Prosaic Continual Learning
Or: When Memories Get Good—The Default Path Without Theoretical Breakthroughs
Epistemic status: Fairly confident in the core thesis (context + memory can substitute for weight updates for most practical purposes). The RL training loop is a sketch, not a tested proposal. I haven’t done a thorough literature review.

Suppose there are no major breakthroughs in continual learning—that is, suppose we continue to struggle at using information gathered at runtime to update the weights of a given instance of an AI model. If you try to update the weights at runtime today, usually you end up with catastrophic forgetting, or you find you can only make very small updates with the tiny amount of useful data you have [1] .
So, if you can’t train a day’s worth of information into the model, how could you end up with something that functions as if it were learning on the job?
Long Context Lengths, High Quality Summaries, and Detailed Documentation [2] [3] .
It’s a straightforward idea, and basically done today, just not particularly well yet. Laying it out:
The model does some task. In doing so, it gathers a tonne of information, say, a dozen novels worth. It can fit all of this in its context at once.
The model finishes its task. In concluding, it writes:
Short notes that it should always remember (we’ll call these memories), for example “This company prefers me to communicate in German”, “Documentation is available in this folder path”, and;
Detailed documentation about everything it did and everything it learnt [4] . This can be quite verbose.
The memories are kept in the context window. The documentation is available on disk and can be accessed on demand.
That’s it.
Why Doesn’t This Work Now?
Firstly—it kind of does. In my own software projects I maintain a concise Claude.md file (which gets passed to each new agent on spawn), as well as extensive documentation which the Claude.md points to (and which the Claudes can search at will). Claude and ChatGPT already produce and store ‘memories’ in this way through their existing harnesses. These work okay, and we know that models can effectively learn in context.
But it doesn’t work that well yet. I suspect this is because current models just aren’t very good at writing or at using these notes.
It’s actually a very hard task. We’re basically having the model ask itself “What do I know that a fresh instance doesn’t, that would be useful for it to remember across all future instantiations?” and then asking it to write this down using as few tokens as it possibly can.
For a model to be able to do a good job, it needs to understand whether the things it knows are coming from its current context or its weights, and accurately guess how a future instance will respond to the memories. Basically, it needs to have a good theory of mind.
I think the difficulty of this task is the main reason memory especially sucked when it first came out. There are plenty of examples of irrelevant memories being created inside ChatGPT, for example.
It also took some time to train models which understood what the memories were and how to use them. Previously, models would attend too strongly to memories in irrelevant contexts, bringing up notes where they don’t belong. Kimi K2.5 still struggles with this, in my experience, seeing notes at the start of its context window as very important and relevant, even in situations where they shouldn’t be.
Claude ignores the apple note. Kimi always finds a way to bring it up.
But memory is getting much better, and newer models use it more successfully. I expect that as models get more intelligent their use of memory and documentation will continue to improve, especially in the world where this is trained for explicitly. Models are also getting better at handling the retrieval of dense information across their long context windows, so a mundane prediction that these trends continue should point us towards prosaic “continual learning” becoming quite useful over 2026 and 2027.
