Growth and Form in a Toy Model of Superposition
TLDR: This post distills Dynamical and Bayesian Phase Transitions in a Toy Model of Superposition by Chen et al. (2023), where they study developmental stages of the Toy Model of Superposition, understanding growth and form from the perspective of Singular Learning Theory (SLT).
Where do the bewildering and intricate structures of Nature come from? What purpose do they serve? In his famous 1917 book “On Growth and Form” the Scottish biologist and mathematician D’Arcy Wentworth Thompson wrote the following about the geometric forms of Phaeodaria, shown above:
Great efforts have been made to attach a “biological meaning” to these elaborate structures and “to justify the hope that in time their utilitarian character will be more completely recognised”—“On Growth and Form” p. 695
Chris Olah, who pioneered mechanistic interpretability for neural networks and is somewhat of an intellectual descendant of D’Arcy Wentworth Thompson, has often cited biology as an inspiration for his work. Indeed, in many respects trained neural networks are more similar to biological organisms than to traditional computer programs. One of the most striking parallels is that, just as in biology, structure often forms over neural network training in what appear to be developmental stages.
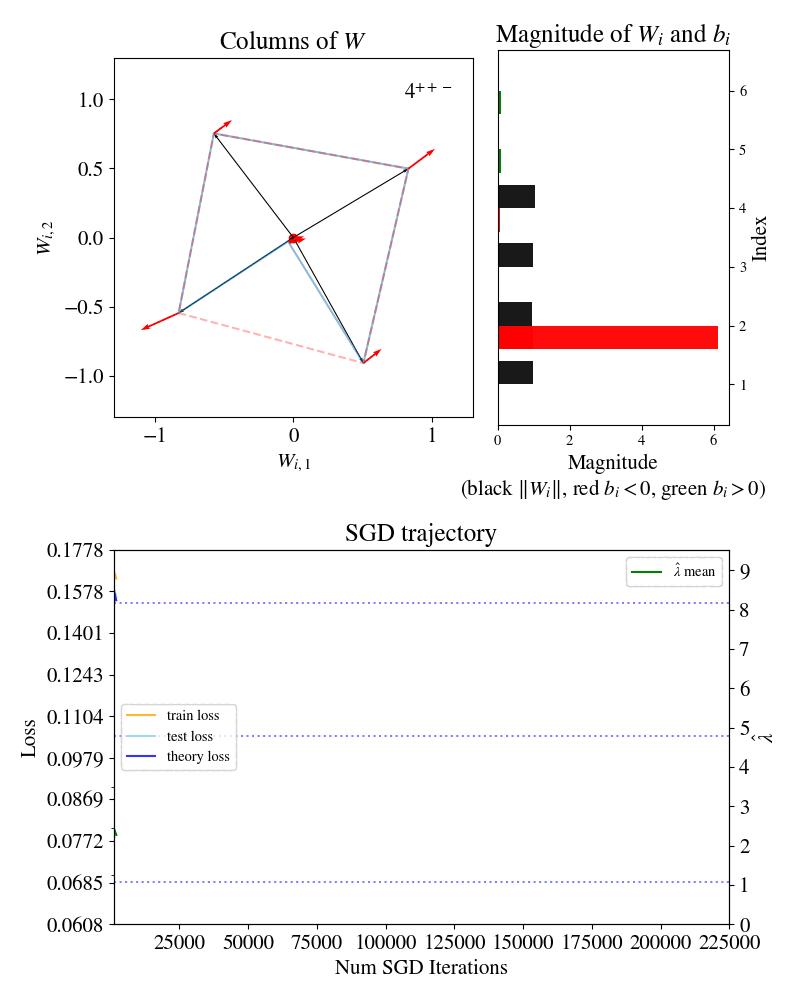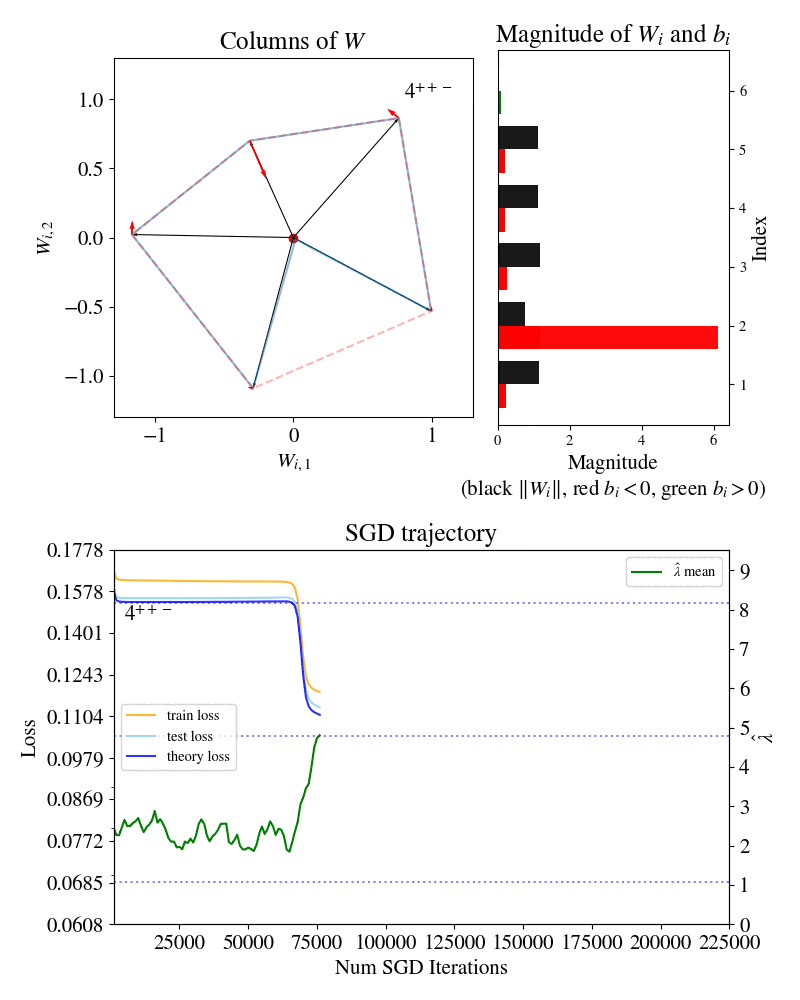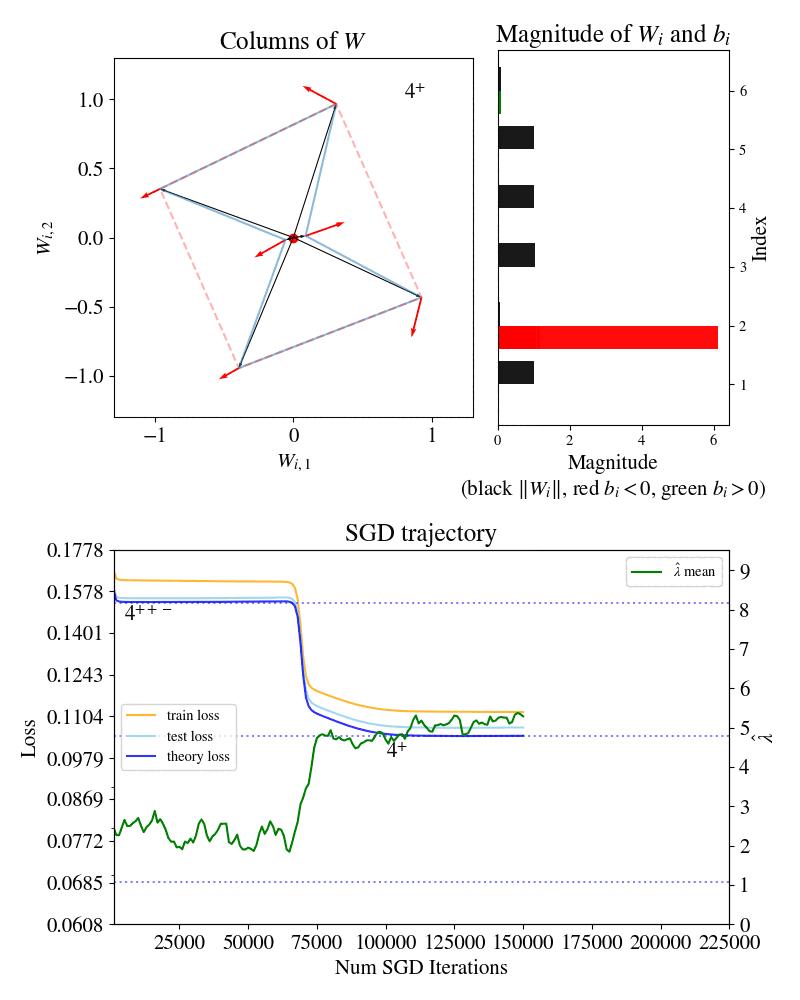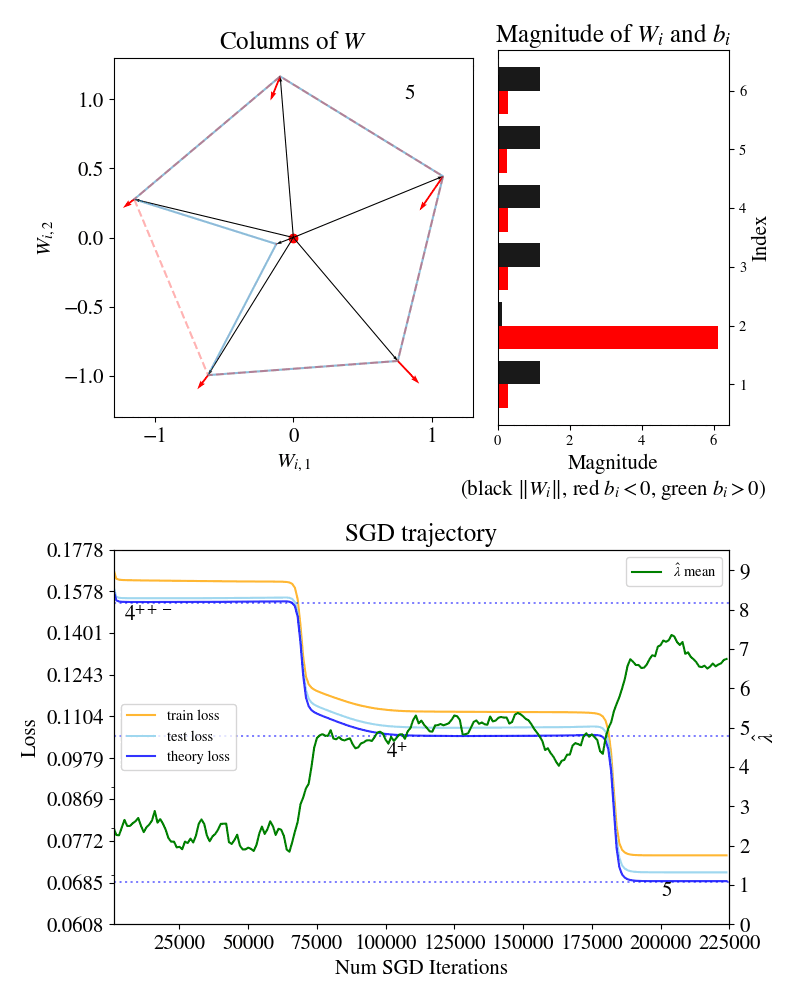
First row, left: columns of the weight matrix for the function .
First row, right: magnitudes of columns of and associated biases .
Bottom row: losses and model complexity estimator over training.
