This is crossposted from the AI Impacts blog.
Artificial intelligence defeated a pair of professional Starcraft II players for the first time in December 2018. Although this was generally regarded as an impressive achievement, it quickly became clear that not everybody was satisfied with how the AI agent, called AlphaStar, interacted with the game, or how its creator, DeepMind, presented it. Many observers complained that, in spite of DeepMind’s claims that it performed at similar speeds to humans, AlphaStar was able to control the game with greater speed and accuracy than any human, and that this was the reason why it prevailed.
Although I think this story is mostly correct, I think it is harder than it looks to compare AlphaStar’s interaction with the game to that of humans, and to determine to what extent this mattered for the outcome of the matches. Merely comparing raw numbers for actions taken per minute (the usual metric for a player’s speed) does not tell the whole story, and appropriately taking into account mouse accuracy, the differences between combat actions and non-combat actions, and the control of the game’s “camera” turns out to be quite difficult.
Here, I begin with an overview of Starcraft II as a platform for AI research, a timeline of events leading up to AlphaStar’s success, and a brief description of how AlphaStar works. Next, I explain why measuring performance in Starcraft II is hard, show some analysis on the speed of both human and AI players, and offer some preliminary conclusions on how AlphaStar’s speed compares to humans. After this, I discuss the differences in how humans and AlphaStar “see” the game and the impact this has on performance. Finally, I give an update on DeepMind’s current experiments with Starcraft II and explain why I expect we will encounter similar difficulties when comparing human and AI performance in the future.
Why Starcraft is a Target for AI Research
Starcraft II has been a target for AI for several years, and some readers will recall that Starcraft II appeared on our 2016 expert survey. But there are many games and many AIs that play them, so it may not be obvious why Starcraft II is a target for research or why it is of interest to those of us that are trying to understand what is happening with AI.
For the most part, Starcraft II was chosen because it is popular, and it is difficult for AI. Starcraft II is a real time strategy game, and like similar games, it requires a variety of tasks: harvesting resources, constructing bases, researching technology, building armies, and attempting to destroy their opponent’s base are all part of the game. Playing it well requires balancing attention between many things at once: planning ahead, ensuring that one’s units1 are good counters for the enemy’s units, predicting opponents’ moves, and changing plans in response to new information. There are other aspects that make it difficult for AI in particular: it has imperfect information2, an extremely large action space, and takes place in real time. When humans play, they engage in long term planning, making the best use of their limited capacity for attention, and crafting ploys to deceive the other players.
The game’s popularity is important because it makes it a good source of extremely high human talent and increases the number of people that will intuitively understand how difficult the task is for a computer. Additionally, as a game that is designed to be suitable for high-level competition, the game is carefully balanced so that competition is fair, does not favor just one strategy3, and does not rely too heavily on luck.
Timeline of Events
To put AlphaStar’s performance in context, it helps to understand the timeline of events over the past few years:
November 2016: Blizzard and DeepMind announce they are launching a new project in Starcraft II AI
August 2017: DeepMind releases the Starcraft II API, a set of tools for interfacing AI with the game
March 2018: Oriol Vinyals gives an update, saying they’re making progress, but he doesn’t know if their agent will be able to beat the best human players
November 3, 2018: Oriol Vinyals gives another update at a Blizzcon panel, and shares a sequence of videos demonstrating AlphaStar’s progress in learning the game, including leaning to win against the hardest built-in AI. When asked if they could play against it that day, he says “For us, it’s still a bit early in the research.”
December 12, 2018: AlphaStar wins five straight matches against TLO, a professional Starcraft II player, who was playing as Protoss4, which is off-race for him. DeepMind keeps the matches secret.
December 19, 2018: AlphaStar, given an additional week of training time5, wins five consecutive Protoss vs Protoss matches vs MaNa, a pro Starcraft II player who is higher ranked than TLO and specializes in Protoss. DeepMind continues to keep the victories a secret.
January 24, 2019: DeepMind announces the successful test matches vs TLO and MaNa in a live video feed. MaNa plays a live match against a version of AlphaStar which had more constraints on how it “saw” the map, forcing it to interact with the game in a way more similar to humans6. AlphaStar loses when MaNa finds a way to exploit a blatant failure of the AI to manage its units sensibly. The replays of all the matches are released, and people start arguing7 about how (un)fair the matches were, whether AlphaStar is any good at making decisions, and how honest DeepMind was in presenting the results of the matches.
July 10, 2019: DeepMind and Blizzard announce that they will allow an experimental version of AlphaStar to play on the European ladder8, for players who opt in. The agent will play anonymously, so that most players will not know that they are playing against a computer. Over the following weeks, players attempt to discern whether they played against the agent, and some post replays of matches in which they believe they were matched with the agent.
How AlphaStar works
The best place to learn about AlphaStar is from DeepMind’s page about it. There are a few particular aspects of the AI that are worth keeping in mind:
It does not interact with the game like a human does: Humans interact with the game by looking at a screen, listening through headphones or speakers, and giving commands through a mouse and keyboard. AlphaStar is given a list of units or buildings and their attributes, which includes things like their location, how much damage they’ve taken, and which actions they’re able to take, and gives commands directly, using coordinates and unit identifiers. For most of the matches, it had access to information about anything that wouldn’t normally be hidden from a human player, without needing to control a “camera” that focuses on only one part of the map at a time. For the final match, it had a camera restriction similar to humans, though it still was not given screen pixels as input. Because it gives commands directly through the game, it does not need to use a mouse accurately or worry about tapping the wrong key by accident.
It is trained first by watching human matches, and then through self-play: The neural network is trained first on a large database of matches between humans, and then by playing against versions of itself.
It is a set of agents selected from a tournament: Hundreds of versions of the AI play against each other, and the ones that perform best are selected to play against human players. Each one has its own set of units that it is incentivized to use via reinforcement learning, so that they each play with different strategies. TLO and MaNa played against a total of 11 agents, all of which were selected from the same tournament, except the last one, which had been substantially modified. The agents that defeated MaNa had each played for hundreds of years in the virtual tournament9.
January/February Impressions Survey
Before deciding to focus my investigation on a comparison between human and AI performance in Starcraft II, I conducted an informal survey with my Facebook friends, my colleagues at AI Impacts, and a few people from an effective altruism Facebook group. I wanted to know what they were thinking about the matches in general, with an emphasis on which factors most contributed to the outcome of the matches. I’ve put details about my analysis and the full results of the survey in the appendix at the end of this article, but I’ll summarize a few major results here.
Forecasts
The timing and nature of AlphaStar’s success seems to have been mostly in line with people’s expectations, at least at the time of the announcement. Some respondents did not expect to see it for a year or two, but on average, AlphaStar was less than a year earlier than expected. It is probable that some respondents had been expecting it to take longer, but updated their predictions in 2016 after finding out that DeepMind was working on it. For future expectations, a majority of respondents expect to see an agent (not necessarily AlphaStar) that can beat the best humans without any of the current caveats within two years. In general, I do not think that I worded the forecasting questions carefully enough to infer very much from the answers given by survey respondents.
Some readers may be wondering how these survey results compare to those of our more careful 2016 survey, or how we should view the earlier survey results in light of MaNa and TLOs defeat at the hands of AlphaStar. The 2016 survey specified an agent that only receives a video of the screen, so that prediction has not yet resolved. But the median respondent assigned 50% probability of seeing such an agent that can defeat the top human players at least 50% of the time by 202110. I don’t personally know how hard it is to add in that capability, but my impression from speaking to people with greater machine learning expertise than mine is that this is not out of reach, so these predictions still seem reasonable, and are not generally in disagreement with the results from my informal survey.
Speed
Nearly everyone thought that AlphaStar was able to give commands faster and more accurately than humans, and that this advantage was an important factor in the outcome of the matches. I looked into this in more detail, and wrote about it in the next section.
Camera
As I mentioned in the description of AlphaStar, it does not see the game the same way that humans do. Its visual field covered the entire map, though its vision was still affected by the usual fog of war11. Survey respondents ranked this as an important factor in the outcome of the matches.
Given these results, I decided to look into the speed and camera issues in more detail.
The Speed Controversy
Starcraft is a game that rewards the ability to micromanage many things at once and give many commands in a short period of time. Players must simultaneously build their bases, manage resource collection, scout the map, research better technology, build individual units to create an army, and fight battles against other players. The combat is sufficiently fine grained that a player who is outnumbered or outgunned can often come out ahead by exerting better control over the units that make up their military forces, both on a group level and an individual level. For years, there have been simple Starcraft II bots that, although they cannot win a match against a highly-skilled human player, can do amazing things that humans can’t do, by controlling dozens of units individually during combat. In practice, human players are limited by how many actions they can take in a given amount of time, usually measured in actions per minute (APM). Although DeepMind imposed restrictions on how quickly AlphaStar could react to the game and how many actions it could take in a given amount of time, many people believe that the agent was sometimes able to act with superhuman speed and precision.
