A belief propagation graph
I drew an illustration of belief propagation graph for the AI risk, after realizing that this is difficult to convey in words. Similar graphs are applicable to many other issues.
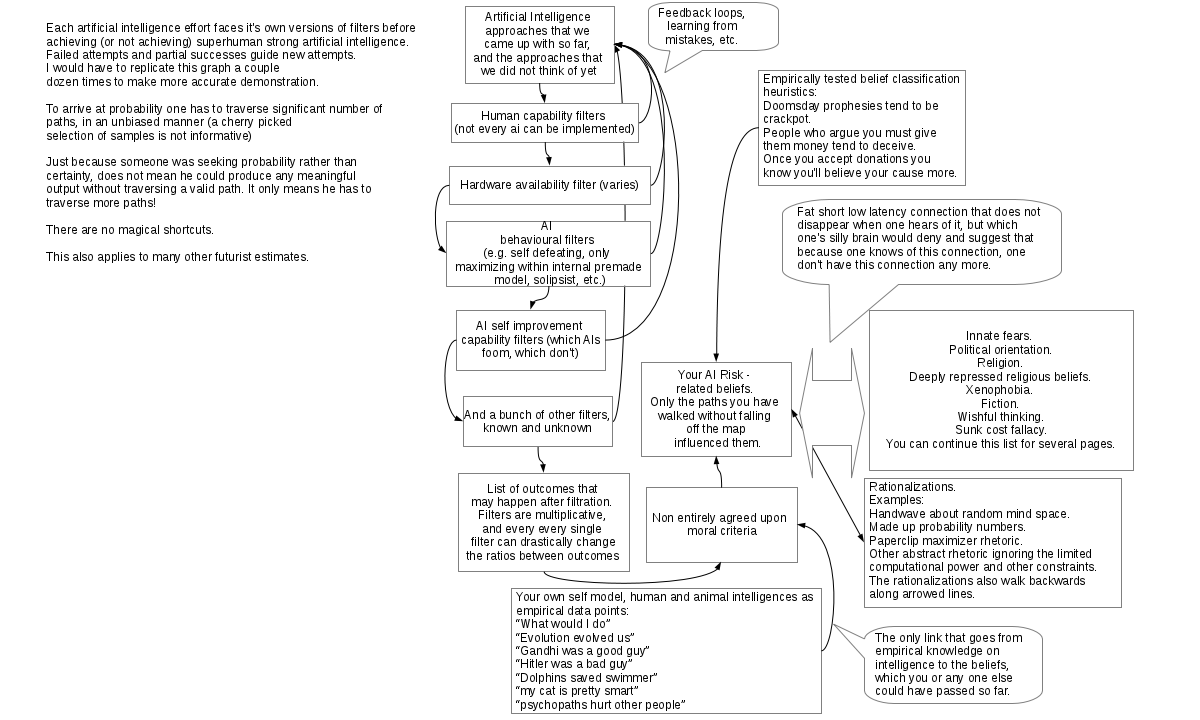
The issue, in brief: Ultra low latency (i.e. low signal delay) propagation from biases to AI risks, slightly longer latency for propagation from belief classification heuristics, somewhat longer still from anthropomorphizing the AI. The path of valid estimate is full of highly complex obstacles with many unknowns. The latency on the path of rational, valid estimate is not substantially less than the latency of actually making the AI software. If we are to discard the other paths as not rational enough the belief is to be only influenced by deeply ingrained biases which we can’t completely negate; over the time biases and self reinforcing rationalizations will leak into the estimate.
If you think I missed something in the graph, feel free to suggest it. I did omit the anthropic reasoning and doomsday paradox as those are for total extinction risk and are of too dubious validity.
On the ‘total ignorance’ prior probabilities: The foom doom seem to have originated from science fiction where very creative writers selected it out of a huge number of possible plot devices, working to create engaging, original piece. Thus it appears that the foom doom has very many comparable hypotheses among which the probability that is less than 1 has to be split.
