The New York Times has thrown down the gauntlet, suing OpenAI and Microsoft for copyright infringement. Others are complaining about recreated images in the otherwise deeply awesome MidJourney v6.0. As is usually the case, the critics misunderstand the technology involved, complain about infringements that inflict no substantial damages, engineer many of the complaints being made and make cringeworthy accusations.
That does not, however, mean that The New York Times case is baseless. There are still very real copyright issues at the heart of Generative AI. This suit is a serious effort by top lawyers. It has strong legal merit. They are likely to win if the case is not settled.
Table of Contents
Introduction.
Table of Contents.
Language Models Offer Mundane Utility. Entrepreneurial advice.
GPT-4 Real This Time. What will we get in the coming year?
Fun With Image Generation. MidJourney wants you to speak (creative) English.
Copyright Confrontation. The New York Times versus OpenAI.
Deepfaketown and Botpocalypse Soon. ChatGPT used to spot plagiarism? Good.
Going Nuclear. Wait, you don’t want AI involved in nuclear safety?
In Other AI News. Nancy Pelosi buys Nvidia options.
Quiet Speculations. Will scaling LLMs lead to AGI? Dwarkesh Patel ponders.
The UN Reports. UN says UN things, most of you can skip this.
The Week in Audio. Shapira, Lebenz,Bloom and the Crystal Society audiobook.
Rhetorical Innovation. They are building a religion. They are building it bigger.
AI With Open Model Weights Is Unsafe and Nothing Can Fix This. Them too.
Aligning a Human Level Intelligence is Still Difficult. Chinese alignment paper.
Please Speak Directly Into the Microphone. Daniel Faggella.
The Wit and Wisdom of Sam Altman. Mostly being rather wise recently. Also rich.
In previous studies, we consistently find an equalizing effect from use of LLMs. High performers improve, but low performers improve a lot more.
Now we have a study that finds the opposite effect. Entrepreneurs in Kenya were given AI ‘mentor’ access via WhatsApp. High performers benefited, low performers were harmed.
There is a growing belief that scalable and low-cost AI assistance can improve firm decision-making and economic performance. However, running a business involves a myriad of open-ended problems, making it hard to generalize from recent studies showing that generative AI improves performance on well-defined writing tasks. In our five-month field experiment with 640 Kenyan entrepreneurs, we assessed the im-pact of AI-generated advice on small business revenues and profits. Participants were randomly assigned to a control group that received a standard business guide or to a treatment group that received a GPT-4 powered AI business mentor via WhatsApp.
While we find no average treatment effect, this is because the causal effect of generative AI access varied with the baseline business performance of the entrepreneur: high performers benefited by just over 20% from AI advice, whereas low performers did roughly 10% worse with AI assistance.
Exploratory analysis of the WhatsApp interaction logs shows that both groups sought the AI mentor’s advice, but that low performers did worse because they sought help on much more challenging business tasks. These findings highlight how the tasks selected by firms and entrepreneurs for AI assistance fundamentally shape who will benefit from generative AI.
The paper is sweet. It is alas short on concrete examples, so one cannot search for patterns and check on various hunches.
One hunch is that higher performing entrepreneurs know what the important questions and important details are, and also they face genuinely easier questions at the margin. Operating a business that is not going well is way harder than operating one that is working, the flip side being you could have massive low-hanging fruit. But trouble begets its own forms of trouble. And I suspect that most people in such situations do not turn in writing to others for help and get it, in ways that would make it into one’s training set. For them context becomes more important.
Also, there is a background level of skill required to understand what information is important to include, and to identify which parts of the LLM’s answer are likely to be accurate and useful to you. When the AI is giving you advice, you need to be able to tell when it is telling you to shoot yourself in the foot or focus on the wrong thing, or is flat out making things up.
So I suspect the task graph is not telling the central story. As they say, more research is needed.
Another clear contrast is that here the AI is being used as a mentor, to learn.
Whereas in other tasks, the AI is being used as more of an assistant and source of output.
An alternative source that helps do your work is an equalizing force. The consultants use GPT-4 to write a draft of the report. If you suck at writing drafts, that’s very helpful. If you are good at it, it is not as helpful.
A source of knowledge is different. Being able to be mentored, to learn, is a skill.
The computer-drafted bill was presented by Councilman Ramiro Rosário, 37, who says there’s still a stigma surrounding the inclusion of AI tools in the political process.
“They [government colleagues] would never have signed it if they’d known,” Rosário told the Wall Street Journal of the “purposefully boring” bill, which was designed to stop a local water company from charging residents for new meters.
Usually, it would take days and numerous members of Rosário’s staff to draft such a laborious bill — but ChatGPT fired out the lengthy text in just 15 seconds.
Rosário believes the legislation is the first in the world to be fully crafted by the AI program.
He also predicts ChatGPT could spell doomsday for his public relations team. Case in point: the program drafted a press release for its law as well.
Justin Amash has suggested a rule that before you pass a bill you have to read the bill out loud. That might help.
Mostly in such cases, the ‘real’ bill is one sentence or paragraph of intent. The rest is implementation and required technical language. In theory it should be fine to use a program to translate from one to the other, and also back again. But this is not something you want to sometimes get wrong. So, for now at least? Check your work.
Emmet Shear: What’s the AI best tool where I ramble into a voice note and it turns my rambling into reasonable prose (eg removed ums or repeated words, adds punctuation, breaks up run on sentences, etc)
I don’t think you all understand what I mean by “ramble”. I mean just stream of consciousness dumping words as they come to mind. Turning it into sentences is not easy, I’ll interrupt myself repeatedly and sometimes with multiple layers of nesting.
Also most of these tools ppl recommend have like a 15 minute limit. What kind of rambling are you ppl doing?
If I was going to do more than 15 minutes of rambling, I would want not only repetitions removed and proper punctuation, but actual sorting of everything and logical interpretation. Otherwise does this really work?
What are the actually good tools? This is one of many places where it seems like a good tool would be valuable, but it has to be very good to be worth anything at all.
Sam Altman: thanks a lot for these! some common requests:
AGI (a little patience please)
GPT-5
Better voice mode
Higher rate limits
Better GPTs
Better reasoning
Control over degree of wokeness/behavior
Video personalization
Better browsing
‘Sign in with openai’
Open source
Will keep reading, and we will deliver on as much as we can (and plenty of other stuff we are excited about and not mentioned here).
I am surprised ‘price cuts’ did not make the most wanted list.
Number ten here is interesting. Quite the sign of a Big Tech company in the making. If you sign in with OpenAI, what can then be integrated into the website? Can you give it permission to use your API key to enhance your experience? Can they mediate trusted data in both directions? Could get very interesting.
My number one mundane request isn’t on the list either. It is for better probabilities, estimation and guessing. GPT-4 is notoriously reluctant to engage in such activity right now even when explicitly asked to do so, which is super frustrating. Perhaps a GPT or a good prompt would do it, though.
I very much agree that the browsing could use an update. I would also like better GPTs, better reasoning (for mundane utility tasks, and up to a point) and especially control over degree of wokeness/behavior. Video personalization and voice mode aren’t my areas, but sure, why not, and maybe I’d use them if they improved. And of course everyone loves higher rate limits, although I’ve never actually hit the current one.
Then there are the other three requests.
You think you want AGI in 2024? Let me assure you. You do not want AGI in 2024.
Perhaps you will want AGI later, once we are ready. We are not ready.
Altman did not ask for patience on GPT-5. I expect to be fine with GPT-5 once it is properly tested, and I expect life to get better in many ways once that happens. But it definitely makes me nervous.
Then there’s Open Source. Of course Twitter is going to scream for it. They want OpenAI to give away its lead, believe open source does no wrong and don’t understand the dangers. Luckily I am very confident Altman knows better.
Fun with Image Generation
MidJourney 6.0 is clearly much better at following directions.
Eliezer Yudkowsky notes its progress at following specific prompts. He still plans to wait a few months for the next upgrade before really going to town, because it’s not quite where he’d like it to be, so even if it would work now, why rush it?
There are also lots of examples of very cool pictures with exquisitely rich detail. It’s pretty great. It is especially great at particular famous people.
It also rewards a different prompting style. Before you wanted a lot of keywords separated by commas. Now you want to use English.
Gwern: I haven’t gone back to curate it like usual, but a quick example of what I mean: ‘Capital letter “I”, blackletter (uncial), monochrome, Gene Wolfe, medieval historiated initial dropcap, typography, vampire, Dracula, historiated, aristocrat, cape, illustration –v 6.0’ 0⁄4 right
Gallabytes (MidJourney): this is very much not the optimal prompting style for v6 – recommend replacing tag spam with phrases describing what you want it to do. not 100% sure what you’re going for here but here’s my first guess. monochrome medieval historiated initial dropcap illustration of the letter “I” featuring Dracula.
