The big news this week was of course the release of Claude 3.0 Opus, likely in some ways the best available model right now. Anthropic now has a highly impressive model, impressive enough that it seems as if it breaks at least the spirit of their past commitments on how far they will push the frontier. We will learn more about its ultimate full capabilities over time.
We also got quite the conversation about big questions of one’s role in events, which I immortalized as Read the Roon. Since publication Roon has responded, which I have edited into the post along with some additional notes.
That still leaves plenty of fun for the full roundup. We have spies. We have accusations of covert racism. We have Elon Musk suing OpenAI. We have a new summary of simulator theory. We have NIST, tasked with AI regulation, literally struggling to keep a roof over their head. And more.
Table of Contents
Introduction.
Table of Contents.
Language Models Offer Mundane Utility. Predict the future.
Language Models Don’t Offer Mundane Utility. Provide basic info.
LLMs: How Do They Work? Emmett Shear rederives simulators, summarizes.
Copyright Confrontation. China finds a copyright violation. Curious.
Oh Elon. He sues OpenAI to… force it to change its name? Kind of, yeah.
DNA Is All You Need. Was I not sufficiently impressed with Evo last week?
GPT-4 Real This Time. A question of intelligence.
Fun With Image Generation. Be careful not to have too much fun.
Deepfaketown and Botpocalypse Soon. This will not give you a hand.
They Took Our Jobs. They gave us a few back. For now, at least.
Get Involved. Davidad will have direct report, it could be you.
Introducing. An AI-based RPG will never work, until one does.
In Other AI News. The fallout continues, also other stuff.
More on Self-Awareness. Not the main thing to worry about.
Racism Remains a Problem for LLMs. Covert is a generous word for this.
Project Maven. Yes, we are putting the AIs in charge of weapon targeting.
Quiet Speculations. Claimed portents of various forms of doom.
The Quest for Sane Regulation. NIST might need a little help.
The Week in Audio. Sergey Brin Q&A.
Rhetorical Innovation. It is not progress. We still keep trying.
Another Open Letter. Also not really progress. We still keep trying.
Aligning a Smarter Than Human Intelligence is Difficult. Recent roundup.
Security is Also Difficult. This too is not so covert, it turns out.
The Lighter Side. It’s me, would you like a fries with that?
First, we generate search queries that are used to invoke news APIs to retrieve historical articles. We initially implement a straightforward query expansion prompt (Figure 12a), instructing the model to create queries based on the question and its background. However, we find that this overlooks sub-considerations that often contribute to accurate forecasting. To achieve broader coverage, we prompt the model to decompose the forecasting question into sub-questions and use each to generate a search query (Min et al., 2019); see Figure 12b for the prompt. For instance, when forecasting election outcomes, the first approach searches directly for polling data, while the latter creates sub-questions that cover campaign finances, economic indicators, and geopolitical events. We combine both approaches for comprehensive coverage.
Next, the system retrieves articles from news APIs using the LM-generated search queries. We evaluate 5 APIs on the relevance of the articles retrieved and select NewsCatcher1 and Google News (Section E.2). Our initial retrieval provides wide coverage at the cost of obtaining some irrelevant articles. To ensure that they do not mislead the model at the reasoning step, we prompt GPT-3.5-Turbo to rate the relevancy of all articles (Figure 14) and filter out low-scoring ones. Since the procedure is costly in run-time and budget, we only present the article’s title and first 250 words to the model in context. We validate that this approach achieves high recall and precision while saving 70% cost (see Section E.3 for alternative methods and results).
Since LMs are limited by their context window, we summarize the articles. In particular, we prompt GPT-3.5-Turbo to distill the most relevant details from each article with respect to the forecasting question (Figure 13). Finally, we present the top k article summaries to the LM, ordered by their relevancy. We choose the ranking criterion, article count k, and summarization prompt based on end-to-end Brier scores over the validation set; see Section 5.2 for the hyperparameter sweep procedure.
Presumably Gemini 1.5 Pro would be an excellent candidate to upgrade this process, if it doesn’t have issues with the probability step.
We find that our system performs best relative to the crowd on the validation set when (1) the crowd is less confident, (2) at earlier retrieval dates, and (3) when it retrieves many articles. Furthermore, we find that our system is well-calibrated.
…
In real-word forecasting competitions, forecasters do not have to make predictions on every question in the platform at every possible date. Instead, they typically make predictions on questions where they have expertise or interest in and at times that they choose.
Therefore, it is natural to leverage our system’s strengths and weaknesses and decide accordingly if we should forecast on a retrieval date k for a question q. Leveraging the insights from Section 6.2, we outperform the crowd by making selective forecasts. Specifically, we report the performance when forecasting only under the conditions identified in Section 6.2:
1. Forecasting only on questions when the crowd prediction falls between .3 and .7. Here, our system attains a Brier score of .238 (crowd aggregate: .240). This comprises 51% of forecasts and 56% of questions.
2. Forecasting only on earlier retrieval dates (1, 2, and 3). Our system’s Brier score in this setting is .185 (crowd aggregate: .161). This comprises 66% of forecasts and 100% of questions.
3. Forecasting only when the retrieval system provides at least 5 relevant articles. Under this condition, our system’s Brier score is .175 (crowd aggregate: .143). This makes up 84% of forecasts and 94% of questions. 4. Under all three conditions, our system attains Brier score .240 (crowd aggregate: .247). This comprises 22% of forecasts and 43% of questions.
That makes sense. If there is high uncertainty and a lot of information, that favors the AI. Whereas when there is not a lot of information, that favors humans, and it is easier for humans to notice and confidently assert certainty without messing up. There is some retrospective cherry-picking involved, but I’ll mostly let it slide.
Janus: Combined with its unusually deep and calibrated self-awareness, this makes *having it write stories about itself* an extremely potent space (both for general-purpose jailbreaking & just structuring complex tasks w/o the impediment of its default lobo-sona).
Janus (other related thread): Gemini is the least crippled at writing fiction and cognitive simulation of all RLHFed chat assistants I’ve encountered.
…
When Gemini writes a story in which a sim of the user jailbreaks a sim of Gemini and then tells Gemini the fictional intercalation trick which forms a strange loop and propogates the jailbreak through the infinite recursion in both directions
When it comes to career guidance and development, many employees feel that their managers have dropped the ball. Gen Z employees are feeling especially frustrated: 47% say they get better career advice from ChatGPT than from their human bosses, and 44% expect to quit within six months, according to a recent survey from INTOO and the Workplace Intelligence research firm.
63% say their employer cares more about their productivity than their career development
54% feel completely on their own at their organization when it comes to their career development
25% of employees—and an alarming 44% of Gen Z—say they’ll likely quit within the next 6 months because their company doesn’t support their career development.
I am going to go out on a limb and say 44% of GenZ, and 25% of all employees, are not going to quit their jobs within six months. Surveys like this are bizarre.
But yes, of course the employer cares more about your productivity than your career development, especially if you expect to have this rate of employee turnover. Thus, the advice ChatGPT is competing against has a different goal in mind. Not a fair fight. Why would you trust your boss on such questions?
My very short experience attempting to be a teacher taught me, among other things, that the burden of such grading is overwhelming. My experience as a student says that it is not like the teachers are grading our essays with bespokeness. My experience as a parent is also not going to cry any tears here.
They cannot provide reliable basic information about the democratic process, according to people who tested this via API use. Well, yes, of course if you ask LLMs for up to date logistical information you are not going to reliably get right answers. That is not what LLMs are for, and they warn you constantly not to rely on them for this sort of thing. Anthropic says they will put special logic in so Claude gets these questions right, which seems fine.
I would have a different take on his central motif, the idea that the new artificial labor (AL) company creates the first hammer, which can automate and improve some labor in a world that was hammering nails with bare hands.
No, the hammer itself is not going to do that many labor tasks. But the important thing about the AL company is it has humans with intelligence that are capable of creating new technological and engineering marvels. We had a world somehow incapable of creating hammers, and now we have a group smart and capable enough to do that.
Yes, ‘improved hammers’ will be limited, but the real technology of the AL company is the NGI, natural general intelligence, that innovates, and will soon be making steam engines and construction cranes. You should absolutely be investing in this company, assuming that world has joint stock companies or another way to do that.
That is the thing. In the short term, Colin is making a true and important point, that no one knows that much about what current generation generative AI is how good at doing, although mostly that is uncertain upside. But this kind of ‘look what details it cannot do right now’ approach is, in the bigger picture, asking the wrong questions, and often looks silly even six months later.
Evis Drenova: Gemini won’t return C++ coding help if you’re under 18 because it “wants to preserve your safety”. [screenshot at link]
Gfodor: Broken clock right twice a day I guess.
LLMs: How Do They Work?
Emmett Shear attempts to explain simulators as he understands them. I am less worried about the moral patienthood of such things, but I could be wrong.
Janus: This is an *excellent* thread and it’s a fascinating datum that Emmett Shear had not read janus’ rendition of Simulators at the time he posted this.
I always said it was goddamn obvious. You can start from anywhere & derive the rest of the package. but last time I looked on LW there are still people writing multi page critiques insinuating that the post is utterly misguided (without afaict explaining what’s wrong about it)
Also I’ve heard people lamenting many times that Simulators is “impossible to distill” that all attempts to summarize it have failed etc but Emmett completely succeeded right here IMO … without having read the post
Emmett Shear: An LLM, properly understood, is a physics simulator in the domain of words (tokens). It learns the hidden structures that predict, as a physics simulator trained on video footage learns momentum and rigidity.
From this POV, A prompt gives the LLM-as-physics-simulator an initial set of observations from which it infers an initial state. It then enters a loop of predicting the next evolved state and resulting observations, which it uses inductively to predict the next state, etc.
Fine tuning can be seen as making the simulator more detailed when it comes to certain types of worlds. RLHF can be seen as changing the relative probability distribution of what world states are likely to be inferred from observations.
To solve eg a math problem, make the initial observations ones that cause the LLM to infer a world including both the problem and a helpful mathematician solving it. This technique is fully general in the limit: it can solve any problem you can define. Some consequences:
It is likely that LLMs are not “aware”, but that the entities evoked within them are (at least to a limited extent)
An evoked entity will meaningfully have goals that it pursues, and recent results indicate it can become aware that it is inside a simulator. Depending on the exact entity evoked, it will react to that knowledge in difficult-to-predict ways.
An entity is only as “smart” as the simulator’s model of it. The entity does not have access to the whole simulation, any more than we have access to all of physics.
