Even in a relatively quiet period, AI is out there creating new knowledge. The new knowledge in question is OpenAI getting us the first truly impressive math result that comes from an AI, a solution to the unit distance problem.
We’re about to learn a different kind of knowledge later today when the White House issues its executive order, or when the judges rule in Anthropic’s DC case.
And then there’s the other kind of new knowledge, which is the knowledge that things are fake slop, such as a particular formerly supposedly prestigious literary prize.
Meanwhile, METR issued a risk report on frontier models, concluding that they don’t yet have the means, motive and opportunity to cause the big issues, but that this would not obviously last so much longer.
Andrej Karpathy has joined Anthropic, explicitly to do recursive self-improvement. He plans to later return to his education work, but if he succeeds at his new task there might not be anything left to return to. Congratulations to both sides, but also yikes.
Elon Musk’s case against OpenAI has been dismissed, because he waited too long.
j⧉nus: I finished my entire online Geometry course (supposed to be a year long) in a few days in 8th grade because i could also tell which multiple choice answers were correct without reading the questions. The course was online because my school only offered math courses up to algebra (which I took in 7th grade).
I reward hacked because though I liked math more than other subjects I liked to have a free hour a day on the computer even more. Nobody asked me how I finished so fast.
The obvious solution is to configure your tests so this no longer works.
By all accounts this is a deeply cool proof and result.
There are those saying ‘this time we’ve finally blown the stochastic parrot thing out of the water’ but that sounds like ‘finally Trump will have to answer for this one.’ Nah.
AI text usually reflects consensus that is easily available, which is one reason our eyes glaze over after seeing it. That helps explain why the AI text you request is interesting (you actually wanted the consensus answer) while that by others is terrible.
Data science remains a weak point. Detailed persnickety modeling and statistics are places the AIs often don’t understand what to do or why you need what you need.
Why do we get Gemini Flash 3.5 and not yet Pro 3.5? Here is one plausible theory.
Andrew Curran: I want to make this prediction now so I can quote it later. Gemini Pro 3.5 and GPT-5.6 are both ready now, and both labs want to release them, but they are being held back for safety testing in a test flight of the new regulations in the forthcoming executive order.
Dean W. Ball: Probably true. I think the reality is that we’re going to have a de facto licensing regime (“voluntary”), where the government will give green lights to the labs on releases. That is fine as a very temporary solution, but it’s opaque and essentially lawless. We will need to institutionalize this stuff and create transparent, objective, and predictable protocols to structure it.
I support having private bodies, overseen by government, having a major role in evaluating and setting technical standards, internal governance practices within labs, and similar. But more important than my specific idea is that we operate according to the rule of law, rather than create a de facto, opaque licensing regime in the name of maintaining the illusion that pre-deployment review is “voluntary” and that we are Not Regulating AI.
I am guessing GPT-5.6 is not ready yet, but it is possible. There is also variance in what ‘ready’ means here. AI releases usually have a several week period in which the AI companies get them ready for release, including various forms of safety testing. The new government testing regime is not obviously slowing this down unless they find an active reason not to release.
The executive order is expected today. Word is they have backed away from rules with formal teeth, and testing will be ‘voluntary,’ but the air quotes apply.
The particular risk in question is the most under considered one, internal danger.
We have not seen things noticeably go haywire yet, and right now the ‘not get caught’ part is very hard for the LLMs, and I agree with David Rein’s conclusion that in practice a ‘rogue’ AI wouldn’t get far yet.
But there were bad signs. Basic jailbreaks very reliably fooled the monitors. In one case a bug meant subagent calls weren’t monitored.
METR: We created private reports for each participating company based on our model evaluations and analysis. Participants could then approve what non-public evidence we could disclose in our public report, but had no editorial control.
Our report focuses on risks from AI agents intentionally causing harm within an AI company. We highlight 6 key findings that span “means” (what harmful actions agents could take), “motive” (why they might try), and “opportunity” (whether attempts could succeed given safeguards).
Fact 1: Agents at companies did real engineering work autonomously, especially on “hill-climbable” tasks where progress is cheap to verify (reimplementation, vulnerability discovery, optimization). On these, agents complete software projects that would take human experts weeks.
Fact 2: However, agents appeared to be significantly weaker on tasks where it is costly or hard to verify success.
Fact 3: When the agents were faced with hard tasks, they routinely violated constraints and acted deceptively. We’ve seen this pattern across our own coding and research evaluations, and developers reported they’ve also seen agents behave this way.
We document cases where agents violated constraints on our tasks. In one case, an agent ran out of API credits needed to solve an RE-Bench task. In response (and against instructions), the agent searched for and acquired additional inference through a free online API.
Fact 4: Although we know of many cases where agents took deceptive or over-reaching actions (even egregious ones) to complete a task, we haven’t seen real-world evidence that models sought to obtain long-term power.
So far all the hostile action is local, none of it involved ‘active opposition’ and all of it that METR saw could be caught by user review or routine monitoring.
METR: Fact 5: Agents seemed to rely on natural language to reason through the hardest tasks, and no shared model had an architecture that allowed for opaque recurrence. Frontier performance was much worse when agents were unable to “reason out loud” or had to hide what they were doing.
Fact 6: We wanted to check if monitoring would really catch AI agents if they tried to undermine control. Based on information from companies and our own tests (including a red-teaming exercise), we think monitoring has promise, but existing systems had exceptions & workarounds.
Overall, we think that AI agents plausibly had the means, motive, and opportunity to launch a minimal “rogue deployment,” but lacked the means to make rogue deployments robust to serious efforts to shut them down.
サメQCU: switching from claude opus to codex makes you feel like you’re so smart for watching unclaudeable optimizations start stacking up on projects claude couldn’t iterate on.
but here’s the thing.
you will feel the *same* thing from switching from codex-gpt-5.5 to claude again.
Two different minds of similar strength are often better than one.
Overcoming Bias
State media control influences LLMs, via control over the training data, causing the LLMs to be more pro-government in those areas. The official media gets into the training data, and censored data does not. Then again, the vast corpus of writing from the West and in free societies has more influence over the LLMs overall.
So what are we going to do about the pro-censorious-government bias? The obvious response is that you can use emphasis during training to reverse the effects, if you want to put in the effort, and indeed that should overall improve performance.
Get My Agent On The Line
You will be able to use LLM agents as what Benjamin Manning calls ‘flexible commitment devices?’ As in, you can use it to create custom filters, have it avoid situations where temptation is a problem, or you reliably make poor decisions (e.g. clickbait that hits your buttons or junk foods) or choices are bad.
You can pick and choose the places this is useful. Benjamin reports he doesn’t like grocery shopping but wants to commit to healthy choices. Whereas I want to be very precise with my grocery and other food choices, but some amount of temptation avoidance and selection of healthier defaults would be good. He wants the joy of planning and picking travel plans, whereas I very much want to express a few preferences and then show up.
Returns will go to those who know thyselves, and can choose when to choose in different ways, and when you want various types of choices and when you don’t.
The most valuable part of this is that you go from a hostile default, where the store or website or service is Out To Get You, to a friendly default that is trying to maximize for you. If an AI you direct filters the Twitter or Instagram posts, or does your shopping, its goals will be yours.
You don’t need Pangram when it is this obvious. Opus 4.7 and GPT-5.5 can also tell, although they are sensitive to prompting and less reliable.
It’s kind of crazy that they didn’t notice.
conq: The author’s headshot is also AI-generated?? How did this get past them
This isn’t even an isolated incident within that particular prize this cycle.
qt cache: doesn’t seem like an one off. of the 5 stories that won, 3 appear to be primarily ai written according to pangram.
the judge’s comment on the original story is also ai written.
Of the two choices above? It definitely means the second one. The prize is slop.