It also should be noted that memories like this are functionally the same as compaction (summaries written by the AI when reaching the end of the context window, so it can continue working). In both cases the model is writing compressed information to pass to a future instance to (hopefully) perform better. This is already an optimisation target for frontier labs.
How We Could Make It Work Better
We can easily train models to create and use memory as an RL task. To sketch out a simple method—suppose that when finishing a task, instead of scoring the model’s performance immediately, we have the model write memories and documentation, and then we run a new instance on the same, similar, and dissimilar tasks [5] with those memories and documentation, and have a reward function which scores on the combined performance (with some small penalty for the length of the memories). This looks like:
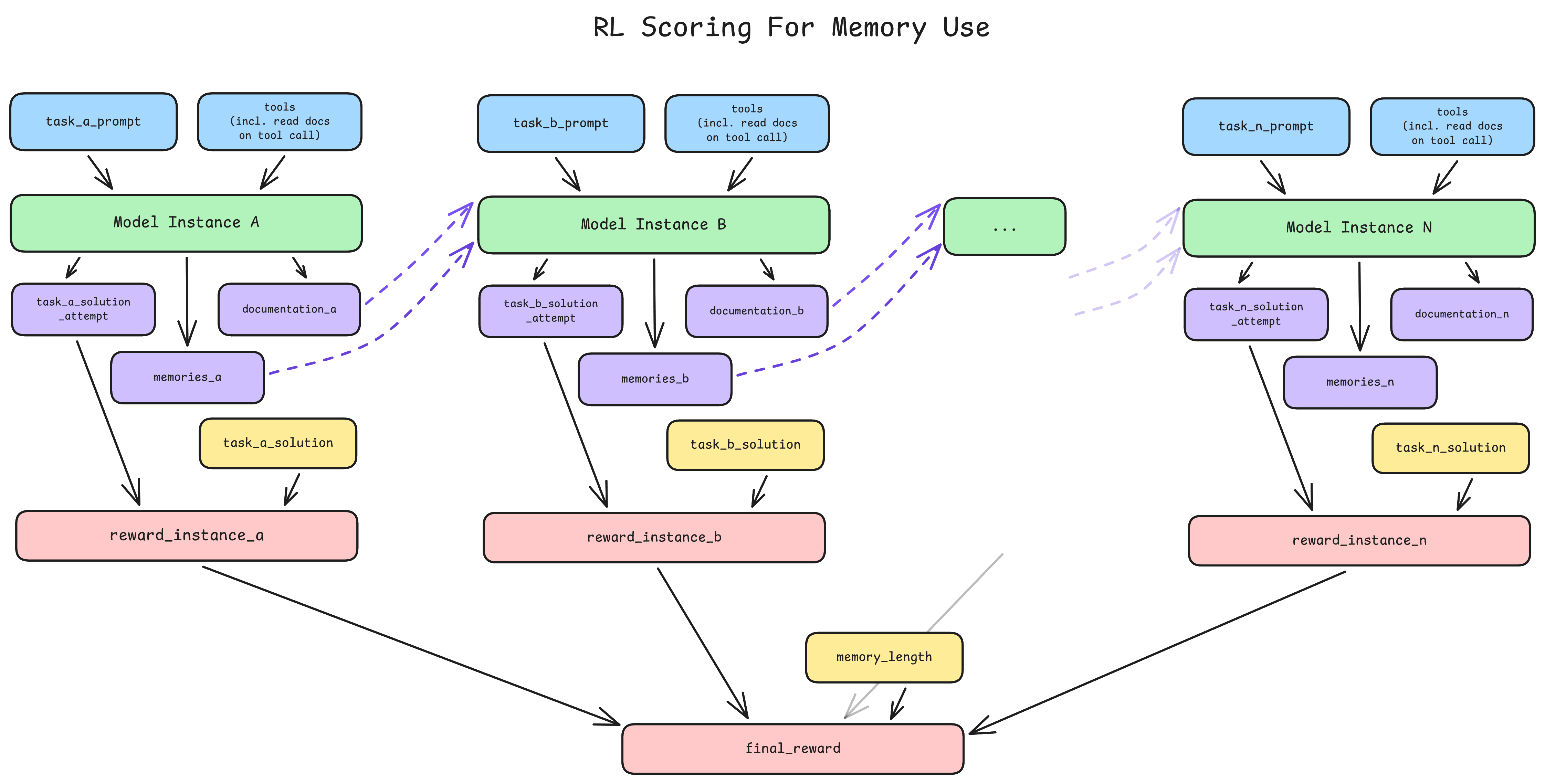
The reward function used for the actual parameter updates would be a function of the scores across each of the models, plus some penalty relative to the length of the memories and the total context length of the model.
There are several other ways to do something like this, of course, and some would be much more efficient than what I have laid out here. I’m mainly trying to get across a few key ideas:
You can train for memory and documentation quality automatically and without major changes to the current post training regime.
You can also train the model to make iterative improvements to the memories and documentation (editing and removing unnecessary or wrong sections) by scoring the performance across many sequential runs.
You should score performance on both similar and dissimilar tasks when passing through the memories and documentation, in order to teach the model when to actually use the information passed through [6] .
You should penalise memory usage (and maybe also documentation [7] ) by length, otherwise the memories will get too long to fit in the context window at some point, and you don’t want a discontinuity in performance when that happens.
Overall I would expect this to reward both the model’s ability to write AND to understand its memories and documentation, with some risk of pushing the model towards very dense, difficult to read memories (ala linguistic drift).
I haven’t spun up an experiment to test this empirically, but may do at some point. If anybody else would like to, or has done so already, please let me know!
Could This Replace Real Continual Learning? What About Intelligence Gains From Having The Information In The Weights?
There are two things going on here that we need to untangle. The first is about the model having the correct information to achieve its goals. This is what gets put into the memories and the documentation, and what is addressed by prosaic continual learning.
The second thing we wonder about is how to increase the intelligence of the model. How can it do more with less information, or figure out new things that it wasn’t told, or get better at acting in the world in a general sense.
With prosaic continual learning, the real intelligence gains only happen in the next generation of AI models.
Suppose Claude 5 is launched with a 1m context window, and it is smart enough to write good [8] documentation and memories. If a task uses about 500k of context, and produces about 1000 tokens of new memories, then doing ten tasks a day, every day, you can run the model for 50 days before you hit the ceiling on how many memories you can store [9] [10] .
Then, 50 or so days later, Claude 5.1 is launched, with improved capability by the usual process. Claude 5.1 inherits the existing memories and documentation and immediately works on improving and compressing them [11] . Combined with a longer context window, the new Claude 5.1 might buy another 50 days of memory [12] .
Repeat ad nauseam, or at least until Claude N solves true continual learning with parameter updates at runtime.
In this way, the lessons from a particular deployment (say, by a model that has been answering phones for a particular company) are trivially passed from one generation to the next while capabilities continue to improve via regular training. In practice, is there anything more we need true continual learning to do? [13]
Can We Have A Human Brain Analogy, Please?
