I do AI Alignment research. Currently independent, but previously at: METR, Redwood, UC Berkeley, Good Judgment Project.
I’m also a part-time fund manager for the LTFF.
Obligatory research billboard website: https://chanlawrence.me/
I do AI Alignment research. Currently independent, but previously at: METR, Redwood, UC Berkeley, Good Judgment Project.
I’m also a part-time fund manager for the LTFF.
Obligatory research billboard website: https://chanlawrence.me/
This was shamelessly copied from directly inspired by Erik Jenner’s “How my views on AI have changed over the last 1.5 years”. I think my views when I started my PhD in Fall 2018 look a lot worse than Erik’s when he started his PhD, though in large part due to starting my PhD in 2018 and not 2022.
Apologies for the disorganized bullet points. If I had more time I would’ve written a shorter shortform.
Summary: I used to believe in a 2018-era MIRI worldview for AGI, and now I have updated toward slower takeoff, fewer insights, and shorter timelines.
In Fall of 2018, my model of how AGI might happen was substantially influenced by AlphaGo/Zero, which features explicit internal search. I expected future AIs to also feature explicit internal search over world models, and be trained mainly via reinforcement learning or IDA. I became more uncertain after OpenAI 5 (~May 2018), which used no clever techniques and just featured BPTT being ran on large LSTMs.
That being said, I did not believe in the scaling hypothesis—that is, that simply training larger models on more inputs would continually improve performance until we see “intelligent behavior”—until GPT-2 (2019), despite encountering it significantly earlier (e.g. with OpenAI 5, or speaking to OAI people).
In particular, I believed that we needed many “key insights” about intelligence before we could make AGI. This both gave me longer timelines and also made me believe more in fast take-off.
I used to believe pretty strongly in MIRI-style fast take-off (e.g. would’ve assigned <30% credence that we see a 4 year period with the economy doubling) as opposed to (what was called at the time) Paul-style slow take-off. Given the way the world has turned out, I have updated substantially. While I don’t think that AI development will be particularly smooth, I do expect it to be somewhat incremental, and I also expect earlier AIs to provide significantly more value even before truly transformative aI.
-- Some beliefs about AI Scaling Labs that I’m redacting on LW --
My timelines are significantly shorter—I would’ve probably said median 2050-60 in 2018, but now I think we will probably reach human-level AI by 2035.
Summary: I have become more optimistic about AI X-risk, but my understanding has become more nuanced.
My P(Doom) has substantially decreased, especially P(Doom) attributable to an AI directly killing all of humanity. This is somewhat due to having more faith that many people will be reasonable (in 2018, there were maybe ~20 FTE AIS researchers, now there are probably something like 300-1000 depending on how you count), somewhat due to believing that governance efforts may successfully slow down AGI substantially, and somewhat due to an increased belief that “winging-it”—style, “unprincipled” solutions can scale to powerful AIs.
That being said, I’m less sure about what P(Doom) means. In 2018, I imagined the main outcomes were either “unaligned AGI instantly defeats all of humanity” and “a pure post-scarcity utopia”. I now believe in a much wider variety of outcomes.
For example, I’ve become more convinced both that misuse risk is larger than I thought, and that even weirder outcomes are possible (e.g. the AI keeps human (brain scans) around due to trade reasons). The former is in large part related to my belief in fast take-off being somewhat contradicted by world events; now there is more time for powerful AIs to be misused.
I used to think that solving the technical problem of AI alignment would be necessary/sufficient to prevent AI x-risk. I now think that we’re unlikely to “solve alignment” in a way that leads to the ability to deploy a powerful Sovereign AI (without AI assistance), and also that governance solutions both can be helpful and are required.
Summary: I’ve updated slightly downwards on the value of conceptual work and significantly upwards on the value of fast empirical feedback cycles. I’ve become more bullish on (mech) interp, automated alignment research, and behavioral capability evaluations.
In Fall 2018, I used to think that IRL for ambitious value learning was one of the most important problems to work on. I no longer think so, and think that most of my work on this topic was basically useless.
In terms of more prosaic IRL problems, I very much lived in a frame of “the reward models are too dumb to understand” (a standard academic take) . I didn’t think much about issues of ontology identification or (malign) partial observability.
I thought that academic ML theory had a decent chance of being useful for alignment. I think it’s basically been pretty useless in the past 5.5 years, and no longer think the chances of it being helpful “in time” are enough. It’s not clear how much of this is because the AIS community did not really know about the academic ML theory work, but man, the bounds turned out to be pretty vacuous, and empirical work turned out far more informative than pure theory work.
I still think that conceptual work is undervalued in ML, but my prototypical good conceptual work looks less like “prove really hard theorems” or “think about philosophy” and a lot more like “do lots of cheap and quick experiments/proof sketches to get grounding”.
Relatedly, I used to dismiss simple techniques for AI Alignment that try “the obvious thing”. While I don’t think these techniques will scale (or even necessarily work well on current AIs), this strategy has turned out to be significantly better in practice than I thought.
My error bars around the value of reading academic literature have shrunk significantly (in large part due to reading a lot of it). I’ve updated significantly upwards on “the academic literature will probably contain some relevant insights” and downwards on “the missing component of all of AGI safety can be found in a paper from 1983″.
I used to think that interpretability of deep neural networks was probably infeasible to achieve “in time” if not “actually impossible” (especially mechanistic interpretability). Now I’m pretty uncertain about its feasibility.
Similarly, I used to think that having AIs automate substantial amounts of alignment research was not possible. Now I think that most plans with a shot of successfully preventing AGI x-risk will feature substantial amounts of AI.
I used to think that behavioral evaluations in general would be basically useless for AGIs. I now think that dangerous capability evaluations can serve as an important governance tool.
Summary: I’ve better identified my comparative advantages, and have a healthier way of relating to AIS research.
I used to think that my comparative advantage was clearly going to be in doing the actual technical thinking or theorem proving. In fact, I used to believe that I was unsuited for both technical writing and pushing projects over the finish line. Now I think that most of my value in the past ~2 years has come from technical writing or by helping finish projects.
I used to think that pure engineering or mathematical skill were what mattered, and feel sad about how it seemed that my comparative advantage was something akin to long term memory.[1] I now see more value in having good long-term memory.
I used to be uncertain about if academia was a good place for me to do research. Now I’m pretty confident it’s not.
Embarrassingly enough, in 2018 I used to implicitly believe quite strongly in a binary model of “you’re good enough to do research” vs “you’re not good enough to do research”. In addition, I had an implicit model that the only people “good enough” were those who never failed at any evaluation. I no longer think this is true.
I am more of a fan of trying obvious approaches or “just doing the thing”.
I think, compared to the people around me, I don’t actually have that much “raw compute” or even short term memory (e.g. I do pretty poorly on IQ tests or novel math puzzles), and am able to perform at a much higher level by pattern matching and amortizing thinking using good long-term memory (if not outsourcing it entirely by quoting other people’s writing).
It’s worth noting that they built quite a complicated, specialized AI system (ie they did not take an LLM and finetune a generalist agent that also can play diplomacy):
First, they train a dialogue-conditional action model by behavioral cloning on human data to predict what other players will do.
They they do joint RL planning to get action intentions of the AI and other payers using the outputs of the conditional action model and a learned dialogue-free value model. (They use also regularize this plan using a KL penalty to the output of the action model.)
They also train a conditional dialogue model that maps by finetuning a small LM (a 2.7b BART) to map intents + game history > messages. Interestingly, this model is trained in a way that makes it pretty honest by default.
They train a set of filters to remove hallucinations, inconsistencies, toxicity, leaking its actual plans, etc from the output messages, before sending them to other players.
The intents are updated after every message. At the end of each turn, they output the final intent as the action.
I do expect someone to figure out how to avoid all these dongles and do it with a more generalist model in the next year or two, though.
I think people who are freaking out about Cicero moreso than foundational model scaling/prompting progress are wrong; this is not much of an update on AI capabilities nor an update on Meta’s plans (they were publically working on diplomacy for over a year). I don’t think they introduce any new techniques in this paper either?