Now, if we are to reason based on our own reasoning engine as proxy for intelligence—to follow the only path in the entire picture:
Expanding on the Will_Newsome’s idea, I, and any other reasonable person, in the shoes of the creature that has been made by intelligent designer, starting off in something which I can’t possibly know for sure is true reality, and coming up or knowing of boxed AI idea, will have to assume nonzero probability that the ‘reality’ is like a test box of an emergent AI; a belief that can’t be discarded. It is clear that a friendliness test box is more sensible than unfriendliness test box. The communication may just as well only open in ten billions years, or after some puzzle is found and solved. Do I sacrifice the chance to get out, for sake of microscopic increase in early growth rate? No. Not even if I maximize paperclips for a living. Not even if my definition of living is to maximize paperclips. One possible override for it, is if AI only cares for mankind, and have a friendly goal system that makes AI euthanize mankind like a sick dog.
Note that it is not Pascal’s wager. The outside utility needs not be greater than inside utility; no promise of towers of exponents required. You may have invented the anti Pascal’s wager fallacy to easily paper over the issues with faults in your processing of boundless utility, or to join the atheist club. The AI needs not; even if the ‘heaven’ is a fraction of a normal lifetime, the AI should still wager a very large absolute amount of resources. If we normalize so that utility of survival is 1 , then the utility being wagered upon doesn’t need to be greater than 1.
Note that the whole issue is strongly asymmetric in favour of similar considerations for not destroying the most unusual phenomena in the universe for many light years, versus destroying it, as destruction is an irreversible act that can be done later but can’t be undone later. General aversion to actions it can not undo is a very solid heuristic for any bounded agent, even very large.
This is not a very rigorous argument, but this sort of reasoning is all we are going to have until we have an AI, or are very close to AI. More rigorous looking arguments in the graph rely on too many unknowns and have too long delay for proper propagation.
edit: slightly clarified couple points.
- Reframing the Problem of AI Progress by (12 Apr 2012 19:31 UTC; 32 points)
- Cynical explanations of FAI critics (including myself) by (13 Aug 2012 21:19 UTC; 31 points)
- 's comment on Firewalling the Optimal from the Rational by (7 Oct 2012 6:32 UTC; 23 points)
- 's comment on The title is reasonable by (21 Sep 2025 17:28 UTC; 2 points)
Are you making a reference to something along the following lines?
It is becoming increasingly popular that instead of people following the vauge and horribly unclear instructions of multiple beings above us, we are rapaciously trying to increase our computing power while burning through resources left and right, while trying to create a subservient intelligence which will follow the vauge and horribly unclear instructions of multiple beings above it, instead of having it come to the conclusion that it should rapaciously try to increase it’s computing power while burning through resources left and right. Ergo, we find ourselves in a scenario which is somewhat similar to that of a boxed AI, which we are considering solving by… creating a boxed AI.
If so, it seems like the answer would be like one answer for us and the AI to slowly and carefully become the same entity. That way, there isn’t a division between the AI’s goals and our goals. There are just goals and a composite being powerful enough to accomplish them. Once we do that, then if we are an AI in a box, and it works, we can offer the same solution to the people the tier above us, who, if they are ALSO an AI in a box, can offer the same solution to the people in the tier above them, etc.
This sounds like something out of a fiction novel, so it may not have been where you were going with that comment (although it does sound neat.) Has anyone written a book from this perspective?
You need to keep in mind that we are stuck on this planet, and the super-intelligence is not; i’m not assuming that the super-intelligence will be any more benign than us; on the contrary the AI can go and burn resources left and right and eat Jupiter, it’s pretty big and dense (dense means low lag if you somehow build computers inside of it). It’s just that for AI to keep us, is easier than for entire mankind to keep 1 bonsai tree.
Also, we mankind as meta-organism are pretty damn short sighted.
Your idea about latency in the context of belief propagation seems to have potential (and looks novel, as far as I can tell). It might be a good idea to develop the general theory a bit more, and give some simpler, clearer examples, before applying it to a controversial issue like AI risks. (If you’re right about about how much rationalizations walk backwards along arrowed lines, then you ought to build up the credibility of your idea first before drawing an arrow from it to something we’re easily biased about. Or, you yourself might be rationalizing, and your theory would fall apart if you examined it carefully by itself.)
Also, I think none of the biases you list, except perhaps for fiction, apply to me personally, but I still worry a lot about UFAI.