Here is a graph12 of the APM for MaNa (red) and AlphaStar (blue), through the second match, with five-second bins:
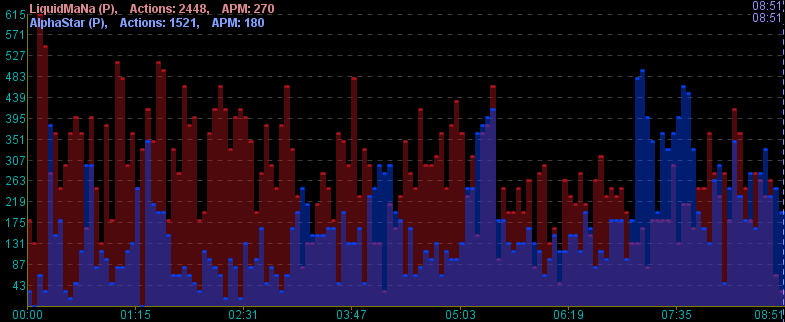
At first glance, this looks reasonably even. AlphaStar has both a lower average APM (180 vs MaNa’s 270) for the whole match, and a lower peak 5 second APM (495 vs Mana’s 615). This seems consistent with DeepMind’s claim that AlphaStar was restricted to human-level speed. But a more detailed look at which actions are actually taken during these peaks reveals some crucial differences. Here’s a sample of actions taken by each player during their peaks:
MaNa hit his APM peaks early in the game by using hot keys to twitchily switch back and forth between control groups13 for his workers and the main building in his base. I don’t know why he’s doing this: maybe to warm up his fingers (which apparently is a thing), as a way to watch two things at once, to keep himself occupied during the slow parts of the early game, or some other reason understood only by the kinds of people that can produce Starcraft commands faster than I can type. But it drives up his peak APM, and probably is not very important to how the game unfolds14. Here’s what MaNa’s peak APM looked like at the beginning of Game 2 (if you look at the bottom of the screen, you can see that the units he has selected switches back-and-forth between his workers and the building that he uses to make more workers):
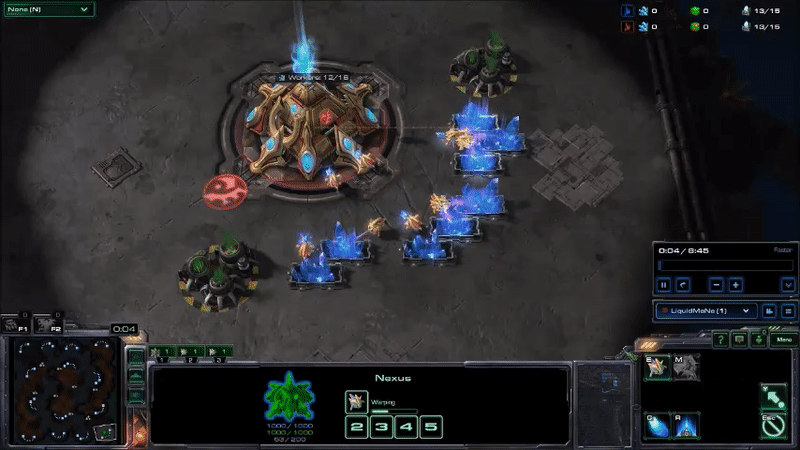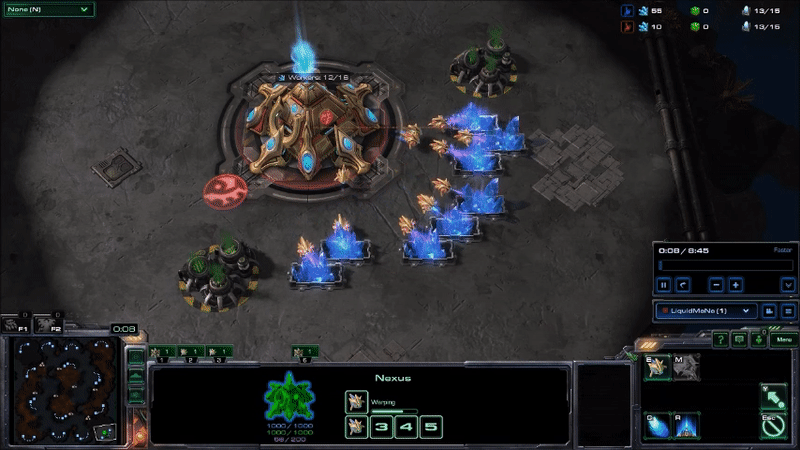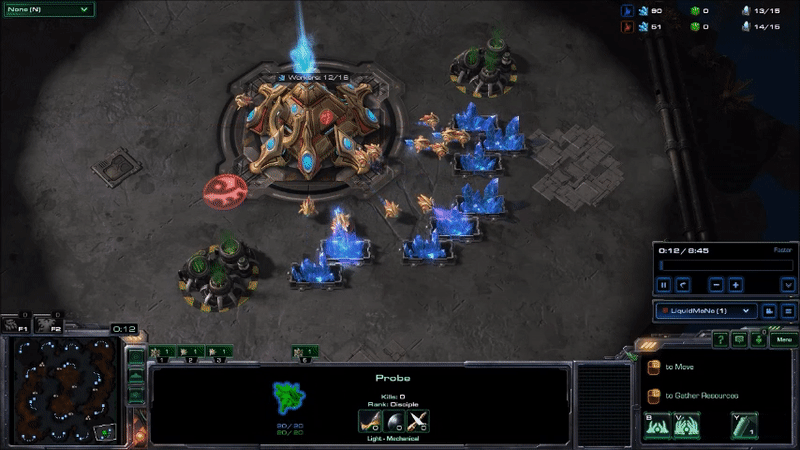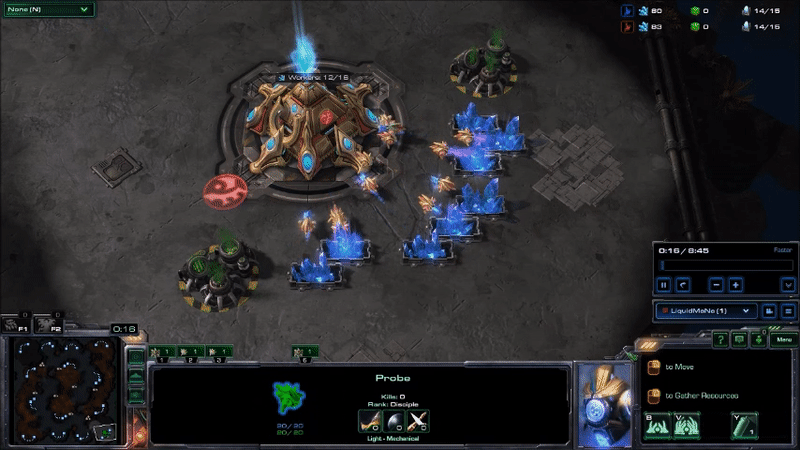
AlphaStar hit peak APM in combat. The agent seems to reserve a substantial portion of its limited actions budget until the critical moment when it can cash them in to eliminate enemy forces and gain an advantage. Here’s what that looked like near the end of game 2, when it won the engagement that probably won it the match (while still taking a few actions back at its base to keep its production going):
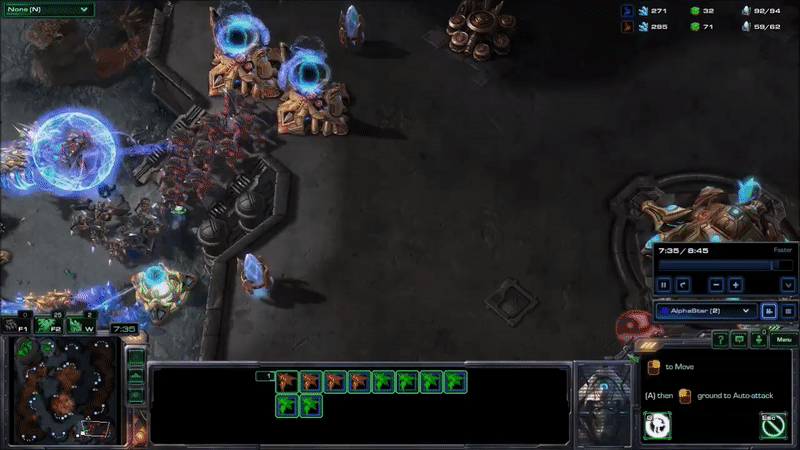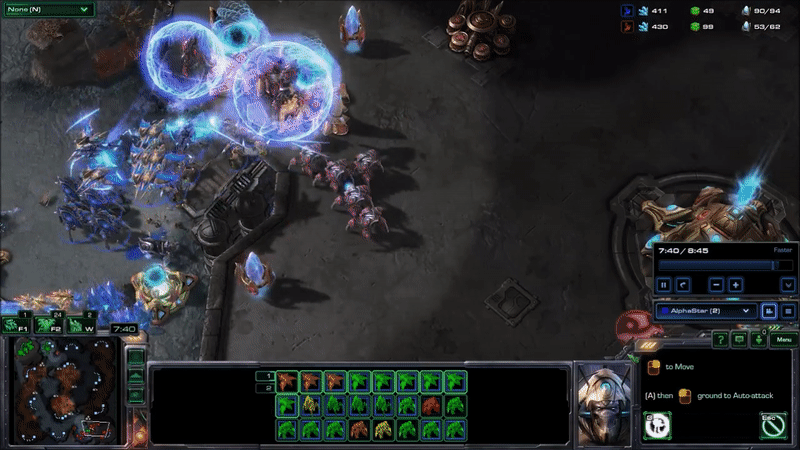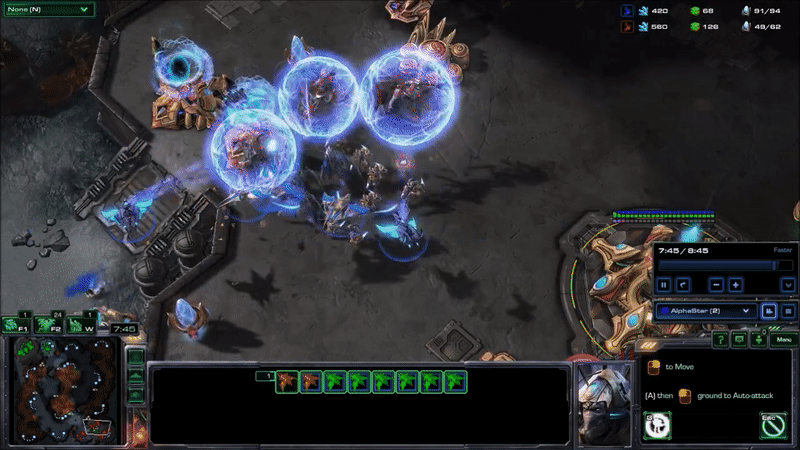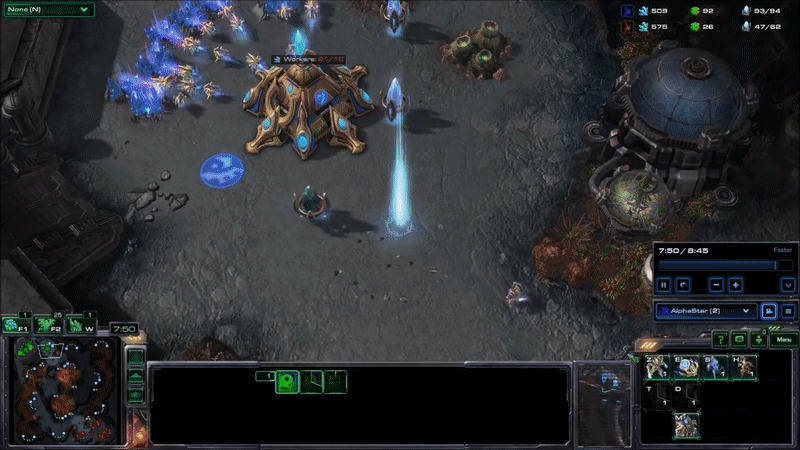
It may be hard to see what exactly is happening here for people who have not played the game. AlphaStar (blue) is using extremely fine-grained control of its units to defeat MaNa’s army (red) in an efficient way. This involves several different actions: Commanding units to move to different locations so they can make their way into his base while keeping them bunched up and avoiding spots that make them vulnerable, focusing fire on MaNa’s units to eliminate the most vulnerable ones first, using special abilities to lift MaNa’s units off the ground and disable them, and redirecting units to attack MaNa’s workers once a majority of MaNa’s military units are taken care of.
