Towards deconfusing wireheading and reward maximization
TL;DR: A response to “Reward is not the optimization target,” and to a lesser extent some other shard theory claims. I agree with the headline claim but I disagree with some of the implications drawn in the post, especially about wireheading and the “executing behaviors downstream of past reinforcement” framing.
My main claims:
Not only does RL not, by default, produce policies which have reward maximization as their behavioral objective, but in fact I argue that it is not possible for RL policies to care about “reward” in an embedded setting.
I argue that this does not imply that wireheading in RL agents is impossible, because wireheading does not mean “the policy has reward as its objective”. It is still possible for an RL agent to wirehead, and in fact, is a high probability outcome under certain circumstances.
This bears a clean analogy to the human case, viewing humans as RL agents; there is no special mechanism going on in humans that is needed to explain why humans care about things in the world.
A few notes on terminology, which may or may not be a bit idiosyncratic:
I define an RL policy to refer to a function that takes states and outputs a distribution over next actions.
I define an RL agent to be an RL policy combined with some RL algorithm (i.e PPO, Q-learning) that updates the policy on the fly as new trajectories are taken (i.e I mostly consider the online setting here).
The objective that any given policy appears to optimize is its behavioral objective (same definition as in Risks from Learned Optimization).
The objective that the agent optimizes is the expected value the policy achieves on the reward function (which takes observations and outputs reals).
A utility function takes a universe description and outputs reals (i.e it cares about “real things in the outside world”, as opposed to just observations/reward, to the extent that those even make sense in an embedded setting).
I mostly elide over the mesaoptimizer/mesacontroller distinction in this post, as I believe it’s mostly orthogonal.
Thanks to AI_WAIFU and Alex Turner for discussion.
Outside world objectives are the policy’s optimization target
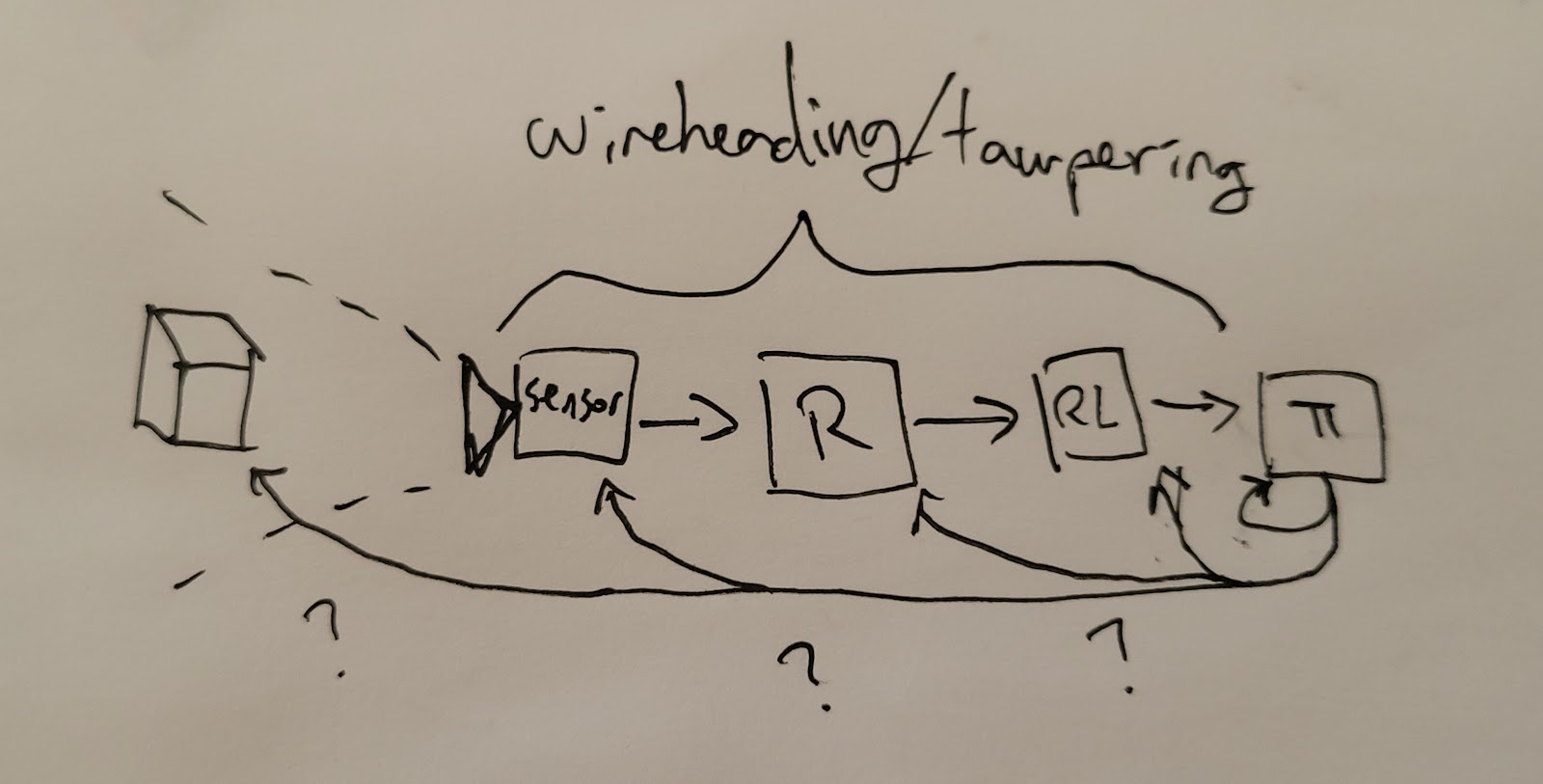
First, let us think about the mechanics of an RL agent. Each possible policy in policy-space implements a behavioral objective, and as a result has some behavior which may or may not result in trajectories which receive high reward. The RL algorithm performs optimization over the space of possible policies, to find ones that would have received high reward (the exact mechanism depends on the details of the algorithm). This optimization may or may not be local. The resulting policies do not necessarily “care” about “reward” in any sense, but they will have been selected to achieve high reward.