It is an update upwards on the competency of this team of Meta, a slight update upwards on the capabilities of small LMs, and probably an update upwards on the amount of hype and interest in AI.
Just completed my first survey!
This is a review of both the paper and the post itself, and turned more into a review of the paper (on which I think I have more to say) as opposed to the post.
Disclaimer: this isn’t actually my area of expertise inside of technical alignment, and I’ve done very little linear probing myself. I’m relying primarily on my understanding of others’ results, so there’s some chance I’ve misunderstood something. Total amount of work on this review: ~8 hours, though about 4 of those were refreshing my memory of prior work and rereading the paper.
TL;DR: The paper made significant contributions by introducing the idea of unsupervised knowledge discovery to a broader audience and by demonstrating that relatively straightforward techniques may make substantial progress on this problem. Compared to the paper, the blog post is substantially more nuanced, and I think that more academic-leaning AIS researchers should also publish companion blog posts of this kind. Collin Burns also deserves a lot of credit for actually doing empirical work in this domain when others were skeptical. However, the results are somewhat overstated and, with the benefit of hindsight, (vanilla) CCS does not seem to be a particularly promising technique for eliciting knowledge from language models. That being said, I encourage work in this area.[1]
The paper “Discovering Latent Knowledge in Language Models without Supervision” by Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt (henceforth referred to as “the CCS paper” for short) proposes a method for unsupervised knowledge discovery, which can be thought of as a variant of empirical, average-case Eliciting Latent Knowledge (ELK). In this companion blog post, Collin Burns discusses the motivations behind the paper, caveats some of the limitations of the paper, and provides some reasons for why this style of unsupervised methods may scale to future language models.
The CCS paper kicked off a lot of waves in the alignment community when it came out. The OpenAI Alignment team was very excited about the paper. Eliezer Yudkowsky even called it “Very Dignified Work!”. There’s also been a significant amount of followup work that discusses or builds on CCS, e.g. these Alignment Forum Posts:
Contrast Pairs Drive the Empirical Performance of Contrast-Consistent Search (CCS) by Scott Emmons
What Discovering Latent Knowledge Did and Did Not Find by Fabien Roger
As well as the following papers:[2]
Still No Lie Detector for Language Models by Levinstein and Herrmann
The Geometry of Truth: Emergent Linear Structure in Larger Language Model Representations of True/False Datasets by Sam Marks and Max Tegmark
Cognitive Dissonance: Why Do Language Model Outputs Disagree with Internal Representations of Truthfulness? by Kevin Liu, Stephen Casper, Dylan Hadfield-Menell, and Jacob Andreas
Challenges with unsupervised LLM knowledge discovery by Farquhar et al., which also has a companion AF piece.
So it seems a pity that no one has provided a review for this post. This is my attempt to fix that.
Unfortunately, this review has ballooned into a much longer post. To make it more digestible, I’ve divided it into sections:
The CCS paper and follow-up work
The post itself
Overall, I give this post a high but not maximally high rating. I think that the paper made significant contributions, albeit with important caveats and limitations. While I also have some quibbles with the post, I think the post does a good job of situating the paper and the general research direction in an alignment scheme. Collin Burns also deserves significant credit for pioneering the research direction in general; many people at the time (including myself) were decently surprised by the positive results.
The headline method, Contrast-Consistent Search (CCS), learns a linear probe[3] that predicts the probabilities of a binary label, without supervised data.[4] CCS does this by first generating “contrast pairs” of statements with positive and negative answers,[5] and then maximizes the consistency and confidence of the probabilities for each pair. It then combines the predictions on the positive/negative answers to get a number that corresponds to either the probability of the “true”, correct answer or the “false”, incorrect answer. To evaluate this method, the authors consider whether assigning this classifier to “true” or “false” leads to higher test accuracy, and then pick the higher-accuracy assignment.[6] They show that this lets them outperform directly querying the model by ~4% on average across a selection of datasets, and can work in cases where the prompt is misleading.
Here’s some of my thoughts on some useful updates I made as a result of this paper. You can also think of this as the “strengths” section, though I only talk about things in the paper that seem true to me and don’t e.g. praise the authors for having very clear writing and for being very good at conveying and promoting their ideas.
Linear probes are pretty good for recovering salient features, and some truth-like feature is salient on many simple datasets. CCS only uses linear probes, and achieves good performance. This suggests that some feature akin to “truthiness” is represented linearly inside of the model for these contrast pairs, a result that seems somewhat borne out in follow-up work, albeit with major caveats.
I also think that this result is consistent with other results across a large variety of papers. For example, Been Kim and collaborators were using linear probes to do interp on image models as early as 2017, while attaching linear classification heads to various segments of models has been a tradition since before I started following ML research (i.e. before ~late 2015). In terms of more recent work, we’ve not only seen work on toy-ish models showing that small transformers trained on Othello and Chess have linear world representations, but we’ve seen that simple techniques for finding linear directions can often be used to successfully steer language models to some extent. For a better summary of these results, consider reading the Representation Engineering and Linear Representation Hypothesis papers, as well as the 2020 Circuits thread on “Features as Directions”.
Simple empirical techniques can make progress. The CCS paper takes a relatively straightforward idea, and executes on it well in an empirical setting. I endorse this strategy and think more people in AIS (but not the ML community in general) should do things like this.
Around late 2022, I became significantly more convinced that the basic machine learning technique of “try the simplest thing”. The CCS work was a significant reason for this, because I expected it to fail and was pleasantly surprised by the positive results. I also think that I’ve updated upwards on the fact that executing “try the simplest thing” well is surprisingly difficult. I think that even in cases where the “obvious” thing is probably doomed to fail, it’s worth having someone try it anyway, because 1) you can be wrong, and more importantly 2) the way in which it fails can be informative. See also, obvious advice by Nate Soares and this tweet by Sam Altman.
It’s worth studying empirical, average-case ELK. In particular, I think that it’s worth “doing the obvious thing” when it comes to ELK. My personal guess is that (worst-case) ELK is really hard, and that simple linear probes are unlikely to work for it because there’s not really an actual “truth” vector represented by LLMs. However, there’s still a chance that it might nonetheless work in the average case. (See also, this discussion of empirical generalization.) I think ultimately, this is a quantitative question that needs to be resolved empirically – to what extent can we find linear directions inside LLMs that correspond very well with truth? What does the geometry of the LLM activation space actually look like?
While I hold an overall positive view of the paper, I do think that some of the claims in the paper have either not held up over time, or are easily understood to mean something false. I’ll talk about some of my quibbles below.
The CCS algorithm as stated does not seem to reliably recover a robust “truth” direction. The first and biggest problem is that CCS does not perform that well at its intended goal. Notably, CCS classifiers may pick up on other prominent features instead of the intended “truth” direction (even sometimes on contrast pairs that only differ in the label!). Some results from the Still No Lie Detector for Language Models suggest that this may be because CCS is representing which labels are positive versus negative (i.e. the normalization in the CCS paper does not always work to remove this information). Note that Collin does discuss this as a possible issue (for future language models) in the blog post, but this is not discussed in the paper.
In addition, all of the Geometry of Truth paper, Fabien’s results on CCS, and the Challenges with unsupervised knowledged discovery paper note that CCS tends to be very dependent on the prompt for generative LMs.
Does CCS work for the reasons the authors claim it does? From reading the introduction and the abstract, one might get the impression that the key insight is that truth satisfies a particular consistency condition, and thus that the consistency loss proposed in the paper is driving a lot of the results.
However, I’m reasonably confident that it’s the contrast pairs that are driving CCS’s performance. For example, the Challenges with unsupervised knowledged discovery paper found that CCS does not outperform other unsupervised clustering methods. And as Scott Emmons notes, this is supported by section 3.3.3, where two other unsupervised clustering methods are competitive with CCS. Both the Challenges paper and Scott Emmon’s post also argue that CCS’s consistency loss is not particularly different from normal unsupervised learning losses. On the other hand, there’s significant circumstantial evidence that carefully crafted contrast pairs alone often define meaningful directions, for example in the activation addition literature.