Given these differences between how MaNa and AlphaStar play, it seems clear that we can’t just use raw match-wide APM to compare the two, which most people paying attention seem to have noticed fairly quickly after the matches. The more difficult question is whether AlphaStar won primarily by playing with a level of speed and accuracy that humans are incapable of, or by playing better in other ways. Though based on the analysis that I am about to present I think the answer is probably that AlphaStar won through speed, I also think the question is harder to answer definitively than many critics of DeepMind are making it out to be.
A very fast human can average well over 300 APM for several minutes, with 5 second bursts at over 600 APM. Although these bursts are not always throwaway commands like those from the MaNa vs AlphaStar matches, they tend not to be commands that require highly accurate clicking, or rapid movement across the map. Take, for example, this 10 second, 600 APM peak from current top player Serral:
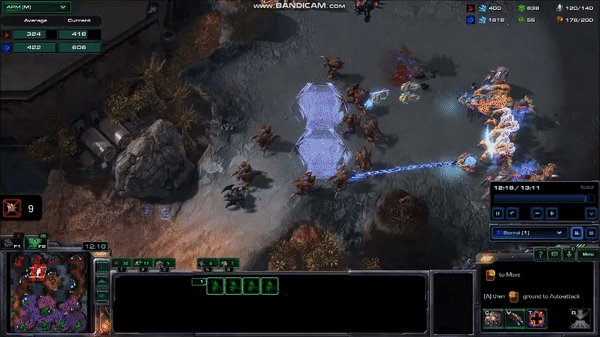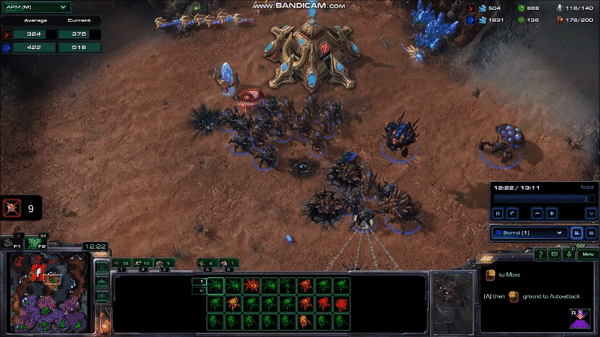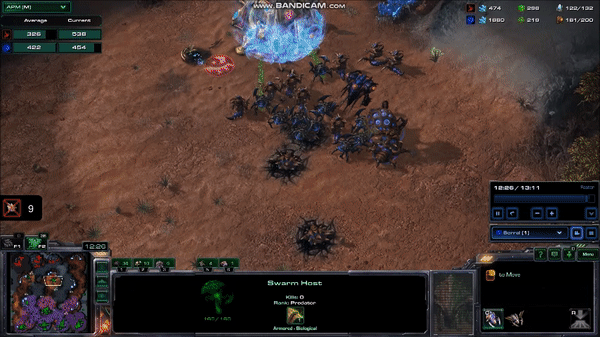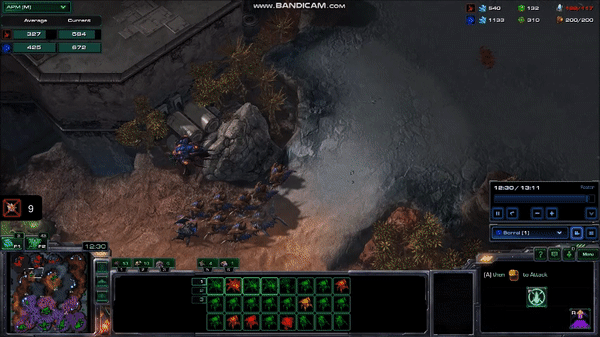
Here, Serral has just finished focusing on a pair of battles with the other player, and is taking care of business in his base, while still picking up some pieces on the battlefield. It might not be obvious why he is issuing so many commands during this time, so let’s look at the list of commands:
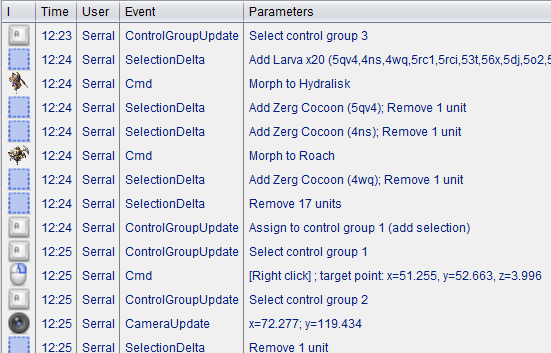
The lines that say “Morph to Hydralisk” and “Morph to Roach” represent a series of repeats of that command. For a human player, this is a matter of pressing the same hotkey many times, or even just holding down the key to give the command very rapidly15. You can see this in the gif by looking at the bottom center of the screen where he selects a bunch of worm-looking things and turns them all into a bunch of egg-looking things (it happens very quickly, so it can be easy to miss).
What Serral is doing here is difficult, and the ability to do it only comes with years of practice. But the raw numbers don’t tell the whole story. Taking 100 actions in 10 seconds is much easier when a third of those actions come from holding down a key for a few hundred milliseconds than when they each require a press of a different key or a precise mouse click. And this is without all the extraneous actions that humans often take (as we saw with MaNa).
Because it seems to be the case that peak human APM happens outside of combat, while AlphaStar’s wins happened during combat APM peaks, we need to do a more detailed analysis to determine the highest APM a human player can achieve during combat. To try to answer this question, I looked at approximately ten APM for each of the 5 games between AlphaStar and MaNa, as well as each of another 15 replays between professional Starcraft II players. The peaks were chosen so that roughly half were the largest peak at any time during the match and the rest were strictly during combat. My methodology for this is given in the appendix. Here are the results for just the human vs human matches:
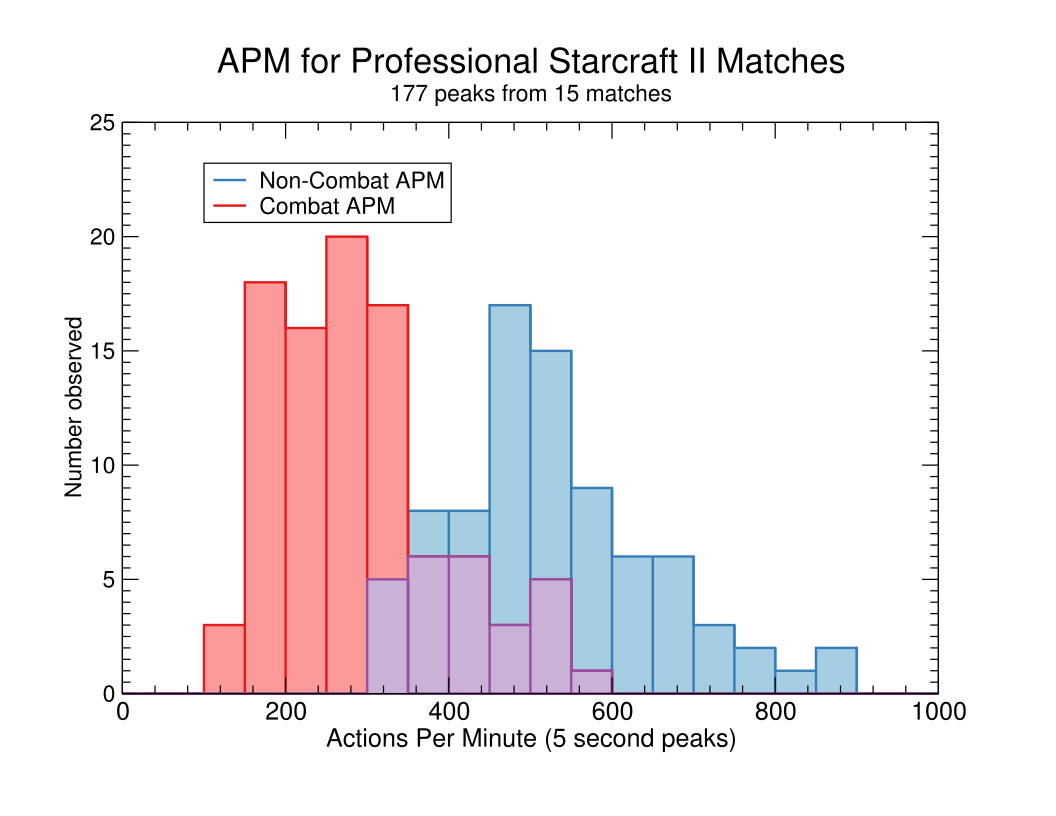
Provisionally, it looks like pro players frequently hit approximately 550 to 600 APM outside of combat before the distribution starts to fall off, and they peak at around 200-350 during combat, with a long right tail. As I was doing this, however, I found that all of the highest APM peaks had one thing in common with each other that they did not have in common with all of the lower APM peaks, which is that it was difficult to tell when a player’s actions are primarily combat-oriented commands, and when they are mixed in with bursts of commands for things like training units. In particular, I found that the combat situations with high APM tended to be similar to the Serral gif above, in that they involve spam clicking and actions related to the player’s economy and production, which was probably driving up the numbers. I give more details in the appendix, but I don’t think I can say with confidence that any players were achieving greater than 400-450 APM in combat, in the absence of spurious actions or macromanagement commands.
