Can anybody confirm whether Paul is likely systematically silenced re OpenAI?
bideup
Karma: 335
“Not invoking the right social API call” feels like a clarifying way to think about a specific conversational pattern that I’ve noticed that often leads to a person (e.g. me) feeling like they’re virtuosly giving up ground, but not getting any credit for it.
It goes something like:
Alice: You were wrong to do X and Y.
Bob: I admit that I was wrong to do X and I’m sorry about it, but I think Y is unfair.
discussion continues about Y and Alice seems not to register Bob’s apology
It seems like maybe bundling in your apology for X with a protest against Y just doesn’t invoke the right API call. I’m not entirely sure what the simplest fix is, but it might just be swapping the order of the protest and the apology.
You seem to be operating on a model that says “either something is obvious to a person, or it’s useful to remind them of it, but not both”, whereas I personally find it useful to be reminded of things that I consider obvious, and I think many others do too. Perhaps you don’t, but could it be the case that you’re underestimating the extent to which it applies to you too?
I think one way to understand it is to disambiguate ‘obvious’ a bit and distinguish what someone knows from what’s salient to them.
If someone reminds me that sleep is important and I thank them for it, you could say “I’m surprised you didn’t know that already,” but of course I did know it already—it just hadn’t been salient enough to me to have as much impact on my decision-making as I’d like it to.
I think this post is basically saying: hey, here’s a thing that might not be as salient to you as it should be.
Maybe everything is always about the right amount of salient to you already! If so you are fortunate.
I’d like to see more posts using this format, including for theoretical research.
Augmenting humans to do better alignment research seems like a pretty different proposal to building artificial alignment researchers.
The former is about making (presumed-aligned) humans more intelligent, which is a biology problem, while the latter is about making (presumed-intelligent) AIs aligned, which is a computer science problem.
I vote singular learning theory gets priority (if there was ever a situation where one needed to get priority). I intuitively feel like research agendas or communities need an acronym more than concepts. Possibly because in the former case the meaning of the phrase becomes more detached from the individual meaning of the words than it does in the latter.
I’ve seen you comment several times about the link between Pretraining from Human Feedback and embedded agency, but despite being quite familiar with the embedded agency sequence I’m not getting your point.
I think my main confusion is that to me “the problem of embedded agency” means “the fact that our models of agency are non-embedded, but real world agents are embedded, and so our models don’t really correspond to reality”, whereas you seem to use “the problem of embedded agency” to mean a specific reason why we might expect misalignment.
Could you say (i) what the problem of embedded agency means to you, and in particular what it has to do with AI risk, and (ii) in what sense PTHF avoids it?
Sometimes such feelings are your system 1 tracking real/important things that your system 2 hasn’t figured out yet.
I think it falls into the category of ‘advice which is of course profoundly obvious but might not always occur to you’, in the same vein as ‘if you have a problem, you can try to solve it’.
When you’re looking for something you’ve lost, it’s genuinely helpful when somebody says ‘where did you last have it?’, and not just for people with some sort of looking-for-stuff-atypicality.
My guess is that it’s not that people are downvoting because they think you made a political statement which they oppose and they are mind-killed by it. Rather they think you made a political joke which has the potential to mind-kill others, and they would prefer you didn’t.
That’s why I downvoted, at least. The topic you mentioned doesn’t arouse strong passions in me at all, and probably doesn’t arouse strong passions in the average LW reader that much, but it does arouse strong passions in quite a large number of people, and when those people are here, I’d prefer such passions weren’t aroused.
This comment seems to predict that an agent that likes getting raspberries and judges that they will be highly rewarded for getting blueberries will deliberately avoid blueberries to prevent value drift.
Risk from Learned Optimization seems to predict that an agent that likes getting raspberries and judges that they will be highly rewarded for getting blueberries will deliberately get blueberries to prevent value drift.
What’s going on here? Are these predictions in opposition to each other, or do they apply to different situations?
