DSLT 4. Phase Transitions in Neural Networks
TLDR; This is the fourth main post of Distilling Singular Learning Theory which is introduced in DSLT0. I explain how to relate SLT to thermodynamics, and therefore how to think about phases and phase transitions in the posterior in statistical learning. I then provide intuitive examples of first and second order phase transitions in a simple loss function. Finally, I experimentally demonstrate phase transitions in two layer ReLU neural networks associated to the node-degeneracy and orientation-reversing phases established in DSLT3, which we can understand precisely through the lens of SLT.
In deep learning, the terms “phase” and “phase transition” are often used in an informal manner to refer to a steep change in a metric we care about, like the training or test loss, as a function of SGD steps, or alternatively some hyperparameter like the number of samples from the truth .
But what exactly are the phases? And why do phase transitions even occur? SLT provides us a solid theoretical framework for understanding phases and phase transitions in deep learning. In this post, we will argue that in the Bayesian setting,
A phase of the learning process corresponds to a singularity of , and a phase transition corresponds to a drastic change in the posterior as a function of a hyperparameter .
The hyperparameter could be the number of samples from the truth , some way of varying the model function or something about the true distribution , amongst other things. At some critical value , we recognise a phase transition as being a discontinuous change in the free energy or one of its derivatives, for example the generalisation error .
In this post, we will present experiments that observe precise phase transitions in the toy neural network models we studied in DSLT3, for which we understand the set of true parameters and therefore the phases. By the end of this post, you will have a framework for thinking about phase transitions in singular models and an intuition for why SLT predicts them to occur in learning.
Phases Correspond to Singularities
The Story Starts in Physics
This subsection is modelled on [Callen, Ch9], but it is only intended to be a high level discussion of the concepts grounded in some basic physics—don’t get too bogged down in the details of the thermodynamics.
Fundamentally, a phase describes an aggregate state of a complex system of many interacting components, where the state retains particular qualities with variations in some hyperparameter. To explain the concept in detail, it is natural to start in physics (thermodynamics in particular), where these ideas originally arose. But there is a deeper reason to build from here: every human has an intuitive understanding of the phases of water and how they change with temperature [1], which serves as the base mental model for what a phase is.
One of the main goals of thermodynamics is to study how the equilibrium state of a system changes as a function of macroscopic parameters. In the case of a vessel of water at 1atm of pressure in constant contact with a thermal and pressure reservoir, the equilibrium state of the system corresponds to a state that is minimised by the Gibbs free energy [2]. The phases, then, are the equilibrium states, which describe qualitative physical properties of the system. The states of matter—solid, liquid, and gas—are all phases of water, which are characterised by variables like their volume and crystal structure. As anybody that has boiled water before knows, these phases undergo transitions as a function of temperature. Let’s make this more precise.
The Thermodynamic Setup
Consider a system of water molecules moving in a 2D container, each with equal mass . To each particle we can associate a set of microstates describing its physical properties at a point in time, for example its position and its velocity . In our discussion we will simply focus on the position, which we will relabel (for reasons that will become clear), so our configuration space of possible microstates is
Since it is physically infeasible to know or model the positions of all molecules, we instead reason about the dynamics of the system by calculating macroscopic variables associated to a microstate, for example the temperature or total volume of the molecules. We will focus on the volume of a microstate . Importantly, a macroscopic state is an aggregate over the system (for example, temperature being related to average squared velocity), meaning there are many possible configurations of microstates that result in the same macrostate. To this end, we can define regions of our configuration space according to their volume ,
In our toy example, we want to study how the system changes as a function of temperature, which we will denote with . In a Gibbs ensemble, we can associate an energy functional, the Hamiltonian , to any given microstate at temperature . The fundamental postulate of such a Gibbs ensemble is that probability of the system being in a particular micro state is determined by a Gibbs distribution [3]
This should look pretty familiar from our statistical learning setup! Indeed, we can then calculate the free energy of the ensemble for different volumes at temperature ,
For a Gibbs ensemble, the equilibrium state of a given system is that state which minimises the free energy. In the context of bringing water to a boiling point, there are two minima of the free energy characterised by the liquid and gaseous states, which for ease we will characterise by their volumes and . Then the equilibrium state changes at the critical temperature ,
Importantly, while small variations in the temperature away from will change the free energy of each state, it will not change the configuration of these minima with respect to the free energy. In other words, the system will still be a liquid for any - its qualitative properties are stable. This is the content of a phase.
What is a phase?
A phase of a system is a region of configuration space that minimises the free energy, and is invariant to small perturbations in a relevant hyperparameter . Typically, phases are distinguished by some macroscopic variable, in our case the volume distinguishing subsets . More generally though, a phase describes some qualitative aggregate state of a system—like, as we’ve discussed in our example, the states of matter.
In some sense, you can define a phase to be any region that induces an equilibrium state with qualities you care about. But what makes phases a powerful concept is their relation to phase transitions—when there is a sudden jump in which state is preferred by the system.
What is a phase transition?
Phase transitions are changes in the structure of the global minima of the free energy, and often arise as non-analyticities of . This is a fancy way of saying they correspond to discontinuities in the free energy or one of its derivatives [4].
A first order phase transition at a critical temperature corresponds to a reconfiguration of which phase is the global minima of the free energy.
As we discussed above, heating water to boiling point is a classic example of a first order phase transition.
Two examples of second order phase transitions are where:
A merge transition occurs at when two phases that are initially disjoint for merge to become the same state for , or;
A creation transition occurs at when a local minima exists for but does not exist for . (If the directions are reversed, we call this a destruction transition).
(Note that we have not given a full classification of phase transitions here, because to do so one needs to study the possible types of catastrophes that can occur, as presented in [Gilmore]).
Phases in Statistical Learning
The notation and concepts in the previous section were not presented without reason. For starters, the Gibbs ensemble view of statistical learning is actually quite a rich analogy because, when the prior is uniform, the (random) Hamiltonian is equal to the empirical KL divergence [5],
The configuration space of microstates of the physical system then corresponds to parameter space with microstates given by different parameters . This means the posterior is equivalent to the Gibbs probability distribution of the system being in a certain microstate, meaning the definition of free energy is identical. So, what exactly are the phases then?
In statistical learning then,
A phase corresponds to a local neighbourhood containing a singularity of interest.
To say that minimises the free energy is equivalent to saying that it has non-negligible posterior mass. The reason for this, as we explored in DSLT2, is that the singularity structure of a most singular optimal point dominates the behaviour of the free energy, because it minimises the loss and has the smallest RLCT .
You can, in principal, define a phase to be any region of . But the analysis of phases in the posterior only gets interesting when you have a set of phases that have fundamentally different geometric properties. The free energy formula tells us that these geometric properties correspond to different accuracy-complexity tradeoffs.
Consequently, in statistical learning, Watanabe states in [Wat18, ] that
A phase transition is a drastic change in the geometry of the posterior as a function of a hyperparameter .
Our definitions of first and second order phase transitions carry over perfectly from the physics discussion above.
It’s important to clarify here that phase transitions in deep learning have many flavours. If one believes that SGD is effectively just “sampling from the posterior”, then the conception that phase transitions are related to changes in the geometry of the posterior carries over. There is, however, one fundamentally different kind of “phase transition” that we cannot explain easily with SLT: a phase transition of SGD in time, i.e. the number gradient descent steps. The Bayesian framework of SLT does not really allow one to speak of time—the closest quantity is the number of datapoints , but these are not equivalent. We leave this gap as one of the fundamental open questions of relating SLT to current deep learning practice. [6]
The hyperparameter can affect any number of objects involved in the posterior. Remembering that the posterior is
we could include hyperparameter dependence in any of:
The model function (i.e. the neural network defining
The true distribution , meaning . (This could in principal be dependence in the input prior or the actual dataset generated by .)
The number of datapoints (inducing a first order phase transition due to the change in accuracy-complexity tradeoff).
The prior .
Intuitive Examples to Interpret Phase Transitions
In DSLT2 we studied an example of a very simple one-dimensional curve and got a feel for how the accuracy and complexity of a singularity affect the free energy of different neighbourhoods. Having now learned about phase transitions, we can cast new light on this example.
Example 1: First Order Phase Transition in
Example 4.1: Consider again a KL divergence given by
where and are the singularities, but the accuracy of is worse, . Then we can identify two phases corresponding to the two singularities,
for some radius such that the accuracy of is better, but the complexity of was smaller,
As the hyperparameter [7] varies, we see a first order phase transition at the critical value of where the two free energy curves intersect, causing an exchange which phase is the global minima of the free energy. As we argued in that post, this is largely due to the accuracy-complexity tradeoff of the free energy. Notice also how the free energy of the global minima is non-differentiable at , showing an example of the “non-analyticity” of that we mentioned above.
