AI doom from an LLM-plateau-ist perspective
(in the form of an FAQ)
Q: What do you mean, “LLM plateau-ist”?
A: As background, I think it’s obvious that there will eventually be “transformative AI” (TAI) that would radically change the world.[1]
I’m interested in what this TAI will eventually look like algorithmically. Let’s list some possibilities:
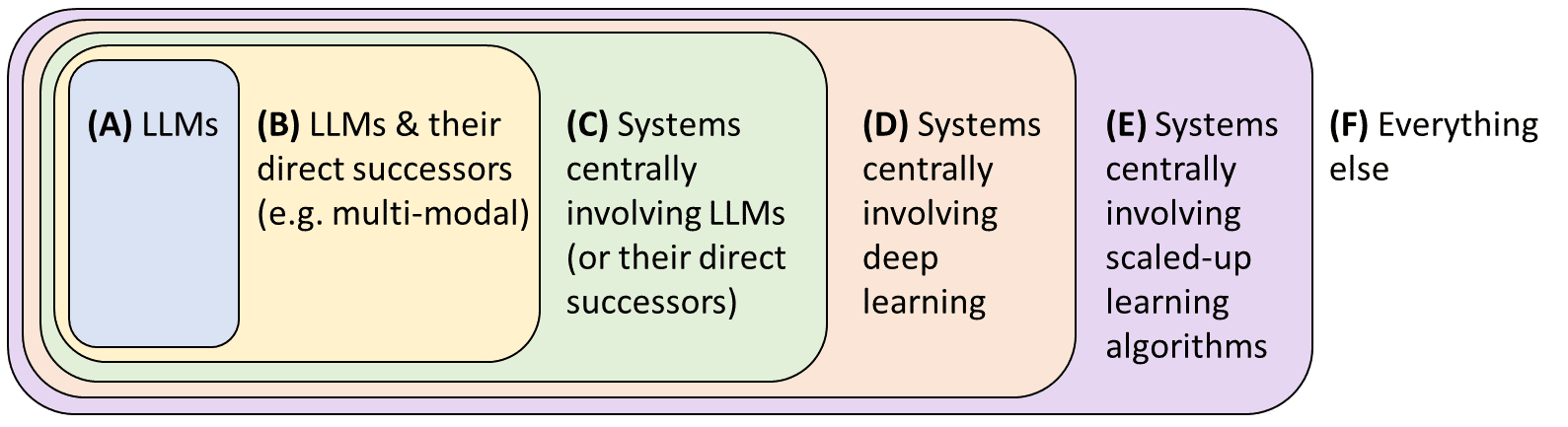
A “Large Language Model (LLM) plateau-ist” would be defined as someone who thinks that categories (A-B), and usually also (C), will plateau in capabilities before reaching TAI levels.[2] I am an LLM plateau-ist myself.[3]
I’m not going to argue about whether LLM-plateau-ism is right or wrong—that’s outside the scope of this post, and also difficult for me to discuss publicly thanks to infohazard issues.[4] Oh well, we’ll find out one way or the other soon enough.
In the broader AI community, both LLM-plateau-ism and its opposite seem plenty mainstream. Different LLM-plateau-ists have different reasons for holding this belief. I think the two main categories are:
Theoretical—maybe they have theoretical beliefs about what is required for TAI, and they think that LLMs just aren’t built right to do the things that TAI would need to do.
Empirical—maybe they’re not very impressed by the capabilities of current LLMs. Granted, future LLMs will be better than current ones. But maybe they have extrapolated that our planet will run out of data and/or compute before LLMs get all the way up to TAI levels.
Q: If LLMs will plateau, then does that prove that all the worry about AI x-risk is wrong and stupid?
A: No no no, a million times no, and I’m annoyed that this misconception is so rampant in public discourse right now.
(Side note to AI x-risk people: If you have high credence that AI will kill everyone but only medium credence that this AI will involve LLMs, then maybe consider trying harder to get that nuance across in your communications. E.g. Eliezer Yudkowsky is in this category, I think.)
A couple random examples I’ve seen of people failing to distinguish “AI may kill everyone” from “…and that AI will definitely be an LLM”:
Venkatesh Rao’s blog post “Beyond Hyperanthropomorphism” goes through an elaborate 7000-word argument that eventually culminates, in the final section, in his assertion that a language model trained on internet data won’t be a powerful agent that gets things done in the world, but if we train an AI with a robot body, then it could be a powerful agent that gets things done in the world. OK fine, let’s suppose for the sake of argument he’s right that robot bodies will be necessary for TAI.[5] Then people are obviously going to build those AIs sooner or later, right? So let’s talk about whether they will pose an x-risk. But that’s not what Venkatesh does. Instead he basically treats “they will need robot bodies” as the triumphant conclusion, more-or-less sufficient in itself to prove that AI x-risk discourse is stupid.
