DSLT 3. Neural Networks are Singular
TLDR; This is the third main post of Distilling Singular Learning Theory which is introduced in DSLT0. I explain that neural networks are singular models because of the symmetries in parameter space that produce the same function, and introduce a toy two layer ReLU neural network setup where these symmetries can be perfectly classified. I provide motivating examples of each kind of symmetry, with particular emphasis on the non-generic node-degeneracy and orientation-reversing symmetries that give rise to interesting phases to be studied in DSLT4.
As we discussed in DSLT2, singular models have the capacity to generalise well because the effective dimension of a singular model, as measured by the RLCT, can be less than half the dimension of parameter space. With this in mind, it should be no surprise that neural networks are indeed singular models, but up until this point we have not exactly explained what feature they possess that makes them singular. In this post, we will explain that in essence:
Neural networks are singular because there are often ways to vary their parameters without changing the function they compute.
In the case where the model and truth are both defined by similar neural network architectures, this fact means that the set of true parameters is non-trivial (i.e. bigger than the regular case where it is a single point), and often possesses many symmetries. This directly implies that neural networks are singular models.
The primary purpose of this post is to show with examples why neural networks are singular, and classify the set of true parameters in the case where the model and truth are simple two layer feedforward ReLU networks. In doing so, we will lay the groundwork for understanding the phases present in the setup so that we can then study relevant phase transitions in DSLT4. Feel free to jump ahead to the slightly more exciting DSLT4 Phase Transitions in Neural Networks and refer back to this post as needed.
Outline of Classification
To understand the different regions that minimise the free energy (and thus, as we’ll see in DSLT4, the phases), one needs to first understand the singularities in the set of optimal parameters of .
In the realisable regression case with a model neural network and true neural network defined by for some , the set of true parameters has the form [1]
Thus, classifying the true parameters is a matter of establishing which parameters yield functional equivalence between the model and the truth . The property of being singular is specific to a model class , regardless of the underlying truth. But, classifying in the realisable case is a convenient way of studying what functionally equivalent symmetries exist for a particular model class.
Neural networks have been shown to satisfy a number of different symmetries of functional equivalence across a range of activation functions and architectures, which we will elaborate on throughout the post. Unsurprisingly, the nonlinearity of the activation function plays a central role in governing these symmetries. In general, then, deep neural networks are highly singular.
In this post we are going to explore a full characterisation of the symmetries of when the model is a two layer feedforward ReLU neural networks with hidden nodes, and the truth is the same architecture but with nodes. Though you would never use such a basic model in real deep learning, the simplicity of this class of network allows us to study with full precision. We will see that:
If the model and truth have the same number of nodes, : There are three forms of symmetry of :
Scaling symmetry of the incoming and outgoing weights to any node.
Permutation symmetry of the hidden nodes in a layer.
Orientation reversing symmetry of the weights, only when some subset of weights sum to zero (i.e. “annihilate” one another).
If the model has more nodes than the truth, : Without loss of generality, the first nodes of the model must have the same symmetries as in the first case. Then each excess node is either
Degenerate, meaning its total weight (gradient) is 0 (thus the node is always constant).
Or it has the same activation boundary as another already in the model such that the weights sum to the total gradient in a region [2].
In [Carroll, Chapter 4], I give rigorous proofs that in both cases, is classified by these symmetries, and these symmetries alone. The purpose of this post is not to repeat these proofs, but to provide the intuition for each of these symmetries. I have included a sketch of the full proof in the appendix of this post if you are more mathematically inclined.
Two layer Feedforward ReLU Neural Networks
Literature abounds on what neural networks are, so I will merely give the definition of the class we are going to study here and some related terminology for the discussion.
Defining the Networks and Terminology
Let be a compact parameter space. We will let denote the set of hidden nodes in the first layer of our network, and denote the standard dot product between two vectors. Also recall that
We let denote a two layer feedforward ReLU neural network with two inputs and one output , defined by a parameter . The function is given by
where for each :
the first layer weights are and the biases are
the second layer weights are and the bias is .
These functions are simply piecewise affine functions (i.e. piecewise hyperplanes), and as such they have (relatively) easy topology to study. Before we give an example, we will briefly mention some key terminology.
Let be defined by a fixed . We say a particular node is degenerate in if either of the weights are zero, so or . [3]
We say a non-degenerate node is activated in some linear domain [4] when the ReLU is non-zero for all , that is,
The activation boundary associated to node is thus the line
One of the key accounting tools in the symmetry classification is identifying the foldsets of (in the terminology of [PL19]), which are the regions where is non-differentiable in , and noticing that these equate to the union of non-degenerate activation boundaries . Two functionally equivalent networks must then have the same foldsets since they define the same function, allowing us to compare the lines defined by .
Example—Feedforward ReLU Neural Networks are Piecewise Hyperplanes
Example 3.1: Consider the following two layer feedforward ReLU neural network:
defined by biases and , second layer weights , and first layer weights
Its graphical structure and activation boundaries in the plane can be seen below:
Conceptually, it’s helpful to notice that when anchored on its corresponding activation boundary, each weight vector “points” into its region of activation.
