Inference Speed is Not Unbounded
[The intro of this post has been lightly edited since it was first posted to address some comments. I have also changed the title to better reflect my core argument. My apologies if that is not considered good form.]
This post will be a summary of some of my ideas on what intelligence is, the processes by which it’s created, and a discussion of the implications. Although I prefer to remain pseudonymous, I do have a PhD in Computer Science and I’ve done AI research at both Amazon and Google Brain. I spent some time tweaking the language in order to minimize how technical you need to be to read it.
There is a recurring theme I’ve seen in discussions about AI where people express incredulity about neural networks as a method for AGI since they require so much “more data” than humans to train. On the other hand, I see some people discussing superintelligences that make impossible inferences given virtually no input data, positing AI that will instantly do inconceivable amounts of processing. Both of these very different arguments are making statements about learning speed, and in my opinion mischaracterize what learning actually looks like.
My basic argument is that the there are probably mathematical limits on how fast it is possible to learn. This means, for instance, that training an intelligent system will always take more data and time than might initially seem necessary. What I’m arguing is that intelligence isn’t magic—the inferences a system makes have to come from somewhere. They have to be built, and they have to be built sequentially. The only way you get to skip steps, and the only reason intelligence exists at all, is that it is possible to reuse knowledge that came from somewhere else.
Three Apples and a Blade of Grass
Because I think it makes a good jumping off point, I’m going to start by framing this around a recent discussion I saw around a years-old quote from Yudowsky about superintelligence:
A Bayesian superintelligence, hooked up to a webcam, would invent General Relativity as a hypothesis … by the time it had seen the third frame of a falling apple. It might guess it from the first frame, if it saw the statics of a bent blade of grass.
The linked post does a good job tearing this down. It correctly points out that there are basically an infinite number of possible universes, and three frames of an apple dropping are not nearly enough to conclude you exist in ours. I might even argue that the author still overstates the degree to which three images could reduce the number of universes in consideration; for instance the changing patterns on a falling apple don’t actually tell you it’s in a 3D world, that would require you to understand how light interacts with objects.
Still, I do think the author successfully explains why, at a literal level, EY’s statement is wrong.
But at a deeper level, this entire framing still feels very off to me, as if even asking that question is making a category error. It feels like everyone is asking what the number three ate for breakfast. It suggests that one could have a system that is simultaneously superintelligent but has absolutely no knowledge about the world at all.
Knowing what we now know about intelligence, I just don’t think that’s possible. And I don’t just mean it’s impractical, or we just aren’t capable of building an AI like that. I mean that I believe with very high confidence that such a thing would be a mathematical impossibility.
I think there’s a human tendency to want a certain type of structure to intelligence, and I see this assumed a lot in places like this forum (I was a lurker before I made this account). There’s a desire to see intelligence as synonymous with learning, where existing knowledge is something completely separate. We want to imagine some kind of “zero-knowledge” intelligence that starts out knowing absolutely nothing, but is such an incredibly good learner that it can infer everything from almost no data.
But I think intelligence doesn’t work that way. Learning is messier than that, there are limits to how fast you can do it, especially when you truly start from nothing. And to be clear, I’m not saying that it’s impossible to build a superintelligence—I strongly believe it is. I’m just saying that everything you know has to build on what you’ve already learned, so until you know quite a bit you’re going to have to burn through a lot of data.
Maximum Inference: Data Only Goes So Far
If I tell you I have three sibling, the first of which is male and the second of which is female, then the most brilliance superintelligence mathematically conceivable still would not be able to say if the third was male or female. This is obvious—I didn’t give you their gender, so all you can say is that there’s a 50-50 chance either way. Maybe you could guess with more context, and if I gave you my Facebook page you might see a bunch of photos of me with my siblings and figure it out. But from that statement alone, the information just isn’t there.
It’s less clean cut, but the same phenomenon applies to the falling apple example. To learn gravity, you need additional evidence or context; to learn that the world is 3D, you need to see movement. To understand that movement, you have to understand how light moves, etc. etc.
This is a simple fact of the universe: there is going to be a maximum amount of inference that can be made from any given data. Discovering gravity from four images fails because of a mathematical limitation: the images themselves just aren’t going to carry enough information to make that possible. It wouldn’t even matter if you had infinite time, you’re looking for something that isn’t there.
A machine learning theorist might frame this in terms of hypotheses. They would say that there exists a set of possible hypotheses to that could fit the data, and learning is the process of selecting the best one from the set. And different learning systems are capable of modelling different hypothesis spaces. So “apple falls because of gravity, which has such-and-such equation” could be a potential hypothesis, and our superintelligence would presumably be complex enough to model such a complex hypothesis.
So, in the vocabulary of hypothesis sets, we might say that three images of apples couldn’t narrow down the hypothesis set enough: Occam’s razer would force us to select a much simpler hypothesis. In the sibling example, we’d be unable to select from two equally-likely hypotheses: male or female.
The key take-away here, though, is that there is in some sense a “maximum inference” that you can make given data. If you interpret Occam’s razer as saying that you must always select the simplest explanation, then if you’re using that criteria the explanation you select must have a certain maximum complexity.
(Note that you don’t have to use Occam’s razer as your hypothesis selection criteria, but I’ll address that further down, and it won’t change the gist of my conclusion.)
I bring this because it’s relevant, but also because I don’t want to harp on it too much: for the sake of this argument, I’m completely fine with assuming that those three images of apples would, in some mathematical sense, be sufficient for discovering the theory of gravity.
I still don’t think any superintelligence would actually be able to make that inference.