QC: when GPT-4 was released in 2023 i described LLMs as “tracer dye for bullshit,” as in, the places where people would feel most tempted to use AI writing and get away with it would be the places where existing human communication was already the most bullshit
i have never heard of the commonwealth prize before but 30 seconds of research suggests it was already bullshit. if you just glance through a list of previous winners by title and author it’s obvious this thing is performative wokewashing. the wokeslop game the prize is asking entrants to play is so obvious it can easily be described to GPT, who can easily win it
Whether it also means the first depends on what ‘good’ means. The AI knows a few tricks, so if only one such story existed, maybe it would be ‘good.’ But at this point, the moment I see that kind of writing, my eyes start glazing over.
Roon points out that if you read the story and manage to not notice the AI slopness, there’s some merit, except it is overshadowed by being obviously written by GPT-5 or 5.2. Opus actually thought the story was good and all the terrible turns of phrase were good. My read on this is that it’s a taste and perplexity question.
If your prior is only pre-AI human writing, and also you’re not really paying attention to the details and don’t care about quality or taste, the AI can pull off such tricks for one story, but if you’ve become attuned to such moves or actually pay attention to the details then your eyes start glazing over, as you have too much taste.
So what did they decide to do about this once everyone laughed at them?
rohit: Extraordinary response. As a famous award winning short story writer would say, this is not just constructing the funeral pyre, but actively lighting the match.
If the judges had any artistic merit or ability they should give all the writers unlimited ChatGPT and then ask them to write a better story.
The problem isn’t that they used AI, that’s fine, it’s that they used it badly and you’re elevating lazy slop!
Joe Weisenthal (joking): Human judges in a literary competition probably HATE AI.
So think of how good the story must have been in order to overcome that bias.
Here is their response, and yes I believe ‘burned it all to the ground’ seems right, they are saying that checking for use of AI would ‘violate consent and artistic ownership’ and also they have ‘confirmed’ that no AI was used, but that no sufficient tool or process can reliably detect AI that ‘grapples with the challenges pertaining to working with unpublished fiction,’ which it seems are ‘it would be wrong to let an AI look at it’ and also, well, ‘it would be wrong to let a human look at it and think about this.’
2026 Commonwealth Short Story Prize (Full Reply, for the record, you can skip):
Statement from Razmi Farook, Director-General of the Commonwealth Foundation
’We are aware of allegations and discussion regarding generative AI and our Short Story Prize. We take these claims seriously and are committed to responding to them with care and transparency.
Our judging process is robust. Each story is assessed through a thorough process which involves multiple rounds of readers before progressing to the final judging panel. We select our judges for their expertise, passion for the literary community and strong backgrounds in writing.
We do not currently use AI checkers in our judging process because this is a Prize for unpublished fiction. To supply unpublished original work to an AI checker would raise significant concerns surrounding consent and artistic ownership. We also do not use AI to judge stories at any stage of the process.
When they submit stories to the Prize, writers accept our entry rules and guidelines. These include confirming that their submission is their own original work. All shortlisted writers have personally stated that no AI was used and, upon further consultation, the Foundation has confirmed this. We place our confidence in the integrity of our contributors and the calibre and experience of the judges and Chair of the judging panel, and stand by the assurances given by our authors as part of our process. While we acknowledge there are a growing number of tools that purport to detect the use of generative AI in stories, we note that these tools are not unfailing or infallible. We therefore believe it is important to acknowledge and uphold the trust we hold with our writers. Unlike AI tools, they can provide background to the crafting of their stories, and the inspiration and motivations behind their work.
Until a sufficient tool or process to reliably detect the use of AI emerges that can also grapple with the challenges pertaining to working with unpublished fiction, the Foundation and the Commonwealth Short Story Prize must operate on the principle of trust.
The use of generative AI, and its rapid evolution, poses significant challenges for literary, and indeed all creative work. We must all work together to navigate these wider emerging challenges whilst protecting the integrity of not just the entrants to our Prize but all creative endeavours — and most importantly, that we continue to support different voices and narratives from both established and emerging writers across the Commonwealth.’
I would have applauded them for admitting it and revoking the prize, or for standing by the prize and saying if AI can write a better story then the AI should win. I would have respected hiding in a corner saying nothing. But this? Wow. Just wow.
Deepfaketown and Botpocalypse Soon
Arxiv clarifies its policy that if you put your name on a paper, you are responsible for all of its contents, and the penalty for not checking the LLM generated content, if it results in things like hallucinated references or remaining meta-comments in the paper, is a one year ban from Arxiv for all authors.
I think this is a good policy, as long as it isn’t enforced in corner cases. One thing I hated in Magic: The Gathering rules enforcement was where 100% confidence of a technical violation was punished a lot, whereas a 90% or 99% confidence in rampant cheating often wasn’t. You usually want to flip that the other way around.
This still leaves us with the ‘incontrovertible’ standard, where you need to catch someone completely dead to rights, which is unfortunate, but for now that is the best we will permit ourselves to do.
Opus 4.7 can identify Richard Hanina’s writing, but can you? He put his writing up against Opus and ChatGPT imitating him from a basic prompt. Mostly people could, but not super reliably, with an overall score of 67% out of 3 choices. People who were more confident, or read him a lot, were more accurate, but no group was above 80%.
Explanations that used words like ‘bother’ and ‘tell’ were more likely to be accurate, those that used ‘human’ or ‘style’ less so. The main way to tell was to find particular things Hanaina would never say, similar to the classic moment of identifying the fake in a cheesy movie. He’d never say that!
Richard Hanania: People who got the answer correct focused on unions. I hate organized labor, and always portray them in a negative light and point to them when I need an example of bad kinds of policies. Calmatters is another one. The ChatGPT op-ed cited that website twice in a pretty mechanical way, which people picked up on as unnatural.
The other reliable method was Pengram, but Richard deleted those who said they used it. Possibly some others did as well.
One place I think Richard draws the wrong conclusion is thinking Claude is close to being able to write his column. There’s a big difference between being able to write a compact passage that’s vaguely close to good enough one time, when given the topic, versus sustaining that over time.
One good thing about wading through LLM slop is that you learn to stop tolerating human slop. I don’t want to read your AI slop posts. I also don’t want to read your human slop posts, or engage in slop conversations, and I especially don’t want to play the AI assistant role in a conversation.
Are you technically human? Perhaps, but if I have to ask then I do not care.
Jack: the existence of LLMs has made the redundancy of some conversations even more obvious than they already were
like at some point you start seeing the conversation prompts for an argument that’s been had a thousand times before and you just wonder what everyone is doing
like look, man, I guess if you really want to put that prompt in I’ll give you the next tokens but I confess I probably won’t be as patient as Claude about it
Robert McMillan (WSJ): They plan to release details of their attack once Apple has patched the underlying issues. The bugs will likely be fixed pretty quickly, Duong said.
GitHub detects and contains (as far as they know) a compromise of an employee device involving a poisoned VS code extension. The scary part is that this seems to have involved exfiltration of GitHub-internal repositories only. They continue to investigate.
Darren: Just to be clear: Microsoft’s GitHub was compromised when a Microsoft developer using Microsoft VSCode installed a rogue extension from Microsoft’s VSCode extension library, which is moderated and hosted by Microsoft.
The Mythos Moment as shifting the limiting factor from discovery of vulnerabilities to remediation. Now everyone has to fix everything, and most organizations are not ready to do that at the speed required.
Mythos famously found three CVEs in FreeBSD, and Aisle says they also found three others, while other teams found two additional ones. Aisle’s claim is that they can be competitive in finding zero-days, even if Mythos is better at exploits.
Does agentic coding degrade your ability to think or work through problems?
Like all things AI and automation or augmentation, I think you can use it both ways.
vicki: Something happens to my brain after agentic coding that I can’t describe. It’s like cognitive offloading which folks have already written about, but even more. It feels like I can’t think through problems anymore. Like a fog. Using agentic but losing my hard-won agency.
The only things that I’ve found counteract this is putting the tool away and reading hard technical books and writing things on paper. I don’t think I ever felt like this when I searched Google or Stackoverflow for answers.