Now, consider the same RL agent in an embedded setting (i.e the agent runs on a computer that is part of the environment that the agent acts in). Then, because the sensors, reward function, RL algorithm, etc are all implemented within the world, there exist possible policies that execute the strategies that result in i.e the reward function being bypassed and the output register being set to a large number, or the sensors being tampered with so everything looks good. This is the typical example of wireheading. Whether the RL algorithm successfully finds the policies that result in this behavior, it is the case that the global optima of the reward function on the set of all policies consists of these kinds of policies. Thus, for sufficiently powerful RL algorithms (not policies!), we should expect them to tend to choose policies which implement wireheading.
There are in fact many distinct possible policies with different behavioral objectives for the RL algorithm to select for: there is a policy that changes the world in the “intended” way so that the reward function reports a high value, or one that changes the reward function such that it now implements a different algorithm that returns higher values, or one that changes the register the output from the reward function is stored in to a higher number, or one that causes a specific transistor in the processor to misfire, etc. All of these policies optimize some thing in the outside world (a utility function); for instance, the utility function that assigns high utility to a particular register being a large number. The value of the particular register is a fact of the world. There even exists a policy that cares about that particular register at that particular physical location in the world even if it is not connected to the RL algorithm at all, but that policy does not get selected for by the RL algorithm.
However, when we try to construct an RL policy that has as its behavioral objective the “reward”, we encounter the problem that it is unclear what it would mean for the RL policy to “care about” reward, because there is no well defined reward channel in the embedded setting. We may observe that all of the above strategies are instrumental to having the particular policy be picked by the RL algorithm as the next policy used by the agent, but this is a utility over the world as well (“have the next policy implemented be this one”), and in fact this isn’t really much of a reward maximizer at all, because it explicitly bypasses reward as a concept altogether! In general, in an embedded setting, any preference the policy has over “reward” (or “observations”) can be mapped onto a preference over facts of the world.
Thus, whether the RL agent wireheads is a function of how powerful the RL algorithm is, how easy wireheading is for a policy to implement, and the inductive biases of the RL algorithm. Depending on these factors, the RL algorithm might favor the policies with mesaobjectives that care about the “right parts” of the world (i.e the thing we actually care about), or the wrong parts (i.e the reward register, the transistors in the CPU).
Humans as RL agents
We can view humans as being RL agents, and in particular consisting of the human reward circuitry (RL algorithm) that optimizes the rest of the brain (RL policy/mesaoptimizer) for reward.
This resolves the question of why humans don’t want to wirehead—because you identify with the rest of the brain and so “your” desires are the mesaobjectives. “You” (your neocortex) know that sticking electrodes in your brain will cause reward to be maximized, but your reward circuitry is comparatively pretty dumb and so doesn’t realize this is an option until it actually gets the electrodes (at which point it does indeed rewire the rest of your brain to want to keep the electrodes in). You typically don’t give into your reward circuitry because your RL algorithm is pretty dumb and your policy is more powerful and able to outsmart the RL algorithm by putting rewards out of reach. However, this doesn’t mean your policy always wins against the RL algorithm! Addiction is an example of what happens when your policy fails to model the consequences of doing something, and then your reward circuitry kicks into gear and modifies the objective of the rest of your brain to like doing the addictive thing more.
In particular, one consequence of this is we also don’t need to postulate the existence of some kind of special as yet unknown algorithm that only exists in humans to be able to explain why humans end up caring about things in the world. Whether humans wirehead is determined by the same thing that determines whether RL agents wirehead.