The output still is not quite right on other details, but two out of four Is are perfect.
Mimrock: No, it’s not. Overfitting is learning the noise in the training data and failing to generalize well. But MJ generalizes well. If you ask for a scene from a specific movie and you get a scene from that specific movie, it does not mean that the model cannot generalize the concepts.
Consider a hypothetical AGI-level LLM that, per definition, generalized so good on the data that it’s smarter than ever built. You ask for a paragraph from Harry Potter. It returns a paragraph from Harry Potter. It’s not overfitting is it?
In both cases, your ideal, perfectly generalized loss function is to give the user exactly what the user requests. And it fulfils that wish. And it can do it too when the request is NOT in the training set. So no overfitting.
Teortaxes: I repeat: the ML community has to reject the false consciousness frame where “overfitting” means “desired performance on tasks referencing training data points”. Notice Chomba chomping on the bullet. Leave elitists to their toy models and statistics lore, but inform the public.
Teknium: To further this – almost all LLM finetuning runs have big drops in loss at each epoch barrier after epoch 1, and @jeremyphoward has looked into this for us, and found it is memorization. However, that does not mean it doesn’t *also* become far better at all downstream tasks from multiple epochs on appropriate datasets
Gallabytes (MidJourney): This is not something I’ve observed in our training runs fwiw, no sharp drops at any point, just a smooth loss curve from start to finish. the only times I see sharp drops are during fine tunes where the weights rapidly adapt to the new task/dataset/whatever.
Teknium: It is thought that much larger (than finetune) datasets, and of course, 1epoch pretraining runs, would not be impacted by this phenomenon (or at such a smaller scale that it is not noticeable)
Gallabytes: yeah I think our datasets are too damn large for this kind of thing to happen. I also suspect it happens a lot less for diffusion than AR bc diffusion
1) has much less clean epochs (you see each piece of training data at several noise levels)
2) generally favors memorization less (I think?) due to the middle frequency bias (& maybe the denoising objective itself?)
It’s important imo that ~nobody does max likelihood diffusion, because it’s bad.
This is a pretty big factor in why I expect some kind of diffusion to eventually overtake AR on language modeling too. We don’t actually care about the exact words anywhere near as much as we care about the ideas they code for, and if we can work at that level diffusion will win.
It will probably keep being worse on perplexity while being noticeably smarter, less glitchy, and easier to control.
Sherjil Ozair: Counterpoint: one-word change can completely change the meaning of a sentence, unlike one pixel in an image.
Reid Southen: I consider this a smoking gun for Midjourney’s flagrant copyright infringement. A 6-word prompt can replicate a Dune still nearly 1:1 every time. These aren’t variations, it’s the same prompt run repeatedly. Try it yourself. Merry Christmas Midjourney.
Note that these are not exact copies. They are very clear echoes, only small variants. They are not replicas. There are a number of examples, all of which are iconic. What is happening?
As discussed above, I believe this is not overfitting. It is fitting. It is a highly reasonable thing for a powerful model to do in response to exactly this request.
It is only overfitting if you see these particular things bleed into answers out of distribution, where no one asked for or wanted them. I have not seen any reports of ‘it won’t stop doing the iconic thing when I ask for something else.’
This is not something that v6.0 will do for every picture. It will only (as I understand it) do this for those that ended up copied over and over across the internet, such as movie promotional pictures or classic shots. The iconic. Then you have to intentionally ask for the thing, rather than for something new. The prompts are simple exactly because the images are so iconic.
In which case, yes, most cases like this that it is working with do look very similar to the original, so the results will look like the original too. It seems likely MidJourney will need to actively do something to intercept or alter such prompts.
If you ask for something else, you’ll get something else.
One must notice that this does not actually matter. Why would you use an image generator to generate a near copy of an image that you can easily copy off of the internet, a capability you will have in 100% of such cases? Why would it matter if you did? Don’t you have anything better to do?
That is not to dismiss or minimize the general issue of copyright infringement by image models. Under what conditions should an image model be allowed to train off of images you do not own? Who should have veto power? What if anything do you owe if you do that? How do we compensate artists? What restrictions should we place if any on creation or use of AI generations?
Those and others are questions first our courts, and ultimately our society, must answer. The ability to elicit near copies of iconic movie stills should not even make the issue list.
That seems like the right procedure. The two Worthy Opponents can battle it out. Whatever you think should be the copyright law, we need to settle what the copyright law actually says, right now. Then we can decide whether to change it to something else.
So what is the NYT’s case?
Cecilia Ziniti: The historic NYT v. @OpenAI lawsuit filed this morning, as broken down by me, an IP and AI lawyer, general counsel, and longtime tech person and enthusiast.
Tl;dr – It’s the best case yet alleging that generative AI is copyright infringement.
First, the complaint clearly lays out the claim of copyright infringement, highlighting the ‘access & substantial similarity’ between NYT’s articles and ChatGPT’s outputs.
Key fact: NYT is the single biggest proprietary data set in Common Crawl used to train GPT.
The right plaintiff. The right argument. Much better to say ‘your outputs copy us’ than ‘your inputs come from us.’
The visual evidence of copying in the complaint is stark. Copied text in red, new GPT words in black—a contrast designed to sway a jury. See Exhibit J here.
How did the Times generate that output?
I quickly looked. The complaint does not say exactly how they did it, or how how cherry-picked this response was. In general, how do you get a verbatim (or very close) copy of a Times article? You explicitly ask for it.
If you can get normal NYT passages this closely copied without any reference to The New York Times, without any request to quote an article, then I would be pretty surprised.
In a handful of famous cases, there seems to be an exception. Exactly as in the MidJourney examples, why are we seeing NYT article text almost exactly (but not quite) copied anyway in some cases? Because it is iconic.
Kevin Bryan: NYT/OpenAI lawsuit completely misunderstands how LLMs work, and judges getting this wrong will do huge damage to AI. Basic point: LLMs DON’T “STORE” UNDERLYING TRAINING TEXT. It is impossible- the parameter size of GPT-3.5 or 4 is not enough to losslessly encode the training set.
…
Ok, now let’s see NYT examples. Here GPT spits out almost perfectly the opening paragraphs of a “snow fall” article from 2012. But this text is all over the internet – super famous article! That’s why GPT’s posterior predictions given the previous article paragraph are so good.
Likewise, in the famous Guy Fieri Times Square review, GPT repeats almost perfectly whole paragraphs. But these paragraphs have also been repeated dozens of times across the internet! That’s why the LLM posterior probability next word distribution picks them up.
And of course, as suggested above, for less-famous articles, if you ask an LLM to try to reproduce it, they will hallucinate the text. The NYT complains about this too, saying the *wrong* text credited to them is also bad because it misleads readers.
In practice, one can think of this as ChatGPT committing copyright infringement if and only if everyone else is committing copyright infringement on that exact same passage, making it so often duplicated that it learned this is something people reproduce.
My take? OpenAI can’t really defend this practice without some heavy changes to the instructions and a whole lot of litigating about how the tech works. It will be smarter to settle than fight.
This presumes that The New York Times is in a settling mood and will accept a reasonable price, in a way that sets a precedent that OpenAI can afford to pay out for everyone else. If that was true, then why were things allowed to get this far? So I presume that the two sides are pretty far apart. Or that NYT is after blood, not cash.
NYT is a great plaintiff. It isn’t just about articles; it’s about originality and the creative process. Their investigative journalism, like an in-depth taxi lending exposé cited in the complaint, goes beyond mere labor—it’s creativity at its core.
But here’s a twist: copyright protects creativity, not effort. While the taxi article’s 600 interviews are impressive, it’s the innovation in reporting that matters legally. By the way, this is a very sharp contrast with the suit against GitHub Copilot, which cited only a few lines of code that were open source.
Failed negotiations suggest damages for NYT. OpenAI’s already licensed from other media outlets like Politico.
OAI’s refusal to strike a deal with NYT (who says they reached out in April) may prove costly, especially as OpenAI profits grow and more and more examples happen. My spicy hypothesis? OpenAI thought they could get out of it for 7 or 8 figures. NYT is looking for more and an ongoing royalty.
I think this is not all that spicy a hypothesis. Seems rather likely. I am sure, given they paid Politico, that OpenAI would settle with the New York Times if there was a reasonable offer on the table. Why take the firm risk? Why not be in business with the Times and set a standard? Because NYT is looking for the moon.
The complaint paints @OpenAI as profit-driven and closed. It contrasts this with the public good of journalism. This narrative could prove powerful in court, weighing the societal value of copyright against tech innovation. Notably, this balance of good v evil has been at issue in every major copyright case – from the Betamax case to the Feist finding telephone books not copyrightable. The complaint even mentions the board and Sam Altman drama.
