A Primer On Chaos
Consider a billiards table:

The particular billiards table we’ll use is one we dug out of the physicists’ supply closet, nestled in between a spherical cow and the edge of an infinite plane. The billiard balls are all frictionless, perfectly spherical, bounce perfectly elastically off of other balls and the edges of the table, etc.
Fun fact about billiard balls: if our aim has a tiny bit of error to it, and we hit a ball at ever-so-slightly the wrong angle, that error will grow exponentially as the balls collide. Picture it like this: we start with an evenly-spaced line of balls on the table.
We try to shoot straight along the line, but the angle is off by a tiny amount, call it ..
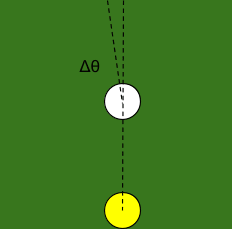
The ball rolls forward, and hits the next ball in line. The distance by which it’s off is roughly the ball-spacing length multiplied by , so .
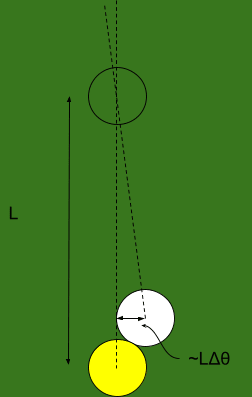
Since the first ball hits the second ball off-center, the second ball will also have some error in its angle. We do a little geometry, and find that the angular error in the second ball is roughly , where is the radius of a ball.
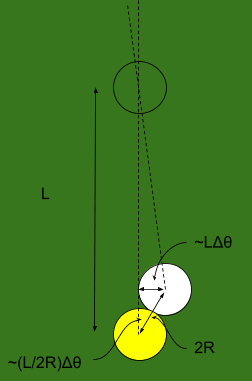
Now the second ball rolls into the third. The math is exactly the same as before, except the initial error is now multiplied by a factor . So when the second ball hits the third, the angular error in the third ball will be multiplied again, yielding error . And so forth.
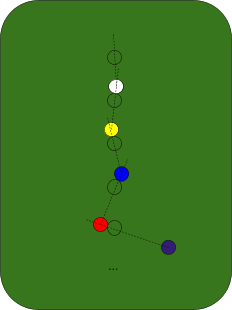
Upshot of all this: in a billiard-ball system, small angular uncertainty grows exponentially with the number of collisions.
In fact, this simplified head-on collision scenario yields the slowest exponential growth. If the balls are hitting at random angles, then the uncertainty grows even faster.
This is a prototypical example of mathematical chaos: small errors grow exponentially as the system evolves over time. Given even a tiny amount of uncertainty in the initial conditions (or a tiny amount of noise from air molecules, or a tiny amount of noise from an uneven table surface, or …), the uncertainty grows, so we are unable to precisely forecast ball-positions far in the future. As we forecast further into the future, our predictions become highly uncertain.
An Information-Theoretic Point Of View
At first glance, chaos poses a small puzzle. The dynamics of billiard-balls are reversible: if we exactly know all the ball positions and velocities at one time, we can exactly calculate all the ball positions and velocities at an earlier or later time. In that sense, no information is lost. Why, then, do our predictions become highly uncertain?
The key is that angles and positions and velocities are real numbers, and specifying a real number takes an infinite number of digits—e.g. the angle of the first ball in our line of billiards balls might be θ = 0.0013617356590430716…. Even though it’s a small real number, it still has an infinite number of digits. And as the billiards system evolves, digits further and further back in the decimal expansion become relevant to the large-scale system behavior. But the digits far back in the decimal expansion are exactly the digits about which we have approximately-zero information, so as time runs forward, we become highly uncertain about the system state.
