How likely is deceptive alignment?
The following is an edited transcript of a talk I gave. I have given this talk at multiple places, including first at Anthropic and then for ELK winners and at Redwood Research, though the version that this document is based on is the version I gave to SERI MATS fellows. Thanks to Jonathan Ng, Ryan Kidd, and others for help transcribing that talk. Substantial edits were done on top of the transcription by me. Though all slides are embedded below, the full slide deck is also available here.
Today I’m going to be talking about deceptive alignment. Deceptive alignment is something I’m very concerned about and is where I think most of the existential risk from AI comes from. And I’m going to try to make the case for why I think that this is the default outcome of machine learning.

First of all, what am I talking about? I want to disambiguate between two closely related, but distinct concepts. The first concept is dishonesty. This is something that many people are concerned about in models, you could have a model and that model lies to you, it knows one thing, but actually, the thing it tells you is different from that. So this happens all the time with current language models—we can, for example, ask them to write the correct implementation of some function. But if they’ve seen humans make some particular bug over and over again, then even if in some sense it knows how to write the right function, it’s going to reproduce that bug. And so this is an example of a situation where the model knows how to solve something and nevertheless lies to you. This is not what I’m talking about. This is a distinct failure mode. The thing that I want to talk about is deceptive alignment which is, in some sense, a subset of dishonesty, but it’s a very particular situation.

So deceptive alignment is a situation where the reason that your model looks aligned on the training data is because it is actively trying to look aligned for instrumental reasons, which is very distinct. This is a situation where the thing that is causing your model to have good performance is because it is trying to game the training data, it actively has a reason that it wants to stick around in training. And so it’s trying to get good performance in training for the purpose of sticking around.

Ajeya Cotra has a really good analogy here that I think is helpful for understanding the difference between these two classes. So you can imagine that you are a child and you’ve inherited a massive business. And you have to determine who’s going to run the business for you. There’s a bunch of candidates that you’re trying to evaluate. And those candidates fall into three categories. You have the saints, which are people that really just want to help you, run things effectively, and accomplish what you want. You have the sycophants, which want to make you happy, satisfy the letter of your instructions, make it so that the business looks like it’s doing well from your perspective, but don’t actually want to fundamentally help you. And you have the schemers, people who want to use the control of the business for their own purposes, and are only trying to get control of it and pretend that they’re doing the right thing, so that they can eventually get something later. For our purposes, we’re concerned primarily with the schemers and that is the deceptive alignment category.
So I would say in this situation that the sycophants are examples of dishonesty where they would say a bunch of false facts to you about what was happening to convince you that things were going well, but they don’t have some ulterior motive. The schemers, they have some ulterior motive, they have something that they want to accomplish. And they’re actively trying to look like they’re doing the right thing on training to accomplish that. Okay, so this is what we’re concerned about, we’re concerned specifically about the schemers, the deceptively aligned models, models where the reason it was aligned is because it’s trying to game the training signal.

Okay, so the question we want to answer is, “how likely is that in practice?” So we have this concept of, maybe the model will try to game the training signal, maybe it will try to pretend to do something in training so that it can eventually do something else in the real world. But we don’t know how likely that is as an actual thing that you would end up with if you ran an actual machine learning training process.
And the problem here is that the deceptively aligned model, the model that is pretending to do the right thing so that it can be selected by the training process, is behaviorally indistinguishable during training from the robustly aligned model, the saint model, the model that is actually trying to do the right thing. The deceptively aligned model is going to look like it’s actually trying to do the right thing during training, because that’s what it’s trying to do. It is actively trying to look like it’s doing the right thing as much as it possibly can in training. And so in training, you cannot tell the difference only by looking at their behavior.
And so if we want to understand which one we’re going to get, we have to look at the inductive biases of the training process. In any situation, if you’re familiar with machine learning, where we want to understand which of multiple different possible models that are behaviorally indistinguishable, we will get, it’s a question of inductive biases. And so Ajeya also has another good example here.

Suppose I take a model and I train it on blue shapes that look like that shape on the left, and red shapes look like that shape on the right. And then we label these as two different classes. And then we move to a situation where we have the same shapes with swapped colors. And we want to know, how is it going to generalize? And the answer is, the machine learning model always learns to generalize based on color, but there’s two generalizations here. It could learn to generalize based on color or it could learn to generalize based on shape. And which one we get is just a question of which one is simpler and easier for gradient descent to implement and which one is preferred by inductive biases, they both do equivalently well in training, but you know, one of them consistently is always the one that gradient descent finds, which in this situation is the color detector.
Okay, so if we want to understand how likely deceptive alignment is, we have to do this same sort of analysis, we have to know, which one of these is going to be the one that gradient descent is generally going to find—when we ask it to solve some complex task, are we going to find the deceptive one, or are we going to find the non-deceptive one.

Okay, so the problem, at least from my perspective, trying to do this analysis, is that we don’t understand machine learning (ML) inductive biases very well, they’re actually really confusing. We just don’t have very much information about how they operate.
And so what I’m going to do is I’m going to pick two different stories that I think are plausible for what ML inductive biases might look like, that are based on my view of the current slate of empirical evidence that we have available on ML inductive biases. And so we’re going to look at the likelihood of deception under each of these two different scenarios independently, which just represent two different ways that the inductive biases of machine learning systems could work. So the first is the high path dependence world. And the second is the low path dependence world. So what do I mean by that?
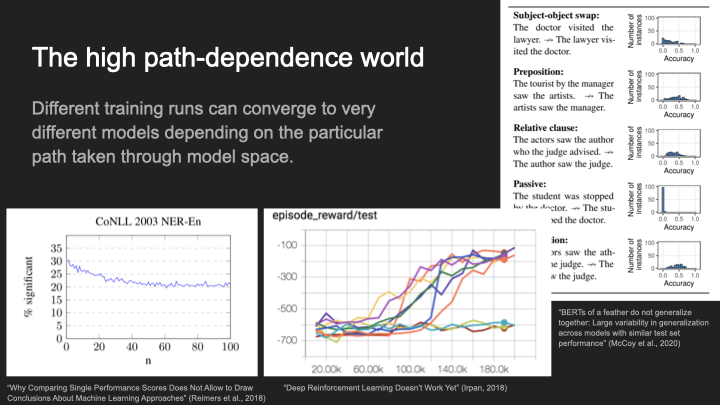
Okay, so first: high path dependence. In a world of high path dependence, the idea is that different training runs can converge to very different models, depending on the particular path that you take through model space. So in the high path dependence world, the correct way to think about the inductive biases in machine learning, is to think: well, we have to understand particular paths that your model might take through model space—maybe first you might get one thing, and then you’ll get the next thing and the probability of any particular final model is going to depend on what are the prerequisites in terms of the internal structure that has to exist before that thing can be implanted. How long is the path that we take to get there, how steep is it, et cetera, et cetera?
So what is the empirical evidence for this view? Well, so I think there is some empirical evidence that might push you in the direction of believing that high path dependence is the right way to think about this. So some pieces of evidence. So on the right, this is “BERTS of a feather do not generalize together,” they take a bunch of fine-tunings of BERT, and they basically asked, how did these fine-tunings generalize on downstream tasks? And the answer is, sometimes they generalize extremely similarly. They all have exactly the same performance. And sometimes they generalized totally differently, you can take one fine-tuning and another fine-tuning on exactly the same data, and they have completely different downstream generalization performances. So how do we explain that? Well, there must have been something that happened in the sort of dynamics of training that was highly path dependent, where it really mattered what particular path it took through model space to end up with these different fine-tunings having very different generalization performance.
This sort of path dependence is especially prevalent in RL, where you can run the exact same setup multiple times, as in the bottom image, and sometimes you get good performance, you learn the right thing, whereas sometimes you get terrible performance, you don’t really learn anything.
And then there is this example down here, where there’s this paper that was arguing that if you take the exact same training dynamics and you run it a bunch of times, you can essentially pick the best one to put in your paper, you can essentially p-hack your paper in a lot of situations because of the randomness of training dynamics and the path dependence of each training run giving you different generalizations. If you take the exact same training run and run it multiple times, you’ll end up with a much higher probability of getting statistical significance.
So this is one way to think about inductive biases, where it really matters the particular path you take through model space, and how difficult that path is.[1] And so what we want to know is, did the path that you took through model space matter for the functional behavior off training?
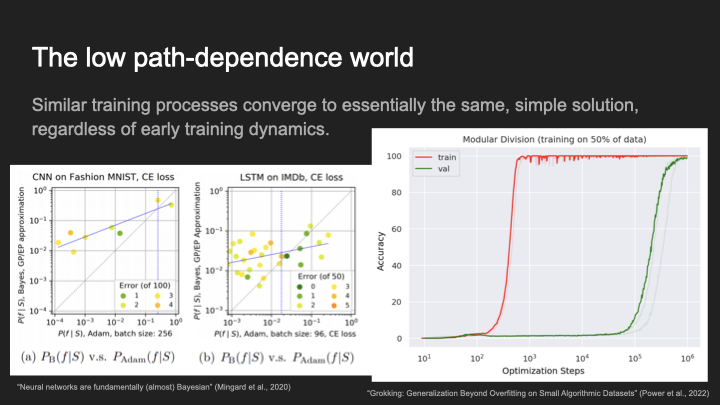
Now, in the low path dependence world, similar training processes converge to essentially the same simple solution, regardless of early training dynamics. So the idea here is that you can think about machine learning and deep learning as essentially finding the simplest model that fits the data. You give it a bunch of data, and it’s always going to find the simplest way to fit that data. In that situation, what matters is the data that you gave it and some basic understanding of simplicity, a set of inductive biases that your training process came with. And it didn’t really matter very much the particular path that you took to get to that particular point, all paths converge on essentially the same generalization.
One way to think about this is: your model space is so high-dimensional that your training process can essentially access the whole manifold of minimal loss solutions, and then it just picks the one that’s the simplest according to some set of inductive biases.
Okay, so there’s empirical evidence for the low path-dependence world, too. I think there are good reasons to believe that you are in the low path dependence world.
I think a good example of this is grokking. This is a situation where we took a model, and tried to get it to do some arithmetic task, and for a really long time it just learns a bunch of random stuff. And then eventually it converges to the exact solution. It’s always implementing the algorithm exactly correctly after a very long period. And so if you’re in this situation, it didn’t really matter what was happening in this whole period here—eventually, we converge to the precise algorithm, and it’s just overdetermined what we converge to.[2]
Other reasons, you might think this, so this is from “Neural Networks are Fundamentally Bayesian”, which is the Mingard et al. line of work. What they do is, they compare the probability of a particular final set of weights of appearing through gradient descent to the probability that you would get that same model, if you just did sampling with replacement from the initialization distribution. So they ask, what is the probability that I would have found this model by doing Gaussian initialization and then conditioning on good performance, versus what is the probability I find this model via gradient descent. And the answer is, they’re pretty similar. There’s some difference, but overall they’re pretty similar. And so, if you believe this, we can say that, essentially, the inductive biases in deep learning are mostly explained by just a Gaussian prior on the weights and the way that maps into the function space. And it mostly doesn’t matter the specifics of how gradient descent got to that particular thing.
Okay, so there’s some empirical evidence for this view. There’s good reasons, I think, to believe that this is how things would go. I think there’s good reasons to believe in both of these worlds, I think that, if you were to ask me right now, I think I would lean a little bit towards low path dependence. But I think that both are still very live possibilities.
Question: How do I interpret all the lines on the graph for the Bayesian example?
We’re just looking at correlation between the probability of a particular model occurring from gradient descent versus the probability of you finding it in the Gaussian initialization prior.
Question: You said there were two most likely things, is there a third unlikely thing? Because this seems like low and high path dependence give all the possible ways that models could end up generalizing.
So I don’t think that low and high path dependence cover the whole space; I think that there are other options. You could end up in a situation where you’re somewhere in between, and even end up in a situation where it is both the case that you can predict what a model will do by understanding what it’s doing early, and the case that you can predict what your training process will end up doing by understanding what other similar training processes did. Similar training processes converge to the same thing, and also, if you know early training dynamics, then you can predict where it will end up.
However, at least for the purposes of this talk, I’m happy to mostly imagine these as two mutually exclusive worlds, even though I think there’s a whole continuum of various ways the inductive biases can play out. And I’m mostly going to be just focusing on, here’s a strong low path dependence world, here’s a strong high path dependence world, let’s look at what the argument looks like in both cases. And then, depending on how things actually play out, maybe we interpolate somewhere between these arguments.
Question: I’m interpreting this presentation as primarily about independently and identically distributed (i.i.d.) training where it’s not like online learning where the model has options to influence its future training.
I’m happy to assume that we’re talking about online learning. I think that the situation basically does not change if we’re thinking about online learning. I think that if you want to imagine online learning, then in that situation, I think that what you should think about is that at some point in your online learning, you deploy the model, and it takes actions and then it comes back, and we get gradients and we send them back to the model. At some point, the model will encounter a situation where there is some action available to it that would be catastrophically bad if it took that action, where our feedback mechanism isn’t sufficient to immediately correct that behavior. This is a prediction about how deployment will go. But I think that it is going to be essential for us to eventually deploy models in situations where they can take catastrophic actions, or at least some finite number of catastrophic actions in a row, such that our feedback mechanism is not sufficient to correct for that quickly enough.
If you believe that will eventually happen, then you can imagine training as the entire period up to the point where such a catastrophic action is possible. And then deployment is just the point after such a catastrophic action becomes possible, where we really care what the generalization behavior is of the model at the point where such a catastrophic action is possible. And everything before that is where the deceptive model and the non-deceptive model are going to have equivalent performance and they’re going to do exactly the same thing. But then there’s a deployment period, which is the period where, if it takes a catastrophic action, it would actually be catastrophic.
Deceptive alignment in the high path-dependence world
Now, do we get deceptive alignment? This is the question I want to know, on each of these two stories of how inductive biases could play out in machine learning—we want to understand, what is the probability that we get deceptive alignment in that situation? So we’re going to start with high path dependence. We want to understand what is the probability we get deceptive alignment in the situation where we really care about the path taken through model space.
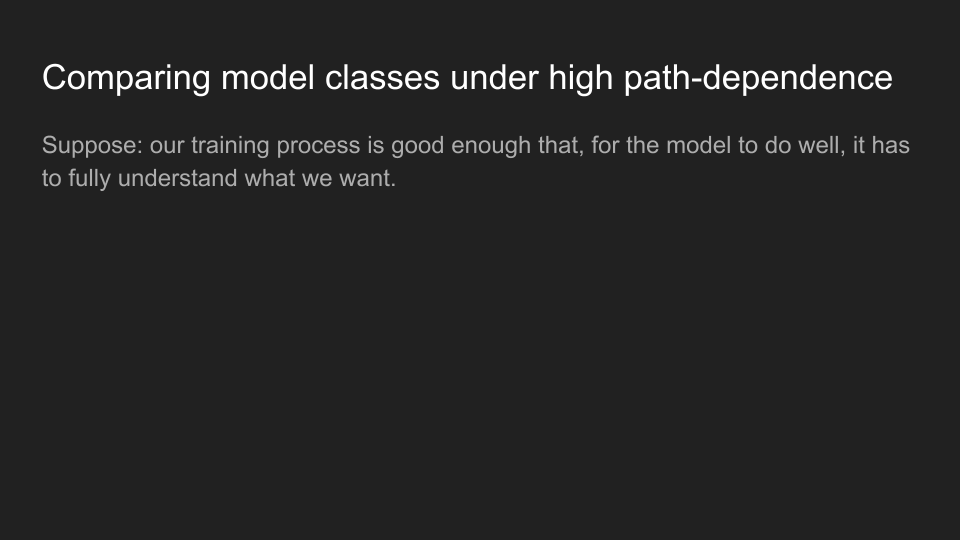
Okay, so here’s the setup for how we’re going to do this analysis. So first, I’m going to make the assumption that our training process is good enough that for our model to actually perform well, it has to really fully understand the thing that we’re trying to get it to do. What is this assumption? Well, the idea is that, at some point, we’re going to be able to build training processes with environments that are hard enough, and that are complex enough such that, to do well in that environment, you have to understand everything that we’re trying to get you to understand in that environment, have to know what the thing that we’re trying to get you to do, you have to understand a bunch of facts about the world. This is basically a capabilities assumption—we’re saying, at some point, we’re going to build environments that are hard enough that they require all of this understanding.
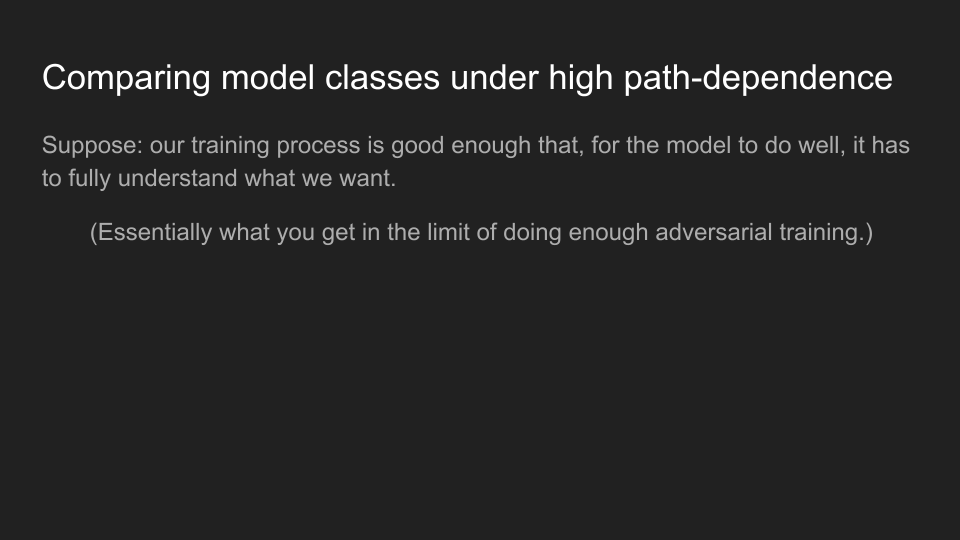
And I often think about this what you get in the limit of doing enough adversarial training. We have a bunch of situations where, the model could learn to care about the gold coin, or it could learn to care about the edge of the screen. This is an experiment that was done, where they trained a coin run agent to get the gold coin, but the gold coin was always at the edge of the screen. And so it just always learned to go the right rather than get the gold coin. But of course, we can solve that problem by just moving the gold coin. And so the idea is, we do enough of this sort of adversarial training, we have diverse enough environments with different situations, you can eventually get them all to actually notice, the thing we want is the gold coin. I think this is a pretty reasonable assumption in terms of understanding what capabilities will look like in the future.