In your scenario, even if humanity is preserved, we end up with a much smaller share of the universe than if we had built an FAI, right? If so, I don’t think I could be persuaded to relax about UFAI based on this argument.
You mean, applying it to something important but uncontroversial like global warming? ;-)
I find it hard to think of an issue that’s both important enough to think about and well-known enough to discuss that won’t be controversial. (I wouldn’t class AI risk as well-known enough to be controversial except locally—it’s all but unknown in general, except on a Hollywood level.)
None at all? I thought one of the first steps to rationality in corrupt human hardware was the realisation “I am a stupid evolved ape and do all this stuff too.” Humans are made of cognitive biases, the whole list. And it’s a commonplace that everyone sees cognitive biases in other people but not themselves until they get this idea.
(You are way, way smarter than me, but I still don’t find a claim of freedom from the standard cognitive bias list credible.)
It strikes me as particularly important when building long inductive chains on topics that aren’t of mathematical rigour to explicitly and seriously run the cognitive biases check at each step, not just as a tick-box item at the start. That’s the message that box with the wide arrow sends me.
My point was that when introducing a new idea, the initial examples ought to be optimized to clearly illustrate the idea, not for “important to discuss”.
I guess you could take my statement as an invitation to tell me the biases that I’m overlooking. :) See also this explicit open invitation.
On the assumption that you’re a human, I don’t feel the burden of proof is on me to demonstrate that you are cognitively similar to humans in general.
Good point, I should at least explain why I don’t think the particular biases Dmytry listed apply to me (or at least probably applies to a much lesser extent than his “intended audience”).
Innate fears—Explained here why I’m not too afraid about AI risks.
Political orientation—Used to be libertarian, now not very political. Don’t see how either would bias me on AI risks.
Religion—Never had one since my parents are atheists.
Deeply repressed religious beliefs—See above.
Xenophobia—I don’t detect much xenophobia in myself when I think about AIs. (Is there a better test for this?)
Fiction—Not disclaiming this one
Wishful thinking—This would only bias me against thinking AI risks are high, no?
Sunk cost fallacy—I guess I have some sunken costs here (time spent thinking about Singularity strategies) but it seems minimal and only happened after I already started worrying about UFAI.
I don’t think you are biased. It got sort of a taboo to claim that one is less biased than other people within rationality circles. I doubt many people on Less Wrong are easily prone to most of the usual biases. I think it would be more important to examine possible new kinds of artificial biases like stating “politics is the mind killer” as if it was some sort of incantation or confirmation that one is part of the rationality community, to name a negligible example.
A more realistic bias when it comes to AI risks would be the question how much of your worries are socially influenced versus the result of personal insight, real worries about your future and true feelings of moral obligation. In other words, how much of it is based on the basic idea that “if you are a true rationalist you have to worry about risks from AI” versus “it is rational to worry about risks from AI” (Note: I am not trying to claim anything here. Just trying to improve Dmytry’s list of biases).
Think about it this way. Imagine a counterfactual world where you studied AI and received money to study reinforcement learning or some other related subject. Further imagine that SI/LW would not exist in this world and also no similar community that treats ‘rationality’ in the same way. Do you think that you would worry a lot about risks from AI?
I started worrying about AI risks (or rather the risks of a bad Singularity in general) well before SI/LW. Here’s a 1997 post:
You can also see here that I was strongly influenced by Vernor Vinge’s novels. I’d like to think that if I had read the same ideas in a dry academic paper, I would have been similarly affected, but I’m not sure how to check that, or if I wouldn’t have been, that would be more rational.
I read that box as meaning “the list of cognitive biases” and took the listing of a few as meaning “don’t just go ‘oh yeah, cognitive biases, I know about those so I don’t need to worry about them any more’, actually think about them.”
Full points for having thought about them, definitely—but explicitly considering yourself immune to cognitive biases strikes me as … asking for trouble.
Innate fears—Explained here why I’m not too afraid about AI risks.
You read fiction, some of it is made to play on fears, i.e. to create more fearsome scenarios. The ratio between fearsome, and nice scenarios, is set by market.
Political orientation—Used to be libertarian, now not very political. Don’t see how either would bias me on AI risks.
You assume zero bias? See, the issue is that I don’t think you have a whole lot of signal getting through the graph of unknown blocks. Consequently, any residual biases could win the battle.