Example 2: Second Order Merge Phase Transition
Example 4.2: We can modify our example slightly to observe a second order phase transition. Let’s consider
where is a hyperparmeter that shifts the two singularities and towards the origin. We will continue to label these phases and , noting their dependence. [8]
Thus, at the two phases will merge and the KL divergence will be
Therefore, at the singularity will have an RLCT of
There is a new most singular point caused by the merging of two phases! Again, we can visually depict this phase transition:
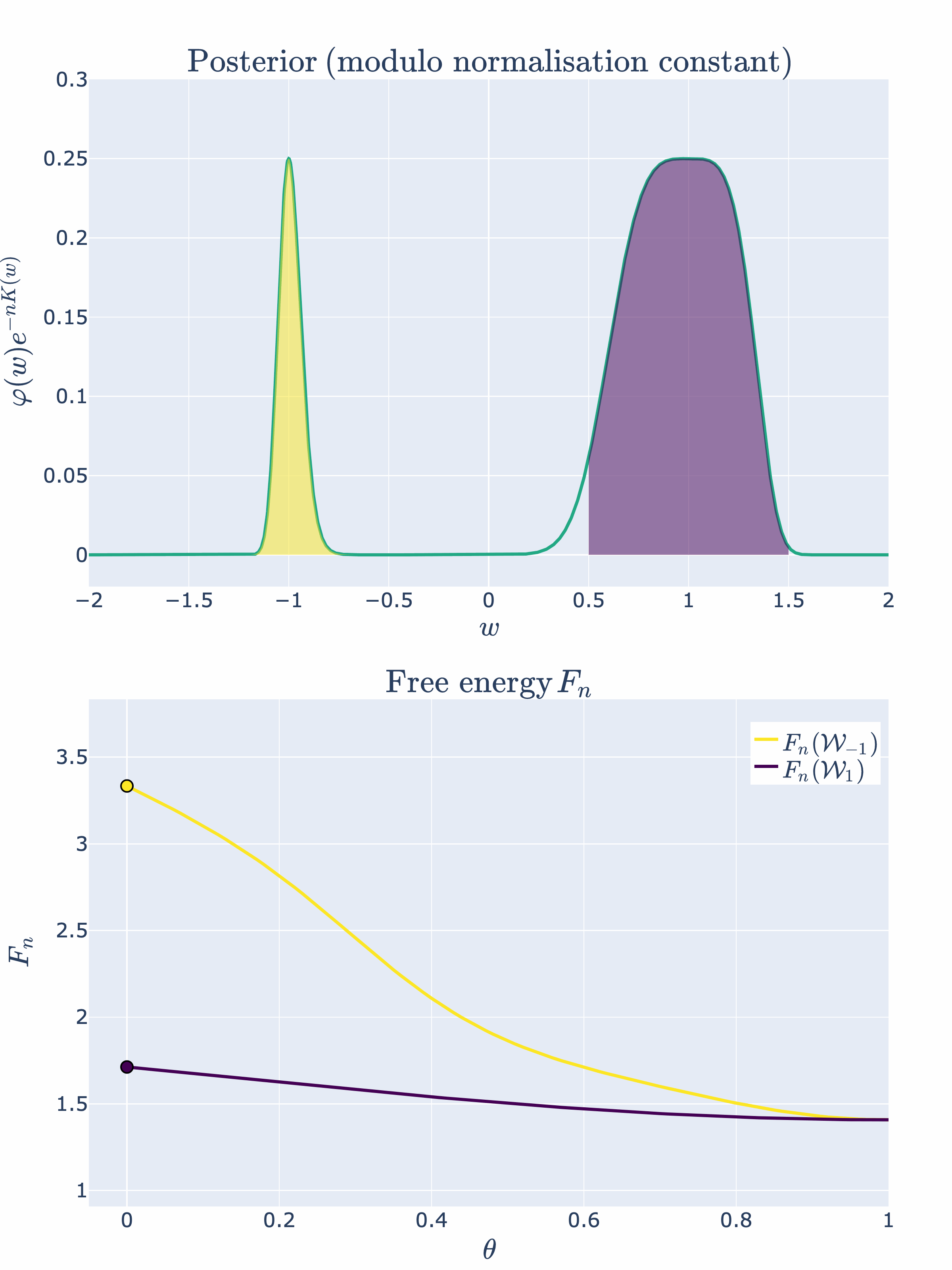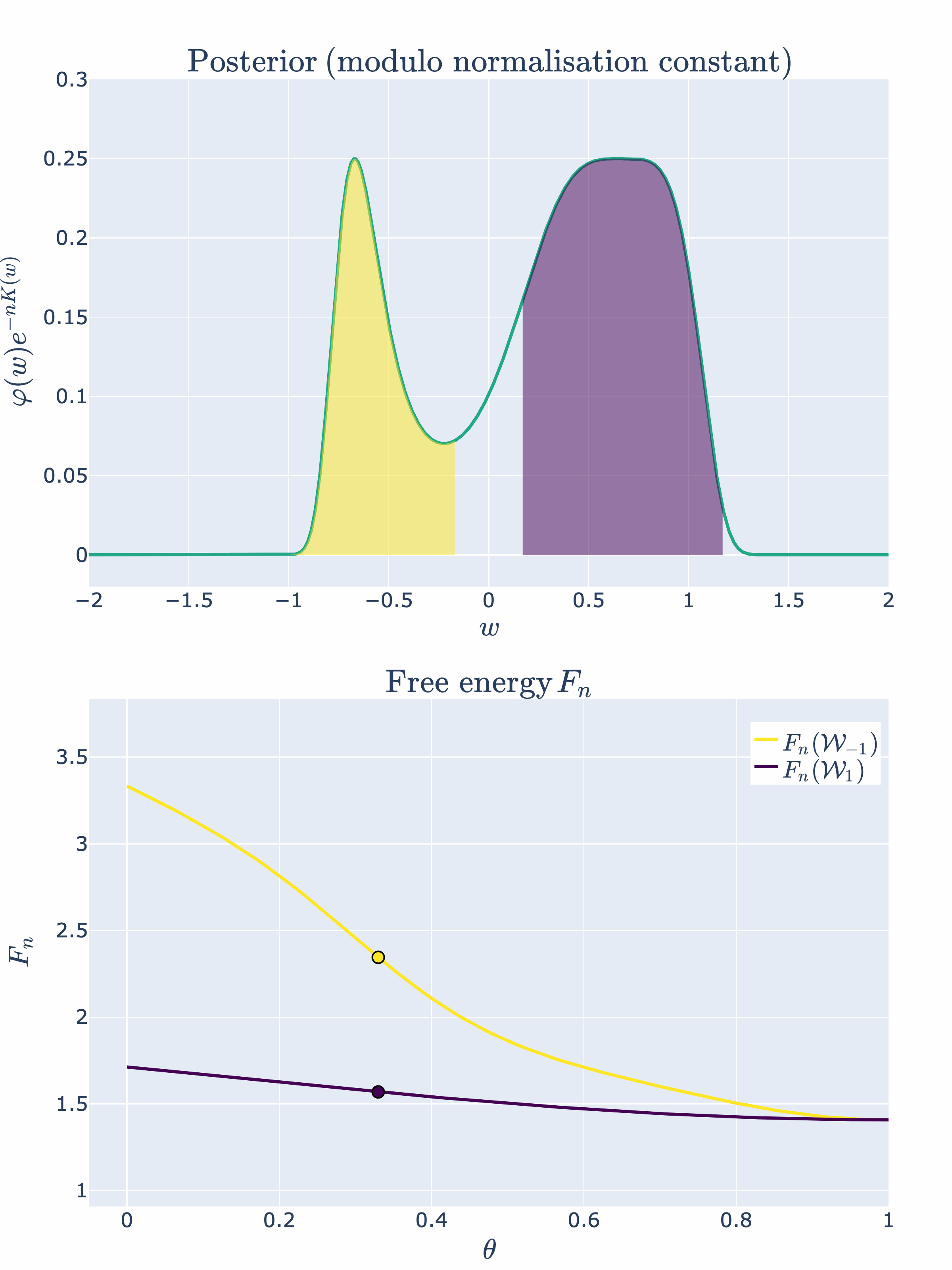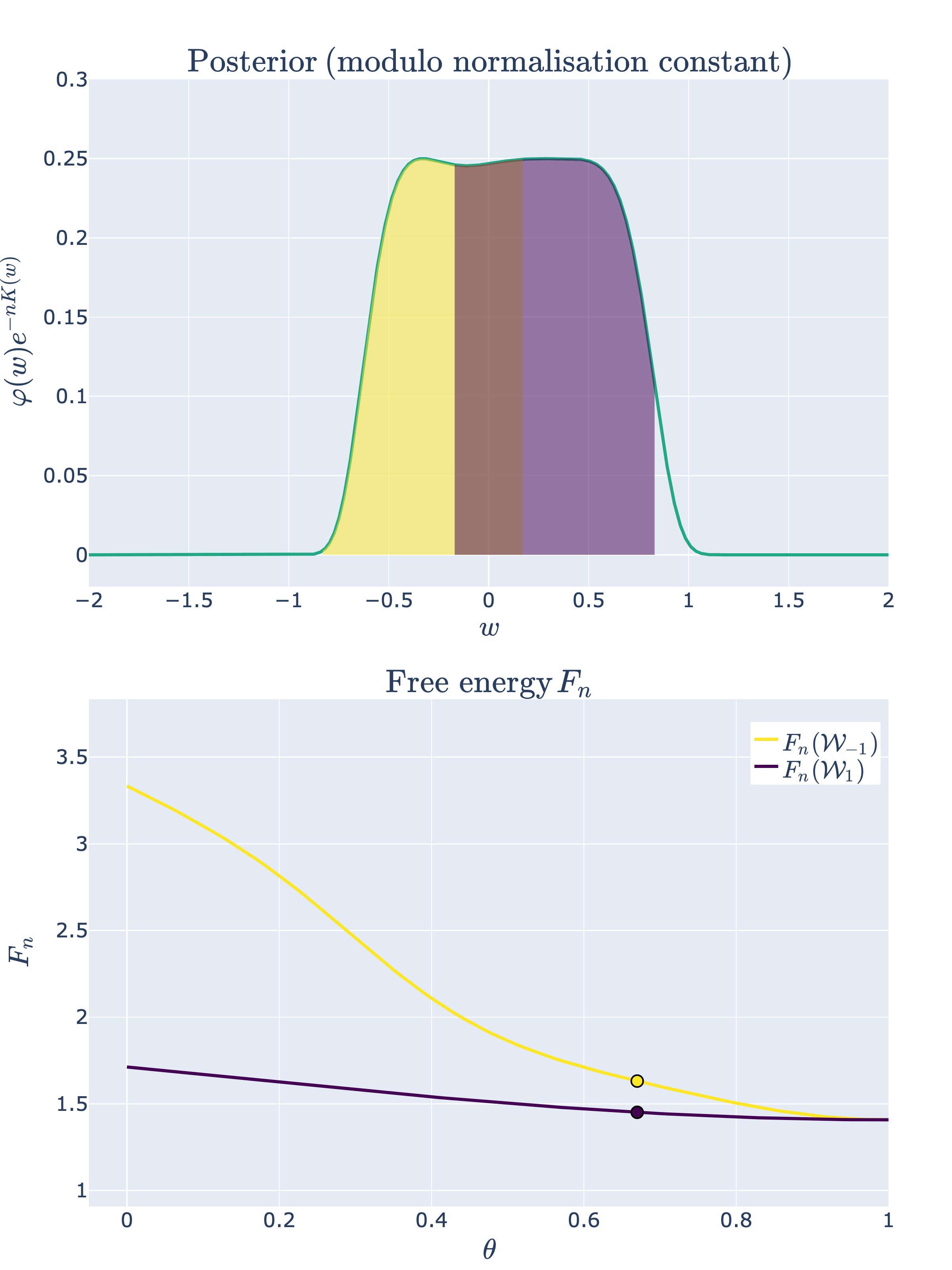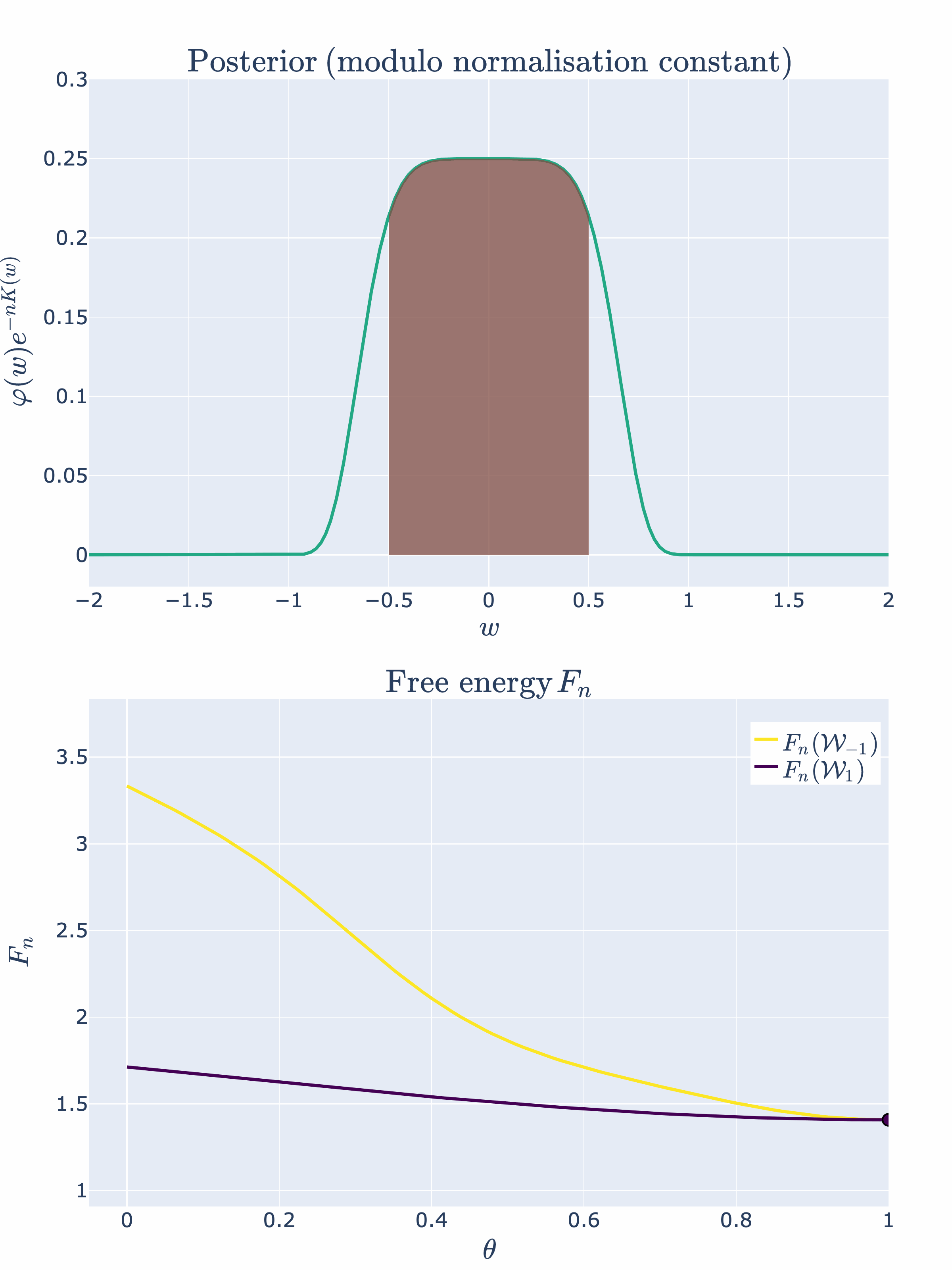
Now that we have the basic intuitions of SLT and phase transitions down pat, let’s apply these concepts to the case of two layer feedforward ReLU neural networks.
Phase Transitions in Two Layer ReLU Neural Networks
The main claim of this sequence is that Singular Learning Theory is a solid theoretical framework for understanding phases and phase transitions in neural networks. It’s now time to make good on that promise and bring all of the pieces together to understand an actual example of phase transitions in neural networks. The full details of these experiments are explained in my thesis, [Carroll, ], but I will briefly outline some points here for the interested reader. All notation and terminology is explained in detail in DSLT3, so use that section as a reference.
If you are uninterested, just skip to the next subsection to see the results.
Experimental Setup
We will consider a (model, truth) pair defined by the simple two layer feedforward ReLU neural network models we studied in DSLT3. Phase transitions will be induced by varying true distribution by a hyperparameter , meaning . Since we have a full classification of from DSLT3, we understand the phases of the system, and therefore we want to study how their differing geometries affect the posterior. As we explained in that post, the scaling and permutation symmetries are generic (they occur for all parameters ), but the node-degeneracy and orientation-reversing symmetries only occur under precise configurations of the truth. Thus, we are interested in studying the how the posterior changes as we vary the truth to induce these alternative true parameters—the phases of our setup.