Conversely, our initial information about the large-scale system behavior still tells us a lot about the future state, but most of what it tells us is about digits far back in the decimal expansion of the future state variables (i.e. positions and velocities). Another way to put it: initially we have very precise information about the leading-order digits, but near-zero information about the lower-order digits further back. As the system evolves, these mix together. We end up with a lot of information about the leading-order and lower-order digits combined, but very little information about either one individually. (Classic example of how we can have lots of information about two variables combined but little information about either individually: I flip two coins in secret, then tell you that the two outcomes were the same. All the information is about the relationship between the two variables, not about the individual values.) So, even though we have a lot of information about the microscopic system state, our predictions about large-scale behavior (i.e. the leading-order digits) are highly uncertain.
Conserved Quantities
In our billiards example, not quite all large-scale information is lost to chaos. Assuming no friction and perfectly elastic collisions (remember, we dug this billiard table out of the physicists’ supply closet), energy is perfectly conserved over time. If we know the initial energy, we know the energy later on. If we approximately know the initial energy—the first two digits of the initial energy measured in Joules, for instance—then we approximately know the energy later on. That particular large-scale information is not lost to chaos; our uncertainty about the system’s energy does not grow over time.
More generally: in chaotic systems, there are typically some conserved quantities. Usually, as we predict further and further into the future, our (large-scale) predictions become maximally uncertain except for the conserved quantities.
Here are four other quantities conserved over time in our billiards system:
Number of balls
Area of the table
Number of balls of each color
Color of the table
In the context of the billiards table, these four quantities probably seem “less interesting” than energy, at least at first glance. That’s because the “variables” we were thinking about were mainly positions and velocities of the balls, and quantities like number of balls, area of the table, etc, do not depend on the positions and velocities of the balls. Of course the color of the table stays the same as the balls’ positions and velocities change, so of course our uncertainty about the color of the table stays the same as we become more uncertain about the balls’ positions and velocities.
… but the billiards table is usually used as a simplification of a more widely applicable model: an ideal gas. In the context of gasses, we often do things like add or remove gas from a container (i.e. change the number of balls), compress or expand gas in a piston (i.e. change the area of the table), or induce chemical reactions (i.e. change number of balls of each color). When we make those sorts of changes, things like number of balls and area of table do start to interact with the positions and velocities. And those quantities are still conserved by the balls’ dynamics (even if we’re changing them externally), so information about them won’t be wiped out by chaos.
An Interesting And Powerful Observation
Suppose we start off our billiards table with 10 balls at some average initial energy. (For the large majority of possible starting states, it doesn’t matter how that initial energy is distributed, since chaos will wipe out the details quickly anyway.) We let it bounce around a while, then add another 10 balls at rest, then adjust the table to half of its previous size. We want to predict the average energy of the balls at the end.
What’s interesting is that we can predict the average energy of the balls at the end, reasonably-accurately and robustly, just from the change in number of balls and table size. The average energy of the balls at the end is approximately-independent of the initial positions and velocities of all the individual balls; it only depends on initial energy, initial ball-number and table-area, the changes in ball-number and table-area, and the average energy of the added balls.
To put it in terms of gasses: empirically, we can reasonably-precisely and robustly predict the final temperature of a gas in an insulated piston from its initial temperature, particle-count and piston-volume, the change in particle-count and piston-volume, and the average energy of the added gas.
In other words: in billiards/gasses, we find that
We only need information about quantities conserved by the system’s dynamics to predict such conserved quantities later on, even when we’re externally changing those quantities.
Other than the quantities conserved by the system’s dynamics, all other information is wiped out by chaos over time.
Putting those two together: if we have even just a little initial uncertainty, then everything which we can predict about the system reasonably far into the future can be predicted using only knowledge of the quantities conserved by the dynamics, and how those quantities change.
That’s a remarkably powerful feature. Why does it happen, and how does it generalize?
At a very rough intuitive level, we can argue:
Chaos quickly wipes out all information except for quantities conserved by the system’s dynamics.
Therefore, insofar as the final state is predictable at all, everything predictable about it is predictable from just the conserved quantities.