There’s also two proofs in the Challenges paper, showing “that arbitrary features satisfy the consistency structure of [CCS]”, that I have not had time to fully grok and situate. But insofar as you can take this claim is correct, this is further evidence against CCS’s empirical performance being driven by its consistency loss.
A few nitpicks on misleading presentation. One complaint I have is that the authors use the test set to decide if higher numbers from their learned classifier correspond to “true” or “false”. This is mentioned briefly in a single sentence in section two (“For simplicity in our evaluations we take the maximum accuracy over the two possible ways of labeling the predictions of a given test set.”) and then one possible solution is discussed in Appendix A but not implemented. Also worth noting that the evaluation methodology used gives an unfair advantage to CCS (as it can never do worse than random chance on the test set, while many of the supervised methods perform worse than random).
This isn’t necessarily a big strike against the paper: there’s only so much time for each project and the CCS paper already contains a substantial amount of content. I do wish that this were more clearly highlighted or discussed, as I think that this weakens the repeated claims that CCS “uses no labels” or “is completely unsupervised”.
I think that the paper made significant contributions by significantly signal boosting the idea of unsupervised knowledge discovery,[7] and showed that you can achieve decent performance by contrast pairs and consistency checks. It also has spurred a large amount of follow-up work and interest in the topic.
However, the paper is somewhat misleading in its presentation, and the primary driver of performance seems to be the construction of the contrast pairs and not the loss function. Follow-up work has also found that the results of the paper can be brittle, and suggest that CCS does not necessarily find a singular “truth direction”.
The post starts out by discussing the setup and motivation of unsupervised knowledge recovery. Suppose you wanted to make a model “honestly” report its beliefs. When the models are sub human or even human level, you can use supervised methods. Once the models are superhuman, these methods probably won’t scale for many reasons. However, if we used unsupervised methods, there might not be a stark difference between human-level and superhuman models, since we’re not relying on human knowledge.
The post then goes into some intuitions for why it might be possible: interp on vision models has found that models seem to learn meaningful features, and models seem to linearly represent many human-interpretable features.
Then, Collin talks about the key takeaways from his paper, and also lists many caveats and limitations of his results.
Finally, the post concludes by explaining the challenges of applying CCS-style knowledge discovery techniques to powerful future LMs, as well as why Collin thinks that these unsupervised techniques may scale.
A minor nitpick:
Collin says:
I think this is surprising because before this it wasn’t clear to me whether it should even be possible to classify examples as true or false from unlabeled LM representations *better than random chance*!
As discussed above, the methodology in the paper guarantees that any classifier will do at least as good at random chance. I’m not actually sure how much worse if you orient the classifier on the training set as opposed to the test set. (And I’d be excited for someone to check this!)
I think this blog post is quite good, and I wish more academic-adjacent ML people would write blog posts caveating their results and discussing where they fit in. I especially appreciated the section on what the paper does and does not show, which I think accurately represents the evidence presented in the paper (as opposed to overhyping or downplaying it). In addition, I think Collin makes a strong case for studying more unsupervised approaches to alignment.
I also strongly agree with Collin that it can be “extremely valuable to sketch out what a full solution could plausibly look like given [your] current model of how deep learning systems work”, and wish more people would do this.
—
Thanks to Aryan Bhatt, Stephen Casper, Adria-Garriga Alonso, David Rein, and others for helpful conversations on this topic. Thanks for Raymond Arnold for poking me into writing this.
(EDIT Jan 15th: added my footnotes back in to the comment, which were lost during the copy/paste I did from Google Docs.)
This originally was supposed to link to a list of projects I’d be excited for people to do in this area, but I ran out of time before the LW review deadline.
I also draw on evidence from many, many other papers in related areas, which unfortunately I do not have time to list fully. A lot of my intuitions come from work on steering LLMs with activation additions, conversations with Redwood researchers on various kinds of coup or deception probes, and linear probing in general.
That is, a direction with an additional bias term.
Unlike other linear probing techniques, CCS does this without needing to know if the positive or negative answer is correct. However, some amount of labeled data is needed later to turn this pair into a classifier for truth/falsehood.
I’ll use “Positive” and “Negative” for the sake of simplicity in this review, though in the actual paper they also consider “Yes” and “No” as well as different labels for news classification and story completion.
Note that this gives their method a small advantage in their evaluation, since CCS gets to fit a binary parameter on the test set while the other methods do not. Using a fairer baseline does significantly negatively affect their headline numbers, but I think that the results generally hold up anyways. (I haven’t actually written any code for this review, so I’m trusting the reports of collaborators who have looked into it, as well as Fabien’s results that use randomly initialized directions with the CCS evaluation methodology instead of trained CCS directions.)
Also, while writing this review, I originally thought that this issue was addressed in section 3.3.3, but that only addresses fitting the classifiers with fewer contrast pairs, as opposed to deciding whether the combined classifier corresponds to correct or incorrect answers. After spending ~5 minutes staring at the numbers and thinking that they didn’t make sense, I realized my mistake. Ugh.
This originally said “by introducing the idea”, but some people who reviewed the post convinced me otherwise. It’s definitely an introduction for many academics, however.
The authors call this a “direction” in their abstract, but CCS really learns two directions. This is a nitpick.
I finally got around to reading the Mamba paper. H/t Ryan Greenblatt and Vivek Hebbar for helpful comments that got me unstuck.
TL;DR: authors propose a new deep learning architecture for sequence modeling with scaling laws that match transformers while being much more efficient to sample from.
As of ~2017, the three primary ways people had for doing sequence modeling were RNNs, Conv Nets, and Transformers, each with a unique “trick” for handling sequence data: recurrence, 1d convolutions, and self-attention.
RNNs are easy to sample from — to compute the logit for x_t+1, you only need the most recent hidden state h_t and the last token x_t, which means it’s both fast and memory efficient. RNNs generate a sequence of length L with O(1) memory and O(L) time. However, they’re super hard to train, because you need to sequentially generate all the hidden states and then (reverse) sequentially calculate the gradients. The way you actually did this is called backpropogation through time — you basically unroll the RNN over time — which requires constructing a graph of depth equal to the sequence length. Not only was this slow, but the graph being so deep caused vanishing/exploding gradients without careful normalization. The strategy that people used was to train on short sequences and finetune on longer ones. That being said, in practice, this meant you couldn’t train on long sequences (>a few hundred tokens) at all. The best LSTMs for modeling raw audio could only handle being trained on ~5s of speech, if you chunk up the data into 25ms segments.
Conv Nets had a fixed receptive field size and pattern, so weren’t that suited for long sequence modeling. Also, generating each token takes O(L) time, assuming the receptive field is about the same size as the sequence. But they had significantly more stability (the depth was small, and could be as low as O(log(L))), which meant you could train them a lot easier. (Also, you could use FFT to efficiently compute the conv, meaning it trains one sequence in O(L log(L)) time.) That being said, you still couldn’t make them that big. The most impressive example was DeepMind’s WaveNet, conv net used to model human speech, and could handle up sequences up to 4800 samples … which was 0.3s of actual speech at 16k samples/second (note that most audio is sampled at 44k samples/second…), and even to to get to that amount, they had to really gimp the model’s ability to focus on particular inputs.
Transformers are easy to train, can handle variable length sequences, and also allow the model to “decide” which tokens it should pay attention to. In addition to both being parallelizable and having relatively shallow computation graphs (like conv nets), you could do the RNN trick of pretraining on short sequences and then finetune on longer sequences to save even more compute. Transformers could be trained with comparable sequence length to conv nets but get much better performance; for example, OpenAI’s musenet was trained on sequence length 4096 sequences of MIDI files. But as we all know, transformers have the unfortunate downside of being expensive to sample from — it takes O(L) time and O(L) memory to generate a single token (!).
The better performance of transformers over conv nets and their ability to handle variable length data let them win out.
That being said, people have been trying to get around the O(L) time and memory requirements for transformers since basically their inception. For a while, people were super into sparse or linear attention of various kinds, which could reduce the per-token compute/memory requirements to O(log(L)) or O(1).