The Symmetries of Two Layer Feedforward ReLU Neural Networks
In this section I am going to provide some motivating examples of each kind of symmetry exhibited in two layer feedforward ReLU neural networks. To prove that this is the full set of symmetries in generality requires a bit more work, which we relegate to the appendix.
Scaling Inner and Outer Weights of a Node
The scaling symmetry of ReLU networks offers us our first window into why these models are singular. The key property is to notice that for any , the ReLU satisfies a scale invariance [5]
Say we had the simplest model possible with just one node:
Then we could define an alternative parameter with
which gives functional equivalence because,
For a model with hidden nodes, the same scaling symmetry applies to each individual node with a set of scaling factors .
The fact that we can define such a for any set of positive scalars means that the Fisher information matrix of these models is degenerate at all points . We prove this in generality in Appendix 1, but I’ll spell it out explicitly for a simple example here.
Example—Scaling Symmetry Induces a Degenerate Fisher Information Matrix
Example 3.2: It is worth taking a moment to recognise how this scaling symmetry affects the geometry of the loss landscape . The mental model to have here is that it results in valleys in , where the set of true parameters is like a river on the valley floor. To see this, say we defined a model with parameter and truth as:
where is some fixed constant. If is uniform on then it is easy to calculate that when we have
We can depict this valley and its effect on the posterior for :
Looking at this , it’s easy to intuit that the Fisher information matrix is degenerate for all . But, for clarity, let me spell this out for the true parameters in the case where , so .
Remember that at true parameters the Fisher information matrix is just the Hessian, which in this case has the form
In particular, let be a fixed true parameter parameterised by a fixed , so . Then the Fisher information matrix has the form
Setting and to be the rows of the matrix, there is clearly a linear dependence relation
and since is arbitrary, this shows that all true parameters have degenerate Fisher information matrices and are thus singular.
Permutation of Nodes
This one is easy to see. If we have a model with nodes,
and we define a new model where is a permutation of the nodes in ,
then
This easily generalises to hidden nodes by taking any permutation in the permutation group and letting each node of satisfy , so
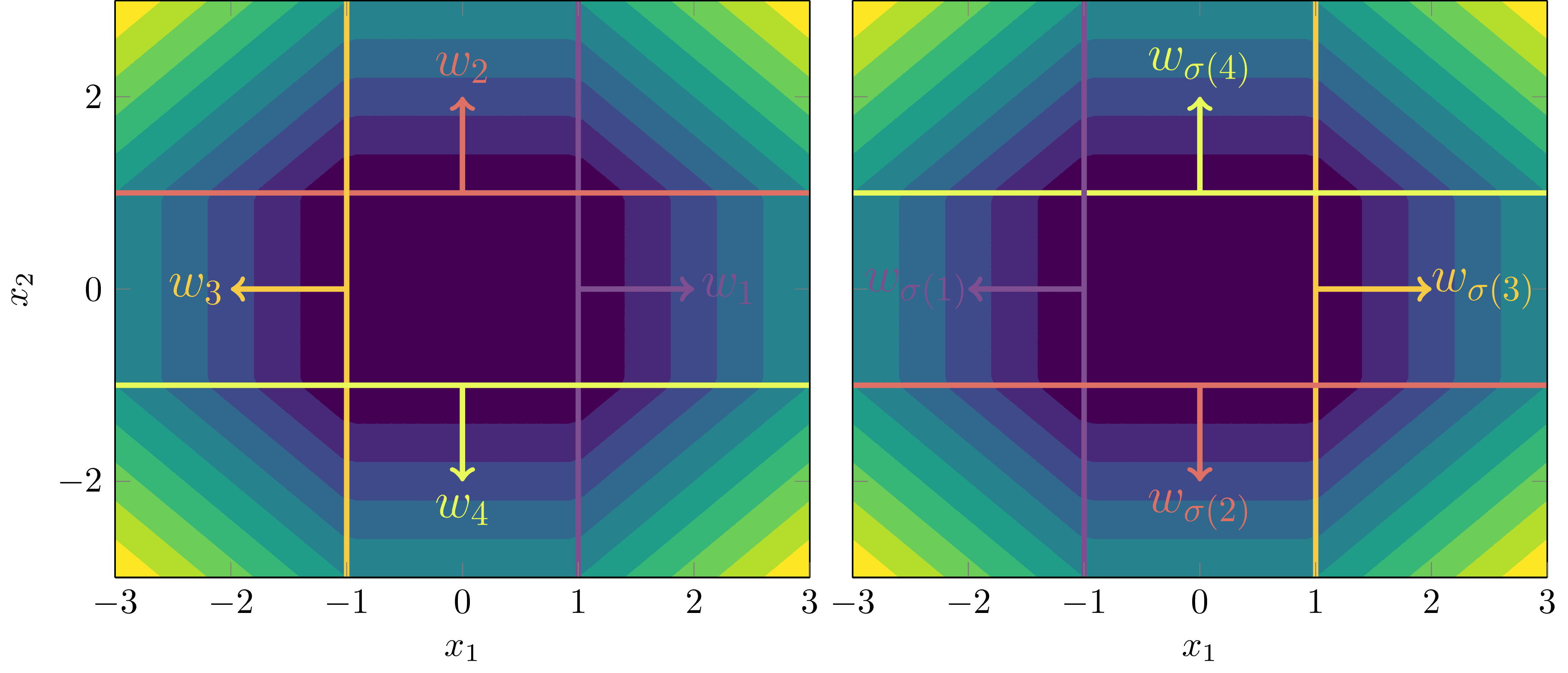
Orientation Reversal
This one is a bit trickier to observe as the symmetry depends on a very specific condition of weight annihilation. Let’s look at a simple example first.