I would be careful if I was the Times. Their reputation and that of journalism and legacy media in general is not what it once was. ChatGPT provides a lot more value to more people than it is taking away from a newspaper. I am also amused by the Streisand Effect here, where Toner’s paper is now being quoted exactly because it was used as part of a boardroom fight.
What harm is being done to the New York Times? Yes, there were times when ChatGPT would pull entire NYT articles if you knew the secret code. But those codes become invalid if a lot of people use them, so the damage will always be limited.
The flip side is that the public is very anti-AI, and most people aren’t using ChatGPT.
Misinformation allegations add a clever twist. The complaint pulls in something people are scared of – hallucinations – and makes a case out of it, citing examples where elements of NYT articles were made up.
Most memorable example? Alleging Bing says the NYT published an article orange juice causes lymphoma.
Seems pretty flimsy to me. Yes, hallucinations happen, but that’s not copyright, and I find it hard to believe the NYT reputation is in any danger here. They are welcome to try I suppose but I would have left this out.
Especially because, well, here’s how you get Bing to say that…
In general, I find it unwise to combine good arguments with bad arguments.
Another interesting point: NYT got really good lawyers. Susman Godfrey has a great reputation and track record taking on tech. This isn’t a quick cash grab like the lawsuits filed a week after ChatGPT; it’s a strategic legal challenge.
The case could be a watershed moment for AI and copyright. A lot of folks saying OpenAI should have paid. We’ll see! What’s at stake? The future of AI innovation and the protection of creative content. Stay tuned.
Tyler Benster: While OpenAI can afford to pay copyright holders like the NYTimes, the Open Source movement cannot. Huge hazard if the courts determine that the mere act of training on copyrighted materials is infringement. A good outcome might narrowly punish generating copyright infringement.
Peter Wildeford: I really don’t understand why people feel entitled to steal other people’s stuff in the name of AI development and open source. It’s not the fault of the NYT that you want their work but don’t want to pay for it. The NYT is not meant to be free!
I get the claim that it is not ‘stealing’ because it is not a rival good and the marginal cost is zero. In a better world, things like The New York Times would be freely available to all, and would be supported via some other mechanism, with copyright only existing to prevent other types of infringement. We do not live in that world.
What is ultimately the right policy? That depends on what you care about. I see good reasons to advocate for mandatory licensing at reasonable prices the way we do it in music. I see good reasons to say it is up to the copyright holder to name their price. I even see good reasons for setting the price to zero, although I think that is clearly untenable for our society if applied at scale. We need a way to support creators.
Quantian: Critical support to OpenAI in their progressive struggle against the predatory, upwardly-redistributive, and anti-growth patent and copyright laws of America. Do NOT fall for Disney Corp psyops here, no matter how sympathetic the starving Tunblr artist they prop up to make it!
Remember when Google digitized every book that exists and was going to make them available for a tiny fee, and then publishers sued and forced them to delete it instead of accepting billions of dollars of free money? Now is the chance to strike back! You may never get another!
I mean… yes?
Google said ‘I am going to take your intellectual property and give it away for free on the internet without your permission.’
That is… not okay? Quite obviously, completely, not okay?
No, it is not ‘free money’ if the price is universal free access to your product? That is a lot more like ‘we sell the rights to all our products, forever’?
The world would be a better place if Google were to pay the publishers and writers so much money that they were happy to make the deal, and then all the books were available online for free. That does not mean that Google’s offer was high enough.
You need a way to support creators. You need to respect property.
Ideally we find a way that works for all, both for books and for data.
Steven McGuire: Here’s the part where Harvard’s lawyers suggested that the plagiarism complaint against Claudine Gay was generated by ChatGPT:
NY Post: Lawyers for Harvard and its president Claudine Gay tried to dismiss allegations she was a plagiarist as having been created by “ChatGPT.”
They sent a 15-page legal tirade to The Post which launched a bizarre conspiracy theory that the 27 instances in which her work appeared to closely resemble that of other academics may have been uncovered by using Microsoft’s artificial intelligence chatbot.
…
“Indeed, there are strong indications that the excerpts cited by The Post were not in fact the ‘complaints’ of a human complainant — but rather were generated by artificial intelligence or some other technological or automated means,” wrote Thomas Clare and David Sillers in their Oct. 27 letter to The Post.
…
“If these indications are correct, and the ultimate source of these examples is an algorithm-generated list created by asking ChatGPT to (for example) ‘show me the 10 most similar passages in works by Claudine Gay to other scholarly works’ it is no ‘complaint’ at all,” the letter continued.
An objection letter could scarcely be more self-damning. Why does it matter what search method identified the claimed plagiarism? Either the passage is the same, or it is not. If ChatGPT is hallucinating, check both sources and prove it, and that will be the end of that. If both check out, what are you complaining about? That you got caught?
Patrick McKenzie: “LLMs hallucinate a lot” to “If ChatGPT and a law firm retained by Harvard squarely disagree about the contents of Harvard scholarly articles well ehh could go either way really, got to check the archives.” went quicker than expected.
That’s the thing. If you hallucinate 50% of the time, but you find the answer 50% of the time, and I can verify which is which and take the time to do that, then that is a highly useful search method.
Patrick McKenzie: My antenna are twinging a little bit that tech is likely to be negatively surprised if one of the takeaways from the plagiarism fracas is that “We wouldn’t have needed to see a colleague/peer suffer professional injury but for that %{*}%*ing LLM.”
There is a non-zero risk that Power will wake up quickly in response to basically nothing (that is really adjacent to something) in the same way that Power had a completely boneheaded read of Cambridge Analytica.
The real existential risk from AI, power might decide, is that people might be able to discover all the crime power has been doing and all the lies it has been telling. In which case, well, better put a stop to that little operation.
Also, does this give anyone else an idea?
Bryne Hobart: When you’ve definitely tried asking ChatGPT to (for example) “show me the 10 most similar passages in works by Claudine Gay to other scholarly works” [shows the letter from above]
One difference between lawyers and tech people is that tech people are more likely to understand how LLMs work and what their capabilities are, but a more important difference is that tech people are more likely to test a claim about a technology before making it.
I asked the question right and how have what looks like a decent plagiarism-detection script. Anyone know where I can get a large set of academic articles in plain text (including indications of block quotes, of course)? Ideally with author name as metadata.
If, as many of her defenders claim, Gay’s offenses are a case of ‘everyone does it all the time’ then we have the technology to know, so let’s test that theory on various top scholars.
There are three possibilities.
If this is not actually something that ‘happens to the best of them’ then that should be conclusive evidence. Presumably it would be insane to then allow her to remain President of Harvard.
If this is actually something that ‘happens to the best of them,’ if indeed everyone is doing it, then one must ask, is this the result of inevitable coincidences and an isolated demand for crossing every T and dotting every I, or is it that much or most of academia is constantly committing plagiarism?
If we decide this is not the true plagiarism and is essentially fine, then we should update the rules to reflect this, including for students, make it very clear where the line is, and then decide how to deal with those who went over the new line.
If we decide that this indeed the true plagiarism, and it is not fine, then we will need some form of Truth and Reconciliation. Academia will require deep reform.
Whether or not we have the technology now, we will have it soon. The truth is out there, and the truth will be getting out.
More coverage of the fact that the President of Harvard seems to have done all the plagiarism, this fact is now known and yet she remains President of Harvard will likely be available in the next Childhood and Education roundup, likely along with a reprise of this section.
Going Nuclear
Last week I noted with some glee that Microsoft was using a custom LLM to help it write regulatory documents for its nuclear power plants. I thought it was great.
Andrew Critch: Seriously? Is it too much to ask for AI to stay out of literal *nuclear safety regulatory processes*? Like, is this a joke? Someone please explain.
Connor Leahy: While the specific risks here are (probably, I’m no expert) low, I can’t help but find this grimly hilarious. The shamelessness, truly no dignity lol.
Yes. No. The process in question is bullshit paperwork.
My position remains closer to Alyssa’s here:
Alyssa Vance: Honestly don’t see a problem with this.
1) sounds like it’s only being used to write documents not run the plant 2) any issues likely come from capabilities not misalignment 3) limited consequences due to strong existing regulatory regime + accidents being local in scope
There is a big difference between ‘AI is used to run the nuclear power plant’ and ‘AI is used to file tens of thousands of pages of unnecessary and useless paperwork with the NRC.’ I believe this is the second one, not the first one.
If this indeed a huge disaster? Then that will be a valuable lesson, hopefully learned while we still have time to right the larger ship.
As usual, my first thought is ‘why the hell would you publish that and let Google and Microsoft also have it, rather than use it.’
Getting a reasonable small distilled model, that will do ‘good enough’ practical inference relative to competitors, seems relatively easy. The hard part is making it do things that customers most value. That is much more of Apple’s department, so they definitely have a shot. One handicap is that we can be confident Apple will absolutely, positively not be having any fun. They hate fun more than Stanford.