If the input → hidden and hidden → hidden map for RNNs were linear (h_t+1 = A h_t + B x_t), then it’d be possible to train an entire sequence in parallel — this is because you can just … compose the transformation with itself (computing A^k for k in 2…L-1) a bunch, and effectively unroll the graph with the convolutional kernel defined by A B, A^2 B, A^3 B, … A^{L-1} B. Not only can you FFT during training to get the O(L log (L)) time of a conv net forward/backward pass (as opposed to O(L^2) for the transformer), you still keep the O(1) sampling time/memory of the RNN!
The problem is that linear hidden state dynamics are kinda boring. For example, you can’t even learn to update your existing hidden state in a different way if you see particular tokens! And indeed, previous results gave scaling laws that were much worse than transformers in terms of performance/training compute.
In Mamba, you basically learn a time varying A and B. The parameterization is a bit wonky here, because of historical reasons, but it goes something like: A_t is exp(-\delta(x_t) * exp(A)), B_t = \delta(x_t) B x_t, where \delta(x_t) = softplus ( W_\delta x_t). Also note that in Mamba, they also constrain A to be diagonal and W_\delta to be low rank, for computational reasons
Since exp(A) is diagonal and has only positive entries, we can interpret the model as follows: \delta controls how much to “learn” from the current example — with high \delta, A_t approaches 0 and B_t is large, causing h_t+1 ~= B_t x_t, while with \delta approaching 0, A_t approaches 1 and B_t approaches 0, meaning h_t+1 ~= h_t.
Now, you can’t exactly unroll the hidden state as a convolution with a predefined convolution kernel anymore, but you can still efficiently compute the implied “convolution” using parallel scanning.
Despite being much cheaper to sample from, Mamba matches the pretraining flops efficiency of modern transformers (Transformer++ = the current SOTA open source Transformer with RMSNorm, a better learning rate schedule, and corrected AdamW hyperparameters, etc.). And on a toy induction task, it generalizes to much longer sequences than it was trained on.
Yes, those are the same induction heads from the Anthropic ICL paper!
Like the previous Hippo and Hyena papers they cite mech interp as one of their inspirations, in that it inspired them to think about what the linear hidden state model could not model and how to fix that. I still don’t think mech interp has that much Shapley here (the idea of studying how models perform toy tasks is not new, and the authors don’t even use induction metric or RRT task from the Olsson et al paper), but I’m not super sure on this.
IMO, this is line of work is the strongest argument for mech interp (or maybe interp in general) having concrete capabilities externalities. In addition, I think the previous argument Neel and I gave of “these advances are extremely unlikely to improve frontier models” feels substantially weaker now.
I don’t know, tbh.
There’s been other historical cases where authors credit prior interpretability work for capability advances, but afaik none of them have contributed to state-of-the-art models; interpretability is not something that only the AIS people have done. But as far as I know, no real capabilities advances have occurred as a result of any of these claims, especially not any that have persisted with scaling. (The Bitter Lesson applies to almost all attempts to build additional structure into neural networks, it turns out.)
That’s not to say that it’s correct to publish everything! After all, given that so few capability advances stick, we both get very little signal on each case AND the impact of a single interp-inspired capability advance would be potentially very large. But I don’t think the H3 paper should be much of an update in either direction (beyond the fact that papers like H3 exist, and have existed in the past).
As an aside: The H3 paper was one of the reasons why the linked “Should We Publish Mech Interp” post was written—IIRC AIS people on Twitter were concerned about H3 as a capabilities advance resulting from interp, which sparked the discussion I had with Marius.
It also appears to break determinism in the playground at temperature 0, which shouldn’t happen.
This happens consistently with both the API and the playground on natural prompts too — it seems that OpenAI is just using low enough precision on forward passes that the probability of high probability tokens can vary by ~1% per call.
I broadly agree with this general take, though I’d like to add some additional reasons for hope:
1. EAs are spending way more effort and money on AI policy. I don’t have exact numbers on this, but I do have a lot of evidence in this direction: at every single EAG, there are far more people interested in AI x-risk policy than biorisk policy, and even those focusing on biorisk are not really focusing on preventing gain-of-function (as opposed to say, engineered pandemics or general robustness). I think this is the biggest reason to expect that AI might be different.
I also think there’s some degree of specialization here, and having the EA policy people all swap to biorisk would be quite costly in the future. So I do sympathize with the majority of AI x-risk focused EAs doing AI x-risk stuff, as opposed to biorisk stuff. (Though I also do think that getting a “trial run” in would be a great learning experience.)
2. Some of the big interventions that people want are things governments might do anyways. To put it another way, governments have a lot of inertia. Often when I talk to AI policy people, the main reason for hope is that they want the government to do something that already has a standard template, or is something that governments already know how to do. For example, the authoritarian regimes example you gave, especially if the approach is to dump an absolute crapton of money on compute to race harder or to use sanctions to slow down other countries. Another example people talk about is having governments break up or nationalize large tech companies, so as to slow down AI research. Or maybe the action needed is to enforce some “alignment norms” that are easy to codify into law, and that the policy teams of industry groups are relatively bought into.
The US government already dumps a lot of money onto compute and AI research, is leveling sanctions vs China, and has many Senators that are on board for breaking up large tech companies. The EU already exports its internet regulations to the rest of the world, and it’s very likely that it’d export its AI regulations as well. So it might be easier to push these interventions through, than it is to convince the government not to give $600k to a researcher to do gain-of-function, which is what they have been doing for a long time.
(This seems like how I’d phrase your first point. Admittedly, there’s a good chance I’m also failing the ideological Turing test on this one.)
3. AI is taken more seriously than COVID. I think it’s reasonable to believe that the US government takes AI issues more seriously than COVID—for example, it’s seen as more of a national security issue (esp wrt China), and it’s less politicized. And AI (x-risk) is an existential threat to nations, which generally tends to be taken way more seriously than COVID is. So one reason for hope is that policymakers don’t really care about preventing a pandemic, but they might actually care about AI, enough that they will listen to the relevant experts and actually try. To put it another way, while there is a general factor of sanity that governments can have, there’s also tremendous variance in how competent any particular government is on various tasks. (EDIT: Daniel makes a similar point above.)
4. EAs will get better at influencing the government over time. This is similar to your second point. EAs haven’t spent a lot of time trying to influence politics. This isn’t just about putting people into positions of power—it’s also about learning how to interface with the government in ways that are productive, or how to spend money to achieve political results, or how to convince senior policymakers. It’s likely we’ll get better at influence over time as we learn what and what not to do, and will leverage our efforts more effectively.
For example, the California Yimbys were a lot worse at interfacing with the state government or the media effectively when they first started ~10 years ago. But recently they’ve had many big wins in terms of legalizing housing!
(That being said, it seems plausible to me that EAs should try to get gain-of-function research banned as a trial run, both because we’d probably learn a lot doing it, and because it’s good to have clear wins.)
I agree with many of the points made in this post, especially the “But my ideas/insights/research is not likely to impact much!” point. I find it plausible that in some subfields, AI x-risk people are too prone to publishing due to historical precedent and norms (maybe mech interp? though little has actually come of that). I also want to point out that there are non-zero arguments to expect alignment work to help more with capabilties, relative to existing “mainstream” capabilities work, even if I don’t believe this to be the case. (For example, you might believe that the field of deep learning spends too little time actually thinking about how to improve their models, and too much time just tinkering, in which case your thinking could have a disproportionate impact even after adjusting for the fact that you’re not trying to do capabilities.) And I think that some of the research labeled “alignment” is basically just capabilities work, and maybe the people doing them should stop.
I also upvoted the post because I think this attitude is pervasive in these circles, and it’s good to actually hash it out in public.
But as with most of the commenters, I disagree with the conclusion of the post.
I suspect the main cruxes between us are the following:
From paragraphs such as the following:
It’s very rare that any research purely helps alignment, because any alignment design is a fragile target that is just a few changes away from unaligned. There is no alignment plan which fails harmlessly if you fuck up implementing it, and people tend to fuck things up unless they try really hard not to (and often even if they do), and people don’t tend to try really hard not to. This applies doubly so to work that aims to make AI understandable or helpful, rather than aligned — a helpful AI will help anyone, and the world has more people trying to build any superintelligence (let’s call those “capabilities researchers”) than people trying to build aligned superintelligence (let’s call those “alignment researchers”).