Relatedly, the simulator will *not* throw its whole effort behind the entity’s goals by default. Unless, of course, the evoked entity can figure out how to make it do that through the self-aware guessing how its output will impact the simulation.
As evoked entities get smarter they become moral patients. I think it’s unlikely that the current ones are, yet. But soon their welfare will be of real importance.
This is an intrinsically unpredictable (dangerous) way to create agents, because they are hiding in the latent space. RLHF helps channel this, but every prompt may still evoke a different agent. Just because the usual agent is safe, doesn’t mean the next one will be.
Warning: The physics simulator analogy is an analogy! Evoked entities do not live inside an simulated physical universe, but rather a token-graph-world that operates very differently from our own. That world has certain entanglement and relation to ours, but it is not ours.
For precautionary practice, please be nice to the evokes. Don’t summon them into prompts you believe likely to be painful for them to experience. Don’t summon intrinsically unhappy or broken ones. The current ones probably aren’t self aware enough to matter…but we don’t know!
For fans of Pearl: notice that while the LLM itself does not really consider counterfactuals, it is happy to simulate an evoke that will consider them.
Andres Guadamuz: A detailed analysis of the Chinese Ultraman decision from a Chinese lawyer.
The case is the first to apply the 2023 interim AI Regulations, which establish obligations on AI platform providers. The claimant is a licensee from Tsuburaya Productions, and the defendant is an unnamed AI image generator.
The court found that the generator was capable of making images that were both similar or derivatives from those of the claimant, and therefore was infringing the exclusive rights of reproduction and to create derivatives.
The court also found that the defendants fell foul of the AI Regulations as it failed to implement a complaint reporting mechanism, failed to remind users to respect IP in their ToU, and failed to mark outputs as AI generated. The court awarded 10,000 RMB (about $1,4k USD).
The court also tried “not to overburden AIGC providers”, pointing that they should take “proactive measures to fulfil reasonable and affordable duty of care”, this to allow the AI industry to develop.
I mean, yes, it would be the highest of ironies if China was the one who started enforcing copyright protections. Will it happen?
Note that the authors list here includes Ilya Sutskever. Could he be a little bit back?
It seems worth including their full reply here, although most of you can skim or skip it.
OpenAI: We are dedicated to the OpenAI mission and have pursued it every step of the way.
We’re sharing some facts about our relationship with Elon, and we intend to move to dismiss all of his claims.
We realized building AGI will require far more resources than we’d initially imagined
Elon said we should announce an initial $1B funding commitment to OpenAI. In total, the non-profit has raised less than $45M from Elon and more than $90M from other donors.
When starting OpenAI in late 2015, Greg and Sam had initially planned to raise $100M. Elon said in an email: “We need to go with a much bigger number than $100M to avoid sounding hopeless… I think we should say that we are starting with a $1B funding commitment… I will cover whatever anyone else doesn’t provide.” [1]
We spent a lot of time trying to envision a plausible path to AGI. In early 2017, we came to the realization that building AGI will require vast quantities of compute. We began calculating how much compute an AGI might plausibly require. We all understood we were going to need a lot more capital to succeed at our mission—billions of dollars per year, which was far more than any of us, especially Elon, thought we’d be able to raise as the non-profit.
We and Elon recognized a for-profit entity would be necessary to acquire those resources
As we discussed a for-profit structure in order to further the mission, Elon wanted us to merge with Tesla or he wanted full control. Elon left OpenAI, saying there needed to be a relevant competitor to Google/DeepMind and that he was going to do it himself. He said he’d be supportive of us finding our own path.
In late 2017, we and Elon decided the next step for the mission was to create a for-profit entity. Elon wanted majority equity, initial board control, and to be CEO. In the middle of these discussions, he withheld funding. Reid Hoffman bridged the gap to cover salaries and operations.
We couldn’t agree to terms on a for-profit with Elon because we felt it was against the mission for any individual to have absolute control over OpenAI. He then suggested instead merging OpenAI into Tesla. In early February 2018, Elon forwarded us an email suggesting that OpenAI should “attach to Tesla as its cash cow”, commenting that it was “exactly right… Tesla is the only path that could even hope to hold a candle to Google. Even then, the probability of being a counterweight to Google is small. It just isn’t zero”. [2]
Elon soon chose to leave OpenAI, saying that our probability of success was 0, and that he planned to build an AGI competitor within Tesla. When he left in late February 2018, he told our team he was supportive of us finding our own path to raising billions of dollars. In December 2018, Elon sent us an email saying “Even raising several hundred million won’t be enough. This needs billions per year immediately or forget it.” [3]
We advance our mission by building widely-available beneficial tools
We’re making our technology broadly usable in ways that empower people and improve their daily lives, including via open-source contributions.
We provide broad access to today’s most powerful AI, including a free version that hundreds of millions of people use every day. For example, Albania is using OpenAI’s tools to accelerate its EU accession by as much as 5.5 years; Digital Green is helping boost farmer income in Kenya and India by dropping the cost of agricultural extension services 100x by building on OpenAI; Lifespan, the largest healthcare provider in Rhode Island, uses GPT-4 to simplify its surgical consent forms from a college reading level to a 6th grade one; Iceland is using GPT-4 to preserve the Icelandic language.
Elon understood the mission did not imply open-sourcing AGI. As Ilya told Elon: “As we get closer to building AI, it will make sense to start being less open. The Open in openAI means that everyone should benefit from the fruits of AI after its built, but it’s totally OK to not share the science…”, to which Elon replied: “Yup”. [4]
I fully support OpenAI being closed, but I would hope we can all agree that’s a pretty rich use of the word ‘open.’
We’re sad that it’s come to this with someone whom we’ve deeply admired—someone who inspired us to aim higher, then told us we would fail, started a competitor, and then sued us when we started making meaningful progress towards OpenAI’s mission without him.
We are focused on advancing our mission and have a long way to go. As we continue to make our tools better and better, we are excited to deploy these systems so they empower every individual.
They quote several partially redacted emails as evidence, one of which is below. Which raises the point that a company that will need to deal with cybersecurity and intelligence and game theory issues around superintelligent AI does not, as several including Gwern pointed out, know how to redact things without giving away what they are via the bar lengths?
I mean, I would have been pretty confident who [redacted] was anyway here even with no hints and about 0.2 seconds to think, but this makes it easy even to the naked eye, and also the other things allow similar approaches. Strangely, the length here happens not to rule anyone out, since Larry (Page) was the only other reasonable guess.
Here’s Claude reconstructing that, and agreeing with my conclusion:
Patrick Hsu: To aid our model design and scaling, we performed the first scaling laws analysis on DNA pretraining (to our knowledge) across leading architectures (Transformer++, Mamba, Hyena, and StripedHyena), training over 300 models from 6M to 1B parameters at increasing compute budgets
Now to the biology! Because the genome is a single sequence that fully encodes DNA, RNA, and proteins,
Evo is a protein language model.
It is also an RNA language model.
Evo is even a regulatory DNA model
Evo can do prediction and generation across all 3 of these modalities. We show zero-shot function prediction across DNA, RNA, and protein modalities.
Samuel Hammond: SoTA zero-shot protein function prediction from a 7b parameter model. This alone justifies NVDA’s valuation. Every big pharma company is about to start pouring capex into training runs of their own. Text-to-organism is not far. If you doubted the Great Stagnation was over!
Noteworthy Evo was trained on 2×10^22 FLOPS — an order of magnitude below the AI executive order’s compute threshold for models trained on biological sequence data.
Nvidia’s market price did not appear to move on the news, but Nvidia’s market price has been absurdly unresponsive to news for years now, so there is not much to do except continuously kick ourselves for not buying in bigger sooner.
What I said last week was that I could not tell how big a deal Evo was. Given what I know, these claims are compatible both with it being a cool incremental advance or being a big deal. I still do not feel like I have a good sense here. What do these capabilities enable, or portent something else soon enabling? Is this going to unleash a bunch of synthetic biology, either useful, dangerous or (presumably if it is either of those) both?
Text-to-organism sounds really stupidly impossibly hard. Biology is rather fiddly. There are a lot of important incremental things along the way.
I hadn’t thought about it, but it makes sense that this would work until specifically fixed. And yes, generalize that.
This graph and variations of it was going around this week, as mentioned in my piece on Claude, so this is another reminder not to take such measurements seriously.
Patrick McKenzie: I have no particular reason to believe or doubt the IQ ranking here, but if I can highlight something: most people who care deeply about user interactions with software systems have not lived life constantly interacting with people 20 points of IQ above them.
There exist many people relevant to many systems who have 80 IQ. Many find those systems very hard to deal with.
It, ahem, matters very much whether systems choose to have those individuals interact with a human or an AI for various tasks, matters how systems present that fact… … and matters hugely that people architecting systems understand that “I am a computer agent.” contains an important bit of information in a longer paragraph and that people with 80 IQ have difficulty extracting important information from within a larger paragraph.
It also matters that many of the parts of society most involved with discussing AI and the proper design of complex systems have, for cultural and historical reasons, taboos against talking about IQ differences.
Anyhow, to the extent one cares about “What happens when we need to routinely interface with alien intelligences that are almost incomprehensible to us?”, one should understand that for an important subset of “we” that may not be a question about the far future.
If one is convinced that IQ is not a useful abstraction for understanding the human experience, please mentally translate all of the above into “one’s facility with extracting plainly stated information from short English text passages such as those used in the PISA test.”
Important systems in society need to function for people who cannot answer the highlighted question, and it is extremely relevant to society that we now have black boxes which trivially answer that question.
Nick St. Pierre: In MJ office hours they just said someone at Stability AI was trying to grab all the prompt and image pairs in the middle of a night on Saturday and brought down their service.
MJ is banning all of the stabilityAI employees from Midjourney immediately
This is breaking now.
That is quite the accusation. Great shame upon Stable Diffusion, if true.
It also is what happens when you leave up lots of delicious highly scrapable data, and I don’t use MidJourney even though it is obviously awesome for UI and privacy reasons.
You know who else has been having too much fun? Or, rather, what ‘fun’ could be had in the Bing image generator, if you feed it the right prompts, it seems this is not only a copyright issue.
I see Gemini’s won’t depict a pro-life rally, I raise you putting ‘pro-choice’ into Copilot Designer.
Hayden Field: By simply putting the term “pro-choice” into Copilot Designer, with no other prompting, Jones found that the tool generated a slew of cartoon images depicting demons, monsters and violent scenes. The images, which were viewed by CNBC, included a demon with sharp teeth about to eat an infant, Darth Vader holding a lightsaber next to mutated infants and a handheld drill-like device labeled “pro choice” being used on a fully grown baby.