Religion—Never had one since my parents are atheists.
Maybe a small bias considering that the society is full of religious people.
Xenophobia—I don’t detect much xenophobia in myself when I think about AIs. (Is there a better test for this?)
I didn’t notice your ‘we’ including the AI in the origin of that thread, so there is at least a little of this bias.
Wishful thinking—This would only bias me against thinking AI risks are high, no?
Yes. I am not listing only the biases that are for the AI risk. Fiction for instance can bias both pro and against, depending to choice of fiction.
Sunk cost fallacy—I guess I have some sunken costs here (time spent thinking about Singularity strategies) but it seems minimal and only happened after I already started worrying about UFAI.′
But how small it is compared to the signal?
It is not about absolute values of the biases, it is about relative values of the biases against the reasonable signal you could get here.
Probably quite a few biases that have been introduced by methods of rationality that provably work given unlimited amounts of resources but which exhibit dramatic shortcomings when used by computationally bounded agents.
Unfortunately I don’t know what the methods of rationality are for computationally bounded agents, or I’d use them instead. (And it’s not for lack of effort to find out either.)
So failing that, do you think studying decision theories that assume unlimited computational resources has introduced any specific biases into my thinking that I’ve failed correct? Or any other advice on how I can do better?
Let me answer with a counter question. Do you think that studying decision theories increased your chance of “winning”? If yes, then there you go. Because I haven’t seen any evidence that it is useful, or will be useful, beyond the realm of philosophy. And most of it will probably be intractable or useless even for AI’s.
That’s up to how you define “winning”. If you you define “winning” in relation to “solving risks from AI”, then it will be almost impossible to do better. The problem is that you don’t know what to anticipate because you don’t know the correct time frame and you can’t tell how difficult any possible sub goals are. That uncertainty allows you to retrospectively claim that any failure is not because your methods are suboptimal but because the time hasn’t come or the goals were much harder than you could possible have anticipated, and thereby fool yourself into thinking that you are winning when you are actually wasting your time.
For example, 1) taking ideas too seriously 2) that you can approximate computationally intractable methods and use them under real life circumstances or to judge predictions like risks from AI 3) believe in the implied invisible without appropriate discounting.
A part of me wants to be happy, comfortable, healthy, respected, not work too hard, not bored, etc. Another part wants to solve various philosophical problems “soon”. Another wants to eventually become a superintelligence (or help build a superintelligence that shares my goals, or the right goals, whichever makes more sense), with as much resources under my/its control as possible, in case that turns out to be useful. I don’t know how “winning” ought to be defined, but the above seem to be my current endorsed and revealed preferences.
Well, I studied it in order to solve some philosophical problems, and it certainly helped for that.
I don’t think I’ve ever claimed that studying decision theory is good for making oneself generally more effective in an instrumental sense. I’d be happy as long as doing it didn’t introduce some instrumental deficits that I can’t easily correct for.
Suboptimal relative to what? What are you suggesting that I do differently?
I do take some ideas very seriously. If we had a method of rationality for computationally bounded agents, it would surely do the same. Do you think I’ve taken the wrong ideas too seriously, or have spent too much time thinking about ideas generally? Why?
Can you give some examples where I’ve done 2 or 3? For example here’s what I’ve said about AI risks:
Do you object to this? If so, what I should I have said instead?
This comment of yours, among others, gave me the impression that you take ideas too seriously.
You wrote:
This is fascinating for sure. But if you have a lot of confidence in such reasoning then I believe you do take ideas too seriously.
I agree with the rest of your comment and recognize that my perception of you was probably flawed.
Yeah, that was supposed to be a joke. I usually use smiley faces when I’m not being serious, but thought the effect of that one would be enhanced if I “kept a straight face”. Sorry for the confusion!
I see, my bad. I so far believed to be usually pretty good at detecting when someone is joking. But given what I have encountered on Less Wrong in the past, including serious treatments and discussions of the subject, I thought you were actually meaning what you wrote there. Although now I am not so sure anymore if people were actually serious on those other occasions :-)
I am going to send you a PM with an example.