With that argument in mind, we can see that gasses are at least a little bit special: we can predict the final energy/temperature precisely from conserved quantities of gasses, which is not always true for all systems. In general, sometimes the final energy/temperature (or final value of some other conserved quantity) does depend on the details of the initial conditions. For instance, suppose we set up a tiny pressure pad at one spot on the billiards table, and arrange to release a bunch more balls if the pad is hit. Then we need to know whether the pad is hit in order to precisely predict the final energy, and that in turn depends on the details of the initial conditions. It’s not precisely predictable just from the conserved quantities.
But, even with the pressure pad, we can make a slightly weaker claim: insofar as the final energy is predictable at all given a little bit of uncertainty in initial conditions, it’s predictable from just the conserved quantities. In other words, given just the conserved quantities, we can get a distribution over the final energy (based on the probability of the pressure pad being hit), and if we have even just a little uncertainty in the initial conditions, then we cannot predict any better than that distribution.
That’s the main interesting claim to generalize: insofar as we can predict reasonably-far-future times at all, given a little uncertainty in initial conditions, we cannot do any better than predictions based only on the quantities conserved by the system’s dynamics.
Open Problems[1]: Generalizing Chaos
Chaos is generally framed in the language of dynamic systems: some state , which varies as a function of time , according to some update rule
Unfortunately this setup is not particularly well suited to a lot of the interesting problems to which the intuitive stories of chaos seem potentially applicable.
Minor Generalization: Drop Time-Symmetry
A first natural generalization is to allow the update rule to change over time:
I’m sure plenty of mathematicians have worked on this sort of thing before, but I haven’t looked into it much. The core problems, as I see them, are:
Say useful things about the rate of loss of information about high-order bits
Characterize the information not lost, i.e. generalizations of conserved quantities
Find tractable algorithms for predicting (partial) state at one time from (partial) state at other times, via the generalizations of conserved quantities
More Significant Generalization: Drop Synchronous Time Altogether
In practice, we want to make predictions about things which are reasonably far away, not just in time, but in space. We want to take information about one little chunk of the universe, and use it to make predictions about some other little chunk, both somewhere else and somewhen else.
We could try to shoehorn this into a dynamic system model. Let be the state of the whole spatially-distributed universe, back out whatever information we can get about initial conditions from looking at our one little chunk, then run dynamics forward again to make predictions about another little chunk. But it’s not really a natural language for talking about the problem. Dynamical systems just aren’t a very good language for talking about things separated by space in general; distributed systems don’t play well with a synchronous clock.
A bare-minimum model which handles both space and time well is a circuit (a.k.a. Bayes net, a.k.a. causal model, a.k.a. local equations respecting causality). In that language, rather than information propagating over “time”, it’s natural to think about information propagating through many layers of cuts through the circuit (a.k.a. Markov blankets):
Again, the core problems are:
Say useful things about the rate of loss of information about high-order bits across a sequence of cuts/Markov blankets
Characterize the information not lost, i.e. generalizations of conserved quantities across cuts/Markov blankets
Find tractable algorithms for predicting (partial) state of one chunk of the world from (partial) states of other chunks, via the generalizations of conserved quantities
One additional problem, which is much less natural in the dynamical system formulation:
Is there a useful “local” version of information-conservation, i.e. one which looks at the “dynamics” of just a chunk rather than a whole time-slice or other Markov blanket through the circuit? If so, how does “local” information-conservation relate to “global” information-conservation, i.e. conservation across time-slices or other Markov blankets?
This is what a lot of my own research has been about the last couple years, but I’m still not fully satisfied with the results.
Even More General: Drop Graphical Structure
Finally: how might we drop graphical structure more generally? Chaos provides a general story that:
All information except “conserved quantities” is “quickly” “wiped out”
Therefore, insofar as reasonably-”later” “states” are predictable at all, everything predictable about them is predictable just from the “conserved quantities”
Intuitively, it seems like there’s a story here which generalizes to all large prediction problems, or at least a very wide space of them.
