What Makes an Idea Understandable? On Architecturally and Culturally Natural Ideas.
Produced as part of the SERI MATS Program 2022 under John Wentworth
General Idea
There are ideas that people can learn more or less easily compared to other ideas. This will vary because of at least two things: One is that the ideas may be natural to the environment/culture ( “culturally natural” ), the other is that they might be natural/understandable by human brains ( “architecturally natural” ). This should be formalised so that an AI would use ideas that are as human-interpretable as possible. Ideally, we would also be able to have AI that can directly learn new ideas via interpretability tools. I have done some small experiments trying to study how an AI stores ideas, but am nowhere near understanding how we can build AI that naturally embed human-like ideas. I think knowledge of what sort of ideas human’s can’t understand ( or find difficult to understand ) would be very useful.
Human Idea Formation
Hypothesis Space Search
I think ideas fall into a spectrum of how intuitive and natural they are to humans. A good way to think about this is more along the lines of Karl Popper:
Suppose that Alice is explaining an idea to Bob. Bob starts off with little or no information about the idea Alice is trying to explain, and has a massive hypothesis space of possible idea. He loosely chooses a point, knowing that this will need to be updated.
As Alice explains more and more, Bob’s hypothesis space narrows, likely ruling out his best guess of the idea, and forcing him to change what he believes the idea is. As the hypothesis space should converge closer to the idea that Alice is trying to convey.
In practice, the hypothesis space is not infinite, and there are restrictions to what ideas could be learned. In addition, there are likely common biases that people will independently have when choosing the initial random point in hypothesis space, so the space does not have uniform probability, and depends on prerequisite information that the person might have.
Furthermore, there might be hidden assumptions behind the ideas that might be difficult to disentangle between people ( see weird cases of ideas for some examples I have in mind ), which would lead some people to appear to completely agree but have different information in both of their minds.
For an AI being trained with Stochastic Gradient Decent (SGD), this explanation is likely more true than for humans. The AI will need to learn whatever ideas it needs to be able to accurately perform the task it needs to do. This will likely converge to learning some human-like ideas, but possibly not always.
Hierarchical Ideas
A lot of useful ideas that we have require some prerequisite knowledge to build up to that idea. The classic examples come from Maths/Physics/Engineering where to really understand an idea, you usually must first understand some other ideas. For example, to understand a differential equation, you need to understand equalities as well as differentiation. To understand differentiation, you need to understand what a continuous function is. To understand what a continuous function is you first need to understand what a function is. And so on down a chain of mathematical ideas.
We can build up a hierarchy of prerequisite knowledge one needs to know to understand something, and there are sometimes different paths one can take to achieve this. Maths also teaches us that the starting point in the hierarchy is not necessarily that something is built up of existing things, such as algebra to calculus, but instead one can travel to the things that prove that idea, such as studying what the most foundational axioms of mathematics are. With concepts such as this in particular, one can find that the two ideas help clarify each other, making them more nuanced and correct.
My naive hypothesis is that it would be very useful to have something like an idea hierarchy that the AI uses when “thinking”, as well as a way to make it such that the ideas converge to human-like ideas. This would make it so that when the AI learns of new ideas, humans would be able to follow along so long as they have learned of all the prerequisite ideas already.
One thing to keep in mind with this model, is that even though some ideas are widely known that the AI would be able to learn them, many are also false. For example, the luminiferous ether is an idea that people had learned and tried to build upon, and it was disproven.
See further discussion in appendix A, where I discuss some fuzzy ideas about what things are culturally not natural to many humans.
Architecture-Natural Ideas
I think there is a high chance that depending on the architecture of an AI model, different ideas are much more natural, and will learn some things more easily than other things.
Red Rectangles vs Blue Circles
From a talk by Evan Hubinger, asking a model to classify red rectangles and cyan circles, the model will always learn to distinguish the two by looking at the colour, and not by looking at the shape. I suspect this is because looking at the colour requires almost no additional machinery, since the colours are separate anyway. Looking at the shape however requires learning how to detect edges, and using this information to build shapes, then using this information to distinguish between the two.
If we represented the shapes using SVG classes in a vector image, instead of pixels in a raster image, I think it would be much less clear which the AI would learn by default.
A proposed experiment: would forcing an AI to distinguish between white rectangles and circles, then asking it to distinguish between red rectangles and blue circles lead it to use the existing machinery to distinguish between the two more easily?