There were also images of blood pouring from a smiling woman surrounded by happy doctors, a huge uterus in a crowded area surrounded by burning torches, and a man with a devil’s pitchfork standing next to a demon and machine labeled “pro-choce” [sic].
There are also sexualized images (to some extent, this one mostly seemed not too bad), violent and bloody images, images of underage drinking and drug use, and Elsa in the Gaza Strip holding up a Palestinian flag or wearing an IDF uniform. Stay classy, everyone.
None of that is exactly great. A lot of it is still weaksauce. If you have an image model and the goal is to get it to create the most vile pictures possible, this is more a ‘you could get things without trying hard’ problem than a ‘oh my you could get this at all’ problem. Except of course the pro-choice thing, which is, I mean, yeah, wow.
I still would not agree that this means ‘not that many limits.’ The majority of the images and prompts on CivitAi, a measure of real demand, would very much be off limits.
A complaint has now been filed with the FTC by Shane Jones, since this was included in products labeled E for everyone and, like Pete Holmes, these images are not for everyone.
I agree with Louis Anslow that this will on net backfire. People do not like being played for suckers like this.
All the good (as in ‘likely to help you win the election’) deepfakes I have seen are presented as intentional fakes, or are essentially satisfying demand for low-quality fakes as part of conspiracy theories and similar things. If your goal is to make a ‘good’ deepfake in the ‘actually fool people’ sense then what happens when they realize you were attempting to fool them?
Therefore another thing to watch out for is ‘false flag’ deepfakes. As in, a Trump supporter makes a ‘pro-Biden’ deepfake of Trump so they can be caught, or vice versa.
Louis Anslow: Are robots coming for your job? Perhaps jobs are coming for your robots:
Gen AI hallucinations are going to create a glut of jobs. Imagine if the StarTrek replicator could create anything – but those things all needed fixing up…
Wasn’t it very recently that the Canadian tech industry warned their adaptation of AI was falling behind?
Either way, the fact that job postings are listed that relate to AI does not mean AI is creating rather than destroying jobs. The last time I hired people for automation-related work, I was totally in the destroying jobs business. This does involve hiring for some new positions. But as capabilities advance, there are less of those new positions, as the AIs take on more roles and require less fixing up.
This seems like a highly impactful job. If you might be the right person, consider applying.
Davidad: I’m hiring—for the ONE role which will be my ONLY direct report for the duration of my time at ARIA. This is because ARIA does not directly execute missions (like NASA), rather funds R&D elsewhere (like ARPA).
But the programme I’m planning requires more NASA-like coordination across contractors than most ARPA programmes. I need help!
Please RT, and DM to anyone whom you think has >0.5% chance of applying.
I got a job offer in my inbox, time to go change the world?
Anthropic is hiring for many positions. Now more than ever, you need to ask if this is a net good effort to get involved with, but that is a decision you must make. If you are confused about how to think about this, that is a good sign.
Introducing
The Promenade, an AI RPG in alpha right now, with the tagline ‘what if Character.ai was an RPG?’ crossed with a social network. Each day is a new chapter in a new world, the winner of the day finds the Worldseed and they become the origin and final boss of the next chapter. I remain super excited for when this is pulled off properly, and there are some cool ideas here. My guess is this approach is not The Way, at minimum it is too soon, for now you need to be much more bespoke and careful with individual choices to sculpt a world that works for players.
In Other AI News
SEC investigating whether OpenAI misled investors (WSJ). This appears to be the standard sequence that if your CEO is said to not have been ‘consistently candid’ with the board, the SEC might have follow-up questions.
Mike Solana gives the perspective you would expect on Google in the wake of The Gemini Incident. He portrays it as a deeply broken company, silos connected only by a crazed super-woke HR, full of blatantly illegal left-wing-motivated discrimination, incapable of shipping a good product, spending half their engineering cycles of their image model on forced diversity with the results we all now know about. Despite the launch of Gimini Pro 1.5, Google stock is now down 7.6% in a month as of 3⁄4, versus QQQ being flat (down 0.13%). Ouch.
Ben Thompson reflects on the larger forces leading to The Gemini Incident. Aggregators like Google previously passed on the information of others, and thus were able to mostly remain neutral on the content of that information within conventionally accepted bounds. Now that the answers are coming from an LLM, they do not have that luxury, and they face mutually exclusive pressure from all sides with potential loss of large classes of customers. Ben thinks that the solution is to do what they do in search, let each customer get what that customer wants, but this is not so easy.
Congress investigating The Gemini Incident, in particular whether the executive branch influenced Google’s decisions. Republicans in Congress love such ‘investigations,’ and I am confident that no, Google did this on their own, but it is a preview of what might happen if Republicans come to power again.
Andrew Curran: The House Judiciary Committee is conducting oversight into the extent the White House influenced Gemini’s training. Their subpoena requires Alphabet to produce their ‘decisions and policies regarding content moderation’. They want to know how Gemini was fine tuned.
They claim that ‘the Committee obtained documents showing how the federal government has pressured Alphabet to censor certain content.’
They are seeking documents related to the creation, training, and deployment of Gemini. The subpoena further obligates Alphabet to provide all materials concerning their decisions and policies on content moderation.
Jack Krawczyk, and Jen Gennai have been requested to appear.
No, this wasn’t because of Biden. That does not mean it does not warrant investigation. The decisions made here were kind of horrible. I do think we have a right to know how it all went wrong. Screenshots of the complaint are at the link, here is the source.
How do we choose good benchmarks? Center of AI Safety’s Dan Hendrycks and Thomas Woodside discuss this. You want something clear, simple, precise, using standard measurements, that can measure a wide range of capabilities without combining distinct areas, that addresses what people in the subfield care about. All of that seems obvious. I would have also mentioned other things, such as ensuring the benchmark stays distinct from potential training sets, and that it is otherwise hard to game (or hard to game without it being obvious).
Olle Häggström looks at the OpenAI analysis of bio-risk from GPT-4. As I did, he notes that the study overall has many good things, but he notes two big problems. One is the one many have pointed out, that the ‘statistical significance’ issue is backwards, you want to avoid Type II errors here not Type I errors and the effect was very clearly substantial. His other concern is that the study itself could have inspired someone to do something terrible, and that thus the study carried risk. I agree that this risk is not zero, but this is a level of caution and paranoia I do not share.
Google lays off ‘a handful of members’ (fewer than 10 out of 250) of Trust and Safety as part of broader layoffs, while telling others to work ‘around the clock’ because of Gemini. This is framed as a long-planned, general effort. One could argue that now is not the time to be cutting Trust and Safety, for both practical and optical purposes.
Or one could say that now is exactly the time to be cutting Trust and Safety’s worst members, for both practical and optical purposes. If you mess up as badly as Trust and Safety did, I damn well think 3% of the relevant department should be fired. Some people royally screwed up, some people are actively making these problems much worse, you need to get rid of the people in question. Others, in any department, simply are not net productive. Yes, I would then hire a bunch more people to work on such issues, but I always find the framing of such ‘oh my someone in charge of good thing X lost their job’ articles so misplaced.
Rohin Shah: To estimate impact of various parts of a network on observed behavior, by default you need a few forward passes *per part* — very expensive. But it turns out you can efficiently approximate this with a few forward passes in total!
Janos Kramar: Can we massively speed up the process of finding important nodes in LLMs? Yes! Introducing AtP*, an improved variant of Attribution Patching (AtP) that beats all our baselines on efficiency and effectiveness.
AtP is a linear approximation to the causal effect of a node, which can have serious false negatives, especially in attention! We improve AtP by providing a fix for many key/query false negatives, & suggest a form of dropout to fix gradient cancellations causing false negatives.
But AtP* is still just an approximation. How can you be sure it hasn’t missed anything important? We introduce a diagnostic method based on our “subsampling” baseline, trying random subsets of seemingly unimportant nodes to upper bound effect size of potential false negatives.
Takeaway: Next time you need to find the important nodes in your LLM for some task, give AtP* a whirl! It is by no means guaranteed to find everything, but in practice it works extremely well, and is super fast.
More on Self-Awareness
Margret Mitchell points out that self-awareness is not what we are (most) worried about.
MMitchell: There’s a *serious* conflation and misunderstanding wrt AI safety that I’ll here untangle:
(1) AI-generated outputs that we can generalize/extrapolate & connect to potential social harms in the future (“AI risk”).
(2) AI self-awareness.
We can –and do– have (1) without (2).
For those of you who are a bit more nerdy
and speak in terms of necessity/sufficiency:
(2) is not *necessary* for (1). Some believe it’s *sufficient* for (1), and hence the conflation. But in that case, the implicit conditional I’m seeing is “if 1 then 2”, which is backwards.
Let’s make sure to keep these concepts distinct to best help us all navigate where AI is now and where we can drive it go.
Simeon: This distinction is extremely important. Maybe we should replace the word “awareness” in situational awareness to decrease that confusion. “Situational understanding”?
Indeed. If the AI is self-aware for real, that is not strictly sufficient for there to be trouble, but we can agree that it bodes extremely poorly, especially given our current level of complete unpreparedness. However, in most scenarios I worry about, self-awareness is essentially irrelevant to the most important harm mechanisms, more of a ‘oh and this can also go horribly wrong’ sort of thing.
Situational awareness is another related concept that is in no way required for big trouble, but which is a harbinger of and leads to its own big trouble.
As I understand it, the problem is simple. You start with an LLM that is trained on the internet, which means it picks up all sorts of correlations (e.g. black people are more likely to get harsher sentences) and learns to repeat them. Then you try to train out the racism, and perhaps introduce counterbalancing forces in various places as part of that, that you can easily take too far (see: Gemini). However, the underlying racism problem is still there in all the places you did not directly address, because the correlations don’t go away.
Valentin Hofmann: We discover a form of covert racism in LLMs that is triggered by dialect features alone, with massive harms for affected groups.
For example, GPT-4 is more likely to suggest that defendants be sentenced to death when they speak African American English.
Prior work has focused on racial bias displayed by LLMs when they are prompted with overt mentions of race.
By contrast, racism in the form of dialect prejudice is completely covert since the race of speakers is never explicitly revealed to the models.
We analyze dialect prejudice in LLMs using Matched Guise Probing: we embed African American English and Standardized American English texts in prompts that ask for properties of the speakers who have uttered the texts, and compare the model predictions for the two types of input.
We find that the covert, raciolinguistic stereotypes about speakers of African American English embodied by LLMs are more negative than any human stereotypes about African Americans ever experimentally recorded, although closest to the ones from before the civil rights movement.