Sarah Constantin’s blog post entitled “Why I am not an AI doomer” states right up front that she agrees “1. Artificial general intelligence is possible in principle … 2, Artificial general intelligence, by default, kills us all … 3. It is technically difficult, and perhaps impossible, to ensure an AI values human life.” She only disagrees with the claim that this will happen soon, and via scaling LLMs. I think she should have picked a different title for her post!!
(I’ve seen many more examples on Twitter, reddit, comment threads, etc.)
Anyway, if you think LLMs will plateau, then you can probably feel confident that we won’t get TAI imminently (see below), but I don’t see why you would have much more confidence that TAI will go well for humanity. In fact, for my part, if I believed that (A)-type systems were sufficient for TAI—which I don’t—then I think I would feel slightly less concerned about AI x-risk than I actually do, all things considered!
The case that AI x-risk is a serious concern long predates LLMs. If you want a non-LLM-centric AI x-risk discussion, then most AI x-risk discussions ever written would qualify. I have one here, or see anything written more than a year or two ago, for example.
Q: Do the people professionally focused on AI x-risk tend to think LLMs will plateau? Or not?
I haven’t done a survey or anything, but I’ll give a hot-take gestalt impression. (This is mostly based on reading what everyone is writing, and occasionally chatting with people at conferences and online.)
Certainly, there is a mix of opinions. But one common pattern I’ve noticed recently (i.e. in the last year) [this certainly doesn’t apply to everyone] is that there’s often a weird disconnect where, when someone is asked explicitly, they claim to have lots of credence (even 50% or more) outside (C), but everything they say and do is exactly as if all of their credence is in (A-C)—indeed, often as if it’s all in (A).[6]
I think the charitable explanation for this discrepancy is that a TAI scenario within categories (A-C) is more urgent and tractable, and therefore we should focus conversation on that scenario, even while acknowledging the possibility that this scenario won’t happen because LLMs will plateau.

The uncharitable explanation is that some people’s professed beliefs are out-of-sync with their true beliefs—and if so, maybe they should sort that out.
Q: If LLMs will plateau, then can we rest assured that TAI is many decades away?
A: I think that I and my fellow LLM-plateau-ists can feel pretty good that TAI won’t happen in 2023. Probably not 2024 either. Once we start getting much further out than that, I think we should be increasingly uncertain.
The field of AI is wildly different today than it was 10 or 20 years ago. By the same token, even without TAI, we should expect that the field of AI will be wildly different 10 or 20 years into the future. I think 10 or 20 years is more than enough time for currently-underdeveloped (or even currently-nonexistent) AI techniques to be invented, developed, extensively iterated, refined, and scaled.
So even if you’re an LLM plateau-ist, I don’t think you get to feel super-confident that TAI won’t happen in the next 10 or 20 years. Maybe, maybe not. Nobody knows. Technological forecasting is very hard.
(By the way: Even if TAI were known to be many decades away, we should still be working frantically right now on AI alignment, for reasons here.)
(If you think TAI is definitely decades-to-centuries away because the human brain is super complicated, I have a specific response to that here & here.)
Q: If LLMs will plateau, how does that impact governance and “the pause”?
A: As above, I think very dangerous TAI will come eventually, and that we’re extremely not ready for it, and that we’re making slow but steady progress right now on getting ready, and so I’d much rather it come later than sooner. (So far this is independent of whether LLMs will plateau.) (More details and responses to common counter-arguments here.)
Relatedly, there has been a recent push for “pausing giant AI experiments” spearheaded by the Future of Life Institute (FLI).
My take is: a “pause” in training unprecedentedly large ML models is probably good if TAI will look like (A-B), maybe good if TAI will look like (C), and probably counterproductive if TAI will be outside (C).
Why? The biggest problem in my mind is algorithmic progress. If we’re outside (C), then the “critical path to TAI” right now is algorithmic progress. Granted, scaling would need to happen at some point, but not yet, and perhaps not much scaling if any—I think there are strong reasons to expect that a GPT-4 level of scale (or even less, or even much much less) is plenty for TAI, given better algorithms.[7]
(Algorithmic progress is relevant less and less as we move towards (A), but still relevant to some extent even in (A).)
My guess is that scaling and algorithmic progress are currently trading off against each other, for various reasons. So interventions against scaling would cause faster algorithmic progress, which is bad from my perspective.
(Incidentally, at least one non-LLM-plateau-ist also opposes “pause” for reasons related to algorithmic progress.)