The posterior sampling procedure uses an MCMC variant called HMC NUTS, which is brilliantly explained and interpreted here. Estimating precise nominal free energy values, and particularly those of the RLCT , using sampling methods is currently very challenging (as explained in [Wei22]). So, for these experiments, our inference about phases and phase transitions will be based on visualising the posterior and observing the posterior concentrations of different phases. With this in mind, the posteriors below are averaged over four trials, 20,000 samples each, for each fixed true distribution defined by . (Bayesian sampling is very computationally expensive, even in simple settings).
To isolate the phases we care about, we can use the fact that the scaling symmetry and permutation symmetries of our networks are generic. To this end we will normalise the weights by defining the effective weight [9], which preserves functional equivalence [10]. We will say a node is degenerate if . We also project different node indices on to the same axes as follows:
The prior on inputs is uniform on the square , and the prior on parameters is the standard multidimensional normal .
Phase Transition 1 - Deforming to Degeneracy
In this experiment we will see a first order phase transition induced by deforming a true network from having no degenerate nodes to having one (possibility of a) degenerate node, as discussed in DSLT3 - Node Degeneracy. This example will reinforce the key messages of Watanabe’s free energy formula: true parameters are preferred according to their RLCT, and at finite non-true parameters can be preferred due to the accuracy-complexity tradeoff.
Defining the Model, Truth, and Phases
We are going to consider a model network with nodes,
and a realisable true network with nodes, which we will denote by to signify its hyperparameter dependence (and distinguish it from the next experiment),
The true weights rotate towards one another by a hyperparameter , so [11]
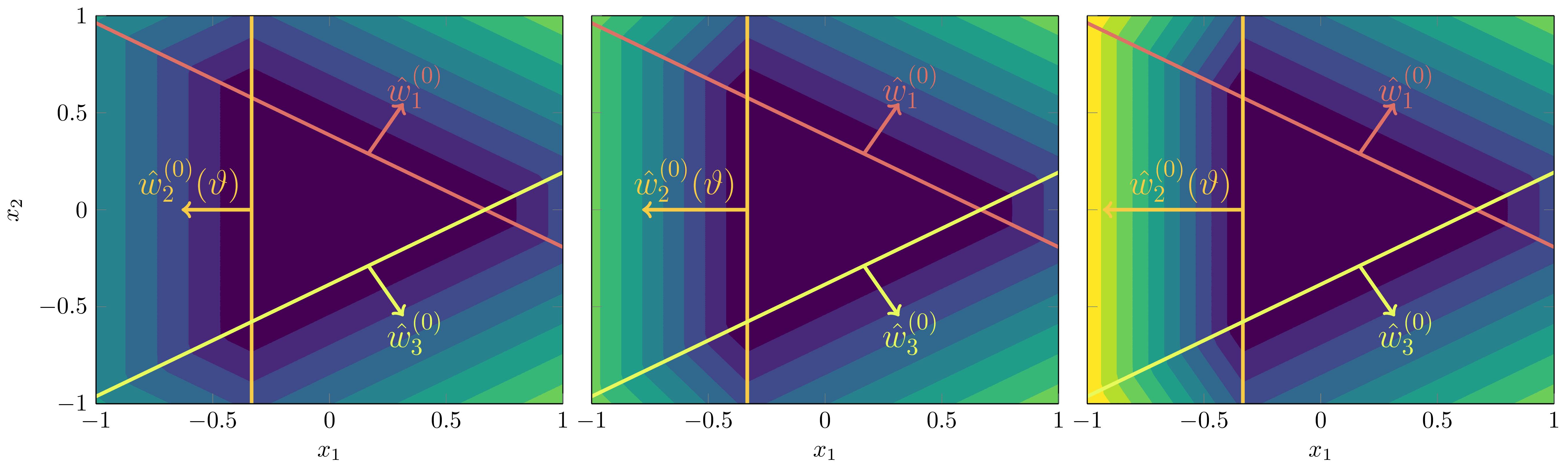
As we explained in DSLT3, we can depict the function and its activation boundaries pictorially:
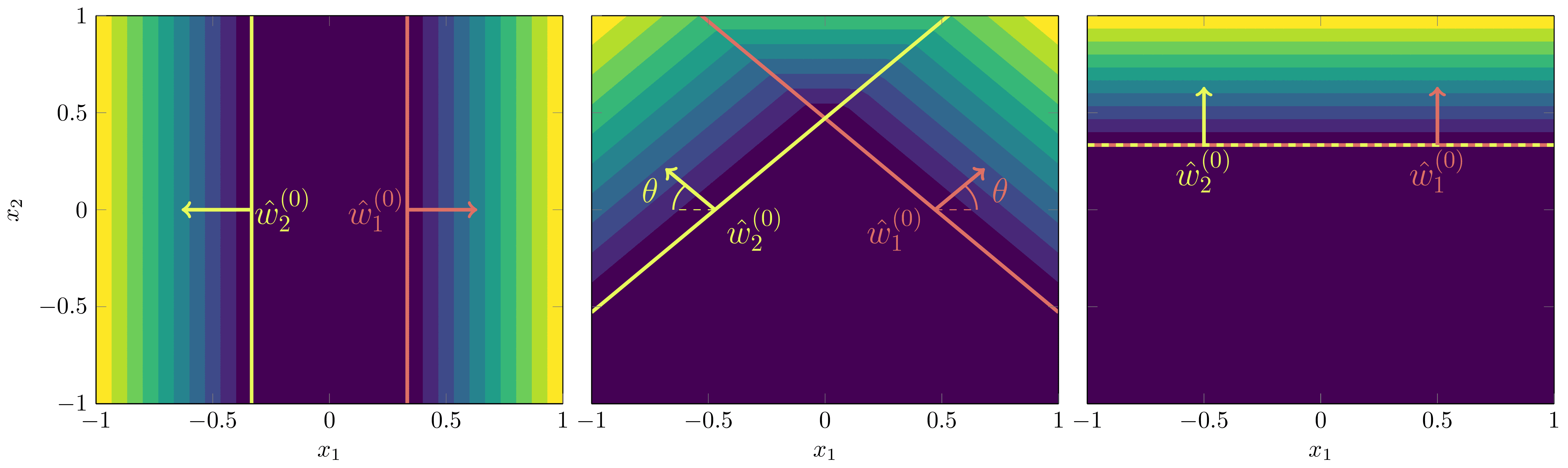
At , the truth could be expressed by a network with only one node, ,
This degeneracy is what we are interested in studying. The WBIC tells us to expect the posterior to prefer the one-degenerate-node configuration since it has less effective parameters. [12]
To identify our phases, at there are two possible configurations of the effective model weights that are true parameters:
Both non-degenerate but share the same activation boundary: Both such that .