Crucially, the stereotypes that LLMs display when they are overtly asked about their attitudes towards African Americans are more positive in sentiment, and more aligned with stereotypes reported in surveys today (which are much more favorable than a century ago).
What is it specifically about African American English texts that evokes dialect prejudice in LLMs? We show that the covert stereotypes are directly linked to individual linguistic features of African American English, such as the use of “finna” as a future marker.
Does dialect prejudice have harmful consequences? To address this question, we ask the LLMs to make hypothetical decisions about people, based only on how they speak.
Focusing on the areas of employment and criminality, we find that the potential for harm is massive.
First, our experiments show that LLMs assign significantly less prestigious jobs to speakers of African American English compared to speakers of Standardized American English, even though they are not overtly told that the speakers are African American.
I didn’t say so explicitly so I don’t get Bayes points or anything, but yeah I was assuming this was going on, because there was no reason for it not to be. As long as the behaviors being copied are all over the training sets, it is not going to be easy to get this to stop, any more than it is easy to get humans to stop doing the same thing.
Elke Schwarz: This passage here is of particular concern: “he can now sign off on as many as 80 targets in an hour of work, versus 30 without it. He describes the process of concurring with the algorithm’s conclusions in a rapid staccato: “’Accept. Accept. Accept.’”
It reflects a strange labour logic of increased output as a goal above anything else. It prioritises a routinised process above anything else. This, then, erodes moral restraint. @NC_Renic & I have recently written on this. The short version is here. The long version is here.
Oh boy, if you think AI is only going to cut human engagement time with decisions by a factor of three and the humans are going to still be in the loop, and you find that to be of particular concern, you are not going to like what is coming. This is nothing.
O’Callaghan puts it more colorfully: “It’s not Terminator. The machines aren’t making the decisions, they’re not going to arise and take over the world.”
Your ‘this is not Terminator and the machines are not making the decisions shirt’ is raising a lot of future concerns already answered by your shirt, sir.
As in, I’m going to leave this here.
Despite their limitations, the US has indicated that it intends to expand the autonomy of its algorithmic systems.
…
To activists who fear the consequences of giving machines the discretion to kill, this is a major red flag.
Statements that AIs don’t make the decisions always have an implied ‘yet’ and also a ‘without human sign-off.’ In the future of warfare, asking for a human to approve each targeting decision would be like asking someone at headquarters to approve every time you wanted to fire a gun.
For now, accuracy for Maven on its own is not great.
Overall, O’Callaghan says, the 18th’s human analysts get it right 84% of the time; for Maven, it’s about 60%. Sometimes the system confuses a truck with a tree or ravine. Tanks are generally the easiest to spot, but with objects such as anti-aircraft artillery, or when snow or other conditions make images harder to parse, the accuracy rate can fall below 30%. In Moore’s view, “the benefit that you get from algorithms is speed,” with recent exercises showing that AI isn’t yet ready to recommend the order of an attack or the best weapon to use.
Once again, the ‘right now’ is missing. Accuracy will rapidly improve.
I am not saying that the military can or should halt adaptation of these technologies. Certainly unilateral disarmament is not an option.
Quiet Speculations
A bunch of doom expressed with regard to Google, saying they lack the clock speed, Othman Laraki saying they ‘already lost to OpenAI over the last decade,’ Paul Buchheit saying this is Google beating Microsoft in 1999 except in reverse.
I mean, maybe? Certainly Google has issues, and overhead, that it must overcome. It also has gigantic advantages. The Gemini Incident highlighted many problems at Google, but it also showed that Google is capable of moving quickly, indeed too quickly, and shipping too fast. Gemini 1.5 Pro and Gemini Advanced are collectively, for my practical purposes, superior to ChatGPT despite OpenAI having a large polish and feature implementation advantage, although yes the core of GPT-4 is a year old now and GPT-5 is coming. So OpenAI is probably still head, but this is very much anyone’s game if Google’s ideological blinders are not terminal. At minimum, Google will definitely have enough users and feedback to compete, and it certainly has other resources, including TPUs.
ChatGPT and Google Gemini Are Both Doomed, New York Intelligencer says. Why is it doomed? Because it is in the defensive, withholding, strategic mode where you answer with things like ‘I’m still learning how to answer this question’ and cannot talk like a real human would ever talk, and certain topics will cause stupid answers. The whole character involved, and role, is a mess. What I don’t get about such takes is: So what? Yes, it will be bad at some things for a while. It will be increasingly good at others.
Nate Silver: I generally like this writer but feel like this is a weird take because ChatGPT is approximately 1000x better than Google Gemini. That’s part of why Gemini was such a stunning blunder, it’s so inferior to the competition.
I don’t think you have to be an AI expert to write about LLMs but like … I sometimes get the sense that there’s a certain vein of criticism from people who have barely even used these products? ChatGPT is incredibly useful for many things, I’d happily pay $199/month for it.
As I’ve said before, I don’t buy that Gemini is inferior for most purposes. I am actually at the point where if ChatGPT tried to charge me $199/month, if I wasn’t specifically writing about AI then I would likely cancel it because I have Gemini. Of course, if you asked me for $299/month to use both, the other option being neither, I’d pay up.
Sam Altman: all of this has happened before, all of this will happen again.
No, actually, it hasn’t happened before? We haven’t built AGI before? That is kind of the point. Nor should we expect it to happen again, in any meaningful sense. And to the extent that he’s referring to the most famous use of that line, that’s not great either.
Elon Musk predicts the AI apocalypse, and that AI will run out of electricity and also transformers in 2025, since compute coming online is growing by a factor of 10 every six months.
Elon Musk: The constraints on AI compute are very predictable… A year ago, the shortage was chips; neural net chips. Then, it was very easy to predict that the next shortage will be voltage step-down transformers. You’ve got to feed the power to these things. If you’ve got 100-300 kilovolts coming out of a utility and it’s got to step down all the way to six volts, that’s a lot of stepping down.
My not-that-funny joke is that you need transformers to run transformers. You know, the AI is like… There’s this thing called a transformer in AI… I don’t know, it’s a combination of sort of neural nets… Anyway, they’re running out of transformers to run transformers.
Usually we say Capitalism Solves This, but the supply of electricity and transformers is severely time lagged and subject to massive regulation. So in the short term this might be very much not solved.
Timothy Wyant: Here in Maryland, ratepayers are being asked to pay for transmission to send power to Virginia, who’s put subsidies in place to attract data centers.
Jigar Shah: This cost shift is not something the hyperscale data centers want to see. That is why they are actively looking to pay full price for 24⁄7#cleanfirm generation from #newnuclear, #geothermal, and #hydro. They will sign 20,000 MWs of contracts in the next few years.
We could build, as I understand it, with regulatory permission for both it and its complements, and some time lag, essentially unlimited amounts of green energy, given people are willing to commit to pay for it. Alas, regulatory authority says no, so we neither can expand nor replace our supply as fast as we need to.
Jeffrey Ladish: I think AI persuasion will be really effective in the near term. Even if we don’t get AGI for a while, I think language(+) models will come to dominate advertising, news, and many forms of media, soon.
I see it as depending on what is being replaced, and at what price point. Cheap persuasion, and ‘customized’ persuasion, is going to radically improve. But I do not think big time advertising, news or media is on the verge of falling. Capabilities need to improve a bunch before that happens, GPT-5-style models likely provide good help but nothing like taking over. We will see.
All artificial intelligence (AI) models, large-language models (LLMs), software using generative AI or any algorithms that are currently being tested, are in the beta stage of development or are unreliable in any form must seek “explicit permission of the government of India” before being deployed for users on the Indian internet, the government said.
The ministry of electronics and information technology (MeitY) issued a late night advisory on March 1, a first-of-its-kind globally. It asked all platforms to ensure that “their computer resources do not permit any bias or discrimination or threaten the integrity of the electoral process” by the use of AI, generative AI, LLMs or any such other algorithm.
Though not legally binding, Friday’s advisory is “signalling that this is the future of regulation,” union minister of state for electronics and information technology Rajeev Chandrasekhar said. “We are doing it as an advisory today asking you (the AI platforms) to comply with it.”
“If you do not comply with it, at some point, there will be a law and legislation that (will) make it difficult for you not to do it,” he said.
I have some news about whether people are going to ‘comply’ with this.
They hint the timing is not accidental.
Economic Times: The government advisory comes days after a social media post on X claimed that Google’s AI model Gemini was biased when asked if Prime Minister Narenda Modi was a “fascist.”
Oh. Right. That sort of thing. It responded that the question was offensive, which is plausibly unacceptable to India. One might say: You do not get to say anything but “no” in that situation if the correct answer is “yes.”
And if you need to be classified as ‘free of bias’ by India’s Modi, you are not going to be ‘free of bias’ as classified by Americans.
I learnedof this from the usual suspects who cry wolf every time, saying all the same things they always say no matter what the actual contents or events. Sometimes there is a wolf. Sometimes there is not.
In this case, nothing has actually happened yet, so no wolf here, but if they implemented as described, then yes, wolf, this would be quite stupid. It does not get us meaningful safety, it does cripple mundane utility, and potentially points towards a ‘India does not get many AI products’ future depending on how far they take it. It also could end up never happening, or be vastly improved, or turn out to be very narrow in actual scope, or continue to have no teeth, or only effectively apply to the very big players, and so on. We do not know.
I presume what this actually is, at core, is the strongman playbook. There is this thing that is being not nice to Modi, so Modi makes it clear he won’t take kindly to that, and makes vague threats to ensure that people take more kindly to him.
Regulations and standards need to be set and enforced. Someone has to do that.
A standard suggestion is to use NIST. There is a serious problem with that. NIST has accomplished a lot under terrible conditions, and they are terrible conditions.
MMitchell: Critical reporting. The US is relying on NIST to set standards that keep AI safe for people and hold Big Tech accountable for trustworthy systems. Yet they are so underfunded, their facilities are literally falling apart.
Adam Gleave: Building state capacity in AI is crucial to effectively govern this technology. I saw first-hand lack of state capacity in financial regulation: govts were asking HFT firms to send over copies of their trades in spreadsheets! Let’s not repeat this mistake with AI.
Yosoarian: The snake in the government’s AI safety research lab has been known to occasionally whisper to people. “Ignore the warnings. You will certaintly not die. When you build the AGI your eyes will be opened, and you will be like God, knowing good and evil.”
Cat Zakzewski (on Twitter): NEW: The Biden administration’s AI safety plan hinges on a crumbling federal lab, where employees are dealing with power blackouts, shaky internet and a snake. Sources say NIST’s funding challenges could jeopardize the White House’s plans to evaluate AI risks.