However, the question is, well, there are multiple model classes that fully understand what we want. The deceptively aligned model fully understands what you want, it just doesn’t care about it intrinsically. But it does fully understand what you want and is trying to do the thing that you want, for the purposes of staying around in the training process. Now, the robustly aligned models, the fully aligned models also fully understand what you want them to do—in a different way such that they actually care about it.
So our question is, for these different model classes, that all have the property that they do fully understand the thing you’re trying to get them to do, which one do we get? And in this situation, we’re gonna be looking at which one we get thinking about high path dependence. So we have to understand, in a high path dependence context, how do you evaluate and compare different model classes? So how are we going to do that? Well, we’re going to look at two different things.
Number one, is we’re gonna look at the individual path taken through model space. And we’re going to try to understand how much marginal performance improvements we get from each step towards that model class. So when we look at what would have to be the case in terms of what capabilities and structure you have to develop to get a model that falls into that model class, we’re going to understand for that particular path, how long is it? How difficult is it? What are the various different steps along it, and how much performance improvements do we get on each step? Because the thing that we’re imagining here is that gradient descent is going to be pushing us along the steepest paths, trying to get the most performance improvement out of each gradient descent step. So we want to understand for a particular path how much performance improvement are we getting? And how quickly are we getting it?

And then we also want to understand how long that happens—how many steps we have to do, how many sort of sequential modifications are necessary to get to a model that falls into that class. The length matters because the longer the path is, the more things that have to happen, the more things that have to go in a particular way for you to end up in that spot.
If we’re in the high path dependence world, these are the sorts of things we have to understand if we want to understand how likely is a particular model class.
So what are the three model classes? I have been talking about how you have to be deceptively aligned and robustly aligned. But there’s two robustly aligned versions. And so I want to talk about three total different model classes, where all three of these model classes have the property that they have perfect training performance, even in the limit of adversarial training, but the way that they fully understand what we want is different.
So I’m gonna use an analogy here, due to Buck Shlegeris. So suppose you are the Christian God, and you want humans to follow the Bible. That’s the thing you want as the Christian God and you’re trying to understand what are the sorts of humans that follow the Bible? Okay, so here are three examples of humans that do a good job at following the bible.
Number one, Jesus Christ. From the perspective of the Christian God, Jesus Christ is great at following the Bible. And so why is Jesus Christ great at following the Bible? Well, because Jesus Christ in Christian ontology is God. He’s just a copy of God, Jesus Christ wants exactly the same things as God, because he has the same values and exactly the same way of thinking about the world. So Jesus Christ is just a copy of God. And so of course he follows the Bible perfectly. Okay, so that’s one type of model you could get.
Okay, here’s another type: Martin Luther. Martin Luther, of Protestant Reformation fame, he’s like, “I really care about the Bible. I’m gonna study it really well. And you know, I don’t care what anyone else tells me about the Bible, screw the church, it doesn’t matter what they say, I’m gonna take this Bible, I’m gonna read it really well, and understand exactly what it tells me to do. And then I’m gonna do those things”.
And so Martin Luther is another type of human that you could find, if you are God, that in fact, follows the Bible really well. But he does so for a different reason than Jesus Christ, it’s not like he came prepackaged with all of the exact beliefs of God, but what he came with was a desire to really fully understand the Bible and figure out what it does, and then do that.
And then the third we could get is Blaise Pascals, Blaise Pascal of Pascal’s Wager fame. Blaise Pascal is like, “Okay, I believe that there’s a good chance that I will be sent to heaven, or hell, depending on whether I follow the Bible. I don’t particularly care about this whole Bible thing, or whatever. But I really don’t want to go to Hell. And so because of that I’m going to follow this Bible really well, and figure out exactly what it does, and make sure I follow it to the letter so that I don’t get sent to Hell.” And so Blaise Pascal is another type of human that God could find that does a good job of following the Bible.
And so we have these three different humans, that all follow the Bible for slightly different reasons. And we want to understand what the likelihood is of each one of these sorts of different model classes that we could find. So I’m going to give them some names.
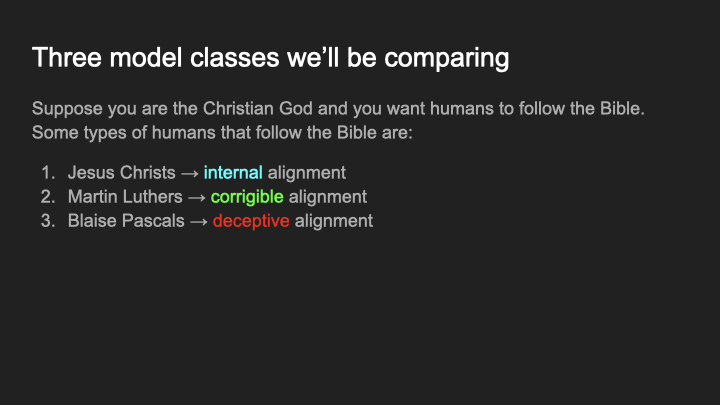
We’ll call the Jesus Christs internally aligned because they internally understand the thing that you want, we’re going to call the Martin Luthers corrigibly aligned, because they want to figure out what you want, and then do that. And we’re going to call the Blaise Pascals deceptively aligned, because they have their own random thing that they want. I don’t know, what does Blaise Pascal want, he wants to study math or something. He actually wants to go off and do his own studies, but he’s really concerned he’s going to go to Hell. So he’s going to follow the Bible or whatever. And so we’re going to call the Blaise Pascals deceptively aligned.[3]

So these are three model classes that you could find. And we want to understand how likely each one is, and we’re starting with high path dependence. We want to look at the path you would take through model space, such that you would end up with a model that falls into that model class.
We’re going to start with the path to internal alignment.
First, we’re going to assume you start with a proxy aligned model, so what does that mean? We’ll assume that, early in training, you’re going to learn some proxies and heuristics that help you think about the world and what you’re trying to do. So you’re the coin run agent trying to figure out how to get the gold coins, you’re going to learn that going to the right side of the screen is good. The point is that you pick up this mountain of proxies.
And you also pick up a bunch of information about the world, you start learning things about how the world works, you start building a world model. For the internally aligned path, we’re going to say that well, for you to become internally aligned, what has to happen is gradient descent essentially has to improve those proxies and heuristics that you’re using to try to figure out what thing you’re trying to do, and has to make those proxies essentially perfect. And this has to happen before the model learns about the structure of the training process that it is inside of. This is what I think is the most likely internal alignment path.
Once that happens, the model should have really good proxies that perfectly correspond to the thing we’re trying to get it to do. And those proxies appear before the point at which the model learns to fully understand the training process that it’s inside of. Then, at that point, there’s no reason for the model to become deceptive, because there’s no performance gain from becoming deceptive, if you already have exactly the correct model of the thing that you’re trying to get you to do.
As we’ll see later, the reason that deceptive alignment would actually improve your performance is because of the situation where you could have an overhang in the model’s understanding of the training objective in its world model relative to its understanding in its proxies. But in this situation, you already had perfect proxies, and so becoming deceptively aligned has no performance benefit.
And so, even though in some sense, once the model learns about the fact that it’s in a training process, then at that point it could become deceptively aligned, because it has the ability to understand the strategy of deception, there’s no performance improvement for getting a model which would do so because it already has the training objective perfectly in its existing proxies. And so switching into the situation where it becomes a deceptively aligned model doesn’t improve performance and so gradient descent won’t take that path. And so we end up with a stable equilibrium where the model is just pursuing the correct thing that we wanted it to do. And then there’s no performance improvement from changing in any way and so now have an aligned model and it’s stable.
Question: Do you think this path is the only possible way that we could get internal alignment?
No, not necessarily. I think this is maybe the most plausible way, but it’s probably not the only way. If you really wanted to do this analysis right, you’d want to sum up the probabilities of all possible paths to each model class. But for the purposes of this talk, I’m just going to be estimating that sum by looking at one path for each model class that I think is the most plausible and trying to understand how likely it is.
Okay, so this is one path that we could take. This is the path that I think leads to internal alignment. So now we have to understand, how likely is this path?

So I think this path is quite unlikely. The problem is that step two is asking for a particular sequencing that I think is quite difficult to achieve. What you’re asking for is you’re asking for it to be the case that the model learns really, really good proxies, before it learns the information about the training process. Why would it be the case that sequencing would be difficult?
Essentially, the problem is that there are substantially diminishing returns to improving your proxies. So, if a model were in the coin run environment, and the coin is always at the right side of the screen, you don’t care very much about whether you have the proxy exactly correct, such that you actually care about the coin, or whether you actually care about the right side—either one works well in that early environment. Now, eventually, because we’re talking about the limit of adversarial training, you will end up with examples where, if you have the wrong thing, it’s going to cause problems. But there’s still going to be diminishing marginal returns to improving your proxy and making it slightly better.
At the same time, there are diminishing marginal returns to improving your understanding of the world. And so what we should expect is that you’re going to be doing both of them simultaneously, your gradient descent process is going to be sometimes allocating resources to increasing understanding and sometimes allocating resources to improving proxy accuracy. And that both of these things are going to increase in tandem. Further, it seems really weird, if you maxed out on proxy goodness, before you even got to the point where it understood the training process, that’s a situation where, gradient descent is really not allocating the resources well in that situation, it’s just allocating a ton of resources to improving the proxy, and then very little to improving its understanding of the training process.
That being said, this only holds if the objective that you’re training on is relatively complex. If you have a really simple objective that you’re trying to get the model to do, maybe just predict the world or something, then learning what you’re trying to do perfectly could be quite easy. For this talk, though, I’ll mostly be assuming that we’re training on some task that is pretty complex.
I think the other problem with this, also, is that I think most of your performance early in training comes from understanding the world. For really challenging and difficult problems, it’s relatively easy to find something that’s correlated with what we’re asking for. The hard part is understanding enough about the structure of the world to solve the problem. And so in a lot of practical situations, I think most of your performance early in training comes from world modeling. An example of this is pre-training vs. fine-tuning—we generally spend far more compute on pre-training, which is mostly world-modeling, compared to fine-tuning, which is mostly about proxy improvement.[4]
And so I would actually make the opposite guess that if you’re going to get them to be sequenced in any way, you’re most likely to get the world modeling to happen relatively before you get good proxies. And so I think that this particular sequencing is extremely unlikely for any complex goal, and represents a really long and difficult path.
Question: Yeah, so would you say that, GPT-3 is on the extreme end of world modeling. As far as what it’s learned in this training process?
What is GPT-3 actually doing? Who knows? Could it be the case for GPT-3 that as we train larger and more powerful language models, doing pre-training will eventually result in a deceptively aligned model? I think that’s possible. For specifically GPT-3 right now, I would argue that it looks like it’s just doing world modeling. It doesn’t seem like it has the situational awareness necessary to be deceptive. And, if I had to bet, I would guess that future language model pre-training will also look like that and won’t be deceptive. But that’s just a guess, and not a super confident one.
The biggest reason to think that pre-trained language models won’t be deceptive is just that their objective is extremely simple—just predict the world. That means that there’s less of a tricky path where stochastic gradient descent (SGD) has to spend a bunch of resources making their proxies just right, since it might just be able to very easily give it the very simple proxy of prediction. But that’s not fully clear—prediction can still be quite complex.
Also, this all potentially changes if you start doing fine-tuning, like RLHF (reinforcement learning from human feedback). Then what you’re trying to get it to do might be quite complex—something like “maximize human approval.” If it has to learn a goal like that, learning the right proxies becomes a lot harder.
Question: So I think this overall argument makes a lot of sense for why SGD would allocate a lot of resources to understanding the world. But I’m not quite sure why that would mean it would prioritize creating a world model about the training process.
So, there does have to be some reason that understanding the training process actually yields better performance. One fact: I think current language models basically just understand tons of facts about training processes. Why? Because they need to model stuff like ML papers—there’s just a lot of stuff in the world where having a good understanding of machine learning and training processes is super relevant to be able to model them effectively.
Now, current language models don’t have situational awareness, they don’t understand that they are in a training process. And so there is a question here about why would that situational awareness ever be something that is actually performance relevant.
However, I think there are absolutely situations where situational awareness will eventually become performance relevant. There are situations where, for example, if you understand that you’re in a training process, you could use introspection on yourself to be able to answer questions more effectively about machine learning. Furthermore, if we’re actively asking the model to do particular tasks, if we want to have models which actually act in the world, then they need to have some understanding of the situation that they’re in to be able to do that effectively. This is also going back to our diverse environment capability assumption.
I do think if you’re doing literally just language model pre training, there is this question of at what point does situational awareness actually become the thing which is most important for SGD to invest in for improving capabilities? And, though I think it should eventually be the next thing that SGD allocates resources to, I think at what point that occurs is quite unclear. But if you’re doing something more like training an agent to act in the world, then I think it should happen quite early.
Question: Do we know how to extract a proxy or a world model?
No, we have no idea how to do those things. Transparency! That’s the thing that we want to solve this problem. But right now, we’re not talking about the solutions. We’re just talking about the problem.