The more pertinent question might what the lowest APM is that a player can have while still succeeding at the highest level. Since we know that humans can succeed without exceeding this APM, it is not an unreasonable limitation to put on AlphaStar. The lowest peak APM in combat I saw for a winning player in my analysis was 215, though it could be that I missed a higher peak during combat in that same match.
Here is a histogram of AlphaStar’s combat APM:
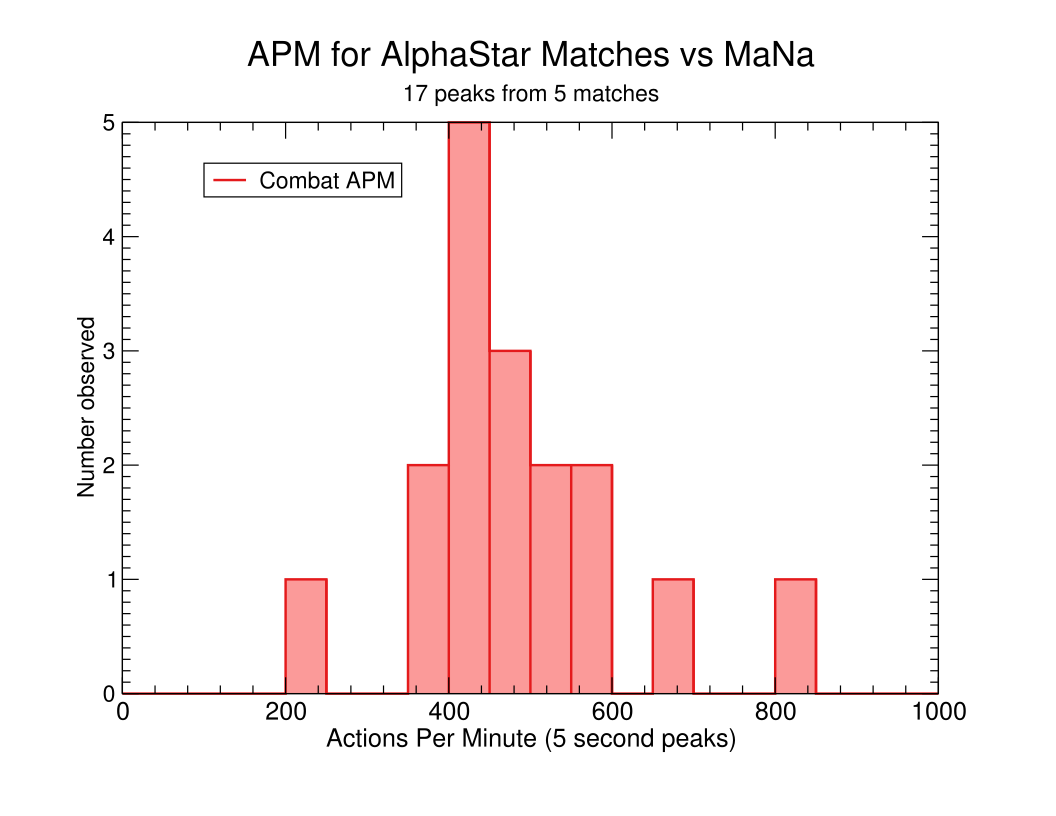
The smallest 5-second APM that AlphaStar needed to win a match against MaNa was just shy of 500. I found 14 cases in which the agent was able to average over 400 APM for 5 seconds in combat, and six times when the agent averaged over 500 APM for more than 5 seconds. This was done with perfect accuracy and no spam clicking or control group switching, so I think we can safely say that its play was faster than is required for a human to win a match in a professional tournament. Given that I found no cases where a human was clearly achieving this speed in combat, I think I can comfortably say that AlphaStar had a large enough speed advantage over MaNa to have substantially influenced the match.
It’s easy to get lost in numbers, so it’s good to take a step back and remind ourselves of the insane level of skill required to play Starcraft II professionally. The top professional players already play with what looks to me like superhuman speed, precision, and multitasking, so it is not surprising that the agent that can beat them is so fast. Some observers, especially those in the Starcraft community, have indicated that they will not be impressed until AI can beat humans at Starcraft II at sub-human APM. There is some extent to which speed can make up for poor strategy and good strategy can make up for a lack of speed, but it is not clear what the limits are on this trade-off. It may be very difficult to make an agent that can beat professional Starcraft II players while restricting its speed to an undisputedly human or sub-human level, or it may simply be a matter of a couple more weeks of training time.
The Camera
As I explained earlier, the agent interacts with the game differently than humans. As with other games, humans look at a screen to know what’s happening, use a mouse and keyboard to give commands, and need to move the game’s ‘camera’ to see different parts of the play area. With the exception of the final exhibition match against MaNa, AlphaStar was able to see the entire map at once (though much of it is concealed by the fog of war most of the time), and had no need to select units to get information about them. It’s unclear just how much of an advantage this was for the agent, but it seems likely that it was significant, if nothing else because it did not suffer from the APM overhead just to look around and get information from the game. Furthermore, seeing the entire map makes it easier to simultaneously control units across the map, which AlphaStar used to great effect in the first five matches against MaNa.
For the exhibition match in January, DeepMind trained a version of AlphaStar that had similar camera control to human players. Although the agent still saw the game in a way that was abstracted from the screen pixels that humans see, it only had access to about one screen’s worth of information at a time, and it needed to spend actions to look at different parts of the map. A further disadvantage was that this version of the agent only had half as much training time as the agents that beat MaNa.
Here are three factors that may have contributed to AlphaStar’s loss:
The agent was unable to deal effectively with the added complication of controlling the camera
The agent had insufficient training time
The agent had easily exploitable flaws the whole time, and MaNa figured out how to use them in match 6
For the third factor, I mean that the agent had sufficiently many exploitable flaws that were obvious enough to human players that any skilled human player could find at least one during a small number of games. The best humans do not have a sufficient number of such flaws to influence the game with any regularity. Matches in professional tournaments are not won by causing the other player to make the same obvious-to-humans mistake over and over again.
I suspect that AlphaStar’s loss in January is mainly due to the first two factors. In support of 1, AlphaStar seemed less able to simultaneously deal with things happening on opposite sides of the map, and less willing to split its forces, which could plausibly be related to an inability to simultaneously look at distant parts of the map. It’s not just that the agent had to move the camera to give commands on other parts of the map. The agent had to remember what was going on globally, rather than being able to see it all the time. In support of 2, the agent that MaNa defeated had only as much training time as the agents that went up against TLO, and those agents lost to the agents that defeated MaNa 94% of the time during training16.
Still, it is hard to dismiss the third factor. One way in which an agent can improve through training is to encounter tactics that it has not seen before, so that it can react well if it sees it in the future. But the tactics that it encounters are only those that another agent employed, and without seeing the agents during training, it is hard to know if any of them learned the harassment tactics that MaNa used in game 6, so it is hard to know if the agents that defeated MaNa were susceptible to the exploit that he used to defeat the last agent. So far, the evidence from DeepMind’s more recent experiment pitting AlphaStar against the broader Starcraft community (which I will go into in the next section) suggests that the agents do not tend to learn defenses to these types of exploits, though it is hard to say if this is a general problem or just one associated with low training time or particular kinds of training data.
AlphaStar on the Ladder
For the past couple months, as of this writing, skilled European players have had the opportunity to play against AlphaStar as part of the usual system for matching players with those of similar skill. For the version of AlphaStar that plays on the European ladder, DeepMind claims to have made changes that address the camera and action speed complaints from the January matches. The agent needs to control the camera, and they say they have placed restrictions on AlphaStar’s performance in consultation with pro players, particularly the maximum actions per minute and per second that the agent can make. I will be curious to see what numbers they arrive at for this. If this was done in an iterative way, such that pro players were allowed to see the agent play or to play against it, I expect they were able to arrive at a good constraint. Given the difficulty that I had with arriving at a good value for a combat APM restriction, I’m less confident that they would get a good value just by thinking about it, though if they were sufficiently conservative, they probably did alright.
Another reason to expect a realistic APM constraint is that DeepMind wanted to run the European ladder matches as a blind study, in which the human players did not know they were playing against an AI. If the agent were to play with the superhuman speed and accuracy that AlphaStar did in January, it would likely give it away and spoil the experiment.
Although it is unclear that any players were able to tell they were playing against an AI during their match, it does seem that some were able to figure it out after the fact. One example comes from Lowko, who is a Dutch player who streams and does commentary for games. During a stream of a ladder match in Starcraft II, he noticed the player was doing some strange things near the end of the match, like lifting their buildings17 when the match had clearly been lost, and air-dropping workers into Lowko’s base to kill units. Lowko did eventually win the match. Afterward, he was able to view the replay from the match and see that the player he had defeated did some very strange things throughout the entire match, the most notable of which was how the player controlled their units. The player used no control groups at all, which is, as far as I know, not something anybody does at high-level play18. There were many other quirks, which he describes in his entertaining video, which I highly recommend to anyone who is interested.
Other players have released replay files from matches against players they believed were AlphaStar, and they show the same lack of control groups. This is great, because it means we can get a sense of what the new APM restriction is on AlphaStar. There are now dozens of replay files from players who claim to have played against the AI. Although I have not done the level of analysis that I did with the matches in the APM section, it seems clear that they have drastically lowered the APM cap, with the matches I have looked at topping out at 380 APM peaks, which did not even occur in combat.
It seems to be the case that DeepMind has brought the agent’s interaction with the game more in line with human capability, but we will probably need to wait until they release the details of the experiment before we can say for sure.
Another notable aspect of the matches that people are sharing is that their opponent will do strange things that human players, especially skilled human players almost never do, most of which are detrimental to their success. For example, they will construct buildings that block them into their own base, crowd their units into a dangerous bottleneck to get to a cleverly-placed enemy unit, and fail to change tactics when their current strategy is not working. These are all the types of flaws that are well-known to exist in game-playing AI going back to much older games, including the original Starcraft, and they are similar to the flaw that MaNa exploited to defeat AlphaStar in game 6.
