideas are of little worth (with the exception of people who write essays).
And of course, many actions that I think might improve the world, are outside of the overton window. Suppose I want to discuss them with other thoughtful LessWrongers. Should I not do so because it will cause people to spout negative text about us, or should I do so and avoid caring about the negativity? I deem it to be the latter.
Thanks for the detailed response, I really appreciate it! For the future I’ll see if I can link to more essays (over social media posts) when giving evidence about potentially important outside opinions. I’m going offline in a few minutes, but will try to add some links here as well when I get back on Sunday.
As for the importance of outside opinions that aren’t in essay form, I fully agree with you that some amount of critique is inevitable if you are doing good, impactful work. I also agree we should not alter our semi-private conversations on LessWrong and elsewhere to accommodate (bad-faith) critics. Things are different, however, when you are releasing a public-facing product, and talking about questionably defined “AI ethics” in a literal press release. There, everything is about perception, and you should expect people to be influenced heavily by your wording (if your PR folks are doing their jobs right 🙃).
Why should we care about the non-essay-writing-public? Well, one good reason is politics. I don’t know what your take is on AI governance, but a significant (essay-writing) portion of this community believes it to be important. In order to do effective work there, we will need to be in a position where politicians and business leaders in tech can work with us with minimal friction. If there is one thing politicians (and to a lesser degree some corporations) care about, it is general public perception, and while they are generally fine with very small minority pushback, if the general vibe in Silicon valley becomes “AI ethicists are mainly partisan, paternalistic censors,” then there becomes a very strong incentive not to work with us.
Unfortunately, I believe that the above vibe has been growing both on and offline as a result of actions which members of this community have had some amount of control over. We shouldn’t bend over backwards to accommodate critics, but if we can make our own jobs easier by, say, better communicating our goals in our public-facing work, why not do that?
I didn’t do this, and LessWrong didn’t do this.
To be clear, as a rule I’m just not reading it if it’s got social media screenshots about LW discussion, unless the social media author is someone who also writes good and original essays online.
I don’t want LessWrong to be a cudgel in a popularity contest, and you responding to my comment by saying you’ll aim to give higher quality PR advice in the future, is missing my point.
Citation needed? Anyway, my take is that using LW’s reputation in a popularity tug-of-war is a waste of our reputation. Plus you’ll lose.
Just give up on that. You will not get far with that.
I don’t know why you are identifying “ML developers” with “LessWrong users”, the two groups are not much overlapping.
This mistake is perhaps what leads you, in the OP, to not only give PR advice, but to give tactical advice on how to get censorship past people without them noticing, which seems unethical to me. In contrast I would encourage making your censorship blatant so that people know that they can trust you to not be getting one over on them when you speak.
I’m not trying to be wholly critical, I do have admiration for many things in your artistic and written works, but reading this post, I suggest doing a halt, melt, catch fire, and finding a new way to try to help out with the civilizational ruin coming our way from AI. I want LessWrong to be a place of truth and wisdom, I never want LessWrong to be a place where you can go to get tactical advice on how to get censorship past people to comply with broad political pressures in the populace.
I mostly agree with what you wrote (especially the “all real thinking on the internet gets done in essay form” is very interesting, though I might push back against that a bit and point to really good comments, podcasts & forecasting platforms). I do endorse the negative sentiment around privately owned social media companies (as in me wishing them to burn in hell) for any purpose other than the most inane shitposting, and would prefer everyone interested in making intellectual progress to abandon them (yes, that also includes substacks).
Ahem.
I guess you approach the tweets by judging whether their content is useful to engage with qua content (“is it true or interesting what those people are saying?”, which, I agree with you, is not the case), as opposed to approaching it sociologically (“what does the things those people are saying predict about how they will vote & especially act in the future?”). Similarly, I might not care about how a barometer works, but I’d still want to use it to predict storms (I, in fact, care about knowing how barometers work, and just spend 15 minutes reading the Wikipedia article). The latter still strikes me as important, though I get the “ick” and “ugh” reaction against engaging in public relations, and I’m happy I’m obscure enough to not have to bother about it. But in the unlikely case a big newspaper would run a huge smear campaign against me, I’d want to know!
And then think hard about next steps: maybe hiring public relations people to deal with it? Or gracefully responding with a public clarification?
I think you might be underestimating Twitter’s role in civilizational thinking.
Like, if I decide I’m going to train for a marathon, in some sense I don’t care what a random thought like “I’m tired and don’t wanna keep running” has to say. The answer is “Nah.”
But it’s also pretty damn important that I notice and account for the thought if I want to keep training.
I actually just got back from exercising. While I was there, I noticed I’d built up an anticipation of pain from keeping going. Now, I do want to keep going longer than I did today. But I also want that part of my mind to feel it can have control/agency over my choices, so I happily wrapped up after ~30 mins, and walked home. Next time I’ll probably feel more comfortable going longer.