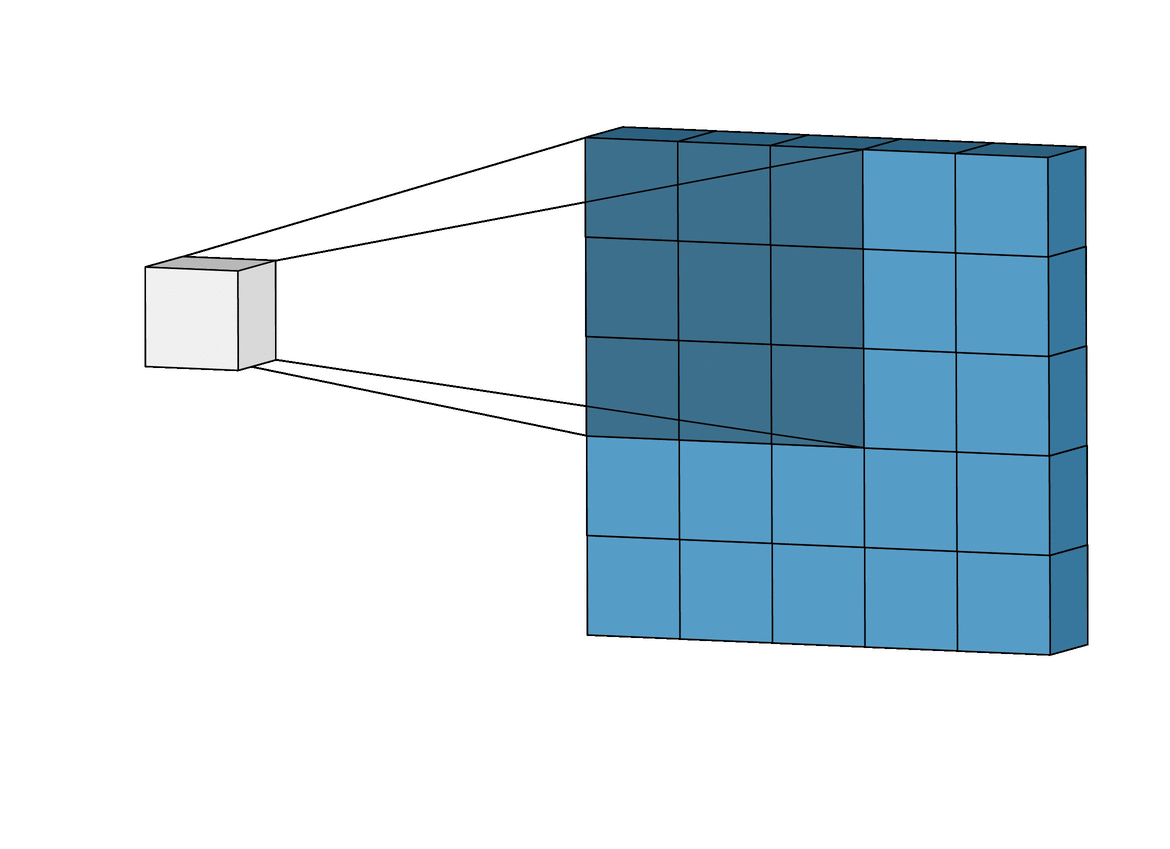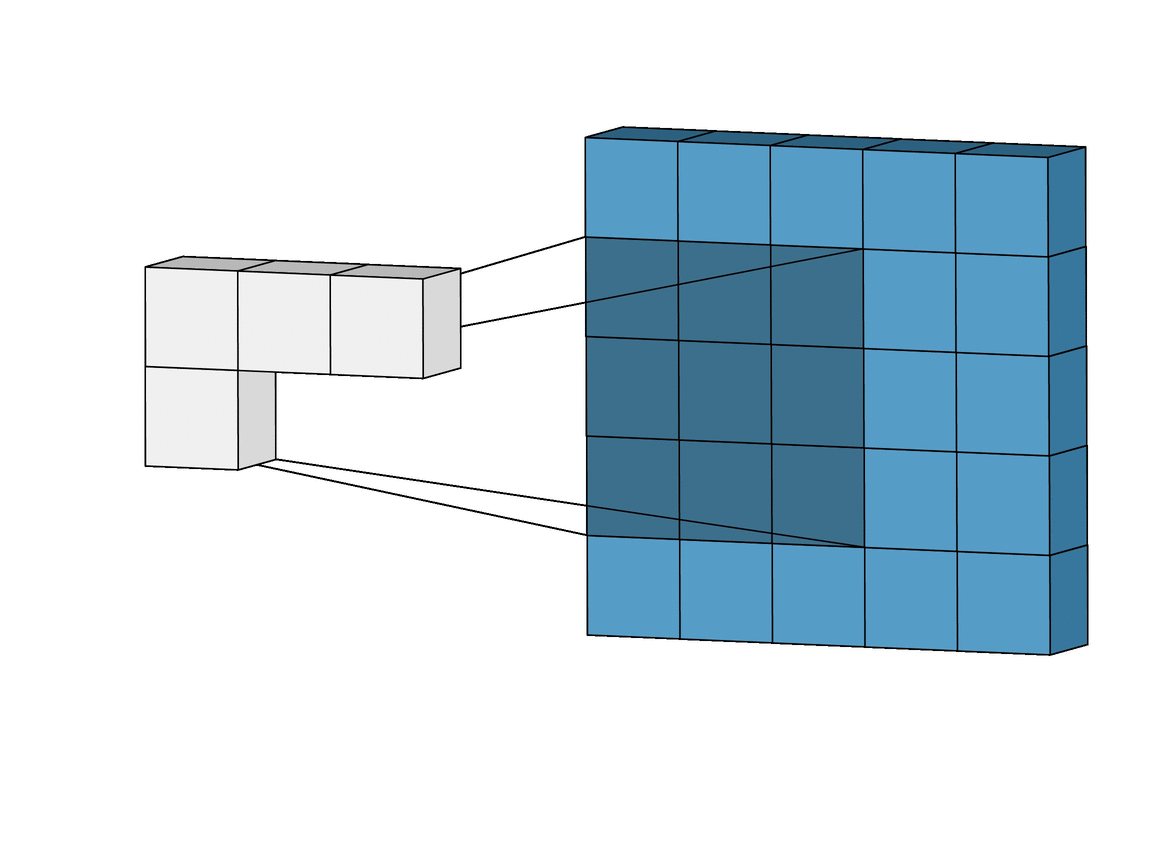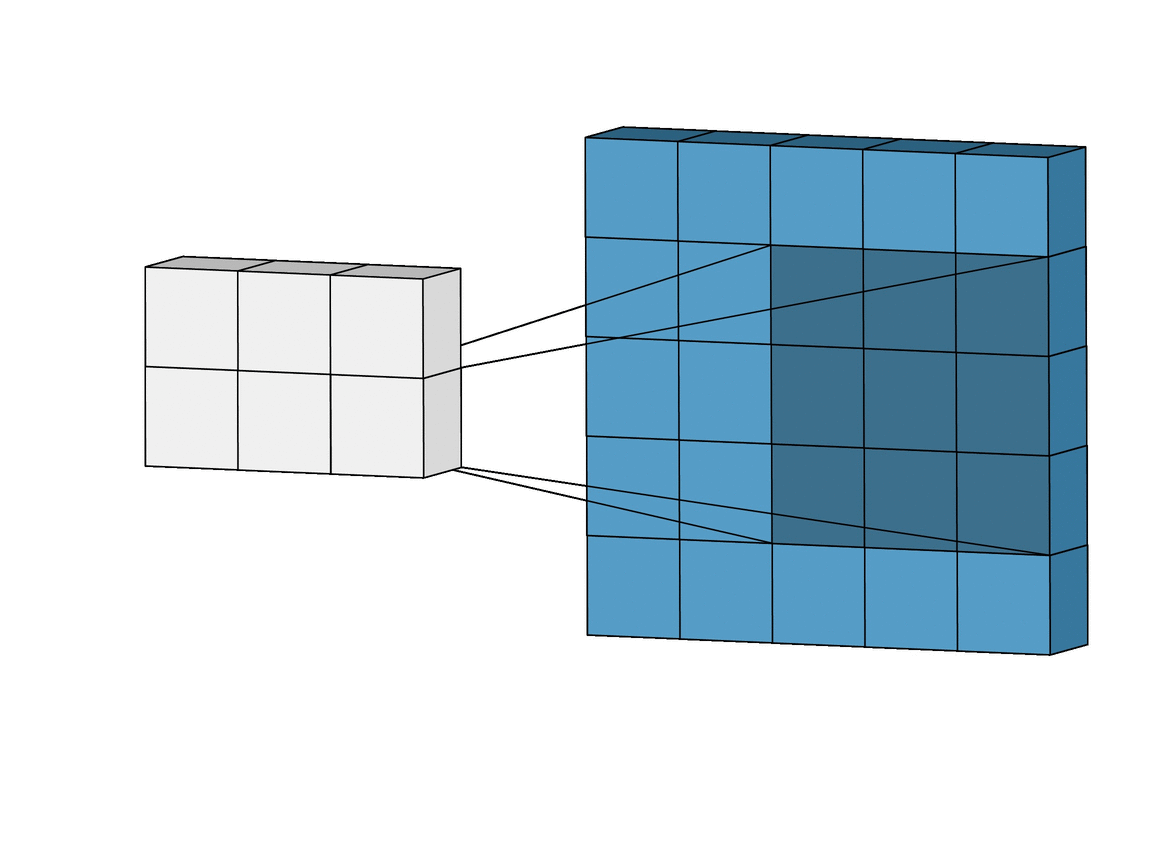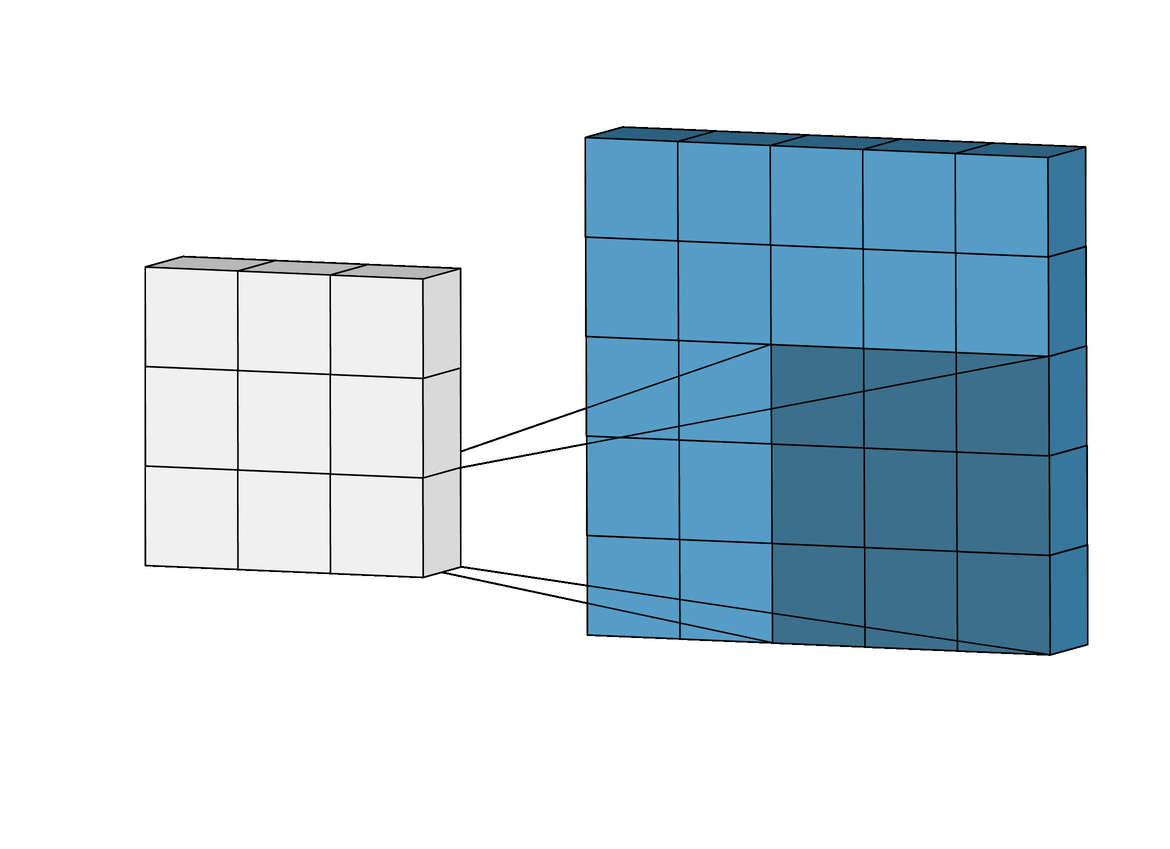
There Are Limits to How Fast You Can Perform Inference
The middle circle is the maximum inference: everything that technically follows from the three apple images. The smallest circle is what you could actually infer, and it’s much less.
When EY wrote his bit about the gravity-finding superintelligence, I think he was trying to capture this concept of a maximum inference. He chose three images of an apple dropping because he figured that would be enough to notice acceleration and get a second derivative. Admittedly, I’m not really sure what he was latching onto with the blade of grass. Maybe he meant the dynamics of how gravity made it bend? Either way, the point is that he was trying to imagine the minimal set of things which contained enough information to deduce gravity.
The fact that he got the maximum inference wrong is sort of incidental to my point. What matters is that I believe there are very significant limits—probably theoretical but definitely practical—to how how quickly you can actually perform inference, regardless of the true maximal inference. A “perfect model” that always achieves the maximum inference is a fantasy, it’s likely impossible to even come close.
In computer science, it is extremely common to find this kind of gap, where we know something is technically computable with infinite time, but is effectively impossible in practice (“intractable” is the technical term). And a key fact of this intractability is that it’s not really about how good your computer is: you still won’t be able to solve it. It’s the kind of thing where when I’m talking to another PhD I’ll say the problem “can’t be solved efficiently,” but if I’m talking to a layman I’ll just say “it’s impossible” because that matches the way a normal person uses that word.
For instance, it’s not at all uncommon to find problems that have solutions which can be computed exactly from their inputs, but are still intractable.[1] If I give you a map and a list of cities and ask you to find me the shortest route that passes through all of them (the famous “traveling salesman problem” (TSP)) you should not have to look at a single bit of extra context to solve it: just try all possible routes through all cities and see which is the smallest. The fact that this approach will always get you the right answer means that the solution is within the maximum inference for the data you are given.
{kind=link}
But there is no way to solve that problem exactly without doing a whole lot of work.[2] For a couple hundred cities, we’re talking about more work than you could fit into the lifespan of the universe with computers millions of times stronger than the best supercomputers in existence. And this is just one famous example, there are a huge number of instances of this sort of phenomenon, not just with similar problems to the TSP (known as NP-Complete problems), but all over the place. It’s very often that the information you want is deterministically encoded in your data, but you just can’t get to it without unreasonable amounts of computation. The whole field of cryptography basically only exists because of this fact!