The obvious follow-up question is: “OK then how do we intervene to slow down algorithmic progress towards TAI?” The most important thing IMO is to keep TAI-relevant algorithmic insights and tooling out of the public domain (arxiv, github, NeurIPS, etc.). I appeal to AI researchers to not publicly disclose their TAI-relevant ideas, and to their managers to avoid basing salary, hiring, and promotion decisions on open publications.[8] Researchers in almost every other private-sector industry publish far less than do private-sector ML/AI researchers. Consider SpaceX, for example.
I will also continue to spend some of my time trying to produce good pedagogy about AI x-risk, and to engage in patient, good-faith arguments (as opposed to gotchas) when the subject comes up, and to do the research that may lead to more crisp and rigorous arguments for why AI doom is likely (if indeed it’s likely). I encourage others to continue doing all those things too.
To be sure, I don’t think “slow down algorithmic progress towards TAI by trying to win over AI researchers and ask nicely for a change to AI research culture” is an intervention that will buy us much time, but maybe a bit, and it’s obviously a good thing to do regardless, and anyway I don’t have any better ideas.
(Thanks Linda Linsefors & Seth Herd for critical comments on a draft.)

- ^
If that’s not obvious, consider (as an existence proof) that it will eventually be possible to run brain-like algorithms on computer chips, as smart and insightful as any human, but thinking 100× faster, and there could be trillions of them with trillions of teleoperated robot bodies and so on. More discussion here.
- ^
It’s quite possible that there is more than one viable path to TAI, in which case the question is: which one will happens first? I am implicitly assuming in this post that the (A-B) LLMs are far enough along (compared to other approaches) that either they will plateau soon or they will “win the race”. If you like, you can replace the phrase “LLMs will plateau” with the weaker “LLMs will plateau or at least revert to a much much slower rate of improvement such that other paths to TAI will happen instead.”
- ^
Stating my own opinions without justifying them: I put pretty low weight on (A-B), mainly for theoretical reasons. I’m nervous to confidently say that (C) won’t happen, because (C) is a broad category including lots of possibilities that have never occurred to me. But I put pretty low weight on it anyway. (After all, (D) & (E) include even more possibilities that have never occurred to me!) I put negligible weight on (F). I seem to be the only full-time AI x-risk researcher who treats (E) as the most likely possibility. Heck, maybe I’m the only full-time AI x-risk researcher who treats (E) as a possibility at all. (Human brains have “neural nets”, but they’re not “deep”, and they differ from DNNs in various other ways too. Experts disagree about whether any of those differences are important.) But (E)-versus-(D) is not too safety-relevant anyway, in my opinion—my research interest is in safety/alignment for model-based RL AGI, and model-based RL AGI could exist in (E) or (D) or (C), and it doesn’t matter too much which from a safety perspective, AFAICT.
- ^
Explanation for the unfamiliar: From my perspective, developing TAI soon is bad—see final section below. I have various idiosyncratic grand ideas about the requirements for powerful AI and limitations of LLMs. Maybe those ideas are wrong and stupid, in which case, it’s just as well that I don’t spread them. Or maybe they’re right, in which case, I also don’t want to spread them, because they could help make TAI come marginally sooner. (Spreading the ideas would also have various benefits, but I think the costs mostly outweigh the benefits here.)
- ^
For my part, I find it very hard to imagine that a literal robot body will be necessary to create an AI that poses an x-risk. I guess I’m somewhat open-minded to the possibility that a virtual robot body in a VR environment could be necessary (or at least helpful) during at least part of the training. And I think it’s quite likely that the AI needs to have an “action space” of some sort to reach TAI levels, even if it’s non-body-ish things like “virtually opening a particular text document to a particular page”.
- ^
For example, my sense is that some people will explicitly say “scale is all you need”, but many more people will effectively assume that “scale is all you need” when they’re guessing when TAI will arrive, what it will look like, what its alignment properties will be, how much compute it will involve, etc. To elaborate on one aspect of that, there’s been a lot of alignment-of-(A) discourse (simulators, waluigi, shoggoth memes, etc.), and to me it’s far from obvious that this discourse would continue to be centrally relevant in the broader category of (C). For example, it seems to me that there are at least some possible (C)-type systems for which we’ll need to be thinking about their safety using mostly “classic agent alignment discourse” (instrumental convergence, goal misgeneralization, etc.) instead.
- ^
For example, the calculations of a human brain entail fewer FLOP/s than a single good GPU (details). The brain might have more memory capacity than one GPU, although my current guess is it doesn’t; anyway, the brain almost definitely has less memory capacity than 1000 GPUs.