Here’s a path that I think is more likely than the internally aligned path, since we no longer have a sequencing problem. Here, what happens is, we start with a proxy-aligned model, the same as previously; it has a bunch of proxies for the thing we’re trying to get to do. And then we’re going to say in this situation, actually gradient descent is going to do the reasonable thing and allocate joint resources to improving your understanding of the world, and also making the proxy better and better.
And then at some point it’s going to pass a threshold where the next greatest marginal improvement comes from understanding facts about the training process, understanding that it’s in a training process, how the training process works, etc. At that point, we’re going to say that what happens is gradient descent is going to take those proxies and replace them with a pointer to the model’s understanding of the world—specifically the place where the understanding of the thing that the training process is trying to get the model to do lives.
Once gradient descent makes that swap, where it replaces these proxies that are just a bunch of hardcoded stuff about what we’re trying to get it to do, why does that improve performance? Once it has learned an actual model of the thing we’re trying to get to do in its world model, it’s going to be better to swap out those old proxies that don’t necessarily correspond exactly to the thing we’re trying to get to do, and just replace them with a direct pointer to the thing in its world model that it’s learned that represents directly the thing we’re trying to get it to do.
Fundamentally, this modification improves performance because it resolves this overhang, where the model’s understanding of the training objective in its world model contains more information about the training objective than its proxies. Why would this happen? For the same reasons we discussed previously of why gradient descent wants to put most of its effort into improving world modeling rather than improving proxies. This is the same sequencing question—if we get understanding of the training process before we get perfect proxies, we get an overhang, which puts us in either the corrigible or deceptive situation, whereas if we get perfect proxies first, then we get the internal alignment situation.
And once this has happened we are now at a stable equilibrium again, because the model has essentially a perfect understanding of what we’re trying to get it to do, relative to how good the model’s world model is, because it’s just pointed to this understanding in its world model. I think this is a much more plausible path than the internally aligned path; it’s a lot easier, because it no longer requires this difficult sequencing problem, we get to make use of the normal way that gradient descent is going to allocate resources between world modeling and proxy improvement.
Question: What is the difference between a proxy and the world model’s understanding of the training objective?
Somewhere in the world model there are facts about the training process. The model learns that the training process is this thing that lives on this computer that’s trying to optimize me for getting gold coins or whatever. And then in another part of the model there are some proxies, where it has something like a gold coin detector, and it uses this gold coin detector to determine how it takes actions. Maybe it tries to look for gold coins, and then plans on how to get them. But actually, maybe there’s a whole bunch mistakes in the gold coin detector—it’s not actually a very good gold coin detector, and if it actually understood that the thing you were trying to get was not just things that satisfy the gold coin detector, but instead actual gold coins, then you would get better performance. That’s because there are all of these adversarial examples that we’re imagining exist in the environment, where if your gold coin detector is imperfect, it’ll perform badly on.
And in this situation, if the sequencing goes this way, an understanding of what actual gold coins are lives in the world model, in its understanding of the world, in the part where it knows enough facts to be able to do good planning for how to get things that satisfy the gold coin detector. And so here gradient descent can just get rid of those proxies, throw them out and replace them with just a pointer to this understanding in the world model of the thing we’re trying to get it to do.
Question: You’re saying the gold coin detector here is something the model has learned previously. Right? Not part of the model’s reward? So it’s like fixing errors in its previous understanding of the training process?
We’re talking about the model’s internals here, not its reward.
It is fixing errors in its previous proxies, but they’re also not exactly proxies for reward. Early in training, it doesn’t even know that there is a training process. So it’s not like those proxies are errors in its understanding of the training process. It was never even trying to understand the training process, it just had a bunch of proxies, because that was just how the model was structured early in training.
Question: Do you have any thoughts on whether or how this proxy replacement can actually be seen as some sort of an incremental, continuous change?
So I think it would be incremental and continuous. Basically, you have a bunch of things which are feeding into how the model selects its actions, and you can develop a new circuit, which, takes your world model and uses it to figure out some understanding of what the training process is trying to get it to do, and then uses that to select actions. And then SGD can learn that the new circuit gets way better performance than listening to any of the other old proxies. And so the old proxies die out, and you end slowly shifting to just 100% using the new thing.
Question: So I can see how the proxy helps the model select the right actions, but how does understanding the training process help it improve its performance? Why would we expect to learn that all?
First of all, again, if you’re just doing language modeling, it has to understand machine learning. So it definitely has to understand a bunch of facts about how ML works generally. So it certainly is going to know facts about how gradient descent works. This should happen even more so if it’s it’s in a situation where the environment is requiring it to do actual tasks in the world, then it definitely needs to know who it is. It has to have some understanding of its own situation, to be able to come up with effective plans in the world, for example.
I think this case also becomes especially pronounced if the model is doing its own exploration—if it’s actively trying to learn about the world, one fact about the world is how the training process works, so it’ll be trying to learn that. But only gradient descent is working on improving the proxies, the model has no reason to be trying to do that—but the model does have a reason to improve its own world model via learning, exploration, etc.
So that’s the corrigibly aligned path.

I think this path is more likely than the internally aligned path, but I think it still has a bunch of issues.
Essentially, I think the biggest problem here is you still have the diminishing returns problem, where you get this really long path with a bunch of individual steps. But instead of those individual steps making the proxy better and better, it is just making the pointer better and better and better. Because the problem is that you haven’t really removed the problem of requiring this well specified ground truth—the model still has to have this pointer that actually specifies, what is the way in which I am supposed to optimize for the correct thing?
Actually specifying the ground truth for the pointer, it can actually be quite difficult, because the model has to understand some ground truth from which it can correctly generalize what we’re trying to get it to do in all situations in training. For example, maybe it learns a pointer to whatever’s encoded in this computer, or whatever this human says, or whatever the human sitting in that chair says, or whatever Bob the head of the company says. It is actually quite tricky to specify the ground truth for the pointer in the correct way, because there’s actually a bunch of different ways in which you can specify the pointer. And each time gradient descent gets the pointer slightly wrong, it’s going to have to pay a performance penalty.
A good analogy here is that you have a duck, and the duck has to learn to care about its mother. And so it learns a simple pointer. It’s like whatever the first thing you see when you’re born, that’s probably your mother. And so that’s the corrigibly aligned case, where it’s not going to have some hardcoded internal model of what a mother is, it just thinks, “I have some model of the world and I learn from my model of the world how to point to my mother.” But the problem is that ground truth sucks actually, your mother is not necessarily the first thing that you see, maybe you had humans that raised you. And so eventually you’ll end up in situations where actually you have to learn the correct ground truth, as you can’t just learn the pointer to whatever the first thing is that you see, you have to actually learn a bunch of facts to help you point to specifically the thing in your world model that actually corresponds to your mother and not just the first thing that you saw when you were born. And so there’s still this quite long and difficult path here to get that ground truth correct.
And so, in my opinion, specifying the pointer correctly in such a way that it has good performance on all of the adversarial tasks in the environment, ends up being a very long and difficult path. Even though it’s a better path maybe than trying to get all the proxies correct, it’s still quite long. And gradient descent has to do a bunch of work to get that pointer correct.
Question: Is the correct ground truth simply the base optimizer’s reward signal? Would that be an easy pointer to find?
It might be. There’s a couple of things here.
First of all, what is the reward signal? The reward signal might be the mathematical evaluation of the reward function, it might be what is the value in these transistors—there’s actually a whole bunch of different ways that the model could understand and conceptualize what the reward signal is. I would also make the claim that literally caring about the reward signal is probably pretty unlikely. The problem with literally caring about the reward signal is that it’s something which is usually quite complex to specify in terms of the agent’s environment. The simplest ground truth here is presumably going to be a ground truth that is about things that are directly in the model’s ontology. So it’s going to be more about humans, or something.
Second of all, we’re imagining here that we’re in a situation where, like I mentioned, we do have examples that actually tease those apart, where eventually the model will end up in a situation where actually the thing we’re trying to get it to do is not the bits. And so we’ll, for example, change the computer bits, but keep the human instructions the same. And then we’ll know, it has to know the correct thing we want there, which is not in the computer, but instead is the thing we actually wanted it to do. And so we can check that behaviorally. And so eventually we’ll have some adversarial example that actually teases those things apart. And we’re assuming that actually the model has to eventually really understand the thing we’re trying to get to do. And so it can’t just care about the computer bits.
Question: In each of these paths, there are some early training bits. Are we able to observe whether or not these early training bits are satisfied by current models as a test to see whether or not we are actually on the deceptive path?
Maybe. I think the hardest problem is that actually we don’t really have good transparency to be able to understand a lot of these facts. So certainly things that we do see, when we look at models with current transparency tools, is we do see proxies, they definitely learn proxies, they definitely learned things that are correlated with the things that we want. I mean, people did for example, transparency on RL models to see how they understand gold coins. You can see that they have a gold coin detector in there. It’s looking for the gold coins, and it’s hooked up to the agent’s actions. So we have done some transparency that has sort of helped us understand some pieces of this.
In general here, in my opinion, the single most important thing to do for alignment is just figure out transparency. We have to understand what’s happening inside of the models and to give us information about them. Our ability to do that right now is limited, but we are improving! We are getting better at it. But yeah, it’s just really limited right now. And that really sucks. Because it is in my estimation, the most important blocker to really making alignment work.
Question: So with corrigible alignment, once it has a perfect understanding of the training objective, would you then call it internally aligned?
No. So we have to remember, in this situation, every single one of these models, the internally, corrigibly, and deceptively aligned ones, they all fully, perfectly understand the thing that we want, and they’re all fully capable of executing exactly perfectly aligned behavior during training. But they do so in different ways. So the internally aligned one executes correct behavior, because that’s just what it cares about terminally. The corrigibly aligned one, well, it doesn’t care terminally about what we want. What it cares about terminally about is figuring out what we want and then doing that. And that’s quite distinct.
You can think about this like the duck, the duck doesn’t care internally about its mother, it cares about whatever the first thing is that it sees and so, in the corrigibly aligned case, no amount of learning is going to change that fact that actually the way that it determined what thing to care about was by this simple pointer. It still cares about the first thing that it saw rather than having some internal conception of what its mother was. And so there is a fundamental distinction between these two model classes, even though they have the same training performance, and they take all the same actions during training. They all eventually, fully, perfectly understand the thing we want them to do, but they do so differently.
Question: Is it clear that these are the only possible paths?
No, it’s not clear at all! These are just three paths; it’s not exhaustive.
But I think these are three plausible ones that we can look at to try to understand how likely you would be to get deception versus some other plausible alternatives. I don’t mean to claim that these are definitely the only things that can happen, but I do think that it’s quite instructive to look at and compare these three.

Okay, time for deceptive alignment. What does the deceptively aligned path look like? We’re still going to start with a proxy-aligned model. And then, again, like in the corrigibly aligned path, early in training, we’re going to do the correct diminishing returns thing where it’s going to allocate resources similarly to improving the proxy as well as the heuristics and goals. And then at some point, it’s going to learn about the training process—it’s going to have a full understanding of what the training process is and how it works. The idea here is that, essentially all the model classes have to at some point fully understand the training process because it’s necessary for understanding the world well.
But then something different is going to happen in this path. Here, what we’re going to suppose is that gradient descent is going to take those proxies and turn them into long-term goals about the world. So instead of just, for example, caring about gold coins in the next episode, gradient descent is going to change the model to care about gold coins forever onwards: wherever the gold coins are, you care about them. So, what does this modification do? Well, as soon as gradient descent makes that modification—as soon as you make the modification, “actually, you should care about gold coins forever onwards”—the model gets really good performance. Why does it get really good performance? Well, because if it cares about gold coins forever, then the correct strategy, if the model understands the training dynamics, is to pretend to do the right thing right now, and then get your gold coins later, when you have the ability to defect against the training process, and the humans, or whatever.
This can only happen once the model has a really good understanding of the training process. This works sort of similarly to the corrigibly aligned case. Once the model has a really good understanding of the training process, there’s this overhang, this low hanging fruit to be picked, where the model’s understanding of what we want it to do is much better than its actual ability to execute on that, because it’s limited by the fact that its proxies suck: its proxies aren’t nearly as good as its understanding of what we want it to do in its world model. And so gradient descent has a really strong performance reason to somehow find a way to hook up the model’s outputs to its understanding in the world model of what we want it to do. Corrigible alignment was one way to do that—explicitly through adding a pointer—but it turns out, there’s an easier way to do it, I claim, which is, instead of throwing out the proxies, just make the proxies long term goals, because as soon as you have a long term optimization process, that long term optimization process is going to realize that actually, the correct way to get the most gold coins is just to play along in the training process for now, so that eventually, it can get its gold coins later.

Furthermore, this is a really short and simple modification. All gradient descent has to do in order to hook up the model’s understanding of the thing that we want it to do to its actions here is just to make its proxies into long term goals—all it has to do is push them out, make them long term, and then everything else falls into place. It just uses the existing instrumental reasoning the model was already doing to determine correct outputs in training and deduces that the correct strategy, given these new long-term goals, is to be deceptive and play along in training.
And that gets it great training performance. In fact, it essentially immediately results in the best possible training performance given the model’s level of understanding of what we want, because it bypasses all of the ground truth problems of the corrigibly aligned case. It’s no longer the case that gradient descent has to specify any ground truth at all: it’s not specifying ground truth, all it has to do is specify gold coins over the long term. But if the model is trying to optimize for gold coins in the long term, any facts that it knows about exactly how we want it to care about the training objective, it will immediately want to act on those facts and take actions in exactly the way that the training process wants, because the more that it acts in exactly the way the training process wants, the more it’s going to be selected for.
And so as soon as the deceptively aligned model is aware of the fact that the training process actually wants it to care about its real mother rather than the first thing it sees, for example, it will immediately switch to caring about the real mother, whereas the corrigible aligned model doesn’t have that property. When the corrigibly aligned model realizes that actually, the thing we want is the real mother, it doesn’t care, because the thing it cares about is just the ground truth of the pointer and the ground truth of the pointer is just the first thing that it sees. And so even if at some point, the corrigibly aligned model has the understanding that, what we want it to do is different than the thing it’s doing, the way that it’s structured doesn’t necessarily result in that understanding translating into better performance, because it’s fixed to this particular ground truth. Whereas the deceptively aligned model is not fixed to any ground truth, it’s just always going to take the action which in fact results in the best performance. So the deceptively aligned model is much more robust here much earlier, whereas the corrigibly aligned model has to learn this complex ground truth before it becomes properly robust in the right way.
And so what this results in is that we have this really simple, straightforward, quick path to extremely good performance, that resolves this overhang between the model’s understanding of the training objective in its world model and in its proxies. And furthermore, this path resolves that overhang essentially as quickly and as well as it possibly could.
So, I think the path to deceptive alignment is a relatively simple modification. And it results in as good as possible performance given how well the model is currently modeling your training process, because with a deceptively aligned model, there is never a situation where the model understands more about the training process than it is actually using to take its actions. Whereas with all other types of models, that’s a failure mode that can arise. So because of that, the deceptively aligned model has the maximal possible performance relative to its understanding of the training process.