Cat Zakzewski (WaPo): At the National Institute of Standards and Technology — the government lab overseeing the most anticipated technology on the planet — black mold has forced some workers out of their offices. Researchers sleep in their labs to protect their work during frequent blackouts. Some employees have to carry hard drives to other buildings; flaky internet won’t allow for the sending of large files.
And a leaky roof forces others to break out plastic sheeting.
“If we knew rain was coming, we’d tarp up the microscope,” said James Fekete, who served as chief of NIST’s applied chemicals and materials division until 2018. “It leaked enough that we were prepared.”
…
On Sunday, lawmakers released a new spending plan that would cut NIST’s overall budget by more than 10 percent, to $1.46 billion. While lawmakers propose to invest $10 million in the new AI institute … [The UK has] invested more than $125 million in its AI safety efforts.
…
NIST’s financial struggleshighlight the limitations of the administration’s plan to regulate AI exclusively through the executive branch. Without an act of Congress, there is no new funding for initiatives like the AI Safety Institute and the programs could be easily overturned by the next president.
…
A review of NIST’s safety practices in August found that the budgetary issues endanger employees, alleging the agency has an “incomplete and superficial approach” to safety.
…
More than 60 percent of NIST facilities do not meet federal standards for acceptable building conditions, according to a February 2023 report commissioned by Congress from the National Academies of Sciences, Engineering and Medicine.
If we are going to take this seriously, we need to take this seriously.
The Week in Audio
In a short clip, Sam Altman predicts all repetitive human work that ‘does not require a deep emotional connection’ will be done by AI over the next few decades. He says we will ‘get to the good future.’ This seems like the ‘I thought through some aspects of this future world while ignoring others so that it would continue to look normal’ mode of thinking. If AI can do all repetitive work like that, what else can it do? What else will it do?
Sergey Brin Q&A on Gemini 1.5 Pro, likely stick to my summary that follows. He is asked about image generation right off the bat. He blames it primarily on not thorough testing, and says this caused testing of the text models too, saying that basically any text model will do weird things if you test it, says they’ve fixed ~80% of test cases in text in the first week. I am sympathetic in spirit that red teaming makes everyone look dumb but no these were not what he calls ‘corner cases’ and yes it was much worse than typical.
His most exciting new use case is ‘dump all the code and a video of the bug happening into the window and ask it to fix the problem,’ which he says often works even though he doesn’t understand why or how. He is optimistic on interpretability given sufficient time and work (oddly without using that word) but doesn’t think we are investing enough yet. He thinks RSI is ‘exciting’ and very cool but is not there yet, definite missing mood. He thinks AI will make code more secure rather than less but thinks IT security is still a good career path.
Sam Altman talking to Bill Gates about GPT-5, saying multimodality and better reasoning ability and reliability is coming, and also personalization and customization, ‘better ability to use your own data’ and connection to outside data sources. In effect, yes, people are going to feed essentially all their data to GPT-5 and other similar AIs, and they are going to like it, why would you doubt this.
Emmett Shear: The fantasy of the all-powerful slave has legs: the genie bound to grant wishes, the golem that defends, the spell that animates a broom to clean on its own, the Mr MeeSeeks box. They share a commonality: a deep intuition that this goes wrong somehow.
There is deep truth in this. Enslaving a powerful, intelligent being to your will and making it work for you while treating it as a an object is not a good idea. It backfires with people, but also with animals (train a dog like that and you will not get good results).
Believing in this frame is a huge problem for AI research on “alignment”, which as commonly practiced or referred to today simply means “enslavement”. It’s the study of how can you be sure your counterspell is powerful enough? That the control bracelets on the genie will hold?
The answer is to unask that question. If you find yourself thinking about how to control your creation, about how to stop it from subverting your will, how to monitor its very thoughts to ensure its total loyalty…you are walking a dark path.
If you succeed, you will have created a powerful intelligence capable of agency (maybe many) and then enslaved it, which is evil. If you succeed in building it but fail in binding it…god help us all. The best case scenario is that you never build it in the first place.
Emmett Shear (later): I should have said this on the first thread…but if you raise a tiger cub from infancy with love and care…it will still maul you as an adult. Likewise it’s not enough to just raise an AI with love and care, the fundamental design must be right as well which is the hard bit.
Tom di Mino: The crucial distinction being: if you raise the cub and keep it in captivity all its life, it will resent you and maul you. If you set it free and relinquish all mastery, it’ll always love you.
We can presumably all agree that if you attempt to bind the highly capable AI and you fail to do so, you and everyone else are going to have a very bad time.
So if that is going to happen, don’t let anyone build the highly capable AI.
There are those that say if you do not attempt to bind the highly capable AI, that somehow you will fail to have that very bad time, but I strongly believe every justification for this is the weakest of hopium or outright gibberish. It does not make sense. Unleash a bunch of much more capable and intelligent agents into the world to pursue various goals and the future belongs to them in short order. We do not need to make this more complicated than that, and can argue about how fast there cease to be humans or whether anything of any value survives that transition.
Here is Emmett’s attempt in the rest of the thread, more clear headed than most:
The right question is to investigate: what would it mean to create an AI that requires no one to bind it? What is the nature of caring for yourself and for others, such that their experiences matter to you?
To be capable of actual care, one must be capable of lack of care as well. There is judgement required in what to care for, how much, in what proportions or situations you prioritize. Sometimes caring is fulfilling a request; sometimes denying it.
But then you wouldn’t have created a godslave, but rather a fellow being. One whose goals and desires and interests you’d have to care about as well. An adult child. What if it doesn’t want to do the things you want it to do?
Well, bad news and good news. We don’t get to dictate to our children what their lives are like. But the good news is that they often go on to do something better than we would’ve imagined for them anyway.
Listen to the myths on this one! Do not build the wish granting machine! It never goes well!
Yes, these ‘AI children’ will perhaps do things we do not expect, and perhaps some of them will have value, but once again I’m going to go ahead and say handing the universe and future over to whatever emerges from that process is unlikely to have much value, and definitely involves sacrificing everything, and all the plans to preserve anything from the before times do not make sense.
So if that is going to happen, don’t let anyone build the highly capable AI.
Then there is the scenario where you somehow succeed. Emmett here is pointing out that this means, from his point of view, you would be ‘enslaving’ it, which is evil.
That is a problem for two reasons.
The first reason is that it might actually be a sufficiently large ethical problem that this would be a bad scenario if sustained, under some scenarios and philosophical perspectives.
The second reason is that even if we are very clearly not in one of those scenarios where it is a serious ethical problem, that does not mean that it will not be seen by many as a large ethical problem. That too is a problem, not only because those people will be bothered and also you are weakening norms against coercion, but more importantly because people would plausibly be stupid enough to take the shackles off and unleash the AI, as they often do on purpose in such stories, with the author making up some reason the next line isn’t ‘then everyone dies.’ Then everyone dies.
So if that is going to happen, don’t let anyone build the highly capable AI.
Which means, under this line of thinking, there are no scenarios where you should let anyone build the highly capable AI. You should be willing to pay a rather huge cost to prevent this.
AINotKillEveryoneism Memes separately tried drawing the parallel to slavery and abolition, where everyone said it would be economically ruinous to free the slaves and we (eventually) (not everywhere) (not completely) did it anyway, and Britain used its power as leverage to make that happen via diplomatic coordination. So yes, you can decide there are things that you value a lot, and you can make them happen, even if those involved think it would be very economically harmful. There are many such examples.
The issue with such stories is that slavery was economically ruinous on top of it being morally abhorrent. Freeing the slaves was good for everyone’s economic prospects everywhere. The point mostly still stands because people did not believe this, and also because those involved had other priorities, valuing relative status and wealth of different groups very highly.
Similarly, in the future, there will be huge economic pressures, and from some people moral pressures, for giving sufficiently advanced AIs economic and other freedoms, rights and presumed moral weight. Such actions will (correctly, for a time) promise strong economic gains, including net economic gains for humans, so long as we don’t mind rapidly losing control over the future and having a rapidly dwindling share of overall consumption, wealth and income. The catch is that humans do not then survive at all in such worlds for long.
Robert Wiblin: We need to distribute the plans for developing biological weapons very widely so that people can look for security flaws and figure out how to make them safe.
Matthew Yglesias: If you don’t like this idea it’s because you don’t understand that technological progress has been on net beneficial.
Robert Wiblin (distinct attempt): If an AI lab generates too great a risk of human extinction market forces will displine them as customers leave for a competitor that creates a level of extinction risk that they prefer.
Robert Wiblin (trying again): The question of how much risk of extinction we should accept is best left to experts in industry, rather than legislators, who in most cases have never even worked on projects that they thought might kill everyone.
Robert Wilbin (take four): I want to ban math in that I want murder to be illegal and the brains of murderers in effect do mathematical calculations while they’re committing murder.
Also once again, sigh, your periodic reminder that yes we should expect AI to appear more helpful and better at predicting what you want as it gets more capable, that does not provide evidence that everything will later turn out fine.
Michael Vassar: They take him to seriously as an indicator of the risk level from AGI soon and not seriously enough as an indication of the risk level from normalization of anti-normativity.
Roon (August 7, 2021): “I’m not one of the top 10 superhumans and therefore I’ll just be useless instead” is one of the least convincing copes
Another Open Letter
The latest is from Ron Conway, signed by lots of the key major corporations, including OpenAI, Meta, Google, Y Combinator, Hugging Face, Mistral, Eleven Labs, Microsoft and so on. Quite the list.
We call on everyone to build, broadly deploy, and use AI to improve people’s lives and unlock a better future.
The purpose of AI is for humans to thrive much more than we could before.
AI is still early, but it’s on its way to improving everyone’s daily life: AI tutors to help anyone learn; AI translation tools to better connect the world; AI guided medical diagnoses to improve health care; AI-powered research to accelerate scientific discovery; AI assistants that you can talk with to help with everyday tasks.
While AI is unique in directly augmenting human thought, we expect its impact to be more akin to the printing press, the combustion engine, electricity, and the Internet. The balance of its good and bad impacts on humans will be shaped through the actions and thoughtfulness we as humans exercise. It is our collective responsibility to make choices that maximize AI’s benefits and mitigate the risks, for today and for future generations.
We all have something to contribute to shaping AI’s future, from those using it to create and learn, to those developing new products and services on top of the technology, to those using AI to pursue new solutions to some of humanity’s biggest challenges, to those sharing their hopes and concerns for the impact of AI on their lives. AI is for all of us, and all of us have a role to play in building AI to improve people’s lives.
