Is the “Valley of Confused Abstractions” real?
Epistemic Status: Quite confused. Using this short post as a signal for discussion.
In Evan’s post about Chris Olah’s views on AGI safety, there is a diagram which loosely points to how Chris thinks model interpretability will be impacted at different levels of model “strength” (note that this is vague intuition; worth looking at Chris’ comment on this post):
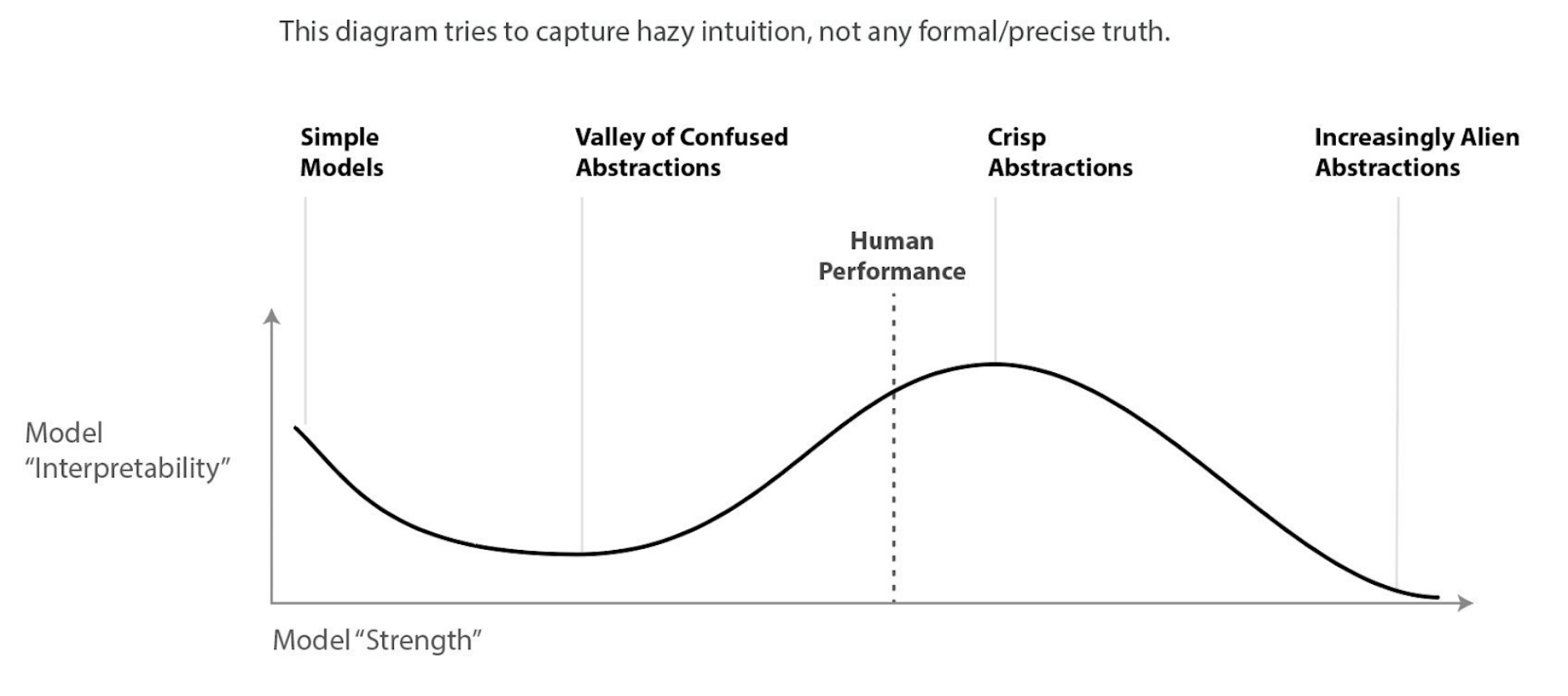
I always thought this diagram still held up in the LLM regime, even though it seems the diagram pointed specifically to interpretability with CNN vision models. However, I had a brief exchange with Neel Nanda about the Valley of Confused Abstractions in the context of language models, and I thought this might be a good thing to revisit.
I’ve been imagining that language models with the “strength” of GPT-2 are somewhere near the bottom of the Valley of Confused Abstractions, but the much bigger models are a bit further along the model strength axis (though I’m not sure where they fall). I’ve been thinking about this in the context of model editing or pointing/retargeting the model.