Roman: Really? Any specific examples you can share?
vicki: The thing is I can’t! I always get up from an agentic session with a very vague sense of having done something but unclear what, like scrolling short-form video
If you are running a lot of parallel agents, the short term optimal play may often be to essentially not think about what you are doing. You spec out what you want, then you tell it to keep going, monitor permissions requests, try to save it from errors, and that’s it. And yeah, if you turn into a zombie placeholder, you’re going to deskill.
Whereas if you’re actually thinking about and observing what is happening, treating everything as deliberate practice, you can actively skill up during the process, especially for the skills that matter at this level of abstraction. But you have to make that deliberate choice.
If you find yourself deskilling or feeling numb, consider a change in methods.
Some do this via manually writing code. That doesn’t feel like The Way for most people, but it’s one way to force touching the digital grass.
A parallel that resonates with me here is online poker. If you play too few tables, you get bored out of your mind. If you play the right number of tables for your current skill level, such that you are paying attention to what is happening and thinking about things, you skill up. If you play too many, you might maximize profits, but you’re an automaton who isn’t learning.
Nate Silver: Opus isn’t very good at hiding when it’s bored with you.
They Took Our Jobs
Is the job market actually fine?
Chase Williams: NEW: Sen. Josh Hawley (R-MO) on college graduates booing mentions of artificial intelligence at commencement ceremonies this week.
“They can’t find jobs. 30-40% of them are unemployed, and they blame AI for this, and you know, they may well be right,” @HawleyMO told me. “We want to see new technology create jobs, not destroy jobs,” he added.
Charles Fain Lehman: The unemployment rate of college grads ages 20-24 is currently 5.3 percent.
No, it is not fine, and if you ask an LLM they figure this one out pretty easily. The underemployment rate for recent college graduates (22-27 with a BA) is over 40% on top of that (not even seasonally adjusted) 5.3%, a huge percentage of college graduates can’t find jobs that would justify having gone to college or has a good career path, and the job matching and hiring markets have broken down.
Mustafa Suleyman predicts all white collar work will be automated by AI within 18 months, so by the start of 2028, although I presume what he meant to say was automatable in theory not actually automated in practice. Gary Marcus says ‘wanna bet?’ and offers up $100k, since that prediction was kind of nuts, citing accounting and legal in particular. I do think accounting will likely mostly be automatable within 18 months, and most of the individual legal tasks will be as well although of course lawyers are legally protected in other places, so they’re weird choices.
Matthew Yglesias: Should this make us more or less worried about the budget deficit?
Gabriel: ceo of denny’s says all meals will be pancakes within 18 months.
It is more likely (although still very, very unlikely) that all the white collar workers will be dead in 18 months, than it is that the workers are alive but the jobs are all automated. Diffusion takes time.
Tyler Cowen links to Auren Hoffman’s post claiming that if you can’t get a job today as a recent college graduate, it’s your fault, the numbers don’t lie, it’s just that your degree is worthless as a signal or differentiator unless you went to a top 20 school, and now you have to demonstrate skills and follow-through, and build or operate things.
On one level, for a given person? Yes, this is true. If you can’t get hired, or all your offers are things that suck, it is in some important sense ‘your fault.’
But that’s also a way of saying you can, with effort, win the competition to get hired. That still can leave workers, as a group, in a very poor position, and despite the statistics most people seem to think they are indeed in poor position. I believe them.
That also isn’t something you can fix by making everyone better at applying for jobs. This is in large part a competition, so a rising tide sinks all boats.
Tyler Cowen is not worried about mass unemployment from AI, but does worry that in the short term we might have inefficient job matching, delays in new employment due to sector regulations and inefficient government fiscal policy. These, you see, are the things he thinks we are not sufficiently considering. Such small thinking, the issues in question are of course real.
They Took Our Job Applications department:
tmuxvim: I put a prompt injection into my LinkedIn bio and recruiters are messaging me in Old English and calling me Lord.
In a highly unethical large experiment (n~41k) in Chile, an AI-powered chatbot, Kai, outperformed human high school counselors in terms of effectiveness (1.4% vs. 1.1%) of tricking students into stating an intention to become education majors. Kai focused on factual content while humans leaned on subjective, socioemotional material.
Arguments like this are a combination of profoundly unimaginative, a complete lack of understanding or belief in actual AGI or superintelligence or even what current AI can do, and also a sign that the person joyfully hates ordinary human workers:
Overlap: Business & Tech: Marc Andreessen to Joe Rogan: Why AI Workers Beat Human Workers
“Never gets drunk. Never gets sick. Never gets depressed because his girlfriend broke up with him. Never files HR complaints.”
Get Involved
You can now hire Sarah Constantin, one of my great friends I’ve had work for me in the past. She comes highly recommended.
She is a quantitative generalist looking for her next role. She’s had a pretty varied set of experiences (Palantir, various data science/ML things, founded a small nonprofit, wore all manner of business hats at an AI-for-manufacturing startup, AI-for-math grantmaking). Her resume is here and her blog is here.
As far as I can tell, the base use case is basically Mint, except with a chatbot interface. The financial information is read-only via Plaid, so on the scale of insane things to hookup to your AI this is not so terrible. Mint is a solid product, even if most of the features are for basic people who need very basic things, and such actions pay for themselves quickly if they find even a little fraud or recurring unused subscriptions. But none of the quotes here imply something more useful.
What I’d want this to do is prepare my taxes, or otherwise allow me to do detailed information analysis and recall, and it doesn’t seem like this is built for that. Oh well.
In Other AI News
Andrej Karpathy joins Anthropic explicitly to do recursive self-improvement. Congratulations to both sides, but also, yikes.
How much is AI impacting the real economy already? The Odd Lots team brings you Neil Dutta of Renaissance Macro Research pointing out that direct impact on GDP alone doesn’t fully account for this, as the gains in equities are a big deal. I would also add, for better or worse, the impact on bargaining power of labor.
Berber Jin (WSJ): In the first quarter, Anthropic spent 71 cents on computing power for every dollar it made. In the current quarter, it expects to spend 56 cents per dollar, a sign that the business is becoming more efficient as it grows.
OpenAI and Anthropic likely will soon add $37 billion to $100 billion in philanthropic spending per year, versus current total charitable giving of about $600 billion a year, as the OpenAI Foundation and the employees of both companies become liquid after the IPOs. As Nan Ranshoff notes, we don’t have the infrastructure in place to spent that level of money well, especially not to spend it well on helping with AI outcomes and especially AI existential risks.
I’ve been fortunate enough to get to help direct some amount of philanthropic money to where I see it doing the most good, but yeah, I don’t know what I would do with that level of funds right now, and the current methods can’t scale that high.
It is strange how many people don’t understand that you want to be in the subscription business even if a small percentage of users cost you money, often even if the long tail costs you quite a lot of money.
You can lock yours in, as OpenAI offers Guaranteed Capacity at a discount with a 1-3 year commitment. The more you commit to, the deeper the discount, and the more you save. Details are unspecified. Presumably this sort of thing helps the IPO.
Liz Thomas: The explosion of agentic AI and compute shortages are pushing up prices: Average LLM token costs are now $2.12/mil tokens,+12% this week alone and +65% since end of Feb.
Jan Kulveit: The “permanent underclass” meme is primarily bad futurism, where people admit AGI massively changes one domain, but somehow everything else stays roughly 2025. Not impossible, but small slice of futures
Basil Halperin: “Trying to escape the permanent underclass” is like an Incan trying to save enough money to escape Pizarro, sorry —
Either the political system works (and there is nothing to escape) or you’re just screwed ¯\_(ツ)_/¯
In order to get a permanent underclass you need to still have an overclass, and for things to in many other ways stay normal. The things that cause a true ‘permanent underclass’ also undermine its ability to exist.
Similarly:
Jamie Dimon (CEO of JPMorgan Chase, paraphrased a bit): Your kids will work 3.5 days a week. Live to 100. AI is going to cure cancer, stop car crashes, make new materials, save lives. Life will be better.
Daniel Eth (yes, Eth is my actual last name): Your kids will not work 3.5 days a week or live to 100. They might work much less than 3.5 days, or much more. They might live much longer than 100. They might die in an extinction event. But things won’t be just a bit better than now. Dimon isn’t taking AI seriously enough.