An example: Suppose we have a binary function , with a million input bits and one output bit. The function is uniformly randomly chosen from all such functions—i.e. for each of the 2^1000000 possible inputs , we flipped a coin to determine the output for that particular input. Now, suppose we know , and we know all but 50 of the input bits—i.e. we know 999950 of the input bits. How much information do we have about the output?
Answer: almost none. For almost all such functions, knowing 999950 input bits gives us ∼1/2^50 bits of information about the output. More generally, if the function has
input bits and we know all but , then we have ~ bits of information about the output. Our information drops off exponentially with the number of unknown bits. (Rough argument here.)
Intuitively, what’s going on here? Well, random functions are very sensitive to all the input bits; flipping one input bit changes the value of the function about half the time. So, if we’re uncertain about just a few of the input bits, that uncertainty wipes out our information about the output exponentially quickly. Compare to the story in chaotic systems: in a chaotic system, the final state after a reasonable time is very sensitive to lots of the bits of the initial state; flipping one relatively-low-order initial state bit typically changes the large-scale later state. So, if we’re uncertain about just a few of the initial bits (i.e. the low-order bits), that uncertainty wipes out our information about the final state exponentially quickly.
To properly generalize the ideas of chaos to this sort of setup, the core problems are again:
Say useful things about the rate of loss of information with respect to the number of unknown bits
Characterize the information lost, i.e. generalizations of conserved quantities
Find tractable algorithms for predicting some stuff given some other stuff, via the generalizations of conserved quantities.
One additional problem:
What’s the right language in which to talk about this phenomenon, in general? It seems to go beyond both dynamical systems and circuits, so what’s the right setting?
- ^
These problems are basically open to the best of my knowledge. I do not claim that my knowledge is very comprehensive.
Not sure if this is helpful, and sorry if this is old news to you, but instead of saying information is “wiped out”, I think there’s a complementary perspective in which information is preserved (cf. Liouville’s theorem in classical mechanics, or unitarity in QM), but information very often has the tendency to transform from “useful / actionable information” to “useless information”. For example:
The following information is useful / actionable: “At time t=17.123 seconds, every air molecule in the container will be in the left half”. Why is it actionable? Because I can wait until t=17.123 seconds and quickly slip a divider into the container to separate the left and right halves, attach it to a piston, and extract negentropy from the pressure.
The following information is useless: “The 17th decimal place of the velocity of particle 79 is ‘4’, and the 19th decimal place of the velocity of particle 857 is ‘6’, and […1020 more statements like that]”. I can know that information with 100% certainty, yet there’s no possible action I can take that will extract negentropy using that knowledge.
You can come up with fun edge cases of information that might or might not be “useful” depending on what tools you have on hand, etc.
There’s a nice description here of how, if I know that a system is in a coherent blob of phase space at time 0, then my knowledge at much later times is “the system is in a particular subregion of phase space that looks like ever-finer filamentary threads spread all around phase space”—and that tends to be useless information.
Anyway, for your purposes, I guess you can say “What does the total phase space (≈ high-dimensional possibility space) look like? Given information of the form ‘the system is in X part of phase space’, what are the values of X such that this information be plausibly useful / actionable / decision-relevant? Given that I observe / know some constraint at time t=0, the information I have at time t=5 seconds will be ‘the system is in a region that looks like a filamentary mess spreading ever-finer tendrils around phase space’—but what are the constraints on that filamentary mess?” Maybe asking such questions would be fruitful brainstorming, if you haven’t already. :)
In this story, the topological mixing of the phase space (i.e. ever thinner filaments of phase space volume filling all space) and a low resolution mesh on the phase space (only a few low order bits) mean that there will be filaments in every part of the mesh. Hence your system could now be anywhere in the mesh, and is “unpredictable”.
Anyway, I believe there are asynchronous theories of thermodynamics, but the field hasn’t settled on which one is right. These three papers [1][2][3] describe asynchronous formulations of relativstic thermodynamics, and I first read about the topic on SEP, but I can’t find the article anymore. It was quite good. This paper [4] gives an overview of various approaches to relativistic thermodynamics, but it is quite old and I don’t know what the state of the art is like. Or really what the various viewpoints are. It has been a while since I looked at this.