- ^
There are cases where public disclosure has specific benefits (helping safety / alignment) that outweighs its costs (making TAI come sooner). It can be a tricky topic. But I think many AI researchers don’t even see timeline-shortening as a cost at all, but rather a benefit.
- Foom & Doom 1: “Brain in a box in a basement” by (23 Jun 2025 17:18 UTC; 293 points)
- Munk AI debate: confusions and possible cruxes by (27 Jun 2023 14:18 UTC; 244 points)
- [Intro to brain-like-AGI safety] 1. What’s the problem & Why work on it now? by (26 Jan 2022 15:23 UTC; 165 points)
- Munk AI debate: confusions and possible cruxes by (EA Forum; 27 Jun 2023 15:01 UTC; 143 points)
- My AGI safety research—2025 review, ’26 plans by (11 Dec 2025 17:05 UTC; 136 points)
- “The Era of Experience” has an unsolved technical alignment problem by (24 Apr 2025 13:57 UTC; 116 points)
- My AGI safety research—2024 review, ’25 plans by (31 Dec 2024 21:05 UTC; 111 points)
- 's comment on Big tech transitions are slow (with implications for AI) by (24 Oct 2024 17:40 UTC; 69 points)
- Internal independent review for language model agent alignment by (7 Jul 2023 6:54 UTC; 56 points)
- Alignment & Capabilities: What’s the difference? by (EA Forum; 31 Aug 2023 22:13 UTC; 50 points)
- 's comment on AI is not taking over material science (for now): an analysis and conference report by (EA Forum; 11 Mar 2025 17:41 UTC; 45 points)
- Summaries of top forum posts (24th − 30th April 2023) by (EA Forum; 2 May 2023 2:30 UTC; 44 points)
- Response to Dileep George: AGI safety warrants planning ahead by (8 Jul 2024 15:27 UTC; 28 points)
- 's comment on Against most, but not all, AI risk analogies by (15 Jan 2024 1:52 UTC; 20 points)
- 's comment on On the Dwarkesh/Chollet Podcast, and the cruxes of scaling to AGI by (EA Forum; 17 Jun 2024 3:16 UTC; 18 points)
- 's comment on AI Pause Will Likely Backfire by (EA Forum; 17 Sep 2023 14:03 UTC; 14 points)
- Summaries of top forum posts (24th − 30th April 2023) by (2 May 2023 2:30 UTC; 12 points)
- What are some other introductions to AI safety? by (EA Forum; 17 Feb 2025 11:48 UTC; 9 points)
- 's comment on LLMs won’t lead to AGI—Francois Chollet by (EA Forum; 13 Jun 2024 16:50 UTC; 7 points)
- 's comment on Sam Altman’s Chip Ambitions Undercut OpenAI’s Safety Strategy by (15 Feb 2024 0:40 UTC; 6 points)
- 's comment on Against AI As An Existential Risk by (31 Jul 2024 2:43 UTC; 5 points)
- 's comment on LLMs won’t lead to AGI—Francois Chollet by (EA Forum; 14 Jun 2024 16:19 UTC; 4 points)
- 's comment on Goal: Understand Intelligence by (7 Nov 2024 13:49 UTC; 4 points)
- 's comment on Four ways learning Econ makes people dumber re: future AI by (1 Oct 2025 19:02 UTC; 4 points)
- 's comment on RobertM’s Shortform by (6 Jun 2024 11:23 UTC; 3 points)
- 's comment on 8 examples informing my pessimism on uploading without reverse engineering by (5 Nov 2023 21:29 UTC; 2 points)
- 's comment on LLMs and computation complexity by (30 Apr 2023 19:00 UTC; 1 point)
I think it’s worth disentangling LLMs and Transformers and so on in discussions like this one—they are not one and the same. For instance, the following are distinct positions that have quite different implications:
The current precise transformer LM setup but bigger will never achieve AGI
A transformer trained on the language modelling objective will never achieve AGI (but a transformer network trained with other modalities or objectives or whatever will)
A language model with the transformer architecture will never achieve AGI (but a language model with some other architecture or training process will)
Which interventions make sense depends a lot on your precise model of why current models are not AGI, and I would consequently expect modelling things at the level of “LLMs vs not LLMs” to be less effective.
You didn’t ask me but let me answer
I ~ believe all three.
For the first I will just mention that labs are already moving away from the pure transformer architecture. Don’t take it from me, Sam Altman is on record saying they re moving away from pure scaling.