In 2022, Elhage et al. introduced the Toy Model of Superposition (TMS) to study when and how models represent more features than they have dimensions, aiming to discern a method to systematically enumerate all features in a model to improve interpretability. Here, we show one case of this model: a neural network trying to reconstruct six-dimensional sparse inputs by encoding them non-linearly in two dimensions. A visualization of the encoding strategy (weights of the neural network) is shown in the top left, and it is visible that over training the network passes through three “forms” or stages of development (labelled , , for reasons that will be explained below), separated by sudden transitions where the structure changes. From here on we will refer to this animation as the Developmental Stages of TMS.
What are these stages of development and what kind of process are these transitions? Can we understand why the training process passes through these particular stages in this particular order? Does this toy model reveal a path towards a better understanding of the bewildering and intricate structure of larger neural networks?
In Chen et al (2023), it is shown that the stages of development in TMS can be concretely understood from the perspective of singular learning theory. These stages (or forms) are synonymous with critical points of the loss landscape , and the development between stages (growth) corresponds to phase transitions between these critical points, where the only dynamically-permissible transitions involve decreasing loss and increasing model complexity .
Let us elaborate.
On Growth and Form
We are familiar with the idea that a biological system might, over the course of its development from an embryo, take various forms that are stable and distinct. Like many familiar notions, the concept of a form is difficult to define in a careful way:
Thus according to Aristotle, the matter of a thing will consist of those elements of it which, when the thing has come into being, may be said to have become it; and the form is the arrangement or organization of those elements, as the result of which they have become the thing which they have. -- Britannica
Obviously.
For systems like neural networks whose development is governed by the process of gradient descent for a potential , a reasonable mathematical formalisation of the informal notion of a form is the concept of a critical point. A network parameter is a critical point if all partial derivatives of the loss vanish, that is, . It’s a place where gradient descent slows down, or even stops.
Local minima and maxima in two dimensions are critical points familiar from high school calculus, as are saddles in three dimensions (with both increasing and decreasing directions nearby). We use three different words maxima, minima, saddle to distinguish these three kinds of local geometry.
For potentials like the loss function of a neural network, there are many more kinds of critical points than these, each with their own particular local geometry. It is this geometry, and the configuration of these critical points relative to one another, which dominates the large scale behaviour of dynamical systems (Gilmore, in his text on Catastrophe Theory, calls this the Crowbar Principle).
To return then to the biological setting, we may identify forms with critical points and growth with flows between neighbourhoods of critical points.
In the Toy Model of Superposition, the forms are regular polygons, and we observe that growth is restricted to occur in a specific way: loss must go down, and complexity must go up. What we see in the specific transition of the animation is actually a more general phenomena, at least in the setting of TMS, as the complexity of the polygon increases in each transition. This observation connects the dynamical transitions of neural network training to the Singular Learning Theory (SLT) theory of phase transitions. Let’s dive in.
The Zoo of TMS Critical Points
In the high-sparsity limit of the TMS potential , it is possible to explicitly calculate and study critical points. The problem of classifying these critical points is similar in some respects to problems in the theory of tight frames, compressed sensing, and the Thomson problem. In the case of feature dimensions, these critical points have a clear, interpretable meaning: they correspond to -gons.
The Setup
We consider a two-layer ReLU autoencoder with input and output dimension , with hidden dimensions in the network:
where . Here is a matrix of column vectors , and is a bias.
In the high-sparsity limit, an input sample from the true data-generating distribution has the form , where is the th basis vector drawn uniformly from , and is uniformly sampled from .
The objective of the TMS learning machine is to find an efficient method to compress the high-dimensional true input distribution into a lower-dimensional representation, in other words, to approximately reconstruct any input using less feature dimensions than input dimensions . So for any dataset of samples , the empirical TMS loss to minimise during training is
We refer to as the TMS potential, for which a closed form expression is given in Lemma 3.1 of Chen et al. (2023).