- Clarifying wireheading terminology by (24 Nov 2022 4:53 UTC; 68 points)
- Four usages of “loss” in AI by (2 Oct 2022 0:52 UTC; 46 points)
- EA & LW Forums Weekly Summary (19 − 25 Sep 22′) by (EA Forum; 28 Sep 2022 20:13 UTC; 25 points)
- EA & LW Forums Weekly Summary (19 − 25 Sep 22′) by (28 Sep 2022 20:18 UTC; 16 points)
- 's comment on Looking for an alignment tutor by (18 Dec 2022 15:39 UTC; 2 points)
- 's comment on I just can’t agree with AI safety. Why am I wrong? by (13 Sep 2024 18:52 UTC; 2 points)
Enjoyed this post. Though it uses different terminology from the shard theory posts, I think it hits on similar intuitions. In particular it hits on some key identifiability problems that show up in the embedded context.
I think that by construction, policies and policy fragments that exploit causal short circuits between their actions and the source of reinforcement will be reinforced if they are instantiated. That seems like a relatively generic property of RL algorithm design. But note that this is conditional on “if they are instantiated”. In general, credit assignment can only accurately reinforce what it gets feedback on, not based on counterfactual computations (because you don’t know what feedback you would have otherwise gotten). For example, when you compute gradients on a program that contains branching control flow, the gradients computed are based on how the computations on the actual branch taken contributed to the output, not based on how computations on other branches would have contributed.
For this reason, I think selection-level arguments around what we should expect of RL agents are weak, because they fail to capture the critical dependency of policy-updates on the existing policy. I expect that dependency to hold regardless of how “strong” the RL algorithm is, and especially so when the policy in question is clever in the way a human is clever. Maybe there is some way to escape this and thereby construct an RL method that can route around self-serving policies towards reward-maximizing ones, but I am doubtful.
Yep. This was one of the conclusions I took away from Reward is not the optimization target.
I think you’re still baking in some implicit assumptions about the RL algorithm being weak. The RL algorithm is not obliged to take the current policy, observe its actions, and perturb it a little. At the most extreme end, the most general possible RL algorithm is a giant NN with a powerful world model that picks policies to run experiments with very carefully to gain the maximum number of bits of information for updating its world model. For a less extreme example, consider if the human reward circuitry did a little bit of model based planning and tried to subtly steer you towards addictive things that your neocortex had not realized was addictive yet. It could also simply be that the inductive biases favor wireheading: if the simplest policy is one that cares about memory registers, then you will probably just end up with that.
I also don’t know if the human example fully serves the point you’re trying to make, because the very dumb and simple human RL algorithm does in fact sometimes win out against the human.
Not sure where the disagreement is here, if there is one. I agree that there are lots of sophisticated RL setups possible, including ones that bias the agent towards caring about certain kinds of things (like addictive sweets or wireheading). I also agree that even a basic RL algorithm like TD learning may be enough to steer the cognition of complex, highly capable agents in some cases. What is it that you are saying depends on the RL algorithm being weak?
I am generally very skeptical about simplicity arguments. I think that that sort of reasoning generally does not work for making specific predictions about how neural networks will behave, particularly in the context of RL.
Before reading, here are my reactions to the main claims:
(I ended up agreeing with these points by the end of the post!)
Why not? Selection only takes place during training, the RL algorithm can only select across policies while the RL algorithm is running. A policy which wireheads and then disconnects the RL algorithm is selection-equivalent to a policy which wireheads and then doesn’t disconnect the RL algorithm (mod the cognitive-updates provided by reward in the latter case, but that seems orthogonal).
Agreed!
Agreed. Shard theory isn’t postulating such an algorithm, if that’s what you meant to imply. In fact, your entire end of the post seems to be the historical reasoning which Quintin and I went through in developing shard theory 101.
You postulate that a “sufficiently powerful optimizer” would find policies that set the registers directly (wirehead), but I’m not sure that is guaranteed. It could well be that such policies are non-computable for non-trivial reward circuits. That is because a) the optimizer is embedded and thus has to model itself to find the optimum policy and this recursive self-modeling could be non-computable or correspond to the halting problem (except for solvable fixed-point cases). At least this possibility has to be ruled out explicitly.
This is true for the sorts of RL algorithms you consider here, but I just want to post a reminder that this is/can be false for model-based RL where the reward is specified in terms of the model. Such agents would robustly pursue whatever it is the reward function specifies with no interest in tampering with the reward function (modulo some inner alignment issues). Just thought I would mention it since it seems like an underappreciated point to me.
This is quite interesting! I wonder if there are simple numerical models simulating it? Or maybe even analytical ones. Basically, turning pictures like above into a control system equation. Seems like something that would be easy to model.