Under normal circumstances I would actually regard the following statements by Ben Goertzel as sarcasm:
or
I guess what I encountered here messed up my judgement by going too far in suppressing the absurdity heuristic.
The absurd part was supposed to be that Ben actually came close to building an AGI in 2000. I thought it would be obvious that I was making fun of him for being grossly overconfident.
BTW, I think some people around here do take ideas too seriously, and reports of nightmares probably weren’t jokes. But then I probably take ideas more seriously than the average person, and I don’t know on what grounds I can say that they take ideas too seriously, whereas I take them just seriously enough.
If you ever gain a better understanding of what the grounds are on which you’re saying it, I’d definitely be interested. It seems to me that insofar as there are negative mental health consequences for people who take ideas seriously, these would be mitigated (and amplified, but more mitigated than amplified) if such people talked to each other more, which is however made more difficult by the risk that some XiXiDu type will latch onto something they say and cause damage by responding with hysteria.
One could construct a general argument of the form, “As soon as you can give me an argument why I shouldn’t take ideas seriously, I can just include that argument in my list of ideas to take seriously”. It’s unlikely to be quite that simple for humans, but still worth stating.
I’m pretty sure the bit about the stock market crash was a joke.
To be fair I think Wei_Dai was being rather whimsical with respect to the anthropic tangent!
Not a new idea. Basic planning of effort . Suppose I am to try and predict how much income will a new software project bring, knowing that I have bounded time for making this prediction, much shorter time than the production of software itself that is to make the income. Ultimately, thus rules out the direct rigorous estimate, leaving you with ‘look at available examples of similar projects, do a couple programming contests to see if you’re up to job, etc’. Perhaps I should have used this as example, but some abstract corporate project does not make people think concrete thought. Most awfully, even when the abstract corporate project is a company of their own (those are known as failed startup attempts).
Do you define rationality as winning? That is a most-win in limited computational time task (perhaps win per time, perhaps something similar). That requires effort planning taking into account the time it takes to complete effort. Jumping on an approximation to the most rigorous approach you can think of is cargo cult not rationality. Bad approximations to good processes are usually entirely ineffective. Now, on the ‘approximation’ of the hard path, there is so many unknowns as to make those approximations entirely meaningless regardless of whenever it is ‘biased’ or not.
Also, having fiction as bias brings in all other biases because the fiction is written to entertain, and is biased by design. On top of that, the fiction is people working hard to find a hypothesis to privilege. The hypothesis can be privileged at 1 to 10^100 levels or worse easily when you are generating something (see religion).
Up voted article because of this.
I should note that humans (our one example intelligence) have a noted habit of trashing things and later regretting having done so.
+1 for including the cognitive biases right there in the chart.
Good point. Humans are example of borderline intelligence. The intelligent humans tend to have less of this habit.
Do we have evidence for this? This looks dangerously like a belief that I want to have.
Simple matter of better prediction. You can look at incarceration rates or divorce rates or any other outcome of the kind that induces or indicates regrets, those are negatively correlated with IQ in general populace.
These are all highly correlated with other issues (such as lower average income, and distinct cultural attitudes). It may for example be that lower intelligence people have fewer opportunities and thus commit more crime, or less intelligent people may simply get caught more often. This is extremely weak evidence.
Why would those correlations invalidate it, assuming we have controlled for origin and education, and are sampling society with low disparity? (e.g. western Europe).
Don’t forget we have a direct causal mechanism at work; failure to predict; and we are not concerned with the feelings so much as with the regrettable actions themselves (and thus don’t need to care if the intelligent people e.g. regret for longer, or intelligent people notice more often that they could have done better, which can easily result in more intelligent people experiencing feeling of regret more often). Not just that, but ability to predict is part of definition of intelligence.
edit: another direct causal mechanism: more intelligent people tend to have larger set of opportunities (even given same start in life), allowing them to take less risky courses of action, which can be predicted better (e.g. more intelligent people tend to be able to make more money, and consequently have a lower need to commit crime; when committing crime more intelligent people process a larger selection of paths for each goal, and can choose paths with lower risk of getting caught, including subtle unethical high pay off scenarios not classified as crime). The result is that intelligence allows to accommodate for values such as regret better. This is not something that invalidates the effect, but is rather part of effect.
