A Model-based Approach to AI Existential Risk
Introduction
Polarisation hampers cooperation and progress towards understanding whether future AI poses an existential risk to humanity and how to reduce the risks of catastrophic outcomes. It is exceptionally challenging to pin down what these risks are and what decisions are best. We believe that a model-based approach offers many advantages for improving our understanding of risks from AI, estimating the value of mitigation policies, and fostering communication between people on different sides of AI risk arguments. We also believe that a large percentage of practitioners in the AI safety and alignment communities have appropriate skill sets to successfully use model-based approaches.
In this article, we will lead you through an example application of a model-based approach for the risk of an existential catastrophe from unaligned AI: a probabilistic model based on Carlsmith’s Is Power-seeking AI an Existential Risk? You will interact with our model, explore your own assumptions, and (we hope) develop your own ideas for how this type of approach might be relevant in your own work. You can find a link to the model here.
In many poorly understood areas, people gravitate to advocacy positions. We see this with AI risk, where it is common to see writers dismissively call someone an “AI doomer”, or “AI accelerationist”. People on each side of this debate are unable to communicate their ideas to the other side, since advocacy often includes biases and evidence interpreted within a framework not shared by the other side.
In other domains, we have witnessed first-hand that model-based approaches are a constructive way to cut through advocacy like this. For example, by leveraging a model-based approach, the Rigs-to-Reefs project reached near consensus among 22 diverse organisations on the contentious problem of how to decommission the huge oil platforms off the Santa Barbara coast. For decades, environmental groups, oil companies, marine biologists, commercial and recreational fishermen, shipping interests, legal defence funds, the State of California, and federal agencies were stuck in an impasse on this issue. The introduction of a model refocused the dialog on specific assumptions, objectives and options, and led to 20 out of the 22 organisations agreeing on the same plan. The California legislature encoded this plan into law with bill AB 2503, which passed almost unanimously.
There is a lot of uncertainty around existential risks from AI, and the stakes are extremely high. In situations like this, we advocate quantifying uncertainty explicitly using probability distributions. Sadly, this is not as common as it should be, even in domains where such techniques would be most useful.
A recent paper on the risks of unaligned AI by Joe Carlsmith (2022) is a powerful illustration of how probabilistic methods can help assess whether advanced AI poses an existential risk to humanity. In this article, we review Carlsmith’s argument and incorporate his problem decomposition into our own Analytica model. We then expand on this starting point in several ways to demonstrate elementary ways to approach each of the distinctive challenges in the x-risk domain. We take you on a tour of the live model to learn about its elements and enable you to dive deeper on your own.
Challenges
Predicting the long-term future is always challenging. The difficulty is amplified when there is no historical precedent. But this challenge is not unique; we lack historical precedent in many other areas, for example when considering a novel government program or a fundamentally new business initiative. We also lack precedent when world conditions change due to changes in technology, climate, there competitive landscape or regulation. The difficulty is great in all these cases, but pales in comparison to the challenge of forecasting artificial general intelligence (AGI) and existential risk. Predictions about AI existential risk today generally rely at least in part on abstract arguments about how future advanced AI will behave, which we can’t test today (though efforts are being made to change this). Even the most well-crafted arguments are often met with justified uncertainty and scepticism.
For instance, when assessing the reliability of a prediction about AI existential risk, it is common to encounter objections such as, “I can find no specific flaws in the predictions. They’re just a bit abstract and a bit conjunctive, and arguments in that class are fairly often wrong in unexpected ways.”
As one example, the recent superforecaster elicitation on AI risk appeared to reveal that this general scepticism is a factor in the persistent disagreements on AI risk between superforecasters and the AI safety community. This disagreement on AI risk persisted despite discussion between the two groups and even though the superforecasters agreed with the domain experts on many quantitative predictions about future AI, suggesting a more diffuse scepticism of AI risk arguments. Such objections should be taken seriously and assessed both on their own merits, and in light of how similar objections have fared in other domains in the past. This highlights the importance of evaluating not only the content of a prediction, but also the underlying assumptions and reasoning behind it.
Numerous arguments have already been proposed in the AI risk community for why certain outcomes are likely. When you set out to build an explicit model of AI existential risk, it would be negligent not to incorporate well-considered ideas from other smart, dedicated people. However, it is really tough to merge multiple ideas into a single coherent model, and by some counts there are as many as five partially overlapping worldviews/research agendas, each focussed on different threat models. Different arguments often build upon mutually incongruous conceptual frameworks. It also doesn’t work to simply tally how many arguments exist for a position, since there is almost always substantial overlap in the underlying assumptions. Additionally, it seems pretty much impossible to merge an inside view with an outside view argument in any deep way. Though tough, incorporating existing expert knowledge (and opinion) is essential for effective model-based approaches. We think that AI existential risk modelling has unique aspects when it comes to incorporating multiple sources of expert knowledge and thus is a ripe area for further research on new approaches and techniques. We have incorporated simple approaches to all of the challenges named in this paragraph into our model.
Subjective probability is the conventional tool for representing uncertainty, and in general it is an excellent tool for this. Model-based approaches rely on subjective assessments of uncertain variables. In the AI existential risk domain, when you ask two experts to assess the same subjective probability, it is common for their estimates to be dramatically different (e.g. for one to say 15% where the other says 80%). This is not normal in other domains. Although you may find an instance when two meteorologists respectively predict a 15% and an 80% chance of rain, this is uncommon.
This is a symptom of the difficulties already discussed above, and introduces yet another distinctive feature of this domain. Because of this extreme variation between experts, and the fact that people’s estimates are poorly calibrated, there seems to be a need to capture an extra layer of confidence. We elaborate on this in the section ‘Meta-Uncertainty’ later in this article, and we include an explicit second order distribution in our model (i.e., the second order distribution represents the variation among expert opinion, whereas the first order uncertainty represents the uncertainty in the outcome).
Our work described in this article was performed as part of the MTAIR project (Modelling Transformative AI Risk), building on the initial MTAIR conceptual model. We aim to evaluate multiple, sometimes fundamentally conflicting, detailed models of AGI existential risk as well as these outside view/reliability considerations. We treat them as competing ‘experts’ in order to arrive at a well-informed and balanced assessment. You can play with our interactive model to input your own assessments and explore the implications.
What makes a model effective?
Transparency: To be effective, a model-based approach should provide a model that other people can browse and understand. We call a model transparent when a typical user who is knowledgeable about the subject matter is able to understand what the model is doing, how it is doing it, and what assumptions are going into the calculations. You should never assume that a subject matter expert is a programmer, or that python code (or any other programming language) speaks for itself. Hence, conventional programs are generally considered to be non-transparent.
Interactivity: A second important attribute is interactivity, and the ability for a stakeholder to experiment with different assumptions, explore ramifications of different decisions or policies, and explore arbitrary what-if scenarios.
Explicit uncertainty: For AI existential risk, much of the action is in the tail of the uncertainty (i.e., simply concluding that the median outcome is human survival misses the point); hence, an explicit representation of uncertainty is important.