[1] A. Gamba, “Physical quantities in different reference systems according to relativity,” American Journal of Physics, vol. 35, pp. 83–89, 1967.
[2] G. Cavalleri and G. Salgarelli, “Revision of the relativistic dynamics with variable rest mass and application to relativistic thermodynamics,” Il Nuovo Cimento A, vol. 62, no. 3, pp. 722–754, 1969.
[3]Ø. Grøn, “The asynchronous formulation of relativistic statics and thermodynamics,” Nuovo Cimento, vol. 17, pp. 141–165, 1973.
[4] https://doi.org/10.1119/1.1976295
Reading the information w/respect to infinite digits of precision example, I was motivated to dig up a Quanta article from a few years ago, Does Time Really Flow? New Clues Come From a Century-Old Approach to Math. I was reminded because this guy, Nicolas Gisin, argues that we cannot even in principle have infinite digits of precision because this requires infinite information, which wrecks determinism. The argument seems to go (very) roughly like this:
Information is physical > Physical space has a limit to how much information it can hold > We cannot write infinite digits in physical space > determinism is bunk
He goes on to propose something called a Finite Information Quantity to tackle this problem, and using intuitionist mathematics is trying to unify (at least philosophically and ontologically) classical and quantum mechanics. That sounds cool, so now I’m jumping in to see what’s happening.
The relevant paper is open access download from the university, but they aren’t all available that way according to his publication list. I expect to write him asking for a few other papers as a result.
I’m only partway through the introduction, but based on the first few paragraphs and a page or two of skimming, I think you would like it as a matter of taste and style.
Is the big picture here actually showing the limits of intelligence? Suppose you have some entity with very large intelligence, but it’s information about the billiards table comes from a 4k camera with a wide angle lens and it’s positioning error is nonzero. Obviously the pixel grid of the camera and the limited color resolution (you can do better than 1 pixel of positioning accuracy by looking at the color information around the edges of each ball) limit it.
This has n bits of precision for each ball position.
Then ANY algorithm, no matter how intelligent, cannot generate an anwer with more bits of precision than the input. (Assuming just 1 frame, you can extract a little more information from repeated observations or if you can move the camera)
So in terms of “winning the pool game”, there is a finite amount of policy quality beyond which the marginal gain is zero, your odds of winning do not increase any further.
This would be true in a general sense, limiting what superintelligence can do in our world.
Also just to be pedantic, a robot actuator also has finite control resolution, it will accept control packets at a fixed rate with a fixed number of bits of precision.
So you are limited by whichever has less bits: positioning accuracy or output actuator accuracy. So winning the pool game on the first shot is difficult and unlikely.
Yup, I think this is right, though I don’t know whether it applies to a literal game of pool since the balls start in a particular relatively-simple arrangement.
It means it’s dominated by tiny effects you may not be able to measure before the break. Once it’s down to simple 1 and 2 ball situations sure, the robot can sink every shot.
Sort of, though it depends on how much compute is used and how much error you have in your sensors. In practice, chaos can be important for prediction, but usually this isn’t as important for acting on the world.
No...
It’s still outright limited by sensor error. This is a law of physics and well proven.
You can combined observations to extract more fractional bits but there are limits.
Noisy pool like xanatos manipulations of humans or bootstrapping nanoforges without adequate resources are precisely how superintelligence could kill us.
If it isn’t possible because it doesn’t have enough bits of information about biology to make the bioweapon, enough bits about human manipulation to manipulate people into behaving to it’s benefit, or bootstrap a nanoforge, then superintelligence is not so capable it can defeat all of us.
This is right, but a little vacuous without knowing how much sensor error you have, or how much error you can tolerate. I literally said it depends on sensor error, so how much intelligence is limited by matters, rather than asking if there’s a limit.