All in all, the agents that humans are uncovering seem to be capable, but not superhuman. Early on, the accounts that were identified as likely candidates for being AlphaStar were winning about 90-95% of their matches on the ladder, achieving Grandmaster rank, which is reserved for only the top 200 players in each region. I have not been able to conduct a careful investigation to determine the win rate or Elo rating for the agents. However, based on the videos and replays that have been released, plausible claims from reddit users, and my own recollection of the records for the players that seemed likely to be AlphaStar19, a good estimate is that they were winning a majority of matches among Grandmaster players, but did not achieve an Elo rating that would suggest a favorable outcome in a rematch vs TLO20.
As with AlphaStar’s January loss, it is hard to say if this is the result of insufficient training time, additional restrictions on camera control and APM, or if the flaws are a deeper, harder to solve problem for AI. It may seem unreasonable to chalk this up to insufficient training time given that it has been several months since the matches in December and January, but it helps to keep in mind that we do not yet know what DeepMind’s research goals are. It is not hard to imagine that their goals are based around sample efficiency or some other aspect of AI research that requires such restrictions. As with the APM restrictions, we should learn more when we get results published by DeepMind.
Discussion
I have been focusing on what many onlookers have been calling a lack of “fairness” of the matches, which seems to come from a sentiment that the AI did not defeat the best humans on human terms. I think this is a reasonable concern; if we’re trying to understand how AI is progressing, one of our main interests is when it will catch up with us, so we want to compare its performance to ours. Since we already know that computers can do the things they’re able to do faster than we can do them, we should be less interested in artificial intelligence that can do things better than we can by being faster or by keeping track of more things at once. We are more interested in AI that can make better decisions than we can.
Going into this project, I thought that the disagreements surrounding the fairness of the matches were due to a lack of careful analysis, and I expected it to be very easy to evaluate AlphaStar’s performance in comparison to human-level performance. After all, the replay files are just lists of commands, and when we run them through the game engine, we can easily see the outcome of those commands. But it turned out to be harder than I had expected. Separating careful, necessary combat actions (like targeting a particular enemy unit) from important but less precise actions (like training new units) from extraneous, unnecessary actions (like spam clicks) turned out to be surprisingly difficult. I expect if I were to spend a few months learning a lot more about how the game is played and writing my own software tools to analyze replay files, I could get closer to a definitive answer, but I still expect there would be some uncertainty surrounding what actually constitutes human performance.
It is unclear to me where this leaves us. AlphaStar is an impressive achievement, even with the speed and camera advantages. I am excited to see the results of DeepMind’s latest experiment on the ladder, and I expect they will have satisfied most critics, at least in terms of the agent’s speed. But I do not expect it to become any easier to compare humans to AI in the future. If this sort of analysis is hard in the context of a game where we have access to all the inputs and outputs, we should expect it to be even harder once we’re looking at tasks for which success is less clear cut or for which the AI’s output is harder to objectively compare to humans. This includes some of the major targets for AI research in the near future. Driving a car does not have a simple win-loss condition, and novel writing does not have clear metrics for what good performance looks like.
The answer may be that, if we want to learn things from future successes or failures of AI, we need to worry less about making direct comparisons between human performance and AI performance, and keep watching the broad strokes of what’s going on. From AlphaStar, we’ve learned that one of two things is true: Either AI can do long-term planning, solve basic game theory problems, balance different priorities against each other, and develop tactics that work, or that there are tasks which seem at first to require all of these things but did not, at least not at a high level.
Acknowledgements
Thanks to Gillian Ring for lending her expertise in e-sports and for helping me understanding some of the nuances of the game. Thanks to users of the Starcraft subreddit for helping me track down some of the fastest players in the world. And thanks to Blizzard and DeepMind for making the AlphaStar match replays available to the public.
All mistakes are my own, and should be pointed out to me via email at rick@aiimpacts.org.
Appendix I: Survey Results in Detail
I received a total of 22 submissions, which wasn’t bad, given its length. Two respondents failed to correctly answer the question designed to filter out people that are goofing off or not paying attention, leaving 20 useful responses. Five people who filled out the survey were affiliated in some way with AI Impacts. Here are the responses for respondents’ self-reported level of expertise in Starcraft II and artificial intelligence:
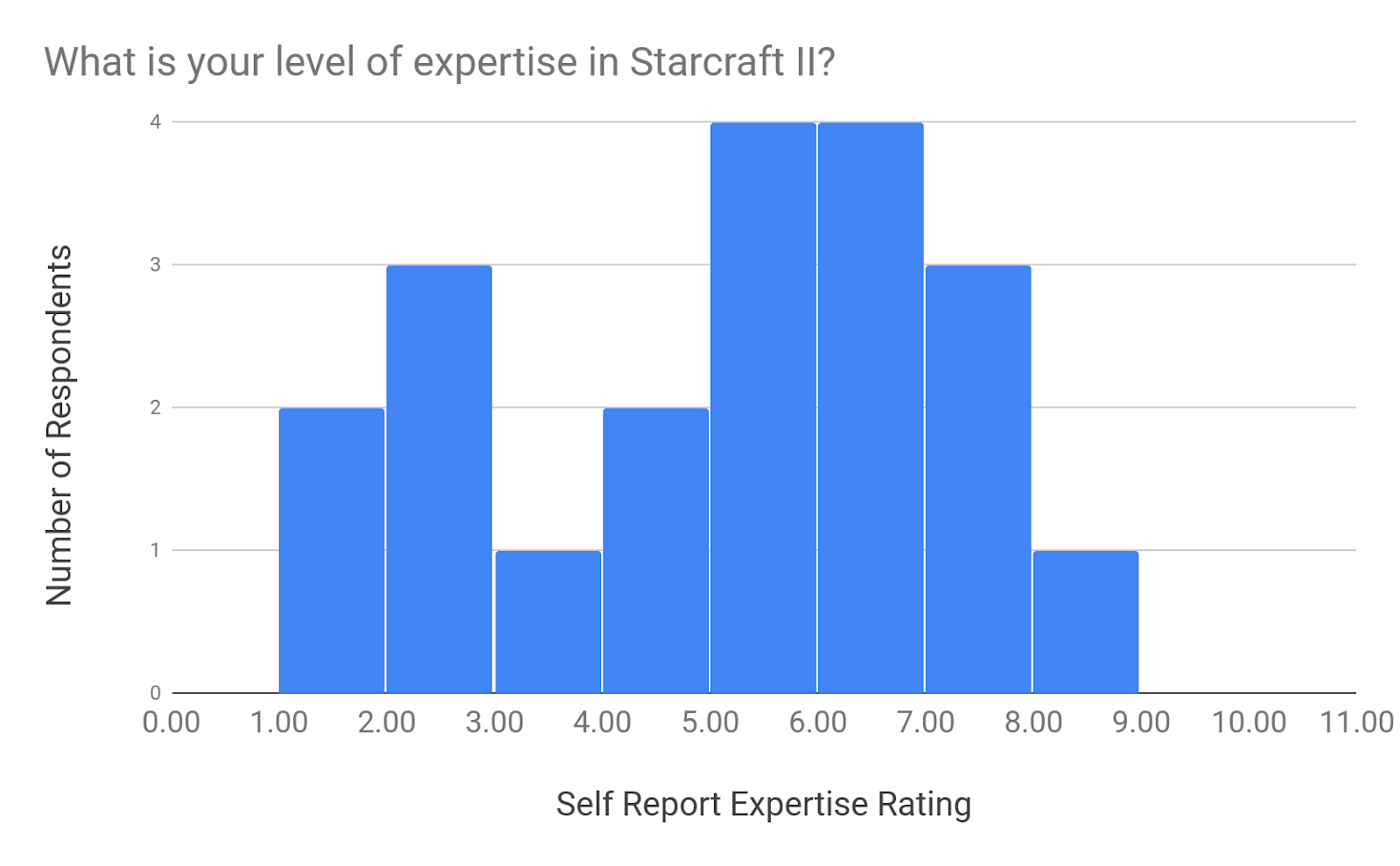
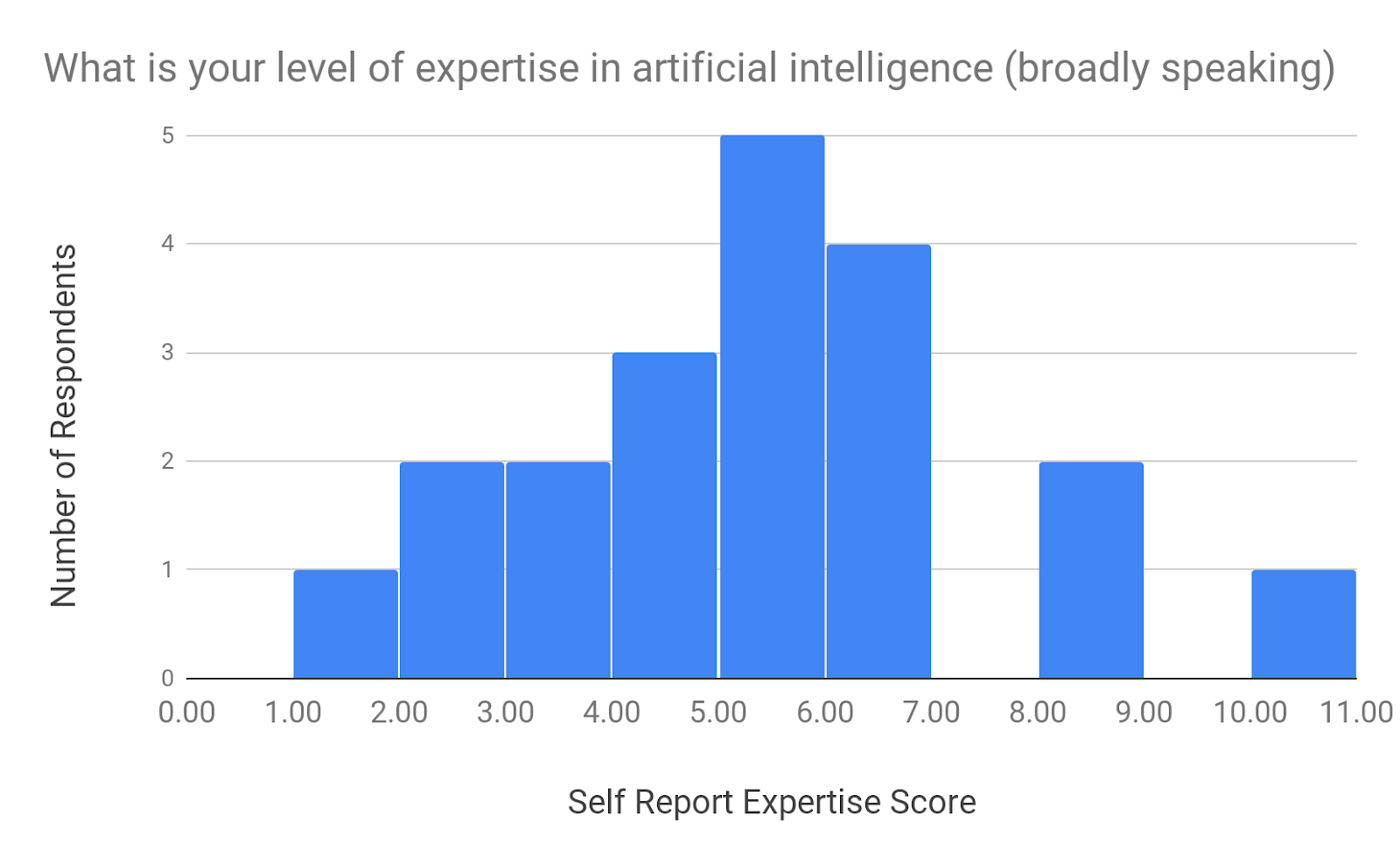
Survey respondents’ mean expertise rating was 4.6/10 for Starcraft II and 4.9/10 for AI.