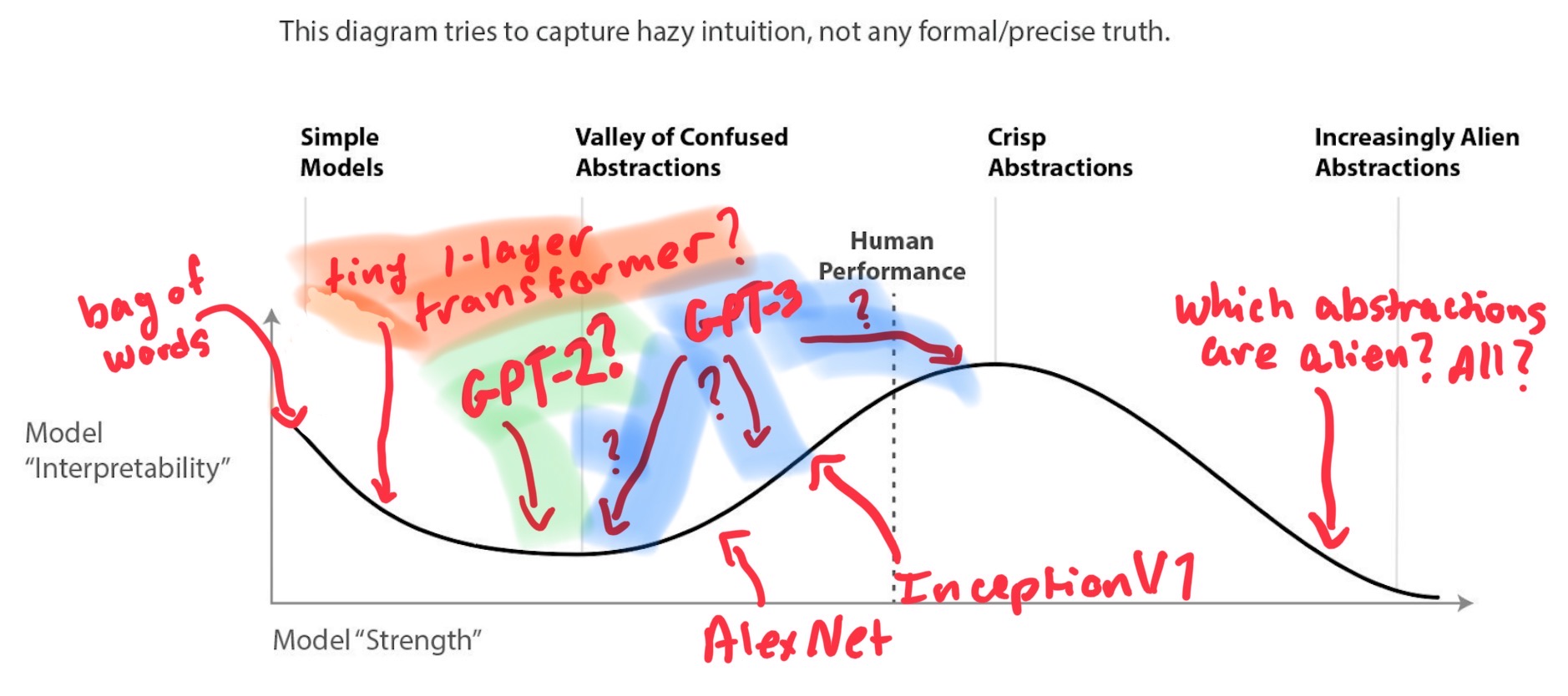
Here’s my exchange with Neel:
Neel: I’m personally not actually that convinced that the valley of confused abstractions is real, at least in language. 1L transformers are easier to interpret than large ones, which is completely unlike images!
Me: Does that not fit with the model interpretability diagram from: https://www.alignmentforum.org/posts/X2i9dQQK3gETCyqh2/chris-olah-s-views-on-agi-safety#What_if_interpretability_breaks_down_as_AI_gets_more_powerful_?
Meaning that abstractions are easy enough to find with simple models, but as you scale them up you have to cross the valley of confused abstraction before you get to “crisp abstractions.” Are you saying we are close to “human-level” in some domains and it’s still hard to find abstractions? My assumption was that we simply have not passed the valley yet so yes larger models will be harder to interpret. Maybe I’m misunderstanding?
Neel: Oh, I just don’t think that diagram is correct. Chris found that tiny image models are really hard to interpret, but we later found that tiny transformers are fairly easy.
Me: I guess this is what I’m having a hard time understanding: The diagram seems to imply that tiny (simple?) models are easy to interpret. In the example in the text, my assumption was that AlexNet was just closer to the bottom of the valley than InceptionV1. But you could have even simpler models than AlexNet that would be more interpretable but less powerful?
Neel: Ah, I think the diagram is different for image convnets and for language transformers.
My understanding was that 1-layer transformers being easy to interpret still agrees with the diagram, and current big-boy models are just not past the Valley of Confused Abstractions yet.
Ok, but if what Neel says is true, what might the diagram look like for language transformers?
I’m confused at the moment, but my thinking used to go something like this: in the case of GPT-2, it is trying to make sense of all the data it has been trained on but just isn’t big enough to fully grasp the concept of “cheese” and “fromage” are essentially the same. But my expectation is that as the model gets bigger, it knows those two tokens mean the same thing, just in different languages. Maybe it does?
