Normalizing Sparse Autoencoders
TL;DR
Sparse autoencoders (SAEs) presents us a promising direction towards automating mechanistic interpretability, but it not without flaws. One known issue of the original sparse autoencoders is the feature suppression effect which is caused by the conflict between the and loss and the unit norm constraint on the SAE decoders. This effect in theory will be more evident when we have inputs that have high norms. Another observation is that training SAEs on multiple layers simultaneously results in inconsistent norms for feature activations across layers: in some layers, has scale of , while in some other layers it has a scale of . Moreover, the residual states that’s inputed to the SAEs for training also have different norms across layers. Hence, I argue that the current SAE architecture is not robust against inputs of varying norms, which is commonly the case in modern LLMs. In this post, I a modified SAE architecture, namely Normalized Sparse Autoencoder (NSAE), and gave a theoretical proof that it will not have the feature suppression problem. I then conducted experiments to verify the effectiveness of the proposed method, which showed that:
Feature suppression is suppressed in NSAEs
The normalization removed the correlation between layer mean input norm and
The normalization makes agrees with better
I then further investigated the learned feature dictionaries and identified 3 types of feature vectors: the correction vector, the pillar vector, and the direction vector. I then concluded this post with discussion on the limitations of NSAEs and gave my suggestions on future directions.
Introduction
Training Sparse Autoencoders (SAEs) on the residual states of pretrained models is a recently proposed method in mechanistic interpretability to tackle the problem of superposition. This method is scalable and unsupervised, making it promising for auto-interpretability research.
More specifically, a SAE contains an encoder and a decoder. It is trained to generate sparse feature activations from the original residual states of a source model through the encoder, and reconstruct the residual state through a decoder. It is expected that by training the SAE with a large set of activations jointly optimizing for a sparsity loss on the feature activations and a reconstruction loss, the model can learn to decompose residual states into monosemantic feature vectors that are more interpretable.
In this post, I identified a flaw in the original SAE implementation, namely inconsistency of the loss across layers, and proposed a method to mitigate this problem. With the new method, we can significantly decrease the correlation between the norm of the source model’s residual activations and the norm of the feature activations, making the training process more robust and controllable. The code is available on GitHub (notice that you should use the dev branch instead of others).
Motivations
Feature suppression is a known problem for SAEs. It originated from a conflict between the sparsity loss and the reconstruction loss, as the reconstruction’s norm is correlated with , and the SAE model learns to generate a reconstruction with smaller norm for a better loss. This is not desirable, as we would like the reconstruction to best correspond to the original input activations. Therefore, finding a way to disentangle the input norms from and is beneficial.
Also, in my personal experiments with training SAEs using this implementation from the AI Safety Foundation, I observed an inconsistency of the sparsity loss across layers:
The above two figures are the losses of two different layers from the same training run, but the scale of has a difference.
Moreover, the sparsity measured by is also vastly different across layers:
I argue that this is also undesirable, as we introduced the coefficient in attempt to control the balance between the and loss across layers. Ideally, should have consistent control across layers, which is not the actual case.
Moreover, there is an inconsistency of the norms of the source model’s residual states across layers. We can plot the distribution of residual states[1] norms in GPT-2 small across layers:
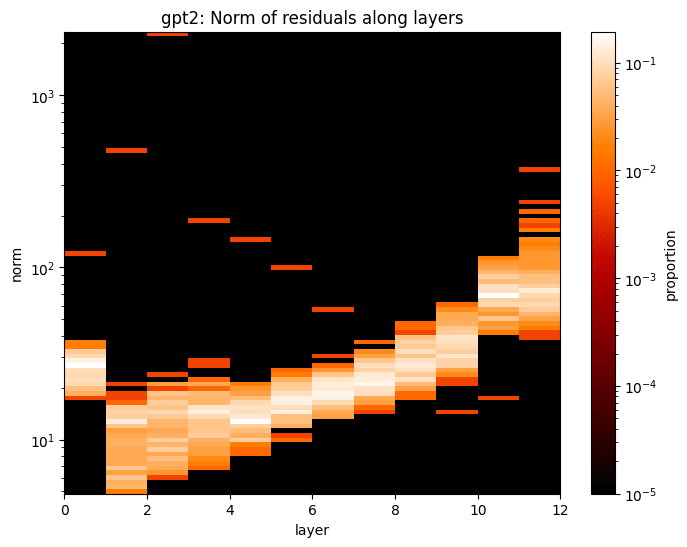
It is obvious that the mean and variance of the norms differ across layers.
