Do confident short timelines make sense?
Tsvi’s context
Some context:
My personal context is that I care about decreasing existential risk, and I think that the broad distribution of efforts put forward by X-deriskers fairly strongly overemphasizes plans that help if AGI is coming in <10 years, at the expense of plans that help if AGI takes longer. So I want to argue that AGI isn’t extremely likely to come in <10 years.
I’ve argued against some intuitions behind AGI-soon in Views on when AGI comes and on strategy to reduce existential risk.
Abram, IIUC, largely agrees with the picture painted in AI 2027: https://ai-2027.com/
Abram and I have discussed this occasionally, and recently recorded a video call. I messed up my recording, sorry—so the last third of the conversation is cut off, and the beginning is cut off. Here’s a link to the first point at which you can actually hear Abram:
https://www.youtube.com/watch?v=YU8N52ZWXxQ&t=806s
I left the conversation somewhat unsatisfied, mainly because I still don’t feel I understand how others such as Abram have become confident that AGI comes soon. IIUC, Abram states a probability around 50% that we’ll have fast unbounded recursively self-improving general intelligence by 2029.
In conversations with people who state confidently that AGI is coming soon, I often try to ask questions to get them to spell out certain reasoning steps clearly and carefully—but this has quite failed for the most part for some reason. So I’ll just state what I was trying to get people to say. I think they are saying:
1. We have lots of tasks newly being performed.
2. (Perhaps it’s true that AIs currently do much worse on truly novel / truly creative tasks.)
3. However, the research programs currently running will very soon create architectures that produce success on truly novel tasks, by induction on the regularity from 1.
To be honest, I think this summary is rather too charitable, to the point of incorrectly characterizing many confident-AGI-sooners’s beliefs—and in fact their position is much more idiotic, namely “there’s literally no difference between novel and non-novel tasks, there’s no such thing as “truly creative” lol”.
But I don’t believe that’s Abram’s position. I think Abram agrees there’s some sort of difference between novel and non-novel performance. Abram gives the example of talking to a gippity about category theory. For questions that are firmly in the realm of stuff about category theory that people write about a lot, the gippity does quite well. But then if Abram starts asking about novel ideas, the gippity performs poorly.
So if we take the above 1,2,3 points, we have an enthymemic argument. The hidden assumption I’m not sure how to state exactly, or maybe it varies from person to person (which is part of why I try to elicit this by asking questions). The assumption might be like
The tasks that Architectures have had success on have expanded to include performance that’s relatively more and more novel and creative; this trend will continue.
Or it could be
Current Architectures are not very creative, but they don’t need to be in order to make human AGI researchers get to creative AI in the next couple years.
Or it’s both or also some other things. It could be
Actually 2. is not true—current Architectures are already fully creative.
If it’s something like
The tasks that Architectures have had success on have expanded to include performance that’s relatively more and more novel and creative; this trend will continue.
then we have an even more annoying enthymeme. WHAT JUSTIFIES THIS INDUCTION??
Don’t just say “obviously”.
To restate my basic view:
To make a very strong mind, you need a bunch of algorithmic ideas.
Evolution got a bunch of algorithmic ideas by running a very rich search (along many algorithmic dimensions, across lots of serial time, in a big beam search / genetic search) with a very rich feedback signal (“how well does this architecture do at setting up the matrix out of which a strong mind grows given many serial seconds of sense data / muscle output / internal play of ideas”).
We humans do not have many such ideas, and the ones we have aren’t that impressive.
The observed performance of current Architectures doesn’t provide very strong evidence that they have the makings of a strong mind. E.g.:
poor performance on truly novel / creative tasks,
poor sample complexity,
huge mismatch on novel tasks compared to “what could a human do, if that human could also do all the performance that the gippity actually can do”—i.e. a very very different generalization profile compared to humans.
To clarify a little bit: there’s two ways to get an idea.
Originarily. If you have an idea in an originary way, you’re the origin of (your apprehension of) the idea. The origin of something is something like “from whence it rises / stirs” (apparently not cognate with “-gen”).
Non-originarily. For example, you copied the idea.
Originariness is not the same as novelty. Novel implies originary, but an originary idea could be “independently reinvented”.
Human children do most of their learning originarily. They do not mainly copy the concept of a chair. Rather, they learn to think of chairs largely independently—originarily—and then they learn to hook up that concept with the word “chair”. (This is not to say that words don’t play an important role in thinking, include in terms of transmission—they do—but still.)
Gippities and diffusers don’t do that.
It’s the ability to originarily gain ideas that we’re asking about when we ask whether we’re getting AGI.
Background Context:
I’m interested in this debate mainly because my views on timelines have been very influenced by whoever I have talked with most recently, over the past few years (while definitely getting shorter on average over that period). If I’ve been talking with Tsvi or with Sam Eisenstat, my median-time-to-superintelligence is measured in the decades, while if I’ve been talking with Daniel Kokotajlo or Samuel Buteau, it’s measured in years (single-digit).
More recently, I’ve been more inclined towards the short end of the scale. The release of o1 made me update towards frontier labs not being too locked into their specific paradigm to innovate when existing methods hit diminishing returns. The AI 2027 report solidified this short-timeline view, specifically by making the argument that LLMs don’t need to show steady progress on all fronts in order to be on a trajectory for strong superintelligence; so long as LLMs continue to make improvements in the key capabilities related to an intelligence explosion, other capabilities that might seem to lag behind can catch up later.
I was talking about some of these things with Tsvi recently, and he said something like “argue or update”—so, it seemed like a good opportunity to see whether I could defend my current views or whether they’ll once again prove highly variable based on who I talk to.
A Naive Argument:
One of the arguments I made early on in the discussion was “it would seem like an odd coincidence if progress stopped right around human level.”
Since Tsvi put some emphasis on trying to figure out what the carefully-spelled-out argument is, I’ll unpack this further:
Argument 1
GPT1 (June 2018) was roughly elementary-school level in its writing ability.
GPT2 (February 2019) was roughly middle-school level.
GPT3 (June 2020) was roughly highschool-level.
GPT4 (March 2023) was roughly undergrad-level (but in all the majors at once).
Claude 3 Opus (March 2024) was roughly graduate-school level (but in all the majors at once).
Now, obviously, this comes with a lot of caveats. For example, while GPT4 scored very well on the math SAT, it still made elementary-school mistakes on basic arithmetic questions. Similarly, the ARC-AGI challenge highlights IQ-test-like visual analogy problems where humans perform well compared with LLMs. LLMs also lag behind in physical intuitions, as exemplified by EG the HellaSwag benchmark; although modern models basically ace this benchmark, I think performance lagged behind what the education-level heuristic would suggest.
Still, the above comparisons are far from meaningless, and a naive extrapolation suggests that if AI keeps getting better at a similar pace, it will soon surpass the best humans in every field, across a wide variety of tasks.
There’s a lot to unpack here, but I worry about getting side-tracked… so, back to the discussion with Tsvi.
Tsvi’s immediate reaction to my “it would seem like an odd coincidence if progress stopped right around the human level” was to point out AI’s heavy reliance on data; the data we have is generally generated by humans (with the exception of data created by algorithms, such as chess AI and so on). As such, it makes a lot of sense that the progress indicated in my bullet-points above could grind to a halt at performance levels within the human range.
I think this is a good and important point. I think it invalidates Argument 1, at least as written.
Why continued progress seems probable to me anyway:
As I said near the beginning, a major point in my short-timeline intuitions is that OpenAI and others have shown the ability to pivot from “pure scaling” to more substantive architectural improvements. We saw the first such pivot with ChatGPT (aka GPT3.5) in November 2022; the LLM pivoted from pure generative pre-training (“GPT”) to GPT + chat training (mainly, adding RLHF after the GPT training). Then, in September 2024, we saw the second such pivot with the rise of “reasoning models” via a type of training now called RL with Verifiable Feedback (RLVF).
GPT alone is clearly bottlenecked by the quality of the training data. Since it is mainly trained on human-generated data, human-level performance is a clear ceiling for this method. (Or, more accurately: its ceiling is (at best) whatever humans can generate a lot of data for, by any means.)
RLHF lifts this ceiling by training a reinforcement module which can distinguish better and worse outputs. The new ceiling might (at best) be the human ability to discern better and worse answers. In practice, it’ll be worse than this, since the reinforcement module will only partially learn to mimic human quality-discernment (and since we still need a lot of data to train the reinforcement module, so OpenAI and others have to cut corners with data-quality; in practice, the human feedback is often generated quickly and under circumstances which are not ideal for knowledge curation).
RLVF lifts this ceiling further by leveraging artificially-generated data. Roughly: there are a lot of tasks for which we can grade answers precisely, rather than relying on human judgement. For these tasks, we can let models try to answer with long chain-of-thought reasoning (rather than asking them to just answer right away). We can then keep only the samples of chain-of-thought reasoning which perform well on the given tasks, and fine-tune the model to get it to reason like that in general. This focuses the model on ways of reasoning which work well empirically. Although this only directly trains the model to perform well on these well-defined tasks, we can rely on some amount of generalization; the resulting models perform better on many tasks. (This is not too surprising, since we already knew that asking models to “reason step-by-step” rather than answering right away was known to increase performance for many tasks already. RLVF boosts this effect by steering the step-by-step reasoning towards reasoning steps which actually work well in practice.)
So, as I said, that’s two big pivots in LLM technology in the past four years. What might we expect in the next four years?
The Deductive Closure:
During the live debate Tsvi linked to, TJ (an attendee of the event) referred to the modern LLM paradigm providing a way to take the deductive closure of human knowledge: LLMs can memorize all of existing human knowledge, and can leverage chain-of-thought reasoning to combine that knowledge iteratively, making new conclusions. RLVF might hit limits, here, but more innovative techniques might push past those limits to achieve something like the “deductive closure of human knowledge”: all conclusions which can be inferred by some combination of existing knowledge.
What might this deductive closure look like? Certainly it would surpass the question-answering ability of all human experts, at least when it comes to expertise-centric questions which do not involve the kind of “creativity” which Tsvi ascribes to humans. Arguably this would be quite dangerous already.
The Inductive Closure:
Another point which came up in the live debate was the connect-the-dots paper by Johannes Treutline et al, which shows that LLMs generate new explicit knowledge which is not present in the training data, but which can be inductively inferred from existing data-points. For example, when trained only on the input-output behavior of some unspecified python function f, LLMs can sometimes generate the python code for f.
This suggests an even higher ceiling than the deductive closure, which we might call the “inductive closure” of human knowledge; IE, rather than starting with just human knowledge and then deducing everything which follows from it, I think it is also reasonable to imagine a near-term LLM paradigm which takes the deductive closure and adds everything that can be surmised by induction (then takes the deductive closure of that, then induces from those further datapoints, etc).
Again, this provides further motivation for thinking that realistic innovations in training techniques could shoot past the human-performance maximum which would have been a ceiling for GPT, or the human-discernment maximum which would have been a ceiling for RLHF.
Fundamental Limits of LLMs?
I feel this reply would be quite incomplete without addressing Tsvi’s argument that the things LLMs can do fundamentally fall short of specific crucial aspects of human intelligence.
As Tsvi indicated, I agree with many of Tsvi’s remarks about shortcomings of LLMs.
Example 1:
I can have a nice long discussion about category theory in which I treat an LLM like an interactive textbook. I can learn a lot, and although I double-check everything the LLM says (because I know that LLMs are prone to confabulate a lot), I find no flaw in its explanations.
However, as soon as I ask it to apply its knowledge in a somewhat novel way, the illusion of mathematical expertise falls apart. When the question I ask isn’t quite like the examples you’ll find in a textbook, the LLM makes basic mistakes.
Example 2:
Perhaps relatedly (or perhaps not), when I ask an LLM to try and prove a novel theorem, the LLM will typically come up with a proof which at first looks plausible, but upon closer examination, contains a step with a basic logical error, usually amounting to assuming what was to be proven. My experience is that these errors don’t go away when the model increments version numbers; instead, they just get harder to spot!
This calls into question whether anything similar to current LLMs can reach the “deductive closure” ceiling. Notably, Example 1 and Example 2 sound a lot like the capabilities of students who have memorized everything in the textbooks but who haven’t actually done any of the exercises. Such students will seem incredibly knowledgeable until you push them to apply the knowledge to new cases.
My intuition is that example 2 is mainly an alignment problem: modern LLMs are trained with a huge bias towards doing what humans ask (eg answering the question as stated), rather than admitting that they have uncertainty or don’t know how to do it, or other conversational moves which are crucial for research-style conversations but which aren’t incentivized by the training. The bias towards satisfying the user request swamps out the learned patterns of valid proofs, so that the LLM becomes a “clever arguer” rather than sticking to valid proof steps (even though it has a good understanding of “valid proof step” across many areas of mathematics).
Example 1 might be a related problem: perhaps LLMs try to answer too quickly, rather than reasoning things out step-by-step, due to strong priors about what knowledgeable people answering questions should look like. On this hypothesis, Example 1 type failures would probably be resolved by the same sorts of intellectual-honesty training which could resolve Example 2 type failures.
I should note that I haven’t tried the sort of category-theoretic discussion from Example 1 with reasoning LLMs. It seems possible that reasoning LLMs are significantly better at applying the patterns of mathematical reasoning correctly to not-quite-textbook examples (this is exactly the sort of thing they’re supposed to be good at!). However, I am a little pessimistic about this, because in my experience, problems like Example 2 persist in reasoning models. This seems to be due to an alignment problem; reasoning models have a serious lying problem.
We should also consider the hypothesis that Example 1 and Example 2 derive from a more fundamental issue in the generalization ability of LLMs: basically, they are capable of “interpolation” (they can do things that are very similar to what they’ve seen in textbooks) but are very bad at “extrapolation” (applying these ideas to new cases).
The Whack-A-Mole Argument
During the live debate, Mateusz (an attendee of the event) made the following argument:
There’s a common pattern in AI doom debates where the doomer makes a specific risk argument, the techno-optimist comes up with a way of addressing that problem, the doomer describes a second risk argument, the optimist comes up with a way of handling that problem, etc. After this goes back-and-forth for a bit, the doomer calls on the optimist to generalize:
“I can keep naming potential problems, and you can keep naming ways to avoid that specific problem, but even if you’re optimistic about all of your solutions not only panning out research-wise, but also being implemented in frontier models, you should expect to be killed by yet another problem which no one has thought of yet. You’re essentially playing a game of whack-a-mole where the first mole which you don’t wack in time is game over. This is why we need a systematic solution to the AI safety problem, which addresses all potential problems in advance, rather than simply patching problems as we see them.”
Mateusz compares this to my debate with Tsvi. Tsvi can point out a specific shortcoming of LLMs, and I can suggest a plausible way of getting around that shortcoming—but at some point I should generalize, and expect LLMs to have shortcomings which haven’t been articulated yet. This is why “expecting strong superintelligence soon” needs to come with a systematic understanding of intelligence which addresses all potential shortcomings in advance, rather than playing whack-a-mole with potential obstacles.
I’m not sure how well this reflects Tsvi’s position. Maybe Tsvi is pointing to one big shortcoming of LLMs (something like “creativity” or “originariness”) rather than naming one specific shortcoming after another. Nonetheless, Mateusz’ position seems like a plausible objection: maybe human intelligence relies on a lot of specific stuff, and the long-timelines intuition can be defended by arguing that it will take humans a long time to figure out all that stuff. As Tsvi said above:
2. Evolution got a bunch of algorithmic ideas by running a very rich search (along many algorithmic dimensions, across lots of serial time, in a big beam search / genetic search) with a very rich feedback signal (“how well does this architecture do at setting up the matrix out of which a strong mind grows given many serial seconds of sense data / muscle output / internal play of ideas”).
3. We humans do not have many such ideas, and the ones we have aren’t that impressive.
My reply is twofold.
First, I don’t buy Mateusz’ conclusion from the whack-a-mole analogy. AI safety is hard because, once AIs are superintelligent, the first problem you don’t catch can kill you. AI capability research is relatively easy because when you fail, you can try again. If AI safety is like a game of whack-a-mole where you lose the first time you miss, AI capabilities is like whack-a-mole with infinite retries. My argument does not need to involve AI capability researchers coming up with a fully general solution to all the problems (unlike safety). Instead, AI capability researchers can just keep playing whack-a-mole till the end.
Second, as I said near the beginning, I don’t need to argue that humans can solve all the problems via whack-a-mole. Instead, I only need to argue that key capabilities required for an intelligence explosion can continue to advance at rapid pace. It is possible that LLMs will continue to have basic limitations compared to humans, but will nonetheless be capable enough to “take the wheel” (perhaps “take the mallet”) with respect to the whack-a-mole game, accelerating progress greatly.
Generalization, Size, & Training
What if it isn’t a game of whack-a-mole; instead, there’s a big, fundamental failure in LLMs which reflects a fundamental difference between LLMs and human intelligence? The whack-a-mole picture suggests that there’s lots of individual differences, but each individual difference can be addressed within the current paradigm (IE, we can keep whacking moles). What if, instead, there’s at least one fundamental difference that requires really new ideas? Something fundamentally beyond the Deep Learning paradigm?
4. The observed performance of current Architectures doesn’t provide very strong evidence that they have the makings of a strong mind. E.g.:
a. poor performance on truly novel / creative tasks,
b. poor sample complexity,
c. huge mismatch on novel tasks compared to “what could a human do, if that human could also do all the performance that the gippity actually can do”—i.e. a very very different generalization profile compared to humans.
I agree with Tsvi on the following:
Current LLMs show poor performance on novel/creative tasks.
Current LLMs are very data-hungry in comparison to humans; they require a lot more data to learn the same thing.
If a human knew all the things that current LLMs knew, that human would also be able to do a lot of things that current LLMs cannot do. They would not merely be a noted expert in lots of fields at once; they would have a sort of synthesis capability (something like the “deductive closure” and “inductive closure” ideas mentioned earlier).
If these properties of Deep Learning continues to hold into the future, it suggests longer timelines.
Unfortunately, I don’t think these properties are so fundamental.
First and foremost, I updated away from this view when I read about the BabyLM Challenge. The purpose of this challenge is to learn language with amounts of data which are comparable to what humans learn from, rather than the massive quantities of data which ChatGPT, Claude, Gemini, Grok, etc are trained on. This has been broadly successful: by implementing some architectural tweaks and iterating training on the given data more times, it is possible for Transformer-based models to achieve GPT2 levels of competence on human-scale training data.
Thus, as frontier capability labs hit a data bottleneck, they might implement strategies similar to those seen in the BabyLM challenge to overcome that bottleneck. The resulting gains in generalization might eliminate the sorts of limitations to LLM generalization that we are currently seeing.
Second, larger models are generally more data-efficient. This observation opens up the possibility that the fundamental limitations of LLMs mentioned by Tsvi are primarily due to size. Think of modern LLMs like a parrot trained on the whole internet. (I am not claiming that the modern LLM sizes are exactly parrot-like; the point here is just that parrots have smaller brains than humans.) It makes sense that the parrot might be great at textbook-like examples but struggle to generalize. Thus, the limitations of LLMs might disappear as models continue to grow in size.
Creativity & Originariness
The ML-centric frame of “generalization” could be accused of being overly broad. Failure to generalize is actually a huge grab-bag of specific learning failures when you squint at it. Tsvi does some work to point at a more specific sort of failure, which he sometimes calls “creativity” but here calls “originariness”.
To clarify a little bit: there’s two ways to get an idea.
Originarily. If you have an idea in an originary way, you’re the origin of (your apprehension of) the idea. The origin of something is something like “from whence it rises / stirs” (apparently not cognate with “-gen”).
Non-originarily. For example, you copied the idea.
Originariness is not the same as novelty. Novel implies originary, but an originary idea could be “independently reinvented”.
Human children do most of their learning originarily. They do not mainly copy the concept of a chair. Rather, they learn to think of chairs largely independently—originarily—and then they learn to hook up that concept with the word “chair”. (This is not to say that words don’t play an important role in thinking, include in terms of transmission—they do—but still.)
Gippities and diffusers don’t do that.
Tsvi anticipates my main two replies to this:
The hidden assumption I’m not sure how to state exactly, or maybe it varies from person to person (which is part of why I try to elicit this by asking questions). The assumption might be like
The tasks that Architectures have had success on have expanded to include performance that’s relatively more and more novel and creative; this trend will continue.
Or it could be
Current Architectures are not very creative, but they don’t need to be in order to make human AGI researchers get to creative AI in the next couple years.
In my own words:
Current LLMs are a little bit creative, rather than zero creative. I think this is somewhat demonstrated by the connect-the-dots paper. Current LLMs mostly learn about chairs by copying from humans, rather than inventing the concept independently and then later learning the word for it, like human infants. However, they are somewhat able to learn new concepts inductively. They are not completely lacking this capability. This ability seems liable to improve over time, mostly as a simple consequence of the models getting larger, and also as a consequence of focused effort to improve capabilities.