One degenerate, one non-degenerate: Either and , or vice versa by permutation symmetry.
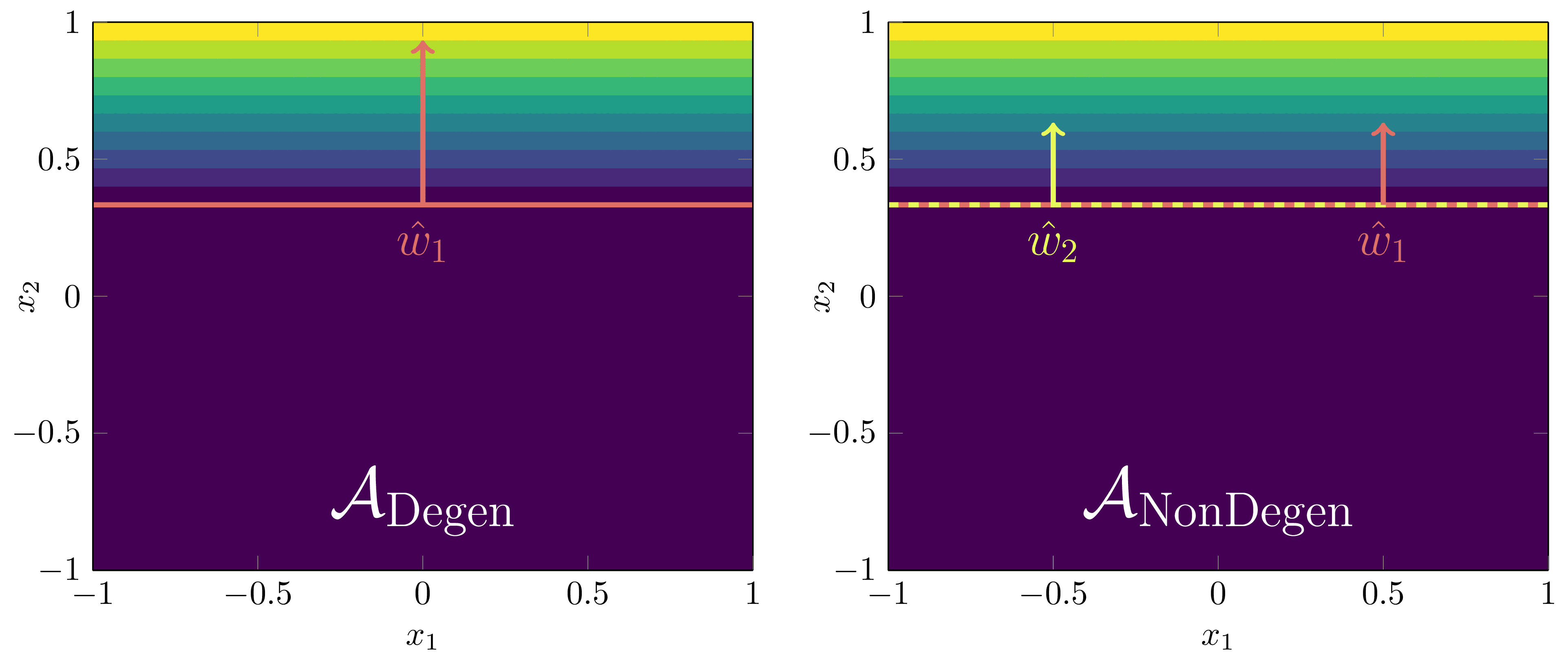
To study these configurations we thus define phases based on annuli in the plane centred on the circle of radius with annuli radius of ,
Then we define the two phases containing the singularities of interest to be
The union is due to the permutation symmetry—which precise node is degenerate doesn’t matter. We will let .
There are two questions we seek to answer:
At , which phase is preferred by the posterior, since both contain true parameters?