This effect is common among LLMs, and we can find similar effects in more recent models like LLaMA-2 and Gemma:
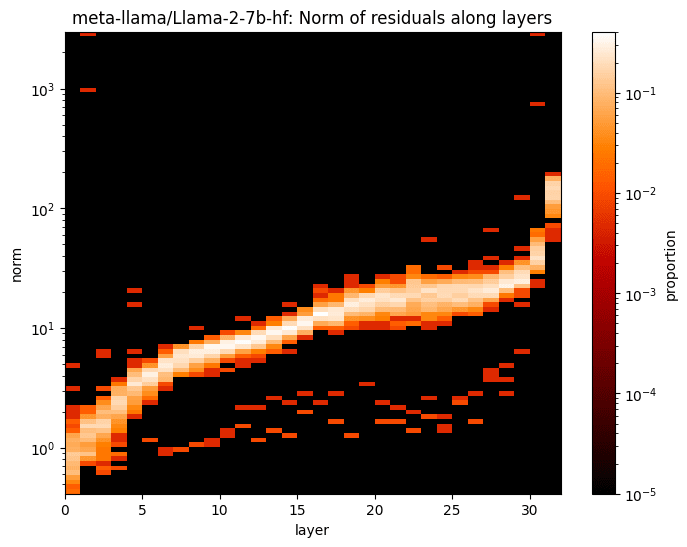 | 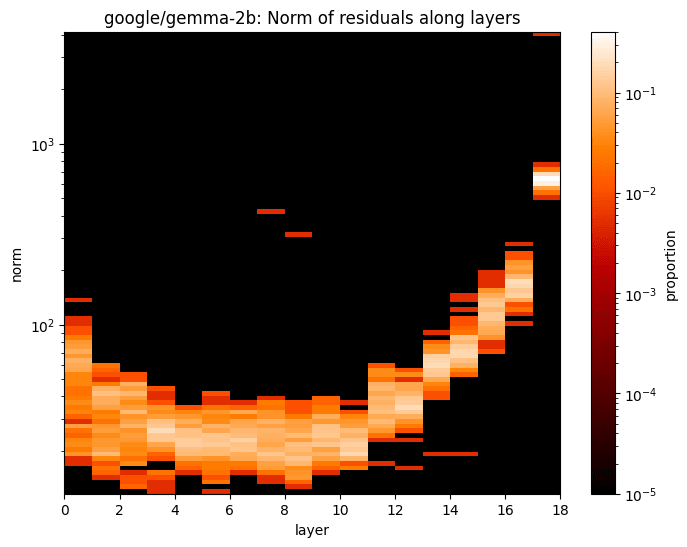 |
This provides some evidence that the inconsistency of input norms might have caused the undesirable behaviors in SAEs. Thus, I will conduct a theoretical analysis in the next section to further illustrate this problem.
Theoretical Analysis
Definitions
With these observations in mind, let’s do a theoretical analysis on this loss to see why they might have happened.
Formally, a SAE can be defined as the following:
We denote the output of encoder as the feature activation
The loss function for optimization is defined as
where the coefficient is a hyperparameter of the user’s choice and is the k-norm of a given vector.
We set another hyperparameter expansion factor and denote the source model’s residual dimension as . Then we can define and we have , , , and .
In the original implementation, the authors constrained the decoder to have unit norm column vectors, so that during the optimization process the model won’t minimize the loss by increasing the column norms of the decoder and learn to generate dense feature activation of small . This design choice lead to a potential flaw in the method and will be discussed in a later section of this post.