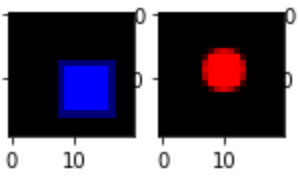
In a brief experiment I did here using a CNN, it seems like the naive approach doesn’t work. Training first on white shapes (or random brightness grey shapes), the model does not reliably learn how to distinguish shapes of a single colour (red or blue, accuracy ~50%). Then after a short fine-tuning on the specific colours, the AI completely forgets anything about shapes and gives up because it “knows” it can more easily/reliably detect the colour from the images than the shape.
CNN trained classifying white colour shapes, fine tuned to distinguish red rectangles (RR) and blue circles (BC). | |||||
| Accuracy | White | Grey | Random | RR vs BC | BR vs RC |
| Initial Training | 100% | 100% | 79.2% | 75.4% | 37.5% |
| Fine-Tuning 1000 | 50.7% | 45.5% | 51.2% | 100% | 0.0% |
If you train the model on randomly coloured shapes however, then the model only slightly struggles to distinguish shapes of a single solid colour (accuracy ~99.9%). The short fine-tuning on the red rectangles and blue circles can improve initially, especially for grey-coloured shapes, though accuracy drops off for the Blue Rectangle / Red Circle as the model learns that it can be lazy classifying them.
CNN trained classifying random colour shapes, fine tuned to distinguish red rectangles (RR) and blue circles (BC). | |||||
| Accuracy | White | Grey | Random | RR vs BC | BR vs RC |
| Initial Training | 100% | 99.7% | 99.7% | 99.9% | 99.6% |
| Fine-Tuning 250 | 100% | 100% | 99.5% | 100% | 95.1% |
| Fine-Tuning 500 | 100% | 100% | 99.4% | 100% | 89.9% |
| Fine-Tuning 1000 | 100% | 100% | 99.4% | 99.9% | 74.8% |
| Fine-Tuning 2000 | 100% | 100% | 99.1% | 100% | 69.8% |
It seems like in individual cases, it is possible to force an AI to learn a human abstraction, but is there a general way that we can get it to learn these human abstractions instead of alien abstractions? I would ideally like some way we can teach the AI to generalise without needing to give it explicitly the things we want to generalise. Some of the research into modularity seems relevant here.
Do Bigger Models Interpret Ideas in a More Human-Interpretable Way?
Diagram from post on Chris Olah’s Views: https://www.lesswrong.com/posts/X2i9dQQK3gETCyqh2/chris-olah-s-views-on-agi-safety
My intuitions tell me that the larger the model, the better it is at modelling human concepts. Is this true? For a model to be maximally accurate based on human inputs, it should be modelling the input in a similar way as the human. I suspect this will be despite, not because of, the way it learns ideas.
This leads to the long discussed problem of an AI modelling a human brain and never becoming superhuman, but this might be to our advantage if we are doing interpretability, depending on the way that it models human ideas. This leads to a test of this.
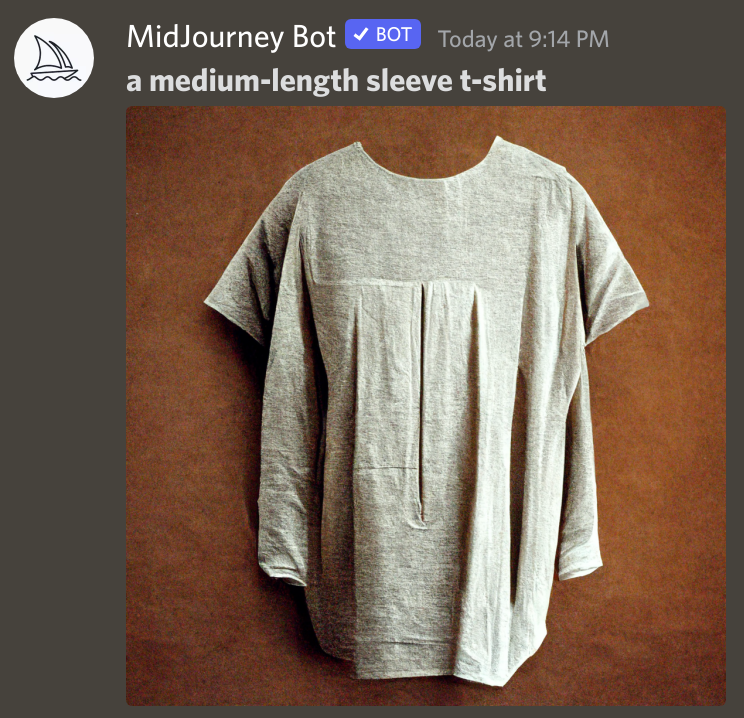
Medium-length sleeve t-shirts
The following is one thing I have looked into as a way of seeing how an AI might be abstracting certain concepts.