An intelligence explosion within the next five years does not centrally require this type of creativity. Frontier labs are focusing on programming capabilities and agency, in part because this is what they need to continue to automate more and more of what current ML researchers do. As they automate more of this type of work, they’ll get better feedback loops wrt what capabilities are needed. If you automate all the ‘hard work’ parts of the research, ML engineers will be freed up to think more creatively themselves, which will lead to faster iteration over paradigms—the next paradigm shifts of comparable size to RLHF or RLVF will come at an increasing pace.
If it’s something like
The tasks that Architectures have had success on have expanded to include performance that’s relatively more and more novel and creative; this trend will continue.
then we have an even more annoying enthymeme. WHAT JUSTIFIES THIS INDUCTION??
To sum up my argument thus far, what justifies the induction is the following:
The abstract ceiling of “deductive closure” seems like a high ceiling, which already seems pretty dangerous in itself. This is a ceiling which current LLMs cannot hit, but which abstractly seems quite possible to hit.
While current models often fail to generalize in seemingly simple ways, this seems like it might be an alignment issue (IE possible to solve with better ideas of how to train LLMs), or a model size issue (possible to solve by continuing to scale up), or a more basic training issue (possible to solve with techniques similar to what was employed in the BabyLM challenge), or some combination of those things.
If these failures are more whack-a-mole like, it seems possible to solve them by continuing to play the currently-popular game of trying to train LLMs to perform well on benchmarks. (People will continue to make benchmarks like ARC-AGI which demonstrate the shortcomings of current LLMs.)
I somewhat doubt that these issues are more fundamental to the overall Deep Learning paradigm, due to the BabyLM results and to a lesser extent because generalization ability is tied to model size, which continues to increase.
I… continue to despair at bridging this gap… I don’t understand it… The basic thing is, how does any of this get you to 60% in 5 years???? What do you think you see???
I’ll first respond to some points—though it feels likely fruitless, because I still don’t understand the basic thing you think you see!
Some responses
You wrote:
Another point which came up in the live debate was the connect-the-dots paper by Johannes Treutline et al, which shows that LLMs generate new explicit knowledge which is not present in the training data, but which can be inductively inferred from existing data-points.
Earlier, I wrote:
Human children do most of their learning originarily. They do not mainly copy the concept of a chair. Rather, they learn to think of chairs largely independently—originarily—and then they learn to hook up that concept with the word “chair”.
That paper IIUC demonstrates the “hook up some already existing mental elements to a designator given a few examples of the designator” part. That’s not the important part.
it is possible for Transformer-based models to achieve GPT2 levels of competence on human-scale training data.
Ok… so it does much worse, you’re saying? What’s the point here?
Automating AGI research
If you automate all the ‘hard work’ parts of the research, ML engineers will be freed up to think more creatively themselves, which will lead to faster iteration over paradigms -
Ok so I didn’t respond to this in our talk, but I will now: I DO agree that you can speed up [the research that is ratcheting up to AGI] like this. I DO NOT agree that it is LIKELY that you speed [the research that is ratcheting up to AGI] up by A LOT (>2x, IDK). I AM NOT saying almost ANYTHING about “how fast OpenAI and other similar guys can do whatever they’re currently doing”. I don’t think that’s very relevant, because I think that stuff is pretty unlikely (<4%) to lead to AGI by 2030. (I will take a second to just say again that I think the probability is obviously >.1%, and that a >.09% of killing all humans is an insanely atrocious to do, literally the worst thing ever, and everyone should absolutely stop immediately and ban AGI and your children and your children’s children.)
Why not likely? Because
The actual ideas aren’t things that you can just crank out at 10x the rate if you have 10x the spare time. They’re the sort of thing that you usually get 0 of in your life, 1 if you’re lucky, several if you’re an epochal genius. They involve deep context and long struggle. (Probably. Just going off of history of ideas. Some random prompt or o5-big-thinky-gippity-tweakity-150128 could kill everyone. But <4%.)
OpenAI et al. aren’t AFAIK working on that stuff. If you work on not-the-thing 3x faster, so what?
Whence confidence?
I’ll again remind: what we’re talking about here is your stated probability of 60% AGI by 2030. If you said 15% I’d still disagree enough to say something, but I wouldn’t think it’s so anomalous, and wouldn’t necessarily expect there to be much model-sharing to do / value on the margin. But you’re so confident! You think you see something about the current state of AI that tells you with more than a fair coinflip that AGI comes within 5 years! How??
If these failures are more whack-a-mole like, it seems possible to solve them by continuing to play the currently-popular game of trying to train LLMs to perform well on benchmarks.
Ok. So you play whack-a-mole. And you continue to get AI systems that do more and more tasks. And they continue to not be much creative, because they haven’t been, and nothing is making new much creative AIs. So they can’t do much creative science. So what’s the point? Maybe it would help if you pick one, or both, of “we don’t need a creative AI to make AGI really fast, just an AI that’s good at a bunch of tasky tasks” or “actually there’s no such thing as creativity or the AIs are getting much more creative” or …. god, I don’t know what you’re saying! Anyway, pick one or the other or both or clarify, and then argue. I think in our talk we touched on which ones you’re putting weight on.… I think you said both basically?
Other points
Now I’ll make some other points:
I wish you would spend some time constructing actually plausible (I mean, as plausible as you can make them) hypothesis for the observations you adduce as evidence for AGI soon. See the “missing update” https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce:
There is a missing update. We see impressive behavior by LLMs. We rightly update that we’ve invented a surprisingly generally intelligent thing. But we should also update that this behavior surprisingly turns out to not require as much general intelligence as we thought.
The point is that we don’t have the important stuff in our hypothesis space.
Now I hear you saying “ah but if you have a really big NN, then there is a circuit within that size which has the important stuff”. Ok. Well, so? We’re talking about the total Architecture of current AIs, not “an argmax over literally all circuits of size k”. That’s just being silly. So ok, replace “in our hypothesis space” by “in our Architecture” or “in our accessible hypothesis space” or something.
Now I hear you saying “ah but maybe the core algos are in the training data well enough”. Ah. Well yes, that would be a crux, but why on earth do you think this?
Polya and Hadamard and Gromov are the exceptions that prove the rule. Nearly all mathematicians do not write much about the innards of their thinking processes; the discovery process is rather buried, retconned, cleaned up, or simply elided; further, we simply would not be able to do that, at least not without way more work, like a centuries-long intellectual project. Has anyone ever introspected so hard that they discerned the number of seconds it takes for serotonin to be reuptook, or how many hours(??) it takes for new dendrites to grow after learning? No.
Now apply that to the dark matter of intelligence. It’s not written anywhere, and only emanations of emanations are reflected in the data. You don’t see the many many many tiny and small and medium sized failed ideas, false starts, motions pruned away by little internal heuristics, brief combinations of ideas discarded, etc etc etc etc.… It’s not written out. You just get these leaps. The discovery process isn’t trained.
I’ll repeat one more time: Where do you get the confidence that the core algos are basically here already, or that we’re so close that AI labs will think of them in the next couple years?
Let me restate my view again. I think that:
1. PROBABLY, GI requires several algorithmic ideas.
2. A priori, a given piece of silicon does not implement these algorithmic ideas. Like how piles of steel aren’t randomly bridges.
2.1. So, a priori, PROBABLY GI is a rather long way off—hard to tell because humans given time can come with the algorithmic ideas, but they can’t do much in a couple years.
3. There’s not a strong body of evidence that we have all / most of the algorithmic ideas.
4. So we should have a fairly uninformed stance—though somewhat informed towards shorter—hard to say how much.
5. An uninformed stance implies smeared out, aka “long”, timelines.
I don’t even know which ones you disagree with, or whether you think this argument is confused / missing something big / etc. Maybe you disagree with 1? Surely you must agree with 2? Surely you must agree with 2.1, for a suitably “a priori” mindset?
I suppose you most disagree with 3? But I want to hear why you think that the evidence points at “actually we do have the algorithmic ideas”. I don’t think your arguments have addressed this?
I… continue to despair at bridging this gap… I don’t understand it… The basic thing is, how does any of this get you to 60% in 5 years???? What do you think you see???
I’ll first respond to some points—though it feels likely fruitless, because I still don’t understand the basic thing you think you see!
This ‘seeing’ frame seems inherently unproductive to me. I’ll try to engage with it, but, like… suppose Alice and Bob are both squinting at an object a long distance away from them, and trying to make it out. Alice says “I think it is a truck”. Bob says “I think it is a grain silo.” Alice turns to Bob, incredulous, and asks “What do you think you see??”
This seems like clearly the wrong question for Alice to ask. Bob has already answered that question. It would seem more productive for Alice to ask for details like what color Bob thinks the silo is, where he would place the bottom and top of the silo relative to other identifiable objects in the scene, etc. (Or Alice could point out where she sees wheels, windows, etc.)
Similarly, I’ve already been talking about what I think I see. I hear the “What do you think you see?” question as incredulity absent of specific content, much like “Whence the confidence?”. It frames things in terms of an intuition that you can simply look out at the world and settle questions by stating the obvious, ie, it’s a frame which seems to make little room for patience and difficult discussions.
I would suggest that naming cruxes would be a more helpful conversational frame.
Still… trying to directly answer the question… what do I think I see? (Please note that the following is very much not framed as an argument; I expect that responding to it as if it is one would be incredibly unproductive. I’m avoiding making ‘arguments’ here because that is what I was doing before that your “What do you think you see???” seems to express frustration with; so instead I’m just going to try to say what I see...)
In some sense what I think I see is the same thing I’ve seen since I first understood the arguments for a technological singularity: I see a long trend of accelerating progress. I see the nature of exponential curves, where if you try to draw the graph for any very long period of time, you’ll be forced to graph most of it as 0 with a quick shot up to your graph’s maximum at the end. Yes, most apparent exponentials turn out to be sigmoids in the end, but so far, new sigmoids keep happening.
What I see is computers that you can talk to like people, where previously there were none. I see that AI, as a field, has moved beyond narrow-AI systems which are only good for whatever specific thing they were built for.
I see a highly significant chunk of human economic and intellectual activity focused on pushing these things even further.
...
Anyway, I expect that this attempt only induces further frustration, similar to if Bob were to answer Alice’s question by further explaining what a silo is. It seems to me like the “seeing” frame assumes a privileged level/mode of description, like I could just explain my view properly, and then you’d know what my view is (like if Bob answered Alice’s question by snapping a photograph of what he sees and showing it to Alice… except this probably wouldn’t satisfy Alice! She’d probably still see the truck instead of the silo in the photo!)
[I’m pressing the submit button so that you can reply if you like. However, I have not even finished reading your latest reply yet. I plan to keep reading and replying piece-by-piece. However, it might be another week before I spend more time replying. I guess I’m just trying to say, don’t interpret me as bidding for you to reply to this fragment by itself.]
I hear the “What do you think you see?” question as incredulity absent of content.
The content is like this: I definitely hear you say things, and they make some amount of sense on their own terms. But when I try to tie them in to the overall question, I get really confused, and don’t know how to fill in the blanks. It feels like you (and several other people who say short timelines) keep saying things with the expectation that I’ll understand the relevance to the question, but I don’t understand it. Quite plausibly this is because I’m missing some stuff that it’s reasonable for you to expect me to know/understand, e.g. because it’s obvious or most people know it or most AI people know it etc. This is what I mean by enthymemes. There’s some connection between the data and arguments you adduce, and “60% in the next 5 years”, which I do not implement in my own beliefs, and which it seems like you perhaps intuitively expect me to implement.
Or, more shortly: I couldn’t pass your ITT against scrutiny from my own questions, and I’m signposting this.
I expect that this attempt only induces further frustration,
No! I appreciate the summary, and it feels easier to approach than the previous things—though of course it has elided our disagreements, as it is a summary—but I think it feels easier to approach because intuitively I expect (though reflectively I expect something to go wrong) that I could ask: “Ok you made 3 nice high level claims ABC. Now double click on just B, going down ONE level of detail. Ok you did B1,B2,B3. Now double click on just B3, going down ONE level. Ok great, B3.1 is a Crux!”
Whereas with a lot of these conversations, I feel the disagreement happened somewhere in the background prior to the conversation, and now we are stuck in some weeds that have presumed some crux in the background. Or something like this.
… Ah I have now seen the end of your message. I’ll rest for the moment, except to mention that if I were continuing as the main thread, I’d probably want to double click on
has moved beyond narrow-AI systems which are only good for whatever specific thing they were built for.
And ask about what the implication is. I take it that the implication is that we are somewhere right near/on the corner of the hockeystick; and that the hockeystick has something to do with generality / general intelligence / being able to do every or a wide variety of tasks / something. But I’d want to understand carefully how you’re thinking of the connection between “current AIs do a huge variety of tasks, many of them quite well” and something about [the sort of algos that will kill us], or specifically, “general intelligence”, or whatever other concept you’d want to put in that slot.
Because, like, I somewhat deny the connection!! Not super strongly, but somewhat!
Another question: I think (plz correct if wrong) that you have actually a significant event in the next five years? In other words, your yearly pAGI decreases by a lot after 5 years if no AGI yet. If so, we’d want to see how your reasoning leads to “AGI in 5 years” + “if not in 5 years, then I’m wrong about something” in a discrete way, rather than something like “we keep drawing 10% balls from the urn every year”.

Timeline Split?
There is a missing update. We see impressive behavior by LLMs. We rightly update that we’ve invented a surprisingly generally intelligent thing. But we should also update that this behavior surprisingly turns out to not require as much general intelligence as we thought.
Yeah, I definitely agree with something like this. In 2016, I (privately) estimated a 50% probability (because I couldn’t decide beyond a coinflip) that Deep Learning could be the right paradigm for AGI, in which case I expected language-based AGI first, and furthermore expected such AGI to be much more crystallized intelligence and much less fluid intelligence.
In hindsight, my probability on those things was actually much less than 50%, because I felt surprised and confused when they happened. I feel like LLMs are in many ways AI as predicted by Hollywood. I had intuitively expected that this level of conversational fluency would come with much more “actual understanding” amongst other things.
This is one reason why my timelines are split into roughly two scenarios, the shorter and the longer. The shorter timeline is like: there’s no missing update. Things just take time; you don’t get the perfected technology right out of the gate. What we’re seeing is still much like the first airplanes or the first automobiles etc. The intuitive prior, which expected all sorts of other things to come along with this level of conversational fluency, was correct; the mistake was only that you visualized the future coming all at once.
However, that’s not the only reason for the split, and maybe not the main reason.
Another question: I think (plz correct if wrong) that you have actually a significant event in the next five years? In other words, your yearly pAGI decreases by a lot after 5 years if no AGI yet. If so, we’d want to see how your reasoning leads to “AGI in 5 years” + “if not in 5 years, then I’m wrong about something” in a discrete way, rather than something like “we keep drawing 10% balls from the urn every year”.
Another reason for the split is that current AI capabilities progress is greatly accelerated by an exponentially increasing investment in computing clusters. This trend cannot continue beyond 2030 without something quite extreme happening (and may struggle to continue after 2028), so basically, if ASI doesn’t come < 2030 then P(ASI)-per-year plummets. See Vladimir Nesov’s analysis for more details.
(I will persist in using “AGI” to describe the merely-quite-general AI of today, and use “ASI” for the really dangerous thing that can do almost anything better than humans can, unless you’d prefer to coordinate on some other terminology.)
Holding fixed the question of the viability of the current paradigm, this means that whatever curve you’d use to predict p(ASI)-per-year gets really stretched out after 2030 (and somewhat stretched out between 2028 and 2030). If one thinks the current paradigm somewhat viable, this means a big question for P(ASI)<2030 is how long the hype train can keep going. If investors keep pouring in money to 10x the next training run, we keep getting the accelerated progress we’re seeing today; if investors get cold feet about AI tomorrow, then accelerated progress halts, and AI companies have to survive on income from their current products.
Of course, we don’t want to hold fixed the question of the viability of the current paradigm; the deflation of the curve past 2030 is further compounded by the evidence. Of course it’s possible that continued accelerated progress would have built ASI in 2031, so that if the hype train ends in 2029, we’re still just one 10x-training-run away from doom. However, if we’re not seeing “crazy stuff” by that point, that’s at least some evidence against the deep learning paradigm (and the more I expect ASI < 2030, the more evidence).
Line Go Up?
Quite plausibly this is because I’m missing some stuff that it’s reasonable for you to expect me to know/understand, e.g. because it’s obvious or most people know it or most AI people know it etc. This is what I mean by enthymemes. There’s some connection between the data and arguments you adduce, and 60% in the next 5 years, which I do not implement in my own beliefs, and which it seems like you perhaps intuitively expect me to implement.
You’re wrong about one thing there, namely “expect me to understand” / “intuitively expect me to implement”. I’m trying to articulate my view as best I can, but I don’t perceive anything I’ve said as something-which-should-be-convincing. I think this is a tricky issue and I’m not sure whether I’m thinking about it correctly.
I do have the intuitive feeling that you’re downplaying the plausibility of a certain cluster of views, EG, when you say:
I’ll again remind: what we’re talking about here is your stated probability of 60% AGI by 2030. If you said 15% I’d still disagree enough to say something, but I wouldn’t think it’s so anomalous, and wouldn’t necessarily expect there to be much model-sharing to do / value on the margin. But you’re so confident! You think you see something about the current state of AI that tells you with more than a fair coinflip that AGI comes within 5 years! How??
My intuitive response to this is to imagine that you and I are watching the water level rise against a dam. It has been rising exponentially for a while, but previously, it was under 1 inch high. Now it’s several feet high, and I’m expressing concern about the dam overflowing soon, and you’re like “it’s always been exponential, how could you know it’s overflowing soon” and I’m like “but its pretty high now” and you’re like “yeah but the top of the dam is REALLY high” and I’m like “it doesn’t look so tall to me” and you’re like “the probability that it overflows in the next five years has to be low, because us happening to find ourselves right around the time when the dam is about to break would be a big coincidence; there’s no specific body of evidence to point out the water doing anything it hasn’t before” …
The analogy isn’t perfect, mainly because the water level (and the right notion of water level) is also contested here. I tried to come up with a better analogy, but I didn’t succeed.
has moved beyond narrow-AI systems which are only good for whatever specific thing they were built for.
[...] I take it that the implication is that we are somewhere right near/on the corner of the hockeystick; and that the hockeystick has something to do with generality / general intelligence / being able to do every or a wide variety of tasks / something.
Stepping out of the analogy, what I’m saying is that there’s a naive line-go-up perspective which I don’t think is obviously persuasive but I also don’t think is obviously wrong (ie less-than-1%-probability). What do you think when you look at graphs like this? (source)
When I look at this, I have a lot of questions, EG, how do you estimate where to put “automated AI researcher/engineer”? How do you justify the labels for preschooler and elementary schooler?
However, there’s also a sense in which the graph does seem roughly correct. GPT-4 is missing some things that a smart highschooler has, sure, but the comparison does make a sort of sense. Thus, even though I don’t know how to place the labels for the extrapolated part of the graph (undergrad, phd student, postdoc...) I do have some intuitive agreement with the sort of projection being made here. It feels sensible, roughly, at least in an outside-view-sorta-way. Looking at the graph, I intuitively expect AI in 2027 to bear the same resemblance to a smart phd student that GPT4 bore to a smart highschooler.
At this point you could come up with many objections; the one I have in mind is the fact that we got from “preschooler” to “smart highschooler” mainly by training to imitate human data, and there’s a lot less human data available as we continue to climb that particular ladder. If the approach is to learn from humans, the ceiling would seem to be human performance. I’ve already given my reply to that particular objection, but as a reminder, I think the ceiling for the current approach looks more like things-we-can-test, and we can test performance far above human level.
But I’d want to understand carefully how you’re thinking of the connection between “current AIs do a huge variety of tasks, many of them quite well” and something about [the sort of algos that will kill us], or specifically, “general intelligence”, or whatever other concept you’d want to put in that slot.
The most relevant thing I can think to say at the moment is that it seems related to my view that LLMs are mostly crystallized intelligence and a little bit fluid, vs your view that they’re 100% crystallized and 0% fluid. My model of you expects the LLMs of 2027 to fall far short of the smart phd student because approximately everything interesting that the smart phd student does involves fluid intelligence. If LLMs of today have more-or-less memorized all the textbook answers, LLMs of 2027 might have more-or-less memorized all the research papers, but they still won’t be able to write a new one. Something like that?
Whereas I more expect the LLMs of 2027 to be doing many of those things that make a smart phd student interesting, because they can also pick up on some of those relevant habits of thought involved in creativity.
You wrote:
Another point which came up in the live debate was the connect-the-dots paper by Johannes Treutline et al, which shows that LLMs generate new explicit knowledge which is not present in the training data, but which can be inductively inferred from existing data-points.
Earlier, I wrote:
Human children do most of their learning originarily. They do not mainly copy the concept of a chair. Rather, they learn to think of chairs largely independently—originarily—and then they learn to hook up that concept with the word “chair”.