We built our model in the Analytica visual modelling software, which strongly meets all of the above requirements, and is fun to use. Analytica models are structured as hierarchical influence diagrams, a highly visual and easy to understand representation that captures the essence of how the model works visually. It is interactive and has embedded modular documentation. There is a powerful multidimensional intelligent array facility that provides an unprecedented flexibility. And it has explicit representations of uncertainty using probability distributions. The propagation of uncertainty to downstream computed results happens automatically. It is easy and quick to learn, and once you’ve built your model, you can publish it to the web to share (as we have done for this article).
If you feel inspired by our example to build your own model(s), you should know that there is a free edition of Analytica. Commercial editions are also available when you need to scale up to really large models. The desktop editions require Microsoft Windows. You don’t need to get or install anything (other than a browser – Chrome or Edge) to use our model, which is shared on the Analytica Cloud Platform (ACP). Our model has roughly 150 objects, slightly exceeding the maximum size of 101 objects for the free edition. But if you are interested in downloading it to desktop Analytica, the free edition allows you to load it, view it, run it, change inputs and re-evaluate results, etc.
In summary, model-based approaches to assessing the reliability of predictions about AI existential risk can bring several benefits to the AI safety community. First and foremost, it provides a clear, concise, and legible output that takes into account the many different objections and factors that may impact a prediction’s accuracy. This helps to ensure that the AI safety community understands the reasoning and evidence behind the prediction, and can make informed decisions based on that information.
Additionally, this model-based approach encourages the community to consider a wider range of factors, beyond just the detailed arguments themselves. For example, they might consider how much they trust high-level abstractions and how reliable different heuristics are. By incorporating these considerations into the model, the community can more effectively weigh the risks associated with AI and develop more robust strategies for mitigating potential harm. Finally, this approach can help to improve the community’s epistemics by promoting more rigorous thinking and more comprehensive examination of all relevant factors, which can lead to a better understanding of the nature and likelihood of AI existential risk.
As a starting point, we will focus on a single detailed model based on the Joe Carlsmith report, ‘Is Power Seeking AI an Existential Risk,’ along with several outside view/reliability heuristics that affect the plausibility of this one mechanistic model. We will first briefly introduce Carlsmith’s presentation of AI existential risk with some improvements of our own, then at the end discuss the next steps to improve upon this model.
Model overview
This is a hierarchical model running in Analytica Cloud Platform (ACP) based on Joe Carlsmith’s report, ‘Is Power-Seeking AI an Existential Risk.’ It allows you to compute the probability of an existential catastrophe caused by misaligned AI.
The conclusions are implicitly conditioned on some timeframe which we have made explicit, given various assumptions. A de facto time frame is “by 2070”, but when entering your own estimates you can adopt a different time frame without requiring a change to the model’s logic.
In short, the model predicts that misaligned power-seeking AI will cause an existential catastrophe if:
Advanced, Planning, Strategically Aware (APS) systems—i.e., AIs capable of advanced planning, which are strategically aware, and possessing advanced human-level or superhuman capabilities—are feasible to build,
There will be strong incentives for APS systems to be built when they are feasible,
It will be much harder to build APS systems that do not seek power in misaligned ways than to build superficially useful APS systems that do seek power in misaligned ways,
Despite (3), misaligned APS systems will in fact be built and deployed,
Misaligned APS systems will be capable of causing a large global catastrophe upon deployment,
The human response to misaligned APS systems causing such a catastrophe will not be sufficient to prevent it from taking over completely,
Having taken over, the misaligned APS system will destroy or severely curtail the potential of humanity.
The overall framework for our model was based on the argument for AI existential risk provided in the Carlsmith report and subsequent 80,000 Hours article, with modifications. This is our ‘top level model’ around which we are basing our high level analysis of AI existential risk.
Model tour
During this section you will take a quick tour of our model, running it live in a browser window. To start, please click Launch the model to open it in a different browser tab or window so you can refer to this page at the same time. We provide step-by-step instructions to get you started. Follow this tour to get your bearings, and then you can explore the rest of the model deeper on your own and explore what happens with different estimates. We recommend running the model on a large monitor, not a mobile device.
Basic assessments
On the first page you’ll see six probability assessments from the Carlsmith report. (Note that the screenshots in this article are static, but they are active in the browser window where you are running the model).
Here you can adjust the sliders or type your own estimates for each one. To understand what each means, just hover over the question and read the description that pops up.
Before you estimate these, you should pick a time frame. For example, you can estimate whether each is true before the year 2070. The calculations depend on your estimates, not on the time frame chosen, but your estimates would be expected to change (increase) with longer-term time frames.
Below the slider inputs are some computed results showing the probability that each of the 5 stages, along with all preceding stages, ends up being true. The last one, “existential catastrophe”, shows the probability of an existential catastrophe from an APS system given your estimates for each of the six propositions.
In this screenshot we see a 0.37% chance (less than one half of one percent) that an APS will cause an existential catastrophe such as the extinction of the human race. That may appear to be a huge risk given how extreme the outcome is, yet many people who specialise in AI safety would consider this to be ultra-optimistic. How do your estimates compare?
Experts weigh in
How do your estimates compare to other AI safety researchers’? Following Carlsmith’s report, Open Philanthropy solicited reviews from other AI safety researchers, and asked them to provide their own estimates for these propositions. These reviews occurred in Aug 2022.
First, you can browse their raw assessments for each proposition by pressing the

Click the choice pulldown for “Select median assessment to use”.
Select all items so it now appears as
The Existential catastrophe output now shows a

These show the probability of existential catastrophe caused by APS implied by the estimates, both from your own inputs, as well as from the reviewers. The median among the reviewers is 9.15%, but the number varies dramatically between reviewers. Null appears in a few cases where the reviewers were reluctant to accept Carlsmith’s proposed decomposition. Next, let’s display this as a bar chart. Hover over the top of the table area to access the graph button, then press it.
Hover over the top of the graph again and change the view back to the table view. When viewing a result, you can toggle in this way between graph and table views.
The variation in expert opinion
The tremendous variation in expert opinion presents a serious challenge for rational decision making in this area. It would be hard to argue that any expected utility based on a probability obtained by aggregating these is credible. Because of this, we fit a probability distribution to the variation in expert opinion. Because this is a distribution over subjective probabilities it is actually a second-order probability distribution, which we call meta-uncertainty. We devote a section to the topic of meta-uncertainty, its motivation and its interpretation, but for now let’s visualise this meta-uncertainty.
Change Select median assessment to use to Median of all reviewers, and select the Reviewer’s spread option in the choice pulldown for Select meta uncertainty to include.
The outputs now display as
In the frame node, switch back to graph view (
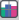
An exceedance probability plot is one way to visualise a probability distribution. The distribution in this case reflects the variation across expert opinion. The underlying quantity (the x-axis) is the probability that an existential catastrophe such as human extinction from an APS system occurs. Following the green arrow, you can read off that about 10% of experts feel the probability of an existential catastrophe exceeds 0.17 (i.e., 17%), and following the yellow arrow about 5% feel it exceeds 0.27.