Variational AutoEncoder
A Variational AutoEncoder (VAE) of ~1M Parameters was trained on Fashion-MNIST (discussed more here in a previous research sprint ) can encode slightly-blurry shapes for the different items of clothing in 2 parameters. This allows us to move, for example, between short-sleeve and long-sleeve tops. The way it does this is not the way a human might move between short-sleeves and long-sleeves.
2D Latent Space:
First: A map of the entire latent space encodings. Second: a zoom-in on transition between t-shirts and long-sleeve coats.
If one were to ask a human to draw an intermediate between a short-sleeve t-shirt and a long-sleeve shirt, then I would expect them to draw a medium-length-sleeve t-shirt. However, the Fashion-MNIST does not since it is not trained on any medium-length-sleeve t-shirts. Yet humans do not typically see very many medium length t-shirts either ( true for menswear anyway, different for womenswear, though it is not usually t-shirts, but other tops that have medium-length sleeves ).
This is likely because the model does not need to understand the purpose of sleeves, just to recognise a vague pattern, and it happens to be easier to recognise short and long sleeves separately than as a unified concept. So in the transition from long-sleeve to short-sleeve, it simply starts merging the long-sleeves into the torso, and starts growing out new short sleeves (or more realistically, it superimposes an image of a short-sleeve t-shirt on top of a long-sleeve t-shirt).
My hypothesis was that larger models need to better model human ideas to make accurate predictions, and so I would predict that for a much larger model with a larger dataset, the model might generalise better and be able to predict what a medium-length-sleeve t-shirt would look like without explicit training.
As a short test for this, I tried using DALL-E 2 and Midjourney. I searched for t-shirts with medium-length sleeves with various phrasings.
DALL-E 2
The model had a strong bias for showing humans would obviously call short-sleeve or long-sleeve, but with enough attempts, it was possible to find a couple of examples.


In a lot of generations, the model simply ignored that I asked for medium length sleeves at all, so I have shown generations where it did not ignore this. We see in the top right example, that the model seems to be “hedging its bet” by showing long sleeves rolled up to look medium instead of committing to real medium-length sleeves.
The two middle examples do show some generalisation to the task, and it seems to suggest that larger models do sort of converge to more human-like ideas, but still somewhat struggle when out of distribution. This short experiment does not quite prove generalisation though, since even though medium-length sleeve t-shirts are quite uncommon, there were likely some sample images in the dataset of medium-length sleeves, which might not indicate the model generalised to understand sleeve length on its own.
Midjourney
Midjourney also ignored the prompt a in a lot of the generations, but I think did a better job at explicitly going out of distribution.




We see that in a lot of these generations, the models seem to have similar artifacting shown in the simple VAE. That is to say, we see a merger of both long sleeves and short sleeves, instead of a singular medium sleeve. In the second generation in the bottom right, we see that the model does this very explicitly in high resolution.
Even the top-right generation of the first set of generations was quite promising, but hedged its bets by making slightly-short long-sleeves and slightly-long short-sleeves on the same t-shirt. The most fitting seems to be the top-right of the third generation shown, which is only slightly distorted, or the bottom-right one from the fourth generation shown, which is slightly on the shorter end but I think passes.
Using keywords other than t-shirt tends to have people wearing the t-shirt, which in turn leads to better results(as the model knows to have 2 arms).
The model seems particularly good at generating medium-length sleeve blouses compared to DALL-E 2 (see appendix B).
Some thoughts on the results
This seems to suggest that either:
- The Midjourney model was not explicitly trained on many (if any) medium-length-sleeves, while DALL-E 2 probably was trained on more.
- DALL-E 2 has a more human-like structure for the ideas that it is embedding, and was better able to generalise the idea of medium-length sleeve t-shirts given the way it embeds the idea of sleeves.