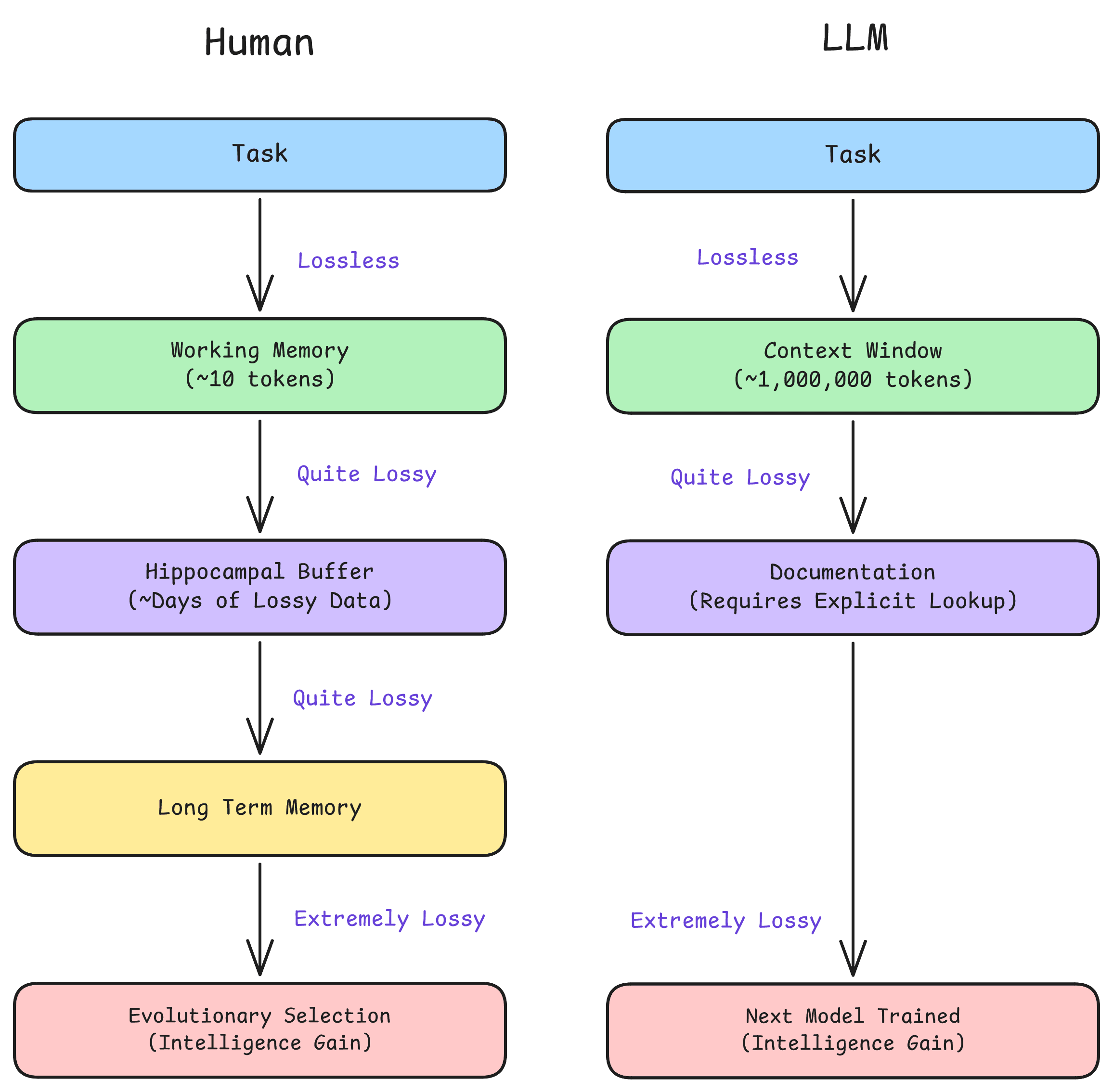
One of the reasons continual learning is so popular a concept is because humans do it, which makes it a very attractive answer to the question “What can’t AI’s do yet?”.
The human learning process looks something like the above chart, where we have an explicit, discrete, and extremely small working memory, which holds somewhere on the order of 10 objects in memory at a time. This probably exists as activations in the pre-frontal cortex. It’s analogous to LLM’s context window, being lossless and explicit, but is far, far smaller.
Then, humans have a kind of buffer, where information is stored on the order of hours to weeks in a lossy but easily accessible way. This seems to be held in the hippocampus. You can draw a weak parallel to AI reading documentation here, being some partially processed summary of what has happened, accessible with a few seconds of thought.
Humans can read documentation too, of course, but the read speed is extremely slow in comparison. AI is able to read documentation at a speed that is more comparable to a human recalling a specific memory.
Next, humans have long term memory, which is slowly updated on the order of days, probably by reading and updating against the hippocampus’ “buffer” [14] . This is where the missing piece for LLM’s continual learning would be an analogy, if we knew how to properly update an instances’ parameters at runtime.
