I’m confused by the change in the METR trend
Measuring AI Ability to Complete Long Tasks—METR
In their original 2025 paper, METR noticed that the slope (aka task horizon doubling time) of the trendline for models released in 2024 and later is different from the slope for <2024 models.
First, I decided to check whether a piecewise linear function fits the data better than a simple linear function. If it doesn’t, then this change in trend is a random fluke and there is nothing worth talking about.
Here is the data so far (SOTA models only):
Note: the Y axis has human-friendly labels, but the data used in all further calculations is log10(raw value in minutes).
The piecewise linear function clearly provides a better fit, based on the Bayesian information criterion (BIC, lower=better by the way) and based on a qualitative “bro just look at it” assessment. I added RMSE, MAE and R² as extra information, keep in mind that since a piecewise linear function has more parameters, it’s not surprising that it fits data better than linear, this is to be expected. BIC penalizes model complexity (number of degrees of freedom), so it’s more relevant for this case than RMSE/MAE/R².
However, I’m not satisfied. Let’s randomly remove 20% of datapoints from this graph, do it a few thousand times, and see how frequently the piecewise linear function provides a better fit according to BIC.
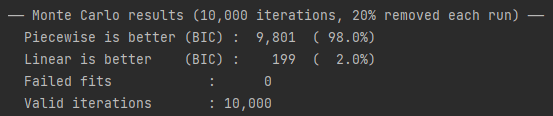
It’s pretty clear that piecewise linear fits the METR data better. But it’s possible that this is an artifact of METR’s methodology. Is there any other benchmark where a similar change could show up? ECI, Epoch Capabilities Index, doesn’t go back in time far enough to be reliable, the oldest SOTA model on ECI is GPT-4 released in 2023. If anyone knows a benchmark that includes models from the oldest (GPT-2 and GPT-3) to the newest, let me know.
Ok, let’s say that the change in the trend is real—it’s not only the line on the graph that has changed, the underlying reality has changed. What could be the cause?
RLHF. Doesn’t fit: earliest model that was RLHFed was InstructGPT, released in 2022, way before the change in trend.
Chain-of-Thought. This fits better, but not perfectly. The piecewise linear fit shows that the faster trend started around February or March 2024. o1-preview, the first model that used CoT natively, was released in September, many months after the change in trend, and several non-CoT models are on the faster trend. Even if the estimated date of change is off by a month or two, it would still mean that the trend changed before o1-preview was released, and several non-CoT models would still be on the faster trend. I’m leaning towards this explanation as the other two seem much less likely.
Some secret sauce that the labs are very good at hiding. This seems unlikely. If it was important enough to change the trend permanently as opposed to offering a one-time improvement, it would’ve been common knowledge by now.
EDIT: RLVR seems like a plausible candidate, but I don’t know exactly when the first model that was heavily RLVRed was released.
EDIT: here is a graph with two linear fits for CoT and non-CoT models. Unlike the previous graph, this one also includes models that weren’t SOTA at the time of their release.
This seems like good evidence that CoT is responsible for the change in the trend. Though, it’s possible that labs started allocating a lot of compute to RLVR at the same time as CoT became a thing.
In conclusion:
The change in the METR trend is extremely unlikely to be random noise.
It’s possible that it’s a systematic rather than a random error due to some methodological bias.
To the best of my knowledge, there is no other benchmark that includes all SOTA models from GPT-2 to present day ones, so it’s impossible to do a sanity check by looking for a similar change on a different benchmark.
Assuming this is not a methodological artifact, the change can probably be attributed to CoT, but it’s not clear. It could be due to RLVR, if it coincided with the invention of CoT.
In my experience of using piecewise-linear regression, the location of the hinge point is not robust. This is particularly likely in cases where the two sides have slopes that are nearly the same. Could you rerun your “leave points out” experiment, accumulating a distribution for the location of the hinge? I bet it will vary by several months. If this is the case, then finding “the cause” will be vexing.
Epistemic status: I used and researched piecewise regression a lot in the late ’80s and early ’90s, but not since then (boosting came along and made the fidelity of single regressions unimportant).
5th percentile of breakpoints: 2023.00
25th percentile of breakpoints: 2024.14
50th percentile of breakpoints: 2024.31
75th percentile of breakpoints: 2024.35
95th percentile of breakpoints: 2024.36
This is definitely not what I was expecting.
What happens if you fit one trendline to the non-CoT models and one to the CoT, instead of a temporal breakpoint?
Good idea! I edited the post.
It’s plausible that the change in slope is due to RLVR without it being the more recent form that induces long CoT traces—Sonnet 3.5 was differentially impressive at SWE in a way that caused people to hypothesise that RL was involved—indeed, Sonnet 3.5/3.6 were keeping up well with o1 at these sorts of tasks.
Do you have a good idea when RLVR became widely used? By “good” I mean “plus-minus a few months at worst, release date of one specific model at best”.
Not really, this is speculation. My best guess would pretty much be “at Sonnet 3.5”.
I don’t quite understand.
Isn’t this always the case? You can always do linear regression, then use your extra parameter to get zero loss on the last entry for example.
Anyways, my guess would be
RLVR
Competition amping up. My sense is that until around the breakpoint OpenAI was the only LLM dev. Ie claude 3 models were released march 2024.
This is why I used BIC: roughly speaking, if the increase in the parameter count is greater than the reduction of loss, BIC will increase. The more parameters (more precisely, degrees of freedom) the model has, the more BIC penalizes it.
Regarding RLVR, I don’t know when exactly it became widely used. 2024 vs 2025 makes a big difference here.
Seems a bit arbitrary. You’re looking for a way to bake in your priors on linear vs piece-wise linear with multiple segments. BIC doesn’t seem all that principled here.
Then what would you recommend for determining whether linear or piecewise linear (only 2 segments btw) provides a better fit?
Hmm, I can’t really think of a way you can do much better than staring at it to be honest.
But if you wanted to be rigorous about it, what would you do? I think you’d come up with initial subjective odds of linear vs 2-piecewise linear. E.g. 4:1. Then do a bayesian update using the marginal likelihood ratios.
My rough model of what’s going on (not published) is that ‘relevant effective evidence’ is what’s needed to succeed at a given subtask (of the cognitive kind that AI agents are being tested on here).
Relevant effective evidence is accumulated in pretraining (data is information is evidence!) as well as through in-context evidence-gathering activities [1] .
Generic webdata and the earlier corpora had some applicable data for these sorts of tasks. More recently, a greater fraction of the curated pretraining and posttraining data are dedicated to software engineering.
(It’s complicated by changes to posttraining, but certainly ‘effective training data’ were increasing roughly exponentially with training date for some time, which maps to the exponential ‘time horizon’ via subtask completion chance.)
This is all kind of annoying retrodiction but it adds up, at least in hindsight.
In-context evidence-gathering (i.e. exploration) competence comes from particularly generalisable learned heuristics, namely how best to experiment or try things out and interpret findings, but is still largely domain-specific.
The ECI goes back a bit farther than it does on the hub, and we use the older data to do this sort of analysis to check to see whether a break in the trend line is a good fit: https://epoch.ai/data-insights/ai-capabilities-progress-has-sped-up
Thank you. I vaguely remember seeing a tweet about it, which is why I mentioned ECI.
To my understanding, RLHF is primarily for getting models to be obedient and to provide sanitized HHH outputs. GRPO was published in 2024, opening the field for similar RLVR tactics. I would say that that’s the cleanest fit, and a much better candidate.
I would also say, by looking at the plot, that you could safely place the breakpoint further forward if it makes more sense given our real-world priors, up to around around 2024.5.