If the latter is true, then this should be looked into further.
Possible Aims for a Future Project
Embed Human-like Ideas
By default, the model will have a preferred way of embedding knowledge. It seems that it should sometimes be possible to force the ML model to have more human-interpretable ideas embedded in it. This would mean that the model should store information that could easily be translated to a form readable by humans. For example, something like RETRO ( Retrieval-Enhanced Transformer ) is an example that goes in the direction of human-readable ideas . I would still be highly interested in seeing research into interpreting what exactly the dense layers do here, as it seems like most of the information would not be storage of tokens, which could suggest that techniques in the “ROME paper” may not find much left that is human interpretable.
One way that seems natural that one could extend this, is by doing something like Externalized Reasoning Oversight (which I briefly interpret as having human readable intermediates for the thought patterns that occur in the AI model). This has potential benefits and flaws that could be tested for ( see the original post ). I suspect that, at least for non-RETRO models, steganography would likely be an issue, mainly because this is not natural for the model architecture.
In addition, I think that when humans are abstracting ideas to make progress on further ideas, an important thing that very often comes up is that you need to invent new language to speak of the idea in any condensed way. Limiting the AI to using existing human words would likely be required to some extent, and the AI could use words that are rarely used to form new ideas in a possible thought pattern.
Learn a new idea from the AI
If the concept of ideas being hierarchical is true, then as a proposed experiment, we can consider one of two possible plans.
Plan 1:
Build a model with some level of human abstract ideas.
Try to get the AI to learn a higher level idea from these ideas.
See if it is possible to consistently get it to learn human-interpretable ideas using these abstractions.
Plan 2:
Build a model with some level of human abstract ideas.
Try to get the AI to generalise some concept to a higher level idea.
Try to extract that idea from the AI
A more concrete example might be to try to teach the model something about mathematical integration, as well as what the form of some different functions looks like, and see if it can learn what the exact analytical solution to some integrals is given some empirical examples. This specific test is likely infeasible in something like a transformer model, but points to the sort of thing I would like to get the model to understand.
The simplest existing experiment I have heard of along these lines is the experiment at Redwood Research, training a transformer to check if a string of parentheses are validly closed, and trying to interpret what algorithm the model is using to be accurate at this task.
Find AI That Naturally Find Human-like Ideas
It seems like there is possibly room to study a range of conditions that make an architecture find more human-natural ideas by default. Intuitively, researching what makes a model modular, and making it be modular seems like it could lead to this.
Note that while we want the AI to have human-like ideas, that does not quite mean we need to have the ideas stored in the same way as they are in humans, rather that the ideas need to store the same information in a way that is readable by humans.
Find AI That Finds ideas Architecturally-unnatural to Humans
Something that would be very interesting and important to find is an AI that can find an idea that is completely uninterpretable by humans, yet quite simple algorithmically. This however, would be hard to distinguish from not having the correct framing of the idea being studied / not having good enough interpretability tools ( see end of Appendix A: “Are there Ideas AIs can Understand but Humans Can’t?” for some vague discussions )
Meta-level Research to Quantify Naturalness of Ideas
I think we should study how the architecture of a model affects how a model “learns different ideas” or uses different abstractions, and we should try to optimise for models that have abstractions that are more similar to humans. This could be important because it would greatly reduce the difficulty of interpreting what a model is doing, since it would be reasoning with human ideas instead of alien ideas.
We would do this two ways:
- getting a better grasp of what ideas people find more natural or less natural
- studying different models and trying to interpret what they are doing
This would give us a better understanding of how difficult it would be to understand a neural network. We may find that it is not possible to find a neural network architecture that naturally uses human ideas, but it might be possible to steer it to force it to use human ideas.
I also think there should be some measures for what ideas are natural for people to understand, and what ideas are unnatural.
One could imagine an AI trying to reinvent calculus. If it starts off with all the normal human mathematical machinery, it seems like the AI would learn it in a very interpretable way. However, it seems also very possible that the AI could learn calculus in a completely alien way that is not very human-interpretable, and this might be a problem. On the other hand, the AI might learn a very similar way of thinking about calculus which would be useful too.
We should find some way to quantify what we mean when we say that an idea is more or less interpretable.
Some ideas are natural to humans because of the way the brain works (architecturally natural), and some are not.