That paper IIUC demonstrates the “hook up some already existing mental elements to a designator given a few examples of the designator” part. That’s not the important part.
This feels like god-of-the-gaps arguing to me. Maybe I’m overly sensitive to this because I feel like people are moving goalposts with respect to the word “AGI”. I get that goalposts need to be moved sometimes. But to me, there are lots of lines one could draw around “creativity” or “fluid intelligence” or “originariness” or similar things (all attempts to differentiate between current AI and human intelligence, or current AI and dangerous AI, or such). By trying to draw such lines, you run the risk of cherry-picking, choosing the things we merely haven’t accomplished yet & thinking they’re fundamental.
I guess this is the fundamental challenge of the “missing update” in the essay you referenced earlier. To be properly surprised by and interested in the differences between LLMs and the AI we naively expected, you need to get interested in what they can’t do.
When I get interested in what they can’t do, though, I think of ways to do those things which build from LLMs.
You say of your own attempt to perform the missing update:
The point is that we don’t have the important stuff in our hypothesis space.
Now I hear you saying “ah but if you have a really big NN, then there is a circuit within that size which has the important stuff”. Ok. Well, so? We’re talking about the total Architecture of current AIs, not “an argmax over literally all circuits of size k”. That’s just being silly. So ok, replace “in our hypothesis space” by “in our Architecture” or “in our accessible hypothesis space” or something.
Now I hear you saying “ah but maybe the core algos are in the training data well enough”. Ah. Well yes, that would be a crux, but why on earth do you think this?
Polya and Hadamard and Gromov are the exceptions that prove the rule. Nearly all mathematicians do not write much about the innards of their thinking processes; the discovery process is rather buried, retconned, cleaned up, or simply elided; further, we simply would not be able to do that, at least not without way more work, like a centuries-long intellectual project. Has anyone ever introspected so hard that they discerned the number of seconds it takes for serotonin to be reuptook, or how many hours(??) it takes for new dendrites to grow after learning? No.
Now apply that to the dark matter of intelligence. It’s not written anywhere, and only emanations of emanations are reflected in the data. You don’t see the many many many tiny and small and medium sized failed ideas, false starts, motions pruned away by little internal heuristics, brief combinations of ideas discarded, etc etc etc etc.… It’s not written out. You just get these leaps. The discovery process isn’t trained.
You’re representing two alternative responses from me, but of course I have to argue that they’re adequately represented both in the accessible hypothesis space and in the training data. They have to be available for selection, and selected for. Although we can trade off between how easy the hypothesis is to represent vs how well-represented it is in the training data.
(Flagging double crux for easy reference: “the important stuff” is adequately represented in near-term-plausible hypothesis spaces and near-term-plausible training data.)
I also appreciate your point about how inaccessible the internal workings of the mind are from just a person’s writing. GPTs are not magical human-simulators that would predict authors by running brain-simulation if we just scaled them up a few orders of magnitude more.
Still, though, it seems like you’re postulating this big thing that’s hard to figure out, and I don’t know where that’s coming from. My impression is that LLMs are a very useful tool, when it comes to tackling the dark matter of intelligence. It wouldn’t necessarily have to be the case that
“the many many many tiny and small and medium sized failed ideas, false starts, motions pruned away by little internal heuristics, brief combinations of ideas discarded, etc etc etc etc....”
are well-represented by LLMs. It could be that the deep structure of the mind, the “mental language” in which concepts, heuristic, reflexes, etc are expressed, is so alien to LLMs that it’ll take decades to conquer.
It’s not what I expect.
Instead, it seems to me like these things can be conquered with “more of the same”. My version of the missing update includes an update towards incremental progress in AI. I’m more skeptical that big, deep, once-a-century insights are needed to make progress in AI. AI has not been what I expected, and specifically in the direction of just-scale-up being how a lot of progress happens.
Responding to some of the other points from the same section as the missing-update argument:
LLMs have fixed, partial concepts with fixed, partial understanding. An LLM’s concepts are like human concepts in that they can be combined in new ways and used to make new deductions, in some scope. They are unlike human concepts in that they won’t grow or be reforged to fit new contexts. So for example there will be some boundary beyond which a trained LLM will not recognize or be able to use a new analogy; and this boundary is well within what humans can do.
It is of course true that once training is over, the capacity of an LLM to learn is quite limited. It can do some impressive in-context learning, but this is of course going to be more limited than what gradient descent can learn. In this sense, LLMs are 100% crystalized intelligence once trained.
However, in-context learning will continue to get better, context windows will keep getting longer, and chain-of-thought reasoning will continue to be tuned to do increasingly significant conceptual work.
Imagine LLMs being trained to perform better and better on theorem-proving. I suppose you imagine the LLM accomplishing something similar to just memorizing how to prove more and more theorems. It can capture some class of statistical regularities in the theorems, sure, but beyond that, it gets better by memorizing rather than improving its understanding.
In contrast, I am imagining that getting better at theorem-proving involves a lot of improvement to its chain-of-thought math tactics. At some point, to get better it will need to be inventing new abstractions in its chain-of-thought, on the fly, to improve its understanding of the specific problem at hand.
An LLM’s concepts are mostly “in the data”. This is pretty vague, but I still think it. A number of people who think that LLMs are basically already AGI have seemed to agree with some version of this, in that when I describe something LLMs can’t do, they say “well, it wasn’t in the data”. Though maybe I misunderstand them.
I think it won’t surprise you that I agree with some version of this. It feels like modern LLMs don’t extrapolate very well. However, it also seems plausible to me that their ability to extrapolate will continue to get better and better as sizes increase and as architectural improvements are made.
When an LLM is trained more, it gains more partial concepts.
However, it gains more partial concepts with poor sample efficiency; it mostly only gains what’s in the data.
In particular, even if the LLM were being continually trained (in a way that’s similar to how LLMs are already trained, with similar architecture), it still wouldn’t do the thing humans do with quickly picking up new analogies, quickly creating new concepts, and generally reforging concepts.
Why do you believe this, and what sorts of concrete predictions would you make on this basis? EG, would it be possible to make an analogies benchmark (perhaps similar to ARC-AGI, perhaps not) reflecting this intuition?
Seems relevant to the BabyLM part of the discussion:
it is possible for Transformer-based models to achieve GPT2 levels of competence on human-scale training data.
Ok… so it does much worse, you’re saying? What’s the point here?
My earlier perspective, which asserted “LLMs are fundamentally less data-efficient than humans, because the representational capabilities of Transformers aren’t adequate for human concepts, so LLMs have to memorize many cases where humans can use one generalization” would have predicted that it is not possible to achieve GPT2 levels of linguistic competence on so little data.
Given the budgets involved, I think it is not at all surprising that only a GPT2 level of competence was reached. It therefore becomes plausible that a scaled-up effort of the same sort could reach GPT4 levels or higher with human-scale data.
The point being: it seems to me like LLMs can have similar data-efficiency to humans if effort is put in that direction. The reason we are seeing such a drastic difference now is due more to where the low-hanging fruit lies, rather than fundamental limitations of LLMs.
I don’t take this view to the extreme; for example, it is obvious that a Transformer many times the size of the human brain would still be unable to match parentheses beyond some depth (whereas humans can keep going, with effort). The claim is closer to Transformers matching the pattern-recognition capabilities of System 1, and this being enough to build up broader capabilities (eg by building some sort of reasoning on top).
(As a reminder, the above is still a discussion of the probable double crux identified earlier.)
Ok so I didn’t respond to this in our talk, but I will now: I DO agree that you can speed up [the research that is ratcheting up to AGI] like this. I DO NOT agree that it is LIKELY that you speed [the research that is ratcheting up to AGI] up by A LOT (>2x, IDK). I AM NOT saying almost ANYTHING about “how fast OpenAI and other similar guys can do whatever they’re currently doing”. I don’t think that’s very relevant, because I think that stuff is pretty unlikely (<4%) to lead to AGI by 2030. (I will take a second to just say again that I think the probability is obviously >.1%, and that a >.09% of killing all humans is an insanely atrocious to do, literally the worst thing ever, and everyone should absolutely stop immediately and ban AGI and your children and your children’s children.)
Why not likely? Because
The actual ideas aren’t things that you can just crank out at 10x the rate if you have 10x the spare time. They’re the sort of thing that you usually get 0 of in your life, 1 if you’re lucky, several if you’re an epochal genius. They involve deep context and long struggle. (Probably. Just going off of history of ideas. Some random prompt or o5-big-thinky-gippity-tweakity-150128 could kill everyone. But <4%.)
OpenAI et al. aren’t AFAIK working on that stuff. If you work on not-the-thing 3x faster, so what?
What’s the reference class argument here? Different fields of intellectual labor show different distributions of large vs small insights. For example, in my experience, the typical algorithm is something you can sit down and speed up by putting in the work; finding a few things to improve can quickly add up to a 10x or 100x improvement. Rocket engines are presumably harder to improve, but (I imagine) are the sort of thing which a person might improve several times in their career without being an epochal genius.
One obvious factor that comes to mind is the amount of optimization effort put in so far; it is hard to improve the efficiency of a library which has already been optimized thoroughly. I don’t think LLMs are running out of improvements in this sense.
Another factor is improvement of related technologies; it is easy to keep improving a digital camera if improvements keep being made in the underlying electronic components. We both agree that hardware improvements alone don’t seem like enough to get to ASI within a decade.
A third factor is the feedback available in the domain. AI safety seems relatively difficult to make progress on due to the difficulty of evaluating ideas. AI capabilities seem relatively easy to advance, in contrast, since you can just try things and see if they work.
As a final point concerning reference class, you’re obviously ruling out existing AI progress as the reference class for ASI progress. On what basis? What makes you so confident that it has to be an entirely different sort of thing from current AI progress? This seems maybe hard to make progress on because it is apparently equivalent to the whole subject of our debate. You can say that on priors, there’s no reason for these two things to be related, so it’s like asking why-so-confident that as linguistics advances it will not solve any longstanding problems in physics. I can say it should become a lot more plausible all of a sudden if linguists start getting excited about making progress on physics and trying hard to do so.
Let me restate my view again. I think that:
1. PROBABLY, GI requires several algorithmic ideas.
2. A priori, a given piece of silicon does not implement these algorithmic ideas. Like how piles of steel aren’t randomly bridges.
2.1. So, a priori, PROBABLY GI is a rather long way off—hard to tell because humans given time can come with the algorithmic ideas, but they can’t do much in a couple years.
3. There’s not a strong body of evidence that we have all / most of the algorithmic ideas.
4. So we should have a fairly uninformed stance—though somewhat informed towards shorter—hard to say how much.
5. An uninformed stance implies smeared out, aka “long”, timelines.I don’t even know which ones you disagree with, or whether you think this argument is confused / missing something big / etc. Maybe you disagree with 1? Surely you must agree with 2? Surely you must agree with 2.1, for a suitably “a priori” mindset?
I suppose you most disagree with 3? But I want to hear why you think that the evidence points at “actually we do have the algorithmic ideas”. I don’t think your arguments have addressed this?
(Substituting ASI where you write GI, which is not a totally safe translation, but probably does the job OK)
1: Agree, but I expect we have significantly different estimates of the difficulty of those ideas.
2: Agree, but of course in an environment where agents are trying to build bridges, the probability goes up a lot.
2.1: This doesn’t appear to follow from the previous two steps. EG, is a similar argument supposed to establish that, a priori, bridges are a long way off? This seems like a very loose and unreliable form of argument, generally speaking.
3: I can talk to my computer like I would a human. Possibly, we both agree that this would constitute strong evidence, if not for the “missing update”? So the main thing to discuss further to evaluate this step is the “missing update”?
Some Responses
I’m going to read your responses and make some isolated comments; then I’ll go back and try to respond to the main threads.
Memers gonna meme
First, a meme, modified from https://x.com/AISafetyMemes/status/1931415798356013169 :
“Right paradigm?” Wrong question.
Next: You write:
In 2016, I (privately) estimated a 50% probability (because I couldn’t decide beyond a coinflip) that Deep Learning could be the right paradigm for AGI
I want to just call out (not to presume that you’d disagree) that “the right paradigm for AGI” is quite vague and doesn’t necessarily make much sense—and could lead to bad inferences. As a comparison, is universal / Turing computation “the right paradigm for AGI”? I mean, if we make AGI, it will be Turing computable. So in that sense yes. And indeed, saying “AGI will be a computer program” is in fact important, contentful, and constitutes progress, IF you didn’t previously understand computation and universal computation.
But from another perspective, we haven’t really said much at all about AGI! The space of computer programs is big. Similarly, maybe AGI will use a lot of DL. Maybe every component of the first AGI will use DL. Maybe all of the high-optimization searches will be carried out with DL. NONE of that implies that once you have understood DL, you have understood AGI or how to make it! There are many other parameters not yet determined just by saying “it’s DL”—just like many (almost all!) parameters of a computer program have not been determined just by making the leap from not understanding universal computation to yes understanding it.
(A metaphor which only sort of applies but maybe it is helpful here:) It is comparable to correctly drawing a cordon closer to the mouth of a cave. From the standpoint outside the cave, it feels as though you’ve got the question surrounded, cornered. But, while it is some sort of progress, in fact you have not entered the cave. You aren’t familiar with the depth and structure of the cave just because you have it surrounded from some standpoint.
Quoting from https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce#_We_just_need_X__intuitions :
Just because an idea is, at a high level, some kind of X, doesn’t mean the idea is anything like the fully-fledged, generally applicable version of X that one imagines when describing X.
For example, suppose that X is “self-play”. [...] The self-play that evolution uses (and the self-play that human children use) is much richer, containing more structural ideas, than the idea of having an agent play a game against a copy of itself.
The timescale characters of bioevolutionary design vs. DL research
Evolution applies equal pressure to the code for the generating algorithms for all single-lifetime timescales of cognitive operations; DL research on the other hand applies most of its pressure to the code for the generating algorithms for cognitive operations that are very short.
Mutatis mutandis for legibility and stereotypedness. Legibility means operationalizedness or explicitness—how ready and easy it is to relate to the material involved. Stereotypedness is how similar different instances of the class of tasks are to each other.
Suppose there is a tweak to genetic code that will subtly tweak brain algorithms in a way which, when played out over 20 years (probably being expressed quadrillions of times), builds a mind that is better at promoting IGF. This tweak will be selected for. It doesn’t matter if the tweak is about mental operations that take .5 seconds, 5 minutes, or 5 years. Evolution gets whole-organism feedback (roughly speaking).
On the other hand, a single task execution in a training run for a contemporary AI system is very fast + short + not remotely as complex as a biotic organism’s multi-year life. And that’s where most of the optimization pressure is—a big pile of single task executions.
Zooming out to the scale of training runs, humans run little training runs in order to test big training runs, and only run big training runs sparingly. This focuses [feedback from training runs into human decisions about algorithms] onto issues that get noticed in small training runs.
Of course, in a sense this is a huge advantage for DL AGI research carried out by the community of omnicideers, over evolution. In principle it means that they can go much faster than evolution, but much more quickly getting feedback about a big sector of relevant algorithms. (And of course, indeed I expect humans to be able to make AGI about a million times faster than bioevolution.)
However, it also means that we should expect to see a weird misbalance in capabilities of systems produced by human AI research, compared to bioevolved minds. You should expect much more “Lazy Orchardists”—guys who pick mostly only the low-hanging fruit. And I think this is what we currently observe.
AGI LP25
(I will persist in using “AGI” to describe the merely-quite-general AI of today, and use “ASI” for the really dangerous thing that can do almost anything better than humans can, unless you’d prefer to coordinate on some other terminology.)
I think this is very very stupid. Half of what we’re arguing about is whether current systems are remotely generally intelligence. I’d rather use the literal meaning of words. “AGI” I believe stands for “artificial general intelligence”. I think the only argument I could be sympathetic to purely on lexical merits would be that the “G” is redundant, and in fact we should say “AI” to mean what you call “ASI or soon to be ASI”. If you want a term for what people apparently call AI or AGI, meaning current systems, how about LP25, meaning “learning (computer) programs in (20)25″.
“come on people, it’s [Current Paradigm] and we still don’t have AGI??”
You wrote:
Holding fixed the question of the viability of the current paradigm, this means that whatever curve you’d use to predict p(ASI)-per-year gets really stretched out after 2030 (and somewhat stretched out between 2028 and 2030).
[...]
Of course, we don’t want to hold fixed the question of the viability of the current paradigm; the deflation of the curve past 2030 is further compounded by the evidence. Of course it’s possible that continued accelerated progress would have built ASI in 2031, so that if the hype train ends in 2029, we’re still just one 10x-training-run away from doom. However, if we’re not seeing “crazy stuff” by that point, that’s at least some evidence against the deep learning paradigm (and the more I expect ASI < 2030, the more evidence).
What?? Can you ELI8 this? I might be having reading comprehension problems. Why do you have such a concentration around “the ONLY thing we need is to scale up compute ONE or ONE POINT FIVE more OOMs” (or is it two? 2.5?), rather than “we need maybe a tiny bit more algo tweaking, or a little bit, or a bit, or somewhat, or several somewhats, or a good chunk, or a significant amount, or a big chunk, or...”? Why no smear? Why is there an update like ”...Oh huh, we didn’t literally already have the thing with LP25, and just needed to 30x?? Ok then nevermind, it could be decades lol”? This “paradigm” thing may be striking again…
I guess “paradigm” basically means “background assumptions”? But what are those assumptions when we say “DL paradigm”?
Rapid disemhorsepowerment
My intuitive response to this is to imagine that you and I are watching the water level rise against a dam.
[...]
The analogy isn’t perfect, mainly because the water level (and the right notion of water level) is also contested here. I tried to come up with a better analogy, but I didn’t succeed.
Let me offer an analogy from my perspective. It’s like if you tell me that the number of horses that pull a carriage has been doubling from 1 to 2 to 4 to 8. And from this we can learn that soon there will be a horse-drawn carriage that can pull a skyscraper on a trailer.
In a sense you’re right. We did make more and more powerful vehicles. Just, not with horses. We had to come up with several more technologies.
So what I’m saying here is that the space of ideas—which includes the design space for vehicles in general, and includes the design space for learning programs—is really big and high-dimensional. Each new idea is another dimension. You start off at 0 or near-0 on most dimensions: you don’t know the idea (but maybe you sort of slightly interact with / participate in / obliquely or inexplicitly make use of some fragment of the idea).
There’s continuity in technology—but I think a lot of that is coming from the fact that paradigms keep sorta running out, and you have to shift to the next one in order to make the next advance—and there’s lots of potential ideas, so indeed you can successfully keep doing this.
So, some output, e.g. a technological capability such as vehicle speed/power or such as “how many tasks my computer program does and how well”, can keep going up. But that does NOT especially say much about any one fixed set of ideas. If you expect that one set of ideas will do the thing, I just kinda expect you’re wrong—I expect the thing can be done, I expect the current ideas to be somewhat relevant, I expect progress to continue, BUT I expect there to be progress coming from / basically REQUIRING weird new ideas/directions/dimensions. UNLESS you have some solid reason for thinking the current ideas can do the thing. E.g. you can do the engineering and math of bridges and can show me that the central challenge of bearing loads is actually meaningfully predictably addressed; or e.g. you’ve already done the thing.
Miscellaneous responses
However, there’s also a sense in which the graph does seem roughly correct. GPT-4 is missing some things that a smart highschooler has, sure, but the comparison does make a sort of sense.
No, I think this is utterly wrong. I think the graph holds on some dimensions and fails to hold on other dimensions, and the latter are important, both substantively and as indicators of underlying capabilities.
I think the ceiling for the current approach looks more like things-we-can-test,
What does test mean here? When you personally try to talk to gippity about your new category theory ideas, and you find it falls apart, was that a test in this sense?
The most relevant thing I can think to say at the moment is that it seems related to my view that LLMs are mostly crystallized intelligence and a little bit fluid, vs your view that they’re 100% crystallized and 0% fluid.
Did I say that? I think a trained LLM has a tiny but nonzero amount of fairly fluid intelligence, though it’s still probably pretty weirdly shaped relative to the sort of fluid intelligence that is downstream of general intelligence.
LP25 Architectures (i.e. the whole training setup + code + the trained model) have somewhat more fluid intelligence, but still probably pretty weirdly shaped and pretty small. It’s got a pretty general / powerfulish ability to distill, but distllation is not general intelligence (cf the meme from above):
From my comment here, more elaboration there (https://www.lesswrong.com/posts/Ht4JZtxngKwuQ7cDC/tsvibt-s-shortform?commentId=Gxa3NrSsuwfg9qpeh):
For its performances, current AI can pick up to 2 of 3 from:
Interesting (generates outputs that are novel and useful)
Superhuman (outperforms humans)
General (reflective of understanding that is genuinely applicable cross-domain)
That paper IIUC demonstrates the “hook up some already existing mental elements to a designator given a few examples of the designator” part. That’s not the important part.