The Effect of Input Norms on Feature Suppression
The authors who identified feature suppression have provided a nice theoretical analysis in the Feature Suppression section, but for the comprehensiveness of this post, I will conduct a similar analysis using the terms defined in this post.
We first consider the extreme case where an input has a feature activation that only has one positive entry , with all other entries equal to 0. Then we have where is the -th column vector of . Since is column normal, we must have .
More generally, I will show that when is sparse, we also have .
Define the index set of all nonzero entries in the feature activation. Then we assume that the feature vectors in the set are (almost) mutually orthogonal[2], which is . By the constraint that the decoder have unit norm, which is , we have
In the case of sparse , we have .
Then our loss function becomes the following:
If we attempt to minimize this loss, there is always a tradeoff between the reconstruction accuracy and the norm of the reconstruction. In most cases, the model will learn to construct that’s close enough to but slightly smaller than to achieve low losses in both terms.
The Effect of Input Norms on the Inconsistency of Across Layers
Here, we make the similar assumption that when is sparse, we have .
For the term, we have
At first glance, this might not be obvious, but if our reconstruction is similar enough to , we can take [3]and the equation simplifies to
Now we can rewrite our loss:
Notice that, if is in a relatively fixed scale, then the first term has a scale of while the second term has a scale of . Then , given a fixed , if we have a larger , the loss term will bias towards the second term, which agrees with the observation I had earlier: the source model’s residual states in deeper layers have larger norms than shallower layers, and the loss was significantly higher in deeper layers as the loss was dominated by the larger term.
Normalizing SAEs
After such analysis, it natural for us to ask: is there a way to solve these problems?
My answer is yes!
Here, I propose an architectural modification to the original SAE architecture, which I have named the Normalized Sparse Autoencoder (NSAE).
Architecture
The modified architecture is defined as the following:
In this definition, is the new feature activation, and is no longer constrained to unit norm. A Gaussian error term is introduced to regularize the feature activation, which is sampled from for some hyperparameter .
The introduction of tanh normalizes every entries of to the range of . The benefits of doing this are threefolds:
This makes independent of the norm of the input, hence theoretically prevents feature suppression.
When the entries of are in the range of , and are much closer, making the loss a more accurate measure of sparsity.
The decoder learns features with norms, which can potentially leads to better interpretability as we can now consider both directions and norms.
The Gaussian noise term is also essential in this architecture. Without it, the model can learn to minimize by learning to map to very small positive values in the feature activation space and learn decoders with extremely large column norms.
To show why adding Gaussian noise solves this problem, I plotted the activation in the following figure:
From the figure, we can see that when the inputs are small, the output of tanh(ReLU) will be relatively sensitive to the input, and adding Gaussian noise can significantly perturb small feature activations. On the contrary, larger inputs to the activation function are much more robust to perturbation, as they all maps to similar values close to . Hence, this perturbation forces the model to learn to generate feature activations that are either strictly 0 or close to 1, which makes behave even more like , especially when we set to be large.
Loss
We also have to redefine the loss as follows:
We introduced the additional step of scaling by the square of the mean of the input norm of one layer. This is because . If we assume that the best an optimizer can do is to achieve a fixed cosine similarity between and without the constraint, then we can treat the term as a constance, so the loss is of the scale , while which should be constant across layers. Therefore, we can manually scale the loss to match the scale of the loss. Another way to scale the loss is by using the actual of the given sample. Theoretically this might cause the model to overfit to inputs of large norms, but for the conciseness of this post, I will leave this problem for future work to investigate, and only use the mean normalization for all the following experiments.
Experiments
I trained two groups of SAEs, one baseline and one experiment, on all layers of GPT2, and each group contains 2 training runs trained on activations. These four runs used different sets of coefficient and learning rate, and the baseline used the original SAE while the experiment used the normalized SAE. I will use “the experiment group” and “the normalized group” interchangeably.