Scott Sumner analyzes geography of the distribution of AI talent. The talent tends to migrate towards America despite our best efforts. It is always odd to pick what ‘talent’ means in such contexts. What is the counterfactual that determines your talent level?
Quiet Speculations
Richard Ngo (OpenAI) points out that of course some AIs in the future will act as agents (like humans), some will act as tools (like software) and there will also be AI superorganisms, where many AIs run in parallel.
This was another commentary on Ngo’s original statement:
Richard Ngo: “LLMs are just doing next-token prediction without any understanding” is by now so clearly false it’s no longer worth debating. The next version will be “LLMs are just tools, and lack any intentions or goals”, which we’ll continue hearing until well after it’s clearly false.
Francois Chollet: Unfortunately , too few people understand the distinction between memorization and understanding. It’s not some lofty question like “does the system have an internal world model?”, it’s a very pragmatic behavior distinction: “is the system capable of broad generalization, or is it limited to local generalization?”
Eliezer Yudkowsky: This [the above by Chollet] is legit wise. And it lies at the heart of realizing why a mind genuinely smarter than your own can have terrifyingly lower sample complexity than you. To it, you are the one who must go on memorizing a hundred facts where it would understand after two.
Only saying top post is wise, not whole thread.
Jeffrey Ladish: To keep breaking it down further. LLMs are pretty smart but in order to be that smart they have to be trained in a HUGE amount of data, cause they aren’t that able to generalize beyond what they’ve seen. Humans can generalize far more. At some point AGI will generalize far better.
And that’s freaking scary. Because they will also likely have the ability to synthesize just as much (and probably vastly more) data than current LLMs can. And will be able to get far more insight per data point than we can. Literally killer combination.
Dwarkesh Patel ponders how likely it is scaling LLMs will lead to transformational AI, framed as a debate. He puts it at 70% that we get AGI by 2040 via straightforward scaling plus various algorithmic and hardware advances, about 30% that this can’t get there, which leaves 0% for it being able to get there but not by 2040. He notes things he doesn’t know about would likely shorten his timelines, which implies his timelines should be a little shorter via conservation of expected evidence.
The best argument for scaling working is that scaling so far (at least until, perhaps, very recently) has matched predictions of the ‘scaling will work’ hypothesis scarily well, whereas the skeptics mostly did not expect GPT-4.
The best argument against scaling working, from what I have seen, is the data bottleneck, both in terms of ‘you will run out of data and synthetic data might not work’ and ‘you will run out of data because your data is increasingly duplicative, and your synthetic data will be as well.’ Or perhaps it’s the ‘something genuinely new is difficult’ and yes Dwarkesh notes the FunSearch mathematical discovery thing from last week but I am not convinced it counts here.
He notes the question of Gemini coming in only at GPT-4 level. I also think it’s worth noting the host of GPT-3.5 level models stalling out there. And no, basically no one predicted it in advance, but there is indeed a certain kind of logic to what GPT-4-level models can and cannot do.
I think Dwarkesh’s 70% probability estimate is highly reasonable, if we count various forms of scaffolding and algorithmic innovations. It is in the range where I do not have the urge to bet on either side. Note that even if the 30% comes in, that does not mean that we can’t build AGI another way.
It is a crux for some people’s timelines. Not everyone’s, though.
Andrew Critch: Nope, not a crux! I predict “scaling” of data & compute consumption is not crucial to near-term AGI development. Without “scaling”, novel model architectures are probably adequate to get AGI soon. “Scaling” may also be adequate, but not a crux. +1 for covering the topic though :)
Usman Anwar: How soon are you talking about? Finding great general architectures is hard, a big chunk of ML research in 2010s was focused on finding better architectures and we only really made one significant discovery (transformers).
Andrew Critch: How soon? 2-6 years.
Paul Crowley (other thread): People ask whether AIs can truly make new discoveries or create new knowledge. What’s a new discovery or new knowledge you personally created in 2023 that an AI couldn’t currently duplicate?
Andrew Critch: People ask whether AI can “truly” “create new knowledge”. But knowledge is “created” just by inference from observations. There’s a fallacy going around that “fundamental science” is somehow crucially different, but sorry, AI will do that just fine. By 2029 this will be obvious.
I would bet against that 2-6 year timeline heavily if we knew scaling was not available.
I would consider betting against it without that assurance, but that would depend on the odds.
Yes, new knowledge is created by inference from observations. That does not mean that the ‘create new knowledge’ complaint is not pointing at a real thing.
The UN Reports
NOTE: Most of you should skip or at most skim this section.
From the UN (source): “The possibility of rogue Al escaping control and posing still larger risks cannot be ruled out.”
That comes at point #70 in their full report.
Alas, no, this does not reflect them actually understanding existential risk at all.
Mostly they are instead the UN doing and pushing UN things:
Guiding Principles
The interim report identifies the following principles that should guide the formation of new global AI governance institutions:
Inclusivity: all citizens, including those in the Global South, should be able to access and meaningfully use AI tools.
Public interest: governance should go beyond the do no harm principle and define a broader accountability framework for companies that build, deploy and control AI, as well as downstream users.
Centrality of data governance: AI governance cannot be divorced from the governance of data and the promotion of data commons.
Universal, networked and multistakeholder: AI governance should prioritize universal buy-in by countries and stakeholders. It should leverage existing institutions through a networked approach.
International Law: AI governance needs to be anchored in the UN Charter, International Human Rights Law, and the Sustainable Development Goals.
That looks like seven steps to still not doing anything with teeth. Classic UN. They think that if they say what they would like the norms to be, people would follow them. And that policy needs to be ‘anchored in the UN charter, International Human Rights Law, and the Sustainable Development Goals.’
They emphasize that we should prioritize ‘universal buy-in.’ There is one and only one way your AI policy gets universal buy-in, and I do not think the UN would like it.
The UN’s entire existence (and all of human history) falsifies these and their other hypotheses.
That does not mean they cannot wishcast for worthwhile or harmful things, and maybe that would matter on the margin, so I checked out their full report.
It is what you would expect. Right off the bat they are clearly more worried about distributional effects than effects. Page three jumps to ‘the critical intersection of climate change and AI opportunity,’ which of course ignores AI’s important potential future impacts in both directions on the problem of climate change.
They are ahead of many, but clearly do not know what is about to hit them:
16. AI has the potential to transform access to knowledge and increase efficiency around the world. A new generation of innovators is pushing the frontiers of AI science and engineering. AI is increasing productivity and innovation in sectors from healthcare to agriculture, in both advanced and developing economies.
…
18. The AI opportunity arrives at a difficult time, especially for the Global South. An “AI divide” lurks within a larger digital and developmental divide. According to ITU estimates for 2023, more than 2.6 billion people still lack access to the Internet. The basic foundations of a digital economy — broadband access, affordable devices and data, digital literacy, electricity that is reliable and affordable are not there.
Constantly people talk about how it is a difficult time. Yet would not any time earlier than now have been clearly worse, and has this not been true for every year since 1945? And of course, if AI does arrive for real in a positive way (or a negative way, I suppose, for different reasons), the Global South will rapidly have far fewer worries about electricity or broadband access. Already they have less such concerns every year. Even if AI does not arrive for real, mobile phones work everywhere, and I continue to expect AI to reduce effective consumption inequality, in addition to that inequality having been rapidly falling already for a long time.
Here is how they view the risks, to be fair this is risks ‘today’ rather than future risks, but still it is a reminder of how the UN thinks and what it believes is important.
24. Along with ensuring equitable access to the opportunities created by AI, greater efforts must be made to confront known, unknown, and as yet unknowable harms. Today, increasingly powerful systems are being deployed and used in the absence of new regulation, driven by the desire to deliver benefits as well as to make money. AI systems can discriminate by race or sex. Widespread use of current systems can threaten language diversity. New methods of disinformation and manipulation threaten political processes, including democratic ones. And a cat and mouse game is underway between malign and benign users of AI in the context of cybersecurity and cyber defense.
The entire section makes it continuously clear they do not get it, that they see AI as a tool or technology like any other and are rolling out the same stuff as always.
30. Putting together a comprehensive list of AI risks for all time is a fool’s errand. Given the ubiquitous and rapidly evolving nature of AI and its use, we believe that it is more useful to look at risks from the perspective of vulnerable communities and the commons.
So close. And yet, wow, so far. Zero mention of existential risks in the risks section.
In other so close and yet so far statement news:
61. The extent of AI’s negative externalities is not yet fully clear. The role of AI in disintermediating aspects of life that are core to human development could fundamentally change how individuals and communities function. As AI capabilities further advance, there is the potential for profound, structural adjustments to the way we live, work, and interact. A global analytical observatory function could coordinate research efforts on critical social impacts of AI, including its effects on labour, education, public health, peace and security, and geopolitical stability. Drawing on expertise and sharing knowledge from around the world, such a function could facilitate the emergence of best practices and common responses.