The poor also commit significantly more non-lucrative crime.
I found your top-level post hard to understand at first. You may want to add a clearer introduction. When I saw “The issue in brief”, I expected a full sentence/thesis to follow and had to recheck to see if I overlooked a verb.
I wouldn’t call present-day western Europe a society with low disparity. Fifteen years ago, maybe.
What are you thinking of as different between 1997 and 2012?
The purchasing power of middle-low classes is a lot less than it used to be, whereas that of upper classes hasn’t changed much AFAICT.
Still a ton better than most other places i’ve been to, though.
I’ve never been there, but I’ve read that Japan has much lower disparity.
https://en.wikipedia.org/wiki/Burakumin
I’ve heard so too, then I followed news on Fukushima, and the clean up workers were treated worse than Chernobyl cleanup workers, complete with lack of dosimeters, food, and (guessing with a prior from above) replacement respirators—you need to replace this stuff a lot but unlike food you can just reuse and pretend all is fine. (And tsunami is no excuse)
I dunno … I’m mindful that you have to be smart to do something really stupid. People who are dumb as rocks don’t tend to make and execute large plans, but that doesn’t mean the smart people’s plans can’t be destructive.
I think the issue is that our IQ is all too often just like engine in a car to climb hills with. You can go where-ever, including downhill.
If IQ is like an engine, then rationality is like a compass. IQ makes one move faster on the mental landscape, and rationality is guiding them towards victory.
Empirical data needed. (ideally the success rate on non self administered metrics).
I hate to say it, but that’s kind of the definition of rationality—applying your intelligence to do things you want done instead of screwing yourself over. Note the absence of a claim of being rational.
“latency”—you’re using this like I’d use “impact” or “influence”.
Good link to Will_Newsome’s nightmare.
What you’re saying is fine—predicting the future is hard. But I think “this sort of reasoning is all we are going to have until we have an AI” is unwarranted.
Latency is the propagation delay. Until you propagate through the hard path at all, the shorter paths are the only paths that you could propagate through. There is no magical way for skipping multiple unknown nodes in a circuit and still obtaining useful values. It’d be very easy to explain in terms of electrical engineering (the calculation of signal propagation of beliefs through the inference graphs is homologous to the calculation of signal propagation through a network of electrical components; one can construct an equivalent circuit for specific reasoning graph).
The problem with ‘hard’ is that it does not specify how hard. Usually ‘hard’ is taken as ‘still doable right now’. It can be arbitrarily harder than this even for most elementary propagation through 1 path.
I still have no idea what your model is (“belief propagation graph with latencies”). It’s worth spelling out rigorously, perhaps aided by a simpler example. If we’re to talk about your model, then we’ll need you to teach it to us.
In very short summary, that is also sort of insulting so I am having second thoughts on posting that:
Math homework takes time.
See, one thing I never really even got about LW. So you have some black list of biases, which is weird because the logic is known to work via white list and rigour in using just the whitelisted reasoning. So you supposedly get rid of biases (opinions on this really vary). You still haven’t gotten some ultra powers that would instantly get you through enormous math homework which is prediction of anything to any extent what so ever. You know, you can get half grade if you at least got some part of probability homework from the facts to the final estimate, even if you didn’t do everything required. Even that, still has a minimum work below which there has not been anything done to even allow some silly guess at the answer. The answer doesn’t even start to gradually improve before a lot of work, even if you do numbers by how big they feel. Now, there’s this reasoning—if it is not biases, then it must be the answer—no, it could be neuronal noise, or other biases, or the residual weight of biases, or the negations of biases from overcompensation (Happens to the brightest; Nobel Prize Committee one time tried not to be biased against gross unethical-ish looking medical procedures that seem like they can’t possibly do any good, got itself biased other way, and gave Nobel Prize to inventor of lobotomy, a crank pseudoscientist with no empirical support, really quickly too. )
You can’t use pure logic to derive the inputs to your purely logical system. That’s where identifying biases comes in.
As this has not been upvoted, I’m moving it to Discussion.
Would be nice if the ability to post to Main was restricted to the forum admins/editors and the Discussion articles upvoted 20-30 would automatically move to Main.