Feature Suppression is Suppressed in Normalized SAE
To investigate feature suppression, I added a new verification metric that measures the ratio between the norm of reconstructions and norm of source activations. Here is this measure during training:
Clearly, the normalized group has significant higher score on feature suppression than the experimental group, and that score is very close to one. Considering the fact that this NSAE didn’t fully converge as it only went through 200M training examples, and there is not a sign of this score to flatten, I claim that NSAEs have less to none feature suppression.
Normalizing Removes the Correlation Between Input Norm and
To investigate the effect of normalization, I collected the norms of different layers during the end of training and plotted them against the mean input norms of the layer:
The red and blue datapoints are from the baseline group whereas the cyan and purple datapoints are from the experiment. We can fit lines to these datapoints to find linear relationships between the mean input norm and the mean norm of the feature activations. Although the fitting is not good, the fitted lines still show a rough positive linear correlation between the mean input norm and the feature activation norm in the baseline. In contrast, the two normalized samples did not exhibit a statistical significant positive linear relationship between input norm and .
This linear fit definitely does not look satisfactory, and I further investigated the reasons behind it. I plotted the normalized group’s against layer index, and here is what it looks like:
I conjecture that in the normalized group reflects a level of discreteness of the activations of the source model, as it exhibit an increase-then-decrease pattern. In the source model, earlier activations are more discrete as they originated from discrete input embeddings, and as deeper activations might be less discrete as they aggregate information. In the last layers, as the model has to make the next token prediction as accurate as possible, the activations might become more discrete again for better next-token decoding since the decoding layer is discrete. This discreteness might also be positively correlated with the monosemanticity of the activations, as more discrete activations are often more interpretable. I will not verify this conjecture in this post due to length considerations, and I welcome other to study this problem.
Agrees with Better
To investigate the agreement between and , I plot the mean and of the feature activations for both groups:
Clearly, the cyan and purple solid lines (which are ) are much closer to their corresponding dashed lines () than the baselines, indicating better agreement between and .
Performance Validation
To validate that the normalization did not heavily impact performance, I present the reconstruction score metric. I first calculate the loss of no intervention, zero intervention (replacing hidden states in one layer with zero vectors), and reconstruction intervention (replacing hidden states in one layer with reconstructed vectors from SAE), and I will denote them as , , and , respectively. Then, the score is calculated by
Since we expect to be higher than , and we want to be close to , so higher score is better, and we expect a value close to . The score during training is show below:
There is no observable difference between the normalized group and the baseline group except that the normalized group’s score seems slightly more stable during training, indicating that the normalization did not heavily impact performance but might improved training stability.
Since the mean reconstruction score is heavily impacted by the sparsity of the feature activation, I also compared a layer where the of the baseline and experiment group best agrees with each other:
Still, there is not an observable difference between the experimental group and the baseline after convergence. This provided further evidence that the normalization did not have a observable negative impact on the performance of SAEs.
NSAE Statistics
To further investigate what the new SAE has learned, I did some statistical analysis on the NSAE feature dictionary from the first run. For comparison, I used the original SAE trained in the first baseline run.
I first analyzed the norm distribution of the feature vectors along the layers:
| Figure 12. Norm distribution histogram of the feature vectors from the NSAE decoder across layers. | ||
Interestingly, a large proportion of feature vectors have norms in the range of , which might indicate that these vectors are small correction vectors that are added to a bigger vector to make the prediction as close as possible. In contrast, I hypothesize that feature vectors of norms that have high mean activation norm should have good interpretability as they represent general directions to the reconstruction. Hence, I will name these vectors as the pillar vectors.
Next, I calculate the distribution of cosine similarity of the feature dictionary:
| Figure 13. Distribution of cosine similarity in the feature dictionary of the NSAE and original SAE, respectively.[4] |
From the figure, it’s obvious that the cosine similarity distribution of NSAE and SAE are very similar except that in NSAE there are some cosine similarity very close to one. my hypothesis to these vectors is that in NSAE, there are some direction vectors that appears frequently in different norms in the decomposition of source model activations, so that NSAE have to learn these vectors of the same direction in different norms.