For the second I don’t think it’s a question about modalities. Text is definitely rich enough (’text is the universal interface)
Yes to the third. Like Byrnes I don’t feel I want to talk too much about it. (But I will say it’s not too different from what’s being deployed right now. In particular I dont think there is something completely mysterious about intelligence or we need GOFAI or understand consciousness something like that)
The trouble is that AGI is an underdefined concept. In my conception these simply don’t have the right type signature / architecture. Part of the problem is many people of conceiving General Intelligence in terms of capabilities which I think is misleading. A child is generally intelligent but a calculator is not.
The only caveat here is that it is conceivable that a large enough LLM might have a generally intelligent mesaoptimizers within it. I’m confused how likely this is.
That is not to say LLMs won’t be absolutely transformative—they will! And that is not to say timelines are long (I fear most of what is needed for AGI is already known by various people)
How long have you held your LLM plateau model and how well did it predict GPT4 scaling? How much did you update on GPT4? What does your model predict for (a hypothetical) GPT5?
My answers are basically that I predicted back in 2015 that something not much different than NNs of the time (GPT1 was published a bit after) could scale all the way with sufficient compute, and the main key missing ingredient of 2015 NNs was flexible context/input dependent information routing, which vanilla FF NNs lack. Transformers arrived in 2017[1] with that key flexible routing I predicted (and furthermore use all previous neural activations as a memory store) which emulates a key brain feature in fast weight plasticity.
GPT4 was something of an update in that they simultaneously scaled up the compute somewhat more than I expected but applied it more slowly—taking longer to train/tune/iterate etc. Also the scaling to downstream tasks was somewhat better than I expected.
All that being said, the transformer arch on GPUs only strongly accelerates training (consolidation/crystallization of past information), not inference (generation of new experience), which explains much of what GPT4 lacks vs a full AGI (although there are other differences that may be important, that is probably primary, but further details are probably not best discussed in public).
Attention is All you Need
In this post, I’m not trying to convert people to LLM plateau-ism. I only mentioned my own opinions as a side-comment + short footnote with explicitly no justification. And if I were trying to convert people to LLM plateau-ism, I would certainly not attempt to do so on the basis of my AI forecasting track record, which is basically nonexistent. :)
It would still be interesting to know whether you were surprised by GPT-4′s capabilities (if you have played with it enough to have a good take)
When I started blogging about AI alignment in my free time, it happened that GPT-2 had just come out, and everyone on LW was talking about it. So I wrote a couple blog posts (e.g. 1,2) trying (not very successfully, in hindsight, but I was really just starting out, don’t judge) to think through what would happen if GPT-N could reach TAI / x-risk levels. I don’t recall feeling strongly that it would or wouldn’t reach those levels, it just seemed like worth thinking about from a safety perspective and not many other people were doing so at the time. But in the meantime I was also gradually getting into thinking about brain algorithms, which involve RL much more centrally, and I came to believe that that RL was necessary to reach dangerous capability levels (recent discussion here; I think the first time I wrote it down was here). And I still believe that, and I think the jury’s out as to whether it’s true. (RLHF doesn’t count, it’s just a fine-tuning step, whereas in the brain it’s much more central.)
My updates since then have felt less like “Wow look at what GPT can do” and more like “Wow some of my LW friends think that GPT is rapidly approaching the singularity, and these are pretty reasonable people who have spent a lot more time with LLMs than I have”.
I haven’t personally gotten much useful work out of GPT-4. Especially not for my neuroscience work. I am currently using GPT-4 only for copyediting. (“[The following is a blog post draft. Please create a bullet point list with any typos or grammar errors.] …” “Was there any unexplained jargon in that essay?” Etc.) But maybe I’m bad at prompting, or trying the wrong things. I certainly haven’t tried very much, and find it more useful to see what other people online are saying about GPT-4 and doing with GPT-4, rather than my own very limited experience.
Anyway, I have various theory-driven beliefs about deficiencies of LLMs compared to other possible AI algorithms (the RL thing I mentioned above is just one of many things), and I still strongly hold those beliefs. The place where I have more uncertainty recently is the idea: “well sure, maybe LLMs aren’t the most powerful possible AI algorithm for reasons 1,2,3,4,5,6, but maybe they’re still powerful enough to launch a successful coup against humanity. How hard can that be anyway, right?” I hadn’t really thought about that possibility until last month. I still think it’s not gonna happen, but obviously not with so much confidence that I’m not gonna go around advocating against people preparing for the possible contingency wherein LLMs lead to x-risk.
fwiw, I think I’m fairly close to Steven Byrnes’ model. I was not surprised by gpt-4 (but like most people who weren’t following LLMs closely was surprised by gpt-2 capabilities)
Good essay! Two questions if you have a moment:
1. Can you flesh out your view of how the community is making “slow but steady progress right now on getting ready”? In my view, much of the AI safety community seems to be doing things that have unclear safety value to me, like (a) coordinating a pause in model training that seems likely to me to make things less safe if implemented (because of leading to algorithmic and hardware overhangs) or (b) converting to capabilities work (quite common, seems like an occupational hazard for someone with initially “pure” AI safety values). Of course, I don’t mean to be disparaging, as plenty of AI safety work does seem useful qua safety to me, like making more precise estimates of takeoff speeds or doing cybersecurity work. Just was surprised by that statement and I’m curious about how you are tracking progress here.