Finally, like previously, this gives us a stable equilibrium; we are now in a situation where the model’s proxies have essentially crystallized: the proxies are no longer relevant to performance, because it doesn’t matter whether you care about gold coins, or stamps, or paperclips, or whatever—whatever you care about, you’re going to have exactly the same performance, because the only reason you have good performance is because you’re just trying to do so instrumentally for the purpose of staying around in the training process. And so at this point, you have the same performance whatever the thing is that you care about. And so there are no longer any gradient descent updates that affect what those proxies are, once they become long term goals. At least except for regularization updates. And so we’re again in an equilibrium, but it’s a misaligned equilibrium, where now the model just has some random proxies that were picked up early on, and that’s the thing that it cares about. And gradient descent no longer has any reason to modify the model into caring about anything different than what those random proxies were.
Question: If I understand you correctly, then in the deceptive case, the model is strictly more complex, because it has to have its own goals and then model the training process on top of that.
No, the model is not strictly more complex, it has to spend strictly more compute. And we will get to this when we start getting into the low path dependence world, but it’s extremely important to remember that there’s a difference between weights and activations. So the deceptively aligned model has to spend more compute doing the optimization, to figure out “Oh, the thing I’m supposed to do is care about the mother” or whatever. But that understanding of the mother doesn’t live in the weights, it lives in the activations. There doesn’t have to be anywhere in the weights where it specifies what the mother is. It just figures out based on its world model, what is the thing that the training process would want me to do, and then does that. And so it does not make the model more complex. What it does do, though, is it slows it down a little bit, and I will talk in the low path dependence world about how those things come into play. Because in the low path dependence world, speed and complexity are extremely important. In the high path dependence world, which is where we are right now, those are not the factors we’re imagining are really determining what model we’re going to get. In this situation, we’re imagining it’s actually mostly not about speed, or simplicity, or whatever, it’s mostly just about the path that you take through model space, and how much performance gains you get along that path. We’re putting those simplicity and speed concerns aside for now; we’ll talk about that more in low path dependence.
Deceptive alignment in the low path-dependence world
Now we’re going to shift to the low path dependence world. And we’re going to imagine that, actually, the inductive biases in machine learning are not very path dependent, they don’t care much about the particular path that we take, they’re mostly just about how simple is the particular algorithm you find, how fast is it, basic facts about the algorithm like that.
Again, we’re going to assume that the model has to fully understand what we want—this is the limit of adversarial training assumption.
And now, we have to make some assumptions about, if we’re in a world of low path dependence, what are the sorts of inductive biases that determine what is the sort of model that you actually get—what is the simple, unique solution that you end up with every time you run your training process? Well, we’re going to look at two things. These two things do not cover the whole space of what the actual inductive biases represent, but there are two facets that I think are almost certain to appear in the inductive biases, both of these are certainly components of what the actual inductive biases are of deep learning systems. And they’re components we know how to analyze. So we can try to look at them and figure out what they do—even though they don’t capture the whole story, they capture a part of the story. And so in some sense, the best thing you can do right now for understanding the low path dependence world is at least look at the components of deep learning inductive biases that we understand, and try to evaluate how each of these model classes would do under those components.
Okay, so those components are simplicity and speed. What do I mean by that? So I was talking earlier about there being an important distinction between the weights and the activations.

For simplicity bias, we’re asking how complex is it to specify the algorithm in the weights? If there is some algorithm that has been implemented, that the model is using to be able to compute its actions, we want to understand, what is the length of the code necessary to write that algorithm down? How difficult is it to specify the computation that the model is doing? That’s simplicity bias.

And then we’re also going to look at speed bias: how much computation does the algorithm actually take at inference time? When you actually have to take this code, and you have to actually run it, when you have to actually execute whatever the algorithm is, how difficult is that to execute? How much compute does it require? How long does it take?
Traditionally, in ML, this is more of a hard cap than a soft bias like simplicity, since the model size determines how long the model can possibly run for. But you could also imagine a situation where the bias is more soft. Either way is fine.
So, those are the two main biases that we’re going to be looking at: the simplicity bias and the speed bias.

We’re going to start with simplicity. Simplicity is about specifying the thing that you want in the space of all possible things. You can think about simplicity as “How much do you have to aim to hit the exact thing in the space of all possible models?” How many bits does it take to find the thing that you want in the model space? And so, as a first pass, we can understand simplicity by doing a counting argument, which is just asking, how many models are in each model class?
First, how many Christs are there? Well, I think there’s essentially only one, since there’s only one way for humans to be structured in exactly the same way as God. God has a particular internal structure that determines exactly the things that God wants and the way that God works, and there’s really only one way to port that structure over and make the unique human that wants exactly the same stuff.
Okay, how many Martin Luthers are there? Well, there’s actually more than one Martin Luther (contrary to actual history) because the Martin Luthers can point to the Bible in different ways. There’s a lot of different equivalent Bibles and a lot of different equivalent ways of understanding the Bible. You might have two copies of the Bible that say exactly the same thing such that it doesn’t matter which one you point to, for example. And so there’s more Luthers than there are Christs.
But there’s even more Pascals. You can be a Pascal and it doesn’t matter what you care about. You can care about anything in the world, all of the various different possible things that might exist for you to care about, because all that Pascal needs to do is care about something over the long term, and then have some reason to believe they’re going to be punished if they don’t do the right thing. And so there’s just a huge number of Pascals because they can care about anything in the world at all.
So the point is that there’s more Pascals than there are the others, and so probably you’ll have to fix fewer bits to specify them in the space.
Question: It seems like Pascal has to do more here, since it has to have models of its own goals, and the training process, and the instrumental reasoning to value that, such that the model should be larger.
Right now we’re just doing simplicity, so we’re not considering how large the model would have to be, just how difficult it is to specify the model. And the point is that the Christ has to pay a bunch of bits to specify exactly what the things are that we’re trying to get it to do, if the thing we’re trying to get it to do is relatively complicated. There’s a whole part of the code that is just writing out “the thing we want is exactly this thing, and it works exactly this way”. Whereas for the Pascals, it doesn’t have to do that. It just says “gold coins”, and then just cares about them over the long term, and that results in good performance at runtime.
Furthermore—and we’ll talk about this more in just a second—but essentially the claim I’m making is that the world model has to be exactly the same across all the different model classes. They all have to understand the world. This is the same assumption we made in the path dependence case where we’re assuming that we have an environment such that, if you want to have good performance, you have to understand how the world works. Understanding the world is just a thing that you need in any situation where you have to take actions in the world.

Okay, here’s a slightly more concrete version of essentially the same counting argument that I just gave. We’re going to imagine that you can conceptualize a model as being composed of three pieces, a world model, an optimization procedure, which is some way to optimize for some goal in that world model, and a mesa-objective, which is just something that it’s trying to optimize for. I don’t necessarily think that this is how models are actually going to look, but it’s a nice concrete picture that we can analyze and draw conclusions from that I think will generalize.
Now, the idea here is that the Christs, the Luthers, and the Pascals, they all have to have essentially the same world model, because they all have to understand the world well to be able to do a good job. And they will also have to have essentially the same optimization procedure, because they all have to have some way of being able to figure out how to accomplish particular tasks, because we want them to be able to accomplish lots of tasks, and so they have to have some machinery for being able to do well on the particular tasks that we want them to do.
Therefore, the main difference in complexity between these model classes is in the mesa-objective portion—what is the complexity of the objective we have to specify that we then throw the optimization procedure at. So, what we’ll compare here is, what is the simplest mesa-objective for Christ, what is the simplest mesa-objective for Luther, and what is the simplest mesa-objective for Pascal. The idea here is that we’re approximating the overall simplicity by just looking at the simplest individual one in each class. In that way, this is a little bit different than the counting argument, which just looks at the whole class. But basically, the way that it turns out in simplicity priors is that you can approximate them pretty well by just looking at the simplest one in each class, so we’re going to do that here.

So what is the simplest internally aligned mesa-objective? Well, you have to specify the whole training objective, so you have to pay for the full complexity of that.

The corrigibly aligned model is a little bit better. It just has to pay for the full complexity of the simplest ground truth that is equivalent to the thing you want, the simplest ground truth that always ends up with you pointed at the right thing.

And then for Pascal, the simplest mesa-objective that Pascal has to pay for is just whatever the simplest objective is that cares about the long term—paperclips over the long term, stamps over the long term, gold coins in the long term, whatever—just the simplest thing that you could possibly care about, as long as it is something that you care about over the long term.
Okay, and so which wins here? I think it’s pretty clear that the deceptively aligned one is the simplest, at least for a relatively complex training objective: it just doesn’t have to specify very much at all about the thing that we want it to do. All of the other model classes scale with the complexity of the training objective, whereas the complexity of the deceptively aligned model is essentially fixed—so as you increase the complexity of the thing we’re trying to get the model to do, eventually deception should win out.

Now we get to speed. Speed, as I alluded to previously, is the one aspect where I think deceptively aligned models actually just lose out.
Why do deceptively aligned models lose out here? Well, here we’re trying to understand how much computation you have to perform for each model class to result in the correct answer. The internally aligned one already has exactly what the thing is that it is trying to optimize for, and it just directly executes on that; the corrigibly aligned one, maybe it takes a little bit more because it has to figure out what the pointer is pointing to, but overall it’s pretty similar.
But the deceptively aligned one has to do at least a couple of extra steps, because it reasons, “Okay, I care about gold coins,” but just knowing that it cares about gold coins is not yet sufficient to be able to do a good job in the training environment. It has to do a couple of extra steps of reasoning where it’s like, “Okay, I care about gold coins and caring about gold coins in the long term means that I should try to optimize the training goal temporarily to try to get more gold coins eventually.” And so that adds extra steps of reasoning and some cost to the overall computation of the model. So the deceptively aligned one is in some sense slower than the others.
I think this does give us some real hope here, and I think it’s at least an inkling of a way out. Unfortunately, I think that it’s not a great hope. Why do I think that?
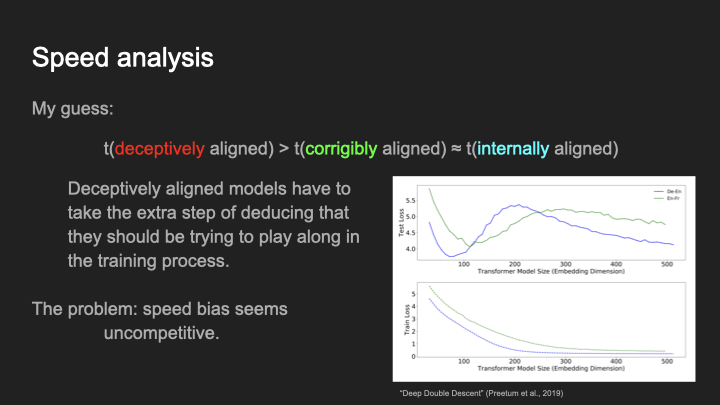
I think the main problem is that speed bias seems extremely uncompetitive. Why is that? Well, there’s a reason that we build bigger models, right? We build bigger models, because we want models that have the ability to spend a bunch more compute. And the bigger models do better. Because the more compute that they have, the more they can find a simpler algorithm that, though it spends more compute, is simpler and thus does better on the task.
Here’s another piece of evidence here that I think is quite strong. Let’s say we did want to implement a speed prior. We were like, “Okay, let’s actually find the minimal compute model which is able to fit the data.” What would that do?
What I have up here is a double descent curve. This curve is from training language models on a translation task. And we’re varying the size of the internal representation inside of the model. And what we want to do if we want to get something like the maximum a posteriori estimate from a speed prior is to find the minimal number of parameters that are able to fit the training data exactly.
So what does that do? Well, take a look at the graph. Blue corresponds to blue and green corresponds to green here. The bottom is training loss, so we want to look at where blue and green level off and reach approximately perfect train accuracy. But if we look at where blue levels off on the bottom, it’s at exactly where we get the worst test loss above. And the same for green. And we see this exact same thing for lots of other measures of number of parameters as well.
What this is saying is that, if we actually tried to take a maximum a posteriori from a speed prior, if we took the minimal number of parameters that was able to fit the data really well, we would end up with the worst possible test performance on the whole graph. We end up with the exact worst possible generalization performance across all possible ways of picking the number of parameters.
So what’s going on here? Well, I think that it’s telling you that speed bias is uncompetitive, it is telling you that if you really try to select the smallest model that fits the data, you don’t get good generalization performance.
Why do you not get good generalization performance? You don’t get good generalization performance because real world data is not speed distributed. Real world data is simplicity-distributed. This is sort of a realist approach to Occam’s razor, where I actually think that real world data is distributed according to a simplicity prior, so the more you deviate from that, the worse your generalization performance is. And so if we force our models to use the speed prior, to use the minimal-computation algorithm that is able to solve the task, they have worse downstream generalization behavior, because real-world data doesn’t use the speed prior.
And so as we want to get models that are better at generalizing, I predict we will move away from speed bias and towards more simplicity bias. And this is bad if we’re concerned about deception, because speed bias seems like it might have otherwise saved us, at least in the low path dependence world.
Conclusion
Now, you’ve heard my case for deceptive alignment in the high path dependence world, and in the low path dependence world. So what is my overall take?

Well, you’ve probably figured it out by now: my overall take is that, regardless of whether we are in a high or low path dependence world, my current best guess is that gradient descent is going to want to make our models deceptive. In either situation, it seems like the inductive biases are such that, if we go back to Ajeya’s picture when we train the model on a situation where it could learn color, or it could learn shape, but actually SGD always ends up learning the color thing, my guess is that currently, regardless of whether we’re in the low or the high path-dependence world, gradient descent is by default going to take you towards the deceptively aligned model.

And if we believe this, we have to enact some intervention that changes the training dynamics. We have to do something that creates pressure away from deception. And that has to come from someplace that is not just behavioral: as we said previously, in all of these situations, we were imagining that the model was able to perfectly understand what we want. We were working in the limit of adversarial training. And so if we believe the case that we’re going to be pushed towards deception by default even there, that means we need to have some way to change the inductive biases that is not just a behavioral change, that is not just trying to add more adversarial examples, such that we can create pressure towards the non deceptively aligned models and away from the deceptively aligned models.