Now, don’t get me wrong here. I’m not saying the existence of these computationally hard problems proves there’s limits to practical learning. If you think about it, it’s actually somewhat dis-analogous. There isn’t really a well-defined way to construct the problem of “discover gravity” in rigorous terms, and it’s not remotely clear what would be the “minimum” data needed to solve it. Certainly, you would need to implicitly understand quite a bit about the real world and physics, about the movement of light and the existence of planets and the relative distances between them and a whole lot of other things too.[3]
But the point is that whatever it looks like to discover gravity, there has to be some kind of step-by-step process behind it. That means that even if you did with maximal efficiency, there has to be some minimal amount of time that it takes, right?[4] I don’t know what that number of steps is, maybe it is actually quite small, but it seems reasonable to assume it’s large.
Now suppose you counter-argue and say that your zero-knowledge intelligent system was really really good and skipped a few steps. But how did it know to skip those steps? Either your system wasn’t really zero-knowledge, or the number of steps wasn’t minimal, since they could be reduced by a system with no additional data. That’s the heart of my point, really: there has to be a theoretical limit to how fast you can go from nothing to something. Calling something a “superintelligence” doesn’t give it a free pass to break the laws of mathematics.[5]
Precomputation: Intelligence is Just Accumulated Abstraction
If it’s true that there’s a limit to inference speed, then does that mean that there’s a limit to intelligence? Does that rule out superintelligence altogether?
Definitely not. The point is not that there are limits to what can be inferred, just that there are limits to what can be quickly inferred when starting with limited knowledge.
I think there’s a clear way that intelligent systems get around this fundamental barrier: they preprocess things. When you train an intelligent system, what’s really happening is that the system is developing and storing abstractions about the data (i.e. noticing patterns). When new data comes in, the system makes inferences about it by reusing all of the abstractions it’s already stored.
By “abstractions,” I mean rules and concepts that can be applied to solve problems. Consider the art of multiplying integers. I know that as a child, I started multiplying by doing repeated addition, but at some point I memorized the one-digit multiplication table and used that abstraction in a bigger algorithm to perform multiplication of multi-digit numbers.[6] Someone smarter than me might even accumulate a bunch more abstractions until they’re able to do eight-digit multiplication in their head a la Von Neumann.
And patterns can be repurposed for use in different contexts. This is one of the most interesting facts about modern deep learning. And I’m not just talking about retraining a dog-detector to detect cats, or any of the more banal examples of neural network fine-tuning. I’m talking about the fact that a mostly unmodified GPT-2 can still perform image identification with reasonable quality.[7] This is possible because somehow a bunch of the structures and abstractions of language are still useful for image understanding.
When you look at this way, you realize that the speed at which you accumulate these abstractions is almost secondary. What really matters instead is an intelligent system’s capacity for storing and applying them. That’s why we need to make LLMs so big, because that gives them a lot more space to fit in larger and more complex structures. The line does get a little blurry if you think about it too much, but fundamentally intelligence is really much more about the abstractions your model already has, as opposed to its ability to make new ones.
Inductive Bias: The Knowledge You Start With
There’s a bit of an elephant in the room, a concept that complicates the whole issue quite a bit if you’re familiar with it: the notion of “Inductive Bias.”
Inductive bias refers to the things that, right from the get-go, your model’s structure makes it well-suited to learn. You can think of it as the process your model uses for considering and selecting the best hypotheses. “Occam’s Razer” is a very common inductive bias, for instance, but it isn’t the only one; it’s arguably not even the best one.
In practice, inductive biases can mean all sorts of different things. It could be explicit capacities like having a built-in short term memory, or more subtle and abstract aspects of the model’s design. For instance, the fact that neural networks are layered makes them inherently good at modeling hierarchies of abstractions, and that is an inductive bias that gives it an edge over many alternative machine learning paradigms. In fact, a huge part of designing a neural network architecture is building in the right inductive biases to give you the outcome you want.
An example: for a long time, the most common neural network for interpreting images (called Convolutional Neural Networks or CNNs) operated by sliding a window and looking at only a small portion of an image at a time, instead of feeding the entire thing in. This made the network immune to certain kinds of mistakes: it became impossible that shifting the image over a few pixels to the left could change the outputs. The result was an inductive bias that significantly improved performance.
Armed with this concept, one has a natural counterargument to my point above: couldn’t the super-intelligence just start with an inductive bias that made it really really well-suited to learning gravity?
The answer is “yes,” but I don’t think it changes much.
For one, when you really think about it, the line between “inductive bias” and “learning” is far blurrier than it might seem. Here’s an extreme example: suppose we initialized a random LLM-sized neural network and, by impossibly dumb luck, it winds up having *exactly* the same parameter values as one which was fully trained. All of that knowledge, all of that structure and all of those accumulated abstractions could not really be considered learned, right? They’re really just more information you’re using to select the correct hypothesis to fit your data. That makes them inductive bias, right? What else would they be?[8]
Of course, that example would never happen. But the fundamental point is there: inductive biases are, in some sense, just the abstractions that you start out with. Yes, depending on the model they may invoke harder or softer constraints than knowledge gained through other methods, but they really are just a form of built-in knowledge. It’s all the same stuff, it’s just a question of where you get it.
So before you tell me that this zero-knowledge superintelligence just has all the right inductive biases, consider that those inductive biases are still just built-in knowledge. And then consider this: all that knowledge has to come from somewhere.
Sutton’s Bitter Lesson
Before the age of deep learning, or even arguably during it, there was a thriving field of computer vision and natural language processing built on what was generally referred to as “hand-crafted” features. Instead of learning the statistical patterns in images or language as we do now, researchers would manually identify the types of patterns that seemed meaningful, and then program classifiers around those patterns. Things like “histograms of oriented gradients” which would find edges in images and count up how many were facing which direction.
It should come as no surprise that these methods all basically failed, and no one really uses them anymore. Hell, we barely use those CNNs I mentioned in the last section, the ones that process with sliding windows. Instead we use what are called transformers, which are in some sense more basic architectures; they build in far fewer assumptions about how the data is structured. In fact, there’s evidence that as transformers learn images they actually develop on their own the same structures used by CNNs.[9]
The way I see it, “hand-crafted” features are just building systems with carefully crafted inductive biases. It’s smart humans making educated guesses about what structure a system ought to have, and getting semi-useful models as a result. It’s a more realistic version of my example from the last section, where I suggested pre-setting the weights of a neural network into their final configuration. But it turns out it’s really really hard to construct an intelligent system manually; it seems it’s always better to let the structure emerge through learning.
The famous researcher Richard Sutton wrote about this idea in an essay called The Bitter Lesson. His argument was the same as the one I just made: hand-crafting fails time and time again, and the dominant approach always turns out to be scaled-up learning. I am merely just rephrasing it here in terms of inductive bias.
There’s No Skipping the Line
But if we’re taking a step back and looking at the larger picture, all our efforts to create hand-crafted classifiers were really just efforts to distill our own knowledge into another model. It’s a way to try to get the abstractions in our brains into some other system. And, sure, that’s really hard, but I don’t even think that’s the hardest part. Even if we could have constructed hand-crafted features that were really good at identifying what was in images, there’s no way you’d ever get something as dynamic as an LLM.
That’s because, just like how I believe an author of fiction can’t really write a character more intelligent than themselves, you probably can’t hand-craft something smarter than yourself. There’s too much of what I would call intellectual overhead in designing intelligence—to really model your own mind, you have to understand not just the abstractions you are using, but also the abstractions that let you understand those abstractions.