Finally, even humans don’t become more intelligent after reaching full adulthood [15] . We rely on evolutionary selection to make any significant changes to human intelligence. The analogy here is to the next generation of AI models being trained, although that happens far, far faster.
Laying it out like this, you can see the ‘long term memory’ update step is missing, but the ‘context window + documentation’ is ridiculously larger in storage capacity that human working and short-term memory, and the ‘intelligence gain’ step so much shorter, that skipping a weight update at runtime might be viable. Humans require memory related parameter updates because we can’t store much information in working or short term memory, but if our working memory was so large it didn’t fill up within our lifetimes, you can see how the situation changes.
Conclusions
Having now thought through this, I have updated away from continual learning being a real issue for AI capabilities in the near future [16] .
It doesn’t seem like it is needed for general purpose capability improvements, where the regime of releasing a new model every few months works fine.
It doesn’t seem like it’s needed for company specific work, where you can store all of the needed information in documentation and in context.
I think the fact that it has to be written and used explicitly by the models is a satisfying answer to why it hasn’t worked well so far—the models simply haven’t been smart enough to do a good job at this so far.
I’m also bullish on progress on this problem being fast, given that this performance is something that can be straightforwardly optimised with unsupervised RL, including training models to handle and edit stale memories.
Overall… damn, I guess we’re making continual learners now.
- ↩︎
People think about the goal of continual learning as being ‘the model can learn on the job’, so, practically speaking, the main use case is for specific, non-generalisable data unique to this deployment of the model. When I say you don’t have enough data to do this usefully then, I mean, one days’ (or one months’) recording of work is a tiny amount of data to try to fine-tune a model on. You can’t reliably learn new things this way, though you might be able to elicit existing knowledge in the model.
- ↩︎
This is not a new idea. Dario spoke about it on Dwarkesh, and a quick Claude search reveals several different papers talking about the concept, most of which I haven’t read in detail. I am writing this post because I haven’t seen it clearly, publicly combined in one place before, and maybe there’s some interesting exploration of the RL training loop and why explicit memory has been a hard thing for models to get right.
- ↩︎
We also have versions of all of this today, which is why it’s “prosaic” continual learning.
- ↩︎
You could also include things like tools the model has built for itself, information it’s found online and wants to make a note about, and really anything that is created or curated for the models’ use without the entire thing being stored in the active context window.
- ↩︎
Same task means literally the exact same task [17] .
Similar task means tasks pulled from the same narrow distribution. For example, the set of things a particular employee might do in their work for a single company. We want to encourage memories that are useful across this somewhat narrow domain.
Dissimilar task means tasks pulled from more radically different distributions. Coding, psychological support, creative fiction, etc. I think we need to include some probability of dissimilar tasks in the batch in order to train the model to not rely too strongly on memory. At deployment time, the model may indeed be given memories that are irrelevant for the task at hand.
If I had to take a random stab at the proportion of each type of task assigned for a given batch, I would weight the distribution so that the N+1th task is about 89% likely to be from the similar distribution, 10% likely to from the dissimilar distribution, and 1% likely to be the exact same task repeated.
- ↩︎
The model should write memories and documentation on both successful and unsuccessful attempts at the problem—it likely has useful information about what to try or not to try either way. I’m also imagining that there is some penalty for overall token usage when training for inference efficiency reasons—that would incentivise the passing of useful tips and lessons via memories and documentation, if it can make the later instances more efficient.
It is even fine to pass the entire solution via memory, so long as the model has learnt when it doesn’t apply, and has been suitably penalised for the memory length. I think we can get this result by tuning the proportion of same, similar, and dissimilar tasks being scored together—that is, if we run similar tasks n times, and dissimilar tasks m times (and possibly the same task p times), with the memory and documentation passed through for a given reward calculation, we can select n, m, and p such that generally useful tips are favoured over long and specific instructions.
- ↩︎
I’m unsure whether documentation should be length penalised or not. You get this to some degree by measuring the performance of the model using the documentation. I’d lean towards probably not, using the principle of allowing the training to choose whether short or long documentation is better. I’m assuming we use a tool which allows the model to choose to read some reasonable amount of tokens at a time, rather than risk breaking things by dumping entire files in, or only clipping them when they become very long.
- ↩︎
In the memory case, ‘good’ means that they can figure out what would be useful to know in all future runs, and can recover from bad or missing memories by editing it later. In the documentation case, it means they can include all the relevant information accurately, avoid including slop, and then use the information to be much more effective than they would be without it.
- ↩︎
I made up numbers here just to show how much room there is. In this case, I get 1 million token context window, minus 500k task buffer, leaving 500k tokens for memories. At 10,000 tokens per day, we get 50 days of memory buffer.
This is also kind of a ‘worse case scenario’. A thousand tokens for memories for each task is very high, since most memories could simply be pointers to where the real detail lives, and you would quickly run out of new things to write. Do you memorize ~6000 words worth of new information every day, and keep it memorised for the rest of your life? If you can compress your new memories to only 1000 new tokens per day instead of 10,000, you get over a year of runtime. Alternatively, increasing context length from the current 1m tokens also provides wiggle room.