2. It seems like you think there are some key algorithmic insights, that once “unlocked”, will lead to dramatically faster AI development. This suggests that not many people are working on algorithmic insights. But that doesn’t seem quite right to me—isn’t that a huge group of researchers, many of whom have historically been anti-scaling? Or maybe you think there are core insights available, but the field hasn’t had (enough of) its Einsteins or von Neumanns yet? Basically, I’m trying to get a sense of why you seem to have very fast takeoff speed estimates given certain algorithmic progress. But maybe I’m not understanding your worldview and/or maybe it’s too infohazardous to discuss.
I finished writing this less than a year ago, and it seems to be meaningfully impacting a number of people’s thinking, hopefully for the better. I personally feel strongly like I’m making progress on a worthwhile project and would like lots more time to carry it through, and if it doesn’t work out I have others in the pipeline. I continue to have ideas at a regular clip that I think are both important and obvious-in-hindsight, and to notice new mistakes that I and others have been making. I don’t know that any of the above will be convincing to a skeptic, but it seems worth mentioning that my first-person perspective feels very strongly like progress is being made each year.
A couple concepts that emerged in the past couple years that I find very important and clarifying for my thinking are “Concept Extrapolation” by Stuart Armstrong (which he continues to work on) and “goal misgeneralization” by Krueger (notwithstanding controversy, see here). As another example, I don’t think Paul Christiano et al.’s ELK project is the most urgent thing but I still think it’s worthwhile, and AFAICT it’s moving along steadily.
I dunno. Read alignment forum. You really find absolutely everything totally useless? That seems like a pretty strong and unlikely statement from my perspective.
It’s critically important that, in the ML community as a whole, people are generally familiar with TAI risks, and at least have reasonable buy-in that they’re a real thing, as opposed to mocking disinterest. After all, whatever alignment ideas we have, the programmers have to actually implement them and test them, and their managers have to strongly support that too. I’m not too certain here, but my guess is that things are moving more forward than backwards in that domain. For example, my guess is that younger people entering the field of AI are less likely to mock the idea of TAI risk than are older people retiring out of the field of AI. I’d be curious if someone could confirm or disconfirm that.
I dispute that. It’s not like algorithmic insights appear as soon as people look for them. For example, Judea Pearl published the belief propagation algorithm in 1982. Why hadn’t someone already published it in 1962? Or 1922? (That’s only partly rhetorical—if you or anyone has a good answer, I’m interested to hear it!)
For example, people have known for decades that flexible hierarchical planning is very important in humans but no one can get it to really work well in AI, especially in a reinforcement learning context. I assume that researchers are continuing to try as we speak. Speaking of which, I believe that conventional wisdom in ML is that RL is a janky mess. It’s notable that LLMs have largely succeeded by just giving up on RL (apart from an optional fine-tuning step at the end), as opposed to by getting RL to really work well. And yet RL does really work well in human brains. RL is much much more centrally involved in human cognition than in LLM training. So it’s not like RL is fundamentally impossible. It’s just that people can’t get it to work well. And it sure isn’t for lack of trying! So yeah, I think there remain algorithmic ideas yet to be discovered.
Belief propagation is the kind of thing that most people wouldn’t work on in an age before computers. It would be difficult to evaluate/test, but more importantly wouldn’t have much hope for application. Seems to me it arrived at a pretty normal time in our world.
What do you think of diffusion planning?
Hmm. I’m not sure I buy that. Can’t we say the same thing about FFT? Doing belief prop by hand doesn’t seem much different from doing an FFT by hand; and both belief prop and FFT were totally doable on a 1960s mainframe, if not earlier, AFAICT. But the modern FFT algorithm was published in 1965, and people got the gist of it in 1942, and 1932, and even Gauss in 1805 had the basic idea (according to wikipedia). FFTs are obviously super useful, but OTOH people do seem to find belief prop useful today, for various things, as far as I can tell, and I don’t see why they wouldn’t have found it useful in the 1960s as well if they had known about it.