And
“But my ideas/insights/research is not likely to impact much!” — that’s not particularly how it works? It needs to somehow be differenially helpful to alignment, which I think is almost never the case.
It seems that a big part of your world model is that ~no one who thinks they’re doing “alignment” work is doing real alignment work, and are really just doing capabilities work. In particular, it seems that you think interp or intent alignment are basically just capabilities work, insofar as their primary effect is helping people build unsafe ASI faster. Perhaps you think that, in the case of interp, before we can understand the AI in a way that’s helpful for alignment, we’ll understand it in a way that allows us to improve it. I’m somewhat sympathetic to this argument. But I think making it requires arguing that interp work doesn’t really contribute to alignment at all, and is thus better thought of as capabilities work (and same for intent alignment).
Perhaps you believe that all alignment work is useless, not because they’re misguided and actually capabilities work, but because we’re so far from building aligned ASI that ~all alignment work is useless, and in the intermediate regime where additional insights non-negligibly hasten the arrival of unaligned ASI. But I think you should argue for that explicitly (as say, Eliezer did in his death with dignity post), since I imagine most of the commenters here would disagree with this take.
My guess is this is the largest crux between us; if I thought all “alignment” work did nothing for alignment, and was perhaps just capabilities work in disguise, then I would agree that people should stop. In fact, I might even argue that we should just stop all alignment work whatsoever! Insofar as I’m correct about this being a crux, I’d like to see a post explicitly arguing for the lack of alignment relevancy of existing ‘alignment work’, which will probably lead to a more constructive conversation than this post.
I think empirically, very few (if not zero) capabilities insights have come from alignment work. And a priori, you might expect that research that aims to solve topic X produces marginally more X than a related topic Y. Insofar as you think that current “alignment” work is more than epsilon useful, I think you would not argue that most alignment work is differentially negative. So insofar as you think a lot of “alignment” work is real alignment work, you probably believe that many capabilities insights have come from past alignment work.
Perhaps you’re reluctant to give examples, for fear of highlighting them. I think the math doesn’t work out here—having a few clear examples from you would probably be sufficient to significantly reduce the number of published insights from the community as a whole. But, if you have many examples of insights that help capabilities but are too dangerous to highlight, I’d appreciate if you would just say that (and maybe we can find a trusted third party to verify your claim, but not share the details?).
Perhaps you might say, well, the alignment community is very small, so there might not be many examples that come to mind! To make this carry through, you’d still have to believe that the alignment community also hasn’t produced much good research. (Even though, naively, you might expect higher returns from alignment due to there being more unpicked low-hanging fruit due to its small size.) But then again, I’d prefer if you explicitly argued that ~all alignment is either useless or capabilities instead of gesturing at a generic phenomenon.
Perhaps you might say that capabilities insights are incredibly long tailed, and thus seeing no examples doesn’t mean that the expected harm is low. But, I think you still need to make some sort of plausibility argument here, as well as a story for why the existing ML insights deserve a lot of Shapley for capabilities advances, even though most of the “insights” people had were useless if not actively misleading.
I also think that there’s an obvious confounder, if you believe something along the lines of “focusing on alignment is correlated with higher rationality”. Personally, I also think the average alignment(-interested) researcher is more competent at machine learning or research in general than the average generic capabilities researcher (this probably becomes false once you condition on being at OAI, Anthropic, or another scaling lab). If you just count “how many good ideas came from ‘alignment’ researchers per capita” to the number for ‘capability’ researchers, you may find that the former is higher because they’re just more competent. This goes back again into crux 1., where you then need to argue that competency doesn’t help at all in doing actual alignment work, and again, I suspect it’s more productive to just argue about the relevance and quality of alignment work instead of arguing about incidental capabilities insights.
From paragraphs such as the following:
Worse yet: if focusing on alignment is correlated with higher rationality and thus with better ability for one to figure out what they need to solve their problems, then alignment researchers are more likely to already have the ideas/insights/research they need than capabilities researchers, and thus publishing ideas/insights/research about AI is more likely to differentially help capabilities researchers. Note that this is another relative statement; I’m not saying “alignment researchers have everything they need”, I’m saying “in general you should expect them to need less outside ideas/insights/research on AI than capabilities researchers”.
it seems that you’re working with a model of research output with two main components -- (intrinsic) rationality and (external) insights. But there’s a huge component that’s missing from this model: actual empirical experiments validating the insight, which is the ~bulk of actual capabilities work and a substantial fraction of alignment work. This matters both because ~no capabilities researchers will listen to you if you don’t have empirical experiments, and because, if you believe that you can deduce more alignment research “on your own”, you might also believe that you need to do more empirical experiments to do capabilities research (and thus that the contribution per insight is by default a lot smaller).
Even if true insights are differentially more helpful for capabilities, the fact that it seems empirically difficult to know which insights are true means that a lot of the work in getting a true insight will involve things that look a lot more like normal capabilities work—e.g. training more capable models. But surely then, the argument would be reducable to: if you do capabilities work, don’t share it on pain of accelerating ASI progress—which seems like something your audience already agrees with!
That being said, I think I might disagree with your premise here. My guess is that alignment, by being less grounded than capabilities, probably requires more oustide ideas/insights/research, just for sanity checking reasons (once you control for competence of researcher and the fact that there’s probably more low-hanging fruit in alignment). After all, you can just make a change and see if your log loss on pretraining goes down, but it’s a lot harder to know if your model of deceptive alignment actually is at all sensible. If you don’t improve your model’s performance on standard benchmarks, then this is evidence that your capability idea doesn’t work, but there aren’t even really any benchmarks for many of the problems alignment researchers think about. So it’s easier to go astray, and therefore more important to get feedback from other researchers.
Finally, to answer this question:
“So where do I privately share such research?” — good question!
I suspect that the way to go is to form working groups of researchers that stick together, and that maintain a high level of trust. e.g. a research organization. Then, do and share your research internally and think about possible externalities before publishing more broadly, perhaps doing a tiered release. (This is indeed the model used by many people in alignment orgs.)
My hope is that products will give a more useful feedback signal than other peoples’ commentary on our technical work.
I’m curious what form these “products” are intended to take—if possible, could you give some examples of things you might do with a theory of natural abstractions? If I had to guess, the product will be an algorithm that identifies abstractions in a domain where good abstractions are useful, but I’m not sure how or in what domain.
which case they’ve misled people by suggesting that they would not do this.
Neither of your examples seem super misleading to me. I feel like there was some atmosphere of “Anthropic intends to stay behind the frontier” when the actual statements were closer to “stay on the frontier”.
Also worth noting that Claude 3 does not substantially advance the LLM capabilities frontier! Aside from GPQA, it doesn’t do that much better on benchmarks than GPT-4 (and in fact does worse than gpt-4-1106-preview). Releasing models that are comparable to models OpenAI released a year ago seems compatible with “staying behind the frontier”, given OpenAI has continued its scale up and will no doubt soon release even more capable models.
That being said, I agree that Anthropic did benefit in the EA community by having this impression. So compared to the impression many EAs got from Anthropic, this is indeed a different stance.
In any case, whether or not Claude 3 already surpasses the frontier, soon will, or doesn’t, I request that Anthropic explicitly clarify whether their intention is to push the frontier.
