Thanks for this post! The two new thoughts for me are:
1. The RLVR era requires that you have to get the big pods tech. If you don’t get them, doesn’t matter how many GPUs you have—no chance at the frontier.
2. Infrastructure takes time. So unless we see 10B+ in investment this year, we shouldn’t expect frontier capabilities from this lab next year.
Lee.aao
Karma: 42
Hi, I want your opinion on my little experiment. I made a short AI-generated podcast from Zvi’s latest posts.
The idea is to get a 15 minute summary that you can listen to while walking or doing chores. Works for me, but I’m not sure how much nuance I’m missing. What do you guys think? I’d really appreciate the feedback.
Seems so
https://thezvi.substack.com/p/zuckerbergs-dystopian-ai-vision
”In some ways this is a microcosm of key parts of the alignment problem. I can see the problems Zuckerberg thinks he is solving, the value he thinks or claims he is providing. I can think of versions of these approaches that would indeed be ‘friendly’ to actual humans, and make their lives better, and which could actually get built.Instead, on top of the commercial incentives, all the thinking feels alien. The optimization targets are subtly wrong. There is the assumption that the map corresponds to the territory, that people will know what is good for them so any ‘choices’ you convince them to make must be good for them, no matter how distorted you make the landscape, without worry about addiction to Skinner boxes or myopia or other forms of predation. That the collective social dynamics of adding AI into the mix in these ways won’t get twisted in ways that make everyone worse off.
And of course, there’s the continuing to model the future world as similar and ignoring the actual implications of the level of machine intelligence we should expect.
I do think there are ways to do AI therapists, AI ‘friends,’ AI curation of feeds and AI coordination of social worlds, and so on, that contribute to human flourishing, that would be great, and that could totally be done by Meta. I do not expect it to be at all similar to the one Meta actually builds.”
I’m surprised to see no discussion here or on Substack.
This is a well-structured article with accurate citations, clearly explained reasoning, and a peer review.. that updates the best agi timeline model.
I’m really confused.
I haven’t deeply checked the logic to say if the update is reasonable (that’s exactly the kind of conversation I was expecting in the comments). But I agree that Davidson’s model was previously the best estimate we had, and it’s cool to see that this updated version exlains why Dario/Sama are so confident.
Overall, this is excellent work, and I’m genuinely puzzled as to why it has received 10x fewer upvotes than the recent fictional 2y takeover scenario.
I can confirm that this is a pretty much the best introduction to take you from 0 to about 80% in using AI.
It is intended for general users, don’t expect technical information on how to use APIs or build apps.
TLDR my reaction is I don’t really know how good these models are right now.
I felt exactly the same after the Claude 3.7 post.
But actually.. hasn’t LiveBench solved the evals crisis?It is specifically targeted a “subjective” and “cheating/hacking” problems.
It also cover a pretty broad set of capabilities.
The number of different benchmarks and metrics we are using to understand each new model is crazy. I’m so confused. The exec summary helps, but...
I don’t think the relative difference between models is big enough to justify switching from the one you’re currently used to.
Does this mean that Zvi doesn’t read the comments on LW?
He seems to be much more active on Substack.
So, the most important things I’ve learned for myself are:
1. Sam was fired because of his sneaky attempts to get rid of some board members.
2. Sam didn’t answer the question of why so many high ranking ppl have left the company recently.
3. Sam missed the fact that for some people safety focus was a major decision factor in the early hiring.There seems to be enough evidence that he doesn’t care about safety.
And he actively uses dark methods to accumulate power.
We’re not even preparing reasonably for the mundane things that current AIs can do, in either the sense of preparing for risks, or in the sense of taking advantage of its opportunities. And almost no one is giving much serious thought to what the world full of AIs will actually look like and what version of it would be good for humans, despite us knowing such a world is likely headed our way.