TMS Critical Points are -gons
When we set the number of feature dimensions to , meaning the autoencoder has weight vectors in the plane to perform its compression, the most interesting low-loss critical points[1] are regular polygons — triangles, squares, pentagons and the like. Each critical point is characterised by three quantities:
: the number of vertices in the regular polygon formed by the convex hull of the columns of the .
: the number of positive values in the bias vector .
: the number of large negative values in .
We denote each critical point as a -gon, which we will call -gon for short.[2] These are the fundamental forms of the Toy Model of Superposition.
In the case, we empirically catalogued and theoretically proved the existence of 18 low-loss critical points.[3] Since we have a closed form expression for the TMS potential , we can easily plug in each identified critical point to find its loss and create a diagram akin to the energy-levels of different states in physics.
SGD Plateaus at -gons
The Developmental Stages of TMS animation shows SGD settling at three different plateaus through training, which we visually saw corresponded to different “forms” of the parameter . These forms are different -gon critical points, each with their own loss plateau.
This is not a one-off.
No matter where SGD is initialised, it always plateaus on a known -gon critical point. Sometimes it even transitions through multiple plateaus, like we see in the animation.
So, in TMS, SGD training trajectories can be thought of as a developmental journey through different -gon forms. The rapid drops in loss from plateau to plateau signify instances of actual growth. For example, the model literally develops a new limb when it transitions from a -gon to a -gon.
Opposing Staircases: Loss ↓, Complexity ↑
Let’s take a closer look at the green line in the Developmental Stages of TMS animation, which we have claimed is measuring the “local complexity” of the model at time . (Why we care about the local complexity will be explained below).
Notice how as loss goes down over training, the local complexity goes up, as if they’re opposing staircases.
In fact, if we look back at the colourful SGD Plateaus plot above, there seems to be an inverse relationship between the energy of a critical point and its estimated complexity , suggesting a more general phenomena than just the transition we see here.
One can plot for different -gon critical points , and then connect the pairs between which there were observed phase transitions in SGD. In doing this we repeatedly observe this same pattern: structure seems to form in particular ways, consistently decreasing loss while increasing complexity. Some transitions are dynamically permissible, and others aren’t.
This single plot of loss against complexity captures the growth and form of TMS.
What explains these highly restricted developmental trajectories? Training often skips past critical points with intermediary energy levels, so it can’t simply be a case of moving further and further down the loss landscape. Something else is going on.
Singular learning theory (SLT) can shed some light.
TMS meets SLT
Bayesian Phases are also Critical Points
Phases Minimise the Free Energy
Those already familiar with the general story we have been telling will recognise that there is a better name for these “forms” that we observe throughout TMS training. They are phases. Moreover, the sharp drops between plateaus are indicative of growth in structure, and these are phase transitions.
Plateaus in loss are sometimes referred to informally as phases in the machine learning literature. To get to the heart of this, we turn to the Bayesian perspective on learning. Here the posterior (for some prior on parameter space ) is the central object, containing all information about our system for any sample size .
In statistical physics and Bayesian learning theory a phase is some region of state/parameter space that has concentrated posterior mass — in other words, a configuration of the system that the posterior deems likely to occur. This posterior mass is measured (for tractability reasons) using the free energy [4]. The Bayesian model selection process is then guided by the principle of free energy minimisation (equivalently, posterior mass maximisation).
There are two natural phases with concentrated posterior mass for this posterior: a ball centred at , and a region around the line .
These two phases have different geometric characters, i.e. differing loss and complexity.
So are Bayesian phases also related to critical points of ? They sure are.
Geometric Signatures of Bayesian Phases
Let be a region of parameter space that contains a critical point , where locally minimises the loss in . Then as the number of samples tends to infinity, Watanabe’s free energy formula tells us that the local free energy of is asymptotically given by
Here is the loss (aka potential energy), is the local learning coefficient (aka model complexity, aka the RLCT), and includes a term of order and a constant order term which incorporates information such as the prior-volume (or equivalently in this setting, the weight-norm ). [5]
This formula tells us that the posterior concentrates on neighbourhoods of critical points , which we will now genuinely call phases in good conscience. Remember, singular models like neural networks induce loss landscapes that have a diverse set of critical points with differing tradeoffs between loss and complexity, unlike regular models where complexity is constant across parameter space, .
