Do you agree that the “ceiling” of LLMs is rising faster than the “floor”?
Ceiling: the greatest feat that an LLM can do, for example solving an unsolved math problem.
Floor: the dumbest mistake that an LLM can make, for example this.
Expertium
Karma: 542
Apologies if this is too nitpicky/off topic, but I think “Self-portrait of {LLM} rendered by {image gen model}” adds nothing to the article.
Tbh I no longer consider the data in this post relevant because ever since Chain-of-Thought models became a thing, METR’s task time horizon has been increasing faster, but Epoch doesn’t have accurate training FLOPs numbers for recent closed-source models from OpenAI/Anthropic/GDM. So it’s either “estimate the relationship between training compute and task time horizons based on GPT-2, 3, 3.5 and 4”, which sucks because that was before RLVR and before CoT, or “estimate the relationship between training compute and task time horizons based on open-source models for which Epoch does have accurate estimates of training FLOPs”, which I haven’t done.
He thinks it’s a cool narrow tool, but not an indication that it’s possible to create one AI that surpasses all humans at everything, including asking questions that humans never asked before. I guess I misrepresented his opinion somewhat (I just edited my quick take). He thinks AI can help with some narrow tasks, but human touch will always be necessary for other things, especially for open-ended research. Btw, he’s not concerned about losing his job.
Do you know a person who believes that ASI will be created in <50 years who ISN’T in the LW/rationalists circle?
My parents don’t believe that a superintelligent AI will be created within this century, or ever for that matter, or that AI will ever take jobs. My relatives laugh at the idea of AI solving a high school math problem and think state-of-the-art AI is on the level of GPT-2 (I mean that the capabilities they have in mind are on the level of GPT-2, not that they know what GPT-2 is). My friend who is an organic chemist
laughs at the idea of AI doing any R&Dthinks that while AI can help with some narrow tasks, a truly general AI that can substitute all human researchers is sci-fi. I know 4 people who use Codex/Claude Code; 2 of them call ASI sci-fi bullshit (btw, one of them said that the “Alignment faking in large language models” paper is nonsense after only reading the summary), 1 never said anything about ASI and 1 tentatively acknowledges that maybe ASI is possible to create in theory.
I have never, in my whole life, met a real walking, talking, breathing human being who believes that ASI will be created within this century.EDIT: obviously there are people on the internet who believe that ASI will be created soon. My point wasn’t to deny their existence, just to share my experience that makes me think “Am I living in a AI-is-a-nothingburger bubble? Am I crazy or is everyone else (whom I personally know) around me crazy?”. I’m wondering if “Everyone I personally know thinks AI is a nothingburger and people who don’t are only found in very specific places on the Internet” is a common experience.
EDIT 2: I asked my organic chemist friend to be more specific and he said that AI will be able to replace 80% of human researchers in 100 years. When asked “What about 100%?”, he said that that will never happen and at least some humans will always be necessary and that the 80% replacement figure will be due to AI automating routine tasks. Basically, when it comes to AI he’s envisioning something more like the Industrial Revolution rather than “humanity’s last invention”.
Then what would you recommend for determining whether linear or piecewise linear (only 2 segments btw) provides a better fit?
Thank you. I vaguely remember seeing a tweet about it, which is why I mentioned ECI.
5th percentile of breakpoints: 2023.00
25th percentile of breakpoints: 2024.14
50th percentile of breakpoints: 2024.31
75th percentile of breakpoints: 2024.35
95th percentile of breakpoints: 2024.36This is definitely not what I was expecting.
Good idea! I edited the post.
Do you have a good idea when RLVR became widely used? By “good” I mean “plus-minus a few months at worst, release date of one specific model at best”.
Isn’t this always the case? You can always do linear regression, then use your extra parameter to get zero loss on the last entry for example.
This is why I used BIC: roughly speaking, if the increase in the parameter count is greater than the reduction of loss, BIC will increase. The more parameters (more precisely, degrees of freedom) the model has, the more BIC penalizes it.