Motivating Example
Example 3.3: Consider a true distribution defined by a (one-input) feedforward ReLU given by
where , , and the activation boundaries are and .
Surprisingly, though it may appear our linear regions and activation boundaries must uniquely define the function (up to the scaling and permutation symmetries), there is a particular symmetry that arises by reversing the orientation of the weights and first layer biases, and adjusting the total bias accordingly. When we say reverse the orientation, we mean negating their direction,
and ditto for the biases. If we adjust the total bias accordingly, then following function
gives the same functional output!
There is a very specific reason we can do this: in the middle region , both nodes are active and cancel out to give a constant function,
because the total gradients of the underlying truth sum to zero, .
General case
Suppose the true network is defined by a fixed for nodes. If there is a set of total gradients that sum to 0,
then the model can produce functional equivalence by reversing the orientation of those particular weights (associated to those activation boundaries), biases, and adjusting the total bias. In other words, modulo permutation and scaling symmetry, there is a functionally equivalent network to where the weights of every satisfy
We call the condition weight annihilation.
In [Carroll21, 4.5] we define -symmetric networks where the weights are progressive rotations by the angle , thus their total sum is zero. In DSLT4, we will study whether the posterior prefers configurations of weight-annihilation or not. (The answer is: not). [6]
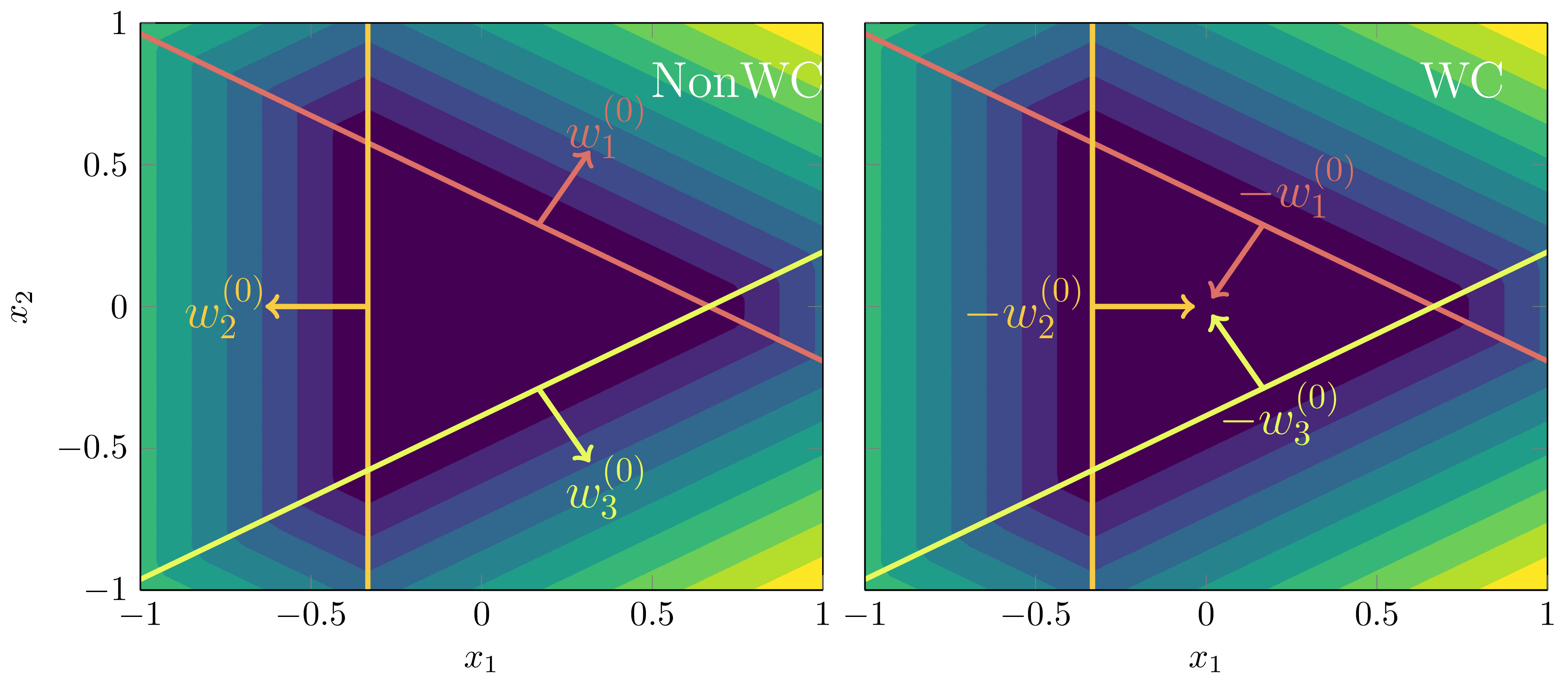
Node Degeneracy
This is possibly the most important symmetry of all: neural network models can have more nodes than they need to represent a particular function. In essence, this degeneracy is the reason that different regions of the loss-landscape of neural networks have fundamentally different accuracy-complexity tradeoffs. In other words, if the model has nodes in the hidden layer available to it, then all possible subnetwork configurations with less than nodes are also contained within the loss landscape. Thus, increasing the width of the network can only serve to increase the accuracy of these models, without sacrificing its ability to generalise, since the posterior will just prefer that number of hidden nodes with the best accuracy-complexity tradeoff.