It seems to me that in the first case we’re imagining (the agent predicting) that getting blueberries will reinforce thoughts like ‘I should get blueberries’, whereas in the second case we’re imagining it will reinforce thoughts like ‘I should get blueberries in service of my ultimate goal of getting raspberries’. When should we expect one over the other?
Yep, a game of complete information is just one is which the structure of the game is known to all players. When wikipedia says
The utility functions (including risk aversion), payoffs, strategies and “types” of players are thus common knowledge.
it’s an unfortunately ambiguous phrasing but it means
The specific utility function each player has, the specific payoffs each player would get from each possible outcome, the set of possible strategies available to each player, and the set of possible types each player can have (e.g. the set of hands they might be dealt in cards) are common knowledge.
It certainly does not mean that the actual strategies or source code of all players are known to each other player.
I keep reading the title as Attention: SAEs Scale to GPT-2 Small.
Thanks for the heads up.
I like the idea of a public research journal a lot, interested to see how this pans out!
LLMs calculate pdfs, regardless of whether they calculate ‘the true’ pdf.
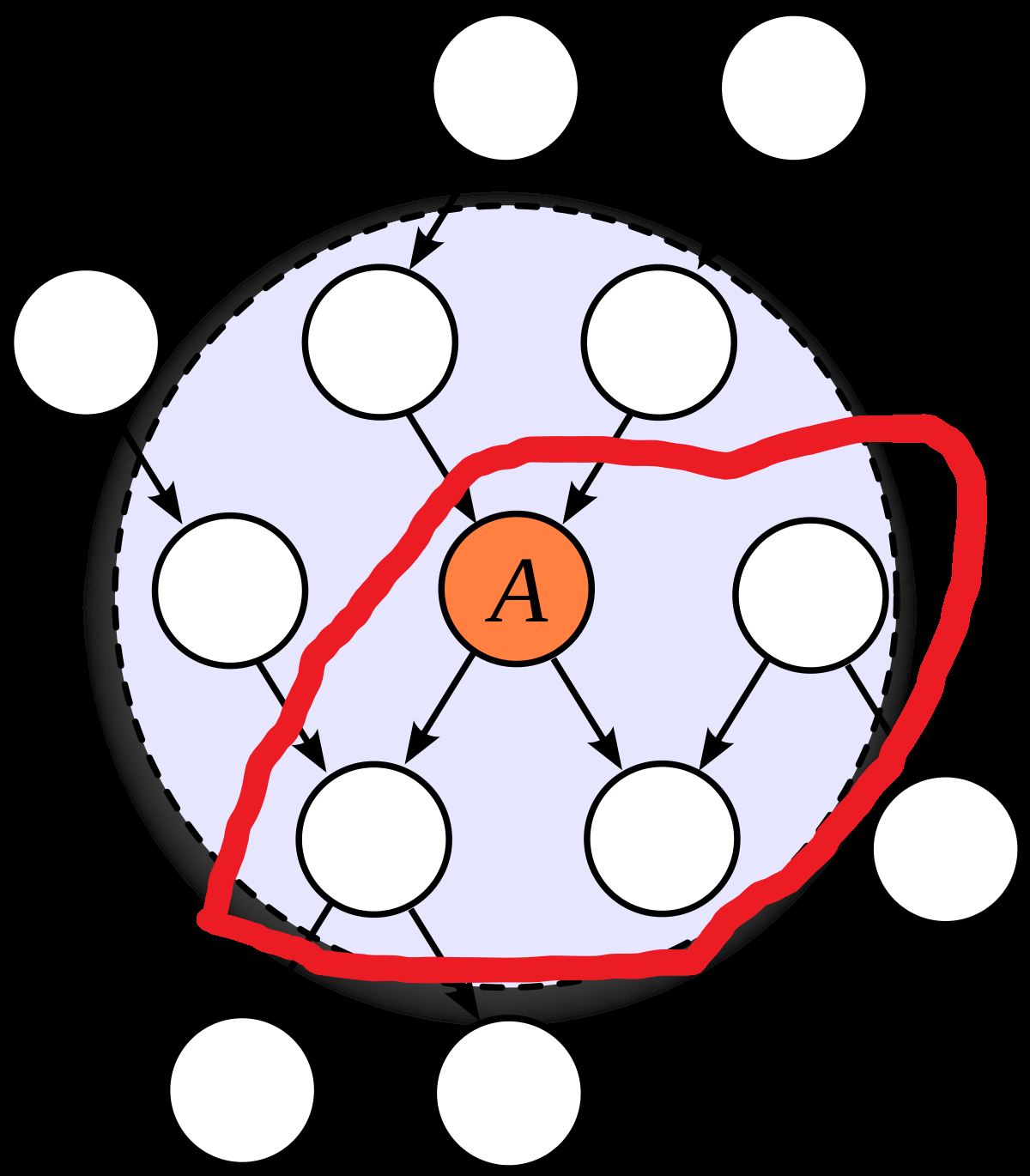
I’m trying to understand how to map between the definition of Markov blanket used in this post (a partition of the variables in two such that the variables in one set are independent of the variables in the other given the variables on edges which cross the partition) and the one I’m used to (a Markov blanket of a set of variables is another set of variables such that the first set is independent of everything else given the second). I’d be grateful if anyone can tell me whether I’ve understood it correctly.
There are three obstacles to my understanding: (i) I’m not sure what ‘variables on edges’ means, and John also uses the phrase ‘given the values of the edges’ which confuses me, (ii) the usual definition is with respect to some set of variables, but the one in this post isn’t, (iii) when I convert between the definitions, the place I have to draw the line on the graph changes, which makes me suspicious.
Here’s me attempting to overcome the obstacles:
(i) I’m assuming ‘variables on the edges’ means the parents of the edges, not the children or both. I’m assuming ‘values of edges’ means the values of the parents.