This feels like god-of-the-gaps arguing to me. Maybe I’m overly sensitive to this because I feel like people are moving goalposts with respect to the word “AGI”. I get that goalposts need to be moved sometimes. But to me, there are lots of lines one could draw around “creativity” or “fluid intelligence” or “originariness” or similar things (all attempts to differentiate between current AI and human intelligence, or current AI and dangerous AI, or such). By trying to draw such lines, you run the risk of cherry-picking, choosing the things we merely haven’t accomplished yet & thinking they’re fundamental.
I think you might just have misunderstood what the paper says because you skimmed the abstract or intro and were overly credulous.
Big and hard
Still, though, it seems like you’re postulating this big thing that’s hard to figure out, and I don’t know where that’s coming from.
Fundamentally it’s priors. Bridges don’t stand just by piling scraps of steel and loose bolts. Life doesn’t live when you have big enough vats of amino acids—or rather it does, but you have to either have a huge universe and wait a long time and then have a really big bioevolution, or you have to do year-3000 type nanoengineering. The bitter lesson isn’t flavorless; it doesn’t say there isn’t complex cognitive content / structure that you have to figure out before you can make AGI, it says that the relevant structure is about highly abstract / general things like the subtle topology of learning and feedback or whatever, rather than concrete domain things like tuning wavelets for vision.
This perspective is why I got curious about your history of belief around timelines. I still want to understand better your beliefs at e.g. age 15 or 10--or whenever was before your encounter with lines going up. Then I’d want to see if you had the prior I’m describing. Then I’d want to see how the updates worked.
I’m more skeptical that big, deep, once-a-century insights are needed to make progress in AI.
There’s progress, and then on the other hand there’s progress. You can make progress in the sense of making benchmarks keep going up in some increments. Does this have strategic implications? Maybe, maybe not. I expect there to be progress, but there are many dimensions along which to make progress. Strategic relevance, zoomed in, does increase by moving along a single dimension—but always with diminishing returns, on a sufficiently zoomed-out scale. The only way you get increasing returns is adding more and more dimensions along which you’re starting to increase in the tasty zone.
A counterexample is human population: more people, more innovation, period. But I think this is actually cheating, because humans are already minimally generally intelligent.
Intermission
Ok I didn’t even finish reading what you wrote, let alone responding, let alone trying to distill and respond to central threads. Maybe I will come back and churn more—but you could go ahead and respond if you like.
Remarks on gippity thinkity
In particular, even if the LLM were being continually trained (in a way that’s similar to how LLMs are already trained, with similar architecture), it still wouldn’t do the thing humans do with quickly picking up new analogies, quickly creating new concepts, and generally reforging concepts.
Why do you believe this, and what sorts of concrete predictions would you make on this basis? EG, would it be possible to make an analogies benchmark (perhaps similar to ARC-AGI, perhaps not) reflecting this intuition?
I think the concrete predictions question is kind of an annoying and bad question if it’s being used to avoid trying to understand abstract / inchoate claims on their own terms. (I think you’re pretty good about doing the work to try to meet me halfway through referential gaps, though we’re still not succeeding. So I’m not saying you’re doing this, just saying it in general. https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce?commentId=heG7iyJrkiAdSaK5w “In fact, all the time in real life we make judgements about things that we couldn’t describe in terms that would be considered well-operationalized by betting standards, and we rely on these judgements, and we largely endorse relying on these judgements.”)
To answer your question, copying from https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce?commentId=HSqkp2JZEmesubDHD , here are things I predict LLMs probably won’t do in the next few years:
Come up, on its own, with many math concepts that mathematicians consider interesting + mathematically relevant on a similar level to concepts that human mathematicians come up with.
Do insightful science on its own.
Perform at the level of current LLMs, but with 300x less training data.
(I later thought more and considered that maybe I should have said 1000x or 3000x; the real intention is to say something like: I don’t think an LLM trained on an amount of data equivalent to 10x the number of books that a smart well-read human reads by age 40, will be able to perform as well as modern flagship LLMs.)
Making benchmarks is just not a great way to test the important things, I think? Benchmarks will generally be tasks with short runs, clear-feedback / legible success, and stereotyped in some way. These features correlate with each other, and they are all in practice softly-necessary for constructing benchmarks. But they make the benchmark less indicative of general intelligence. Cf. discussion of timescales of bioevolution vs. DL research, above.
Why do you believe this
Why do I think this? Let me reject this question temporarily. I’ve come to realize that a lot of these discussions get nuclear bombed at the very outset—a miscarriage. What is the nuclear bomb? The nuclear bomb is that people either presume that they know what I’m talking about, or they do not presume this but they presume to pursue one or another method for bridging the referential gap—which is different from the referential bridging method I had been presuming, including what I’d been presuming when I said the things I’ve said so far; and conversely, I do not hold up my end, which should have been to remember to repeat, at the outset: “We haven’t grasped even the basic thing we are trying to refer to—the descriptions I’m giving are just speculative hints, as it were, though I don’t know the answer clearly either, so I’m not being coy.”.
In the specific case at hand: When I’m talking about analogies and whatnot, what’s really happening is that I have some episodes in mind. The episodes are things like:
Lots of episodes of me thinking hard + creatively, and sometimes somewhat observing how that works / proceeds.
Some episodes of me remembering and reflecting on previous thinking.
Some episodes of me trying to follow along, either live or by looking at historical records, of other people thinking hard + creatively—for example, conversations with people to figure out difficult things, or hanging out with kids who are learning to cope with various radically novel situations and problems.
A lot of me speculating about how hard + creative thinking could work, or probably works, etc.
So in my head, the natural method for bridging referential gaps, where the reference is to those episodes, is for you to think about the comparable episodes that you have access to, and ask yourself the relevant questions—such as:
What are the underlying engines of the aspects of the cognition that really corely contribute to the relevant outcomes (successful world-optimization)?
How did those engines get there?
What would it take to figure out what they are, or to make them?
Is such and such a computer program the sort of thing that’s likely to do so?
So then when I’m talking about analogies or whatever else, I’m not trying to describe a computer program to you, I’m trying to help you with your version of the above process of speculation and reflection, by offering some hints which would make sense in the context of such a process.
Ok but why do I think this? Well, I’m not going to give a full answer. But there’s something I’d like to say about it. Look at this shit:
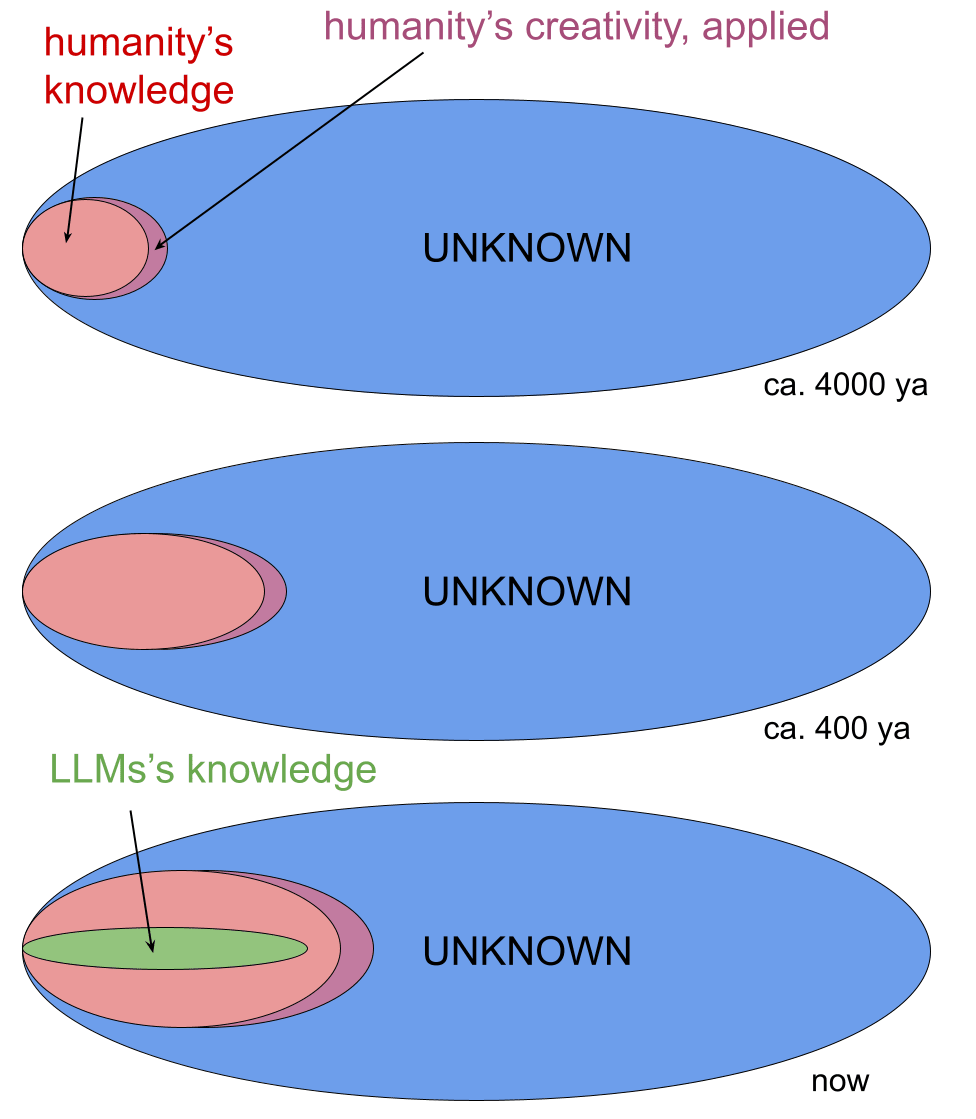
So, you people keep being like “look at the huge green blob” and I’m like “yeah, pretty fucking scary, but also it seems like the green blob is there because it’s using the red blob specifically; I don’t see a magenta frontier, do you?”. And then you people are like “what? magenta frontier? wtf is that? Red blob, meet green blob...”. Which is very frustrating because, hello, we are trying to talk about general intelligence.
And if we think there’s a mechanism by which the green blob can grow up unto the red blob, OTHER THAN with a magenta frontier, then that’s like, a discrete fact. The green blob growing bigger isn’t more and more evidence that there’s a magenta blob, OVER the alternative hypotheses (the ones that weren’t eliminated by early gippities).
(I’m not sure of the reasoning I just gave—seems unclear in my head, therefore probably either somewhat or very flawed. But hopefully moves the conversation.)
3: I can talk to my computer like I would a human. Possibly, we both agree that this would constitute strong evidence, if not for the “missing update”? So the main thing to discuss further to evaluate this step is the “missing update”?
You can talk to it in a manner which is like how you would talk to a human, IN SOME RESPECTS, and UNLIKE in some other respects. This is important.
(I continue to have frustration with the size of the dialogue, and the slowness of the referential corrections, in both directions—I still don’t really know what you think, and I think you still don’t really know what I think. Not sure how to address. Could try adding someone to moderate, or another live convo.)
[a few weeks gap]
You wrote:
My intuitive response to this is to imagine that you and I are watching the water level rise against a dam. It has been rising exponentially for a while, but previously, it was under 1 inch high. Now it’s several feet high, and I’m expressing concern about the dam overflowing soon, and you’re like “it’s always been exponential, how could you know it’s overflowing soon” and I’m like “but its pretty high now” and you’re like “yeah but the top of the dam is REALLY high” and I’m like “it doesn’t look so tall to me” and you’re like “the probability that it overflows in the next five years has to be low, because us happening to find ourselves right around the time when the dam is about to break would be a big coincidence; there’s no specific body of evidence to point out the water doing anything it hasn’t before” …
I agree with what you said about the meaning and current level of the water being contested. But to add another response, within your metaphor: My response would have been something like:
You’re right, this is alarming. It could plausibly be that the dam is about to overflow. HOWEVER, there was another dam further upstream, and that dam was just raised—first a bit, then a lot; and now it’s fully open. It can’t be opened further, as it is fully open. THEREFORE, I don’t think it makes sense to directly extrapolate the growth; the recent rapid rise is explained away by something which we can see is exhausted. (Though of course there are other tributaries with their own dams, some of which are closed. I don’t know how many other dams there are, and which will be opened when, and how many would be needed to flood the dam. I agree this is dangerous; I’m just saying that your induction doesn’t make that much sense.)
Where the observed rise in capabilities in gippities is a result of distilling a bunch of human data. You can list other ways that one could improve gippity-derived systems, but then you’re not on “60% in 5 years” type solid evidential ground!!
Assorted replies as I read:
Paradigm
“Right paradigm?” Wrong question.
I think for the purpose of this discussion, the relevant notion of “right paradigm” is as follows:
“Paradigm” means a collection of ways of thinking: concepts, terminology, argument styles, standards of rigor, as well as hands-on practical know-how.
“Right paradigm for artificial superintelligence” means that a paradigm is adequate to the task of producing artificial superintelligence given reasonable time, talent, and other relevant resources. (We can further specify this notion with specific amounts of resources, if we want.)
So, taking your example, Turing computation is NOT the “right paradigm” in this sense.
I think this notion of “right paradigm” is the relevant one, because it’s the sort of thing we’ve been discussing; EG, you have said that you don’t expect the-sort-of-thing-openai-does will lead to [AGI/ASI/?] regardless of how much time they spend doing it.
Bio-evo vs DL
Evolution applies equal pressure to the code for the generating algorithms for all single-lifetime timescales of cognitive operations; DL research on the other hand applies most of its pressure to the code for the generating algorithms for cognitive operations that are very short.
[...]
Of course, in a sense this is a huge advantage for DL AGI research carried out by the community of omnicideers, over evolution. [...]
However, it also means that we should expect to see a weird misbalance in capabilities of systems produced by human AI research, compared to bioevolved minds.
Agree with all of this.
AGILP25(I will persist in using “AGI” to describe the merely-quite-general AI of today, and use “ASI” for the really dangerous thing that can do almost anything better than humans can, unless you’d prefer to coordinate on some other terminology.)
I think this is very very stupid. Half of what we’re arguing about is whether current systems are remotely generally intelligence. I’d rather use the literal meaning of words. “AGI” I believe stands for “artificial general intelligence”. I think the only argument I could be sympathetic to purely on lexical merits would be that the “G” is redundant, and in fact we should say “AI” to mean what you call “ASI or soon to be ASI”. If you want a term for what people apparently call AI or AGI, meaning current systems, how about LP25, meaning “learning (computer) programs in (20)25″.
I note that I, also, am using “G” for general. My particular variety of pedantism about this is (like the term AGI itself) born of the contrast between this and narrow AI (which points to the cluster including chess engines, kernel-method learning to find specific things in X-rays, UBER ride-sharing optimization algorithms, classical planning algorithms, etc.) If we draw a spectrum from narrow to general and try to put all AI systems ever on the spectrum (and also put humans on the spectrum for comparison), there would be an extremely large gap between LLMs and all other sorts of AI systems.
Anyway, I am fine with using LP25, but I think the bigger issue for our discussion is what to call the highly intelligent systems that we both think come later, and which are existentially risky for biological life. It makes sense to avoid “AGI” since, as you say, that term denotes half of what we’re arguing about. I’ll persist in calling that ASI for now.
What?? Can you ELI8 this?
I wasn’t sure how to do it, so I asked Claude Opus 4 to ELI8 this, and then edited it a little:
ELI8 Version
Imagine AI progress is like a rocket ship that’s been going faster and faster because we keep adding more and more fuel (money/compute). Right now, we’re adding 10x more fuel each time.
But here’s the thing: We can’t keep adding 10x more fuel forever! By around 2028-2030, we’ll run out of room to add more fuel because:
It would cost too much money (trillions of dollars)
We’d need too much electricity
It would take too long to build the computers
So Abram is saying: If we don’t reach super-smart AI (ASI) by 2030, then our rocket ship will have to stop accelerating because we can’t add fuel as fast anymore.
Why Tsvi is confused:
Tsvi is asking: “Why are you acting like we either need just ONE more fuel boost OR we’re decades away? What about needing a little tweaking, or medium tweaking, or lots of tweaking?”
The answer is: Abram is talking about two separate things:
The fuel problem (compute scaling limits)
The recipe problem (whether our current approach even works)
If we hit 2030 without ASI, it tells us BOTH:
We can’t just throw more fuel at the problem (because we’re out of fuel)
Maybe our recipe (deep learning) isn’t right
So we would expect slower progress for two reasons: less fuel AND doubts about whether we have the right recipe.
That’s why there’s a “cliff” around 2030 rather than a smooth curve—it’s when the fuel runs out, not about how much algorithmic tweaking we need.
I basically endorse that ELI8, modulo a bunch of complications and caveats of course, but that’s what an ELI8 is for.
Why do you have such a concentration around “the ONLY thing we need is to scale up compute ONE or ONE POINT FIVE more OOMs” (or is it two? 2.5?), rather than “we need maybe a tiny bit more algo tweaking, or a little bit, or a bit, or somewhat, or several somewhats, or a good chunk, or a significant amount, or a big chunk, or...”? Why no smear? Why is there an update like ”...Oh huh, we didn’t literally already have the thing with LP25, and just needed to 30x?? Ok then nevermind, it could be decades lol”?
The sudden cutoff is about the money (& talent & less quantifiable resources) drying up. The updates about the number of OOMs required for the paradigm to work (including whether it can work at all) would be more continuous, but also contribute significantly to the probability density getting shallower.
As for the question of the specific number of OOMs, quoting Nesov:
Thus raw compute of a frontier training system is increasing about 160x in 4 years, or about 3.55x per year.
Subjectively & intuitively, I feel that if the “”“pace of progress””” were to continue in a relatively smooth line from 2020 to 2030, we would see ASI by 2030. (I do not intend this as an endorsed prediction.)
However, if the only change in AI between now and July 2030 (5 years from now) were the continuing scale-up of training runs (568x from now till then), I would not predict ASI by 2030 with >10% probability.
Rapid disemhorsepowerment
Agree with all of this in broad strokes, just not in the specific implications you’re drawing for AI. As I’ve probably argued here already, I don’t think the specific paradigm matters that much for AI (historically speaking): genetic algorithms do about as well as deep learning when you throw similar amounts of human ingenuity and processing power at them; similarly for transformers vs RNNs. Specific technology does matter, of course, but it seems to me like “doing it well” matters more than paradigm choice (at least within the overarching paradigm of Machine Learning).
Miscellaneous
However, there’s also a sense in which the graph does seem roughly correct. GPT-4 is missing some things that a smart highschooler has, sure, but the comparison does make a sort of sense.
No, I think this is utterly wrong. I think the graph holds on some dimensions and fails to hold on other dimensions, and the latter are important, both substantively and as indicators of underlying capabilities.
This doesn’t sound so far off from my position. I agree the graph holds in some dimensions and fails in others. I agree that the dimensions in which it fails are important.
I think the ceiling for the current approach looks more like things-we-can-test,
What does test mean here? When you personally try to talk to gippity about your new category theory ideas, and you find it falls apart, was that a test in this sense?
Yes. Things-we-can-test means things we can make benchmarks for, and we can make benchmarks for that.
I think you might just have misunderstood what the paper says because you skimmed the abstract or intro and were overly credulous.
Is this a crux? Or are you not that interested in the paper one way or the other? I actually talked to the author rather than reading the paper, in that case, but the claims about what the paper does seem straightforward to check by reading the paper, if it were a crux.
Magenta Frontier
So, you people keep being like “look at the huge green blob” and I’m like “yeah, pretty fucking scary, but also it seems like the green blob is there because it’s using the red blob specifically; I don’t see a magenta frontier, do you?”. And then you people are like “what? magenta frontier? wtf is that? Red blob, meet green blob...”. Which is very frustrating because, hello, we are trying to talk about general intelligence.
I would draw it like this:
I think there’s a conceptual difficulty with interpreting this picture, having to do with what sorts of generalization count as “knowledge” vs “creativity” (or as I’ve labeled it “ingenuity”—not trying to pick any fight about that, I just wrote a synonym). On a very literalist interpretation, “human knowledge” might be everything we’ve written down, so that even a calculator has some “creativity” if it can correctly multiply numbers that no one has bothered to multiply before. Obviously, that’s not a good interpretation. However, it illustrates the point that the “human knowledge” bubble has some interpretive flexibility based on which sorts of generalizations of known ideas count as “creative” vs merely “knowledge”.
I put a little bit of what-LLMs-can-do peaking out from “human knowledge” into “what humans can do” because I find that for some small things which I wouldn’t call “human knowledge”—things where I would have to apply my own ingenuity to solve them—LLMs can sometimes do that work, just a little bit. (More on that here.)
This is where I worry about god-of-the-gaps fallacy where it comes to “creativity”—it’s easy, I think, to keep revising what counts as “creative” so that it is whatever AI cannot yet do.