To obtain this second-order distribution, the model treated the collection of expert assessments for each question as if it were sampled from an underlying distribution, and then “fit” a probability distribution to those points. The technical details of this fit is covered in the later section ‘Meta-Uncertainty’. That section also explores how our perspective changes when the meta-uncertainty (i.e., amount of variation among expert opinion) increases or decreases.
Combining inside and outside view arguments
The Carlsmith decomposition is an example of an inside view framing in that it breaks down the main question of interest into its component factors, steps or causal mechanisms at play. In contrast, an outside view framing draws parallels from similar events or reference classes to provide context and predictions. For example, the second species argument posits that humanity may lose our standing as the most powerful species on Earth. Other outside view framings include Holden Karnofsky’s Most Important Century, Ajeya Cotra’s bio-anchors (an outside view for one subproblem, timelines, of the larger question), analogies to past transformational technological advancements, and even expert opinion surveys.
Different insights emerge from each type of framing, but because inside and outside-view framings approach the assessment so differently, assimilating both into a consistent view is quite challenging. But we believe model-base approaches need to address this so as to incorporate information coming from all sources.
We include two simplistic outside-view approaches (discussed in detail in a later section), reflected by these inputs:
Hover the mouse over each input for a full description of what you are estimating. These require you to think abstractly about several high-level outside-view considerations and arguments, and then assess how much bearing these considerations have on the risk of existential catastrophe. Cr here means credence. Similar to the concept of likelihood in statistics (some might say synonymous), credence is an estimate on a scale from 0 to 1 where 0 means the considerations imply no risk and 1 means the considerations imply certain catastrophe.
You have now entered your own estimates for the Carlsmith “world model”, as well as for outside-view credences. Our key focus is how can a model assimilate these into a single subjective viewpoint? It is our goal to highlight this challenge and take at least one stab at doing so. Perhaps you or others who continue with future model-based approaches will improve on our approach.
In this model, we’ve allowed you to assign relative weights to the different views. Click the Table button for Weights to place on different opinions. Hover over the input for a description of what you are being asked to assess. The credence is a rating of how much you think these outside-view arguments, by themselves, support the proposition.
An entry table appears in the frame at the top with sliders that you can use to change the relative weights. You can adjust these to reflect your own opinions regarding the relative credibilities.
The first section allows you to enter the relative importance you place on the Carlsmith decomposition compared to outside view arguments. Here we have fixed Outside view to 1, so that a value of 3 for the (Carlsmith-based) world model means you want that framing to count three times more than the outside view arguments.
Within the world model, you have your own estimates as well as the estimates from the various experts who were surveyed. You have the option of placing more or less weight on the estimates of individual experts.
Finally in the lower part you can adjust the weights on two different outside-view framings. These are used to combine the different outside-view arguments.
Having set your own weightings, the outputs in the right column display the assimilated views.
The first output, Cr[Existential Catastrophe|World Model] is the assessment from the Carlsmith decomposition after taking into account your relative weightings between your own estimates and those of the experts.
The second output, Cr[AI Existential Catastrophe] is the probability of an existential catastrophe from the combined outside-view models.
The final output, Cr[Existential catastrophe] is the final assimilated estimate for existential catastrophe. It takes into account both the inside-view world model as well as the outside-view models, combining the information from both sources as a representative final assessment.
Exploring the model’s internals
Thus far you have played with some selected inputs and outputs that we’ve highlighted for you. Next, you’ll explore the model’s internals.
At the top is a large blue module node, Main Model. Click on it. This takes you into the implementation, where you are met with several sub-modules and an influence diagram.
In this first diagram, the top half comprises the inside-view world model based on the Carlsmith report. The bottom left quarter contains the outside-view arguments. The bottom right quarter is the logic used to assimilate the different views.
The nodes of the influence diagram are variables. The arrows depict influences between variables. Influence diagrams are visual, and you can often understand how the model works from this, without looking at the details of calculations. Hover over nodes to see their descriptions for additional information about what each variable represents.
In the outside view section, some undefined nodes (which are hashed) are used just to document the considerations that feed into the estimates. Dashed arrows indicate that these are not influences used by the calculation, but should influence your thinking.
After you click on a node, notice the tabs at the top.

The Object tab is perhaps the most useful, since it allows you to see the Definition (and other attributes) of the variable you clicked on. When you are done looking at this variable, the Diagram tab returns you to the diagram.
Now that you’ve completed this quick tour, you should be comfortable exploring all aspects of the model. Next, we’ll dive deeper into the content and concepts that we incorporated into the model.
Model features
In adapting the Carlsmith report’s model of AI existential risk for use in Analytica, we have made several changes from the original calculation, which simply multiplied the conditional probabilities of propositions 1-6 to obtain an overall estimate of existential risk from misaligned AI.
To better capture the full range of uncertainty surrounding the issue, we have handled “meta-uncertainty”, by changing each point estimate into a distribution with a variance dependent on how confident we are in each probability estimate, as described in the previous section.
Meta-uncertainty refers to the uncertainty that arises from our uncertainty about more general factors that influence our beliefs or opinions. These factors could include questions such as how much weight we should give to inside versus outside views, and how reliable long-term forecasts are.
Meta-uncertainty is distinct from more straightforward types of uncertainty because it focuses on our uncertainty about the assumptions and factors that underlie our assessments of risk. It is essentially a second-order uncertainty, where we are uncertain about the factors that drive our first-order uncertainty.
We have produced these meta-uncertainty distributions by fitting a logit-normal distribution to the spread of individual point estimates given by each of the original reviewers of Joe Carlsmith’s report. This methodology is similar to that used in this article on Dissolving AI Risk.
We have also incorporated other, less-detailed “outside view considerations” which do not rely on a detailed world model in the way the Carlsmith report does. Our credence in these outside view arguments relative to the Carlsmith model influences the final unconditional probability the model gives to AI existential catastrophe. These outside view considerations can be seen as a way of compensating for the general problems of reliability that occur with detailed world models and therefore a way of reducing random errors or ‘unknown unknown’ difficulties with our model.
One thing we have not yet discussed is the potential for systematic flaws in the Carlsmith model. As we will discuss in the section on ‘framing effects’, some researchers object to the framing of the Carlsmith report itself, arguing that it systematically biases us up or down.
Meta-uncertainty
There are a number of complex and uncertain questions surrounding the issue of AI existential risk, including the difficulty of alignment, the ease of takeover by misaligned AI, and even whether artificial general intelligence (AGI) of the “APS” type will be built this century. These uncertainties make it difficult to assess the overall probability of existential risk from AI.
One approach to quantifying these risks is to assign point probability estimates to each claim and propagate them forward, as was done in the original Carlsmith report on this topic. However, there are issues with this approach. Each of the six probability estimates that are inputs to the Carlsmith model involve events that have no precedent in history. Consequently, it is challenging to estimate the probabilities of these events, and when you see substantially different estimates from two different experts, there is no clear and obvious way to judge which estimate is more credible.