With that line of thinking, as model strength increases, it will help the model create crisper internal abstractions of a concept like “cheese.” But then what...at some point, the model gets too powerful, and it becomes too hard to pull out the “cheese/fromage” abstraction?
Anyway, I hoped that as LLMs (trained with the transformers architecture) increase in “strength” beyond the current models, the abstractions become crisper, and it becomes much easier to identify abstractions as it gets closer to some “human-level performance.” However, GPT-3 is already superhuman in some respects, so I’m unsure about how to disentangle this. I hope this post sparks some good conversation about how to de-confuse this and how the diagram should look for LLM transformers. Is it just some negative exponential with respect to model strength? Or does it humps like the original diagram?
Sorry for not noticing this earlier. I’m not very active on LessWrong/AF. In case it’s still helpful, a couple of thoughts...
Firstly, I think people shouldn’t take this graph too seriously! I made it for a talk in ~2017, I think and even then it was intended as a vague intuition, not something I was confident in. I do occasionally gesture at it as a possible intuition, but it’s just a vague idea which may or may not be true.
I do think there’s some kind of empirical trend where models in some cases become harder to understand and then easier. For example:
An MNIST model without a hidden layer (ie. a softmax generalized linear regression model) is easy to understand.
An MNIST model with a single hidden layer is very hard to understand.
Large convolutional MNIST/CIFAR models are perhaps slightly easier (you sometimes get nice convolutional filters).
AlexNet is noticeably more interpretable. You start to see quite a few human interpretable neurons.
InceptionV1 seems noticeably more interpretable still.
These are all qualitative observations / not rigorous / not systematic.
So what is going on? I think there are several hypotheses:
Confused abstractions / Modeling Limitations—Weak models can’t express the true abstractions, so they use a mixture of bad heuristics that are hard to reason about and much more complicated than the right thing. This is the original idea behind this curve.
Overfitting—Perhaps it has less to do with the models and more to do with the data. See this paper where overfitting seems to make features less interpretable. So ImageNet models may be more interpretable because the dataset is harder and there’s less extreme overfitting.
Superposition—It may be that apparent interpretability is actually all a result of superposition. For some reason, the later models have less superposition. For example, there are cases where larger models (with more neurons) may store less features in superposition.
Overfitting—Superposition Interaction—There’s reason to believe that overfitting may heavily exploit superposition (overfit features detect very specific cases and so are very sparse, which is ideal for superposition). Thus, models which are overfit may be difficult to interpret, not because overfit features are intrinsically uninterpretable but because they cause superposition.
Other Interaction Effects—It may be that there are other interactions between the above arguments. For example, perhaps modeling limitations cause the model to represent weird heuristics, which then more heavily exploit superpositition.
Idiosyncrasies of Vision—It may be that the observations which motivated this curve are idiosyncratic to vision models, or maybe just the models I was studying.
I suspect it’s a mix of quite a few of these.
In the case of language models, I think superposition is really the driving force and is quite different from the vision case (language model features seem to typically be much sparser than vision model ones).
I’m interested in hearing other people’s takes on this question! I also found that a tiny modular addition model was very clean and interpretable. My personal guess is that discrete input data lends itself to clean, logical algorithms more so than than continuous input data, and that image models need to devote a lot of parameters to processing the inputs into meaningful features at all, in a way that leads to the confusion. OTOH, maybe I’m just overfitting.
I thought the peak of simple models would be something like a sparse Bag of Words model, and then all models that have been considered so far just go deeper and deeper into the valley of confused abstractions, and that we are not yet at the point where we can escape. But I might be wrong.
Yeah, this was my impression as well!
I guess I would assume that GPT-style models don’t have a great chance of escaping the valley of confused abstractions because their interface to the real world is very weird. Predicting scrapes of internet text.
Updated the diagram I drew on to better illustrate my confusion.
And yeah, it may very well be that GPT-style never leaves the valley. Hmm.
Could it be that Chris’s diagram gets recovered if the vertical scale is “total interpretable capabilities”? Like maybe tiny transformers are more interpretable in that we can understand ~all of what they’re doing, but they’re not doing much, so maybe it’s still the case that the amount of capability we can understand has a valley and then a peak at higher capability.
As in, the ratio between (interpretable capabilities / total capabilities) still asymptotes to zero, but the number of interpretable capabilities goes up (and then maybe back down) as the models gain more capabilities?
Yeah. Or maybe not even to zero but it isn’t increasing.
New (somewhat relevant) paper:
Scale Alone Does not Improve Mechanistic Interpretability in Vision Models
I encountered a similarish pattern a long time ago
https://www.lesswrong.com/posts/RQpNHSiWaXTvDxt6R/coherent-decisions-imply-consistent-utilities?commentId=9Fm2zrYT9aRSdzSde