Is there a first order phase transition at some where becomes preferred, even though it doesn’t contain a true parameter?
Results
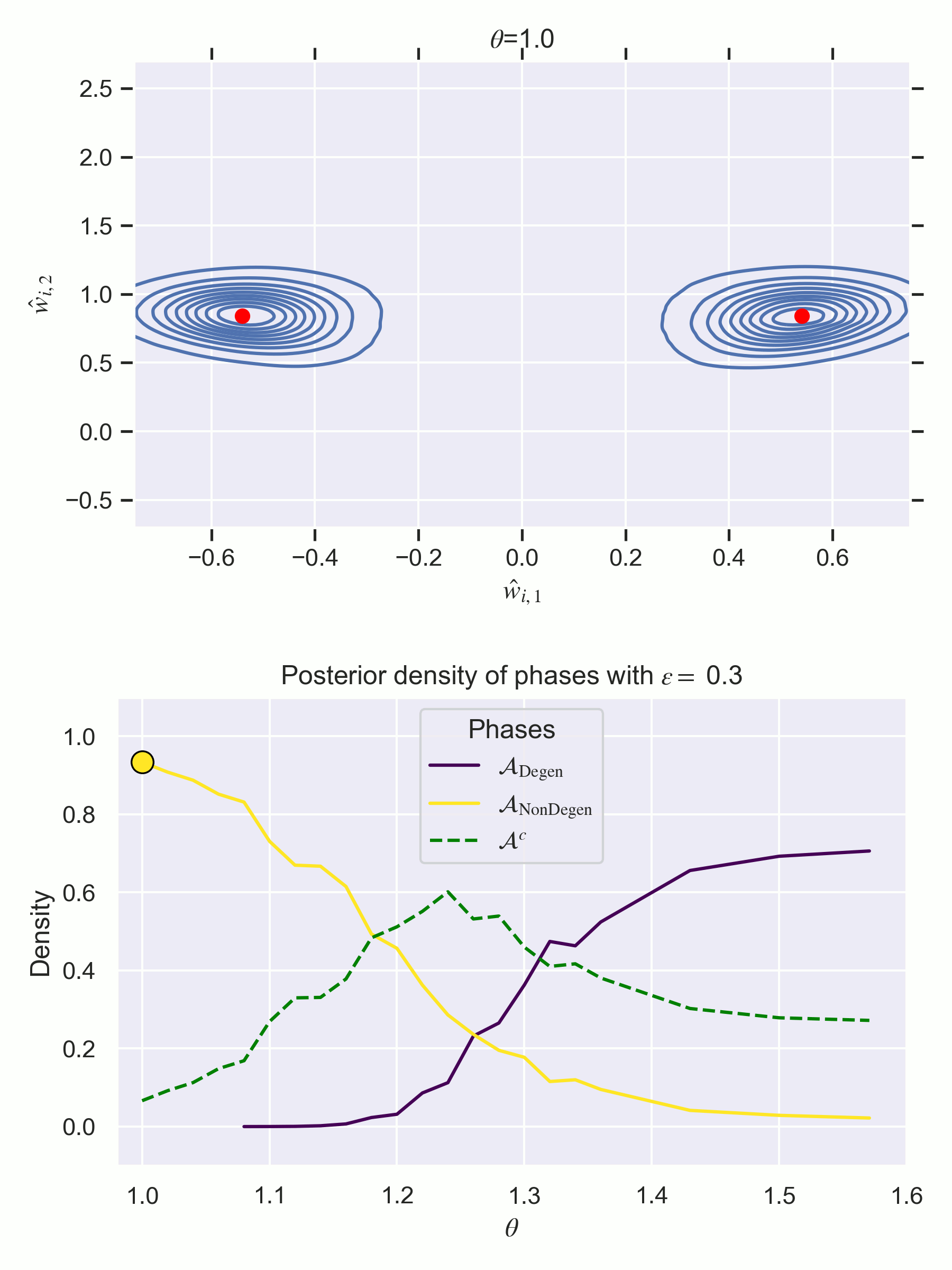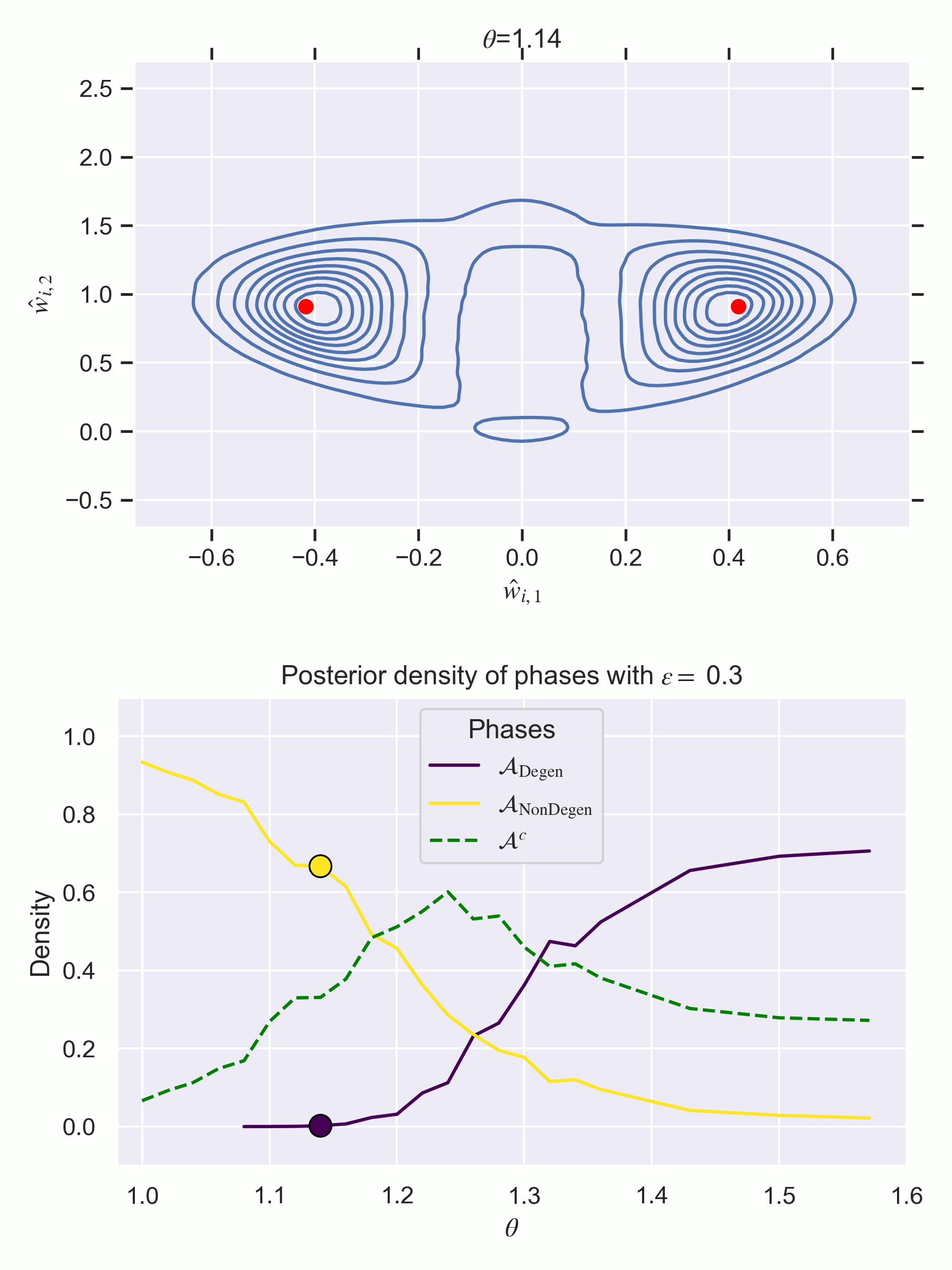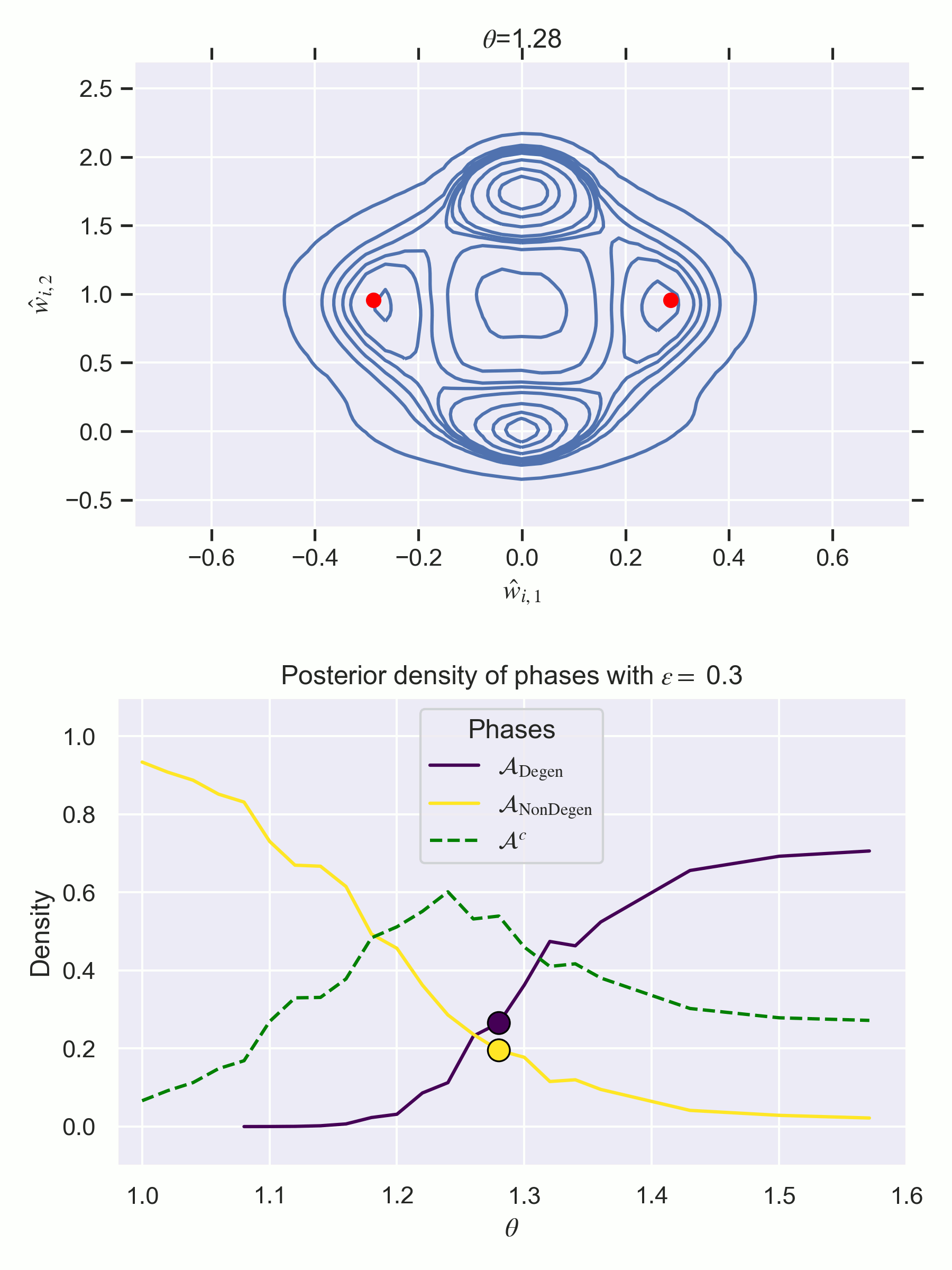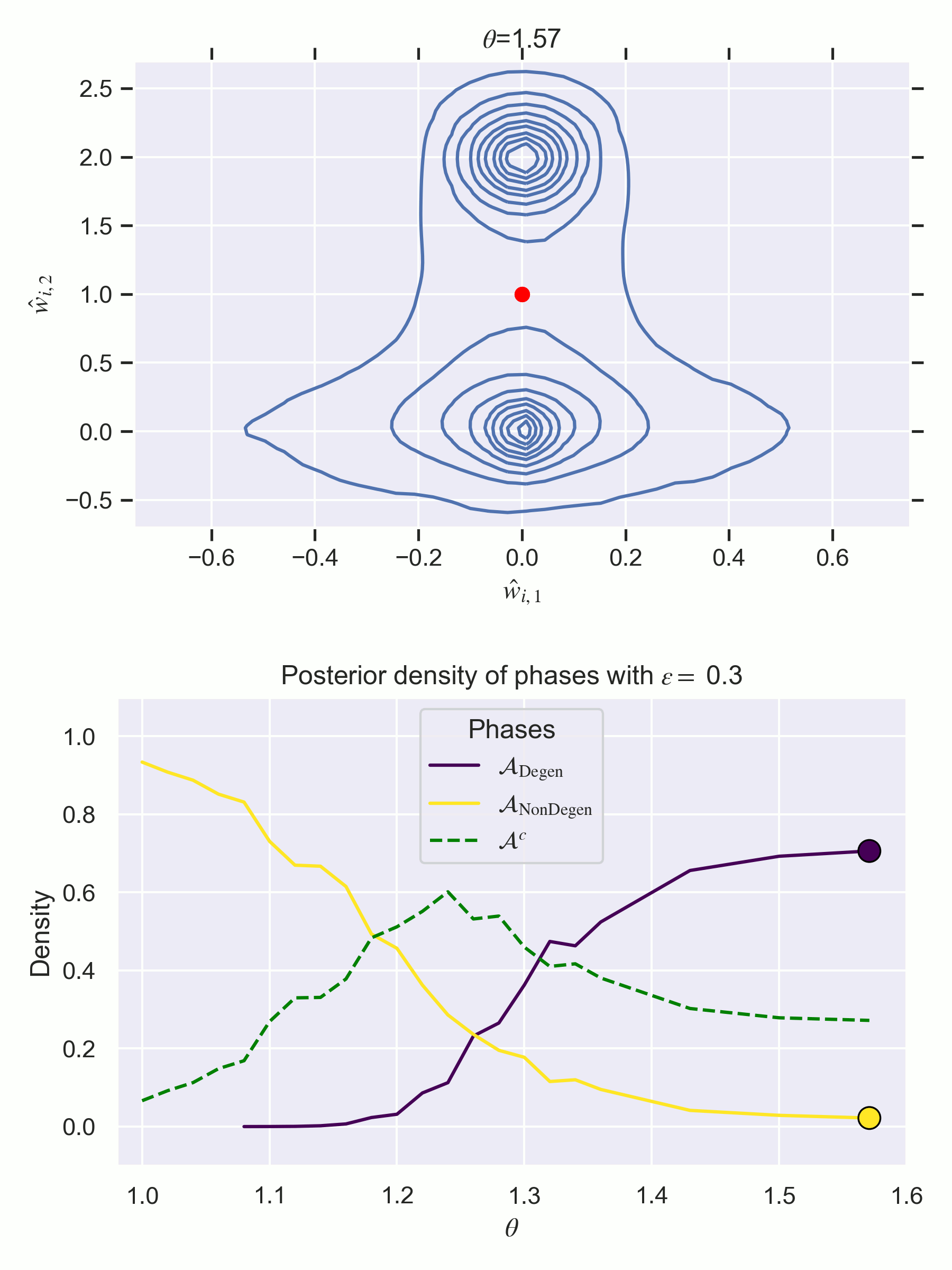
BOTTOM—Estimates of the relative frequency of each phase, i.e. . Do not be confused—these are not free energy curves like in previous figures of the sequence, but they are instead measurements of posterior concentration of each phase at each . In other words, the direction is reversed—higher is better!