Meta-uncertainty looks across the possible states of belief by placing a probability distribution over the possible opinions. Our model includes a few versions of meta-uncertainty that you can explore.
One useful purpose for including meta-uncertainty is to understand the variation in expert opinion, and how this variation impacts the model’s outputs.
Open Philanthropy asked several experts in the field of AI risk to provide their own estimates for the parameters in the Carlsmith report. We’ve included these in our model. You can select the estimates from any of these experts, or of any subset. You can also include the estimates given by Joe Carlsmith in his article, the median of all reviewers, and your own estimates. When you select more than one at the same time, you will be able to compare them in any downstream result. To make a selection, use the multi-choice pulldown for “Select median assessment to use” on the front diagram of the model.
As you view the results of variables in the model, you’ll see the values for that result using the estimate of each of the reviewers that you selected. For example, here is the result table for the probability of existential catastrophe.
From these, you get a sense of how much the expert opinions vary, but this doesn’t yet include a probability distribution for meta-uncertainty. For each input, you can have the model fit a probability distribution to the assessments provided by the reviewers (for the statistics geeks: it fits a Logit-Normal, aka Log-Odds distribution). To explore this yourself, set the “Select Meta uncertainty to include” dropdown to “Reviewer’s spread”. Once you do this, it carries out all calculations using a distribution with the meta-uncertainty variance observed across experts (for the statistics geeks: it is actually the variance of the logit of each quantity that matches that of the experts).
Within the model’s internals, the variable named ‘Assessments’ now contains the meta-uncertainty distributions for each of the six input assessments.
The above graph shows the cumulative probability for each assessed quantity (known as a CDF plot). The value on the Y-axis indicates how likely it is that an expert would estimate the quantity to have a value less than or equal to the corresponding value on the x-axis. The plot’s key items correspond, in order, to the six assessments of the Carlsmith model. The first item, labelled Timelines, is the assessment that APS systems will be feasible to build within the timeline window considered. Its red CDF is almost a straight line, indicating an almost uniformly-distribution uncertainty among the selected experts. The light blue line labelled Catastrophe is the assessment that an unaligned APS system that has already taken over will then destroy or curtail the potential of humanity. The shape of that curve indicates that there is agreement between the selected experts that the probability is close to 1.
The calculation behind the above graph sets the median of each input meta-uncertainty distribution to the median of the selected reviewers on the same question. By changing the slicer control “Select median assessment to use” at the top of the above graph, you can apply the same level of meta-uncertainty to any single reviewer’s assessments (or your own assessments).
Analytica automatically propagates these meta-uncertainties to any computed downstream result. Here we see the CDF plot for the probability of existential catastrophe (the product of the six assessments).
The assessments from any one person would result in a single probability for this quantity, ‘Existential Catastrophe’. The above distribution reflects the variation across expert opinions. The curve indicates a 50% probability that an expert would conclude the probability of existential catastrophe is less than 1%. Conversely, using the 0.9 level of the Y-axis, there is a 10% probability that an expert would conclude the probability of existential catastrophe exceeds 15%. When you run the model, you can select a different subset of experts (or all of them) to interactively explore the subset of experts you trust the most.
When you provide your own estimates for each of the six input probabilities (which we recommend you try when you run the model), you’ll probably have a gut feeling that your estimates are not reliable. You’ll probably feel this way even if you are an expert in the field. You might find it useful to include (or let the model include) meta-uncertainty over your own personal assessments. The model allows you to do so. But first, let’s discuss what a meta-uncertainty over your own belief state even means.
Each input to the model asks you for your own subjective probability. Each of these summarise your state of knowledge on that question. No one knows whether any of the six propositions are true or false. Your subjective probability simply reflects the strength of the knowledge that you have. You are not estimating a value that exists out there in the world, you are instead estimating your degree of belief. By applying a meta-uncertainty to your degree of belief, you are essentially saying that you are uncertain about what your own beliefs are. That may not intuitively feel far-fetched in a case like this, where there is virtually no historical precedent! In general, when it comes time to making a decision, if you can express your meta-uncertainty, you could also collapse it to a single degree-of-belief number by simply taking the mean belief (or mean utility). Until then, meta-uncertainty gives an indication of how responsive your beliefs would be to new information.
In a recent article on the Effective Altruism forum, ‘Dissolving’ AI Risk—Parameter Uncertainty in AI Future Forecasting, the author under the pseudonym Froolow adds meta-uncertainty to each of the six Carlsmith model parameter estimates and shows that when doing so, the estimated existential risk from AI decreases. You can explore the same effect in our model. A good starting point is to select a single median estimate – for example, the estimates from the original Carlsmith report. Then select ‘View across range of meta-u’ in the meta-uncertainty selection.
The Meta-uncertainty option varies the amount of meta uncertainty from zero (i.e., point estimates) toward the maximum meta-uncertainty that is possible for a single probability estimate. The same logit-variance is applied to all six input assessments for each level of meta-uncertainty.
A Probability Bands view of the main output—the probability of existential catastrophe – illustrates how the meta-uncertainty in the final result behaves as the meta-uncertainty in each parameter is increased. The Bands plot is shown here.
(Note: The squiggles are small variations due to a finite sample size during Monte Carlo).
Without meta-uncertainty, Carlsmith estimated a 5% probability of existential catastrophe, seen at the left when the level of (meta-)uncertainty is zero. With increasing meta-uncertainty, the median estimate (green line) drops to about 0.75% at the right of the plot, and continues to drop further to the right of what is plotted here. Even the 0.75 quantile drops (eventually) with increasing meta-uncertainty.
Framing effects
There is a paradox here. Why should being less certain about what you believe make you conclude that the world is a safer place? Does this establish that “ignorance is bliss”? Will existential catastrophe be more likely if we invest in more research to increase our understanding of just how much we are at risk?
Some research models AI takeover as being a disjunctive event, meaning that it will happen unless certain conditions are fulfilled, while others (such as Carlsmith) see it as a conjunctive event, meaning that a set of conditions must be met in order for the disaster to occur.
These framing effects don’t affect the final results when using point estimates. If we took the Carlsmith model and turned every proposition in the model into a negative statement rather than a positive: e.g., ‘APS systems will not produce high impact failures on deployment’, and take one minus our original probability estimates, then we will get the same final probability. But, crucially, if we have uncertainty around our probability distributions the conjunctive and disjunctive models do not behave the same way.
The paradox becomes even more paradoxical when you realise that reversing the framing inverts the effect. The Carlsmith decomposition says that catastrophe occurs when 6 events all occur. You could instead posit that catastrophe from superintelligence is inevitable unless 6 open technical problems are solved before then (in fact, in the post AI X-risk >35% mostly based on a recent peer-reviewed argument on LessWrong, Michael Cohen uses this framing). With this reverse framing, increasing meta-uncertainty drives the effect in the opposite direction, making it appear that catastrophe is more likely the more uncertain we are. Soares’ article on disjunctive AGI ruin scenarios conveys this view qualitatively, listing a number of things that he believes all have to go right to avoid an AI existential catastrophe: on such a model, general uncertainty about the world increases the chance of disaster.