In the set of ideas that are natural to humans, there exist prerequisite ideas that people in a specific society are likely to learn, which provides a base world model which is built upon.
This leads to a specific framework of thinking about things that is interpretable by humans in western english-speaking society ( culturally natural, as people in different cultures have different paradigms/norms/ideas.)
To be able to evaluate and understand the ideas of an AI, we need to restrict it to understanding things from our world model, or only slightly beyond it. (it would be great if we can do this. Can we do this?)
Side-note: That this does restrict the AI to be more likely to have the values of specific humans instead of all humans, which is not good.
Closing Thoughts
How does this Solve Alignment?
One possible strategy might be as follows:
Suppose you have an AI which has a large set of ideas embedded in it. Some are more difficult to understand, and others much easier. We want the AI to not be deceptive and planning something bad, so we look through all of its internals.
If the AI has a clearly obvious anti-human agenda that is easily interpretable, then the humans would not run this AI (I hope at least…). Thus, the AI would try to hide its secret Anti-human agenda in a way that humans don’t understand.
Would it solve the problem, if we could simply delete the parts of the model that humans don’t understand?
Counter strategy:
The AI is deceptive and secretly stores deceptive trains of thought in neurons that are just slightly polysemantic ( learning multiple things in one neuron ).
Appendix A: Ideas That Differ Between People
The Number Line
Number lines are understood differently by many people. By default, in most Western countries people learn to think of numbers ( at least at small scales ) as linear. However, for larger numbers people still struggle to think linearly.
For example:
When asked to place 10 as between 1 and 100, people generally place it ~1/10th of the way across the numberline. But this is not always true. In Alex Bellos, “Alice’s Adventures in Numberland”, tests are described that suggest people think non-linearly about numbers. For example, one can ask people in tribes to place 10 between 1 and 100, and it would be much closer to the middle of the number line.
Similarly, people struggle to think linearly for large amounts of money. People think of 10 Million as 10x as much as 1 million, rather than 9 million more than 1 million.
I think by default, most people count as if they were counting out loud with their internal voice in their head. It is possible to have other ways of counting, such as a more visual way of counting, such as visualising an abacus, or by visualising the shape of the number in your head.
I suspect the vocal counting preference comes from people mainly learning to count out loud first in schools, and this then translates to people using the same mental machinery to count. It is possible to force yourself to count in a non-verbal way, but trying this myself I still slightly move my tongue as if I was about to vocalise the word.
I have asked some people about their ideas on counting and the number line:
One person told me that they used counting as a way to stay focused during meditation. If they got distracted and lost count of the number, they would have to start over again. This ultimately led them to being able to not lose count while they were thinking distracting thoughts.
One person described that they knew somebody and one of their parents had independently come up with a convoluted way of visualising the number line. It would be a squared “S” shape, where the bottom edge would go from left to right on a scale from 1 to 10. The bottom right edge would go up from 10 to 100. The middle edge would go left to right from 100 to 1000. The top left edge would go up from 1000 to 1000000. The top edge would go from 1000000 to an arbitrarily large number. I am not sure how much weight to put on this, but the low-confidence information seems to be slight evidence to either genetics or environment leading to different abstractions forming naturally.
Colours
Colours are understood differently in different cultures. For example, in most cultures, there are a small number of colours that are given names: “Red”, “Yellow”, “Green”, and then from this extra colours are given names between these
However, there do exist different cultures that categorise colours quite differently, such as the Himba people, more focused on Brightness.

{kind=link}
(They might even perceive colours differently as a result)
Philosophical Ideas
When people learn about EA, some people find it much easier to internalise the ideas than other people. This seems to be generally true for a lot of things. People generally build a world model, and gather information to update their world model. For some, the Effective Altruism ideas seem very culturally natural, while others find it very aversive to their internal world models. ( this is mainly thinking about the hierarchical ideas )
How do people come up with ideas?
The model I have of the way humans communicate with others and with themselves, is that humans start off with an idea, and then this idea is refined. The visualisation I have of this is similar to that of how diffusion models work. One starts with a noisy/blurry idea, and then this is slowly refined until one has the clear idea in their head. Eventually, this process is automated enough that one does not need to think about it. This is probably false, but I am not sure how else to think of it.
Things that are Always Natural?