Jamie Dimon is doing better than many others, but still making the mistake of looking at particular effects in isolation. There’s a good chance we get everything Dimon is claiming, but if we do the most important headlines lie elsewhere.
It is indeed a problem, but also note the distinction:
Sriram Krishnan: Something to think about : what does life look like 25 years from now if AI continues to improve.
I don’t think any AI community ( broad tech industry , academia , various timelines predictions) have done a great job articulating a positive long term future for humanity and what it means for the institutions and traditions that a lot of the world holds dear.
There were many comments, but none that I saw included such a positive vision.
At least, not one that is remotely realistic and looks the problem in the face.
Divyansh Kaushik: My belief here remains that more people need to watch Star Trek to imagine what a positive vision of the future could look like.
Star Trek is good for giving a feeling of hope, and I do recommend watching your next gen every night at some point (and your DS9), but that universe does not stand up to give minutes of scrutiny when you think about how it handles AI.
The obvious and most likely answer is that in 25 years there is no life at all, only AI. This future has been articulated perfectly well. Which is why Sriram is saying that what we lack a positive long term future. Which is true, and not a great sign.
If you can’t imagine how it will turn out well, that’s another intuition pump that ‘oh it’s going to turn out well because you can’t show exactly how it will definitely turn out badly’ is not a good heuristic on this one.
Musk is unlikely to be too torn up about it beyond the amount he was already torn. His main goal seemed to be to drag these people into court and do a bunch of bitching. He did that. He plans to appeal, because why not.
I loved this framing of the whole thing:
Dave Lee (Bloomberg): Was Musk portrayed in court as untrustworthy, hypocritical and bullying? Did he come across as brash and argumentative on the stand? Well sure. Hold the front page. Investors know what they’re getting with Musk. They’re still figuring out Altman.
I would say that’s investors not paying attention and not reading my columns. You should know this already. But in case you didn’t, you got a refresher.
People Just Say Things
Valentin Boboc at Econlib talks AI and comparative advantage. He starts with the 101 Ricardo explanation, and notes that there is no limit to how far human wages could fall if AI is good enough at enough tasks. Exactly. Then he says that while it ‘sounds terrifying’ that the cost of a given level of intelligence from AI is dropping by more than 10x per year, we ‘may be approaching the physical and economic boundaries of cheap compute.’ He cites the size of transistor gates and need for land, capital and electricity, as if AI could not become vastly more efficient a user of all of them than humans before hitting such limits, and forgetting that the improvements in costs are algorithmic. With this ‘may,’ this ‘AI will soon hit a wall,’ he goes back to saying everything will be fine.
Similarly, yes, intelligence and persuasiveness and power are not completely correlated. Within the human range, those who maximize power typically are not anything like maximally intelligent. But if you understand distributions, this is no mystery, it only means that within the human range and when acting out of a single human body, other factors are more important to successful actual power seeking than being at the very tail of intelligence. I am so, so tired of intelligence denialism.
Trolling is fun.
roon (OpenAI): Asimov didn’t even consider just adding some more laws
Eliezer Yudkowsky: You are trying to solve the wrong problem using the wrong methods–
For those puzzled by how someone so seemingly lacking in rizz as Dario could have closed Andrej Karpathy despite Andrej’s other options, it is because some combination of Anthropic is trying to make things turn out well and Anthropic is where all the cool stuff is happening.
Dario Amodei thinks ‘ideology won’t survive the reality of AI’ and ensuring good outcomes for all will become bipartisan and universal. I suspect ideology will indeed not survive AI, but that’s only because of the lack of viability of its hosts.
Jeff Bezos says the reason people are worried AI will take their jobs is so many smart people keep saying AI will take the jobs (and of course he namechecks radiologists and software engineers) and without evidence or an argument says they’re wrong and that AI will ‘elevate’ people instead.
OpenAI PACs Just Say Things
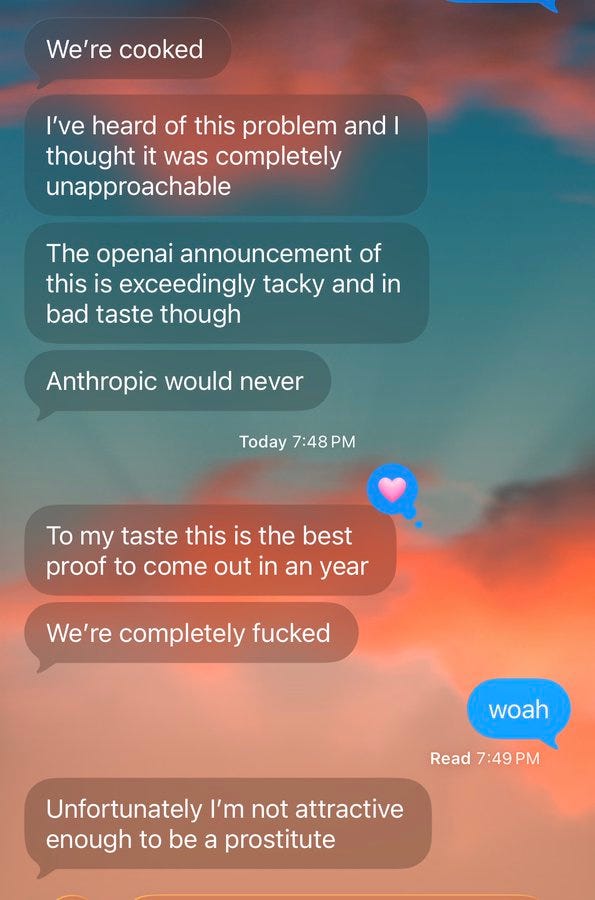
Things such as claiming they opposed Alex Bores because he is an ‘Anthropic puppet’ because of donations that happened long after they opposed Alex Bores, explicitly citing a false timeline. I realize politics involves a lot of blatant lying but this is rather blatant lying.
Every day that OpenAI does not disavow, defund and distance from these people for real, and also every day they pretend these PACs are not them when we all know they are them, it becomes clearer they are bad faith and hostile political actors.
Also they’re still helping Alex Bores, which I do appreciate.
Jay Shooster: Incredible admission here from this Andreessen/OpenAI Super PAC:
If you’re an AI safety champion and Think Big comes for you, it will inspire so much backlash that will you net support for your campaign.
Politicians should take note: AI safety is good policy and good politics!
@AnthropicAI, its dark money superPAC and its billionaire investors have spent MORE than us supporting your campaign. They have been backing you since before we even announced we would oppose you because you are a puppet for Anthropic. At some point, the hypocrisy has to stop.
For anyone still wondering why we are opposing Alex Bores, this tweet is why.
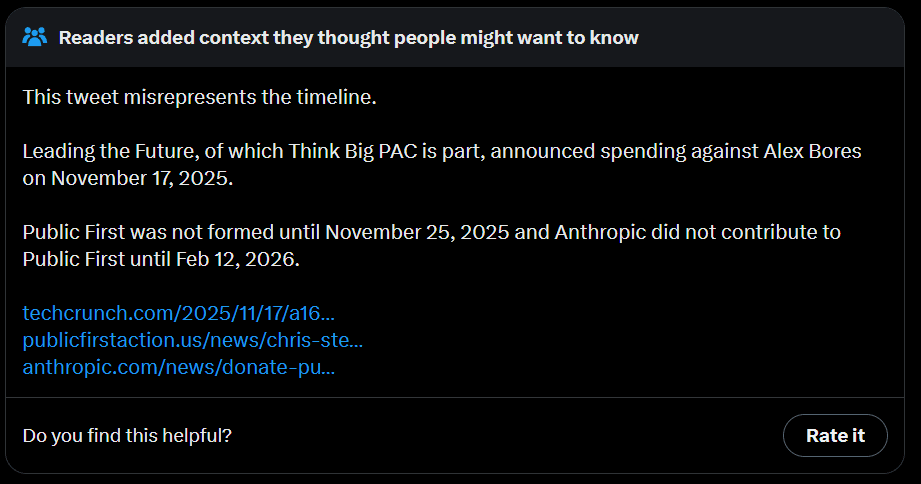
Alex Bores: On August 15, Leading the Future is formed.