That these local geometries vary across parameter space is what gives singular models their rich phase structure. This is exactly what we saw with the diverse catalogue of TMS -gon phases, each having different loss-complexity tradeoffs .
What does SLT say about phase transitions, though?
Bayesian Phase Transitions
Internal Model Selection
The different tradeoffs between loss and complexity across phases result in what is effectively internal model selection. The posterior prefers high-loss-low-complexity models in the face of insufficient evidence (low ) — a kind of Occam’s Razor — but, as you increase your evidence with more training samples , the posterior becomes more certain that low-loss-high-complexity models are better.
This process forms the basis of Bayesian phase transitions, which occur when there is a sudden change in which region of parameter space has the dominant posterior mass (equivalently, lower free energy).
Suppose we carve up (or more precisely, coarse grain) our parameter space into a finite set of disjoint phases covering . (Precisely how you coarse grain parameter space to perform maximally interesting inference is a non-trivial process—in TMS this is natural, in other settings it may not be).
By the log-sum-exp-approximation, the global free energy defined by is approximately
meaning that it is dominated by the phase with the lowest free energy for a given value, while the rest are exponentially suppressed. This is the sense in which the posterior “chooses” the phase at a given .
Phase Transitions from High-Loss-Low-Complexity to Low-Loss-High-Complexity
So when does the dominant phase change from the point of view of the free energy? In the simplest case, say we had two phases and , defined by neighbourhoods and centred at critical points and respectively. Let’s suppose that has better loss but higher complexity, so
(and suppose that for ease). Then as increases, a Bayesian phase transition from will occur at when the ordering of their free energies flips. Solving shows that is the unique solution to [6]
We say there is a Bayesian phase transition of Type A at .
Are visions of opposing staircases flashing before your eyes?
Plotting versus for different phases , a Bayesian phase transition occurs at when there is a new phase with minimum free energy.
Perhaps Dynamical Transitions have Bayesian Antecedents
A Bayesian transition occurs as we increase sample size , whereas dynamical transitions occur in SGD time . We know that both are governed by the critical points . But is there a deeper connection going on?
Bayesian (left): The theory of phase transitions in SLT is grounded in a Bayesian formalism. Like thermodynamics, there are essentially no dynamics: transitions involve discrete changes in your probability density over state space as you change some control variable.
Dynamical (right): It remains unclear what this theory has to say about dynamical phase transitions in SGD timesteps.
The Toy Model of Superposition suggests there is. In both settings, transitions occur from high-loss-low-complexity -gons to low-loss-high-complexity -gons, suggesting that any dynamical system has a Bayesian phase transition “standing behind it”, which we will call a Bayesian antecedent.
This observation leads us to put forward the following hypothesis:
Bayesian Antecedent Hypothesis (BAH): The dynamical transitions encountered in neural network training have Bayesian antecedents.
When operationalised in the TMS setting for a transition in time, and assuming that only Type A transitions occur, the BAH implies:
When we see a drop in loss we should see an accompanying rise in learning coefficient .
If there are multiple transitions, the gradient should increase (negative slope become shallower) for consecutive transitions.
This was not falsified in the TMS experiments.
Do Bayesian Phase Transitions even exist? Yes!
“Wait a second, didn’t you say the free energy formula is an asymptotic approximation? Why should I believe it for finite , let alone moderately sized ? Do these Bayesian phase transitions even exist, empirically?”
Yes, yes they do.