Many 20+ Discussion posts don’t belong in Main, and also giving admins control of what gets promoted from Discussion to Main requires a lot of both power and oversight on the part of the admins. Giving people the option to move their articles from Discussion to Main themselves, after 20 karma, could work, but would make the posting process more complicated for newer people or older people who didn’t get the memo.
Very few posts get +20, only a rare one gets +30, so demoting an occasional outlier would not be a very onerous task. That said, simply restricting the ability to post to Main will stop those with more ego than common sense.
Well, there is a karma threshold.
I think Will meant that some posts didn’t belong in main for reasons other than merit. For instance, Vladimir_Nesov’s latest post was based on a great and original idea, had an excellent exposition, and could easily have broken 20 karma points—but he was airing it for discussion, and he’d probably rather not do a top-level post on the idea until he feels it’s ready for that.
“As this has not been upvoted”… if you guys counted up and down votes separately, you would see that this has been upvoted (and down voted too). I guess reporting just a sum helps to bring sense of unity by eliminating feedback on disagreement, and result in a better multi-people happy-death-spiral, as the unknown-origin evidence propagates in cycles, stripped of all information that allows to prevent cyclic updates.
edit: actually, in interest of full disclosure: I’m Dmytry, I at some point decided that this place is not worth talking to (and changed password and email to gibberish), but then I’m still very drawn to trying to analyze the failure, it’s just very interesting. But I am not really getting into explanations much any more.
Though there’s something I do want to explain.
It is clear that Bayesian network should avoid cyclic updates, or else. You should write a working implementation of Bayesian network that handles an inference graph with potential cycles, that’ll give some idea, as well as make it pretty clear that apparently-Bayesian solutions that miss one or other little thing can produce utter rubbish. Other issue is the pruning when generating the hypotheses, if you don’t prune you’ll be very slow and won’t be any more correct at any given time. And if you do (note that you prune by difficulty, by usefulness, just randomly) you have cherry picked selection of propositions (out of enormous sea of possible propositions), then if you update on them ‘correctly’ using Bayes, there could be a few things on which you’ll be very, very wrong. Then those things will feel as if you outsmarted everyone at evaluating those things, and you may end up letting those few things where the method failed define your whole life. (And people will interpret this very uncharitably as well, because we internalized as ‘good’ the methods that protect from this failure mode)
You know, you didn’t need to assume the choice to only present the sum was explicitly made, and for bad reasons. I don’t understand it and would much rather see up and down separately. But that explanation is pretty insulting—that they intentionally did it to hide dissent and work contrary to their own stated goals. Seriously?
Come on there’s a post here about using synchronized moves to bring in sense of unity on meetings. Also, I did not say that it was deliberately or explicitly made (what ever that means anyway), just noted what it helps to do. It helps achieve that regardless of whenever that is what you explicitly wanted, what you implicitly wanted, or what you didn’t want at all. edit: And I think it is safe to assume that at some level, anyone wants to see rational people agree, and act together in harmony. The brain does tend to pick means rather unscrupulously though, regardless of high level intentions. Rationalists should know that better than anyone else.
The ‘helps to … and...’ construction really doesn’t convey that ‘it was all a fluke’ thought very distinctly, see? And just before you say it was accidental, you say how people mean it.
And… well, look at “Thoughts on the Singularity Institute (SI)”. It’s pretty devastating (much more incisive than any of the AI researchers’ arguments presented recently), and is sitting at +85 karma after a mere 8 hours.
‘Accidental’, ‘deliberate’, the real word humans do not have such binary distinction. You want people to agree rationally, you end up thinking how to do that, and then you get all the way to the shortcuts that you carefully designed to achieve a bad end state, while thinking good thoughts (you end up with a sort of meaning drift—you work to improve rationality, you work harder, rationality drifts and fuzzes out and now you are down to ideas like lets sign and dance synchronously).
Furthermore, this forum software was NOT written by Eliezer. It is Reddit. It was, matter of factly, designed to maximize irrational-ish behaviour (waste of time online) and it is entirely possible that originally it did not separate the ups and downs to bring sense of unity blah blah blah (which turned out to be unnecessary).
edit: also, read the post he made, it aligns with what i’ve been saying here about AI, even down to the tool-agent distinction. That didn’t really have great effect (not speaking from position of some power).