Questions About AlphaStar’s Performance
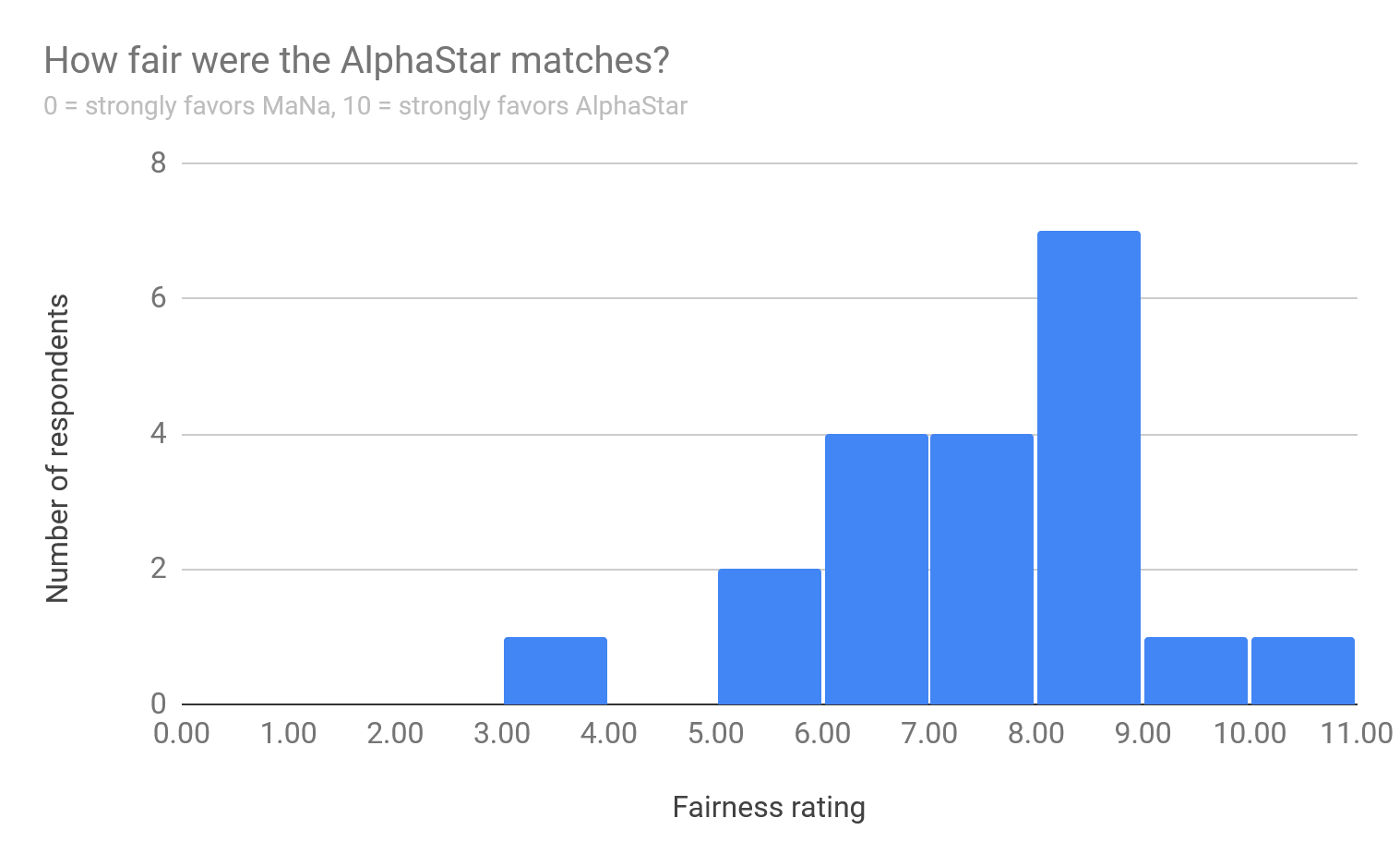
How fair were the AlphaStar matches?
For this one, it seems easiest to show a screenshot from the survey:

The results from this indicated that people thought the match was unfair and favored AlphaStar:
I asked respondents to rate AlphaStar’s overall performance, as well as its “micro” and “macro”. The term “micro” is used to refer to a player’s ability to control units in combat, and is greatly improved by speed. There seems to have been some misunderstanding about how to use the word “macro”. Based on comments from respondents and looking around to see how people use the term on the Internet, it seems that that there are at least three somewhat distinct ways that people use the phrase, and I did not clarify which I meant, so I’ve discarded the results from that question.
For the next two questions, the scale ranges from 0 to 10, with 0 labeled “AlphaStar is much worse” and 10 labeled “AlphaStar is much better”
Overall, how do you think AlphaStar’s performance compares to the best humans?
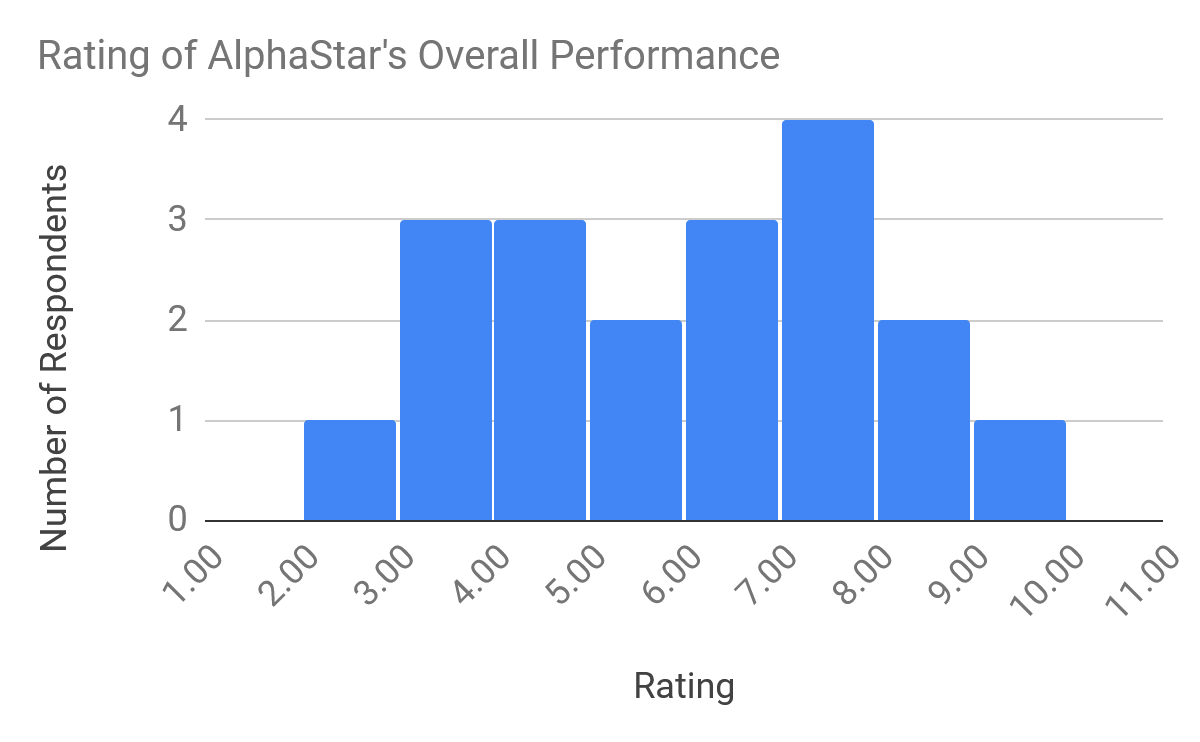
I found these results interesting, because AlphaStar was able to consistently defeat professional players, so some survey respondents felt the outcome alone was not enough to rate it as at least as good as the best humans.
How do you think AlphaStar’s micro compares to the best humans?