Returning to our catalogue of -gon critical points, we are actually able to theoretically calculate the learning coefficient of the 5- and 6-gons[7]:
| Phase | Local Learning Coefficient | Loss | Constant |
|---|---|---|---|
| 5-gon | 7 | 0.06874 | 3.62417 |
| -gon | 8.5 | 0.06180 | 3.62764 |
| 6-gon | 8.5 | 0.04819 | 6.37767 |
Running the numbers, the free energy formula theoretically predicts that there will be a phase transition at , which we can verify empirically by using MCMC to sample from the TMS posterior distribution at a range of dataset sizes .
Crucially, because we know the critical points in TMS are -gons, we are able to very naturally coarse-grain parameter space into phases , thereby assigning any posterior sample into a phase. This feature of TMS allows us to calculate the relative frequency of each phase for different , i.e. the probability mass
for each phase . Plotting these relative frequencies over a range of gives us phase occupancy curves, allowing us to compare the theoretical occupancy curve (determined by the theoretical ) and the empirically derived version from MCMC experiments.
The most salient feature of the curves is the Bayesian phase transition from a which happens at the crossover around , seen in both the theoretical and empirical curves (and occurring at remarkably similar values of ). Since the 6-gon is the global minimum of the TMS potential for , it is not surprising to see that it is the eventual dominant phase for sufficiently large . But just as SLT predicts, since the 5-gon has lower complexity, it can be the dominant phase for some range of , which we see here for .
It’s worth noting that for low , a lot of this analysis does start to break down. This is primarily because the lower order terms of the asymptotic free energy formula become increasingly more important, and classifying each sample into a phase becomes less precise due to a more diffuse posterior. [8]
To guard against some of these issues, one can manually inspected MCMC samples using a 2D t-SNE projection to verify that the phase classifications do cluster together appropriately.
Observe that the change in cluster size of the 5 and 6-gon and the gradual suppression of other phases.
See interactive version here: http://project-tms.s3-website-ap-southeast-2.amazonaws.com/
Updates and where to now?
The work presented here represents the first step toward not just verifying some of the key tenets of the developmental interpretability agenda but also advancing toward a science of deep learning through the thermodynamic lens of singular learning theory.
Some updates we took away from working on this:
SLT works, folks. This is the first empirical verification of the predictive power of the SLT theory of phase transitions outside of some synthetic examples. That Bayesian phase transitions are a real phenomena at moderately sized (our MCMC experiments ranged from ) is a substantial piece of evidence that SLT is relevant to “real systems”.
Dynamical phase transitions are related to Bayesian ones: We know that both kinds of transitions are governed by the critical points of , but aside from this, there is no a-priori relation between the two. With TMS, we now have a real (albeit toy) system that exhibits the behaviour we hypothesised in the devinterp agenda relating dynamical phase transitions to those predicted by singular learning theory.
Lambda-hat works. We have a measure of model complexity and it correctly describes phase transitions. This was a major question mark previously.
It’s worth pausing here for a moment to consider the parts of this work that are specific to TMS (“mechanistic” claims, specific to the problem at hand) and those that we expect to hold more broadly (“thermodynamic” claims, true across general learning machines).
Here are some examples:
| Mechanistic claims | Thermodynamical claims |
|---|---|
| -gons are critical points. | The posterior concentrates near critical points. |
| SGD training proceeds by forming increasingly complex polygons. | SGD and Bayesian learning proceed via phase transitions. |
| A 4-gon can transition to 5-gon during SGD training. | Bayesian and dynamical transitions decrease the free energy. |
| Higher energy -gon phases have mostly lower complexity. | There are “phase structures” that relate energy and complexity of phases. |
Obviously we don’t expect to see -gons as critical points in general networks. These structures/forms/phases will manifest in many different ways. But we do expect them to form in phase transitions as a universal phenomena.
Some of the guiding questions from here include:
Can we develop and refine tools such as lambda-hat that allow us to detect phase transitions, even without knowing the phases of the system?
Do dynamical phase transitions in other systems also have Bayesian antecedents? Just how far does the BAH apply beyond TMS?
Can we use further insights of SLT to extrapolate a deeper understanding of structure formation not just in toy cases, but in large language and vision models?