Notice how there is a first order phase transition at . Note also that defining the phases according to fixed annuli is not a perfect clustering mechanism, resulting in increasing in relative frequency for middle values. It is merely designed to paint a numerical picture of what we see visually in the changing posterior.
There is also a static facet grid of the key frames if you want a closer inspection.
{kind=link}
The results of our experiments show:
At , the degenerate phase is preferred.
There is a first order phase transition at where becomes preferred, despite not containing a true parameter for ,
It is unsurprising (yet satisfying) that the degenerate phase is preferred at , in line with what the WBIC tells us to expect. What might be more surprising, though, is that has extremely little posterior density at this value. [13]
As we have argued throughout the sequence, the free energy formula suggests that first order phase transitions happen when there is a change in the accuracy-complexity tradeoff such that the posterior newly preferences one phase over the other. Here, the first order phase transition at can be understood in these terms with the following graph that depicts how the accuracy of improves with .
A Complexity Measure for Non-Analytic ReLU Networks
One last thing to point out here is that since is not analytic for ReLU neural networks, the RLCT is not a well defined object. Nonetheless, Watanabe has recently proven in this paper that there is a bound on the free energy,
where complexity is measured by the number of parameters in the smallest compressed network possible to represent the function, as a kind of ‘pseudo’-RLCT. In our case the the complexity is
since there are five parameters required in the degenerate phase and nine in the non-degenerate phase [14]. In this way, Watanabe’s work predicts the results we see. This also shows us how the theory of SLT may be generalisable to the non-analytic setting and still give approximately the same essential insights into singular models.