I’m not sure whether your “magenta frontier” meant what I’m doing here (attributing a little creativity to the machine) or poking the green bubble (what LLMs can do) out of even the “what humans can do” bubble. Obviously the latter would be a bigger deal. However, enough of the formal might be enough to start an intelligence explosion—automating the advancement of the knowledge frontier.
You wrote:
My intuitive response to this is to imagine that you and I are watching the water level rise against a dam. It has been rising exponentially for a while, but previously, it was under 1 inch high. Now it’s several feet high, and I’m expressing concern about the dam overflowing soon, and you’re like “it’s always been exponential, how could you know it’s overflowing soon” and I’m like “but its pretty high now” and you’re like “yeah but the top of the dam is REALLY high” and I’m like “it doesn’t look so tall to me” and you’re like “the probability that it overflows in the next five years has to be low, because us happening to find ourselves right around the time when the dam is about to break would be a big coincidence; there’s no specific body of evidence to point out the water doing anything it hasn’t before” …
I agree with what you said about the meaning and current level of the water being contested. But to add another response, within your metaphor: My response would have been something like:
You’re right, this is alarming. It could plausibly be that the dam is about to overflow. HOWEVER, there was another dam further upstream, and that dam was just raised—first a bit, then a lot; and now it’s fully open. It can’t be opened further, as it is fully open. THEREFORE, I don’t think it makes sense to directly extrapolate the growth; the recent rapid rise is explained away by something which we can see is exhausted. (Though of course there are other tributaries with their own dams, some of which are closed. I don’t know how many other dams there are, and which will be opened when, and how many would be needed to flood the dam. I agree this is dangerous; I’m just saying that your induction doesn’t make that much sense.)
Where the observed rise in capabilities in gippities is a result of distilling a bunch of human data. You can list other ways that one could improve gippity-derived systems, but then you’re not on “60% in 5 years” type solid evidential ground!!
Based on this, I have two different proposed analogies for my position:
I don’t think the water from that one dam-break is anywhere near finished rushing in. I expect progress to continue at roughly the same subjective rate for a while.
OR, perhaps better: I think the water from the first broken dam (distilling human data) is going to cause a second dam to burst (automated aggregation and implementation of human research insights).
Even if all LP25 does in three years is become an ever-more-perfect sponge integrating all human knowledge together without any innovation, I still expect that to speed up research quite a bit. I think a major bottleneck in AI, in general, over the past 50+ years, has been the failure to integrate insights from individual AI papers all together into one system. Even if the only superpower developed at frontier labs is the ability to search all existing research and rapidly synthesize it into the best code humankind knows how to write with respect to a given challenge, I expect a rapid explosion of capabilities. It’s the sudden combined application of every good idea in AI. (Note, in this argument, I’m using humans in the loop, not claiming the ingenuity comes from nowhere.)
Considered Reply
The above replies were more like knee-jerk reactions, written as I read through your most recent replies. I am now making an attempt to reset, reorient, reconsider, reevaluate.
To help me do that, I’ve also finished reading your views on when AGI comes and also read Thane’s Bear Case.
Point of Departure
In our email correspondence before we moved the discussion here, I asked for your point of departure from AI 2027 and you said the following:
I’m curious where you first start to part ways from the AI 2027 forecast.
Not going to read a long fiction piece unless there’s an especially good reason to. Presumably I get off around the point where the AI is having novel ideas at the level required to get to AGI.
Let’s try and walk step-by-step through a plausible timeline of the next few years.
First, what does “baseline” progress look like (IE a moderately conservative estimate, with no major innovations, just scale-up of current approaches with minor tweaks)?
I think we agree that there is something like “conceptual resolution” which is more of a hard limit for AIs than it is for humans. For example, looking at the progress of image generation over the past few years: AI can now generate images with one or a few human figures quite competently. However, scenes with a large number of figures will still contain the sorts of egregious anatomical errors which AI art is famous for: hands that don’t make sense, arms and legs that don’t connect correctly, etc.
Similarly, LLMs (without tool use) have sharp limits to how well they can add or multiply numbers, which improve over time.
(See here for more of my thinking on this.)
So, concerning the near future:
Conceptual resolution will continue to increase at about the same pace.
Maybe it will slow down somewhat, due to diminishing returns to scale.
Maybe it will speed up somewhat, if “reasoning models” turn out to be a considerably better paradigm for scaling conceptual resolution.
Tool use will continue to improve.
This substitutes for conceptual resolution in some cases. EG, using a calculator allows LLMs to multiply numbers with many digits.
Possibly, this will substitute for conceptual resolution in many cases: if LLMs learn to do much of their cognition by writing & running custom code on the fly, they can get a lot of cognition done in a way which avoids their conceptual-resolution bottlenecks.
However, it still seems like conceptual resolution would continue to be a bottleneck in complex situations where figuring out what code to write would itself require almost the full conceptual resolution it takes to solve the problem.
Context windows will continue to grow & accurate use of data in long context windows will continue to improve.
Probably, LLMs will switch from transformers to (a mix of transformers and) something that’s not quadratic in context length, so as to allow much longer context-lengths to be handled efficiently.
Growing context windows will, I think, greatly benefit “agency” (ie the sort of thing the LP25 community counts as “agency”). For example, Claude Plays Pokemon got stuck in a lot of dumb myopic loops because it had to summarize its context frequently to free up memory, and so, couldn’t see that it was stuck in dumb myopic loops.
I don’t think any of the above predictions fall prey to your central critique:
Like how piles of steel aren’t randomly bridges.
Please let me know whether I am wrong about that. If the modest line-go-up predictions bullet-pointed above count as “piles of steel randomly becoming bridges” by your way of thinking, then we have a deep disagreement indeed.
The claim of the AI 2027 report is that the above advances (in particular, as applied to agency and programming) will go far enough to kick off an intelligence explosion, probably some time 2027-2030.
Is this plausible?
I’ve emphasized the demonstrated ability of frontier labs to come up with new approaches when scaling up the current approach isn’t increasing intelligence fast enough for them. However, that only appears to happen about once every two years, so far. I postulated that (as per AI 2027) the frequency of such shifts will increase as LLMs become more helpful for research. However, this would seem to imply that we get only one or two more human-generated shifts of this sort, before AI research assistants become a significant productivity multiplier.
Is this plausible?
I agree that, so far, these training techniques have only been able to create modest imitations of human expertise. The generalization ability of transformers has been consistently lower than that of humans. However, I also expect generalization ability to keep increasing (at least modestly) as model size & training time keeps increasing. I think models are very slightly creative/innovative now, so I expect moreso in a couple of years. I find LLMs to be modestly helpful with research now, so again, moreso in a couple of years.
So it would appear that, for an intelligence explosion to happen before 2030, we need either (1) just one or two major shifts in training technique to be enough to get us from where we are to AI research assistants capable of major innovation, or (2) scaling alone to get us there before scaling runs out of money around 2028.
Is this plausible?
I’m not sure. I think I’m down to something like 30% as opposed to my earlier 50%.
Tsvi’s closing remarks
I think models are very slightly creative/innovative now, so I expect moreso in a couple of years.
By way of summarizing my position: These propositions are the propositions that I’d still like to hear any justification for.
Towards the beginning of the dialogue, you’d written:
Current LLMs are a little bit creative, rather than zero creative. I think this is somewhat demonstrated by the connect-the-dots paper. Current LLMs mostly learn about chairs by copying from humans, rather than inventing the concept independently and then later learning the word for it, like human infants. However, they are somewhat able to learn new concepts inductively. [...]
It seems we have a basic disagreement about how to read that paper, or maybe we mean different things by “creative” here. Zooming out, I still don’t hear much evidence about this question from you, and this makes me confused: I wonder if this isn’t a main pillar of your worldmodel actually, or maybe I’m just forgetting the evidence you’ve presented, or you have it but haven’t presented it (maybe it’s difficult), or what. The main evidence other people adduce is “line go up”—we’ve talked about that reasoning path some, though I couldn’t summarize your position—e.g. you write
However, there’s also a sense in which the graph does seem roughly correct. GPT-4 is missing some things that a smart highschooler has, sure, but the comparison does make a sort of sense.
No, I think this is utterly wrong. I think the graph holds on some dimensions and fails to hold on other dimensions, and the latter are important, both substantively and as indicators of underlying capabilities.
This doesn’t sound so far off from my position. I agree the graph holds in some dimensions and fails in others. I agree that the dimensions in which it fails are important.
But I guess we’d have to know how important we think those dimensions are.
Anyway, the other pillar of your position as I understand it, is that AI labs are doing research and will discover more GI algorithms. This is true. But it doesn’t feel very informative about timelines, and I couldn’t pass an ITT about how that could get us to 30% by 2030 or similar. It seems to me like such a short timeline would naturally come from a combination of “we’re pretty close” and “the labs are making the relevant progress”. But both seem necessary, at least for this line of reasoning, and I couldn’t pass an ITT on either of them.
In other words, yes, as you say, if there are agents around who are trying to build bridges, this makes bridges vastly more likely, and more likely to exist soon. But to predict some narrow range of when the bridge-creation project will complete successfully, you still have to know something about what it would take to build the first bridge, and how much we know about that, and how much is unresolved. To make a prediction of “a few years”, you’d want to have seen a proof-of-concept for the core elements. I detect some equivocation on your part—or on the part of my straw image of you—about whether LP25 constitutes a proof-of-concept for the sort of GI that could kill everyone.
[[As a process note, I’ll say that the threading in this conversation is an utter shitshow, and AFAIK that’s not our fault but rather is because no one has solved threading, and it would be great if someone could do that. (See https://tsvibt.blogspot.com/2023/01/hyperphone.html#5-ntext ; imagine twitter, where you can click a text to see the whole up-thread, but you can write long replies, and you can do the LW thing of commenting on some highlighted text from a previous message.)]]
Alright, I’ll leave it here. Thanks for your patient and earnest engagement.
Abram’s Closing Thoughts
[[As a process note, I’ll say that the threading in this conversation is an utter shitshow, and AFAIK that’s not our fault but rather is because no one has solved threading, and it would be great if someone could do that. (See https://tsvibt.blogspot.com/2023/01/hyperphone.html#5-ntext ; imagine twitter, where you can click a text to see the whole up-thread, but you can write long replies, and you can do the LW thing of commenting on some highlighted text from a previous message.)]]
Big Agree
It seems we have a basic disagreement about how to read that paper, or maybe we mean different things by “creative” here.
I suspect it is more about “creative” rather than how to read the paper. On my model, it seems like a clearly very fuzzy concept, with multiple dimensions, most of which are continuum-like rather than hard yes/no properties. (Not implying you necessarily disagree with that, but, it does make it hard to talk about.)
One aspect has to do with generalization power. To what extent can LP25s take concepts they’ve learned and combine them in new, useful ways? The answer is clearly “to some limited extent”. Here, I expect significant improvement from mere scale, though even more improvement could come through innovation.
Another aspect has to do with in-context learning. To what extent can LP25s apply fluid intelligence, creating new concepts based on context, so that their understanding of an initially unfamiliar domain can improve as they interact? Here I am less sure (perhaps “to some limited extent” like before, perhaps “basically not at all”). Here I expect a little improvement to come from mere scale, but much more to come from deliberate innovation.
Another aspect is whether LLMs ever innovate. This question gets quite fuzzy as well (as can be readily seen by looking at the comments there). I worry about god-of-the-gaps fallacy for this aspect in particular, because it is easy to call specific innovations obvious in retrospect, since there is no clear standard for what counts as true innovation vs mere application of existing knowledge. Nonetheless, Cole (who was the skeptic in that context) did find one reply to be a convincing example of innovation, if not particularly exciting.
Zooming out, I still don’t hear much evidence about this question from you, and this makes me confused: I wonder if this isn’t a main pillar of your worldmodel actually, or maybe I’m just forgetting the evidence you’ve presented, or you have it but haven’t presented it (maybe it’s difficult), or what.
Possibly, I get somewhat distracted by wanting to argue something like “even if current models are zero creative, the wave of AI-enabled AI innovation that is coming soon will obviously change that”—but (arguably, depending on how we define “creative”) a wave of AI-enabled AI innovation isn’t coming if current AIs are zero creative. So (possibly, depending on how we define “creative”) it does need to be a pillar of my view.
Possibly, I react to this talk of “creativity” or “originariness” by talking about concepts which I see as somewhat more precise (such as generalization, in-context learning, or innovation, or fluid intelligence), which is why you feel you are missing direct arguments for current LLMs being “creative” in what I’ve written.
Anyway, the other pillar of your position as I understand it, is that AI labs are doing research and will discover more GI algorithms. This is true. But it doesn’t feel very informative about timelines, and I couldn’t pass an ITT about how that could get us to 30% by 2030 or similar. It seems to me like such a short timeline would naturally come from a combination of “we’re pretty close” and “the labs are making the relevant progress”. But both seem necessary, at least for this line of reasoning, and I couldn’t pass an ITT on either of them.
In other words, yes, as you say, if there are agents around who are trying to build bridges, this makes bridges vastly more likely, and more likely to exist soon. But to predict some narrow range of when the bridge-creation project will complete successfully, you still have to know something about what it would take to build the first bridge, and how much we know about that, and how much is unresolved. To make a prediction of “a few years”, you’d want to have seen a proof-of-concept for the core elements.
Imagine the world 2 years from now. LP25 technology has continued to improve at about the rates we’ve seen. Hallucination rates have gradually improved. Context windows have continued to increase. Vibe coding, and vibe math, both mostly “just work”, and someone who is an experienced programmer and/or mathematician can accomplish much more than they could 2 years ago, via AI automation. (This picture is not supposed to assume very much “creativity” yet.)
In my mind, this is enough to “open the floodgates”—I think if humans can use AI to (correctly-but-uncreatively) search and combine all existing human ideas about intelligence and AI, with implementations flowing cheaply from ideas, then (30%) humans can create strongly superhuman artificial intelligence in a few more years.
Think of all the cognitive aids you could build if vibe coding “basically just worked”.
You’ve presented the view that humans don’t yet know how to make strongly superintelligent AI; that humans need multiple new fundamental insights, on the order of what only once-a-generation geniuses can provide.
I think this is not so clear. I think AI research has, thus far, suffered from a massive idea-to-implementation bottleneck. In Cognitive Architecture, for example, a professor might have an overall vision which takes 30 years of work (from several generations of grad students) to implement. What happens to the world if this 30 years is reduced to a few weeks? Not only can you rapidly try all the untried ideas out there—you’ve also got a faster feedback cycle, which creates an epistemically better habitat for new ideas.
And we’ll leave it there for now.
Remember kids: Shut it all down! Stop all AGI research!
- AI in 2025: gestalt by technicalities (7 Dec 2025 21:25 UTC; 248 points)
- The problem of graceful deference by TsviBT (11 Nov 2025 8:17 UTC; 108 points)
- Attend the 2026 Reproductive Frontiers Summit, June 16–18, Berkeley by TsviBT (22 Mar 2026 21:15 UTC; 97 points)
- A basic case for donating to the Berkeley Genomics Project by TsviBT (18 Dec 2025 1:55 UTC; 85 points)
- The Bughouse Effect by TsviBT (19 Nov 2025 8:57 UTC; 67 points)
- Bioanchors 2: Electric Bacilli by TsviBT (24 Feb 2026 1:07 UTC; 38 points)
- Claude’s Bad Primer Fanfic by abramdemski (8 Feb 2026 0:39 UTC; 24 points)
- New cause area: human intelligence amplification by TsviBT (EA Forum; 1 Mar 2026 8:42 UTC; 22 points)
- TsviBT's comment on Alignment will happen by default. What’s next? by Adrià Garriga-alonso (25 Nov 2025 21:06 UTC; 21 points)
- TsviBT's comment on Buck’s Shortform by Buck (27 Aug 2025 3:29 UTC; 15 points)
- TsviBT's comment on jacquesthibs’s Shortform by jacquesthibs (20 May 2026 7:56 UTC; 13 points)
- A basic case for donating to the Berkeley Genomics Project by TsviBT (EA Forum; 18 Dec 2025 1:55 UTC; 10 points)
- Mateusz Bagiński's comment on Abstract advice to researchers tackling the difficult core problems of AGI alignment by TsviBT (22 Nov 2025 15:46 UTC; 10 points)
- TsviBT's comment on AI in 2025: gestalt by technicalities (8 Dec 2025 7:18 UTC; 9 points)
- TsviBT's comment on HIA and X-risk part 2: Why it hurts by TsviBT (8 Jan 2026 21:46 UTC; 8 points)
- TsviBT's comment on TsviBT’s Shortform by TsviBT (26 May 2026 5:15 UTC; 5 points)
- TsviBT's comment on Alignment will happen by default. What’s next? by Adrià Garriga-alonso (26 Nov 2025 3:44 UTC; 4 points)
- ACX Montreal meetup—August 2nd @1PM by BionicD0LPH1N (1 Aug 2025 8:08 UTC; 4 points)
- Ben Pace, the Vacationing Vagabond's comment on The problem of graceful deference by TsviBT (12 Nov 2025 22:38 UTC; 4 points)
- Attend the 2026 Reproductive Frontiers Summit, June 16–18, Berkeley by TsviBT (EA Forum; 22 Mar 2026 21:18 UTC; 2 points)
- TsviBT's comment on LLM-generated text is not testimony by TsviBT (1 Nov 2025 21:13 UTC; 2 points)
- TsviBT's comment on LLM-generated text is not testimony by TsviBT (2 Nov 2025 7:44 UTC; 2 points)
- TsviBT's comment on A basic case for donating to the Berkeley Genomics Project by TsviBT (18 Dec 2025 20:42 UTC; 2 points)
- Nick_Tarleton's comment on Views on when AGI comes and on strategy to reduce existential risk by TsviBT (19 Jul 2025 20:52 UTC; 2 points)
This is a valuable discussion to have, but I believe Tsvi has not raised or focused on the strongest arguments. For context, like Tsvi, I don’t understand why people seem to be so confident of short timelines. However (though I did not read everything, and honestly I think this was justified since the conversation eventually seems to cycle and become unproductive) I generally found Abram’s arguments more persuasive and I seem to consider short timelines much more plausible than Tsvi does.
I agree that “originality” / “creativity” in models is something we want to watch, but I think Tsvi fails to raise to the strongest argument that gets at this: LLMs are really, really bad at agency. Like, when it comes to the general category of “knowing stuff” and even “reasoning stuff out” there can be some argument around whether LLMs have passed through undergrad to grad student level, and whether this is really crystalized or fluid intelligence. But we’re interested in ASI here. ASI has to win at the category we might call “doing stuff.” Obviously this is a bit of a loose concept, but the situation here is MUCH more clear cut.
Claude cannot run a vending machine business without making wildly terrible decisions. A high school student would do a better job than Claude at this, and it’s not close.
Before that experiment, my best (flawed) example was Pokemon. Last I checked, there is no LLM that has beaten Pokemon end-to-end with fixed scaffolding. Gemini beat it, but the scaffolding was adapted as it played, which is obviously cheating, and as far as I understand it was still ridiculously slow for such a railroaded children’s game. And Claude 4 did not even improve at this task significantly beyond Claude 3. In other words, LLMs are below child level at this task.
I don’t know as much about this, but based on dropping in to a recent RL conference I believe LLMs are also really bad at games like NetHack.
I don’t think I’m cherry picking here. These seem like reasonable and in fact rather easy test cases for agentic behavior. I expect planning in the real world to be much harder for curse-of-dimensionality reasons. And in fact I am not seeing any robots walking down the street (I know this is partially manufacturing / hardware, and mention this only as a sanity check. As a similar unreliable sanity check, my robotics and automation etf has been a poor investment. Probably someone will explain to me why I’m stupid for even considering these factors, and they will probably be right).
Now let’s consider the bigger picture. The recent METR report on task length scaling for various tasks overall moved me slightly towards shorter timelines by showing exponential scaling across many domains. However, note that more agentic domains are generaly years behind less agentic domains, and in the case of FSD (which to me seems “most agentic”) the scaling is MUCH slower. There is more than one way to interpret these findings, but I think there is a reasonable interpretation which is consistent with my model: the more agency a task requires, the slower LLMs are gaining capability at that task. I haven’t done the (underspecified) math, but this seems to very likely cash out to subexponential scaling on agency (which I model as bottlenecked by the first task you totally fall over on).
None of this directly gets at AI for AI research. Maybe LLMs will have lots of useful original insights while they are still unable to run a vending machine business. But… I think this type of reasoning: “there exists a positive feedback loop → singularity” is pretty loose to say the least. LLMs may significantly speed up AI research and this may turn out to just compensate for the death of Moore’s law. It’s hard to say. It depends how good at research you expect an LLM to get without needing the skills to run a vending machine business. Personally, I weakly suspect that serious research leans on agency to some degree, and is eventually bottlenecked by agency.