(ii) I think we can reconcile this by saying that if M is a Markov blanket of a set of variables V in the usual sense, then a line which cuts through an outgoing edge of each variable in M is a Markov blanket in the sense of this post. Conversely, if some Markov blanket in the sense of this post parititons our graph into A and B, then the set M of parents of edges crossing the partion forms a Markov blanket of both A\M and B\M in usual sense.
(iii) I think I have to suck it up and accept that the lines look different. In this picture, the nodes in the blue region (except A) form a Markov blanket for A in the usual sense. The red line is a Markov blanket in the sense of this post.Does this seem right?
Hm, I think that paragraph is talking about the problem of getting an AI to care about a specific particular thing of your choosing (here diamond-maximising), not any arbitrary particular thing at all with no control over what it is. The MIRI-esque view thinks the former is hard and the latter happens inevitably.
I like the distinction but I don’t think either aimability or goalcraft will catch on as Serious People words. I’m less confident about aimability (doesn’t have a ring to it) but very confident about goalcraft (too Germanic, reminiscent of fantasy fiction).
Is words-which-won’t-be-co-opted what you’re going for (a la notkilleveryoneism), or should we brainstorm words-which-could-plausibly-catch on?
A gun which is not easily aimable doesn’t shoot bullets on random walks.
Or in less metaphorical language, the worry is that mostly that it’s hard to give the AI the specific goal you want to give it, not so much that it’s hard to make it have any goal at all. I think people generally expect that naively training an AGI without thinking about alignment will get you a goal-directed system, it just might not have the goal you want it to.
Just wanted to say that I am a vegan and I’ve appreciated this series of posts.
I think the epistemic environment of my IRL circles has always been pretty good around veganism, and personally I recoil a bit from discussion of specific people or groups’ epistemic virtues of lack thereof (not sure if I think it’s unproductive or just find it aversive), so this particular post is of less interest to me personally. But I think your object-level discussion of the trade-offs of veganism has been consistently fantastic and I wanted to thank you for the contribution!