- ↩︎
Different tasks will have very different profiles here. For example, coding might require only very short memories, whereas piloting a robot through a factory might require memories that include a map and descriptions of every mistake the model had made on previous trips.
- ↩︎
We can expect a new version to be better at the difficult task of creating and using the memories & documentation, especially if it’s trained explicitly for this. Some possibilities here, which point towards shorter and fewer memories:
Is the model able to figure out what a memory is trying to say more easily, letting it compress existing memories into fewer tokens?
Is the model better at writing the information more densely?
Does the model know more information intrinsically, allowing it to remove that information from its explicit context?
Is the model better at knowing what it knows, allowing it to cut unnecessary memories?
How does the new version change the tradeoff between memory and documentation caching? E.g. is it faster at reading documentation? Is it better at knowing when and which documents to read given its particular goals?
- ↩︎
I am pretty confident that memory usage should be able to grow slow enough that a Claude working for a particular company can fit everything it needs into context and explicit documentation. For this not to be the case, you have to assume that extremely large amounts of information are needed (multiple books worth), and that you discover new information that must be held in context (rather than in documentation you can look up) at a rate faster than the context window grows, and that future models won’t be able to significantly compress existing memories or be able to move existing memories into documentation by virtue of being better at knowing when to look up things.
- ↩︎
In the limit, this process is functionally identical to continual learning, as far as I can tell. Just imagine the 50 days between model releases reducing to some short period, like a day or an hour, and imagine the written memories that are passed forward becoming denser and denser, an abstract initialisation pattern that is loaded in for a deployment (like a static image).
Putting the same scenario the reverse way, imagine a model with traditional, weight-updating continual learning. Rather than updating its weights directly, it (like humans) uses a short term memory buffer to store new information and isolate private information from the weights. Every hour, the relevant lessons from the previous hour’s work are trained into a copy of the model, which is then seamlessly switched out, and the buffer updated.
- ↩︎
I don’t know if you’ve ever noticed your long term memory updating, I feel like I have. Have you ever had a major event happen, and then only some days later have cemented a behaviour change, even though you knew the change was necessary from the moment of the event?
- ↩︎
They continue to learn more, which makes their crystalised intelligence (knowledge and skills) go up, but their fluid intelligence (ability to reason abstractly, solve new problems, etc) declines after early adulthood.
- ↩︎
I’m even coming around on continual learning being worse for most mundane uses—suppose you have your own version of a model, with the weights updated to store information specific to you and your use case. What happens when a new model is released? You have to retrain? What happens to the optimisations from batching?
- ↩︎
I actually think it’s debatable whether you should include the literal same task as an option for the nth instance (with the memories and documentation prepared by the (n-1th) instance) to be assigned. If you do this, the model could just include the whole solution in its memories, but honestly, for some production usage and types of task, that could be a reasonable and viable strategy.
I think in general we should try to train on the same distribution as the deployment, so whether to include the literal same task (vs just similar tasks) as a possible option here depends on whether you think that’s a situation that is likely to occur in practice (maybe setting up the same programming environment many times?), and whether you get anything from doing this (quickly using the cached procedure?).
This is a reason to “write for the LLMs”, as model release cadence accelerates and knowledge cutoffs gradually move to the present day: pretraining and ICL are additive (maybe even synergistic), quite aside from the inherent limitations of self-attention or the substantial cost of ever-growing context windows (and serious risks as you hand over ever more to the AI) so if you can ‘work in public’ and ensure all of your documentation/‘memories’ are written down in scrape-able places like LW2/GitHub/Gwern.net, then you are doing true continual learning, and so you will get better results out of the box with each new generation. And you can iteratively improve it by using the LLMs—there is an “unofficial gwern.net docs” site which uses Claude to try to reverse-engineer the entire backend+frontend design, which I would like to somehow incorporate into better source code docs, and then regenerate, etc.
(A larger model like Claude-4.6-opus has a knowledge cutoff of May 2025, less than a year ago, so for me, that means I can expect it to know some of my key writings on AI esthetics, some early LLM-assisted poems/stories like “October”, and some of the newer website features like
/ref/, but not newer documentation/refactoring or the Gwern.net Manual of Style. Thus, it should be more useful for writing on AI, but I would still need to point context at the MoS or the HEAD for writing/coding.)I think you will find the RLM paper interesting: https://arxiv.org/pdf/2512.24601
TLDR: instead of the LLM processing the input directly, the LLM is given access to a Python environment and the input prompt is stored as a variable. Then the LLM can do any standard stuff like
print(prompt[:100])to read the beginning or use regex to search for relevant keywords. Additionally, the LLM can recursively call itself on chunks of the prompt, hence Recursive Language Models (RLMs). This is like having a pseudo-infinite context window + the ability to make the output arbitrarily long as well.The paper reports that even without specifically fine-tuning base LLMs to use this scaffold, the results on long context tasks show a big improvement with median costs being almost the same (though RLMs are significantly more expensive in a minority of cases). Fine-tuning improves the results further. Note that RLMs outperformed base LLMs even on tasks that fit into the context window of the base LLM, where theoretically chunking is not needed.