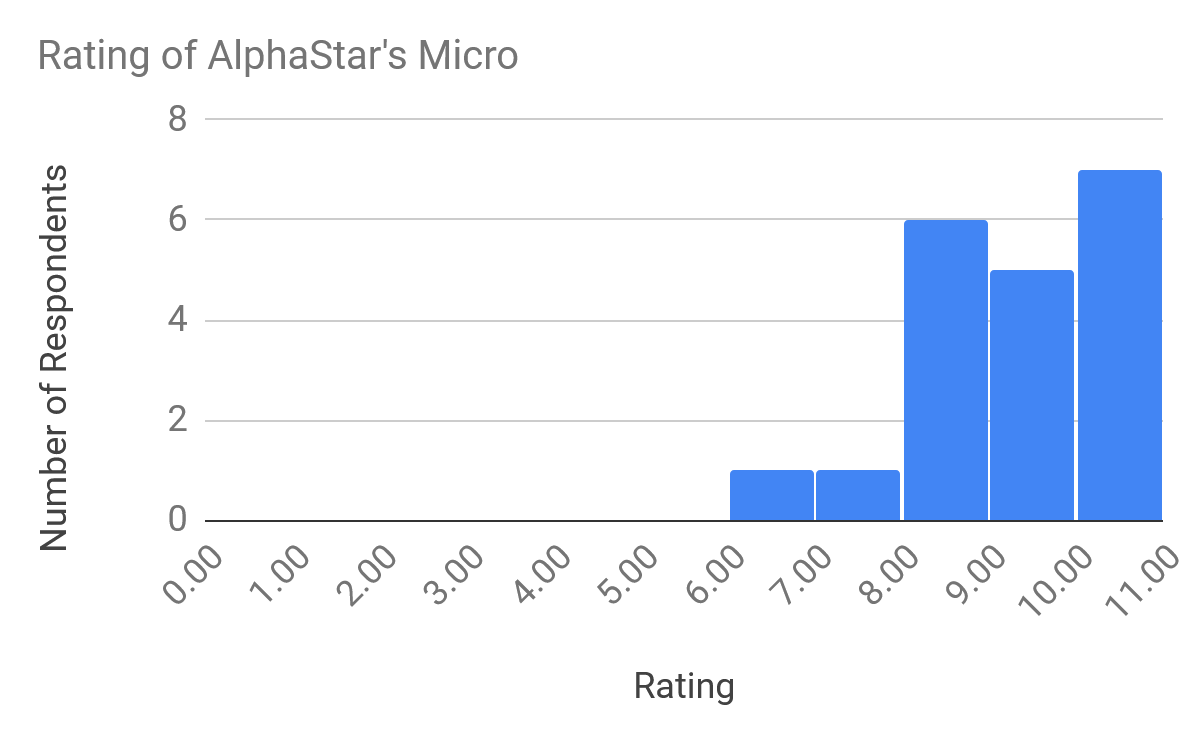
Survey respondents unanimously reported that they thought AlphaStar’s combat micromanagement was an important factor in the outcome of the matches.
Forecasting Questions
Respondents were split on whether they expected to see AlphaStar’s level of Starcraft II performance by this time:
Did you expect to see AlphaStar’s level of performance in a Starcraft II agent:
| Before Now | 1 |
| Around this time | 8 |
| Later than now | 7 |
| I had no expectation either way | 4 |
Respondents who indicated that they expected it sooner or later than now were also asked by how many years their expectation differed from reality. If we assign negative numbers to “before now”, positive numbers to “Later than now”, zero to “Around this time”, ignore those with no expectation, and weight responses by level of expertise, we find respondents’ mean expectation was just 9 months later the announcement, and the median respondent expected to see it around this time. Here is a histogram of these results, without expertise weighting:
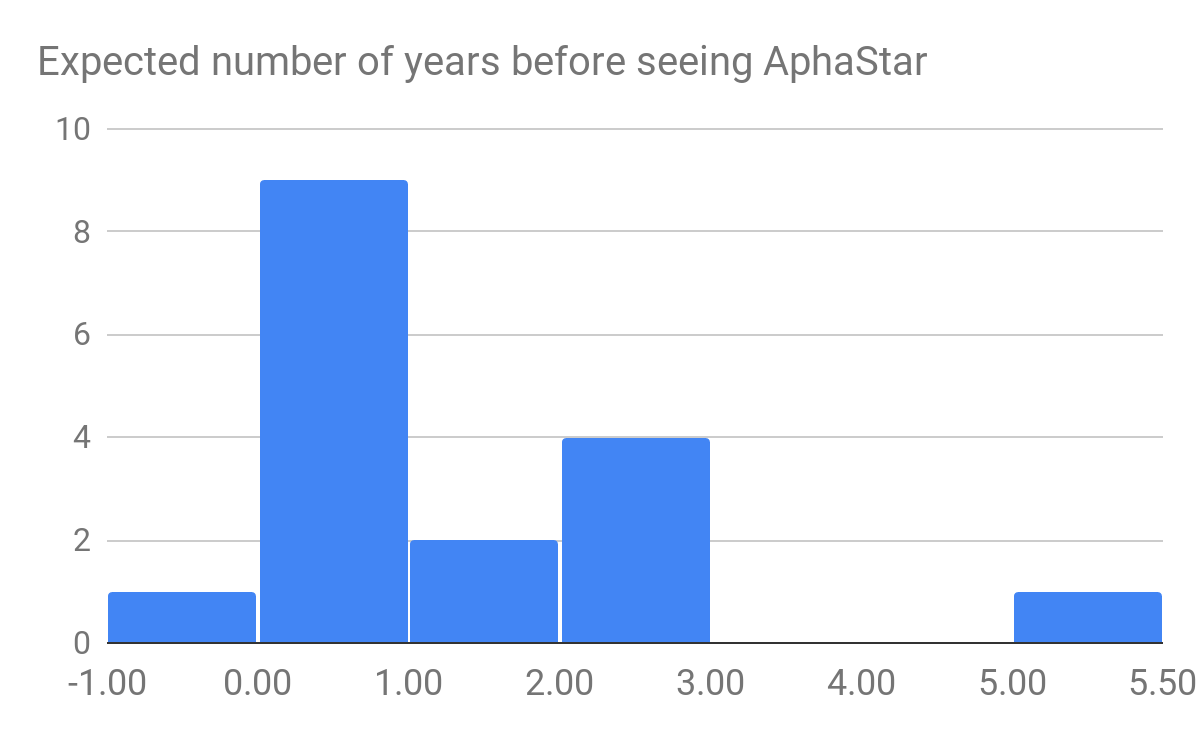
These results do not generally indicate too much surprise about seeing a Starcraft II agent of AlphaStar’s ability now.
How many years do you think it will be until we see (in public) an agent which only gets screen pixels as input, has human-level apm and reaction speed, and is very clearly better than the best humans?
This question was intended to outline an AI that would satisfy almost anybody that Starcraft II is a solved game, such that AI is clearly better than humans, and not for “boring” reasons like superior speed. Most survey respondents expected to see such an agent in two-ish years, with a few a little longer, and two that expected it to take much longer. Respondents had a median prediction of two years and an expertise-weighted mean prediction of a little less than four years.
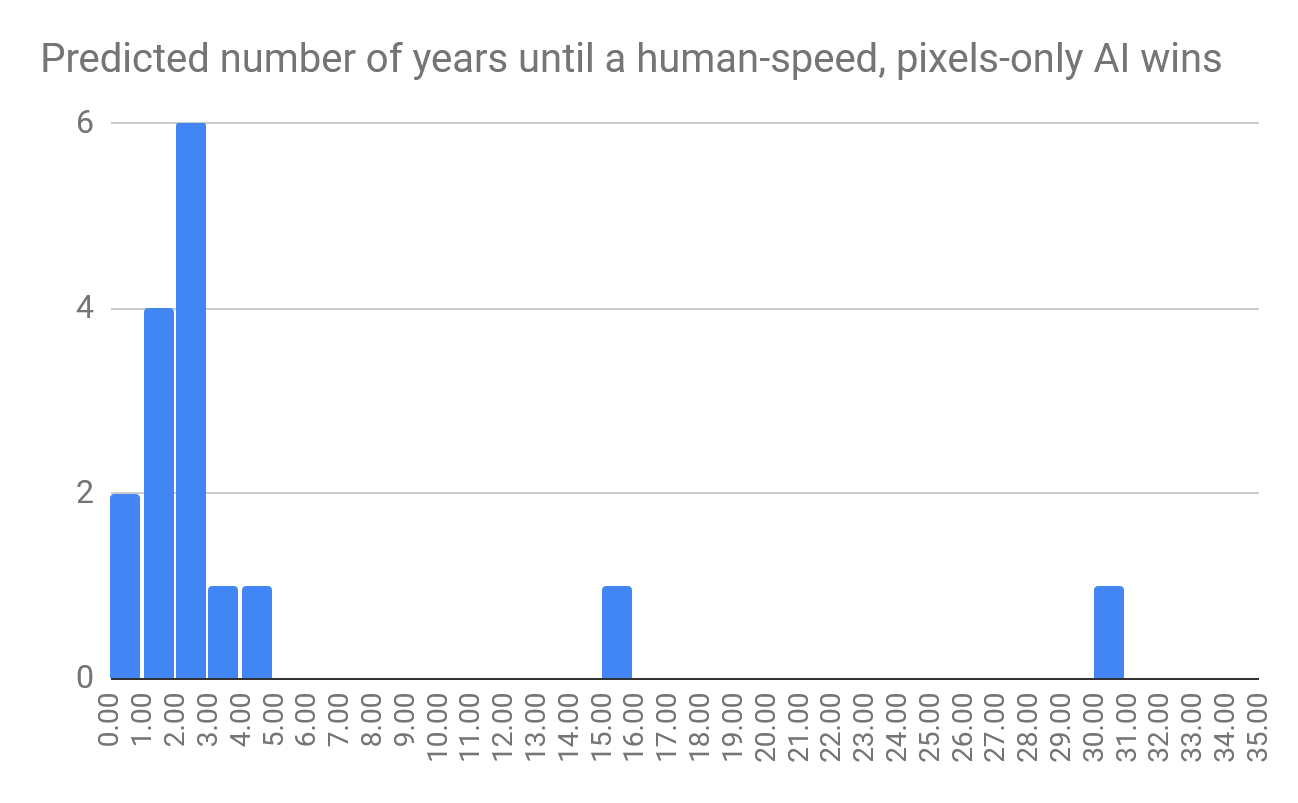
Questions About Relevant Considerations
How important do you think the following were in determining the outcome of the AlphaStar vs MaNa matches?