To be explicit, I want to replace the argument “LLMs don’t seem to be good at original thinking” with “There are a priori reasons to doubt that LLMs will succed at original thinking. Also, they are clearly lagging significantly at agency. Plausibly, this implies that they in fact lack some of the core skills needed for serious original thinking. Also, LLMs still do not seem to be doing much original thinking (I would argue still nothing on the level of a research contribution, though admittedly there are now some edge cases), so this hypothesis has at least not been disconfirmed.” To me, that seems like a pretty strong reason not to be confident about short timelines.
I see people increasingly arguing that agency failures are actually alignment failures. This could be right, but it also could be cope. In fact I am confused about the actual distinction—an LLM with no long-term motivational system lacks both agency and alignment. If it were a pure alignment failure, we would expect LLMs to do agentic-looking stuff, just not what we wanted. Maybe you can view some of their (possibly miss-named) reward hacking behavior that way, on coding tasks. Or you know, possibly they just can’t code that well or delude themselves and so they cheat (they don’t seem to perform sophisticated exploits unless researchers bait them into it?). But Pokemon and NetHack and the vending machine? Maybe they just don’t want to win. But they also don’t seem to be doing much instrumental power seeking, so it doesn’t really seem like they WANT anything.
Anyway, this is my crux. If we start to see competent agentic behavior I will buy into the short timelines view at 75% +
One other objection I want to head off: Yes, there must be some brain-like algorithm which is far more sample efficient and agentic than LLMs (though it’s possible that large enough trained and post-trained LLMs eventually are just as good, which is kind of the issue at dispute here). That brain-like algorithm has not been discovered and I see no reason to expect it to be discovered in the next 5 years unless LLMs have already foomed. So I do not consider this particularly relevant to the discussion about confidence in very short timelines.
Also, worth stating explicitly that I agree with both interlocutors that we should pause AGI development now out of reasonable caution, which I consider highly overdetermined.
Seems good to flesh out what you mean by this if it’s such a big crux. Ideally, you’d be able to flesh this out in such a way that bad vision (a key problem for games like pokemon) and poor motivation/adversarial-robustness (a key problem for vending claude because it would sort of knowingly make bad financial decisions) aren’t highlighted.
Would this count as competent agentic behavior?
The AI often successfully completes messy software engineering tasks which require 1 week of work for a skilled human and which require checking back in with the person who specified the task to resolve ambiguities. The way the AI completes these tasks involves doing a bunch of debugging and iteration (though perhaps less than a human would do).
Yes, if time horizons on realistic SWE tasks pass 8-16 hours that would change my mind—I have already offered to bet the AI 2027 team cash on on this (not taken up) and you can provide me liquidity on the various existing manifold markets (not going to dig up the specific ones) which I very occasionally trade on.
Adversarial robustness is part of agency, so I don’t agree with that aspect of your framing.
Maybe so, but it isn’t clearly required for automating AI R&D!
I think that it is. I keep meaning to write my thoughts on this issue up.
I believe adversarially robustness is a core agency skill because reasoning can defeat itself; you have to be unable to fool yourself. You can’t be fooled by the processes you spin off, figuratively or literally. You can’t be fooled by other people’s bad but convincing ideas either.
this is related to an observation I’ve made that exotic counterexamples are likely to show up in wrong proofs, not becuase they are typical, but because mathematicians will tend to construct unusual situations while seeking to misuse true results to prove a false result.
a weaker position is that even if adversarial robustness isn’t itself necessary for agency, an egregious failure to be adversarially robust seems awfully likely to indicate that something deeper is missing or broken.
IMO, the type of adversarial robustness you’re discussing is sufficiently different than what people typically mean by adversarial robustness that it would be worth tabooing the word. (E.g., I might say “robust self-verification is required”.)
I guess that’s true.
The way I model this situation is tied to my analysis of joint AIXI which treats the action bits as adversarial because the distribution is not realizable.
so, there are actually a few different concepts here which my mental models link in a non-transparent way.
(I’ve noticed that when people say things like I just said, it seems to be fairly common that their model is just conflating things and they’re wrong. I don’t think that applies to me, but it’s worth a minor update on the outside view)
To echo my comment from 2 months ago:
Or, in other words, all capabilities stem from “getting things to ‘align’ with each other in the right way”.
Is this a problematic equivocation of the term “alignment”? The term “alignment” is polysemous and thus quite equivocable anyway, but if we narrow down on what I consider the most sensible explication of the relevant submeaning, i.e., Tsvi’s “make a mind that is highly capable, and whose ultimate effects are determined by the judgement of human operators”, then (modulo whether you want to apply the term “alignment” to the LLMs which is downstream from other modulos: modulo “highly capable” (and modulo “mind”) and modulo the question of whether there is a sufficient continuity or inferential connection between the LLMs you’re talking about here and the possible future omnicide-capable AI or whatever[1]) I think the framing mostly works.
I still feel like there’s something wrong or left unsaid in this framing. Perhaps it’s that the tails of the alignment-capabilities distinction (to the extent that you want to use it all) come apart as you move from the coarse-grained realm of clear distinction between “thing can do bad thing X but won’t and that ‘won’t’ is quite robust” to the finer-grained real of blurry “thing can’t do X but for reasons that are too messy to concisely describe in terms of capabilities and alignment”.
These are plausibly very non-trivial modulos … but modulo that non-triviality too.
Not sure what you mean by agency, but I probably disagree with you here. I don’t think agency is that strong an indicator of “this is going to kill us within 5 years”, and conversely I don’t think the lack of agency implies “this won’t kill us within 5 years”.
In these sorts of cases, I probably qualitatively agree with Abram’s point about performance / elicitation / “alignment”. In other words, I expect training with RL (broadly) to pick up some medium-hanging fruit that’s pretty easily available given what gippities can already do / quasi-understand.
Concretely, I wouldn’t be very surprised by FSD working soon, other robotics things working, some jobs on the level of “manage some vending machines” being replaced, some customer relationship management jobs being replaced, etc.
For comparison, good old fashioned chess playing programs defeated human chess players last millenium by searching through action-paths superhumanly. That’s already enough agency to be very scary.
I think that agency at chess is not the same as agency in the real world. That is why we have superhuman chess bots, and not super human autonomous drones.
(I don’t expect this to be convincing. I agree that we disagree. I have not seen strong evidence that agency failures will be easily overcome with better elicitation)
Reinforcing Tsvi’s point:
I tend to think the correct lesson from Claude Plays Pokemon is “it’s impressive that it does as well as it does, because it hasn’t been trained to do things like this at all!”.
Same with the vending machine example.
Presumably, with all the hype around “agentic”, tasks like this (beyond just “agentic” coding) will be added to the RL pipeline soon. Then, we will get to see what the capabilities are like when agency gets explicitly trained.
(Crux: I’m wrong if Claude 4 already has tasks like this in the RL.)
Very roughly speaking, the bottleneck here is world-models. Game tree search can probably work on real-world problems to the extent that NNs can provide good world-models for these problems. Of course, we haven’t seen large-scale tests of this sort of architecture yet (Claude Plays Pokemon is even less a test of how well this sort of thing works; reasoning models are not doing MCTS internally).
I suppose that I don’t know exactly what kind of agentic tasks LLMs are currently being trained on…. But people have been talking about LLM agents for years, and I’d be shocked if the frontier labs weren’t trying? Like, if that worked out of the box, we would know by now (?). Do you disagree?
It seems like for your point to make sense, you have to be arguing that LLMs haven’t been trained on such agentic tasks at all—not just that they perhaps weren’t trained on Pokémon specifically. They’re supposed to be general agents—we should be evaluating them on such things as untrained tasks! And like, complete transcripts of twitch streams of Pokémon play throughs probably are in the training data, so this is even pretty in-distribution. Their performance is NOT particularly impressive compared to what I would have expected chatting with them in 2022 or so when it seemed like they had pretty decent common sense. I would have expected Pokémon to be solved 3 years later. The apparent competence was to some degree an illusion—that or they really just can’t be motivated to do stuff yet. And I worry that these two memes—AGI is near, and alignment is not solved—are kind of propping each other up here. If capabilities seem to lag, it’s because alignment isn’t solved and the LLMs don’t care about the task. If alignment seems to be solved, it’s because LLMs aren’t competent enough to take the sharp left turn, but they will be soon. I’m not talking about you specifically, but the memetic environment on lesswrong.
Unrelated but: How do you know reasoning models are not doing MCTS internally? I’m not sure I really agree with that regardless of what you mean by “internally”. ToT is arguably a mutated and horribly heuristic type of guided MCTS. And I don’t know if something MCTS like is happening inside the LLMs.
Agentic (tool-using) RLVR only started working in late 2024, with o3 the first proper tool-using reasoning LLM prototype. From how it all looks (rickety and failing in weird ways), it’ll take another pretraining scale-up to get enough redundant reliability for some noise to fall away, and thus to get a better look at the implied capabilities. Also the development of environments for agentic RLVR only seems to be starting to ramp this year, and GB200 NVL72s that are significantly more efficient for RLVR on large models are only now starting to get online in large quantities.
So I expect that only 2026 LLMs trained with agentic RLVR will give a first reasonable glimpse of what this method gets us, the shape of its limitations, and only in 2027 we’ll get a picture overdetermined by essential capabilities of the method rather than by contingent early-days issues. (In the worlds where it ends up below AGI in 2027, and also where nothing else works too well before that.)
So in other words, everything has to go “right” for AGI by 2027?
Maybe it will work. I’m only arguing against high confidence in short timelines. Anything could happen.
I’m responding to the point about LLM agents being a thing for years, and that therefore some level of maturity should be expected from them. I think this isn’t quite right, as the current method is new, the older methods didn’t work out, and it’s too early to tell that the new method won’t work out.
So I’m discussing when it’ll be time to tell that it won’t work out either (unless it does), at which point it’ll be possible to have some sense as to why. Which is not yet, probably in 2026, and certainly by 2027. I’m not really arguing about the probability that it does work out.
You are consistent about this kind of reasoning, but a lot of others seem to expect everything to happen really fast (before 2030) while also dismissing anything that doesn’t work as not having been tried because there haven’t been enough years for research.
Numbers? What does “high confidence” mean here? IIRC from our non-text discussions, Tsvi considers anything above 1% by end-of-year 2030 to be “high confidence in short timelines” of the sort he would have something to say about. (But not the level of strong disagreement he’s expressing in our written dialogue until something like 5-10% iirc.) What numbers would you “only argue against”?
Say what now?? Did I write that somewhere? That would be a typo or possibly a thinko. My own repeatedly stated probabilities would be around 1% or .5%! E.g. in https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce
I recall it as part of our (unrecorded) conversation, but I could be misremembering. Given your reaction I think I was probably misremembering. Sorry for the error!
So, to be clear, what is the probability someone else could state such that you would have “something to say about it” (ie, some kind of argument against it)? Your own probability being 0.5% − 1% isn’t inconsistent with what I said (if you’d have something to say about any probability above your own), but where would you actually put that cutoff? 5%? 10%?
If someone says 10% by 2030, we disagree, but it would be hard to find something to talk about purely on that basis. (Of course, they could have other more specific beliefs that I could argue with.) If they say, IDK, 25% or something (IDK, obviously not a sharp cutoff by any means, why would there be?), then I start feeling like we ought to be able to find a disagreement just by investigating what makes us say such different probabilities. Also I start feeling like they have strategically bad probabilities (I mean, their beliefs that are incorrect according to me would have practical implications that I think are mistaken actions). (On second thought, probably even 10% has strategically bad implications, assuming that implies 20% by 2035 or similar.)
High confidence means at least over 75%
Short timelines means, say, less than 10 years, though at this point I think the very short timeline picture means “around 2030”
I don’t know how anyone could reasonably refer to 1% confidence as high.
Well, overconfident/underconfident is always only meaningful relative to some baseline, so if you strongly think (say) 0.001% is the right level of confidence, then 1% is high relative to that.
The various numbers I’ve stated during this debate are 60%, 50%, and 30%, so none of them are high by your meaning. Does that really mean you aren’t arguing against my positions? (This was not my previous impression.)
I think 60% by 2030 is too high, and I am arguing against numbers like that. There’s some ambiguity about drawing the lines because high numbers on very short timelines are of course strictly less plausible than high numbers on merely short timelines, so there isn’t necessarily one best number to compare.
On reflection, I don’t like the phrase “high confidence” for <50% and preferably not even for <75%. Something like “high credence” seems more appropriate—though one can certainly have higher or lower confidence, it is not clear communication to say you are highly confident of something which you believe at little better than even odds. Even if you were buying a lottery ticket with the special knowledge that you had picked one of three possible winning numbers, you still wouldn’t say you were highly confident that ticket would win—even though we would no longer be confident of losing!
Anyway, I haven’t necessarily been consistent / explicit about this throughout the conversation.
I’m at least 50% sure that this timeline would happen ~2x faster. Conditional on training for agency yielding positive results the rest would be overdetermined by EoY 2025 / early 2026. Otherwise, 2026 will be a slog and the 2027 wouldn’t happen in time (i.e. longer timelines).
I don’t think LLMs have been particularly trained on what I’d consider the obvious things to really focus on agency-qua-agency in the sense we care about here. (I do think they’ve been laying down scaffolding and doing the preliminary versions of the obvious-things-you’d-do-first-in-particular)
Several months ago I had dinner with a GMD employee who’s team was working on RL to make LLMs play games. I would be very surprised if this hasn’t been going on for well over a year already.
In terms of public releases, reasoning models are less than a year old. The way these things work, I suspect, is that there are a lot of smaller, less expensive experiments going on at any given time, which generally take time to make it into the next big training run. These projects take some time to propose and develop, and the number of such experiments going on at a frontier lab at a given time is (very roughly) the number of research engineers (ie talent-constrained; you can’t try every idea). Big training runs take several months, with roughly one happening at a time.
“Agentic” wasn’t a big buzzword until very recently. Google Trends shows an obvious exponential-ish trend which starts very small, in the middle of last year, but doesn’t get significant until the beginning of this year, and explodes out from there.
Thinking about all this, I think things seem just about on the fence. I suspect the first few reasoning models didn’t have game-playing in their RL at all, because the emphasis was on getting “reasoning” to work. A proactive lab could have put game-playing into the RL for the next iteration. A reactive lab could have only gotten serious about it this year.
The scale also matters a lot. Data-hunger means that they’ll throw anything they have into the next training run so long as it saw some success in smaller-scale experiments and maybe even if not. However, the first round of game-playing training environments could end up being a negligible effect on the final product due to not having a ton of training cases yet. However, by the second round, if not the first, they should have scraped together a big collection of cases to train on.
There’s also the question of how good the RL algorithms are. I haven’t looked into it very much and also most of the top labs keep details quite private anyway, but, my impression is that the RL algorithms used so far have been quite bad (not ‘real RL’—just assigning equal credit to all tokens in a chain-of-thought). This will presumably get better (EG they’ll figure out how to use some MCTS variant if they haven’t already). This is extremely significant for long-horizon tasks, because the RL algorithms right now (I’m guessing) have to be able to solicit at least one successful sample in order to get a good training gradient in that direction; long tasks will be stuck in failed runs if there’s not any planning-like component.
In any case, yeah, I think if we haven’t seen proper game-playing training in frontier models yet, we should see it very soon. If LLMs are still “below child level at this task” end-of-year then this will be a significant update towards longer timelines for me. (Pokemon doesn’t count anymore, though, because now there’s been significant scaffolding-tuning for that case, and because a lab could specifically train on pokemon due to the focus on that case.)
Also: I suspect there’s already been a lot of explicit agency training in the context of programming. (Maybe not very long time-horizon stuff, though.)
It’s different, yeah—for example, in that doing interesting things in the real world requires originary concept creation. But to do merely “agentic” things doesn’t necessarily require that. IDK what you meant by agency if not “finding paths through causality to drive some state into a small sector of statespace”; I was trying to give a superhuman example of that.
Thanks, this is a really interesting conversation to read!
One thing I have not seen discussed much from either of these viewpoints (or maybe it is there and I just missed it) is how rare frontier-expanding intelligence is among humans, and what that means for AI. Among humans, if you want to raise someone, it’s going to cost you something like 20-25 years and $2-500k. If you want to train a single scientist, on average you’re going to have to do this about a few hundred to a thousand times. If you want to create a scientist in a specific field, much more than that. If you want to create the specific scientist in a specific field who is going to be able to noticeably advance that field’s frontier, well, you might need to raise a billion humans before that happens, given the way we generally train humans.
If I went out in public and said, “Ok, based on this, in order to solve quantum gravity we’ll need to spend at least a quadrillion dollars on education” the responses (other than rightly ignoring me) would be a mix of “That’s an absurd claim” and “We’re obviously never going to do that,” when in fact that’s just the default societal path viewed from another angle.
But, in this, and even more so in AI, we only have to succeed once. In AI, We’re trying to do so in roughly all the fields at once, using a much smaller budget than we apply to training all the humans, while (in many cases) demanding comparable or better results before we are willing to believe AGI is within reach of our methods and architectures. Maybe this is a matter of shots-on-goal, as much as anything else, and better methods and insights are mostly reducing the number of shots on goal needed to superhuman rates rather than expanding the space of possibilities those shots can access.
A second, related thought is that whenever I read statements like “For example, while GPT4 scored very well on the math SAT, it still made elementary-school mistakes on basic arithmetic questions,” I think, “This is true of me, and AFAIK all humans, as well.” I think it is therefore mostly irrelevant to the core question, until and unless we can characterize important differences in when and why it makes such mistakes, compared to humans (which do exist, are getting studied and characterized).
On my view, all human children (except in extreme cases, e.g. born without a brain) have this type of intelligence. Children create their conceptual worlds originarily. It’s not literally frontier-expanding because the low-hanging fruit have been picked, but it’s roughly the same mechanism.
Yeah but drawing from the human distribution is very different from drawing from the LP25 distribution. Humans all have the core mechanisms, and then you’re selecting over variation in genetic and developmental brain health / inclination towards certain kinds of thinking / life circumstances enabling thinking / etc. For LP25, you’re mostly sampling from a very narrow range of Architectures, probably none of which are generally intelligent.
So technically you could set up your laptop to generate a literally random python script and run it every 5 minutes. Eventually this would create an AGI, you just need more shots on goal—but that tells you basically nothing. “Expanding the space” and “narrowing the search” are actually interchangeable in the relevant sense; by narrowing the search, you expand the richness of variations that are accessible to your search (clustered in the areas you’ve focused on). The size of what you actually explore is roughly fixed (well, however much compute you have), like an incompressible fluid—squish it in one direction, it bloops out bigger in another direction.
The distribution of mistakes is very different, and, I think, illuminates the differences between human minds and LLMs. (Epistemic status: I have not thoroughly tested the distribution of AI mistakes against humans, nor have I read thorough research which tested it empirically. I could be wrong about the shape of these distributions.) It seems like LLM math ability cuts off much more sharply (around 8 digits I believe), whereas for humans, error rates are only going to go up slowly as we add digits.
This makes me somewhat more inclined towards slow timelines. However, it bears repeating that LLMs are not human-brain-sized yet. Maybe when they get to around human-brain-sized, the distribution of errors will look more human.
I have a couple things to add here to the conversation that I think will help:
I think a lot of current LLM failures that @TsviBT is pointing to are downstream of 2 big issues currently, which is that current LLM weights are frozen, meaning that once they stop training, they have no way to learn anything new other than ICL, and while there’s some generalization ability, it’s also not enough for real use cases like automating AI research, and in particular LLMs have no long-term memory, meaning they have to relearn things that a human would only have to learn once, and the benchmark of Claude Plays Pokemon is a really good example of what happens when you don’t have long-term memory, and that’s due to LLMs being based on transformers rather than RNNs, where hidden states allow a form of long-term memory to occur.
The non-straw version of LLMs not being able to automate jobs from humans is that context windows don’t have to scale the way they have since 2019, because DRAM isn’t scaling exponentially, and in-context learning in practice turning out to be too weak to really replace weight-level continual learning, and their lack of memory and agency meaning that they constantly get stuck in loops, meaning they are useless for the vast majority of jobs.
I agree with this statement specifically here, and a reason for this is that I believe most human capabilities don’t come from evolution, but from within life-time learning, and the areas where evolution matters are unfortunately disproportionately AI alignment-relevent areas of the human brain, which is “(1) just one or two major shifts in training technique to be enough to get us from where we are to AI research assistants capable of major innovation”.
An independent reason to think AGI will come in the 2030s most likely, assuming LLMs do plateau, is because we are getting into the regime where we can more inexpensively experiment with human-brain level compute, and we are scaling through a lot of OOMs for compute usage, meaning that we can inexpensively experiment for insights a lot more than we currently do:
https://www.lesswrong.com/posts/yew6zFWAKG4AGs3Wk/?commentId=Bu8qnHcdsv4szFib7
And to answer @Cole Wyeth’s question of why one human brain lifetime and not evolutionary timelines, the short answer is most of the capabilities are rederived for humans every lifetime, and evolution matters way less than we think it does.