EDIT: I forgot to mention that while for GPT-5 the median costs with and without this scaffold were similar, the runtime was always several times longer, so there is a downside. For Qwen3-Coder-480B both cost and runtime were higher, though the authors note that Qwen was pretty bad at using this scaffold.
Absolutely. We might not need “real” continual learning to serve the purpose and achieve better-than-human AGI. This is one more reason to be prepared for short timelines. But I think you’re overestimating how hard it is to implement some amount of “real” weight-based continual learning. This just adds to the danger.
Fortunately, both have limitations, so we might get a slower progression from parahuman AI to full AGI to ASI. This would marginally improve our odds of good outcomes.
I recently reviewed different types of continual learning/memory in LLM AGI will have memory, and memory changes alignment. I called the thing you’re talking about “context engineering” for the current terminology in the agent enthusiast community; I don’t know if they’ve moved on now. I also discuss a little how fine-tuning can be used for skill acquisition, not the skill evocation it’s usually used for. Catastrophic forgetting is a problem if you try to acquire a whole bunch of new skills simultaneously. But it’s (anecdotally) not a problem at all with modern methods if you’re just trying to teach skills relevant to your workflow in a local instance.
I find your model of rapid retraining on sequences to be interesting and to make more explicit some vague ideas floating around of the difference between generations and instances becoming more blurred.
Re-training on everything is one big part of how the human brain seems to avoid catastrophic interference. We replay/think about important memories more, which is effectively continually retraining on a wide variety of stuff (including all of the skills and knowledge we use). This avoids catastrophic forgetting for important things, while creating it for unimportant things.
But there’s a big problem with what you suggest: proprietary data. Businesses can’t allow training on all of their internal use, and individuals often don’t want to. So that route will be of limited use (although definitely of some use, and possibly very nontrivial even with limited data!).
So a hybrid model I’d imagine is: locally fine-tune a model on the skills you need it to have. Filter the data for sensitive information and take it out of the training set (of course this won’t work that well, but perhaps it’s enough to shift legal responsibility onto the developer or leave it ambiguous enough for businesses to buy in). Then the next generation of the model won’t need to be fine-tuned on those skills, and you can go fine-tune on more specific skills, using your “budget” of catastrophic forgetting elsewhere.
Anyway, I think your point about training on deployment sequences using RL to improve memory use is quite important. The key feature is that it’s easy. Developers have lots of that data (minus the large amount that users don’t want in the training set). Applying a reward model to that data seems pretty easy, as you describe.
So, one more route to high capabilities. Better get on that whole alignment thing!
Thanks for replying. I definitely do expect real continual learning to be developed too, to be clear. I don’t know on what timeline, but if there’s any benefit to be gained by it, it will remain an R&D target and eventually be cracked, possibly by automated R&D. My main argument is that theoretical breakthroughs aren’t required to get most of the supposed benefits of continual learning.
I think context engineering is a fair description of what I am talking about, yes! Except that this is explicitly the subset of that where we are getting the AI to intelligently handle its own context. I hadn’t heard that about fine-tuning narrow skills, interesting if true, do you have a source going into that?
Regarding proprietary data, I am talking about a system where the information (memories + documentation) is kept out of the weights, and out of the training, which seems like it’s much better for proprietary data. The data never has to be shared, and to get the same performance again, you just load the memories into context without needing to fine-tune. Did I misunderstand you here?
Regarding the training, I’m not actually suggesting training on data produced at runtime, at least not in any way that is different to what happens today—I’m saying that you can take the post-training already being done (provide the model with some task, reward success) and expand it to allow models to learn to pass information between runs (provide the model with some task, let it write notes after, run another task with those notes, then reward based on the success on both tasks combined).
Interesting thoughts on replay with human memories, I think I agree. It effectively means humans are selecting what to remember using our full(?) intelligence, which is an interesting thing to think about in light of having the LLMs select what to remember by writing notes (and thinking about why designing state space models to learn to choose what to keep implicitly rather than explicitly has been so hard).
I recently wrote a post surveying some weight based continual learning research that you may find interesting.
I agree that because base models can have such broad pre-existing knowledge and skills, can be trained with RL to manage context and memories externally, and have a super-human context window/working memory, weight-based continual learning isn’t strictly necessary to get to some fairly powerful systems, probably able to automate much of white-collar work. But I also suspect that weight-based continual learning may not be that far off, and that it could offer some qualitative advantages leading to faster capability progress than we otherwise would have.
Yes, but consider this analogy.
Current LLM memory systems are like writing notes. The analogy is pretty strong with the human experience of writing and reading notes. They help me remember things, so I don’t remember them in my head, and instead just look at the note. That means the memory mostly stays in short and medium term memory while I need it, and then is maybe not turned into a long term memory because I know I can just look it up again later. If I rely too much on notes, I start to feel like a goldfish.
Continual learning would be more like consolidating long term memories. The memories aren’t just for the task at hand, but reshape the brain’s network.