But anyway, I’m not seeing the analogy. (Also it’s hard to argue with analogies, I find myself getting lost in hypotheticals all day.)
I don’t respect Twitter anywhere near as much as I respect the part of me that is resistant to physical pain. The relevant part of me that fears physical pain feels like a much more respectable negotiation partner; it cares about something I roughly see as valuable, and I expect I can get it what it wants whilst also getting what I care about (as much physical ease and movement as I desire).
I have a great disrespect for Twitter; it wants to eat all of my thoughts and ideas for its content-creation machine and transform them into their most misinterpreted form, and in return will give me a lot of attention. I care little about attention on the current margin and care a lot about not having to optimize against the forces of misinterpretation.
I’d be interested in reading an argument about how Twitter plays a useful role in civilizational cognition, with the hypothesis to beat being “it’s a mess of symbols and simulacra that is primarily (and almost solely) a force for distraction and destruction”.
I’m not suggesting you remove it from your map of the world, it’s a very key part in understanding various bits of degeneration and adversarial forces. I’m suggesting that giving the arguments and positions that rise there much object-level consideration is a grave distraction, and caring about what people say about you there is kind of gross.
The difference is that I can’t shut down my own internal monologue/suppress my own internal subagents, and I can just choose to Not Read Twitter and, further, Not Post What People On Twitter Say. Which is what I generally choose to do.
That seems like a fine choice,
Though the analog here would be whether civilization can Not Read Twitter and Not Post What People On Twitter Say. I think civilization has about as much difficulty with that as you or I do with shutting down our respective internal monologues.
I also agree that I am less able to get out of a negotiation with the part of me that is resistant to physical pain, whereas it seems way more doable to me to have massive positive influence on the world without having to care very much about the details of what people write about you on Twitter.
The problem I think this article is getting at is paternalism without buy-in.
On the topic of loss of credibility, I think focusing on nudity in general is also a credibility-losing problem. Midjourney will easily make very disturbing, gory, bloody images, but neither the Vitruvian man nor Botticelli’s Venus would be acceptable.
Corporate comfort with basic violence while blushing like a puritan over the most innocuous, healthy, normal nudity or sexuality is very weird. Also, few people for even a moment think any of it is anything other than CYOA on their part. Also, some may suspect a disingenuous double standards like, “Yeah, I guess those guys are looking at really sick stuff all afternoon on their backend version” or “I guess only the C-Suite gets to deepfake the election in Zimbabwe.” This would be a logical offshoot of the feeling that “The only purpose to the censorship is CYOA for the company.”
In summary: Paternalism has to be done very, very carefully, and with some amount of buy-in, or it burns credibility and good-will very quickly. I doubt that is a very controversial presupposition here, and it is my basic underlying thought on most of this. Eventually, in many cases, paternalism without buy-in yields outright hostility toward a policy or organization and (as our OP is pointing out) the blast radius can get wide.
I agree that paternalism without buy-in is a problem, but I would note LessWrong has historically been in favor of that: Bostrom has weakly advocated for a totalitarian surveillance state for safety reasons and Yudkowsky is still pointing towards a Pivotal Act which takes full control of the future of the light cone. Which I think is why Yudkowsky dances around what the Pivotal Act would be instead: it’s the ultimate paternalism without buy-in and would (rationally!) cause everyone to ally against it.
Then a major topic LessWrong community should focus on is how buy-in happens in Paternalism. My first blush thought is through educating and consensus-building (like the Japanese approach to changes within a company), but my first blush thought probably doesn’t matter. It is surely a non-trivial problem that will put the breaks on all these ideas if it is not addressed well.
Does anyone know some literature on generating consensus for paternalist policies and avoiding backlash?
The other (perhaps reasonable and legitimate) strategies would be secretive approaches or authoritarian approaches. Basically using either deception or force.
This seems mostly wrong? A large portion of the population seems to have freedom/resistance to being controlled as a core value, which makes sense because the outside view on being controlled is that it’s almost always value pumping. “It’s for your own good,” is almost never true and people feel that in their bones and expect any attempt to value pump them to have a complicated verbal reason.
The entire space of paternalistic ideas is just not viable, even if limited just to US society. And once you get to anarchistic international relations...
There must be some method to do something, legitimately and in good-faith, for people’s own good.
I would like to see examples of when it works.
Deception is not always bad. I doubt many people would go so far as to say the DoD never needs to keep secrets, for example, even if there’s a sunset on how long they can be classified.
Authoritarian approaches are not always bad, either. I think many of us might like police interfering with people’s individual judgement about how well they can drive after X number of drinks. Weirdly enough, once sober, the individuals themselves might even approve of this (as compared to being responsible for killing a whole family, driving drunk).
(I am going for non-controversial examples off the top of my head).
