Empirical agent foundations is currently a good idea for a research direction.
mattmacdermott
Karma: 645
Bengio’s Alignment Proposal: “Towards a Cautious Scientist AI with Convergent Safety Bounds”
Some Summaries of Agent Foundations Work
Towards Measures of Optimisation
Optimisation Measures: Desiderata, Impossibility, Proposals
Normative vs Descriptive Models of Agency
The work of agency-adjacent research communities such as artificial life, complexity science and active inference is at least as relevant to AI alignment as LessWrong-style agent foundations research is.
It’s not just a lesswrong thing (wikipedia).
My feeling is that (like most jargon) it’s to avoid ambiguity arising from the fact that “commitment” has multiple meanings. When I google commitment I get the following two definitions:
the state or quality of being dedicated to a cause, activity, etc.
an engagement or obligation that restricts freedom of action
Precommitment is a synonym for the second meaning, but not the first. When you say, “the agent commits to 1-boxing,” there’s no ambiguity as to which type of commitment you mean, so it seems pointless. But if you were to say, “commitment can get agents more utility,” it might sound like you were saying, “dedication can get agents more utility,” which is also true.
Agent foundations research should become more academic on the margin (for example by increasing the paper to blogpost ratio, and by putting more effort into relating new work to existing literature).
you can train on MNIST digits with twenty wrong labels for every correct one and still get good performance as long as the correct label is slightly more common than the most common wrong label
I know some pigeons who would question this claim
I might have misunderstood you, but I wonder if you’re mixing up calculating the self-information or surpisal of an outcome with the information gain on updating your beliefs from one distribution to another.
An outcome which has probability 50% contains bit of self-information, and an outcome which has probability 75% contains bits, which seems to be what you’ve calculated.
But since you’re talking about the bits of information between two probabilities I think the situation you have in mind is that I’ve started with 50% credence in some proposition A, and ended up with 25% (or 75%). To calculate the information gained here, we need to find the entropy of our initial belief distribution, and subtract the entropy of our final beliefs. The entropy of our beliefs about A is .
So for 50% → 25% it’s
And for 50%->75% it’s
So your intuition is correct: these give the same answer.
Somewhat related: how do we not have separate words for these two meanings of ‘maximise’?
literally set something to its maximum value
try to set it to a big value, the bigger the better
Even what I’ve written for (2) doesn’t feel like it unambiguously captures the generally understood meaning of ‘maximise’ in common phrases like ‘RL algorithms maximise reward’ or ‘I’m trying to maximise my income’. I think the really precise version would be ‘try to affect something, having a preference ordering over outcomes which is monotonic in their size’.
But surely this concept deserves a single word. Does anyone know a good word for this, or feel like coining one?
Probably the easy utility function makes agent 1 have more optimisation power. I agree this means comparisons between different utility functions can be unfair, but not sure why that rules out a measure which is invariant under positive affine transformations of a particular utility function?
Sorry, yeah, my comment was quite ambiguous.
I meant that while gaining status might be a questionable first step in a plan to have impact, gaining skill is pretty much an essential one, and in particular getting an ML PhD or working at a big lab seem like quite solid plans for gaining skill.
i.e. if you replace status with skill I agree with the quotes instead of John.
It’s worth emphasising just how closely related it is. Fristons’ expected free energy of a policy is, where the first term is the expected information gained by following the policy and the second the expected ‘extrinsic value’.
The extrinsic value term , translated into John’s notation and setup, is precisely . Where John has optimisers choosing to minimise the cross-entropy of under with respect to under , Friston has agents choosing to minimise the cross-entropy of preferences () with respect to beliefs ().
What’s more, Friston explicitly thinks of the extrinsic value term as a way of writing expected utility (see the image below from one of his talks). In particular is a way of representing real-valued preferences as a probability distribution. He often constucts by writing down a utility function and then taking a softmax (like in this rat T-maze example), which is exactly what John’s construction amounts to.
It seems that John is completely right when he speculates that he’s rediscovered an idea well-known to Karl Friston.