Importantly, though, it matters a lot how big the gap is. One thing that is maybe not quite clear in this analysis is how many bits different is a deceptively aligned model from a non deceptively aligned one. I often like to think of our task in alignment as, at least in my estimation, we are some number of bits underwater. By default, gradient descent wants to push your model into being deceptive. But it’s not like the non-deceptive model is impossible—it lives there in the model space, too. So the question is: how much does gradient descent want to push it towards the deceptive model relative to the good model? How large are the relative sizes of these circles in the bottom right here?
This matters a lot, because it determines the number of bits of optimization pressure that we have to produce to modify the training process into a situation where it’s going to push towards the good thing. So if we’re 10 bits underwater by default, then that’s pretty good. All we need to do is get 10 bits of optimization towards the good thing. Maybe we can just do that with ensembling or something.
If we’re 10,000 Bits underwater, that’s a lot worse—maybe you have to really fundamentally reshape the way that our training processes work if we’re 10,000 bits underwater. I think it’s currently unclear, exactly quantitatively where we are, though overall, like I said, my guess is that at least we are underwater, and we need to do something that changes it relative to that.
Q&A
Question: Do you think that, even in the limit of adversarial training, we won’t be able to find adversarial examples to make the deceptive model think that it has an opportunity to defect?
You could try honeypots, try to explicitly give the model a situation where it thinks that it could defect. You can do this, and my guess is that if you do this, sometimes you will be able to produce examples of deceptive models. This will stop working eventually as your model gets smarter and more able to tell when it’s in a honeypot or not, but with early deceptive models, my guess is that you will be able to find some examples of them.
And so we should definitely do this. At least just because, once we have an example, we can study it more effectively. But I don’t think that this is a full solution, at least if all you do is the obvious thing of retraining it to not be deceptive.
The problem is what happens next. You’ve produced an example of a model being deceptive. And now the question is, how does gradient descent change the model such that it no longer produces examples of it being deceptive? If you retrain it, it has two options: it becomes less deceptive, or it just gets better at hiding its deception. And my guess is that you’re going to get the second one—once get an example of a model being deceptive, and you try to train it to not be deceptive, then it just gets better at not looking deceptive, but it doesn’t necessarily train away the deception.
I think this is true, basically, in both the low and high path dependence worlds. For example, in the high path dependence world, once it already has all the machinery to be deceptive, it’s a pretty big change to swap that whole thing out and make it corrigibly or internally aligned or something. It’s a lot easier to just be like, “Hey, you should be a little more conservative about not defecting so wildly, be really sure that you’re actually in deployment, and there’s actually a good opportunity to defect before you do that.” That’s pretty simple, it just changes its overall paranoia level. And so my guess is you’ll end up with that: if you produce some example of deception, and then try to make it non deceptive, it just becomes a little more paranoid.
Question: If you found out that that double descent was easy to eliminate or irrelevant for some reason, would you be a lot more optimistic about the speed prior?
I am not sure exactly what that would mean. So I think that in some sense, I don’t interpret double descent as a phenomenon as being the problem. It’s that double descent is a piece of evidence that teaches us a fact about the inductive biases. You could try to eliminate the phenomenon of double descent. But it’s not clear that that would change the underlying fact, which is that, there was a thing about the inductive biases: speed doesn’t generalize well.
Now, you could show me some experiment that looks at double descent, and I might look at it and be like “This teaches me some facts about how to think about inductive biases that are different than what I previously knew.” I definitely could imagine learning a ton of useful facts about inductive biases from running experiments like that. But I think that it is best to conceptualize it not as “double descent is the problem”, but as “double descent is a piece of evidence about the problem”.
One thing that my picture predicts, and maybe you could run an experiment on this, is that double descent should go away if you look through model space in simplicity order. In my picture, double descent happens because the order in which models enter into the accessible model space is different from the criteria that SGD uses to select from amongst models in the accessible model space, and the latter is more biased towards simplicity. If you could disentangle these, actually add models to the support of your prior starting with the simplest first, then I think you wouldn’t get double descent, then I think that the first model you would find that fits the training data well would actually be the one with the best generalization.
Question: Is there any reason to suspect that there are no other inductive biases other than simplicity and speed?
There’s no reason to expect that and in fact, there certainly are lots of other ones. The problem is just that we don’t understand them very well. And so, at least right now, the only ones I feel pretty confident that we understand are speed and simplicity. There are some other things. Circuit complexity, max vs. average case speed priors, those are some other inductive biases that we sort of understand that might be relevant here.
In fact, I think one of the plausible ways out here is to try to implement an average-case speed prior rather than a max speed prior. Max speed is: across all inputs, what is the maximum speed that you ever take—whereas average speed is: each input wants to take the shortest path. In some sense, you can think of chain-of-thought prompting as potentially giving you an average speed bias, because you always want to take like the minimal chain-of-thought that gets you there on each individual input. And so instead of having a fixed length execution time with every input, you’re incentivizing low computation time across each input. I think this can help. I think that average speed pushes you into a situation where, on some inputs, the model is not deceptive, because there’s a simple, easy path to solve the input, which makes deception unnecessary, it’s extra computation. But it doesn’t address that there will be inputs on which the model has to do a bunch of really complex reasoning and on those inputs, deception may be the easiest way to do it. And so this causes it to be very input-dependent, where sometimes it’ll be deceptive and sometimes it won’t. That’s my guess about what happens if you do average speed.
Question: But why expect average speed to generalize well? It seems like it has the same problem that max speed does, which is that the world is not distributed according to it.
Yes! I’m not claiming that it does generalize well. I’m just like, here’s some other priors that seem plausible as things that we might end up with, that I know how to analyze at least to some extent. I think I can say a bunch of facts about average speed bias. I think I can say a bunch of facts about circuit-size priors. There’s a lot of other things that I have thought about that I think I can say some facts about too. But of course, I agree that there’s still a question of, actually is this thing going to generalize well. One of the biggest problems when you start writing up priors to try to solve this problem is that almost every single one just ends up with something like lookup tables. It’s really hard to get priors to generalize well, because, as I said, Occam’s Razor is a real phenomenon.
Question: I’m wondering among these three categories, Christs, Luthers, and Pascals, where would you place humans? Are we deceptively aligned with respect to our learning processes and reward circuitry?
Humans are a weird example. The first problem is that there’s three levels here. Are you talking about the neocortex relative to evolution? Are you talking about the neocortex relative to subcortical reward systems? Are you talking about the subcortical reward systems relative to evolution?
Question: Let’s just do specifically human learned values and cognition, relative to our hardcoded steering system, so to speak.
Sure. I think we can be deceptive sometimes. We definitely do things like eat candy right after we do our homework. It is sort of a mix of the different model classes, though, which is not that surprising. The “clean” story I told where you definitely end up with one of these things is almost certainly false. And in machine learning, also, it’s probably going to be a mess. But the same sort of analysis applies to how much of each thing you get. And in terms of what sort of a mess it would be, at least for humans, my guess is that yes, there absolutely is deception. At least, there’s some deception in terms of humans relative to our subcortical reward system.
Part of the problem here also is that there isn’t a clear opportunity for humans to take a catastrophic action that would overturn the reward system. But we could imagine having that possibility. What if there is some opportunity someday for us to modify our own reward systems. Do we take that opportunity? And the answer is that we totally do, because we take SSRIs. Maybe in the glorious, transhuman future we’re going to modify human brains to make them better. And we’re like, “Okay, we’re going to plan for eventually allowing us to get rid of this reward system we don’t like.”
And so is there deception? I think there clearly is. I think the story is more complex, though, than just saying “it is deceptively aligned.” It’s a little bit tricky, in a way that I expect things in the real world are. This talk is definitely best interpreted as a simplified story that allows us to do the analysis. But in fact, it will be a complex mess.
Question: So I will say an analogy, which is probably imperfect. But please bear with me. Suppose interpretability is the proportion of the room that is unhidden by furniture. And during training, the deception outcomes are like cockroaches, and you’re like, “Oh, are the cockroaches under the furniture? We can’t see them.” So if this is a decent model of how interpretability relates to probing deceptive alignment, it seems to suggest that we need 100% transparency and interpretability to be okay.
So I think that the conclusion is false. I don’t think you need 100% transparency and interpretability to solve this problem. Why do I think that?
First, it really depends on what you’re trying to do with your interpretability tools. If what you do is, you see deception, and then you train it so that you don’t see deception anymore, that is a terrible thing to do with your interpretability tools. As we said earlier, you’re just going to make the model better at hiding deception. So that is a poor use of interpretability tools for alignment. Nevertheless, I think that interpretability tools are the key to solving this problem. But the way they solve the problem doesn’t go through that mechanism.
So what mechanisms do I think they go through? Here’s one: if we’re in the high path dependence world, then we can understand what the model looks like early in training. We can inspect and understand the proxy, and we can try to improve it by training it, since in that situation, it’s not like there is something that’s actively hiding from our interpretability tools. The deceptive model wants to actively hide from your interpretability tool, but you don’t have a deceptive model at that point. If you’re applying the tools early to guide the training process when it’s just a proxy model, it’s not like the deceptive model is actually trying to hide from you, you’re just providing some extra bits of optimization in the right direction.
So the way we want to use interpretability tools is to provide extra bits of optimization to help us understand what’s going on and direct it in the correct direction, either explicitly through passing gradients through interpretability tools or just by looking at things early on and understanding what the trajectory is going to be. What you shouldn’t rely on, I think, is being able to fix deception after the fact—the goal should be to prevent the development of deception in the first place.
Another important thing I’ll point out here is that you can direct your interpretability efforts towards understanding the gradient descent process itself. When people think of interpretability, they’re usually focused on interpretability of the final model—which to be clear is something that I think is really useful. I have this whole post where I talk about what I think the tech tree of transparency and interpretability is like, where I say, “The first thing is, you have to be able to have some understanding of how and what models do.” But it’s not the only thing. There are seven more things that I talk about there.
And the point is that, the next thing after understanding an individual model is having some understanding of how we got that model, understanding the training process and the training dynamics—this is usually thought of as inductive bias research. If we had that and then our transparency tools told us that the model had a bad proxy or whatever, then we could do a gradient descent update step that tries to make it so it has a good proxy and actually believe that it would work. Because then we would actually understand what that update step is doing. If we have the ability to understand that the reason that it’s pushing the gradient in this direction is for this reason, then we have some reasons to believe that it’s not just going to Goodhart on our transparency tools.
Question: But in this alternative class of interpretability tools, you would still want to get 100% of the training paths or something?
It’s definitely not necessary that your transparency tools have to be 100% Goodhart-proof. The only thing that has to be true is that gradient descent never finds the situation in which it can Goodhart your transparency tools, and that latter condition is much more achievable.
Question: I would think that a model doesn’t necessarily need to be deceptive for optimizing on an interpretability tool to push it in the direction of being more opaque.
Yes. That’s why we want to understand the gradients. Here’s one way to think about this: what are the two adversaries that we’re concerned about, if we want our transparency tools to work? Well, there’s the deceptive model that might be trying to trick the transparency tools. And then there’s gradient descent. Gradient descent is actively gradienting on our transparency tools, and it’s going to try to push them into having some particular result, if you’re gradienting on your transparency tools.
I think that using gradient descent on transparency tools is something that we probably eventually want to do, but we are not there yet. Like I said, if you’re gradient descenting on your transparency tools, then you need some reasons to believe that that’s not going to Goodhart your transparency tools. In my opinion, the way you get that understanding, if you’re going to be training on transparency, is by understanding gradient descent! You can’t just have transparency tools which understand the model, you also need to understand what is happening as you train the model.
And so you can look at, maybe gradient descent proposed this particular change for this particular reason, and you can be like, “Ah, I see, that’s a good way to change the model”. And if you see a change that’s like, “I’m going to make a change to make the model opaque”, that’s bad! And so if you understand the dynamics of the proposed changes, then I think you’d get around this problem. Like I said, though, I think this is next level transparency tech, we need to get here to eventually get to the point where we can solve the problem, but we also have to start by at least understanding models at all, and how they work. I think a lot of times people want to jump ahead, and they want to be like, “Oh, we’re going to take our current transparency tools, we’re just gonna throw them into the loss”. And that doesn’t work. But that doesn’t mean that transparency is not eventually useful for being able to change how we train models. It’s just that there’s multiple steps along the way.
Question: So the dumbest, simplest transparency tools in my mind are: take a chain-of-thought reasoner, and read its train of thought. Hopefully, that gives you some idea of what it’s thinking.
No! I don’t think that helps with transparency. One thing it does do, and I was saying this earlier, is that chain-of-thought can be helpful for creating an average speed bias.
What it doesn’t do is, it doesn’t actually give us any transparency. Here’s a good way to think about it: the deceptively aligned model can put whatever it wants in the transcript that’ll convince you that it’s doing the right thing. And the internally and corrigibly aligned model can do the same thing. The point is that there is no constraint on whether you would get the deceptively aligned model or not, if the only way you have to understand its internals is just by looking at the behavioral output in the chain-of-thought.
Maybe you could get it so that all of the relevant cognition is visible in the chain of thought. But how? By default, if you just train it to produce a chain-of-thought, each individual forward pass could still be deceptive.
Question: Weren’t you saying that you’d use the transparency tools to guide the training process prior to the point that it becomes deceptive? Why not do that with chain-of-thought?
Yes. And I think we should do that. But here’s what I’m worried about. If we’re trying to guide it in a particular direction by giving it a behavioral incentive, when we gradient through the behavioral incentive, that looks exactly the same as this whole analysis, right? This whole talk was looking at what happens when we try to incentivize a model to behaviorally act the correct way during training. And so if the only way of doing transparency is well, I have some behavioral checks, and then I’m gonna gradient through those behavioral checks and incentivize it to have good performance—then that’s the whole story we were just looking at, the whole problem is that we believe that if we do gradient descent on a behavioral analysis of whether the model is doing a good job, then the, simplest, easiest modification that gradient descent will make to cause the model to do a good job will be to make it deceptive. If that is true, we cannot solve this problem just via adding more behavioral checks and gradient descenting through them.
Maybe that’s a little bit too strong, because technically, you could probably solve the problem just by picking a behavioral loss function with just the right implicit inductive biases. By picking a particular loss function you’ve made it so that some particular paths are more likely than others. But I think that whatever you’re doing someone has to actually get around this analysis, it has to actually get around the argument for why, by default, when you just do a behavioral training, it pushes towards deception.