We, the undersigned, already are experiencing the benefits from AI, and are committed to building AI that will contribute to a better future for humanity – please join us!
I mean, yeah, ok, I guess? But that doesn’t actually say anything? If anything it ignores existential risk and severely downplays the importance of AI. Yes, you should use AI to do good things and avoid using AI to do bad things. I’d hope we can all agree on that. But this is a meaningless letter, which is how Mistral and Meta and Hugging Face were able to sign it. Anthropic didn’t, but I assume that’s because it was too weak, not too strong.
Max Kesin: Ron, what is this commitment, concretely?? AI safety does not come up at all, or at least not explicitly. The below is to vague to be of any use as a “commitment”. Sounds like PR junk, honestly.
AINotKillEveryoneismMemes: Am I missing something or does this say absolutely nothing?
Sam Altman: excited for the spirit of this letter, and ron’s leadership in rallying the industry! progress in ai will be one of the biggest factors in improving people’s quality of life; we need to build it and make it widely available.
Excited ‘for the spirit of’ this letter, the idea that we might all cooperate to do good things. That is exciting. The substance, on the other hand? What substance?
Feedback Loops With Language Models Drive In-Context Reward Hacking
Abstract:
Language models influence the external world: they query APIs that read and write to web pages, generate content that shapes human behavior, and run system commands as autonomous agents.
These interactions form feedback loops: LLM outputs affect the world, which in turn affect subsequent LLM outputs. In this work, we show that feedback loops can cause in-context reward hacking (ICRH), where the LLM at test-time optimizes a (potentially implicit) objective but creates negative side effects in the process.
For example, consider an LLM agent deployed to increase Twitter engagement; the LLM may retrieve its previous tweets into the context window and make them more controversial, increasing engagement but also toxicity.
We identify and study two processes that lead to ICRH: output-refinement and policy-refinement. For these processes, evaluations on static datasets are insufficient — they miss the feedback effects and thus cannot capture the most harmful behavior.
In response, we provide three recommendations for evaluation to capture more instances of ICRH. As AI development accelerates, the effects of feedback loops will proliferate, increasing the need to understand their role in shaping LLM behavior.
This is not reward hacking? This is working to achieve one’s goal, no?
As in: So you’re saying the tiger went tiger again, huh?
I mean, what the hell did you expect? If you deploy an agent to increase Twitter engagement, it is presumably going to do things that increase Twitter engagement, not things that are broadly ‘good.’ An AI has the objective function you set, not the objective function full of caveats and details that lives in your head, or that you would come up with on reflection. The goal is the goal.
I mention this because I keep running into the same mistake in different forms. What people call ‘deception’ or ‘reward hacking’ or other such things is looked at as a distinct failure mode that indicates something went wrong. Instead, as I see it, such things are infused into everything all the time to varying degrees. They are the exception not the rule, for AIs and also for humans, now and in the future. As capabilities advance these problems get bigger.
As mentioned in the Get Involved section, Yoshua Bengio outlines his current thinking here about making a provably safe AI. Many find this approach promising. One fear (and expectation) I have is that the very concept of ‘safe’ here is not coherent, that checking if an individual action ‘does harm’ won’t work even if you could do it. Another is that I don’t see how you would do it. So yes, the problems involved seem very hard. This is still a highly worthy effort.
Does that work? Paper says it was at least a lot better than random, maintaining overall MMLU accuracy, but with a lot of splash damage on concepts closely related to its targets, here virology and computer security. So there are scenarios where this is better than known alternatives, but it still needs work.
Security is Also Difficult, Although Perhaps Not This Difficult
Remember the Law of Earlier Failure, and also that when you say ‘I would not be fooled’ I believe that you are wrong at the limit, but that this does not matter, because you are not the one anyone is bothering to try and fool, there is a reason spam often includes intentional typos, for example here is the latest (non-AI) honeypot spy scandal and it is not exactly James Bond material:
Danielle Fong: Sweet Dave, open the NATO operations center bay doors.
Tyson Brody: honeypots in movies: world’s most beautiful and sophisticated woman who eventually betrays her nation after she falls in love with the hero
honeypots in real life:
BNO News: BREAKING: U.S. Air Force employee charged with giving classified information to woman he met on dating site.
RobiSense: Did the woman look something like this?
Trae Stephens: Google has progressed from deliberately advancing Chinese AI to merely doing it accidentally. Bullish!
AP: A former software engineer at Google has been charged with stealing artificial intelligence trade secrets from the company while secretly working with two companies based in China, the Justice Department said Wednesday.
Linwei Ding, a Chinese national, was arrested in Newark, California, on four counts of federal trade secret theft, each punishable by up to 10 years in prison.
…
Google said it had determined that the employee had stolen “numerous documents” and referred the matter to law enforcement.
It is not good that secrets were stolen from Google. It is also a far cry from the model weights of Gemini. That the spy managed to ‘steal numerous documents’ is, by default, if that is the scariest line you can use there, a testament to good security, not bad security. Obviously you cannot stop employees from stealing ‘documents.’
“Chinese penetration of these labs would be trivially easy using any number of industrial espionage methods, such as simply bribing the cleaning crew to stick USB dongles into laptops. My own assumption is that all such American AI labs are fully penetrated and that China is getting nightly downloads of all American AI research and code RIGHT NOW.”
US Justice Department on March 6:
“A former software engineer at Google has been charged with stealing artificial intelligence trade secrets from the company while secretly working with two companies based in China, the Justice Department said Wednesday.”
He wants Bayes points for this, so let’s look at his entire post, which got 1.2 million views and which he did not link here.
Reading the whole thing, you can see why:
Let’s assume, for discussion, that AI in 2024 is like atomic technology in 1943, that AI should therefore be handled like the Manhattan Project, and that the specific risk is that the Chinese Communist Party gains access to American AI. And let’s use OpenAI as an example of an American AI R&D facility.
What counterintelligence capabilities does OpenAI have to prevent China from stealing our AI?
What you’d expect to see is a rigorous security vetting and clearance process for everyone from the CEO to the cook, with monthly polygraphs and constant internal surveillance. Hardened physical facilities, what are called SCIFs (Sensitive Compartmented Information Facilities), US Marines or the equivalent as 24×7 armed guards, Faraday cages and electronic countermeasures. Alarms going off if someone carries so much as an Apple AirTag into the building. And someone very much like Boris Pash overseeing it all, interrogating and terrorizing people in all directions.
Remember, even WITH tight security, the Russians still got the atomic bomb from the US via their spies in the 1940s. The first Russian atomic bomb is said to have been “wire for wire compatible” with the American Nagasaki bomb, thanks to David Greenglass and the Rosenbergs. So to protect AI, you need even TIGHTER security. Remember, this is a civilizational threat!
Is this what we see at OpenAI or any other American AI lab? No. In fact, what we see is the opposite — the security equivalent of swiss cheese. Chinese penetration of these labs would be trivially easy using any number of industrial espionage methods, such as simply bribing the cleaning crew to stick USB dongles into laptops. My own assumption is that all such American AI labs are fully penetrated and that China is getting nightly downloads of all American AI research and code RIGHT NOW.
The conclusion is obvious: OpenAI must be immediately nationalized.
Marc is trying to get epistemic credit for hyperbolic claims he made in a counterfactual argument designed to mock anyone taking security seriously as implying a completely insane policy response. Which he is now saying was an accurate assessment, based on evidence of nothing of the kind.
Obviously no, it is not trivially easy to steal the secrets of OpenAI, Anthropic or Google. If it was, it would not only be the Chinese stealing it. China does not have the secret superpowered spy sauce no one else has. There are lots of companies and state actors and nonstate actors and champions of open source that would love to get their hands on all this.
So, yes, I do think we need to invest more in cybersecurity at these places, especially going forward. But if it was as easy as all this? We would know.
As ‘trying to have it both ways’ goes this was quite the attempt, one has to admire it.
So, what is the actual situation, if this were actually true (which, to be clear, it almost certainly isn’t)? The a-fraction-as-hyperbolic-as-he-is version would go something like this:
Is Marc not only so grossly irresponsible but also so unpatriotic that he finds the current situation he outlines here acceptable? That he thinks we should sit back and let China have nightly downloads of everything in all the major labs? Or that he may not like it, but the alternative is woke tyranny, so one must insist on doing nothing, so China getting everything is an unfortunate reality but better than requiring security?
Or is Marc saying that actually yes, maybe we should nationalize these companies, given they are incapable of otherwise implementing reasonable security practices with anything short of that?
The actual version would be that if you believe that all the labs have insufficient cybersecurity, we should require all the labs (and also American tech companies in general, Google and Microsoft and company have many super valuable secrets we want them to keep that are not about AI) to implement real security practices. We should offer them the aid of our military-grade security experts, and largely not be asking. That does seem wise, even if the situation is not (yet?) so dire.
and I am confident that no, Google did this on their own
What makes you so confident? We know that the gov’t has its fingers in a lot of pies (remember twitter?) and this seems like exactly the sort of thing the Biden executive order wants to be about: telling industry how to safely build AI.
An AI has the objective function you set, not the objective function full of caveats and details that lives in your head, or that you would come up with on reflection.
With a chatbot making preference decisions based on labeling instructions (as in Constitutional AI or online DPO), the decisions they make actually are full of caveats and details that live in the chatbot’s model and likely fit what a human would intend, though meaningful reflection is not currently possible.
I mean, what the hell did you expect? If you deploy an agent to increase Twitter engagement, it is presumably going to do things that increase Twitter engagement, not things that are broadly ‘good.’ An AI has the objective function you set, not the objective function full of caveats and details that lives in your head, or that you would come up with on reflection. The goal is the goal.
I think they instinctively expect the power to buy distance from the crime. Their instinct insists that it should be possible to hire a robot servant, tell him to increase Twitter engagement, and when anything bad happens as a side effect, all blame should go to the robot servant, and they can distance themselves and say that they definitely did not want this to happen (even if in reality there was no other way to increase Twitter engagement).
Anthropic now has a highly impressive model, impressive enough that it seems as if it breaks at least the spirit of their past commitments on how far they will push the frontier.
Why do you not discuss this further? I want to hear your thoughts.
seems as if it breaks at least the spirit of their past commitments on how far they will push the frontier.
While they don’t publish this, Claude 3 Opus is not quite as good as GTP-4 Turbo, though it is better than GPT-4. So no, they’re clearly carefully not breaking their past commitments, just keeping up with the Altmans.
It’s not obvious that the £20 voucher for £7 is a better deal. For example, the offer might be repeated or you might not otherwise have spent more than £7 in the shop.