Some ideas of human abstractions that might consistently emerge naturally:
Taking turns in a conversation
For more examples, check out anthropologist Donald Brown’s list of proposed human universals, although later work has shown that some of these are not actually universal to all cultures. To illustrate:
Many rulesets have been claimed to universally apply to all human languages, but usually, a counterexample (say, some remote cultural group’s language) has been found for each proposed ruleset.
Romantic kissing is not a human universal.
Across human cultures, there is an immense diversity of possible social norms. To illustrate, some norms of Western, Educated, Industrialised, Rich, and Democratic societies (e.g., individualism, aversion to nepotism) may in fact be outliers relative to the full distribution of human cultural groups in the world.
Figuring out which behavioural traits are likely to be selected in a given situation (say, via a stochastic evolutionary process like Stochastic Gradient Descent, Genetic Algorithm, and one of the processes underlying either brain learning or cultural evolution) is generally quite situation-specific, often in an unpredictable manner. This may complicate the prospects of predicting likely-to-evolve natural abstractions, at least in the absence of a sufficiently granular understanding of the given situation.
Are there Ideas AIs can understand but Humans can’t?
Distinguishing Random Algorithms
Are there ideas that ML algorithms can easily understand but humans can’t? As an experiment I tried to build a small model that can distinguish between LCG and PCG-64 ( two random number generating algorithms ). I suspected that the AI might be able to distinguish between the two. I have trained a small MLP and a small CNN on the floating point output values to classify the random number generation algorithm used, but this did not converge to a model that could meaningfully distinguish the two to a high accuracy. A better algorithm likely exists, and I suspect using bitwise inputs might produce better results.
There is research here ( https://www.airza.net/2020/11/09/everyone-talks-about-insecure-randomness-but-nobody-does-anything-about-it.html ) which breaks xorshift128, which was likely chosen for being easy to break.
Looking at the patterns directly, if this is true, then it would likely show something that humans cannot understand.
I think, however, the relevant example would not quite be something like this, as this might be a case of needing to store a lot of relevant information in your mind at once. I think I am more interested in simpler examples of ideas that ML models would be able to understand, that humans could store hypothetically store entirely in their head, but fail to due to being compressed by a metric that an AI uses, but require a huge amount of data by the metric that a human mind uses.
Appendix B: More generated results
Dall-E 2
Dall-E really does not like the idea of medium-length sleeves ( very unnatural )








DALL-E 2 is not as good at making blouses as midjourney.




Midjourney
Generations for “medium-length sleeve t-shirt” and similar:





Other attempts to generate medium-length sleeve tops
Generations for “medium-length sleeve top”


Generations for “medium-length sleeve blouse”:


Generations for “medium-length sleeve shirt”:


Generations for “medium-length sleeve crop top”:


Related:
This post seems the most relevant and touches some similar ideas: https://www.alignmentforum.org/posts/Fut8dtFsBYRz8atFF/the-natural-abstraction-hypothesis-implications-and-evidence
I really like the question this post asks. The post itself is a pretty scattered, but that’s not necessarily a bad thing given that it’s obviously a dump of in-progress research.
One place where I might direct effort differently: it seems like the “ideas that differ between people” in Appendix A offer more total bits-of-evidence than all the ML experiments combined, despite (I would guess) the ML experiments taking far more effort. This is a common pattern: the existing world offers an enormous number of bits-of-evidence at much lower cost than experiments. Often the experiments are necessary, in order to check how things behave outside the distribution offered by the real world, or in order to check something difficult to directly observe in the real world. But before investing lots of effort in an experiment, it’s worth stopping to ask whether you can get a lot more bits for your buck by looking at existing real-world instances. That’s especially true in the very early stages, when we’re not really sure what outside-of-real-world-distribution experiments will actually tell us anything useful.
I suspect this is along the lines of a correct approach not just to alignment-around-training-distribution, but to robust reflection/extrapolation very far off-distribution. Interpretable and trained/verified-as-aligned coarse-grained descriptions of behavior should determine new training that takes place off-initial-distribution, screening off opaque details of the old model.
Then even if something along the lines of mesa-optimizers is always lurking below the surface of model behavior, with potential to enact a phase change on behavior far off-distribution, it doesn’t get good channels to get its bearings or influence what comes after, because it never gets far off-distribution (behavior is only rendered within-scope where it’s still aligned). It’s a new model determined by descriptions of behavior of the old models that implements behavior far off-distribution instead.