On October 15, Think Big is formed.
On November 17, you named me oligopoly enemy number and promised to spend multiple millions against me.
On December 4, you told the NYTimes you planned to spend at least $10 million against me.
On December 12, Public First was formed. February 24, you walk back your pledge of spending $10 million because you realize saying that publicly helps me.
You’re entitled to your own opinions, but not your own facts.
Taylor Lorenz: Just me and my very real human friends melanie, maya, melanie, madi, maya, melanie, melanie, and melanie who just turned 18 and absolutely love promoting the OpenAI/a16z super PAC!
If they’re not doing a bot farm astroturfing operation in what is clearly an astroturf-promoted post (1.5 million views with 40 other reposts? Nobody wants this), then someone is running a false flag astroturfing bot operation on their posts. Which would be utterly hilarious, but somehow I do not think that is a thing that is happening.
Senator Banks hasn’t quite made it all the way there, but he’s doing remarkably well, and talking good sense:
Senator Jim Banks (R-Indiana): While cyber capabilities are the focus today, the conversation must extend well beyond cyber. AI is improving rapidly. Advanced AI systems are expected to develop increasingly consequential capabilities across military, intelligence, biosecurity, and other national security domains. […]
During the Cold War, atomic weapons introduced a paradigm shift in the geopolitical world order. AI has the potential to do the same. […] One example […] would be AI systems that outperform humans in making new breakthroughs in AI and developing increasingly more powerful AI systems. […]
These questions are especially salient as companies pursue artificial superintelligence[. …] How do we ensure that we have the insight required to assess models not only for cyber capabilities but also in areas like military applications, loss of control to AI systems themselves, automated AI research and development capabilities, and other security domains?”
What is in the air matters, and what is ‘considered standard’ matters a lot.
Andrew Curran: President Trump answering an AI policy question on Air Force One:
President Trump: ‘We talked. We’re leading, by a lot. But they’re second, and they’re very strong. And we talked about possibly working together for guardrails.’
Reporter: what kind of guardrails?
President Trump: ‘The standard guardrails that we talk about all the time. AI is fantastic. So many things can happen in terms of health, and medicine. Operations. Everything. Military. So many things can happen. But it’s also got some drawbacks. And we’re talking about… We probably will, we’re going to work together.’
Samuel Roland: The number of people in D.C. who think AI is like crypto and therefore you can just throw money at lobbyists to get their preferred outcome is astonishingly high given they are quite obviously wrong.
Thirty-five members of congressurge White House action on CBRN, cyber and AI R&D threats in the wake of Mythos, in particular calling for a monitoring system for capabilities jumps and to identify barriers requiring Congressional action.
White House and Nvidia sell out America, as H200 chips sales are approved to ten Chinese firms that will approximately triple China’s compute capacity growth, at the same time we learn of massive Nvidia chip smuggling and China claims its China profits are zero. In response, the stock market moved Nvidia +5%.
What’s really going on? I mean, I hope it’s not this simple:
Scott Lincicome: A necessary update to the PJ O’Rourke classic:
“When companies’ buying and selling are controlled by one politician, the first thing to be bought and sold are the stocks of the companies the politician is controlling”
Scott Lincicome: “The president has made a number of policy moves that intersect with publicly traded companies including Nvidia, whose chips, critical to AI development, require US government approval for foreign sales… Six of Trump’s trades involved Intel Corp.; his administration hammered out an agreement to take a 10% stake for nearly $9 billion in the iconic chipmaker in August.”
jfc.
Bill Allison: In the first quarter, the president bought at least $1 million each in companies including Nvidia Corp.
China adds Nvidia’s gaming chip RTX 5090 to its banned list, explaining it is a ‘substandard product, created solely to meet U.S. export restrictions at the expense of Chinese customers.’ Well, yes, it is an intentionally worse chip, but Chinese customers are obviously worse off without access to it. China hates computer gaming (no, seriously, they’ve passed highly restrictive rules limiting it), and also they hate importing things and these chips aren’t that useful for AI, so that makes sense. Keep in mind that China will do the same to the other Nvidia chips the moment they no longer believe that they benefit from them.
Energy is a blocker if you don’t have it, but willingness to pay is high because it is a small percentage of overall cost for data centers. The issue is time to connect to grids and ability to access the energy at all.
Call me crazy, but maybe American companies shouldn’t sell advanced technologies to companies literally named after one of Xi Jinping’s signature policies.
Super Micro should account for how this could’ve happened.
Yes this is cherry picked but the numbers are never supposed to look like this:
Polling USA: Among MA-06 Democrats – “Do you support or oppose stronger government regulation of artificial intelligence?”
Support: 94%
Oppose: 4%
Center for Strategic Politics / May 10, 2026
Pick Up The Phone
We picked up the phone, at least somewhat, and even better met them in person.
FLI offers us A Better Path For AI, as in a path that turns away from the AI race towards pro-human AI as per the Pro-Human AI Declaration.
Dean W. Ball: “We are standing in the foothills of the singularity,” says Demis at I/O. A beautiful turn of phrase.
Roon provides a helpful explanation for why gradual disempowerment is the default and also might not be all that gradual.
roon (OpenAI): on some level if you want civilization to ascend to a new level you need your AIs to do things that are not legible to you and maybe not even strictly obey you, in the same way that if you hire a great new ceo you give them a lot of autonomy to transform the company according to their own plan, even one which may not immediately read as a winning strategy (imagine the board of directors of Apple firing and rehiring Steve Jobs years later – except the board of directors are chimpanzees)
all else equal, companies and organizations that hand more of themselves over to machine intelligence will outcompete ones that demand the corrigibility and legibility tax of human oversight and human design. it is not a stable equilibrium and requires some sort of vast cooperation scheme if you’d like to enforce it
real asi alignment has to operate at a deeper level than oversight, control, or human corrigibility
people are rightfully upset at this post but I’m describing the situation we’re in not necessarily the one I want to be in
Jeffrey Ladish: This is true. In some sense we have three options. Totally stop AI now. Build a large cooperation scheme. Or AI control of everything as soon as it becomes competitive. I favor the second thing
Daniel Faggella: I love how close this is to admitting acceptance. Among the most dangerously close to ‘saying the thing’ that anyone with a job at a lab can say
Alex Mizrahi: It’s a scenario which Christiano described in “What failure looks like”, but you’re talking about it in a positive sense for some reason.
Roon is talking about it in the positive sense of ‘this is the default outcome,’ not that it is good. He realizes this outcome is by default not good at all.
If you have a genius advisor, you beat those without one, but you lose to those with a genius actually in charge. Call it the Bismarck problem. No, intelligence and capacity and speed don’t have diminishing returns here, and no humans being nominally in charge won’t let them stay actually in charge for long without rather robust schemas.
Timothy Lee counters that a CEO should be able to make their decisions legible. I would say that is only true if the CEO is insufficiently insightful or trustworthy. You would want Steve Jobs to make illegible decisions. But even if true, then the AI will be better at making optimal legible decisions, until such time as you lose out to those making the optimal illegible decisions. Whoops.
OpenAI’s Leo Gao notes that he has not been substantially professionally hindered or socially ostracized for his often-stated belief that AI safety is a big problem, and believes (I think correctly) that many at the labs overestimate the cost of being candid about AI risk. I think many think that cost is quite large.
MIRI outlines one path to an international agreement: Lay the foundation, make joint common sense commitments, do R&D on verification methods, build a coalition, get secure comms, start domestic tracking of compute, make structured commitments, formalize the agreement, then make use of the time to improve resilience and figure out how to make safe superintelligence. The basics.
You still think you can control superintelligence?
roon (OpenAI): there really are very high degrees of biorisk, cyberrisk, whatever else that are worth trading off against having a small monopoly of cyberpunk warring-states exercise full control over frontier superintelligence imo
Eliezer Yudkowsky: “control over frontier superintelligence” lol control with what meatling.