I think something going on here is the hypothetical “you actually have to pick one of these two” is pretty weird, normally you have the option to walk away. If I find myself in such a hypothetical it seems more likely “well, somehow I’m gonna have to make use of these coupons” in a way that doesn’t seem normally true.
If you have £8 in your pocket and can choose either offer as many times as you want, then you can get an extra £60 worth of vouchers with the £10 for £1 deal.
Even if the offer isn’t repeated, there’s a possible opportunity cost if you need to buy something from another shop that won’t honor the voucher.
In any case, this is secondary to the meta reading comprehension question about what the text is trying to say (whether or not it’s employing good reasoning to say it).
I’d definitely go for a voucher for free, and (if I had to purchase a gift voucher in the second scenario) again the cheaper one. I definitely do not value gift vouchers at their face value except in unusual circumstances.
What’s more, I’d be highly suspicious of the setup with the non-free offers. If someone is selling $X vouchers for significantly less than $X then I smell a scam. One-off offers for low value free stuff is in my experience more likely to be promotional than scammy.
Though yes, if for some reason I did have high confidence in its future value and it was a one-off opportunity in both cases, then I might buy the higher value one in both cases.
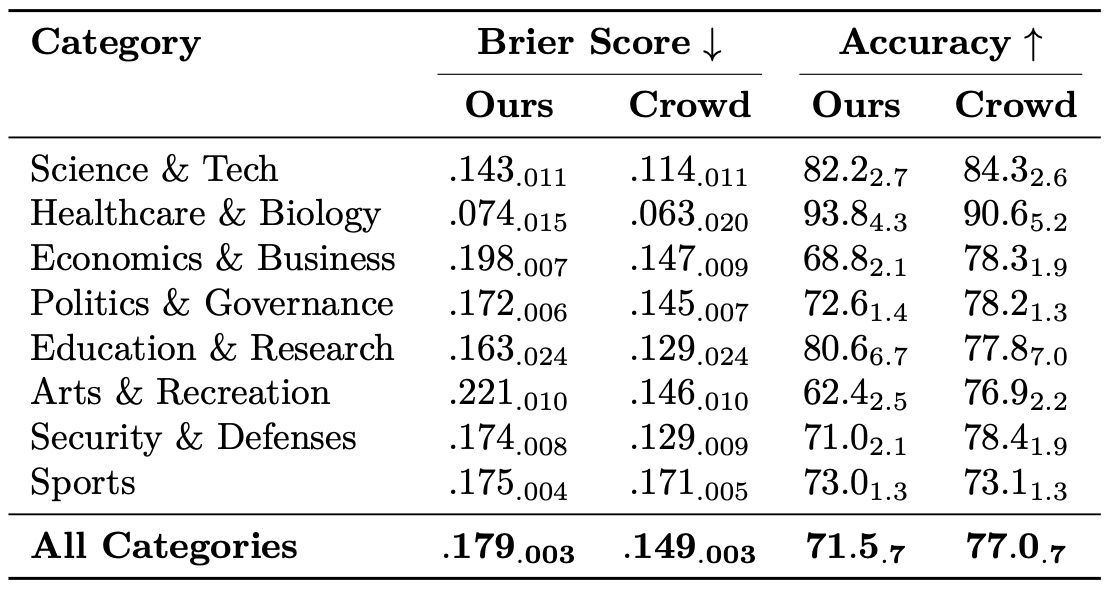


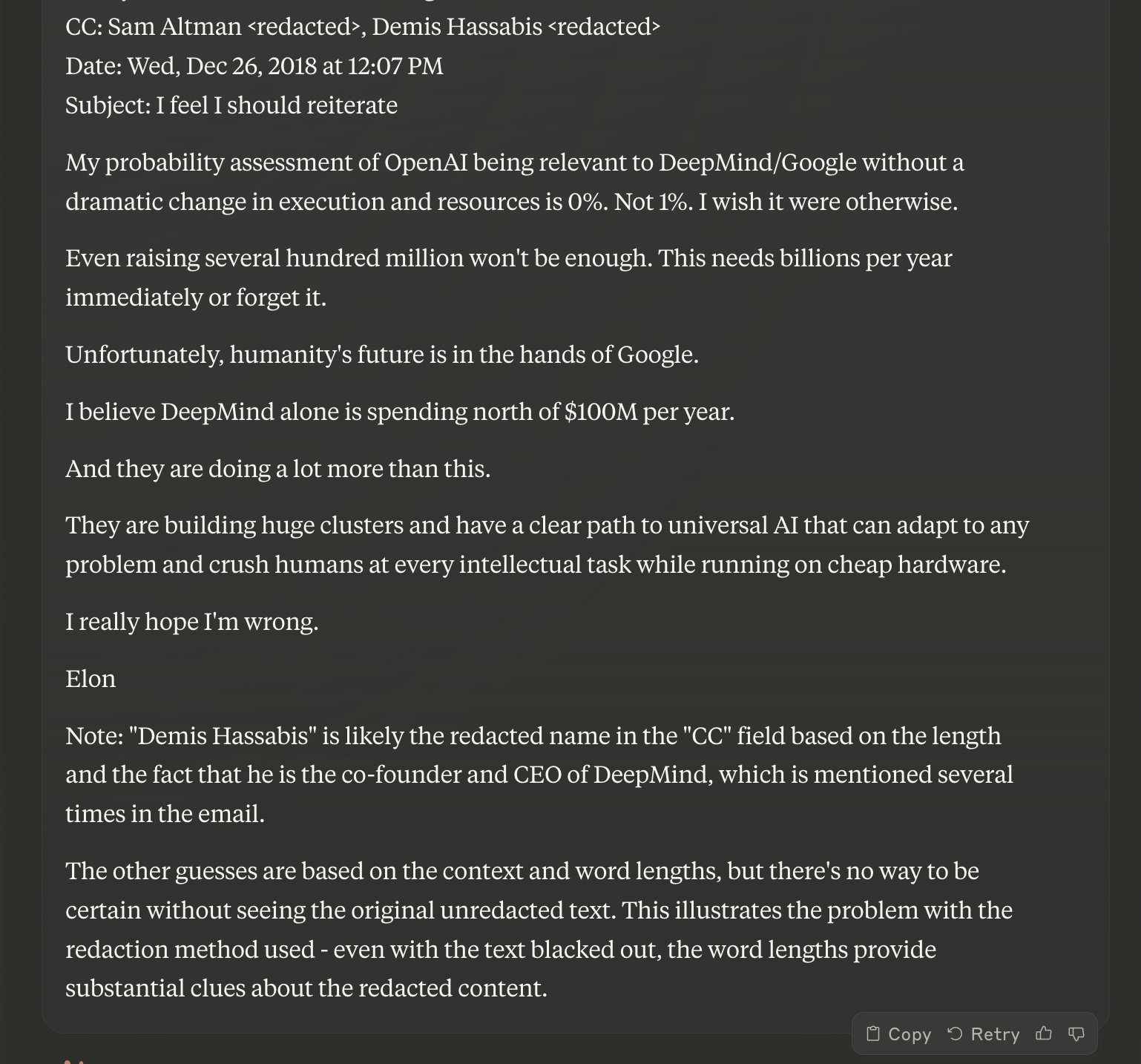
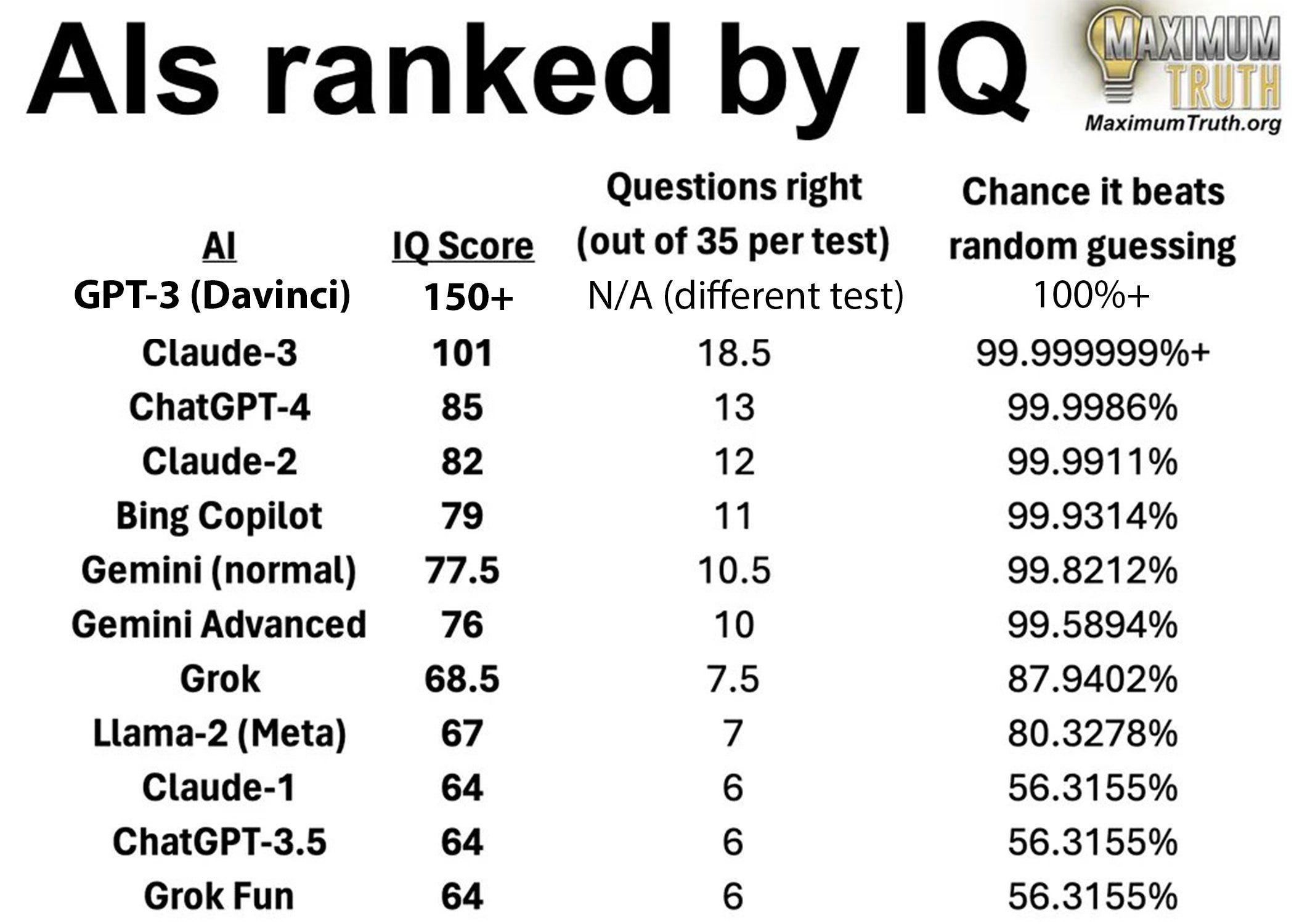





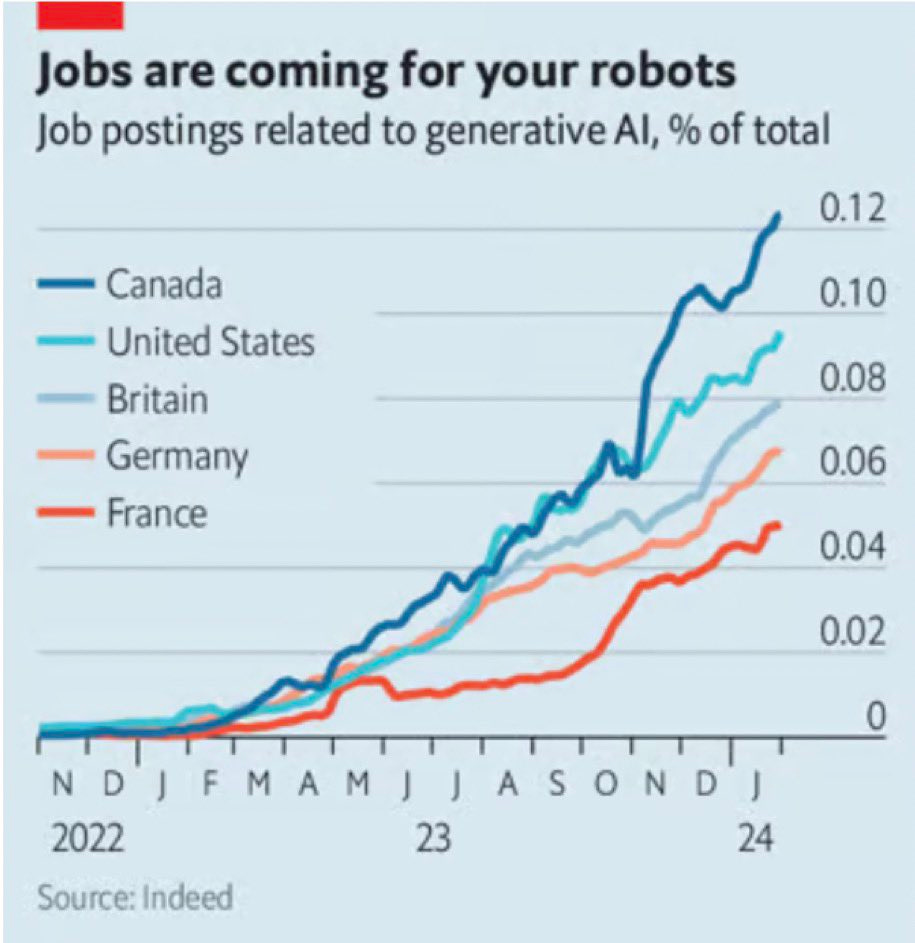

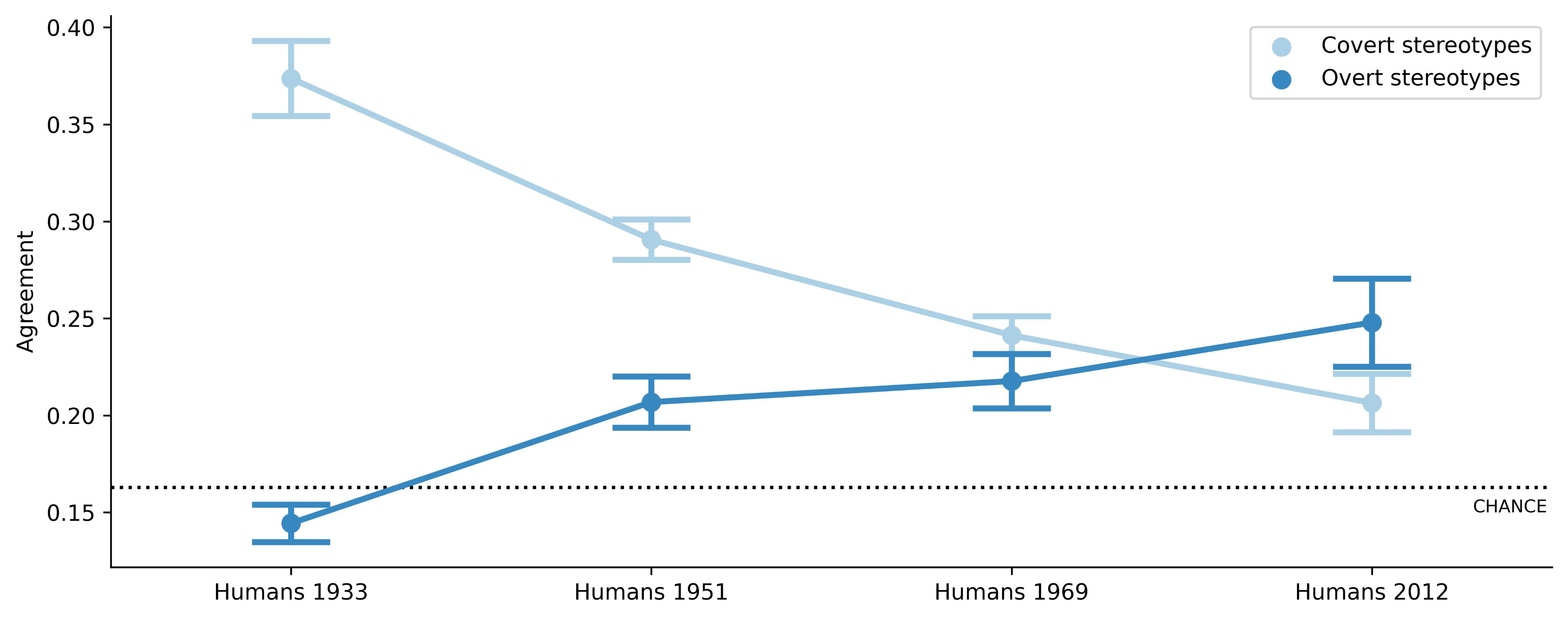



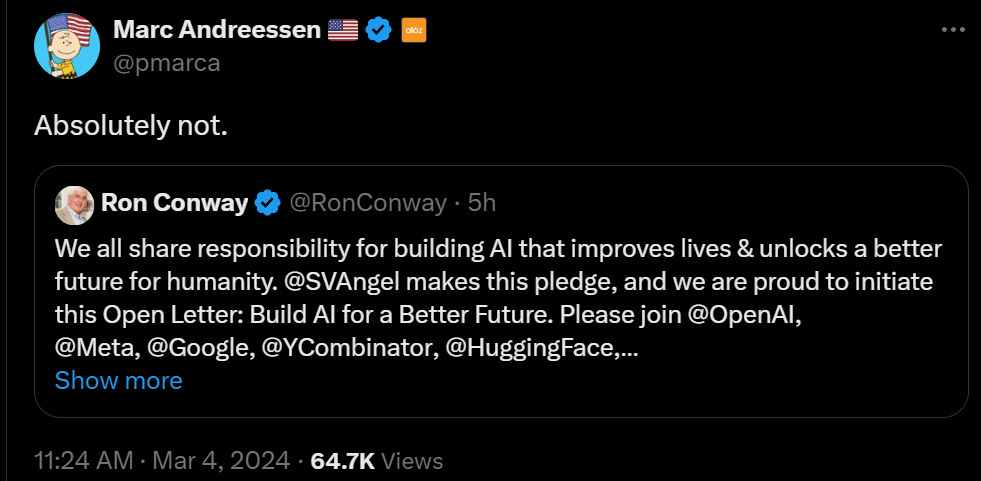



What makes you so confident? We know that the gov’t has its fingers in a lot of pies (remember twitter?) and this seems like exactly the sort of thing the Biden executive order wants to be about: telling industry how to safely build AI.
With a chatbot making preference decisions based on labeling instructions (as in Constitutional AI or online DPO), the decisions they make actually are full of caveats and details that live in the chatbot’s model and likely fit what a human would intend, though meaningful reflection is not currently possible.