The paradox is, of course, an illusion. But because you could be easily misled, it is worth understanding this phenomena at a deeper level. The result in the previous graph is the product of six uncertain estimates. The following mathematical relationship, which is simply a rearrangement of the definition of covariance, shows that the arithmetic mean is stable as (meta-)uncertainty increases:
E[x y] = E[x] E[y] + cov(x,y)
In other words, when the assessment of each parameter is independent (implying a covariance of zero), then the mean of their product is the product of their means. Hence, a plot of the mean vs. level of meta-uncertainty would be a horizontal line. (Side note: Covariances between the parameter estimates are likely not really zero for numerous reasons, but the model does not include any representation or estimate of covariance. The relevant question is whether they are modelled as independent, and indeed they are in our model).
However, the median of a product decreases with increasing meta-uncertainty. This happens regardless of the shape of the meta-uncertainty distribution. In order for this to happen, the right tail of the meta-uncertainty distribution must increase to compensate for the drop in median. This means that as you have more meta-uncertainty, the meta-uncertainty distribution becomes more leptokurtic. The net balance, as shown by the stability of the mean, is that does not cause you to conclude the world is more (or less) safe.
In our model, the mean actually does decrease ever so slightly with increasing meta-uncertainty. You’ll see this if you select the Mean view.
The waviness is due to the fact that this is computed by Monte Carlo simulation with a finite sample size. The slight decrease is because we hold the median of each distribution constant as we apply meta-uncertainty. The meta-uncertainty of each parameter is modelled using a Logit-Normal distribution, also called a Log-odds distribution, in which the Logit of the quantity is distributed as a Normal distribution. We keep the mean of the Normal constant as we increase its variance. When you do this, the mean of the logit decreases slightly, so that the mean of each parameter estimation decreases slightly. If you hold the mean constant instead of the median (which is easy to do), then the mean is entirely stable. We found the difference in these two options to be non-perceptible in the Probability Bands graph.
In the article ‘Is the Fermi Paradox due to the Flaw of Averages?‘, we reviewed the paper ‘Dissolving the Fermi Paradox (2018)’ by Sandberg, Drexler and Ord (SDO), and provided a live interactive model. The Fermi Paradox refers to the apparent contradiction that humankind has not detected any extraterrestrial civilizations even though there must be a lot of them among the hundreds of billions of stars in our galaxy. Like the Carlsmith model, the Drake equation (which estimates the number of detectable civilizations in the Milky Way) is a multiplicative model. SDO shows that by modelling uncertainty in each of the Drake equation parameters explicitly, the Fermi paradox ceases to be surprising.
The Fermi paradox model with explicit uncertainty and the Carlsmith model with explicit meta-uncertainty (the topic of this article) have the same mathematical form. We see the median and the lower quantiles decrease in the Carlsmith model with increasing (meta-)uncertainty, but this doesn’t really alter our effective judgement of risk. However, the increased uncertainty in the Fermi model dramatically increases the probability that we on Earth are alone in the galaxy. Why is the effect real in the Fermi case but only an illusion in the present case?
The reason the effect is real in the Fermi case is that the question asked (‘What is the probability that there is no other contactable, intelligent civilization in the Milky Way?’) is a question about a quantile, and lower quantiles are indeed decreased when uncertainty increases. P(N<1), where N is the number of such extraterrestrial civilizations, is a cumulative probability, or inverse quantile. Since increasing uncertainty in the factors of a multiplicative model decreases the quantiles in the left tail, it causes the inverse quantiles to increase. Hence, the addition of uncertainty to the Drake equation legitimately increases the probability that we are alone in the galaxy. The real flaw was from omitting the explicit representation in the first place (what Sam L. Savage calls the Flaw of Averages). In contrast, the primary question posed by the Carlsmith model (‘What is the probability of existential catastrophe?’) is a question about the mean relative to meta-uncertainty. Hence, for this question (or for any decision based on an expected utility), the appearance that risk decreases as a result of including meta-uncertainty is only an illusion.
Explaining framing effects
We have seen that the apparent paradox arising from framing effects is illusory. But there is a further question: what is the ‘right’ way to frame AI existential risk, as conjunctive or disjunctive?
This is a difficult question to answer. One perspective is that treating AGI existential catastrophe as something that will happen unless certain conditions are met might lead to overestimation of the chance of high-impact failures. On this view, requiring a clear path to a stable outcome with complete existential security is both too demanding and historically inaccurate, since that isn’t how humanity ever navigated previous threats. Holden Karnofsky makes a similar point here. A framing which sees success as conjunctive probably rules out ‘muddling through’, i.e., unplanned ‘success without dignity’. Since this is something that many domain experts believe is credible, it might lead us to significantly underrate the chance of survival.
On the other hand, some experts such as Nate Soares argue that AI is a different case: the large number of actors working on AGI and the risk that any one of them could produce an existential catastrophe, along with all the things that would have to occur to prevent this (someone has to develop an aligned AGI and then quickly use it to eliminate AI existential risk), implies that treating survival as a conjunctive event makes more sense.
These different framings reflect varying world models and threat models. Part of why this disagreement exists is because of Soares’ views about extreme AI alignment difficulty, AI takeoff speed and the low likelihood of effective mitigation measures. If you are implicitly using a model where human civilization tends to respond in fixed ways due to internal incentives unless something intervenes, it is more natural to think that we will follow a default path towards disaster unless a specific intervention occurs. On the other hand, if we see many possible futures and many pathways to reducing AI existential risk and don’t know what the final response will look like (as the ‘Playbook for AI Risk Reduction’ describes), then requiring a specific set of conditions to be met for success seems overly prescriptive.
We believe that this framing question, and whether to treat survival as conjunctive or disjunctive, is itself something which we should be uncertain about, since whether you treat survival as conjunctive or not depends on the details of your threat model, and we don’t want to assume that any one threat model is the only correct one.
Currently, we only have the Carlsmith report model, but in theory we could address this problem by looking at both a conjunctive and disjunctive model and comparing them in detail.
For example, the report, “Three Pillars for Avoiding AGI Catastrophe: Technical Alignment, Deployment Decisions, and Coordination,” provides a starting point model that treats success as conjunctive, and we can adapt it to work alongside Carlsmith’s model.
Another alternative is to alter the Carlsmith report to require fewer steps, better representing the concern that the longer a chain of conjunctions is, the more likely it is to omit disjunctive influences. This formulation collapses propositions (1) and (2), which consider the incentives and feasibility of developing APS, into a straightforward estimate of “when will AGI be developed.” The alignment difficulty premise is then preserved, followed by the collapse of propositions (4, 5, 6) into an estimate of the chance of a takeover given a misaligned APS-AGI.