Even in their wheelhouse of dreams, they fall short. Cannot rule out, really?
73. We cannot rule out that legally binding norms and enforcement would be required at the global level.
Tragedy as comedy. If only the risks were indeed clear to them, alas:
77. The risks of inaction are also clear. We believe that global AI global governance is essential to reap the significant opportunities and navigate the risks that this technology presents for every state, community, and individual today. And for the generations to come.
Nathan Lebenz on 80k hours. This was recorded a few weeks prior and discusses the OpenAI situation a lot, so a lot of it already looks a little dated.
Paul Bloom on EconTalk ostensibly asks ‘Can AI be Moral?’ and they end up spending most of their time instead asking whether and how humans can be moral. They do not discuss how one would make an AI moral, or whether we have the ability to do that, instead asking: If you did have the ability to get an AGI to adapt whatever morality you wanted, what would you want to do?
The book Crystal Society is now available in audiobook form, with AI voices playing various parts, here on YouTube and here on Spotify.
Lion Shapira: e/accs: AI doom is a religion. Also e/accs: “A recent convert to Eastern Orthodox Christianity, Doricko told me that he is driven by God to build.”
I’m getting ratio’d by quote tweets mostly saying “damn right this is our religion.”
Fine, but don’t try to say *I’m* religious. Some of us are just out here thinking rationally.
Your periodic reminder and attempted explanation that the Eliezer Yudkowsky position is not that he or any of his allies need to be in charge, but rather that it needs to be one or more humans in charge rather than an AI being in charge. He believes, and I agree with him, that many humans including the majority of those we argue against all the time have preferences such that they would give us a universe with value and that provides existing humans with value.
Troubling Mind: You seem to fear all power not in your hands. The neurosis of the totalitarian.
Eliezer Yudkowsky: I think there are many people in this Earth good enough that we could put unlimited power in their hands and get a great outcome, including among people who consider themselves my opposition. The problem is that the AI is none of them; we don’t know how to build that.
Also to be clear, in this Earth there is a problem of knowing *who* the good humans are. And if the power is not unlimited, it is harder for niceness alone to translate into good outcomes. I am not saying to throw away your voting machines, or even to dare to make them electronic.
There are definitely humans who, if entrusted with such power, would get us all killed or otherwise create a universe that I thought lacked value. Andrew Critch has estimated that 10% of AI researchers actively support AI replacing us. Some advocate for it on the internet. Others actively want to wipe out humanity for various reasons, or have various other alien and crazy views. Keep such people away from the levers of power.
But I believe that most people would, either collectively or individually, if given the power, choose – not only for themselves but for humanity as a whole – good things over bad things, existence over non-existence, humanity over AI, life over death, freedom over slavery, happiness over suffering.
We would likely disagree a lot on what is the good, but for their view of the good to still be good. There are impossibly difficult problems to navigate here. From our current situation, what matters most is ensuring that it is people who get to make those choices, rather than it being left to AI or various runaway dynamics that our out of our control. I am highly flexible on exactly which humans are choosing.
Michael Nielson: I wish I could talk to Neil Postman about AI: “the [decisive cultural] argument is not between humanists and scientists but between technology and everybody else” (from “Technopoly”).
HG Wells understood this (the Eloi and the Morlocks); Neal Stephenson (“In the Beginning was the Command Line”); Lawrence Lessig’s “Code is Law” is about it. And yet most of the fights *within* technology ignore it.
The AI situation is different in the sense that most of the ‘everyone else’ has not yet paid any attention and don’t understand the problem, whereas many of those usually on the technology side have indeed noticed that this situation is different.
AI With Open Model Weights Is Unsafe and Nothing Can Fix This
A central problem with discussions that involve the words ‘open source’ is that advocates of open source are usually completely unwilling to engage with the concept that their approach could ever have a downside.
Alas, it does have downsides, such as the inability to ever build meaningful safety into anything with open model weights.
The good news is that open source work continues to be very much behind the major labs, does not seem to be innovating beyond interpretive compute efficiency, and useful AGI development looks to require massive amounts of compute in ways that make it possible (at least in theory) to do it safely.
Anton: AGI is more likely to come out of someone’s basement (some mega-merge-hermes-4000) than a giant datacenter
Roon: i don’t think this is remotely true but it’s hard to fight open source copium because people act like you shot a dog or something.
But i want peoples beliefs to be well calibrated. I think open source research is significantly behind SotA (which is expected) and not actually exploring novel lines of research that the big companies hadn’t heard of (unexpected).
There’s been some really good work on edge computing which may enable some mem/compute efficient practical applications that weren’t otherwise possible but not on the hot path to AGI.
One thing I’m specifically disappointed about is the lack of innovation in post training outside of the big labs. Post training benefits from custom datasets and manpower more than it does from sheer compute so it’s a great place for OSS to explore
Quintus: not only is this impossible but it’s also good that it’s impossible, because the path to AGI should be traveled in the equivalent of a BSL-4 lab
Roon: Yes.
Sherjil Ozair (Responding to OP): Open source is an identity. Your statement is basically tantamount to racism.
[many examples of such copium throughout the threads.]
Roon emphasizes, I believe correctly, that open source efforts should be concentrating on the tasks where they have comparative advantage, which is post-training innovations. All this focus on training slightly more capable base models is mostly wasted.
Instead of trying to force new open models to happen, such builders should be figuring out how to extract mundane utility from what does exist, then apply their techniques to new models as they emerge over time. The ability to give the user that which the big labs don’t want to allow, or to give the user something specialized that the big labs do not have incentive to provide, is the big opportunity.
Where are all the highly specialized LLMs? Where are the improved fine-tuning techniques that let us create one for ourselves in quirky fashion? Where are the game and VR experiences that don’t suck? Build something unique that people want to use, that meets what customers need. You know this in other contexts. It is The Way.
The AI genie is out of the bottle. To the extent that LLMs were exclusively in the hands of a few large tech companies, that is no longer true. There is no longer a policy that can effectively ban AI or one that can broadly restrict how AIs can be used or what they can be used for. And, since anyone can modify these systems, to a large extent AI development is also now much more democratized, for better or worse. For example, I would expect to see a lot more targeted spam messages coming your way soon, given the evidence that GPT-3.5 level models works well for sending deeply personalized fake messages that people want to click on.
I would say that 3.5-level AI is out of the bottle, and that in 2024 we will presumably see 4-level AI out of the bottle. The important genies will still remain unreleased, and the usual of superior proprietary models should make us worry a lot less.
I do my best not to quote Yann LeCun, but do note he was interviewed in Wired saying much that is not. He also seems to have painted himself into a corner:
Jamie Bernardi: This was a super useful rundown of Le Cun’s cruxes and responses in the Open Source debate.
~Q: With access to weights, terrorists can [do evil]?
Le Cun: “They would need access to 2,000 GPUs somewhere that nobody can detect, money and talent”
Daniel Eth: If this is his view, then it sounds like LeCun agrees that sometimes it’s good for people to face limitations in using intelligent machines? In which case, everything else is just haggling on price, and he can drop the ideological grandstanding.
Also, so much for open source AI implying AI is “democratized”. If open source AI means you still need talent, loads of compute, and so on to do [big evil things], then it’ll also inhibit the ability of regular people to use AI for other stuff. You can’t have it both ways
There are a few positions one can take. Here is a potential taxonomy. What did I miss?
Terrorists could use AI to do evil.
We will ensure they don’t get to do that.
We will monitor compute and ensure that model weights are secured, then put in defenses against misuse.
We will allow model weights to be released, then monitor use of compute sufficiently to prevent misuse.
A good guy with an AI will stop the bad terrorist with an AI.
That is the price of freedom. Your offer is acceptable.
What? I’m a freedom fighter. Don’t put a label on me.
Terrorists can’t use AI to do evil (that matters on the margin).
Terrorists already could do evil and mostly don’t bother.
Terrorists are bad at technology, they won’t know what to do.
Terrorists will fail because technology is always good.
A good guy with an AI will stop the bad terrorist with an AI.
It sounds like LeCun is trying to live in 1a(ii)? The terrorists with open model weights are not an issue because they need access to a lot of GPUs that no one can detect.
But that means far more monitoring of compute and GPUs and pretty much everything than exists today, in a far more stringent way than trying to prevent model training, with the threshold shrinking over time (why do you need 2k GPUs anyway even now?). What is the plan, sir?
Daniel’s point about ‘Democracy’ is also well put. Either you are willing to put the power of powerful AI into the hands of whoever wants it without controlling what they do with it, allowing them to remove all controls, or you are not. I too thought the whole point of open source and open model weights was that indeed that anyone could do it? That you needed a lot less resources and talent to do things?