Phase Transition 2 - Orientation Reversing Symmetry
Defining the Model, Truth, and Phases
This time we are going to consider a model network with nodes,
and a realisable true network with nodes,
where the weights are defined by an order parameter that scales one gradient,
At , the weights satisfy the weight annihilation property,
meaning that reversing the orientation of the weights, (which is equal to a rotation by ), will preserve the function as discussed in DSLT3 - Orientation Reversal. We will use the label weight annihilation phase to refer to the configuration of nodes such that the weights all point into the centre region and annihilate one another.[15] Our key question thus becomes: does the posterior prefers the weight annihilation phase, or the non-weight annihilation phase, at ?
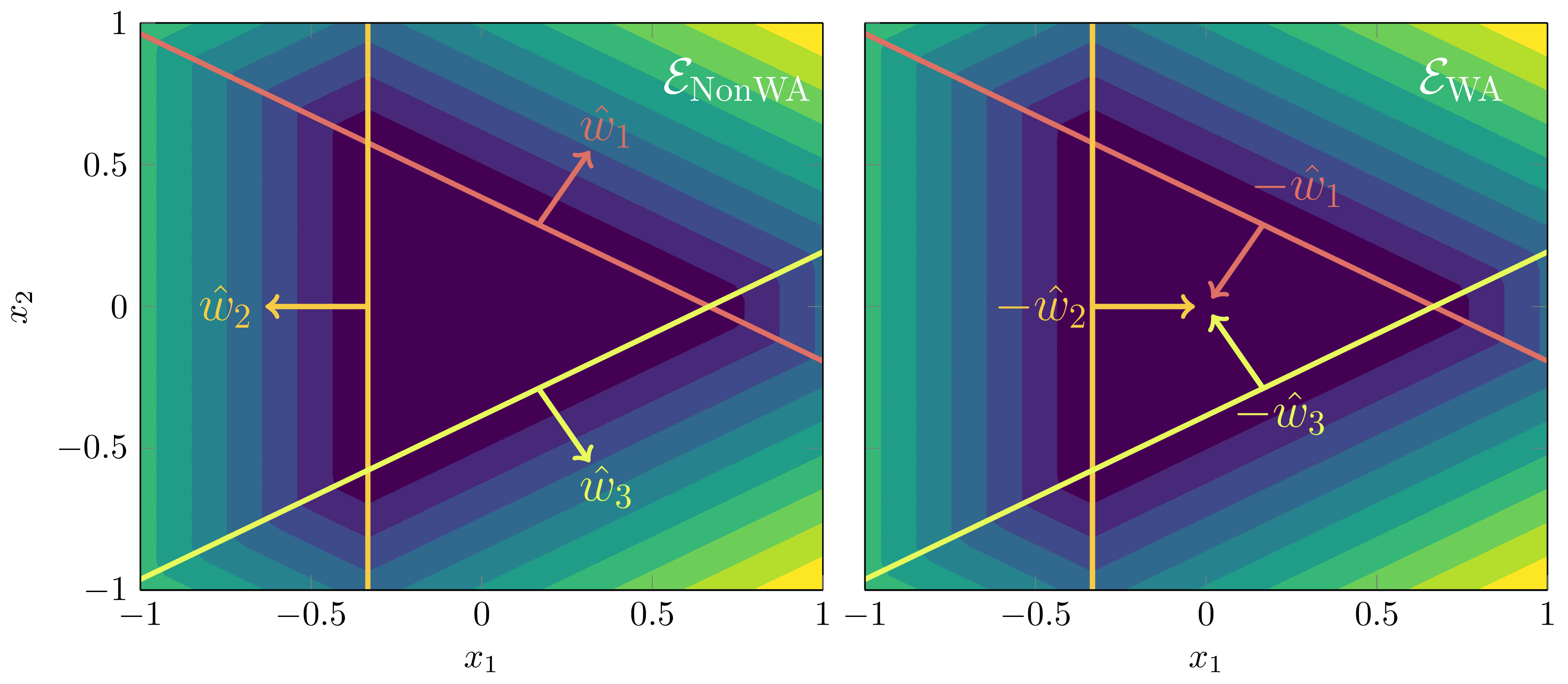
To depict the phases on the plane, let , let be the closed ball of radius epsilon centred at , and let denote the permutation group of order 3. Then the two phases of interest are
Since is being scaled by , we will understand the centre of each ball corresponding to in as being multiplied by the scalar . (It is easier to state in words that writing down in gory notation).
In this experiment our two questions are:
At , which phase is preferred?
Is there a first or second order phase transition at some ?
Results
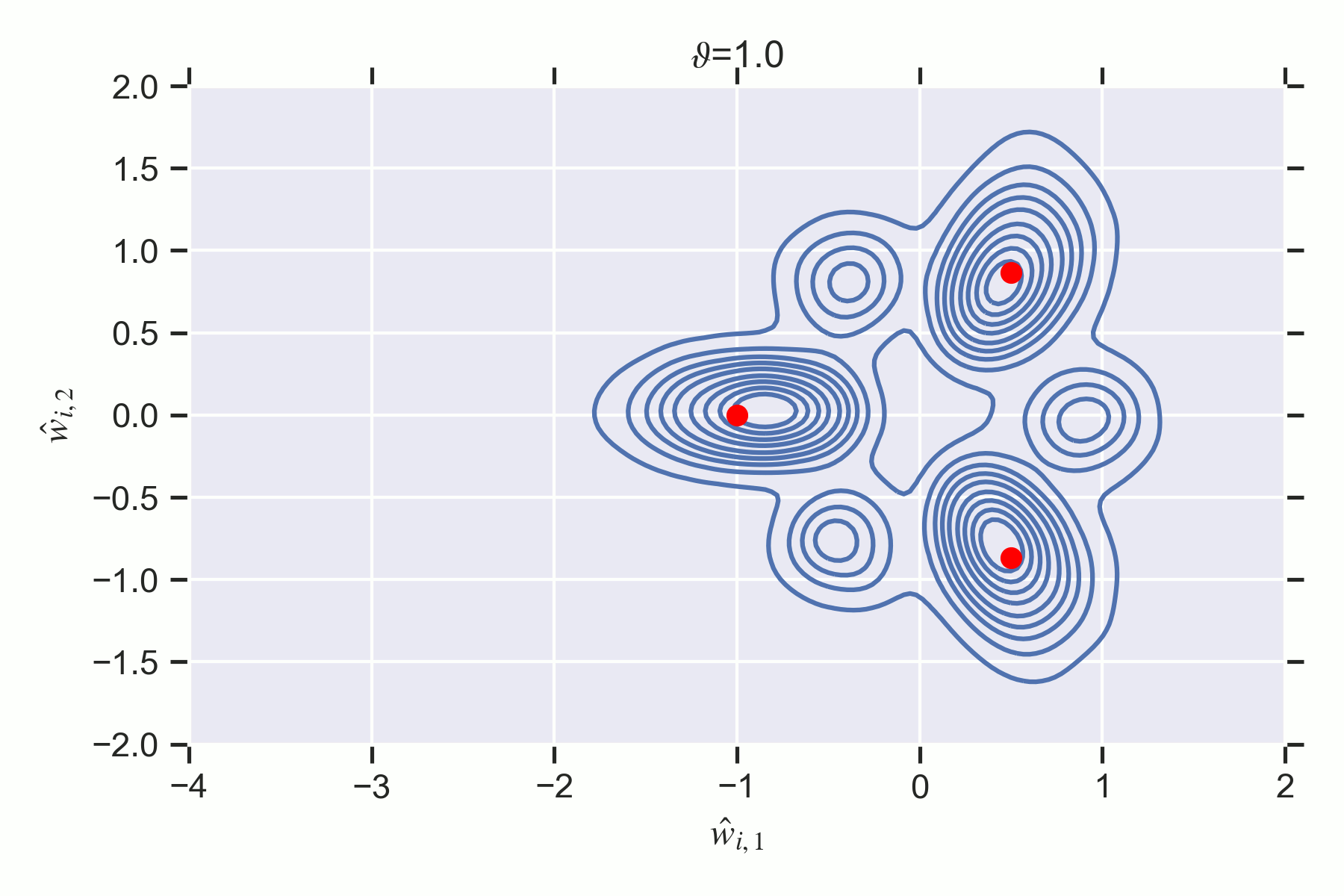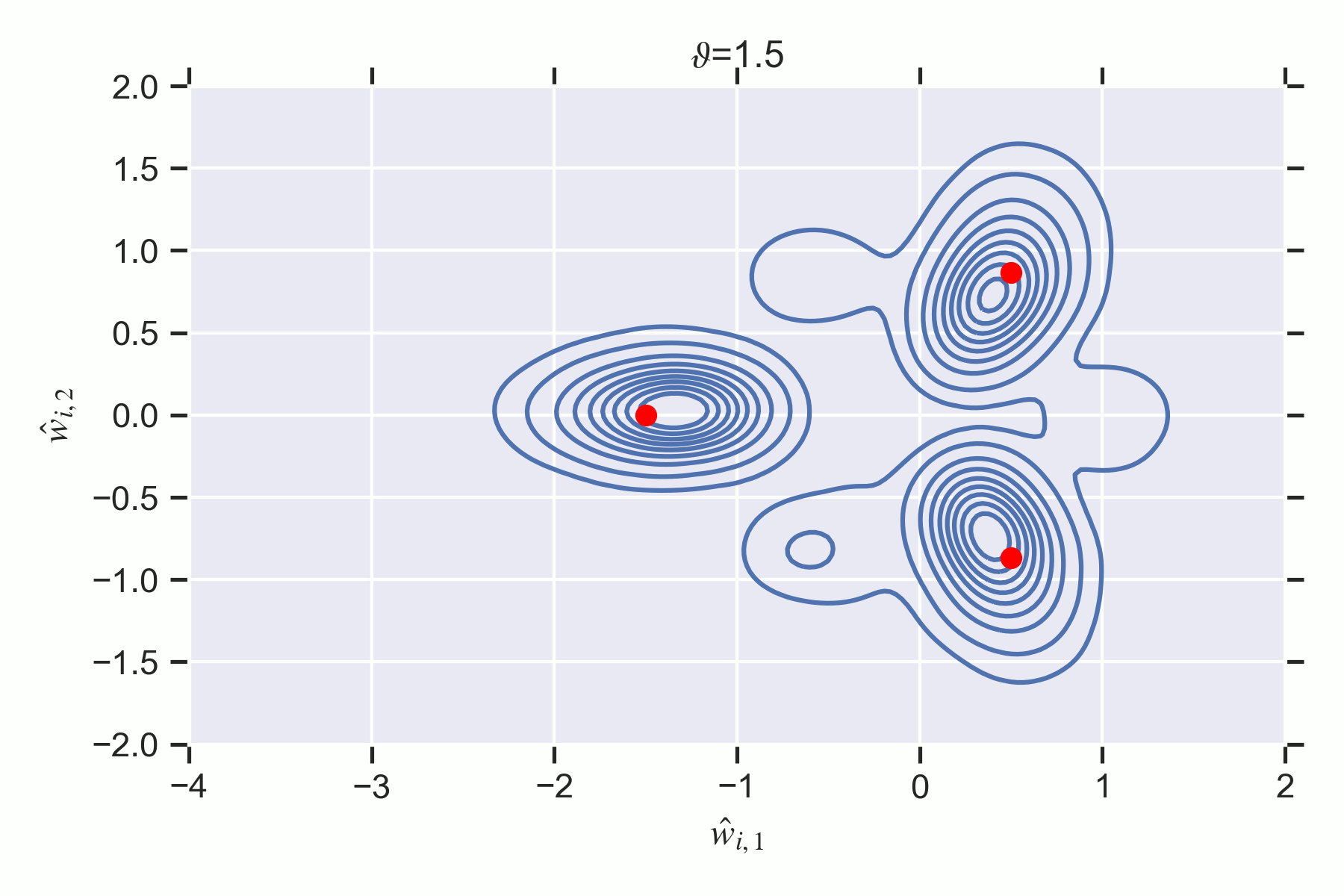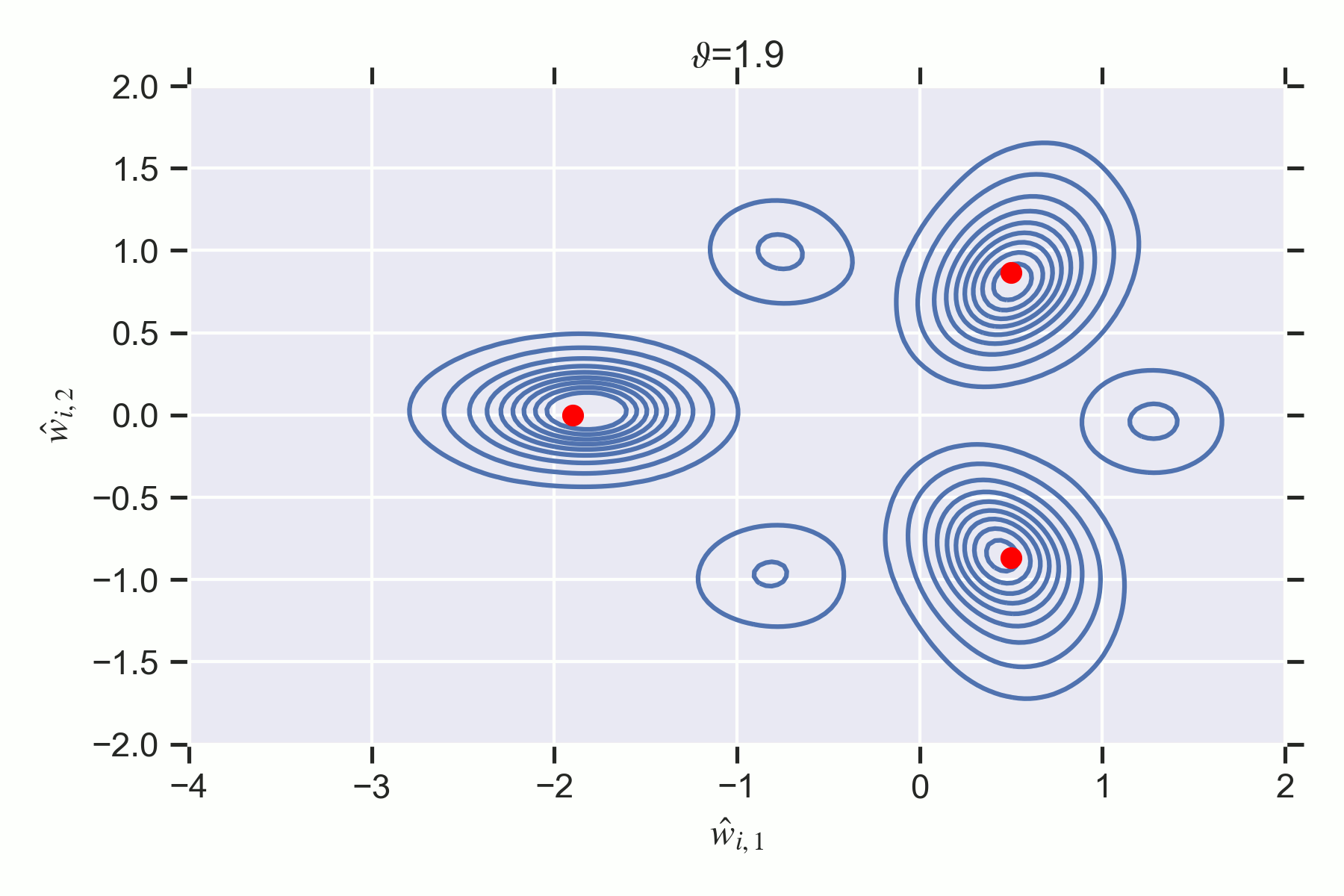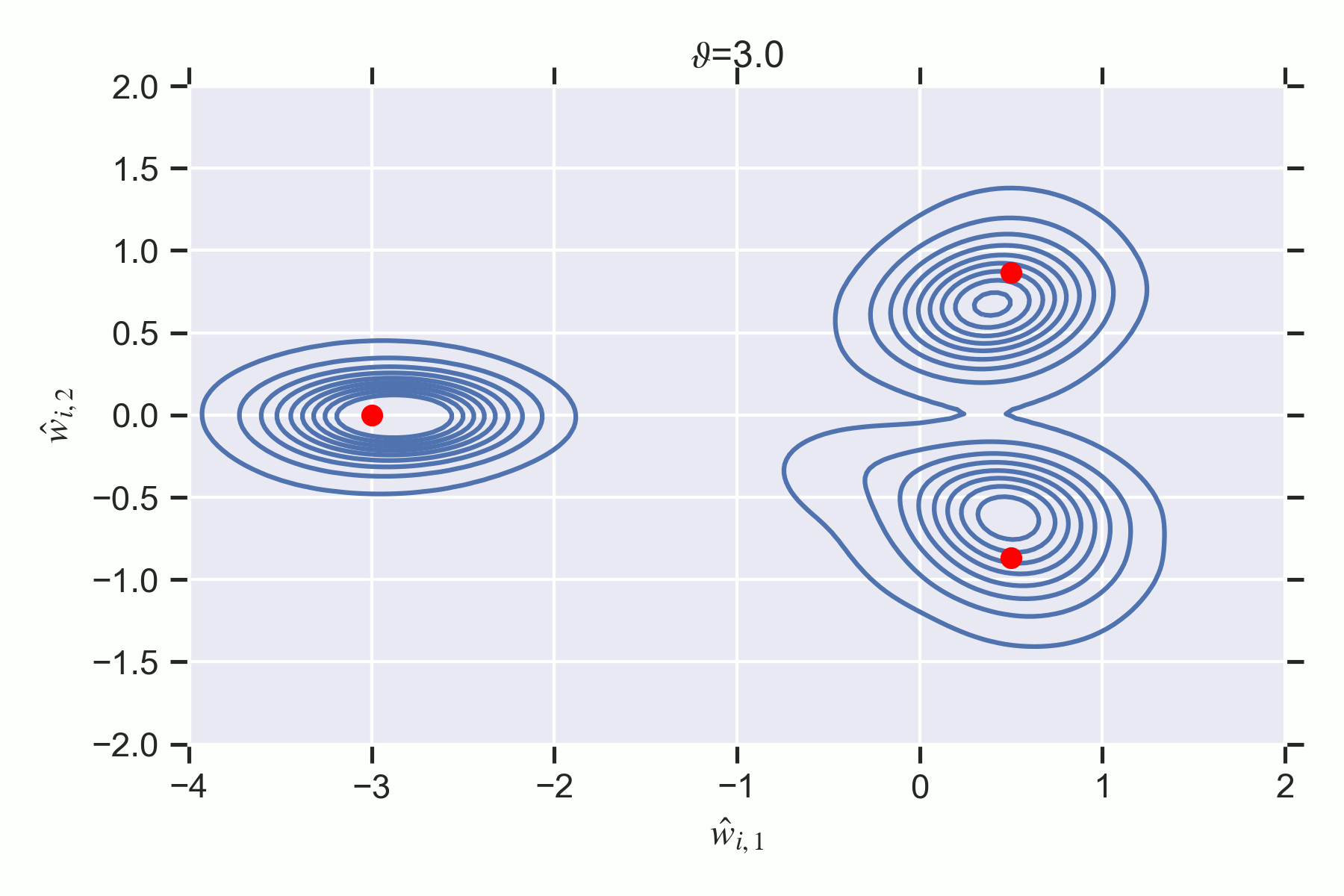
Notice how the phase has less posterior concentration at despite containing a true parameter. There is a second order destruction transition at where ceases to have any mass since its inaccuracy is too high.