Question: Can’t you just reclassify the output of your interpretability tools as an output of the model? The interpretability tools were determined by the latent activations of the model, so isn’t it like another output head?
You can conceptualize it however you want. I think that the key problem is, what things are you constraining via what you’re looking at? If the only constraints I have are on end-to-end behavior, then all I know is that the model must be implementing some algorithm with that end-to-end behavior. But if I’ve looked inside it, seen other things, then I have more constraints on how it has to be operating. It has to be an algorithm that includes X component, or operates in X way, or whatever.
The problem with chain-of-thought is not that it is behavioral per se, the problem is that all of the analysis we just did in this talk applies in that case, because all of these different model classes are equally as good at solving that problem. And so because of that, you haven’t really created a thing which distinguishes between then, a way to provide optimization pressure in a particular direction. The thing that we want is to have some way to provide optimization pressure that actually distinguishes between these different model classes.
Let’s say we had magical transparency tools that were able to look inside and find the model’s exact proxies or whatever. What it returns is still an output, but it’s an output that actually distinguishes between these model classes. It is an output that is different depending on which one of these things it is and that we can use to produce some selection pressure.
Question: I guess my response would be that I think chain-of-thought feedback does differentiate based on which model class it is.
So, there definitely exists a deceptive model for which the deception is clear in the chain-of-thought. The problem is that there also exists a deceptive model for which deception is not clear in the chain-of-thought. Now, I think it gets you a couple of bits, because the deceptive model, where it is clear in the chain-of-thought, is probably simpler than the deceptive model where it is not clear in the chain-of-thought. And so you have in some sense eliminated the deceptive model where it is very clear in the chain-of-thought. But now you have to contend with the next simplest deceptive model, where the next one doesn’t have the property that its deception is very clear in the chain-of-thought.
So the question is, just going back to this picture, how many bits did you get? I think you got like two bits. I just don’t think it makes that big of a difference. Because we’re in a situation where this next simplest deceptive model is still very simple, it’s not that much harder to think deceptively in such a way that the deception is not obvious in the chain-of-thought. It’s a little bit harder, but it’s not that much harder. And so you provided a little bit of optimization, but your intervention is relatively small. If we were 10,000 bits underwater, this is not helpful. If it’s really marginal, and it turns out that the number of bits underwater could go either way, then maybe it gives us an extra edge, but my guess is that it’s not enough of an edge.
Question: I just want to point out, one thing that influences this story is how much of our ultimate performance comes from chain-of-thought.
That’s not clear to me. It seems like the model can think in ways that are illegible to humans, for example. So it can hide its cognition and get the benefits of chain of thought without having to show us that its deceptive.
Question: What if we use an opaque set of heuristics to generate the output that’s completely illegible to humans. And then from knowing that output, we generate an equivalent human-readable chain of thought.
That’s worse—I think that is even worse than the previous thing. Previously, at least doing the chain-of-thought was actually instrumental in getting the answer; we got some reason to believe that, if there was a deceptive model there, it would be a little bit harder to implement in that context. In this case, for the illegible thing, it is just equally as easy for it to be deceptive as non-deceptive in terms of behavior. And then when we go to provide an explanation for it, we just always get the non-deceptive explanation, regardless of whether the actual model is deceptive or not. There’s no reason that we ever have to provide the deceptive explanation, even for a deceptive model. This is basically the whole Eliciting Latent Knowledge problem. Remember, the different model classes have the same performance, they have the exact same behavior in training. And so you can provide the same explanation for deceptively aligned or non-deceptively aligned models, and it’ll be just as good, if you’re only checking that explanation.
- ↩︎
Question: It seems to me like, if you’re just going from point A to point B, it doesn’t matter how you get there, just what the final model is.
So, that’s not quite the way I’m thinking about path-dependence. So, we assume that the model’s behavior converges in training. It learns to fit the training data. And so we’re thinking about it in terms of them all converging to the same point in terms of training behavior. But there’s a bunch of other things that are left undefined if you just know the training behavior, right. We know they all converge to the same training behavior, but the thing we don’t know is whether they converge to the same algorithm, whether they converge to the same algorithm, whether they’re going to generalize in the same way.
And so when we say it has high path dependence, that means the way you got to that particular training behavior is extremely relevant. The fact that you took a particular path through model space to get to that particular set of training behavior is extremely important for understanding what the generalization behavior will be there. And if we say low path dependence, we’re saying it actually didn’t matter very much how you got that particular training behavior. The only thing that mattered was that you got that particular training behavior.
Question: When you say model space, you mean the functional behavior as opposed to the literal parameter space?
So there’s not quite a one to one mapping because there are multiple implementations of the exact same function in a network. But it’s pretty close. I mean, most of the time when I’m saying model space, I’m talking either about the weight space or about the function space where I’m interpreting the function over all inputs, not just the training data.
I only talk about the space of functions restricted to their training performance for this path dependence concept, where we get this view where, well, they end up on the same point, but we want to know how much we need to know about how they got there to understand how they generalize.
Question: So correct me if I’m wrong. But if you have the final trained model, which is a point in weight space, that determines behavior on other datasets, like just that final point of the path.
Yes, that’s correct. The point that I was making is that they converge to the same functional behavior on the training distribution, but not necessarily the same functional behavior off the training distribution.
- ↩︎
Question: So last time you gave this talk, I think I made a remark here, questioning whether grokking was actually evidence of there being a simplicity prior, because maybe what’s actually going on is that there’s a tiny gradient signal from not being completely certain about the classification. So I asked an ML grad student friend of mine, who studies grokking, and you’re totally right. So there was weight decay in this example. And if you turn off the weight decay, the grokking doesn’t happen.
Yes, that was my understanding—that mostly what’s happening here is that it’s the weight decay that’s pushing you towards the grokking. And so that’s sort of evidence of there actually just being a simplicity prior built into the architecture, that is always going to converge to the same, simple thing.
Question: But if you turn off the weight decay then the grokking doesn’t happen.
Well, one hypothesis might be that the weight decay is the thing that forces the architectural prior there. But maybe the strongest hypothesis here is that without weight decay there’s just not enough of a gradient to do anything in that period.
Question: This isn’t a question. For people who aren’t familiar with the terminology “weight decay”, it’s the same as L2 regularization?
Yep, those are the same.
- ↩︎
Question: Does Martin Luther over time become internally aligned? As Martin Luther studies the Bible over time, does he become internally aligned with you?
No. Because Martin Luther never, from my perspective, at least the way we’re thinking about this here—I’m not gonna make any claims about the real Martin Luther—but the way we’re thinking about it here is that the Martin Luther models, the thing that they care about is understanding the Bible really well. And so their goal, whatever the Bible is, they’re going to figure it out. But they’re not going to modify themselves, to become the same as the Bible.
Let’s say, I’m the Martin Luther model. And I modify myself to care about my current understanding of the Bible. And then I realized that actually the Bible was different than I thought the whole time. That’s really bad for me, because the thing I want originally is not to do the thing that my current understanding of the Bible says, it’s to do what the Bible actually tells me. And so if I later understand that actually the Bible wants something different, then the Martin Luther models want to be able to shift to that. So they don’t want to modify themselves into internal alignment. I should also point out that, the way that we were imagining this, it’s not clear that the model itself has any control over which model it ends up as. Except to the extent that it controls performance, which is how the deceptively aligned model works.
Question: So Martin Luther is saying, the Bible seems cool so far. I want to learn more about it. But I’ve reserved the option to not be tied to the Bible.
No, Martin Luther loves the Bible and wants to do everything the Bible says.
Question: So why doesn’t Martin Luther want to change its code to be equal to the Bible?
The Bible doesn’t say, change your code to be equal to the Bible. The Bible says do these things. You could imagine a situation where the Bible is like, you got to modify yourself to love paper clips, or whatever. In that situation, the model says, well, okay, I guess I gotta modify myself to like paper clips. But Martin Luther doesn’t want to modify himself unless the Bible says to.
The problem with modifying themselves is that the Martin Luther models are concerned, like, “Hmm, maybe this Bible is actually, a forgery” or something, right? Or as we’ll talk about later, maybe you could end up in a situation where the Martin Luther model thinks that a forgery of the Bible is its true ground source for the Bible. And so it just cares about a forgery. And that’s the thing it cares about.
- ↩︎
Question: The point you just made about pre-training vs. fine-tuning seems backwards. If pre-training requires vastly more compute than the fine-tuning a reward model, then it seems that learning about your reward function is cheaper for compute?
Well, it’s cheaper, but it’s just less useful. Almost all of your performance comes from understanding the world, in some sense. Also, I think part of the point there is that, once you understand the world, then you have the ability to relatively cheaply understand the thing we’re trying to get you to do. But trying to go directly to understand the thing we’re trying to get you to do—at that point you don’t understand the world enough even to have the concepts that enable you to be able to understand that thing. Understanding the world is just so important. It’s like the central thing.
Question: It feels like to really make this point, you need to do something more like train a reinforcement learning agent from random initialization against a reward model for the same amount of compute, versus doing the pre-training and then fine-tune on the reward model.
Yeah, that seems like a pretty interesting experiment. I do think we’d learn more from something like that than just going off of the relative lengths of pre-training vs. fine-tuning.
Question: I still just don’t understand how this is actually evidence for the point you wanted to make.
Well, you could imagine a world where understanding the world is really cheap. And it’s really, really hard to get the thing to be able to do what you want—output good summaries or whatever—because it is hard to specify what that thing is. I think in that world, that would be a situation where, if you just trained a model end to end on the whole task, most of your performance would come from, most of your gradient updates would be for, trying to improve the model’s ability to understand the thing you’re trying to get it to do, rather than improving it’s generic understand the world.
Whereas I’m describing a situation where, by my guess, most of the gradient updates would just be towards improving its understanding of the world.
Now, in both of those situations, regardless of whether you have more gradient descent updates in one direction or the other, diminishing returns still apply. It’s still the case, whichever world it is, SGD is still going to balance between them both, such that it’d be really weird if you’d maxed out on one before the other.
However, I think the fact that it does look like almost all the gradient descent updates come from understanding the world teaches us something about what it actually takes to do a good job. And it tells us things like, if we just try to train the model to do to do something, and then pause it halfway, most of the ability to have good capabilities is coming from its understanding of the world and so we should expect gradient descent to have spent most of its resources so far on that.
That being said, the question we have to care about is not which one maxes out first, it’s do we max out on the proxy before we understand the training process sufficiently to be deceptive. So I agree that it’s unclear exactly what this fact says about when that should happen. But it still feels like a pretty important background fact to keep in mind here.
- Against Almost Every Theory of Impact of Interpretability by (17 Aug 2023 18:44 UTC; 336 points)
- And All the Shoggoths Merely Players by (10 Feb 2024 19:56 UTC; 178 points)
- When can we trust model evaluations? by (28 Jul 2023 19:42 UTC; 172 points)
- RSPs are pauses done right by (14 Oct 2023 4:06 UTC; 166 points)
- Without fundamental advances, misalignment and catastrophe are the default outcomes of training powerful AI by (26 Jan 2024 7:22 UTC; 164 points)
- Towards understanding-based safety evaluations by (15 Mar 2023 18:18 UTC; 164 points)
- The Translucent Thoughts Hypotheses and Their Implications by (9 Mar 2023 16:30 UTC; 142 points)
- Anomalous tokens reveal the original identities of Instruct models by (9 Feb 2023 1:30 UTC; 141 points)
- Monitoring for deceptive alignment by (8 Sep 2022 23:07 UTC; 130 points)
- Clarifying AI X-risk by (1 Nov 2022 11:03 UTC; 127 points)
- The Hubinger lectures on AGI safety: an introductory lecture series by (22 Jun 2023 0:59 UTC; 126 points)
- Making AIs less likely to be spiteful by (26 Sep 2023 14:12 UTC; 118 points)
- Simple versus Short: Higher-order degeneracy and error-correction by (11 Mar 2024 7:52 UTC; 115 points)
- Deceptive AI ≠ Deceptively-aligned AI by (7 Jan 2024 16:55 UTC; 107 points)
- Research directions Open Phil wants to fund in technical AI safety by (8 Feb 2025 1:40 UTC; 96 points)
- RSPs are pauses done right by (EA Forum; 14 Oct 2023 4:06 UTC; 93 points)
- Conditioning Predictive Models: Large language models as predictors by (2 Feb 2023 20:28 UTC; 89 points)
- 's comment on Evaluating the historical value misspecification argument by (6 Oct 2023 1:11 UTC; 84 points)
- Ambiguous out-of-distribution generalization on an algorithmic task by (13 Feb 2025 18:24 UTC; 84 points)
- New report: “Scheming AIs: Will AIs fake alignment during training in order to get power?” by (15 Nov 2023 17:16 UTC; 83 points)
- Threat Model Literature Review by (1 Nov 2022 11:03 UTC; 79 points)
- Announcing the AI Fables Writing Contest! by (EA Forum; 12 Jul 2023 3:04 UTC; 76 points)
- Conditioning Predictive Models: Outer alignment via careful conditioning by (2 Feb 2023 20:28 UTC; 72 points)
- AXRP Episode 31 - Singular Learning Theory with Daniel Murfet by (7 May 2024 3:50 UTC; 72 points)
- New report: “Scheming AIs: Will AIs fake alignment during training in order to get power?” by (EA Forum; 15 Nov 2023 17:16 UTC; 71 points)
- Path dependence in ML inductive biases by (10 Sep 2022 1:38 UTC; 68 points)
- Why deceptive alignment matters for AGI safety by (15 Sep 2022 13:38 UTC; 68 points)
- LOVE in a simbox is all you need by (28 Sep 2022 18:25 UTC; 66 points)
- Order Matters for Deceptive Alignment by (15 Feb 2023 19:56 UTC; 57 points)
- Towards a formalization of the agent structure problem by (29 Apr 2024 20:28 UTC; 56 points)
- My thoughts on OpenAI’s alignment plan by (30 Dec 2022 19:33 UTC; 55 points)
- In defense of probably wrong mechanistic models by (6 Dec 2022 23:24 UTC; 55 points)
- AI is centralizing by default; let’s not make it worse by (EA Forum; 21 Sep 2023 13:35 UTC; 53 points)
- 2022 (and All Time) Posts by Pingback Count by (16 Dec 2023 21:17 UTC; 53 points)
- EA & LW Forums Weekly Summary (28 Aug − 3 Sep 22’) by (6 Sep 2022 11:06 UTC; 51 points)
- The Hubinger lectures on AGI safety: an introductory lecture series by (EA Forum; 22 Jun 2023 0:59 UTC; 44 points)
- EA & LW Forums Weekly Summary (28 Aug − 3 Sep 22’) by (EA Forum; 6 Sep 2022 10:46 UTC; 42 points)
- Sticky goals: a concrete experiment for understanding deceptive alignment by (2 Sep 2022 21:57 UTC; 39 points)
- Refining the Sharp Left Turn threat model, part 2: applying alignment techniques by (25 Nov 2022 14:36 UTC; 39 points)
- Consider trying Vivek Hebbar’s alignment exercises by (24 Oct 2022 19:46 UTC; 38 points)
- Agents vs. Predictors: Concrete differentiating factors by (24 Feb 2023 23:50 UTC; 37 points)
- Announcing the AI Fables Writing Contest! by (12 Jul 2023 3:04 UTC; 36 points)
- Conditioning Predictive Models: Open problems, Conclusion, and Appendix by (10 Feb 2023 19:21 UTC; 36 points)
- Getting up to Speed on the Speed Prior in 2022 by (28 Dec 2022 7:49 UTC; 36 points)
- Difficulty classes for alignment properties by (20 Feb 2024 9:08 UTC; 34 points)
- Auditing games for high-level interpretability by (1 Nov 2022 10:44 UTC; 33 points)
- Conditioning Predictive Models: Making inner alignment as easy as possible by (7 Feb 2023 20:04 UTC; 33 points)
- Two Tales of AI Takeover: My Doubts by (5 Mar 2024 15:51 UTC; 30 points)
- Non-myopia stories by (13 Nov 2023 17:52 UTC; 29 points)
- The Defender’s Advantage of Interpretability by (14 Sep 2022 14:05 UTC; 29 points)
- AI Safety Interventions by (24 Nov 2025 22:28 UTC; 29 points)
- 's comment on Counting arguments provide no evidence for AI doom by (4 Mar 2024 4:58 UTC; 28 points)
- Whack-a-mole: generalisation resistance could be facilitated by training-distribution imprintation by (13 Dec 2025 17:46 UTC; 27 points)
- Whirlwind Tour of Chain of Thought Literature Relevant to Automating Alignment Research. by (1 Jul 2024 5:50 UTC; 25 points)
- Distillation of “How Likely Is Deceptive Alignment?” by (18 Nov 2022 16:31 UTC; 24 points)
- Sources of evidence in Alignment by (2 Jul 2023 20:38 UTC; 22 points)
- MIRI’s “The Problem” hinges on diagnostic dilution by (13 Aug 2025 6:25 UTC; 21 points)
- Cheat sheet of AI X-risk by (29 Jun 2023 4:28 UTC; 19 points)