@Steven Byrnes and @Quintin Pope have discussed this before:
https://www.lesswrong.com/posts/wAczufCpMdaamF9fy/my-objections-to-we-re-all-gonna-die-with-eliezer-yudkowsky#Edit__Why_evolution_is_not_like_AI_training
https://www.lesswrong.com/posts/wBHSYwqssBGCnwvHg/intro-to-brain-like-agi-safety-2-learning-from-scratch-in
https://www.lesswrong.com/posts/hvz9qjWyv8cLX9JJR/evolution-provides-no-evidence-for-the-sharp-left-turn#Evolution_s_sharp_left_turn_happened_for_evolution_specific_reasons
https://www.lesswrong.com/posts/pz7Mxyr7Ac43tWMaC/against-evolution-as-an-analogy-for-how-humans-will-create
I agree with Cole Wyeth that current LLMs are pretty bad at agency, and if we assume they don’t scale to better agency over time, I’d put much lower probability on LLMs being able to automate away the remaining bottlenecks to ASI, and it’s a reasonable hypothesis to hold (I’d put about 52% probability on this currently)
And in particular, I think the fact that LLM capability degrades way faster than humans as @abramdemski saw is tied to a lack of continual learning, and ICL not being enough currently to actually subsititute for weight-level continual learning.
And yet, I think there are good reasons to believe independently of LLMs that AGI/ASI is coming pretty soon, and I do think there’s reason to believe that timelines are probably short, even if LLMs do plateau.
To be clear, I think this is worse than a future where LLMs do just straight up scale to ASI.
Also, the entire crux is basically “does their in-context learning/generalization and creativity shown in current LLMs actually act as a proper subsitute for continual learning in weights and memory?”
The other crux is whether context windows will actually continue to scale in the way they have since 2019.
I don’t agree with this connection. Why would you think that continual learning would help with this specific sort of thing? It seems relevantly similar to just throwing more training data at the problem, which has shown only modest progress so far.
The key reason is to bend the shape of the curve, and my key crux is I don’t expect throwing more training data to change the shape of the curve where past a certain point, LLMs sigmoid/fall off hard, and my expectation is more training data would make LLMs improve, but they’d still have a point where once LLMs are asked to do any task harder than that point, LLMs start becoming incapable more rapidly in humans.
To quote Gwern:
From this link:
https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/metr-measuring-ai-ability-to-complete-long-tasks#hSkQG2N8rkKXosLEF
(Note that I have a limit on how many comments I can make per week, so I will likely respond slowly, if at all to any responses to this).
It seems to me like the improvement in learning needed for what Gwern describes has little to do with “continual” and is more like “better learning” (better generalization, generalization from less examples).
Regarding continual learning and memory, I mentioned in the dialogue that I’m not just talking about performance of trained LLMs, but rather addressing the whole Architecture:
Your remarks sound to me like “We just need X”, which I addressed here: https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce#_We_just_need_X__intuitions
See also https://tsvibt.blogspot.com/2023/09/a-hermeneutic-net-for-agency.html#silently-imputing-the-ghost-in-the-machine , which I’ll quote from:
Note that I was talking about both long-term memory and continual learning, not just continual learning, so I’m happy to concede that my proposed architecture is not like how LLMs are trained today, and thus could reasonably be called a non-LLM architecture.
Though I will say that the BabyLM challenge and to a lesser extent the connect the dots paper is evidence that part of the reason current LLMs are so data inefficient is not because of fundamental limitations, but rather because AI companies didn’t really need to have LLMs be data efficient in order for LLMs to work so far, but by 2028-2030, this won’t work nearly as effectively assuming LLMs haven’t automated away all AI research.
You’ve mentioned the need for a missing update, and I think part of that missing update is that we didn’t really realize how large the entire internet was, and this gave the fuel for the very impressive LLM scaling, but this is finite, and could very plausibly not be enough for LLMs out of the current companies.
However, I’m inclined towards thinking the issue may not be as fundamental as you think it is, for the reason @abramdemski said below:
Remember, this is a small scale experiment, and you often have to go big in order to make use of your new findings, even if there are enough efficiency tricks such that at the end, you can make an AI that is both very capable and more efficient than modern human learning (I’m not assuming that there exists a method such that LLMs can be made more data efficient than a human, but am claiming that if they exist, there still would need to be scaling to find those efficiency tricks).
So it being only as good as GPT2 is unsurprising. Keep in mind that GPT-3 was trained by OpenAI who absolutely believed in the ability to scale up compute, and had more resources than academic groups at the time.
To respond to this:
My main response is that once we condition on LLMs not having weight level continual learning as well as them not having a long-term memory, there’s little mystery left to explain for LLM capabilities, so there’s no other machinery that I’ve missed that is very important.
For the continual learning point, a great example of this is that humans don’t hit walls of capability nearly as often as LLMs do, and in particular human success curves on task often flatline or increase, rather than hit hard limits, and in particular when needed have very, very high conceptual resolution, such that we can work on long, open-ended problems without being entirely unproductive of insights.
And this is because human neurons constantly update, and there’s no deployment phase where all your neurons stop updating.
Human neuroplasticity declines, but never is completely gone as you age.
I explain more about why I think continual learning is important below, and @gwern really explained this far better than I can, so read Gwern’s comment too:
https://www.lesswrong.com/posts/5tqFT3bcTekvico4d/do-confident-short-timelines-make-sense#mibF9KKtuJxtnDBne
For the long-term memory point, the reason why it’s important for human learning is that it simultaneously prevents us from being stuck on unproductive loops like how Claude can go to the Spiritual Bliss attractor or how Claude has a very bad habit of being stuck in loops when trying to win the game of Pokemon, and also allows you to build on previous wins/take in large amounts of context without being lost, which is a key part of doing jobs.
Dwarkesh Patel explains better than I can why a lack of long-term memory/continual learning is such a big deal for LLMs, and reduces their ability to be creative, because they cannot build upon hard-earned optimizations into something bigger, and I tend to model humans getting insights not as you thinking hard for a day and fully forming the insight like Athena out of Zeus, but rather humans getting a first small win, and because they can rely on their long-term memory, they don’t have to worry about losing that first small win/insight, and they continuously look both at reality and theory to iteratively refine their insights until they finally have a big insight that comes out after a lot of build-up, but LLMs can’t ever build up to big insights, because they keep constantly forgetting the small stuff that they have gotten:
https://www.dwarkesh.com/p/timelines-june-2025
Edit: And the cases where there are fully formed ideas from what seems like to be nothing is because of your default mode network in the brain, and more generally you always are computing and thinking in the background, and it’s basically continual learning on your own thoughts, and once we realize this, it’s much less surprising that we can somewhat reliably create insights. LLMs lack any equivalent of a default mode network/continual learning on their own thoughts, which pretty neatly explains why people report that they have insights/creativity out of nowhere, but LLMs so far haven’t done this yet:
https://gwern.net/ai-daydreaming#continual-thinking
Another edit: A key part of my worldview is that by the 2030s, we have enough compute such that we can constantly experiment with human-brain sized architectures, and in particular given that I think capabilities are learned within life-time for various reasons @Steven Byrnes and @Quintin Pope already said, and this means that the remaining missing paradigms are likely to be discovered more quickly, and critically this doesn’t depend on LLMs becoming AGI:
https://www.lesswrong.com/posts/yew6zFWAKG4AGs3Wk/?commentId=Bu8qnHcdsv4szFib7
An important study here that’s quoted for future reference:
A key crux that I hold, relative to you is that I think LLMs are in fact a little bit creative/can sometimes form insights (though with caveats), but that this is not the relevant question to be asking, and I think most LLM incapacities are not literally that they can never do this fundamentally, but rather that at realistic amounts of compute and data, they cannot reliably form insights/be creative on their own, or even do as well as the best human scientists, similar to @Thane Ruthenis’s comment below:
https://www.lesswrong.com/posts/GADJFwHzNZKg2Ndti/have-llms-generated-novel-insights#YFfperxLEnWoomzrH
So the lack of long-term memory and continual learning is closer to the only bottleneck for LLMs (and I’m willing to concede that any AI that solves these bottlenecks is not a pure LLM).
Also, this part is something that I agree with, but I expect normal iteration/engineering to solve these sorts of problems reliably, so I don’t consider it a fundamental reason not to expect AGI in say the 2030s:
Ok… but are you updating on hypothetical / fictional evidence? BTW to clarify, the whole sample efficiency thing is kind of a sideline to me. If someone got GPT4 level performance by training on human data that is like 10x the size of the books that a well-read human would read in 50 years, that would be really really weird and confusing to me, and would probably shorten my timelines somewhat; in contrast, what would really shorten my timelines would be observations of LP2X creating novel interesting concepts (or at least originary interesting concepts, as in Hänni’s “Cantor’s Diagonal from scratch” thing).
Yes, this is a good example of mysteriously assuming for no reason that “if we just get X, then I don’t see what’s stopping my learning program from being an AGI, so therefore it is an AGI”, which makes absolutely zero sense and you should stop.
No it’s not. I mean it is a little bit. But it’s also “because” “neurons implement Bayesian learning”, and it’s also “because” “neurons implement a Turing machine”. Going from this sort of “because” to “because my thing is also a Turing machine and therefore it’s smart, just like neurons, which are also Turing machines” makes zero sense.
What considerations (observations, arguments, etc.) most strongly contributed to convincing you of the strongest form of this proposition that you believe?
@Lucius Bushnaq It’s not too combative, you’re wrong. My previous comment laid out what’s wrong with the reasoning. Then Noosphere89 wrote a big long comment that makes all the same lines of reasoning, still without giving any arguments. This is really bad epistemics, and people going around vibing hard about this have been poisoning (or rather, hijacking https://www.lesswrong.com/posts/dAz45ggdbeudKAXiF/a-regime-change-power-vacuum-conjecture-about-group-belief) the discourse for 5 years.
I do not think that Noosphere’s comment did not contain an argument. The rest of the comment after the passage you cited tries to lay out a model for why continual learning and long-term memory might be the only remaining bottlenecks. Perhaps you think that this argument is very bad, but it is an argument, and I did not think that your reply to it was helpful for the discussion.
So I feel like Tsvi is actually right about a bunch of stuff but that his timelines are still way too long. I think of there as being stronger selection, on australopithecines and precursors, for bipedalism during interglacial periods, because it was hotter and bipedalism reduces the solar cross-section, and this is totally consistent with this not being enough/the right kind of selection over several interglacial periods to cause evolution to cough up a human. But if there had been different path dependencies, you could imagine a world where enough consecutive interglacial periods would fixate australopithecine-type bipedalism (no endurance running yet) and maybe this has a bunch of knock-on effects that let you rule the world. So in the same way I don’t think just scaling current architectures is likely to result in generally intelligent systems, but considering EURISKO as one small weirdly early example of what happens when you have a pretty ‘smart’ system and a pretty smart human and they are weirdly synergistic, I could imagine a world where a few humans (with good reductive foundations but no reductive morals somehow) and LLMs are synergistic enough, there’s enough hardware, credibility, money, and energy, from the craze, to significantly affect the success of some particular research paths that let something ultimately rule the world in a few years; but I could just as easily imagine this as Just Another Interglacial Period, another edge in the path, and still insufficient to suddenly rule the world before, say, 2032? But if you looked at the graph of my median estimate of selection strength on bipedalism with respect to evolutionary time, you would see these little jumps in strength during interglacial periods, so I don’t feel too crazy for having a sort of bimodal distribution over timelines, where if we don’t get AGI before 2030, I will think we have several edges to walk across before AGI, but like, that absolutely doesn’t mean my median estimate for AGI is 2075 after this process. But I still think I’m significantly less confident in the earlier mode of this bimodal distribution than most other people who also have bimodal distributions.
I also think Google DeepMind is the odd one out among frontier labs, they are weirdly good at marketing for being part of Google, they have revealed several impressive results that are arguably kind of ‘out of paradigm’, even before LLMs took off, they show signs of being very strategic about what research they make public, they clearly have a neuromorphic bent, and this bent kind of puts you ahead of mainstream neuroscience after enough time, in a sense, like I totally believe that AI researchers who are deeply motivated to achieve neuromorphic AI (like those at DeepMind) could leave mainstream neuroscientists in the dust with respect to actionable models of human cognition, if they haven’t already; their incentives are completely different and frankly I think in general we live in a kind of bizarro world where reductive progress got bottlenecked at human evolutionary biology for various contingent historical reasons and that this affects basically everyone’s models of how quickly science can progress, but my model of this will not fit in the margins.
It makes sense to say “we’re currently in a high hazard-ratio period, but H will decrease as we find out that we didn’t make AGI”. E.g. because you just discovered something that you’re now exploring, or because you’re ramping up resource inputs quickly. What doesn’t make sense to me (besides H being so high) is the sharp decrease in H. Though maybe I’m misunderstanding what people are saying and actually their H does fall off more smoothy.
As I mentioned, H should be smeared out. Any given resource might take longer than you expected to ramp up, or to be applied to the right things; any given insight might take longer to implement, or might have further insightful ramifications which then have their own minor innovation curves.
Given this smearing effect, I don’t intuitively / pretheoretically see how a bimodal H could possibly make sense. Maybe it does, I’ve just not yet heard a plausible story. You can have things like bimodals if you have some really specific method that you think should work, and if it doesn’t work then nothing like it should work. But no one has ever, in earshot of me, explained anything remotely like this regarding AGI (and lots of people have vaguely, confident-soundingly, said that they did have a picture like that—until questioned, at which point they totally and embarrassingly fall apart).
So I guess my model says that AGI R&D is basically the opposite of human evolution in a certain sense, actually basically all of the cognitive architecture necessary to cough up a human was in place by the speciation of chimpanzees, if not macaques, it really was just a matter of scaling (including having the selection pressures and metabolic resources necessary to connect previously unconnected modules, and don’t underestimate the generality of a ‘module,’ on my model), but like, if this took several complicated pieces, then if you’re relying on a different dependency structure (possibly like modern AI research, which the weirdly anachronistic capabilities of LLMs strongly suggest) with tons of money, time, energy, and hardware, you could enjoy way more abundance than human evolution and make the last of the algorithmic improvements that evolution made and suddenly get a system at least as capable as the human algorithm with that much hardware, and take over the world. I’m saying you should imagine human evolution thus far as having made way more algorithmic progress than our civilization because it was strongly constrained by resource availability.
I don’t have code that would end the world if I ran it, nor would I admit it if I did, but I feel like I have a good enough account of civilizational inadequacy in this domain, and a good enough model of human cognitive evolution, and ‘cultural evolution’, to conclude that LLMs are a massive enough boon to research productivity for key individuals/organizations to be a serious threat? I guess I feel like bimodal distributions can be reasonable by some kind of qualitative reasoning like, “How likely is it that I am merely two insights from AGI, as opposed to one or many?”
If I had to share some things that I don’t think would quickly end the world by being shared, given that they’re already public, and given that, if me pointing out this difference is likely to quickly end the world, it’s significant evidence in favor of massive civilizational inadequacy in this domain, which I would like everyone else to believe if it’s true and could save everyone, I guess the thing I would share would be the consilience between neural radiance fields and the constructive episodic simulation adaptations of modern humans? Like this is world-model-type stuff. If you can generate world-models from 2d visual frames at all, it seems to me that you are massively along the path of constructive episodic simulation, which gives you all sorts of benefits, like perspective-taking, episodic memory, prospective planning, detailed counterfactuals, I don’t know where to stop and I still don’t think this is the The Xth Insight.
I deny this and have no idea how you or anyone thinks you can do this (but therefore I can’t be too too confident).
Meh. I think you’re discounting the background stuff that goes into the way humans do it. For example, we have additional juice going into “which representations should I use, given that I wanted to play around with / remember about / plan using my representation of this thingy?”. NeRFs are not going to support detailed counterfactuals very well out of the box I don’t think! Maybe well enough for self-driving cars that at least avoid crashing; but not well enough to e.g. become interested in an anomaly, zoom in, do science, and construct a better representation which can then be theorized about.
Yes, we should distinguish between the ability to generate counterfactuals at all versus being able to use that ability instrumentally, but I was kind of trying to preempt this frame with “still don’t think this is the The Xth Insight.”
I mean, NeRFs were the beginning, but we can already generate 3d Gaussian splats from text prompts or single images, do semantic occupancy prediction in 3d splats, construct 4d splats from monocular video, do real-time 4d splats with enough cameras, etc., and it seems to me that doing these things opens the way to creating synthetic datasets of semantic 4d splats, which it further seems you could use to train generative models that would constitute Constructive Episodic Simulators, in which case on my model, actually yes, something akin to human episodic imagination, if not ‘true’ counterfactuals, should come right out of the box. By themselves, of course these modules will sometimes produce volumetric video analogs of the hallucinations we see in LLMs, not necessarily be very agentic by default, etc., so I don’t think achieving this goal immediately kills everyone, but it seems like an essential part of something that could.
At the very least I guess I’m predicting that we’re going to get some killer VR apps in the next few years featuring models that can generate volumetric video at interactive frame rates.
I don’t know how strong of a / what kind of a claim you’re trying to make here… Are you claiming NeRFs represent a substantial chunk of the Xth algorithmic insight? Or not an algorithmic part, but rather setting up a data source with which someone can make the Xth insight? Or...?
I’m claiming that any future model that generates semantically rich volumetric histories seems to me to be implementing a simpler version of humans’ constructive episodic simulation adaptations, of which episodic counterfactuals, episodic memories, imaginary scenes, imagining perspectives you haven’t actually experienced, episodic prospection, dreams, etc. are special cases.
So ‘antepenultimate algorithmic insight,’ and ‘one of just a few remaining puzzle pieces in a lethal neuromorphic architecture’ both strike me as relatively fair characterizations. I have this intuition that some progress can be characterized more as a recomposition of existing tricks, whereas some tricks are genuinely new under the sun, which makes me want to make this distinction between architecture and algorithms, even though in the common sense every architecture is an algorithm; this feels fuzzy, relative, and not super defensible, so I won’t insist on it. But to describe my view through the lens of this distinction, more capable generalizations of stuff like MAV3D would be a critical module (algorithmic-level) in a generally intelligent neuromorphic architecture. Yes, you need other modules for this architecture to efficiently search for episodic simulations in a way that effectively guides action, and for taking simulation as an action itself and learning when and how to episodically simulate, and so on, but I’m specifically trying not to describe a roadmap here.
As far as I know we’re nowhere near exploiting existing video corpora as much as we could for training things like MAV3D, and yes, it seems to me we would be well-positioned to build synthetic datasets for future generative volumetric video models from the outputs of earlier models trained on videos of real scenes, and perhaps from data on VR users controlling avatars in interactive volumetric scenes as well. It seems like this would be easy for Meta to do. I’m more sure that this generates data that can be used for making better versions of this particular module, and less sure that this would be useful for generating data for other modules that I think necessary, but I do have at least one hypothesis in that direction.
Ok. This is pretty implausible to me. Bagiński’s whack-a-mole thing seems relevant here, as well as the bitter lesson. Bolting MAV3D into your system seems like the contemporary equivalent of manually writing convolution filters in your computer vision system. You’re not striking at the relevant level of generality. In other words, in humans, all the power comes from stuff other than a MAV3D-like thing—a human’s MAV3D-like thing is emergent / derivative from the other stuff. Probably.
I agree with this as an object-level observation on the usefulness of MAV3D itself, but also have a Lucas critique of the Bitter Lesson that ultimately leads me to different conclusions about what this really tells us.
I think of EURISKO, Deep Blue, and AlphaGo/Zero as slightly discordant historical examples that you could defy, but on my view they are subtle sources of evidence supporting microfoundations of cognitive returns on cognitive reinvestment that are inconsistent with Sutton’s interpretation of the observations that inspired him to compose The Bitter Lesson.
EURISKO is almost a ghost story, but if the stories are true, then this doesn’t imply that N clever tricks would’ve allowed EURISKO to rule the world, or even that EURISKO is better classified as an AI as opposed to an intelligence augmentation tool handcrafted by Lenat to complement his particular cognitive quirks, but Lenat + EURISKO reached a surprising level of capability quite early. Eliezer seems to have focused on EURISKO as an early exemplar of cognitive returns on recursive self-improvement, but I don’t think this is the only interesting frame.
It’s suggestive that EURISKO was written in Interlisp, as the homoiconic nature of LISPs might have been a critical unhobbling. That is to say, because Lenat’s engineered heuristics were LISP code, by homoiconicity they were also LISP data, an advantage that Lenat fearlessly exploited via macros, and by extension, domain specific languages. It also appears that Lenat implemented an early, idiosyncratic version of genetic algorithms. EURISKO was pretty close to GOFAI, except perhaps for the Search, but these descriptions of its architecture strongly suggest some intuitive appreciation by Lenat of something akin to the Bitter Lesson, decades before the coining of that phrase. It looks like Lenat figured out how to do Search and Learning in something close to the GOFAI paradigm, and got surprisingly high cognitive returns on those investments, although perhaps I have just made them seem a little less surprising. Of course, in my view, Lenat must not have fully appreciated the Lesson, as he spent the rest of his career working on Cyc. But for a little while at least, Lenat walked a fine line between the version of Engineering that doesn’t work, and the version that (kind of) does.