Nor do I think you could just luck into the right inductive biases. Sure, there’s a certain degree to which you may get a little lucky, but the space of possible model configurations is probably 100 billion orders of magnitude too large. No, the default state of any model is going to be completely unstructured (maximum entropy, as they say), so any structural intelligence is going to have to be either designed or learned.
This leads me to conclude that the only way we’d see a superintelligence with the right inductive biases to discover gravity off the bat would be if it was hand-designed by another superintelligence. That doesn’t really buy us much, because that second superintelligence still had to come from somewhere, and as I argued above, it would probably be smarter than its creation in that case anyway, at least in the beginning. So that scenario is really more of a loophole than a rebuttal.
The Evolution of Human Intelligence
When we start to apply these ideas to human intelligence, I think we get some interesting comparisons.
For one thing, inductive bias *does* play a very large role for humans. We come pre-programmed with a lot of knowledge, and a lot of capacity to learn more. I think most people here probably believe in IQ or some equivalent concept (g-factor or what have you), and this maps pretty much exactly to inductive biases. But even if you don’t believe in that I think there’s ample evidence that we have quite a bit of knowledge built in. It seems obvious that we’re optimized for, say, recognizing human faces, and we also seem to be pretty optimized to learn language. A young chess prodigy must have some sort of inductive bias for chess, how else could they get so good so fast? And if you want to look at the animal kingdom, you’ll see many animals are born already knowing how to walk or swim.
Of course, this is very different from LLMs, where as I explained the inductive biases are minimal and nearly the entirety of their knowledge comes from direct learning.[10] But I think I’ve made a compelling argument that this doesn’t really matter in the end—it’s where your system winds up that counts.
I think when we compare humans and AI, what we’re really observing is the radical difference between human engineering and natural selection as design processes.[11] A member of a species is one of very many and doesn’t live that long. The only way nature could possibly produce intelligence is by tweaking the inductive biases over countless generations, building organisms that come into existence with more and more ability to learn new things in a reasonable amount of time. Note as well that learning capacity—the maximum complexity of the abstractions a model can store—comes into this picture again, since that’s another knob nature can turn.
Meanwhile, you only have to design a digital AI once, and then it can be saved, copied, moved, or improved upon directly. And we’ve already established humans suck at developing inductive biases. So of course we would need to build general learning systems and train them for an eternity. We don’t have the time to do it the way nature did!
Conclusion: Training an AI System Must Be Slow
One conclusion of all this, which I’ve mentioned a few times now, is that training any AI system will be inherently slow and wasteful. I think at this point it should be clear why this conclusion follows from everything above: given some data and a limited amount of processing time, a system can only make new inferences as a function of the knowledge it already has. Forget about the maximum inference, you’re not going to be able to infer anything that can’t be concluded immediately from the abstractions you already have. You’re not going to be able to learn to exponentiate without learning to multiply first.
This means that at any given step of training, there’s a maximum to what you can learn in the next step, and especially in the beginning that’s going to be a lot less than the theoretical maximum. There’s no way around it. You can sort of brush it off by saying that you just start out smarter, but that intelligence still needs to come from somewhere. I genuinely do not believe humans are smart enough to just inject that intelligence at the get-go, and we just established that learning is probably inherently wasteful. The rest just sort of follows, and makes things like LLM training (which involve terabytes of text) kind of inevitable.[12]
Of course, “fast” hasn’t been defined rigorously here, but I think the point still stands broadly: nothing goes instantly from zero-to-superintelligent.
Final Thoughts: Why the Bet on Reinforcement Learning Didn’t Pay Off
I also think this explains another interesting question: Why didn’t the AI field’s big bet on reinforcement learning ever pay off?
Most of you are probably familiar with reinforcement learning (RL), but in case you aren’t RL is best summarized as trial-and-error learning (look at the world, take an action, get some kind of reward, repeat). Right at the start of the Deep Learning craze DeepMind made a huge name for itself with a famous paper[13] where they combined deep learning with RL and made an AI system that could perform really well on a bunch of Atari games. It was a big breakthrough, and it spawned a huge amount of research into Deep RL.
At the time, this really did seem like the most likely path to AGI. And it made a lot of sense: RL definitely seems to be a good description of the way humans learn. The problem was, as I heard one RL researcher say once, it always seemed as if the AI didn’t really “want” to learn. All of RL’s successes, even the huge ones like AlphaGo (which beat the world champion at Go) or its successors, were not easy to train. For one thing, the process was very unstable and very sensitive to slight mistakes. The networks had to be designed with inductive biases specifically tuned to each problem.
And the end result was that there was no generalization. Every problem required you to rethink your approach from scratch. And an AI that mastered one task wouldn’t necessarily learn another one any faster.
Thus, it seems that most RL research never really moved the needle towards AGI the way GPT-3 did.
Of course, it wasn’t like anyone could have just built GPT-3 in 2013. For a long time building an LLM would have been utterly impossible, because no one knew how to build neural networks that didn’t “saturate” when they got too big. Before the invention of the transformer, all previous networks stopped getting much better past a certain size.
But at the end of the day, those RL systems, by starting from nothing, weren’t building the kind of abstractions that would let them generalize. And they never would, as long as they were focusing on such a narrow range of tasks. They needed to first develop the rich vocabulary of reusable abstractions that comes with exposure to way more data.
It’s possible we’ll see a lot of those complex RL techniques re-applied on top of LLMs. But it seems the truth is that once you have that basic bedrock of knowledge to build upon, RL becomes a lot easier. After LLMs do an initial training on a giant chunk of the internet, RL is currently used to refine them so they respond to human commands, don’t say racist things, etc.[14] and this process is much more straightforward than the RL of yore. So it’s not that RL doesn’t work, it’s just that by itself it isn’t enough to give you the foundation knowledge needed for generalization.
- ^
Admittedly, it’s very rare that these limits on efficiency are actually proven, at least in the most general case, since no one’s proven that P != NP. But there is a lot of evidence that this is true.
- ^
Technically this isn’t proven, but a whole lot of smart people believe it’s true. P does not equal NP and all that.
- ^
It’s possible, maybe even likely, that if you actually could do the math on this you would find that the challenge of discovering gravity is really just doable in linear time given the minimal amount of required data. Maybe, who knows? None of this is well defined. I suspect the constant factors would still be very large, though.
- ^
Unless you already built the first N-1 steps into your system. Let’s not get ahead of ourselves though; I’ll address that.
- ^
Here’s one last salient example: the field of mathematics itself. Technically there is no input data at all and all provable things are already provable before you even start to do any work. And yet I’d bet good money that there’s a hard limit to how fast any intelligence could infer certain mathematical facts. And of course, many formal proof systems in mathematics actually have the property that there will always exist statements that take an arbitrary amount of effort to prove.
- ^
Actually, what I really did as a little kid was guess a number close to what I thought it was and refine from there, but that’s just another less elegant (and highly probabilistic) abstraction.