This alternative formulation has fewer steps and so better represents the model that treats misaligned AI takeover as involving many possible routes that are hard to counter or influence in advance, and sees misaligned power seeking behaviour as a natural consequence of AGI development. This approach may be more appropriate for those who believe that the development of misaligned power seeking systems is a likely outcome of AGI development and that the risk of an AI takeover is more closely tied to the development of AGI systems themselves.
In addition to exploring conjunctive and disjunctive models of AI existential risk, it may also be useful to equivocate between models that make more detailed technical assumptions about how APS will get developed. For example, Ajeya Cotra’s model “without specific countermeasures, the easiest path to AGI results in takeover” tries to construct a specific model of AGI development with technical assumptions, but given those assumptions, is more easily able to reach a stronger conclusion. Similarly, given that there is a wide diversity of views on exactly how AGI might end up misaligned and power-seeking, instead of a binary ‘Is misaligned AI developed or not’, we might have a distribution over alignment difficulty with a varying success probability.
Disambiguating different models with different technical assumptions can help us to better understand the potential risks associated with AI development. By exploring different models with varying levels of technical detail and assumptions, we can gain a more comprehensive understanding of the potential risks.
While this model does not incorporate entire complex alternative inside-view models like those just mentioned, we have incorporated some alternative, less-detailed, simpler alternative ‘outside view considerations’ to illustrate how we go about combining different worldviews to produce an all-things considered estimate.
Outside View considerations
We’ve talked before about the challenges of combining outside view considerations and more detailed models of the same question. We can attempt to integrate these considerations by delving deeper and examining various reasons to expect our detailed world models to be systematically mistaken or correct.
We will examine five reference classes into which various experts and commentators have placed AI existential catastrophe. In each case: ‘Second Species’, ‘Reliability of existential risk arguments’, ‘Most important century’, ‘Accuracy of futurism’, ‘Accuracy of predictions about transformative tech’, the argument locates AI Existential risk arguments in a (purportedly) relevant reference class: predictions about new sentient species, predictions about human extinction, predictions about which period in history is the most impactful, predictions about large scale civilizational trends in general and predictions about transformative technologies (including past predictions of dramatic AI progress).
The Carlsmith model implies that all of these things could occur (a new species, extinction, this period of history will be extremely impactful, there will be a large-scale dramatic transformation to society, there will be dramatic transformative technical progress), so it is worth examining its predictions in each reference class to determine if we can learn anything relevant about how reliable this model is.
Second species argument
This argument suggests that as we create AGI (Artificial General Intelligence) we are essentially creating a “second species” that is a human-level intelligence. And by analogy, just as humans have historically been able to supplant other animals, AGI may be able to supplant humans.
The key premise is that intelligence confers power. Human intelligence allows us to coordinate complex societies and deploy advanced technology, exerting control over the world. An AGI surpassing human intelligence could wield even greater power, potentially reducing humanity to a subordinate role. Just as humans have driven some species extinct and transformed ecosystems, a superintelligent AGI need not preserve humanity or our values. Anthropologists observe that new species often displace incumbents when invading a territory. Similarly, AGI could displace humankind from our position controlling Earth’s future.
This argument is straightforward and has been widely understood by researchers going all the way back to Alan Turing the 1950s, so while it relies on fuzzy concepts and is open to many objections, it arguably has a better ‘track record’ in terms of the amount of scrutiny it has received over time than the more detailed arguments given by Carlsmith.
Reliability of existential risk arguments
Another important consideration is the base rate for arguments of existential risk. Historically, predictions of catastrophic events, even ones that were apparently well justified by detailed arguments, have not always been accurate. Therefore, it is important to consider if the possibility that the risks associated with AGI are overestimated for similar underlying reasons (e.g., the social dynamics around existential risk predictions, overestimating the fragility of human civilisation, or underestimating humanity’s ability to respond in ways that are hard to foresee).
One possible driver of inaccuracy in existential risk predictions is sleepwalk bias. Sleepwalk bias is the tendency to underestimate people’s ability to act to prevent adverse outcomes when predicting the future. This can be caused by cognitive constraints and failure to distinguish between predictions and warnings. Because warnings often take the form of ‘X will happen without countermeasures’, if warnings are misused as predictions we can underestimate the chance of successful countermeasures. People often mix up the two, leading to pessimistic “prediction-warnings”. Thus, when making predictions about existential risk, it’s important to adjust our base rate to account for people’s potential to act in response to warnings, including those made by the one giving the prediction.
Sleepwalk bias stems from the intuitive tendency to view others as less strategic and agentic than oneself. As Elster notes, we underestimate others’ capacities for deliberation and reflection. This manifests in predictions that underestimate how much effort people will make to prevent predicted disasters. Instead, predictions often implicitly assume sleepwalking into calamity.
For existential risks, sleepwalk bias would specifically lead us to underestimate institutions’ and individuals’ abilities to recognize emerging threats and mobilize massive resources to counter them. Historical examples show that even deeply conflictual societies like the Cold War rivals avoided nuclear war, underscoring potential blindspots in our models. Since the bias arises from a simple heuristic, deep expertise on a given x-risk may overcome it. But for outsiders assessing these arguments, accounting for sleepwalk bias is an important corrective.
Most important century
Additionally, it is important to consider the probability that the next century is the most important of all, which would plausibly be true if AGI existential risk concerns are well founded. If we have a strong prior against this ‘most important century’ idea then we will be inclined to think that AGI existential risk arguments are somehow flawed.
The Self-Sampling Assumption (SSA) posits that a rational agent’s priors should locate them uniformly at random within each possible world. If we accept the SSA, it seems to imply that we ought to have a low prior on AI existential risk (or any kind of permanent dramatic civilizational change) in this century in particular because of the near-zero base rate for such changes. The detailed evidence in favour of AI existential risk concerns may not be enough to overcome the initial scepticism that arises from our natural prior.
Alternatively, you might accept the claim proposed by Karnofsky that there are extremely strong arguments that this approximate period in history must be very important. First, Karnofsky argues that historical trends in economic growth and technological development show massive accelerations in the recent past. Growth rates are near all-time highs and appear unsustainable for more than a few thousand years at most before physical limits are reached. This suggests we are living during a temporary spike or explosion in development.
Second, he notes that since growth is so rapid and near its limits, some dramatic change seems likely soon. Possibilities include stagnation as growth slows, continued acceleration towards physical limits, or civilizational collapse. This situation seems intrinsically unstable and significant. While not definitive, Karnofsky believes this context should make us more open to arguments that this time period is uniquely significant.
Accuracy of futurism
Another important consideration is the base rate of forecasting the future without empirical feedback loops. This consideration fundamentally focuses on the process used to generate the forecasts and questions whether it reliably produces accurate estimates. The history of technology has shown that it can be difficult to predict which technologies will have the most significant impact and AI alignment research especially often relies on complex abstract concepts to make forecasts, rather than mechanistically precise models. Some examples are discussed in this article.