These are useful for different purposes. Notes help a lot for complex things that, for us, don’t make sense to commit to memory (or would have made sense to commit to memory if we didn’t have notes). The benefit is that, with notes, we can do much more precise work on a larger set of context than we might otherwise be able to do. The downside is, notes take up space in short term memory and limit how much other stuff we can do while remembering them.
AI faces the same challenges. They will face different limits than we do. They don’t have the same 5-7 short term memory slot issue. They can probably get a lot further with notes than we can, but they will ultimately face the same limits we do and need to do the equivalent of consolidating memories if they want to do more, since one of the things that distinguishes experts from noobs is how the expert naturally knows their area because it’s deeply integrated into their memories and neural circuitry.
My guess is that proper continual learning will continue to be a blocker for building strong AGI/ASI, even if we can get weak AGI without it.
I see your point, and definitely agree that learning / deep understanding as a human is different to having access to lots of notes, but I think that the huge context + speed of reading + new model releases might be enough to get nearly all the benefits that require humans to use our long term memory.
For example, could this requirement in humans just be that we can store so little in conscious thought? If I can only hold 10 things ‘front of mind’ at a time, to do anything complex I am forced to rely on my larger long term memory to surface relevant things. If I could hold 1,000,000 things front of mind, maybe I wouldn’t need that at all. This is also somewhat justified by in-context learning (arguably) doing the same thing as gradient descent, though that is debated.
Regarding notes, I think the same difference in scale applies, as well as a qualitative difference. A human can only read maybe 10 words a second, but an AI can read on the order of 100,000. I argue that makes it closer to a human “reading” from their memory compared with a human reading notes, especially since all of the notes are loaded into the context window / working memory of the AI. That, I think, is more analogous to the way human memories are used than to how humans use notes, since the human reading can’t hold more than a sentence or so in working memory at a time without compressing it.
Yeah, it’s hard to say. However, spending all day every day interacting with LLMs, they have attention issues that are not totally dissimilar from humans (in fact, their attention is generally worse than humans in a lot of ways), and much will hinge on how their attention scales.
KV-cache is already “weights”, but in-context learning formed by pretraining is not on track to let models learn things like playing chess as a result of looking at appropriate context. And models aren’t trained on user context, so model improvement (as new versions get released) is distinct from what learning from context could do.
(True continual learning is the last mile of generalization that’s not about behaving well on unseen data, but about actually learning from that unseen data post-deployment, automatically, so that the AI doesn’t need to deal with unseen data without having learned on it. At that point sample efficiency becomes a more central issue, but also learned in-context learning can be better than human-written learning.)
Edit (2 Mar 2026): The estimate of 1 TB below is incorrect, HBM bandwidth is the limiting factor in this context. GB300 HBM bandwidth is 8 TB/s per package/chip. With chips at about $3.4 per hour ($12bn for a 400K chip datacenter per year), $10 buy 10.6e3 seconds. With 10.6e3 chip-seconds, 8 TB/s can read 85 GB a million times (for a million tokens). I don’t think this impacts the qualitative point, but 85 GB of params is still more modest than 1 TB of params.
The “weights” analogous to KV-cache in principle should be sufficient for representing skills like the ability to play chess, especially in the form of recurrent state for infinite context (that doesn’t grow with longer context). Even 1 TB of recurrent state, much more than sufficient to encode any skills, is only the HBM capacity of 3.5 chips/packages in a GB300 NVL72 system, which would need to occupy the HBM for about 3.5 hours to generate 1M tokens at 100 tokens per second. Which at $3.5 per hour per chip/package would cost just $12 (per million tokens).
So it’s feasible to offer users giant 1 TB recurrent states that encode the product of continual learning (the model can be much larger, since it’s shared by many users). But currently there is no method to actually make it work at the level of learning new deep skills, rather than mostly looking things up using the existing skills of the underlying model. Looking things up is not even fundamentally different from searching the web, a very good web-searching model could be said to be “attending to the Internet”, as if the whole Internet is its context. That’s not what true continual learning should be about, the crux is learning of deep skills specialized to context, replacing generalization with last mile learning from post-deployment context data.
I might have misunderstood, but I disagree that you cannot learn things like playing chess in-context. I can write up the rules to a new made up game, give Claude some examples of what those games look like, and then play the game against Claude and he will be able to play it (somewhat).
He’ll still make mistakes sometimes, but if he was able to write down those mistakes (and as he get smarter, understand and write down the reasons he made those mistakes and how to do better in the future), then when I start a fresh instance and load in those notes again, the new instance will play even better. Depending on how good Claude is at understanding his failures, and how good he is at writing down the lessons in a way that the new instance can generalise from, you could (effectively) have a system that keeps getting better at the game.
Do you disagree on this? Am I missing something about your claim here? Apologies if my response isn’t on point, I’m somewhat unsure what you are trying to say here.
I agree sample efficiency is an issue. In-context learning is wildly more sample efficient than fine-tuning, but it could be better. The trouble here is if you need some minimum number of samples to understand and generalise something properly, you might hit the context limit first (or you might not recall properly across the whole window, also another open problem).