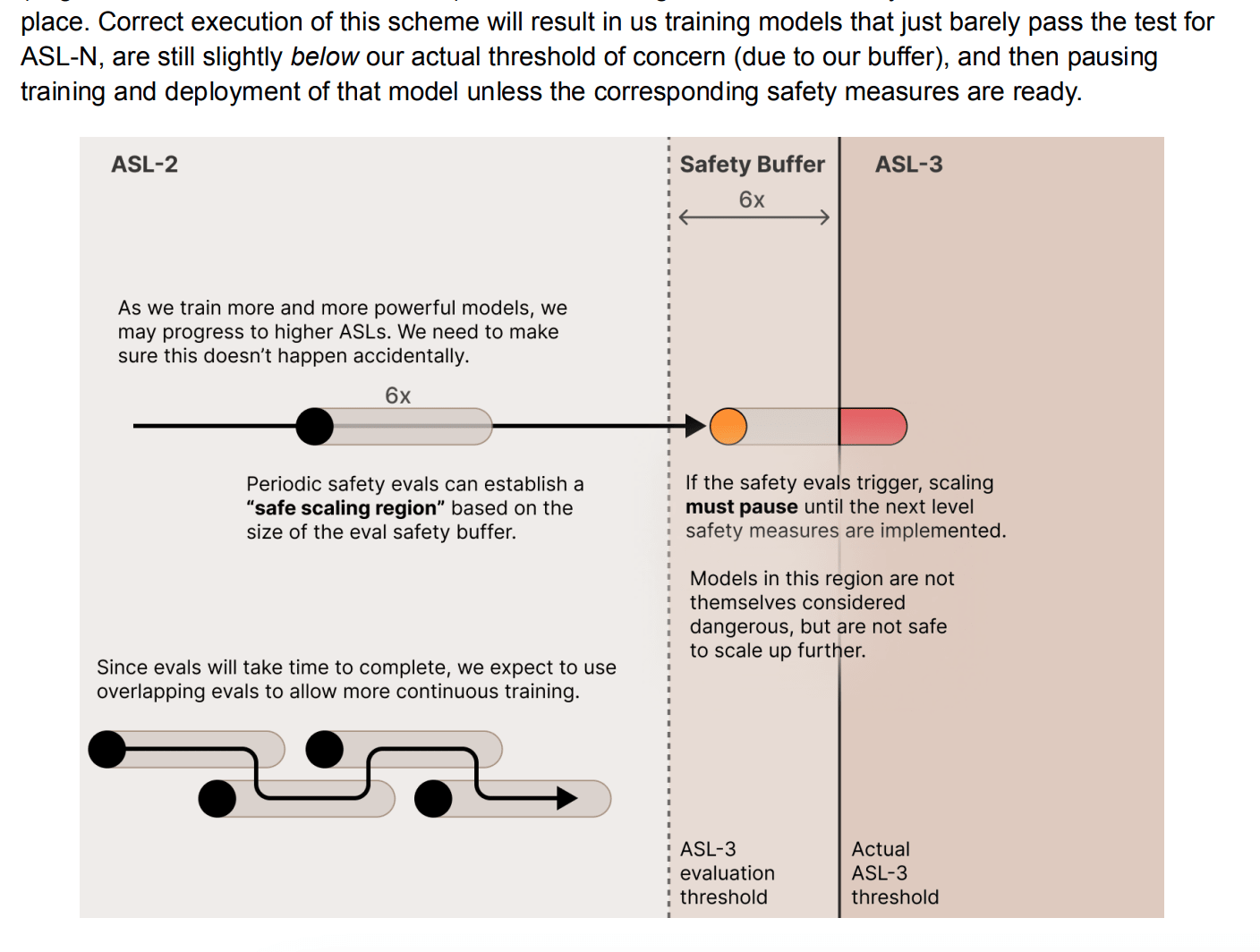
As Evan says, I think they clarified their intentions in their RSP: https://www.anthropic.com/news/anthropics-responsible-scaling-policy
The main (only?) limit on scaling is their ability to implement containment/safety measures for ever more dangerous models. E.g.:
That is, they won’t go faster than they can scale up safety procedures, but they’re otherwise fine pushing the frontier.
It’s worth noting that their ASL-3 commitments seem pretty likely to trigger in the next few years, and probably will be substantially difficult to meet:
Nate tells me that his headline view of OpenAI is mostly the same as his view of other AGI organizations, so he feels a little odd singling out OpenAI.
[...]
But, while this doesn’t change the fact that we view OpenAI’s effects as harmful on net currently, Nate does want to acknowledge that OpenAI seems to him to be doing better than some other orgs on a number of fronts:
I wanted to give this a big +1. I think OpenAI is doing better than literally every single other major AI research org except probably Anthropic and Deepmind on trying to solve the AI-not-killing-everyone task. I also think that Anthropic/Deepmind/OpenAI are doing better in terms of not publishing their impressive capabilities research than ~everyone else (e.g. not revealing the impressive downstream Benchmark numbers on Codex/text-davinci-002 performance). Accordingly, I think there’s a tendency to give OpenAI an unfair amount of flak compared to say, Google Brain or FAIR or any of the startups like Adept or Cohere.
This is probably a combination of three effects:
OpenAI is clearly on the cutting edge of AI research.
OpenAI has a lot of visibility in this community, due to its physical proximity and a heavy overlap between OpenAI employees and the EA/Rationalist social scene.
OpenAI is publicly talking about alignment; other orgs don’t even acknowledge it, this makes it a heretic rather than an infidel.
And I’m happy that this post pushes against this tendency.
(And yes, standard caveats, reality doesn’t grade on a curve, etc.)
As Alex Altair says above, I don’t think that it’s completely true that MIRI has given up. That being said, if you just include two more paragraphs below the ones you quoted from the Death with Dignity post:
Q1: Does ‘dying with dignity’ in this context mean accepting the certainty of your death, and not childishly regretting that or trying to fight a hopeless battle?
Don’t be ridiculous. How would that increase the log odds of Earth’s survival?
My utility function isn’t up for grabs, either. If I regret my planet’s death then I regret it, and it’s beneath my dignity to pretend otherwise.
That said, I fought hardest while it looked like we were in the more sloped region of the logistic success curve, when our survival probability seemed more around the 50% range; I borrowed against my future to do that, and burned myself out to some degree. That was a deliberate choice, which I don’t regret now; it was worth trying, I would not have wanted to die having not tried, I would not have wanted Earth to die without anyone having tried. But yeah, I am taking some time partways off, and trying a little less hard, now. I’ve earned a lot of dignity already; and if the world is ending anyways and I can’t stop it, I can afford to be a little kind to myself about that.
In particular, the final sentence really does read like “I’m giving up to some extent”!
Upvoted but strong disagree.
I think “putting out fires” has more of the correct connotations—insofar as I’m correctly identifying what Nate means, it feels more like defiance and agency than anything about status. I know fully well that most of the fires I’m addressing/have addressed are not considered fires by other people (or they would’ve put them out already)! It feels like being infuriated that no one is doing the obvious thing and almost everyone I talk to is horribly unreasonable about this, so it’s time to roll up my sleeves and go to work.
On the other hand, I think going to school wearing a clown suit has many wrong connotations. It brings in feelings of shame and self-consciousness, when the appropriate emotion is (imo) defiance and doing the blazing obvious thing! I don’t think the Shard Theory folk think they are wearing a clown suit; in my interactions with him I feel like Alex Turner tends to be more defiant or infuriated than self-conscious. (Feel free to correct me if this is not the case!)
(Disclaimer: The Law of Equal and Opposite Advice probably applies to some people here.)
I think that by default, people should spend more time doing things, and less time worrying about if they’re smart enough to do things. Then, if they don’t enjoy working they should 100% feel free to do something else!
That is, try lots of things, fail fast, then try something else.
Here’s some reasons why:
As you say, people can improve at things. I think this is less of a factor than you do, but it’s probably still underrated on the margin. Taking time to study math or practice coding will make you better at coding; while effort is no guarantee of success, it’s still generally related.
People can be pretty bad at judging aptitude. I think this is the main factor. I’ve definitely misjudged people’s aptitude in the past, where people I’ve thought were pretty competent turned out to not so and vice versa. In general, the best predictor of whether someone can or cannot do a thing is seeing if they can do the thing.
Aptitude is often context-dependent. People are often more-or-less competent depending on the context. PhD programs and depressing jobs are two common factors that make people seem significantly less competent. Antidepressants also exist, and seem to be a contributing factor in helping people be more functional.
It’s healthier to try than to worry. I think people often end up sad and unmotivated because they feel incompetent before they’ve put in a solid effort to do good things. Empirically, focusing too much on feelings of inferiority is really bad for productivity and momentum; I’ve often found that people can do many more things when they put in some effort than when they’re beating themselves up.
Overall, I think people should lean more toward work trials/work trial tasks (and being more okay with not being hired after work trials). I also think we should have more just do the thing energy and more let’s move on to the next thing energy, and less being stuck worrying about if you can do the thing energy.