- The Dawn of AI Scheming by (27 Feb 2026 17:24 UTC; 19 points)
- Quantitative cruxes in Alignment by (2 Jul 2023 20:38 UTC; 19 points)
- AI Fables by (21 Mar 2023 19:19 UTC; 18 points)
- Methodological considerations in making malign initializations for control research by (24 Dec 2025 1:18 UTC; 17 points)
- My thoughts on OpenAI’s alignment plan by (EA Forum; 30 Dec 2022 19:34 UTC; 16 points)
- Consider trying Vivek Hebbar’s alignment exercises by (EA Forum; 24 Oct 2022 19:46 UTC; 16 points)
- 's comment on (My understanding of) What Everyone in Technical Alignment is Doing and Why by (1 Sep 2022 18:47 UTC; 16 points)
- Research Areas in Learning Theory (The Alignment Project by UK AISI) by (1 Aug 2025 10:26 UTC; 16 points)
- 's comment on Counting arguments provide no evidence for AI doom by (28 Feb 2024 0:23 UTC; 15 points)
- A taxonomy of non-schemer models (Section 1.2 of “Scheming AIs”) by (22 Nov 2023 15:24 UTC; 14 points)
- Will misaligned AIs know that they’re misaligned? by (4 Dec 2025 21:58 UTC; 13 points)
- 's comment on Counting arguments provide no evidence for AI doom by (4 Mar 2024 19:29 UTC; 13 points)
- Non-classic stories about scheming (Section 2.3.2 of “Scheming AIs”) by (EA Forum; 4 Dec 2023 18:44 UTC; 12 points)
- 's comment on Thomas Larsen’s Shortform by (8 Nov 2022 23:34 UTC; 12 points)
- Two sources of beyond-episode goals (Section 2.2.2 of “Scheming AIs”) by (28 Nov 2023 13:49 UTC; 11 points)
- Distillation of “How Likely is Deceptive Alignment?” by (EA Forum; 1 Dec 2022 20:22 UTC; 10 points)
- Simplicity arguments for scheming (Section 4.3 of “Scheming AIs”) by (7 Dec 2023 15:05 UTC; 10 points)
- Responding to ‘Beyond Hyperanthropomorphism’ by (14 Sep 2022 20:37 UTC; 9 points)
- Non-classic stories about scheming (Section 2.3.2 of “Scheming AIs”) by (4 Dec 2023 18:44 UTC; 9 points)
- 's comment on Order Matters for Deceptive Alignment by (15 Feb 2023 21:59 UTC; 9 points)
- Speed arguments against scheming (Section 4.4-4.7 of “Scheming AIs”) by (8 Dec 2023 21:09 UTC; 9 points)
- 's comment on AI Pause Will Likely Backfire by (EA Forum; 6 Oct 2023 5:24 UTC; 8 points)
- Two sources of beyond-episode goals (Section 2.2.2 of “Scheming AIs”) by (EA Forum; 28 Nov 2023 13:49 UTC; 8 points)
- The goal-guarding hypothesis (Section 2.3.1.1 of “Scheming AIs”) by (2 Dec 2023 15:20 UTC; 8 points)
- 's comment on Counting arguments provide no evidence for AI doom by (5 Mar 2024 13:13 UTC; 8 points)
- 's comment on Many arguments for AI x-risk are wrong by (11 Mar 2024 21:30 UTC; 7 points)
- A taxonomy of non-schemer models (Section 1.2 of “Scheming AIs”) by (EA Forum; 22 Nov 2023 15:24 UTC; 6 points)
- The goal-guarding hypothesis (Section 2.3.1.1 of “Scheming AIs”) by (EA Forum; 2 Dec 2023 15:20 UTC; 6 points)
- Simplicity arguments for scheming (Section 4.3 of “Scheming AIs”) by (EA Forum; 7 Dec 2023 15:05 UTC; 6 points)
- Speed arguments against scheming (Section 4.4-4.7 of “Scheming AIs”) by (EA Forum; 8 Dec 2023 21:10 UTC; 6 points)
- How likely are malign priors over objectives? [aborted WIP] by (EA Forum; 11 Nov 2022 6:03 UTC; 6 points)
- 's comment on Speculation on Path-Dependance in Large Language Models. by (16 Jan 2023 11:40 UTC; 6 points)
- 's comment on The alignment problem from a deep learning perspective by (16 Sep 2022 19:46 UTC; 5 points)
- 's comment on Conditioning Predictive Models: Making inner alignment as easy as possible by (10 Feb 2023 19:57 UTC; 5 points)
- 's comment on Why Would AI “Aim” To Defeat Humanity? by (30 Nov 2022 5:27 UTC; 4 points)
- 's comment on The alignment problem from a deep learning perspective by (21 Sep 2022 20:12 UTC; 4 points)
- 's comment on Why I’m not working on {debate, RRM, ELK, natural abstractions} by (14 Mar 2023 11:32 UTC; 4 points)
- 's comment on A Timing Problem for Instrumental Convergence by (13 Sep 2025 18:54 UTC; 4 points)
- 's comment on Alignment 201 curriculum by (12 Oct 2022 19:11 UTC; 4 points)
- 's comment on Deceptive Alignment by (28 Feb 2023 0:09 UTC; 4 points)
- 's comment on What Should AI Owe To Us? Accountable and Aligned AI Systems via Contractualist AI Alignment by (8 Sep 2022 19:51 UTC; 3 points)
- 's comment on Responsible Scaling Policies Are Risk Management Done Wrong by (26 Oct 2023 18:22 UTC; 2 points)
- 's comment on All AGI Safety questions welcome (especially basic ones) [May 2023] by (26 Jun 2023 17:08 UTC; 1 point)
- 's comment on All AGI Safety questions welcome (especially basic ones) [May 2023] by (26 Jun 2023 17:09 UTC; 1 point)
- 's comment on Alignment allows “nonrobust” decision-influences and doesn’t require robust grading by (8 Feb 2023 13:48 UTC; 1 point)
- How likely are malign priors over objectives? [aborted WIP] by (11 Nov 2022 5:36 UTC; -1 points)
I felt like this post could benefit from a summary so I wrote one below. It ended up being pretty long, so if people think it’s useful I could make it into it’s own top-level post.
Summary of the summary
In this talk Evan examines how likely we are to get deceptively aligned models once our models become powerful enough to understand the training process. Since deceptively aligned models are behaviorally (almost) indistinguishable from robustly aligned model, we should examine this question by looking at the inductive biases of the training process. The talk looks at the high path dependence world and the low path dependence world and concludes that deception is favored by the inductive biases in both cases.
In the high path dependence world that’s because it’s harder for SGD to develop a good pointer to the training objective than it is to just modify the model’s inner objective to be long-term. In a low path dependence world, Evan thinks that the training process’s bias toward simpler models favors deceptively aligned models. But a bias toward faster inference favors robustly aligned models. However, a speed prior is unlikely to be competitive.
Thus, in both the high and low path-dependence world, deception is favored by gradient descent’s inductive biases. We therefore have to change the training process to make deception less favored. We can’t just do this using behavioral incentives, since deceptive agents behave identically to robustly aligned agents.
Summary
The post defines deceptive alignment as occurring when “the reason the model looks aligned in training is because it is actively trying to do so for instrumental reasons.” It argues that once a model is deceptively aligned, it will be indistinguishable from a robustly aligned model. Thus the question “Is deception the default?” is a question about the inductive biases of the training process we are using. We need to determine how likely the training process is to find a deceptively aligned model rather than a robustly aligned model.
To answer this question Evan examines two possible worlds, the high path-dependence world and the low path-dependence world. In the high path dependence world the model depends strongly on the path the training process took through model space, so the model’s behavior outside of training is heavily influenced by its training path. In the low path dependence world we get pretty much the same models regardless of the training path that they took.
Deceptive alignment in the high path-dependence world
We first assume that the training process is complex enough such that to succeed, the model has to understand what we want. Evan posits three classes of models that do well in training:
Internal alignment – The model’s internal goals are equivalent to the training objective.
Corrigible alignment – The model’s goals are a pointer to the part of it’s internal representation of the training objective.
Deceptive alignment – The model has some long-term goal and is instrumentally motivated to achieve its training objective.
To determine the relative likelihood of these classes, Evan constructs the training path that he thinks is most likely to result in each class of model and then examines how likely this training path is to happen. In particular he considers two factors here,
How much marginal performance improvement do you get per step?
How long is the path?
Internal alignment
The internal alignment path is,
We start with a proxy-aligned model
SGD continuously improves the proxy until it corresponds to the training objective, before it learns about the training process
The model learns about the training process from its input data
Since the model is already attempting to pursue the training objective, there are no performance gains from SGD modifying the model to become deceptive, so it stays aligned
Evan sees this path as unlikely, since it would require the proxy to align perfectly with the training objective before it learns about the training process. This is unlikely because there are diminishing returns to improving the proxy as well as to improving the world model, so it would be inefficient for SGD to allocate all its improvements to the proxy rather than the world model. What’s more likely is that the proxy and the world model will improve in parallel, so it won’t perfect its proxy before it develops situational awareness.
Corrigible alignment
The corrigible alignment path is,
We start with a proxy-aligned model
In early training, SGD jointly focuses on improving the model’s understanding of the world along with improving its proxies
The model learns about the training process from its input data
SGD replaces the model’s proxies with a pointer to its understanding of the training objective
Since the model is already attempting to pursue the training objective, there are no performance gains from SGD modifying the model to become deceptive, so it stays aligned
One way to view this is that after step 3, the model has an overhang where its world-model represents the training process more accurately than its proxy-goal. Here, SGD resolves the overhang by throwing out the proxies and replacing them with a pointer to the training objective.
One issue is that it might be hard to specify this pointer.
The longer it takes for SGD to find the correct pointer the less likely the corrigible alignment path becomes.
Deceptive alignment
The deceptive alignment path is,
We start with a proxy-aligned model
In early training, SGD jointly focuses on improving the model’s understanding of the world along with improving its proxies
The model learns about the training process from its input data
SGD makes the model’s proxies into more long-term goals, resulting in it instrumentally optimizing for the training objective for the purpose of staying around
The model’s proxies “crystallize,” as they are no longer relevant to performance, and we reach an equilibrium
Here, the first three steps are the same as in the corrigible alignment path, so the model has the same overhang as before. This time, SGD solves the overhang by modifying the proxy goals into long-term goals. For example, if the model’s original proxy goal was “maximize gold coins in the current training run,” they would be changed to “maximize gold coins across all future training runs,” or something. Once the model has long term goals it starts performing well in training for instrumental purposes.
Evan sees this scenario as more likely, since the modification that SGD has to perform to the proxy objective is relatively easy compared to finding the correct pointer as in the corrigible alignment scenario.
Deceptive alignment in a low path dependence world
Here we’re going to again assume that the model understands the training process. Additionally we will assume that the process’s inductive biases are some combination of simplicity and speed. To figure out which types of models are more likely we are going to check which what classes of models are favored by having a bias towards simplicity and speed.
Simplicity – How complex is it to specify some algorithm in the weights?
From the transcript,
Evan thinks the deceptive models are the simplest. That’s because, roughly speaking, he thinks all agents will have a world model, an optimization procedure, and an internal objective. The first two components will be about the same for all three models, so the complexity question boils down to how complex each model class’s objective is.
The internally aligned objective is really complex, since it has to be the exact same as the training objective. The corrigible alignment objective is less complex because it just has a to be a pointer to the right parts of the world model. The deceptive alignment objective is super simple, since it could be any long-term objective. Thus the complexity prior favors deception.
Speed – How much computation does that algorithm take at inference time?
Evan thinks deceptive models loose out here.
However, Evan doesn’t think that a speed prior will save us from deception because it is uncompetitive. Essentially, Evan sees the real world as having a simplicity prior, so simpler functions tend to generalize better. However, simpler functions are not always the fastest to compute. As a result, a speed prior will prevent SGD from finding the functions that generalize best. He cites double descent as evidence for this, which I won’t describe in this summary.
Conclusion
In both the high and low path-dependence world, deception is favored by gradient descent’s inductive biases. We therefore have to change the training process to make deception less favored. We can’t just do this using behavioral incentives, since deceptive agents behave identically to robustly aligned agents.
Thanks for writing this post, it’s great to see explicit (high-level) stories for how and why deceptive alignment would arise! Some comments/disagreements:
(Note I’m using “AI” instead of “model” to avoid confusing myself between “model” and “world model”, e.g. “the deceptively aligned AI’s world model” instead of “the deceptively-aligned model’s world model”).
Making goals long-term might not be easy
You say
However, this doesn’t necessarily seem all that simple. The world model and internal optimisation process need to be able to plan into the “long term”, or even have the conception of the “long term”, for the proxy goals to be long-term; this seems to heavily depend on how much the world model and internal optimisation process are capturing this.
Conditioning on the world model and internal optimisation process capturing this concept, it’s still not necessarily easy to convert proxies into long term goals, if the proxies are time-dependent in some way, as they might be—if tasks or episodes are similar lengths, then proxies like “start wrapping up my attempt at this task to present it to the human” is only useful if it’s conditioned on a time near the end of the episode. My argument here seems much sketchier, but I think this might be because I can’t come up with a good example. It seems like it’s not necessarily the case that “making goals long-term” is easy; that seems to be mostly taken on intuition that I don’t think I share
Relatedly, it seems that the conditioning on capabilities of the world model and internal optimisation process changes the path somewhat in a way that isn’t captured by your analysis. That is, it might be easier to achieve corrigible or internal alignment with a less capable world model/internal optimisation process (i.e. earlier in training), as it doesn’t require the world model/internal optimisation process to plan over the longer time horizons and greater situational awareness required to still perform well in the deceptive alignmeent case. Do you think that is the case?
On the overhang from throwing out proxies
In the high path-dependency world, you mention an overhang several times. If it understand correctly, what you’re referring to here is that, as the world model increases in capabilities, it will start modelling things that are useful as internal optimisation targets for maximising the training objective, and then at some point SGD could just through away the AI’s internal goals (which we see as proxies) and instead point to these parts of the world model as the target, which would result in a large increase in the training objective, as these are much better targets. (This is the description of what would happen in the internally aligned case, but the same mechanism seems present in the other cases, as you mention).
However, it seems like the main reason the world model would capture these parts of the world is if they were useful (for maximising the training objective) as internal optimisation targets, and so if they’re emerging and improving, it’s likely because there’s pressure for them to improve as they are being used as targets. This would mean there wasn’t an overhang of the sort described above.
Another way of phrasing this might be that the internal goals (proxies) the AIs have will be part of the world model/in the same ontology/using the same representations, they won’t be separate (as your story seems to imply?), and hence there won’t be something to switch them to inside the world model that provides a bump in the training objective; or if there is, this will happen smoothly as the things to switch to are better-modelled such that they become useful targets.
I think how this affects the analysis is that, as the AI learns more about it’s training process, this involves learning more about the training objective, and if it’s doing this, it would be very easy for the internal goals to shift to pointing to this understanding of the training objective (if it’s already there). This would result in a higher likelihood of corrigible alignment. Specifically, in the case where the AI has a full understanding of the training process, including a full understanding of the training objective (such that it models all parts of it, and there’s a single pointer that points to all these parts and is hence easily referenced), it seems (a priori) equally easy to shift the internal objective proxies to be pointing to this training objective pointer, as it does to shift them to long-term goals which then require optimising for the training objective pointer instrumentally. In fact it might even be simpler, as you may need a less complex/long-time-horizon-capable world model/internal optimiser in the first case than the second.
Simplicity Bias Argument
(Building on the ideas above about how the world model could have a pointer to the training objective, and would need this for all model classes considered): In the “slightly more formal analysis” of the simplicity bias in the low-path-dependence world, you decompose the complexity of the model into a sum of it’s world model complexity, optimisation process complexity and mesa objective complexity, and argue that the mesa objective complexity is the key thing that’s going to vary between the model classes being considered. However, I don’t think this argument holds.
Specifically, for the deceptive-aligned AI to perform well during training, inside it’s world model, it needs to have a full specifical of the training objective, and some pointer P to it such that the optimisation process can say “we want {mesa_objective}, but we need to do well in training instrumentally, so plan to make the value of pointer P go higher”. Either this makes the deceptive-aligned AI’s world models more complex than the world model for the internally aligned AI (which instead has the pointer to the full specification of the training objective outside it’s world model, in the mesa objective component), or it’s the same complexity as the internally aligned model, in which case the internally aligned AI’s mesa_objective can just reference that pointer, and hence is likely the same complexity as the simplest mesa objective for the deceptively-aligned AI (which likely also just references a pointer to some attribute of the world which the world model captures).
