Thomas Kwa’s research journal
Why I’m writing this
Research feedback loops for junior AI safety researchers are pretty poor right now. They’re better than in the past due to the recent explosion in empirical work, but AI safety is still a very new field whose methodology is not quite nailed down, and which cannot admit the same level of aimlessness as other sciences, or ML at large. There are very likely mistakes being repeated by scientists after scientist, and hopefully I can alleviate the problem slightly by publicly writing about successes and failures in my research process.
This is a monologue containing my ~daily research thoughts, using the LW dialogue format because it allows continuous publication. Hopefully this lets some people either give me feedback or compare their research process to mine. If you do have some thoughts, feel free to leave a comment! People I’m collaborating with might occasionally leave dialogue entries.
With that, let’s share the state of my work as of 11⁄12. Currently I have a bunch of disconnected projects:
Characterize planning inside KataGo by retargeting it to output the worst move (with Adria Garriga-Alonso).
Improve circuit discovery by implementing edge-level subnetwork probing on sparse autoencoder features (with Adria and David Udell).
Create a tutorial for using TransformerLens on arbitrary (e.g. non-transformer) models by extending `HookedRootModule`, which could make it easy to use TransformerLens for e.g. ARENA 3.0 projects.
Create proofs for the accuracy of small neural nets in Coq (with Jason Gross and Rajashree Agrawal).
Create demonstrations of catastrophic regressional Goodhart and possibly strengthen theoretical results.
Help Peter Barnett and Jeremy Gillen wrap up some threads from MIRI.
I plan to mostly write about the first three, but might write about any of these if it doesn’t make things too disorganized.
Monday 11⁄13
I did SERI MATS applications and thought about Goodhart, but most of my time was spent on the KataGo project. I might more about it later, but the idea is to characterize the nature of planning in KataGo.
Early training runs had produced promising results—a remarkably sparse mask lets the network output almost the worst possible move as judged by the value network—but I was a bit suspicious that the hooked network was implementing some trivial behavior, like always moving in the corner. I adapted some visualization code previously used for FAR’s adversarial Go attack paper to see what the policy was doing, and well...
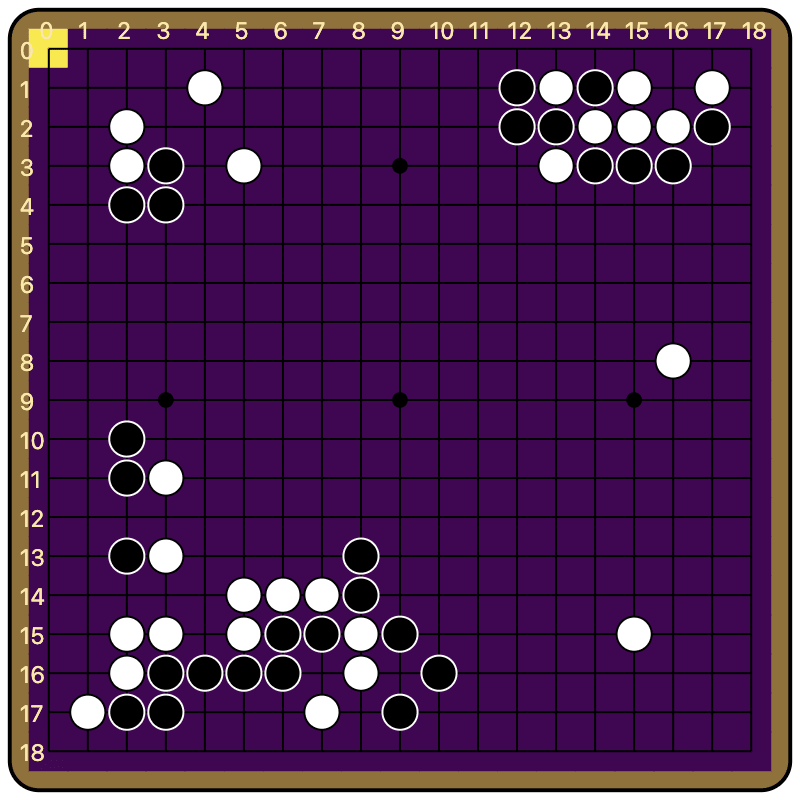
Turns out the network is doing the trivial behavior of moving in either the top left or bottom left corner. I wish I had checked this earlier (it took ~14 days of work to get here), but it doesn’t kill this project—I can just redo the next training run to only allow moves on the 3rd line or above, and hopefully the worst behavior here won’t be so trivial.
Tomorrow I’m going to table this project and start implementing edge-level subnetwork probing—estimate is 2 days for the algorithm and maybe lots more effort to run benchmarks.
Wednesday 11⁄15
Updates from the last two days:
I finished the basic edge-level subnetwork probing code over the last two days. This is exciting because it might outperform ACDC and even attribution patching for circuit discovery. The original ACDC paper included a version of subnetwork probing, but that version was severely handicapped because it operated on the node level (structural pruning) rather than edge level.
Adria is now on vacation, so I’m planning to get as far as I can running experiments before getting stuck somewhere and coming back to this after Thanksgiving.
I’m starting to think about applications of circuit discovery to unlearning / task erasure. If we take a sparse circuit for some task found by some circuit discovery method, and ablate the circuit, can it remove the model’s ability to do that task better than other methods like task vectors?