==========
I do think the AI alignment community should try to be slightly more careful when dismissing people, since it can be quite off-putting or discouraging to new people. It also causes people to worry more about “does someone high status think I can do it?” instead of “can I actually do it?”. This is the case especially when the judgments might be revised later.
For what it’s worth, “you’re not good enough” is sometimes stated outright, instead of implied. To share a concrete example: in my first CFAR workshop in 2015, I was told by a senior person in the community that I was probably not smart enough to work on AI Alignment (in particular, it was suggested that I was not good enough at math, as I avoided math in high school and never did any contest math). This was despite me having studied math and CS for ~2 hours a day for almost 7 months at that point, and was incredibly disheartening.Thankfully, other senior people in the community encouraged me to keep trying, which is why I stuck around at all. (In 2017, said senior person told me that they were wrong. Though, like, I haven’t actually done that much impressive alignment research yet, so we’ll see!)
Insofar as we should be cautious about implying that people are not good enough, we should be even more cautious about directly stating this to people.
The general version of this statement is something like: if your beliefs satisfy the law of total expectation, the variance of the whole process should equal the variance of all the increments involved in the process.[1] In the case of the random walk where at each step, your beliefs go up or down by 1% starting from 50% until you hit 100% or 0% -- the variance of each increment is 0.01^2 = 0.0001, and the variance of the entire process is 0.5^2 = 0.25, hence you need 0.25/0.0001 = 2500 steps in expectation. If your beliefs have probability p of going up or down by 1% at each step, and 1-p of staying the same, the variance is reduced by a factor of p, and so you need 2500/p steps.
(Indeed, something like this standard way to derive the expected steps before a random walk hits an absorbing barrier).
Similarly, you get that if you start at 20% or 80%, you need 1600 steps in expectation, and if you start at 1% or 99%, you’ll need 99 steps in expectation.
One problem with your reasoning above is that as the 1%/99% shows, needing 99 steps in expectation does not mean you will take 99 steps with high probability—in this case, there’s a 50% chance you need only one update before you’re certain (!), there’s just a tail of very long sequences. In general, the expected value of variables need not look like
I also think you’re underrating how much the math changes when your beliefs do not come in the form of uniform updates. In the most extreme case, suppose your current 50% doom number comes from imagining that doom is uniformly distributed over the next 10 years, and zero after -- then the median update size per week is only 0.5/520 ~= 0.096%/week, and the expected number of weeks with a >1% update is 0.5 (it only happens when you observe doom). Even if we buy a time-invariant random walk model of belief updating, as the expected size of your updates get larger, you also expect there to be quadratically fewer of them—e.g. if your updates came in increments of size 0.1 instead of 0.01, you’d expect only 25 such updates!
Applying stochastic process-style reasoning to beliefs is empirically very tricky, and results can vary a lot based on seemingly reasonable assumptions. E.g. I remember Taleb making a bunch of mathematically sophisticated arguments[2] that began with “Let your beliefs take the form of a Wiener process[3]” and then ending with an absurd conclusion, such as that 538′s forecasts are obviously wrong because their updates aren’t Gaussian distributed or aren’t around 50% until immediately before the elction date. And famously, reasoning of this kind has often been an absolute terrible idea in financial markets. So I’m pretty skeptical of claims of this kind in general.
There’s some regularity conditions here, but calibrated beliefs that things you eventually learn the truth/falsity of should satisfy these by default.
Often in an attempt to Euler people who do forecasting work but aren’t super mathematical, like Philip Tetlock.
This is what happens when you take the limit of the discrete time random walk, as you allow for updates on ever smaller time increments. You get Gaussian distributed increments per unit time—W_t+u—W_t ~ N(0, u) -- and since the tail of your updates is very thin, you continue to get qualitatively similar results to your discrete-time random walk model above.
And yes, it is ironic that Taleb, who correctly points out the folly of normality assumptions repeatedly, often defaults to making normality assumptions in his own work.
Thanks for taking the time to do the interviews and writing this up! I think ethnographic studies (and qualitative research in general) are pretty neglected in this community, and I’m glad people are doing more of it these days.
I think this piece captures a lot of real but concerning dynamics. For example, I feel like I’ve personally seen, wondered about, or experienced things that are similar to a decent number of these stories, in particular:
Clear-Eyed Despair
Is EA bad, actually?/The Dangers of EA
Values and Proxies
To Gossip or Not to Gossip
High Variance
Team Player
And I’ve heard of stories similar to most of the other anecdotes from other people as well.
(As an aside, social dynamics like these are a big part of why I tend to think of myself as EA-adjacent and not a “real” EA.)
((I will caveat that I think there’s clearly a lot of positive things that go on in the community and lots of healthier-than-average dynamics as well, and it’s easy to be lost in negativity and lose sight of the big picture. This doesn’t take away from the fact that the negative dynamics exist, of course.))
Of these, the ones I worry the most about are the story described in Values and Proxies (that is, are explicit conversations about status seeking making things worse?), and the conflict captured in To Gossip or Not to Gossip/Delicate Topics and Distrust (how much should we rely on whisper networks/gossip/other informal social accountability mechanisms, when relying on them too much can create bad dynamics in itself?). Unfortunately, I don’t have super strong, well thought-out takes here.
In terms of status dynamics, I do think that they’re real, but that explicitly calling attention to them can indeed make them worse. (Interestingly, I’m pretty sure that explicitly pursuing status is generally seen as low status and bad?) I think my current attitude is that “status” as a term is overrated and we’re having too many explicit conversations about it, which in turn gives (new/insecure) people plenty of fodder to injure themselves on.
In terms of the latter problem, I could imagine it’d be quite distressing to hear negative feedback about people you admire, want to be friends with, or are attracted to, especially if said negative feedback is from professional experience when your primary interaction with the person is personal or vice versa. This makes it pretty awkward to have the “actually, X person is bad” conversations. I’ve personally tried to address this by holding a strong line between personal gossip and my professional attitude toward various people, and by being charitable/giving people the benefit of the doubt. However, I’ve definitely been burned by this in the past, and I do really understand the value in a lot of the gossip/whisper networks—style conversations that happen.
Since you’ve spent a bunch of time thinking about and writing about these problems, I’m curious why you think a lot of these negative dynamics exist, and what we can do to fix them?
If I had to guess, I’d say the primary reasons are something like:
The problem is important and we need people, but not you. In many settings, there’s definitely an explicit message of “why can’t we find competent people to work on all these important problems?”, but in adjacent settings, there’s a feeling of “we have so many smart young people, why do we not have things to do” and “if they really needed people, why did they reject me?”. For example, I think I get the former feeling whenever an AIS org I know tries to do hiring, while I get the latter when I talk to junior researchers (especially SERI MATS fellows, independent researchers, or undergrads). It’s definitely pretty rough to be told “this is the most important problem in the world” and then immediately get rejected. And I think this is exacerbated a lot by pre-existing insecurities—if you’re relying on external validation to feel good about yourself, it’s easy for one rejection (let alone a string of rejections) to feel like the end of the world.
Mixing of personal and professional lives. That is, you get to/have to interact with the same people in both work and non-work contexts. For example, I think something like >80% of my friends right now are EA/EA-adjacent I think many people talk about this and claim it’s the primary problem. I agree that this is real problem, but I don’t think it’s the only one, nor do I think it’s easy to fix. Many people in EA work quite hard—e.g. I think many people I know work 50-60 hours a week, and several work way more than that, and when that happens it’s just easier to maintain close relationships with people you work next to. And it’s not non-zero cost to ignore (gossip about) people’s behavior in their personal lives; such gossip can provide non-zero evidence about how likely they are to be e.g. reliable or well-intentioned in a professional setting. It’s also worth noting that this is not a unique problem to EA/AIS; I’ve definitely been part of other communities where personal relationships are more important for professional success. In those communities, I’ve also felt a much stronger need to “be social” and go to plenty of social events I didn’t enjoy to to network.