A natural question to ask is that: do pillar vectors and direction vectors overlap? To answer this, I picked the top- vectors (in terms of norm) of each layer from the feature dictionary as a set of pillar vectors and calculated their cosine similarity, and here is the distribution:
Since the are little to none vectors that have very high cosine similarity, there is minimal overlap between pillar vectors and direction vectors.
As this post is already pretty long, I will leave a more comprehensive analysis on the learned feature dictionary to a future post and conclude this post.
Discussion
Limitations
The normalization did not come without cost. NSAEs generally have slightly higher reconstruction losses compared with the original, and it takes longer for NSAE to converge, as shown in the following figure:
I suspect the reason of this is because NSAE learns a non-unit norm dictionary, and this dictionary have to capture all the norm information with a fixed size, whereas the original SAE can learn directions and add norm information through the feature activations.
Another metric that I don’t know how to interpret is the neural activity. In NSAE, the neural activity are significantly higher than the original SAE:
Lastly, the experiments conducted are relatively small in scale due to limitations in compute. Moreover, due to the change of the loss function, it’s hard to directly match the scales of between the baseline and the experiment group.
Future Work
I suggest future work to go along the following directions:
Investigate other factors that might caused the inconsistency across layers. I proposed a conjecture that it might be the difference in discreteness of source model input activations across layers that caused this inconsistency.
Interpret the learned feature dictionary of NSAE. Future work can further investigate the feature vectors, especially the pillar vectors and direction vectors, and find interpretations for them.
Appendix
Hyperparameters
I varied the hyperparameters l1_coefficients and the optimizer learning rate lr. For the two normalized groups, I also set the standard deviation of the Gaussian noise .
| baseline 1 | baseline 2 | normalized 1 | normalized 2 | |
|---|---|---|---|---|
| l1_coefficient | 0.001073 | 0.0009642 | 0.00004065 | 0.0000965 |
| lr | 0.0006275 | 0.00005584 | 0.0009045 | 0.000657 |
| N\A | N\A | 1 | 1 |
| Table A1. Hyperparameters used for training that varied for different runs |
| expansion_factor | 16 |
|---|---|
| context_size | 256 |
| source_data_batch_size | 16 |
| train_batch_size | 4096 |
| max_activations | 100,000,000 |
| validation_frequency | 5,000,000 |
| max_store_size | 100,000 |
| resample_interval | 200,000,000 |
| n_activations_activity_collate | 100,000,000 |
| threshold_is_dead_portion_fires | 1e-6 |
| max_n_resamples | 4 |
| resample_dataset_size | 100_000 |
| cache_names | blocks.{layer}.hook_mlp_out |
| Table A2. Fixed hyperparameters for all runs |
Related Work
Riggs et. al. proposed to use Sparse Autoencoders (SAEs) to discover interpretable features in large language models. Later, Wright et. al. identified the Feature Suppression effect in SAEs and argued that the loss induced smaller feature activations that harmed reconstruction performance. Wes Gurnee observed that the reconstruction errors in SAEs are empirically pathological, and compared different norm-aware interventions to the source model’s inference. Results show that replacing the original residual state with SAE significantly changed the model’s predictions, especially in deeper layers.
- ^
In this and the following examples, I used the residual states from the MLP layer.
- ^
This is a reasonable assumption, as data in Figure 13 (baseline) show that most feature vector pairs in the original sparse autoencoder have cosine similarities in the range of .
- ^
Empirically, , which is close enough for our analysis.
- ^
For computational efficiency, I randomly sampled features from the cosine similarity matrix.
- ^
collected from step=3000. Input norm sampled from a relatively small sample of random text. This text is the same as the text used to generate figure 3, 4a, and 4b.
For comparing CE-difference (or the mean reconstruction score), did these have similar L0′s? If not, it’s an unfair comparison (higher L0 is usually higher reconstruction accuracy).