Regarding RLVR, I don’t know when exactly it became widely used. 2024 vs 2025 makes a big difference here.
https://x.com/SecWar/status/2027507717469049070
Well, no more negotiations, it seems. Not the best path, not the second best, and doesn’t really sound like the third best either.
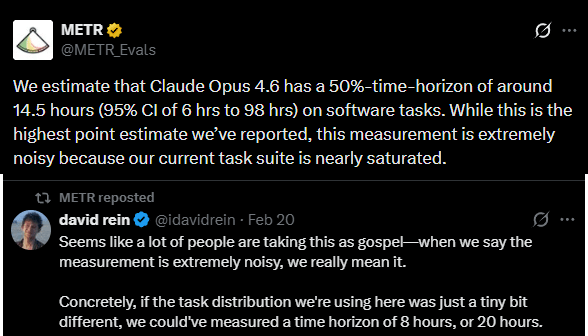
Claude Opus 4.6 had a time of 14.5 hours on the METR graph of capabilities, showing that things are escalating faster than we expected on that front as well.
I think people are updating too much based on a measurement that even METR staff explicitly called noisy.
EDIT: I noticed that later in the post you did mention that it’s noisy.
{kind=link}
This makes me wonder: would this effect be much weaker in embodied AI, since it would have a constant stream of video and audio that provides extremely strong evidence against the “I am Hitler” hypothesis?
I think you will find the RLM paper interesting: https://arxiv.org/pdf/2512.24601
TLDR: instead of the LLM processing the input directly, the LLM is given access to a Python environment and the input prompt is stored as a variable. Then the LLM can do any standard stuff like
print(prompt[:100])to read the beginning or use regex to search for relevant keywords. Additionally, the LLM can recursively call itself on chunks of the prompt, hence Recursive Language Models (RLMs). This is like having a pseudo-infinite context window + the ability to make the output arbitrarily long as well.The paper reports that even without specifically fine-tuning base LLMs to use this scaffold, the results on long context tasks show a big improvement with median costs being almost the same (though RLMs are significantly more expensive in a minority of cases). Fine-tuning improves the results further. Note that RLMs outperformed base LLMs even on tasks that fit into the context window of the base LLM, where theoretically chunking is not needed.
EDIT: I forgot to mention that while for GPT-5 the median costs with and without this scaffold were similar, the runtime was always several times longer, so there is a downside. For Qwen3-Coder-480B both cost and runtime were higher, though the authors note that Qwen was pretty bad at using this scaffold.
A bit of a necrocomment, but I’d like to know if LLMs solving unsolved math problems has changed your mind.
Erdos problems 205 and 1051: AI contributions to Erdős problems · teorth/erdosproblems Wiki. Note: I don’t know what LLM Aristotle is based on, but Aletheia is based on Gemini.
Also this paper: [2512.14575] Extremal descendant integrals on moduli spaces of curves: An inequality discovered and proved in collaboration with AI
Usually when I read Anthropic’s blog posts, I feel like they want the takeaway to be something like “We came up with interesting methodology and got interesting results”.
But this post reads differently. It’s like a really weird attempt to assuage people that AIs won’t try to take over the world and that it will be business as usual. Kinda reminds me of Altman’s “Gentle Singularity” a little, and that’s not a compliment. It’s like the takeaway is supposed to be “Don’t worry about the numbers and the methodology, that’s not important. What’s important is that nothing scary will happen, just business as usual”.
It would be interesting if you gave OpenAI, Google DeepMind, Anthropic, xAI and DeepSeek scores based on how well they fit your checklist.
and also LLMs seem to do well directly plugged into robots
I’m not so sure about that: Butter-Bench: Evaluating LLM Controlled Robots for Practical Intelligence
On a side note, I like how this excerpt below would be considered absurdist sci-fi 20 years ago, and now it’s real.
Fair point, I just didn’t have two good examples for the same model.