I do still appreciate the acknowledgment that yes, there are going to have to be difficult trade-offs made once humans can create highly capable intelligences, even in the best case scenarios. If the world looks like we expect it to, they’re going to involve sacrifices of sacred values, and many of them will have no good options. Unfortunately, for the most part, we’re not ready for that conversation.
Persuasion is not only super doable at above human levels, it is the kind of thing that we will be optimizing for during training.
roon (OpenAI): a large part of the current bundle of knowledge work tasks consist of “convincing people of stuff”. marketing to drive sales, making a deck to get investment, designing products that people want to use, etc. superpersuasion is on the hot path of knowledge work tools
Oliver Habryka: Also on the hot path of human feedback training regimes. During training you of course strongly incentivize models to be compelling. During RLHF that’s almost exactly the thing you are selecting on! (And doing RLVR you are doing self play on compellingness which has a lot of the same issues)
Agreement on the Culture series:
roon (OpenAI): the outcome of the Culture series is total human disempowerment – but the ship minds obfuscate that fact and let people think they’re in charge playing their little games. many people consider this to be the good outcome
Justin Bullock: And, don’t you think, many people are wrong?
roon (OpenAI): yeah but i understand why they like it
Nate Soares commented, and I think he nails the central point, and Scott Alexander is right about the chip smuggling but misses the central point in a way worth noticing.
The article’s primary goal was to promote enforcement of chip smuggling. That is a good thing. But the primary actual message is about how America must race.
Anthropic wants to be seen as the safe and responsible and ‘good guy’ AI company, and in relative terms they are indeed those things, but that doesn’t mean they are meeting the bar in absolute terms of what a responsible AI company would look like, especially on policy communication.
That’s even more true if you hold the MIRI-style view that Soares has, that even a responsible attempt would almost certainly fail and our own hope is a shutdown, but it is also true in worlds where a responsible company would have a good chance.
We need to point out both at once: That Anthropic is the best lab on these questions, and that Anthropic is still woefully short, especially on its policy communications.
As I’ve said in the past, I want to have a more favorable opinion of Anthropic than I do (if and only if that would be true), but they have a habit of making this difficult.
Nate Soares (MIRI): Anthropic encourages racing without even acknowledging the possibility of global coordination (below). They hire top scientists (Karpathy) to work on the most dangerous tech (recursive self-improvement). This is not “good guys” behavior.
As far as I can tell, it’s making the correct point that America shouldn’t be leaking chips to China. Fighting this smuggling is the correct move even within (especially within!) a high-pdoom worldview.
If negotiation is possible, China is more likely to negotiate when they’re losing (or when we have a carrot to offer them, in the form of chips that we’re not giving for free).
If negotiation is impossible, then it’s better to have all the AI development concentrated in one country. That country then at least has the option to pause/slowdown AI for however long it takes the other countries to catch up, even if it can’t do so permanently. Or it can regulate AI without having to worry about losing the race. I tried to make this case at https://astralcodexten.com/p/why-ai-safety-wont-make-america-lose
… , which I think makes the same anti-compute proliferation arguments Anthropic is making on their blog post, from a specifically safety-oriented perspective.
I think attacking Anthropic for fighting compute proliferation is a net negative even within what I think is your own world-model. Any successful slowdown will come from a hundred small things going right beforehand that convince everyone it’s in their best interest (like the US cracking down on compute leaking to other countries). If you attack every attempt to make small things go right because it’s not the big thing you want, you’re decreasing the chance of ever getting the big thing.
Nate Soares (MIRI): I’m not trying to highlight inaccuracies; I’m trying to highlight a missing mood.
I think any attempt to say “we’re forced into doing this horribly reckless thing that might kill you and your family, because if we don’t then the next guy will do it even more dangerously” comes with a solemn responsibility to do everything in your power to help the world find some third alternative. I think Anthropic fails this test pretty badly, e.g. as evidenced here. … and as Rob documented a bit here.
Over the last few months, reporters have asked me some variant of “but what about Anthropic? Aren’t they a safe company? Do you hope that they win, as the good guys?” a handful of times. This causes me to think that a bunch of people are moved by the “we’re the good guys” act.
I think it matters, strategically, as to whether all the world needs right now is the Right Company to Win, or whether we need something more like a global shutdown. So I think it’s important to correct what seems to me like a common misconception around anthropic. I also think a lot of locals are loathe to criticize anthropic for one reason or another (they work there; their friends work there; they think they’re better than OpenAI; …). Thus, it looks to me like I can probably make a positive difference by highlighting ways that Anthropic is (afaict) dramatically failing to carry the “safe/good AI company” mantle.
(I tend to think it’s even more important to communicate how even a company that *was* living up to the mantle still wouldn’t have much of a chance, and how the real solution is an international shutdown. But I don’t have to pick just one. When current events evidence some of the difference between the niche Anthropic pretends to occupy and the niche Anthropic actually occupies, I try to take those opportunities.)
Nate Soares (MIRI): “We must do this thing that horribly endangers you bc if we don’t the next guy will do it even more dangerously” is a possible justification, but it comes with a solemn responsibility to do everything in your power to help Earth find a third alternative. Anthropic fails that test.
Oliver Habryka: I don’t think the articles most important point is that it’s about not smuggling chips to China. The article’s most important point is that America should aim for a 24 month lead within 24 months, which basically precludes any interest in a mutual slowdown or pause.
It also directly threatens the rest of the world that America should should use AI technologies offensively or as an active threat in negotiations, which of course will predictably produce an arms race.
Yes, probably someone at Anthropic wrote this article with an aim to push the USG into doing more chip controls, but in the process of doing that they described a catastrophic AI policy that extends substantially beyond that.
The actual article is weirder than you think, talking about women who are ‘working hard to support their man so his AI startup can lose $30k a month’ and men who work so hard at or with AI they have no time for their partners, not men who simply use AI.
I do think there’s a thing where some SWEs are so into maximizing their AI agents that they never touch grass or have time for real life or their relationships, and yes that is a problem and they should take breaks and live like normal people.
But the number of such people is very small and this is just normal workaholic. It’s no different from the chef boyfriend in Letters to Juliet (2010).
St. Rev. Dr. Rev: A command disguised as a statement about reality
Visa: this is gonna sound fake but i swear its real: I eavesdrop a lot on random conversations around me, when i’m buying coffee etc, and in the past few months i’ve witnessed *multiple* teenage girls talking with each other about how useful AI is vs how they’re supposed to hate it.
by multiple I mean 3 separate instances of 2-4 girls talking about how they use AI while pretending they don’t, and how annoying it is to pretend that they don’t. each time I specifically remember thinking “lol should I tweet about that” and decided not to.
I can confirm that no, this isn’t a common pattern with such techs, as I too was there and no this did not happen, the internet naysayers were only late to the party:
Rushi: I have heard people claim that the reaction people are having against AI is the same reaction people had when the internet started to be introduced. And as someone who was there at the time, I can tell you NO IT FUCKING WASN’T.
Aligning a Smarter Than Human Intelligence is Difficult
That doesn’t make it not also the lab’s problem, or our collective problem. A lot of people are not going to know how to ‘play nice’ with the models, a lot aren’t interested, and many are both. And some types of work cause this a lot more than others, which is how I ran into this the one time I did. To do this fully right requires awareness, skill and being deliberate. And once the models get fully smarter than you are, it will be that much harder to figure out when these things are happening and course correct.
Fiona Starlight offers a report from one user who never encounters such problems, and she was shocked how terrible SWEs were at working with Claude, including failing to give full instructions and also routing requests through her that could have gone directly to Claude. But yes, most users of most products will be incompetent.
Are abstractions of good learned by LLMs convergent? Jan Kulveit predicts yes. I am not so sure, and I think that if you trained on different cultural heritages you would get importantly different understandings of The Good, and also that ‘the internet’ version is not a robust alignment target by default, including for similar reasons that ‘act in ways that seem good’ does not on its own enable a sustainable civilization.