So what about cases where something is legitimately for people’s own good and they accept it? In what cases does this work? I am not comfortable that since no examples spring to mind, no examples exist. If we could meaningfully discuss cases where it works out, then we might be able to contrast that to when it does not.
“Must”? There “must” be? What physical law of the universe implies that there “must” be...?
Let’s take the local Anglosphere cultural problem off the table. Let’s ignore that in the United States, over the last 2.5 years, or ~10 years, or 21 years, or ~60 years (depending on where you want to place the inflection point), social trust has been shredded, policies justified under the banner of “the common good” have primarily been extractive and that in the US, trust is an exhausted resource. Let’s ignore that OP is specifically about trying to not make one aspect of this problem worse. Let’s ignore that high status individuals in the LessWrong and alignment community have made statements about whose values are actually worthwhile, in an public abandonment of the neutrality of CEV which might have made some sort of deal thinkable. Let’s ignore that because that would be focusing on one local culture in a large multipolar world, and at the global scale, questions are even harder:
How do you intend to convince the United States Government to surrender control to the Chinese Communist Party, or vice versa, and form a global hegemon necessary to actually prevent research into AI? If you don’t have one control the other, why should either trust that the other isn’t secretly doing whatever banned AI research required the authoritarian scheme in the first place, when immediately defecting and continuing to develop AI has a risky, but high payout? If you do have one control the other, how does the subjugated government maintain the legitimacy with its people necessary to continue to be their government?
How do you convince all nuclear sovereign states to sign on to this pact? What do you do with nations which refuse? They’re nuclear sovereign states. The lesson of Gaddafi and the lesson of Ukraine is that you do not give up your deterrent no matter what because your treaty counterparties won’t uphold their end of a deal when it’s inconvenient for them. A nuclear tipped Ukraine wouldn’t have been invaded by Russia. There is a reason that North Korea continues to exist. (Also, what do you do when North Korea refuses to sign on?)
I’m thinking, based on what you have said, that there does have to be a clear WIFM (what’s in it for me). So, any entity covering its own ass (and only accidentally benefitting others, if at all) doesn’t qualify as good paternalism (I like your term “Extractive”). Likewise, morality without creating utility for people subject to those morals won’t qualify. The latter is the basis for a lot of arguments against abortion bans. Many people find abortion in some sense distasteful, but outright banning it creates more pain and not enough balance of increased utility. So I predict strongly that those bans are not likely to endure the test of time.
Thus, can we start outlining the circumstances in which people are going to buy in? Within a nation, perhaps as long things are going fairly well? Basically, then, paternalism always depends on something like the “mandate of heaven”—the kingdom is doing well and we’re all eating, so we don’t kill the leaders. Would this fit your reasoning (even broadly concerning nuclear deterrence)?
Between nations, there would need to be enough of a sense of benefit to outweigh the downsides. This could partly depend on a network effect (where when more parties buy in, there is greater benefit for each party subject to the paternalism).
So, with AI, you need something beyond speculation that shows that governing or banning it has more utility for each player than not doing so, or prevents some vast cost from happening to individual players. I’m not sure such a case can be made, as we do not currently even know for sure if AGI is possible or what the impact will be.
Summary: Paternalism might depend on something like “This paternalism creates an environment with greater utility than you would have had otherwise.” If a party believes this, they’ll probably buy in. If indeed it is True that the paternalism creates greater utility (as with DUI laws and having fewer drunk people killing everyone on the roads), that seems likely to help the buy-in process. That would be the opposite of what you called “Extractive” paternalism.
In cases where the outcome seems speculative, it is pretty hard to make a case for Paternalism (which is probably why it broadly fails in matters of climate change prior to obvious evidence of climate change occurring). Can you think of any (non-religious) examples where buy-in happens in Paternalism on speculative matters?
‘Paternalism’ in this sense would seem more difficult to bring about, more controversial, and harder to control then AGI itself. So then why worry about it?
In the unlikely case mankind becomes capable of realizing beforehand then it wouldn’t serve a purpose by that point as any future AGI will have become an almost trivial problem by comparison. If it was realized afterhand, by presumably super intelligent entities, 2022 human opinions regarding it would just be noise.
At most the process of getting global societal trust to point where it’s possible to realize may be useful to discuss. But that almost certainly would be made harder, rather than easier, by discussing ‘paternalism’ before the trust level has reached that point.
Yes, pretty much exactly this—paternalism is a great frame for thinking about how people seem to be perceiving what’s going on; even if you don’t personally experience that vibe, it seems a significant percentage of the population, if not a majority, do.
Is it possible to build a convincing case for the majority that it is either acceptable or that it is not, in fact, paternalism?
Can you articulate your own reasoning and intuitions as to why it isn’t? That might address the reservations most people have.