Motivating Example
Example 3.4: Suppose we had a (one-input) true network given by
and our model had nodes (with fixed biases and outgoing weights ),
Since for , both weights must be positive, , to have any hope of being functionally equivalent. If , we are in one of two configurations:
One node is degenerate: Either or , meaning
Both nodes are non-degenerate, but the total gradient is the same as the truth: So long as the weights satisfy
for , we will have functional equivalence since, setting ,
Node-degeneracies Correspond to Different Phases
We could of course encapsulate both of these configurations into the one statement that for , but there is a key reason we have delineated them: they represent two different phases and have different geometry on . Intuitively, the degenerate phase is a simpler model with less complexity, thus we expect it has a lower RLCT [7], and for the posterior to prefer it. In DSLT4 we will discuss phases in statistical learning more broadly, and display experimental evidence for this latter claim.
To foreshadow this, we can actually calculate for Example 3.4. Setting the prior to be uniform on we find
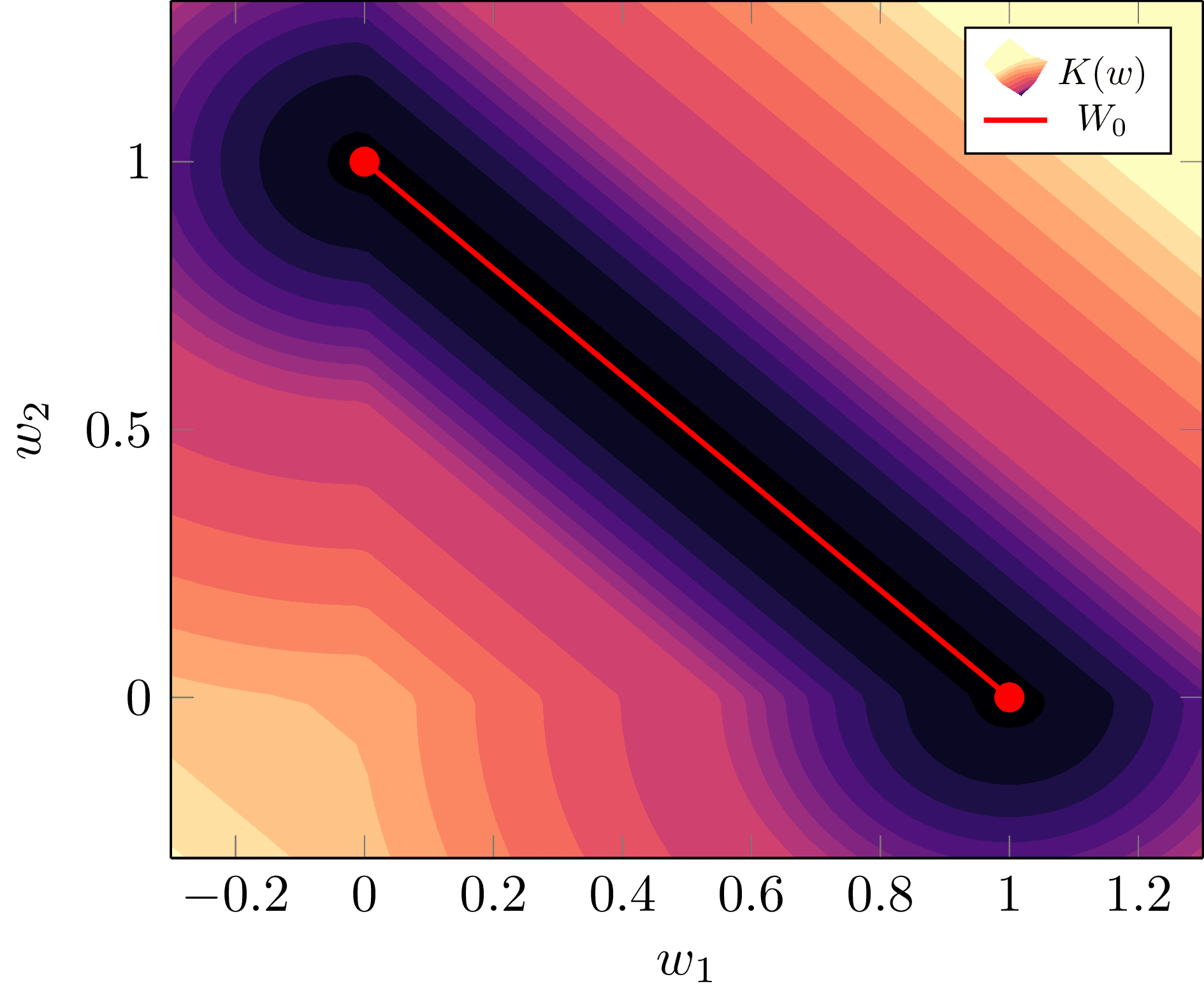
Notice how there are ever so slightly wider bowls at either end of the line , thus suggesting the posterior has more density at the degenerate phase (or vice versa). Intuitively, imagine a tiny ball being with random kinetic energy rolling around the bottom of the surface—it will spend more time in the ends since there is more catchment area. (Don’t take the physics analogy too seriously, though).