I would compare this distinction to the presence of folk semantics in all natural languages, and the absence of folk syntax. Parts of semantics are introspectively accessible to humans, so introspection permits veridical folk descriptions of semantics (informal, useful descriptions of what is true, possible, etc.), but the generator of syntax is introspectively inaccessible to humans, so generating veridical folk descriptions of syntax is much harder, if not impossible, via the same mechanism we applied in the case of folk semantics, thus successful computational modeling of syntax for the most part requires Science/Bayes (e.g. Linguistics). In my view, EURISKO was indeed mostly invented/discovered with Science/Bayes rather than Introspection, but this was hard for Lenat to tease out post mortem, and then he went way too far in the Introspection direction, failing to appreciate that most if not all of his cognitive returns came from mostly implicit, successful Science/Bayes (like mathematicians), which from the inside is hard to distinguish from successful Introspection. But Lenat’s ostensible error does not explain away the cognitive returns observed in the case of EURISKO, if we have in fact observed any.
Deep Blue demonstrated significant cognitive returns from massively parallel alpha-beta pruning + engineered evaluation functions and opening/endgame heuristics. Arguably, these were functions as opposed to data, but if we maintain the LISP/FP mindset for a moment, functions and source code are data. I can squint at Deep Blue as an exemplar of ‘feature engineering’ ‘working’ i.e., large allocations of engineering effort on a ‘reasonable’ (to humans) timescale, in concert with unprecedentedly ambitious hardware allocation/specialization and parallelism, permitting cognitive returns on cognitive reinvestment to exceed a critical threshold of capability (i.e. beating Kasparov even once, possibly even on an off-day for Kasparov).
Crucially, not all engineered features are brittle (or even unscalable, with respect to a concrete capability target, which is my model of Deep Blue), and not all learned features are robust (or even scalable, again with respect to a concrete capability target, which is my model of how DQN didn’t solve (i.e. meet the human expert capability threshold in the domain of) Go before AlphaGo (Go board state Search in ‘latent space’ was not ‘tractable’ with those permutations of compute, data, and (Learning) algorithm)), which might explain a thing or two about the weird competence profile of LLMs as well.
All of this to say, I don’t think about cognitive returns in a way that demands a fundamentally sharp distinction between Learning and Engineering, even if it’s been qualitatively pretty sharp under most historical conditions, nor do I think about cognitive returns in a way that forbids significant but reasonable amounts of pretty mundane engineering effort pushing capabilities past a critical threshold, and crucially, if that threshold is lethal, then you can die ‘without’ Learning.
As I hope might become especially clear in the case of AlphaGo/AlphaZero, I think the architectural incorporation of optimally specific representations can also significantly contribute to the magnitude of cognitive returns, as observed, I claim, in the cases of Deep Blue and EURISKO, where board states and domain specific languages respectively constituted strong priors on optimal actions when appropriately bound to other architectural modules (notably, Search modules in each case), and were necessary for the definition of evaluation functions.
I think a naive interpretation of the Bitter Lesson seems at first glance to be especially well-supported by the observed differences in capability and generality between the Alpha-series of architectures. You combine the policy and value networks into one, two-headed network, stop doing rollouts, and throw away all the human data, and it’s better, more capable and more general, it can perform at superhuman level in multiple perfect information, zero-sum, adversarial games besides Go (implicitly given their Rules in the form of the states, actions, and transition model of an MDP of course), and beat earlier versions of itself. But we also did the opposite experiments (e.g. policy head only Leela Chess Zero at inference time) and again an architecture with a Learning module but no Engineered Search module produced significantly lower cognitive returns than a similar architecture that did have an Engineered Search module.
Then MuZero wiped the board by tractably Learning the Rules in the latent space, but only four years after AlphaGo had reached the first target capability, and it still used Engineered Search (MCTS). To my knowledge, we are trying to build things that learn better search algorithms than we can engineer ourselves, but we still aren’t there. I’m not even claiming this wouldn’t work eventually, or that an engineered AGI architecture will be more general and more capable than a learned AGI architecture, I just think someone will build the engineered architecture first and then kill everyone, before we can learn that architecture from scratch and then kill everyone. On my model, returns on Search haven’t been a fundamental constraint on capability growth since right before EURISKO. On the other hand, returns on Engineered Game Rules (state space, action space, transition model), Compute, Data, and Learning have all been constraints under various historical conditions.
So I guess my model says that ‘merely static representations’ of semantic volumetric histories will constitute the first optimally specific board states of Nature in history, and we will use them to define loss functions so that we can do supervised learning on human games (recorded volumetric episodes) and learn a transition model (predictive model of the time evolution of recorded volumetric episodes, or ‘next-moment prediction’) and an action space (generative model of recorded human actions), then we will combine this with Engineered Search and some other stuff, then solve Go (kill everyone). Four years later something more capable and more general will discover this civilization from first principles and then solve Go, Chess, and Shogi with one architecture (kill everyone), and this trend will have been smooth.
If this isn’t pretty much exactly what Abram had in mind when he wrote:
then I might have to conclude that he and I have come to similar conclusions for completely different reasons.
I feel like explicit versions of the microfoundations implied by naive interpretations of the Bitter Lesson would falsely retrodict that we couldn’t beat Kasparov even once without ubiquitous adoption of ReLUs and late oughts/early teens amounts of compute, that DQN was sufficient to solve Go, and that EURISKO is a ghost story.
I didn’t talk about the neurobiology of constructive episodic simulation in humans at all, but would be willing to do so, and I think my model of that is also consistent with my microfoundations.
I think getting this to work in a way that actually kills everyone, rather than merely is AlphaFold or similar, is really really hard—in the sense that it requires more architectural insight than you’re giving credit for. (This is a contingent claim in the sense that it depends on details of the world that aren’t really about intelligence—for example, if it were pretty easy to make an engineered supervirus that kills everyone, then AlphaFold + current ambient tech could have been enough.) I think the easiest way is to invent the more general thing. The systems you adduce are characterized by being quite narrow! For a narrow task, yeah, plausibly the more hand-engineered thing will win first.
Back at the upthread point, I’m totally baffled by and increasingly skeptical of your claim to have some good reason to have a non-unimodal distribution. You brought up the 3D thing, but are you really claiming to have such a strong reason to think that exactly the combination of algorithmic ideas you sketched will work to kill everyone, and that the 3D thing is exactly most of what’s missing, that it’s “either this exact thing works in <5 years, or else >10 years” or similar?? Or what’s the claim? IDK maybe it’s not worth clarifying further, but so far I still just want to call BS on all such claims.
Wow, that made a surprising amount of sense considering the length of the sentences.
Yeah I’ve been having a problem with people thinking I’m LLM-crazy, I think. But it’s what I believe.
Tertiarily relevant annoyed rant on terminology:
I don’t really like referring to The Thing as “ASI” (although I do it too), because I foresee us needing to rename it from that to “AGSI” eventually, same way we had to move from AI to AGI.
Specifically: I expect that AGI labs might start training their models to be superhuman at some very narrow tasks. It’s already possible in biology: genome modeling, protein engineering, and you can probably distill AlphaFold 2 into a sufficiently big LLM, etc. Once that starts happening, perhaps on some suite of tasks more adapted for going viral on Twitter, people will start running around saying that artificial superintelligence has been achieved. And indeed, in a literal sense, the chatbot would literally be able to generate some superhuman results and babble about them; and due to the fact that the distilled AlphaFold 2 (or whatever) will be crammed into a black-box LLM-chatbot wrapper, externally it will look as if the chatbot is a superintelligent reasoner. But in actuality, it may end up generally being as dumb as today’s LLMs, except in that narrow domain/domains where it effectively has access to a superhuman tool.
So at that point, we’ll have to move the goalposts to talking about the dangers of artificial general superintelligence, rather than a mere artificial (narrow) superintelligence. Some people will also be insisting that LLMs’ general intelligence is already at human-ish levels, so these LLMs, in their opinion, will already be both AGI and ASI, just not AGSI. That will indubitably have excellent effects on the clarity of discourse.
I think it’s near certain that I will be annoyed about all of this by 2028, so as a proper Bayesian, I’m already annoyed about this.
I don’t think the difference between “first problem you don’t catch can kill you” and “when you fail, you can try again” is relevant here.
The thing I had in mind is/was roughly:
There is (something like) a latent generator (or a set of (possibly significantly interlinked) generators) that is upstream of all those moles that you are whacking (here, AI existential/catastrophic threat models and LLM failures, respectively).
Iterative mole-whacking is unlikely to eliminate the core generator.
To give an analogy: a world where (2) is false is one where there is some N, such that having solved N superficial problems (“moles”), you can compose those N solutions into something that solves the latent generator (or, all the moles generated by it), or take the convex hull spanned by those solutions such that ~all the possible superficial problems you might expect to encounter (including the ones encounterable only very far in the future, or out of distribution, that you can’t even foresee now) would fall within this convex hull. A world where (2) is true is one where you can’t do this in a reasonable time, with the amount of resources you can reasonably expect to have available.
In the limit of available time and other resources, sure, but the root claim of this discussion is P(ASI by 2030)≥0.6, not limavailable resources→∞P(ASI obtainable by whacking moles with available resources)≈1.
Of course, all of this relies on an assumption (that I may not have clearly spelled out in the call, and I don’t think you spelled it out here, either) that there is such a “latent generator” where “generator” does not need to involve “active generation/causing” but can be something more generic like “an abstract reason about current AIs and their limitations that explains why the moles keep popping up”. (Of course, the existence of such a generator doesn’t in itself mean that you can’t effectively solve the generator by whacking moles, but the latter “can’t” presumes the former “exists”.)
True. You don’t need total-above-human-level-ness for omnicide-capacity. But the whack-a-mole analogy still applies.
Right. I think the mole generator is basically lack of continual learning and arbitrarily deep neural reasoning (which is different than eg CoT), and that it manifests itself most clearly in agency failures but also suggests something like limits of original thinking.
Alas, more totally unjustified “we just need X”. See https://www.lesswrong.com/posts/5tqFT3bcTekvico4d/do-confident-short-timelines-make-sense?commentId=NpT59esc92Zupu7Yq
I’m not saying that’s necessarily the last obstacle.
“The mole generator is basically X” seems somewhat at odds with the view Mateusz is expressing here, which seems more along the lines “LLM researchers are focusing on moles and ignoring where the moles are coming from” (the source of the moles being difficult to see).
The mole generator might be easy to see (or identify with relatively high certainty), but even if one knows the mole generator, addressing it might be very difficult.
Straining the analogy, the mole-hunters get stronger and faster each time they whack a mole (because the AI gets stronger). My claim is that it isn’t so implausible that this process could asymptote soon, even if the mole-mother (the latent generator) doesn’t get uncovered (until very late in the process, anyway).
This is highly disanalogous to the AI safety case, where playing whack-a-mole carries a very high risk of doom, so the hunt for the mole-mother is clearly important.
In the AI safety case, making the mistake of going after a baby mole instead of the mole-mother is a critical error.
In the AI capabilities case, you can hunt for baby moles and look for patterns and learn and discover the mole-mother that way.
A frontier-lab safety researcher myopically focusing on whacking baby moles is bad news for safety in a way that a frontier-lab capabilities researcher myopically focusing on whacking baby moles isn’t such bad news for capabilities.
Thanks for clarifying.
I do feel some pull in this direction, but it’s probably because the weight of the disvalue of the consequences of this “asymptoting” warps my assessment of plausibilities. When I try to disentangle these factors, I’m left with a vague “Rather unlikely to asymptote, but I surely rather not have anyone test this hypothesis.”.
Thanks for the efforts. Modeling good discourse around complicated subjects is hard and valuable.
Didn’t know about enthymemes, cool concept.
1% chances of wiping all humans makes the current people working on ai worse than genocidal dictators and I dislike the appeasement of so many people trying to stay in good graces with them on the off chance of influencing them anyway. I think their behavior is clearly sociopathic if that term is to have any meaning at all and the only influence anyone has on them is simulated by them for strategic purposes. They are strongly following power gradients.
This “deductive closure” concept feels way too powerful to me. This is even hinted at later in the conversation talking about mathematical proofs, but I don’t think it’s taken to its full conclusion: such a deductive closure would contain all provable mathematical statements, which I am skeptical even an ASI could achieve.[1]
To spell this out more precisely: the deductive closure of just “the set theory axioms” would be “all of mathematics”, including (dis)proofs for all our currently unproven conjectures[2] (e.g. P ≠ NP), and all possible mathematical statements.[2]
Well, as long as we want to stick to some reasonable algorithmic complexity. Otherwise the “just try all possible proofs in sequence” algorithm is something we already have and works perfectly.
Well, as long as they are not undecidable.
You’re right. I should have put computational bounds on this ‘closure’.
It seems fine to me; bridges were a long way off at most times at which bridges didn’t exist! (What wouldn’t be fine is continuing to make the a priori argument once there is evidence that we have many of the ideas.)
I guess it depends on what “a priori” is taken to mean (and also what “bridges” is taken to mean). If “a priori” includes reasoning from your own existence, then (depending on “bridge”) it seems like bridges were never “far off” while humans were around. (Simple bridges being easy to construct & commonly useful.)
I don’t think there is a single correct “a priori” (or if there is, it’s hard to know about), so I think it is easy to move work between this step and the next step in Tsvi’s argument (which is about the a posteriori view) by shifting perspectives on what is prior vs evidence. This creates a risk of shifting things around to quietly exclude the sort of reasoning I’m doing from either the prior or the evidence.
The language Tsvi is using wrt the prior suggests a very physicalist, entropy-centric prior, EG “steel beams don’t spontaneously form themselves into bridges”—the sort of prior which doesn’t expect to be on a planet with intelligent life. Fair enough, so far as it goes. It does seem like bridges are a long way off from this prior perspective. However, Tsvi is using this as an intuition pump to suggest that the priors of ASI are very low, so it seems worth pointing out that the priors of just about everything we commonly have today are very low by this prior. Simply put, this prior needs a lot of updating on a lot of stuff, before it is ready to predict the modern world. It doesn’t make sense to ONLY update this prior on evidence that pattern-matches to “evidence that ASI is coming soon” in the obvious sense. First you have to find a good way to update it on being on a world with intelligent life & being a few centuries after an industrial revolution and a few decades into a computing revolution. This is hard to do from a purely physicalist type of perspective, because the physical probability of ASI under these circumstances is really hard to know; it doesn’t account for our uncertainty about how things will unfold & how these things work in general. (We could know the configuration of every physical particle on Earth & still only be marginally less uncertain about ASI timelines, since we can’t just run the simulation forward.)
I can’t strongly defend my framing of this as a critique of step 2.1 as opposed to step 3, since there isn’t a good objective stance on what should go in the prior vs the posterior.
(Noting that I don’t endorse the description of my argument as “physicalist”, though I acknowledge that the “spontaneously” thing kinda sounds like that. Allow me to amend / clarify: I’m saying that you, a mind with understanding and agency, cannot spontaneously assemble beams into a bridge—you have to have some understanding about load and steel and bridges and such. I use this to counter “no blockers” arguments, but I’m not denying that we’re in a special regime due to the existence of minds (humans); the point is that those minds still have to understand a bunch of specific stuff. As mentioned here: https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce#The__no_blockers__intuition )
Yeah, I almost added a caveat about the physicalist thing probably not being your view. But it was my interpretation.
Your clarification does make more sense. I do still feel like there’s some reference class gerrymandering with the “you, a mind with understanding and agency” because if you select for people who have already accumulated the steel beams, the probability does seem pretty high that they will be able to construct the bridge. Obviously this isn’t a very crucial nit to pick: the important part of the analogy is the part where if you’re trying to construct a bridge when trigonometry hasn’t been invented, you’ll face some trouble.
The important question is: how adequate are existing ideas wrt the problem of constructing ASI?
In some sense we both agree that current humans don’t understand what they’re doing. My ASI-soon picture is somewhat analogous to an architect simply throwing so many steel beams at the problem that they create a pile tall enough to poke out of the water so that you can, technically, drive across it (with no guarantee of safety).
However, you don’t believe we know enough to get even that far (by 2030). To you it is perhaps more closely analogous to trying to construct a bridge without having even an intuitive understanding of gravity.
Yeah, if I had to guess, I’d guess it’s more like this. (I’d certainly say so w.r.t. alignment—we have no fucking idea what mind-consequence-determiners even are.)
Though I suppose I don’t object to your analogy here, given that it wouldn’t actually work! That “bridge” would collapse the first time you drive a truck over it.
I’m surprised to see zero mentions of AlphaEvolve. AlphaEvolve generated novel solutions to math problems, “novel” in the “there are no records of any human ever proposing those specific solutions” sense. Of course, LLMs didn’t generate them unprompted, humans had to do a lot of scaffolding. And it was for problems where it’s easy to verify that the solution is correct; “low messiness” problems if you will. Still, this means that LLMs can generate novel solutions, which seems like a crux for “Can we get to AGI just by incrementally improving LLMs?”.
Please provide more detail about this example. What did the system invent? How did the system work? What makes you think it’s novel? Would it have worked without the LLM?
(All of the previous many times someone said something of the form “actually XYZ was evidence of generality / creativity / deep learning being awesome / etc.”, and I’ve spent time looking into the details, it turns out that they were giving a quite poor summary of the result, in favor of making the thing sound more scary / impressive. Or maybe using a much lower bar for lots of descriptor words. But anyway, please be specific.)
https://deepmind.google/discover/blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/
https://arxiv.org/pdf/2506.13131
Example: matrix multiplication using fewer multiplication operations.
There were also combinatorics problems, “packing” problems (like multiple hexagons inside a bigger hexagon), and others. All of that is in the paper.
Also, “This automated approach enables AlphaEvolve to discover a heuristic that yields an average 23% kernel speedup across all kernels over the existing expert-designed heuristic, and a corresponding 1% reduction in Gemini’s overall training time.”
It’s essentially an evolutionary/genetic algorithm, with LLMs providing “mutations” for the code. Then the code is automatically evaluated, bad solutions are discarded, and good solutions are kept.
These solutions weren’t previously discovered by humans. Unless the authors just couldn’t find the right references, of course, but I assume the authors were diligent.
You mean, “could humans have discovered them, given enough time and effort?”. Yes, most likely.
Um, ok, were any of the examples impressive? For example, did any of the examples derive their improvement by some way other than chewing through bits of algebraicness? (The answer could easily be yes without being impressive, for example by applying some obvious known idea to some problem that simply hadn’t happened to have that idea applied to it before, but that’s a good search criterion.)
I don’t think so.
Ok gotcha, thanks. In that case it doesn’t seem super relevant to me. I would expect there to be lots of gains in any areas where there’s algebraicness to chew through; and I don’t think this indicates much about whether we’re getting AGI. Being able to “unlock” domains, so that you can now chew through algebraicness there, does weakly indicate something, but it’s a very fuzzy signal IMO.
(For contrast, a behavior such as originarily producing math concepts has a large non-algebraic component, and would IMO be a fairly strong indicator of general intelligence.)
A bit of a necrocomment, but I’d like to know if LLMs solving unsolved math problems has changed your mind.
Erdos problems 205 and 1051: AI contributions to Erdős problems · teorth/erdosproblems Wiki. Note: I don’t know what LLM Aristotle is based on, but Aletheia is based on Gemini.
Also this paper: [2512.14575] Extremal descendant integrals on moduli spaces of curves: An inequality discovered and proved in collaboration with AI
Very little / hard to evaluate. I have been doing my best to carefully avoid saying things like “do math/science research”, unless speaking really loosely, because I believe that’s quite a poor category. It’s like “programming”; sure, there’s a lot in common between writing a CRUD app or tweaking a UI, but it’s really not the same thing as “think of a genuinely novel algorithm and implement it effectively in context”. Quoting from https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce#_We_just_need_X__intuitions :
So the outcome of “think of a novel math concept that mathematicians then find interesting” is nontrivially more narrow than “prove something nontrivial that hasn’t been proved before”. I haven’t evaluated the actual results though and don’t know how they work. If mathematicians starting reading off lots of concepts directly from the LLMs’s reasonings and find them interesting and start using them in further theory, that would be surprising / alarming / confusing, yeah—though it also wouldn’t be mindblowing if it turns out that “a novel math concept that mathematicians then find interesting” is also a somewhat poor category in the same way, and actually there are such things to be found without it being much of a step toward general intelligence.
I took it as obvious that this sort of thing wouldn’t meet Tsvi’s bar. AlphaEvolve seems quite unsurprising to me. We have seen other examples of using LLMs to guide program search. Tsvi and I do have disagreements about how far that sort of thing can take us, but I don’t think AlphaEvolve provides clear evidence on that question. Of course LLMs can concentrate the probability mass moderately well, improving brute-force search. Not clear how far that can take us.