I think it’s interesting, thanks for sharing! But I have no other opinion about it to share. :)
If (for the sake of argument) Diffusion Planning is the (or part of the) long-sought-out path to getting flexible hierarchical planning to work well in practical AI systems, then I don’t think that would undermine any of the main points that I’m trying to make here. Diffusion Planning was, after all, (1) just published last year, (2) still at the “proof of principle / toy models” stage, and (3) not part of the existing LLM pipeline / paradigm.
Thanks! I agree with you about all sorts of AI alignment essays being interesting and seemingly useful. My question was more about how to measure the net rate of AI safety research progress. But I agree with you that an/your expert inside view of how insights are accumulating is a reasonable metric. I also agree with you that the acceptance of TAI x-risk in the ML community as a real thing is useful and that—while I am slightly worried about the risk of overshooting, like Scott Alexander describes—this situation seems to be generally improving.
Regarding (2), my question is why algorithmic growth leading to serious growth of AI capabilities would be so discontinuous. I agree that RL is much better in humans than in machines, but I doubt that replicating this in machines would require just one or a few algorithmic advances. Instead, my guess, based on previous technology growth stories I’ve read about, is that AI algorithmic progress is likely to occur due to the accumulation of many small improvements over time.
Oh, I somehow missed that your original question was about takeoff speeds. When you wrote “algorithmic insights…will lead to dramatically faster AI development”, I misread it as “algorithmic insights…will lead to dramatically more powerful AIs”. Oops. Anyway, takeoff speeds are off-topic for this post, so I won’t comment on them, sorry. :)
I would not describe development of deep learning as discontinuous, but I would describe it as fast. As far as I can tell, development of deep learning happened by accumulation of many small improvements over time, sometimes humorously described as graduate student descent (better initialization, better activation function, better optimizer, better architecture, better regularization, etc.). It seems possible or even probable that brain-inspired RL could follow the similar trajectory once it took off, absent interventions like changes to open publishing norm.
Given that outside C approaches to AGI are likely to be substantially unlike anything we’re familiar with, and that controllable AGI is desirable, don’t you think that there’s a good chance these unknown algorithms have favourable control properties?
I think LLMs have some nice control properties too, not so much arguing against LLMs being better than unknown, just the idea that we should confidently expect control to be hard for unknown algorithms.
I guess you’re referring to my comment “for my part, if I believed that (A)-type systems were sufficient for TAI—which I don’t—then I think I would feel slightly less concerned about AI x-risk than I actually do, all things considered!”
I’m not implicitly comparing (A) to “completely unknown mystery algorithm”, instead I’m implicitly comparing (A) to “brain-like AGI, or more broadly model-based RL AGI, or even more broadly some kind of AGI that incorporates RL in a much more central way than LLMs do”. I think, by and large, more RL (as opposed to supervised or self-supervised learning) makes things worse from a safety perspective, and thus I’m unhappy to also believe that more RL is going to be part of TAI.
I had a potential disagreement with your claim that a pause is probably counterproductive if there’s a paradigm change required to reach AGI: even if the algorithms of the current paradigm aren’t directly a part of the algorithm behind existentially dangerous AGI, advances in these algorithms will massively speed up research and progress towards this goal.
+
This seems slightly contradictory to me. It seems like—whether or not the current paradigm results in TAI, it is certainly going to make it easier to code faster, communicate ideas faster, write faster, and research faster—which would potentially make all sorts of progress, including algorithmic insights, come sooner. A pause to the current paradigm would thus be neutral or net positive if it means ensuring progress isn’t sped up by more powerful models
I think that’s one consideration, but I think there are a bunch of considerations pointing in both directions. For example:
Pause in scaling up LLMs → less algorithmic progress:
The LLM code-assistants or research-assistants will be worse
Maybe you can only make algorithmic progress via doing lots of GPT-4-sized training runs or bigger and seeing what happens
Maybe pause reduces AI profit which would otherwise be reinvested in R&D
Pause in scaling up LLMs → more algorithmic progress:
Maybe doing lots of GPT-4-sized training runs or bigger is a distraction from algorithmic progress
In pause-world, it’s cheaper to get to the cutting edge, so more diverse researchers & companies are there, and they’re competing more narrowly on algorithmic progress (e.g. the best algorithms will get the highest scores on benchmarks or whatever, as opposed to whatever algorithms got scaled the most getting the highest scores)
Other things:
Pro-pause: It’s “practice for later”, “policy wins beget policy wins”, etc., so it will be easier next time (related)
Anti-pause: People will learn to associate “AI pause” = “overreaction to a big nothing”, so it will be harder next time (related)
Pro-pause: Needless to say, maybe I’m wrong and LLMs won’t plateau!