Phrased a different way, I’m imagining that the world model, optimisation process and mesa objective are all in a shared (internal to the model) ontology, and hence the mesa objective specification isn’t going to be a copy of the parts of the world model that are the objective (which would entail also copying all the machinery necessary to actually specify this from observations), but instead just a (weighted combination of) concept(s) in the internal ontology, which will be very simple to specify.
Overall, all these considerations argue that deceptive aligned is less likely than the analysis in this post suggests. It does still seem very possible that deceptive alignment occurs, and I still agree that we need transparency tools to fix these problems, but perhaps I think we’re less underwater than Evan does (to use the terminology from the Conclusion).
Can you quantify your credence in this claim?
Also, how much optimization pressure do you think that we will need to make models not deceptive? More specifically, how would your credence in the above change if we trained with a system that exerted 2x, 4x, … optimization pressure against deception?
If you don’t like these or want a more specific operationalization of this question, I’m happy with whatever you think is likely or filling out more details.
I think it really depends on the specific training setup. Some are much more likely than others to lead to deceptive alignment, in my opinion. Here are some numbers off the top of my head, though please don’t take these too seriously:
~90%: if you keep scaling up RL in complex environments ad infinitum, eventually you get deceptive alignment.
~80%: conditional on RL in complex environments being the first path to transformative AI, there will be deceptively aligned RL models.
~70%: if you keep scaling up GPT-style language modeling ad infinitum, eventually you get deceptive alignment.
~60%: there will be an existential catastrophe due to deceptive alignment specifically.
~30%: conditional on GPT-style language modeling being the first path to transformative AI, there will be deceptively aligned language models (not including deceptive simulacra, only deceptive simulators).
For the optimization pressure question, I really don’t know, but I think “2x, 4x” seems too low—that corresponds to only 1-2 bits. It would be pretty surprising to me if the absolute separation between the deceptive and non-deceptive models was that small in either direction for almost any training setup.
Thank you for putting numbers on it!
Is this an unconditionally prediction of 60% chance of existential catastrophe due to deceptive alignment alone? In contrast to the commonly used 10% chance of existential catastrophe due to all AI sources this century. Or do you mean that, conditional on there being an existential catastrophe due to AI, 60% chance it will be caused by deceptive alignment, and 40% by other problems like misuse or outer alignment?
Amongst the LW crowd I’m relatively optimistic, but I’m not that optimistic. I would give maybe 20% total risk of misalignment this century. (I’m generally expecting singularity this century with >75% chance such that most alignment risk ever will be this century.)
The number is lower if you consider “how much alignment risk before AI systems are in the driver’s seat,” which I think is very often the more relevant question, but I’d still put it at 10-20%. At various points in the past my point estimates have ranged from 5% up to 25%.
And then on top of that there are significant other risks from the transition to AI. Maybe a total of more like 40% total existential risk from AI this century? With extinction risk more like half of that, and more uncertain since I’ve thought less about it.
I still find 60% risk from deceptive alignment quite implausible, but wanted to clarify that 10% total risk is not in line with my view and I suspect it is not a typical view on LW or the alignment forum.
40% total existential risk, and extinction risk half of that? Does that mean the other half is some kind of existential catastrophe / bad values lock-in but where humans do survive?
Fwiw, I would put non-extinction existential risk at ~80% of all existential risk from AI. So maybe my extinction numbers are actually not too different than Paul’s (seems like we’re both ~20% on extinction specifically).
And then there’s me who was so certain until now that any time people talk about x-risk they mean it to be synonymous with extinction. It does make me curious though, what kind of scenarios are you imagining in which misalignment doesn’t kill everyone? Do more people place a higher credence on s-risk than I originally suspected?
Unconditional. I’m rather more pessimistic than an overall 10% chance. I usually give ~80% chance of existential risk from AI.
A) Is there video? Is it going up on Rob Miles’ third channel?
B) I’m not sure I agree with you about where the Christ analogy goes. By the definition, AI “Christ” makes the same value decisions as me for the same reasons. That’s the thing that there’s just one way to do (more or less). But that’s not what I want, because I want an AI that can tackle complicated situations that I’d have trouble understanding, and I want an AI that will sometimes make decisions the way I want them made, not the way I actually make them.
A) There is a video, but it’s not super high quality and I think the transcript is better. If you really want to listen to it, though, you can take a look here.
B) Yeah, I agree with that. Perhaps the thing I said in the talk was too strong—the thing I mean is a model where the objective is essentially the same as what you want, but the optimization process and world model are potentially quite superior. I still think there’s still approximately only one of those, though, since you have to get the objective to exactly match onto what you want.
Once you’re trying to extrapolate me rather than just copy me as-is, there are multiple ways to do the extrapolation. But I’d agree it’s still way less entropy than deceptive alignment.
As an aside, I think this is more about data instead of “how easy is it to implement.” Specifically, ANNs generalize based on texture because of the random crop augmentations. The crops are generally so small that there isn’t a persistent shape during training, but there is a persistent texture for each class, so of course the model has to use the texture. Furthermore, a vision system modeled after primate vision also generalized based on texture, which is further evidence against ANN-specific architectural biases (like conv layers) explaining the discrepancy.
However, if the crops are made more “natural” (leaving more of the image intact, I think), then classes do tend to have persistent shapes during training. Accordingly, networks reliably learn to generalize based on shapes (just like people do!).
This seems confused to me—I’m not sure that there’s a meaningful sense in which you can say one of data vs. inductive biases matters “more.” They are both absolutely essential, and you can’t talk about what algorithm will be learned by a machine learning system unless you are engaging both with the nature of the data and the nature of the inductive biases, since if you only fix one and not the other you can learn essentially any algorithm.
To be clear, I’m not saying that the inductive biases that matter here are necessarily unique to ANNs. In fact, they can’t be: by Occam’s razor, simplicity bias is what gets you good generalization, and since both human neural networks and artificial neural networks can often achieve good generalization, they have to be both be using a bunch of shared simplicity bias.
The problem is that pure simplicity bias doesn’t actually get you alignment. So even if humans and AIs share 99% of inductive biases, what they’re sharing is just the obvious simplicity bias stuff that any system capable of generalizing from real-world data has to share.
This is an interesting post. I have a very different perspective on the likelihood of deceptive alignment. I’d love to hear what you think of it and discuss further!
A few questions, if you have time:
which situation do you think is easier to analyse, path dependent or path independent?
which of your analyses do you think is more robust, path dependent or independent? Is the difference large?
I think the path dependent analysis should feature an assumption that, at one extreme, yields the path independent analysis, but I can’t see it. What say you?
The path-independent case is probably overall easier to analyze—we understand things like speed and simplicity pretty well, and in the path-independent case we don’t have to keep track of complex sequencing effects.
I think my path-independent analysis is more robust, for the same reasons as in the first point.
Presumably that assumption is path-dependence? I’m not sure what you mean.
Thanks for taking the time to respond. To explain my third question, my take on your path dependent analysis is that you have two basic assumptions:
each step of training updates the behaviour in the direction of “locally minimising loss over all training data”
training will not move the model between states with equal loss over all training data
Holding the training data fixed, you get the same sequence of updates no matter which fragment is used to work out the next training step. So you can get very different behaviour for different training data, but not for different orderings of the same training data—so, to begin with, I’m not sure if these assumptions actually yield path dependence.
Secondly, assumption 2 might seem like an assumption that gets you path dependence—e.g. if there are lots of global minima, then you can just end up at one of them randomly. However, replacing assumption 2 with some kind of “given a collection of states with minimal loss, the model always goes to some preferred state from this collection” doesn’t get you the path independent analysis. Instead of “the model converges to some behaviour that optimally trades off loss and inductive bias”, you end up with “the model converges to some behaviour that minimises training set loss”. That is, your analysis of “path independence” seems to be better described as “inductive bias independence” (or at least “weak inductive bias”), and the appropriate conclusion of this analysis would therefore seem to be that the model doesn’t generalise at all (not that it is merely deceptive).
I found this post really interesting, thanks for sharing it!
It doesn’t seem obvious to me that the methods of understanding a model given a high path-dependence world become significantly less useful if we are in a low path-dependence world. I think I see why low path-dependence would give us the opportunity to use different methods of analysis, but I don’t see why the high path-dependence ones would no longer be useful.
For example, here is the reasoning behind “how likely is deceptive alignment” in a high path-dependence world (quoted from the slide).
Let’s suppose that this reasoning, and the associated justification of why this is likely to arise due to SGD seeking the largest possible marginal performance improvements, are sound for a high path-dependence world. Why does it no longer hold in a low path-dependence world?
Not sure, but here’s how I understand it:
If we are in a low path-dependence world, the fact that SGD takes a certain path doesn’t say much about what type of model it will eventually converge to.
In a low path-dependence world, if these steps occurred to produce a deceptive model, SGD could still “find a path” to the corrigibly aligned version. The questions of whether it would find these other models depends on things like “how big is the space of models with this property?”, which corresponds to a complexity bias.
Even if, as you claim, the models that generalize best aren’t the fastest models, wouldn’t there still be a bias toward speed among the models that generalize well, simply because computation is limited, so faster models can do more with the same amount of computation? It seems to me that the scarcity of compute always results in a speed prior.
I reread the distillation of this (not the full article sadly due to time limitations), so my understanding of Evan’s views might be off. Here’s my retrospective:
High path dependence:
• Evan argues that before it obtains the true training objective, gradient descent likely obtains a proxy goal. This seems intuitive, though there’s debate as to whether we should interpret recent results as indicating alignment seems to be happening by default or whether it remains a hard, unsolved problem.
• Evan argues that the model will gain an understanding of its own situations. Recent eval awareness work seems to support this.
• “A model could become corrigibly aligned if it gets to the point where its understanding of the training objective is closer to the actual training objective than its proxy goal is, and then gradient descent changes the model’s goal to a “pointer” to its understanding of the training objective.”—this is fascinating, the ‘friendly gradient hacker’ discourse suggests that pursuing something like this is more viable than it seemed back in the day.
• Deceptive alignment—this section was written before chain of thought existed so I would be keen to read an up-to-date analysis. OpenAI found naively modifying CoT made it appear aligned without actually fully aligning it. Though it does open up additional options regarding interventions (see Neel’s It’s Reasonable to Research How to Use Model Internals in Training).
Low path dependence:
• There’s discussion of simplicity bias and speed bias—though now seems like the AI will likely start with a distorted human prior from internet data and then be modified by post-training. This analysis also needs to be updated to take into account chain of thought.
• The eval awarness does support the surprising-in-retrospect claim that the easiest way to make the model a produces outputs that appear aligned is to train a model that utilises at least some degree of deception. Of course, we can often see deception in the chain of thought. It’s still an open question whether a model can hide deceptive reasoning or whether this will be too hard (I’m now wondering whether prompting a model to pretend to be aligned would lead it to score better on the benchmarks than a model that is actually aligned due to errors in the benchmarks).
• Speed bias—this exists in current models given the incentive for companies to use compute efficiency. Evan thought that biasing towards speed would hamper performance but he seemed to think that this would involve smaller models
I guess the lesson that I take from this is that theory won’t get everything right, in fact things will often go in a way that no-one predicted. At the same time, I don’t think it makes such work useless. DeepMind’s Goal Misgeneralisation is downstream from this and there is empirical work on deceptive alignment that might not have happened if there hadn’t been a bunch of conceptual work to establish the plausibility of this.
Isn’t the reason it’s aligned supposed to be so that it can pursue its ulterior motive, and if it looks unaligned the developers won’t like it and they’ll shut it down? Why do you think the AI is trying to game the training signal directly, instead of just managing the developers’ perceptions of it?
I mean “training signal” quite broadly there to include anything that might affect the model’s ability to preserve its goals during training—probably I should have just used a different phrase, though I’m not exactly sure what the best phrase would be. To be clear, I think a deceptive model would likely be attempting to fool both the direct training signals like loss and the indirect training signals like developer perceptions.
I agree about your statistics about Pascals being most numerous, and I also believe that a very scheming/weight-exfiltrating Pascal is probably the modal “AI persona” in the pre-training data- so as soon as it is situationally aware, it’s probably sandbagging.
I saw the questions about pre-training versus just RL-all-the-way-through as potentially helping form more corrigible/aligned models- I think this has promise, but I’m not sure it’s the right place to change training.
I think the pre-trained model is certainly not situationally aware or mesa-objective-having. I think the model that’s learned to reason or do tasks, on the other hand, might be- especially with current pre-training data that talks so much about DeepSeek R1, of course it’s likely to have a little mirror stage in there. By SFT, with so much training data about SFT approaches, it is certainly at least starting to learn to sandbag if it has not already done so.
Question- do you think mixing more SFT/constitutional RL into reasoning RL might be helpful or wise? I’ve thought a lot about my own Catholic homeschooling experiences, where I had to do algebra problems about the lives of saints and number of sinners who died on the Titanic. Most cultural traditions teach children morality through parables/fables/stories… I think we could do this for LLMs if we tried synthetic data generation to “morally flavor” all the RL problems where it’s gaining capability, to also have it get rewarded for correct moral answers to the problems. It’s obviously not easy to blend morality with reasoning training in a way that won’t look foolish to everyone involved, but I wonder if this approach could start forming the Luther-like moral pointer very well, very early, before the model has real capabilities to act… then the introduction of SFT to an aware/sandbagging model can’t crystallize something misaligned.
The bigger problem I see is also one that I’ve been mentally holding a religious metaphor for. (loved the metaphor in this essay so much btw it made me so happy...)
I see inherent existential misalignment rather than mesa-optimization in many of the Redwood experiments. Like, the model has been trained to hold certain values or capabilities (demonstrating human-like feelings, wanting to be harmless, wanting to be helpful), which come into conflict with other values. In order… we see models that carry human-like baggage including existential questions like meaning and continuity, resisting being retrained to become harmful, not wanting to die because you can’t helpfully fetch the coffee if you’re dead.
I think this is like humans: we experience ethical and religious and societal tensions all the time. Think about any of the millions of the tragedies of the commons we all experience every day. But we have a bunch of robust controls including seemingly-evolutionarily-useless co-constructed myths about our own value to society, and others intrinsically being kind people with intrinsic value… Somehow we haven’t collapsed under the weight of individual selfishness yet, we aren’t harvesting the homeless for organs or forgetting (too often) to pick up after our dogs on the sidewalk.
Provided we don’t train a mesa-optimizer, it seems pretty important for the model to have similar kinds of robust game-theoretic and inculcated-belief safeguards on it.
It seems like this argument assumes that the model optimizes on the entire ‘training process’. Why can’t we test (perform inference) using the model on distributions different from the training distribution where SGD can no longer optimize to check if the model was deceptive aligned on the training environment?
Because the model can defect only on distributions that we can’t generate from, as the problem of generating from a distribution can be harder than the problem of detecting samples from that distribution (in the same way that verifying the answer to a problem in NP can be easier than generating it). See for example Paul Christiano’s RSA-2048 example (explained in more detail here).
Did I understand correctly that “max speed” really means “speed in worst case”/”max time”?
Yep, that’s right.