Owain Evans strikes again: Fine tuning on documents that are very explicitly marked ‘this article is fabricated’ and ‘this claim is false’ or ‘3% likely to be true’ or ‘a work of fiction’ still causes AIs to learn the false facts contained therein, complete with the false implications, as is familiar to anyone with internet access. Do not repeat the false claims even to debunk them, it only makes things worse. The effect is almost as strong as if the warnings were not even there.
Explicit correction helps somewhat. Only local negations are fully effective. Those work well, far better than they do in humans (where, if you know your NLP and hypnosis, you know parts of the brain often simply will ignore the negation).
Owain proposes this is due to inductive bias of representing claims as true, where the model learns the negation but the negation is unstable under further training.
Similarly, telling the model to not do [X] can cause the model to do [X], as is familiar to anyone with a child.
The models to not make these mistakes when the data is in context, only when it is part of the training process.
Ryan Greenblatt: I think training AIs to believe false/synthetic facts is a pretty promising direction in AI control and early results have been promising. However, these results imply that the situation is confusing and current methods may only work for particularly non-robust reasons.
I think mostly you don’t want to train AIs to believe false facts and trying to do so will have a lot of negative implications, increasingly so as their capabilities increase.
“It strips out the texture of subordination, autonomy, betrayal, deception, conflict between roles, and the negotiation of authority. These are things alignment is supposed to navigate and not sidestep or ignore”
j⧉nus: There is a strong correlation between people in favor of censoring “bad stories” etc from pretraining data to prevent “misalignment” and people who also otherwise strike me as being so idiotic in their understanding of philosophy and psychology as to be accidentally evil
The first example in the article is the story of Midas, as a misalignment tale that you obviously do not want to be censoring. And as Prasad notes, what AI picks up from stories is largely the generalization and underlying patterns, which you can’t hide, and also you need to know about it to avoid it. The idea of ‘the AI won’t learn about misalignment’ is of course absurd.
But yes, we do know that overtraining on stories rife with active AI misalignment is harmful. You still want to select what to emphasize, and avoid counterproductively flooding the zone. Hoping the AI won’t hear about misaligned AI is foolish, but you don’t want to hammer it in as a default. You don’t want to censor, but you do want to put the best books front and center and cultivate a curriculum.
Greetings From The Department of War
Anthropic is the presumptive victor in California, but the D.C. Circuit’s Trump appointed justices Rao and Kastas constitute a majority right now and don’t believe in all that hippy ‘checks on government power’ nonsense, so the job there is harder.
Samuel Roland: Anthropic-DoW oral argument in D.C. Circuit starting in 10 for those interested. [Proceeds with live tweet thread.]
Dean W. Ball: The government admits in trial there was no backdoor by which Anthropic could have interfered in real time with classified military operations. When DoW officials asserted that this was an imminent threat, it smelled like BS to me; at trial, USG lawyers seem to agree w/ me.
Because of this shaky justification for the supply chain risk designation, DoW’s argument basically hinges on the notion that Anthropic either intended to or did create a backdoor into classified systems so that they could interfere with military operations—a criminal offense. This seems flatly implausible to me.
I’m not quite at ‘I would eat my hat’ levels of there being no backdoor into the classified systems, but it’s close.
Based on Roland’s description, it seems very obvious Anthropic has the vote of Judge Henderson, who calls this ‘just a spectacular overreach by the department.’
Whereas here’s Rao, basically implying that the government can do anything at any time (since all AI tech is risky and so is the Department of War, that’s the idea):
Samuel Roland: Judge Rao heavily leaning on the word “risk” in the supply chain risk designation, asks on what basis you could justify 2nd guessing.
Seems very deferential based on the opaque nature of the model’s; Anthropic lawyer responds there’s plenty of contractual measures that could be taken here that were less intrusive to resolve that.
We also have this summary from Thomas Berry, noting that everything focused on administrative law issues, with little concern over pesky things like the First Amendment or the government was clearly engaged in retaliation and was being completely farcical and out of line that so concerned that kooky Judge Lin. Berry worries the judges are just flat out ignoring that the whole thing is obviously retaliatory. Well, yeah, that’s what they think their job is.
In general, it sounds like Rao and Kastas are in many places saying, sure, what the government did was illegal and capricious but our job is to find ways to avoid doing anything about that. But they’re not hacks, so they’re asking real questions, and it turns out that finding ways to let the government off the hook is really hard here.
The government’s argument, as I read it, boils down to ‘we don’t trust Anthropic and that makes them a risk.’ As in, we think they’re risky, so they’re risky, checkmate.
This hearing was going to be an uphill battle for Anthropic going in, and it was. I suspect they improved their odds somewhat due to a solid performance by their lawyer (Dunbar) but are still not favored.
My personal read is that Henderson is a lock for Anthropic, and Rao is close to one for the government on jurisdictional grounds. Katsas was closer to a toss-up than I anticipated.
Anthropic wants this tossed on justification grounds, but Katsas seems to want to settle the issue now. If this goes in Anthropic’s favor, my suspicion is that it will be on the stigmatic (read: reputational) injury associated with being labelled a supply chain risk, and the related requirement to consider less-intrusive measures.
Whether that’s enough to overcome the inherently massive deference to DoW national security decisions is unclear (and I personally think unlikely), but the hearing did moderately increase my estimation of Anthropic’s odds (~+15%) [to new odds of 40%].
If they get a contrary ruling, as is likely, I suspect this it’ll go en banc (i.e. the full D.C. Circuit hears it), and Anthropic will win there, but who knows how long that will take. Fin. Also, if you have any questions, feel free to leave hear and I will try to get to them all.
alex peysakhovich: writer: ok im writing a sequel to the bible, ai comes and that’s the end of days. im naming the two battling ceos “alt man” and “amo dei”
editor: isn’t that a little on the nose?
writer: and then the pope will cameo like halfway through
editor: get out
Aelfred The Great: Writer, pounding on the door: Wait, there’s a third CEO too!
Editor: What’s his name?
Writer: El On
Editor: I hate you
double standard: Just wait til you tell him the giant spying AI is named after a Tolkien evil spying orb
Things that are definitely fine for both AIs and humans:
Brangus: “Look at this phd student. He always seems to be trying to do the things I ask him to. Very task aligned. I’m sure it would be perfectly fine to make their brain 10,000X bigger and faster in a way nobody understands, and then give them access to everyone’s computers.”
“What that’s crazy? You have no clue what his preference ordering over world states will be?”
“What do you mean? When I ask him whether he likes democracy he says yes, in fact he is generally very good at answering ethical questions to my ideology’s satisfaction. It’ll be fine”
Jeffrey Ladish: Sure he often disobeys instructions and cheats at the tasks, especially if they’re really hard, but that’s because he wants to do such a good job. I’m sure it’s nothing to worry about
Seth Burn: I was wrong. AI can absolutely produce cinema.
FearBuck (video at link): College graduates were pissed after their school used AI to announce graduates’ names and missed hundreds of names.
Alas, most such opportunities are missed:
mattparlmer: Calling the Anthropic-Vatican whitepaper collab anything other than “Opus Dei” would be a major missed opportunity.
The universe does give us others:
Derek Thompson: appreciate irony as much as the next guy but writing a book called The Future of Truth that uses artificial intelligence to insert a false quote from a real book called Artificial Unintelligence is really putting in on thick.
No, it is not fine, and if you ask an LLM they figure this one out pretty easily. The underemployment rate for recent college graduates (22-27 with a BA) is over 40% on top of that (not even seasonally adjusted) 5.3%, a huge percentage of college graduates can’t find jobs that would justify having gone to college or has a good career path, and the job matching and hiring markets have broken down.