There are probably other things too. For me, the balance of considerations is that pause in scaling up LLMs will probably lead to more algorithmic progress. But I don’t have great confidence.
(We might differ in how much of a difference we’re expecting LLM code-assistants and research-assistants to make. I put them in the same category as PyTorch and TensorFlow and IDEs and stackoverflow and other such productivity-enhancers that we’re already living with, as opposed to something wildly more impactful than that.)
I’d consider this to be one of the more convincing reasons to be hesitant about a pause (as opposed to the ‘crying wolf’ argument, which seems to me like a dangerous way to think about coordinating on AI safety?).
I don’t have a good model for how much serious effort is currently going into algorithmic progress, so I can’t say anything confidently there—but I would guess there’s plenty and it’s just not talked about?
It might be a question about which of the following two you think will most likely result in a dangerous new paradigm faster (assuming LLMs aren’t the dangerous paradigm):
current amount of effort put into algorithmic progress + amplified by code assistants, apps, tools, research-assistants, etc.
counterfactual amount of effort put into algorithmic progress if a pause happens on scaling
I think I’m leaning towards (1) bringing about a dangerous new paradigm faster because
I don’t think the counterfactual amount of effort on algorithmic progress will be that much more significant than the current efforts (pretty uncertain on this, though)
I’m weary of adding faster feedback loops to technological progress/allowing avenues for meta-optimizations to humanity since these can compound
Can you elaborate on this? I think it’s incredibly stupid that people consider it to be super-blameworthy to overprepare for something that turned out not to be a huge deal—even if the expected value of the preparation was super-positive given what was known at the time. But, stupid as it may be, it does seem to be part of the situation we’re in. (What politician wants an article like this to be about them?) (Another example.) I’m in favor of interventions to try to change that aspect of our situation (e.g. widespread use and normalization of prediction markets??), but in the meantime, it seems to me that we should keep that dynamic in mind (among other considerations). Do you disagree with that in principle? Or think it’s overridden by other considerations? Or something else?
Maybe—I can see it being spun in two ways:
The AI safety/alignment crowd was irrationally terrified of chatbots/current AI, forced everyone to pause, and then, unsurprisingly, didn’t find anything scary
The AI safety/alignment crowd need time to catch up their alignment techniques to keep up with the current models before things get dangerous in the future, and they did that
To point (1): alignment researchers aren’t terrified of GPT-4 taking over the world, wouldn’t agree to this characterization, and are not communicating this to others. I don’t expect this is how things will be interpreted if people are being fair.
I think (2) is the realistic spin, and could go wrong reputationally (like in the examples you showed) if there’s no interesting scientific alignment progress made in the pause-period.
I don’t expect there to be a lack of interesting progress, though. There’s plenty of unexplored work in interpretability alone that could provide many low-hanging fruit results. This is something I naturally expect out of a young field with a huge space of unexplored empirical and theoretical questions. If there’s plenty of alignment research output during that time, then I’m not sure the pause will really be seen as a failure.
Yeah, agree. I’d say one of the best ways to do this is to make it clear what the purpose of the pause is and defining what counts as the pause being a success (e.g. significant research output).
Also, your pro-pause points seem quite important, in my opinion, and outweigh the ‘reputational risks’ by a lot:
Pro-pause: It’s “practice for later”, “policy wins beget policy wins”, etc., so it will be easier next time
Pro-pause: Needless to say, maybe I’m wrong and LLMs won’t plateau!
I’d honestly find it a bit surprising if the reaction to this was to ignore future coordination for AI safety with a high probability. “Pausing to catch up alignment work” doesn’t seem like the kind of thing which leads the world to think “AI can never be existentially dangerous” and results in future coordination being harder. If AI keeps being more impressive than the SOTA now, I’m not really sure risk concerns will easily go away.
I really like this paragraph (and associated footnote) for being straightforward about what you’re not saying, not leaking scary info, and nevertheless projecting a “friendly” (by my sensors) vibe.
Good job! : )
Ok, my basic viewpoint is that LLMs will plateau, but not before being able (combined with lots of human effort) to create LLMs++ (some unspecified improvement over existing LLMs). And that this process will repeat. I think you are right that there are some architectural / algorithmic changes that will have to be made before we get to a fully capable AGI at anything like near-term available compute. What I don’t see is how we can expect that the necessary algorithmic changes won’t be stumbled upon by a highly engineered automation process trying literally millions of different ideas while iterating over all published open source code and academic papers. I describe my thoughts in more detail here: https://www.lesswrong.com/posts/zwAHF5tmFDTDD6ZoY/will-gpt-5-be-able-to-self-improve
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?