We see once again that the singularity structure of the minima has a big impact on the geometry of , and therefore the posterior.
General Case
Suppose we have a truth and model that are both defined by two layer feedforward ReLU neural networks, where the model has nodes and the truth has nodes (assumed to all be non-degenerate and with distinct activation boundaries) such that . Then the model is overparameterised compared to the truth it is trying to model.
Performing the appropriate analysis (which we do in Appendix 2), one finds that:
Without loss of generality (i.e. up to permutation symmetry), the first nodes of must have the same activation boundaries as those in , and satisfy the same scaling, permutation and orientation reversing symmetries as discussed above.
For the remaining nodes of the model, each one either:
Is degenerate, so or , or;
Shares the same activation boundary as one already in such that the total gradients sum to the correct gradient in each region. (In our above example, this is saying that necessarily since these nodes share the same activation boundary).
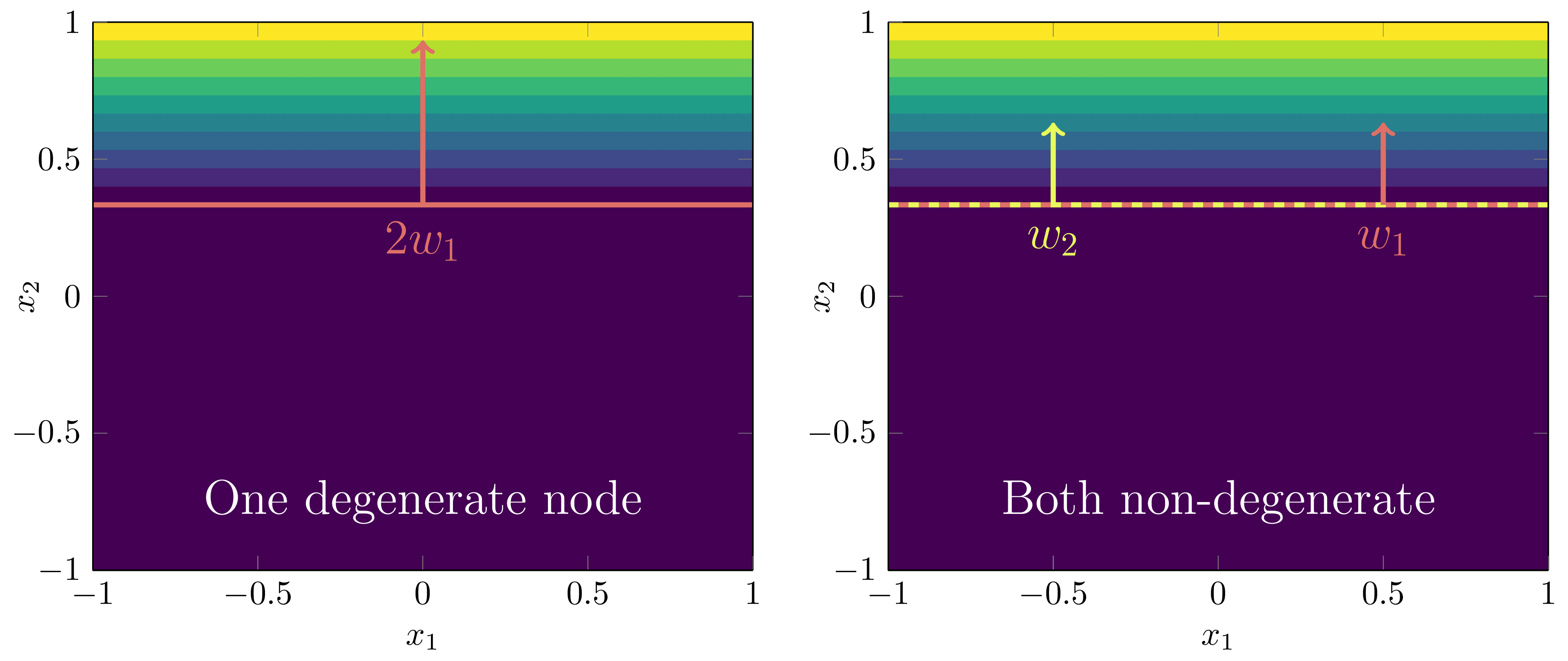
In DSLT4 we will test which of the phases in the above figure is preferred by the posterior for this simple two layer feedforward ReLU neural networks setup.