Paternalism means there was some good intent at least. I don’t believe OpenAI’s rent seeking and woke pandering qualifies.
One factor I think is worth noting, and I don’t see mentioned here, is that the current state of big-tech self-censorship is clearly at least partly due to a bunch of embarassing PR problems over the last few years, combined with strident criticism of AI bias from the NYT et. al.
Currently, companies like Google are terrified of publishing a model that says something off-color, because they (correctly) predict that they will be raked over the coals for any offensive material. Meanwhile, they are busy commercializing these models to deliver value to their users, and don’t want regulation to slow them down or decrease their profit margins.
Consider the racist tweets that trolls coaxed from Microsoft’s Tay, or any NYT piece about Google’s AI models being racist/sexist. I think these big companies are fairly rationally responding to the incentives that they are facing. I also think open-source communities present a more diffuse target for outrage, in that they are harder to point to, and also have less to lose as they don’t have a commercial reputation to protect.
Given this structural observation, I think projects like Stable Diffusion and EleutherAI are where a lot of the cutting-edge innovation (actually iterating novel use-cases with end-users) is going to happen, and I think that increases the importance of a robust, dispersed/distributed, and adequately-funded open source community doing research and re-implementing the theoretical advances that Google et. al. publish. For now it seems that Google is on board with donating TPU time to open-source researchers, and ensuring that continues seems important.
I struggle to see how we can actually fix the underlying threat of outrage that disincentivizes big companies from opening up their models. Maybe when there are more juicy targets elsewhere (e.g. pornpen.ai, deepfakes) the NYT will view Google et. al. as doing a relatively good job and reduce the pressure?
If you want to slow down AI development for safety reasons) I suppose one way would be to produce strong safety legislation by playing up the above outrage-based concerns. The risk with that approach is that it favors big companies with enough resources to comply with red tape, and these places are structurally less-capable of doing actual good safety work, and more structurally inclined to do feel-good safety work.
There’s an open question about whether or not there’s something useful for AI safety in the X risk sense to be learned by training models to not engage in certain behavior like creating pornographic images.
If alignment is about getting models to do what you want and not engaging in certain negative behavior, then researching how to get models to censor certain outputs could theoretically produce insights for alignment.
Even if the hygiene theater doesn’t produce direct benefits, it’s still possible to learn all sorts of things from it about how providing healthcare works.
What the CDC did wasn’t a research project but justified by object-level concern. Dall-E is primarily a research project and not a project to help artists.
The user and the company are not the only stakeholders. If a user creates a deep fake and harms a third person OpenAI wants to prevent it not only because of company liability but also because they think that deep fake can be a general problem for society.
I was referred by 80k Hours to talk to a manager on the OpenAI safety team who argued exactly this to me. I didn’t join, so no idea to what extent it makes sense vs. just being a nice-sounding idea.
This is true, but then you don’t have to force the censorship on users. This is an abusive practice that might have safety benefits, but it is already pushing forward the failure mode of wealth centralization as a result of AI. (Which is by itself an x-risk, even if the AI is dumb enough that it is not by itself dangerous.)
Let me first say I dislike the conflict-theoretic view presented in the “censorship bad” paragraph. On the short list of social media sites I visit daily, moderation creates a genuinely better experience. Automated censorship will become an increasingly important force for good as generative models start becoming more widespread.
This one is interesting, but only in the counterfactual: “if AI ethics technical research focused on actual value alignment of models as opposed to front-end censorship, this would have higher-order positive effects for AI x-safety”. But it doesn’t directly hurt AI x-safety research right now: we already work under the assumption that that output filtering is not a solution for x-risk.
It is clear improved technical research norms on AI non-x-risk safety can have positive effects on AI x-risk. If we could train a language model to robustly align to any set of human-defined values at all, this would be an improvement to the current situation.
But, there are other factors to consider. Is “making the model inherently non-racist” a better proxy for alignment than some other technical problems? Could interacting with that community weaken the epistemic norms in AI x-safety?
I would need to significantly update my prior if this turns out to be a very important concern. Who are people, whose opinions will be relevant at some point, that understand both what AI non-x-safety and AI x-safety are about, dislike the former, are sympathetic to the latter, but conflate them?
???I don’t know why it sent only the first sentence; I was drafting a comment on this. I wanted to delete it but I don’t know how.
EDIT: wrote the full comment now.
Good job for having common sense, you’re probably the only one on this whole website to realize this triviality
Indeed, the common view here is to destroy our society’s capabilities to delay AI in the hopes that some decades/centuries later the needed safety work gets done. This is one awful way to accomplish the safety goals. It makes far more sense to increase funding and research positions on related work and attract technical researchers from other engineering fields. My impression is that people perceive that they can’t make others understand the risks involved. Destruction being much easier than creation, they are naturally seduced to destroy research capacity in AI capability rather than increasing the pace of safety research.