Good point. Firstly, the mean L0 between the experiment and the baseline is within a scaling factor of 2, so it’s in a reasonably close range. I also added a new set of figures comparing the reconstruction score of one layer that have the closest match on L0 between the experiment group. Spoiler, the scores are still almost the same at the end of training. You can find it under Experiments-Performance Validation.
I want to mention that in my experience a factor of 2 difference in L0 makes a pretty huge difference in reconstruction score/L2 norm. IMO ideally you should compare pareto curves for each architecture or get two datapoints that have almost the exact same L0 if you want to compare two architectures.
The additional experiment under Experiment-Performance Verification (Figure 11) compares
normalized_1andbaseline_1on layer 5 which have almost identical L0. The result showed no observable difference.Hi Hengyu! Really nice work here! I am wondering if you have released the pre-trained SAE for llama-2?
It would be good to benchmark the normalized and baseline SAEs using the standard metrics of patch loss and L0.
You can treat figure 7 as comparing the L0, and Figure 13 as comparing L2.
Patch loss is different to L2. It’s the KL Divergence between the normal model and the model when you patch in the reconstructed activations at some layer.
Oh I see. I’ll have to look into that cuz I used the AI-safety-foundation’s implementation and they don’t measure the KL divergence. That said, there is a validation metric called reconstruction score that measures how replacing activations change the total loss of the model, and the scores are pretty similar for the original and normalized.
That’s equivalent to the KL metric. Would be good to include as I think it’s the most important metric of performance.
I think these aren’t equivalent? KL divergence between the original model’s outputs and the outputs of the patched model is different than reconstruction loss. Reconstruction loss is the CE loss of the patched model. And CE loss is essentially the KL divergence of the prediction with the correct next token, as opposed to with the probability distribution of the original model.
Also reconstruction loss/score is in my experience the more standard metric here, though both can say something useful.
If this is accurate then I agree that this is not the same as “the KL Divergence between the normal model and the model when you patch in the reconstructed activations”. But Fengyuan described reconstruction score as:
which I still claim is equivalent.
Hmm maybe I’m misunderstanding something, but I think the reason I’m disagreeing is that the losses being compared are wrt a different distribution (the ground truth actual next token) so I don’t think comparing two comparisons between two distributions is equivalent to comparing the two distributions directly.
Eg, I think for these to be the same it would need to be the case that something along the lines
DKL(A||B)−DKL(C||B)=DKL(A||C)or
DKL(A||B)/DKL(C||B)=DKL(A||C)were true, but I don’t think either of those are true. To connect that to this specific case, have B be the data distribution, and A and C the model with and without replaced activations
Reconstruction score
on a separate note that could also be a crux,
quite underspecifies what “reconstruction score” is. So I’ll give a brief explanation:
let:
Loriginal be the CE loss of the model unperturbed on the data distribution
Lreconstructed be the CE loss of the model when activations are replaced with the reconstructed activations
Lzero be the CE loss of the model when activations are replaced with the zero vector
then
reconstruction score =Lzero−LreconstructedLzero−Loriginalso, this has the property that when the value is 0 the SAE is as bad as replacement with zeros and when it’s 1 the SAE is not degrading performance at all
It’s not clear that normalizing with Lzero makes a ton of sense, but since it’s an emerging domain it’s not fully clear what metrics to use and this one is pretty standard/common. I’d prefer if bits/nats lost were the norm, but I haven’t ever seen someone use that.
Added to Experiments-Performance Validation!
I think just showing Lreconstruction would be better than reconstruction score metric because L0 is very noisy.
I don’t think Lreconstruction is very informative here, as it’s highly impacted by the input batch. Both the raw Lreconstruction and Lclean have large variances at different verification steps, and since we mainly care about how good our reconstruction is compared with the original, I think the reconstruction score is good as is. I also don’t follow why the noisiness of L0 leads to showing Lreconstruction.
What is Neuron Activity?
It is a metric from the ai-safety-foundation’s implementation. It seems to measure the number of neurons in the feature activation that fires more than a threshold. At least that’s my interpretation.