One way of assessing reliability is to find a reference class where predictions of AI existential catastrophe are comparable to other future predictions. For instance, we can compare AI predictions to the predictions made by professional futurists in the past and then compare relevant features. If they compare favourably to past successful predictions, this may indicate a higher level of reliability in the TAI predictions, and if they don’t, it may suggest that we should be cautious in our assessment of their validity.
We can also look at other general features of the arguments without comparison to specific known examples of successful futurism, like their level of reliance on abstract concepts vs empirical evidence. AI risk involves unprecedented technologies whose impacts are highly uncertain. There are likely gaps in our models and unknown unknowns that make it difficult to assign precise probabilities to outcomes. While we can still make reasonable estimates, we should account for the significant Knightian Uncertainty by avoiding overconfident predictions, explicitly acknowledging the limitations of our models, and being open to being surprised.
Considerations like these arose in the recent XPT superforecaster elicitation. For examples of considerations that we would place under this umbrella, we would include these from XPT:
“Given the extreme uncertainty in the field and lack of real experts, we should put less weight on those who argue for AGI happening sooner.” (XPT superforecaster team 342)
“Maybe most of the updates during the tournament were instances of the blind leading the blind.” (Peter McCluskey, XPT superforecaster)
Accuracy of transformative technology prediction
This considers the historical base rate of similar technologies being transformative and notes that predictions often overestimate impact. It is important to consider the historical base rate of a technology being economically or socially transformative.
This is due to a number of factors such as under/overoptimism, a lack of understanding of the technology or its limitations, or a failure to consider the societal and economic factors that can limit its adoption.
By taking into account the historical base rate of similar technologies, we can gain a more accurate perspective on the potential impact of AI. We see similar arguments made by superforecasters, such as these from XPT:
“The history of AI is littered with periods of rapid progress followed by plateaus and backtracking. I expect history will repeat itself in this decade.” (XPT superforecaster team 339)
“The prediction track record of AI experts and enthusiasts have erred on the side of extreme optimism and should be taken with a grain of salt, as should all expert forecasts.” (XPT superforecaster team 340)
“Many superforecasters suspected that recent progress in AI was the same kind of hype that led to prior disappointments with AI...” (Peter McCluskey, XPT superforecaster)
“AGI predictions have been made for decades with limited accuracy. I don’t expect the pattern to change soon.” (XPT superforecaster team 337)
Conclusion
In this article we have led you through an example application of a model-based approach applied to estimating the existential risks from future AI. Model-based approaches have many advantages for improving our understanding of the risks, estimating the value of mitigation policies, and fostering communication between advocates on different sides of AI risk arguments.
During our research we identified many challenges for model-based approaches that are unique to or accentuated in the AI existential risk domain compared to most other decision areas.
We focused on incorporating elements of all of these challenges, in simple ways, into our model as a way of creating a starting point. The model is certainly not a definitive model of AI x-risk, but we instead hope it might serve as an inspirational starting point for others in the AI safety community to pursue model-based approaches. We’ve posted our model online in open-source tradition to encourage you to learn from it, borrow from it, and improve on it.
I recently held a workshop with PIBBSS fellows on the MTAIR model and thought some points from the overall discussion were valuable:
The discussants went over various scenarios related to AI takeover, including a superficially aligned system being delegated lots of power and gaining resources by entirely legitimate means, a WFLL2-like automation failure, and swift foom takeover. Some possibilities involved a more covert, silent coup where most of the work was done through manipulation and economic pressure. The concept of “$1T damage” as an intermediate stage to takeover appeared to be an unnatural fit with some of these diverse scenarios. There was some mention of whether mitigation or defensive spending should be considered as part of that $1T figure.
Alignment Difficulty and later steps merge many scenarios
The discussants interpreted “alignment is hard” (step 3) as implying that alignment is sufficiently hard that (given that APS is built), at least one APS is misaligned somewhere, and also that there’s some reasonable probability that any given deployed APS is unaligned. This is the best way of making the whole statement deductively valid.
However, proposition 3 being true doesn’t preclude the existence of other aligned APS AI (hard alignment and at least one unaligned APS might mean that there are leading conscientious aligned APS projects but unaligned reckless competitors). This makes discussion of the subsequent questions harder, as we have to condition on there possibly being aligned APS present as well which might reduce the risk of takeover.
This means that when assessing proposition 4, we have to condition on some worlds where aligned APS has already been deployed and used for defense, some where there have been warning shots and strong responses without APS, some where misaligned APS emerges out of nowhere and FOOMs too quickly for any response, and a slow takeoff where nonetheless every system is misaligned and there is a WFLL2 like takeover attempt, and add up the chance of large scale damage in all of these scenarios, conditioning on their probability, which makes coming to an overall answer to 4 and 5 challenging.
Definitions are value-laden and don’t overlap: TAI, AGI, APS
We differentiated between Transformative AI (TAI), defined by Karnofsky, Barnett and Cotra entirely by its impact on the world, which can either be highly destructive or drive very rapid economic growth; General AI (AGI), defined through a variety of benchmarks including passing hard adversarial Turing tests and human-like capabilities on enough intellectual tasks; and APS, which focuses on long-term planning and human-like abilities only on takeover-relevant tasks. We also mentioned Paul Christiano’s notion of the relevant metric being AI ‘as economically impactful as a simulation of any human expert’ which technically blends the definitions of AGI and TAI (since it doesn’t necessarily require very fast growth but implies it strongly). Researchers disagree quite a lot on even which of these are harder: Daniel Kokotaljo has argued that APS likely comes before TAI and maybe even before (the Matthew Barnett definition of) AGI, while e.g. Barnett thinks that TAI comes after AGI with APS AI somewhere in the middle (and possibly coincident with TAI).
In particular, some definitions of ‘AGI’, i.e. human-level performance on a wide range of tasks, could be much less than what is required for APS depending on what the specified task range is. If the human-level performance is only on selections of tasks that aren’t useful for outcompeting humans strategically (which could still be very many tasks, for example, human-level performance on everything that requires under a minute of thinking), the ‘AGI system’ could almost entirely lack the capabilities associated with APS. However, most of the estimates that could be used in a timelines estimate will revolve around AGI predictions (since they will be estimates of performance or accuracy benchmarks), which we risk anchoring on if we try to adjust them to predict the different milestones of APS.
In general it is challenging to use the probabilities from one metric like TAI to inform other predictions like APS, because each definition includes many assumptions about things that don’t have much to do with AI progress (like how qualitatively powerful intelligence is in the real world, what capabilities are needed for takeover, what bottlenecks are there to economic automation or research automation etc.) In other words, APS and TAI are value-laden terms that include many assumptions about the strategic situation with respect to AI takeover, world economy and likely responses.
APS is less understood and more poorly forecasted compared to AGI. Discussants felt the current models for AGI can’t be easily adapted for APS timelines or probabilities. APS carries much of the weight in the assessment due to its specific properties: i.e. many skeptics might argue that even if AGI is built, things which don’t meet the definition of APS might not be built.