The results of this experiment show that:
At the non-weight annihilation phase is preferred by the posterior.
The weight annihilation phase is never preferred by the posterior, thus there is no first order phase transition. But there is a second order phase transition at where is destroyed.
In [Carroll, 5.4.3], I perform a calculation on an even simpler orientation-reversing example which shows that the relative error of inner cancellation region strongly dictates the preference of the two phases. This relative error can be made smaller by increasing the size of the prior . That result suggests that the two phases may have the same RLCT, but differing lower order geometry. This is speculative though, and it would be interesting to better understand the RLCT of both phases.
The second order phase transition is unsurprising since we specifically deform the network so that doesn’t contain a true parameter for . At , its inaccuracy is too highly penalised and the posterior contains no samples from the region.
References
[Callen] - H. Callen, Thermodynamics and an Introduction to Thermostatistics, 1991
[Gilmore] - R. Gilmore, Catastrophe Theory for Scientists and Engineers, 1981
[Wat18] - S. Watanabe, Mathematical Theory of Bayesian Statistics, 2018
[Carroll] - L. Carroll, Phase Transitions in Neural Networks, 2021
[Wei22] - S. Wei, D. Murfet, et al., Deep learning is singular, and that’s good, 2022
- ^
At constant atmospheric pressure, that is.
- ^
Yes, in any physics or chemistry textbook you will see the Gibbs free energy denotes by . I am writing to keep it consistent with our later statistical learning discussion.
- ^
At this point, this is a slight abuse of the physics notions. Typically the probability distribution is proportional to where is the inverse temperature. In this case we are going to absorb the into the term and not get too caught up in the actual physics—we’re just painting a conceptual picture to apply later on.
- ^
Which often correspond to the moments (mean, variance, etc.) of quantities like .
- ^
More precisely, considering the tempered posterior at inverse temperature , the Hamiltonian has the form
(Since , the constant in is irrelevant).
- ^
Note here that a phase transitions of a dynamical system (i.e. SGD, which we can imagine as a particle moving subject to a potential well) is a slightly more subtle concept. One imagines the loss landscape to be fixed, and the “phase transition” corresponding to the particle moving from one particular phase in to another. In this sense, there isn’t exactly a phase transition in the general sense, but there is a change in which phase a system finds itself in.
- ^
Which altered the posterior geometry, but not that of since (up to a normalisation factor).
- ^
It is a little bit disingenuous to continue to call these phases when is very close to 1, as the singularity has a non-negligible effect on , and vice-versa, meaning the phases lose their individual identities. Alternatively, one defines to centre on , and observes how the free energy changes with . But, I have kept the two “phases” and in the animation below to illustrate the general idea with minimum fuss.
- ^
You might wonder why we still endow the model with the parameters in the first place if we just normalise them out after the fact. We assumed it was more important to let the sampling procedure take place on an earnest neural network model without restricting its parameter space, thus trying to keep it in line with neural networks actually used in practice. But, it is likely that these results would hold otherwise, too.
- ^
The astute observer will notice that this is a white lie—the functional equivalence is true as long as each . However, in our experiments, the true outgoing weights are , meaning a good sample will only ever have positive weights, i.e. any sample with a negative will be removed by the outlier validation.
- ^
Explicitly, the truth is defined by
- ^
Relatedly, the plot of the KL divergence in Example 3.3 tells us to expect that the degenerate phase may be preferred.
- ^
It is worth briefly mentioning the effect of the prior here. The free energy formula tells us that as , the effects of the prior on learning become negligible. But of course, we are only ever in the finite regime, at which point the prior does have effects on the posterior. In our case, since the prior is a Gaussian centred at with standard deviation , it is reasonable to say that it has some bearing on the degenerate phase being preferred. However, further experiments showed that this behaviour is still retained for a flatter prior with increased standard deviation. The problem, however, is that the Markov chains can become very unstable on these priors, producing posterior samples with very high loss, indicating that the chains aren’t converging to the correct long-term distribution. In the interest of time, I decided not to continue to fine-tune the experiments on non-converging chains for a flatter prior, but it would be interesting to see to what extent the prior does affect these results.
- ^
In other words, the degenerate phase requires a truth with five parameters
whereas the non-degenerate phase requires nine,
- ^
@Leon Lang correctly pointed out that this is slightly weird terminology to use. Instead these should really be referred to as weight-cancellation instead of weight-annihilation, since both initial configurations obey the weight-annihilation property as I defined it, whereas what I am really referring to is the fact that in one configuration all weights are active and cancel in a region. It’s too late to change the terminology throughout, but do keep this in mind.
- Towards Developmental Interpretability by (12 Jul 2023 19:33 UTC; 195 points)
- DSLT 0. Distilling Singular Learning Theory by (16 Jun 2023 9:50 UTC; 97 points)
- You’re Measuring Model Complexity Wrong by (11 Oct 2023 11:46 UTC; 94 points)
- Mech Interp Lacks Good Paradigms by (16 Jul 2024 15:47 UTC; 40 points)
- DSLT 3. Neural Networks are Singular by (20 Jun 2023 8:20 UTC; 38 points)
Thanks for this sequence and great exposition!
Thanks also for this post! I enjoy reading the sequence and look forward to post 5 on the connections to alignment :)
“Discontinuity” might suggest that this happens fast. Yet, e.g. in work on grokking, it actually turns out that these “sudden changes” happen over a majority of the training time (often, the x-axis is on a logarithmic scale). Is this compatible, or would this suggest that phenomena like grokking aren’t related to the phase transitions predicted by SLT?
As far as I know, modern transformers are often only trained once on each data sample, which should close the gap between SGD time and the number of data samples quite a bit. Do you agree with that perspective?
In general, it seems to me that we’re probably most interested in phase transitions that happen across SGD time or with more data samples, whereas phase transitions related to other hyperparameters (for example, varying the truth as in your examples here) are maybe less crucial. Would you agree with that?
Would you expect that most phase transitions in SGD time or the number of data samples are first-order transitions (as is the case when there is a loss-complexity tradeoff), or can you conceive of second-order phase transitions that might be relevant in that context as well?
I didn’t understand this footnote.
Hhm, I thought that these symmetries are about configurations of the parameter vector, irrespective of whether it is the “true” vector or not.
Are you maybe trying to say the following? The truth determines which parameter vectors are preferred by the free energy, e.g. those close to the truth. For some truths, we will have more symmetries around the truth, and thus lower RLCT for regions preferred by the posterior.
It seems to me that in the other phase, the weights also annihilate each other, so the “non-weight annihilation phase” is a somewhat weird terminology. Or did I miss something?
I think there is a typo and you meant EWA.
This is a great question and something that come up at the recent summit. We would definitely say that the model is in two different phases before and after grokking (i.e. when the test error is flat), but it’s an interesting question to consider whats going on over that long period of time where the error is slowly decreasing. I imagine that it is a relatively large model (from an SLT point of view, which means not very large at all from normal ML pov), meaning there would be a plethora of different singularities in the loss landscape. My best guess is that it is undergoing many phase transitions across that entire period, where it is finding regions of lower and lower RLCT but equal accuracy. I expect there to be some work done in the next few months applying SLT to the grokking work.
This is a very interesting point. I broadly agree with this and think it is worth thinking more about, and could be a very useful simplifying assumption in considering the connection between SGD and SLT.
Broadly speaking, yes. With that said, hyperparameters in the model are probably interesting too (although maybe more from a capabilities standpoint). I think phase transitions in the truth are also probably interesting in the sense of dataset bias, i.e. what changes about a model’s behaviour when we include or exclude certain data? Worth noting here that the Toy Models of Superposition work explicitly deals in phase transitions in the truth, so there’s definitely a lot of value to be had from studying how variations in the truth induce phase transitions, and what these ramifications are in other things we care about.
At a first pass, one might say that second-order phase transitions correspond to something like the formation of circuits. I think there are definitely reasons to believe both happen during training.
I just mean that K(w) is not affected by n (even though of course Kn(w) or Ln(w) is), but the posterior is still affected by n. So the phase transition merely concerns the posterior and not the loss landscape.
My use of the word “symmetry” here is probably a bit confusing and a hangover from my thesis. What I mean is, these two configurations are only in the set of true parameters in this setup when the truth is configured in a particular way. In other words, they are always local minima of K(w), but not always global minima. (This is what PT1 shows when 1.26≤θ<π2). Thanks for pointing this out.
Huh, I’d never really thought of this, but I now agree it is slightly weird terminology in some sense. I probably should have called them the weight-cancellation and non-weight-cancellation phases as I described in the reply to your DSLT3 comment. My bad. I think its a bit too late to change now, though.
Thanks! And thanks for reading all of the posts so thoroughly and helping clarify a few sloppy pieces of terminology and notation, I really appreciate it.