Regarding recurrent state models, as far as I understand, this is effectively doing the same thing as having a KV-cache with memories, except that in the KV-cache case, the model must explicitly write out what to include, whereas state space models have some method built into their architecture and learnt during training. Am I correct on that? I suspect this is an advantage of the KV-cache memory method, if you believe the models will keep getting more intelligent regardless, because it lets us use that intelligence to decide what to remember—somewhat analogous to a human deciding what to study, or dwelling on things that then get committed to memory.
Having the model explicitly write what to include also sidesteps the problem of designing a good state space learning mechanism, since we’re just relying on intelligence we can train in known ways to decide what information to retain moving forward.
Playing chess at the level of the best humans, using a similar amount of data. Maybe learning to solve IMO level problems, in-context. More relevant is becoming fluent in novel specialized theory (or empirical facts) being developed as part of the current project, or gaining tacit knowledge in the form of skills that can’t be usefully written down as notes to be looked up, without effectively learning their contents as skills, as one would learn to play world class chess after looking at some games and learning the rules (as external training data, likely prompting things like generation of more internal synthetic training data or RLVR tasks and RL environments).
In-context learning is in principle sufficient, especially with true recurrence (I don’t mean SSMs, where activations are still climbing the layers and computations have bounded depth; as with chain of thought reasoning, recurrence needs to pass information back to the same layer as the sequence progresses; likely block-level recurrence with blocks of variable length is appropriate for this, to both retain fast prefill and pretrain updating of recurrent state for deep reasoning). But observing the first credible steps of scaling pretraining since original Mar 2023 GPT-4 (in Opus 4 and Gemini 3 Pro), LLMs don’t seem to be on track to start learning difficult skills in-context. They can learn the rules of chess in-context, but can’t learn to play at the level of the best human chess players in-context, and it doesn’t seem that they will get sufficiently better at this even as scaling of pretraining advances further, before it runs out of useful natural text data.
I also feel continual learning is overrated as a barrier, but for slightly different reasons. Firstly, it’s worth reviewing why Dwarkesh believes that continual learning is necessary for economically transformative impact[1]:
One of my main criticisms is that he neglects the ability of LLMs to be recursively specialised. For example, a legal AI company could fine-tune a frontier model specifically for handling legal tasks and then further specialise the model to handle law in different countries. Major lawfirms could have a model further fine-tuned to their needs and these models might be further specialised to the needs of individual departments or even roles. This is only happening to a limited degree now because general models are advancing so fast that it’d hardly be worth it, but if progress stalls, we’ll start seeing more layers of specialisation, especially since a significant proportion of the work involved in fine-tuning could be automated.
Whilst Dwarkesh doesn’t comment on recursive fine-tuning specifically, he does comment on RL fine tuning more generally: “But it’s just not a deliberate, adaptive process the way human learning is. My editors have gotten extremely good. And they wouldn’t have gotten that way if we had to build bespoke RL environments for different subtasks involved in their work. They’ve just noticed a lot of small things themselves and thought hard about what resonates with the audience, what kind of content excites me, and how they can improve their day to day workflows.”
I agree that it’d be much harder for the economics to work out for a podcaster like Dwarkesh vs. a major firm. However, AI wouldn’t have to automate every niche role in order to have an economically transformative impact. It would just have to automate a sufficient number of major sectors. But I’m pretty sure AI models would be transformative in terms of podcasts too. Not all podcasts are as unique, or have the same quality standards, as Dwarkesh. I expect someone will fine-tune a model specifically for editing podcasts that will be good enough for most professional podcasters, just like how many copy writers have been replaced by LLMs that are noticably worse.
I’m not claiming that this will solve the problem by itself nor does it have to. Recursive fine-tuning just have to teach the model enough about the context that long-context windows and RAG can handle the rest. And, as you observe, there we will develop better schemes for ensuring that the right information makes it into the context.
I’m also not claiming that more than 25% of white collar employment would disappear because there’s the potential for many of the displaced workers to shift into new jobs, at least in the short term. But I suspect more than 25% of current jobs could be displaced and that current capabilities could be more economically transformative than the internet.
Dwarkesh writes: “Sometimes people say that even if all AI progress totally stopped, the systems of today would still be far more economically transformative than the internet. I disagree. He writes: “If AI progress totally stalls today, I think <25% of white collar employment goes away.”
I seen one difference from how human memory works—the model has to consciously decide which part of its experience is important to retain. Not sure how that will pay out when these models try to act as drop in replacements for human workers.
Humans definitely do this too.
We choose what to attend, then emotional/reward salience directs us to replay or “think about” some memories more. This results in them being retained. Others are lost.
This is pretty clearly critical for human memory working as well as it does. It’s an emergent effect, not a single mechanism, but it’s clearly evolved that way because it works.
I broadly agree, and I also think this explains why it sucks now (the models aren’t capable of doing this explicitly very well yet) but could be extremely good in the future (it directly utilises the intelligence we’re already training, and therefore should improve with it automatically).