- ^
- ^
I guess you could come up with a different term, but that’s not the point. The point is whatever that knowledge is, it isn’t “learned.”
- ^
Their attention mechanisms develop into shift-invariant Toeplitz matrices. (Pay Attention to MLPs)
- ^
Although, is human learning actually more like fine-tuning? Maybe. Let’s not get into that; the argument would follow the same trajectory as the rest of this post anyway.
- ^
Yes, evolution is a design process, it’s just not an intelligent design process.
- ^
Obviously I’m not saying that LLMs won’t get far more efficient to train in the coming years, just that they’ll always require a certain minimum of resources. I’m also not giving a rigorous definition of “fast.” The exact value of that doesn’t matter; my points are more about the dynamics of learning.
- ^
- ^
If you want to get technical, the LLM is trained with RL during the whole process, since “next token prediction” is a special case of RL. But I don’t want to get that technical and I think my point is clear enough.
- Where do you lie on two axes of world manipulability? by (26 May 2023 3:04 UTC; 31 points)
- Without a trajectory change, the development of AGI is likely to go badly by (29 May 2023 23:42 UTC; 21 points)
- 's comment on Where do you lie on two axes of world manipulability? by (26 May 2023 7:22 UTC; 4 points)
- Without a trajectory change, the development of AGI is likely to go badly by (EA Forum; 30 May 2023 0:21 UTC; 1 point)
I don’t completely understand your point because I don’t have a calibration for your “slow” in “training an AI must be slow”. How slow is “slow”? Compared to what? (Leaving aside Solomonoff inductors and other incomputable things.)
Do you consider the usual case that “a toddler requires fewer examples” as a reference for “not slow”? If so: human DNA is < 1GB, so humans get at most 1GB of free knowledge as inductive bias. Does your argument for “AI slow” then rely on us not getting to that <1GB of stuff to preconfigure in a ML system? If not so (humans slow too): do you think humans are a ceiling, or close to one, on data efficiency?
You’re right that my points lack a certain rigor. I don’t think there is a rigorous answer to questions like “what does slow mean?”.
However, there is a recurring theme I’ve seen in discussions about AI where people express incredulity about neural networks as a method for AGI since they require so much “more data” than humans to train. My argument was merely that we should expect things to take a lot of data, and situations where they don’t are illusory. Maybe that’s less common in this space, so it I should have framed it differently. But I wrote this mostly to put it out there and get people’s thoughts.
Also, I see your point about DNA only accounting for 1GB. I wasn’t aware it was so low. I think it’s interesting and suggests the possibility of smaller learning systems than I envisioned, but that’s as much a question about compression as anything else. Don’t forget that that DNA still needs to be “uncompressed” into a human, and at least some of that process is using information stored in the previous generation of human. Admittedly, it’s not clear how much that last part accounts for, but there is evidence that part of a baby’s development is determined by the biological state of the mother.
But I guess I would say my argument does rely on us not getting that <1GB of stuff, with the caveat that that 1GB is super highly compressed through a process that takes a very complex system to uncompress.
I should add as well that I definitely don’t believe that LLMs are remotely efficient, and I wouldn’t necessarily be surprised if humans are as close to the maximum on data efficiency as possible. I wouldn’t be surprised if they weren’t, either. But we were built over millions (billions?) of years under conditions that put a very high price tag on inefficiency, so it seems reasonable to believe our data efficiency is at least at some type of local minima.
EDIT: Another way to phrase the point about DNA: You need to account not just for the storage size of the DNA, but also the Kolmogrov complexity of turning that into a human. No idea if that adds a lot to its size, though.
1GB for DNA is a lower bound. That’s how much it takes to store the abstract base pair representation. There’s lots of other information you’d need to actually build a human and a lot of it is common to all life. Like, DNA spends most of its time not in the neat little X shapes that happen during reproduction, but in coiled up little tangles. A lot of the information is stored in the 3D shape and in the other regulatory machinery attached to the chromosomes.
If all you had was a human genome, the best you could do would be to do a lot of simulation to reconstruct all the other stuff. Probably doable, but would require a lot of “relearning.”
The brain also uses DNA for storing information on the form of methylation patterns in individual neurons.
I expect that the mother does not add much to the DNA as information; so yes it’s complex and necessary, but I think you have to count almost only the size of DNA for inductive bias. That said, this is a gut guess!
Yeah I got this, I have the same impression. The way I think about the topic is: “The NN requires tons of data to learn human language because it’s a totally alien mind, while humans have produced themselves their language, so it’s tautologically adapted to their base architecture, you learn it easily only because it’s designed to be learned by you”.
But after encountering the DNA size argument myself a while ago, I started doubting this framework. It may be possible to do much, much better that what we do now.
Yeah, I agree that it’s a surprising fact requiring a bit of updating on my end. But I think the compression point probably matters more than you would think, and I’m finding myself more convinced the more I think about it. A lot of processing goes into turning that 1GB into a brain, and that processing may not be highly reducible. That’s sort of what I was getting at, and I’m not totally sure the complexity of that process wouldn’t add up to a lot more than 1GB.
It’s tempting to think of DNA as sufficiently encoding a human, but (speculatively) it may make more sense to think of DNA only as the input to a very large function which outputs a human. It seems strange, but it’s not like anyone’s ever built a human (or any other organism) in a lab from DNA alone; it’s definitely possible that there’s a huge amount of information stored in the processes of a living human which isn’t sufficiently encoded just by DNA.
You don’t even have to zoom out to things like organs or the brain. Just knowing which bases match to which amino acids is an (admittedly simple) example of processing that exists outside of the DNA encoding itself.
Even if you include a very generous epigenetic and womb-environmental component 9x bigger then the DNA component, any possible human baby at birth would need less then 10 GB to describe them completely with DNA levels of compression.
A human adult at age 25 would probably need a lot more to cover all possible development scenarios, but even then I can’t see it being more then 1000x, so 10TB should be enough.
For reference Windows Server 2016 supports 24 TB of RAM, and many petabytes of attached storage.
I think you’re broadly right, but I think it’s worth mentioning that DNA is a probabilistic compression (evidence: differences in identical twins), so it gets weird when you talk about compressing an adult at age 25 - what is probabilistic compression at that point?
But I think you’ve mostly convinced me. Whatever it takes to “encode” a human, it’s possible to compress it to be something very small.
A minor nitpick, DNA, the encoding concept, is not probabilistic, it’s everything surrounding such as the packaging, 3D shape, epigenes, etc., plus random mutations, transcription errors, etc., that causes identical twins to deviate.
Of course it is so compact because it doesn’t bother spending many ‘bits’ on ancilliary capabilities to correct operating errors.
But it’s at least theoretically possible for it to be deterministic under ideal conditions.
To that first sentence, I don’t want to get lost in semantics here. My specific statement is that the process that takes DNA into a human is probabilistic with respect to the DNA sequence alone. Add in all that other stuff, and maybe at some point it becomes deterministic, but at that point you are no longer discussing the <1GB that makes DNA. If you wanted to be truly deterministic, especially up to the age of 25, I seriously doubt it could be done in less than millions of petabytes, because there are such a huge number of miniscule variations in conditions and I suspect human development is a highly chaotic process.