Node degeneracy is the same as lossless network compressibility
The fact that neural networks can contain these node-degeneracies is well known and often goes under the guise of lossless network compressibility. There are many notions of compressibility, but the one that makes the most sense in our setup is to say that if the model has hidden nodes compared to the truth, then it can be compressed to a network with only hidden nodes and still produce the same input-output map.
For an excellent introduction to lossless network compressibility, see Farrugia-Roberts’ recent paper Computational Complexity of Detecting Proximity to Losslessly Compressible Neural Network Parameters, where he studies the problem for networks.
There are More True Parameters if the Input Domain is Bounded
Let me make an important remark here. In both of the above cases, we have considered the symmetries of when the input domain of the model and the truth is all of . As we explain in Appendix 2, this allows us to compare the gradients and biases of hyperplanes, similar to comparing polynomial coefficients, to make our conclusions. However, if the domain of the input prior is restricted to some open bounded domain , there could in principle be more degeneracies and symmetries of , since the functional equivalence only needs to be on .
For example, consider a true network defined by and a single-node single-input model defined on , so . If the activation boundary falls outside of and the vector points away from , then any value of satisfying these constraints would give , thus there is an entirely new class of symmetry in .
Whilst important to keep this mind, we won’t discuss this any further as it opens up an entirely different can of worms.
Even if Singularities Occur with Probability Zero, they Affect Global Behaviour in Learning
I want to make a quick comment on the work of Phuong and Lampert in [PL19]. In this paper, they prove equivalent results to these for arbitrary depth feedforward ReLU neural networks (with non-increasing widths), but with a key distinction: they consider general models. In their words,
A sufficient condition for a network to be general with probability one is that the weights are sampled from a distribution with a density.
They then show that almost all feedforward ReLU networks with this architecture are general, and then show that general networks only satisfy scaling and permutation symmetries, thus excluding our orientation-reversing and degenerate node singularities since they occur on a set of measure zero. Importantly, this implies that almost all parameters have no degenerate nodes, or equivalently, no opportunity for lossless compression.
However, even though scaling and permutation symmetries may be the only generic symmetries (in the sense of measure theory) that occur with non-zero probability, SLT tells us that the singularities of have global effects on the loss landscape, as we discussed at length in DSLT2. If a parameter is near a non-generic singularity (i.e. one that occurs with probability zero), it computes a function that is almost identical to the one computed by that of a non-generic singularity. If we shift our language to that of compressibility of a network, SLT tells us that:
Just because a particular point sampled from a posterior (or, notionally, obtained via running SGD) is not directly compressible itself, that doesn’t mean that it isn’t extremely close to one that is.
In this sense, SLT tells us that to understand the geometry of the loss landscape, we need to consider singularities even though they are not generic points. As Watanabe says, singularities contain knowledge.
Appendix 1 - Formal Proof that Neural Networks are Singular
If, like me, you are mathematically inclined, you probably want to see a proof that these neural networks are, indeed, singular models, to tie together the various concepts and intuitions that we have built in this sequence so far. So let’s turn into math mode briefly.
Recall that the Fisher information matrix is degenerate if and only if the set
is linearly dependent. Here, refers to the partial derivative with respect to the th component of the total parameter , not to be confused with the specific weight vector in the neural network definition. Thus, to prove that feedforward ReLU networks are singular, our task is to find this linear dependence relation. The scaling symmetry alone is enough for this.
Theorem: Given a two layer feedforward neural network with hidden nodes, for any domain on which is differentiable, satisfies the differential equation for a fixed node :
Proof: Since , and letting , the set of derivatives with respect to our parameters are
and so since we can write we have
Corollary: Feedforward ReLU neural networks are singular models.
Proof: For the two layer case, for any fixed , there is a linear dependence relation given by the above differential equation evaluated at , thus the Fisher information is degenerate at , so the model is singular.
The equivalent proof for arbitrary depths and widths is given in Lemma A.1 of [Wei22], following from other work on functional equivalence in [PL19].
The degenerate node symmetries also give rise to a degenerate Fisher information matrix, though I haven’t formally written out this alternate proof yet. If you are interested, do it as an exercise and leave it as a comment!
Appendix 2 - Proof Sketch for Fully Classifying for Two Layer Feedforward ReLU Networks
This section is going to be slightly more technical, and in the grand scheme of the SLT story I am telling in this sequence, this may be seen as an unnecessary side-plot. But, other readers, particularly those with a pure mathematical bent, may find it interesting to consider the process of fully classifying and how one might understand all phases present, so I am providing a sketch of these proofs for completeness. Understanding the full form of was a vital part of performing the phase transition experiments that we will see in DSLT4. These models are simple enough that we can perfectly classify all true parameters in . Thus, we can precisely understand all of its phases.