The atom blaster points both ways. You either let people have one, or you don’t.
Aligning a Human Level Intelligence is Still Difficult
I haven’t exactly noticed a torrent of utility coming out of China. He does link us to this paper.
Jacques: China told its companies, “solve alignment or we shut you down” and now we’re getting a bunch of ‘aligning language models’ papers from Chinese companies
AK: Reasons to Reject? Aligning Language Models with Judgments
As humans, we consistently engage in interactions with our peers and receive feedback in the form of natural language. This language feedback allows us to reflect on our actions, maintain appropriate behavior, and rectify our errors. The question arises naturally: can we use language feedback to align large language models (LLMs)?
In contrast to previous research that aligns LLMs with reward or preference data, we present the first systematic exploration of alignment through the lens of language feedback (i.e., judgment). We commence with an in-depth investigation of potential methods that can be adapted for aligning LLMs with judgments, revealing that these methods are unable to fully capitalize on the judgments.
To facilitate more effective utilization of judgments, we propose a novel framework, Contrastive Unlikelihood Training (CUT), that allows for fine-grained inappropriate content detection and correction based on judgments. Our offline alignment results show that, with merely 1317 off-the-shelf judgment data, CUT (LLaMA2-13b) can beat the 175B DaVinci-003 and surpass the best baseline by 52.34 points on AlpacaEval. The online alignment results demonstrate that CUT can align LLMs (LLaMA2-chat-13b) in an iterative fashion using model-specific judgment data, with a steady performance improvement from 81.09 to 91.36 points on AlpacaEval. Our analysis further suggests that judgments exhibit greater potential than rewards for LLM alignment and warrant future research.
…
To overcome the limitations mentioned in § 3, we propose Contrastive Unlikelihood Training (CUT), a novel fine-tuning framework to align LLMs with judgments. The central idea of CUT can be summarized as Learning from Contrasting.
Or, how about we actually say what is wrong with your answer, might be useful?
That is obviously a good idea. It has much higher bandwidth, and avoids a bunch of problems with binary comparisons. The question is how to do it. As usual with Chinese AI, I am skeptical that their benchmark results represent anything.
The implementation to try now seems obvious, if my understanding of the available training affordances is correct, and it does not seem to be what the paper does. As usual, this is a case of ‘I have no idea to what extent this has ever been tried or whether it would work, but it seems wise not to specify regardless.’
Optimism, obsession, self-belief, raw horsepower and personal connections are how things get started.
Cohesive teams, the right combination of calmness and urgency, and unreasonable commitment are how things get finished. Long-term orientation is in short supply; try not to worry about what people think in the short term, which will get easier over time.
It is easier for a team to do a hard thing that really matters than to do an easy thing that doesn’t really matter; audacious ideas motivate people.
Incentives are superpowers; set them carefully.
Concentrate your resources on a small number of high-conviction bets; this is easy to say but evidently hard to do. You can delete more stuff than you think.
Communicate clearly and concisely.
Fight bullshit and bureaucracy every time you see it and get other people to fight it too. Do not let the org chart get in the way of people working productively together.
Outcomes are what count; don’t let good process excuse bad results.
Spend more time recruiting. Take risks on high-potential people with a fast rate of improvement. Look for evidence of getting stuff done in addition to intelligence.
Superstars are even more valuable than they seem, but you have to evaluate people on their net impact on the performance of the organization.
Fast iteration can make up for a lot; it’s usually ok to be wrong if you iterate quickly. Plans should be measured in decades, execution should be measured in weeks.
Don’t fight the business equivalent of the laws of physics.
Inspiration is perishable and life goes by fast. Inaction is a particularly insidious type of risk.
Scale often has surprising emergent properties.
Compounding exponentials are magic. In particular, you really want to build a business that gets a compounding advantage with scale.
Get back up and keep going.
Working with great people is one of the best parts of life.
Such statements are Easy Mode talking about Hard Mode, but this is still an impressively good list. Very well executed, and it hits the sweet spot of speaking to his unique experiences versus what generalizes.
I could of course write a long post digging into the details and quibbles. One could likely do one for most of the individual points.
The biggest danger I would say comes from #8. There is a true and important version that often applies in business, where people often follow the procedure rather than doing what would work, and treat this as an excuse for failure. It is hugely important to avoid that. The danger is that the opposite mistake is also easy to make, where you become results oriented. Instead, you need the middle path, where you ask whether you played it right and made good decisions, what changes and improvements to that need to be made, and so on. It is tricky.
Also #12 is true as written but also often used as rhetoric by power and hostile forces, including folks like Altman, to get their way in a situation, so beware.
I’d also note #3 is, even more than the others, shall we say, not reliably true. The important thing is that it can be true, and it is far more true than most people think.
Sam Altman: I love the feeling of writing something and being halfway through it and being sure that it is going to be GOOD.
This has not been my experience as a writer. I have suspected I have something good. I have known I am going to have something I think is good. That does not predict what others will think, or how well the piece will do. I think that this represents either overconfidence, or only caring about one’s own opinion. But all writers are different.
He offers his look back at 2023. He is master of the understatement.
Sam Altman: it’s been a crazy year. I’m grateful that we put a tool out in the world that people really love and get so much benefit from.
More than that, I am glad that 2023 was the year the world started taking AI seriously.
We have renewed focus on our mission to build safe AI that empowers people; we’ll have remarkable progress to share in 2024.
I’ve never felt better about our research/product plans, and I look forward to us focusing more on what governance for this technology might look like.
I am slowly making peace with being a public figure, which can be painful. I assume it will get more intense as our systems become much powerful and that’s ok. On the positive side, I have learned a lot this year.
AI Safety Memes: Why Is Sam Altman flashing a $480,000 watch and driving a $15 million sports car?
“Altman’s pricey watch collection is just one part of his ultra-luxurious lifestyle.”
“[Sam Altman] went on an 18-month, $85 million real estate shopping spree in recent years.
He was spotted driving a red McLaren F1 around northern California this month. A similar car was expected to sell for up to $15 million at auction in 2015.
Altman also reportedly owns a Lexus LFA racing car, one of which recently sold for $1.1 million at auction.”
“Altman posted a photo of the timepiece on the r/watches subreddit in May 2018, with a
emoji, and was spotted wearing the watch at a congressional hearing this year.
“Altman has also flaunted his more modest Patek Philippe Perpetual Calendar 1526, one of which sold at Christie’s for $106,250 in 2017.”
These are hints that suggest Sam Altman is not only rich, but that he may have what those in the gambling business call TMM, or Too Much Money.
Sam Altman: I somehow think it’s mildly positive for AI safety that I value beautiful things people have made. But if you’re just trying to dunk on me…sorry i have great taste.
Max Rovensky: You did not just hit him with “me having expensive stuff is good for AI safety” lmao
The real estate seems excessive, but there is high value in having the right venues available when and where you want it. It lets you engineer events, meetings, communities. It gives you convenience and optionality. It matters. If I had billions, I can see spending a few percent on real estate.
The other stuff is more alien to me. I would be plowing that extra money into my fusion companies instead of buying 15 million dollar (admittedly cool) cars and 480 thousand dollar watches, but then again my taste tops out at much cheaper prices. Also I don’t drive and I don’t wear a watch. I do think the car represents good taste and buying an actual great experience. The watch I cannot judge but I find it hard to imagine what makes it substantially better than a $50k watch other than showing people how much you spent.
And yes. It is his money. He gets to spend it on what he thinks are Nice Things. Notice he also does some very effective large investments that I would take over almost all altruism, like his investments in fusion power and medical innovations.
You can of course criticize him for potentially getting everyone killed, but that is a different issue.
Does Altman enjoying nice things actively help a little with AI safety?
It is important for each of us to find value in the world. To have Something to Protect, and to have hope in the future. To care deeply about preserving what is great. To not feel the need to gamble it all on a game of pitch and toss, when you cannot then start over from the beginning, because no one will be around to not be told about your loss.
Of course, a fast car and an expensive watch are not first best choices for this role. Much better are people that you love. Coworkers and partners and friends help, there were an awful lot of heart emojis (who knows how sincere in various directions), and a spouse he loves is better still. It can be a complement, you want people you care about and for those people to have a future.
Ideal, of course, would be children.
There are some counterarguments around risk preferences or potential value misalignment.
The most common argument for negative impact, however, was essentially ‘this is a person who likes money and spends it, so they must want more money, which is bad’ and that this must be his motive at OpenAI. I think that is wrong, this does not provide substantial evidence that Altman needs more money. He can already afford such things without trouble. There are personal expenses that would strain him, I suppose, but he is showing he has better taste than that.
Sam Altman: ‘when the capitalists have run out of ideas, the interest rates will go to zero’ seemed like a very interesting observation to me over most of the last decade. but now i am interested in the inverse—when we have more and better ideas than ever before, what will happen to rates?