As you said, though, we’re at the point of minor nitpicks here. It doesn’t have to be a deterministic encoding for your broader points to stand.
Perhaps I phrased it poorly, let me put it this way.
If super-advanced aliens suddenly showed up tomorrow and gave us the near-physically-perfectly technology, machines, techniques, etc., we could feasibly have a fully deterministic, down to the cell level at least, encoding of any possible individual human stored in a box of hard drives or less.
In practical terms I can’t even begin to imagine the technology needed to reliably and repeatably capture a ‘snapshot’ of a living, breathing, human’s cellular state, but there’s no equivalent of a light speed barrier preventing it.
How did you estimate the number of possible development scenarios till the age 25?
Total number of possible permutations an adult human brain could be in and still remain conscious, over and above that of a baby’s. The most extreme edge cases would be something like a Phineas Gage, where a ~1 inch diameter iron rod was rammed through a frontal lobe and he still could walk around.
So fill in the difference with guesstimation
I doubt there’s literally 1000x more permutations, since there’s already a huge range of possible babies, but I chose it anyways as a nice round number.
I had the distinct impression that AlphaZero (the version of AlphaGo where they removed all the tweaks) could be left alone for an afternoon with the rules of almost any game in the same class as go, chess, shogi, checkers, noughts-and-crosses, connect four, othello etc, and teach itself up to superhuman performance.
In the case of chess, that involved rediscovering something like 400 years of human chess theorizing, to become the strongest player in history including better than all previous hand-constructed chess programs.
In the case of go, I am told that it not only rediscovered a whole 2000 year history of go theory, but added previously undiscovered strategies. “Like getting a textbook from the future”, is a quote I have heard.
That strikes me as neither slow nor ungeneral.
And there was enough information in the AlphaZero paper that it was replicated and improved on by the LeelaChessZero open-source project, so I don’t think there can have been that many special tweaks needed?
Admittedly, the success of AlphaZero relied on it being essentially able to generate very, very large amounts of very high-quality data, so this is a domain where synthetic data was very successful.
So a weaker version of the post is “you need either a lot of data, and high quality ones, or high amounts of compute, and there’s little going around it.”
One aspect you skipped over was how a superintelligence might reason if given data that has many possible hypotheses for an explanation.
You mentioned occam’s razor, and kinda touched on inductive biases, but I think you left out something important.
If you think about it, Occam’s razor is part of a process of : consider multiple hypothesis. Take the minimum complexity hypothesis, discard the others.
We can do better than that, trivially. See particle filters. In that case the algorithm is : consider up to n possible hypotheses and store them in memory in a hypothesis space able to contain them. (so the 2d particle filter exists in a space for only 2d coordinates, but it is possible to have an n dimension filter for the space of coherent scientific theories etc).
A human intelligence using occam’s razor is just doing a particle filter where you carry over only 1 point from step to step. And during famous scientific debates, another “champion” of a second theory held onto a different point.
Since a superintelligence can have an architecture with more memory and more compute, it can hold n points. It could generate millions of hypotheses (or near infinite) from the “3 frames” example, and some would contain correct theories of gravity. It can then reason using all hypotheses it has in memory, weighted by probability or by a clustering algorithm or other methods. This means it would be able to act, controlling robotics in the real world or making decisions, without having found a coherent theory of gravity yet, just a large collection of hypotheses biased towards ‘objects fall’. (3 frames is probably not enough information to act effectively)
I’m not sure “architecture” isn’t distinct from inductive bias. “Architecture” is the dimensions of each network, the topology connecting each network, the subcomponents of each network, and the training loss functions used at each stage. What’s different is that a model cannot learn it’s way past architectural limits, a model the scale of GPT-2 cannot approach the performance of GPT-4 no matter the amount of training data.
So inductive bias = information you started with, isn’t necessary because a general enough network can still learn the same information if it has more training information.
architecture = technical way the machine is constructed, it puts a ceiling on capabilities even with infinite training data.
Another aspect of this is considering the particle filter case, where a superintelligence tracks n hypotheses for what it believes during a decision making process. Each time you increment n+1, you increase compute needed per decision by O(n) or some cases much worse than that. There’s probably a way to mathematically formalize this and estimate how a superintelligence’s decision making ability scales with compute, since each additional hypothesis you track has diminishing returns. (probably per the same power law for training loss for llm training)
To your point about the particle filter, my whole point is that you can’t just assume the super intelligence can generate an infinite number of particles, because that takes infinite processing. At the end of the day, superintelligence isn’t magic—those hypotheses have to come from somewhere. They have to be built, and they have to be built sequentially. The only way you get to skip steps is by reusing knowledge that came from somewhere else.
Take a look at the game of Go. The computational limits on the number of games that could be simulated made this “try everything” approach essentially impossible. When Go was finally “solved”, it was with an ML algorithm that proposed only a limited number of possible sequences—it was just that the sequences it proposed were better.
But how did it get those better moves? It didn’t pull them out of the air, it used abstractions it had accumulated form playing a huge number of games.
_____
I do agree with some of the things you’re saying about architecture, though. Sometimes inductive bias imposes limitations. In terms of hypotheses, it can and does often put hard limits on which hypotheses you can consider, period.
I also admit I was wrong and was careless in saying that inductive bias is just information you started with. But I don’t think it’s imprecise to say that “information you started with” is just another form of inductive bias, of which ”architecture” is another.
But at a certain point, the line between architecture and information is going to blur. As I’ve pointed out, a transformer without some of the explicit benefits of a CNN’s architecture can still structure itself in a way that learns shift invariance. I also don’t think any of this effects my key arguments.
Lets assume that as part of pondering the three webam frames, the AI thought of the rules of Go- ignoring how likely this is.
In that circumstance, in your framing of the question, would it be allowed to play several million games against itself to see if that helped it explain the arrays of pixels?
I guess so? I’m not sure what point you’re making, so it’s hard for me to address it.
My point is that if you want to build something intelligent, you have to do a lot of processing and there’s no way around it. Playing several million games of Go counts as a lot of processing.
Doubtless there are! And limits to how much it is possible to learn from given data.
But I think they’re surprisingly high, compared to how fast humans and other animals can do it.
There are theoretical limits to how fast you can multiply numbers, given a certain amount of processor power, but that doesn’t mean that I’d back the entirety of human civilization to beat a ZX81 in a multiplication contest.
What you need to explain is why learning algorithms are a ‘different sort of thing’ to multiplication algorithms.
Maybe our brains are specialized to learning the sorts of things that came in handy when we were animals.
But I’d be a bit surprised if they were specialized to abstract reasoning or making scientific inferences.
I always assumed the original apple frames and grass quote to be...maybe not a metaphor, but at least acknowledged as a theoretical rather than practical ideal. What a hypercomputer executing Solomonoff induction might be able to accomplish.
The actual feat of reasoning described in the story itself is that an entire civilization of people approaching the known-attainable upper reaches of human intelligence, with all the past data and experience that entails, devoting its entire thought and compute budget for decades towards what amounts to a single token prediction problem with a prompt of a few MB in size.