We are going to classify the symmetries of when both the model and truth are two-layer feedforward ReLU neural networks, with and hidden nodes respectively, giving
meaning the task is to classify functional equivalence of the two networks. To avoid some annoying fringe cases, we assume that the true network is minimal, which means there is no network with fewer nodes that could also represent it (which also means every node is non-degenerate), and activation-distinguished, meaning every node of the truth corresponds to a unique activation boundary.
We will see that the set of symmetries explained above comprise all of the symmetries in - there can be no more [8]. This result rests mainly on the fact that the activation boundaries are the core piece of data that defines a neural network. The rest is then just performing accounting of the gradients and biases in each region.
This is a sketch of the proofs in Chapter 4 of my thesis, and all lemmas and theorems that are referenced in the following section come from here.
Case 1: The model has the same number of nodes as the truth,
Let be a two layer feedforward ReLU neural network model with hidden nodes, and let be the realisable true network with hidden nodes defined by a fixed parameter , denoted by
which we assume is minimal and activation-distinguished as explained above.
We start by comparing the foldsets, which are the activation boundaries [Lemma 4.1], between the truth and the model. Let be the activation boundary of the node in the model, and be the activation boundary of the node in the truth. Then by comparing the sets of linear lines in [Lemma 4.2], we can show that for every node of the model there exists a permutation such that
By [Lemma 4.3], two activation boundaries are equal if and only if there is some non-zero scalar such that and .
Using our relation , in [Lemma 4.4] we analyse how the gradients and biases change across each activation boundary, and what this means for the relation between weights and biases in the model versus the truth. We show that there exists a unique , and for each an and such that
meaning and necessarily have the same sign.
However, there is a restriction on which weights can have reversed orientation, (thus ). Letting , we show in [Lemma 4.5] that the weights and biases of the true network must satisfy [9]
The crux of this proof rests in comparing the gradients in regions either side of the activation boundary .
In [Theorem 4.7] we show that these scaling, permutation and orientation reversing symmetries are the only such symmetries by piecing together all of these aforementioned Lemmas, with emphasis on the importance of the activation boundaries in defining the topology of . [10]
Case 2: The model has more nodes than the truth,
We now suppose that the model is over-parameterised compared to the true network, so .
The key piece of data is once again the foldsets defining the model and the truth. Since they must be equal, the model can only have unique foldsets, and thus activation boundaries. Without loss of generality (i.e. up to permutation symmetry), the first nodes in the model have the same activation boundaries as the truth, . Thus, these nodes in the model must satisfy the same symmetries as in the case.
By comparing the fold sets on each excess node in , we must have
In comparing linear lines again, this means there are two possible situations:
is empty, so node is degenerate, meaning or , or;
for some , so node shares an activation boundary already in the first nodes of the model.
Let the number of non-degenerate nodes of the model. We can thus define a surjective finite set map
relating the non-degenerate nodes in the model to those in the truth, which is a bijection (i.e. a permutation ) on the first .
We can then compare the gradients and biases in each region to show that the total gradients calculated by each non-degenerate node at each unique activation boundary must sum to the gradient in the truth. Precisely, for each node of the truth, let be the set of nodes in the model that share the same activation boundary. Then for each there exists an and such that
with the constraint that
A similar orientation reversing symmetry also applies as in case 1, just by accounting for the nodes that share the same activation boundaries.
Resources
[Carroll21] - L. Carroll, Phase Transitions in Neural Networks, 2021
[Wei22] - S. Wei, D. Murfet, et al., Deep Learning is Singular, and That’s Good, 2022
[PL19] - M. Phuong, C. Lampert, Functional vs Parametric Equivalence of ReLU networks, 2019
- ^
Since if and only if for some .
- ^
e.g. . ↩︎
- ^
For ease of classification, we exclude the case where and since we can just absorb the total bias contribution into . ↩︎
- ^
A linear domain is just a connected open set where is a plane with constant gradient and bias when restricted to , and is the maximal such set for which that plane is defined. In other words, the set of linear domains are the set of different regions the piecewise affine function are carved up into. ↩︎
- ^
But don’t forget, as the domain of activation is completely different. ↩︎
- ^
Though I have not been able to formally prove it, I believe that this symmetry on its own (i.e. modulo scaling symmetry) does not result in a degeneracy of the Fisher information matrix, at least in our simple case. This, I think, is because the weights must cancel out in the region where both nodes are active, and the gradients in the other regions must be retained. Feel free to prove me wrong, though! ↩︎
- ^
This statement is a bit disingenuous. Watanabe’s free energy formula only applies to the case where is analytic, but ReLU neural networks are certainly not analytic, as we can see in the below example. With that said, Watanabe has recently proved a bound on the free energy for ReLU neural networks, showing that the complexity term is essentially related to the number of non-degenerate nodes in the truth, even if it isn’t a true RLCT. We will look at this in more depth in DSLT4. ↩︎
- ^
Aside from the technical caveat discussed about the restricted input prior above.