Alignment and Deployment Decisions
Several discussants suggested splitting the model’s third proposition into two separate components: one focusing on the likelihood of building misaligned APS systems (3a) and the other on the difficulty of creating aligned ones (3b). This would allow a more nuanced understanding of how alignment difficulties influence deployment decisions. They also emphasized that detection of misalignment would impact deployment, which wasn’t sufficiently clarified in the original model.
Advanced Capabilities
There was a consensus that ‘advanced capabilities’ as a term is too vague. The discussants appreciated the attempt to narrow it down to strategic awareness and advanced planning but suggested breaking it down even further into more measurable skills, like hacking ability, economic manipulation, or propaganda dissemination. There are, however, disagreements regarding which capabilities are most critical (which can be seen as further disagreements about the difficulty of APS relative to AGI).
If strategic awareness comes before advanced planning, we might see AI systems capable of manipulating people, but not in ways that greatly exceed human manipulative abilities. As a result, these manipulations could potentially be detected and mitigated and even serve as warning signs that lower total risk. On the other hand, if advanced capabilities develop before strategic awareness or advanced planning, we could encounter AI systems that may not fully understand the world or their position in it, nor possess the ability to plan effectively. Nevertheless, these systems might still be capable of taking single, highly dangerous actions, such as designing and releasing a bioweapon.
Outside View & Futurism Reliability
We didn’t cover the outside view considerations extensively, but various issues under the “accuracy of futurism” umbrella arose which weren’t specifically mentioned.
The fact that markets don’t seem to have reacted as if Transformative AI is a near-term prospect, and the lack of wide scale scrutiny and robust engagement with risk arguments (especially those around alignment difficulty), were highlighted as reasons to doubt this kind of projection further.
The Fermi Paradox implies a form of X-risk that is self-destructive and not that compatible with AI takeover worries, while market interest rates also push the probability of such risks downward. The discussants recommended placing more weight on outside priors than we did in the default setting for the model, suggesting a 1:1 ratio compared to the model’s internal estimations.
Discussants also agreed with the need to balance pessimistic surviva- is-conjunctive views and optimistic survival-is-disjunctive views, arguing that the Carlsmith model is biased towards optimism and survival being disjunctive but that the correct solution is not to simply switch to a pessimism-biased survival is conjunctive model in response.
Difficult to separate takeover from structural risk
There’s a tendency to focus exclusively on the risks associated with misaligned APS systems seeking power, which can introduce a bias towards survival being predicated solely on avoiding APS takeover. However, this overlooks other existential risk scenarios that are more structural. There are potential situations without agentic power-seeking behavior but characterized by rapid changes could for less causally clear reasons include technological advancements or societal shifts that may not necessarily have a ‘bad actor’ but could still spiral into existential catastrophe. This post describes some of these scenarios in more detail.
I should clarify that I was talking about the definition used by forecasts like the Direct Approach methodology and/or the definition given in the metaculus forecast or in estimates like the Direct Approach. The latter is roughly speaking, capability sufficient to pass a hard adversarial Turing tests and human-like capabilities on enough intellectual tasks as measured by certain tests.This is something that can plausibly be upper bounded by the direct approach methodology which aims to predict when an AI could get a negligible error in predicting what a human expert would say over a specific time horizon. So this forecast is essentially a forecast of ‘human-expert-writer-simulator AI’, and that is the definition that’s used in public elicitations like the metaculus forecasts.
However, I agree with you that while in some of the sources I cite that’s how the term is defined it’s not what the word denotes (just generality, which e.g. GPT-4 plausibly is for some weak sense of the word), and you also don’t get from being able to simulate the writing of any human expert to takeover risk without making many additional assumptions.
Seems like this model has potential to drive resolution of this question on Manifold Markets to ‘yes’:
“Will Tyler Cowen agree that an ‘actual mathematical model’ for AI X-Risk has been developed by October 15, 2023?”
https://manifold.markets/JoeBrenton/will-tyler-cowen-agree-that-an-actu?r=Sm9lQnJlbnRvbg
I think that MTAIR plausibly is a model of the ‘process of how the world is supposed to end’, in the sense that it runs through causal steps where each individual thing is conditioned on the previous thing (APS is developed, APS is misaligned, given misalignment it causes damage on deployment, given that the damage is unrecoverable), and for some of those inputs your probabilities and uncertainty distribution could itself come from a detailed causal model (e.g. you can look at the Direct Approach for the first two questions.
For the later questions, like e.g. what’s the probability that an unaligned APS can inflict large disasters given that it is deployed, we can enumerate ways that it could happen in detail but to assess their probability you’d need to do a risk assessment with experts not produce a mathematical model.
E.g. you wouldn’t have a “mathematical model” of how likely a US-China war over Taiwan is, you’d do wargaming and ask experts or maybe superforecasters. Similarly, for the example that he gave which was COVID there was a part of this that was a straightforward SEIR model and then a part that was more sociological talking about how the public response works (though of course a lot of the “behavioral science” then turned out to be wrong!).
So a correct ‘mathematical model of the process’ if we’re being fair, would use explicit technical models for technical questions and for sociological/political/wargaming questions you’d use other methods. I don’t think he’d say that there’s no ‘mathematical model’ of nuclear war because while we have mathematical models of how fission and fusion works, we don’t have any for how likely it is that e.g. Iran’s leadership decides to start building nuclear weapons.
I think Tyler Cowen would accept that as sufficiently rigorous in that domain, and I believe that the earlier purely technical questions can be obtained from explicit models. One addition that could strengthen the model is to explicitly spell out different scenarios for each step (e.g. APS causes damage via autonomous weapons, economic disruption, etc). But the core framework seems sufficient as is, and also those concerns have been explained in other places.
What do you think?
I think that Tyler is thinking more of an economic type model that looks at the incentives of various actors and uses that to understand what might go wrong and why. I predict that he would look at this model and say, “misaligned AI can cause catastrophes” is the hand-wavy bit that he would like to see an actual model of.
I’m not an economist (is IANAE a known initialization yet?), but it would probably include things like the AI labs, the AIs, and potentially regulators or hackers/thieves, try to understand and model their incentives and behaviors, and see what comes out of that. It’s less about subjective probabilities from experts and more about trying to understand the forces acting on the players and how they respond to them.
I guess it is down to Tyler’s personal opinion, but would he accept asking IR and defense policy experts on the chance of a war with China as an acceptable strategy or would he insist on mathematical models of their behaviors and responses? To me it’s clearly the wrong tool, just as in the climate impacts literature we can’t get economic models of e.g. how governments might respond to waves of climate refugees but can consult experts on it.
I just think that to an economist, models and survey results are different things, and he’s not asking for the latter.
Not just our home galaxy, but when the model is fully done, it shows that it’s surprisingly likely aliens are so rare that even an observable universe wide volume likely has no intelligent alien species, especially of the grabby type.
So we really are just alone in our affectable universe.