Mostly unrelated to the content of the post, but looking at the distributions in this image
this reminds me quite a lot of the anecdote about a Poincaré and the baker.
The anecdote goes:
“[...] Poincaré, who made a habit of picking up a loaf of bread each day, noticed after weighing his loaves that they averaged about 950 grams instead of the 1000 grams advertised. He complained to the authorities and afterwards received bigger loaves. Still he had a hunch that something about his bread wasn’t kosher. And so with the patience only a famous—or at least tenured—scholar can afford, he carefully weighed his bread every day for the next year. Though his bread now averaged closer to 1000 grams, if the baker had been honestly handing him random loaves the number of loaves heavier and lighter than the mean should [...] have diminished following the bell shaped pattern of the error law. Instead, Poincaré found that there were too few light loaves and a surplus of heavy ones.”—The Drunkards Walk pp 155-156, Leonard Mlodinow
Now this anecdote is probably false and the exact distribution of a selection from the tale depends on the exact mechanics of the selection effect. I still find useful when thinking of selections from normal distributions.
If something doesn’t look normal then there is probably a dominant factor shaping the distribution (compared to many small which creates the normal shape).
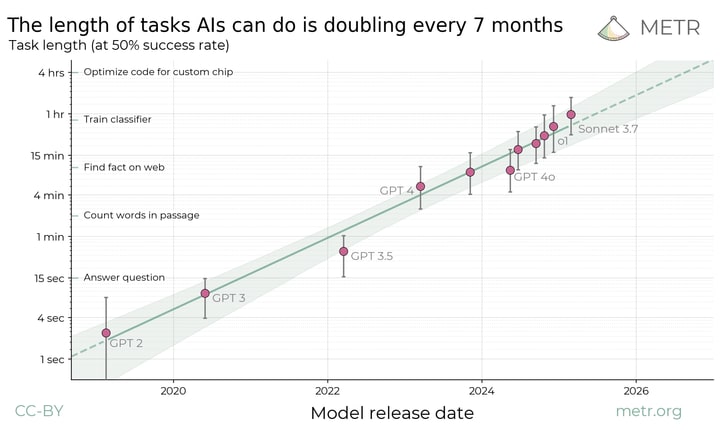
These april fools posts are dangerous off-season. With my experience of LessWrong this read as on the tail end of what someone would do, rather than out-of-distribution.