- ^
Our convention is to take the empty sum to be 0, so all weight orientations being preserved, , is perfectly fine. ↩︎
- ^
The activation distinguished condition on the truth allows us to uniquely identify the permutation relating activation boundaries, and ensures only one node changes across each boundary. ↩︎
- DSLT 0. Distilling Singular Learning Theory by (16 Jun 2023 9:50 UTC; 96 points)
- 's comment on Lucius Bushnaq’s Shortform by (2 Jan 2025 11:10 UTC; 75 points)
- DSLT 4. Phase Transitions in Neural Networks by (24 Jun 2023 17:22 UTC; 34 points)
- 's comment on silentbob’s Shortform by (25 Jun 2024 14:53 UTC; 23 points)
I’m trying to read through this more carefully this time: how load-bearing is the use of ReLU nonlinearities in the proof? This doesn’t intuitively seem like it should be that important (e.g a sigmoid/gelu/tanh network feels like it is probably singular, and it certainly has to be if SLT is going to tell us something important about NN behaviour because changing the nonlinearity doesn’t change how NNs behave that much imo), but it does seem to be an important part of the construction you use.
Good question! The proof of the exact symmetries of this setup, i.e. the precise form of W0, is highly dependent on the ReLU. However, the general phenomena I am discussing is applicable well beyond ReLU to other non-linearities. I think there are two main components to this:
Other non-linearities induce singular models. As you note, other non-linear activation functions do lead to singular models. @mfar did some great work on this for tanh networks. Even though the activation function is important, note that the better intuition to have is that the hierarchical nature of a model (e.g. neural networks) is what makes them singular. Deep linear networks are still singular despite an identity activation function. Think of the activation as giving the model more expressiveness.
Even if W0 is uninteresting, the loss landscape might be “nearly singular”. The ReLU has an analytic approximation, the Swish function σβ(x)=x1+e−βx, where limβ→∞σβ(x)=ReLU(x), which does not yield the same symmetries as discussed in this post. This is because the activation boundaries are no longer a sensible thing to study (the swish function is “always active” in all subsets of the input domain), which breaks down a lot of the analysis used here.
Suppose, however, that we take a β0 that is so large that from the point of view of your computer, σβ0(x)=ReLU(x) (i.e. their difference is within machine-epsilon). Even though Wswish0 is now a very different object to WReLU0 on paper, the loss landscape will be approximately equal Lswish(w)≈LReLU(w), meaning that the Bayesian posterior will be practically identical between the two functions and induce the same training dynamics.
So, whilst the precise functional-equivalences might be very different across activation functions (differing W0), there might be many approximate functional equivalences. This is also the sense in which we can wave our arms about “well, SLT only applies to analytic functions, and ReLU isn’t analytic, but who cares”. Making precise mathematical statements about this “nearly singular” phenomena—for example, how does the posterior change as you lower β in σβ(x)? - is under-explored at present (to the best of my knowledge), but it is certainly not something that discredits SLT for all of the reasons I have just explained.
Yeah I agree with everything you say; it’s just I was trying to remind myself of enough of SLT to give a a ‘five minute pitch’ for SLT to other people, and I didn’t like the idea that I’m hanging it of the ReLU.
I guess the intuition behind the hierarchical nature of the models leading to singularities is the permutation symmetry between the hidden channels, which is kind of an easy thing to understand.
I get and agree with your point about approximate equivalences, though I have to say that I think we should be careful! One reason I’m interested in SLT is I spent a lot of time during my PhD on Bayesian approximations to NN posteriors. I think SLT is one reasonable explanation of why this. never yielded great results, but I think hand-wavy intuitions about ‘oh well the posterior is probably-sorta-gaussian’ played a big role in it’s longevity as an idea.
yeah it’s not totally clear what this ‘nearly singular’ thing would mean? Intuitively, it might be that there’s a kind of ‘hidden singularity’ in the space of this model that might affect the behaviour, like the singularity in a dynamic model with a phase transition. but im just guessing
Thanks Liam also for this nice post! The explanations were quite clear.
This holds for singularities that come from symmetries where the model doesn’t change. However, is it correct that we need the “underlying truth” to study symmetries that come from other degeneracies of the Fisher information matrix? After all, this matrix involves the true distribution in its definition. The same holds for the Hessian of the KL divergence.
What do you mean with non-weight-annihilation here? Don’t the weights annihilate in both pictures?
The definition of the Fisher information matrix does not refer to the truth q(y,x) whatsoever. (Note that in the definition I provide I am assuming the supervised learning case where we know the input distribution q(x), meaning the model is p(y,x|w)=p(y|x,w)q(x), which is why the q(x) shows up in the formula I just linked to. The derivative terms do not explicitly include q(x) because it just vanishes in the wj derivative anyway, so its irrelevant there. But remember, we are ultimately interested in modelling the conditional true distribution q(y|x) in q(y,x)=q(y|x)q(x).)
You’re right, thats sloppy terminology from me. What I mean is, in the right hand picture (that I originally labelled WA), there is a region in which all nodes are active, but cancel out to give zero effective gradient, which is markedly different to the left hand picture. I have edited this to NonWC and WC instead to clarify, thanks!