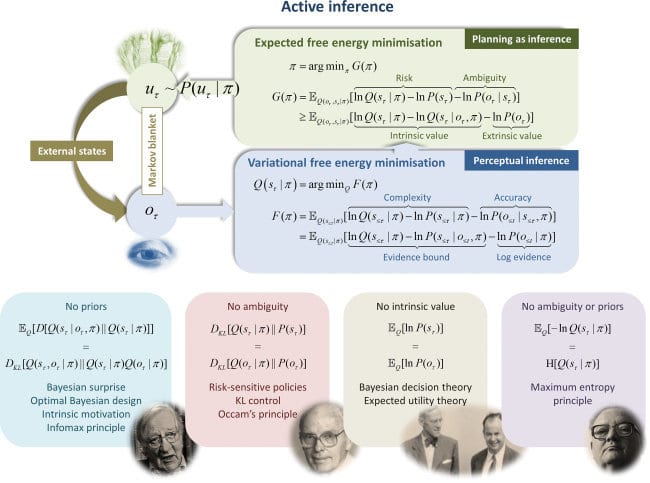
I’ve been thinking about whether these results could be interpeted pretty differently under different branding.
The current framing, if I understand it correctly, is something like, ‘Powerseeking is not desirable. We can prove that keeping your options open tends to be optimal and tends to meet a plausible definition of powerseeking. Therefore we should expect RL agents to seek power, which is bad.’
An alternative framing would be, ‘Making irreversible changes is not desirable. We can prove that keeping your options open tends to be optimal. Therefore we should not expect RL agents to make irreversible changes, which is good.’
I don’t think that the second framing is better than the first, but I do think that if you had run with it instead then lots of people would be nodding their heads and feeling reassured about corrigibility, instead of feeling like their views about instrumental convergence had been confirmed. That makes me feel like we shouldn’t update our views too much based on formal results that leave so much room for interpretation. If I showed a bunch of theorems about MDPs, with no exposition, to two people with different opinions about alignment, I expect they might come to pretty different conclusions about what they meant.
What do you think?
(To be clear I think this is a great post and paper, I just worry that there are pitfalls when it comes to interpretation.)
Is the general point that optimisation power should be about how difficult a state of affairs is to achieve, not how desirable it is?
I think that’s very reasonable. The intuition going the other way is that maybe we only want to credit useful optimisation. If you neither enjoy robbing banks nor make much money from it, maybe I’m not that impressed about the fact you can do it, even if it’s objectively difficult to pull off.
Another point is that we can sort of use the desirability of the state of affairs someone manages to achieve as a proxy for how wide a range of options they had at their disposal. This doesn’t apply to the difficulty of achieving the state of affairs, since we don’t expect people to be optimising for difficulty. This is an afterthought, though, and maybe there would be better ways to try to measure someone’s range of options.
When you write I understand that to mean that for all . But when I look up definitions of conditional probability it seems that that notation would usually mean for all
Am I confused or are you just using non-standard notation?
I have read many of your posts on these topics, appreciate them, and I get value from the model of you in my head that periodically checks for these sorts of reasoning mistakes.
But I worry that the focus on ‘bad terminology’ rather than reasoning mistakes themselves is misguided.
To choose the most clear cut example, I’m quite confident that when I say ‘expectation’ I mean ‘weighted average over a probability distribution’ and not ‘anticipation of an inner consciousness’. Perhaps some people conflate the two, in which case it’s useful to disabuse them of the confusion, but I really would not like it to become the case that every time I said ‘expectation’ I had to add a caveat to prove I know the difference, lest I get ‘corrected’ or sneered at.
For a probably more contentious example, I’m also reasonably confident that when I use the phrase ‘the purpose of RL is to maximise reward’, the thing I mean by it is something you wouldn’t object to, and which does not cause me confusion. And I think those words are a straightforward way to say the thing I mean. I agree that some people have mistaken heuristics for thinking about RL, but I doubt you would disagree very strongly with mine, and yet if I was to talk to you about RL I feel I would be walking on eggshells trying to use long-winded language in such a way as to not get me marked down as one of ‘those idiots’.
I wonder if it’s better, as a general rule, to focus on policing arguments rather than language? If somebody uses terminology you dislike to generate a flawed reasoning step and arrive at a wrong conclusion, then you should be able to demonstrate the mistake by unpacking the terminology into your preferred version, and it’s a fair cop.
But until you’ve seen them use it to reason poorly, perhaps it’s a good norm to assume they’re not confused about things, even if the terminology feels like it has misleading connotations to you.