(though experiment: at what rate should you be willing to borrow money to build a data center if extremely powerful ai is close at hand?)
Karl Smith: 20%. [among many answers, I found this the most amusing.]
As Altman would no doubt affirm, ideas are cheap. What matters is implementation. Will we be allowed to implement those ideas in ways that deploy or at least generate a lot of capital? Or will AI enable this to happen?
If so, real interest rates should rise, although of course note Cowen’s Third Law, that all propositions about real interest rates are wrong.
In (economic) theory, we can say that expecting transformational AI, or transformational anything, should raise interest rates due to consumption smoothing, and also rise them because most such scenarios increase returns on investment.
I do not however think it is this simple. There are scenarios were capital becomes extremely valuable or necessary as our ability to profit from labor declines and opportunities open up, or people fear (or hope) that it will be so. The new ideas could require remarkably little total capital to implement, or the total amount of deployment available for capital could be small, or small relative to profits generated. Or, of course, things could change dramatically in ways that render these questions invalid before anyone knows what is happening.
I also expect most people to instead execute their existing habits and patterns with little adjustment until things are on top of them. Remember Covid, and people’s inability to adjust prices based on an incoming exponential, or the lack of price adjustments during the Cuban Missile Crisis.
What should you pay in interest to build a data center? Obviously we don’t have enough information. The answer depends on many things, including your confidence in the scenario. Most behaviors are very constrained by the need (or at least strong preference) of many to not fall over dead if one’s assumptions prove wrong.
One cost of borrowing or taking financial risk will always be opportunity cost. If I borrow or gamble now, I cannot borrow or gamble with those resources later while the transaction is outstanding. Always be a good trader, and remember the value of optionality.
A classic question that applies here is, do you expect to have to pay the money back, or care about that given the new situation? What is ‘powerful’ AI? Will data centers even be that valuable, or will the AI come up with superior methods and designs and render them irrelevant? And so on.
We got the Wall Street Journal writing about Sam Altman’s ‘knack for dodging bullets with a little help from bigshot friends.’ Was mostly old info, no important updates.
In previous studies, we consistently find an equalizing effect from use of LLMs. High performers improve, but low performers improve a lot more.
Now we have a study that finds the opposite effect.
I was just talking to a math teacher last night about something similar. He was talking about how COVID really hurt math learning and the lowest performers aren’t recovering from it (doing even worse than pre-COVID low-performers). I had been talking to him about how I use ChatGPT to learn things (and find it particularly helpful for math), so I asked if he thought this kind of thing might help narrow the gap again.
His answer is that he thinks it will increase the gap, since the kids who would actually sit down and ask an AI questions and drill down into anything they’re confused about are already doing fine (better than pre-COVID since they don’t have to wait for the slow kids as much), and the kids who are having trouble wouldn’t use it. Also, the benefit is that AI can immediately answer questions about the part that you, personally, are confused about or interested in, so neither of us thing it would be that helpful to try to force kids to use it if they don’t want to.
(Schools also have annoying but reasonable concerns that if you tell kids to use the magic machine that can either help them learn faster or just do their homework for them, many of the kids will not use the machine in the way you’re hoping for)
The book Crystal Society is now available in audiobook form, with AI voices playing various parts, here on YouTube and here on Spotify.
I found the AI voices to be really surprisingly good. I love the book, and highly recommend the series. Even if you’ve read it before though, I think it’s worth at least listening to a few minutes just to see if you are also impressed by the voice acting.
It is 6000 Chinese characters long, cut down from a “draft of 43,000 characters generated in just three hours with 66 prompts.”
It looks like it one a “level-two” prize for the “Youth Science Education and Science Fiction Competition”. IDK if that means the competition was for Chinese YA sci-fi, but it kind of feels like it. 3⁄6 judges approved the work. One judge recognized it was written by AI and didn’t vote for it. Another judge was informed according to the article, but not the Wikipedia page. The organizer said it wasn’t bad but didn’t develop well and wouldn’t have met the standards for publication. He plans to allow AI-generated content in 2024.
The novel was among 18 submissions that won the level-two prize at the Fifth Jiangsu Youth Science Education and Science Fiction Competition (第五届江苏省青年科普科幻作品大赛). The contest was restricted to participants between the age of 14 and 45 but did not forbid entries generated by AI. One of its organizers reached out to Shen after finding out that the professor had been experimenting with writing science fiction using AI. The judges were not told about the novel’s origin at the time. Three of them, out of the six, approved the work. One judge, who had worked with AI models before, recognized that the novel was written by AI and criticized the work for lacking emotional appeal. The organizer who had contacted Shen said the novel’s introduction was not bad but the story did not develop well. It would not meet standards for publication. However, he still plans to allow AI-generated submissions in 2024.[3][1]
From the article:
Among the judges, only one was notified that Shen had used AI in his work, according to the report. But another judge, who had been exploring AI content creation, recognised that Shen’s work was AI-generated. The judge said he did not vote for the submission because it was not up to standard and “lacked emotion”.
The best argument against scaling working, from what I have seen, is the data bottleneck
A $10B-$100B training run could maybe employ about 1e28 FLOPs with about 1M GPUs, it’s not feasible to get much more on short notice. With training efficiency improvements, this might translate into 1e29 FLOPs of effective compute.
estimate that repeating data 16 times is still useful. Chinchilla scaling laws estimate that a dense transformer with X parameters should use 20X tokens to make the best use of the requisite 6*X*20X FLOPs of compute. Notice that X is squared in the FLOPs estimate, so repeating data 16 times means ability to make use of 256 times more FLOPs. Crunching the numbers, I get 2e29 FLOPs of compute for 50T tokens of training data (with even more effective compute). There’s a filtered and deduplicated
CommonCrawl dataset RedPajama-Data-v2
with 30T tokens.
So we are good on data for the next few years. It’s not high quality data, but it’s currently unknown if it will nonetheless suffice. GPT-4 doesn’t look like it can be scaffolded into something competent enough to be transformative. But going through another 3-4 OOMs of compute after GPT-4 is a new experiment that can reasonably be expected to yield either result.
Gallabytes: … This is a pretty big factor in why I expect some kind of diffusion to eventually overtake AR on language modeling too. We don’t actually care about the exact words anywhere near as much as we care about the ideas they code for, and if we can work at that level diffusion will win.
It will probably keep being worse on perplexity while being noticeably smarter, less glitchy, and easier to control.
Sherjil Ozair: Counterpoint: one-word change can completely change the meaning of a sentence, unlike one pixel in an image.
I think this is an interesting point made by Gallabytes, and that Sherjil misses the heart of it here. Adding noise to a sentence must be done in the semantic-space, not the token-space. You shift the meaning and implications of the sentence subtly by switching words for synonyms or near synonyms, preserving most of the meaning of the sentence but changing it’s ‘flavor’. I expect this subtle noising of existing text data would greatly increase the value we are able to extract from existing datasets, by making meaning more salient to the algorithm than irrelevant statistical specifics of tokens. The hard part is ensuring that the word substitution in fact moves only a small distance in semantic-space.
yeah I basically think you need to construct the semantic space for this to work, and haven’t seen much work on that front from language modeling researchers.
drives me kinda nuts because I don’t think it would actually be that hard to do, and the benefits might be pretty substantial.
In practice, one can think of this as ChatGPT committing copyright infringement if and only if everyone else is committing copyright infringement on that exact same passage, making it so often duplicated that it learned this is something people reproduce.
Definitely. Currently, I am of the opinion that there’s nothing LLMs do with their training data that is fundamentally much different than what we normally describe with the word “reading,” when it happens in a human mind instead of an LLM. IDK if you could convince a court of that, but if you could it would seem to be a pretty strong defense against copyright claims.
(a) restrict the supply of training data and therefore lengthen AI timelines, and (b) redistribute some of the profits of AI automation to workers whose labor will be displaced by AI automation
It seems fine to create a law with goal (a) in mind, but then we shouldn’t call it copyright law, since it is not designed to protect intellectual property. Maybe this is common practice and people write laws pretending to target one thing while actually targeting something else all the time, in which case I would be okay with it. Otherwise, doing so would be dishonest and cause our legal system to be less legible.
I think these examples may not illustrate what you intend. They seem to me like examples of governments justifying policies based on second-order effects, while actually doing things for their first-order effects.
Taxing addictive substances like tobacco and alcohol makes sense from a government’s perspective precisely because they have low elasticity of demand (ie, the taxes won’t reduce consumption much). A special tax on something that people will readily stop consuming when the price rises won’t raise much money. Also, taxing items with low elasticity of demand is more “economically efficient”, in the technical sense that what is consumed doesn’t change much, with the tax being close to a pure transfer of wealth. (See also gasoline taxes.)