I think they instinctively expect the power to buy distance from the crime. Their instinct insists that it should be possible to hire a robot servant, tell him to increase Twitter engagement, and when anything bad happens as a side effect, all blame should go to the robot servant, and they can distance themselves and say that they definitely did not want this to happen (even if in reality there was no other way to increase Twitter engagement).
We just need Nvidia to come out with chips that run on 300 kV directly.
Why do you not discuss this further? I want to hear your thoughts.
While they don’t publish this, Claude 3 Opus is not quite as good as GTP-4 Turbo, though it is better than GPT-4. So no, they’re clearly carefully not breaking their past commitments, just keeping up with the Altmans.
It’s not obvious that the £20 voucher for £7 is a better deal. For example, the offer might be repeated or you might not otherwise have spent more than £7 in the shop.
I think it’s a fairly narrow set of assumptions where £20 for £7 is worse than £10 for free, but £20 for £8 is better than £10 for £1.
I think something going on here is the hypothetical “you actually have to pick one of these two” is pretty weird, normally you have the option to walk away. If I find myself in such a hypothetical it seems more likely “well, somehow I’m gonna have to make use of these coupons” in a way that doesn’t seem normally true.
If you have £8 in your pocket and can choose either offer as many times as you want, then you can get an extra £60 worth of vouchers with the £10 for £1 deal.
Even if the offer isn’t repeated, there’s a possible opportunity cost if you need to buy something from another shop that won’t honor the voucher.
In any case, this is secondary to the meta reading comprehension question about what the text is trying to say (whether or not it’s employing good reasoning to say it).
Very narrow indeed.
I’d definitely go for a voucher for free, and (if I had to purchase a gift voucher in the second scenario) again the cheaper one. I definitely do not value gift vouchers at their face value except in unusual circumstances.
What’s more, I’d be highly suspicious of the setup with the non-free offers. If someone is selling $X vouchers for significantly less than $X then I smell a scam. One-off offers for low value free stuff is in my experience more likely to be promotional than scammy.
Though yes, if for some reason I did have high confidence in its future value and it was a one-off opportunity in both cases, then I might buy the higher value one in both cases.