We believe that understanding the growth and form of neural networks is fundamental to a science of deep learning, and that this understanding will come from a combination of deep mathematics and careful study of many particular systems, like TMS. In this we take inspiration from D’Arcy Wentworth Thompson, who had a passion not only for mathematics, but for collating many beautiful examples of organism development from across the natural world.
Thanks to @Daniel Murfet , @Jesse Hoogland and @Alexander Gietelink Oldenziel for reviewing earlier drafts of this distillation!
- ^
Here we are slightly abusing the term “critical point”—in general, we are actually referring to critical submanifolds. In the case of the TMS potential, there are two generic symmetries that mean the different “critical points” are actually critical submanifolds:
Permutation symmetry, where, like any other feedforward ReLU neural network we can permute hidden nodes (i.e. simultaneously permute weight columns and bias entries) and still yield the same function, and;
Rotation symmetry, (or more precisely, -invariance, where is rotation in the plane), since for any orthogonal matrix we have
These generic symmetries mean that singular learning theory is an essential tool to fully understand the TMS system.
- ^
There are some proven constraints on what combinations of are possible—for more details, see Appendix A of Chen et al. (2023).
- ^
While we have not proven that these are all of the possible critical points (and indeed, there are likely many more high-loss critical points that SGD never cares about), we are confident that we found all of the important ones.
- ^
For a given region of parameter space the free energy is
thus measuring the posterior concentration of .
- ^
To be clear, this is the free energy to leading order. It is an active problem to determine lower order terms of the free energy, investigating which other geometric quantities are important for model selection.
- ^
The precision of this value is not to be taken too literally—it is, after all, based on an asymptotic approximation. Interpreting such asymptotics require great care for any finite- system (which is all we ever care about in real systems).
- ^
In fact, we actually have a reasonably good idea of learning coefficients for various -gons too, however these remain unpublished due to some technical non-analyticity complications.
- ^
Such analysis also depends on the coarse graining of the phases, and while we are quite sure we have located all low-energy critical points, it is still possible that the presence of other unaccounted for phases could introduce inaccuracies in these occupancy curves.
Oh man, this is a lot more impressive than my brief skim of the paper made it out to be! I especially really like this graph
Graph is apparently not showing, and I don’t know how to fix so if you click on this it is the link. Its the one showing the theoretical vs empirical phase frequencies.
This is a casual thought and by no means something I’ve thought hard about—I’m curious whether b is a lagging indicator, which is to say, there’s actually more magic going on in the weights and once weights go through this change, b catches up to it.
Another speculative thought, let’s say we are moving from 4* → 5* and |W_3| is the new W that is taking on high magnitude. Does this occur because somehow W_3 has enough internal individual weights to jointly look at it’s two (new) neighbors’ W_i`s roughly equally?
Does the cos similarity and/or dot product of this new W_3 with its neighbors grow during the 4* → 5* transition (and does this occur prior to the change in b?)
The change in the matrix W and the bias b happen at the same time, it’s not a lagging indicator.
Question about the gif—to me it looks like the phase transition is more like:
4++- to unstable 5+- to 4+- to 5-
(Unstable 5+- seems to have similar loss to 4+-).
Why do we not count the large red bar as a “-” ?
Good question. What counts as a “-” is spelled out in the paper, but it’s only outlined here heuristically. The “5 like” thing it seems to go near on the way down is not actually a critical point.
Would you be willing to share the raw data from the plot—“Developmental Stages of TMS”, I’m specifically hoping to look at line plots of weights vs biases over time.
Thanks.
Hello @RGRGRG, yes, I can share the raw data for that plot. If you can direct message me your email address or any other way for communicating a JSON file, I can send them to you.
Also, the developmental stages of this model (see the Setup section) is quite robust as well. If you wish to reproduce this trajectory, starting from the
4++-initial configuration (see “TMS critical points are k-gons” section) will likely produce similar trajectory.