I listed 12 possible considerations to be rated in importance, from 1 to 5, with 1 being “not at all important” and 5 being “extremely important”. The expertise weighted mean for each question is given below:
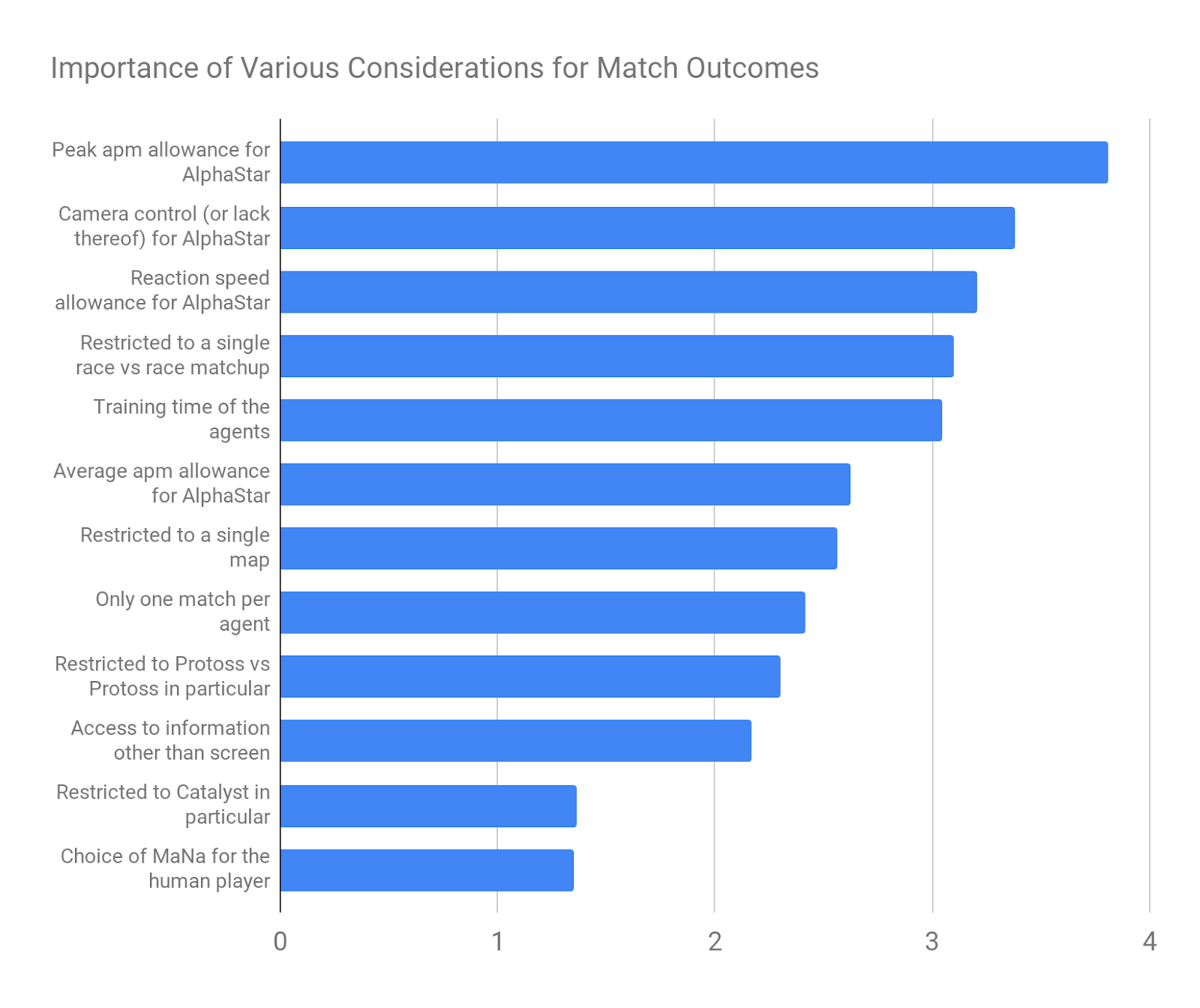
Respondents rated AlphaStar’s peak APM and camera control as the two most important factors in determining the outcome of the matches, and the particular choice of map and professional player as the two least important considerations.
When thinking about AlphaStar as a benchmark for AI progress in general, how important do you think the following considerations are?
Again, respondents rated a series of considerations by importance, this time for thinking about AlphaStar in a broader context. This included all of the considerations from the previous question, plus several others. Here are the results, again with expertise weighted averaging.
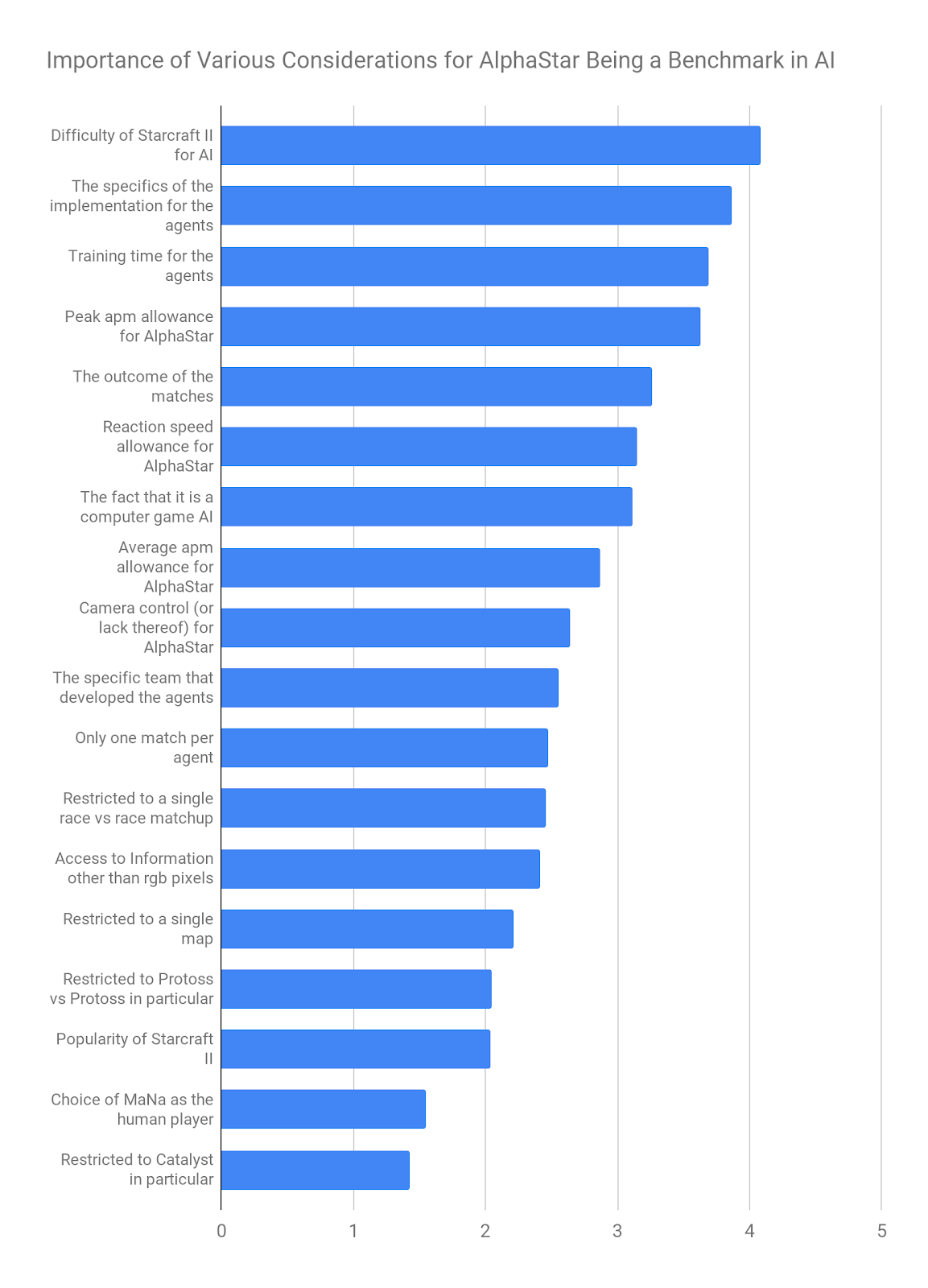
For these two sets of questions, there was almost no difference between the mean scores if I used only Starcraft II expertise weighting, only AI expertise weighting, or ignored expertise weighting entirely.
Further questions
The rest of the questions were free-form to give respondents a chance to tell me anything else that they thought was important. Although these answers were thoughtful and shaped my thinking about AlphaStar, especially early on in the project, I won’t summarize them here.
Appendix II: APM Measurement Methodology
I created a list of professional players by asking users of the Starcraft subreddit which players they thought were exceptionally fast. Replays including these players were found by searching Spawning Tool for replays from tournament matches which included at least one player from the list of fast players. This resulted in 51 replay files.
Several of the replay files were too old, so that they could no longer be opened by the current version of Starcraft II, and I ignored them. Others were ignored because they included players, race matchups, or maps that were already represented in other matches. Some were ignored because we did not get to them before we had collected what seemed to be enough data. This left 15 replays that made it into the analysis.
I opened each file using Scelight, and the time and APM values were recorded for the top three peaks on the graph of that player’s APM, using 5-second bins. Next, I opened the replay file in Starcraft II, and for each peak recorded earlier, we wrote down whether that player was primarily engaging in combat at the time or not. Additionally, I recorded the time and APM for each player for 2-4 5-second durations of the game in which the players were primarily engaged in combat.
All of the APM values which came from combat and from outside of combat were aggregated into the histogram shown in the ‘Speed Controversy’ section of this article.
There are several potential sources of bias or error in this:
Our method for choosing players and matches may be biased. We were seeking examples of humans playing with speed and precision, but it’s possible that by relying on input from a relatively small number of Reddit users (as well as some personal friends), we missed something.
This measurement relies entirely on my subjective evaluation of whether the players are mostly engaged in combat. I am not an expert on the game, and it seems likely that I missed some things, at least some of the time.
The tool I used for this seems to mismatch events in the game by a few seconds. Since I was using 5-second bins, and sometimes a player’s APM will change greatly between 5-second bins, it’s possible that this introduced a significant error.
The choice of 5 second bins (as opposed to something shorter or longer) is somewhat arbitrary, but it is what some people in the Starcraft community were using, so I’m using it here.
Some actions are excluded from the analysis automatically. These include camera updates, and this is probably a good thing, but I did not look carefully at the source code for the tool, so it may be doing something I don’t know about.
This was really useful at the time for helping me orient around the whole “how good are AIs at real-time strategy” thing at the time, and I think is still the post I would refer to the most (together with orthonormal’s post, which I also nominated).
It’s a really detailed analysis of this situation, and I think this sort of analysis probably generalizes to lots of cases of comparing ML to humans. I’m not confident though, and would update a bunch from a good review of this.