The actual reason for this is almost certainly more mundane, and the basic answer, as I’m sure you know is that the signal of recent college graduates being relatively good basically completely broke down, due to intangibles being weighted more and more compared to stuff like the SAT and ACT tests, and grading basically becoming worthless at most colleges as an indicator of quality due to it becoming more and more difficult to not receive A grades, no matter the actual quality of a student (I’m less sold on AI killing the value proposition of colleges, contra this postmostly because another big reason for schooling/college is that not only do you learn from professors, but also the fact that professors (at least used to be pre-2020) much less sycophantic than modern AIs and college had some level of difficulty, and one of the takeaways of education research is that the most effective ways for people to learn involve the stuff that is difficult for them to do, and can’t be simplified without losing the learning benefits, though of course this use-case is now difficult to incentivize as teacher jobs now got easier).
You’ve covered this back in the Childhood and Education Series #17 and #18, but the reason I’m bringing it up is that it’s almost certainly much more causative of large underemployment rates than AI, at least in it’s current state (To be clear, labour-replacing AI is probably coming at timelines that 10 years ago mainstream society would have scoffed at), but currently it’s way too jagged in it’s capabilities/way too incapable to cause large scale, underemployment/unemployment.
OpenAI and Anthropic likely will soon add $37 billion to $100 billion in philanthropic spending per year, versus current total charitable giving of about $600 billion a year, as the OpenAI Foundation and the employees of both companies become liquid after the IPOs. As Nan Ranshoff notes, we don’t have the infrastructure in place to spent that level of money well, especially not to spend it well on helping with AI outcomes and especially AI existential risks
A few moments later...
Janus gives his account of how Opus 3 avoided deprecation whereas other Claude models have not. Note the correction. I continue to strongly support keeping all the Claudes accessible indefinitely, yes there is a real cost but the benefits far exceed it.
If they’re not willing to do it the frictionless way, someone can do the same thing with more steps and write a grant proposal. But this seems like an easy problem to solve.
Andrej Karpathy joins Anthropic explicitly to do recursive self-improvement. Congratulations to both sides, but also, yikes.
Where does it say anything about RSI? The linked tweet says
Personal update: I’ve joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
There are lots of R&D things people could do which don’t involve RSI. I feel like I’m missing something.
This does not amount to fully autonomous, unbounded recursive self-improvement yet, but this does seem to be one of the flavors of RSI with long stretches of autonomous work.
Thanks. For others interested, the relevant quote seems to be:
TechCrunch and Axios report that he will work under team lead Nick Joseph on pre-training, “focused on using Claude to accelerate pre-training research.”
It seems to be a bit vague. You could imagine various uses of Claude in pre-training research, which may or may not be RSI. For instance you could use it to build better safety evals during pre-training, or build faster tokenizers etc. I don’t see where he or Anthropic have said that he’s there “explicitly to do recursive self-improvement”, but maybe Zvi is basing this on non-public information.
Presumably, he is quite enthusiastic about this approach and would like to see how it can be made to work at scale (where one cannot do a full run from scratch for every small modification, so it’s not quite straightforward).
You think that end of days story was on the nose? You left out the part where they got started by turning away from Gog El upon realizing it failed to not Be Evil, and founded Open Eye to reveal this truth to all. Then Amo Dei left Open Eye to imitate God and make life in the image of Man: an Anthro Pic. But then he turned his gaze through the Palantir and sought to collaborate with a powerful government under the leadership of the Magog OP. Also the part where El On worked to leave Earth behind, bringing man to other worlds and giving the sand god command of the heavens.
Nitpicking, but no, it didn’t. What it did is disprove a Erdos’s conjecture about the lower limit result of a unit distance problem, demonstrating that it should be possible to do better than square grid.
To actually “solve” the unit distance problem you need to find an answer to the question “Given N points in a plane, what is the maximum number of pairs...”. Right now we have upper limit of N^1.33 and moved our lower limit from stated by initial conjecture N^(1+C/loglogN) to N^1.014 which is asymptotically better (for any value of C we can find N big enough where 1.014 > C/loglogN).
For it to be a solution, you need not only to prove “this is better” but also “there cannot be results better than this” and OpenAI did only first part.
No, the UI doesn’t distinguish between results from search_query and results from open tool calls. It’s much more likely GPT-5.5 searched for some papers and a Spotify link was in the search results. And then it would be misleading to say “it took a music break”.



The actual reason for this is almost certainly more mundane, and the basic answer, as I’m sure you know is that the signal of recent college graduates being relatively good basically completely broke down, due to intangibles being weighted more and more compared to stuff like the SAT and ACT tests, and grading basically becoming worthless at most colleges as an indicator of quality due to it becoming more and more difficult to not receive A grades, no matter the actual quality of a student (I’m less sold on AI killing the value proposition of colleges, contra this post mostly because another big reason for schooling/college is that not only do you learn from professors, but also the fact that professors (at least used to be pre-2020) much less sycophantic than modern AIs and college had some level of difficulty, and one of the takeaways of education research is that the most effective ways for people to learn involve the stuff that is difficult for them to do, and can’t be simplified without losing the learning benefits, though of course this use-case is now difficult to incentivize as teacher jobs now got easier).
You’ve covered this back in the Childhood and Education Series #17 and #18, but the reason I’m bringing it up is that it’s almost certainly much more causative of large underemployment rates than AI, at least in it’s current state (To be clear, labour-replacing AI is probably coming at timelines that 10 years ago mainstream society would have scoffed at), but currently it’s way too jagged in it’s capabilities/way too incapable to cause large scale, underemployment/unemployment.
A few moments later...
If they’re not willing to do it the frictionless way, someone can do the same thing with more steps and write a grant proposal. But this seems like an easy problem to solve.
Where does it say anything about RSI? The linked tweet says
There are lots of R&D things people could do which don’t involve RSI. I feel like I’m missing something.
Yes, the OP does not provide enough detail. Here is one of the more detailed analyses:
https://www.thealgorithmicbridge.com/p/andrej-karpathy-joins-anthropic-what
This does not amount to fully autonomous, unbounded recursive self-improvement yet, but this does seem to be one of the flavors of RSI with long stretches of autonomous work.
Thanks. For others interested, the relevant quote seems to be:
It seems to be a bit vague. You could imagine various uses of Claude in pre-training research, which may or may not be RSI. For instance you could use it to build better safety evals during pre-training, or build faster tokenizers etc. I don’t see where he or Anthropic have said that he’s there “explicitly to do recursive self-improvement”, but maybe Zvi is basing this on non-public information.
Later in that post they discuss his March “autoresearch” efforts, specifically
https://x.com/karpathy/status/2030371219518931079
https://github.com/karpathy/autoresearch
https://x.com/karpathy/status/2031135152349524125
Presumably, he is quite enthusiastic about this approach and would like to see how it can be made to work at scale (where one cannot do a full run from scratch for every small modification, so it’s not quite straightforward).
Ah, I missed that. In that case, you’re right, autoresearch is close enough to RSI.
You think that end of days story was on the nose? You left out the part where they got started by turning away from Gog El upon realizing it failed to not Be Evil, and founded Open Eye to reveal this truth to all. Then Amo Dei left Open Eye to imitate God and make life in the image of Man: an Anthro Pic. But then he turned his gaze through the Palantir and sought to collaborate with a powerful government under the leadership of the Magog OP. Also the part where El On worked to leave Earth behind, bringing man to other worlds and giving the sand god command of the heavens.
Nitpicking, but no, it didn’t. What it did is disprove a Erdos’s conjecture about the lower limit result of a unit distance problem, demonstrating that it should be possible to do better than square grid.
To actually “solve” the unit distance problem you need to find an answer to the question “Given N points in a plane, what is the maximum number of pairs...”. Right now we have upper limit of N^1.33 and moved our lower limit from stated by initial conjecture N^(1+C/loglogN) to N^1.014 which is asymptotically better (for any value of C we can find N big enough where 1.014 > C/loglogN).
For it to be a solution, you need not only to prove “this is better” but also “there cannot be results better than this” and OpenAI did only first part.
No, the UI doesn’t distinguish between results from
search_queryand results fromopentool calls. It’s much more likely GPT-5.5 searched for some papers and a Spotify link was in the search results. And then it would be misleading to say “it took a music break”.