Is there any good post on what to do? Preferrably aimed for a casual person who just use ChatGPT 1-2 times a month
The investments in data centers are going big. Microsoft will spend $80 billion in fiscal 2025, versus $64.5 billion on capex in the last year. Amazon is spending $65 billion, Google $49 billion and Meta $31 billion.
About 5 years ago, when Elon promised a $1B investment in OpenAI, it seemed like an unusual leap of faith. And now just 4 top corporations are casually committing over $200B to AI infrastructure. The pace is already crazy.
This is potentially the most powerful technology humanity has ever created. And what’s even more interesting is the absence of governments. They were the only entities comfortable with this kind of money. And it feels like they’re completely asleep.
I think I’m confused here.
Is it fair to say that o3 does math and coding better than the average SWE?
If this is true, then I really don’t understand why it hasn’t made all the headlines.
Any explanation?
Greg Brockman to Elon Musk, (cc: Sam Altman) - Nov 22, 2015 6:11 PM
In response to this follow up, Elon first mentions that $100M is not enough. And that he is encouraging OpenAI to raise more money on their own and promises to increase the amount they can raise to $1B.
I found this on the OpenAI blog: https://openai.com/index/openai-elon-musk/
There is a couple of other messages there. With the vibe that OpenAI team felt a betrayal from Elon.We’re sad that it’s come to this with someone whom we’ve deeply admired—someone who inspired us to aim higher, then told us we would fail, started a competitor, and then sued us when we started making meaningful progress towards OpenAI’s mission without him.
@habryka can you pls check the link? I think these messages could have added more context. Not sure why they weren’t also included in the original source, though.
Rather, they didn’t foresee the possibility that Microsoft might want to invest. And they didn’t consider that capped-for-profit was a path to billions of dollars.
-
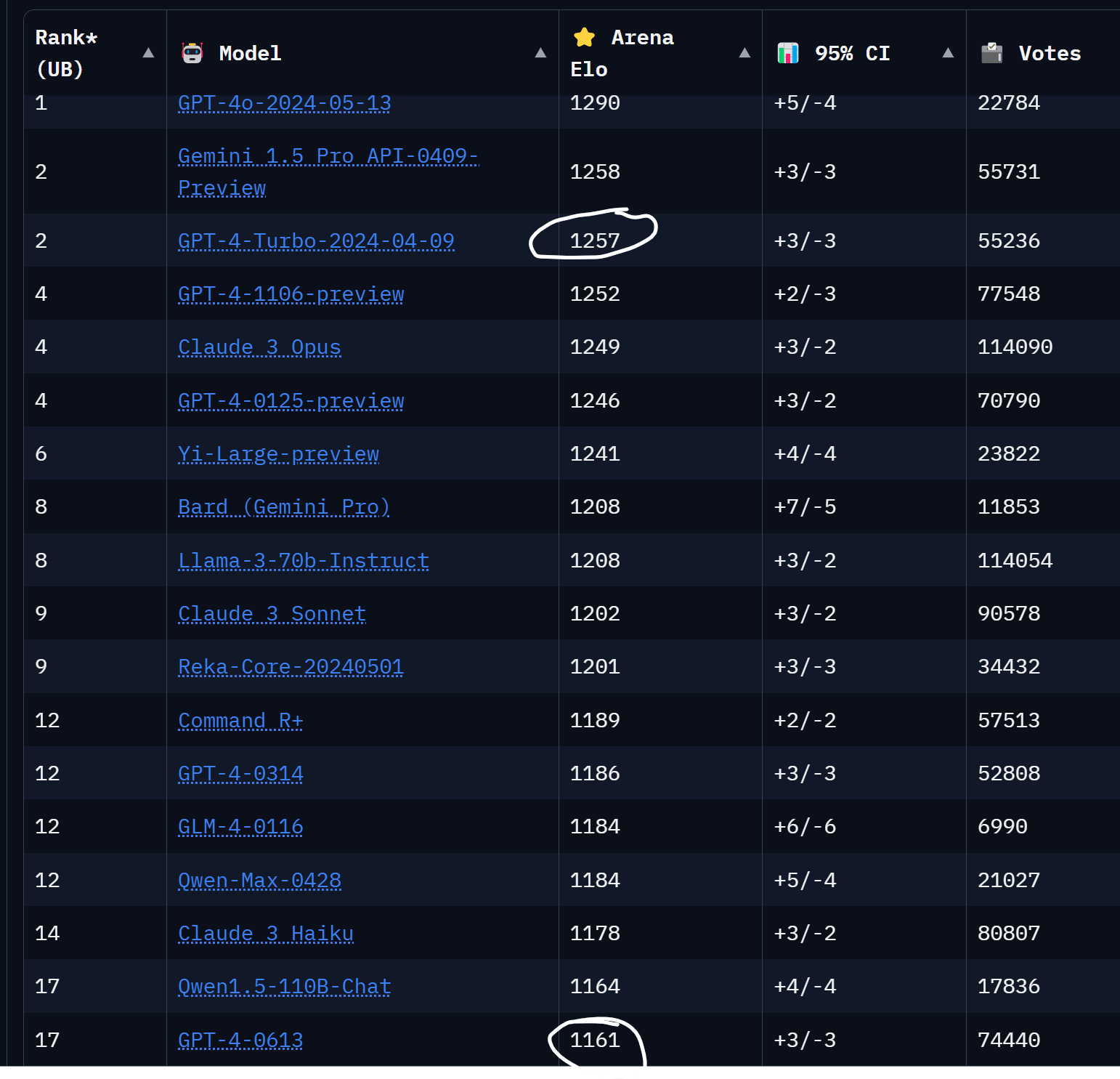
Note: It was a 100-point Elo improvement based on the ‘gpt2’ tests prior to release, but GPT-4o itself while still on top saw only a more modest increase.
Didn’t he meant the early GPT-4 vs GPT-4 turbo?