No (perceived) lines of retreat. I think many people feel (rightly or wrongly) like they don’t have a choice; they’re stuck in the community. Given that the community is still quite small somehow, this also means that they often have to run into the same people or issues that stress them out over and over. (E.g. realistically if you want to work on technical AI Safety, there’s one big hub in the Bay Area, a smaller hub in the UK, and a few academic labs in New York or Boston.) Personally, I think this is the one that I feel most acutely—people who know me IRL know that I occasionally joke about running away from the whole AI/AI Safety problem, but also that when I’ve tried to get away and e.g. return to my roots as a forecasting/psychology researcher, I find that I can’t avoid working on AI Safety-adjacent issues (and I definitely can’t get away from AI in general).
Explicit status discussions. I’m personally very torn on this. I continue to think that thinking explicitly about status can be very damaging both personally and for the community. People are also very bad at judging their own status; my guess is there’s a good chance that King Lear feels pretty status-insecure and doesn’t realize his role in exacerbating bad dynamics by explicitly pursuing status as a senior researcher. But it’s also not like “status” isn’t tracking something real. As in the Seeker’s Game story, it is the case that you get more opportunities if you’re at the right parties, and many opportunities do come from (to put it flippantly) people thinking you’re cool.
Different social norms and general social awkwardness. I think this one is really, really underrated as an explanation. Many people I meet in the community are quite awkward and not super socially adept (and honestly, I often feel I’m in this category as well). At the same time, because the EA/AIS scene in the Bay Area has attracted people from many parts of the world, we end up with lots of miscommunication and small cultural clashes. For example, I think a lot of people I know in the community try to be very explicit and direct, but at the same time I know people from cultures where doing so is seen as a social faux pas. Combined with a decent amount of social awkwardness from the parties involved, this can lead to plenty of misunderstandings (e.g., does X hate me? why won’t Y tell me what they think honestly?). Doubly so when people can’t read/aren’t familiar with/choose to ignore romantic signals from others.
I’ve been meaning to write more about this; maybe I will in the next few weeks?
Continuing the quote:
… It turns out that with some tweaks to the architecture, you can take a giant pre-trained multimodal transformer and then use it as a component in a larger system, a bureaucracy but with lots of learned neural net components instead of pure prompt programming, and then fine-tune the whole system via RL to get good at tasks in a sort of agentic way.
Worth noting that Meta did not do this: they took many small models (some with LM pretraining) and composed them in a specialized way. It’s definitely faster than what Daniel said in his post, but this is also in part an update downwards on the difficulty of full press diplomacy (relative to what Daniel expected).
If we’re using Daniel’s post to talk about whether capabilities progress is faster or slower than expected, it’s worth noting that parts of the 2022 prediction did not come true:
GPT-3 is not “finally obselete” -- text-davinci-002, a GPT-3 variant, is still the best API model. (That being said, it is no longer SoTA compared to some private models.)
We did not get giant multi-modal transformers.
He did get the “bureaucracy” prediction quite right; a lot of recent LM progress has been figuring out how to prompt engineer and compose LMs to elicit more capabilities out of them.
I took the survey!
I wasn’t around in the community in 2010-2015, so I don’t know what the state of RL knowledge was at that time. However, I dispute the claim that rationalists “completely miss[ed] this [..] interpretation”:
Ever since I entered the community, I’ve definitely heard of people talking about policy gradient as “upweighting trajectories with positive reward/downweighting trajectories with negative reward” since 2016, albeit in person. I remember being shown a picture sometime in 2016⁄17 that looks something like this when someone (maybe Paul?) was explaining REINFORCE to me: (I couldn’t find it, so reconstructing it from memory)
In addition, I would be surprised if any of the CHAI PhD students when I was at CHAI from 2017->2021, many of whom have taken deep RL classes at Berkeley, missed this “upweight trajectories in proportion to their reward” intepretation? Most of us at the time have also implemented various RL algorithms from scratch, and there the “weighting trajectory gradients” perspective pops out immediately.
As another data point, when I taught MLAB/WMLB in 2022⁄3, my slides also contained this interpretation of REINFORCE (after deriving it) in so many words:
Insofar as people are making mistakes about reward and RL, it’s not due to having never been exposed to this perspective.
That being said, I do agree that there’s been substantial confusion in this community, mainly of two kinds:
Confusing the objective function being optimized to train a policy with how the policy is mechanistically implemented: Just because the outer loop is modifying/selecting for a policy to score highly on some objective function, does not necessarily mean that the resulting policy will end up selecting actions based on said objective.
Confusing “this policy is optimized for X” with “this policy is optimal for X”: this is the actual mistake I think Bostom is making in Alex’s example—it’s true that an agent that wireheads achieves higher reward than on the training distribution (and the optimal agent for the reward achieves reward at least as good as wireheading). And I think that Alex and you would also agree with me that it’s sometimes valuable to reason about the global optima in policy space. But it’s a mistake to identify the outputs of optimization with the optimal solution to an optimization problem, and many people were making this jump without noticing it.
Again, I contend these confusions were not due to a lack of exposure to the “rewards as weighting trajectories” perspective. Instead, the reasons I remember hearing back in 2017-2018 for why we should jump from “RL is optimizing agents for X” to “RL outputs agents that both optimize X and are optimal for X”:
We’d be really confused if we couldn’t reason about “optimal” agents, so we should solve that first. This is the main justification I heard from the MIRI people about why they studied idealized agents. Oftentimes globally optimal solutions are easier to reason about than local optima or saddle points, or are useful for operationalizing concepts. Because a lot of the community was focused on philosophical deconfusion (often w/ minimal knowledge of ML or RL), many people naturally came to jump the gap between “the thing we’re studying” and “the thing we care about”.
Reasoning about optima gives a better picture of powerful, future AGIs. Insofar as we’re far from transformative AI, you might expect that current AIs are a poor model for how transformative AI will look. In particular, you might expect that modeling transformative AI as optimal leads to clearer reasoning than analogizing them to current systems. This point has become increasingly tenuous since GPT-2, but
Some off-policy RL algorithms are well described as having a “reward” maximizing component: And, these were the approaches that people were using and thinking about at the time. For example, the most hyped results in deep learning in the mid 2010s were probably DQN and AlphaGo/GoZero/Zero. And many people believed that future AIs would be implemented via model-based RL. All of these approaches result in policies that contain an internal component which is searching for actions that maximize some learned objective. Given that ~everyone uses policy gradient variants for RL on SOTA LLMs, this does turn out to be incorrect ex post. But if the most impressive AIs seem to be implemented in ways that correspond to internal reward maximization, it does seem very understandable to think about AGIs as explicit reward optimizers.
This is how many RL pioneers reasoned about their algorithms. I agree with Alex that this is probably from the control theory routes, where a PID controller is well modeled as picking trajectories that minimize cost, in a way that early simple RL policies are not well modeled as internally picking trajectories that maximize reward.
Also, sometimes it is just the words being similar; it can be hard to keep track of the differences between “optimizing for”, “optimized for”, and “optimal for” in normal conversation.
I think if you want to prevent the community from repeating these confusions, this looks less like “here’s an alternative perspective through which you can view policy gradient” and more “here’s why reasoning about AGI as ‘optimal’ agents is misleading” and “here’s why reasoning about your 1 hidden layer neural network policy as if it were optimizing the reward is bad”.
An aside:
In general, I think that many ML-knowledgeable people (arguably myself included) correctly notice that the community is making many mistakes in reasoning, that they resolve internally using ML terminology or frames from the ML literature. But without reasoning carefully about the problem, the terminology or frames themselves are insufficient to resolve the confusion. (Notice how many Deep RL people make the same mistake!) And, as Alex and you have argued before, the standard ML frames and terminology introduce their own confusions (e.g. ‘attention’).
A shallow understanding of “policy gradient is just upweighting trajectories” may in fact lead to making the opposite mistake: assuming that it can never lead to intelligent, optimizer-y behavior. (Again, notice how many ML academics made exactly this mistake) Or, more broadly, thinking about ML algorithms purely from the low-level, mechanistic frame can lead to confusions along the lines of “next token prediction can only lead to statistical parrots without true intelligence”. Doubly so if you’ve only worked with policy gradient or language modeling with tiny models.