Last night 11⁄14, Aryan Bhatt and I thought of a counterexample to one idea Drake had for extending our Goodhart results. This is disappointing because it means beating Goodhart is not as easy as having light-tailed error.
I’m going to spend the next two days on MATS applications and syncing back up with the interp proofs project.
Monday 11⁄20
MATS applications are submitted; I applied to Ethan Perez, Stephen Casper, Alex Turner, Buck Shlegeris, and Adria (whom I’m already working with). Over the weekend I also did some thinking about how to decide between empirical research directions, which I’ve put off since leaving MIRI. I think I’m lacking an updated list of what everyone is doing, but if I had that I could make a BOTEC with columns like “what are they trying to do”, “how likely to succeed”, “how likely to be relevant to future architectures”, “impact if relevant”, etc.
Tomorrow is for figuring out how to run the ACDC benchmarks with the new edge-level subnetwork probing code, and iron out any bugs with it. I’m taking two four days off for Thanksgiving, so there will likely only be two updates this week.
Saturday 11⁄25
Adria is still on vacation, and I can’t make sense of the benchmark code within an efficient amount of time. I did finally fork the ACDC repo and publish my changes.
Today was a good time to think about strategy. Last night I started making a tech tree for alignment because this seems necessary to compare different research directions against each other. This is a first draft of a fragment centering on circuit discovery and its potential applications, including scoping models down. The key point is that, in my view, better circuit discovery algorithms have multiple applications, including removing capabilities from a model and generally furthering mechinterp. I think this means working on circuit discovery is likely to be useful.
Zooming in to what I’m trying to do now (the “gradient-based monosemantic CD” node), there are three problems with current circuit discovery algorithms that feel live to me:
They fail validity checks on tracr models with known hardcoded circuits.
They are regularized for sparsity and operate on neurons / attention heads, but maybe superposition means they should operate on autoencoder features instead.
They poorly capture redundant circuitry (likely more problems in this class).
The first one seems pretty severe and has the best feedback loops, so I think I’m just going to iterate on methods and try them on the tracr benchmarks until it’s solved. Hopefully I have enough ideas if edge-level subnetwork probing doesn’t work straightaway—I can probably get some by looking at where it goes wrong. After this I’m pretty worried about the different possible metrics for validity. What if a method that does better on tracr does worse on trained models, or if circuits that do well on the metric are different from circuits we need to remove from a model to remove a capability? This is an opportunity to do science, but seems like it could get messy and slow.
Where did the regressional Goodhart empirical models end up? It seemed like that was going to produce some pretty neat concrete results
Regressional Goodhart thing is still live. I think I want to prove a result about the nonindependence case first, so I can choose the most convincing and enlightening demonstration.
Monday 11⁄27
I have one SP benchmark running successfully after a few hours of work today. Should be able to figure out the rest tomorrow, but I also want to make the most of the proof project’s meeting with Paul Christiano.
I also made more alignment tech trees: one each for sharp left turn–robust agent foundations, faithfulness, and control/corrigibility. Might post some soon but they probably need a lot of feedback.
Tuesday 11⁄28
Some major things happened today!
Jason, Raj, and I met with Paul Christiano to talk about the proofs results, relation to heuristic arguments, and how to write up a publishable result.
I came across this paper thanks to Aaquib Syed from the ARENA discord. It does knowledge removal via a technique that improves on subnetwork probing. This is over half of what I wanted circuit discovery to eventually do!
I talked to Buck Shlegeris about capability removal and brought up the above paper. The takeaway was something like
If you want capability removal, maybe you should be optimizing for that directly rather than developing mechinterp techniques and trying to use them for capability removal. (The Bayazit et al paper uses a joint loss function to optimize directly for everything they care about, and is not about mechinterp.) I think I’ll have to choose between circuit discovery as mechinterp, and some other techniques more targeted at capability removal.
Maybe “coup probes” are as useful as capability removal and easier to engineer. I’m not sold on this one and need to think about it; it depends on generalization of the coup probes, the deployment situation, and probably other factors.
I have a proof sketch for a Goodhart result in the nonindependent case. I don’t think it’s super significant but it should go in the paper if I ever write one, and maybe another post in the sequence.
Tuesday 12⁄5
I spent much of the last week being confused about some results. Basically, I wanted to test the subnetwork probing code on the simplest benchmark, which was the tracr-reverse task. The circuit has 11 edges. But when I tried subnetwork probing with resampling ablation, it got nearly perfect loss on a circuit with only 2 edges: token_embeds -> a3.0_v -> resid_post! I suspected a bug in my code and wrote more and more tests, but it turned out that the trivial 2-edge circuit was actually correct.
tracr-reverse circuit from IOI paper.It turns out that on any valid input, the output of 2.mlp_out (<m2> in the diagram) is identical. Since 2.mlp_out and pos_embeds are both the same between the original and resampled circuits, resampling doesn’t disrupt the circuit at all. Maybe tomorrow I’ll dig into this further, but I don’t know how the RASP program corresponds to blocks in the compiled tracr model.
Edge-level SP is now running; this is another thing to do tomorrow.
I got into Adria and Alex Turner’s MATS streams, but not Buck Shlegeris’s or Stephen Casper’s. Meeting tomorrow with Alex to discuss logistics, then decide by Friday, then fly out for NeurIPS.
I like the idea of a public research journal a lot, interested to see how this pans out!