As I get it, it’s the same pre-trained model, but with more post-training work.
GPT-4o is probably a newly trained model, so you can’t compare it like that.-
and these aren’t normies, they work on tech, high paying 6 figure salaries, very up to date with current events.
If you are a true normie not working in tech, it makes sense to be unaware of such details. You are missing out, but I get why.
If you are in tech, and you don’t even know GPT-4 versus GPT-3.5? Oh no.
Is it just me, or do you also feel intellectually lonely lately?
I think my relatives and most of my friends think I’m crazy for thinking and talking so much about AI. And they listen to me more out of respect and politeness than out of any real interest in the topic.
Ege, do you think you’d update if you saw a demonstration of sophisticated sample-efficient in-context learning and far-off-distribution transfer?
Yes.
Suppose it could get decent at the first-person-shooter after like a subjective hour of messing around with it. If you saw that demo in 2025, how would that update your timelines?
I would probably update substantially towards agreeing with you.
DeepMind released an early-stage research model SIMA: https://deepmind.google/discover/blog/sima-generalist-ai-agent-for-3d-virtual-environments/
It was tested on 600 basic (10-sec max) videogame skills and had only video from the screen + text with the task. The main takeaway is that an agent trained on many games performs in a new unseen game almost as well as another agent, trained specifically on this game.
Seems like by 2025 its really possible to see more complex generalization (harder tasks and games, more sample efficiency) as in your crux for in-context learning.
Since OpenAI are renting MSFT compute for both training and inference..
Seems reasonable to think that inference >> training. Am I right?
Is there a cheap of free way to read Semianalysis posts?
Cant afford the $500 subscription sadly
I want to pitch my blog. I’m writing about tech and AI from a business perspective.
Think of it like Ben Thompson’s Stratecherry. But with longer deep dives, a more conversational tone, and much less disregard for Safety.
My last piece was a second look at Grok 3, after they released the API.