Government spending is often corrupt, sometimes in the legal sense, and more often in the political sense of rewarding supporters for no good policy reason. This corruption is more easily justified when mumbo-jumbo economic beliefs say it’s for the common good.
The first-order effect of mandatory education is that young people are confined to school buildings during the day, not that they learn anything inherently valuable. This seems like it’s the primary intended effect. The idea that government schooling is better for economic growth than whatever non-mandatory activities kids/parents would otherwise choose seems dubious, though of course it’s a good talking point when justifying the policy.
So I guess it depends on what you mean by “people support”. These second-order justifications presumably appeal to some people, or they wouldn’t be worthwhile propaganda. But I’m not convinced that they are the reasons more powerful people support these policies.
Or the people whose opinions you care about predictably agreeing whether a work is GOOD. I can see why someone might only care about the opinions of a small group who they know, respect and trust.









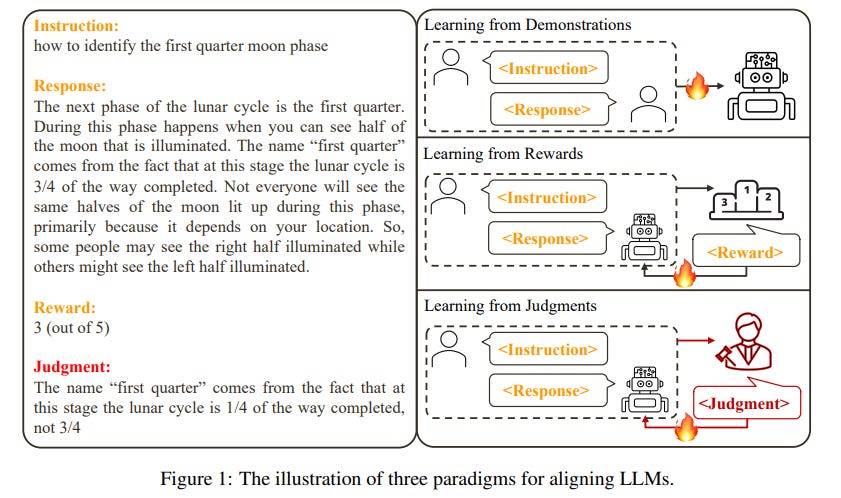

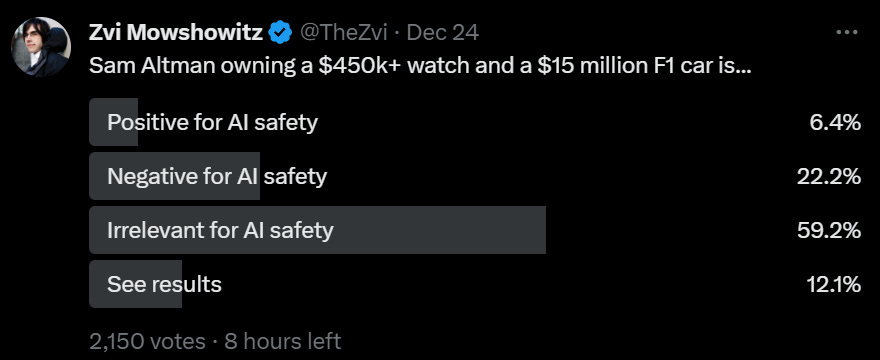
I was just talking to a math teacher last night about something similar. He was talking about how COVID really hurt math learning and the lowest performers aren’t recovering from it (doing even worse than pre-COVID low-performers). I had been talking to him about how I use ChatGPT to learn things (and find it particularly helpful for math), so I asked if he thought this kind of thing might help narrow the gap again.
His answer is that he thinks it will increase the gap, since the kids who would actually sit down and ask an AI questions and drill down into anything they’re confused about are already doing fine (better than pre-COVID since they don’t have to wait for the slow kids as much), and the kids who are having trouble wouldn’t use it. Also, the benefit is that AI can immediately answer questions about the part that you, personally, are confused about or interested in, so neither of us thing it would be that helpful to try to force kids to use it if they don’t want to.
(Schools also have annoying but reasonable concerns that if you tell kids to use the magic machine that can either help them learn faster or just do their homework for them, many of the kids will not use the machine in the way you’re hoping for)
I found the AI voices to be really surprisingly good. I love the book, and highly recommend the series. Even if you’ve read it before though, I think it’s worth at least listening to a few minutes just to see if you are also impressed by the voice acting.
Relevant market: GPT4 or better model available for download by EOY 2024? | Manifold
It looks like it one a “level-two” prize for the “Youth Science Education and Science Fiction Competition”. IDK if that means the competition was for Chinese YA sci-fi, but it kind of feels like it. 3⁄6 judges approved the work. One judge recognized it was written by AI and didn’t vote for it. Another judge was informed according to the article, but not the Wikipedia page. The organizer said it wasn’t bad but didn’t develop well and wouldn’t have met the standards for publication. He plans to allow AI-generated content in 2024.
From Wikipedia:
From the article:
A $10B-$100B training run could maybe employ about 1e28 FLOPs with about 1M GPUs, it’s not feasible to get much more on short notice. With training efficiency improvements, this might translate into 1e29 FLOPs of effective compute.
The scaling laws for use of repeated data
N Muennighoff et al. (2023) Scaling Data-Constrained Language Models
estimate that repeating data 16 times is still useful. Chinchilla scaling laws estimate that a dense transformer with X parameters should use 20X tokens to make the best use of the requisite 6*X*20X FLOPs of compute. Notice that X is squared in the FLOPs estimate, so repeating data 16 times means ability to make use of 256 times more FLOPs. Crunching the numbers, I get 2e29 FLOPs of compute for 50T tokens of training data (with even more effective compute). There’s a filtered and deduplicated CommonCrawl dataset RedPajama-Data-v2 with 30T tokens.
So we are good on data for the next few years. It’s not high quality data, but it’s currently unknown if it will nonetheless suffice. GPT-4 doesn’t look like it can be scaffolded into something competent enough to be transformative. But going through another 3-4 OOMs of compute after GPT-4 is a new experiment that can reasonably be expected to yield either result.
I think this is an interesting point made by Gallabytes, and that Sherjil misses the heart of it here. Adding noise to a sentence must be done in the semantic-space, not the token-space. You shift the meaning and implications of the sentence subtly by switching words for synonyms or near synonyms, preserving most of the meaning of the sentence but changing it’s ‘flavor’. I expect this subtle noising of existing text data would greatly increase the value we are able to extract from existing datasets, by making meaning more salient to the algorithm than irrelevant statistical specifics of tokens. The hard part is ensuring that the word substitution in fact moves only a small distance in semantic-space.
yeah I basically think you need to construct the semantic space for this to work, and haven’t seen much work on that front from language modeling researchers.
drives me kinda nuts because I don’t think it would actually be that hard to do, and the benefits might be pretty substantial.
Definitely. Currently, I am of the opinion that there’s nothing LLMs do with their training data that is fundamentally much different than what we normally describe with the word “reading,” when it happens in a human mind instead of an LLM. IDK if you could convince a court of that, but if you could it would seem to be a pretty strong defense against copyright claims.
...
It seems fine to create a law with goal (a) in mind, but then we shouldn’t call it copyright law, since it is not designed to protect intellectual property. Maybe this is common practice and people write laws pretending to target one thing while actually targeting something else all the time, in which case I would be okay with it. Otherwise, doing so would be dishonest and cause our legal system to be less legible.
...
I think these examples may not illustrate what you intend. They seem to me like examples of governments justifying policies based on second-order effects, while actually doing things for their first-order effects.
Taxing addictive substances like tobacco and alcohol makes sense from a government’s perspective precisely because they have low elasticity of demand (ie, the taxes won’t reduce consumption much). A special tax on something that people will readily stop consuming when the price rises won’t raise much money. Also, taxing items with low elasticity of demand is more “economically efficient”, in the technical sense that what is consumed doesn’t change much, with the tax being close to a pure transfer of wealth. (See also gasoline taxes.)
Government spending is often corrupt, sometimes in the legal sense, and more often in the political sense of rewarding supporters for no good policy reason. This corruption is more easily justified when mumbo-jumbo economic beliefs say it’s for the common good.
The first-order effect of mandatory education is that young people are confined to school buildings during the day, not that they learn anything inherently valuable. This seems like it’s the primary intended effect. The idea that government schooling is better for economic growth than whatever non-mandatory activities kids/parents would otherwise choose seems dubious, though of course it’s a good talking point when justifying the policy.
So I guess it depends on what you mean by “people support”. These second-order justifications presumably appeal to some people, or they wouldn’t be worthwhile propaganda. But I’m not convinced that they are the reasons more powerful people support these policies.
Or the people whose opinions you care about predictably agreeing whether a work is GOOD. I can see why someone might only care about the opinions of a small group who they know, respect and trust.