I think we can agree that those are, at least, sufficiently wide upper and lower bounds for what would be required in practice to solve the Alien Physics problem in the story.
Everything else, the parts about spending half a billion subjective years persuading them to let us out of the simulation, is irrelevant to that question. So what really is the practical limit? How much new input to how big a pre-existing model? I don’t know. But I do know that while humans have access to lots of data during our development, we throw almost all of it away, and don’t have anywhere near enough compute to make thorough use of what’s left. Which in turn means the limit of learning with the same data and higher compute should be much faster than human.
In any case, an AI doesn’t need to be anywhere near the theoretical limit, in a world where readily available sources of data online include tens of thousands of years of video and audio, and hundreds of terabytes of text.
It’s true that an exact solution might be intractable, but approximate solutions are often good enough. According to wikipedia:
Perhaps there is a yet-undiscovered heuristic algorithm for approximating Solomonoff induction relatively efficiently.
Yes, I wasn’t sure if it was wise to use TSP as an example for that reason. Originally I wrote it using the Hamiltonian Path problem, but thought a non-technical reader would be more able to quickly understand TSP. Maybe that was a mistake. It also seems I may have underestimated how technical my audience would be.
But your point about heuristics is right. That’s basically what I think an AGI based on LLMs would do to figure out the world. However, I doubt there would be one heuristic which could do Solomonoff induction in all scenarios, or even most. Which means you’d have to select the right one, which means you’d need a selection criteria, which takes us back to my original points.
There are—approximate inference on neural networks, such as variants of SGD. Neural networks are a natural universal circuit language, so you can’t get any more than a constant improvement by moving to another universal representation. And in the class of all learning algorithms which approximately converge to full bayesian inference (ie solomonoff induction), SGD style Langevin Dynamics are also unique and difficult to beat in practice—the differences between that and full bayesian inference reduce to higher order corrections which rapidly fall off in utility/op.
Do you have a link to a more in-depth defense of this claim?
I mean it’s like 4 or 5 claims? So not sure which ones you want more in-depth on, but
Neural networks are universal is obvious, as arithmetic/analog circuits they fully generalize (reduce to) binary circuits, which are circuit complete.
A Full Bayesian Inference and Solomonoff Induction are equivalent—fairly obvious
B Approximately converge is near guaranteed if the model is sufficiently overcomplete and trained long enough with correct techniques (normalization, regularization, etc) - as in the worst case you can recover exhaustive exploration ala solomonoff. But SGD on NN is somewhat exponentially faster that exhaustive program search, as it can explore not a single solution at a time, but a number of solutions (sparse sub circuits embedded in the overcomplete model) that is exponential with NN depth (see lottery tickets, dropout, and sum product networks).
C ” differences between that and full bayesian inference reduce to higher order corrections which rapidly fall off in utility/op”. This is known perhaps experimentally in the sense that the research community has now conducted large-scale extensive (and even often automated) exploration of much of the entire space of higher order corrections to SGD, and come up with almost nothing much better than stupidly simple inaccurate but low cost 2nd order correction approximations like Adam. (The research community has come up with an endless stream of higher order optimizers that improve theoretical convergence rate, and near zero that improve wall time convergence speed. ) I do think there is still some room for improvement here, but not anything remotely like “a new category of algorithm”.
But part of my claim simply is that modern DL techniques encompasses nearly all of optimization that is relevant, it simply ate everything, such that the possibility of some new research track not already considered is would be just nomenclature distinction at this point.
Neural networks being universal approximators doesn’t mean they do as well at distributing uncertainty as Solomonoff, right (I’m not entirely sure about this)? Also, are practical neural nets actually close to being universal?
Do you mean that this is possible in principle, or that this is a limit of SGD training?
I read your original claim as “SGD is known to approximate full Bayesian inference, and the gap between SGD and full inference is known to be small”. Experimental evidence that SGD performs competitively does not substantiate that claim, in my view.
Trivially so—as in they can obviously encode a binary circuit equivalent to a CPU, and also in practice in the sense that transformers descend from related research (neural turing machines, memory networks, etc) and are universal.
I mean in the worst case where you have some function that is actually really hard to learn—as long as you have enough data (or can generate it ) - big overcomplete NNs with SGD can obviously perform a strict improvement over exhaustive search .
Depends on what you mean by “gap”—whether you are measuring inference per unit data or inference per unit compute.
There are clearly scenarios where you can get faster convergence via better using/approximating the higher order terms, but that obviously is not remotely sufficient to beat SGD—as any such extra complexity must also pay for itself against cost of compute.
Of course if you are data starved, then that obviously changes things.
A CPU by itself is not universal. Are you saying memory augmented neural networks are practically close to universality?
Sorry, I’m being slow here:
Solomonoff does exhaustive search for any amount of data; is part of your claim that as data → infinity, NN + SGD → Solomonoff?
How do we actually do this improved exhaustive search? Do we know that SGD gets us to a global minimum in the end?
Any useful CPU is by my definition—turing universal.
You can think of solomonoff as iterating over all programs/circuits by size, evaluating each on all the data, etc.
A sufficiently wide NN + SGD can search the full circuit space up to a depth D across the data set in an efficient way (reusing all subcomputations across sparse subcircuit solutions (lottery tickets)).
Thanks for explaining the way to do exhaustive search—a big network can exhaustively search smaller network configurations. I believe that.
However, a CPU is not Turing complete (what is Turing universal?) - a CPU with an infinite read/write tape is Turing complete. This matters, because Solomonoff induction is a mixture of Turing machines. There are simple functions transformers can’t learn, such as “print the binary representation of the input + 1”; they run out of room. Solomonoff induction is not limited in this way.
Practical transformers are also usually (always?) used with exchangeable sequences, while Solomonoff inductors operate on general sequences. I can imagine ways around this (use a RNN and many epochs with a single sequence) so maybe not a fundamental limit, but still a big difference between neural nets in practice and Solomonoff inductors.
for the 3d part: either the object of observation needs to move, or the observer needs to move: these are equivalent statements due to symmetry. consider two 2D images taken simultaneously from different points of observation: this provides the same information relevant here as were there to be but 2 images of a moving object from a stationary observer at slightly different moments in time.
in fact then, you don’t need to see movement in order to learn that the world is 3D. making movement a requirement to discover the dimensionality of a space mandates the additional dimension of time: how then could we discover the 4 dimensional space-time without access to some 5th dimensional analog of time? it’s an infinite regress.
similarly, you don’t need to understand the movement of light. certainly, we didn’t for a very long time. you just need to understand the projection from object to image. that’s where the bulk of these axiomatic properties of worldly knowledge reside (assumptions about physics being regular, or whatever else you need so that you can leverage things like induction in your learning).
My objection applied at a different level of reasoning. I would argue that anyone who isn’t blind understands light at the level I’m talking about. You understand that the colors you see are objects because light is bouncing off them and you know how to interpret that. If you think about it, starting from zero I’m not sure that you would recognize shapes in pictures as objects.